---
license: apache-2.0
---
# ContentV: Efficient Training of Video Generation Models with Limited Compute
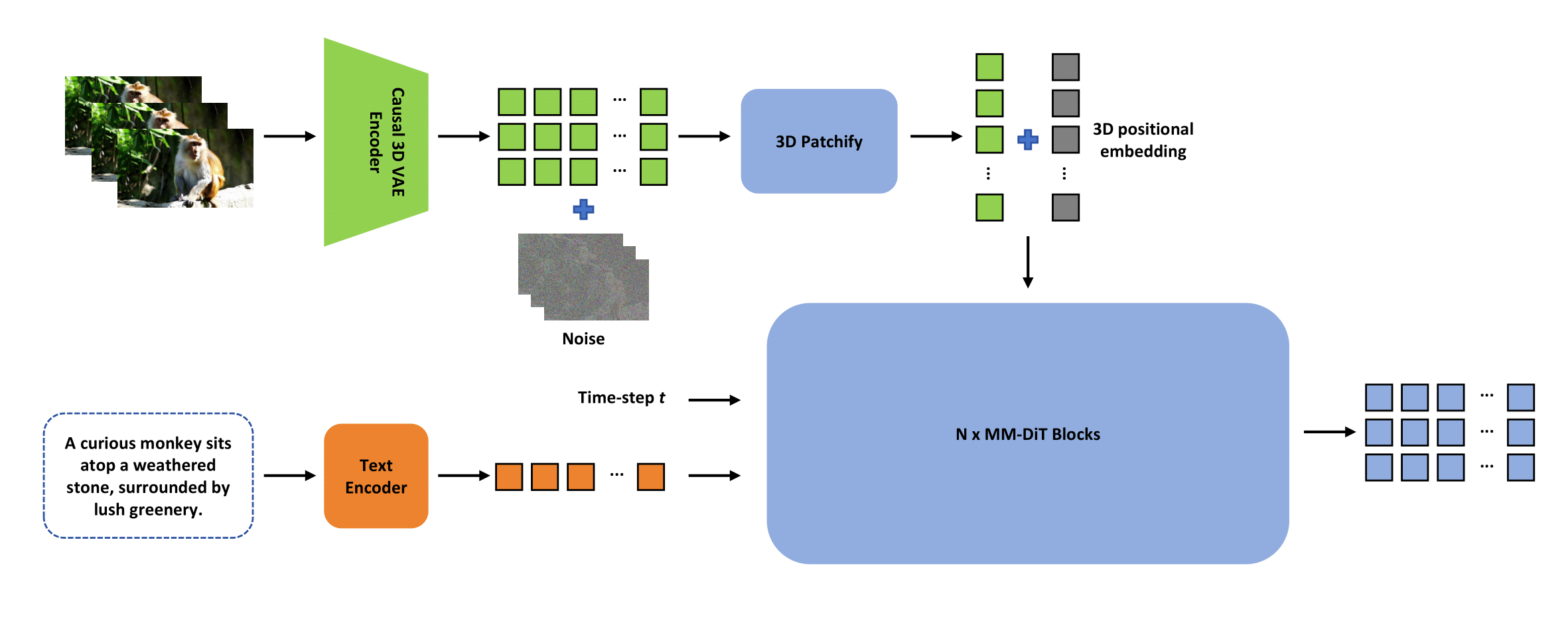
This project presents *ContentV*, an efficient framework for accelerating the training of DiT-based video generation models through three key innovations:
- A minimalist architecture that maximizes reuse of pre-trained image generation models for video synthesis
- A systematic multi-stage training strategy leveraging flow matching for enhanced efficiency
- A cost-effective reinforcement learning with human feedback framework that improves generation quality without requiring additional human annotations
Our open-source 8B model (based on Stable Diffusion 3.5 Large and Wan-VAE) achieves state-of-the-art result (85.14 on VBench) in only 4 weeks of training with 256×64GB NPUs.
## ⚡ Quickstart
#### Recommended PyTorch Version
- GPU: torch >= 2.3.1 (CUDA >= 12.2)
- NPU: torch and torch-npu >= 2.1.0 (CANN >= 8.0.RC2). Please refer to [Ascend Extension for PyTorch](https://gitee.com/ascend/pytorch) for the installation of torch-npu.
#### Installation
```bash
git clone https://github.com/bytedance/ContentV.git
cd ContentV
pip3 install -r requirements.txt
```
#### T2V Generation
```bash
## For GPU
python3 demo.py
## For NPU
USE_ASCEND_NPU=1 python3 demo.py
```
## 📊 VBench
| Model | Total Score | Quality Score | Semantic Score | Human Action | Scene | Dynamic Degree | Multiple Objects | Appear. Style |
|----------------------|--------|-------|-------|-------|-------|-------|-------|-------|
| Wan2.1-14B | 86.22 | 86.67 | 84.44 | 99.20 | 61.24 | 94.26 | 86.59 | 21.59 |
| **ContentV (Long)** | 85.14 | 86.64 | 79.12 | 96.80 | 57.38 | 83.05 | 71.41 | 23.02 |
| Goku† | 84.85 | 85.60 | 81.87 | 97.60 | 57.08 | 76.11 | 79.48 | 23.08 |
| Open-Sora 2.0 | 84.34 | 85.40 | 80.12 | 95.40 | 52.71 | 71.39 | 77.72 | 22.98 |
| Sora† | 84.28 | 85.51 | 79.35 | 98.20 | 56.95 | 79.91 | 70.85 | 24.76 |
| **ContentV (Short)** | 84.11 | 86.23 | 75.61 | 89.60 | 44.02 | 79.26 | 74.58 | 21.21 |
| EasyAnimate 5.1 | 83.42 | 85.03 | 77.01 | 95.60 | 54.31 | 57.15 | 66.85 | 23.06 |
| Kling 1.6† | 83.40 | 85.00 | 76.99 | 96.20 | 55.57 | 62.22 | 63.99 | 20.75 |
| HunyuanVideo | 83.24 | 85.09 | 75.82 | 94.40 | 53.88 | 70.83 | 68.55 | 19.80 |
| CogVideoX-5B | 81.61 | 82.75 | 77.04 | 99.40 | 53.20 | 70.97 | 62.11 | 24.91 |
| Pika-1.0† | 80.69 | 82.92 | 71.77 | 86.20 | 49.83 | 47.50 | 43.08 | 22.26 |
| VideoCrafter-2.0 | 80.44 | 82.20 | 73.42 | 95.00 | 55.29 | 42.50 | 40.66 | 25.13 |
| AnimateDiff-V2 | 80.27 | 82.90 | 69.75 | 92.60 | 50.19 | 40.83 | 36.88 | 22.42 |
| OpenSora 1.2 | 79.23 | 80.71 | 73.30 | 85.80 | 42.47 | 47.22 | 58.41 | 23.89 |
## ✅ Todo List
- [x] Inference code and checkpoints
- [ ] Training code of RLHF
## 🧾 License
This code repository and part of the model weights are licensed under the [Apache 2.0 License](https://www.apache.org/licenses/LICENSE-2.0). Please note that:
- MMDiT are derived from [Stable Diffusion 3.5 Large](https://huggingface.co/stabilityai/stable-diffusion-3.5-large) and trained with video samples. This Stability AI Model is licensed under the [Stability AI Community License](https://stability.ai/community-license-agreement), Copyright © Stability AI Ltd. All Rights Reserved
- Video VAE from [Wan2.1](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) is licensed under [Apache 2.0 License](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B/blob/main/LICENSE.txt)
## ❤️ Acknowledgement
* [Stable Diffusion 3.5 Large](https://huggingface.co/stabilityai/stable-diffusion-3.5-large)
* [Wan2.1](https://github.com/Wan-Video/Wan2.1)
* [Diffusers](https://github.com/huggingface/diffusers)
* [HuggingFace](https://huggingface.co)
## 🔗 Citation
```bibtex
@article{contentv2025,
title = {ContentV: Efficient Training of Video Generation Models with Limited Compute},
author = {Bytedance Douyin Content Team},
journal = {arXiv preprint arXiv:2506.05343},
year = {2025}
}
```