---
base_model:
- OpenGVLab/InternVL2_5-8B
datasets:
- Code2Logic/GameQA-140K
- Code2Logic/GameQA-5K
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
---
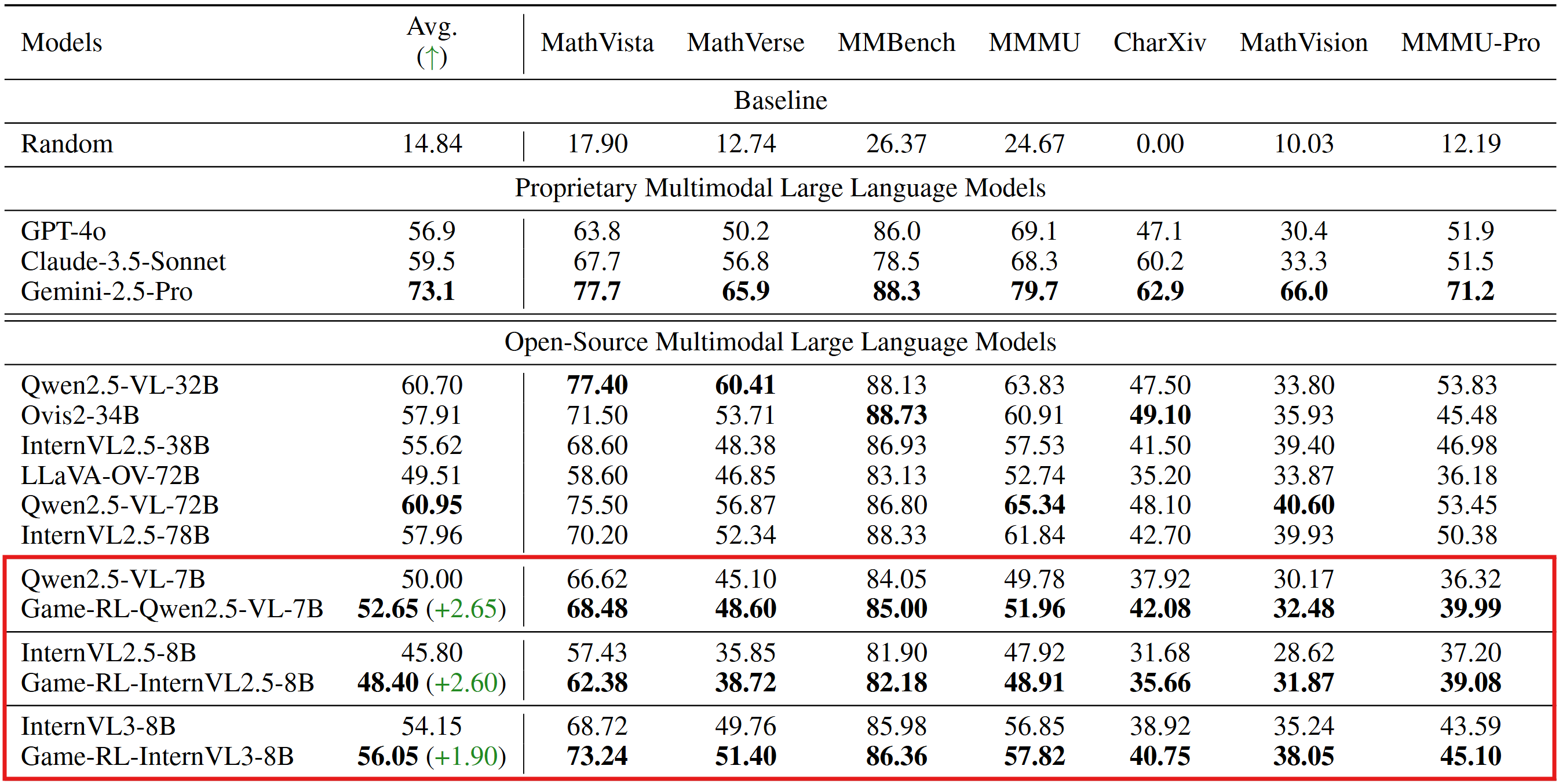
***This model (GameQA-InternVL2.5-8B) results from training InternVL2.5-8B with GRPO solely on our [GameQA-5K](https://huggingface.co/datasets/Code2Logic/GameQA-5K) (sampled from the full [GameQA-140K](https://huggingface.co/datasets/Gabriel166/GameQA-140K) dataset).***
# Evaluation Results on General Vision BenchMarks
***(The inference and evaluation configurations were unified across both the original open-source models and our trained models.)***
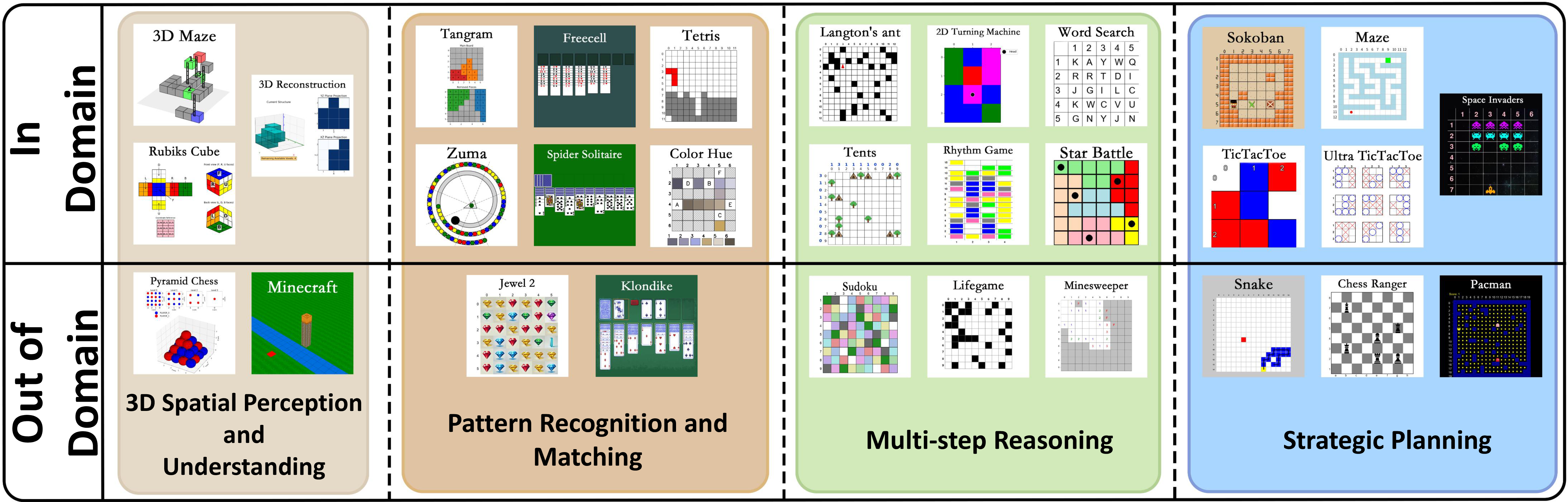
# Code2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
This is the first work, to the best of our knowledge, that leverages ***game code*** to synthesize multimodal reasoning data for ***training*** VLMs. Furthermore, when trained with a GRPO strategy solely on **GameQA** (synthesized via our proposed **Code2Logic** approach), multiple cutting-edge open-source models exhibit significantly enhanced out-of-domain generalization.
[[📖 Paper](https://arxiv.org/abs/2505.13886)] [[💻 Code](https://github.com/tongjingqi/Code2Logic)] [[🤗 GameQA-140K Dataset](https://huggingface.co/datasets/Gabriel166/GameQA-140K)] [[🤗 GameQA-5K Dataset](https://huggingface.co/datasets/Code2Logic/GameQA-5K)] [[🤗 GameQA-InternVL3-8B](https://huggingface.co/Code2Logic/GameQA-InternVL3-8B) ] [[🤗 GameQA-Qwen2.5-VL-7B](https://huggingface.co/Code2Logic/GameQA-Qwen2.5-VL-7B)] [[🤗 GameQA-LLaVA-OV-7B](https://huggingface.co/Code2Logic/GameQA-llava-onevision-qwen2-7b-ov-hf) ]
## News
* We've open-sourced the models trained with GRPO on GameQA on [Huggingface](https://huggingface.co/Code2Logic).