
Amid the swift progress of large language models (LLMs) and their evolution into large multimodal models (LMMs), significant strides have been made in high-resource languages such as English and Chinese. While Arabic LLMs have seen notable progress, Arabic LMMs remain largely unexplored, often narrowly focusing on a few specific aspects of the language and visual understanding. To bridge this gap, we introduce AIN - the Arabic Inclusive Multimodal Model- designed to excel across diverse domains. AIN is an English-Arabic bilingual LMM designed to excel in English and Arabic, leveraging carefully constructed 3.6 million high-quality Arabic-English multimodal data samples. AIN demonstrates state-of-the-art Arabic performance, while also possessing strong English-language visual capabilities.
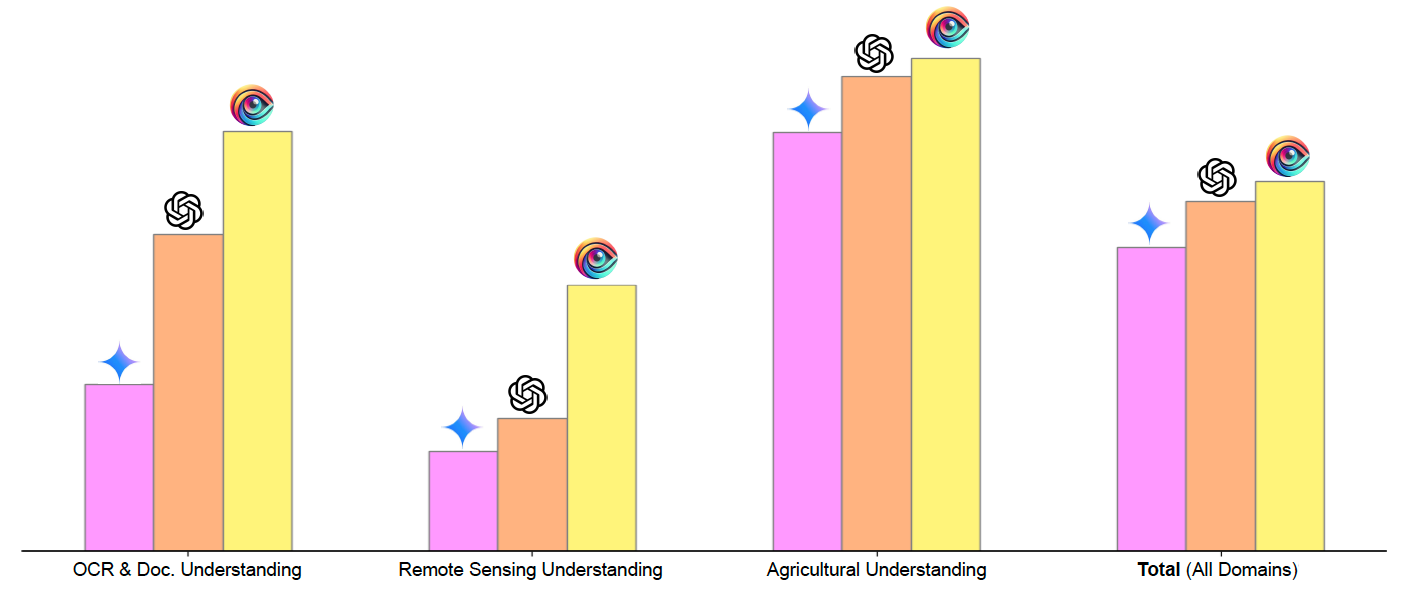

| Models | VQA | OCR | Video | RS | CDT | Agro. | Cult. | Med. | Total |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 🥈55.15 | 🥈54.98 | 🥇69.65 | 🥈27.36 | 🥈62.35 | 🥈80.75 | 🥇80.86 | 🥇49.91 | 🥈60.13 |
| GPT-4o-mini | 48.83 | 39.38 | 🥈66.28 | 16.93 | 56.37 | 78.80 | 65.92 | 🥈47.37 | 52.49 |
| Gemini-1.5-Pro | 46.68 | 28.68 | 42.95 | 17.07 | 47.06 | 72.14 | 56.24 | 33.78 | 52.38 |
| Gemini-1.5-flash | 45.59 | 27.58 | 53.31 | 14.95 | 48.26 | 76.07 | 46.54 | 42.87 | 44.40 |
| InternVL-8B | 30.41 | 15.91 | 51.42 | 5.36 | 30.27 | 44.47 | 20.88 | 29.48 | 28.52 |
| InternVL2.5-1B | 27.22 | 19.45 | 38.20 | 3.39 | 30.75 | 39.53 | 35.68 | 21.27 | 26.94 |
| Qwen-VL-2B | 41.02 | 22.93 | 38.90 | 12.56 | 27.83 | 52.02 | 34.28 | 29.12 | 32.33 |
| Qwen2-VL-7B | 48.76 | 42.73 | 61.97 | 21.30 | 54.67 | 79.32 | 75.96 | 35.81 | 52.57 |
| AIN-7B (ours) | 🥇56.78 | 🥇72.35 | 64.09 | 🥇45.92 | 🥇64.10 | 🥇85.05 | 🥈78.09 | 43.77 | 🏆63.77 |


