ReasonFlux-V2:Internalizing Template-Augmented LLM Reasoning
with Hierarchical Reinforcement Learning
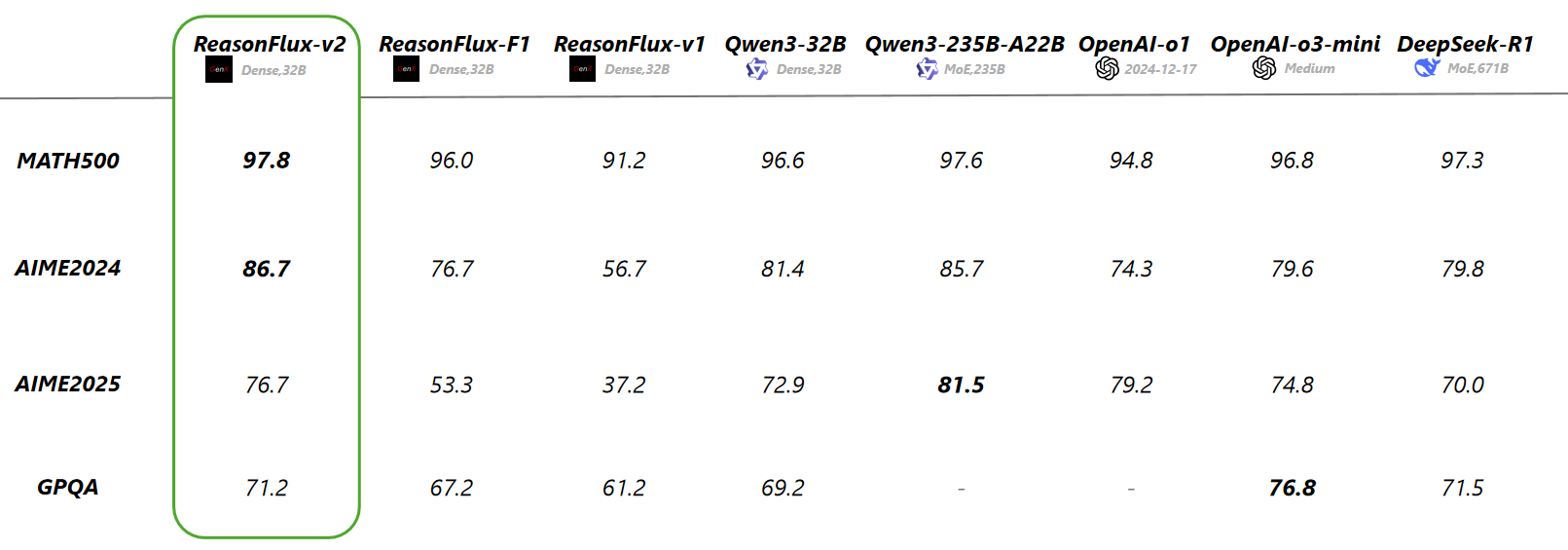
**ReasonFlux-V2** is our new template-augmented reasoning paradigm which **internalize the thought templates** through **iterative hierarchical reinforcement learning**. Specifically, we first develop an automated pipeline to extract thought templates from the problem–solution pairs in training set. To effectively internalize these high-level thought templates and learning a more efficient reasoning paradigm, we propose two collaborative modules: **Template Proposer** which adaptively proposes suitable thought templates based on the input problem; and **Template Reasoner**,which exactly instantiates the proposed templates and performs precise, detailed reasoning. Building upon these modules, we iteratively conduct **hierarchical RL** on optimizing both modules.

**ReasonFlux-V2** offers a more efficient, generalizable solution for enhancing the complex reasoning capabilities of LLMs. Compare with conventional reasoning LLMs, our **ReasonFlux-V2** could correctly and efficiently solve the problems with less token consumption and inference time.
**We will release our paper related with ReasonFlux-V2 soon.**
ReasonFlux-v2 consists of two main modules:
1. **Template Proposer**, which **adaptively** proposes suitable high-level thought templates based on the input problem. It functions as intuitive thinking process of human which helps to **narrow the exploration space** of detailed reasoning process thus **improve the solution efficiency**.
2. **Template Reasoner**, which follow the proposed high-level thought template to efficiently and effectively solve the corresponding problem.

Paper (We will soon release)|[Code](https://github.com/Gen-Verse/ReasonFlux)|[Template](Gen-Verse/ReasonFlux-V2-Template)|[SFT Dataset](https://huggingface.co/datasets/Gen-Verse/ReasonFlux-V2-SFT/) |[DPO Dataset](https://huggingface.co/datasets/Gen-Verse/ReasonFlux-V2-DPO)