
Update model files
Browse files- .gitattributes +9 -0
- README.md +500 -7
- asset/.DS_Store +0 -0
- asset/architecture.png +3 -0
- asset/keye_logo_2.png +3 -0
- asset/keyelogo/Keye-logo--black.png +3 -0
- asset/keyelogo/Keye-logo--white.png +3 -0
- asset/keyelogo/Keye-logo.png +3 -0
- asset/performance.png +3 -0
- asset/post1.jpeg +0 -0
- asset/post1.png +0 -0
- asset/post2.jpeg +3 -0
- asset/post2.png +0 -0
- asset/pre-train.png +3 -0
- asset/teaser.png +3 -0
- configuration_keye_vl_1_5.py +1 -1
- image_processing_keye_vl_1_5.py +1 -1
- modeling_keye_vl_1_5.py +16 -6
- processing_keye_vl_1_5.py +1 -1
.gitattributes
CHANGED
|
@@ -34,3 +34,12 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
asset/architecture.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
asset/keye_logo_2.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
asset/keyelogo/Keye-logo--black.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
asset/keyelogo/Keye-logo--white.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
asset/keyelogo/Keye-logo.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
asset/performance.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
asset/post2.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
asset/pre-train.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
asset/teaser.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,7 +1,500 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
-
|
| 6 |
-
|
| 7 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Kwai Keye-VL
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
<div align="center">
|
| 5 |
+
<img src="asset/keye_logo_2.png" width="100%" alt="Kwai Keye-VL Logo">
|
| 6 |
+
</div>
|
| 7 |
+
|
| 8 |
+
<font size=7><div align='center' >
|
| 9 |
+
[[🍎 Home Page](https://kwai-keye.github.io/)]
|
| 10 |
+
[[📖 Technique Report](https://arxiv.org/abs/2507.01949)]
|
| 11 |
+
[[📊 Keye-VL-8B-Preview](https://huggingface.co/Kwai-Keye/Keye-VL-8B-Preview) ]
|
| 12 |
+
[[📊 Keye-VL-1.5-8B](https://huggingface.co/Kwai-Keye/Keye-VL-1.5-8B/) ]
|
| 13 |
+
[[🚀 Demo](https://huggingface.co/spaces/Kwai-Keye/Keye-VL-8B-Preview)]
|
| 14 |
+
</div></font>
|
| 15 |
+
|
| 16 |
+
## 🔥 News
|
| 17 |
+
|
| 18 |
+
* **`2025.08.28`** 🌟 We are excited to introduce **Kwai Keye-VL-1.5**, a more powerful version! By incorporating innovative `Slow-Fast Video Encoding strategy`, `new LongCoT Cold-Start data pipeline`, and `advanced RL training strategies`, Keye-VL-1.5 reaches new heights in video understanding, image comprehension, and reasoning capabilities. Plus, it now supports an extended context length of up to **128k** tokens for handling longer conversations and complex tasks. Stay tuned for more groundbreaking innovations!
|
| 19 |
+
* **`2025.07.08`** 🌟 Keye-VL is supported by [swift](https://github.com/modelscope/ms-swift) and [vLLM](https://github.com/vllm-project/vllm). Feel free to use it without hesitation!
|
| 20 |
+
* **`2025.07.03`** 🌟 We are excited to announce the release of our comprehensive technical report! You can read it now at [arxiv](https://arxiv.org/abs/2507.01949).
|
| 21 |
+
* **`2025.06.26`** 🌟 We are very proud to launch **Kwai Keye-VL**, a cutting-edge multimodal large language model meticulously crafted by the **Kwai Keye Team** at [Kuaishou](https://www.kuaishou.com/). As a cornerstone AI product within Kuaishou's advanced technology ecosystem, Keye excels in video understanding, visual perception, and reasoning tasks, setting new benchmarks in performance. Our team is working tirelessly to push the boundaries of what's possible, so stay tuned for more exciting updates!
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
<div align="center">
|
| 26 |
+
<img src="asset/teaser.png" width="100%" alt="Kwai Keye-VL Performance">
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
## Contents <!-- omit in toc -->
|
| 30 |
+
|
| 31 |
+
- [🔥 News](#-news)
|
| 32 |
+
- [📐 Quick Start](#-quick-start)
|
| 33 |
+
- [Preprocess and Inference](#preprocess-and-inference)
|
| 34 |
+
- [Evaluation](#evaluation)
|
| 35 |
+
- [👀 Architecture and Training Strategy](#-architecture-and-training-strategy)
|
| 36 |
+
- [🌟 Pre-Train](#-pre-train)
|
| 37 |
+
- [🌟 Post-Train](#-post-train)
|
| 38 |
+
- [📈 Experimental Results](#-experimental-results)
|
| 39 |
+
- [✒️ Citation](#️-citation)
|
| 40 |
+
|
| 41 |
+
## 📐 Quick Start
|
| 42 |
+
### Preprocess and Inference
|
| 43 |
+
|
| 44 |
+
See [keye-vl-utils/README.md](keye-vl-utils/README.md) for details. ```Keye-vl-utils``` contains a set of helper functions for processing and integrating visual language information with Keye Series Model.
|
| 45 |
+
|
| 46 |
+
#### Install
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
pip install --upgrade keye-vl-utils==1.5.2 -i https://pypi.org/simple
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
#### Keye-VL-1.5 Inference
|
| 53 |
+
|
| 54 |
+
```python
|
| 55 |
+
from transformers import AutoModel, AutoTokenizer, AutoProcessor
|
| 56 |
+
from keye_vl_utils import process_vision_info
|
| 57 |
+
|
| 58 |
+
# default: Load the model on the available device(s)
|
| 59 |
+
model_path = "Kwai-Keye/Keye-VL-1.5-8B"
|
| 60 |
+
|
| 61 |
+
model = AutoModel.from_pretrained(
|
| 62 |
+
model_path,
|
| 63 |
+
torch_dtype="auto",
|
| 64 |
+
trust_remote_code=True,
|
| 65 |
+
# flash_attention_2 is recommended for better performance
|
| 66 |
+
attn_implementation="flash_attention_2",
|
| 67 |
+
).eval()
|
| 68 |
+
|
| 69 |
+
model.to("cuda")
|
| 70 |
+
|
| 71 |
+
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
|
| 72 |
+
|
| 73 |
+
# Image Inputs
|
| 74 |
+
## Non-Thinking Mode
|
| 75 |
+
messages = [
|
| 76 |
+
{
|
| 77 |
+
"role": "user",
|
| 78 |
+
"content": [
|
| 79 |
+
{
|
| 80 |
+
"type": "image",
|
| 81 |
+
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
|
| 82 |
+
},
|
| 83 |
+
{"type": "text", "text": "Describe this image./no_think"},
|
| 84 |
+
],
|
| 85 |
+
}
|
| 86 |
+
]
|
| 87 |
+
|
| 88 |
+
## Auto-Thinking Mode
|
| 89 |
+
messages = [
|
| 90 |
+
{
|
| 91 |
+
"role": "user",
|
| 92 |
+
"content": [
|
| 93 |
+
{
|
| 94 |
+
"type": "image",
|
| 95 |
+
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
|
| 96 |
+
},
|
| 97 |
+
{"type": "text", "text": "Describe this image."},
|
| 98 |
+
],
|
| 99 |
+
}
|
| 100 |
+
]
|
| 101 |
+
|
| 102 |
+
## Thinking mode
|
| 103 |
+
messages = [
|
| 104 |
+
{
|
| 105 |
+
"role": "user",
|
| 106 |
+
"content": [
|
| 107 |
+
{
|
| 108 |
+
"type": "image",
|
| 109 |
+
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
|
| 110 |
+
},
|
| 111 |
+
{"type": "text", "text": "Describe this image./think"},
|
| 112 |
+
],
|
| 113 |
+
}
|
| 114 |
+
]
|
| 115 |
+
|
| 116 |
+
# The default range for the number of visual tokens per image in the model is 4-20480.
|
| 117 |
+
# You can set min_pixels and max_pixels according to your needs, such as a token range of 32-1280, to balance performance and cost.
|
| 118 |
+
# min_pixels = 32 * 28 * 28
|
| 119 |
+
# max_pixels = 1280 * 28 * 28
|
| 120 |
+
# e.g.,
|
| 121 |
+
messages = [
|
| 122 |
+
{
|
| 123 |
+
"role": "user",
|
| 124 |
+
"content": [
|
| 125 |
+
{
|
| 126 |
+
"type": "image",
|
| 127 |
+
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
|
| 128 |
+
"min_pixels": 32 * 28 * 28,
|
| 129 |
+
"max_pixels": 1280 * 28 * 28
|
| 130 |
+
},
|
| 131 |
+
{"type": "text", "text": "Describe this image./think"},
|
| 132 |
+
],
|
| 133 |
+
}
|
| 134 |
+
]
|
| 135 |
+
|
| 136 |
+
# Video inputs
|
| 137 |
+
messages = [
|
| 138 |
+
{
|
| 139 |
+
"role": "user",
|
| 140 |
+
"content": [
|
| 141 |
+
{
|
| 142 |
+
"type": "video",
|
| 143 |
+
"video": "http://s2-11508.kwimgs.com/kos/nlav11508/MLLM/videos_caption/98312843263.mp4",
|
| 144 |
+
},
|
| 145 |
+
{"type": "text", "text": "Describe this video."},
|
| 146 |
+
],
|
| 147 |
+
}
|
| 148 |
+
]
|
| 149 |
+
|
| 150 |
+
# You can also set fps and max_frames to restrict total frames send to model.
|
| 151 |
+
# e.g.,
|
| 152 |
+
|
| 153 |
+
messages = [
|
| 154 |
+
{
|
| 155 |
+
"role": "user",
|
| 156 |
+
"content": [
|
| 157 |
+
{
|
| 158 |
+
"type": "video",
|
| 159 |
+
"video": "http://s2-11508.kwimgs.com/kos/nlav11508/MLLM/videos_caption/98312843263.mp4",
|
| 160 |
+
"fps": 2.0,
|
| 161 |
+
"max_frames": 1024
|
| 162 |
+
},
|
| 163 |
+
{"type": "text", "text": "Describe this video."},
|
| 164 |
+
],
|
| 165 |
+
}
|
| 166 |
+
]
|
| 167 |
+
|
| 168 |
+
# Text inputs
|
| 169 |
+
messages = [
|
| 170 |
+
{
|
| 171 |
+
"role": "user",
|
| 172 |
+
"content": "Hello, Keye",
|
| 173 |
+
}
|
| 174 |
+
]
|
| 175 |
+
|
| 176 |
+
# Preparation for inference
|
| 177 |
+
text = processor.apply_chat_template(
|
| 178 |
+
messages, tokenize=False, add_generation_prompt=True
|
| 179 |
+
)
|
| 180 |
+
image_inputs, video_inputs, mm_processor_kwargs = process_vision_info(messages)
|
| 181 |
+
inputs = processor(
|
| 182 |
+
text=[text],
|
| 183 |
+
images=image_inputs,
|
| 184 |
+
videos=video_inputs,
|
| 185 |
+
padding=True,
|
| 186 |
+
return_tensors="pt",
|
| 187 |
+
**mm_processor_kwargs
|
| 188 |
+
)
|
| 189 |
+
inputs = inputs.to("cuda")
|
| 190 |
+
|
| 191 |
+
# Inference: Generation of the output
|
| 192 |
+
generated_ids = model.generate(**inputs, max_new_tokens=1024)
|
| 193 |
+
generated_ids_trimmed = [
|
| 194 |
+
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 195 |
+
]
|
| 196 |
+
output_text = processor.batch_decode(
|
| 197 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 198 |
+
)
|
| 199 |
+
print(output_text)
|
| 200 |
+
```
|
| 201 |
+
|
| 202 |
+
#### Deployment
|
| 203 |
+
- We recommend using vLLM for fast deployment and inference.
|
| 204 |
+
|
| 205 |
+
##### Install
|
| 206 |
+
```bash
|
| 207 |
+
pip install keye-vl-utils==1.5.2 "vllm>=0.9.2"
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
##### Offline Inference
|
| 211 |
+
```bash
|
| 212 |
+
# refer to https://github.com/QwenLM/Qwen2.5-VL?tab=readme-ov-file#inference-locally
|
| 213 |
+
|
| 214 |
+
from transformers import AutoProcessor
|
| 215 |
+
from vllm import LLM, SamplingParams
|
| 216 |
+
from keye_vl_utils import process_vision_info
|
| 217 |
+
|
| 218 |
+
model_path = "/hetu_group/jky/playground_hhd_2/2025/20250626_keye/Keye-VL-8B-Preview"
|
| 219 |
+
|
| 220 |
+
llm = LLM(
|
| 221 |
+
model=model_path,
|
| 222 |
+
limit_mm_per_prompt={"image": 10, "video": 10},
|
| 223 |
+
trust_remote_code=True,
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
sampling_params = SamplingParams(
|
| 227 |
+
temperature=0.3,
|
| 228 |
+
max_tokens=256,
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
# image
|
| 232 |
+
image_messages = [
|
| 233 |
+
{
|
| 234 |
+
"role": "user",
|
| 235 |
+
"content": [
|
| 236 |
+
{
|
| 237 |
+
"type": "image",
|
| 238 |
+
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
|
| 239 |
+
},
|
| 240 |
+
{"type": "text", "text": "Describe this image./think"},
|
| 241 |
+
],
|
| 242 |
+
},
|
| 243 |
+
]
|
| 244 |
+
|
| 245 |
+
# video
|
| 246 |
+
video_messages = [
|
| 247 |
+
{
|
| 248 |
+
"role": "user",
|
| 249 |
+
"content": [
|
| 250 |
+
{
|
| 251 |
+
"type": "video",
|
| 252 |
+
"video": "http://s2-11508.kwimgs.com/kos/nlav11508/MLLM/videos_caption/98312843263.mp4",
|
| 253 |
+
},
|
| 254 |
+
{"type": "text", "text": "Describe this video./think"},
|
| 255 |
+
],
|
| 256 |
+
},
|
| 257 |
+
]
|
| 258 |
+
|
| 259 |
+
# Here we use video messages as a demonstration
|
| 260 |
+
messages = video_messages
|
| 261 |
+
|
| 262 |
+
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
|
| 263 |
+
prompt = processor.apply_chat_template(
|
| 264 |
+
messages,
|
| 265 |
+
tokenize=False,
|
| 266 |
+
add_generation_prompt=True,
|
| 267 |
+
)
|
| 268 |
+
image_inputs, video_inputs, video_kwargs = process_vision_info(
|
| 269 |
+
messages, return_video_kwargs=True
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
mm_data = {}
|
| 273 |
+
if image_inputs is not None:
|
| 274 |
+
mm_data["image"] = image_inputs
|
| 275 |
+
if video_inputs is not None:
|
| 276 |
+
mm_data["video"] = video_inputs
|
| 277 |
+
|
| 278 |
+
llm_inputs = {
|
| 279 |
+
"prompt": prompt,
|
| 280 |
+
"multi_modal_data": mm_data,
|
| 281 |
+
# FPS will be returned in video_kwargs
|
| 282 |
+
"mm_processor_kwargs": video_kwargs,
|
| 283 |
+
}
|
| 284 |
+
|
| 285 |
+
outputs = llm.generate([llm_inputs], sampling_params=sampling_params)
|
| 286 |
+
generated_text = outputs[0].outputs[0].text
|
| 287 |
+
|
| 288 |
+
print(generated_text)
|
| 289 |
+
```
|
| 290 |
+
|
| 291 |
+
##### Online Serving
|
| 292 |
+
- Serve
|
| 293 |
+
```bash
|
| 294 |
+
vllm serve \
|
| 295 |
+
Kwai-Keye/Keye-VL-8B-Preview \
|
| 296 |
+
--tensor-parallel-size 8 \
|
| 297 |
+
--enable-prefix-caching \
|
| 298 |
+
--gpu-memory-utilization 0.8 \
|
| 299 |
+
--host 0.0.0.0 \
|
| 300 |
+
--port 8000 \
|
| 301 |
+
--trust-remote-code
|
| 302 |
+
```
|
| 303 |
+
|
| 304 |
+
- Openai Chat Completion Client
|
| 305 |
+
```python
|
| 306 |
+
import base64
|
| 307 |
+
import numpy as np
|
| 308 |
+
from PIL import Image
|
| 309 |
+
from io import BytesIO
|
| 310 |
+
from openai import OpenAI
|
| 311 |
+
from keye_vl_utils import process_vision_info
|
| 312 |
+
import requests
|
| 313 |
+
|
| 314 |
+
|
| 315 |
+
# Set OpenAI's API key and API base to use vLLM's API server.
|
| 316 |
+
openai_api_key = "EMPTY"
|
| 317 |
+
openai_api_base = "http://localhost:8000/v1"
|
| 318 |
+
|
| 319 |
+
client = OpenAI(
|
| 320 |
+
api_key=openai_api_key,
|
| 321 |
+
base_url=openai_api_base,
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
# image url
|
| 325 |
+
image_messages = [
|
| 326 |
+
{
|
| 327 |
+
"role": "user",
|
| 328 |
+
"content": [
|
| 329 |
+
{
|
| 330 |
+
"type": "image_url",
|
| 331 |
+
"image_url": {
|
| 332 |
+
"url": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg"
|
| 333 |
+
},
|
| 334 |
+
},
|
| 335 |
+
{"type": "text", "text": "Describe this image./think"},
|
| 336 |
+
],
|
| 337 |
+
},
|
| 338 |
+
]
|
| 339 |
+
|
| 340 |
+
chat_response = client.chat.completions.create(
|
| 341 |
+
model="Kwai-Keye/Keye-VL-8B-Preview",
|
| 342 |
+
messages=image_messages,
|
| 343 |
+
)
|
| 344 |
+
print("Chat response:", chat_response)
|
| 345 |
+
|
| 346 |
+
# image base64-encoded
|
| 347 |
+
|
| 348 |
+
import base64
|
| 349 |
+
|
| 350 |
+
image_path = "/path/to/local/image.png"
|
| 351 |
+
with open(image_path, "rb") as f:
|
| 352 |
+
encoded_image = base64.b64encode(f.read())
|
| 353 |
+
encoded_image_text = encoded_image.decode("utf-8")
|
| 354 |
+
image_messages = [
|
| 355 |
+
{
|
| 356 |
+
"role": "user",
|
| 357 |
+
"content": [
|
| 358 |
+
{
|
| 359 |
+
"type": "image_url",
|
| 360 |
+
"image_url": {
|
| 361 |
+
"url": f"data:image;base64,{encoded_image_text}"
|
| 362 |
+
},
|
| 363 |
+
},
|
| 364 |
+
{"type": "text", "text": "Describe this image./think"},
|
| 365 |
+
],
|
| 366 |
+
},
|
| 367 |
+
]
|
| 368 |
+
|
| 369 |
+
chat_response = client.chat.completions.create(
|
| 370 |
+
model="Kwai-Keye/Keye-VL-8B-Preview",
|
| 371 |
+
messages=image_messages,
|
| 372 |
+
)
|
| 373 |
+
print("Chat response:", chat_response)
|
| 374 |
+
|
| 375 |
+
# video, refer to https://github.com/QwenLM/Qwen2.5-VL?tab=readme-ov-file#start-an-openai-api-service
|
| 376 |
+
video_messages = [
|
| 377 |
+
{"role": "user", "content": [
|
| 378 |
+
{"type": "video", "video": "http://s2-11508.kwimgs.com/kos/nlav11508/MLLM/videos_caption/98312843263.mp4"},
|
| 379 |
+
{"type": "text", "text": "Describe this video./think"}]
|
| 380 |
+
},
|
| 381 |
+
]
|
| 382 |
+
|
| 383 |
+
def prepare_message_for_vllm(content_messages):
|
| 384 |
+
vllm_messages, fps_list = [], []
|
| 385 |
+
for message in content_messages:
|
| 386 |
+
message_content_list = message["content"]
|
| 387 |
+
if not isinstance(message_content_list, list):
|
| 388 |
+
vllm_messages.append(message)
|
| 389 |
+
continue
|
| 390 |
+
|
| 391 |
+
new_content_list = []
|
| 392 |
+
for part_message in message_content_list:
|
| 393 |
+
if 'video' in part_message:
|
| 394 |
+
video_message = [{'content': [part_message]}]
|
| 395 |
+
image_inputs, video_inputs, video_kwargs = process_vision_info(video_message, return_video_kwargs=True)
|
| 396 |
+
assert video_inputs is not None, "video_inputs should not be None"
|
| 397 |
+
video_input = (video_inputs.pop()).permute(0, 2, 3, 1).numpy().astype(np.uint8)
|
| 398 |
+
fps_list.extend(video_kwargs.get('fps', []))
|
| 399 |
+
|
| 400 |
+
# encode image with base64
|
| 401 |
+
base64_frames = []
|
| 402 |
+
for frame in video_input:
|
| 403 |
+
img = Image.fromarray(frame)
|
| 404 |
+
output_buffer = BytesIO()
|
| 405 |
+
img.save(output_buffer, format="jpeg")
|
| 406 |
+
byte_data = output_buffer.getvalue()
|
| 407 |
+
base64_str = base64.b64encode(byte_data).decode("utf-8")
|
| 408 |
+
base64_frames.append(base64_str)
|
| 409 |
+
|
| 410 |
+
part_message = {
|
| 411 |
+
"type": "video_url",
|
| 412 |
+
"video_url": {"url": f"data:video/jpeg;base64,{','.join(base64_frames)}"}
|
| 413 |
+
}
|
| 414 |
+
new_content_list.append(part_message)
|
| 415 |
+
message["content"] = new_content_list
|
| 416 |
+
vllm_messages.append(message)
|
| 417 |
+
return vllm_messages, {'fps': fps_list}
|
| 418 |
+
|
| 419 |
+
|
| 420 |
+
video_messages, video_kwargs = prepare_message_for_vllm(video_messages)
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
chat_response = client.chat.completions.create(
|
| 424 |
+
model="Kwai-Keye/Keye-VL-8B-Preview",
|
| 425 |
+
messages=video_messages,
|
| 426 |
+
max_tokens=128,
|
| 427 |
+
extra_body={
|
| 428 |
+
"mm_processor_kwargs": video_kwargs
|
| 429 |
+
}
|
| 430 |
+
)
|
| 431 |
+
|
| 432 |
+
print("Chat response:", chat_response)
|
| 433 |
+
```
|
| 434 |
+
|
| 435 |
+
### Evaluation
|
| 436 |
+
See [evaluation/KC-MMBench/README.md](evaluation/KC-MMBench/README.md) for details.
|
| 437 |
+
|
| 438 |
+
## 👀 Architecture and Training Strategy
|
| 439 |
+
|
| 440 |
+
<div align="center">
|
| 441 |
+
<img src="asset/architecture.png" width="100%" alt="Kwai Keye Architecture">
|
| 442 |
+
<i> The Kwai Keye-VL-1.5 model architecture is based on the Qwen3-8B language model and incorporates a vision encoder initialized from the open-source SigLIP. It supports SlowFast video encoding and native dynamic resolution, preserving the original aspect ratio of images by dividing each into a 14x14 patch sequence. A simple MLP layer then maps and merges the visual tokens. The model uses 3D RoPE for unified processing of text, image, and video information.</i>
|
| 443 |
+
</div>
|
| 444 |
+
|
| 445 |
+
|
| 446 |
+
### 🌟 Pre-Train
|
| 447 |
+
|
| 448 |
+
|
| 449 |
+
<div align="center">
|
| 450 |
+
<img src="https://github.com/user-attachments/assets/83db5863-1227-435c-9e70-be8a18319a67" width="100%" alt="Kwai Keye Pretraining">
|
| 451 |
+
<i> A SlowFast video (generated by Kling) encoding demonstration: the Slow processes a smaller number of frames at higher resolution, while the Fast handles more frames at lower resolution.</i>
|
| 452 |
+
</div>
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
### 🌟 Post-Train
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
<div align="center">
|
| 459 |
+
<img src="https://github.com/user-attachments/assets/2c529a7d-7e18-4c3f-bafc-cb29fed8ff3b" width="100%" alt="Post-Training Pipeline">
|
| 460 |
+
<br>
|
| 461 |
+
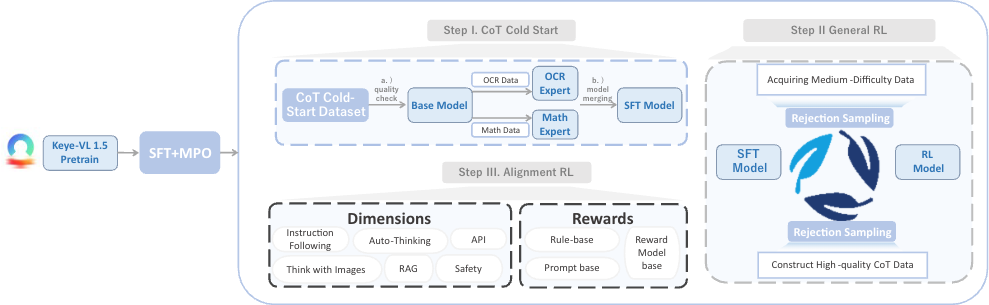
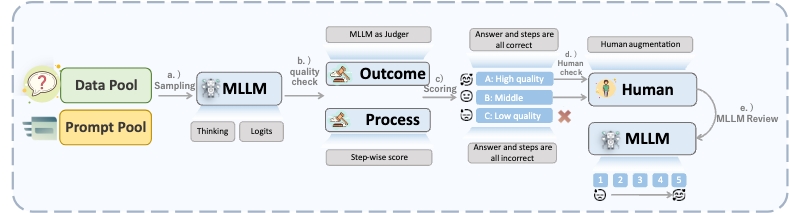
<i>The post-training process includes non-reasoning stage and reasoning stage. The non-reasoning stage is composed of SFT and MPO training. The reasoning stage consists of three key steps: CoT Cold Start (we construct a five-step construction pipeline to generate high-quality CoT Cold-Start Dataset and apply model merging to refine model performance), General RL (we concentrate on improving Keye-VL-1.5's reasoning ability, applying GSPO, we propose progressive hint sampling to fully take advantage of hard problems and iteratively improve the cold-start and general RL model), and Alignment RL (improving Keye-VL-1.5's instruction following, format adherence, preference alignment and RAG ability with our reward system, we construct instruction following data, reasoning data and RAG data for RL training in this step).</i>
|
| 462 |
+
</div>
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
## 📈 Experimental Results
|
| 466 |
+
|
| 467 |
+
<div align="center">
|
| 468 |
+
<img src="https://github.com/user-attachments/assets/76771d48-cd95-4782-b592-71f94160d9f1" width="100%" alt="Kwai Keye-VL-1.5 Performance">
|
| 469 |
+
</div>
|
| 470 |
+
|
| 471 |
+
1. Keye-VL-1.5-8B establishes itself with powerful, state-of-the-art perceptual abilities that are competitive with leading models.
|
| 472 |
+
2. Keye-VL-1.5-8B demonstrates exceptional proficiency in video understanding. Across a comprehensive suite of authoritative public video benchmarks, including Video-MME, Video-MMMU, TempCompass, LongVideoBench, and MMVU, the model's performance significantly surpasses that of other top-tier models of a comparable size.
|
| 473 |
+
3. In evaluation sets that require complex logical reasoning and mathematical problem-solving, such as WeMath, MathVerse, and LogicVista, Kwai Keye-VL-1.5-8B displays a strong performance curve. This highlights its advanced capacity for logical deduction and solving complex quantitative problems.
|
| 474 |
+
|
| 475 |
+
|
| 476 |
+
## ✒️ Citation
|
| 477 |
+
|
| 478 |
+
If you find our work helpful for your research, please consider citing our work.
|
| 479 |
+
|
| 480 |
+
```bibtex
|
| 481 |
+
@misc{Keye-VL-1.5,
|
| 482 |
+
title={Kwai Keye-VL-1.5 Technical Report},
|
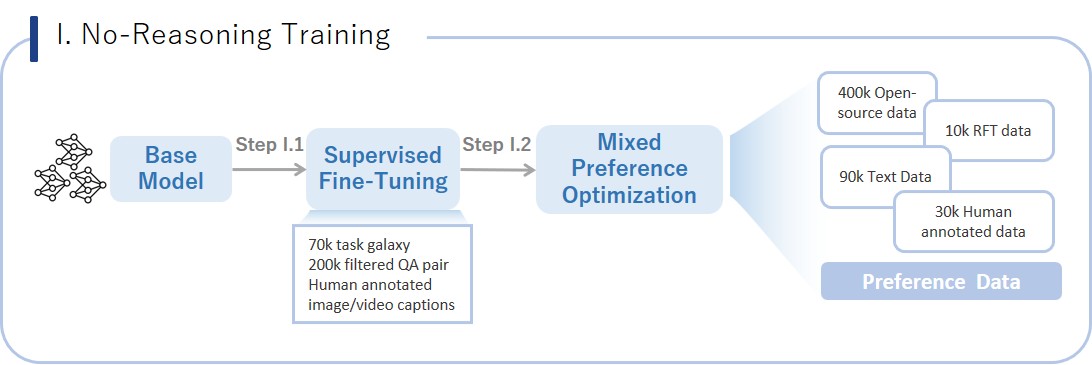
| 483 |
+
author={Kwai Keye Team},
|
| 484 |
+
year={2025},
|
| 485 |
+
eprint={TBD},
|
| 486 |
+
}
|
| 487 |
+
@misc{kwaikeyeteam2025kwaikeyevltechnicalreport,
|
| 488 |
+
title={Kwai Keye-VL Technical Report},
|
| 489 |
+
author={Kwai Keye Team},
|
| 490 |
+
year={2025},
|
| 491 |
+
eprint={2507.01949},
|
| 492 |
+
archivePrefix={arXiv},
|
| 493 |
+
primaryClass={cs.CV},
|
| 494 |
+
url={https://arxiv.org/abs/2507.01949},
|
| 495 |
+
}
|
| 496 |
+
```
|
| 497 |
+
|
| 498 |
+
## Acknowledgement
|
| 499 |
+
|
| 500 |
+
Kwai Keye-VL is developed based on the codebases of the following projects: [SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384), [Qwen3](https://github.com/QwenLM/Qwen3), [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL), [VLMEvalKit](https://github.com/open-compass/VLMEvalKit). We sincerely thank these projects for their outstanding work.
|
asset/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
asset/architecture.png
ADDED

|
Git LFS Details
|
asset/keye_logo_2.png
ADDED
|
|
Git LFS Details
|
asset/keyelogo/Keye-logo--black.png
ADDED
|
|
Git LFS Details
|
asset/keyelogo/Keye-logo--white.png
ADDED
|
|
Git LFS Details
|
asset/keyelogo/Keye-logo.png
ADDED
|
|
Git LFS Details
|
asset/performance.png
ADDED

|
Git LFS Details
|
asset/post1.jpeg
ADDED
|
asset/post1.png
ADDED
|
asset/post2.jpeg
ADDED

|
Git LFS Details
|
asset/post2.png
ADDED
|
asset/pre-train.png
ADDED

|
Git LFS Details
|
asset/teaser.png
ADDED

|
Git LFS Details
|
configuration_keye_vl_1_5.py
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
# coding=utf-8
|
| 2 |
-
# Copyright 2025 The Keye Team and The HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
# and OPT implementations in this library. It has been modified from its
|
|
|
|
| 1 |
# coding=utf-8
|
| 2 |
+
# Copyright 2025 The Kwai Keye Team and The HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
# and OPT implementations in this library. It has been modified from its
|
image_processing_keye_vl_1_5.py
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
# coding=utf-8
|
| 2 |
-
# Copyright 2024 The Keye team,
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
# and OPT implementations in this library. It has been modified from its
|
|
|
|
| 1 |
# coding=utf-8
|
| 2 |
+
# Copyright 2024 The Kwai Keye team, and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
# and OPT implementations in this library. It has been modified from its
|
modeling_keye_vl_1_5.py
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
# coding=utf-8
|
| 2 |
-
# Copyright 2025 The Keye Team and The HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
# and OPT implementations in this library. It has been modified from its
|
|
@@ -466,6 +466,11 @@ class KeyeVL1_5VisionAttention(nn.Module):
|
|
| 466 |
values = values.transpose(1, 2)
|
| 467 |
|
| 468 |
if not use_flash_attn:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 469 |
attention_interface: Callable = eager_attention_forward
|
| 470 |
if self.config._attn_implementation != "eager":
|
| 471 |
if self.config._attn_implementation == "sdpa" and output_attentions:
|
|
@@ -1649,8 +1654,8 @@ class KeyeVL1_5FlashAttention2(KeyeVL1_5Attention):
|
|
| 1649 |
|
| 1650 |
class KeyeVL1_5SdpaAttention(KeyeVL1_5Attention):
|
| 1651 |
"""
|
| 1652 |
-
|
| 1653 |
-
`
|
| 1654 |
SDPA API.
|
| 1655 |
"""
|
| 1656 |
|
|
@@ -1739,7 +1744,7 @@ class KeyeVL1_5SdpaAttention(KeyeVL1_5Attention):
|
|
| 1739 |
|
| 1740 |
|
| 1741 |
|
| 1742 |
-
|
| 1743 |
"eager": KeyeVL1_5Attention,
|
| 1744 |
"flash_attention_2": KeyeVL1_5FlashAttention2,
|
| 1745 |
"sdpa": KeyeVL1_5SdpaAttention,
|
|
@@ -1758,7 +1763,13 @@ class KeyeVL1_5DecoderLayer(nn.Module):
|
|
| 1758 |
)
|
| 1759 |
# config._attn_implementation = "eager"
|
| 1760 |
# assert config._attn_implementation == "flash_attention_2", f"config._attn_implementation is {config._attn_implementation}"
|
| 1761 |
-
self.self_attn =
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1762 |
self.mlp = Qwen3MLP(config)
|
| 1763 |
self.input_layernorm = Qwen3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 1764 |
self.post_attention_layernorm = Qwen3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
|
@@ -2455,7 +2466,6 @@ class KeyeVL1_5ForConditionalGeneration(Qwen3PreTrainedModel, GenerationMixin):
|
|
| 2455 |
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 2456 |
|
| 2457 |
spatial_merge_size = self.config.vision_config.spatial_merge_size
|
| 2458 |
-
|
| 2459 |
if inputs_embeds is None:
|
| 2460 |
inputs_embeds = self.model.embed_tokens(input_ids)
|
| 2461 |
if pixel_values is not None:
|
|
|
|
| 1 |
# coding=utf-8
|
| 2 |
+
# Copyright 2025 The Kwai Keye Team and The HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
# and OPT implementations in this library. It has been modified from its
|
|
|
|
| 466 |
values = values.transpose(1, 2)
|
| 467 |
|
| 468 |
if not use_flash_attn:
|
| 469 |
+
logger.warning_once(
|
| 470 |
+
"Flash attention is not enabled, which may impact performance. "
|
| 471 |
+
"Consider using `attn_implementation='flash_attention_2'` when loading the model "
|
| 472 |
+
"for better performance."
|
| 473 |
+
)
|
| 474 |
attention_interface: Callable = eager_attention_forward
|
| 475 |
if self.config._attn_implementation != "eager":
|
| 476 |
if self.config._attn_implementation == "sdpa" and output_attentions:
|
|
|
|
| 1654 |
|
| 1655 |
class KeyeVL1_5SdpaAttention(KeyeVL1_5Attention):
|
| 1656 |
"""
|
| 1657 |
+
KeyeVL1_5 attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
|
| 1658 |
+
`KeyeVL1_5Attention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
|
| 1659 |
SDPA API.
|
| 1660 |
"""
|
| 1661 |
|
|
|
|
| 1744 |
|
| 1745 |
|
| 1746 |
|
| 1747 |
+
ATTENTION_CLASSES = {
|
| 1748 |
"eager": KeyeVL1_5Attention,
|
| 1749 |
"flash_attention_2": KeyeVL1_5FlashAttention2,
|
| 1750 |
"sdpa": KeyeVL1_5SdpaAttention,
|
|
|
|
| 1763 |
)
|
| 1764 |
# config._attn_implementation = "eager"
|
| 1765 |
# assert config._attn_implementation == "flash_attention_2", f"config._attn_implementation is {config._attn_implementation}"
|
| 1766 |
+
self.self_attn = ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
|
| 1767 |
+
if not config._attn_implementation == "flash_attention_2":
|
| 1768 |
+
logger.warning_once(
|
| 1769 |
+
"Flash attention is not enabled, which may impact performance. "
|
| 1770 |
+
"Consider using `attn_implementation='flash_attention_2'` when loading the model "
|
| 1771 |
+
"for better performance."
|
| 1772 |
+
)
|
| 1773 |
self.mlp = Qwen3MLP(config)
|
| 1774 |
self.input_layernorm = Qwen3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 1775 |
self.post_attention_layernorm = Qwen3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
|
|
|
| 2466 |
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 2467 |
|
| 2468 |
spatial_merge_size = self.config.vision_config.spatial_merge_size
|
|
|
|
| 2469 |
if inputs_embeds is None:
|
| 2470 |
inputs_embeds = self.model.embed_tokens(input_ids)
|
| 2471 |
if pixel_values is not None:
|
processing_keye_vl_1_5.py
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
# coding=utf-8
|
| 2 |
-
# Copyright 2025 The Keye Team and The HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
# and OPT implementations in this library. It has been modified from its
|
|
|
|
| 1 |
# coding=utf-8
|
| 2 |
+
# Copyright 2025 The Kwai Keye Team and The HuggingFace Inc. team. All rights reserved.
|
| 3 |
#
|
| 4 |
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
# and OPT implementations in this library. It has been modified from its
|