
End of training
Browse files- README.md +19 -16
- all_results.json +10 -10
- classification_report.png +0 -0
- confusion_matrix.png +0 -0
- eval_results.json +5 -5
- model.safetensors +1 -1
- train_results.json +6 -6
- trainer_state.json +87 -12
- training_args.bin +1 -1
README.md
CHANGED
|
@@ -45,7 +45,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 45 |
|
| 46 |
This model is a fine-tuned version of [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) on the imagefolder dataset.
|
| 47 |
It achieves the following results on the evaluation set:
|
| 48 |
-
- Loss: 0.
|
| 49 |
- Precision: 0.9936
|
| 50 |
- Recall: 0.9934
|
| 51 |
- F1: 0.9934
|
|
@@ -82,21 +82,24 @@ The following hyperparameters were used during training:
|
|
| 82 |
|
| 83 |
### Training results
|
| 84 |
|
| 85 |
-
| Training Loss | Epoch | Step |
|
| 86 |
-
|
| 87 |
-
| 1.576 | 1.0 | 38 |
|
| 88 |
-
| 1.5469 | 2.0 | 76 |
|
| 89 |
-
| 1.5081 | 3.0 | 114 |
|
| 90 |
-
| 1.4278 | 4.0 | 152 |
|
| 91 |
-
| 1.2938 | 5.0 | 190 |
|
| 92 |
-
| 1.0696 | 6.0 | 228 | 0.
|
| 93 |
-
| 0.789 | 7.0 | 266 | 0.
|
| 94 |
-
| 0.506 | 8.0 | 304 | 0.
|
| 95 |
-
| 0.2876 | 9.0 | 342 | 0.
|
| 96 |
-
| 0.1722 | 10.0 | 380 | 0.
|
| 97 |
-
| 0.1082 | 11.0 | 418 | 0.
|
| 98 |
-
| 0.0715 | 12.0 | 456 | 0.
|
| 99 |
-
| 0.0492 | 13.0 | 494 | 0.
|
|
|
|
|
|
|
|
|
|
| 100 |
|
| 101 |
|
| 102 |
### Framework versions
|
|
|
|
| 45 |
|
| 46 |
This model is a fine-tuned version of [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) on the imagefolder dataset.
|
| 47 |
It achieves the following results on the evaluation set:
|
| 48 |
+
- Loss: 0.0266
|
| 49 |
- Precision: 0.9936
|
| 50 |
- Recall: 0.9934
|
| 51 |
- F1: 0.9934
|
|
|
|
| 82 |
|
| 83 |
### Training results
|
| 84 |
|
| 85 |
+
| Training Loss | Epoch | Step | Accuracy | Error Rate | F1 | Validation Loss | Precision | Recall | Top1 Accuracy |
|
| 86 |
+
|:-------------:|:-----:|:----:|:--------:|:----------:|:------:|:---------------:|:---------:|:------:|:-------------:|
|
| 87 |
+
| 1.576 | 1.0 | 38 | 0.3479 | 0.6521 | 0.2952 | 1.5660 | 0.3007 | 0.3684 | 0.3684 |
|
| 88 |
+
| 1.5469 | 2.0 | 76 | 0.3854 | 0.6146 | 0.3215 | 1.5353 | 0.3141 | 0.4079 | 0.4079 |
|
| 89 |
+
| 1.5081 | 3.0 | 114 | 0.4436 | 0.5564 | 0.3961 | 1.4782 | 0.5684 | 0.4671 | 0.4671 |
|
| 90 |
+
| 1.4278 | 4.0 | 152 | 0.5866 | 0.4134 | 0.5840 | 1.3718 | 0.7088 | 0.6053 | 0.6053 |
|
| 91 |
+
| 1.2938 | 5.0 | 190 | 0.8290 | 0.1710 | 0.8378 | 1.1909 | 0.8582 | 0.8355 | 0.8355 |
|
| 92 |
+
| 1.0696 | 6.0 | 228 | 0.9205 | 0.0795 | 0.9215 | 0.9353 | 0.9243 | 0.9211 | 0.9211 |
|
| 93 |
+
| 0.789 | 7.0 | 266 | 0.9691 | 0.0309 | 0.9673 | 0.6347 | 0.9680 | 0.9671 | 0.9671 |
|
| 94 |
+
| 0.506 | 8.0 | 304 | 0.9752 | 0.0248 | 0.9739 | 0.3910 | 0.9750 | 0.9737 | 0.9737 |
|
| 95 |
+
| 0.2876 | 9.0 | 342 | 0.9814 | 0.0186 | 0.9802 | 0.2126 | 0.9808 | 0.9803 | 0.9803 |
|
| 96 |
+
| 0.1722 | 10.0 | 380 | 0.9818 | 0.0182 | 0.9799 | 0.1409 | 0.9809 | 0.9803 | 0.9803 |
|
| 97 |
+
| 0.1082 | 11.0 | 418 | 0.9939 | 0.0061 | 0.9934 | 0.0794 | 0.9936 | 0.9934 | 0.9934 |
|
| 98 |
+
| 0.0715 | 12.0 | 456 | 0.9939 | 0.0061 | 0.9934 | 0.0577 | 0.9936 | 0.9934 | 0.9934 |
|
| 99 |
+
| 0.0492 | 13.0 | 494 | 0.9879 | 0.0121 | 0.9867 | 0.0440 | 0.9872 | 0.9868 | 0.9868 |
|
| 100 |
+
| 0.0375 | 14.0 | 532 | 0.0266 | 0.9936 | 0.9934 | 0.9934 | 0.9939 | 0.9934 | 0.0061 |
|
| 101 |
+
| 0.029 | 15.0 | 570 | 0.0313 | 0.9936 | 0.9934 | 0.9934 | 0.9939 | 0.9934 | 0.0061 |
|
| 102 |
+
| 0.0158 | 16.0 | 608 | 0.0408 | 0.9872 | 0.9868 | 0.9867 | 0.9879 | 0.9868 | 0.0121 |
|
| 103 |
|
| 104 |
|
| 105 |
### Framework versions
|
all_results.json
CHANGED
|
@@ -1,18 +1,18 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
"eval_accuracy": 0.9939393939393939,
|
| 4 |
"eval_error_rate": 0.0060606060606061,
|
| 5 |
"eval_f1": 0.993419541966282,
|
| 6 |
-
"eval_loss": 0.
|
| 7 |
"eval_precision": 0.9936145510835913,
|
| 8 |
"eval_recall": 0.993421052631579,
|
| 9 |
-
"eval_runtime":
|
| 10 |
-
"eval_samples_per_second":
|
| 11 |
-
"eval_steps_per_second": 0.
|
| 12 |
"eval_top1_accuracy": 0.993421052631579,
|
| 13 |
-
"total_flos":
|
| 14 |
-
"train_loss": 0.
|
| 15 |
-
"train_runtime":
|
| 16 |
-
"train_samples_per_second":
|
| 17 |
-
"train_steps_per_second": 0.
|
| 18 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 16.0,
|
| 3 |
"eval_accuracy": 0.9939393939393939,
|
| 4 |
"eval_error_rate": 0.0060606060606061,
|
| 5 |
"eval_f1": 0.993419541966282,
|
| 6 |
+
"eval_loss": 0.02658209018409252,
|
| 7 |
"eval_precision": 0.9936145510835913,
|
| 8 |
"eval_recall": 0.993421052631579,
|
| 9 |
+
"eval_runtime": 48.6228,
|
| 10 |
+
"eval_samples_per_second": 3.126,
|
| 11 |
+
"eval_steps_per_second": 0.103,
|
| 12 |
"eval_top1_accuracy": 0.993421052631579,
|
| 13 |
+
"total_flos": 4.889238721360036e+17,
|
| 14 |
+
"train_loss": 0.005142551405649436,
|
| 15 |
+
"train_runtime": 1686.6977,
|
| 16 |
+
"train_samples_per_second": 21.628,
|
| 17 |
+
"train_steps_per_second": 0.676
|
| 18 |
}
|
classification_report.png
ADDED
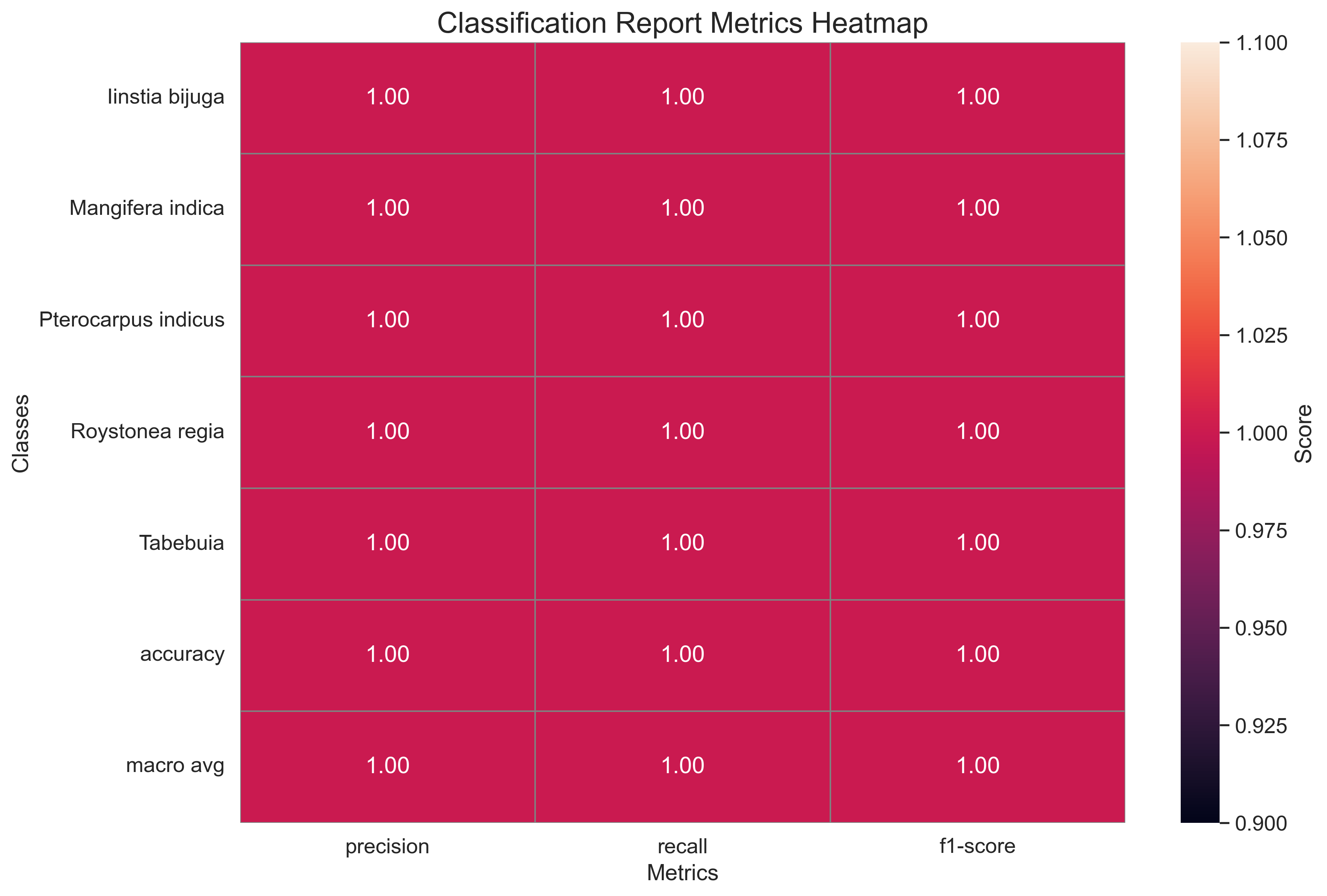
|
confusion_matrix.png
ADDED
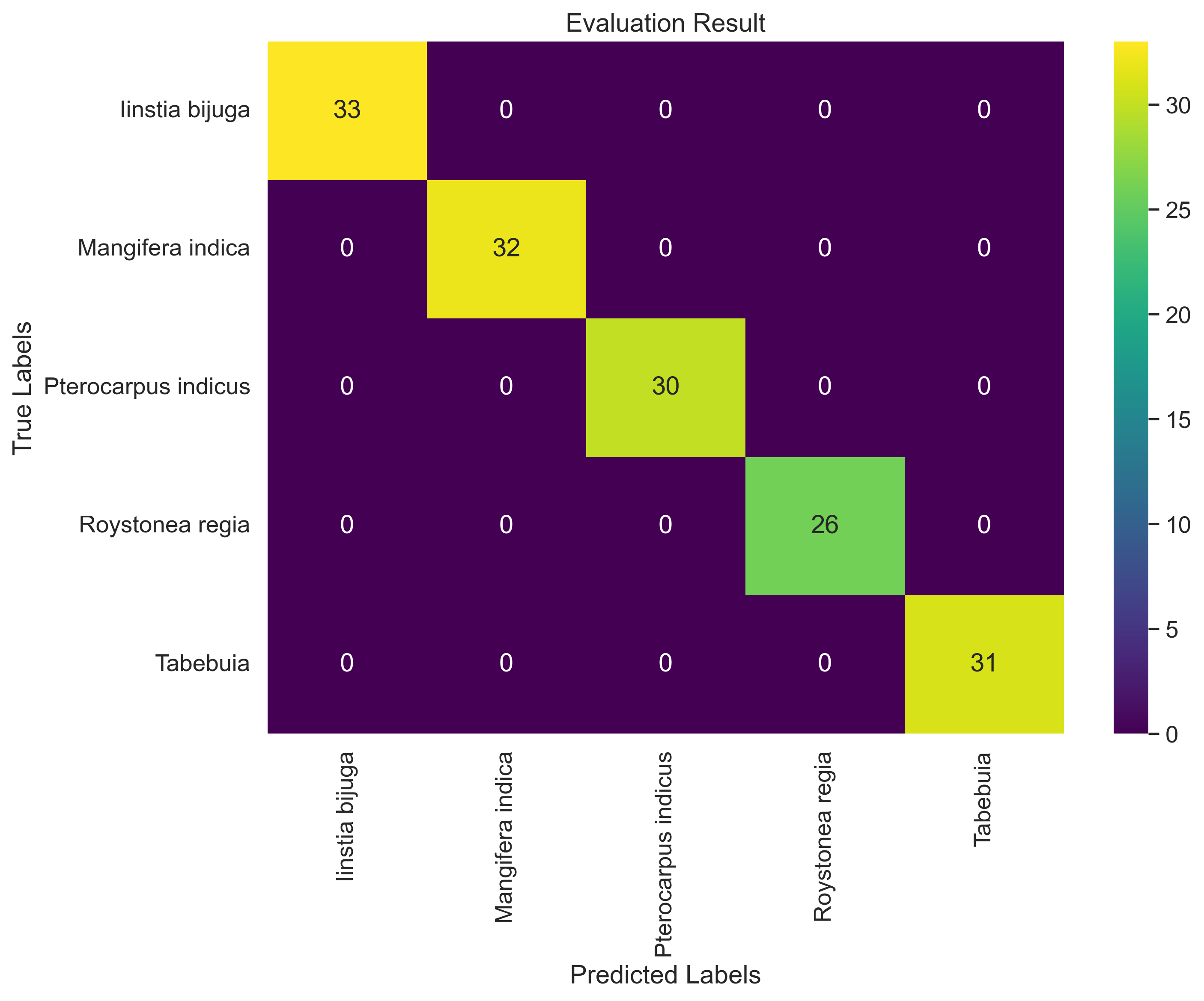
|
eval_results.json
CHANGED
|
@@ -1,13 +1,13 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
"eval_accuracy": 0.9939393939393939,
|
| 4 |
"eval_error_rate": 0.0060606060606061,
|
| 5 |
"eval_f1": 0.993419541966282,
|
| 6 |
-
"eval_loss": 0.
|
| 7 |
"eval_precision": 0.9936145510835913,
|
| 8 |
"eval_recall": 0.993421052631579,
|
| 9 |
-
"eval_runtime":
|
| 10 |
-
"eval_samples_per_second":
|
| 11 |
-
"eval_steps_per_second": 0.
|
| 12 |
"eval_top1_accuracy": 0.993421052631579
|
| 13 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 16.0,
|
| 3 |
"eval_accuracy": 0.9939393939393939,
|
| 4 |
"eval_error_rate": 0.0060606060606061,
|
| 5 |
"eval_f1": 0.993419541966282,
|
| 6 |
+
"eval_loss": 0.02658209018409252,
|
| 7 |
"eval_precision": 0.9936145510835913,
|
| 8 |
"eval_recall": 0.993421052631579,
|
| 9 |
+
"eval_runtime": 48.6228,
|
| 10 |
+
"eval_samples_per_second": 3.126,
|
| 11 |
+
"eval_steps_per_second": 0.103,
|
| 12 |
"eval_top1_accuracy": 0.993421052631579
|
| 13 |
}
|
model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 111317164
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62798162e3f57ffa189d6ee7c57129c330720ace9dcf029005622f20bf4eb7dd
|
| 3 |
size 111317164
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss": 0.
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 16.0,
|
| 3 |
+
"total_flos": 4.889238721360036e+17,
|
| 4 |
+
"train_loss": 0.005142551405649436,
|
| 5 |
+
"train_runtime": 1686.6977,
|
| 6 |
+
"train_samples_per_second": 21.628,
|
| 7 |
+
"train_steps_per_second": 0.676
|
| 8 |
}
|
trainer_state.json
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
{
|
| 2 |
-
"best_metric": 0.
|
| 3 |
-
"best_model_checkpoint": "convnext-tiny-224-finetuned-barkley\\checkpoint-
|
| 4 |
-
"epoch":
|
| 5 |
"eval_steps": 500,
|
| 6 |
-
"global_step":
|
| 7 |
"is_hyper_param_search": false,
|
| 8 |
"is_local_process_zero": true,
|
| 9 |
"is_world_process_zero": true,
|
|
@@ -334,13 +334,88 @@
|
|
| 334 |
"step": 494
|
| 335 |
},
|
| 336 |
{
|
| 337 |
-
"epoch":
|
| 338 |
-
"
|
| 339 |
-
|
| 340 |
-
|
| 341 |
-
"
|
| 342 |
-
"
|
| 343 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 344 |
}
|
| 345 |
],
|
| 346 |
"logging_steps": 500,
|
|
@@ -369,7 +444,7 @@
|
|
| 369 |
"attributes": {}
|
| 370 |
}
|
| 371 |
},
|
| 372 |
-
"total_flos":
|
| 373 |
"train_batch_size": 32,
|
| 374 |
"trial_name": null,
|
| 375 |
"trial_params": null
|
|
|
|
| 1 |
{
|
| 2 |
+
"best_metric": 0.02658209018409252,
|
| 3 |
+
"best_model_checkpoint": "convnext-tiny-224-finetuned-barkley\\checkpoint-532",
|
| 4 |
+
"epoch": 16.0,
|
| 5 |
"eval_steps": 500,
|
| 6 |
+
"global_step": 608,
|
| 7 |
"is_hyper_param_search": false,
|
| 8 |
"is_local_process_zero": true,
|
| 9 |
"is_world_process_zero": true,
|
|
|
|
| 334 |
"step": 494
|
| 335 |
},
|
| 336 |
{
|
| 337 |
+
"epoch": 14.0,
|
| 338 |
+
"train_accuracy": 0.9950657894736842
|
| 339 |
+
},
|
| 340 |
+
{
|
| 341 |
+
"epoch": 14.0,
|
| 342 |
+
"grad_norm": 0.6904532313346863,
|
| 343 |
+
"learning_rate": 1.9527753116224055e-05,
|
| 344 |
+
"loss": 0.0375,
|
| 345 |
+
"step": 532
|
| 346 |
+
},
|
| 347 |
+
{
|
| 348 |
+
"epoch": 14.0,
|
| 349 |
+
"eval_accuracy": 0.9939393939393939,
|
| 350 |
+
"eval_error_rate": 0.0060606060606061,
|
| 351 |
+
"eval_f1": 0.993419541966282,
|
| 352 |
+
"eval_loss": 0.02658209018409252,
|
| 353 |
+
"eval_precision": 0.9936145510835913,
|
| 354 |
+
"eval_recall": 0.993421052631579,
|
| 355 |
+
"eval_runtime": 52.868,
|
| 356 |
+
"eval_samples_per_second": 2.875,
|
| 357 |
+
"eval_steps_per_second": 0.095,
|
| 358 |
+
"eval_top1_accuracy": 0.993421052631579,
|
| 359 |
+
"step": 532
|
| 360 |
+
},
|
| 361 |
+
{
|
| 362 |
+
"epoch": 15.0,
|
| 363 |
+
"train_accuracy": 0.993421052631579
|
| 364 |
+
},
|
| 365 |
+
{
|
| 366 |
+
"epoch": 15.0,
|
| 367 |
+
"grad_norm": 1.3837875127792358,
|
| 368 |
+
"learning_rate": 1.911506206288264e-05,
|
| 369 |
+
"loss": 0.029,
|
| 370 |
+
"step": 570
|
| 371 |
+
},
|
| 372 |
+
{
|
| 373 |
+
"epoch": 15.0,
|
| 374 |
+
"eval_accuracy": 0.9939393939393939,
|
| 375 |
+
"eval_error_rate": 0.0060606060606061,
|
| 376 |
+
"eval_f1": 0.993419541966282,
|
| 377 |
+
"eval_loss": 0.03128606453537941,
|
| 378 |
+
"eval_precision": 0.9936145510835913,
|
| 379 |
+
"eval_recall": 0.993421052631579,
|
| 380 |
+
"eval_runtime": 52.6477,
|
| 381 |
+
"eval_samples_per_second": 2.887,
|
| 382 |
+
"eval_steps_per_second": 0.095,
|
| 383 |
+
"eval_top1_accuracy": 0.993421052631579,
|
| 384 |
+
"step": 570
|
| 385 |
+
},
|
| 386 |
+
{
|
| 387 |
+
"epoch": 16.0,
|
| 388 |
+
"train_accuracy": 0.9985380116959064
|
| 389 |
+
},
|
| 390 |
+
{
|
| 391 |
+
"epoch": 16.0,
|
| 392 |
+
"grad_norm": 2.590073823928833,
|
| 393 |
+
"learning_rate": 1.8565251293796298e-05,
|
| 394 |
+
"loss": 0.0158,
|
| 395 |
+
"step": 608
|
| 396 |
+
},
|
| 397 |
+
{
|
| 398 |
+
"epoch": 16.0,
|
| 399 |
+
"eval_accuracy": 0.9878787878787879,
|
| 400 |
+
"eval_error_rate": 0.012121212121212088,
|
| 401 |
+
"eval_f1": 0.9867362170674966,
|
| 402 |
+
"eval_loss": 0.04083804041147232,
|
| 403 |
+
"eval_precision": 0.9872349657566376,
|
| 404 |
+
"eval_recall": 0.9868421052631579,
|
| 405 |
+
"eval_runtime": 52.9598,
|
| 406 |
+
"eval_samples_per_second": 2.87,
|
| 407 |
+
"eval_steps_per_second": 0.094,
|
| 408 |
+
"eval_top1_accuracy": 0.9868421052631579,
|
| 409 |
+
"step": 608
|
| 410 |
+
},
|
| 411 |
+
{
|
| 412 |
+
"epoch": 16.0,
|
| 413 |
+
"step": 608,
|
| 414 |
+
"total_flos": 4.889238721360036e+17,
|
| 415 |
+
"train_loss": 0.005142551405649436,
|
| 416 |
+
"train_runtime": 1686.6977,
|
| 417 |
+
"train_samples_per_second": 21.628,
|
| 418 |
+
"train_steps_per_second": 0.676
|
| 419 |
}
|
| 420 |
],
|
| 421 |
"logging_steps": 500,
|
|
|
|
| 444 |
"attributes": {}
|
| 445 |
}
|
| 446 |
},
|
| 447 |
+
"total_flos": 4.889238721360036e+17,
|
| 448 |
"train_batch_size": 32,
|
| 449 |
"trial_name": null,
|
| 450 |
"trial_params": null
|
training_args.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 5176
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d1b57bacbaaf9003431d769cf77cb4ade538a6e4c81615d2dad23b4a752322a3
|
| 3 |
size 5176
|