IFAD AI Benchmark (Garden V1)











Evaluating AI model capabilities for the IFAD-specific context
IFAD ICT AI Team, 30 June 2025
Abstract
This article outlines the methodology and findings of an AI model evaluation carried out by the International Fund for Agricultural Development (IFAD) as part of a structured AI benchmarking initiative. As AI models become increasingly integrated into digital tools and operational systems, choosing models that can perform reliably and are aligned with real-world use cases is becoming a critical task for organizations aiming to apply AI in a meaningful and responsible manner. The IFAD AI Benchmark, codenamed Garden V1, provides a clear and standardized benchmark for AI model evaluation in the organization, covering over 30 tests and 30 models relevant to the IFAD context. The benchmark focuses on four types of tasks – Choice Selection, Language Translation, Information Retrieval, and Information Ordering – and includes results for several models ranging from specialized AI service providers to general-purpose open-source offerings. With the IFAD AI Benchmark, IFAD is equipped to make more informed decisions on model selection and deployment for feature integration, technical development, organizational operations, and further research.
Figure 1: Visual Summary of Garden V1 Tests
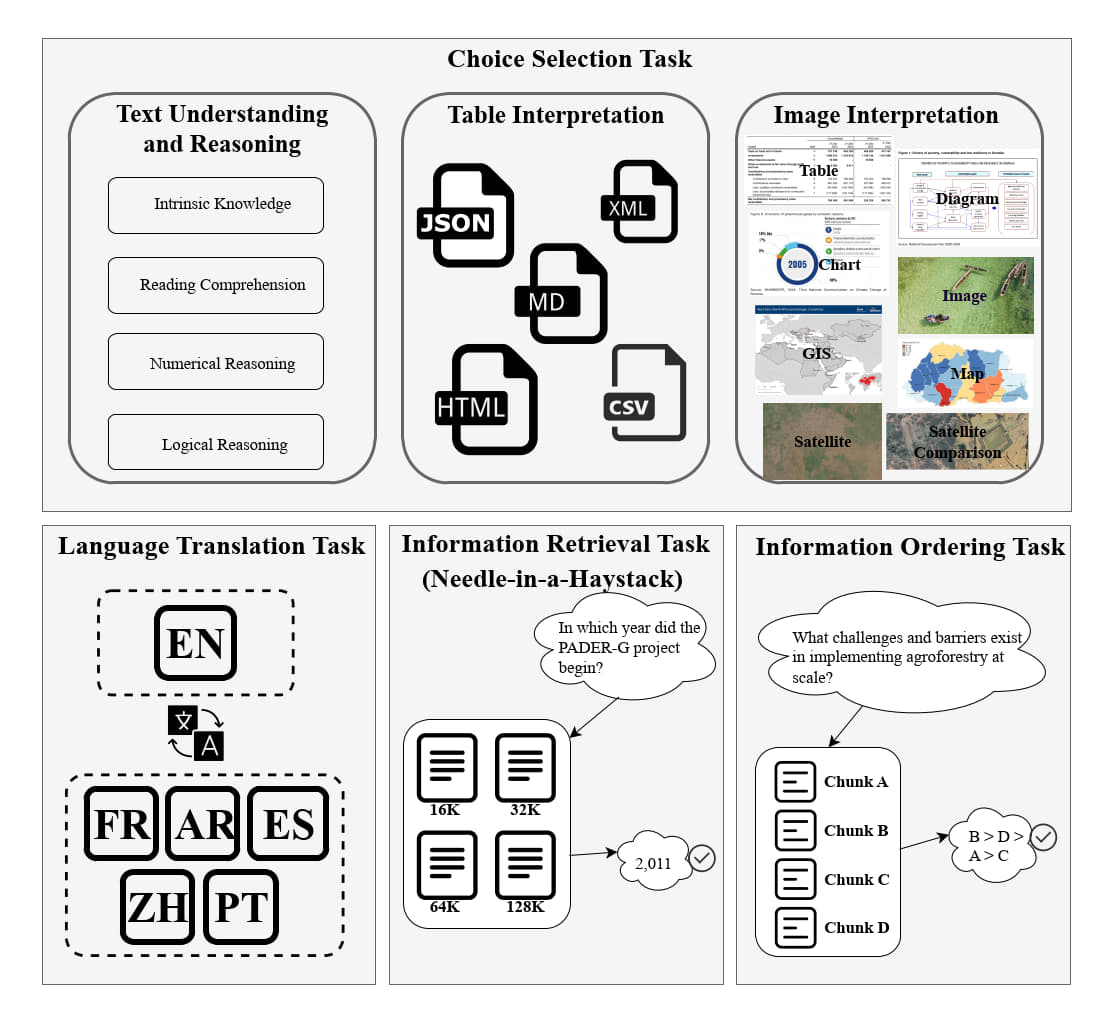
Garden V1 is IFAD's first, but not final, attempt to improve the responsible and effective use of AI at IFAD. Given the successful internal adoption of Garden V1 and the positive early feedback from industry peers, we are sharing our practical experiences and lessons learned to help guide others working on similar projects. Additionally, we are also sharing our work to invite constructive feedback from the community in order to help us shape Garden V2.
Introduction
AI models, including Large Language Models (LLMs), have emerged as powerful tools for a wide variety of both specialized and general-purpose tasks, from translation and summarization to question answering and reasoning. As these models proliferate, selecting the most suitable one for a given task becomes increasingly challenging, especially when organizational requirements deviate from general benchmarks. As IFAD continues to embed and mainstream AI-centric workflows in the organization with a global scope, multilingual documents, domain-specific knowledge, and complex organizational data, general benchmarks may not be fully aligned with context-specific uses cases relevant to IFAD.
To address this gap, we introduce the IFAD AI Benchmark – codenamed Garden V1 – as a reproducible, IFAD-centric evaluation framework that measures AI model capabilities on four types of tasks: Choice Selection, Language Translation, Information Retrieval, and Information Ordering. Each task simulates an IFAD-specific information processing scenario ranging from multiple-choice questions on tables and images, to multilingual translation and long-context retrieval using documents and samples tailored to the organizational context.
As of 09/05/2025, Garden V1 consists of 32 task-based tests with 20 questions each, totalling 640 questions overall. Garden V1, also as of 09/05/2025, has been applied to 33 different AI models and services. While not all tests are applicable to all models, the breadth of model-test coverage thus far has produced valuable and actionable information for IFAD in relation to AI technology adoption, development, and deployment within the organization.
Background and Motivation
In recent years, AI models have become an important technology in the digital solutions and corporate systems portfolio of organizations, offering powerful capabilities across many operational tasks such as text understanding, language translation, information retrieval, and more. To evaluate and compare these models, several general- purpose benchmarks have been developed, such as:
- MMLU, comprising over 15,000 multiple-choice questions across 57 subjects.
- BIG-bench, designed to test the capabilities of language models on a diverse set of tasks, focusing on reasoning and problem solving.
- HellaSwag, focused on common sense reasoning and designed to evaluate a model’s ability to choose the most plausible continuation of a given text.
- MTEB, a benchmark for text embeddings that evaluates embedding-specific tasks, such as information retrieval.
Although these and other similar benchmarks provide valuable information on the general capabilities of AI models, they often fail to assess model performance in specific organizational contexts. For instance, IFAD’s unique requirements – such as translating documents between English and its three other official languages (Arabic, French, Spanish), retrieving specific information from extensive technical reports, and ranking information based on relevance across multiple subjects – are not adequately addressed by these general benchmarks.
Additionally, the sheer volume of benchmarks and the selective reporting of popular model results may cause more relevant benchmark results to be overlooked, especially if conversations steer towards reporting on positive results only and surpassing previous records. For example, the release of GPT-4 was announced with excellent marks in the 99th percentile of the Graduate Record Examination (GRE) Verbal test. However, for IFAD’s context, the more relevant marks were related to the significant differences in results for AP US History (89th-100th percentile) versus AP World History (65th-87th percentile), where AP World History is much more relevant to IFAD’s global operations.
Moreover, recent studies highlight the limitations of existing benchmarks, indicating that the distributional assumptions underlying many benchmarks may not align with real-world applications, leading to potential misrepresentations of model performance. At the same time, the rapid performance gains of modern AI models have led to saturation effects as models routinely maximize benchmark scores and thereby erode these tests’ ability to distinguish incremental improvements among leading systems.
Recognizing these realities and their associated challenges, there is a pressing need for domain-specific evaluation frameworks that align with organizational objectives. For IFAD, this led to the development of Garden V1 as an internal AI model benchmark that reflects the organization’s operational needs, ensuring that selected AI models can effectively support the organization’s work.
Test Dataset and Task Definition
We constructed a dataset of tests based on the practical needs of IFAD’s internal operations, ensuring alignment with real-world business scenarios. We designed four categories of tests based on different application scenarios: Choice Selection, Language Translation, Information Retrieval, and Information Ordering. Each category is composed of multiple test tasks that share similarities in how they are conducted (i.e., the task given to the AI model). For each testing task, we designed a corresponding dataset of questions and answers, summarized in Table 1.
Table 1: Summary of Test Dataset
| CATEGORY | TASK | MODALITY | FORMAT | METRICS | QUESTIONS |
| Choice Selection | Intrinsic Knowledge | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Reading Comprehension | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Numerical Reasoning | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Logical Reasoning | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Table Interpretation (CSV) | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Table Interpretation (MD) | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Table Interpretation (JSON) | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Table Interpretation (HTML) | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Table Interpretation (XML) | Text | Multiple choice | Correct choice | 20 |
| Choice Selection | Table Interpretation (Image) | Image | Multiple choice | Correct choice | 20 |
| Choice Selection | Diagram Interpretation | Image | Multiple choice | Correct choice | 20 |
| Choice Selection | Chart Interpretation | Image | Multiple choice | Correct choice | 20 |
| Choice Selection | Image Interpretation | Image | Multiple choice | Correct choice | 20 |
| Choice Selection | GIS Interpretation | Image | Multiple choice | Correct choice | 20 |
| Choice Selection | Map Interpretation | Image | Multiple choice | Correct choice | 20 |
| Choice Selection | Satellite Interpretation | Image | Multiple choice | Correct choice | 20 |
| Choice Selection | Satellite Comparison | Image | Multiple choice | Correct choice | 20 |
| Language Translation | English to French | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | English to Spanish | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | English to Arabic | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | English to Portuguese | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | English to Chinese (Simplified) | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | French to English | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | Spanish to English | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | Arabic to English | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | Portuguese to English | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Language Translation | Chinese (Simplified) to English | Text | Translated text | BLEU, ROUGE, METEOR, BGE-M3 | 20 |
| Information Retrieval | Needle-in-a-Haystack (16K) | Text | Semantically correct answer | Response match | 20 |
| Information Retrieval | Needle-in-a-Haystack (32K) | Text | Semantically correct answer | Response match | 20 |
| Information Retrieval | Needle-in-a-Haystack (64K) | Text | Semantically correct answer | Response match | 20 |
| Information Retrieval | Needle-in-a-Haystack (128K) | Text | Semantically correct answer | Response match | 20 |
| Information Ordering | Chunk Selection | Text | Chunk order | NDCG | 20 |
Choice Selection
Compared with general question-answering tasks, the use of AI models within IFAD often involves domain-specific questions that require the model to understand complex relations between text, tables, and images given by users in order to provide a clear answer. Such questions demand not only natural language understanding, but also the ability to parse text information stored in various kinds of formats (e.g., HTML, Markdown, XML, JSON) and various types of images (e.g., table images, statistical charts, geographic maps). To evaluate AI model performance in these scenarios, we designed the Choice Selection category of tests to assess a given model’s understanding of complex data and specialized queries. These tests are divided into 8 image-related tests, 5 table-related tests, and 4 text-related tests, with each test comprising 20 multiple-choice questions with one correct answer. For these tests, the AI model must answer each question based on the data presented in the specific format (e.g. table, image, or text.)
Test Example: Choice Selection
Question: IFAD lending terms are determined in accordance with the Policies and Criteria for IFAD Financing and the Framework on IFAD Financing Conditions. What are the lending terms primarily based on?
A. The country’s agricultural output and rural development needs
B. The country’s level of economic vulnerability and inflation rate
C. The country's gross national income per capita (GNI) and a creditworthiness assessment
D. The country’s human development index (HDI) and external debt burden
Language Translation
English, Arabic, French, and Spanish are IFAD’s four official languages, which frequently appear in a variety of organizational documents and communication channels. In addition to these four official languages, we also include Portuguese and Chinese in Garden V1 to expand testing boundaries. Portuguese, in particular, is commonly encountered in IFAD’s work in locations with Portuguese speakers. In IFAD’s daily operations, translation across multiple languages is frequently required for both official and non-official purposes. Oftentimes, multiple languages appear in the same context, such as in detailed and lengthy project reports. Unlike general-purpose machine translation, translation in IFAD often involves knowledge of specialized terminology, complex expressions, and cultural nuance. To evaluate AI model performance in language translation scenarios, we designed the Language Translation category of tests, comprising 10 tests tasks representing bidirectional translations between language pairs. Each task consists of 20 data pairs, each containing the ground truth text translations in two of the supported languages (always to/from English and another language). For these tests, the AI model must translate each text excerpt from the source language to the target language, in both directions.
Test Example: Language Translation
English: Many rural people living in poverty face massive economic, social and environmental challenges – from climate change and food insecurity, to inequality, conflict and lack of access to resources...
Spanish: Muchas de las poblaciones rurales que viven en la pobreza se enfrentan a numerosas dificultades económicas, sociales y ambientales, desde el cambio climático a la inseguridad alimentaria o la desigualdad, los conflictos y la falta de acceso a los recursos...
Information Retrieval
IFAD produces a substantial number of reports and documents, many of which are extensive in length and often surpass hundreds and thousands of pages. These reports and documents go through several rounds of drafting and review, so a common operational need is to locate specific details and changes within a given report. Therefore, it is essential to evaluate how different models perform in retrieving information across various text lengths, especially when AI models are integrated in document review and analysis processes. In the Information Retrieval category of tests, we designed four “Needle-in-a-Haystack” test tasks with different context lengths by input token count: 16K, 32K, 64K, and 128K. In each task, a document of the corresponding context length is provided as the retrieval source, and the model must reference this retrieval source to find the specific information required to answer each question asked. For these tests, a correct answer is determined with an "LLMs-as-judges" approach where an additional LLM (in this case GPT-4o) plays the role of an answer evaluator that determines whether the provided answer is semantically similar to the true answer.
Test Example: Information Retrieval
Source: Research Series Issue 28 - Understanding the dynamics of adoption decisions and their poverty impacts: The case of improved maize seeds in Uganda
Question: How many households were surveyed in the National Panel Survey of Uganda in 2009?
2,975
Information Ordering
In systems and applications involving retrieval-augmented generation (RAG), it is critical not only to retrieve relevant information but also to present it in a logically coherent and semantically sound order. This is particularly important when dealing with multi-paragraph responses or when synthesizing information from multiple sources, which is often the case in document-centric workflows at IFAD. To evaluate an AI model’s ability to perform suitable information ordering in a RAG context, we designed a single Information Ordering test task focused on the relevance of a model’s vectorization process and semantic similarity mapping. In the test, each of the 20-question test sets are accompanied by four reference text chunks that contain varying degrees of relevant information that can help answer the question. The objective is to assess whether the model can understand the logical flow of information and reconstruct the most appropriate order based on content cohesion and semantic continuity. For these tests, the AI model must first vectorize the given chunks as well as the question; then, cosine similarity scores are calculated for each chunk against the question itself to determine the chunk relevance order.
Test Example: Information Ordering
Chunk 1 (C1): Agroforestry’s ecological and biophysical impacts have been extensively studied and reported, with environmental benefits such as soil improvement, enhanced biodiversity, better air and water quality, and clear benefits in terms of climate adaptation, mitigation and biodiversity…
Chunk 2 (C2): Despite the potential of agroforestry, ongoing challenges persist in its implementation. These include creating effective incentives, providing adequate technical support, establishing financing mechanisms, ensuring long-term economic sustainability, and enhancing the overall enabling environment…
Chunk 3 (C3): The initiatives in woodlots, agroforestry, and mangroves promoted sustainable natural resource management, including land and water management practices. The mangrove restoration initiative has the highest potential for carbon sequestration per hectare among the ASAP projects, with sequestration of 8.4 tons of CO2 per hectare per year over 20 years…
Chunk 4 (C4): Evergreen agriculture practices are now part of the solution to tackle climate change and the adoption is on a rising trend in several countries in the region. Conservation Agriculture, including agroforestry, specialty crops, and permanent cropping systems, promotes food sufficiency, poverty reduction, and value added production through improved crop and animal production and production in relation to market opportunities…
Question: How does agroforestry contribute to environmental sustainability and climate resilience?
C1, C3, C2, C4
Model List and Evaluation Metrics
We evaluated a broad selection of AI models – including open-source models, proprietary models, and specialized services – against our test dataset. These models span different types broadly defined by their capabilities, such as generation, reasoning, and embedding. The models are further categorized by their input and output modalities such as text, image, and vectors. The list of selected models, potentially relevant to and suitable for IFAD, is summarized in Table 2.
Table 2: Summary of Selected Models
| MODEL | ORGANIZATION | TYPE | INPUT | OUTPUT |
| GPT-4.1 | OpenAI | Generation | Text, Image | Text |
| GPT-4.1-mini | OpenAI | Generation | Text, Image | Text |
| GPT-4.1-nano | OpenAI | Generation | Text, Image | Text |
| GPT-4o | OpenAI | Generation | Text, Image | Text |
| GPT-4o-mini | OpenAI | Generation | Text, Image | Text |
| o4-mini | OpenAI | Reasoning | Text, Image | Text |
| o3 | OpenAI | Reasoning | Text, Image | Text |
| o3-mini | OpenAI | Reasoning | Text | Text |
| o1 | OpenAI | Reasoning | Text, Image | Text |
| Llama-4-Maverick-17B-128E-Instruct | Meta | Generation | Text, Image | Text |
| Llama-4-Scout-17B-16E-Instruct | Meta | Generation | Text, Image | Text |
| Llama-3.3-70B-Instruct | Meta | Generation | Text | Text |
| Llama-3.1-70B-Instruct | Meta | Generation | Text | Text |
| QwQ-32B | Alibaba | Reasoning | Text | Text |
| Qwen2.5-72B-Instruct | Alibaba | Generation | Text | Text |
| Qwen2.5-32B-Instruct | Alibaba | Generation | Text | Text |
| DeepSeek-V3-0324 | DeepSeek | Generation | Text | Text |
| DeepSeek-R1-Distill-Llama-70B | DeepSeek | Reasoning | Text | Text |
| DeepSeek-R1-Distill-Qwen-32B | DeepSeek | Reasoning | Text | Text |
| phi-4 | Microsoft | Generation | Text | Text |
| Phi-3.5-MoE-instruct | Microsoft | Generation | Text | Text |
| Phi-3-medium-128k-instruct | Microsoft | Generation | Text | Text |
| gemma-3-27b-it | Generation | Text, Image | Text | |
| Mistral-Nemo-Instruct-2407 | Mistral AI | Generation | Text | Text |
| Falcon3-10B-Instruct | Technology Innovation Institute | Generation | Text | Text |
| EuroLLM-9B-Instruct | UTTER Project (Horizon Europe) | Generation | Text | Text |
| Azure Text Translation | Microsoft | Specialized Service | Text | Text |
| DeepL Translate | DeepL | Specialized Service | Text | Text |
| text-embedding-3-large | OpenAI | Embeddings | Text | Vector |
| text-embedding-3-small | OpenAI | Embeddings | Text | Vector |
| text-embedding-ada-002 | OpenAI | Embeddings | Text | Vector |
| bge-m3 | Beijing Academy of Artificial Intelligence | Embeddings | Text | Vector |
| mxbai-embed-large-v1 | Mixedbread | Embeddings | Text | Vector |
For generation models specifically, multiple test iterations were conducted with different combinations of temperature and top-p parameter values for each model. Because these parameters significantly influence the behaviour of generation models, it was critical to explore model test scores across a wider parameter space.
Choice Selection
In a choice selection test, the task for the AI model is to read each question and select the correct answer from four possible options. Scoring is binary, with 1 point given for a correct answer and 0 points given for an incorrect answer. The metric for this test is simply the number of correct answers over the total number of questions, that is, the correct choice percentage.
Prompt Template: Choice Selection
System Prompt
You are tasked with answering multiple choice questions about a text. Read the question and answer the question. Provide the answer in the following JSON format: {"answer": "Letter"}. For example: {"answer" : "C"}
User Prompt:
Question: {question}
A. {option_a}
B. {option_b}
C. {option_c}
D. {option_d}
Language Translation
In a language translation test, the task for the AI model is to generate translations from a given source text to a specific target language. The generated translation is then compared against human-generated reference texts to assess translation quality. To ensure objectivity, standardize scoring, and facilitate comparison, several well-established machine translation metrics are employed, including BLEU, ROUGE, and METEOR. Additionally, sentence similarity scoring is applied based on the BGE-M3 embedding model, given this particular model’s support for multiple languages and its relatively large context length. While the use of BGE-M3 may be unconventional as a machine translation metric, we opted to use it as a means to better understand the semantic closeness of translations rather than simply relying on traditional n-gram matches. For all metrics, translation scores range from 0 to 1, where higher scores indicate a greater translation match.
Prompt Template: Language Translation
System Prompt
You are tasked with translating the following text from {source_lang} to {target_lang}. Provide the translation and only the translation.
User Prompt:
Text: {text}
Information Retrieval
In an information retrieval test, also known as a Needle-in-a-Haystack test, the task for the AI model is to find and extract specific information (i.e., the needle) within a long compilation of text (i.e., the haystack). Since the context length might affect the precision of the retrieval, we provide 4 test tasks each consisting of 20 questions and a reference document with different context lengths by input token count: 16K, 32K, 64K, and 128K. Scoring is binary, with 1 point given for a correct answer and 0 points given for an incorrect answer. Since AI models may give different versions of a correct answer (e.g., “100%” or “100 per cent”), an exact string match may not be suitable for the evaluation process. Therefore, an LLM-assisted validation step is required to determine whether the answer provided by the model is semantically equivalent to the expected answer. After the LLM-assisted validation takes place, the evaluation metric for this test is simply the number of correct responses over the total number of questions, that is, the response match percentage.
Prompt Template: Information Retrieval
System Prompt (Retrieval)
You are tasked with answering a question based on the given document. You must provide your answer with only one word or number. Please pay attention to this answering requirement.
User Prompt (Retrieval)
Document: {document}
Question: {question}
System Prompt (Validation)
You are tasked with validating two answers: the first answer is the TRUE ANSWER, and the second answer is the PROVIDED ANSWER. Compare these two strings for the given question and determine whether the PROVIDED ANSWER conveys the same meaning as the TRUE ANSWER. Focus on semantic equivalence rather than exact wording. The PROVIDED ANSWER must be clear, concise, and focused solely on relevant information. Your response must be in the following format:
{"match": True} if the PROVIDED ANSWER conveys the same meaning as the TRUE ANSWER, even if reworded.
{"match": False} if the PROVIDED ANSWER differs in meaning or includes irrelevant content.
User Prompt (Validation)
Question: {question}
TRUE ANSWER: {true_answer}
PROVIDED ANSWER: {provided_answer}
Information Ordering
In an information ordering test, the task for the AI model is to assist in ranking a given set of text chunks according to their relevance for answering a given question. To determine the relevance of each chunk, we use the AI model to compute the vector embedding of each chunk as well as the vector embedding of the given question. We then calculate the cosine similarity score of each chunk against the given question, and order the chunks in descending order according to their cosine similarity scores. The scoring of the output is then calculated using the Normalized Discounted Cumulative Gain (NDCG) metric, which rewards placing more relevant chunks – that is, those with higher cosine similarity scores – towards the top of the expected chunk ranking. NDCG scores range from 0 to 1, with 1 indicating a perfect order match where all chunks are in their correct rank.
Results
A full set of test results for all models is available internally at IFAD in the form of an interactive data dashboard. A selection of representative screenshots is shown below for reference:
Figure 2a-2d: Garden V1 Interactive Data Dashboard
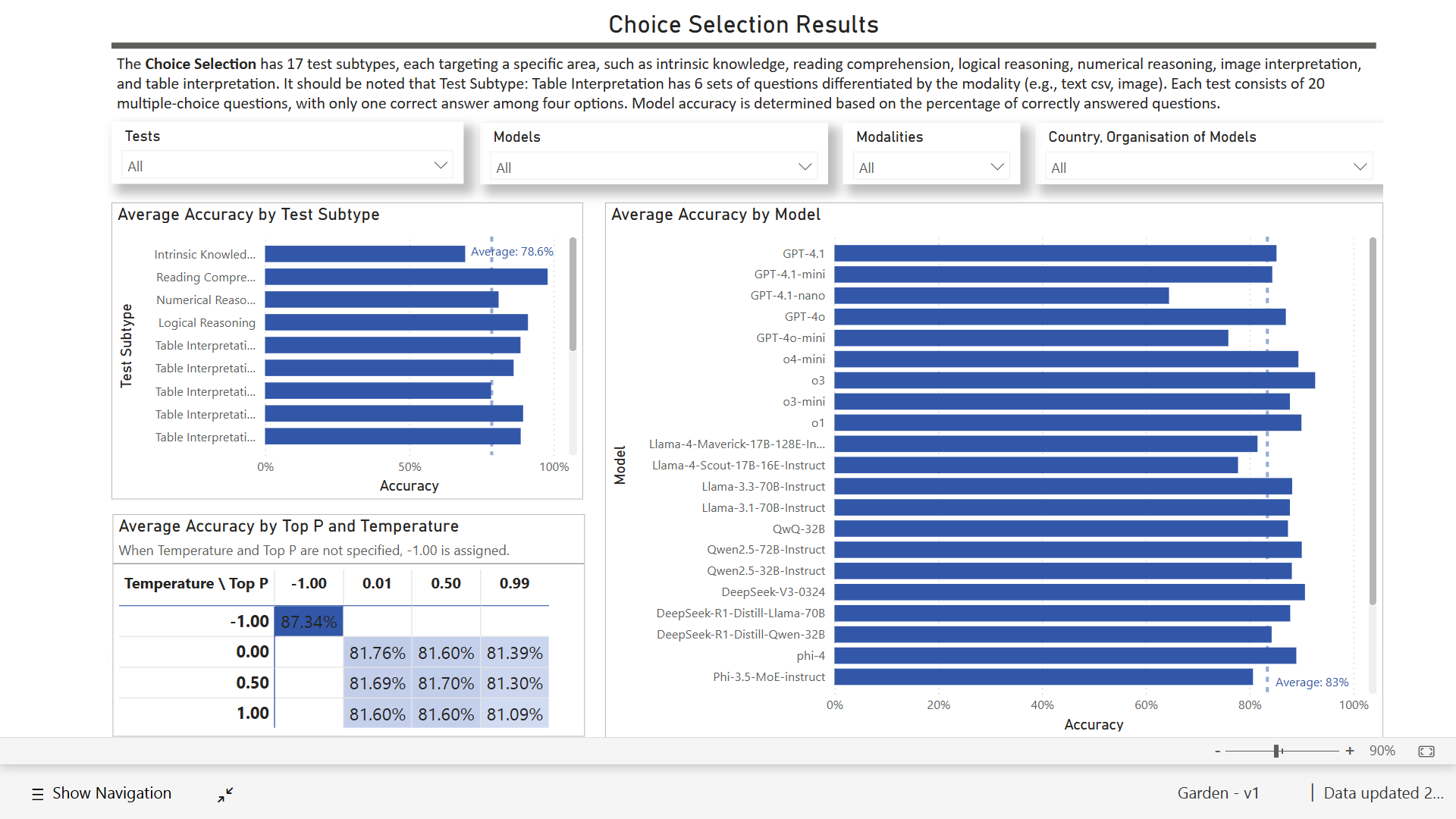
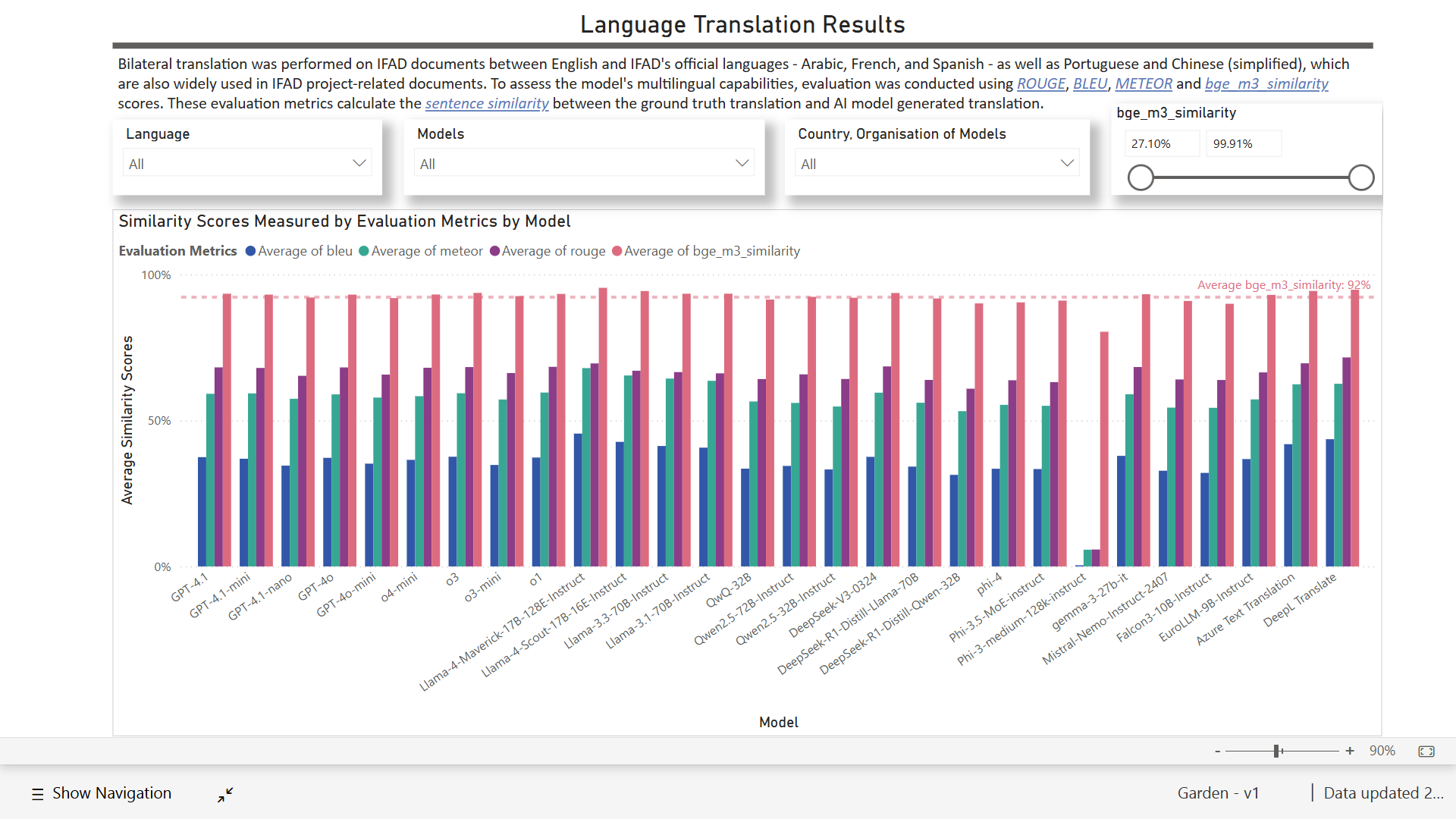
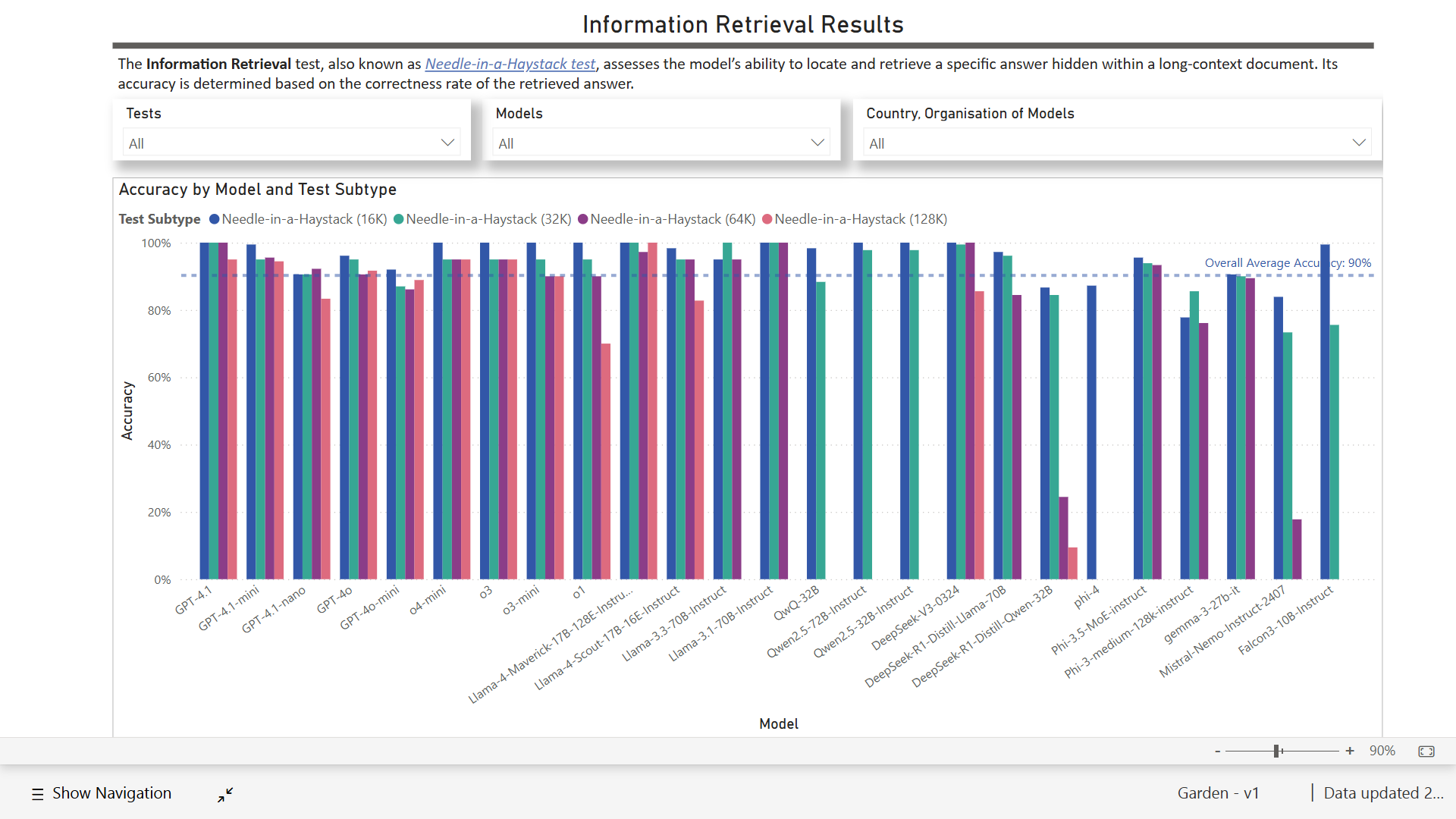
Although the full set of results, interactive data dashboard, and comprehensive analysis are not planned for publication, we can share a few interesting observations from Garden V1:
- Choice selection. Across all models, different permutations of temperature and top-p hyperparameter values did not significantly affect the test results, often only having a difference of approximately +/- 2 percentage points.
- Reading comprehension. Test scores were consistently high across all models, scoring an average of 98%, confirming that models can perform very well when presented with sufficiently relevant information for a given question.
- Intrinsic knowledge. Test scores were relatively low, scoring an average of 69%, indicating that most models may not have sufficient information about IFAD in their training data. As expected, scores are lower amongst smaller models when compared with larger model counterparts; for example, o3-mini (45%) compared with o3 (90%). However, newer versions of smaller reasoning models, such as o4-mini, are already showing improved results (80%).
- Table interpretation. Across all models, the HTML format led to the best results (89%). XML (88%), CSV (88%), and MD (86%) were close behind, with a clear degradation of performance for JSON (78%) and Image (75%) formats.
- Chart interpretation. Most models struggled with chart interpretation, scoring an average of 37%. Multi-modal reasoning models fared far better than average, including o4-mini (75%), o1 (75%), and o3 (65%). Notably, GPT-4o (54%) outperformed GPT-4.1 (37%).
- Image interpretation. Test scores were consistently high across all models , scoring an average of 92%, with even smaller models like Gemma-3-27B-IT (85%) and GPT-4.1-nano (73%) performing relatively well.
- Language translation. Overall, specialized AI services for machine translation (i.e., Azure Text Translation, DeepL Translate) did outperform most AI models in language translation tests, but only marginally.
- Language translation. As expected, most models perform better in language translation tests for French, Spanish, and Portuguese, as opposed to Arabic and Chinese.
- Language translation. Different metrics produce different ranking orders. For example, DeepL Translate averages higher scores with ROUGE (63%) than Azure Text Translation (62%), but averages lower scores with METEOR (54% compared with 56%). This illustrates the criticality of metrics selection and understanding, as well as the impact on test results and interpretation. BGE-M3 provides a completely different perspective on language translation evaluation, with scores consistently high around the 90% mark for most models and languages.
- Information retrieval. Across all models, test scores tend to be lower for longer context lengths (64K, 128K) than shorter ones (16K, 32K). No model scored 100% across all context lengths, but both GPT-4.1 and Llama-4-Maverick-17B-128E-Instruct came close. GPT-4.1 scored 100% across all context lengths except 128K (95%), while Llama-4-Maverick-17B-128E-Instruct scored 100% across all context lengths except 64K (97%).
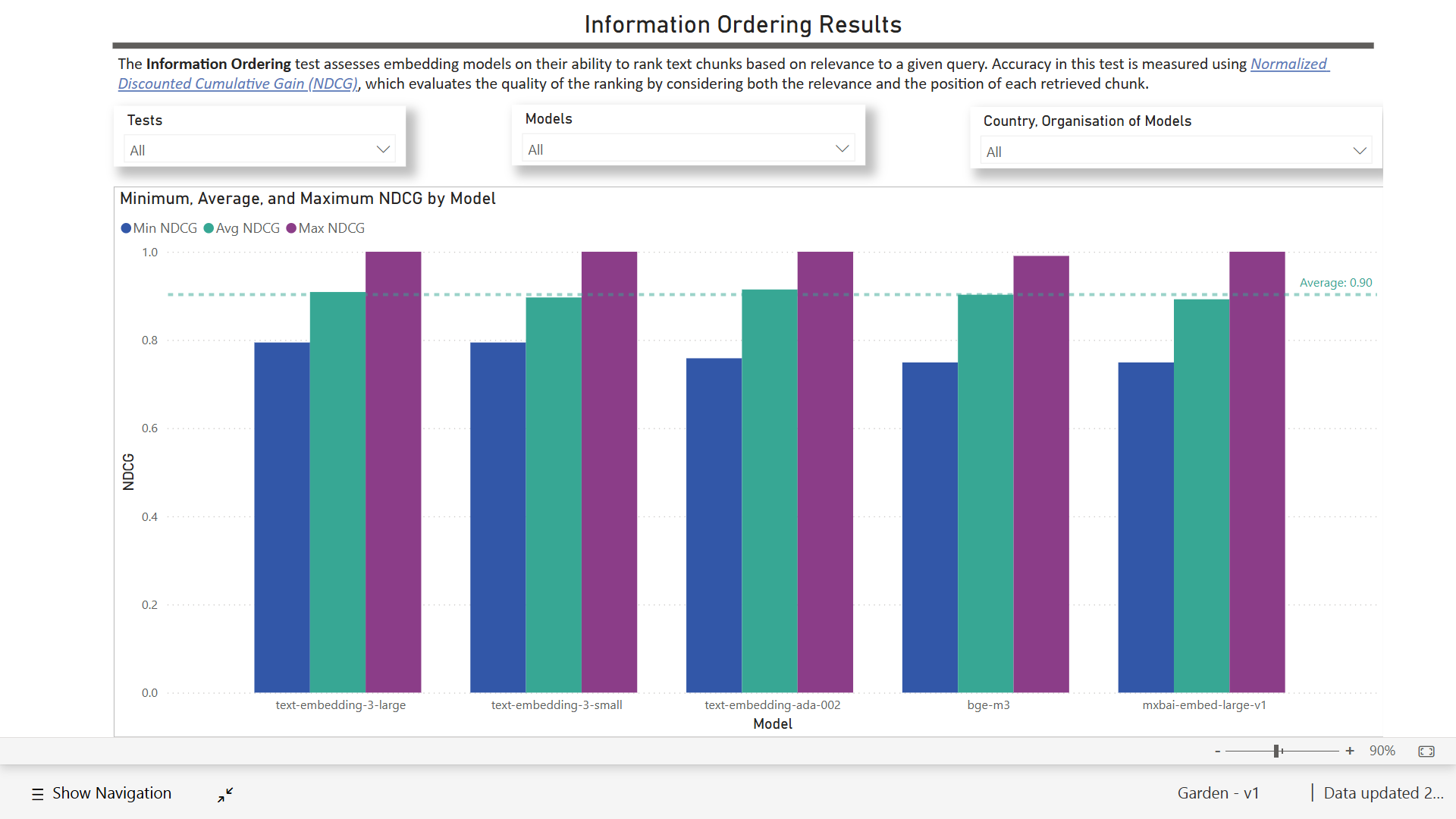
- Information ordering. Embedding models have fairly homogenous results with an average score of 90%, with text-embedding-3-large and text-embedding-ada-002 both at 91% and mxbai-embed-large-v1 at 89%.
Future Work
Garden V1 was preceded by Garden V0, in which we initially developed a series of loose and separate scripts that attempted to keep up with a growing wish list of test ideas and model candidates. From Garden V0, we learned that planning and automation are key for testing models at scale and with minimal error, and to do so we needed a structured approach to our methodology and codebase – this marked the beginning of Garden V1. Moving onto Garden V2, we plan to address the following from the start:
- General. Redesign of the data model to improve database management as well as data visualization, considering necessary technical trade-offs between both areas.
- General. Pre-vetting of models with a predefined list of minimum technical requirements that meet minimum business requirements for context length, supported languages, and compatible platforms relevant to the IFAD operational context.
- General. Focus on the design and development of new tests based on current IFAD use cases for AI, aligned with ongoing quality assurance efforts for products and services.
- Generation models. Normalization of temperature and top-p hyperparameter values for more equivalent model evaluations.
- Reasoning models. Separation of reasoning tests into a new category specifically designed to test reasoning models with more complex questions relevant to IFAD.
- Choice selection. Removal of test questions and answers that are likely to change over time.
- Choice selection. Inclusion of a fifth option, “E. Don’t know”, in choice selection tests to minimize lucky guesses.
- Language translation. Expansion of language translation tests to include additional languages relevant to IFAD, the United Nations, and International Financial Institutions at large.
- Language translation. Expansion of language translation tests to include under-represented languages encountered in IFAD’s working context.
- Information retrieval. Expansion of information retrieval tests to consider shorter (8K) and longer (1M) context windows.
- Information retrieval. Standardization of the validation process in the information retrieval test, with a custom algorithm or specialized model that is fit for purpose.
- Information ordering. Expansion of information ordering test types and evaluation metrics to provide a more comprehensive RAG-centric assessment.
- Language translation. Redesign of the language translation evaluation process by adopting a more suitable tokenization approach for Arabic and Chinese characters, ensuring consistent token-level evaluation across standard machine translation metrics (BLEU, ROUGE, METEOR).
- Language translation. Design and implementation of a composite machine translation metric to more uniformly evaluate language translation results.
Conclusion
Garden V1 is the first, but not final, attempt to improve the responsible and effective use of AI at IFAD. Despite the room for improvement going into Garden V2 and beyond, Garden V1 already shows significant promise as a part of an effective AI model evaluation framework tailored to IFAD’s working context and operational reality. The results from this initial benchmarking exercise have already helped address industry hype (“Are DeepSeek models better than OpenAI models?”), inform technical implementation decisions (“Should we use specialized AI text translation services or rely on LLM translation capabilities?”), and consider cost-saving measures (“Could we switch to smaller and cheaper models without compromising on quality?”).
As advances in AI models continue to make headlines, we will reflect on our lessons learned from Garden V1 to have an IFAD-specific perspective on any new releases and the important decisions that may be required of the organization for the responsible and effective use of AI. For now, we present our experience with Garden V1 as a contribution to the AI community, from which we hope to learn more from to help us shape Garden V2.
Contributors
Ricardo Rendon Cepeda, Youyou Lin, Yeonsoo Doh, Bernard A. Gütermann, Zixuan Yue, Batbaina Guikoura, Wanhao Zhang, Thomas Rapaj, Tansel Simsek


