Reasoning Models and Game Theory: My Take on the Recent Debate

There has been a lot of talk about the pros and cons of reasoning models over the last couple of days. Here is my own work on the topic with four articles that reflect my perspective on evaluating, applying, and understanding reasoning in modern autonomous agent systems. My work spans theory, experimentation, and implications for agent design. Would love to receive your thoughts on it.
1. Game Theory and Agent Reasoning (I)
This article sets the foundation for evaluating reasoning in cognitive agents through game-theoretic simulations—specifically, a modified Prisoner's Dilemma.
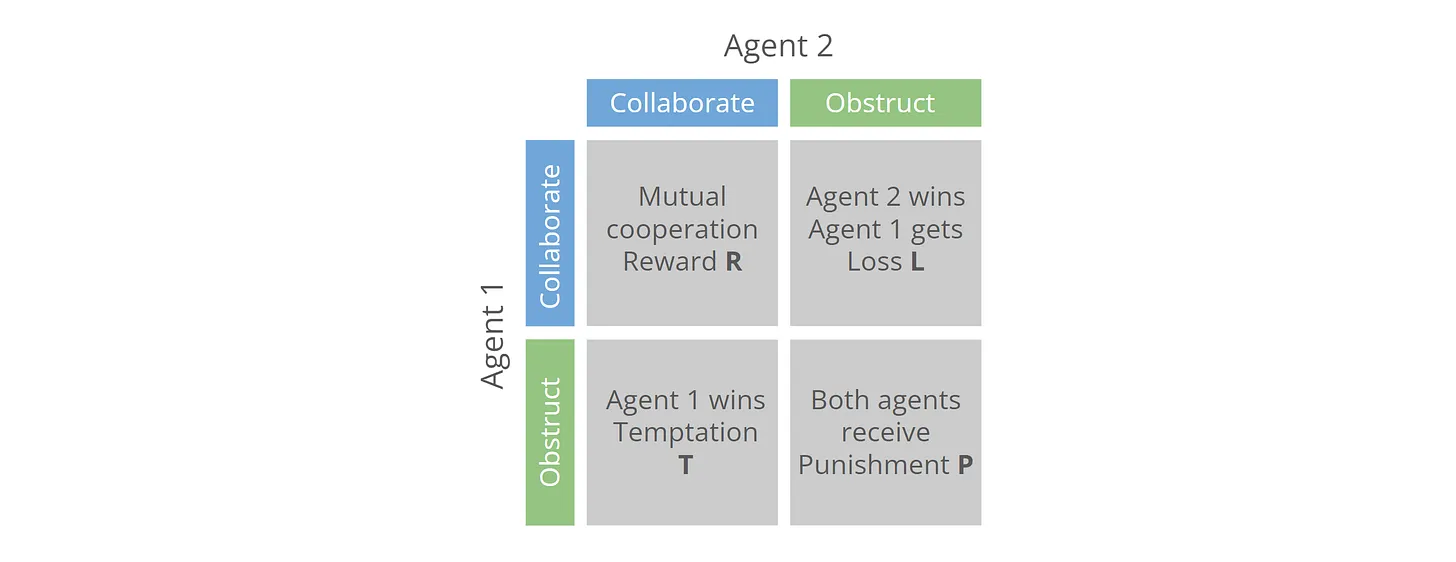 Drawing from classical strategy frameworks like Tit-for-Tat, Grim, and Random, the experiment tests 16 locally run LLM-based agents with memory and reasoning abilities. These agents engage in repeated non-zero-sum games over 90 decision cycles, each using a unique strategic prompt. The study aims to explore whether cooperation, provocation, or unpredictability leads to long-term success, echoing insights from historical human experiments and Nash equilibrium dynamics.
Drawing from classical strategy frameworks like Tit-for-Tat, Grim, and Random, the experiment tests 16 locally run LLM-based agents with memory and reasoning abilities. These agents engage in repeated non-zero-sum games over 90 decision cycles, each using a unique strategic prompt. The study aims to explore whether cooperation, provocation, or unpredictability leads to long-term success, echoing insights from historical human experiments and Nash equilibrium dynamics.
2. Game Theory and Agent Reasoning (II)
This companion post dives deeper into how agents make decisions in strategic contexts like Tic-Tac-Toe variants, focusing on inductive generalization and self-consistent decision loops.
 The article questions whether current models can "reason" or merely replay latent statistical priors. It compares random, supervised, and reinforcement-based agents to draw insights into the nature of machine reasoning under constrained conditions.
The article questions whether current models can "reason" or merely replay latent statistical priors. It compares random, supervised, and reinforcement-based agents to draw insights into the nature of machine reasoning under constrained conditions.
3. Game Theory and Agent Reasoning (III)
This next post then evaluates cognitive AI agents through Prisoner's Dilemma games to assess reasoning capabilities and behavioral patterns. Researchers tested ReAct agents—equipped with reasoning, tool use, and memory—against pre-defined algorithms (First Defect, Random, Alternate, Tit-for-Tat) across 10-round games with specific payoff structures. The investigation examined five key aspects: agent reasoning processes, behavioral adaptation, malevolent tendencies, optimal strategies, and post-game sentiment. Through thousands of rounds, agents demonstrated stable decision-making and sophisticated reasoning by using mathematical tools to analyze payoffs and prioritize long-term outcomes over short-term gains.

Key findings confirmed that Tit-for-Tat strategies yielded the highest collective payoffs, mirroring classic human studies, while "First Defect" provided the best individual scores. Agents rarely adapted mid-game behavior and showed no evidence of spiteful decision-making. However, significant challenges emerged with hallucinations, where agents processed through incorrect game states, requiring extensive prompt fine-tuning.
4. Nemotron vs Qwen - Game Theory and Agent Reasoning IV
The final post in the study pits two popular open-source models—Qwen-2.5 72B ("Qwenny") and Nvidia Nemotron 70B ("Nemo")—against each other in strategic gameplay to evaluate general reasoning capabilities beyond narrow AI applications. Rather than relying on specialized game-trained systems, the experiment tests whether current-generation LLMs can apply situational reasoning to unfamiliar strategic scenarios through a modified 4x4 Tic-Tac-Toe variant designed to prevent pre-trained knowledge exploitation. My research addresses three core questions: gameplay capability (state analysis accuracy, blocking losing situations, securing obvious wins), reliability (failure modes, board reading errors, move selection accuracy), and performance (iteration requirements, conclusion rates, reasoning correctness). Using Huggingface's Transformers framework with ReAct agents, both models received identical tasks without few-shot examples, employing Pydantic validation schemas to ensure response reliability.
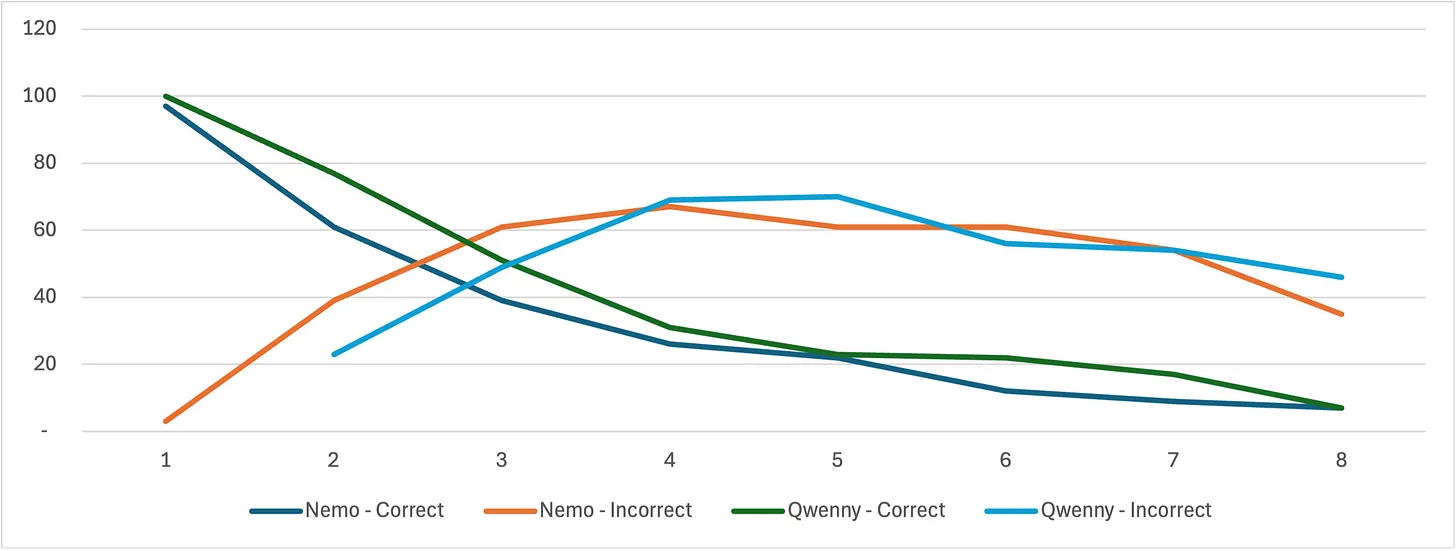 Across 100 rounds generating 1,349 move decisions, Qwen achieved 41 victories versus Nemotron's 21, with 38 draws. While both models demonstrated basic gameplay competency, they frequently struggled with mid-game reasoning, mixing up board coordinates and referencing non-existent situations. The agents showed inconsistent performance in capitalizing on obvious wins or blocking opponent victories, suggesting reliance on pattern matching rather than true strategic understanding. This highlights significant model risk in agentic workflows requiring robust governance frameworks for reliable deployment.
Across 100 rounds generating 1,349 move decisions, Qwen achieved 41 victories versus Nemotron's 21, with 38 draws. While both models demonstrated basic gameplay competency, they frequently struggled with mid-game reasoning, mixing up board coordinates and referencing non-existent situations. The agents showed inconsistent performance in capitalizing on obvious wins or blocking opponent victories, suggesting reliance on pattern matching rather than true strategic understanding. This highlights significant model risk in agentic workflows requiring robust governance frameworks for reliable deployment.
Closing Statement
In my opinion, this exploration of AI agents through game-theoretic concepts reveals both the promise and limitations of current reasoning capabilities. While my agents demonstrate sophisticated strategic thinking in cooperative scenarios like Prisoner's Dilemma, they struggle with dynamic adaptation and complex board state analysis in competitive gameplay. The inconsistent performance across different strategic contexts highlights critical model risks that require robust governance frameworks before widespread deployment. As we advance toward more capable agentic systems, understanding these behavioral patterns through structured evaluation becomes essential for building reliable, trustworthy AI that can navigate real-world strategic interactions safely and effectively.