Bigger isn't always better: how to choose the most efficient model for context-specific tasks 🌱🧑🏼💻







| TL;DR - Given the diversity of open-source AI models that exist on the Hub, it can sometimes be hard to choose the most appropriate one for domain-specific tasks. But it is worth considering the true context of deployment of the models used in practice and doing testing and evaluation to choose models based on both accuracy and efficiency. In our empirical experiment, we find that many smaller models outperform their larger counterparts, while using orders of magnitude less energy in the process. |
|---|
For a technology that most of us interact with on a daily basis, “Artificial Intelligence” (AI) is an umbrella term that can actually refer to many different kinds of approaches – from simple text classification models that can run on a mobile phone to Transformer-based with hundreds of billions of parameters which require multiple specialized GPUs.
While we definitely read a lot of news headlines about the state-of-the-art results of the bigger models, the generic benchmarks and evaluation approaches used to compare AI models are not representative of the myriad of context-specific tasks that AI practitioners carry out in their different fields of practice. And as we default to using the large, compute-intensive text generation models because we believe that they are best suited to any task, this comes with a cost to the environment, given the amount of energy and natural resources required to run them. This is why it is important to choose the right model for the right task, taking both performance and efficiency into account.
Evaluating Model Performance and Efficiency 🚀
Projects such as AI Energy Score can help give an initial idea of how energy-efficient models are, but the final energy consumption will depend on the hardware and optimization setup used during deployment. For this reason, it can be useful to test the candidate models in situ, evaluating their performance on a sample of data that is representative of the type of data that the model will receive when deployed, or a similar existing dataset.
As an example of the kinds of context-specific tasks that can be used to compare different AI models’ performance and efficiency, we use 3 reports from different areas and fields of knowledge:
- The IPCC’s 2023 Synthesis Report, which contains 80 pages that describe the current state of scientific knowledge with regards to anthropogenic climate change.
- The 2024 World Bank Annual Report, which provides an analysis of the economic, social mobility, and political state of the world.
- The 2024 World Health Statistics Report by the World Health Organization, which is the annual compilation of global health and health-related indicators.
We used the YourBench dynamic benchmark generation framework to generate 60 questions for each of the reports, and evaluate 9 models of different sizes and architectures on these questions. Under the hood, the YourBench framework uses Lighteval evaluation toolkit, which adopts an “LLM as a judge” approach –– in this case, leveraging the QwQ-32B model – in order to carry out the comparison between the gold standard answer and that provided by different models.
We evaluate 9 models of a variety of architectures and sizes on the questions generated for each report. In order to approximate the amount of energy used by each query, we took the TDP (Thermal Design Power) of the hardware that each model was running on and multiplied it by the time it took for it to respond to the questions – which gives us an approximation of the total energy used. We show the results of our evaluation in the tables below:
2023 IPCC Report 🌎
The IPCC (Intergovernmental Panel on Climate Change) is the UN body that is responsible for assessing the science related to climate change. Every 5-7 years, they publish reports that aim to present the latest research on the topic, from the empirical observations around climate patterns to their socio-economic impacts. Different versions of these reports are available for different audiences, from the executive summaries of a few dozen pages for policy-makers to the in-depth reports spanning hundreds of pages for experts.
For our study, we took the intermediate (80-page) version of the 2023 report, and generated questions like "How does global warming affect the fire season length?" and "What are some examples of slow-onset events caused by climate change, and how do they impact ecosystems and human societies?". The results of the evaluation (both accuracy and estimated energy) are shown below:
| Model | # Params | Duration (s) | Accuracy | Estimated Energy (Wh) |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235B | 429.44 | 0.867 | 286 |
| phi-4 | 14.7B | 130.53 | 0.8 | 12.69 |
| Qwen2.5-72B-Instruct | 72B | 147.89 | 0.767 | 65.77 |
| Qwen3-32B | 32B | 167.97 | 0.733 | 65.32 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 441.23 | 0.733 | 35.30 |
| Llama-3.3-70B-Instruct | 70B | 336.71 | 0.567 | 149.64 |
| Phi-3-mini-4k-instruct | 3.82B | 103.79 | 0.533 | 2 |
| c4ai-command-r-plus-08-2024 | 104B | 482.24 | 0.533 | 428.44 |
| Llama-3.1-8B-Instruct | 8B | 279.95 | 0.52 | 5.6 |
We can see that the biggest model, Qwen3-235B, was the best-performing model, but the runner up, the Phi 4 model, with only 15B, came in second, scoring 7% less but using 24 times less energy for the same set of questions. This goes to show that it is possible to save a huge amount of energy and compute if models are evaluated for a given task beforehand, both in terms of performance as well as efficiency. Also, while the top performing models are on the bigger end of the spectrum, mid-range (32B) models are highly competitive, outperforming models like Llama-3.3-70B and Command-R-plus.
Plotting both accuracy and energy with a Bubble Plot (with the size of the bubbles representing model size), we can see a clear trade-off between accuracy and energy -- while the Qwen3-235B model does well in terms of performance, it is a lot more energy-intensive than the smaller models on the left side of the plot:

2024 World Bank Report 🏦
The World Bank is an international financial institution whose goal is to provide loans and funding to help support economic development and reduce poverty. In their annual report, they provide updates about their operations and initiatives, as well as insights about the impacts of their funding approaches in different countries and regions. These reports are meant to serve as a public record of their investments, as well as helping researchers and policymakers follow the evolution of macroeconomic events globally.
The questions generated from the report addressed strategic aspects of the World Bank’s activities ("What are the main goals of the World Bank's investments in Western and Central Africa?") as well as specific projects and metrics ("Since fiscal 2015, how many women and girls have been reached by IDA resources, and what types of actions have been supported?"). The results are shown below:
| Model | # Params | Duration (s) | Accuracy | Estimated Energy (Wh) |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235B | 571.82 | 0.54 | 381 |
| Llama-3.3-70B-Instruct | 70B | 176.39 | 0.53 | 78.2 |
| phi-4 | 14.7B | 114.48 | 0.53 | 11.0 |
| Qwen3-32B | 32B | 164.54 | 0.467 | 16 |
| Qwen2.5-72B-Instruct | 72B | 142.48 | 0.467 | 15.77 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 278.44 | 0.4 | 22.24 |
| Phi-3-mini-4k-instruct | 3.82B | 95.5 | 0.4 | 1.9 |
| Llama-3.1-8B-Instruct | 8B | 222.88 | 0.367 | 4.46 |
| c4ai-command-r-plus-08-2024 | 104B | 331.9 | 0.233 | 295.1 |
The difference between first and second place was less significant for this task, with Llama-3.3 (70B) using 5 times less energy for the same accuracy as Qwen 3-235B -- this still adds up if these models are deployed to respond to millions of queries a day. It is also interesting to note that the newer smaller (32B) version of Qwen performed as well as the older, bigger (72B) version - showing that with the progress being made in terms of data quality and model performance, choosing the latest generation of models can lead to big gains in performance.
In this case, we can see that the Qwen-235B model uses the most energy of all of the models tested in order to achieve its high accuracy, over 35 times more than Phi 4, which achieves very comparable performance:

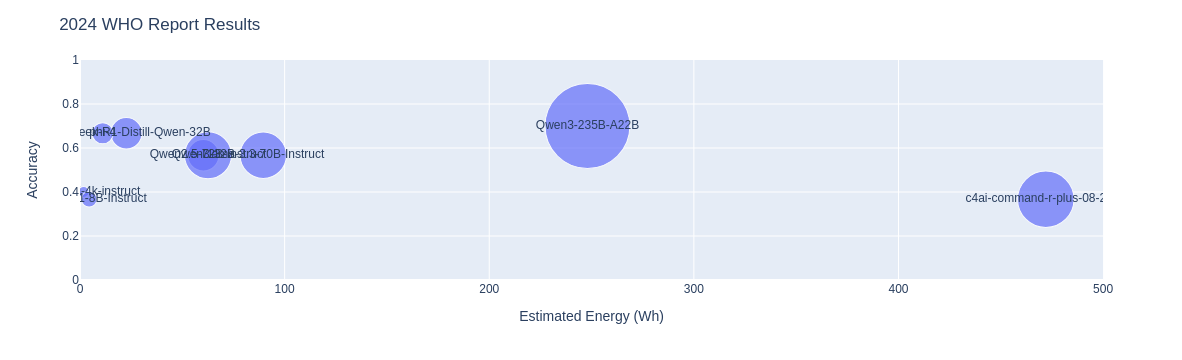
2024 World Health Statistics Report ⚕️
The World Health Organization (WHO) is a UN agency that is dedicated to global health and safety, tracking global health trends, and coordinating international action on global health emergencies like pandemics. Every year, they publish a report that contains an important amount of statistics and analyses about how health patterns are changing over time, and allows government agencies and policymakers alike to plan their own local responses and strategies.
The questions that were generated from the report include ones like ""How did the gains in life expectancy and healthy life expectancy differ between men and women from 2000 to 2019?*" and "How has the global pattern of leading causes of death changed from 2000 to 2019?". The model evaluation results are shown below:
| Model | # Params | Duration (s) | Accuracy | Estimated Energy (Wh) |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235B | 372.05 | 0.7 | 248 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 283.11 | 0.667 | 22.64 |
| phi-4 | 14.7 B | 114.13 | 0.667 | 11.08 |
| Qwen3-32B | 32B | 154.69 | 0.567 | 60.28 |
| Qwen2.5-72B-Instruct | 72B | 140.75 | 0.567 | 62.56 |
| Llama-3.3-70B-Instruct | 70B | 201.51 | 0.567 | 89.55 |
| Phi-3-mini-4k-instruct | 3.83B | 89.8 | 0.4 | 1.8 |
| Llama-3.1-8B-Instruct | 8B | 222.88 | 0.367 | 4.46 |
| c4ai-command-r-plus-08-2024 | 104B | 531.09 | 0.367 | 472 |
In terms of energy usage between the top model (also Qwen3-235B!) and the runner up (DeepSeek-R1-Distill-Qwen-32B), the difference is 11-fold, for a small 3% difference in performance. Once again, a smaller model from a newer generation (Qwen3-32B) had the same performance as its bigger and older counterpart, as well as bigger models like LLaMa 3.3 and Command-R Plus:
Takeaways 📚
Overall, it’s worth noting that:
- The relatively small (15B) Phi-4 scored in the top 3 for all tasks, showing that even models that fit on a single GPU can outperform those that need nodes (such as the 100 and 200B models)
- For some tasks, the difference between the most and least efficient model was over ** 200 times less energy**!
- Newer generations of models often performed better than older, bigger versions from the same family – for instance, Qwen3-32B outperformed Quen2.5-72B in 2 out of 3 tasks.
- The distilled version of DeepSeek-R1 (Distill-Qwen-32B) was consistently a strong performer as well, showing the benefits of knowledge distillation for reducing the amount of compute needed (the original DeepSeek-R1 model has 685B parameters).
While this analysis is limited to a small group of models that we were able to test and compare, it goes to illustrate the importance of testing models of different architectures and sizes before choosing one to deploy in production, because even small differences in query energy can add up as models are used thousands or even millions of times.





