
File size: 2,587 Bytes
e426502 22167d1 e426502 7a45936 b5f0b2d 5f33137 7a45936 29ba86d be5e88c 70199f7 833daf0 70199f7 29ba86d |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
---
license: mit
language:
- en
base_model:
- ResembleAI/chatterbox
pipeline_tag: text-to-speech
tags:
- gguf-connector
---
## gguf quantized version of chatterbox
- base model from [resembleai](https://huggingface.co/ResembleAI)
- text-to-speech synthesis
### **run it with gguf-connector**
```
ggc c2
```
| Prompt | Audio Sample |
|--------|---------------|
|`Hey Connector, why your appearance looks so stupid?`<br/>`Oh, really? maybe I ate too much smart beans.`<br/>`Wow. Amazing.`<br/>`Let's go to get some more smart beans and you will become stupid as well.`<br/> | 🎧 **audio-sample-1**<br><audio controls src="https://huggingface.co/calcuis/chatterbox-gguf/resolve/main/samples%5Caudio1.wav"></audio> |
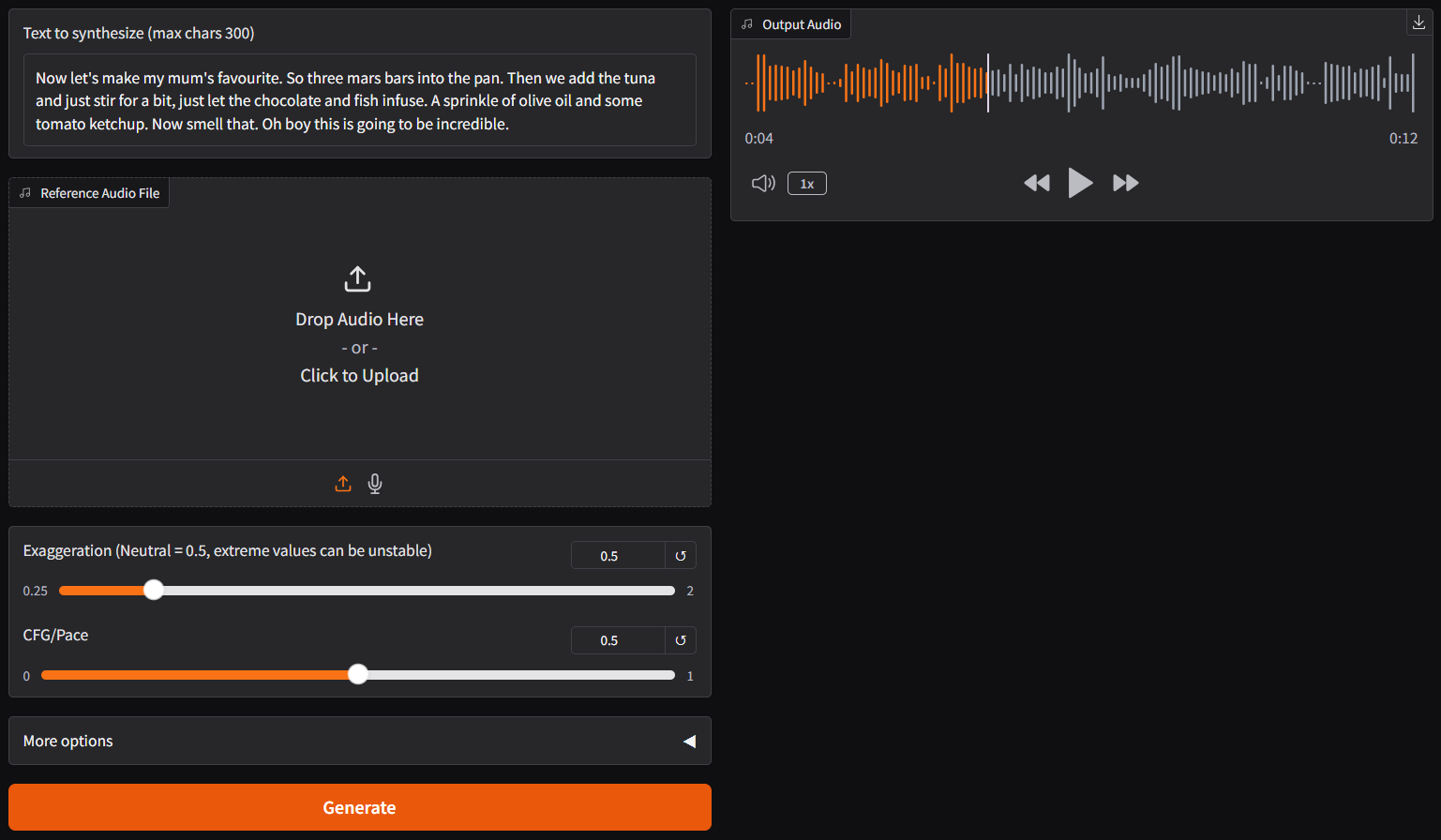
|`Now let's make my mum's favourite. So three mars bars into the pan. Then we add the tuna and just stir for a bit, just let the chocolate and fish infuse. `<br/>`A sprinkle of olive oil and some tomato ketchup. Now smell that. Oh boy this is going to be incredible.`<br/> | 🎧 **audio-sample-2**<br><audio controls src="https://huggingface.co/calcuis/chatterbox-gguf/resolve/main/samples%5Caudio2.wav"></audio> |
### **review/reference**
- simply execute the command (`ggc c2`) above in console/terminal
- opt a `vae`, a `clip(encoder)` and a `model` file in the current directory to interact with (see example below)
>
>GGUF file(s) available. Select which one for ve:
>
>1. t3_cfg-q2_k.gguf
>2. t3_cfg-q4_k_m.gguf
>3. t3_cfg-q6_k.gguf
>4. ve_fp32-f16.gguf
>5. ve_fp32-f32.gguf
>
>Enter your choice (1 to 5): 4
>
>ve file: ve_fp32-f16.gguf is selected!
>
>GGUF file(s) available. Select which one for t3:
>
>1. t3_cfg-q2_k.gguf
>2. t3_cfg-q4_k_m.gguf
>3. t3_cfg-q6_k.gguf
>4. ve_fp32-f16.gguf
>5. ve_fp32-f32.gguf
>
>Enter your choice (1 to 5): 2
>
>t3 file: t3_cfg-q4_k_m.gguf is selected!
>
>Safetensors file(s) available. Select which one for s3gen:
>
>1. s3gen_bf16.safetensors (recommended)
>2. s3gen_fp16.safetensors (for non-cuda user)
>3. s3gen_fp32.safetensors
>
>Enter your choice (1 to 3): _
>
- note: for the latest update, only tokenizer will be pulled to cache automatically during the first launch; you need to prepare the **model**, **encoder** and **vae** files yourself, working like [vision](https://huggingface.co/calcuis/llava-gguf) connector right away; mix and match, more flexible
- run it entirely offline; i.e., from local URL: http://127.0.0.1:7860 with lazy webui
- gguf-connector ([pypi](https://pypi.org/project/gguf-connector)) |