
Upload 9 files
Browse files- .gitattributes +1 -0
- README.md +142 -0
- config.json +41 -0
- generation_config.json +9 -0
- output.safetensors +3 -0
- special_tokens_map.json +23 -0
- tokenizer.json +3 -0
- tokenizer_config.json +195 -0
- zr1-1.5b-livebench.png +0 -0
- zr1_livebench_greedy_lightmode.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
library_name: transformers
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
base_model:
|
| 7 |
+
- deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
|
| 8 |
+
datasets:
|
| 9 |
+
- AI-MO/NuminaMath-CoT
|
| 10 |
+
- codeparrot/apps
|
| 11 |
+
- deepmind/code_contests
|
| 12 |
+
- BAAI/TACO
|
| 13 |
+
- MatrixStudio/Codeforces-Python-Submissions
|
| 14 |
+
pipeline_tag: text-generation
|
| 15 |
+
---
|
| 16 |
+
# ZR1-1.5B
|
| 17 |
+
|
| 18 |
+
ZR1-1.5B is a small reasoning model trained extensively on both verified coding and mathematics problems with reinforcement learning. The model outperforms Llama-3.1-70B-Instruct on hard coding tasks and improves upon the base R1-Distill-1.5B model by over 50%, while achieving strong scores on math evaluations and a 37.91% pass@1 accuracy on GPQA-Diamond with just 1.5B parameters.
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
## Data
|
| 23 |
+
|
| 24 |
+
For training we utilized the [PRIME Eurus-2-RL](https://huggingface.co/datasets/PRIME-RL/Eurus-2-RL-Data) dataset which combines the following math and code datasets:
|
| 25 |
+
- NuminaMath-CoT
|
| 26 |
+
- APPS, CodeContests, TACO, and Codeforces train set
|
| 27 |
+
|
| 28 |
+
We filtered math data by validating that questions are correctly graded when calling the evaluator with reference ground truth, and we removed all code examples with an empty list of test cases. Our final dataset comprised roughly 400k math + 25k code samples.
|
| 29 |
+
|
| 30 |
+
## Training Recipe
|
| 31 |
+
|
| 32 |
+
We employ [PRIME (Process Reinforcement through IMplicit rEwards)](https://arxiv.org/abs/2502.01456), an online RL algorithm with process rewards, motivated by the improvement over GPRO demonstrated in the paper, as well as potentially more accurate token-level rewards due to the learned process reward model. We used the training batch accuracy filtering method from PRIME for training stability, and the iterative context lengthening technique demonstrated in [DeepScaleR](https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2) for faster training, which has also been [shown to improve token efficiency](https://arxiv.org/abs/2503.07572). After a warmup period with maximum generation length set to 12k tokens, we sequentially increased the maximum generation length during training, starting at 8k tokens before increasing to 16k and 24k.
|
| 33 |
+
|
| 34 |
+
We trained on a single 8xH100 node with the following specific algorithmic details.
|
| 35 |
+
|
| 36 |
+
- PRIME + RLOO with token-level granularity
|
| 37 |
+
- No `<think>` token prefill. 0.1 format reward/penalty
|
| 38 |
+
- Main train batch size 256 with n=4 samples per prompt. veRL dynamic batch size with max batch size set per GPU to support training with large generation length
|
| 39 |
+
- Max prompt length 1536, generation length increase over training. Started with 12k intended to ease model into shorter generation length training
|
| 40 |
+
- 12384 -> 8192 -> 16384 -> 24448
|
| 41 |
+
- Start with 1 PPO epoch, increase to 4 during 24k stage
|
| 42 |
+
- Accuracy filtering 0.2-0.8 and relax to 0.01-0.99 during 24k stage
|
| 43 |
+
- Oversample batches 2x for accuracy filtering
|
| 44 |
+
|
| 45 |
+
And the following training hyperparameters:
|
| 46 |
+
|
| 47 |
+
- KL coefficient 0 (no KL divergence term)
|
| 48 |
+
- Entropy coefficient 0.001
|
| 49 |
+
- Actor LR 5e-7
|
| 50 |
+
- Reward beta train 0.05
|
| 51 |
+
- Reward LR 1e-6
|
| 52 |
+
- Reward grad clip 10
|
| 53 |
+
- Reward RM coefficient 5
|
| 54 |
+
|
| 55 |
+
## Evaluation
|
| 56 |
+
|
| 57 |
+
**Coding**
|
| 58 |
+
| | Leetcode | LCB\_generation |
|
| 59 |
+
| :---- | :---- | :---- |
|
| 60 |
+
| ZR1-1.5B | **40%** | **39.74%** |
|
| 61 |
+
| R1-Distill-Qwen-1.5B | 12.22% | 24.36% |
|
| 62 |
+
| DeepCoder-1.5B | 21.11% | 35.90% |
|
| 63 |
+
| OpenHands-LM-1.5B | 18.88% | 29.49% |
|
| 64 |
+
| Qwen2.5-1.5B-Instruct | 20.56% | 24.36% |
|
| 65 |
+
| Qwen2.5-Coder-3B-Instruct | 35.55% | 39.74% |
|
| 66 |
+
| Llama-3.1-8B-Instruct | 14.44% | 23.08% |
|
| 67 |
+
| Llama-3.1-70B-Instruct | 37.22% | 34.62% |
|
| 68 |
+
| Eurus-2-7B-PRIME | 34.44% | 32.05% |
|
| 69 |
+
| Mistral-Small-2503 | \- | <u>38.46%</u> |
|
| 70 |
+
| Gemma-3-27b-it | \- | <u>39.74%</u> |
|
| 71 |
+
| Claude-3-Opus | \- | <u>37.18%</u> |
|
| 72 |
+
|
| 73 |
+
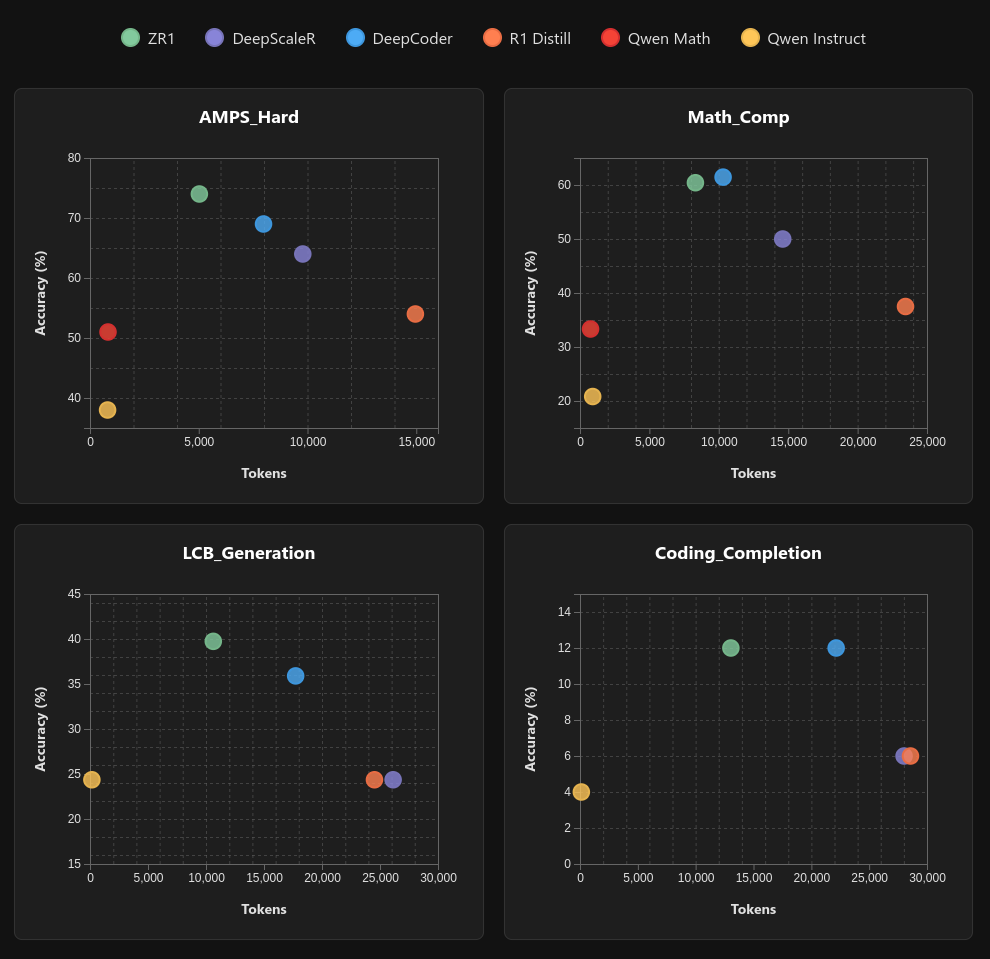
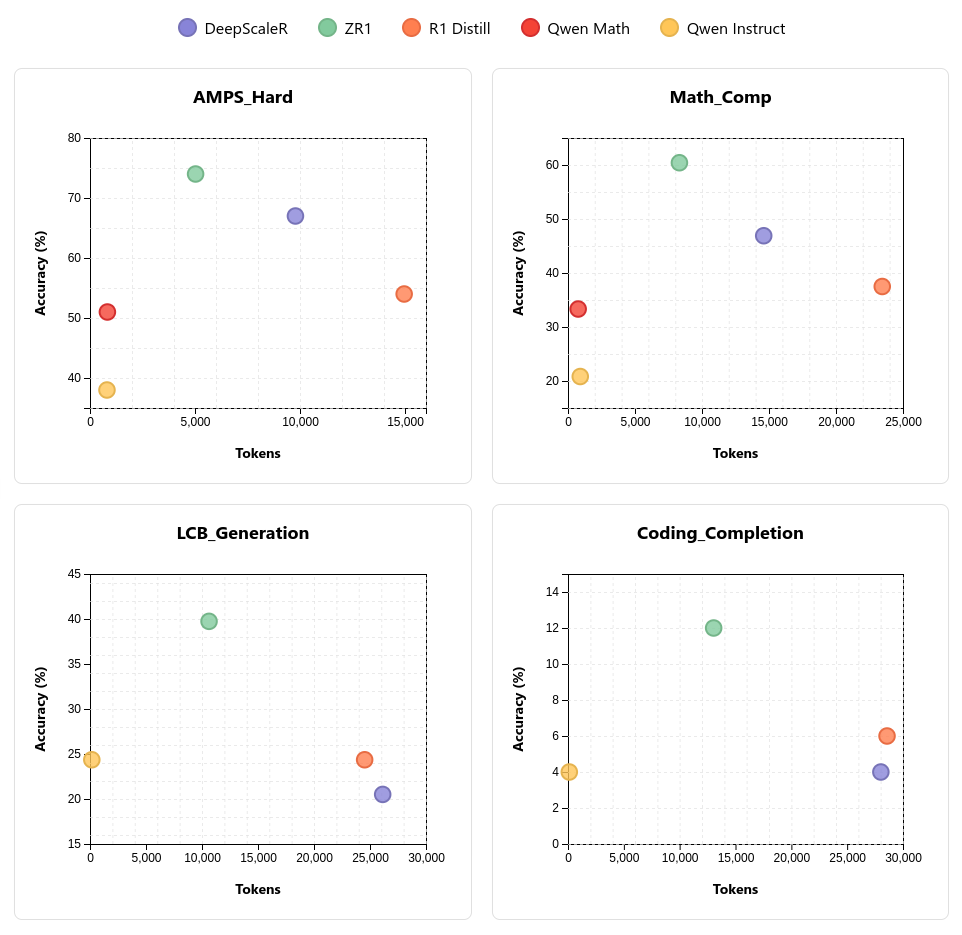
**LiveBench**
|
| 74 |
+
| Model | AMPS Hard | Math\_Comp | LCB\_Generation | Coding\_Completion |
|
| 75 |
+
| :---- | :---- | :---- | :---- | :---- |
|
| 76 |
+
| ZR1-1.5B | **74%** | 60.42% | **39.74%** | **12%** |
|
| 77 |
+
| DeepCoder-1.5B | 69% | **61.46%** | 35.90% | **12%** |
|
| 78 |
+
| DeepScaleR-1.5B | 64% | 50% | 24.36% | 6% |
|
| 79 |
+
| OpenHands-LM-1.5B | 24% | 29.48% | 29.49% | 8% |
|
| 80 |
+
| R1-Distill-1.5B | 54% | 37.50% | 24.36% | 6% |
|
| 81 |
+
| Qwen2.5-1.5B-Instruct | 38% | 20.83% | 24.36% | 4% |
|
| 82 |
+
| Qwen2.5-Math-1.5B-Instruct | 49% | 36.46% | 0% | 0% |
|
| 83 |
+
| Qwen2.5-3B-Instruct | 41% | 17.71% | 28.21% | 10% |
|
| 84 |
+
| R1-Distill-7B | 74% | 61.46% | 44.87% | 14% |
|
| 85 |
+
| Qwen2.5-7B-Instruct | 56% | 29.17% | 38.46% | 40% |
|
| 86 |
+
| Qwen2.5-Math-7B-Instruct | 62% | 45.83% | 16.67% | 4% |
|
| 87 |
+
| R1-Distill-14B | 77% | 69.79% | 64.10% | 18% |
|
| 88 |
+
| Qwen2.5-14B-Instruct | 59% | 43.75% | 46.15% | 54% |
|
| 89 |
+
| R1-Distill-32B | 74% | 75% | 60.26% | 26% |
|
| 90 |
+
| QwQ-32B-Preview | 78% | 67.71% | 52.56% | 22% |
|
| 91 |
+
| QwQ-32B | 83% | 87.5% | 87.18% | 46% |
|
| 92 |
+
| Qwen2.5-32B-Instruct | 62% | 54.17% | 51.23% | 54% |
|
| 93 |
+
| Qwen2.5-Coder-32B-Instruct | 48% | 53.13% | 55.13% | 58% |
|
| 94 |
+
| R1-Distill-Llama-70B\* | 65% | 78.13% | 69.23% | 34% |
|
| 95 |
+
| Qwen2.5-72B-Instruct | 66% | 52.08% | 50% | 62% |
|
| 96 |
+
| Qwen2.5-Math-72B-Instruct | 56% | 59.38% | 42.31% | 42% |
|
| 97 |
+
| DeepSeek-R1\* | 88% | 88.54% | 79.48% | 54% |
|
| 98 |
+
|
| 99 |
+
**General Math**
|
| 100 |
+
| model | AIME24 | AIME25 | AMC22\_23 | AMC24 | GPQA-D | MATH500 | Minerva | Olympiad |
|
| 101 |
+
| :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
|
| 102 |
+
| ZR1-1.5B | 33.75% | 27.29% | 72.06% | 59.17% | **37.91%** | 88.34% | 33.52% | 56.87% |
|
| 103 |
+
| ZR1-1.5B (greedy) | 40% | 26.67% | 71.08% | 53.33% | 37.88% | **89.40%** | 32.72% | 57.93% |
|
| 104 |
+
| DeepScaleR-1.5B | **42.92%** | **27.71%** | 74.40% | **60.69%** | 34.66% | 89.36% | **35.50%** | **59.37%** |
|
| 105 |
+
| DeepScaleR-1.5B (greedy) | 33.33% | 33.33% | 67.47% | 57.77% | 29.29% | 84.60% | 31.62% | 52.44% |
|
| 106 |
+
| DeepCoder-1.5B | 41.88% | 24.79% | **75.30%** | 59.72% | 36.46% | 83.60% | 32.01% | 56.39% |
|
| 107 |
+
| Still-3-1.5B | 31.04% | 23.54% | 65.51% | 56.94% | 34.56% | 86.55% | 33.50% | 53.55% |
|
| 108 |
+
| Open-RS3-1.5B | 31.67% | 23.75% | 64.08% | 51.67% | 35.61% | 84.65% | 29.46% | 52.13% |
|
| 109 |
+
| R1-Distill-1.5B | 28.96% | 22.50% | 63.59% | 50.83% | 33.87% | 84.65% | 31.39% | 51.11% |
|
| 110 |
+
| R1-Distill-1.5B (greedy) | 26.67% | 13.33% | 51.81% | 24.44% | 30.81% | 73.40% | 25.74% | 40% |
|
| 111 |
+
| Qwen2.5-Math-1.5B-Instruct (greedy) | 10% | 6.67% | 42.17% | 26.67% | 28.28% | 75.20% | 28.31% | 40.74% |
|
| 112 |
+
| Qwen2.5-Math-7B-Instruct (greedy) | 20% | 3.33% | 46.99% | 31.11% | 32.32% | 83% | 37.13% | 42.22% |
|
| 113 |
+
| Qwen2.5-Math-72B-Instruct (greedy) | 26.67% | 6.67% | 59.04% | 46.67% | 43.94% | 85.40% | 42.65% | 50.37% |
|
| 114 |
+
| Eurus-2-7B-PRIME (greedy) | 20% | 13.33% | 56.62% | 40% | 36.36% | 81.20% | 36.76% | 44.15% |
|
| 115 |
+
| DeepHermes-3-Llama-3-3B (think prompt, greedy) | 0% | 3.33% | 12.05% | 11.11% | 30.30% | 34.40% | 10.66% | 10.52% |
|
| 116 |
+
| OpenHands-LM-1.5B (greedy) | 0% | 0% | 10.84% | 4.44% | 23.74% | 36.80% | 12.50% | 10.22% |
|
| 117 |
+
|
| 118 |
+
**Short CoT**
|
| 119 |
+
|
| 120 |
+
Our direct answer system prompt was: “Give a direct answer without thinking first.”
|
| 121 |
+
|
| 122 |
+
The table reports the average greedy pass@1 score across the following math evals: AIME24, AIME25, AMC22\_23, AMC24, GPQA-Diamond, MATH-500, MinervaMath, OlympiadBench
|
| 123 |
+
|
| 124 |
+
| | avg pass@1 | max\_tokens |
|
| 125 |
+
| :---- | :---- | :---- |
|
| 126 |
+
| ZR1-1.5B | 51.13% | 32768 |
|
| 127 |
+
| ZR1-1.5B (truncated) | 46.83% | 4096 |
|
| 128 |
+
| ZR1-1.5B (direct answer prompt) | 45.38% | 4096 |
|
| 129 |
+
| ZR1-1.5B (truncated) | **40.39%** | 2048 |
|
| 130 |
+
| ZR1-1.5B (direct answer prompt) | 37% | 2048 |
|
| 131 |
+
| Qwen-2.5-Math-1.5B-Instruct | 32.25% | 2048 |
|
| 132 |
+
| Qwen-2.5-Math-7B-Instruct | 37.01% | 2048 |
|
| 133 |
+
|
| 134 |
+
For Leetcode and LiveBench, we report pass@1 accuracy with greedy sampling. For the rest of the evaluations we report pass@1 accuracy averaged over 16 samples per question, with temperature 0.6 and top_p 0.95.
|
| 135 |
+
|
| 136 |
+
We use the following settings for SGLang:
|
| 137 |
+
|
| 138 |
+
```
|
| 139 |
+
python -m sglang.launch_server --model-path <model> --host 0.0.0.0 --port 5001 --mem-fraction-static=0.8 --dtype bfloat16 --random-seed 0 --chunked-prefill-size -1 --attention-backend triton --sampling-backend pytorch --disable-radix-cache --disable-cuda-graph-padding --disable-custom-all-reduce --disable-mla --triton-attention-reduce-in-fp32
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
For vllm we disable prefix caching and chunked prefill.
|
config.json
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen2ForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 151646,
|
| 7 |
+
"eos_token_id": 151643,
|
| 8 |
+
"hidden_act": "silu",
|
| 9 |
+
"hidden_size": 1536,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"intermediate_size": 8960,
|
| 12 |
+
"max_position_embeddings": 131072,
|
| 13 |
+
"max_window_layers": 21,
|
| 14 |
+
"model_type": "qwen2",
|
| 15 |
+
"num_attention_heads": 12,
|
| 16 |
+
"num_hidden_layers": 28,
|
| 17 |
+
"num_key_value_heads": 2,
|
| 18 |
+
"pad_token_id": 151643,
|
| 19 |
+
"rms_norm_eps": 1e-06,
|
| 20 |
+
"rope_scaling": null,
|
| 21 |
+
"rope_theta": 10000,
|
| 22 |
+
"sliding_window": null,
|
| 23 |
+
"tie_word_embeddings": false,
|
| 24 |
+
"torch_dtype": "bfloat16",
|
| 25 |
+
"transformers_version": "4.50.3",
|
| 26 |
+
"use_cache": true,
|
| 27 |
+
"use_mrope": false,
|
| 28 |
+
"use_sliding_window": false,
|
| 29 |
+
"vocab_size": 151936,
|
| 30 |
+
"quantization_config": {
|
| 31 |
+
"quant_method": "exl2",
|
| 32 |
+
"version": "0.2.8",
|
| 33 |
+
"bits": 4.0,
|
| 34 |
+
"head_bits": 6,
|
| 35 |
+
"calibration": {
|
| 36 |
+
"rows": 115,
|
| 37 |
+
"length": 2048,
|
| 38 |
+
"dataset": "(default)"
|
| 39 |
+
}
|
| 40 |
+
}
|
| 41 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 151646,
|
| 4 |
+
"do_sample": true,
|
| 5 |
+
"eos_token_id": 151643,
|
| 6 |
+
"temperature": 0.6,
|
| 7 |
+
"top_p": 0.95,
|
| 8 |
+
"transformers_version": "4.47.1"
|
| 9 |
+
}
|
output.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:167dd9cee7799c354b3cad06294ecd80db36fe25d3730459e076427afdabcca3
|
| 3 |
+
size 1307797544
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin▁of▁sentence|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end▁of▁sentence|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|end▁of▁sentence|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e20ddafc659ba90242154b55275402edeca0715e5dbb30f56815a4ce081f4893
|
| 3 |
+
size 11422778
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"add_prefix_space": null,
|
| 5 |
+
"added_tokens_decoder": {
|
| 6 |
+
"151643": {
|
| 7 |
+
"content": "<|end▁of▁sentence|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false,
|
| 12 |
+
"special": true
|
| 13 |
+
},
|
| 14 |
+
"151644": {
|
| 15 |
+
"content": "<|User|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": false,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false,
|
| 20 |
+
"special": false
|
| 21 |
+
},
|
| 22 |
+
"151645": {
|
| 23 |
+
"content": "<|Assistant|>",
|
| 24 |
+
"lstrip": false,
|
| 25 |
+
"normalized": false,
|
| 26 |
+
"rstrip": false,
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"special": false
|
| 29 |
+
},
|
| 30 |
+
"151646": {
|
| 31 |
+
"content": "<|begin▁of▁sentence|>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false,
|
| 36 |
+
"special": true
|
| 37 |
+
},
|
| 38 |
+
"151647": {
|
| 39 |
+
"content": "<|EOT|>",
|
| 40 |
+
"lstrip": false,
|
| 41 |
+
"normalized": false,
|
| 42 |
+
"rstrip": false,
|
| 43 |
+
"single_word": false,
|
| 44 |
+
"special": false
|
| 45 |
+
},
|
| 46 |
+
"151648": {
|
| 47 |
+
"content": "<think>",
|
| 48 |
+
"lstrip": false,
|
| 49 |
+
"normalized": false,
|
| 50 |
+
"rstrip": false,
|
| 51 |
+
"single_word": false,
|
| 52 |
+
"special": false
|
| 53 |
+
},
|
| 54 |
+
"151649": {
|
| 55 |
+
"content": "</think>",
|
| 56 |
+
"lstrip": false,
|
| 57 |
+
"normalized": false,
|
| 58 |
+
"rstrip": false,
|
| 59 |
+
"single_word": false,
|
| 60 |
+
"special": false
|
| 61 |
+
},
|
| 62 |
+
"151650": {
|
| 63 |
+
"content": "<|quad_start|>",
|
| 64 |
+
"lstrip": false,
|
| 65 |
+
"normalized": false,
|
| 66 |
+
"rstrip": false,
|
| 67 |
+
"single_word": false,
|
| 68 |
+
"special": true
|
| 69 |
+
},
|
| 70 |
+
"151651": {
|
| 71 |
+
"content": "<|quad_end|>",
|
| 72 |
+
"lstrip": false,
|
| 73 |
+
"normalized": false,
|
| 74 |
+
"rstrip": false,
|
| 75 |
+
"single_word": false,
|
| 76 |
+
"special": true
|
| 77 |
+
},
|
| 78 |
+
"151652": {
|
| 79 |
+
"content": "<|vision_start|>",
|
| 80 |
+
"lstrip": false,
|
| 81 |
+
"normalized": false,
|
| 82 |
+
"rstrip": false,
|
| 83 |
+
"single_word": false,
|
| 84 |
+
"special": true
|
| 85 |
+
},
|
| 86 |
+
"151653": {
|
| 87 |
+
"content": "<|vision_end|>",
|
| 88 |
+
"lstrip": false,
|
| 89 |
+
"normalized": false,
|
| 90 |
+
"rstrip": false,
|
| 91 |
+
"single_word": false,
|
| 92 |
+
"special": true
|
| 93 |
+
},
|
| 94 |
+
"151654": {
|
| 95 |
+
"content": "<|vision_pad|>",
|
| 96 |
+
"lstrip": false,
|
| 97 |
+
"normalized": false,
|
| 98 |
+
"rstrip": false,
|
| 99 |
+
"single_word": false,
|
| 100 |
+
"special": true
|
| 101 |
+
},
|
| 102 |
+
"151655": {
|
| 103 |
+
"content": "<|image_pad|>",
|
| 104 |
+
"lstrip": false,
|
| 105 |
+
"normalized": false,
|
| 106 |
+
"rstrip": false,
|
| 107 |
+
"single_word": false,
|
| 108 |
+
"special": true
|
| 109 |
+
},
|
| 110 |
+
"151656": {
|
| 111 |
+
"content": "<|video_pad|>",
|
| 112 |
+
"lstrip": false,
|
| 113 |
+
"normalized": false,
|
| 114 |
+
"rstrip": false,
|
| 115 |
+
"single_word": false,
|
| 116 |
+
"special": true
|
| 117 |
+
},
|
| 118 |
+
"151657": {
|
| 119 |
+
"content": "<tool_call>",
|
| 120 |
+
"lstrip": false,
|
| 121 |
+
"normalized": false,
|
| 122 |
+
"rstrip": false,
|
| 123 |
+
"single_word": false,
|
| 124 |
+
"special": false
|
| 125 |
+
},
|
| 126 |
+
"151658": {
|
| 127 |
+
"content": "</tool_call>",
|
| 128 |
+
"lstrip": false,
|
| 129 |
+
"normalized": false,
|
| 130 |
+
"rstrip": false,
|
| 131 |
+
"single_word": false,
|
| 132 |
+
"special": false
|
| 133 |
+
},
|
| 134 |
+
"151659": {
|
| 135 |
+
"content": "<|fim_prefix|>",
|
| 136 |
+
"lstrip": false,
|
| 137 |
+
"normalized": false,
|
| 138 |
+
"rstrip": false,
|
| 139 |
+
"single_word": false,
|
| 140 |
+
"special": false
|
| 141 |
+
},
|
| 142 |
+
"151660": {
|
| 143 |
+
"content": "<|fim_middle|>",
|
| 144 |
+
"lstrip": false,
|
| 145 |
+
"normalized": false,
|
| 146 |
+
"rstrip": false,
|
| 147 |
+
"single_word": false,
|
| 148 |
+
"special": false
|
| 149 |
+
},
|
| 150 |
+
"151661": {
|
| 151 |
+
"content": "<|fim_suffix|>",
|
| 152 |
+
"lstrip": false,
|
| 153 |
+
"normalized": false,
|
| 154 |
+
"rstrip": false,
|
| 155 |
+
"single_word": false,
|
| 156 |
+
"special": false
|
| 157 |
+
},
|
| 158 |
+
"151662": {
|
| 159 |
+
"content": "<|fim_pad|>",
|
| 160 |
+
"lstrip": false,
|
| 161 |
+
"normalized": false,
|
| 162 |
+
"rstrip": false,
|
| 163 |
+
"single_word": false,
|
| 164 |
+
"special": false
|
| 165 |
+
},
|
| 166 |
+
"151663": {
|
| 167 |
+
"content": "<|repo_name|>",
|
| 168 |
+
"lstrip": false,
|
| 169 |
+
"normalized": false,
|
| 170 |
+
"rstrip": false,
|
| 171 |
+
"single_word": false,
|
| 172 |
+
"special": false
|
| 173 |
+
},
|
| 174 |
+
"151664": {
|
| 175 |
+
"content": "<|file_sep|>",
|
| 176 |
+
"lstrip": false,
|
| 177 |
+
"normalized": false,
|
| 178 |
+
"rstrip": false,
|
| 179 |
+
"single_word": false,
|
| 180 |
+
"special": false
|
| 181 |
+
}
|
| 182 |
+
},
|
| 183 |
+
"bos_token": "<|begin▁of▁sentence|>",
|
| 184 |
+
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin��>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|>'}}{% endif %}",
|
| 185 |
+
"clean_up_tokenization_spaces": false,
|
| 186 |
+
"eos_token": "<|end▁of▁sentence|>",
|
| 187 |
+
"extra_special_tokens": {},
|
| 188 |
+
"legacy": true,
|
| 189 |
+
"model_max_length": 16384,
|
| 190 |
+
"pad_token": "<|end▁of▁sentence|>",
|
| 191 |
+
"sp_model_kwargs": {},
|
| 192 |
+
"tokenizer_class": "LlamaTokenizerFast",
|
| 193 |
+
"unk_token": null,
|
| 194 |
+
"use_default_system_prompt": false
|
| 195 |
+
}
|
zr1-1.5b-livebench.png
ADDED
|
zr1_livebench_greedy_lightmode.png
ADDED
|