
Update README.md
Browse files
README.md
CHANGED
|
@@ -2,40 +2,40 @@
|
|
| 2 |
license: mit
|
| 3 |
arxiv: 2205.12424
|
| 4 |
datasets:
|
| 5 |
-
-
|
| 6 |
metrics:
|
| 7 |
- accuracy
|
| 8 |
- precision
|
| 9 |
- recall
|
| 10 |
- f1
|
| 11 |
- roc_auc
|
| 12 |
-
model-index:
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
pipeline_tag: text-classification
|
| 37 |
tags:
|
| 38 |
-
-
|
| 39 |
- defect detection
|
| 40 |
- code
|
| 41 |
---
|
|
@@ -46,7 +46,7 @@ tags:
|
|
| 46 |
|
| 47 |
|
| 48 |
## Overview
|
| 49 |
-
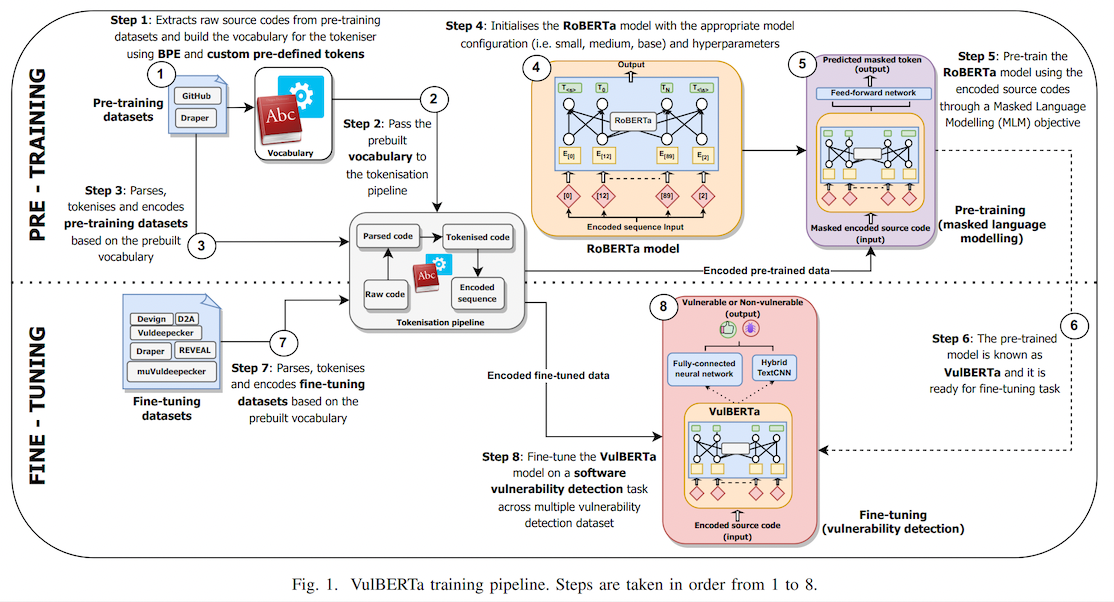
This model is the unofficial HuggingFace version of "[VulBERTa](https://github.com/ICL-ml4csec/VulBERTa/tree/main)" with an MLP classification head, trained on
|
| 50 |
|
| 51 |
> This paper presents presents VulBERTa, a deep learning approach to detect security vulnerabilities in source code. Our approach pre-trains a RoBERTa model with a custom tokenisation pipeline on real-world code from open-source C/C++ projects. The model learns a deep knowledge representation of the code syntax and semantics, which we leverage to train vulnerability detection classifiers. We evaluate our approach on binary and multi-class vulnerability detection tasks across several datasets (Vuldeepecker, Draper, REVEAL and muVuldeepecker) and benchmarks (CodeXGLUE and D2A). The evaluation results show that VulBERTa achieves state-of-the-art performance and outperforms existing approaches across different datasets, despite its conceptual simplicity, and limited cost in terms of size of training data and number of model parameters.
|
| 52 |
|
|
@@ -61,7 +61,7 @@ Note that due to the custom tokenizer, you must pass `trust_remote_code=True` wh
|
|
| 61 |
Example:
|
| 62 |
```
|
| 63 |
from transformers import pipeline
|
| 64 |
-
pipe = pipeline("text-classification", model="claudios/VulBERTa-MLP-
|
| 65 |
pipe("static void filter_mirror_setup(NetFilterState *nf, Error **errp)\n{\n MirrorState *s = FILTER_MIRROR(nf);\n Chardev *chr;\n chr = qemu_chr_find(s->outdev);\n if (chr == NULL) {\n error_set(errp, ERROR_CLASS_DEVICE_NOT_FOUND,\n \"Device '%s' not found\", s->outdev);\n qemu_chr_fe_init(&s->chr_out, chr, errp);")
|
| 66 |
>> [[{'label': 'LABEL_0', 'score': 0.014685827307403088},
|
| 67 |
{'label': 'LABEL_1', 'score': 0.985314130783081}]]
|
|
|
|
| 2 |
license: mit
|
| 3 |
arxiv: 2205.12424
|
| 4 |
datasets:
|
| 5 |
+
- VulDeePecker
|
| 6 |
metrics:
|
| 7 |
- accuracy
|
| 8 |
- precision
|
| 9 |
- recall
|
| 10 |
- f1
|
| 11 |
- roc_auc
|
| 12 |
+
# model-index:
|
| 13 |
+
# - name: VulBERTa MLP
|
| 14 |
+
# results:
|
| 15 |
+
# - task:
|
| 16 |
+
# type: defect-detection
|
| 17 |
+
# dataset:
|
| 18 |
+
# name: vuldeepecker
|
| 19 |
+
# type: vuldeepecker
|
| 20 |
+
# metrics:
|
| 21 |
+
# - name: Accuracy
|
| 22 |
+
# type: Accuracy
|
| 23 |
+
# value: 64.71
|
| 24 |
+
# - name: Precision
|
| 25 |
+
# type: Precision
|
| 26 |
+
# value: 64.80
|
| 27 |
+
# - name: Recall
|
| 28 |
+
# type: Recall
|
| 29 |
+
# value: 50.76
|
| 30 |
+
# - name: F1
|
| 31 |
+
# type: F1
|
| 32 |
+
# value: 56.93
|
| 33 |
+
# - name: ROC-AUC
|
| 34 |
+
# type: ROC-AUC
|
| 35 |
+
# value: 71.02
|
| 36 |
pipeline_tag: text-classification
|
| 37 |
tags:
|
| 38 |
+
- vuldeepecker
|
| 39 |
- defect detection
|
| 40 |
- code
|
| 41 |
---
|
|
|
|
| 46 |

|
| 47 |
|
| 48 |
## Overview
|
| 49 |
+
This model is the unofficial HuggingFace version of "[VulBERTa](https://github.com/ICL-ml4csec/VulBERTa/tree/main)" with an MLP classification head, trained on [VulDeePecker](https://arxiv.org/abs/1801.01681) ([dataset](https://huggingface.co/datasets/claudios/VulDeePecker)), by Hazim Hanif & Sergio Maffeis (Imperial College London). I simplified the tokenization process by adding the cleaning (comment removal) step to the tokenizer and added the simplified tokenizer to this model repo as an AutoClass.
|
| 50 |
|
| 51 |
> This paper presents presents VulBERTa, a deep learning approach to detect security vulnerabilities in source code. Our approach pre-trains a RoBERTa model with a custom tokenisation pipeline on real-world code from open-source C/C++ projects. The model learns a deep knowledge representation of the code syntax and semantics, which we leverage to train vulnerability detection classifiers. We evaluate our approach on binary and multi-class vulnerability detection tasks across several datasets (Vuldeepecker, Draper, REVEAL and muVuldeepecker) and benchmarks (CodeXGLUE and D2A). The evaluation results show that VulBERTa achieves state-of-the-art performance and outperforms existing approaches across different datasets, despite its conceptual simplicity, and limited cost in terms of size of training data and number of model parameters.
|
| 52 |
|
|
|
|
| 61 |
Example:
|
| 62 |
```
|
| 63 |
from transformers import pipeline
|
| 64 |
+
pipe = pipeline("text-classification", model="claudios/VulBERTa-MLP-VulDeePecker", trust_remote_code=True, return_all_scores=True)
|
| 65 |
pipe("static void filter_mirror_setup(NetFilterState *nf, Error **errp)\n{\n MirrorState *s = FILTER_MIRROR(nf);\n Chardev *chr;\n chr = qemu_chr_find(s->outdev);\n if (chr == NULL) {\n error_set(errp, ERROR_CLASS_DEVICE_NOT_FOUND,\n \"Device '%s' not found\", s->outdev);\n qemu_chr_fe_init(&s->chr_out, chr, errp);")
|
| 66 |
>> [[{'label': 'LABEL_0', 'score': 0.014685827307403088},
|
| 67 |
{'label': 'LABEL_1', 'score': 0.985314130783081}]]
|