
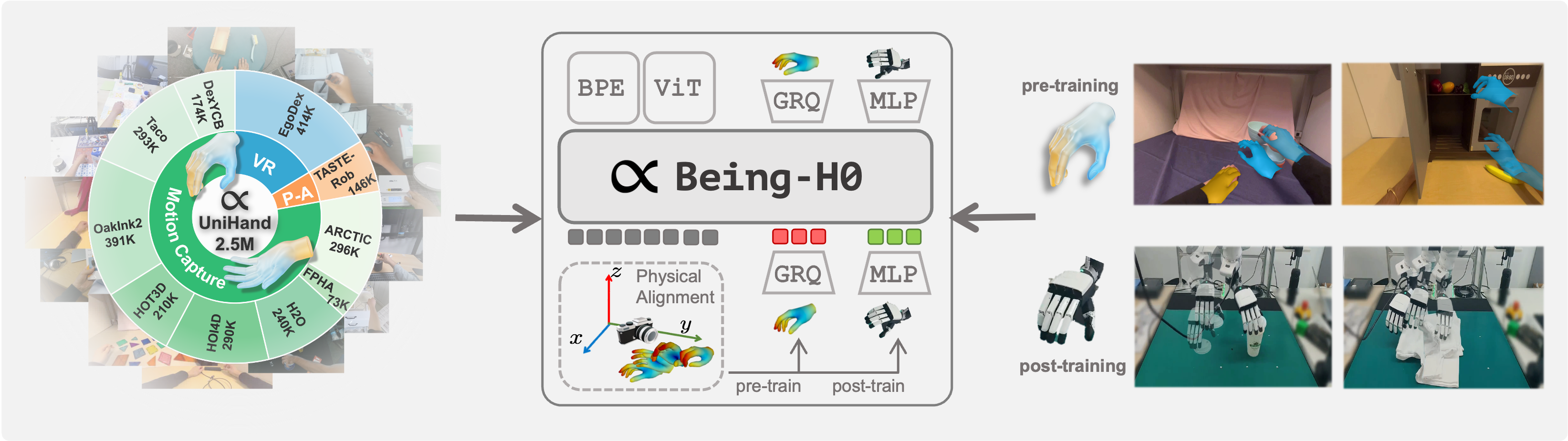
We introduce **Being-H0**, the first dexterous Vision-Language-Action model pretrained from large-scale human videos via explicit hand motion modeling. ## News - **[2025-08-02]**: We release the **Being-H0** codebase and pretrained models! Check our [Hugging Face Model Hub](https://huggingface.co/BeingBeyond/Being-H0) for more details. 🔥🔥🔥 - **[2025-07-21]**: We publish **Being-H0**! Check our paper [here](https://arxiv.org/abs/2507.15597). 🌟🌟🌟 ## Model Checkpoints Download pre-trained models from Hugging Face: | Model Type | Model Name | Parameters | Description | |------------|------------|------------|-------------| | **Motion Model** | [Being-H0-GRVQ-8K](https://huggingface.co/BeingBeyond/Being-H0-GRVQ-8K) | - | Motion tokenizer | | **VLA Pre-trained** | [Being-H0-1B-2508](https://huggingface.co/BeingBeyond/Being-H0-1B-2508) | 1B | Base vision-language-action model | | **VLA Pre-trained** | [Being-H0-8B-2508](https://huggingface.co/BeingBeyond/Being-H0-8B-2508) | 8B | Base vision-language-action model | | **VLA Pre-trained** | [Being-H0-14B-2508](https://huggingface.co/BeingBeyond/Being-H0-14B-2508) | 14B | Base vision-language-action model | | **VLA Post-trained** | [Being-H0-8B-Align-2508](https://huggingface.co/BeingBeyond/Being-H0-8B-Align-2508) | 8B | Fine-tuned for robot alignment | ## Dataset We have provided the dataset for post-training the VLA model. The dataset is available in Hugging Face: | Dataset Type | Dataset Name | Description | |--------------|--------------|-------------| | **VLA Post-training** | [h0_post_train_db_2508](https://huggingface.co/datasets/BeingBeyond/h0_post_train_db_2508) | Post-training dataset for pretrained Being-H0 VLA model | ## Setup ### Clone repository ```bash git clone https://github.com/BeingBeyond/Being-H0.git cd Being-H0 ``` ### Create environment ```bash conda env create -f environment.yml conda activate beingvla ``` ### Install package ```bash pip install flash-attn --no-build-isolation pip install git+https://github.com/lixiny/manotorch.git pip install git+https://github.com/mattloper/chumpy.git ``` ### Download MANO package - Visit [MANO website](http://mano.is.tue.mpg.de/) - Create an account by clicking _Sign Up_ and provide your information - Download Models and Code (the downloaded file should have the format `mano_v*_*.zip`). Note that all code and data from this download falls under the [MANO license](http://mano.is.tue.mpg.de/license). - Unzip and copy the contents in `mano_v*_*/` folder to the `beingvla/models/motion/mano/` folder ## Inference ### Motion Generation - To generate hand motion tokens and render the motion, you should use the Motion Model (`Being-H0-GRVQ-8K`) and the pretrained VLA model (`Being-H0-{1B,8B,14B}-2508`). - You can use the following command to inference. For the `--motion_code_path`, you should use a `+` symbol to jointly specify the wrist and finger motion code paths, e.g., `--motion_code_path "/path/to/Being-H0-GRVQ-8K/wrist/+/path/to/Being-H0-GRVQ-8K/finger/"`. - The `--hand_mode` can be set to `left`, `right`, or `both` to specify which hand to use for the task. ```bash python -m beingvla.inference.vla_internvl_inference \ --model_path /path/to/Being-H0-XXX \ --motion_code_path "/path/to/Being-H0-GRVQ-8K/wrist/+/path/to/Being-H0-GRVQ-8K/finger/" \ --input_image ./playground/unplug_airpods.jpg \ --task_description "unplug the charging cable from the AirPods" \ --hand_mode both \ --num_samples 3 \ --num_seconds 4 \ --enable_render true \ --gpu_device 0 \ --output_dir ./work_dirs/ ``` - **To inference on your own photos**: See [Camera Intrinsics Guide](https://github.com/BeingBeyond/Being-H0/blob/main/docs/camera_intrinsics.md) for how to estimate camera intrinsics and input them for custom inference. ### Evaluation - You can use our pretrained VLA model to post-train on real robot data. When you get your post-trained model (e.g., `Being-H0-8B-Align-2508`), you can use the following commands to communicate with real robot, or evaluate the model on a robot task. - Setup robot communication: ```bash python -m beingvla.models.motion.m2m.aligner.run_server \ --model-path /path/to/Being-H0-XXX-Align \ --port 12305 \ --action-chunk-length 16 ``` - Run evaluation on robot task: ```bash python -m beingvla.models.motion.m2m.aligner.eval_policy \ --model-path /path/to/Being-H0-XXX-Align \ --zarr-path /path/to/real-robot/data \ --task_description "Put the little white duck into the cup." \ --action-chunk-length 16 ``` ## Contributing and Building on Being-H0 We encourage researchers and practitioners to leverage Being-H0 as a foundation for their own creative experiments and applications. Whether you're adapting Being-H0 to new robotic platforms, exploring novel hand manipulation tasks, or extending the model to new domains, our modular codebase is designed to support your innovations. We welcome contributions of all kinds - from bug fixes and documentation improvements to new features and model architectures. By building on Being-H0 together, we can advance the field of dexterous vision-language-action modeling and enable robots to understand and replicate the rich complexity of human hand movements. Join us in making robotic manipulation more intuitive, capable, and accessible to all. ## Citation If you find our work useful, please consider citing us and give a star to our repository! 🌟🌟🌟 **Being-H0** ```bibtex @article{beingbeyond2025beingh0, title={Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos}, author={Luo, Hao and Feng, Yicheng and Zhang, Wanpeng and Zheng, Sipeng and Wang, Ye and Yuan, Haoqi and Liu, Jiazheng and Xu, Chaoyi and Jin, Qin and Lu, Zongqing}, journal={arXiv preprint arXiv:2507.15597}, year={2025} } ``` # Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
We introduce **Being-H0**, the first dexterous Vision-Language-Action model pretrained from large-scale human videos via explicit hand motion modeling. ## News - **[2025-08-02]**: We release the **Being-H0** codebase and pretrained models! Check our [Hugging Face Model Hub](https://huggingface.co/BeingBeyond/Being-H0) for more details. 🔥🔥🔥 - **[2025-07-21]**: We publish **Being-H0**! Check our paper [here](https://arxiv.org/abs/2507.15597). 🌟🌟🌟 ## Model Checkpoints Download pre-trained models from Hugging Face: | Model Type | Model Name | Parameters | Description | |------------|------------|------------|-------------| | **Motion Model** | [Being-H0-GRVQ-8K](https://huggingface.co/BeingBeyond/Being-H0-GRVQ-8K) | - | Motion tokenizer | | **VLA Pre-trained** | [Being-H0-1B-2508](https://huggingface.co/BeingBeyond/Being-H0-1B-2508) | 1B | Base vision-language-action model | | **VLA Pre-trained** | [Being-H0-8B-2508](https://huggingface.co/BeingBeyond/Being-H0-8B-2508) | 8B | Base vision-language-action model | | **VLA Pre-trained** | [Being-H0-14B-2508](https://huggingface.co/BeingBeyond/Being-H0-14B-2508) | 14B | Base vision-language-action model | | **VLA Post-trained** | [Being-H0-8B-Align-2508](https://huggingface.co/BeingBeyond/Being-H0-8B-Align-2508) | 8B | Fine-tuned for robot alignment | ## Dataset We have provided the dataset for post-training the VLA model. The dataset is available in Hugging Face: | Dataset Type | Dataset Name | Description | |--------------|--------------|-------------| | **VLA Post-training** | [h0_post_train_db_2508](https://huggingface.co/datasets/BeingBeyond/h0_post_train_db_2508) | Post-training dataset for pretrained Being-H0 VLA model | ## Setup ### Clone repository ```bash git clone https://github.com/BeingBeyond/Being-H0.git cd Being-H0 ``` ### Create environment ```bash conda env create -f environment.yml conda activate beingvla ``` ### Install package ```bash pip install flash-attn --no-build-isolation pip install git+https://github.com/lixiny/manotorch.git pip install git+https://github.com/mattloper/chumpy.git ``` ### Download MANO package - Visit [MANO website](http://mano.is.tue.mpg.de/) - Create an account by clicking _Sign Up_ and provide your information - Download Models and Code (the downloaded file should have the format `mano_v*_*.zip`). Note that all code and data from this download falls under the [MANO license](http://mano.is.tue.mpg.de/license). - unzip and copy the contents in `mano_v*_*/` folder to the `beingvla/models/motion/mano/` folder ## Inference ### Motion Generation ```bash python -m beingvla.inference.vla_internvl_inference \ --model_path /path/to/Being-H0-XXX \ --motion_code_path "/path/to/Being-H0-GRVQ-8K/wrist+/path/to/Being-H0-GRVQ-8K/finger" \ --input_image ./playground/unplug_airpods.jpg \ --task_description "unplug the charging cable from the AirPods" \ --hand_mode both \ --num_samples 3 \ --num_seconds 4 \ --enable_render true \ --output_dir ./work_dirs/ ``` ### Evaluation Setup robot communication: ```bash python -m beingvla.models.motion.m2m.aligner.run_server \ --model-path /path/to/Being-H0-XXX-Align \ --port 12305 \ --action-chunk-length 16 ``` Run evaluation on robot task: ```bash python -m beingvla.models.motion.m2m.aligner.eval_policy \ --model-path /path/to/Being-H0-XXX-Align \ --zarr-path /path/to/zarr/data \ --task_description "Put the little white duck into the cup." \ --action-chunk-length 16 ``` ## Contributing and Building on Being-H0 We encourage researchers and practitioners to leverage Being-H0 as a foundation for their own creative experiments and applications. Whether you're adapting Being-H0 to new robotic platforms, exploring novel hand manipulation tasks, or extending the model to new domains, our modular codebase is designed to support your innovations. We welcome contributions of all kinds - from bug fixes and documentation improvements to new features and model architectures. By building on Being-H0 together, we can advance the field of dexterous vision-language-action modeling and enable robots to understand and replicate the rich complexity of human hand movements. Join us in making robotic manipulation more intuitive, capable, and accessible to all. ## Citation If you find our work useful, please consider citing us and give a star to our repository! 🌟🌟🌟 **Being-H0** ```bibtex @article{beingbeyond2025beingh0, title={Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos}, author={Luo, Hao and Feng, Yicheng and Zhang, Wanpeng and Zheng, Sipeng and Wang, Ye and Yuan, Haoqi and Liu, Jiazheng and Xu, Chaoyi and Jin, Qin and Lu, Zongqing}, journal={arXiv preprint arXiv:2507.15597}, year={2025} } ```