Datasets:

Update README_JP.md
Browse files- README_JP.md +7 -3
README_JP.md
CHANGED
|
@@ -109,7 +109,7 @@
|
|
| 109 |
</table>
|
| 110 |
</div>
|
| 111 |
|
| 112 |
-
|
| 113 |
|
| 114 |
audio duration: 訓練データセットの合計時間 <br>
|
| 115 |
|
|
@@ -123,6 +123,10 @@ segments = オーディオが分割されるセグメントの数 <br>
|
|
| 123 |
|
| 124 |
step = セグメント*エポック/バッチサイズ。これがモデルファイル名の数字の由来です。<br>
|
| 125 |
|
| 126 |
-
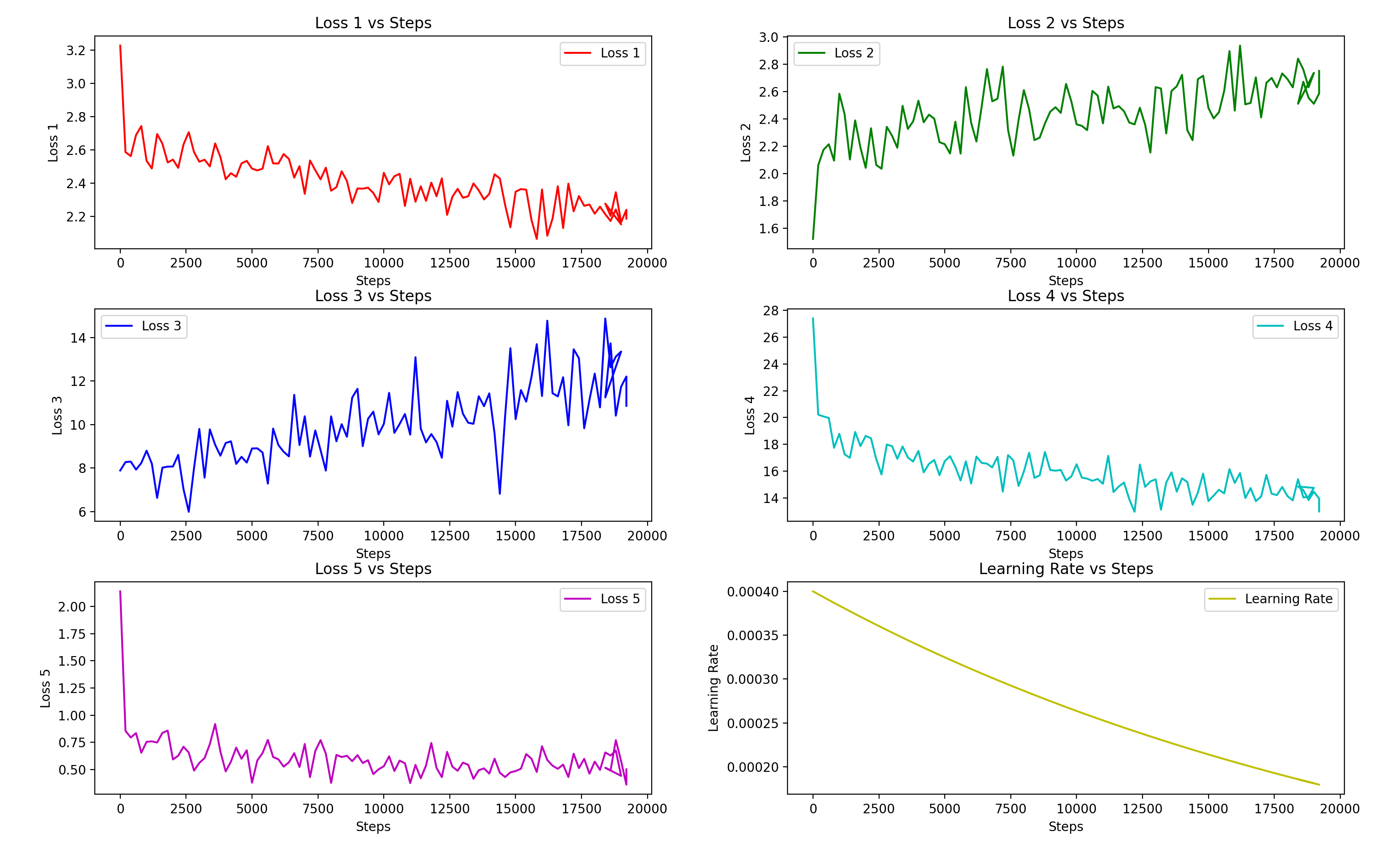
「放浪者」を例にとると: 損失関数グラフ:stepとloss5に注目します。たとえば:<br>
|
|
|
|
|
|
|
|
|
|
| 127 |
|
| 128 |
-
[関連ファイルはこちらをクリックしてください]
|
|
|
|
|
|
| 109 |
</table>
|
| 110 |
</div>
|
| 111 |
|
| 112 |
+
キーパラメータ:<br>
|
| 113 |
|
| 114 |
audio duration: 訓練データセットの合計時間 <br>
|
| 115 |
|
|
|
|
| 123 |
|
| 124 |
step = セグメント*エポック/バッチサイズ。これがモデルファイル名の数字の由来です。<br>
|
| 125 |
|
| 126 |
+
「放浪者」を例にとると: 損失関数グラフ:stepとloss5に注目します。たとえば:<br>
|
| 127 |
+
高音の女性声が原音声の場合、10分の純粋な人声で訓練した場合、約2800epoch(10,000step)で結果が出ました。
|
| 128 |
+
実際に使用したのは5571epoch(19,500step)で、訓練された音色と元の音色にはわずかな違いがあります。詳細は、
|
| 129 |
+
上記のプレビューオーディオをご覧ください。通常のトレーニングでは、10分は十分なトレーニングセットの時間ではありません。<br>
|
| 130 |
|
| 131 |
+
[関連ファイルはこちらをクリックしてください](https://huggingface.co/datasets/jiaheillu/audio_preview/tree/main)<br>
|
| 132 |
+
|