
Update README.md
Browse files
README.md
CHANGED
|
@@ -18,25 +18,21 @@ size_categories:
|
|
| 18 |
|
| 19 |
## Dataset details
|
| 20 |
|
| 21 |
-
Existing Multimodal Large Language Model benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including:
|
| 22 |
-
1) small data scale leading to large performance variance;
|
| 23 |
-
2) reliance on model-based annotations, resulting in significant model bias;
|
| 24 |
-
3) restricted data sources, often overlapping with existing benchmarks and posing a risk of data leakage;
|
| 25 |
-
4) insufficient task difficulty and discrimination, especially the limited image resolution.
|
| 26 |
-
|
| 27 |
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
|
|
|
| 31 |
|
| 32 |
-
|
| 33 |
|
| 34 |
-
|
| 35 |
|
| 36 |
-
|
| 37 |
|
| 38 |
-
|
| 39 |
|
|
|
|
| 40 |
|
| 41 |
|
| 42 |
|
|
|
|
| 18 |
|
| 19 |
## Dataset details
|
| 20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
| 22 |
+
Existing Multimodal Large Language Model benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including:
|
| 23 |
+
1) small data scale leads to a large performance variance;
|
| 24 |
+
2) reliance on model-based annotations results in restricted data quality;
|
| 25 |
+
3) insufficient task difficulty, especially caused by the limited image resolution.
|
| 26 |
|
| 27 |
+
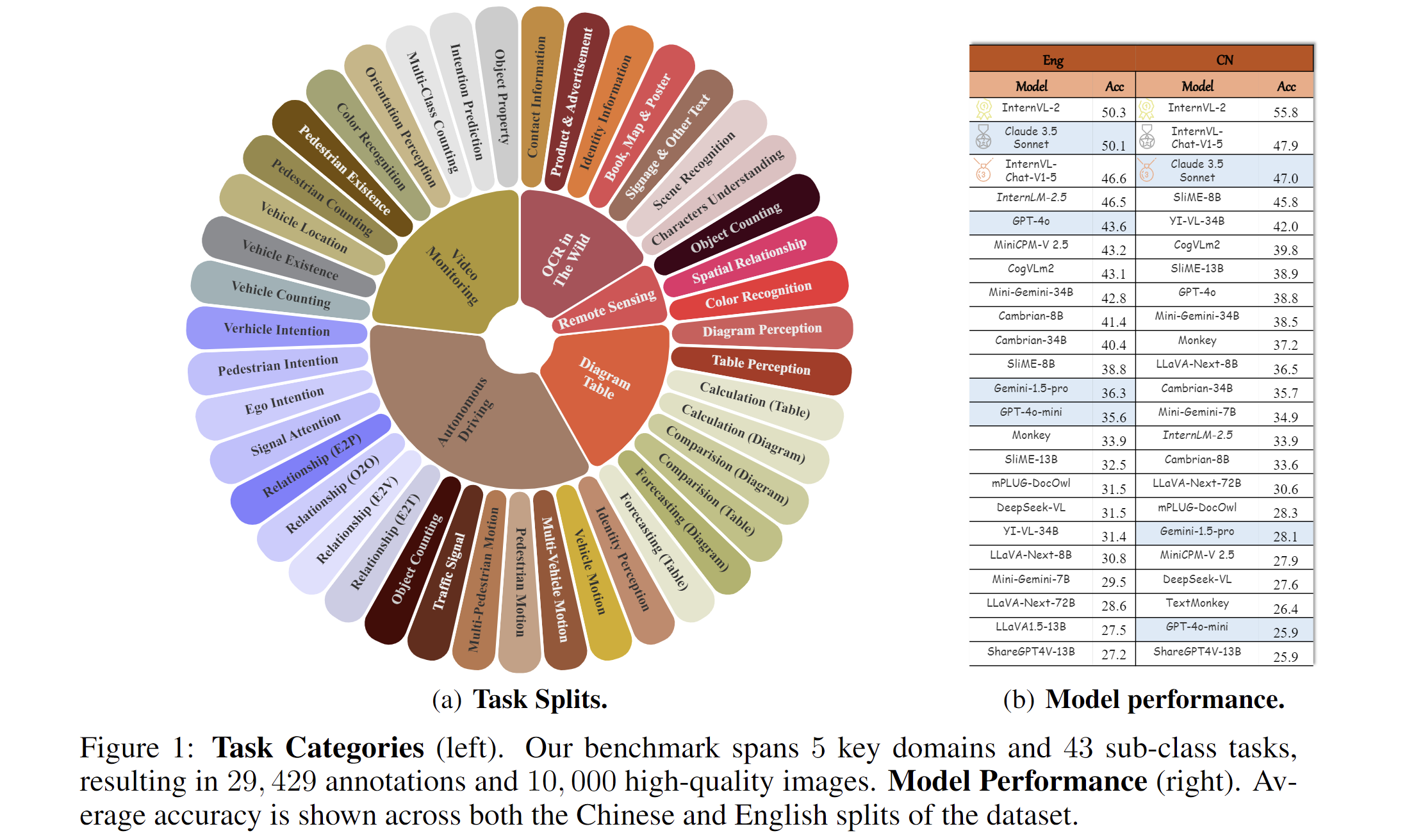
We present MME-RealWord, a benchmark meticulously designed to address real-world applications with practical relevance. Featuring 13,366 high-resolution images averaging 2,000 × 1,500 pixels, MME-RealWord poses substantial recognition challenges. Our dataset encompasses 29,429 annotations across 43 tasks, all expertly curated by a team of 25 crowdsource workers and 7 MLLM experts. The main advantages of MME-RealWorld compared to existing MLLM benchmarks as follows:
|
| 28 |
|
| 29 |
+
1. **Data Scale**: with the efforts of a total of 32 volunteers, we have manually annotated 29,429 QA pairs focused on real-world scenarios, making this the largest fully human-annotated benchmark known to date.
|
| 30 |
|
| 31 |
+
2. **Data Quality**: 1) Resolution: Many image details, such as a scoreboard in a sports event, carry critical information. These details can only be properly interpreted with high- resolution images, which are essential for providing meaningful assistance to humans. To the best of our knowledge, MME-RealWorld features the highest average image resolution among existing competitors. 2) Annotation: All annotations are manually completed, with a professional team cross-checking the results to ensure data quality.
|
| 32 |
|
| 33 |
+
3. **Task Difficulty and Real-World Utility.**: We can see that even the most advanced models have not surpassed 60% accuracy. Additionally, many real-world tasks are significantly more difficult than those in traditional benchmarks. For example, in video monitoring, a model needs to count the presence of 133 vehicles, or in remote sensing, it must identify and count small objects on a map with an average resolution exceeding 5000×5000.
|
| 34 |
|
| 35 |
+
4. **MME-RealWord-CN.**: Existing Chinese benchmark is usually translated from its English version. This has two limitations: 1) Question-image mismatch. The image may relate to an English scenario, which is not intuitively connected to a Chinese question. 2) Translation mismatch [58]. The machine translation is not always precise and perfect enough. We collect additional images that focus on Chinese scenarios, asking Chinese volunteers for annotation. This results in 5,917 QA pairs.
|
| 36 |
|
| 37 |

|
| 38 |
|