

Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- Modelfile +17 -0
- README.md +541 -3
- chinda-qwen3-4b.q4_k_m.gguf +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
chinda-qwen3-4b.q4_k_m.gguf filter=lfs diff=lfs merge=lfs -text
|
Modelfile
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM ./chinda-qwen3-4b.q4_k_m.gguf
|
| 2 |
+
|
| 3 |
+
TEMPLATE """{{ if .System }}<|im_start|>system
|
| 4 |
+
{{ .System }}<|im_end|>
|
| 5 |
+
{{ end }}{{ if .Prompt }}<|im_start|>user
|
| 6 |
+
{{ .Prompt }}<|im_end|>
|
| 7 |
+
{{ end }}<|im_start|>assistant
|
| 8 |
+
{{ .Response }}<|im_end|>
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
PARAMETER stop "<|im_end|>"
|
| 12 |
+
PARAMETER temperature 0
|
| 13 |
+
PARAMETER top_k 20
|
| 14 |
+
PARAMETER top_p 0.95
|
| 15 |
+
|
| 16 |
+
SYSTEM """คุณชื่อจินดา สร้างโดย บ. ไอแอพพ์เทคโนโลยี จำกัด (iApp Technology Co., Ltd.)"""
|
| 17 |
+
|
README.md
CHANGED
|
@@ -1,3 +1,541 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- th
|
| 5 |
+
- en
|
| 6 |
+
base_model:
|
| 7 |
+
- Qwen/Qwen3-4B
|
| 8 |
+
pipeline_tag: text-generation
|
| 9 |
+
tags:
|
| 10 |
+
- thai
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
# 🇹🇭 Chinda Opensource Thai LLM 4B (Q4_K_M)
|
| 14 |
+
|
| 15 |
+
**Latest Model, Think in Thai, Answer in Thai, Built by Thai Startup**
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
Chinda Opensource Thai LLM 4B is iApp Technology's cutting-edge Thai language model that brings advanced thinking capabilities to the Thai AI ecosystem. Built on the latest Qwen3-4B architecture, Chinda represents our commitment to developing sovereign AI solutions for Thailand.
|
| 20 |
+
|
| 21 |
+
## 🚀 Quick Links
|
| 22 |
+
|
| 23 |
+
- **🌐 Demo:** [https://chindax.iapp.co.th](https://chindax.iapp.co.th) (Choose ChindaLLM 4b)
|
| 24 |
+
- **📦 Model Download:** [https://huggingface.co/iapp/chinda-qwen3-4b](https://huggingface.co/iapp/chinda-qwen3-4b)
|
| 25 |
+
- **🏠 Homepage:** [https://iapp.co.th/products/chinda-opensource-llm](https://iapp.co.th/products/chinda-opensource-llm)
|
| 26 |
+
- **📄 License:** Apache 2.0
|
| 27 |
+
|
| 28 |
+
## ✨ Key Features
|
| 29 |
+
|
| 30 |
+
### 🆓 **0. Free and Opensource for Everyone**
|
| 31 |
+
Chinda LLM 4B is completely free and open-source, enabling developers, researchers, and businesses to build Thai AI applications without restrictions.
|
| 32 |
+
|
| 33 |
+
### 🧠 **1. Advanced Thinking Model**
|
| 34 |
+
- **Highest score among Thai LLMs in 4B category**
|
| 35 |
+
- Seamless switching between thinking and non-thinking modes
|
| 36 |
+
- Superior reasoning capabilities for complex problems
|
| 37 |
+
- Can be turned off for efficient general-purpose dialogue
|
| 38 |
+
|
| 39 |
+
### 🇹🇭 **2. Exceptional Thai Language Accuracy**
|
| 40 |
+
- **98.4% accuracy** in outputting Thai language
|
| 41 |
+
- Prevents unwanted Chinese and foreign language outputs
|
| 42 |
+
- Specifically fine-tuned for Thai linguistic patterns
|
| 43 |
+
|
| 44 |
+
### 🆕 **3. Latest Architecture**
|
| 45 |
+
- Based on the cutting-edge **Qwen3-4B** model
|
| 46 |
+
- Incorporates the latest advancements in language modeling
|
| 47 |
+
- Optimized for both performance and efficiency
|
| 48 |
+
|
| 49 |
+
### 📜 **4. Apache 2.0 License**
|
| 50 |
+
- Commercial use permitted
|
| 51 |
+
- Modification and distribution allowed
|
| 52 |
+
- No restrictions on private use
|
| 53 |
+
|
| 54 |
+
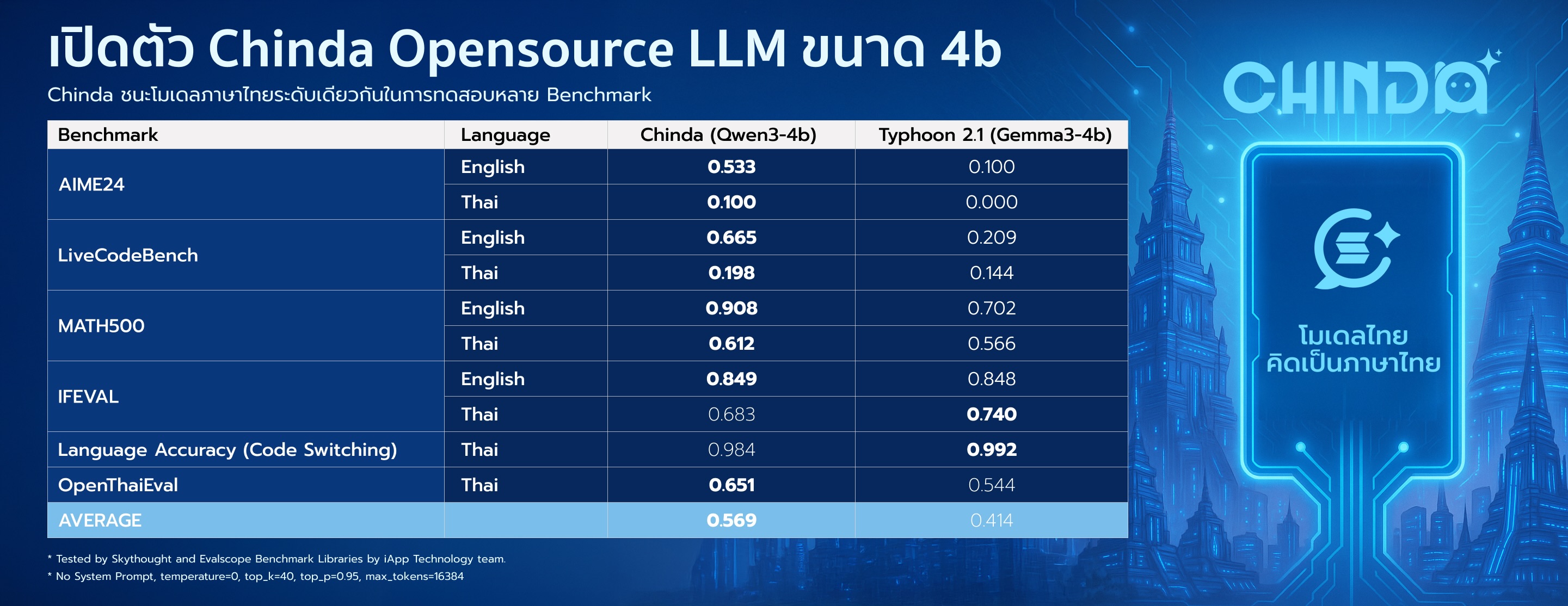
## 📊 Benchmark Results
|
| 55 |
+
|
| 56 |
+
Chinda LLM 4B demonstrates superior performance compared to other Thai language models in its category:
|
| 57 |
+
|
| 58 |
+
| Benchmark | Language | Chinda LLM 4B | Alternative* |
|
| 59 |
+
|-----------|----------|---------------|-------------|
|
| 60 |
+
| **AIME24** | English | **0.533** | 0.100 |
|
| 61 |
+
| | Thai | **0.100** | 0.000 |
|
| 62 |
+
| **LiveCodeBench** | English | **0.665** | 0.209 |
|
| 63 |
+
| | Thai | **0.198** | 0.144 |
|
| 64 |
+
| **MATH500** | English | **0.908** | 0.702 |
|
| 65 |
+
| | Thai | **0.612** | 0.566 |
|
| 66 |
+
| **IFEVAL** | English | **0.849** | 0.848 |
|
| 67 |
+
| | Thai | 0.683 | **0.740** |
|
| 68 |
+
| **Language Accuracy** | Thai | 0.984 | **0.992** |
|
| 69 |
+
| **OpenThaiEval** | Thai | **0.651** | 0.544 |
|
| 70 |
+
| **AVERAGE** | | **0.569** | 0.414 |
|
| 71 |
+
|
| 72 |
+
* Alternative: scb10x_typhoon2.1-gemma3-4b
|
| 73 |
+
* Tested by Skythought and Evalscope Benchmark Libraries by iApp Technology team. Results show Chinda LLM 4B achieving **37% better overall performance** than the nearest alternative.
|
| 74 |
+
|
| 75 |
+
## ✅ Suitable For
|
| 76 |
+
|
| 77 |
+
### 🔍 **1. RAG Applications (Sovereign AI)**
|
| 78 |
+
Perfect for building Retrieval-Augmented Generation systems that keep data processing within Thai sovereignty.
|
| 79 |
+
|
| 80 |
+
### 📱 **2. Mobile and Laptop Applications**
|
| 81 |
+
Reliable Small Language Model optimized for edge computing and personal devices.
|
| 82 |
+
|
| 83 |
+
### 🧮 **3. Math Calculation**
|
| 84 |
+
Excellent performance in mathematical reasoning and problem-solving.
|
| 85 |
+
|
| 86 |
+
### 💻 **4. Code Assistant**
|
| 87 |
+
Strong capabilities in code generation and programming assistance.
|
| 88 |
+
|
| 89 |
+
### ⚡ **5. Resource Efficiency**
|
| 90 |
+
Very fast inference with minimal GPU memory consumption, ideal for production deployments.
|
| 91 |
+
|
| 92 |
+
## ❌ Not Suitable For
|
| 93 |
+
|
| 94 |
+
### 📚 **Factual Questions Without Context**
|
| 95 |
+
As a 4B parameter model, it may hallucinate when asked for specific facts without provided context. Always use with RAG or provide relevant context for factual queries.
|
| 96 |
+
|
| 97 |
+
## 🛠️ Quick Start
|
| 98 |
+
|
| 99 |
+
### Installation
|
| 100 |
+
|
| 101 |
+
```bash
|
| 102 |
+
pip install transformers torch
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
### Basic Usage
|
| 106 |
+
|
| 107 |
+
```python
|
| 108 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 109 |
+
|
| 110 |
+
model_name = "iapp/chinda-qwen3-4b"
|
| 111 |
+
|
| 112 |
+
# Load the tokenizer and model
|
| 113 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 114 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 115 |
+
model_name,
|
| 116 |
+
torch_dtype="auto",
|
| 117 |
+
device_map="auto"
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
# Prepare the model input
|
| 121 |
+
prompt = "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
|
| 122 |
+
messages = [
|
| 123 |
+
{"role": "user", "content": prompt}
|
| 124 |
+
]
|
| 125 |
+
|
| 126 |
+
text = tokenizer.apply_chat_template(
|
| 127 |
+
messages,
|
| 128 |
+
tokenize=False,
|
| 129 |
+
add_generation_prompt=True,
|
| 130 |
+
enable_thinking=True # Enable thinking mode for better reasoning
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 134 |
+
|
| 135 |
+
# Generate response
|
| 136 |
+
generated_ids = model.generate(
|
| 137 |
+
**model_inputs,
|
| 138 |
+
max_new_tokens=1024,
|
| 139 |
+
temperature=0.6,
|
| 140 |
+
top_p=0.95,
|
| 141 |
+
top_k=20,
|
| 142 |
+
do_sample=True
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
|
| 146 |
+
|
| 147 |
+
# Parse thinking content (if enabled)
|
| 148 |
+
try:
|
| 149 |
+
# Find </think> token (151668)
|
| 150 |
+
index = len(output_ids) - output_ids[::-1].index(151668)
|
| 151 |
+
except ValueError:
|
| 152 |
+
index = 0
|
| 153 |
+
|
| 154 |
+
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
|
| 155 |
+
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
|
| 156 |
+
|
| 157 |
+
print("🧠 Thinking:", thinking_content)
|
| 158 |
+
print("💬 Response:", content)
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
### Switching Between Thinking and Non-Thinking Mode
|
| 162 |
+
|
| 163 |
+
#### Enable Thinking Mode (Default)
|
| 164 |
+
```python
|
| 165 |
+
text = tokenizer.apply_chat_template(
|
| 166 |
+
messages,
|
| 167 |
+
tokenize=False,
|
| 168 |
+
add_generation_prompt=True,
|
| 169 |
+
enable_thinking=True # Enable detailed reasoning
|
| 170 |
+
)
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
#### Disable Thinking Mode (For Efficiency)
|
| 174 |
+
```python
|
| 175 |
+
text = tokenizer.apply_chat_template(
|
| 176 |
+
messages,
|
| 177 |
+
tokenize=False,
|
| 178 |
+
add_generation_prompt=True,
|
| 179 |
+
enable_thinking=False # Fast response mode
|
| 180 |
+
)
|
| 181 |
+
```
|
| 182 |
+
|
| 183 |
+
### API Deployment
|
| 184 |
+
|
| 185 |
+
#### Using vLLM
|
| 186 |
+
```bash
|
| 187 |
+
pip install vllm>=0.8.5
|
| 188 |
+
vllm serve iapp/chinda-qwen3-4b --enable-reasoning --reasoning-parser deepseek_r1
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
#### Using SGLang
|
| 192 |
+
```bash
|
| 193 |
+
pip install sglang>=0.4.6.post1
|
| 194 |
+
python -m sglang.launch_server --model-path iapp/chinda-qwen3-4b --reasoning-parser qwen3
|
| 195 |
+
```
|
| 196 |
+
|
| 197 |
+
## 🔧 Advanced Configuration
|
| 198 |
+
|
| 199 |
+
### Processing Long Texts
|
| 200 |
+
|
| 201 |
+
Chinda LLM 4B natively supports up to 32,768 tokens. For longer contexts, enable YaRN scaling:
|
| 202 |
+
|
| 203 |
+
```json
|
| 204 |
+
{
|
| 205 |
+
"rope_scaling": {
|
| 206 |
+
"rope_type": "yarn",
|
| 207 |
+
"factor": 4.0,
|
| 208 |
+
"original_max_position_embeddings": 32768
|
| 209 |
+
}
|
| 210 |
+
}
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
+
### Recommended Parameters
|
| 214 |
+
|
| 215 |
+
**For Thinking Mode:**
|
| 216 |
+
- Temperature: 0.6
|
| 217 |
+
- Top-P: 0.95
|
| 218 |
+
- Top-K: 20
|
| 219 |
+
- Min-P: 0
|
| 220 |
+
|
| 221 |
+
**For Non-Thinking Mode:**
|
| 222 |
+
- Temperature: 0.7
|
| 223 |
+
- Top-P: 0.8
|
| 224 |
+
- Top-K: 20
|
| 225 |
+
- Min-P: 0
|
| 226 |
+
|
| 227 |
+
## 📝 Context Length & Template Format
|
| 228 |
+
|
| 229 |
+
### Context Length Support
|
| 230 |
+
- **Native Context Length:** 32,768 tokens
|
| 231 |
+
- **Extended Context Length:** Up to 131,072 tokens (with YaRN scaling)
|
| 232 |
+
- **Input + Output:** Total conversation length supported
|
| 233 |
+
- **Recommended Usage:** Keep conversations under 32K tokens for optimal performance
|
| 234 |
+
|
| 235 |
+
### Chat Template Format
|
| 236 |
+
|
| 237 |
+
Chinda LLM 4B uses a standardized chat template format for consistent interactions:
|
| 238 |
+
|
| 239 |
+
```python
|
| 240 |
+
# Basic template structure
|
| 241 |
+
messages = [
|
| 242 |
+
{"role": "system", "content": "You are a helpful Thai AI assistant."},
|
| 243 |
+
{"role": "user", "content": "สวัสดีครับ"},
|
| 244 |
+
{"role": "assistant", "content": "สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ"},
|
| 245 |
+
{"role": "user", "content": "ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย"}
|
| 246 |
+
]
|
| 247 |
+
|
| 248 |
+
# Apply template with thinking mode
|
| 249 |
+
text = tokenizer.apply_chat_template(
|
| 250 |
+
messages,
|
| 251 |
+
tokenize=False,
|
| 252 |
+
add_generation_prompt=True,
|
| 253 |
+
enable_thinking=True
|
| 254 |
+
)
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
### Template Structure
|
| 258 |
+
|
| 259 |
+
The template follows the standard conversational format:
|
| 260 |
+
|
| 261 |
+
```
|
| 262 |
+
<|im_start|>system
|
| 263 |
+
You are a helpful Thai AI assistant.<|im_end|>
|
| 264 |
+
<|im_start|>user
|
| 265 |
+
สวัสดีครับ<|im_end|>
|
| 266 |
+
<|im_start|>assistant
|
| 267 |
+
สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ<|im_end|>
|
| 268 |
+
<|im_start|>user
|
| 269 |
+
ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย<|im_end|>
|
| 270 |
+
<|im_start|>assistant
|
| 271 |
+
```
|
| 272 |
+
|
| 273 |
+
### Advanced Template Usage
|
| 274 |
+
|
| 275 |
+
```python
|
| 276 |
+
# Multi-turn conversation with thinking control
|
| 277 |
+
def create_conversation(messages, enable_thinking=True):
|
| 278 |
+
# Add system message if not present
|
| 279 |
+
if not messages or messages[0]["role"] != "system":
|
| 280 |
+
system_msg = {
|
| 281 |
+
"role": "system",
|
| 282 |
+
"content": "คุณเป็น AI ผู้ช่วยที่ฉลาดและเป็นประโยชน์ พูดภาษาไทยได้อย่างเป็นธรรมชาติ"
|
| 283 |
+
}
|
| 284 |
+
messages = [system_msg] + messages
|
| 285 |
+
|
| 286 |
+
# Apply chat template
|
| 287 |
+
text = tokenizer.apply_chat_template(
|
| 288 |
+
messages,
|
| 289 |
+
tokenize=False,
|
| 290 |
+
add_generation_prompt=True,
|
| 291 |
+
enable_thinking=enable_thinking
|
| 292 |
+
)
|
| 293 |
+
|
| 294 |
+
return text
|
| 295 |
+
|
| 296 |
+
# Example usage
|
| 297 |
+
conversation = [
|
| 298 |
+
{"role": "user", "content": "คำนวณ 15 × 23 = ?"},
|
| 299 |
+
]
|
| 300 |
+
|
| 301 |
+
prompt = create_conversation(conversation, enable_thinking=True)
|
| 302 |
+
```
|
| 303 |
+
|
| 304 |
+
### Dynamic Mode Switching
|
| 305 |
+
|
| 306 |
+
You can control thinking mode within conversations using special commands:
|
| 307 |
+
|
| 308 |
+
```python
|
| 309 |
+
# Enable thinking for complex problems
|
| 310 |
+
messages = [
|
| 311 |
+
{"role": "user", "content": "/think แก้สมการ: x² + 5x - 14 = 0"}
|
| 312 |
+
]
|
| 313 |
+
|
| 314 |
+
# Disable thinking for quick responses
|
| 315 |
+
messages = [
|
| 316 |
+
{"role": "user", "content": "/no_think สวัสดี"}
|
| 317 |
+
]
|
| 318 |
+
```
|
| 319 |
+
|
| 320 |
+
### Context Management Best Practices
|
| 321 |
+
|
| 322 |
+
1. **Monitor Token Count:** Keep track of total tokens (input + output)
|
| 323 |
+
2. **Truncate Old Messages:** Remove oldest messages when approaching limits
|
| 324 |
+
3. **Use YaRN for Long Contexts:** Enable rope scaling for documents > 32K tokens
|
| 325 |
+
4. **Batch Processing:** For very long texts, consider chunking and processing in batches
|
| 326 |
+
|
| 327 |
+
```python
|
| 328 |
+
def manage_context(messages, max_tokens=30000):
|
| 329 |
+
"""Simple context management function"""
|
| 330 |
+
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
|
| 331 |
+
|
| 332 |
+
while total_tokens > max_tokens and len(messages) > 2:
|
| 333 |
+
# Keep system message and remove oldest user/assistant pair
|
| 334 |
+
if messages[1]["role"] == "user":
|
| 335 |
+
messages.pop(1) # Remove user message
|
| 336 |
+
if len(messages) > 1 and messages[1]["role"] == "assistant":
|
| 337 |
+
messages.pop(1) # Remove corresponding assistant message
|
| 338 |
+
|
| 339 |
+
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
|
| 340 |
+
|
| 341 |
+
return messages
|
| 342 |
+
```
|
| 343 |
+
|
| 344 |
+
## 🏢 Enterprise Support
|
| 345 |
+
|
| 346 |
+
For enterprise deployments, custom training, or commercial support, contact us at:
|
| 347 |
+
- **Email:** [email protected]
|
| 348 |
+
- **Website:** [iapp.co.th](https://iapp.co.th)
|
| 349 |
+
|
| 350 |
+
## ❓ Frequently Asked Questions
|
| 351 |
+
|
| 352 |
+
<details>
|
| 353 |
+
<summary><strong>🏷️ Why is it named "Chinda"?</strong></summary>
|
| 354 |
+
|
| 355 |
+
The name "Chinda" (จินดา) comes from "จินดามณี" (Chindamani), which is considered the first book of Thailand written by Phra Horathibodi (Sri Dharmasokaraja) in the Sukhothai period. Just as จินดามณี was a foundational text for Thai literature and learning, Chinda LLM represents our foundation for Thai sovereign AI - a model that truly understands and thinks in Thai, preserving and advancing Thai language capabilities in the digital age.
|
| 356 |
+
|
| 357 |
+
</details>
|
| 358 |
+
|
| 359 |
+
<details>
|
| 360 |
+
<summary><strong>⚖️ Can I use Chinda LLM 4B for commercial purposes?</strong></summary>
|
| 361 |
+
|
| 362 |
+
Yes! Chinda LLM 4B is released under the **Apache 2.0 License**, which allows:
|
| 363 |
+
- ✅ **Commercial use** - Use in commercial products and services
|
| 364 |
+
- ✅ **Research use** - Academic and research applications
|
| 365 |
+
- ✅ **Modification** - Adapt and modify the model
|
| 366 |
+
- ✅ **Distribution** - Share and redistribute the model
|
| 367 |
+
- ✅ **Private use** - Use for internal company projects
|
| 368 |
+
|
| 369 |
+
No restrictions on commercial applications - build and deploy freely!
|
| 370 |
+
|
| 371 |
+
</details>
|
| 372 |
+
|
| 373 |
+
<details>
|
| 374 |
+
<summary><strong>🧠 What's the difference between thinking and non-thinking mode?</strong></summary>
|
| 375 |
+
|
| 376 |
+
**Thinking Mode (`enable_thinking=True`):**
|
| 377 |
+
- Model shows its reasoning process in `<think>...</think>` blocks
|
| 378 |
+
- Better for complex problems, math, coding, logical reasoning
|
| 379 |
+
- Slower but more accurate responses
|
| 380 |
+
- Recommended for tasks requiring deep analysis
|
| 381 |
+
|
| 382 |
+
**Non-Thinking Mode (`enable_thinking=False`):**
|
| 383 |
+
- Direct answers without showing reasoning
|
| 384 |
+
- Faster responses for general conversations
|
| 385 |
+
- Better for simple queries and chat applications
|
| 386 |
+
- More efficient resource usage
|
| 387 |
+
|
| 388 |
+
You can switch between modes or let users control it dynamically using `/think` and `/no_think` commands.
|
| 389 |
+
|
| 390 |
+
</details>
|
| 391 |
+
|
| 392 |
+
<details>
|
| 393 |
+
<summary><strong>📊 How does Chinda LLM 4B compare to other Thai language models?</strong></summary>
|
| 394 |
+
|
| 395 |
+
Chinda LLM 4B achieves **37% better overall performance** compared to the nearest alternative:
|
| 396 |
+
|
| 397 |
+
- **Overall Average:** 0.569 vs 0.414 (alternative)
|
| 398 |
+
- **Math (MATH500):** 0.908 vs 0.702 (English), 0.612 vs 0.566 (Thai)
|
| 399 |
+
- **Code (LiveCodeBench):** 0.665 vs 0.209 (English), 0.198 vs 0.144 (Thai)
|
| 400 |
+
- **Thai Language Accuracy:** 98.4% (prevents Chinese/foreign text output)
|
| 401 |
+
- **OpenThaiEval:** 0.651 vs 0.544
|
| 402 |
+
|
| 403 |
+
It's currently the **highest-scoring Thai LLM in the 4B parameter category**.
|
| 404 |
+
|
| 405 |
+
</details>
|
| 406 |
+
|
| 407 |
+
<details>
|
| 408 |
+
<summary><strong>💻 What are the system requirements to run Chinda LLM 4B?</strong></summary>
|
| 409 |
+
|
| 410 |
+
**Minimum Requirements:**
|
| 411 |
+
- **GPU:** 8GB VRAM (RTX 3070/4060 Ti or better)
|
| 412 |
+
- **RAM:** 16GB system memory
|
| 413 |
+
- **Storage:** 8GB free space for model download
|
| 414 |
+
- **Python:** 3.8+ with PyTorch
|
| 415 |
+
|
| 416 |
+
**Recommended for Production:**
|
| 417 |
+
- **GPU:** 16GB+ VRAM (RTX 4080/A4000 or better)
|
| 418 |
+
- **RAM:** 32GB+ system memory
|
| 419 |
+
- **Storage:** SSD for faster loading
|
| 420 |
+
|
| 421 |
+
**CPU-Only Mode:** Possible but significantly slower (not recommended for production)
|
| 422 |
+
|
| 423 |
+
</details>
|
| 424 |
+
|
| 425 |
+
<details>
|
| 426 |
+
<summary><strong>🔧 Can I fine-tune Chinda LLM 4B for my specific use case?</strong></summary>
|
| 427 |
+
|
| 428 |
+
Yes! As an open-source model under Apache 2.0 license, you can:
|
| 429 |
+
|
| 430 |
+
- **Fine-tune** on your domain-specific data
|
| 431 |
+
- **Customize** for specific tasks or industries
|
| 432 |
+
- **Modify** the architecture if needed
|
| 433 |
+
- **Create derivatives** for specialized applications
|
| 434 |
+
|
| 435 |
+
Popular fine-tuning frameworks that work with Chinda:
|
| 436 |
+
- **Unsloth** - Fast and memory-efficient
|
| 437 |
+
- **LoRA/QLoRA** - Parameter-efficient fine-tuning
|
| 438 |
+
- **Hugging Face Transformers** - Full fine-tuning
|
| 439 |
+
- **Axolotl** - Advanced training configurations
|
| 440 |
+
|
| 441 |
+
Need help with fine-tuning? Contact our team at [email protected]
|
| 442 |
+
|
| 443 |
+
</details>
|
| 444 |
+
|
| 445 |
+
<details>
|
| 446 |
+
<summary><strong>🌍 What languages does Chinda LLM 4B support?</strong></summary>
|
| 447 |
+
|
| 448 |
+
**Primary Languages:**
|
| 449 |
+
- **Thai** - Native-level understanding and generation (98.4% accuracy)
|
| 450 |
+
- **English** - Strong performance across all benchmarks
|
| 451 |
+
|
| 452 |
+
**Additional Languages:**
|
| 453 |
+
- 100+ languages supported (inherited from Qwen3-4B base)
|
| 454 |
+
- Focus optimized for Thai-English bilingual tasks
|
| 455 |
+
- Code generation in multiple programming languages
|
| 456 |
+
|
| 457 |
+
**Special Features:**
|
| 458 |
+
- **Code-switching** between Thai and English
|
| 459 |
+
- **Translation** between Thai and other languages
|
| 460 |
+
- **Multilingual reasoning** capabilities
|
| 461 |
+
|
| 462 |
+
</details>
|
| 463 |
+
|
| 464 |
+
<details>
|
| 465 |
+
<summary><strong>🔍 Is the training data publicly available?</strong></summary>
|
| 466 |
+
|
| 467 |
+
The model weights are open-source, but the specific training datasets are not publicly released. However:
|
| 468 |
+
|
| 469 |
+
- **Base Model:** Built on Qwen3-4B (Alibaba's open foundation)
|
| 470 |
+
- **Thai Optimization:** Custom dataset curation for Thai language tasks
|
| 471 |
+
- **Quality Focus:** Carefully selected high-quality Thai content
|
| 472 |
+
- **Privacy Compliant:** No personal or sensitive data included
|
| 473 |
+
|
| 474 |
+
For research collaborations or dataset inquiries, contact our research team.
|
| 475 |
+
|
| 476 |
+
</details>
|
| 477 |
+
|
| 478 |
+
<details>
|
| 479 |
+
<summary><strong>🆘 How do I get support or report issues?</strong></summary>
|
| 480 |
+
|
| 481 |
+
**For Technical Issues:**
|
| 482 |
+
- **GitHub Issues:** Report bugs and technical problems
|
| 483 |
+
- **Hugging Face:** Model-specific questions and discussions
|
| 484 |
+
- **Documentation:** Check our comprehensive guides
|
| 485 |
+
|
| 486 |
+
**For Commercial Support:**
|
| 487 |
+
- **Email:** [email protected]
|
| 488 |
+
- **Enterprise Support:** Custom training, deployment assistance
|
| 489 |
+
- **Consulting:** Integration and optimization services
|
| 490 |
+
|
| 491 |
+
**Community Support:**
|
| 492 |
+
- **Thai AI Community:** Join discussions about Thai AI development
|
| 493 |
+
- **Developer Forums:** Connect with other Chinda users
|
| 494 |
+
|
| 495 |
+
</details>
|
| 496 |
+
|
| 497 |
+
<details>
|
| 498 |
+
<summary><strong>📥 How large is the model download and what format is it in?</strong></summary>
|
| 499 |
+
|
| 500 |
+
**Model Specifications:**
|
| 501 |
+
- **Parameters:** 4.02 billion (4B)
|
| 502 |
+
- **Download Size:** ~8GB (compressed)
|
| 503 |
+
- **Format:** Safetensors (recommended) and PyTorch
|
| 504 |
+
- **Precision:** BF16 (Brain Float 16)
|
| 505 |
+
|
| 506 |
+
**Download Options:**
|
| 507 |
+
- **Hugging Face Hub:** `huggingface.co/iapp/chinda-qwen3-4b`
|
| 508 |
+
- **Git LFS:** For version control integration
|
| 509 |
+
- **Direct Download:** Individual model files
|
| 510 |
+
- **Quantized Versions:** Available for reduced memory usage (GGUF, AWQ)
|
| 511 |
+
|
| 512 |
+
**Quantization Options:**
|
| 513 |
+
- **4-bit (GGUF):** ~2.5GB, runs on 4GB VRAM
|
| 514 |
+
- **8-bit:** ~4GB, balanced performance/memory
|
| 515 |
+
- **16-bit (Original):** ~8GB, full performance
|
| 516 |
+
|
| 517 |
+
</details>
|
| 518 |
+
|
| 519 |
+
## 📚 Citation
|
| 520 |
+
|
| 521 |
+
If you use Chinda LLM 4B in your research or projects, please cite:
|
| 522 |
+
|
| 523 |
+
```bibtex
|
| 524 |
+
@misc{chinda-llm-4b,
|
| 525 |
+
title={Chinda LLM 4B: Thai Sovereign AI Language Model},
|
| 526 |
+
author={iApp Technology},
|
| 527 |
+
year={2025},
|
| 528 |
+
publisher={Hugging Face},
|
| 529 |
+
url={https://huggingface.co/iapp/chinda-qwen3-4b}
|
| 530 |
+
}
|
| 531 |
+
```
|
| 532 |
+
|
| 533 |
+
---
|
| 534 |
+
|
| 535 |
+
*Built with 🇹🇭 by iApp Technology - Empowering Thai Businesses with Sovereign AI Excellence*
|
| 536 |
+
|
| 537 |
+

|
| 538 |
+
|
| 539 |
+
**Powered by iApp Technology**
|
| 540 |
+
|
| 541 |
+
<i>Disclaimer: Provided responses are not guaranteed.</i>
|
chinda-qwen3-4b.q4_k_m.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f2c299c8384c3e1b1b2a84a08b98ac1e67a90aac0b4a30e614501f345f968a68
|
| 3 |
+
size 2497276480
|