

update readme
Browse files- README.md +102 -11
- config.json +7 -69
- images/Phase1_data.png +0 -0
- images/Phase2_data.png +0 -0
- images/jetmoe_architecture.png +0 -0
README.md
CHANGED
|
@@ -1,15 +1,68 @@
|
|
| 1 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
|
| 5 |
-
|
| 6 |
|
| 7 |
-
|
| 8 |
-
- **Academia-Friendly**: By relying exclusively on public datasets and open-sourcing our code, JetMoE-8B is highly accessible for educational and research purposes. It is designed to be fine-tuned even on consumer-grade GPUs, making it feasible for most academic labs.
|
| 9 |
-
- **Efficiency at Scale**: With only 2.2B active parameters during inference, JetMoE-8B provides an optimal balance between computational cost and performance, outperforming similarly sized models such as Gemma-2B across various benchmarks.
|
| 10 |
-
- **Good Performence** JetMoE-8B-chat has been evaluated using the MT-Bench, surpassing Llama-2-13b-chat and Vicuna-13b-v1.3. Here is how JetMoE-8B-chat compares with other models:
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|---------------------|-----------|
|
| 14 |
| GPT-4 | 9.014 |
|
| 15 |
| GPT-3.5-turbo | 7.995 |
|
|
@@ -21,9 +74,10 @@ Welcome to the official repository of JetMoE-8B-chat, a language model that comb
|
|
| 21 |
| Llama-2-7b-chat | 6.269 |
|
| 22 |
|
| 23 |
|
| 24 |
-

|
| 25 |
|
| 26 |
-
|
|
|
|
|
|
|
| 27 |
|
| 28 |
Here's a quick example to get you started with JetMoE-8B-chat:
|
| 29 |
|
|
@@ -61,4 +115,41 @@ if torch.cuda.is_available():
|
|
| 61 |
# Decode the generated text
|
| 62 |
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
|
| 63 |
print(generated_text)
|
| 64 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
base_model: jetmoe/jetmoe-8b
|
| 4 |
+
tags:
|
| 5 |
+
- alignment-handbook
|
| 6 |
+
- generated_from_trainer
|
| 7 |
+
datasets:
|
| 8 |
+
- HuggingFaceH4/ultrachat_200k
|
| 9 |
+
- HuggingFaceH4/airoboros-3.2
|
| 10 |
+
- HuggingFaceH4/Code-Feedback
|
| 11 |
+
- HuggingFaceH4/orca-math-word-problems-200k
|
| 12 |
+
- HuggingFaceH4/SystemChat
|
| 13 |
+
- HuggingFaceH4/capybara
|
| 14 |
+
model-index:
|
| 15 |
+
- name: jetmoe-8b-sft
|
| 16 |
+
results: []
|
| 17 |
+
---
|
| 18 |
|
| 19 |
+
<div align="center">
|
| 20 |
+
<div> </div>
|
| 21 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/641de0213239b631552713e4/ieHnwuczidNNoGRA_FN2y.png" width="500"/>
|
| 22 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/641de0213239b631552713e4/UOsk9_zcbHpCCy6kmryYM.png" width="530"/>
|
| 23 |
+
</div>
|
| 24 |
|
| 25 |
+
# JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars
|
| 26 |
|
| 27 |
+
## Key Messages
|
|
|
|
|
|
|
|
|
|
| 28 |
|
| 29 |
+
1. JetMoE-8B is **trained with less than $ 0.1 million**<sup>1</sup> **cost but outperforms LLaMA2-7B from Meta AI**, who has multi-billion-dollar training resources. LLM training can be **much cheaper than people previously thought**.
|
| 30 |
+
|
| 31 |
+
2. JetMoE-8B is **fully open-sourced and academia-friendly** because:
|
| 32 |
+
- It **only uses public datasets** for training, and the code is open-sourced. No proprietary resource is needed.
|
| 33 |
+
- It **can be finetuned with very limited compute budget** (e.g., consumer-grade GPU) that most labs can afford.
|
| 34 |
+
|
| 35 |
+
3. JetMoE-8B **only has 2.2B active parameters** during inference, which drastically lowers the computational cost. Compared to a model with similar inference computation, like Gemma-2B, JetMoE-8B achieves constantly better performance.
|
| 36 |
+
|
| 37 |
+
<sup>1</sup> We used a 96×H100 GPU cluster for 2 weeks, which cost ~$0.08 million.
|
| 38 |
+
|
| 39 |
+
Website: [https://research.myshell.ai/jetmoe](https://research.myshell.ai/jetmoe)
|
| 40 |
+
|
| 41 |
+
HuggingFace: [https://huggingface.co/jetmoe/jetmoe-8b](https://huggingface.co/jetmoe/jetmoe-8b)
|
| 42 |
+
|
| 43 |
+
Online Demo on Lepton AI: [https://www.lepton.ai/playground/chat?model=jetmoe-8b-chat](https://www.lepton.ai/playground/chat?model=jetmoe-8b-chat)
|
| 44 |
+
|
| 45 |
+
## Authors
|
| 46 |
+
|
| 47 |
+
The project is contributed by [Yikang Shen](https://scholar.google.com.hk/citations?user=qff5rRYAAAAJ), [Zhen Guo](https://zguo0525.github.io/), [Tianle Cai](https://www.tianle.website/#/) and [Zengyi Qin](https://www.qinzy.tech/). For technical inquiries, please contact [Yikang Shen](https://scholar.google.com.hk/citations?user=qff5rRYAAAAJ). For media and collaboration inquiries, please contact [Zengyi Qin](https://www.qinzy.tech/).
|
| 48 |
+
|
| 49 |
+
## Collaboration
|
| 50 |
+
**If you have great ideas but need more resources (GPU, data, funding, etc.)**, welcome to contact **MyShell.ai** via [Zengyi Qin](https://www.qinzy.tech/). **MyShell.ai** is open to collaborations and are actively supporting high-quality open-source projects.
|
| 51 |
+
|
| 52 |
+
## Benchmarks
|
| 53 |
+
We use the same evaluation methodology as in the Open LLM leaderboard. For MBPP code benchmark, we use the same evaluation methodology as in the LLaMA2 and Deepseek-MoE paper. The results are shown below:
|
| 54 |
+
|
| 55 |
+
|Model|Activate Params|Training Tokens|Open LLM Leaderboard Avg|ARC|Hellaswag|MMLU|TruthfulQA|WinoGrande|GSM8k|MBPP|HumanEval|
|
| 56 |
+
|---|---|---|---|---|---|---|---|---|---|---|---|
|
| 57 |
+
|Shot||||25|10|5|0|5|5|3|0|
|
| 58 |
+
|Metric||||acc_norm|acc_norm|acc|mc2|acc|acc|Pass@1|Pass@1|
|
| 59 |
+
|LLaMA2-7B|7B|2T|51.0|53.1|78.6|46.9|38.8|74|14.5|20.8|12.8|
|
| 60 |
+
|LLaMA-13B|13B|1T|51.4|**56.2**|**80.9**|47.7|39.5|**76.2**|7.6|22.0|15.8|
|
| 61 |
+
|DeepseekMoE-16B|2.8B|2T|51.1|53.2|79.8|46.3|36.1|73.7|17.3|34.0|**25.0**|
|
| 62 |
+
|Gemma-2B|2B|2T|46.4|48.4|71.8|41.8|33.1|66.3|16.9|28.0|24.4|
|
| 63 |
+
|JetMoE-8B|2.2B|1.25T|**53.0**|48.7|80.5|**49.2**|**41.7**|70.2|**27.8**|**34.2**|14.6|
|
| 64 |
+
|
| 65 |
+
| Model | MT-Bench Score |
|
| 66 |
|---------------------|-----------|
|
| 67 |
| GPT-4 | 9.014 |
|
| 68 |
| GPT-3.5-turbo | 7.995 |
|
|
|
|
| 74 |
| Llama-2-7b-chat | 6.269 |
|
| 75 |
|
| 76 |
|
|
|
|
| 77 |
|
| 78 |
+
To our surprise, despite the lower training cost and computation, JetMoE-8B performs even better than LLaMA2-7B, LLaMA-13B, and DeepseekMoE-16B. Compared to a model with similar training and inference computation, like Gemma-2B, JetMoE-8B achieves better performance.
|
| 79 |
+
|
| 80 |
+
## Model Usage
|
| 81 |
|
| 82 |
Here's a quick example to get you started with JetMoE-8B-chat:
|
| 83 |
|
|
|
|
| 115 |
# Decode the generated text
|
| 116 |
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
|
| 117 |
print(generated_text)
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
## Model Details
|
| 121 |
+
JetMoE-8B has 24 blocks.
|
| 122 |
+
Each block has two MoE layers: Mixture of Attention heads (MoA) and Mixture of MLP Experts (MoE).
|
| 123 |
+
Each MoA and MoE layer has 8 expert, and 2 experts are activated for each input token.
|
| 124 |
+
It has 8 billion parameters in total and 2.2B active parameters.
|
| 125 |
+
JetMoE-8B is trained on 1.25T tokens from publicly available datasets, with a learning rate of 5.0 x 10<sup>-4</sup> and a global batch-size of 4M tokens.
|
| 126 |
+
|
| 127 |
+
<figure>
|
| 128 |
+
<center>
|
| 129 |
+
<img src="images/jetmoe_architecture.png" width="40%">
|
| 130 |
+
<figcaption>JetMoE Architecture</figcaption>
|
| 131 |
+
</center>
|
| 132 |
+
</figure>
|
| 133 |
+
|
| 134 |
+
## Training Details
|
| 135 |
+
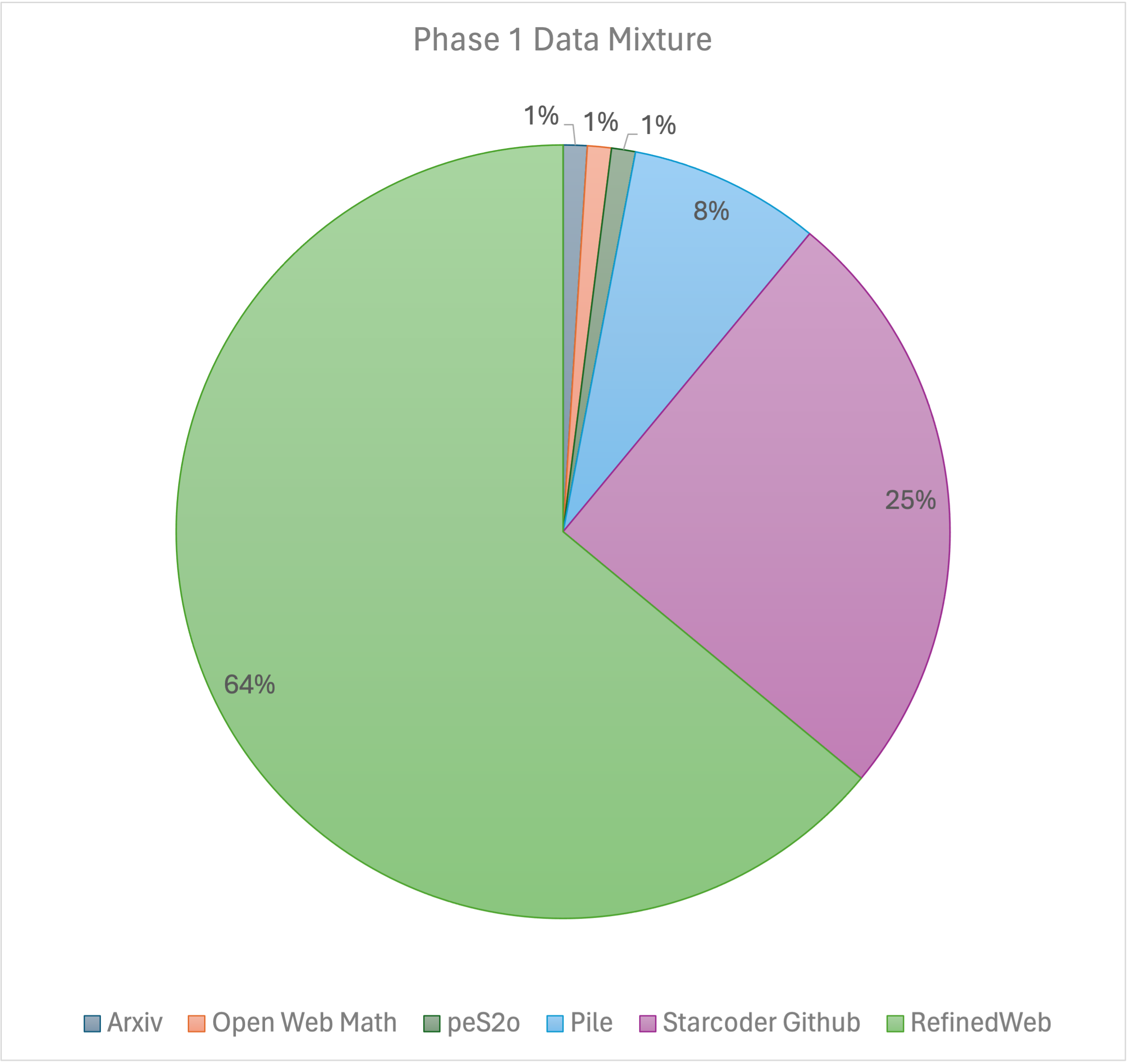
Our training recipe follows the [MiniCPM](https://shengdinghu.notion.site/MiniCPM-Unveiling-the-Potential-of-End-side-Large-Language-Models-d4d3a8c426424654a4e80e42a711cb20?pvs=4)'s two-phases training method. Phase 1 uses a constant learning rate with linear warmup and is trained on 1 trillion tokens from large-scale open-source pretraining datasets, including RefinedWeb, Pile, Github data, etc. Phase 2 uses exponential learning rate decay and is trained on 250 billion tokens from phase 1 datasets and extra high-quality open-source datasets.
|
| 136 |
+
|
| 137 |
+
<figure>
|
| 138 |
+
<center>
|
| 139 |
+
<img src="images/Phase1_data.png" width="60%">
|
| 140 |
+
<img src="images/Phase2_data.png" width="60%">
|
| 141 |
+
</center>
|
| 142 |
+
</figure>
|
| 143 |
+
|
| 144 |
+
## Technical Report
|
| 145 |
+
For more details, please refer to the JetMoE Technical Report (Coming Soon).
|
| 146 |
+
|
| 147 |
+
## JetMoE Model Index
|
| 148 |
+
|Model|Index|
|
| 149 |
+
|---|---|
|
| 150 |
+
|JetMoE-8B-Base| [Link](https://huggingface.co/jetmoe/jetmoe-8B) |
|
| 151 |
+
|JetMoE-8B-SFT| [Link](https://huggingface.co/jetmoe/jetmoe-8B-sft) |
|
| 152 |
+
|JetMoE-8B-Chat| [Link](https://huggingface.co/jetmoe/jetmoe-8B-chat) |
|
| 153 |
+
|
| 154 |
+
## Acknowledgement
|
| 155 |
+
We express our gratitude to [Shengding Hu](https://shengdinghu.github.io/) for his valuable advice on the Phase 2 data mixture. We also express our gratitude to [Exabits](https://www.exabits.ai/) for their assistance in setting up the GPU clusters, and to [Lepton AI](https://www.lepton.ai/) for their support in setting up the chat demo.
|
config.json
CHANGED
|
@@ -1,92 +1,30 @@
|
|
| 1 |
{
|
| 2 |
-
"_attn_implementation_internal": "eager",
|
| 3 |
-
"_commit_hash": "e4d9ef770a272f072cac70d16dd1ae113f5989ae",
|
| 4 |
"_name_or_path": "jetmoe/jetmoe-8b-chat",
|
|
|
|
| 5 |
"activation_function": "silu",
|
| 6 |
-
"add_cross_attention": false,
|
| 7 |
"architectures": [
|
| 8 |
"JetMoEForCausalLM"
|
| 9 |
],
|
| 10 |
-
"auto_map": {
|
| 11 |
-
"AutoConfig": "configuration_jetmoe.JetMoEConfig",
|
| 12 |
-
"AutoModelForCausalLM": "modeling_jetmoe.JetMoEForCausalLM"
|
| 13 |
-
},
|
| 14 |
-
"aux_loss_coef": 0.01,
|
| 15 |
-
"bad_words_ids": null,
|
| 16 |
-
"begin_suppress_tokens": null,
|
| 17 |
-
"bias": true,
|
| 18 |
"bos_token_id": 1,
|
| 19 |
-
"chunk_size_feed_forward": 0,
|
| 20 |
-
"cross_attention_hidden_size": null,
|
| 21 |
-
"decoder_start_token_id": null,
|
| 22 |
-
"diversity_penalty": 0.0,
|
| 23 |
-
"do_sample": false,
|
| 24 |
-
"early_stopping": false,
|
| 25 |
-
"encoder_no_repeat_ngram_size": 0,
|
| 26 |
"eos_token_id": 2,
|
| 27 |
-
"exponential_decay_length_penalty": null,
|
| 28 |
"ffn_hidden_size": 5632,
|
| 29 |
-
"finetuning_task": null,
|
| 30 |
-
"forced_bos_token_id": null,
|
| 31 |
-
"forced_eos_token_id": null,
|
| 32 |
-
"glu": true,
|
| 33 |
-
"id2label": {
|
| 34 |
-
"0": "LABEL_0",
|
| 35 |
-
"1": "LABEL_1"
|
| 36 |
-
},
|
| 37 |
-
"initializer_range": 0.01,
|
| 38 |
-
"is_decoder": false,
|
| 39 |
-
"is_encoder_decoder": false,
|
| 40 |
"kv_channels": 128,
|
| 41 |
-
"label2id": {
|
| 42 |
-
"LABEL_0": 0,
|
| 43 |
-
"LABEL_1": 1
|
| 44 |
-
},
|
| 45 |
"layer_norm_epsilon": 1e-05,
|
| 46 |
"length_penalty": 1.0,
|
| 47 |
-
"max_length": 20,
|
| 48 |
-
"min_length": 0,
|
| 49 |
-
"model_type": "jetmoe",
|
| 50 |
"moe_num_experts": 8,
|
| 51 |
"moe_top_k": 2,
|
| 52 |
-
"
|
| 53 |
-
"
|
| 54 |
-
"n_layer": 24,
|
| 55 |
"n_positions": 4096,
|
| 56 |
-
"
|
| 57 |
-
"num_beam_groups": 1,
|
| 58 |
-
"num_beams": 1,
|
| 59 |
"num_key_value_heads": 16,
|
| 60 |
"num_layers": 24,
|
| 61 |
-
"num_return_sequences": 1,
|
| 62 |
-
"output_attentions": false,
|
| 63 |
-
"output_hidden_states": false,
|
| 64 |
-
"output_scores": false,
|
| 65 |
-
"pad_token_id": null,
|
| 66 |
-
"prefix": null,
|
| 67 |
-
"problem_type": null,
|
| 68 |
-
"pruned_heads": {},
|
| 69 |
-
"remove_invalid_values": false,
|
| 70 |
-
"repetition_penalty": 1.0,
|
| 71 |
-
"return_dict": true,
|
| 72 |
-
"return_dict_in_generate": false,
|
| 73 |
"rms_norm_eps": 1e-05,
|
| 74 |
"rope_theta": 10000.0,
|
| 75 |
"rotary_percent": 1.0,
|
| 76 |
-
"sep_token_id": null,
|
| 77 |
-
"suppress_tokens": null,
|
| 78 |
-
"task_specific_params": null,
|
| 79 |
-
"temperature": 1.0,
|
| 80 |
-
"tf_legacy_loss": false,
|
| 81 |
-
"tie_encoder_decoder": false,
|
| 82 |
"tie_word_embeddings": true,
|
| 83 |
-
"tokenizer_class": null,
|
| 84 |
-
"top_k": 50,
|
| 85 |
-
"top_p": 1.0,
|
| 86 |
-
"torchscript": false,
|
| 87 |
"transformers_version": null,
|
| 88 |
-
"typical_p": 1.0,
|
| 89 |
-
"use_bfloat16": false,
|
| 90 |
"use_cache": true,
|
| 91 |
-
"vocab_size": 32000
|
| 92 |
-
|
|
|
|
|
|
| 1 |
{
|
|
|
|
|
|
|
| 2 |
"_name_or_path": "jetmoe/jetmoe-8b-chat",
|
| 3 |
+
"model_type": "jetmoe",
|
| 4 |
"activation_function": "silu",
|
|
|
|
| 5 |
"architectures": [
|
| 6 |
"JetMoEForCausalLM"
|
| 7 |
],
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
"bos_token_id": 1,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
"eos_token_id": 2,
|
|
|
|
| 10 |
"ffn_hidden_size": 5632,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
"kv_channels": 128,
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
"layer_norm_epsilon": 1e-05,
|
| 13 |
"length_penalty": 1.0,
|
|
|
|
|
|
|
|
|
|
| 14 |
"moe_num_experts": 8,
|
| 15 |
"moe_top_k": 2,
|
| 16 |
+
"hidden_size": 2048,
|
| 17 |
+
"num_hidden_layers": 24,
|
|
|
|
| 18 |
"n_positions": 4096,
|
| 19 |
+
"num_attention_heads": 32,
|
|
|
|
|
|
|
| 20 |
"num_key_value_heads": 16,
|
| 21 |
"num_layers": 24,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
"rms_norm_eps": 1e-05,
|
| 23 |
"rope_theta": 10000.0,
|
| 24 |
"rotary_percent": 1.0,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
"tie_word_embeddings": true,
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
"transformers_version": null,
|
|
|
|
|
|
|
| 27 |
"use_cache": true,
|
| 28 |
+
"vocab_size": 32000,
|
| 29 |
+
"glu": true
|
| 30 |
+
}
|
images/Phase1_data.png
ADDED
|
images/Phase2_data.png
ADDED

|
images/jetmoe_architecture.png
ADDED

|