
docs: add info to model card
Browse files- README.md +101 -1
- config.json +3 -2
README.md
CHANGED
|
@@ -1 +1,101 @@
|
|
| 1 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Model description
|
| 2 |
+
|
| 3 |
+
**DeepMetal** is a model capable of generating lyrics taylored for heavy metal songs.
|
| 4 |
+
The model is based on the [OpenAI GPT-2](https://huggingface.co/gpt2) and has been finetuned on a dataset of 141,718 heavy metal songs lyrics.
|
| 5 |
+
|
| 6 |
+
### Legal notes
|
| 7 |
+
|
| 8 |
+
Due to incertainity about legal rights, the dataset used for training the model is not provided. I hope you'll understand. The lyrics in question have been scraped from scraped from [DarkLyrics](http://www.darklyrics.com/) using the library [metal-parser](https://github.com/lucone83/metal-parser).
|
| 9 |
+
|
| 10 |
+
## Intended uses and limitations
|
| 11 |
+
|
| 12 |
+
The model is released under the [Apache 2.0 license](https://www.apache.org/licenses/LICENSE-2.0). You can use the raw model for lyrics generation or fine-tune it further to a downstream task.
|
| 13 |
+
|
| 14 |
+
## How to use
|
| 15 |
+
|
| 16 |
+
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, it could be good to set a seed for reproducibility:
|
| 17 |
+
|
| 18 |
+
```python
|
| 19 |
+
>>> from transformers import pipeline, set_seed
|
| 20 |
+
>>> generator = pipeline('text-generation', model='lucone83/deep-metal', device=-1) # to use GPU, set device=<CUDA_device_ordinal>
|
| 21 |
+
>>> set_seed(42)
|
| 22 |
+
>>> generator(
|
| 23 |
+
"I'll kill you and your dreams tonight",
|
| 24 |
+
num_return_sequences=1,
|
| 25 |
+
max_length=256,
|
| 26 |
+
min_length=128,
|
| 27 |
+
top_p=0.97,
|
| 28 |
+
top_k=0,
|
| 29 |
+
temperature=0.90
|
| 30 |
+
)
|
| 31 |
+
[{'generated_text': "I'll kill you and your dreams tonight\nYou're already dead\nI'll kill you and your dreams tonight\nNow I'm done\nNo words to say for you\nAnd don't let me down\nYou'll leave with nothing\nNo one could to wait for you\nYou were already dead\nYou were already dead\n\nI want to know what did you do?\nWhen you tried to run away\nI'll kill you and your dreams tonight\nYou're already dead\nI'll kill you and your dreams tonight\nNow I'm done\nNo words to say for you\nAnd don't let me down\nYou'll leave with nothing\nNo one could to wait for you\nYou were already dead\nYou were already dead "}]
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
Of course, it's possible to play with parameters like `top_k`, `top_p`, `temperature`, `max_length` and all the other parameters included in the `generate` method. Please look at the [documentation](https://huggingface.co/transformers/main_classes/model.html?highlight=generate#transformers.generation_utils.GenerationMixin.generate) for further insights.
|
| 35 |
+
|
| 36 |
+
Here is how to use this model to get the features of a given text in PyTorch:
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
from transformers import GPT2Tokenizer, GPT2Model
|
| 40 |
+
|
| 41 |
+
tokenizer = GPT2Tokenizer.from_pretrained('lucone83/deep-metal')
|
| 42 |
+
model = GPT2Model.from_pretrained('lucone83/deep-metal')
|
| 43 |
+
text = "Replace me by any text you'd like."
|
| 44 |
+
encoded_input = tokenizer(text, return_tensors='pt')
|
| 45 |
+
output_features = model(**encoded_input)
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
and in TensorFlow:
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
from transformers import GPT2Tokenizer, TFGPT2Model
|
| 52 |
+
|
| 53 |
+
tokenizer = GPT2Tokenizer.from_pretrained('lucone83/deep-metal')
|
| 54 |
+
model = TFGPT2Model.from_pretrained('lucone83/deep-metal')
|
| 55 |
+
text = "Replace me by any text you'd like."
|
| 56 |
+
encoded_input = tokenizer(text, return_tensors='tf')
|
| 57 |
+
output_features = model(encoded_input)
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
## Model training
|
| 61 |
+
|
| 62 |
+
The dataset used for training this model contained 141,718 heavy metal songs lyrics.
|
| 63 |
+
The model has been trained using an NVIDIA Tesla T4 with 16 GB, using the following command:
|
| 64 |
+
|
| 65 |
+
```bash
|
| 66 |
+
python run_language_modeling.py \
|
| 67 |
+
--output_dir=$OUTPUT_DIR \
|
| 68 |
+
--model_type=gpt2 \
|
| 69 |
+
--model_name_or_path=gpt2 \
|
| 70 |
+
--do_train \
|
| 71 |
+
--train_data_file=$TRAIN_FILE \
|
| 72 |
+
--do_eval \
|
| 73 |
+
--eval_data_file=$VALIDATION_FILE \
|
| 74 |
+
--per_device_train_batch_size=3 \
|
| 75 |
+
--per_device_eval_batch_size=3 \
|
| 76 |
+
--evaluate_during_training \
|
| 77 |
+
--learning_rate=1e-5 \
|
| 78 |
+
--num_train_epochs=20 \
|
| 79 |
+
--logging_steps=3000 \
|
| 80 |
+
--save_steps=3000 \
|
| 81 |
+
--gradient_accumulation_steps=3
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
To checkout the code related to training and testing, please look at the [GitHub repository](https://github.com/lucone83/deep-metal) of the project.
|
| 85 |
+
|
| 86 |
+
## Evaluation results
|
| 87 |
+
|
| 88 |
+
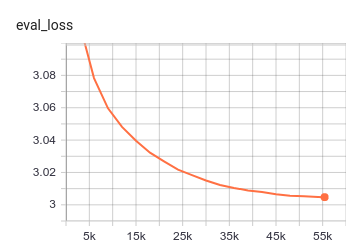
The model achieves the following results:
|
| 89 |
+
|
| 90 |
+
```bash
|
| 91 |
+
{
|
| 92 |
+
'eval_loss': 3.0047452173826406,
|
| 93 |
+
'epoch': 19.99987972095261,
|
| 94 |
+
'total_flos': 381377736125448192,
|
| 95 |
+
'step': 55420
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
perplexity = 20.18107365414611
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
|
config.json
CHANGED
|
@@ -4,7 +4,7 @@
|
|
| 4 |
"GPT2LMHeadModel"
|
| 5 |
],
|
| 6 |
"attn_pdrop": 0.1,
|
| 7 |
-
"bos_token_id":
|
| 8 |
"embd_pdrop": 0.1,
|
| 9 |
"eos_token_id": 50256,
|
| 10 |
"initializer_range": 0.02,
|
|
@@ -25,7 +25,8 @@
|
|
| 25 |
"task_specific_params": {
|
| 26 |
"text-generation": {
|
| 27 |
"do_sample": true,
|
| 28 |
-
"max_length":
|
|
|
|
| 29 |
}
|
| 30 |
},
|
| 31 |
"total_flos": 371606622276943872,
|
|
|
|
| 4 |
"GPT2LMHeadModel"
|
| 5 |
],
|
| 6 |
"attn_pdrop": 0.1,
|
| 7 |
+
"bos_token_id": 50257,
|
| 8 |
"embd_pdrop": 0.1,
|
| 9 |
"eos_token_id": 50256,
|
| 10 |
"initializer_range": 0.02,
|
|
|
|
| 25 |
"task_specific_params": {
|
| 26 |
"text-generation": {
|
| 27 |
"do_sample": true,
|
| 28 |
+
"max_length": 256,
|
| 29 |
+
"min_length": 128
|
| 30 |
}
|
| 31 |
},
|
| 32 |
"total_flos": 371606622276943872,
|