
Update README.md
Browse files
README.md
CHANGED
|
@@ -7,6 +7,8 @@ license: apache-2.0
|
|
| 7 |
---
|
| 8 |
# Model Card for Video-LLaVA - CinePile fine tune
|
| 9 |
|
|
|
|
|
|
|
| 10 |
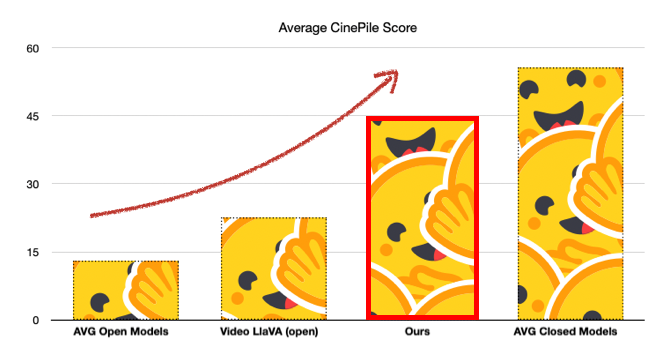
Video multimodal research often emphasizes activity recognition and object-centered tasks, such as determining "what is the person wearing a red hat doing?" However, this focus overlooks areas like theme exploration, narrative and plot analysis, and character and relationship dynamics.
|
| 11 |
CinePile addresses these areas in their benchmark and they find that Large Language Models significantly lag behind human performance in these tasks. Additionally, there is a notable disparity in performance between open and closed models.
|
| 12 |
|
|
|
|
| 7 |
---
|
| 8 |
# Model Card for Video-LLaVA - CinePile fine tune
|
| 9 |
|
| 10 |
+
|
| 11 |
+
|
| 12 |
Video multimodal research often emphasizes activity recognition and object-centered tasks, such as determining "what is the person wearing a red hat doing?" However, this focus overlooks areas like theme exploration, narrative and plot analysis, and character and relationship dynamics.
|
| 13 |
CinePile addresses these areas in their benchmark and they find that Large Language Models significantly lag behind human performance in these tasks. Additionally, there is a notable disparity in performance between open and closed models.
|
| 14 |
|