---
tags:
- mmeb
- transformers
language:
- en
library_name: transformers
license: mit
pipeline_tag: zero-shot-image-classification
---
## MoCa-Qwen25VL-7B
[MoCa: Modality-aware Continual Pre-training Makes Better Bidirectional Multimodal Embeddings](https://arxiv.org/abs/xxxx.pdf). Haonan Chen, Hong Liu, Yuping Luo, Liang Wang, Nan Yang, Furu Wei, Zhicheng Dou, arXiv 2025
This repo presents the `MoCa-Qwen25VL` series of **multimodal embedding models**.
The model is trained based on [Qwen2.5-7B-VL-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-VL-Instruct).
[🏠 Homepage](https://haon-chen.github.io/MoCa/) | [💻 Code](https://github.com/haon-chen/MoCa) | [🤖 MoCa-Qwen25VL-7B](https://huggingface.co/moca-embed/MoCa-Qwen25VL-7B) | [🤖 MoCa-Qwen25VL-3B](https://huggingface.co/moca-embed/MoCa-Qwen25VL-3B) | [📚 Datasets](https://huggingface.co/moca-embed/datasets) | [📄 Paper](https://arxiv.org/abs/2506.23115)
**Highlights**
- SOTA performance on MMEB (General Multimodal) and surpassing many strong baselines on ViDoRe-v2 (Document Retrieval).
- Supports texts, images, and interleaved input.
- Generalize on out-of-distribution data well due to innovative methods.
- Continually pre-trained on 30B interleaved high quality data with modality-aware reconstruction objectives.
- Contrastive fine-tuning on diverse data spanning long-form query-document pairs, curated multimodal pairs, and real-world text pairs.
## Train/Eval Data
- Continual Pre-training data:
- (1) text-only corpus: [DCLM](https://huggingface.co/datasets/moca-embed/dclm_20b)
- (2) common multimodal corpus: PixelProse ([CommonPool](https://huggingface.co/datasets/moca-embed/pixelprose_commonpool), [CC12M](https://huggingface.co/datasets/moca-embed/pixelprose_cc12m_sub_005), and [RedCaps](https://huggingface.co/datasets/moca-embed/pixelprose_redcaps_sub_010)), [MAmmoTH-VL-Instruct](https://huggingface.co/datasets/moca-embed/MAmmoTH-VL-Instruct-12M), and the training set of [MMEB](https://huggingface.co/datasets/moca-embed/MMEB-train)
- (3) long-form document-level image understanding corpus: [DocMatix](https://huggingface.co/datasets/moca-embed/docmatix), VisRAG ([Synthetic](https://huggingface.co/datasets/moca-embed/visrag_syn), [In-domain](https://huggingface.co/datasets/moca-embed/visrag_ind)), and the training set of [ColPali](https://huggingface.co/datasets/moca-embed/tevatron_colpali)
- [Contrastive Learning data](https://huggingface.co/datasets/moca-embed/MoCa-CL-Pairs):
- (1) Long-form document-level multimodal pairs: VisRAG and the training set of [ColPali](https://huggingface.co/datasets/Tevatron/colpali).
- (2) Common multimodal pairs: The training sets of [MMEB](https://huggingface.co/datasets/moca-embed/MoCa-CL-Pairs) and [mmE5](https://huggingface.co/datasets/intfloat/mmE5-synthetic).
- (3) Text-only pairs: Large-scale dense retrieval dataset from E5.
- Eval data:
- [MMEB](https://huggingface.co/datasets/TIGER-Lab/MMEB-eval)
- [ViDoRe-v2](https://huggingface.co/collections/Haon-Chen/vidore-v2-full-683e7a451417d107337b45d2)
## Experimental Results
Performances on MMEB and ViDoRe-v2 benchmarks.
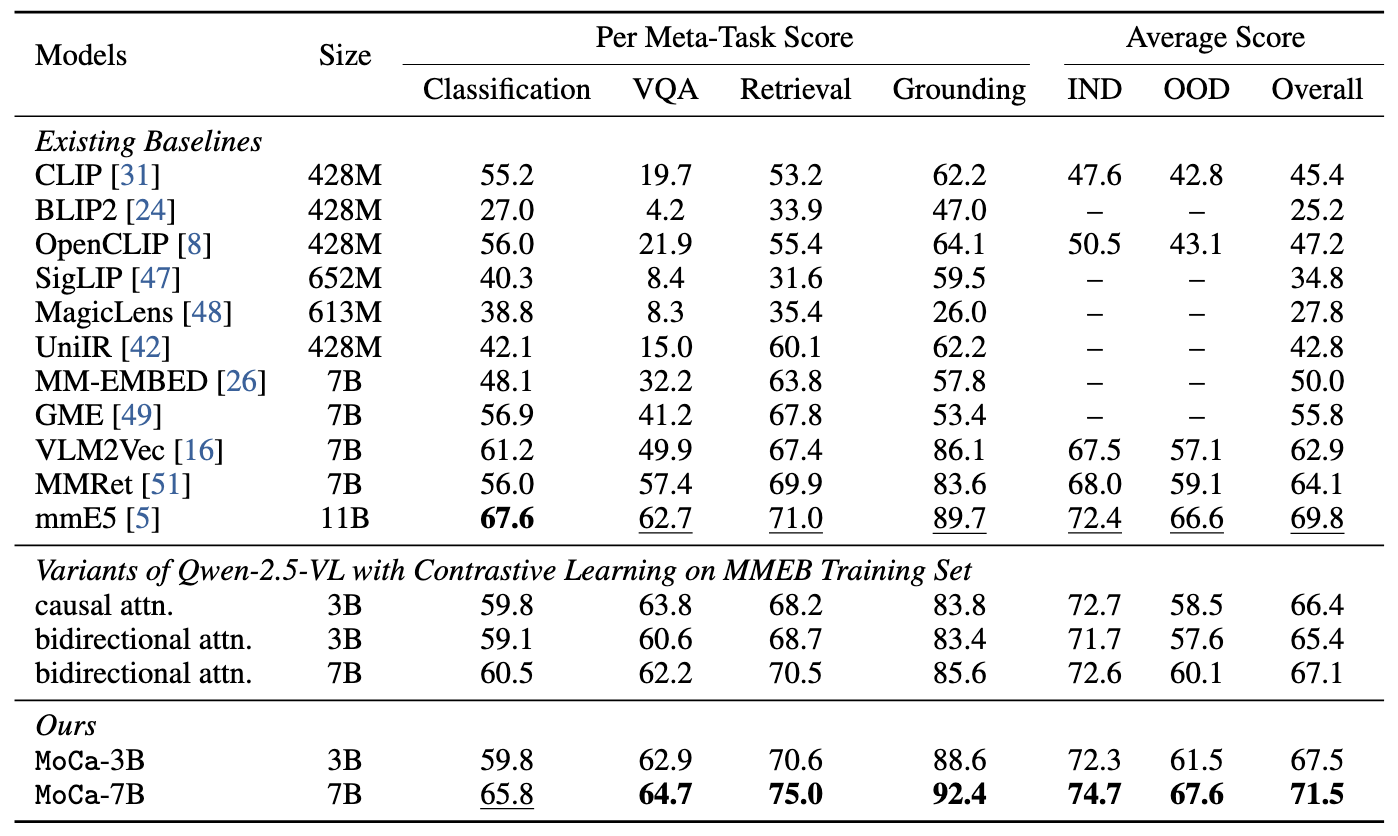
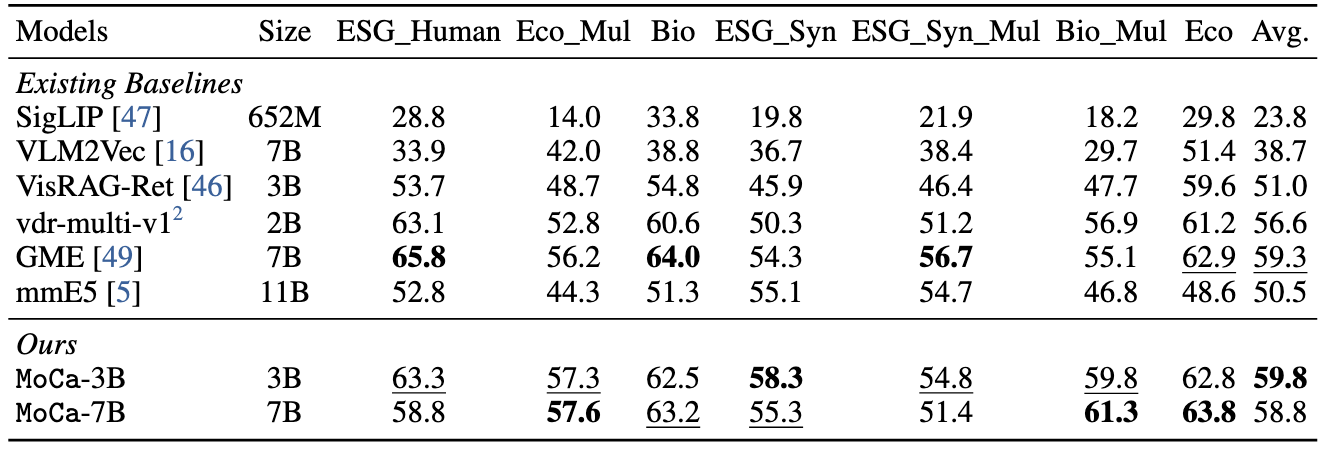 ## Usage
### Transformers
Below is an example we adapted from [VLM2Vec](https://huggingface.co/TIGER-Lab/VLM2Vec-Full).
```bash
git clone https://github.com/haon-chen/MoCa.git
cd MoCa
pip install -r requirements.txt
pip install flash-attn==2.5.8
```
```python
from transformers import AutoProcessor, AutoConfig
from src.vlm_backbone.qwen2_5_vl_embed.qwen2_5_vl_embed import Qwen2_5ForEmbedding
import torch
from PIL import Image
import torch.nn.functional as F
def compute_similarity(q_reps, p_reps):
return torch.matmul(q_reps, p_reps.transpose(0, 1))
model_name = "moca-embed/MoCa-Qwen25VL-7B"
processor_name = "Qwen/Qwen2.5-VL-7B-Instruct"
# Load Processor and Model
processor = AutoProcessor.from_pretrained(processor_name)
config = AutoConfig.from_pretrained(model_name)
model = Qwen2_5ForEmbedding.from_pretrained(
model_name, config=config,
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2',
bidirectional=True,
).to("cuda")
model.eval()
# Image + Text -> Text
inputs = processor(text='<|vision_start|><|image_pad|><|vision_end|>Represent the given image with the following question: What is in the image\n', images=[Image.open(
'figures/example.jpg')], return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = 'A cat and a dog'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**text_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a dog = tensor([[0.5703]], device='cuda:0', dtype=torch.bfloat16)
string = 'A cat and a tiger'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**text_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a tiger = tensor([[0.4551]], device='cuda:0', dtype=torch.bfloat16)
# Text -> Image
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a dog.\n', return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = '<|vision_start|><|image_pad|><|vision_end|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[Image.open('figures/example.jpg')], return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**tgt_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|vision_start|><|image_pad|><|vision_end|>Represent the given image. = tensor([[0.4395]], device='cuda:0', dtype=torch.bfloat16)
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a tiger.\n', return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = '<|vision_start|><|image_pad|><|vision_end|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[Image.open('figures/example.jpg')], return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**tgt_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|vision_start|><|image_pad|><|vision_end|>Represent the given image. = tensor([[0.3242]], device='cuda:0', dtype=torch.bfloat16)
```
## Citation
If you use this model in your research, please cite the associated paper.
```bibtex
@article{chen2025moca,
title={MoCa: Modality-aware Continual Pre-training Makes Better Bidirectional Multimodal Embeddings},
author={Chen, Haonan and Liu, Hong and Luo, Yuping and Wang, Liang and Yang, Nan and Wei, Furu and Dou, Zhicheng},
journal={arXiv preprint arXiv:2506.23115},
year={2025}
}
```
## Usage
### Transformers
Below is an example we adapted from [VLM2Vec](https://huggingface.co/TIGER-Lab/VLM2Vec-Full).
```bash
git clone https://github.com/haon-chen/MoCa.git
cd MoCa
pip install -r requirements.txt
pip install flash-attn==2.5.8
```
```python
from transformers import AutoProcessor, AutoConfig
from src.vlm_backbone.qwen2_5_vl_embed.qwen2_5_vl_embed import Qwen2_5ForEmbedding
import torch
from PIL import Image
import torch.nn.functional as F
def compute_similarity(q_reps, p_reps):
return torch.matmul(q_reps, p_reps.transpose(0, 1))
model_name = "moca-embed/MoCa-Qwen25VL-7B"
processor_name = "Qwen/Qwen2.5-VL-7B-Instruct"
# Load Processor and Model
processor = AutoProcessor.from_pretrained(processor_name)
config = AutoConfig.from_pretrained(model_name)
model = Qwen2_5ForEmbedding.from_pretrained(
model_name, config=config,
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2',
bidirectional=True,
).to("cuda")
model.eval()
# Image + Text -> Text
inputs = processor(text='<|vision_start|><|image_pad|><|vision_end|>Represent the given image with the following question: What is in the image\n', images=[Image.open(
'figures/example.jpg')], return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = 'A cat and a dog'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**text_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a dog = tensor([[0.5703]], device='cuda:0', dtype=torch.bfloat16)
string = 'A cat and a tiger'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**text_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a tiger = tensor([[0.4551]], device='cuda:0', dtype=torch.bfloat16)
# Text -> Image
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a dog.\n', return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = '<|vision_start|><|image_pad|><|vision_end|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[Image.open('figures/example.jpg')], return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**tgt_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|vision_start|><|image_pad|><|vision_end|>Represent the given image. = tensor([[0.4395]], device='cuda:0', dtype=torch.bfloat16)
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a tiger.\n', return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = '<|vision_start|><|image_pad|><|vision_end|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[Image.open('figures/example.jpg')], return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**tgt_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|vision_start|><|image_pad|><|vision_end|>Represent the given image. = tensor([[0.3242]], device='cuda:0', dtype=torch.bfloat16)
```
## Citation
If you use this model in your research, please cite the associated paper.
```bibtex
@article{chen2025moca,
title={MoCa: Modality-aware Continual Pre-training Makes Better Bidirectional Multimodal Embeddings},
author={Chen, Haonan and Liu, Hong and Luo, Yuping and Wang, Liang and Yang, Nan and Wei, Furu and Dou, Zhicheng},
journal={arXiv preprint arXiv:2506.23115},
year={2025}
}
```