
Upload folder using huggingface_hub
Browse files- .gitattributes +3 -0
- README.md +134 -0
- best_model.pt +3 -0
- output.png +3 -0
- output_augmentation.png +3 -0
- output_confusion_matrix.png +0 -0
- output_grad_cam.jpg +0 -0
- training_history.csv +31 -0
- training_plot.png +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
output.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
output_augmentation.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
training_plot.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
library_name: timm
|
| 4 |
+
tags:
|
| 5 |
+
- image-classification
|
| 6 |
+
- mobilevit
|
| 7 |
+
- timm
|
| 8 |
+
- drowsiness-detection
|
| 9 |
+
- computer-vision
|
| 10 |
+
- pytorch
|
| 11 |
+
widget:
|
| 12 |
+
- modelId: your-username/mobilevit-drowsiness-detection
|
| 13 |
+
title: Drowsiness Detection with MobileViT v2
|
| 14 |
+
url: https://huggingface.co/spaces/user-name/repo-name/resolve/main/grid_output.jpg
|
| 15 |
+
datasets:
|
| 16 |
+
- ismailnasri20/driver-drowsiness-dataset-ddd
|
| 17 |
+
- yasharjebraeily/drowsy-detection-dataset
|
| 18 |
+
metrics:
|
| 19 |
+
- accuracy
|
| 20 |
+
- f1
|
| 21 |
+
- precision
|
| 22 |
+
- recall
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
# MobileViT v2 for Drowsiness Detection
|
| 26 |
+
|
| 27 |
+
This repository contains a `MobileViT v2` classification model fine-tuned to detect driver drowsiness from images. The model is a state-of-the-art, lightweight, hybrid architecture combining convolutions with Vision Transformers, making it efficient and accurate. It classifies input images into two categories: `Drowsy` and `Non Drowsy`.
|
| 28 |
+
|
| 29 |
+
This model was trained in PyTorch using the `timm` library and demonstrates high performance on an unseen test set, making it a reliable foundation for driver safety applications.
|
| 30 |
+
|
| 31 |
+
## Model Details
|
| 32 |
+
* **Architecture:** `mobilevitv2_200`
|
| 33 |
+
* **Fine-tuned on:** A combined dataset for driver drowsiness detection.
|
| 34 |
+
* **Classes:** `Drowsy`, `Non Drowsy`
|
| 35 |
+
* **Frameworks:** PyTorch, timm
|
| 36 |
+
|
| 37 |
+
## How to Get Started
|
| 38 |
+
|
| 39 |
+
You can easily use this model with the `timm` and `torch` libraries. First, ensure you have the `best_model.pt` file from this repository.
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
# Install required libraries
|
| 43 |
+
!pip install timm torch torchvision
|
| 44 |
+
|
| 45 |
+
import torch
|
| 46 |
+
import timm
|
| 47 |
+
from PIL import Image
|
| 48 |
+
from torchvision import transforms
|
| 49 |
+
|
| 50 |
+
# --- 1. Setup Model and Preprocessing ---
|
| 51 |
+
# Define the same transformations used for validation/testing
|
| 52 |
+
val_test_transform = transforms.Compose([
|
| 53 |
+
transforms.Resize((224, 224)),
|
| 54 |
+
transforms.ToTensor(),
|
| 55 |
+
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
|
| 56 |
+
])
|
| 57 |
+
|
| 58 |
+
# Define class names (ensure order matches training: Drowsy=0, Non Drowsy=1)
|
| 59 |
+
class_names = ['Drowsy', 'Non Drowsy']
|
| 60 |
+
|
| 61 |
+
# Load the model architecture
|
| 62 |
+
model = timm.create_model('mobilevitv2_200', pretrained=False, num_classes=2)
|
| 63 |
+
|
| 64 |
+
# Load the fine-tuned weights
|
| 65 |
+
model_path = 'best_model.pt'
|
| 66 |
+
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
|
| 67 |
+
model.eval()
|
| 68 |
+
|
| 69 |
+
# --- 2. Run Inference ---
|
| 70 |
+
image_path = 'path/to/your/image.jpg'
|
| 71 |
+
image = Image.open(image_path).convert('RGB')
|
| 72 |
+
|
| 73 |
+
# Preprocess the image
|
| 74 |
+
input_tensor = val_test_transform(image).unsqueeze(0) # Add batch dimension
|
| 75 |
+
|
| 76 |
+
# Get model prediction
|
| 77 |
+
with torch.no_grad():
|
| 78 |
+
output = model(input_tensor)
|
| 79 |
+
probabilities = torch.nn.functional.softmax(output[0], dim=0)
|
| 80 |
+
top_prob, top_class_index = torch.topk(probabilities, 1)
|
| 81 |
+
|
| 82 |
+
class_name = class_names[top_class_index.item()]
|
| 83 |
+
confidence = top_prob.item()
|
| 84 |
+
|
| 85 |
+
print(f"Prediction: {class_name} with confidence {confidence:.4f}")
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
## Training Procedure
|
| 89 |
+
|
| 90 |
+
The model was fine-tuned on a large dataset of over 40,000 driver images. The training process involved:
|
| 91 |
+
- **Data Augmentation:** A strong augmentation pipeline was used for training, including `RandomResizedCrop`, `RandomHorizontalFlip`, `ColorJitter`, and `RandomErasing`.
|
| 92 |
+
- **Transfer Learning:** The model was initialized with weights pretrained on ImageNet, enabling robust feature extraction and fast convergence.
|
| 93 |
+
- **Early Stopping:** Training was halted after 30 epochs of no improvement in validation accuracy to prevent overfitting.
|
| 94 |
+
|
| 95 |
+
### Key Hyperparameters
|
| 96 |
+
- **Image Size:** 224x224
|
| 97 |
+
- **Batch Size:** 64
|
| 98 |
+
- **Optimizer:** AdamW (lr=1e-4)
|
| 99 |
+
- **Scheduler:** ExponentialLR (gamma=0.90)
|
| 100 |
+
- **Loss Function:** CrossEntropyLoss
|
| 101 |
+
|
| 102 |
+

|
| 103 |
+
|
| 104 |
+
## Evaluation
|
| 105 |
+
|
| 106 |
+
The model was evaluated on a completely **unseen test set** (from a different dataset than the primary training data) to ensure a fair assessment of its generalization capabilities.
|
| 107 |
+
|
| 108 |
+
### Key Performance Metrics
|
| 109 |
+
| Metric | Value | Description |
|
| 110 |
+
| :----: | :----: | :------------------------------------------------- |
|
| 111 |
+
| **Accuracy** | 98.18% | Overall correctness on the test set. |
|
| 112 |
+
| **APCER** | 3.57% | Rate of 'Drowsy' drivers missed (False Negatives). |
|
| 113 |
+
| **BPCER** | 0.00% | Rate of 'Non Drowsy' drivers flagged (False Positives). |
|
| 114 |
+
| **ACER** | 1.78% | Average of APCER and BPCER. |
|
| 115 |
+
|
| 116 |
+
*APCER (Attack Presentation Classification Error Rate, adapted here) is the most critical safety metric, as it measures the failure to detect a drowsy driver.*
|
| 117 |
+
|
| 118 |
+

|
| 119 |
+
|
| 120 |
+
### Model Explainability (Grad-CAM)
|
| 121 |
+
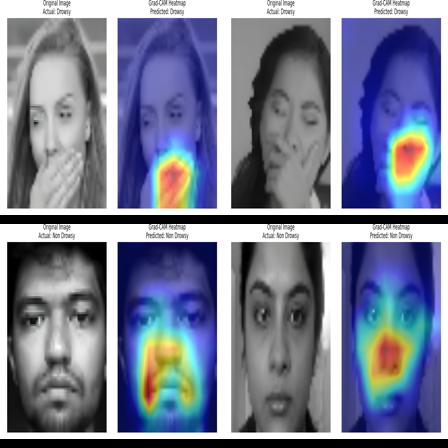
To ensure the model is focusing on relevant facial features, Grad-CAM was used. The heatmaps confirm that the model's predictions are primarily based on the driver's eyes, mouth, and head position, which are key indicators of drowsiness.
|
| 122 |
+
|
| 123 |
+

|
| 124 |
+
|
| 125 |
+
## Intended Use and Limitations
|
| 126 |
+
This model is intended as a proof-of-concept for driver safety systems and academic research. It should not be used as the sole mechanism for preventing accidents in a production environment without further rigorous testing.
|
| 127 |
+
|
| 128 |
+
Real-world performance may vary based on:
|
| 129 |
+
- Lighting conditions (especially at night).
|
| 130 |
+
- Camera angles and distance.
|
| 131 |
+
- Occlusions (e.g., sunglasses, hats, hands on face).
|
| 132 |
+
- Individual differences not represented in the training data.
|
| 133 |
+
|
| 134 |
+
*This model card is based on the training notebook [`MobileViT_Drowsiness.ipynb`](https://github.com/mosesab/MobileViT-Drowsiness-Detection/blob/main/MobileViT_Drowsiness.ipynb).*
|
best_model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fcbe35c8e0c8149bed84189ab3cf0a06429107a968667a9f681ff113bed35867
|
| 3 |
+
size 69935051
|
output.png
ADDED

|
Git LFS Details
|
output_augmentation.png
ADDED

|
Git LFS Details
|
output_confusion_matrix.png
ADDED

|
output_grad_cam.jpg
ADDED
|
training_history.csv
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
epoch,train_loss,train_acc,val_loss,val_acc
|
| 2 |
+
1,0.005245581285077896,0.9985433537428403,0.0022536597098549594,0.9993005036373812
|
| 3 |
+
2,0.005058018809589851,0.9984445980643888,0.0023724412707676803,0.9993005036373812
|
| 4 |
+
3,0.00333882693223768,0.9990618210547108,0.004640081306103603,0.9981813094571909
|
| 5 |
+
4,0.0019675480249330287,0.9994321548489039,0.0011330571216904648,0.9995803021824288
|
| 6 |
+
5,0.0009190954186649758,0.9996790440450326,0.0042279156476276464,0.9987409065472861
|
| 7 |
+
6,0.003519932303200358,0.9989136875370335,0.0022254574140079496,0.999440402909905
|
| 8 |
+
7,0.0008493974372590355,0.9998024886430971,0.005408237440245763,0.9987409065472861
|
| 9 |
+
8,0.0012583149986798944,0.9995309105273553,0.0014416664605325462,0.9995803021824288
|
| 10 |
+
9,0.0004477896281065585,0.9998765554019357,0.0015333133928007877,0.9995803021824288
|
| 11 |
+
10,0.0010184175027428194,0.9996790440450326,0.0008335669395869618,0.9998601007274763
|
| 12 |
+
11,0.0004673596799982551,0.9998518664823228,0.00048003266577130574,0.9998601007274763
|
| 13 |
+
12,0.0004278480958328559,0.9998765554019357,0.0010320477756580264,0.9997202014549526
|
| 14 |
+
13,0.0006154210043430926,0.9998518664823228,0.001365777820691367,0.999440402909905
|
| 15 |
+
14,0.00031554297358610365,0.9999012443215486,0.0020125484583530568,0.9995803021824288
|
| 16 |
+
15,0.0008148343436515399,0.9998024886430971,0.0009892107681903222,0.9998601007274763
|
| 17 |
+
16,0.00044639887271710017,0.9998518664823228,0.0007288139932215199,0.9995803021824288
|
| 18 |
+
17,0.0001811253026875362,0.9999753110803872,0.0005784849157645884,0.9995803021824288
|
| 19 |
+
18,0.00046878313578802293,0.9999259332411614,0.0007865349200535725,0.9997202014549526
|
| 20 |
+
19,6.448918337161184e-05,1.0,0.0007113339355956221,0.999440402909905
|
| 21 |
+
20,0.00033571305326825105,0.9999259332411614,0.0013030710574786868,0.9995803021824288
|
| 22 |
+
21,4.827969234206115e-05,0.9999753110803872,0.000493603309694494,0.9995803021824288
|
| 23 |
+
22,2.9587593322939357e-05,1.0,0.0005621903976394485,0.9998601007274763
|
| 24 |
+
23,0.0002729453408775668,0.9999259332411614,0.0005450556711127411,0.9997202014549526
|
| 25 |
+
24,5.782559405570643e-05,0.9999753110803872,0.0006117059190368832,0.9997202014549526
|
| 26 |
+
25,9.650301194302824e-05,0.9999753110803872,0.0015031366452237724,0.9995803021824288
|
| 27 |
+
26,0.00018091677156248143,0.9999753110803872,0.000420644104269485,0.9998601007274763
|
| 28 |
+
27,0.00040603304785788484,0.9999259332411614,0.0009131295740309233,0.9995803021824288
|
| 29 |
+
28,1.6794279317459968e-05,1.0,0.0007172291170396112,0.9995803021824288
|
| 30 |
+
29,4.037580577003857e-05,1.0,0.0006496535298990078,0.9995803021824288
|
| 31 |
+
30,3.2526824202515245e-05,0.9999753110803872,0.0006385279186205687,0.9995803021824288
|
training_plot.png
ADDED

|
Git LFS Details
|