

add model card (#1)
Browse files- add model card (b7bb36210b8f3a18870abaf5d27e8b9ce0d668b4)
- BIAS.md +6 -0
- EXPLAINABILITY.md +14 -0
- PRIVACY.md +11 -0
- README.md +180 -0
- SAFETY_SECURITY.md +8 -0
- accuracy_plot.png +0 -0
BIAS.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# **Bias**
|
| 2 |
+
|
| 3 |
+
|Field:|Response:|
|
| 4 |
+
|:---:|:---:|
|
| 5 |
+
|Participation considerations from adversely impacted groups (protected classes) in model design and testing:|None|
|
| 6 |
+
|Measures taken to mitigate against unwanted bias:|None|
|
EXPLAINABILITY.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# **Explainability**
|
| 2 |
+
|
| 3 |
+
|Field:|Response:|
|
| 4 |
+
|:---:|:---:|
|
| 5 |
+
|Intended Application(s) & Domain(s):| Text generation, reasoning, summarization, and question answering. |
|
| 6 |
+
|Model Type: |Text-to-text transformer |
|
| 7 |
+
|Intended Users:|This model is intended for developers, researchers, and customers building/utilizing LLMs, while balancing accuracy and efficiency.|
|
| 8 |
+
|Output:|Text String(s)|
|
| 9 |
+
|Describe how the model works:|Generates text by predicting the next word or token based on the context provided in the input sequence using multiple self-attention layers|
|
| 10 |
+
|Technical Limitations:| The model was trained on data that contains toxic language, unsafe content, and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.\<br/\>The model demonstrates weakness to alignment-breaking attacks. Users are advised to deploy language model guardrails alongside this model to prevent potentially harmful outputs.\<br/\>The Model may generate answers that are inaccurate, omit key information, or include irrelevant or redundant text.|
|
| 11 |
+
|Verified to have met prescribed quality standards?|Yes|
|
| 12 |
+
|Performance Metrics:|Accuracy, Throughput, and user-side throughput|
|
| 13 |
+
|Potential Known Risks:|The model was optimized explicitly for instruction following and as such is more susceptible to prompt injection and jailbreaking in various forms as a result of its instruction tuning. This means that the model should be paired with additional rails or system filtering to limit exposure to instructions from malicious sources -- either directly or indirectly by retrieval (e.g. via visiting a website) -- as they may yield outputs that can lead to harmful, system-level outcomes up to and including remote code execution in agentic systems when effective security controls including guardrails are not in place.\<br/\>The model was trained on data that contains toxic language and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.|
|
| 14 |
+
|End User License Agreement:| Your use of this model is governed by the [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/). Additional Information: [Llama 3.1 Community License Agreement](https://www.llama.com/llama3\_1/license/). Built with Llama. |
|
PRIVACY.md
ADDED
|
@@ -0,0 +1,11 @@
|
|
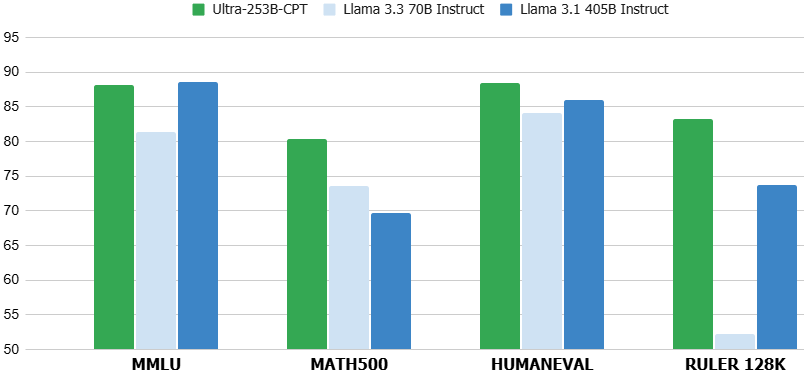
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# **Privacy**
|
| 2 |
+
|
| 3 |
+
|Field:|Response:|
|
| 4 |
+
|:---:|:---:|
|
| 5 |
+
|Generatable or Reverse engineerable personally-identifiable information?|None|
|
| 6 |
+
|Was consent obtained for any personal data used?|None Known|
|
| 7 |
+
|Personal data used to create this model?|None Known|
|
| 8 |
+
|How often is dataset reviewed?|Before Release|
|
| 9 |
+
|Is there provenance for all datasets used in training?|Yes|
|
| 10 |
+
|Does data labeling (annotation, metadata) comply with privacy laws?|Yes|
|
| 11 |
+
|Applicable NVIDIA Privacy Policy|https://www.nvidia.com/en-us/about-nvidia/privacy-policy/|
|
README.md
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
license: other
|
| 4 |
+
license_name: nvidia-open-model-license
|
| 5 |
+
license_link: >-
|
| 6 |
+
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
|
| 7 |
+
|
| 8 |
+
pipeline_tag: text-generation
|
| 9 |
+
language:
|
| 10 |
+
- en
|
| 11 |
+
tags:
|
| 12 |
+
- nvidia
|
| 13 |
+
- llama-3
|
| 14 |
+
- pytorch
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
# Llama-3.1-Nemotron-Ultra-253B-CPT-v1
|
| 18 |
+
|
| 19 |
+
## Model Overview
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
Llama-3.1-Nemotron-Ultra-253B-CPT-v1 is a large language model (LLM) which is a derivative of [Meta Llama-3.1-405B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-405B-Instruct) (AKA the parent model). This model supports a context length of 128K tokens and fits on a single 8xH100 node for inference. While the model was derived from Llama-3.1-405B-Instruct it has undergone a substantial continual pre-training (CPT). This CPT variant can be viewed as a “re-based” derivative of Llama-3.1-405B-Instruct.
|
| 24 |
+
|
| 25 |
+
Llama-3.1-Nemotron-Ultra-253B-v1 is a model which offers a great tradeoff between model accuracy and efficiency. Efficiency (throughput) directly translates to savings. Using a novel Neural Architecture Search (NAS) approach, we greatly reduce the model’s memory footprint, enabling larger workloads, as well as reducing the number of GPUs required to run the model in a data center environment. This NAS approach enables the selection of a desired point in the accuracy-efficiency tradeoff. Furthermore, by using a novel method to vertically compress the model (see details [here](https://arxiv.org/abs/2503.18908)), it also offers a significant improvement in latency.
|
| 26 |
+
|
| 27 |
+
This model served as the basis model for creating Llama-3.1-Nemotron-Ultra-253B-v1, which is part of the Llama Nemotron Collection. You can find the other models in this family here:
|
| 28 |
+
- [Llama-3.1-Nemotron-Nano-8B-v1](https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-8B-v1)
|
| 29 |
+
- [Llama-3.3-Nemotron-Super-49B-v1](https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1)
|
| 30 |
+
- [Llama-3.1-Nemotron-Ultra-253B-v1](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1)
|
| 31 |
+
|
| 32 |
+
This model is ready for commercial use.
|
| 33 |
+
|
| 34 |
+
## License/Terms of Use
|
| 35 |
+
|
| 36 |
+
GOVERNING TERMS: Your use of this model is governed by the [NVIDIA Open Model License.](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) Additional Information: [Llama 3.1 Community License Agreement](https://www.llama.com/llama3\_1/license/). Built with Llama.
|
| 37 |
+
|
| 38 |
+
**Model Developer:** NVIDIA
|
| 39 |
+
|
| 40 |
+
**Model Dates:** Trained between November 2024 and April 2025
|
| 41 |
+
|
| 42 |
+
**Data Freshness:** The pretraining data has a cutoff of 2023 per Llama-3.1-405B-Instruct
|
| 43 |
+
|
| 44 |
+
### Use Case:
|
| 45 |
+
This model can be used as the basis model for any desired application by finetuning to any desired domain or application.
|
| 46 |
+
|
| 47 |
+
### Release Date:
|
| 48 |
+
2025-04-08
|
| 49 |
+
|
| 50 |
+
## References
|
| 51 |
+
|
| 52 |
+
* [\[2411.19146\]Puzzle: Distillation-Based NAS for Inference-Optimized LLMs](https://arxiv.org/abs/2411.19146)
|
| 53 |
+
* [\[2503.18908\]FFN Fusion: Rethinking Sequential Computation in Large Language Models](https://arxiv.org/abs/2503.18908)
|
| 54 |
+
|
| 55 |
+
## Model Architecture
|
| 56 |
+
**Architecture Type:** Dense decoder-only Transformer model
|
| 57 |
+
**Network Architecture:** Llama-3.1-405B-Instruct, customized through Neural Architecture Search (NAS)
|
| 58 |
+
|
| 59 |
+
**This model was developed based on Llama-3.1-405B-Instruct <br>
|
| 60 |
+
** This model has 253B model parameters. <br>
|
| 61 |
+
|
| 62 |
+
The model is a derivative of Llama 3.1-405B-Instruct, using Neural Architecture Search (NAS). The NAS algorithm results in non-standard and non-repetitive blocks. This includes the following:
|
| 63 |
+
|
| 64 |
+
* Skip attention: In some blocks, the attention is skipped entirely, or replaced with a single linear layer.
|
| 65 |
+
* Variable FFN: The expansion/compression ratio in the FFN layer is different between blocks.
|
| 66 |
+
* FFN Fusion: When several consecutive attention layers are skipped, which can result in a sequence of multiple FFNs, that sequence of FFNs are fused into a smaller number of wider FFN layers.
|
| 67 |
+
|
| 68 |
+
For each block of the parent model, we created multiple variants providing different tradeoff profiles of quality vs. computational complexity, discussed in more depth [here](https://arxiv.org/abs/2411.19146). We then search over the blocks to create a model which meets the required throughput and memory constraints while minimizing the quality degradation. To recover performance, the model initially underwent knowledge distillation (KD) for 65 billion tokens. This is followed by a continual pretraining (CPT) phase for 88 billion tokens. While the initial model was infused from the instruct version of Llama 3.1-405B-Instruct, the substantial CPT it has undergone can be viewed as “re-basing” the model. Still, however, the re-based CPT final model should keep some of its instruction following capabilities.
|
| 69 |
+
|
| 70 |
+
## Intended use
|
| 71 |
+
|
| 72 |
+
Llama-3.1-Nemotron-Ultra-253B-CPT-v1 can be used as a base model intended to be used mainly in English and coding languages.
|
| 73 |
+
|
| 74 |
+
## Input
|
| 75 |
+
- **Input Type:** Text
|
| 76 |
+
- **Input Format:** String
|
| 77 |
+
- **Input Parameters:** One-Dimensional (1D)
|
| 78 |
+
- **Other Properties Related to Input:** Context length up to 131,072 tokens
|
| 79 |
+
|
| 80 |
+
## Output
|
| 81 |
+
- **Output Type:** Text
|
| 82 |
+
- **Output Format:** String
|
| 83 |
+
- **Output Parameters:** One-Dimensional (1D)
|
| 84 |
+
- **Other Properties Related to Output:** Context length up to 131,072 tokens
|
| 85 |
+
|
| 86 |
+
## Software Integration
|
| 87 |
+
- **Runtime Engine:** Transformers
|
| 88 |
+
- **Recommended Hardware Microarchitecture Compatibility:**
|
| 89 |
+
- NVIDIA Hopper
|
| 90 |
+
- NVIDIA Ampere
|
| 91 |
+
- **Preferred Operating System(s):** Linux
|
| 92 |
+
|
| 93 |
+
## Model Version
|
| 94 |
+
1.0 (4/8/2025)
|
| 95 |
+
|
| 96 |
+
## Quick Start and Usage Recommendations:
|
| 97 |
+
|
| 98 |
+
You can try the reasoning model built on top of this CPT model in the preview API, using this link: [Llama-3_1-Nemotron-Ultra-253B-v1](https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1).
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
See the snippet below for usage with [Hugging Face Transformers](https://huggingface.co/docs/transformers/main/en/index) library.
|
| 102 |
+
|
| 103 |
+
We recommend using the *transformers* package with version 4.48.3.
|
| 104 |
+
|
| 105 |
+
```py
|
| 106 |
+
import torch
|
| 107 |
+
import transformers
|
| 108 |
+
|
| 109 |
+
model_id = "nvidia/Llama-3_1-Nemotron-Ultra-253B-CPT-v1"
|
| 110 |
+
model_kwargs = {"torch_dtype": torch.bfloat16, "trust_remote_code": True, "device_map": "auto"}
|
| 111 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
|
| 112 |
+
tokenizer.pad_token_id = tokenizer.eos_token_id
|
| 113 |
+
|
| 114 |
+
pipeline = transformers.pipeline(
|
| 115 |
+
"text-generation",
|
| 116 |
+
model=model_id,
|
| 117 |
+
tokenizer=tokenizer,
|
| 118 |
+
max_new_tokens=32768,
|
| 119 |
+
do_sample=False,
|
| 120 |
+
**model_kwargs
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
print(pipeline("Hey how are you?")) # Base model usage
|
| 124 |
+
print(pipeline([{"role": "user", "content": "Hey how are you?"}])) # Chat model usage
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
## Inference:
|
| 128 |
+
**Engine:**
|
| 129 |
+
|
| 130 |
+
- Transformers
|
| 131 |
+
|
| 132 |
+
**Test Hardware:**
|
| 133 |
+
- BF16:
|
| 134 |
+
- 8x NVIDIA H100-80GB
|
| 135 |
+
- 4x NVIDIA B100
|
| 136 |
+
- FP 8
|
| 137 |
+
- 4x NVIDIA H100-80GB
|
| 138 |
+
|
| 139 |
+
## Training Datasets
|
| 140 |
+
|
| 141 |
+
A large variety of training data was used for the knowledge distillation phase before post-training pipeline, 3 of which included: FineWeb, Buzz-V1.2, and Dolma.
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
**Data Collection for Training Datasets:**
|
| 145 |
+
|
| 146 |
+
- Hybrid: Automated, Human, Synthetic
|
| 147 |
+
|
| 148 |
+
**Data Labeling for Training Datasets:**
|
| 149 |
+
|
| 150 |
+
- Hybrid: Automated, Human, Synthetic
|
| 151 |
+
|
| 152 |
+
## Evaluation Datasets
|
| 153 |
+
|
| 154 |
+
We used the datasets listed in the next section to evaluate Llama-3.1-Nemotron-Ultra-253B-CPT-v1.
|
| 155 |
+
|
| 156 |
+
Data Collection for Evaluation Datasets:
|
| 157 |
+
|
| 158 |
+
- Hybrid: Human/Synthetic
|
| 159 |
+
|
| 160 |
+
Data Labeling for Evaluation Datasets:
|
| 161 |
+
|
| 162 |
+
- Hybrid: Human/Synthetic/Automatic
|
| 163 |
+
|
| 164 |
+
## Evaluation Results
|
| 165 |
+
|
| 166 |
+
| Benchmark | Metric | Score |
|
| 167 |
+
|-----------|--------------|--------|
|
| 168 |
+
| GSM-8K | strict-match | 84.99 |
|
| 169 |
+
| MMLU | macro | 88.09 |
|
| 170 |
+
| MATH500 | micro | 80.4 |
|
| 171 |
+
| HumanEval | pass@1 | 88.41 |
|
| 172 |
+
| RULER | 128K | 83.21 |
|
| 173 |
+
|
| 174 |
+
## Ethical Considerations:
|
| 175 |
+
|
| 176 |
+
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
|
| 177 |
+
|
| 178 |
+
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](./EXPLAINABILITY.md), [Bias](./BIAS.md), [Safety & Security](./SAFETY_SECURITY.md), and [Privacy](./PRIVACY.md) Subcards.
|
| 179 |
+
|
| 180 |
+
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
|
SAFETY_SECURITY.md
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# **Safety & Security**
|
| 2 |
+
|
| 3 |
+
|Field:|Response:|
|
| 4 |
+
|:---:|:---:|
|
| 5 |
+
|Model Application(s):|Chat, Instruction Following, Chatbot Development, Code Generation, Reasoning|
|
| 6 |
+
|Describe life critical application (if present):|None Known (please see referenced Known Risks in the Explainability subcard).|
|
| 7 |
+
|Use Case Restrictions:|Abide by the [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/). Additional Information: [Llama 3.1 Community License Agreement](https://www.llama.com/llama3\_1/license/). Built with Llama.|
|
| 8 |
+
|Model and Dataset Restrictions:|The Principle of least privilege (PoLP) is applied limiting access for dataset generation. Restrictions enforce dataset access during training, and dataset license constraints adhered to. Model checkpoints are made available on Hugging Face and NGC, and may become available on cloud providers' model catalog.|
|
accuracy_plot.png
ADDED
|