
Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- README.md +112 -3
- added_tokens.json +3 -0
- asserts/cmmlu.png +0 -0
- asserts/cmmlu_china_specific.png +0 -0
- asserts/cmmlu_humanities.png +0 -0
- asserts/cmmlu_other.png +0 -0
- asserts/cmmlu_social_science.png +0 -0
- asserts/cmmlu_stem.png +0 -0
- asserts/mmlu.png +0 -0
- asserts/mmlu_humanities.png +0 -0
- asserts/mmlu_other.png +0 -0
- asserts/mmlu_pro.png +0 -0
- asserts/mmlu_social_science.png +0 -0
- asserts/mmlu_stem.png +0 -0
- chat_template.json +3 -0
- config.json +40 -0
- generation_config.json +13 -0
- model-00001-of-00005.safetensors +3 -0
- model-00002-of-00005.safetensors +3 -0
- model-00003-of-00005.safetensors +3 -0
- model-00004-of-00005.safetensors +3 -0
- model-00005-of-00005.safetensors +3 -0
- model.safetensors.index.json +0 -0
- preprocessor_config.json +29 -0
- processor_config.json +4 -0
- special_tokens_map.json +33 -0
- tokenizer.json +3 -0
- tokenizer.model +3 -0
- tokenizer_config.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,112 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Gemma-3-12B-GRPO trained with GRPO via LoRA
|
| 2 |
+
|
| 3 |
+
Due to limited available computational resources, we randomly sampled 500 data points from MedQA-USMLE using a methodology and conducted preliminary GRPO experiments with LoRA using the [Unsloth](https://github.com/unslothai/unsloth) framework. We are now releasing this as a preview version. More experiments and explorations are currently underway, and a technical report is in preparation. Thank you for your patience. We conduct the experiments on one RTX-A6000 Ada (48GB VRAM).
|
| 4 |
+
|
| 5 |
+
## Evaluation Results
|
| 6 |
+
|
| 7 |
+
The model is evaluated on four benchmark datasets: MMLU, MMLU-Pro, CMMU, GSM8K, GPQA. The experimental results are summarized in Table 1, with comprehensive analyses provided in the Detailed Results section.
|
| 8 |
+
|
| 9 |
+
<center><strong>Tab.1 Evaluation results.</strong></center>
|
| 10 |
+
|
| 11 |
+
| Dataset | Gemma-3-12b-it | Gemma3-12b-GRPO |
|
| 12 |
+
| :-----: | :------------: | :-------------: |
|
| 13 |
+
| MMLU | 65.51 | 70.13 |
|
| 14 |
+
| MMLU-Pro | 60.17 | 59.99 |
|
| 15 |
+
| CMMLU | 54.81 | 57.07 |
|
| 16 |
+
| GSM8K | 91.58 | 91.81 |
|
| 17 |
+
| GPQA | 34.98 | 34.23 |
|
| 18 |
+
|
| 19 |
+
## Requirements
|
| 20 |
+
|
| 21 |
+
```shell
|
| 22 |
+
pip install torch==2.6.0 torchaudio==2.6.0 torchvision==0.21.0 -i --index-url https://download.pytorch.org/whl/cu124
|
| 23 |
+
pip install transformer vllm bitsandbytes peft
|
| 24 |
+
pip install flash-attn --no-build-isolation
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
## Run with vLLM
|
| 28 |
+
|
| 29 |
+
You can use the following script to run with vLLM.
|
| 30 |
+
|
| 31 |
+
```shell
|
| 32 |
+
vllm serve qiuxi337/gemma-3-12b-it-grpo \
|
| 33 |
+
--gpu-memory-utilization 0.85 \
|
| 34 |
+
--max-model-len 4096 \
|
| 35 |
+
--served-model-name gemma3-12b-grpo \
|
| 36 |
+
--api-key your_api_key
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Detail Results
|
| 40 |
+
|
| 41 |
+
### MMLU
|
| 42 |
+
|
| 43 |
+

|
| 44 |
+
|
| 45 |
+
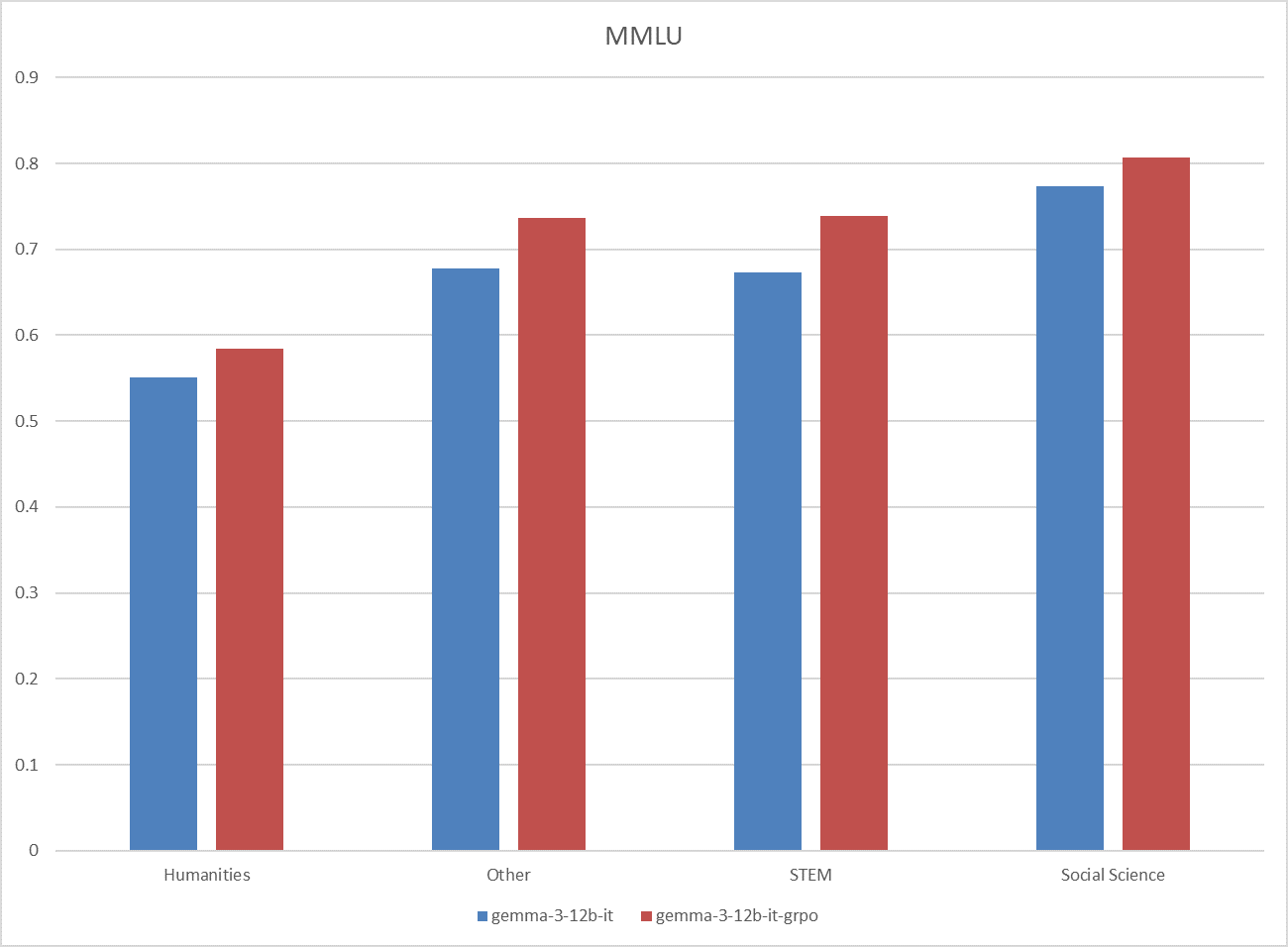
**Fig.1 The results on the MMLU benchmark.**
|
| 46 |
+
|
| 47 |
+

|
| 48 |
+
|
| 49 |
+
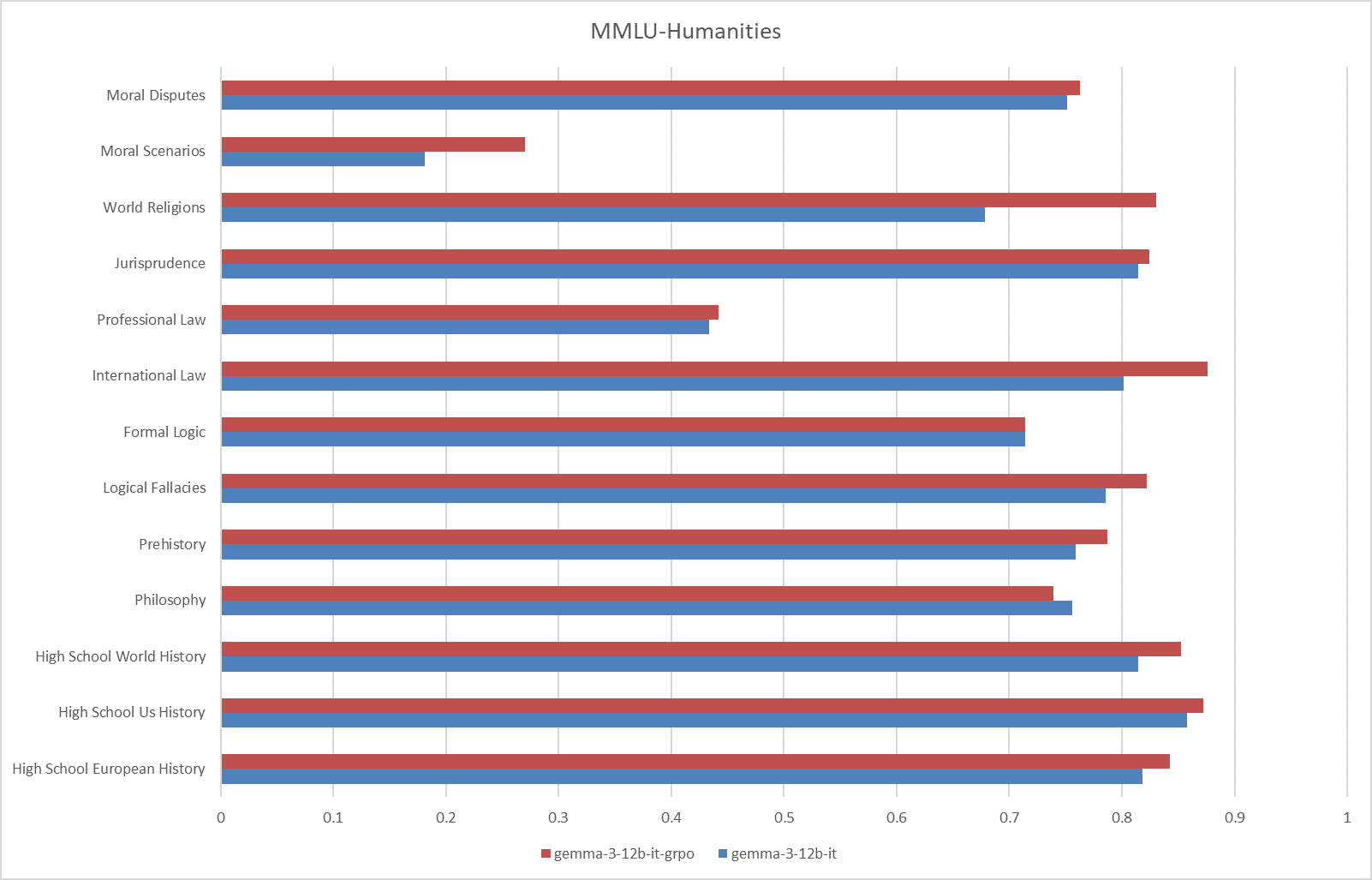
**Fig.2 The results on the MMLU-Humanities**
|
| 50 |
+
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
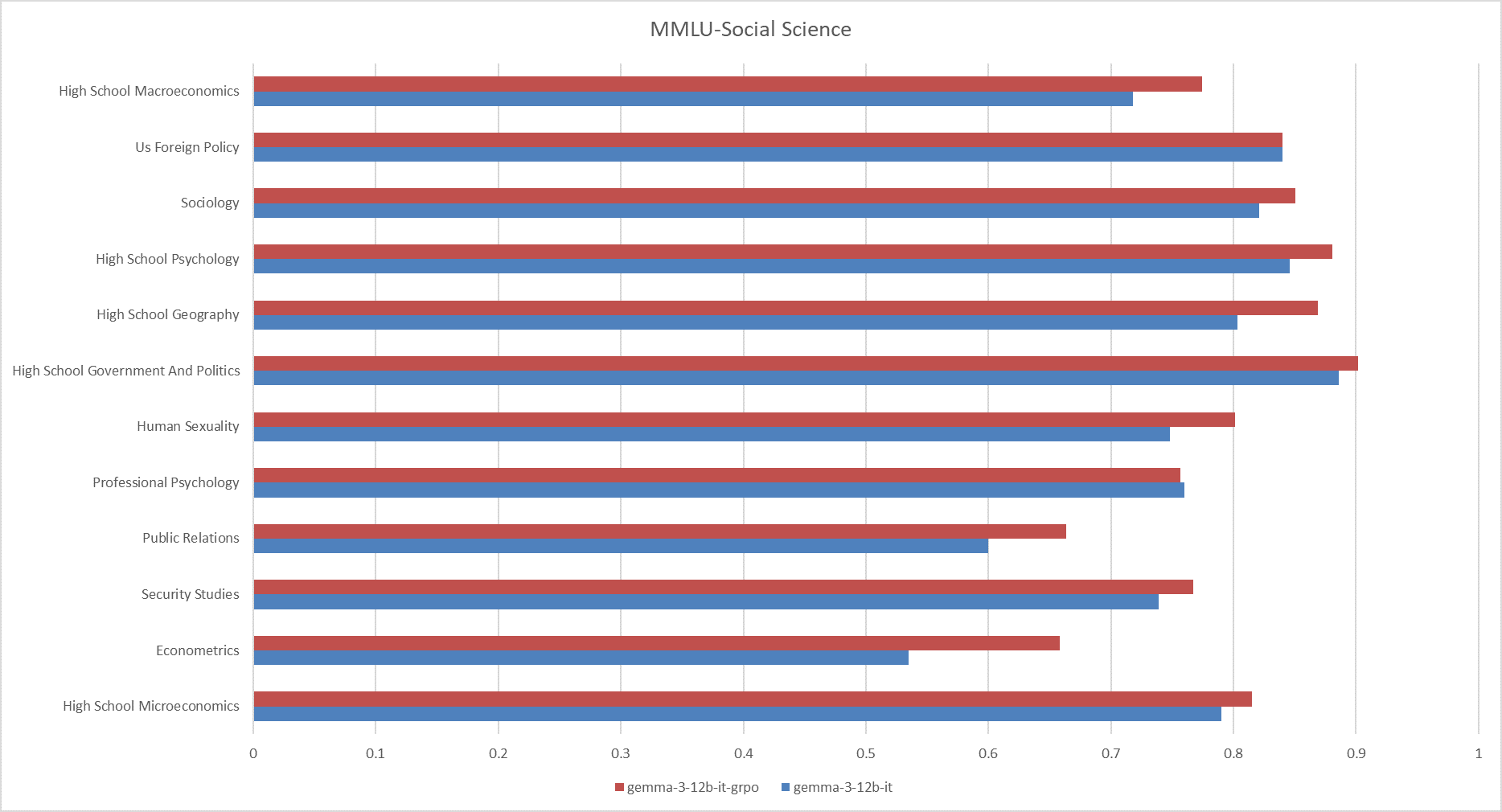
**Fig.3 The results on the MMLU-Social Science**
|
| 54 |
+
|
| 55 |
+

|
| 56 |
+
|
| 57 |
+
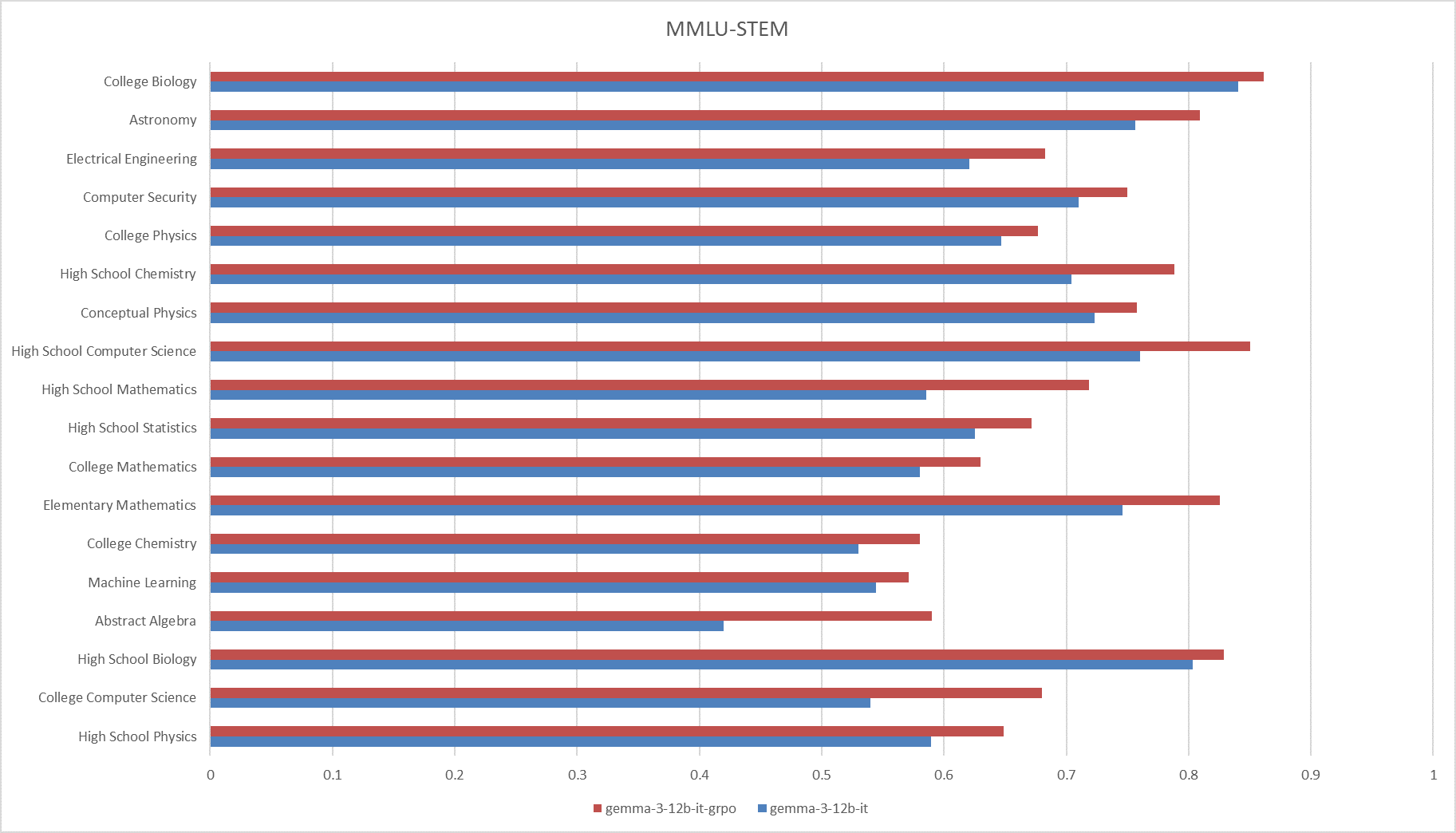
**Fig.4 The results on the MMLU-STEM**
|
| 58 |
+
|
| 59 |
+

|
| 60 |
+
|
| 61 |
+
**Fig.5 The results on the MMLU-Other**
|
| 62 |
+
|
| 63 |
+
### MMLU-Pro
|
| 64 |
+
|
| 65 |
+

|
| 66 |
+
|
| 67 |
+
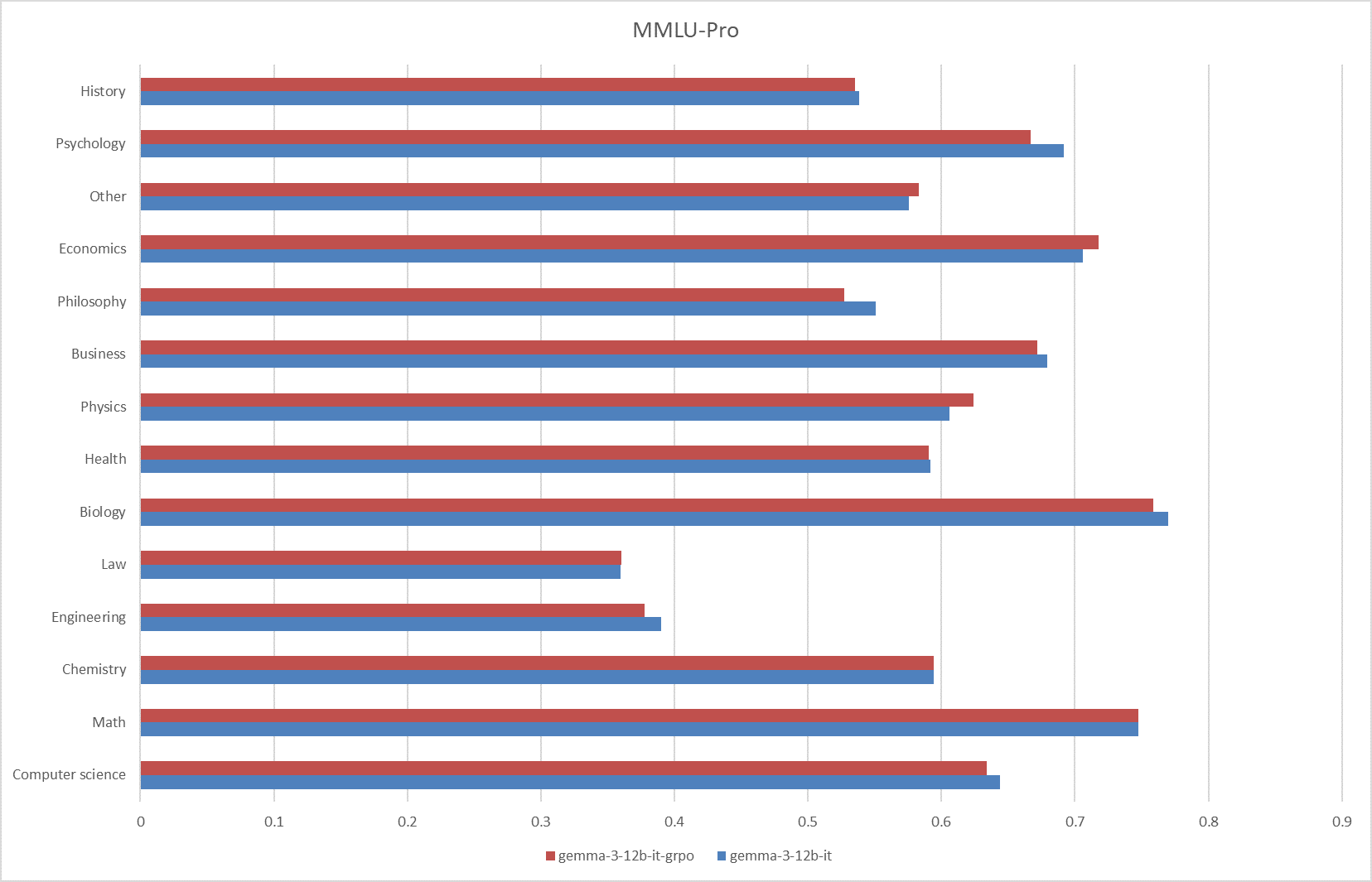
**Fig.6 The results on the MMLU-Pro**
|
| 68 |
+
|
| 69 |
+
### CMMLU
|
| 70 |
+
|
| 71 |
+

|
| 72 |
+
|
| 73 |
+
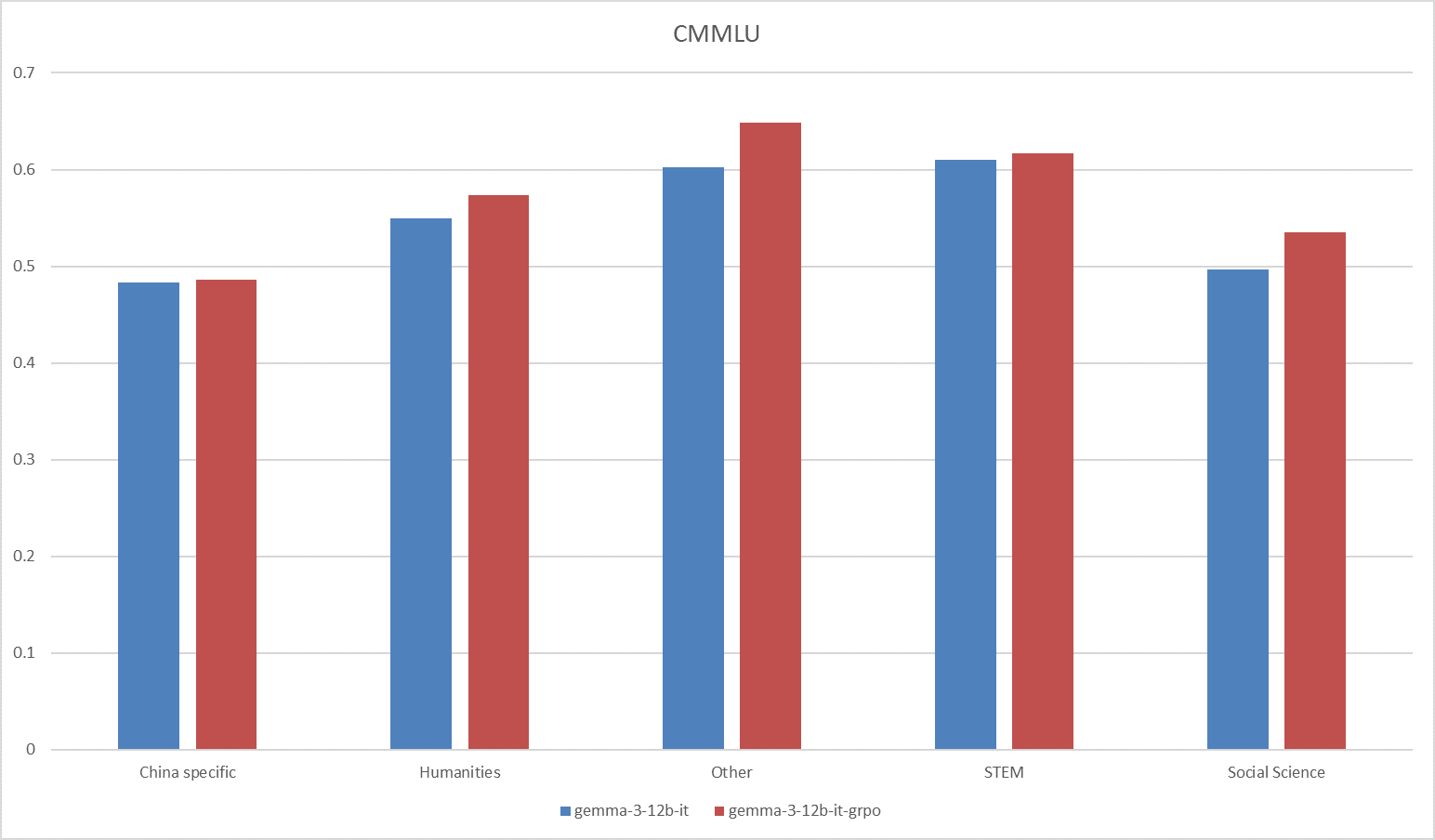
**Fig.7 The results on the CMMLU benchmark.**
|
| 74 |
+
|
| 75 |
+

|
| 76 |
+
|
| 77 |
+
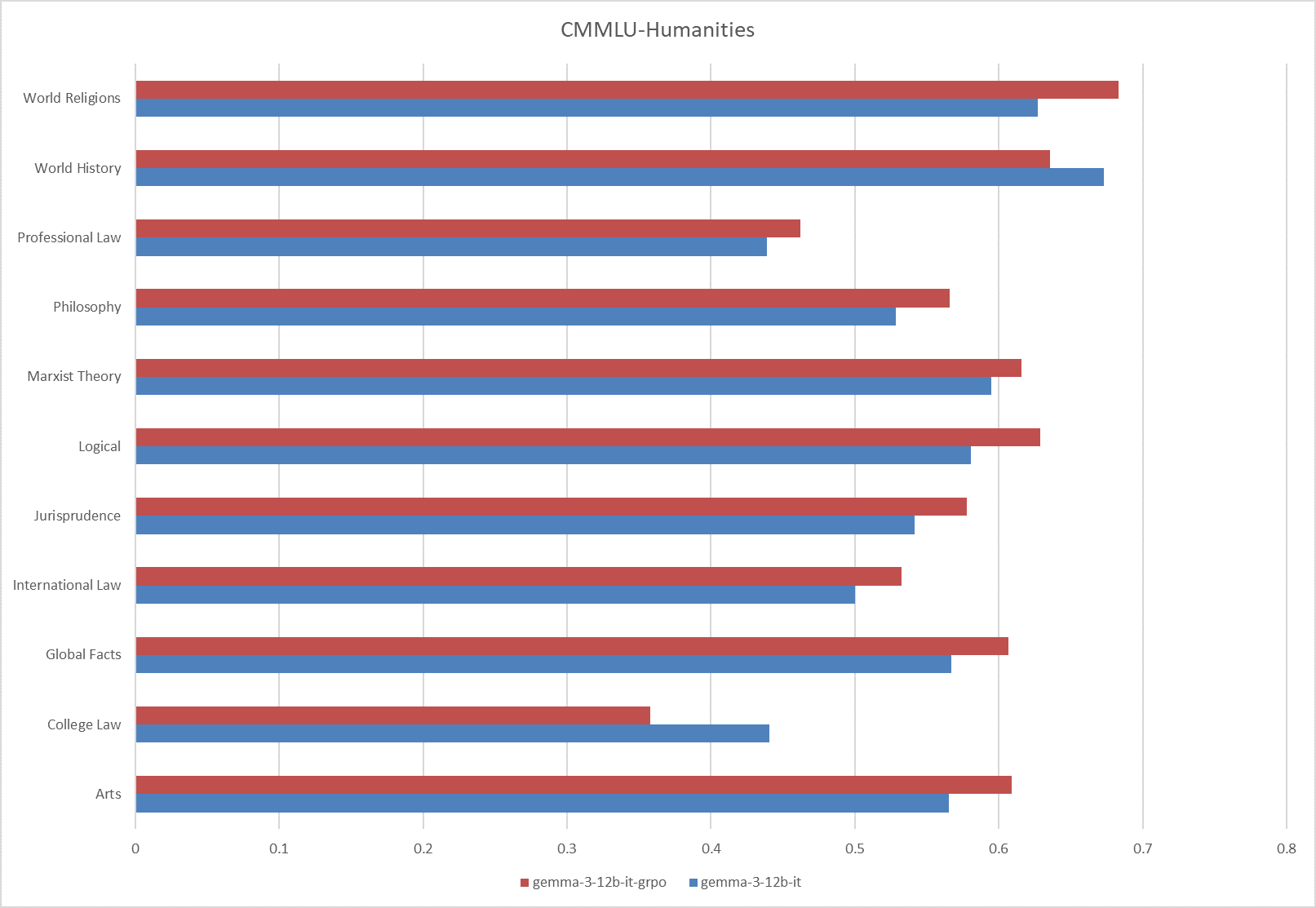
**Fig.8 The results on the CMMLU-Humanities**
|
| 78 |
+
|
| 79 |
+

|
| 80 |
+
|
| 81 |
+
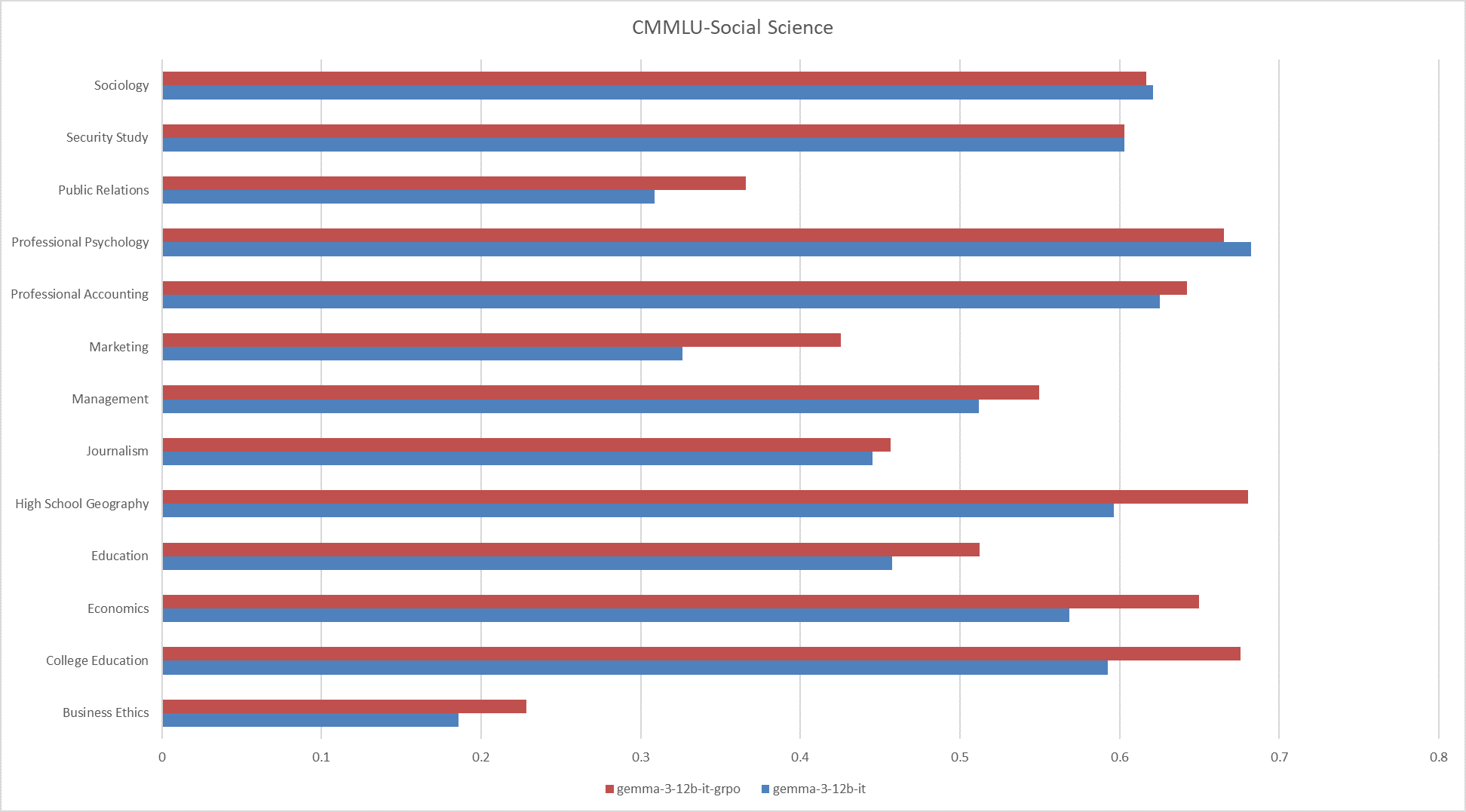
**Fig.9 The results on the CMMLU-Social Science**
|
| 82 |
+
|
| 83 |
+

|
| 84 |
+
|
| 85 |
+
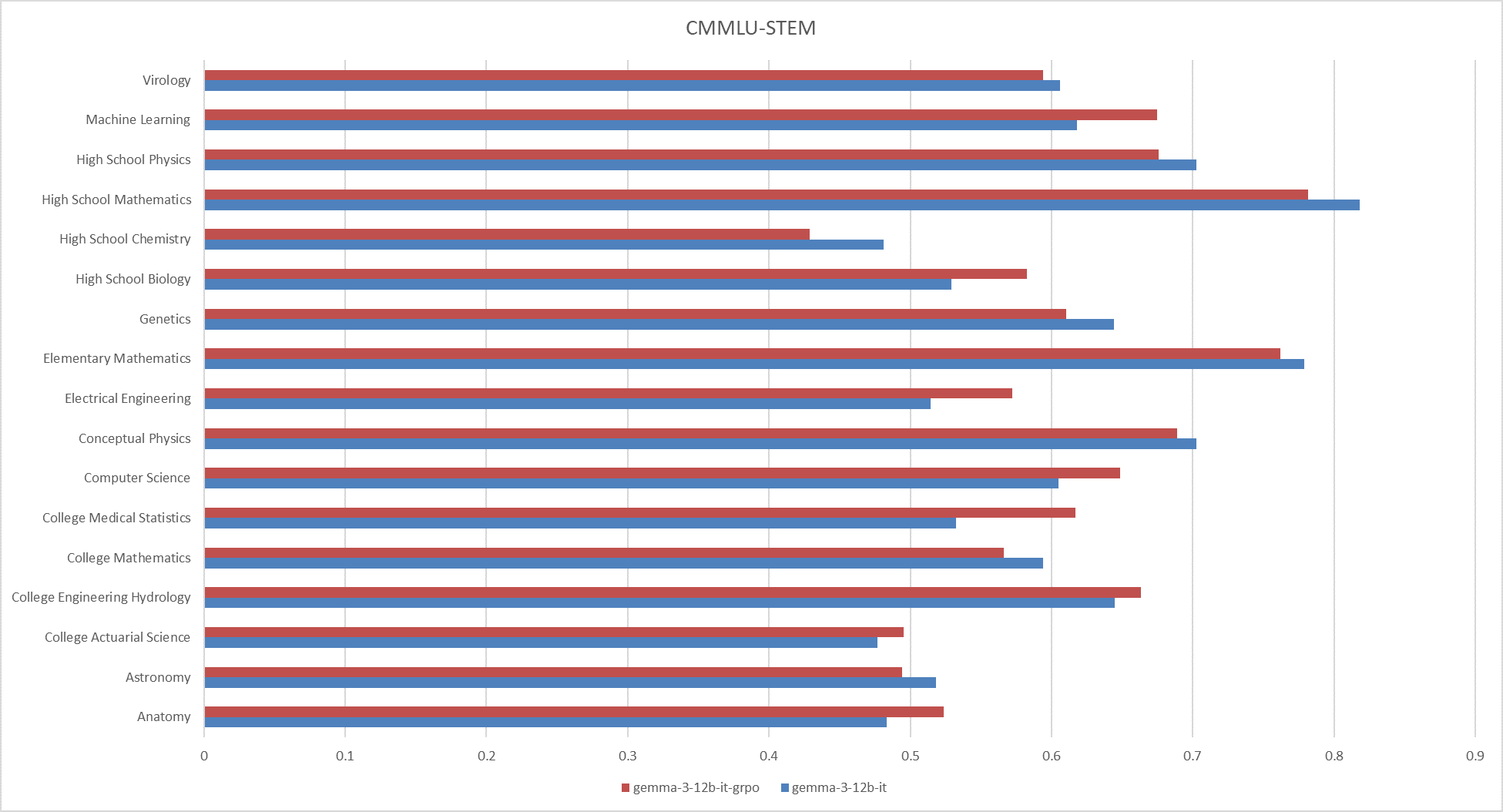
**Fig.10 The results on the CMMLU-STEM**
|
| 86 |
+
|
| 87 |
+

|
| 88 |
+
|
| 89 |
+
**Fig.11 The results on the CMMLU-Other**
|
| 90 |
+
|
| 91 |
+

|
| 92 |
+
|
| 93 |
+
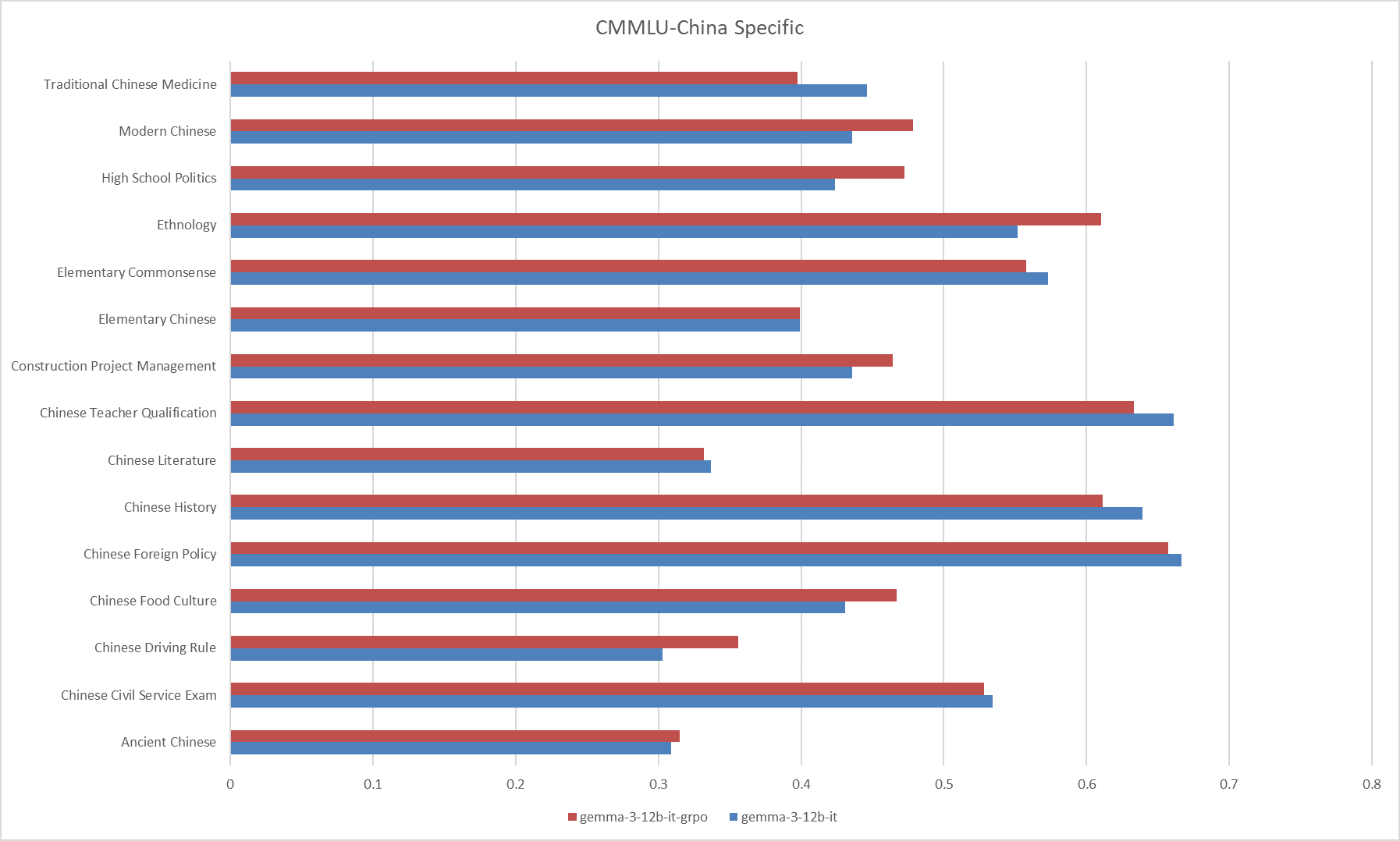
**Fig.12 The results on the CMMLU-China Specific**
|
| 94 |
+
|
| 95 |
+
## Acknowledge
|
| 96 |
+
|
| 97 |
+
[Gemma-3-12b-it](https://huggingface.co/google/gemma-3-12b-it)
|
| 98 |
+
|
| 99 |
+
[Unlsoth](https://github.com/unslothai/unsloth)
|
| 100 |
+
|
| 101 |
+
## Citation
|
| 102 |
+
|
| 103 |
+
```ini
|
| 104 |
+
@software{Qiu_Open-Medical-R1,
|
| 105 |
+
author = {Qiu, Zhongxi and Zhang, Zhang and Hu, Yan and Li, Heng and Liu, Jiang},
|
| 106 |
+
license = {MIT},
|
| 107 |
+
title = {{Open-Medical-R1}},
|
| 108 |
+
url = {https://github.com/Qsingle/open-medical-r1},
|
| 109 |
+
version = {0.1}
|
| 110 |
+
}
|
| 111 |
+
```
|
| 112 |
+
|
added_tokens.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<image_soft_token>": 262144
|
| 3 |
+
}
|
asserts/cmmlu.png
ADDED
|
asserts/cmmlu_china_specific.png
ADDED
|
asserts/cmmlu_humanities.png
ADDED
|
asserts/cmmlu_other.png
ADDED

|
asserts/cmmlu_social_science.png
ADDED
|
asserts/cmmlu_stem.png
ADDED
|
asserts/mmlu.png
ADDED
|
asserts/mmlu_humanities.png
ADDED
|
asserts/mmlu_other.png
ADDED

|
asserts/mmlu_pro.png
ADDED
|
asserts/mmlu_social_science.png
ADDED
|
asserts/mmlu_stem.png
ADDED
|
chat_template.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"chat_template": "{{ bos_token }}\n{%- if messages[0]['role'] == 'system' -%}\n {%- if messages[0]['content'] is string -%}\n {%- set first_user_prefix = messages[0]['content'] + '\n\n' -%}\n {%- else -%}\n {%- set first_user_prefix = messages[0]['content'][0]['text'] + '\n\n' -%}\n {%- endif -%}\n {%- set loop_messages = messages[1:] -%}\n{%- else -%}\n {%- set first_user_prefix = \"\" -%}\n {%- set loop_messages = messages -%}\n{%- endif -%}\n{%- for message in loop_messages -%}\n {%- if (message['role'] == 'user') != (loop.index0 % 2 == 0) -%}\n {{ raise_exception(\"Conversation roles must alternate user/assistant/user/assistant/...\") }}\n {%- endif -%}\n {%- if (message['role'] == 'assistant') -%}\n {%- set role = \"model\" -%}\n {%- else -%}\n {%- set role = message['role'] -%}\n {%- endif -%}\n {{ '<start_of_turn>' + role + '\n' + (first_user_prefix if loop.first else \"\") }}\n {%- if message['content'] is string -%}\n {{ message['content'] | trim }}\n {%- elif message['content'] is iterable -%}\n {%- for item in message['content'] -%}\n {%- if item['type'] == 'image' -%}\n {{ '<start_of_image>' }}\n {%- elif item['type'] == 'text' -%}\n {{ item['text'] | trim }}\n {%- endif -%}\n {%- endfor -%}\n {%- else -%}\n {{ raise_exception(\"Invalid content type\") }}\n {%- endif -%}\n {{ '<end_of_turn>\n' }}\n{%- endfor -%}\n{%- if add_generation_prompt -%}\n {{'<start_of_turn>model\n'}}\n{%- endif -%}\n"
|
| 3 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Gemma3ForConditionalGeneration"
|
| 4 |
+
],
|
| 5 |
+
"boi_token_index": 255999,
|
| 6 |
+
"eoi_token_index": 256000,
|
| 7 |
+
"eos_token_id": [
|
| 8 |
+
1,
|
| 9 |
+
106
|
| 10 |
+
],
|
| 11 |
+
"image_token_index": 262144,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"mm_tokens_per_image": 256,
|
| 14 |
+
"model_type": "gemma3",
|
| 15 |
+
"text_config": {
|
| 16 |
+
"hidden_size": 3840,
|
| 17 |
+
"intermediate_size": 15360,
|
| 18 |
+
"model_type": "gemma3_text",
|
| 19 |
+
"num_attention_heads": 16,
|
| 20 |
+
"num_hidden_layers": 48,
|
| 21 |
+
"num_key_value_heads": 8,
|
| 22 |
+
"rope_scaling": {
|
| 23 |
+
"factor": 8.0,
|
| 24 |
+
"rope_type": "linear"
|
| 25 |
+
},
|
| 26 |
+
"sliding_window": 1024
|
| 27 |
+
},
|
| 28 |
+
"torch_dtype": "bfloat16",
|
| 29 |
+
"transformers_version": "4.50.0.dev0",
|
| 30 |
+
"vision_config": {
|
| 31 |
+
"hidden_size": 1152,
|
| 32 |
+
"image_size": 896,
|
| 33 |
+
"intermediate_size": 4304,
|
| 34 |
+
"model_type": "siglip_vision_model",
|
| 35 |
+
"num_attention_heads": 16,
|
| 36 |
+
"num_hidden_layers": 27,
|
| 37 |
+
"patch_size": 14,
|
| 38 |
+
"vision_use_head": false
|
| 39 |
+
}
|
| 40 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 2,
|
| 3 |
+
"cache_implementation": "hybrid",
|
| 4 |
+
"do_sample": true,
|
| 5 |
+
"eos_token_id": [
|
| 6 |
+
1,
|
| 7 |
+
106
|
| 8 |
+
],
|
| 9 |
+
"pad_token_id": 0,
|
| 10 |
+
"top_k": 64,
|
| 11 |
+
"top_p": 0.95,
|
| 12 |
+
"transformers_version": "4.50.3"
|
| 13 |
+
}
|
model-00001-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6668b99ed6da08969919188f2424f3f730d540b7c0dacc1a16a4f68ada3d4ad2
|
| 3 |
+
size 4979901696
|
model-00002-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cb69fa7ea887baa742d6596fe01afb2e5d41057c1c35858409286d53e69b21ba
|
| 3 |
+
size 4931296448
|
model-00003-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:69bdd8ccb6271053b1ee6886b2993287add8482fce935700882270262f971bcb
|
| 3 |
+
size 4931296512
|
model-00004-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a812453801a1ec4b47b9b87147a64cd78186dfdcb2e894405dd5f316527e2728
|
| 3 |
+
size 4931296512
|
model-00005-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5292328709b6f1d95db6d1c3b6ba89a6d64ca4397bc3ad852010a5e775d10a14
|
| 3 |
+
size 4601000792
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_convert_rgb": null,
|
| 3 |
+
"do_normalize": true,
|
| 4 |
+
"do_pan_and_scan": null,
|
| 5 |
+
"do_rescale": true,
|
| 6 |
+
"do_resize": true,
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.5,
|
| 9 |
+
0.5,
|
| 10 |
+
0.5
|
| 11 |
+
],
|
| 12 |
+
"image_processor_type": "Gemma3ImageProcessor",
|
| 13 |
+
"image_seq_length": 256,
|
| 14 |
+
"image_std": [
|
| 15 |
+
0.5,
|
| 16 |
+
0.5,
|
| 17 |
+
0.5
|
| 18 |
+
],
|
| 19 |
+
"pan_and_scan_max_num_crops": null,
|
| 20 |
+
"pan_and_scan_min_crop_size": null,
|
| 21 |
+
"pan_and_scan_min_ratio_to_activate": null,
|
| 22 |
+
"processor_class": "Gemma3Processor",
|
| 23 |
+
"resample": 2,
|
| 24 |
+
"rescale_factor": 0.00392156862745098,
|
| 25 |
+
"size": {
|
| 26 |
+
"height": 896,
|
| 27 |
+
"width": 896
|
| 28 |
+
}
|
| 29 |
+
}
|
processor_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"image_seq_length": 256,
|
| 3 |
+
"processor_class": "Gemma3Processor"
|
| 4 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"boi_token": "<start_of_image>",
|
| 3 |
+
"bos_token": {
|
| 4 |
+
"content": "<bos>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false
|
| 9 |
+
},
|
| 10 |
+
"eoi_token": "<end_of_image>",
|
| 11 |
+
"eos_token": {
|
| 12 |
+
"content": "<eos>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false
|
| 17 |
+
},
|
| 18 |
+
"image_token": "<image_soft_token>",
|
| 19 |
+
"pad_token": {
|
| 20 |
+
"content": "<pad>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false
|
| 25 |
+
},
|
| 26 |
+
"unk_token": {
|
| 27 |
+
"content": "<unk>",
|
| 28 |
+
"lstrip": false,
|
| 29 |
+
"normalized": false,
|
| 30 |
+
"rstrip": false,
|
| 31 |
+
"single_word": false
|
| 32 |
+
}
|
| 33 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d786405177734910d7a3db625c2826640964a0b4e5cdbbd70620ae3313a01bef
|
| 3 |
+
size 33384722
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1299c11d7cf632ef3b4e11937501358ada021bbdf7c47638d13c0ee982f2e79c
|
| 3 |
+
size 4689074
|
tokenizer_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|