
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +11 -0
- added_tokens.json +6 -0
- config.json +102 -0
- generation_config.json +8 -0
- khmerhomophonecorrector/.DS_Store +0 -0
- khmerhomophonecorrector/.gitattributes +46 -0
- khmerhomophonecorrector/FYP_ Model Tracking - Sheet1.csv +107 -0
- khmerhomophonecorrector/README.md +3 -0
- khmerhomophonecorrector/app.py +216 -0
- khmerhomophonecorrector/batch_size_impact.png +3 -0
- khmerhomophonecorrector/data/.DS_Store +0 -0
- khmerhomophonecorrector/data/test.json +0 -0
- khmerhomophonecorrector/data/train.json +3 -0
- khmerhomophonecorrector/data/val.json +0 -0
- khmerhomophonecorrector/dataset_distribution.png +0 -0
- khmerhomophonecorrector/header.png +3 -0
- khmerhomophonecorrector/homophone_pairs.json +3 -0
- khmerhomophonecorrector/homophone_test.json +272 -0
- khmerhomophonecorrector/infer_from_json.py +270 -0
- khmerhomophonecorrector/khmerhomophonecorrector/added_tokens.json +6 -0
- khmerhomophonecorrector/khmerhomophonecorrector/config.json +102 -0
- khmerhomophonecorrector/khmerhomophonecorrector/generation_config.json +8 -0
- khmerhomophonecorrector/khmerhomophonecorrector/model.safetensors +3 -0
- khmerhomophonecorrector/khmerhomophonecorrector/special_tokens_map.json +21 -0
- khmerhomophonecorrector/khmerhomophonecorrector/spiece.model +3 -0
- khmerhomophonecorrector/khmerhomophonecorrector/tokenizer_config.json +99 -0
- khmerhomophonecorrector/khmerhomophonecorrector/training_args.bin +3 -0
- khmerhomophonecorrector/khmerhomophonecorrector/training_state.json +1 -0
- khmerhomophonecorrector/loss_comparison.png +3 -0
- khmerhomophonecorrector/metrics_comparison.png +3 -0
- khmerhomophonecorrector/model_performance_line_chart.html +0 -0
- khmerhomophonecorrector/model_performance_line_chart.png +0 -0
- khmerhomophonecorrector/model_performance_line_chart_big_bs32_e40.html +0 -0
- khmerhomophonecorrector/model_performance_line_chart_big_bs32_e40.png +0 -0
- khmerhomophonecorrector/model_performance_table.html +80 -0
- khmerhomophonecorrector/test_results.txt +0 -0
- khmerhomophonecorrector/tool/.DS_Store +0 -0
- khmerhomophonecorrector/tool/__pycache__/khnormal.cpython-312.pyc +0 -0
- khmerhomophonecorrector/tool/balance_data.py +39 -0
- khmerhomophonecorrector/tool/clean_data.py +52 -0
- khmerhomophonecorrector/tool/combine_homophones.py +46 -0
- khmerhomophonecorrector/tool/complete_homophone_sentences.py +182 -0
- khmerhomophonecorrector/tool/convert_format.py +107 -0
- khmerhomophonecorrector/tool/convert_training_data.py +108 -0
- khmerhomophonecorrector/tool/debug_homophone_check.py +54 -0
- khmerhomophonecorrector/tool/filter.py +40 -0
- khmerhomophonecorrector/tool/homophone_missing.py +88 -0
- khmerhomophonecorrector/tool/khnormal.py +158 -0
- khmerhomophonecorrector/tool/normalize_khmer.py +52 -0
- khmerhomophonecorrector/tool/segmentation.py +48 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,14 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
khmerhomophonecorrector/batch_size_impact.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
khmerhomophonecorrector/data/train.json filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
khmerhomophonecorrector/header.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
khmerhomophonecorrector/homophone_pairs.json filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
khmerhomophonecorrector/loss_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
khmerhomophonecorrector/metrics_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
khmerhomophonecorrector/training_loss.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
khmerhomophonecorrector/visualization/batch_size_impact.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
khmerhomophonecorrector/visualization/loss_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
khmerhomophonecorrector/visualization/metrics_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
khmerhomophonecorrector/visualization/training_loss.png filter=lfs diff=lfs merge=lfs -text
|
added_tokens.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</s>": 32001,
|
| 3 |
+
"<2en>": 32003,
|
| 4 |
+
"<2km>": 32002,
|
| 5 |
+
"<s>": 32000
|
| 6 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"activation_dropout": 0.1,
|
| 3 |
+
"activation_function": "gelu",
|
| 4 |
+
"adaptor_activation_function": "gelu",
|
| 5 |
+
"adaptor_dropout": 0.1,
|
| 6 |
+
"adaptor_hidden_size": 512,
|
| 7 |
+
"adaptor_init_std": 0.02,
|
| 8 |
+
"adaptor_scaling_factor": 1.0,
|
| 9 |
+
"adaptor_tuning": false,
|
| 10 |
+
"additional_source_wait_k": -1,
|
| 11 |
+
"alibi_encoding": false,
|
| 12 |
+
"architectures": [
|
| 13 |
+
"MBartForConditionalGeneration"
|
| 14 |
+
],
|
| 15 |
+
"asymmetric_alibi_encoding": false,
|
| 16 |
+
"attention_dropout": 0.1,
|
| 17 |
+
"bos_token_id": 32000,
|
| 18 |
+
"bottleneck_mid_fusion_tokens": 4,
|
| 19 |
+
"classifier_dropout": 0.0,
|
| 20 |
+
"d_model": 1024,
|
| 21 |
+
"decoder_adaptor_tying_config": null,
|
| 22 |
+
"decoder_attention_heads": 16,
|
| 23 |
+
"decoder_ffn_dim": 4096,
|
| 24 |
+
"decoder_layerdrop": 0.0,
|
| 25 |
+
"decoder_layers": 6,
|
| 26 |
+
"decoder_tying_config": null,
|
| 27 |
+
"deep_adaptor_tuning": false,
|
| 28 |
+
"deep_adaptor_tuning_ffn_only": false,
|
| 29 |
+
"dropout": 0.1,
|
| 30 |
+
"embed_low_rank_dim": 0,
|
| 31 |
+
"encoder_adaptor_tying_config": null,
|
| 32 |
+
"encoder_attention_heads": 16,
|
| 33 |
+
"encoder_ffn_dim": 4096,
|
| 34 |
+
"encoder_layerdrop": 0.0,
|
| 35 |
+
"encoder_layers": 6,
|
| 36 |
+
"encoder_tying_config": null,
|
| 37 |
+
"eos_token_id": 32001,
|
| 38 |
+
"expert_ffn_size": 128,
|
| 39 |
+
"features_embed_dims": null,
|
| 40 |
+
"features_vocab_sizes": null,
|
| 41 |
+
"forced_eos_token_id": 2,
|
| 42 |
+
"gradient_checkpointing": false,
|
| 43 |
+
"gradient_reversal_for_domain_classifier": false,
|
| 44 |
+
"hypercomplex": false,
|
| 45 |
+
"hypercomplex_n": 2,
|
| 46 |
+
"ia3_adaptors": false,
|
| 47 |
+
"init_std": 0.02,
|
| 48 |
+
"initialization_scheme": "static",
|
| 49 |
+
"is_encoder_decoder": true,
|
| 50 |
+
"layernorm_adaptor_input": false,
|
| 51 |
+
"layernorm_prompt_projection": false,
|
| 52 |
+
"lora_adaptor_rank": 2,
|
| 53 |
+
"lora_adaptors": false,
|
| 54 |
+
"max_position_embeddings": 1024,
|
| 55 |
+
"mid_fusion_layers": 3,
|
| 56 |
+
"model_type": "mbart",
|
| 57 |
+
"moe_adaptors": false,
|
| 58 |
+
"multi_source": false,
|
| 59 |
+
"multi_source_method": null,
|
| 60 |
+
"multilayer_softmaxing": null,
|
| 61 |
+
"no_embed_norm": false,
|
| 62 |
+
"no_positional_encoding_decoder": false,
|
| 63 |
+
"no_positional_encoding_encoder": false,
|
| 64 |
+
"no_projection_prompt": false,
|
| 65 |
+
"no_scale_attention_embedding": false,
|
| 66 |
+
"num_domains_for_domain_classifier": 1,
|
| 67 |
+
"num_experts": 8,
|
| 68 |
+
"num_hidden_layers": 6,
|
| 69 |
+
"num_moe_adaptor_experts": 4,
|
| 70 |
+
"num_prompts": 100,
|
| 71 |
+
"num_sparsify_blocks": 8,
|
| 72 |
+
"pad_token_id": 0,
|
| 73 |
+
"parallel_adaptors": false,
|
| 74 |
+
"positional_encodings": false,
|
| 75 |
+
"postnorm_decoder": false,
|
| 76 |
+
"postnorm_encoder": false,
|
| 77 |
+
"prompt_dropout": 0.1,
|
| 78 |
+
"prompt_init_std": 0.02,
|
| 79 |
+
"prompt_projection_hidden_size": 4096,
|
| 80 |
+
"prompt_tuning": false,
|
| 81 |
+
"recurrent_projections": 1,
|
| 82 |
+
"residual_connection_adaptor": false,
|
| 83 |
+
"residual_connection_prompt": false,
|
| 84 |
+
"rope_encoding": false,
|
| 85 |
+
"scale_embedding": false,
|
| 86 |
+
"softmax_bias_tuning": false,
|
| 87 |
+
"softmax_temperature": 1.0,
|
| 88 |
+
"sparsification_temperature": 3.0,
|
| 89 |
+
"sparsify_attention": false,
|
| 90 |
+
"sparsify_ffn": false,
|
| 91 |
+
"target_vocab_size": 0,
|
| 92 |
+
"temperature_calibration": false,
|
| 93 |
+
"tokenizer_class": "AlbertTokenizer",
|
| 94 |
+
"torch_dtype": "float32",
|
| 95 |
+
"transformers_version": "4.52.4",
|
| 96 |
+
"unidirectional_encoder": false,
|
| 97 |
+
"use_cache": true,
|
| 98 |
+
"use_moe": false,
|
| 99 |
+
"use_tanh_activation_prompt": false,
|
| 100 |
+
"vocab_size": 32004,
|
| 101 |
+
"wait_k": -1
|
| 102 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 32000,
|
| 4 |
+
"eos_token_id": 32001,
|
| 5 |
+
"forced_eos_token_id": 2,
|
| 6 |
+
"pad_token_id": 0,
|
| 7 |
+
"transformers_version": "4.52.4"
|
| 8 |
+
}
|
khmerhomophonecorrector/.DS_Store
ADDED
|
Binary file (12.3 kB). View file
|
|
|
khmerhomophonecorrector/.gitattributes
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
batch_size_impact.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
data/train.json filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
header.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
homophone_pairs.json filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
loss_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
metrics_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
training_loss.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
visualization/batch_size_impact.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
visualization/loss_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
visualization/metrics_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
visualization/training_loss.png filter=lfs diff=lfs merge=lfs -text
|
khmerhomophonecorrector/FYP_ Model Tracking - Sheet1.csv
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Model Name,Batch Size,Num of Epochs,Epochs,Train Loss,Val Loss,WER,BLEU-1,BLEU-2,BLEU-3,BLEU-4,Notes,
|
| 2 |
+
prahokbart_base,8,10,1,0.1789,0.118885,0.0095,99.4068,98.8971,98.4134,97.9704,https://drive.google.com/drive/folders/16BOObaDAzmx6yl__UavLhbQUQj1JiTph,
|
| 3 |
+
,,,2,0.0808,0.066198,,,,,,,
|
| 4 |
+
,,,3,0.0648,0.049457,,,,,,,
|
| 5 |
+
,,,4,0.0466,0.040769,,,,,,,
|
| 6 |
+
,,,5,0.0402,0.035832,,,,,,,
|
| 7 |
+
,,,6,0.029,0.032629,,,,,,,
|
| 8 |
+
,,,7,0.0419,0.030779,,,,,,,
|
| 9 |
+
,,,8,0.0199,0.030187,,,,,,,
|
| 10 |
+
,,,9,0.018,0.029398,,,,,,,
|
| 11 |
+
,,,10,0.017,0.028081,,,,,,,
|
| 12 |
+
,,,,,,,,,,,,
|
| 13 |
+
prahokbart_base,16,10,1,0.344,0.243551,0.0146,98.9618,98.0396,97.1388,96.2967,prahokbart-base-E10-B16.ipynb,prahokbart-base-bs16-e10
|
| 14 |
+
,,,2,0.1701,0.127156,,,,,,,
|
| 15 |
+
,,,3,0.113,0.094204,,,,,,,
|
| 16 |
+
,,,4,0.0994,0.077294,,,,,,,
|
| 17 |
+
,,,5,0.0826,0.06774,,,,,,,
|
| 18 |
+
,,,6,0.0744,0.061196,,,,,,,
|
| 19 |
+
,,,7,0.0727,0.056898,,,,,,,
|
| 20 |
+
,,,8,0.0583,0.054359,,,,,,,
|
| 21 |
+
,,,9,0.0512,0.053133,,,,,,,
|
| 22 |
+
,,,10,0.0567,0.052445,,,,,,,
|
| 23 |
+
,,,,,,,,,,,,
|
| 24 |
+
prahokbart_base,32,10,1,0.4248,,0.0217,98.3017,96.752,95.2542,93.8637,prahokbart-base-E10-B32.ipynb,prahokbart-base-bs32-e10
|
| 25 |
+
,,,2,0.2198,0.1806311905,,,,,,,
|
| 26 |
+
,,,3,0.1831,,,,,,,,
|
| 27 |
+
,,,4,0.15,,,,,,,,
|
| 28 |
+
,,,5,0.137,0.1235590726,,,,,,,
|
| 29 |
+
,,,6,0.1273,,,,,,,,
|
| 30 |
+
,,,7,0.1204,0.1003917083,,,,,,,
|
| 31 |
+
,,,8,0.1096,,,,,,,,
|
| 32 |
+
,,,9,0.1099,,,,,,,,
|
| 33 |
+
,,,10,0.1061,0.09450948983,,,,,,,
|
| 34 |
+
,,,,,,,,,,,,
|
| 35 |
+
prahokbart_big,8,10,1,0.1789,0.118885,0.0095,99.4068,98.8971,98.4134,97.9704,prahokbart-big-E10-B8.ipynb,prahokbart-big-bs8-e10
|
| 36 |
+
,,,2,0.0808,0.066198,,,,,,,
|
| 37 |
+
,,,3,0.0648,0.049457,,,,,,,
|
| 38 |
+
,,,4,0.0466,0.040769,,,,,,,
|
| 39 |
+
,,,5,0.0402,0.035832,,,,,,,
|
| 40 |
+
,,,6,0.029,0.032629,,,,,,,
|
| 41 |
+
,,,7,0.0419,0.030779,,,,,,,
|
| 42 |
+
,,,8,0.0199,0.030187,,,,,,,
|
| 43 |
+
,,,9,0.018,0.029398,,,,,,,
|
| 44 |
+
,,,10,0.0268,0.029082,,,,,,,
|
| 45 |
+
,,,,,,,,,,,,
|
| 46 |
+
prahokbart_big,16,10,1,0.237,0.156053,0.012,99.1946,98.5264,97.8799,97.2795,prahokbart-big-E10-B16.ipynb,prahokbart-big-bs16-e10
|
| 47 |
+
,,,2,0.1137,0.080692,,,,,,,
|
| 48 |
+
,,,3,0.08,0.062454,,,,,,,
|
| 49 |
+
,,,4,0.0672,0.051034,,,,,,,
|
| 50 |
+
,,,5,0.0537,0.045366,,,,,,,
|
| 51 |
+
,,,6,0.0474,0.041196,,,,,,,
|
| 52 |
+
,,,7,0.048,0.038459,,,,,,,
|
| 53 |
+
,,,8,0.0366,0.036974,,,,,,,
|
| 54 |
+
,,,9,0.0305,0.036123,,,,,,,
|
| 55 |
+
,,,10,0.038,0.035709,,,,,,,
|
| 56 |
+
,,,,,,,,,,,,
|
| 57 |
+
prahokbart_big,32,10,1,0.4347,0.328299,0.0142,99.0066,98.1694,97.3646,96.6186,prahokbart-big-E10-B32.ipynb,prahokbart-big-bs32-e10
|
| 58 |
+
,,,2,0.1448,0.107667,,,,,,,
|
| 59 |
+
,,,3,0.1,0.080751,,,,,,,
|
| 60 |
+
,,,4,0.0857,0.066501,,,,,,,
|
| 61 |
+
,,,5,0.0717,0.059016,,,,,,,
|
| 62 |
+
,,,6,0.0608,0.053938,,,,,,,
|
| 63 |
+
,,,7,0.0606,0.050479,,,,,,,
|
| 64 |
+
,,,8,0.0569,0.048502,,,,,,,
|
| 65 |
+
,,,9,0.0569,0.047486,,,,,,,
|
| 66 |
+
,,,10,0.0484,0.047022,,,,,,,
|
| 67 |
+
,,,,,,,,,,,,
|
| 68 |
+
prahokbart_big,32,40,1,0.6786,0.59872,0.008,99.5398,99.162,98.8093,98.4861,prahokbart-big-E10-B32.ipynb,
|
| 69 |
+
,,,2,0.3993,0.318888,,,,,,,
|
| 70 |
+
,,,3,0.1638,0.126617,,,,,,,
|
| 71 |
+
,,,4,0.1196,0.088467,,,,,,,
|
| 72 |
+
,,,5,0.0861,0.068045,,,,,,,
|
| 73 |
+
,,,6,0.0663,0.056211,,,,,,,
|
| 74 |
+
,,,7,0.0599,0.0488,,,,,,,
|
| 75 |
+
,,,8,0.0516,0.043238,,,,,,,
|
| 76 |
+
,,,9,0.047,0.039321,,,,,,,
|
| 77 |
+
,,,10,0.0357,0.035333,,,,,,,
|
| 78 |
+
,,,11,0.0377,0.03289,,,,,,,
|
| 79 |
+
,,,12,0.0335,0.030855,,,,,,,
|
| 80 |
+
,,,13,0.0279,0.029597,,,,,,,
|
| 81 |
+
,,,14,0.0362,0.028269,,,,,,,
|
| 82 |
+
,,,15,0.0206,0.027406,,,,,,,
|
| 83 |
+
,,,16,0.0229,0.026543,,,,,,,
|
| 84 |
+
,,,17,0.0197,0.026183,,,,,,,
|
| 85 |
+
,,,18,0.0167,0.025577,,,,,,,
|
| 86 |
+
,,,19,0.0181,0.02498,,,,,,,
|
| 87 |
+
,,,20,0.0153,0.024927,,,,,,,
|
| 88 |
+
,,,21,0.0137,0.024544,,,,,,,
|
| 89 |
+
,,,22,0.0166,0.024343,,,,,,,
|
| 90 |
+
,,,23,0.0134,0.024054,,,,,,,
|
| 91 |
+
,,,24,0.0121,0.023849,,,,,,,
|
| 92 |
+
,,,25,0.015,0.023575,,,,,,,
|
| 93 |
+
,,,26,0.0114,0.023603,,,,,,,
|
| 94 |
+
,,,27,0.0107,0.023624,,,,,,,
|
| 95 |
+
,,,28,0.0113,0.023694,,,,,,,
|
| 96 |
+
,,,29,0.0113,0.02336,,,,,,,
|
| 97 |
+
,,,30,0.0087,0.023514,,,,,,,
|
| 98 |
+
,,,31,0.0103,0.023472,,,,,,,
|
| 99 |
+
,,,32,0.0082,0.023636,,,,,,,
|
| 100 |
+
,,,33,0.0112,0.02359,,,,,,,
|
| 101 |
+
,,,34,0.0086,0.023592,,,,,,,
|
| 102 |
+
,,,35,0.0081,0.023537,,,,,,,
|
| 103 |
+
,,,36,0.009,0.023482,,,,,,,
|
| 104 |
+
,,,37,0.0089,0.023521,,,,,,,
|
| 105 |
+
,,,38,0.009,0.023539,,,,,,,
|
| 106 |
+
,,,39,0.0078,0.02354,,,,,,,
|
| 107 |
+
,,,40,0.0091,0.023525,,,,,,,
|
khmerhomophonecorrector/README.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
khmerhomophonecorrector/app.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, MBartForConditionalGeneration
|
| 3 |
+
import json
|
| 4 |
+
from khmernltk import word_tokenize
|
| 5 |
+
import torch
|
| 6 |
+
import difflib
|
| 7 |
+
|
| 8 |
+
# Set page config
|
| 9 |
+
st.set_page_config(
|
| 10 |
+
page_title="Khmer Homophone Corrector",
|
| 11 |
+
page_icon="✍️",
|
| 12 |
+
layout="wide"
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
# Custom CSS
|
| 16 |
+
st.markdown("""
|
| 17 |
+
<style>
|
| 18 |
+
.main {
|
| 19 |
+
padding: 2rem;
|
| 20 |
+
}
|
| 21 |
+
.stTextArea textarea {
|
| 22 |
+
font-size: 1.2rem;
|
| 23 |
+
}
|
| 24 |
+
.result-text {
|
| 25 |
+
font-size: 1.2rem;
|
| 26 |
+
padding: 1rem;
|
| 27 |
+
background-color: #f8f9fa;
|
| 28 |
+
border-radius: 0.5rem;
|
| 29 |
+
margin: 0.5rem 0;
|
| 30 |
+
}
|
| 31 |
+
.correction {
|
| 32 |
+
background-color: #ffd700;
|
| 33 |
+
padding: 0.2rem;
|
| 34 |
+
border-radius: 0.2rem;
|
| 35 |
+
}
|
| 36 |
+
.correction-details {
|
| 37 |
+
font-size: 1rem;
|
| 38 |
+
color: #666;
|
| 39 |
+
margin-top: 0.5rem;
|
| 40 |
+
}
|
| 41 |
+
.header-image {
|
| 42 |
+
width: 100%;
|
| 43 |
+
max-width: 800px;
|
| 44 |
+
margin: 0 auto;
|
| 45 |
+
display: block;
|
| 46 |
+
}
|
| 47 |
+
.model-info {
|
| 48 |
+
font-size: 0.9rem;
|
| 49 |
+
color: #666;
|
| 50 |
+
margin-top: 0.5rem;
|
| 51 |
+
}
|
| 52 |
+
</style>
|
| 53 |
+
""", unsafe_allow_html=True)
|
| 54 |
+
|
| 55 |
+
# Display header image
|
| 56 |
+
st.image("header.png", use_column_width=True)
|
| 57 |
+
|
| 58 |
+
# Model configurations
|
| 59 |
+
MODEL_CONFIG = {
|
| 60 |
+
"path": "./prahokbart-big-bs32-e40",
|
| 61 |
+
"description": "Large model with batch size 32, trained for 40 epochs"
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
def word_segment(text):
|
| 65 |
+
return " ".join(word_tokenize(text)).replace(" ", " ▂ ")
|
| 66 |
+
|
| 67 |
+
def find_corrections(original, corrected):
|
| 68 |
+
original_words = [w for w in word_tokenize(original) if w.strip()]
|
| 69 |
+
corrected_words = [w for w in word_tokenize(corrected) if w.strip()]
|
| 70 |
+
|
| 71 |
+
matcher = difflib.SequenceMatcher(None, original_words, corrected_words)
|
| 72 |
+
corrections = []
|
| 73 |
+
|
| 74 |
+
for tag, i1, i2, j1, j2 in matcher.get_opcodes():
|
| 75 |
+
if tag != 'equal':
|
| 76 |
+
original_text = ' '.join(original_words[i1:i2])
|
| 77 |
+
corrected_text = ' '.join(corrected_words[j1:j2])
|
| 78 |
+
if original_text.strip() and corrected_text.strip() and original_text != corrected_text:
|
| 79 |
+
corrections.append({
|
| 80 |
+
'original': original_text,
|
| 81 |
+
'corrected': corrected_text,
|
| 82 |
+
'position': i1
|
| 83 |
+
})
|
| 84 |
+
|
| 85 |
+
return corrections
|
| 86 |
+
|
| 87 |
+
@st.cache_resource
|
| 88 |
+
def load_model(model_path):
|
| 89 |
+
try:
|
| 90 |
+
model = MBartForConditionalGeneration.from_pretrained(model_path)
|
| 91 |
+
tokenizer = AutoTokenizer.from_pretrained(model_path)
|
| 92 |
+
|
| 93 |
+
model.eval()
|
| 94 |
+
|
| 95 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 96 |
+
model = model.to(device)
|
| 97 |
+
|
| 98 |
+
return {
|
| 99 |
+
"model": model,
|
| 100 |
+
"tokenizer": tokenizer,
|
| 101 |
+
"device": device
|
| 102 |
+
}
|
| 103 |
+
except Exception as e:
|
| 104 |
+
st.error(f"Error loading model: {str(e)}")
|
| 105 |
+
return None
|
| 106 |
+
|
| 107 |
+
def process_text(text, model_components):
|
| 108 |
+
if model_components is None:
|
| 109 |
+
return "Error: Model not loaded properly"
|
| 110 |
+
|
| 111 |
+
model = model_components["model"]
|
| 112 |
+
tokenizer = model_components["tokenizer"]
|
| 113 |
+
device = model_components["device"]
|
| 114 |
+
|
| 115 |
+
segmented_text = word_segment(text)
|
| 116 |
+
input_text = f"{segmented_text} </s> <2km>"
|
| 117 |
+
|
| 118 |
+
inputs = tokenizer(
|
| 119 |
+
input_text,
|
| 120 |
+
return_tensors="pt",
|
| 121 |
+
padding=True,
|
| 122 |
+
truncation=True,
|
| 123 |
+
max_length=1024,
|
| 124 |
+
add_special_tokens=True
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
inputs = {k: v.to(device) for k, v in inputs.items()}
|
| 128 |
+
|
| 129 |
+
if 'token_type_ids' in inputs:
|
| 130 |
+
del inputs['token_type_ids']
|
| 131 |
+
|
| 132 |
+
with torch.no_grad():
|
| 133 |
+
outputs = model.generate(
|
| 134 |
+
**inputs,
|
| 135 |
+
max_length=1024,
|
| 136 |
+
num_beams=5,
|
| 137 |
+
early_stopping=True,
|
| 138 |
+
do_sample=False,
|
| 139 |
+
no_repeat_ngram_size=3,
|
| 140 |
+
forced_bos_token_id=32000,
|
| 141 |
+
forced_eos_token_id=32001,
|
| 142 |
+
length_penalty=1.0,
|
| 143 |
+
temperature=1.0
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
corrected = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 147 |
+
corrected = corrected.replace("</s>", "").replace("<2km>", "").replace("▂", " ").strip()
|
| 148 |
+
|
| 149 |
+
return corrected
|
| 150 |
+
|
| 151 |
+
# Header
|
| 152 |
+
st.title("✍️ Khmer Homophone Corrector")
|
| 153 |
+
|
| 154 |
+
# Simple instruction
|
| 155 |
+
st.markdown("Type or paste your Khmer text below to correct homophones.")
|
| 156 |
+
|
| 157 |
+
# Create two columns for input and output
|
| 158 |
+
col1, col2 = st.columns(2)
|
| 159 |
+
|
| 160 |
+
with col1:
|
| 161 |
+
st.subheader("Input Text")
|
| 162 |
+
user_input = st.text_area(
|
| 163 |
+
"Enter Khmer text with homophones:",
|
| 164 |
+
height=200,
|
| 165 |
+
placeholder="Type or paste your Khmer text here...",
|
| 166 |
+
key="input_text"
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
correct_button = st.button("🔄 Correct Text", type="primary", use_container_width=True)
|
| 170 |
+
|
| 171 |
+
with col2:
|
| 172 |
+
st.subheader("Results")
|
| 173 |
+
if correct_button and user_input:
|
| 174 |
+
with st.spinner("Processing..."):
|
| 175 |
+
try:
|
| 176 |
+
# Load model
|
| 177 |
+
model_components = load_model(MODEL_CONFIG["path"])
|
| 178 |
+
|
| 179 |
+
# Process the text
|
| 180 |
+
corrected = process_text(user_input, model_components)
|
| 181 |
+
|
| 182 |
+
# Find corrections
|
| 183 |
+
corrections = find_corrections(user_input, corrected)
|
| 184 |
+
|
| 185 |
+
# Display results
|
| 186 |
+
st.markdown("**Corrected Text:**")
|
| 187 |
+
st.markdown(f'<div class="result-text">{corrected}</div>', unsafe_allow_html=True)
|
| 188 |
+
|
| 189 |
+
# Show corrections if any were made
|
| 190 |
+
if corrections:
|
| 191 |
+
st.success(f"Found {len(corrections)} corrections!")
|
| 192 |
+
st.markdown("**Corrections made:**")
|
| 193 |
+
for i, correction in enumerate(corrections, 1):
|
| 194 |
+
st.markdown(f"""
|
| 195 |
+
<div class="correction-details">
|
| 196 |
+
{i}. Changed "{correction['original']}" to "{correction['corrected']}"
|
| 197 |
+
</div>
|
| 198 |
+
""", unsafe_allow_html=True)
|
| 199 |
+
else:
|
| 200 |
+
st.warning("No corrections were made.")
|
| 201 |
+
except Exception as e:
|
| 202 |
+
st.error(f"An error occurred: {str(e)}")
|
| 203 |
+
elif correct_button:
|
| 204 |
+
st.warning("Please enter text first!")
|
| 205 |
+
|
| 206 |
+
# Footer
|
| 207 |
+
st.markdown("---")
|
| 208 |
+
st.markdown("""
|
| 209 |
+
<div style='text-align: center; padding: 10px;'>
|
| 210 |
+
<a href='https://sites.google.com/paragoniu.edu.kh/khmerhomophonecorrector/home'
|
| 211 |
+
target='_blank'
|
| 212 |
+
style='text-decoration: none; color: #1f77b4; font-size: 16px;'>
|
| 213 |
+
📚 Learn more about this project
|
| 214 |
+
</a>
|
| 215 |
+
</div>
|
| 216 |
+
""", unsafe_allow_html=True)
|
khmerhomophonecorrector/batch_size_impact.png
ADDED

|
Git LFS Details
|
khmerhomophonecorrector/data/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
khmerhomophonecorrector/data/test.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
khmerhomophonecorrector/data/train.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a7d1f07ca76eb9e270b523e5ccd476f348d996c68d94a7c050c9313ea5b43834
|
| 3 |
+
size 25445389
|
khmerhomophonecorrector/data/val.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
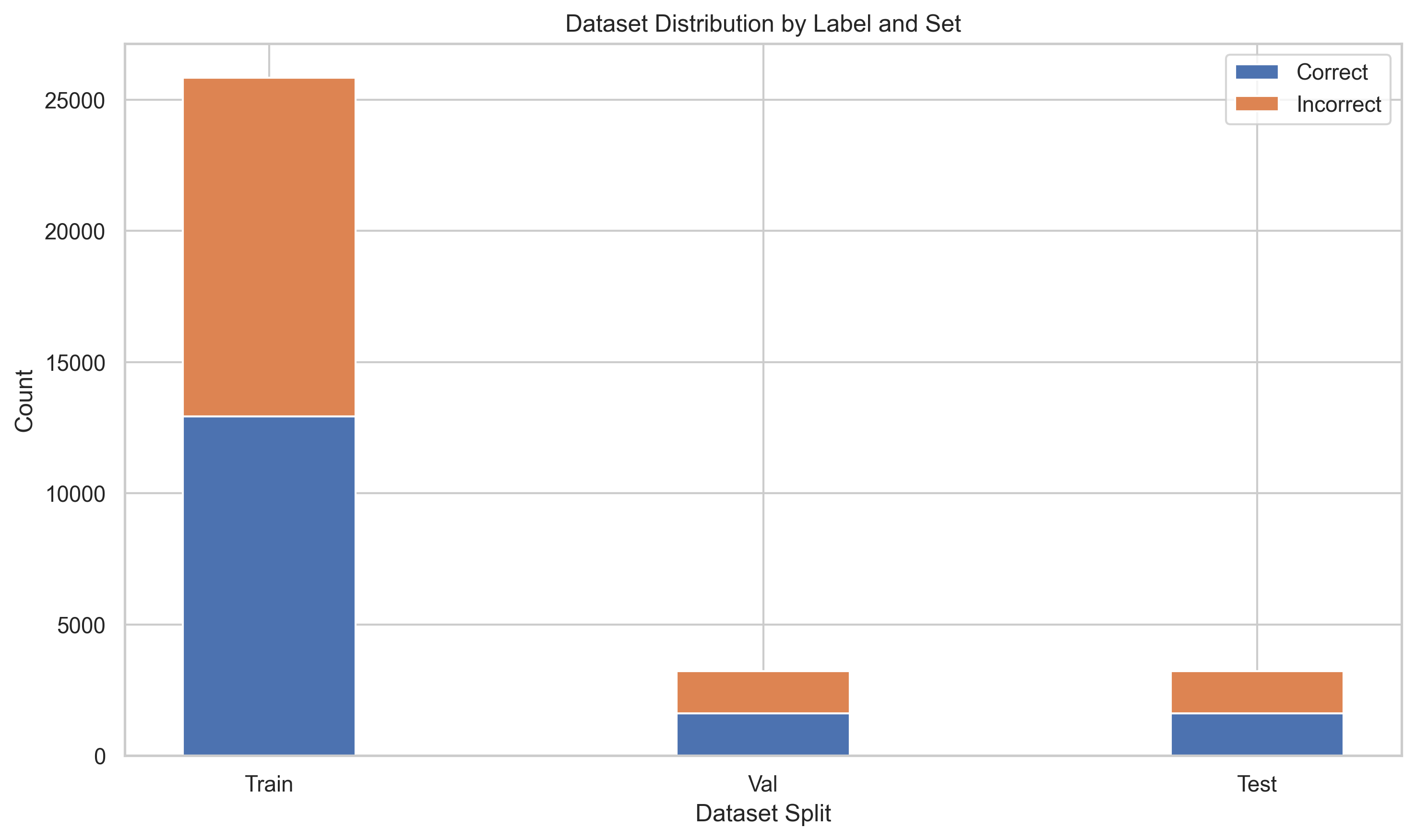
khmerhomophonecorrector/dataset_distribution.png
ADDED
|
khmerhomophonecorrector/header.png
ADDED

|
Git LFS Details
|
khmerhomophonecorrector/homophone_pairs.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f1b62ec06518733f86834a18e229ed67dc0491f0074b9acfbfce96d71033162
|
| 3 |
+
size 32176015
|
khmerhomophonecorrector/homophone_test.json
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"homophones": [
|
| 3 |
+
["ក", "ក៏", "ករ", "ករណ៍"],
|
| 4 |
+
["កល", "កល់"],
|
| 5 |
+
["កាប់", "កប្ប"],
|
| 6 |
+
["កាប", "កាព្យ"],
|
| 7 |
+
["កូត", "កូដ"],
|
| 8 |
+
["កាំ", "កម្ម"],
|
| 9 |
+
["កេះ", "កែះ", "កេស", "កែស"],
|
| 10 |
+
["ក្រិត", "ក្រឹត្យ", "ក្រឹត", "ក្រិដ្ឋ"],
|
| 11 |
+
["កាណ៌", "ការណ៍", "ការ្យ"],
|
| 12 |
+
["ក្លា", "ខ្លា"],
|
| 13 |
+
["កាន់", "កណ្ឌ"],
|
| 14 |
+
["កួរ", "គួរ"],
|
| 15 |
+
["កេរ", "កេរ្តិ៍", "គេ", "គែ", "គេហ៍"],
|
| 16 |
+
["ក្មួយ", "ខ្មួយ"],
|
| 17 |
+
["ក្លាស់", "ខ្លះ"],
|
| 18 |
+
["ក្លែង", "ខ្លែង"],
|
| 19 |
+
["ក្រាស", "ក្រាស់"],
|
| 20 |
+
["ក្រិស", "ក្រេស"],
|
| 21 |
+
["កំពង់", "កំពុង"],
|
| 22 |
+
["ក្រំ", "ក្រម", "គ្រាំ"],
|
| 23 |
+
["ក្រួស", "គ្រោះ"],
|
| 24 |
+
["កោន", "កោណ"],
|
| 25 |
+
["កោត", "កោដ្ឋ", "កោដិ"],
|
| 26 |
+
["កុះ", "កោស", "កូស"],
|
| 27 |
+
["កន្លះ", "កន្លាស់"],
|
| 28 |
+
["ខ្ចប់", "ខ្ជាប់"],
|
| 29 |
+
["ខន្ធ", "ខ័ន", "ខាន់", "ខណ្ឌ"],
|
| 30 |
+
["ខុរ", "ខុល"],
|
| 31 |
+
["ខ្វេះ", "ខ្វែះ"],
|
| 32 |
+
["ខែត្រ", "ខេត្ត"],
|
| 33 |
+
["គន់", "គន្ធ", "គុន", "គុណ", "គណ"],
|
| 34 |
+
["គត", "គត់", "គុត"],
|
| 35 |
+
["គប់", "គុប"],
|
| 36 |
+
["គល់", "គុល", "គឹល"],
|
| 37 |
+
["គាថា", "កថា"],
|
| 38 |
+
["គុំ", "គំ", "គុម្ព", "គមន៏", "គម"],
|
| 39 |
+
["គូថ", "គូទ", "គូធ"],
|
| 40 |
+
["គ្រា", "គ្រាហ៍"],
|
| 41 |
+
["គ្រំ", "គ្រុំ", "គ្រុម"],
|
| 42 |
+
["រងំ", "រងុំ"],
|
| 43 |
+
["ចរណ៍", "ជ័រ"],
|
| 44 |
+
["ចប់", "ជាប់", "ចប"],
|
| 45 |
+
["ចារ", "ចារុ៍"],
|
| 46 |
+
["ចារិក", "ចារឹក", "ចរិត"],
|
| 47 |
+
["ចាក់", "ចក្រ", "ចក្ក"],
|
| 48 |
+
["ច័ន", "ចាន់", "ចណ្ឌ", "ចន្ទ", "ចន្រ្ទ", "ចន្ទន៍"],
|
| 49 |
+
["ចិត", "ចិត្ត", "ចិត្រ្ត"],
|
| 50 |
+
["ចិក", "ចឹក"],
|
| 51 |
+
["ចូរ", "ចូល", "ចូឡ"],
|
| 52 |
+
["ចេះ", "ចេស", "ចែស", "ជែះ", "ជេះ", "ជេស្ឋ"],
|
| 53 |
+
["ច្នៃ", "ឆ្នៃ"],
|
| 54 |
+
["ច្រែស", "ច្រេះ", "ច្រេស", "ច្រែះ"],
|
| 55 |
+
["ច្រាស", "ច្រាស់"],
|
| 56 |
+
["ច្រោះ", "ច្រស"],
|
| 57 |
+
["ច្រៀង", "ជ្រៀង"],
|
| 58 |
+
["ចោទ", "ចោត"],
|
| 59 |
+
["ចំណោត", "ចំណោទ"],
|
| 60 |
+
["ឆន្ទ", "ឆាន់"],
|
| 61 |
+
["ឆ្វេង", "ឈ្វេង"],
|
| 62 |
+
["ជង", "ជង់", "ជង្ឃ"],
|
| 63 |
+
["ជច់", "ជុច"],
|
| 64 |
+
["ជល", "ជល់", "ជុល"],
|
| 65 |
+
["ជន់", "ជន", "ជន្ម"],
|
| 66 |
+
["ជីរ", "ជី", "ជីវ៍"],
|
| 67 |
+
["ជីប", "ជីព"],
|
| 68 |
+
["ជប", "ជប់"],
|
| 69 |
+
["ជួស", "ជោះ"],
|
| 70 |
+
["ជំនួស", "ជំនោះ"],
|
| 71 |
+
["ជំនំ", "ជំនុំ"],
|
| 72 |
+
["ជោក", "ជោគ"],
|
| 73 |
+
["ជំ", "ជុំ"],
|
| 74 |
+
["ជំរំ", "ជុំរុំ"],
|
| 75 |
+
["ជ្រង", "ជ្រោង"],
|
| 76 |
+
["ជ្រង់", "ជ្រុង"],
|
| 77 |
+
["ជ្រួយ", "ជ្រោយ"],
|
| 78 |
+
["ជ្រួស", "ជ្រោះ"],
|
| 79 |
+
["ឈឹង", "ឆឹង"],
|
| 80 |
+
["ញុះ", "ញោះ", "ញោស"],
|
| 81 |
+
["ដ", "ដរ", "ដ៏"],
|
| 82 |
+
["ដប", "ដប់"],
|
| 83 |
+
["ដា", "ដារ"],
|
| 84 |
+
["ដាស", "ដាស់"],
|
| 85 |
+
["ដុះ", "ដុស"],
|
| 86 |
+
["ណ៎ះ", "ណាស់"],
|
| 87 |
+
["ត្រប់", "ទ្រាប់", "ទ្រព្យ"],
|
| 88 |
+
["ត្លុក", "ថ្លុក"],
|
| 89 |
+
["តិះ", "តេះ", "តេស្ត"],
|
| 90 |
+
["ត្រិះ", "ត្រែះ", "ត្រេះ"],
|
| 91 |
+
["ទង់", "ទុង"],
|
| 92 |
+
["ទប់", "ទព្វ"],
|
| 93 |
+
["ទល់", "ទុល"],
|
| 94 |
+
["ទាល់", "ទ័ល"],
|
| 95 |
+
["ទន់", "ទុន"],
|
| 96 |
+
["ទន្ត", "ទណ្ឌ", "ទាន់"],
|
| 97 |
+
["ទា", "ទារ"],
|
| 98 |
+
["ទិច", "ទិត្យ", "តិច"],
|
| 99 |
+
["ទំ", "ទុំ", "ទម"],
|
| 100 |
+
["ទុក", "ទុក្ខ"],
|
| 101 |
+
["ទូ", "ទូរ"],
|
| 102 |
+
["ទាប", "ទៀប", "តៀប"],
|
| 103 |
+
["ទិញ", "ទេញ"],
|
| 104 |
+
["ទៃ", "ទេយ្យ", "ទ័យ"],
|
| 105 |
+
["ទេស", "ទេសន៍", "ទែះ"],
|
| 106 |
+
["ទោះ", "ទស", "ទស់", "ទស្សន៍"],
|
| 107 |
+
["ទោ", "ទោរ"],
|
| 108 |
+
["ទ្រង់", "ទ្រុង"],
|
| 109 |
+
["ធន", "ធន់", "ធុន"],
|
| 110 |
+
["ធំ", "ធុំ"],
|
| 111 |
+
["ធុញ", "ធញ្ញ"],
|
| 112 |
+
["នប់", "នព្វ"],
|
| 113 |
+
["និង", "នឹង", "ហ្នឹង"],
|
| 114 |
+
["នោះ", "នុះ", "នុ៎ះ"],
|
| 115 |
+
["នៅ", "នូវ"],
|
| 116 |
+
["នាក់", "អ្នក"],
|
| 117 |
+
["នាដ", "នាថ"],
|
| 118 |
+
["នរនាថ", "នរនាទ"],
|
| 119 |
+
["នាល", "នាឡិ"],
|
| 120 |
+
["និមិត្ត", "និមិ្មត"],
|
| 121 |
+
["នៃ", "ន័យ", "នី"],
|
| 122 |
+
["បក្ខ", "បក្ស", "ប៉ាក់"],
|
| 123 |
+
["បញ្ចប់", "បញ្ជាប់"],
|
| 124 |
+
["បណ្ឌិត", "បណ្ឌិត្យ"],
|
| 125 |
+
["បាត់", "បត្រ", "បត្ត", "បត្តិ", "ប័តន៍", "ប័ត", "ប័ទ"],
|
| 126 |
+
["បត់", "បទ", "ប័ទ្ម", "បដ", "បថ"],
|
| 127 |
+
["បន្ទំ", "បន្ទុំ"],
|
| 128 |
+
["បាទ", "បាត", "បាត្រ"],
|
| 129 |
+
["បិណ្ឌ", "បិន"],
|
| 130 |
+
["បាស", "បះ"],
|
| 131 |
+
["បុះ", "បុស្ស", "បូស", "បុស្ប"],
|
| 132 |
+
["បិត", "បិទ"],
|
| 133 |
+
["បូ", "បូព៌", "បូណ៌"],
|
| 134 |
+
["បរិបូរ", "បរិបូរណ៍", "បរិបូរណ៌"],
|
| 135 |
+
["បម្រះ", "បម្រាស", "បម្រាស់"],
|
| 136 |
+
["ប្រី", "ប្រិយ"],
|
| 137 |
+
["ប្រឹស", "ប្រឹះ", "ប្រឹស្ឋ", "ប្រើស"],
|
| 138 |
+
["ប្រសិទ្ធ", "ប្រសិទ្ធិ័"],
|
| 139 |
+
["ប្រសូត", "ប្រសូតិ"],
|
| 140 |
+
["ប្រុស", "ប្រុះ"],
|
| 141 |
+
["ប្រួញ", "ព្រួញ"],
|
| 142 |
+
["ប្រួល", "ព្រួល"],
|
| 143 |
+
["ប្រះ", "ប្រាស", "ប្រាស់"],
|
| 144 |
+
["ប្រមាថ", "ប្រមាទ"],
|
| 145 |
+
["អប្រមាថ", "អប្រមាទ"],
|
| 146 |
+
["ប្រៀប", "ព្រៀប", "ព្រាប"],
|
| 147 |
+
["ប្រោះ", "ប្រស់", "ប្រស", "ប្រោស"],
|
| 148 |
+
["ប្រសប់", "ប្រសព្វ"],
|
| 149 |
+
["ប្រេះ", "ប្រែះ"],
|
| 150 |
+
["ប្លៀក", "ភ្លៀក", "ផ្លៀក"],
|
| 151 |
+
["ពន្លត់", "ពន្លុត"],
|
| 152 |
+
["ពាត", "ពាធ", "ពាទ្យ"],
|
| 153 |
+
["ពារ", "ពៀរ"],
|
| 154 |
+
["ព្រាង", "ព្រៀង"],
|
| 155 |
+
["ពិន", "ពិណ", "បុិន"],
|
| 156 |
+
["ពៃ", "ពៃរ៏"],
|
| 157 |
+
["ពេចន៍", "ពេជ្ឈ", "ពេជ្រ", "ពេច", "ពិច"],
|
| 158 |
+
["ពង់", "ពង្ស", "ពុង"],
|
| 159 |
+
["ព័ទ្ធ", "ព៌ត", "ពត្តិ", "ពាត់", "ព័ត"],
|
| 160 |
+
["ពុត", "ពុធ", "ពុទ្ធ", "ពត់"],
|
| 161 |
+
["ពន់", "ពុន", "ពន្ធ"],
|
| 162 |
+
["ព័ន្ធ", "ពាន់"],
|
| 163 |
+
["ពល", "ពល់", "ពុល"],
|
| 164 |
+
["ពស់", "ពោះ"],
|
| 165 |
+
["ពព្រុស", "ពព្រូស"],
|
| 166 |
+
["ពោរ", "ពោធិ៍", "ពោធិ", "ពោ"],
|
| 167 |
+
["ព្រិច", "ព្រេច"],
|
| 168 |
+
["ព្រិល", "ព្រឹល"],
|
| 169 |
+
["ព្រឹត្ត", "ព្រឹត្តិ", "ព្រឹទ្ធ"],
|
| 170 |
+
["ព្រុស", "ព្រួស"],
|
| 171 |
+
["ព្រួស", "ព្រោះ"],
|
| 172 |
+
["ព្រំ", "ព្រហ្ម"],
|
| 173 |
+
["ព្រឹក", "ព្រឹក្ស"],
|
| 174 |
+
["ព្រឹក្សា", "ប្រឹក្សា"],
|
| 175 |
+
["ភប់", "ភព"],
|
| 176 |
+
["ភក្តិ", "ភ័ក", "ភក្រ្ត", "ភ័គ", "ភក្ស"],
|
| 177 |
+
["ភាន់", "ភ័ន្ត", "ភ័ណ្ឌ", "ភ័ណ"],
|
| 178 |
+
["មិត្ត", "មិទ្ធៈ", "មឹត"],
|
| 179 |
+
["មួ", "មួរ"],
|
| 180 |
+
["ម៉ដ្ធ", "ម៉ត់"],
|
| 181 |
+
["ម្រាក់", "ម្រ័ក្សណ៍"],
|
| 182 |
+
["យន់", "យន្ត", "យ័ន្ត", "យ័ន"],
|
| 183 |
+
["រង់", "រុង", "រង្គ", "រង"],
|
| 184 |
+
["រថ", "រដ្ឋ", "រត្ន", "រាត់"],
|
| 185 |
+
["រា", "រាហុ៍"],
|
| 186 |
+
["រាក", "រាគ"],
|
| 187 |
+
["រាក់", "រក្ស", "រ័ក"],
|
| 188 |
+
["រាច", "រាជ", "រាជ្យ"],
|
| 189 |
+
["រាម", "រៀម"],
|
| 190 |
+
["រស", "រស់", "រួស", "រោះ"],
|
| 191 |
+
["រាស់", "រ៉ស់"],
|
| 192 |
+
["រុិល", "រឹល"],
|
| 193 |
+
["រុក", "រុក្ខ"],
|
| 194 |
+
["រុត", "រុទ្ធ", "រុត្តិ"],
|
| 195 |
+
["រុះ", "រូស"],
|
| 196 |
+
["រំ", "រុំ", "រម្យ"],
|
| 197 |
+
["រំលិច", "រំលេច"],
|
| 198 |
+
["រោច", "រោចន៍"],
|
| 199 |
+
["របោះ", "របស់"],
|
| 200 |
+
["រឹង", "រុឹង"],
|
| 201 |
+
["រាំ", "រម្មណ៍"],
|
| 202 |
+
["រៀបរប", "រៀបរាប់"],
|
| 203 |
+
["លក់", "ល័ក្ត", "លក្ខណ៍", "ល័ក្ខ", "លក្ម្សណ៍"],
|
| 204 |
+
["លាប", "លាភ", "លៀប"],
|
| 205 |
+
["លង់", "លុង"],
|
| 206 |
+
["លន់", "លុន"],
|
| 207 |
+
["លប់", "លុប"],
|
| 208 |
+
["លោះ", "លស់", "លួស"],
|
| 209 |
+
["លិច", "លេច"],
|
| 210 |
+
["លាង", "លៀង"],
|
| 211 |
+
["លុត", "លត់", "លុត្ត"],
|
| 212 |
+
["លាប់", "ឡប់"],
|
| 213 |
+
["លិទ្ធ", "លិឍ", "លិត"],
|
| 214 |
+
["លួង", "ហ្លួង"],
|
| 215 |
+
["លេស", "លេះ"],
|
| 216 |
+
["ល្បះ", "ល្បាស់"],
|
| 217 |
+
["វង់", "វង្ស"],
|
| 218 |
+
["វន្ត", "វ័ន", "វាន់"],
|
| 219 |
+
["វត្ត", "វត្ស", "វ័ធ", "វត្ថ", "វដ្ត", "វឌ្ឍន៍", "វាត់", "វត្តន៍"],
|
| 220 |
+
["វ័យ", "វៃ", "វាយ", "វ៉ៃ"],
|
| 221 |
+
["វាត", "វាទ"],
|
| 222 |
+
["វិច", "វេច", "វេជ្ជ", "វេច្ច"],
|
| 223 |
+
["វិញ", "វេញ"],
|
| 224 |
+
["វាច", "វៀច"],
|
| 225 |
+
["វាង", "វៀង"],
|
| 226 |
+
["វាល", "វៀល"],
|
| 227 |
+
["សង់", "សង្ឃ"],
|
| 228 |
+
["ស័ក", "ស័ក្តិ", "សក្យ", "សគ្គ", "សគ៌ៈ"],
|
| 229 |
+
["ស័ង្ខ", "សាំង"],
|
| 230 |
+
["សស្ត្រា", "សាស្ត្រា"],
|
| 231 |
+
["សត្វ", "សត", "សត្យ", "សាត់"],
|
| 232 |
+
["សប្ត", "សព្ទ", "សាប់", "សប្ប"],
|
| 233 |
+
["សប", "សប់", "សព្វ", "សព", "សប្តិ"],
|
| 234 |
+
["សាសន៍", "សស្ត្រ", "សះ"],
|
| 235 |
+
["សិត", "សិទ្ធ", "សិទ្ធិ"],
|
| 236 |
+
["សិង", "សិង្ហ", "សឹង", "សុឹង"],
|
| 237 |
+
["សុក", "សុក្ក", "សុខ", "សុក្រ"],
|
| 238 |
+
["សិរ", "សិរ្ស", "សេ", "សេរ"],
|
| 239 |
+
["សូ", "សូរ", "សូរ្យ", "សូល៍"],
|
| 240 |
+
["សូទ", "សូត", "សូត្រ", "សូធ្យ", "សូទ្រ"],
|
| 241 |
+
["សូន", "សូន្យ"],
|
| 242 |
+
["សូម", "សុំ"],
|
| 243 |
+
["សួ", "សួរ", "សួគ៌"],
|
| 244 |
+
["សេដ្ធ", "សេត"],
|
| 245 |
+
["សោត", "សោធ", "សោធន៍"],
|
| 246 |
+
["សំ", "សម"],
|
| 247 |
+
["សម្បត្តិ", "សម្ប័ទ"],
|
| 248 |
+
["សម្បូរ", "សម្បូណ៍"],
|
| 249 |
+
["សម្រិត", "សំរឹទ្ធ"],
|
| 250 |
+
["សមិត", "សមិតិ", "សមិទ្ធ", "សមិទ្ធិ"],
|
| 251 |
+
["ស្និត", "ស្និទ្ធ"],
|
| 252 |
+
["ស្រស", "ស្រស់"],
|
| 253 |
+
["ស្រុះ", "ស្រុស"],
|
| 254 |
+
["ស្រះ", "ស្រាស់"],
|
| 255 |
+
["ស្លេះ", "ស្លេស្ម"],
|
| 256 |
+
["សេស", "សេះ"],
|
| 257 |
+
["ហត្ថ", "ហាត់"],
|
| 258 |
+
["ហស", "ហស្ត", "ហស្ថ", "ហោះ", "ហស្បតិ៍"],
|
| 259 |
+
["ហាស", "ហ័ស", "ហស្ស"],
|
| 260 |
+
["ហោង", "ហង"],
|
| 261 |
+
["អក", "អករ៍"],
|
| 262 |
+
["អ័ក្ស", "អាក់"],
|
| 263 |
+
["អង់", "អង្គ", "អង"],
|
| 264 |
+
["អដ្ឋ", "អត្ថ", "អឌ្ឍ", "អត្ត", "អាត់"],
|
| 265 |
+
["អន់", "អន្ធ"],
|
| 266 |
+
["អាចារ", "អាចារ្យ"],
|
| 267 |
+
["អាថ៌", "អាទិ"],
|
| 268 |
+
["អាប់", "អប្ប", "អ័ព្ទ"],
|
| 269 |
+
["អារម្មណ៍", "អារម្ភ"],
|
| 270 |
+
["ឥត", "ឥដ្ឋ", "ឥទ្ធិ"]
|
| 271 |
+
]
|
| 272 |
+
}
|
khmerhomophonecorrector/infer_from_json.py
ADDED
|
@@ -0,0 +1,270 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
|
| 3 |
+
from khmernltk import word_tokenize
|
| 4 |
+
import json
|
| 5 |
+
import time
|
| 6 |
+
import argparse
|
| 7 |
+
import os
|
| 8 |
+
from datetime import datetime
|
| 9 |
+
import random
|
| 10 |
+
import re
|
| 11 |
+
from collections import defaultdict
|
| 12 |
+
|
| 13 |
+
def normalize_text(text):
|
| 14 |
+
# Remove all spaces and special markers
|
| 15 |
+
text = re.sub(r'\s+', '', text)
|
| 16 |
+
text = re.sub(r'[«»]', '', text)
|
| 17 |
+
return text
|
| 18 |
+
|
| 19 |
+
def word_segment(text):
|
| 20 |
+
return " ".join(word_tokenize(text)).replace(" ", " ▂ ")
|
| 21 |
+
|
| 22 |
+
def format_output(text):
|
| 23 |
+
"""Format text with proper Unicode handling"""
|
| 24 |
+
return text.replace("</s>", "").replace("<2km>", "").replace("▂", " ").strip()
|
| 25 |
+
|
| 26 |
+
def load_homophone_groups(homophone_json):
|
| 27 |
+
with open(homophone_json, 'r', encoding='utf-8') as f:
|
| 28 |
+
data = json.load(f)
|
| 29 |
+
groups = []
|
| 30 |
+
for group in data['homophones']:
|
| 31 |
+
groups.append([normalize_text(word) for word in group])
|
| 32 |
+
return groups
|
| 33 |
+
|
| 34 |
+
def find_homophones_in_sentence(sentence, homophone_groups):
|
| 35 |
+
found = []
|
| 36 |
+
for group in homophone_groups:
|
| 37 |
+
for word in group:
|
| 38 |
+
if word in sentence:
|
| 39 |
+
found.append((word, group))
|
| 40 |
+
break # Only count the first found from the group
|
| 41 |
+
return found
|
| 42 |
+
|
| 43 |
+
def analyze_homophone_changes(input_text, output_text, homophone_groups):
|
| 44 |
+
input_norm = normalize_text(input_text)
|
| 45 |
+
output_norm = normalize_text(output_text)
|
| 46 |
+
|
| 47 |
+
# Find homophones in input sentence
|
| 48 |
+
input_homophones = find_homophones_in_sentence(input_norm, homophone_groups)
|
| 49 |
+
|
| 50 |
+
if not input_homophones:
|
| 51 |
+
return None, [] # No homophones found
|
| 52 |
+
|
| 53 |
+
# Track replacements
|
| 54 |
+
replacements = []
|
| 55 |
+
all_correct = True
|
| 56 |
+
|
| 57 |
+
for word, group in input_homophones:
|
| 58 |
+
# Check if the word was replaced with a different homophone
|
| 59 |
+
if word in output_norm:
|
| 60 |
+
# Don't add unchanged words to replacements
|
| 61 |
+
continue
|
| 62 |
+
else:
|
| 63 |
+
# Find which homophone from the group was used
|
| 64 |
+
replacement = None
|
| 65 |
+
for alt_word in group:
|
| 66 |
+
if alt_word in output_norm:
|
| 67 |
+
replacement = alt_word
|
| 68 |
+
break
|
| 69 |
+
|
| 70 |
+
if replacement:
|
| 71 |
+
replacements.append(f"'{word}' → '{replacement}'")
|
| 72 |
+
# If the replacement is from the same homophone group, it's correct
|
| 73 |
+
if replacement in group:
|
| 74 |
+
continue # This is a correct replacement
|
| 75 |
+
else:
|
| 76 |
+
all_correct = False
|
| 77 |
+
else:
|
| 78 |
+
replacements.append(f"'{word}' (missing in output)")
|
| 79 |
+
all_correct = False
|
| 80 |
+
|
| 81 |
+
# If there are no replacements, return None to indicate no changes
|
| 82 |
+
if not replacements:
|
| 83 |
+
return None, []
|
| 84 |
+
|
| 85 |
+
return all_correct, replacements
|
| 86 |
+
|
| 87 |
+
def process_text(text, model, tokenizer, device):
|
| 88 |
+
"""Process a single text input"""
|
| 89 |
+
# Word segment the input text
|
| 90 |
+
segmented_text = word_segment(text)
|
| 91 |
+
input_text = f"{segmented_text} </s> <2km>"
|
| 92 |
+
|
| 93 |
+
# Encode input
|
| 94 |
+
inputs = tokenizer(
|
| 95 |
+
input_text,
|
| 96 |
+
return_tensors="pt",
|
| 97 |
+
padding=True,
|
| 98 |
+
truncation=True,
|
| 99 |
+
max_length=512,
|
| 100 |
+
add_special_tokens=True,
|
| 101 |
+
return_token_type_ids=False
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# Move inputs to device
|
| 105 |
+
inputs = {k: v.to(device) for k, v in inputs.items()}
|
| 106 |
+
|
| 107 |
+
# Generate
|
| 108 |
+
with torch.no_grad():
|
| 109 |
+
outputs = model.generate(
|
| 110 |
+
**inputs,
|
| 111 |
+
max_length=512,
|
| 112 |
+
num_beams=3,
|
| 113 |
+
early_stopping=True,
|
| 114 |
+
do_sample=False,
|
| 115 |
+
no_repeat_ngram_size=2,
|
| 116 |
+
forced_bos_token_id=32000,
|
| 117 |
+
forced_eos_token_id=32001,
|
| 118 |
+
length_penalty=0.8,
|
| 119 |
+
temperature=1.0
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
# Decode and format output
|
| 123 |
+
corrected = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 124 |
+
return format_output(corrected)
|
| 125 |
+
|
| 126 |
+
def process_json_file(json_file, output_file, model, tokenizer, device, homophone_groups):
|
| 127 |
+
"""Process sentences from JSON file and save results"""
|
| 128 |
+
print(f"Loading data from: {json_file}")
|
| 129 |
+
|
| 130 |
+
# Read JSON file
|
| 131 |
+
with open(json_file, 'r', encoding='utf-8') as f:
|
| 132 |
+
data = json.load(f)
|
| 133 |
+
|
| 134 |
+
# Extract sentences from the JSON structure
|
| 135 |
+
sentences = []
|
| 136 |
+
if isinstance(data, dict) and "homophones" in data:
|
| 137 |
+
# Handle homophone_test.json format
|
| 138 |
+
for homophone_group in data["homophones"]:
|
| 139 |
+
for word in homophone_group:
|
| 140 |
+
sentences.append(word)
|
| 141 |
+
elif isinstance(data, list):
|
| 142 |
+
# Handle test.json format (list of dicts with 'input' key)
|
| 143 |
+
if all(isinstance(item, dict) and 'input' in item for item in data):
|
| 144 |
+
sentences = [item['input'].strip() for item in data if item.get('input', '').strip()]
|
| 145 |
+
else:
|
| 146 |
+
sentences = [str(text).strip() for text in data if str(text).strip()]
|
| 147 |
+
else:
|
| 148 |
+
# Handle dictionary format
|
| 149 |
+
for char, text_list in data.items():
|
| 150 |
+
for text in text_list:
|
| 151 |
+
# Clean up the text (remove quotes and extra spaces)
|
| 152 |
+
text = text.strip('«»').strip()
|
| 153 |
+
if text:
|
| 154 |
+
sentences.append(text)
|
| 155 |
+
|
| 156 |
+
print(f"Processing {len(sentences)} sentences")
|
| 157 |
+
|
| 158 |
+
# Prepare output file with header
|
| 159 |
+
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
| 160 |
+
with open(output_file, 'w', encoding='utf-8') as f:
|
| 161 |
+
f.write(f"=== Khmer Homophone Correction Results ===\n")
|
| 162 |
+
f.write(f"Generated on: {timestamp}\n")
|
| 163 |
+
f.write(f"Input file: {json_file}\n")
|
| 164 |
+
f.write(f"Model: prahokbart-big-bs32-e40\n")
|
| 165 |
+
f.write("=" * 50 + "\n\n")
|
| 166 |
+
|
| 167 |
+
total_time = 0
|
| 168 |
+
processed_lines = 0
|
| 169 |
+
total_analyzed = 0
|
| 170 |
+
total_corrected = 0
|
| 171 |
+
total_unchanged = 0
|
| 172 |
+
total_incorrect = 0
|
| 173 |
+
|
| 174 |
+
# Process each sentence
|
| 175 |
+
for i, sentence in enumerate(sentences, 1):
|
| 176 |
+
print(f"Processing sentence {i}/{len(sentences)}")
|
| 177 |
+
|
| 178 |
+
start_time = time.time()
|
| 179 |
+
output = process_text(sentence, model, tokenizer, device)
|
| 180 |
+
process_time = time.time() - start_time
|
| 181 |
+
total_time += process_time
|
| 182 |
+
processed_lines += 1
|
| 183 |
+
|
| 184 |
+
# Analyze homophone changes
|
| 185 |
+
is_correct, replacements = analyze_homophone_changes(sentence, output, homophone_groups)
|
| 186 |
+
|
| 187 |
+
# Save to output file
|
| 188 |
+
with open(output_file, 'a', encoding='utf-8') as f:
|
| 189 |
+
f.write(f"\n=== Sentence {i} ===\n")
|
| 190 |
+
f.write(f"Input: {sentence}\n")
|
| 191 |
+
f.write(f"Corrected: {output}\n")
|
| 192 |
+
|
| 193 |
+
if replacements:
|
| 194 |
+
f.write("Changes: " + ", ".join(replacements) + "\n")
|
| 195 |
+
f.write(f"Status: {'✓ Correctly corrected' if is_correct else '✗ Incorrect correction'}\n")
|
| 196 |
+
total_analyzed += 1
|
| 197 |
+
if is_correct:
|
| 198 |
+
total_corrected += 1
|
| 199 |
+
else:
|
| 200 |
+
total_incorrect += 1
|
| 201 |
+
else:
|
| 202 |
+
f.write("Status: No changes needed\n")
|
| 203 |
+
total_unchanged += 1
|
| 204 |
+
|
| 205 |
+
f.write("=" * 50 + "\n")
|
| 206 |
+
|
| 207 |
+
# Calculate accuracy
|
| 208 |
+
accuracy = (total_corrected / total_analyzed * 100) if total_analyzed > 0 else 0
|
| 209 |
+
|
| 210 |
+
# Add summary at the end
|
| 211 |
+
with open(output_file, 'a', encoding='utf-8') as f:
|
| 212 |
+
f.write(f"\nSummary:\n")
|
| 213 |
+
f.write(f"Total sentences processed: {processed_lines}\n")
|
| 214 |
+
f.write(f"Sentences needing correction: {total_analyzed}\n")
|
| 215 |
+
f.write(f"Sentences unchanged (no changes needed): {total_unchanged}\n")
|
| 216 |
+
f.write(f"Correctly corrected: {total_corrected}\n")
|
| 217 |
+
f.write(f"Incorrectly corrected: {total_incorrect}\n")
|
| 218 |
+
f.write(f"Accuracy (among sentences needing correction): {accuracy:.2f}%\n")
|
| 219 |
+
f.write(f"Total processing time: {total_time:.2f} seconds\n")
|
| 220 |
+
f.write(f"Average time per sentence: {total_time/processed_lines:.2f} seconds\n")
|
| 221 |
+
|
| 222 |
+
print(f"\nProcessing complete!")
|
| 223 |
+
print(f"Results saved to: {output_file}")
|
| 224 |
+
print(f"Total sentences processed: {processed_lines}")
|
| 225 |
+
print(f"Sentences needing correction: {total_analyzed}")
|
| 226 |
+
print(f"Sentences unchanged: {total_unchanged}")
|
| 227 |
+
print(f"Correctly corrected: {total_corrected}")
|
| 228 |
+
print(f"Incorrectly corrected: {total_incorrect}")
|
| 229 |
+
print(f"Accuracy: {accuracy:.2f}%")
|
| 230 |
+
print(f"Total time: {total_time:.2f} seconds")
|
| 231 |
+
print(f"Average time per sentence: {total_time/processed_lines:.2f} seconds")
|
| 232 |
+
|
| 233 |
+
def main():
|
| 234 |
+
parser = argparse.ArgumentParser(description='Khmer Homophone Corrector - JSON Processing Version')
|
| 235 |
+
parser.add_argument('--model_path', type=str, default='./prahokbart-big-bs32-e40',
|
| 236 |
+
help='Path to the model directory')
|
| 237 |
+
parser.add_argument('--json_file', type=str, default='data/test.json',
|
| 238 |
+
help='Input JSON file containing Khmer text')
|
| 239 |
+
parser.add_argument('--output_file', type=str, default='test_results.txt',
|
| 240 |
+
help='Output file for corrections')
|
| 241 |
+
parser.add_argument('--homophone_file', type=str, default='homophone_test.json',
|
| 242 |
+
help='JSON file containing homophone groups')
|
| 243 |
+
args = parser.parse_args()
|
| 244 |
+
|
| 245 |
+
# Validate input files
|
| 246 |
+
if not os.path.exists(args.json_file):
|
| 247 |
+
print(f"Error: Input file {args.json_file} not found")
|
| 248 |
+
return
|
| 249 |
+
if not os.path.exists(args.homophone_file):
|
| 250 |
+
print(f"Error: Homophone file {args.homophone_file} not found")
|
| 251 |
+
return
|
| 252 |
+
|
| 253 |
+
print("Loading model...")
|
| 254 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(args.model_path)
|
| 255 |
+
tokenizer = AutoTokenizer.from_pretrained(args.model_path)
|
| 256 |
+
|
| 257 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 258 |
+
model = model.to(device)
|
| 259 |
+
model.eval()
|
| 260 |
+
|
| 261 |
+
print(f"Model loaded successfully. Using device: {device}")
|
| 262 |
+
|
| 263 |
+
# Load homophone groups
|
| 264 |
+
homophone_groups = load_homophone_groups(args.homophone_file)
|
| 265 |
+
|
| 266 |
+
# Process the JSON file
|
| 267 |
+
process_json_file(args.json_file, args.output_file, model, tokenizer, device, homophone_groups)
|
| 268 |
+
|
| 269 |
+
if __name__ == "__main__":
|
| 270 |
+
main()
|
khmerhomophonecorrector/khmerhomophonecorrector/added_tokens.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</s>": 32001,
|
| 3 |
+
"<2en>": 32003,
|
| 4 |
+
"<2km>": 32002,
|
| 5 |
+
"<s>": 32000
|
| 6 |
+
}
|
khmerhomophonecorrector/khmerhomophonecorrector/config.json
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"activation_dropout": 0.1,
|
| 3 |
+
"activation_function": "gelu",
|
| 4 |
+
"adaptor_activation_function": "gelu",
|
| 5 |
+
"adaptor_dropout": 0.1,
|
| 6 |
+
"adaptor_hidden_size": 512,
|
| 7 |
+
"adaptor_init_std": 0.02,
|
| 8 |
+
"adaptor_scaling_factor": 1.0,
|
| 9 |
+
"adaptor_tuning": false,
|
| 10 |
+
"additional_source_wait_k": -1,
|
| 11 |
+
"alibi_encoding": false,
|
| 12 |
+
"architectures": [
|
| 13 |
+
"MBartForConditionalGeneration"
|
| 14 |
+
],
|
| 15 |
+
"asymmetric_alibi_encoding": false,
|
| 16 |
+
"attention_dropout": 0.1,
|
| 17 |
+
"bos_token_id": 32000,
|
| 18 |
+
"bottleneck_mid_fusion_tokens": 4,
|
| 19 |
+
"classifier_dropout": 0.0,
|
| 20 |
+
"d_model": 1024,
|
| 21 |
+
"decoder_adaptor_tying_config": null,
|
| 22 |
+
"decoder_attention_heads": 16,
|
| 23 |
+
"decoder_ffn_dim": 4096,
|
| 24 |
+
"decoder_layerdrop": 0.0,
|
| 25 |
+
"decoder_layers": 6,
|
| 26 |
+
"decoder_tying_config": null,
|
| 27 |
+
"deep_adaptor_tuning": false,
|
| 28 |
+
"deep_adaptor_tuning_ffn_only": false,
|
| 29 |
+
"dropout": 0.1,
|
| 30 |
+
"embed_low_rank_dim": 0,
|
| 31 |
+
"encoder_adaptor_tying_config": null,
|
| 32 |
+
"encoder_attention_heads": 16,
|
| 33 |
+
"encoder_ffn_dim": 4096,
|
| 34 |
+
"encoder_layerdrop": 0.0,
|
| 35 |
+
"encoder_layers": 6,
|
| 36 |
+
"encoder_tying_config": null,
|
| 37 |
+
"eos_token_id": 32001,
|
| 38 |
+
"expert_ffn_size": 128,
|
| 39 |
+
"features_embed_dims": null,
|
| 40 |
+
"features_vocab_sizes": null,
|
| 41 |
+
"forced_eos_token_id": 2,
|
| 42 |
+
"gradient_checkpointing": false,
|
| 43 |
+
"gradient_reversal_for_domain_classifier": false,
|
| 44 |
+
"hypercomplex": false,
|
| 45 |
+
"hypercomplex_n": 2,
|
| 46 |
+
"ia3_adaptors": false,
|
| 47 |
+
"init_std": 0.02,
|
| 48 |
+
"initialization_scheme": "static",
|
| 49 |
+
"is_encoder_decoder": true,
|
| 50 |
+
"layernorm_adaptor_input": false,
|
| 51 |
+
"layernorm_prompt_projection": false,
|
| 52 |
+
"lora_adaptor_rank": 2,
|
| 53 |
+
"lora_adaptors": false,
|
| 54 |
+
"max_position_embeddings": 1024,
|
| 55 |
+
"mid_fusion_layers": 3,
|
| 56 |
+
"model_type": "mbart",
|
| 57 |
+
"moe_adaptors": false,
|
| 58 |
+
"multi_source": false,
|
| 59 |
+
"multi_source_method": null,
|
| 60 |
+
"multilayer_softmaxing": null,
|
| 61 |
+
"no_embed_norm": false,
|
| 62 |
+
"no_positional_encoding_decoder": false,
|
| 63 |
+
"no_positional_encoding_encoder": false,
|
| 64 |
+
"no_projection_prompt": false,
|
| 65 |
+
"no_scale_attention_embedding": false,
|
| 66 |
+
"num_domains_for_domain_classifier": 1,
|
| 67 |
+
"num_experts": 8,
|
| 68 |
+
"num_hidden_layers": 6,
|
| 69 |
+
"num_moe_adaptor_experts": 4,
|
| 70 |
+
"num_prompts": 100,
|
| 71 |
+
"num_sparsify_blocks": 8,
|
| 72 |
+
"pad_token_id": 0,
|
| 73 |
+
"parallel_adaptors": false,
|
| 74 |
+
"positional_encodings": false,
|
| 75 |
+
"postnorm_decoder": false,
|
| 76 |
+
"postnorm_encoder": false,
|
| 77 |
+
"prompt_dropout": 0.1,
|
| 78 |
+
"prompt_init_std": 0.02,
|
| 79 |
+
"prompt_projection_hidden_size": 4096,
|
| 80 |
+
"prompt_tuning": false,
|
| 81 |
+
"recurrent_projections": 1,
|
| 82 |
+
"residual_connection_adaptor": false,
|
| 83 |
+
"residual_connection_prompt": false,
|
| 84 |
+
"rope_encoding": false,
|
| 85 |
+
"scale_embedding": false,
|
| 86 |
+
"softmax_bias_tuning": false,
|
| 87 |
+
"softmax_temperature": 1.0,
|
| 88 |
+
"sparsification_temperature": 3.0,
|
| 89 |
+
"sparsify_attention": false,
|
| 90 |
+
"sparsify_ffn": false,
|
| 91 |
+
"target_vocab_size": 0,
|
| 92 |
+
"temperature_calibration": false,
|
| 93 |
+
"tokenizer_class": "AlbertTokenizer",
|
| 94 |
+
"torch_dtype": "float32",
|
| 95 |
+
"transformers_version": "4.52.4",
|
| 96 |
+
"unidirectional_encoder": false,
|
| 97 |
+
"use_cache": true,
|
| 98 |
+
"use_moe": false,
|
| 99 |
+
"use_tanh_activation_prompt": false,
|
| 100 |
+
"vocab_size": 32004,
|
| 101 |
+
"wait_k": -1
|
| 102 |
+
}
|
khmerhomophonecorrector/khmerhomophonecorrector/generation_config.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 32000,
|
| 4 |
+
"eos_token_id": 32001,
|
| 5 |
+
"forced_eos_token_id": 2,
|
| 6 |
+
"pad_token_id": 0,
|
| 7 |
+
"transformers_version": "4.52.4"
|
| 8 |
+
}
|
khmerhomophonecorrector/khmerhomophonecorrector/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:769ca23f42096c9d6b39066783203be73a2e45501f864d012937ab254c71b784
|
| 3 |
+
size 845114336
|
khmerhomophonecorrector/khmerhomophonecorrector/special_tokens_map.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<s>",
|
| 4 |
+
"</s>",
|
| 5 |
+
"<2km>",
|
| 6 |
+
"<2en>"
|
| 7 |
+
],
|
| 8 |
+
"bos_token": "[CLS]",
|
| 9 |
+
"cls_token": "[CLS]",
|
| 10 |
+
"eos_token": "[SEP]",
|
| 11 |
+
"mask_token": {
|
| 12 |
+
"content": "[MASK]",
|
| 13 |
+
"lstrip": true,
|
| 14 |
+
"normalized": true,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false
|
| 17 |
+
},
|
| 18 |
+
"pad_token": "<pad>",
|
| 19 |
+
"sep_token": "[SEP]",
|
| 20 |
+
"unk_token": "<unk>"
|
| 21 |
+
}
|
khmerhomophonecorrector/khmerhomophonecorrector/spiece.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2b052ec9a665776835d69c50d2226e5e55574db8fbbce5563f217cbe18f91d41
|
| 3 |
+
size 783261
|
khmerhomophonecorrector/khmerhomophonecorrector/tokenizer_config.json
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<pad>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<unk>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "[CLS]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"3": {
|
| 28 |
+
"content": "[SEP]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"4": {
|
| 36 |
+
"content": "[MASK]",
|
| 37 |
+
"lstrip": true,
|
| 38 |
+
"normalized": true,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"32000": {
|
| 44 |
+
"content": "<s>",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"32001": {
|
| 52 |
+
"content": "</s>",
|
| 53 |
+
"lstrip": false,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
},
|
| 59 |
+
"32002": {
|
| 60 |
+
"content": "<2km>",
|
| 61 |
+
"lstrip": false,
|
| 62 |
+
"normalized": false,
|
| 63 |
+
"rstrip": false,
|
| 64 |
+
"single_word": false,
|
| 65 |
+
"special": true
|
| 66 |
+
},
|
| 67 |
+
"32003": {
|
| 68 |
+
"content": "<2en>",
|
| 69 |
+
"lstrip": false,
|
| 70 |
+
"normalized": false,
|
| 71 |
+
"rstrip": false,
|
| 72 |
+
"single_word": false,
|
| 73 |
+
"special": true
|
| 74 |
+
}
|
| 75 |
+
},
|
| 76 |
+
"additional_special_tokens": [
|
| 77 |
+
"<s>",
|
| 78 |
+
"</s>",
|
| 79 |
+
"<2km>",
|
| 80 |
+
"<2en>"
|
| 81 |
+
],
|
| 82 |
+
"bos_token": "[CLS]",
|
| 83 |
+
"clean_up_tokenization_spaces": false,
|
| 84 |
+
"cls_token": "[CLS]",
|
| 85 |
+
"do_lower_case": false,
|
| 86 |
+
"eos_token": "[SEP]",
|
| 87 |
+
"extra_special_tokens": {},
|
| 88 |
+
"keep_accents": true,
|
| 89 |
+
"mask_token": "[MASK]",
|
| 90 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 91 |
+
"pad_token": "<pad>",
|
| 92 |
+
"remove_space": true,
|
| 93 |
+
"sep_token": "[SEP]",
|
| 94 |
+
"sp_model_kwargs": {},
|
| 95 |
+
"strip_accents": false,
|
| 96 |
+
"tokenizer_class": "AlbertTokenizer",
|
| 97 |
+
"unk_token": "<unk>",
|
| 98 |
+
"use_fast": false
|
| 99 |
+
}
|
khmerhomophonecorrector/khmerhomophonecorrector/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:52291c446349172438b91dd34e1e8f993856af8b90cf6a3e46e9a38c1a972524
|
| 3 |
+
size 5432
|
khmerhomophonecorrector/khmerhomophonecorrector/training_state.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"completed_epochs": 40, "best_metric": 0.02335953153669834, "checkpoints": ["checkpoint-16160"]}
|
khmerhomophonecorrector/loss_comparison.png
ADDED

|
Git LFS Details
|
khmerhomophonecorrector/metrics_comparison.png
ADDED

|
Git LFS Details
|
khmerhomophonecorrector/model_performance_line_chart.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
khmerhomophonecorrector/model_performance_line_chart.png
ADDED
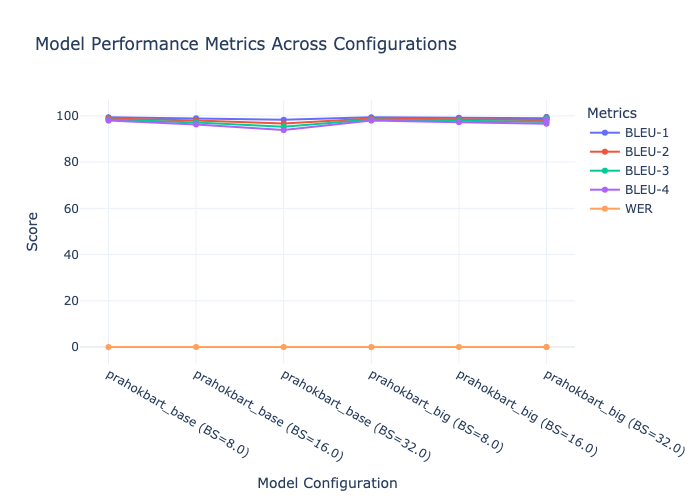
|
khmerhomophonecorrector/model_performance_line_chart_big_bs32_e40.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
khmerhomophonecorrector/model_performance_line_chart_big_bs32_e40.png
ADDED
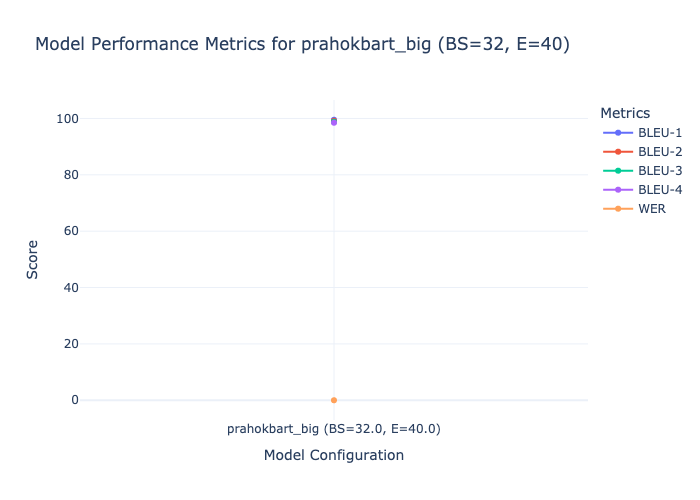
|
khmerhomophonecorrector/model_performance_table.html
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<style type="text/css">
|
| 2 |
+
</style>
|
| 3 |
+
<table id="T_4f546">
|
| 4 |
+
<thead>
|
| 5 |
+
<tr>
|
| 6 |
+
<th class="blank level0" > </th>
|
| 7 |
+
<th id="T_4f546_level0_col0" class="col_heading level0 col0" >Model Config</th>
|
| 8 |
+
<th id="T_4f546_level0_col1" class="col_heading level0 col1" >BLEU-1</th>
|
| 9 |
+
<th id="T_4f546_level0_col2" class="col_heading level0 col2" >BLEU-2</th>
|
| 10 |
+
<th id="T_4f546_level0_col3" class="col_heading level0 col3" >BLEU-3</th>
|
| 11 |
+
<th id="T_4f546_level0_col4" class="col_heading level0 col4" >BLEU-4</th>
|
| 12 |
+
<th id="T_4f546_level0_col5" class="col_heading level0 col5" >WER</th>
|
| 13 |
+
</tr>
|
| 14 |
+
</thead>
|
| 15 |
+
<tbody>
|
| 16 |
+
<tr>
|
| 17 |
+
<th id="T_4f546_level0_row0" class="row_heading level0 row0" >0</th>
|
| 18 |
+
<td id="T_4f546_row0_col0" class="data row0 col0" >prahokbart_base (BS=8.0)</td>
|
| 19 |
+
<td id="T_4f546_row0_col1" class="data row0 col1" >99.407</td>
|
| 20 |
+
<td id="T_4f546_row0_col2" class="data row0 col2" >98.897</td>
|
| 21 |
+
<td id="T_4f546_row0_col3" class="data row0 col3" >98.413</td>
|
| 22 |
+
<td id="T_4f546_row0_col4" class="data row0 col4" >97.970</td>
|
| 23 |
+
<td id="T_4f546_row0_col5" class="data row0 col5" >0.009</td>
|
| 24 |
+
</tr>
|
| 25 |
+
<tr>
|
| 26 |
+
<th id="T_4f546_level0_row1" class="row_heading level0 row1" >1</th>
|
| 27 |
+
<td id="T_4f546_row1_col0" class="data row1 col0" >prahokbart_base (BS=16.0)</td>
|
| 28 |
+
<td id="T_4f546_row1_col1" class="data row1 col1" >98.962</td>
|
| 29 |
+
<td id="T_4f546_row1_col2" class="data row1 col2" >98.040</td>
|
| 30 |
+
<td id="T_4f546_row1_col3" class="data row1 col3" >97.139</td>
|
| 31 |
+
<td id="T_4f546_row1_col4" class="data row1 col4" >96.297</td>
|
| 32 |
+
<td id="T_4f546_row1_col5" class="data row1 col5" >0.015</td>
|
| 33 |
+
</tr>
|
| 34 |
+
<tr>
|
| 35 |
+
<th id="T_4f546_level0_row2" class="row_heading level0 row2" >2</th>
|
| 36 |
+
<td id="T_4f546_row2_col0" class="data row2 col0" >prahokbart_base (BS=32.0)</td>
|
| 37 |
+
<td id="T_4f546_row2_col1" class="data row2 col1" >98.302</td>
|
| 38 |
+
<td id="T_4f546_row2_col2" class="data row2 col2" >96.752</td>
|
| 39 |
+
<td id="T_4f546_row2_col3" class="data row2 col3" >95.254</td>
|
| 40 |
+
<td id="T_4f546_row2_col4" class="data row2 col4" >93.864</td>
|
| 41 |
+
<td id="T_4f546_row2_col5" class="data row2 col5" >0.022</td>
|
| 42 |
+
</tr>
|
| 43 |
+
<tr>
|
| 44 |
+
<th id="T_4f546_level0_row3" class="row_heading level0 row3" >3</th>
|
| 45 |
+
<td id="T_4f546_row3_col0" class="data row3 col0" >prahokbart_big (BS=8.0)</td>
|
| 46 |
+
<td id="T_4f546_row3_col1" class="data row3 col1" >99.407</td>
|
| 47 |
+
<td id="T_4f546_row3_col2" class="data row3 col2" >98.897</td>
|
| 48 |
+
<td id="T_4f546_row3_col3" class="data row3 col3" >98.413</td>
|
| 49 |
+
<td id="T_4f546_row3_col4" class="data row3 col4" >97.970</td>
|
| 50 |
+
<td id="T_4f546_row3_col5" class="data row3 col5" >0.009</td>
|
| 51 |
+
</tr>
|
| 52 |
+
<tr>
|
| 53 |
+
<th id="T_4f546_level0_row4" class="row_heading level0 row4" >4</th>
|
| 54 |
+
<td id="T_4f546_row4_col0" class="data row4 col0" >prahokbart_big (BS=16.0)</td>
|
| 55 |
+
<td id="T_4f546_row4_col1" class="data row4 col1" >99.195</td>
|
| 56 |
+
<td id="T_4f546_row4_col2" class="data row4 col2" >98.526</td>
|
| 57 |
+
<td id="T_4f546_row4_col3" class="data row4 col3" >97.880</td>
|
| 58 |
+
<td id="T_4f546_row4_col4" class="data row4 col4" >97.279</td>
|
| 59 |
+
<td id="T_4f546_row4_col5" class="data row4 col5" >0.012</td>
|
| 60 |
+
</tr>
|
| 61 |
+
<tr>
|
| 62 |
+
<th id="T_4f546_level0_row5" class="row_heading level0 row5" >5</th>
|
| 63 |
+
<td id="T_4f546_row5_col0" class="data row5 col0" >prahokbart_big (BS=32.0)</td>
|
| 64 |
+
<td id="T_4f546_row5_col1" class="data row5 col1" >99.007</td>
|
| 65 |
+
<td id="T_4f546_row5_col2" class="data row5 col2" >98.169</td>
|
| 66 |
+
<td id="T_4f546_row5_col3" class="data row5 col3" >97.365</td>
|
| 67 |
+
<td id="T_4f546_row5_col4" class="data row5 col4" >96.619</td>
|
| 68 |
+
<td id="T_4f546_row5_col5" class="data row5 col5" >0.014</td>
|
| 69 |
+
</tr>
|
| 70 |
+
<tr>
|
| 71 |
+
<th id="T_4f546_level0_row6" class="row_heading level0 row6" >6</th>
|
| 72 |
+
<td id="T_4f546_row6_col0" class="data row6 col0" >prahokbart_big (BS=32.0)</td>
|
| 73 |
+
<td id="T_4f546_row6_col1" class="data row6 col1" >99.540</td>
|
| 74 |
+
<td id="T_4f546_row6_col2" class="data row6 col2" >99.162</td>
|
| 75 |
+
<td id="T_4f546_row6_col3" class="data row6 col3" >98.809</td>
|
| 76 |
+
<td id="T_4f546_row6_col4" class="data row6 col4" >98.486</td>
|
| 77 |
+
<td id="T_4f546_row6_col5" class="data row6 col5" >0.008</td>
|
| 78 |
+
</tr>
|
| 79 |
+
</tbody>
|
| 80 |
+
</table>
|
khmerhomophonecorrector/test_results.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
khmerhomophonecorrector/tool/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
khmerhomophonecorrector/tool/__pycache__/khnormal.cpython-312.pyc
ADDED
|
Binary file (9.4 kB). View file
|
|
|
khmerhomophonecorrector/tool/balance_data.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
|
| 4 |
+
# === Helper: Clean sentence formatting ===
|
| 5 |
+
def clean_text(text):
|
| 6 |
+
return re.sub(r"\s+", " ", text).strip()
|
| 7 |
+
|
| 8 |
+
# === Load correct_homophone.json ===
|
| 9 |
+
with open("correct_homophone.json", "r", encoding="utf-8") as f:
|
| 10 |
+
data = json.load(f)
|
| 11 |
+
|
| 12 |
+
# === Load homophone_test.json for order ===
|
| 13 |
+
with open("homophone_test.json", "r", encoding="utf-8") as f:
|
| 14 |
+
homophone_groups = json.load(f)["homophones"]
|
| 15 |
+
word_order = [word for group in homophone_groups for word in group]
|
| 16 |
+
|
| 17 |
+
# === Balance, clean, and limit each word to max 100 sentences ===
|
| 18 |
+
balanced_data = {}
|
| 19 |
+
|
| 20 |
+
for word, sentences in data.items():
|
| 21 |
+
# Clean each sentence
|
| 22 |
+
cleaned_sentences = [clean_text(s) for s in sentences]
|
| 23 |
+
# Deduplicate and limit to 100
|
| 24 |
+
unique_sentences = list(dict.fromkeys(cleaned_sentences))[:100]
|
| 25 |
+
balanced_data[word] = unique_sentences
|
| 26 |
+
|
| 27 |
+
# === Reorder based on homophone_test.json ===
|
| 28 |
+
ordered_data = {word: balanced_data[word] for word in word_order if word in balanced_data}
|
| 29 |
+
|
| 30 |
+
# === Add any remaining words not in homophone_test.json ===
|
| 31 |
+
for word in balanced_data:
|
| 32 |
+
if word not in ordered_data:
|
| 33 |
+
ordered_data[word] = balanced_data[word]
|
| 34 |
+
|
| 35 |
+
# === Save the final output ===
|
| 36 |
+
with open("balanced_correct_homophone.json", "w", encoding="utf-8") as f:
|
| 37 |
+
json.dump(ordered_data, f, ensure_ascii=False, indent=4)
|
| 38 |
+
|
| 39 |
+
print("✅ Done! Output saved to 'balanced_homophone.json'")
|
khmerhomophonecorrector/tool/clean_data.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
def load_homophones(homophone_file):
|
| 6 |
+
with open(homophone_file, "r", encoding="utf-8") as f:
|
| 7 |
+
data = json.load(f)
|
| 8 |
+
homophone_sets = data["homophones"]
|
| 9 |
+
sorted_homophones = {tuple(sorted(set(group))): group for group in homophone_sets}
|
| 10 |
+
return sorted_homophones
|
| 11 |
+
|
| 12 |
+
def clean_text(text):
|
| 13 |
+
text = text.replace("\n", " ").replace("\r", " ").replace("\t", " ")
|
| 14 |
+
text = re.sub(r'http\S+', '', text)
|
| 15 |
+
text = re.sub(r'\d+', '', text)
|
| 16 |
+
text = re.sub(r'[a-zA-Z]+', '', text)
|
| 17 |
+
text = re.sub(r'[\u2000-\u206F\u25A0-\u25FF]+', '', text)
|
| 18 |
+
text = re.sub(r'[ៗ៚]', '', text)
|
| 19 |
+
text = re.sub(r'[<>()!@#$%^&*_+={}\[\]:;"\'\\|/?.,~-]', '', text)
|
| 20 |
+
text = re.sub(r'\s+', ' ', text) # Replace multiple spaces with one
|
| 21 |
+
return text.strip()
|
| 22 |
+
|
| 23 |
+
def clean_and_combine_txt_files(input_folder, output_file, homophones):
|
| 24 |
+
combined_cleaned_data = []
|
| 25 |
+
|
| 26 |
+
for filename in os.listdir(input_folder):
|
| 27 |
+
if filename.endswith(".txt"):
|
| 28 |
+
file_path = os.path.join(input_folder, filename)
|
| 29 |
+
try:
|
| 30 |
+
with open(file_path, "r", encoding="utf-8") as f:
|
| 31 |
+
content = f.read()
|
| 32 |
+
cleaned = clean_text(content)
|
| 33 |
+
if cleaned:
|
| 34 |
+
combined_cleaned_data.append(cleaned)
|
| 35 |
+
print(f"Processed: {filename}")
|
| 36 |
+
except Exception as e:
|
| 37 |
+
print(f"Error processing {filename}: {e}")
|
| 38 |
+
|
| 39 |
+
with open(output_file, "w", encoding="utf-8") as out:
|
| 40 |
+
json.dump(combined_cleaned_data, out, ensure_ascii=False, indent=4)
|
| 41 |
+
print(f"\n✅ Combined and cleaned content saved to: {output_file}")
|
| 42 |
+
|
| 43 |
+
# File paths
|
| 44 |
+
homophone_file = "homophone_test.json"
|
| 45 |
+
input_folder = "data_khmer"
|
| 46 |
+
output_file = "cleaned_combined_articles.json"
|
| 47 |
+
|
| 48 |
+
# Load homophones (not used yet in this script)
|
| 49 |
+
homophones = load_homophones(homophone_file)
|
| 50 |
+
|
| 51 |
+
# Clean and combine
|
| 52 |
+
clean_and_combine_txt_files(input_folder, output_file, homophones)
|
khmerhomophonecorrector/tool/combine_homophones.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
import ijson
|
| 4 |
+
|
| 5 |
+
# === Helper: Clean up sentence formatting ===
|
| 6 |
+
def clean_text(text):
|
| 7 |
+
return re.sub(r"\s+", " ", text).strip()
|
| 8 |
+
|
| 9 |
+
# === Load small files normally ===
|
| 10 |
+
with open("correct_homophone.json", "r", encoding="utf-8") as f:
|
| 11 |
+
segmented_data = json.load(f)
|
| 12 |
+
|
| 13 |
+
with open("homophone_test.json", "r", encoding="utf-8") as f:
|
| 14 |
+
homophone_groups = json.load(f)["homophones"]
|
| 15 |
+
word_order = [word for group in homophone_groups for word in group]
|
| 16 |
+
allowed_words = set(word_order)
|
| 17 |
+
|
| 18 |
+
# === Stream and Merge balanced_correct_homophone.json ===
|
| 19 |
+
filtered_file = "balanced_homophone.json"
|
| 20 |
+
|
| 21 |
+
with open(filtered_file, "r", encoding="utf-8") as f:
|
| 22 |
+
parser = ijson.kvitems(f, "")
|
| 23 |
+
for word, new_sentences in parser:
|
| 24 |
+
if word not in allowed_words:
|
| 25 |
+
continue # ⚡ Skip words that are not allowed
|
| 26 |
+
|
| 27 |
+
existing = segmented_data.get(word, [])
|
| 28 |
+
|
| 29 |
+
existing_cleaned = {clean_text(s) for s in existing}
|
| 30 |
+
new_cleaned = {clean_text(s) for s in new_sentences}
|
| 31 |
+
|
| 32 |
+
merged = sorted(existing_cleaned.union(new_cleaned))
|
| 33 |
+
segmented_data[word] = merged
|
| 34 |
+
|
| 35 |
+
# === Build the final ordered dataset ===
|
| 36 |
+
ordered_data = {}
|
| 37 |
+
|
| 38 |
+
for word in word_order:
|
| 39 |
+
if word in segmented_data:
|
| 40 |
+
ordered_data[word] = segmented_data[word]
|
| 41 |
+
|
| 42 |
+
# === Save final output ===
|
| 43 |
+
with open("finalcorrect_homophone.json", "w", encoding="utf-8") as f:
|
| 44 |
+
json.dump(ordered_data, f, ensure_ascii=False, indent=4)
|
| 45 |
+
|
| 46 |
+
print("✅ Merging complete! Only words from 'homophone_test.json' included. Check 'finalcorrect_homophone.json'.")
|
khmerhomophonecorrector/tool/complete_homophone_sentences.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import random
|
| 3 |
+
from collections import defaultdict
|
| 4 |
+
from khmernltk import word_tokenize
|
| 5 |
+
|
| 6 |
+
def load_data():
|
| 7 |
+
try:
|
| 8 |
+
# Load the original output file
|
| 9 |
+
with open('incorrect_homophone_sorted.json', 'r', encoding='utf-8') as f:
|
| 10 |
+
incorrect = json.load(f)
|
| 11 |
+
|
| 12 |
+
# Load the analysis file
|
| 13 |
+
with open('incorrect_homophone_analysis4.json', 'r', encoding='utf-8') as f:
|
| 14 |
+
analysis = json.load(f)
|
| 15 |
+
|
| 16 |
+
# Load the correct sentences
|
| 17 |
+
with open('correct_homophone.json', 'r', encoding='utf-8') as f:
|
| 18 |
+
correct = json.load(f)
|
| 19 |
+
|
| 20 |
+
# Load homophone groups
|
| 21 |
+
with open('homophone_test.json', 'r', encoding='utf-8') as f:
|
| 22 |
+
homophones = json.load(f)['homophones']
|
| 23 |
+
|
| 24 |
+
return incorrect, analysis, correct, homophones
|
| 25 |
+
except Exception as e:
|
| 26 |
+
print(f"Error loading files: {e}")
|
| 27 |
+
return None, None, None, None
|
| 28 |
+
|
| 29 |
+
def find_incomplete_homophones(analysis):
|
| 30 |
+
incomplete = {}
|
| 31 |
+
for group_name, group_data in analysis['homophone_summary'].items():
|
| 32 |
+
for word, count in group_data.items():
|
| 33 |
+
if count < 100:
|
| 34 |
+
if group_name not in incomplete:
|
| 35 |
+
incomplete[group_name] = []
|
| 36 |
+
incomplete[group_name].append((word, count))
|
| 37 |
+
return incomplete
|
| 38 |
+
|
| 39 |
+
def find_similar_words(word, correct):
|
| 40 |
+
"""Find words that might be similar to the target word"""
|
| 41 |
+
similar = []
|
| 42 |
+
for other_word in correct.keys():
|
| 43 |
+
if other_word != word and len(other_word) == len(word):
|
| 44 |
+
# Check if they share any characters
|
| 45 |
+
if any(c in other_word for c in word):
|
| 46 |
+
similar.append(other_word)
|
| 47 |
+
return similar
|
| 48 |
+
|
| 49 |
+
def generate_additional_sentences(incorrect, correct, homophones, incomplete):
|
| 50 |
+
# Create mapping from word to its homophone group
|
| 51 |
+
word_to_group = {}
|
| 52 |
+
for group in homophones:
|
| 53 |
+
for word in group:
|
| 54 |
+
word_to_group[word] = group
|
| 55 |
+
|
| 56 |
+
# Process each incomplete group
|
| 57 |
+
for group_name, words in incomplete.items():
|
| 58 |
+
print(f"\nProcessing group: {group_name}")
|
| 59 |
+
for word, current_count in words:
|
| 60 |
+
needed = 100 - current_count
|
| 61 |
+
if needed <= 0:
|
| 62 |
+
continue
|
| 63 |
+
|
| 64 |
+
print(f" Generating {needed} more sentences for {word}")
|
| 65 |
+
|
| 66 |
+
# Initialize if not present
|
| 67 |
+
if word not in incorrect:
|
| 68 |
+
incorrect[word] = []
|
| 69 |
+
|
| 70 |
+
# Strategy 1: Try to use sentences from the same homophone group
|
| 71 |
+
group_words = word_to_group.get(word, [])
|
| 72 |
+
source_words = [w for w in group_words if w in correct and w != word]
|
| 73 |
+
|
| 74 |
+
if source_words:
|
| 75 |
+
print(f" Using {len(source_words)} words from same group")
|
| 76 |
+
attempts = 0
|
| 77 |
+
max_attempts = needed * 10
|
| 78 |
+
|
| 79 |
+
while len(incorrect[word]) < 100 and attempts < max_attempts:
|
| 80 |
+
attempts += 1
|
| 81 |
+
source_word = random.choice(source_words)
|
| 82 |
+
|
| 83 |
+
for sentence in correct[source_word]:
|
| 84 |
+
if len(incorrect[word]) >= 100:
|
| 85 |
+
break
|
| 86 |
+
|
| 87 |
+
tokens = word_tokenize(sentence)
|
| 88 |
+
positions = [i for i, t in enumerate(tokens) if t == source_word]
|
| 89 |
+
|
| 90 |
+
if not positions:
|
| 91 |
+
continue
|
| 92 |
+
|
| 93 |
+
new_tokens = tokens.copy()
|
| 94 |
+
replace_pos = random.choice(positions)
|
| 95 |
+
new_tokens[replace_pos] = word
|
| 96 |
+
new_sentence = ''.join(new_tokens)
|
| 97 |
+
|
| 98 |
+
if new_sentence not in incorrect[word]:
|
| 99 |
+
incorrect[word].append(new_sentence)
|
| 100 |
+
|
| 101 |
+
if len(incorrect[word]) % 20 == 0:
|
| 102 |
+
print(f" {word}: {len(incorrect[word])}/100")
|
| 103 |
+
|
| 104 |
+
# Strategy 2: If still not enough, try similar words
|
| 105 |
+
if len(incorrect[word]) < 100:
|
| 106 |
+
print(f" Trying similar words for {word}")
|
| 107 |
+
similar_words = find_similar_words(word, correct)
|
| 108 |
+
|
| 109 |
+
if similar_words:
|
| 110 |
+
print(f" Found {len(similar_words)} similar words")
|
| 111 |
+
attempts = 0
|
| 112 |
+
max_attempts = (100 - len(incorrect[word])) * 10
|
| 113 |
+
|
| 114 |
+
while len(incorrect[word]) < 100 and attempts < max_attempts:
|
| 115 |
+
attempts += 1
|
| 116 |
+
source_word = random.choice(similar_words)
|
| 117 |
+
|
| 118 |
+
for sentence in correct[source_word]:
|
| 119 |
+
if len(incorrect[word]) >= 100:
|
| 120 |
+
break
|
| 121 |
+
|
| 122 |
+
tokens = word_tokenize(sentence)
|
| 123 |
+
positions = [i for i, t in enumerate(tokens) if t == source_word]
|
| 124 |
+
|
| 125 |
+
if not positions:
|
| 126 |
+
continue
|
| 127 |
+
|
| 128 |
+
new_tokens = tokens.copy()
|
| 129 |
+
replace_pos = random.choice(positions)
|
| 130 |
+
new_tokens[replace_pos] = word
|
| 131 |
+
new_sentence = ''.join(new_tokens)
|
| 132 |
+
|
| 133 |
+
if new_sentence not in incorrect[word]:
|
| 134 |
+
incorrect[word].append(new_sentence)
|
| 135 |
+
|
| 136 |
+
if len(incorrect[word]) % 20 == 0:
|
| 137 |
+
print(f" {word}: {len(incorrect[word])}/100")
|
| 138 |
+
|
| 139 |
+
# Final check
|
| 140 |
+
if len(incorrect[word]) < 100:
|
| 141 |
+
print(f" Warning: Could only generate {len(incorrect[word])} sentences for {word}")
|
| 142 |
+
else:
|
| 143 |
+
print(f" Successfully generated 100 sentences for {word}")
|
| 144 |
+
|
| 145 |
+
return incorrect
|
| 146 |
+
|
| 147 |
+
def save_results(data, filename='incorrect_homophone_completed.json'):
|
| 148 |
+
with open(filename, 'w', encoding='utf-8') as f:
|
| 149 |
+
json.dump(data, f, ensure_ascii=False, indent=2)
|
| 150 |
+
|
| 151 |
+
def main():
|
| 152 |
+
incorrect, analysis, correct, homophones = load_data()
|
| 153 |
+
if not all([incorrect, analysis, correct, homophones]):
|
| 154 |
+
print("Failed to load data files")
|
| 155 |
+
return
|
| 156 |
+
|
| 157 |
+
print("Finding incomplete homophones...")
|
| 158 |
+
incomplete = find_incomplete_homophones(analysis)
|
| 159 |
+
|
| 160 |
+
print(f"\nFound {len(incomplete)} groups with incomplete sentences")
|
| 161 |
+
for group_name, words in incomplete.items():
|
| 162 |
+
print(f"\n{group_name}:")
|
| 163 |
+
for word, count in words:
|
| 164 |
+
print(f" {word}: {count}/100")
|
| 165 |
+
|
| 166 |
+
print("\nGenerating additional sentences...")
|
| 167 |
+
updated_incorrect = generate_additional_sentences(incorrect, correct, homophones, incomplete)
|
| 168 |
+
|
| 169 |
+
# Save the updated results
|
| 170 |
+
save_results(updated_incorrect)
|
| 171 |
+
print("\nDone! Results saved to incorrect_homophone_completed.json")
|
| 172 |
+
|
| 173 |
+
# Print final statistics
|
| 174 |
+
total_words = len(updated_incorrect)
|
| 175 |
+
total_sentences = sum(len(sentences) for sentences in updated_incorrect.values())
|
| 176 |
+
print(f"\nFinal statistics:")
|
| 177 |
+
print(f"Total words: {total_words}")
|
| 178 |
+
print(f"Total sentences: {total_sentences}")
|
| 179 |
+
print(f"Average sentences per word: {total_sentences/total_words:.2f}")
|
| 180 |
+
|
| 181 |
+
if __name__ == "__main__":
|
| 182 |
+
main()
|
khmerhomophonecorrector/tool/convert_format.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
from typing import List, Tuple, Dict
|
| 4 |
+
|
| 5 |
+
def load_files(input_file, homophone_file):
|
| 6 |
+
"""Load input data and homophone groups"""
|
| 7 |
+
with open(input_file, "r", encoding="utf-8") as f:
|
| 8 |
+
data = json.load(f)
|
| 9 |
+
|
| 10 |
+
with open(homophone_file, "r", encoding="utf-8") as f:
|
| 11 |
+
homophones_data = json.load(f)
|
| 12 |
+
|
| 13 |
+
# Create a mapping of words to their homophone groups
|
| 14 |
+
homophone_map = {}
|
| 15 |
+
for group in homophones_data["homophones"]:
|
| 16 |
+
for word in group:
|
| 17 |
+
homophone_map[word] = group
|
| 18 |
+
|
| 19 |
+
return data, homophone_map
|
| 20 |
+
|
| 21 |
+
def clean_text(text, special_tokens):
|
| 22 |
+
"""Clean text by removing special tokens and normalizing whitespace"""
|
| 23 |
+
# Remove special tokens and extra spaces
|
| 24 |
+
words = [w for w in text.strip().split() if w not in special_tokens]
|
| 25 |
+
return ' '.join(words)
|
| 26 |
+
|
| 27 |
+
def strip_punct(word):
|
| 28 |
+
"""Remove Khmer and ASCII punctuation from a word"""
|
| 29 |
+
return re.sub(r'[\u17d4-\u17d6\u200b\u200c\u200d\u17c9\u17ca\u17cb\u17cc\u17cd\u17ce\u17cf\u17d0\u17d1\u17d2\u17d3\u17d4\u17d5\u17d6\u17d7\u17d8\u17d9\u17da\u17db\u17dc\u17dd\u0021-\u002f\u003a-\u0040\u005b-\u0060\u007b-\u007e\u2026\u201c\u201d\u2018\u2019\u00ab\u00bb\u300c\u300d\u300e\u300f\u3010\u3011\u3014\u3015\u3016\u3017\u3018\u3019\u301a\u301b\u301c\u301d\u301e\u301f\u002e\u002c\u0964\u0965]', '', word)
|
| 30 |
+
|
| 31 |
+
def find_homophone_group(word1, word2, homophone_map):
|
| 32 |
+
"""Find if two words are in the same homophone group"""
|
| 33 |
+
if word1 in homophone_map and word2 in homophone_map:
|
| 34 |
+
if homophone_map[word1] == homophone_map[word2]:
|
| 35 |
+
return tuple(sorted(homophone_map[word1])) # Use tuple for set uniqueness
|
| 36 |
+
return None
|
| 37 |
+
|
| 38 |
+
def find_homophone_pair(input_text: str, output_text: str) -> Tuple[str, str]:
|
| 39 |
+
"""Find the homophone pair by comparing input and output texts."""
|
| 40 |
+
input_words = input_text.split()
|
| 41 |
+
output_words = output_text.split()
|
| 42 |
+
|
| 43 |
+
# Find the first different word
|
| 44 |
+
for i, (in_word, out_word) in enumerate(zip(input_words, output_words)):
|
| 45 |
+
if in_word != out_word:
|
| 46 |
+
return in_word, out_word
|
| 47 |
+
|
| 48 |
+
return None, None
|
| 49 |
+
|
| 50 |
+
def convert_format(input_file: str, output_file: str):
|
| 51 |
+
"""
|
| 52 |
+
Convert the dataset format to include proper special tokens and homophone groups.
|
| 53 |
+
Input format:
|
| 54 |
+
{
|
| 55 |
+
"input": "នេះដូច ក៏ ក របស់ទ័ព។",
|
| 56 |
+
"output": "នេះដូច ក ក របស់ទ័ព។",
|
| 57 |
+
"error_word": "ក៏",
|
| 58 |
+
"correct_word": "ក"
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
Output format:
|
| 62 |
+
{
|
| 63 |
+
"input": "នេះដូច ក៏ ក របស់ទ័ព។ </s> <2km>",
|
| 64 |
+
"target": "<2km> នេះដូច ក ក របស់ទ័ព។ </s>",
|
| 65 |
+
"homophone_group": ["ក៏", "ក"],
|
| 66 |
+
"error_type": "homophone"
|
| 67 |
+
}
|
| 68 |
+
"""
|
| 69 |
+
# Read the input file
|
| 70 |
+
with open(input_file, 'r', encoding='utf-8') as f:
|
| 71 |
+
data = json.load(f)
|
| 72 |
+
|
| 73 |
+
# Convert the format
|
| 74 |
+
converted_data = []
|
| 75 |
+
for item in data:
|
| 76 |
+
# Clean the input and output texts
|
| 77 |
+
input_text = item['input'].replace('</s>', '').replace('<2km>', '').strip()
|
| 78 |
+
output_text = item['output'].replace('</s>', '').replace('<2km>', '').strip()
|
| 79 |
+
|
| 80 |
+
# Find the homophone pair
|
| 81 |
+
error_word = item['error_word']
|
| 82 |
+
correct_word = item['correct_word']
|
| 83 |
+
|
| 84 |
+
# Create the converted item
|
| 85 |
+
converted_item = {
|
| 86 |
+
"input": f"{input_text} </s> <2km>",
|
| 87 |
+
"target": f"<2km> {output_text} </s>",
|
| 88 |
+
"homophone_group": [error_word, correct_word],
|
| 89 |
+
"error_type": "homophone"
|
| 90 |
+
}
|
| 91 |
+
converted_data.append(converted_item)
|
| 92 |
+
|
| 93 |
+
# Save the converted data
|
| 94 |
+
with open(output_file, 'w', encoding='utf-8') as f:
|
| 95 |
+
json.dump(converted_data, f, ensure_ascii=False, indent=2)
|
| 96 |
+
|
| 97 |
+
print(f"Converted {len(converted_data)} samples")
|
| 98 |
+
print(f"Saved to {output_file}")
|
| 99 |
+
|
| 100 |
+
# Print a sample for verification
|
| 101 |
+
print("\nSample of converted data:")
|
| 102 |
+
print(json.dumps(converted_data[0], ensure_ascii=False, indent=2))
|
| 103 |
+
|
| 104 |
+
if __name__ == "__main__":
|
| 105 |
+
input_file = "homophone_error_correction.json"
|
| 106 |
+
output_file = "homophone_error_correction_converted.json"
|
| 107 |
+
convert_format(input_file, output_file)
|
khmerhomophonecorrector/tool/convert_training_data.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
from typing import List, Dict, Any
|
| 4 |
+
import random
|
| 5 |
+
|
| 6 |
+
def load_json_file(file_path: str) -> List[Dict[str, Any]]:
|
| 7 |
+
"""Load JSON file and return its contents."""
|
| 8 |
+
with open(file_path, 'r', encoding='utf-8') as f:
|
| 9 |
+
return json.load(f)
|
| 10 |
+
|
| 11 |
+
def save_json_file(data: List[Dict[str, Any]], file_path: str):
|
| 12 |
+
"""Save data to JSON file."""
|
| 13 |
+
with open(file_path, 'w', encoding='utf-8') as f:
|
| 14 |
+
json.dump(data, f, ensure_ascii=False, indent=2)
|
| 15 |
+
|
| 16 |
+
def clean_text(text: str) -> str:
|
| 17 |
+
"""Remove special tokens and clean the text."""
|
| 18 |
+
# Remove special tokens
|
| 19 |
+
text = text.replace('</s>', '').replace('<2km>', '')
|
| 20 |
+
# Remove extra spaces
|
| 21 |
+
text = re.sub(r'\s+', ' ', text)
|
| 22 |
+
return text.strip()
|
| 23 |
+
|
| 24 |
+
def expand_homophone_group(group: List[str]) -> List[str]:
|
| 25 |
+
"""Expand homophone groups to include all common variations."""
|
| 26 |
+
# Common homophone groups in Khmer
|
| 27 |
+
homophone_mappings = {
|
| 28 |
+
'ក': ['ក', 'ក៏', 'ករ', 'ករណ៍'],
|
| 29 |
+
'ករ': ['ក', 'ក៏', 'ករ', 'ករណ៍'],
|
| 30 |
+
'ករណ៍': ['ក', 'ក៏', 'ករ', 'ករណ៍'],
|
| 31 |
+
'ក៏': ['ក', 'ក៏', 'ករ', 'ករណ៍'],
|
| 32 |
+
# Add more mappings as needed
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
expanded_group = set()
|
| 36 |
+
for word in group:
|
| 37 |
+
if word in homophone_mappings:
|
| 38 |
+
expanded_group.update(homophone_mappings[word])
|
| 39 |
+
|
| 40 |
+
return list(expanded_group) if expanded_group else group
|
| 41 |
+
|
| 42 |
+
def create_natural_context(input_text: str, target_text: str) -> tuple:
|
| 43 |
+
"""Create more natural context by adding surrounding text."""
|
| 44 |
+
# Common Khmer sentence starters and connectors
|
| 45 |
+
starters = [
|
| 46 |
+
"នៅពេលនោះ",
|
| 47 |
+
"ដូច្នេះ",
|
| 48 |
+
"ដើម្បី",
|
| 49 |
+
"ព្រោះ",
|
| 50 |
+
"ដោយសារ",
|
| 51 |
+
"នៅក្នុង",
|
| 52 |
+
"នៅលើ",
|
| 53 |
+
"នៅពេល",
|
| 54 |
+
]
|
| 55 |
+
|
| 56 |
+
# Add random starter if the sentence doesn't start with common patterns
|
| 57 |
+
if not any(input_text.startswith(s) for s in starters):
|
| 58 |
+
input_text = f"{random.choice(starters)} {input_text}"
|
| 59 |
+
target_text = f"{random.choice(starters)} {target_text}"
|
| 60 |
+
|
| 61 |
+
return input_text, target_text
|
| 62 |
+
|
| 63 |
+
def convert_format(input_data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
|
| 64 |
+
"""Convert the data format to match seq2seq_homophone.json."""
|
| 65 |
+
converted_data = []
|
| 66 |
+
|
| 67 |
+
for item in input_data:
|
| 68 |
+
# Clean the input and target texts
|
| 69 |
+
input_text = clean_text(item['input'])
|
| 70 |
+
target_text = clean_text(item['target'])
|
| 71 |
+
|
| 72 |
+
# Create more natural context
|
| 73 |
+
input_text, target_text = create_natural_context(input_text, target_text)
|
| 74 |
+
|
| 75 |
+
# Expand homophone group
|
| 76 |
+
homophone_group = expand_homophone_group(item['homophone_group'])
|
| 77 |
+
|
| 78 |
+
# Create new format
|
| 79 |
+
new_item = {
|
| 80 |
+
"input": input_text,
|
| 81 |
+
"target": target_text,
|
| 82 |
+
"homophone_group": homophone_group
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
converted_data.append(new_item)
|
| 86 |
+
|
| 87 |
+
return converted_data
|
| 88 |
+
|
| 89 |
+
def main():
|
| 90 |
+
# Load the input data
|
| 91 |
+
input_data = load_json_file('homophone_pairs.json')
|
| 92 |
+
|
| 93 |
+
# Convert the format
|
| 94 |
+
converted_data = convert_format(input_data)
|
| 95 |
+
|
| 96 |
+
# Save the converted data
|
| 97 |
+
save_json_file(converted_data, 'converted_homophone_pairs.json')
|
| 98 |
+
|
| 99 |
+
print(f"Converted {len(converted_data)} examples")
|
| 100 |
+
print("Sample of converted data:")
|
| 101 |
+
for i, item in enumerate(converted_data[:3]):
|
| 102 |
+
print(f"\nExample {i+1}:")
|
| 103 |
+
print(f"Input: {item['input']}")
|
| 104 |
+
print(f"Target: {item['target']}")
|
| 105 |
+
print(f"Homophone group: {item['homophone_group']}")
|
| 106 |
+
|
| 107 |
+
if __name__ == "__main__":
|
| 108 |
+
main()
|
khmerhomophonecorrector/tool/debug_homophone_check.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
|
| 4 |
+
# Load the segmented output data (main dataset)
|
| 5 |
+
with open("correct_homophone.json", "r", encoding="utf-8") as f:
|
| 6 |
+
segmented_data = json.load(f)
|
| 7 |
+
|
| 8 |
+
# Load the homophone analysis results
|
| 9 |
+
with open("missing_homophone_analysis.json", "r", encoding="utf-8") as f:
|
| 10 |
+
homophone_analysis = json.load(f)
|
| 11 |
+
|
| 12 |
+
# Extract partially missing and under-80-sentence homophones
|
| 13 |
+
partially_missing = homophone_analysis.get("partially_missing_homophones", {})
|
| 14 |
+
under_80 = homophone_analysis.get("under_80_sentences_homophones", {})
|
| 15 |
+
|
| 16 |
+
# Combine the word sets
|
| 17 |
+
debug_words = set()
|
| 18 |
+
|
| 19 |
+
for word_data in partially_missing.values():
|
| 20 |
+
debug_words.update(word_data.keys())
|
| 21 |
+
|
| 22 |
+
for word_data in under_80.values():
|
| 23 |
+
debug_words.update(word_data.keys())
|
| 24 |
+
|
| 25 |
+
# Pre-compile regex patterns for each word
|
| 26 |
+
patterns = {word: re.compile(rf'(?<!\S){re.escape(word)}(?!\S)') for word in debug_words}
|
| 27 |
+
|
| 28 |
+
# Debug: find sentences to fill up to 80
|
| 29 |
+
debug_results = {}
|
| 30 |
+
|
| 31 |
+
for word in debug_words:
|
| 32 |
+
matches = [] # start fresh
|
| 33 |
+
|
| 34 |
+
pattern = patterns[word]
|
| 35 |
+
for key, sentences in segmented_data.items():
|
| 36 |
+
for sentence in sentences:
|
| 37 |
+
# If sentence is tokenized (list), join it into a normal sentence
|
| 38 |
+
if isinstance(sentence, list):
|
| 39 |
+
sentence = ''.join(sentence) # JOIN WITHOUT SPACE (for Khmer)
|
| 40 |
+
|
| 41 |
+
if pattern.search(sentence):
|
| 42 |
+
matches.append(sentence)
|
| 43 |
+
if len(matches) == 80:
|
| 44 |
+
break
|
| 45 |
+
if len(matches) == 80:
|
| 46 |
+
break
|
| 47 |
+
|
| 48 |
+
debug_results[word] = matches # already capped at 80
|
| 49 |
+
|
| 50 |
+
# Save the results
|
| 51 |
+
with open("homophone_debug_results.json", "w", encoding="utf-8") as f:
|
| 52 |
+
json.dump(debug_results, f, ensure_ascii=False, indent=4)
|
| 53 |
+
|
| 54 |
+
print("✅ Completed filling each word up to 80 sentences with regex matching! Saved to 'homophone_debug_results1.json'.")
|
khmerhomophonecorrector/tool/filter.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ijson
|
| 2 |
+
import json
|
| 3 |
+
from collections import OrderedDict
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
|
| 6 |
+
def load_homophones_ordered(homophone_file):
|
| 7 |
+
with open(homophone_file, "r", encoding="utf-8") as f:
|
| 8 |
+
data = json.load(f)
|
| 9 |
+
ordered_words = []
|
| 10 |
+
for group in data["homophones"]:
|
| 11 |
+
ordered_words.extend(group)
|
| 12 |
+
return ordered_words
|
| 13 |
+
|
| 14 |
+
def filter_sentences_fast(segmented_file, homophone_words, output_file):
|
| 15 |
+
filtered_results = OrderedDict((word, []) for word in homophone_words)
|
| 16 |
+
homophone_set = set(homophone_words)
|
| 17 |
+
|
| 18 |
+
with open(segmented_file, "r", encoding="utf-8") as f:
|
| 19 |
+
parser = ijson.kvitems(f, '') # key-value pairs
|
| 20 |
+
|
| 21 |
+
for key, sentence_list in tqdm(parser, desc="Filtering"):
|
| 22 |
+
for sentence in sentence_list:
|
| 23 |
+
tokens_in_sentence = set(sentence)
|
| 24 |
+
matched_words = homophone_set.intersection(tokens_in_sentence)
|
| 25 |
+
for word in matched_words:
|
| 26 |
+
filtered_results[word].append(sentence)
|
| 27 |
+
|
| 28 |
+
with open(output_file, "w", encoding="utf-8") as f:
|
| 29 |
+
json.dump(filtered_results, f, ensure_ascii=False, indent=4)
|
| 30 |
+
|
| 31 |
+
print(f"✅ Fast filtered results saved to {output_file}")
|
| 32 |
+
|
| 33 |
+
# === Run ===
|
| 34 |
+
if __name__ == "__main__":
|
| 35 |
+
homophone_file = "homophone_test.json"
|
| 36 |
+
segmented_file = "segmented_grouped_cleaned.json"
|
| 37 |
+
output_file = "filtered_output.json"
|
| 38 |
+
|
| 39 |
+
homophone_words = load_homophones_ordered(homophone_file)
|
| 40 |
+
filter_sentences_fast(segmented_file, homophone_words, output_file)
|
khmerhomophonecorrector/tool/homophone_missing.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
def load_homophones(homophone_file):
|
| 4 |
+
with open(homophone_file, "r", encoding="utf-8") as f:
|
| 5 |
+
data = json.load(f)
|
| 6 |
+
return data["homophones"]
|
| 7 |
+
|
| 8 |
+
def load_cleaned_data(cleaned_file):
|
| 9 |
+
with open(cleaned_file, "r", encoding="utf-8") as f:
|
| 10 |
+
return json.load(f)
|
| 11 |
+
|
| 12 |
+
def analyze_missing_homophones(homophones, cleaned_data):
|
| 13 |
+
missing_homophones = {}
|
| 14 |
+
partially_missing_homophones = {}
|
| 15 |
+
under_80_sentences_homophones = {}
|
| 16 |
+
between_80_and_99_homophones = {}
|
| 17 |
+
|
| 18 |
+
for homophone_set in homophones:
|
| 19 |
+
homophone_key = ", ".join(homophone_set)
|
| 20 |
+
|
| 21 |
+
word_counts = {}
|
| 22 |
+
words_with_0_sentences = {}
|
| 23 |
+
words_under_80 = {}
|
| 24 |
+
words_between_80_and_99 = {}
|
| 25 |
+
all_zero = True
|
| 26 |
+
|
| 27 |
+
for word in homophone_set:
|
| 28 |
+
sentence_count = len(cleaned_data.get(word, []))
|
| 29 |
+
word_counts[word] = sentence_count
|
| 30 |
+
|
| 31 |
+
if sentence_count > 0:
|
| 32 |
+
all_zero = False
|
| 33 |
+
if sentence_count < 80:
|
| 34 |
+
words_under_80[word] = sentence_count
|
| 35 |
+
elif 80 <= sentence_count < 100:
|
| 36 |
+
words_between_80_and_99[word] = sentence_count
|
| 37 |
+
else:
|
| 38 |
+
words_with_0_sentences[word] = 0
|
| 39 |
+
words_under_80[word] = 0 # also include in under_80
|
| 40 |
+
|
| 41 |
+
if all_zero:
|
| 42 |
+
missing_homophones[homophone_key] = word_counts
|
| 43 |
+
elif words_with_0_sentences:
|
| 44 |
+
partially_missing_homophones[homophone_key] = words_with_0_sentences
|
| 45 |
+
|
| 46 |
+
if words_under_80:
|
| 47 |
+
under_80_sentences_homophones[homophone_key] = words_under_80
|
| 48 |
+
if words_between_80_and_99:
|
| 49 |
+
between_80_and_99_homophones[homophone_key] = words_between_80_and_99
|
| 50 |
+
|
| 51 |
+
return (
|
| 52 |
+
missing_homophones,
|
| 53 |
+
partially_missing_homophones,
|
| 54 |
+
under_80_sentences_homophones,
|
| 55 |
+
between_80_and_99_homophones
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
def save_results(
|
| 59 |
+
missing_homophones,
|
| 60 |
+
partially_missing_homophones,
|
| 61 |
+
under_80_sentences_homophones,
|
| 62 |
+
between_80_and_99_homophones,
|
| 63 |
+
output_file
|
| 64 |
+
):
|
| 65 |
+
results = {
|
| 66 |
+
"completely_missing_homophones": missing_homophones,
|
| 67 |
+
"partially_missing_homophones": partially_missing_homophones,
|
| 68 |
+
"under_80_sentences_homophones": under_80_sentences_homophones,
|
| 69 |
+
"between_80_and_99_homophones": between_80_and_99_homophones
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
with open(output_file, "w", encoding="utf-8") as f:
|
| 73 |
+
json.dump(results, f, ensure_ascii=False, indent=4)
|
| 74 |
+
|
| 75 |
+
print(f"✅ Missing homophones analysis saved to {output_file}")
|
| 76 |
+
|
| 77 |
+
# File paths
|
| 78 |
+
homophone_file = "homophone_test.json"
|
| 79 |
+
cleaned_file = "correct_homophone.json"
|
| 80 |
+
output_file = "missing_homophone_analysis1.json"
|
| 81 |
+
|
| 82 |
+
# Load data and analyze
|
| 83 |
+
homophones = load_homophones(homophone_file)
|
| 84 |
+
cleaned_data = load_cleaned_data(cleaned_file)
|
| 85 |
+
missing_h, partial_h, under_80, between_80_99 = analyze_missing_homophones(homophones, cleaned_data)
|
| 86 |
+
|
| 87 |
+
# Save results
|
| 88 |
+
save_results(missing_h, partial_h, under_80, between_80_99, output_file)
|
khmerhomophonecorrector/tool/khnormal.py
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/python3
|
| 2 |
+
# Copyright (c) 2021-2024, SIL Global.
|
| 3 |
+
# Licensed under MIT license: https://opensource.org/licenses/MIT
|
| 4 |
+
|
| 5 |
+
import enum, re, regex
|
| 6 |
+
|
| 7 |
+
class Cats(enum.Enum):
|
| 8 |
+
Other = 0; Base = 1; Robat = 2; Coeng = 3;
|
| 9 |
+
Shift = 4; Z = 5; VPre = 6; VB = 7; VA = 8;
|
| 10 |
+
VPost = 9; MS = 10; MF = 11; ZFCoeng = 12
|
| 11 |
+
|
| 12 |
+
categories = ([Cats.Base] * 35 # 1780-17A2
|
| 13 |
+
+ [Cats.Other] * 2 # 17A3-17A4
|
| 14 |
+
+ [Cats.Base] * 15 # 17A5-17B3
|
| 15 |
+
+ [Cats.Other] * 2 # 17B4-17B5
|
| 16 |
+
+ [Cats.VPost] # 17B6
|
| 17 |
+
+ [Cats.VA] * 4 # 17B7-17BA
|
| 18 |
+
+ [Cats.VB] * 3 # 17BB-17BD
|
| 19 |
+
+ [Cats.VPre] * 8 # 17BE-17C5
|
| 20 |
+
+ [Cats.MS] # 17C6
|
| 21 |
+
+ [Cats.MF] * 2 # 17C7-17C8
|
| 22 |
+
+ [Cats.Shift] * 2 # 17C9-17CA
|
| 23 |
+
+ [Cats.MS] # 17CB
|
| 24 |
+
+ [Cats.Robat] # 17CC
|
| 25 |
+
+ [Cats.MS] * 5 # 17CD-17D1
|
| 26 |
+
+ [Cats.Coeng] # 17D2
|
| 27 |
+
+ [Cats.MS] # 17D3
|
| 28 |
+
+ [Cats.Other] * 9 # 17D4-17DC
|
| 29 |
+
+ [Cats.MS]) # 17DD
|
| 30 |
+
|
| 31 |
+
khres = { # useful regular sub expressions used later
|
| 32 |
+
# All bases
|
| 33 |
+
"B": "[\u1780-\u17A2\u17A5-\u17B3\u25CC]",
|
| 34 |
+
# All consonants excluding Ro
|
| 35 |
+
"NonRo": "[\u1780-\u1799\u179B-\u17A2\u17A5-\u17B3]",
|
| 36 |
+
# All consonants exclude Bo
|
| 37 |
+
"NonBA": "[\u1780-\u1793\u1795-\u17A2\u17A5-\u17B3]",
|
| 38 |
+
# Series 1 consonants
|
| 39 |
+
"S1": "[\u1780-\u1783\u1785-\u1788\u178A-\u178D\u178F-\u1792"
|
| 40 |
+
"\u1795-\u1797\u179E-\u17A0\u17A2]",
|
| 41 |
+
# Series 2 consonants
|
| 42 |
+
"S2": "[\u1784\u1780\u178E\u1793\u1794\u1798-\u179D\u17A1\u17A3-\u17B3]",
|
| 43 |
+
# Simple following Vowel in Modern Khmer
|
| 44 |
+
"VA": "(?:[\u17B7-\u17BA\u17BE\u17BF\u17DD]|\u17B6\u17C6)",
|
| 45 |
+
# Above vowel (as per shifter rules) with vowel sequences
|
| 46 |
+
"VAX": "(?:[\u17C1-\u17C5]?{VA})",
|
| 47 |
+
# Above vowel with samyok (modern khmer)
|
| 48 |
+
"VAS": "(?:{VA}|[\u17C1-\u17C3]?\u17D0)",
|
| 49 |
+
# Above vowel with samyok (middle khmer)
|
| 50 |
+
"VASX": "(?:{VAX}|[\u17C1-\u17C3]?\u17D0)",
|
| 51 |
+
# Below vowel (with Middle Khmer prefix)
|
| 52 |
+
"VB": "(?:[\u17C1-\u17C3]?[\u17BB-\u17BD])",
|
| 53 |
+
# contains series 1 and no BA
|
| 54 |
+
"STRONG": """ {S1}\u17CC? # series 1 robat?\n (?:\u17D2{NonBA} # nonba coengs\n (?:\u17D2{NonBA})?)?\n | {NonBA}\u17CC? # nonba robat?\n (?: \u17D2{S1} # series 1 coeng\n (?:\u17D2{NonBA})? # + any nonba coeng\n | \u17D2{NonBA}\u17D2{S1} # nonba coeng + series 1 coeng\n )""",
|
| 55 |
+
# contains BA or only series 2
|
| 56 |
+
"NSTRONG": """(?:{S2}\u17CC?(?:\u17D2{S2}(?:\u17D2{S2})?)? # Series 2 + series 2 coengs\n |\u1794\u17CC?(?:{COENG}(?:{COENG})?)? # or ba with any coeng\n |{B}\u17CC?(?:\u17D2{NonRo}\u17D2\u1794 # or ba coeng\n |\u17D2\u1794(?:\u17D2{B})))""",
|
| 57 |
+
"COENG": "(?:(?:\u17D2{NonRo})?\u17D2{B})",
|
| 58 |
+
# final coeng
|
| 59 |
+
"FCOENG": "(?:\u200D(?:\u17D2{NonRo})+)",
|
| 60 |
+
# Allowed shifter sequences in Modern Khmer
|
| 61 |
+
"SHIFT": """(?: (?<={STRONG}) \u17CA\u200C (?={VA}) # strong + triisap held up\n | (?<={NSTRONG})\u17C9\u200C (?={VAS}) # weak + muusikatoan held up\n | [\u17C9\u17CA] # any shifter\n )""",
|
| 62 |
+
# Allowed shifter sequences in Middle Khmer
|
| 63 |
+
"SHIFTX": """(?:(?<={STRONG}) \u17CA\u200C (?={VAX}) # strong + triisap held up\n | (?<={NSTRONG})\u17C9\u200C (?={VASX}) # weak + muusikatoan held up\n | [\u17C9\u17CA] # any shifter\n )""",
|
| 64 |
+
# Modern Khmer vowel
|
| 65 |
+
"V": "[\u17B6-\u17C5]?",
|
| 66 |
+
# Middle Khmer vowel sequences (not worth trying to unpack this)
|
| 67 |
+
"VX": "(?:\u17C1[\u17BC\u17BD]?[\u17B7\u17B9\u17BA]?|"
|
| 68 |
+
"[\u17C2\u17C3]?[\u17BC\u17BD]?[\u17B7-\u17BA]\u17B6|"
|
| 69 |
+
"[\u17C2\u17C3]?[\u17BB-\u17BD]?\u17B6|\u17BE[\u17BC\u17BD]?\u17B6?|"
|
| 70 |
+
"[\u17C1-\u17C5]?\u17BB(?![\u17D0\u17DD])|"
|
| 71 |
+
"[\u17BF\u17C0]|[\u17C2-\u17C5]?[\u17BC\u17BD]?[\u17B7-\u17BA]?)",
|
| 72 |
+
# Modern Khmer Modifiers
|
| 73 |
+
"MS": """(?:(?: [\u17C6\u17CB\u17CD-\u17CF\u17D1\u17D3] # follows anything\n | (?<!\u17BB) [\u17D0\u17DD]) # not after -u\n [\u17C6\u17CB\u17CD-\u17D1\u17D3\u17DD]? # And an optional second\n )""",
|
| 74 |
+
# Middle Khmer Modifiers
|
| 75 |
+
"MSX": """(?:(?: [\u17C6\u17CB\u17CD-\u17CF\u17D1\u17D3] # follows anything\n | (?<!\u17BB [\u17B6\u17C4\u17C5]?) # blocking -u sequence\n [\u17D0\u17DD]) # for these modifiers\n [\u17C6\u17CB\u17CD-\u17D1\u17D3\u17DD]? # And an optional second\n )"""
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
# expand 3 times: SHIFTX -> VASX -> VAX -> VA
|
| 79 |
+
for i in range(3):
|
| 80 |
+
khres = {k: v.format(**khres) for k, v in khres.items()}
|
| 81 |
+
|
| 82 |
+
def charcat(c):
|
| 83 |
+
''' Returns the Khmer character category for a single char string'''
|
| 84 |
+
o = ord(c)
|
| 85 |
+
if 0x1780 <= o <= 0x17DD:
|
| 86 |
+
return categories[o-0x1780]
|
| 87 |
+
elif o == 0x200C:
|
| 88 |
+
return Cats.Z
|
| 89 |
+
elif o == 0x200D:
|
| 90 |
+
return Cats.ZFCoeng
|
| 91 |
+
return Cats.Other
|
| 92 |
+
|
| 93 |
+
def lunar(m, base):
|
| 94 |
+
''' Returns the lunar date symbol from the appropriate set base '''
|
| 95 |
+
v = (ord(m.group(1) or "\u17E0") - 0x17E0) * 10 + ord(m.group(2)) - 0x17E0
|
| 96 |
+
if v > 15: # translate \u17D4\u17D2\u17E0 as well
|
| 97 |
+
return m.group(0)
|
| 98 |
+
return chr(v+base)
|
| 99 |
+
|
| 100 |
+
def khnormal(txt, lang="km"):
|
| 101 |
+
''' Returns khmer normalised string, without fixing or marking errors'''
|
| 102 |
+
# Mark final coengs in Middle Khmer
|
| 103 |
+
if lang == "xhm":
|
| 104 |
+
txt = re.sub(r"([\u17B6-\u17C5]\u17D2)", "\u200D\\1", txt)
|
| 105 |
+
# Categorise every character in the string
|
| 106 |
+
charcats = [charcat(c) for c in txt]
|
| 107 |
+
|
| 108 |
+
# Recategorise base -> coeng after coeng char (or ZFCoeng)
|
| 109 |
+
for i in range(1, len(charcats)):
|
| 110 |
+
if txt[i-1] in "\u200D\u17D2" and charcats[i] in (Cats.Base, Cats.Coeng):
|
| 111 |
+
charcats[i] = charcats[i-1]
|
| 112 |
+
|
| 113 |
+
# Find subranges of base+non other and sort components in the subrange
|
| 114 |
+
i = 0
|
| 115 |
+
res = []
|
| 116 |
+
while i < len(charcats):
|
| 117 |
+
c = charcats[i]
|
| 118 |
+
if c != Cats.Base:
|
| 119 |
+
res.append(txt[i])
|
| 120 |
+
i += 1
|
| 121 |
+
continue
|
| 122 |
+
# Scan for end of syllable
|
| 123 |
+
j = i + 1
|
| 124 |
+
while j < len(charcats) and charcats[j].value > Cats.Base.value:
|
| 125 |
+
j += 1
|
| 126 |
+
# Sort syllable based on character categories
|
| 127 |
+
# Sort the char indices by category then position in string
|
| 128 |
+
newindices = sorted(range(i, j), key=lambda e:(charcats[e].value, e))
|
| 129 |
+
replaces = "".join(txt[n] for n in newindices)
|
| 130 |
+
|
| 131 |
+
replaces = re.sub("(\u200D?\u17D2)[\u17D2\u200C\u200D]+",
|
| 132 |
+
r"\1", replaces) # remove multiple invisible chars
|
| 133 |
+
replaces = re.sub("\u17BE\u17B6", "\u17C4\u17B8", replaces) # confusable vowels
|
| 134 |
+
# map compoound vowel sequences to compounds with -u before to be converted
|
| 135 |
+
replaces = re.sub("\u17C1([\u17BB-\u17BD]?)\u17B8", "\u17BE\\1", replaces)
|
| 136 |
+
replaces = re.sub("\u17C1([\u17BB-\u17BD]?)\u17B6", "\u17C4\\1", replaces)
|
| 137 |
+
replaces = re.sub("(\u17BE)(\u17BB)", r"\2\1", replaces)
|
| 138 |
+
# Replace -u + upper vowel with consonant shifter
|
| 139 |
+
replaces = re.sub(("((?:{STRONG})[\u17C1-\u17C5]?)\u17BB" + \
|
| 140 |
+
"(?={VA}|\u17D0)").format(**khres), "\\1\u17CA",
|
| 141 |
+
replaces, flags=re.X)
|
| 142 |
+
replaces = re.sub(("((?:{NSTRONG})[\u17C1-\u17C5]?)\u17BB" + \
|
| 143 |
+
"(?={VA}|\u17D0)").format(**khres), "\\1\u17C9",
|
| 144 |
+
replaces, flags=re.X)
|
| 145 |
+
replaces = re.sub("(\u17D2\u179A)(\u17D2[\u1780-\u17B3])",
|
| 146 |
+
r"\2\1", replaces) # coeng ro second
|
| 147 |
+
replaces = re.sub("(\u17D2)\u178A", "\\1\u178F", replaces) # coeng da->ta
|
| 148 |
+
# convert lunar dates from old style to use lunar date symbols
|
| 149 |
+
replaces = re.sub("(\u17E1?)([\u17E0-\u17E9])\u17D2\u17D4",
|
| 150 |
+
lambda m:lunar(m, 0x19E0), replaces)
|
| 151 |
+
replaces = re.sub("\u17D4\u17D2(\u17E1?)([\u17E0-\u17E9])",
|
| 152 |
+
lambda m:lunar(m, 0x19F0), replaces)
|
| 153 |
+
replaces = re.sub("\u17D4\u17D2\u17D4", "\u19F0", replaces)
|
| 154 |
+
res.append(replaces)
|
| 155 |
+
i = j
|
| 156 |
+
return "".join(res)
|
| 157 |
+
|
| 158 |
+
# The rest of the script (CLI, khtest, etc.) is omitted for import use.
|
khmerhomophonecorrector/tool/normalize_khmer.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import sys
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
# Add the current directory to Python path
|
| 6 |
+
current_dir = os.path.dirname(os.path.abspath(__file__))
|
| 7 |
+
sys.path.append(current_dir)
|
| 8 |
+
|
| 9 |
+
from khnormal import khnormal
|
| 10 |
+
|
| 11 |
+
def normalize_khmer_text(text):
|
| 12 |
+
"""Normalize Khmer text using khnormal."""
|
| 13 |
+
return khnormal(text)
|
| 14 |
+
|
| 15 |
+
def process_json_file(input_file, output_file):
|
| 16 |
+
"""Process JSON file and normalize Khmer text."""
|
| 17 |
+
try:
|
| 18 |
+
# Read the input JSON file
|
| 19 |
+
with open(input_file, 'r', encoding='utf-8') as f:
|
| 20 |
+
data = json.load(f)
|
| 21 |
+
|
| 22 |
+
# Normalize each word in the pairs
|
| 23 |
+
normalized_data = []
|
| 24 |
+
for pair in data:
|
| 25 |
+
normalized_pair = {
|
| 26 |
+
'input': normalize_khmer_text(pair['input']),
|
| 27 |
+
'target': normalize_khmer_text(pair['target']),
|
| 28 |
+
'homophone_group': pair['homophone_group']
|
| 29 |
+
}
|
| 30 |
+
normalized_data.append(normalized_pair)
|
| 31 |
+
|
| 32 |
+
# Write the normalized data to output file
|
| 33 |
+
with open(output_file, 'w', encoding='utf-8') as f:
|
| 34 |
+
json.dump(normalized_data, f, ensure_ascii=False, indent=2)
|
| 35 |
+
|
| 36 |
+
print(f"Successfully normalized Khmer text and saved to {output_file}")
|
| 37 |
+
|
| 38 |
+
except Exception as e:
|
| 39 |
+
print(f"Error processing file: {str(e)}")
|
| 40 |
+
sys.exit(1)
|
| 41 |
+
|
| 42 |
+
if __name__ == "__main__":
|
| 43 |
+
# Get the parent directory path
|
| 44 |
+
parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
| 45 |
+
|
| 46 |
+
files_to_process = [
|
| 47 |
+
(os.path.join(parent_dir, "data/train.json"), os.path.join(parent_dir, "data/train_normalized.json")),
|
| 48 |
+
(os.path.join(parent_dir, "data/test.json"), os.path.join(parent_dir, "data/test_normalized.json")),
|
| 49 |
+
(os.path.join(parent_dir, "data/val.json"), os.path.join(parent_dir, "data/val_normalized.json"))
|
| 50 |
+
]
|
| 51 |
+
for input_file, output_file in files_to_process:
|
| 52 |
+
process_json_file(input_file, output_file)
|
khmerhomophonecorrector/tool/segmentation.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ijson
|
| 2 |
+
import json
|
| 3 |
+
from khmernltk import sentence_tokenize, word_tokenize
|
| 4 |
+
from collections import defaultdict
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
|
| 7 |
+
INPUT_FILE = "correct_homophone.json"
|
| 8 |
+
HOMOPHONE_FILE = "homophone_test.json"
|
| 9 |
+
OUTPUT_FILE = "segmented_grouped.json"
|
| 10 |
+
|
| 11 |
+
def load_target_keys(homophone_file):
|
| 12 |
+
with open(homophone_file, "r", encoding="utf-8") as f:
|
| 13 |
+
data = json.load(f)
|
| 14 |
+
# Flatten the list of homophone sets
|
| 15 |
+
return [word for group in data["homophones"] for word in group]
|
| 16 |
+
|
| 17 |
+
def process_sentences_from_key(key, data):
|
| 18 |
+
segmented = []
|
| 19 |
+
for article in data:
|
| 20 |
+
try:
|
| 21 |
+
sentences = sentence_tokenize(article)
|
| 22 |
+
for sentence in sentences:
|
| 23 |
+
tokens = word_tokenize(sentence)
|
| 24 |
+
segmented.append(tokens)
|
| 25 |
+
except Exception as e:
|
| 26 |
+
print(f"❌ Error in '{key}': {e}")
|
| 27 |
+
return segmented
|
| 28 |
+
|
| 29 |
+
def main():
|
| 30 |
+
print("🚀 Segmenting with homophone grouping...")
|
| 31 |
+
|
| 32 |
+
target_keys = load_target_keys(HOMOPHONE_FILE)
|
| 33 |
+
results = {}
|
| 34 |
+
|
| 35 |
+
with open(INPUT_FILE, "r", encoding="utf-8") as f:
|
| 36 |
+
parser = ijson.kvitems(f, "")
|
| 37 |
+
|
| 38 |
+
for key, value in tqdm(parser, desc="Processing keys"):
|
| 39 |
+
if key in target_keys:
|
| 40 |
+
results[key] = process_sentences_from_key(key, value)
|
| 41 |
+
|
| 42 |
+
with open(OUTPUT_FILE, "w", encoding="utf-8") as f_out:
|
| 43 |
+
json.dump(results, f_out, ensure_ascii=False, indent=4)
|
| 44 |
+
|
| 45 |
+
print(f"\n✅ Done! Output saved to: {OUTPUT_FILE}")
|
| 46 |
+
|
| 47 |
+
if __name__ == "__main__":
|
| 48 |
+
main()
|