Spaces:
Running
on
Zero

Running
on
Zero

Commit
·
5f870ca
1
Parent(s):
6f2ad11
initial commit
Browse files- app.py +311 -0
- conversation_public.py +517 -0
- examples/icon_256.png +0 -0
- examples/image-text/demo_example.jpg +0 -0
- examples/user_avator.png +0 -0
- gitignore +1 -0
- requirements.txt +30 -0
app.py
ADDED
|
@@ -0,0 +1,311 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import argparse
|
| 3 |
+
import traceback
|
| 4 |
+
import logging
|
| 5 |
+
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', datefmt='%Y-%m-%d %H:%M:%S')
|
| 6 |
+
|
| 7 |
+
import spaces
|
| 8 |
+
import gradio as gr
|
| 9 |
+
from conversation_public import default_conversation
|
| 10 |
+
|
| 11 |
+
auth_token = os.environ.get("TOKEN_FROM_SECRET")
|
| 12 |
+
|
| 13 |
+
##########################################
|
| 14 |
+
# LLM part
|
| 15 |
+
##########################################
|
| 16 |
+
from transformers import AutoProcessor, AutoTokenizer, TextIteratorStreamer
|
| 17 |
+
from vllm import LLM, SamplingParams
|
| 18 |
+
from qwen_vl_utils import process_vision_info
|
| 19 |
+
from threading import Thread
|
| 20 |
+
|
| 21 |
+
# === Prompts ===
|
| 22 |
+
SYSTEM_PROMPT_LLM = "You are a helpful assistant."
|
| 23 |
+
SYSTEM_PROMPT_CAP = "You are given an image and a relevant question. Based on the query, please describe the image in details. Do not try to answer the question."
|
| 24 |
+
|
| 25 |
+
CAPTION_PROMPT = "Question: {}\nPlease describe the image. DO NOT try to answer the question!"
|
| 26 |
+
LLM_PROMPT = """In the following text, you will receive a detailed caption of an image and a relevant question. In addition, you will be provided with a tentative model response. You goal is to answer the question using these information.\n\n### The detailed caption of the provided image: {}\n\n### Note that the caption might contain incorrect solutions, do not be misguided by them.\n\n### A problem to be solved: {}\n\n### A tentative model response: {}\n\n### Note that the above tentative response might be inaccurate (due to calculation errors, incorrect logic/reasoning and so on), under such a case, please ignore it and give your own solutions. However, if you do not have enough evidence to show it is wrong, please output the tentative response."""
|
| 27 |
+
|
| 28 |
+
# === Initialize Models ===
|
| 29 |
+
MLLM_MODEL_PATH = "KaiChen1998/RACRO-7B-CRO-GRPO"
|
| 30 |
+
LLM_MODEL_PATH = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
|
| 31 |
+
|
| 32 |
+
processor = AutoProcessor.from_pretrained(MLLM_MODEL_PATH)
|
| 33 |
+
tokenizer = AutoTokenizer.from_pretrained(LLM_MODEL_PATH)
|
| 34 |
+
|
| 35 |
+
mllm = LLM(model=MLLM_MODEL_PATH, tensor_parallel_size=1, gpu_memory_utilization=0.8,
|
| 36 |
+
device='cuda:0', dtype="bfloat16", limit_mm_per_prompt={"image": 1})
|
| 37 |
+
|
| 38 |
+
llm = LLM(model=LLM_MODEL_PATH, tensor_parallel_size=1, gpu_memory_utilization=0.8,
|
| 39 |
+
device='cuda:0', dtype="bfloat16")
|
| 40 |
+
|
| 41 |
+
mllm_sampling = SamplingParams(temperature=0, max_tokens=8192)
|
| 42 |
+
llm_sampling = SamplingParams(temperature=0.6, top_p=0.95, max_tokens=8192)
|
| 43 |
+
|
| 44 |
+
# === Build Prompts ===
|
| 45 |
+
def build_messages(image_path, question):
|
| 46 |
+
cap_msgs = [
|
| 47 |
+
{"role": "system", "content": SYSTEM_PROMPT_CAP},
|
| 48 |
+
{"role": "user", "content": [{"type": "image", "image": image_path}, {"type": "text", "text": CAPTION_PROMPT.format(question)}]}
|
| 49 |
+
]
|
| 50 |
+
qa_msgs = [
|
| 51 |
+
{"role": "user", "content": [{"type": "image", "image": image_path}, {"type": "text", "text": question + " Please think step by step. The final answer MUST BE put in \\boxed{}."}]}
|
| 52 |
+
]
|
| 53 |
+
return cap_msgs, qa_msgs
|
| 54 |
+
|
| 55 |
+
# === Run Captioning and QA ===
|
| 56 |
+
def run_mllm_tentative(image_tensor, cap_prompt, qa_prompt):
|
| 57 |
+
qa_output = mllm.generate([{"multi_modal_data": {"image": image_tensor}, "prompt": qa_prompt[0]}], sampling_params=mllm_sampling)
|
| 58 |
+
return qa_output[0].outputs[0].text
|
| 59 |
+
|
| 60 |
+
def run_mllm_caption(image_tensor, cap_prompt, qa_prompt):
|
| 61 |
+
cap_output = mllm.generate([{"multi_modal_data": {"image": image_tensor}, "prompt": cap_prompt[0]}], sampling_params=mllm_sampling)
|
| 62 |
+
return cap_output[0].outputs[0].text
|
| 63 |
+
|
| 64 |
+
# === Final Reasoning Step ===
|
| 65 |
+
def run_llm_reasoning(caption, question, answer):
|
| 66 |
+
messages = [
|
| 67 |
+
{"role": "system", "content": SYSTEM_PROMPT_LLM},
|
| 68 |
+
{"role": "user", "content": LLM_PROMPT.format(caption, question, answer)}
|
| 69 |
+
]
|
| 70 |
+
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
| 71 |
+
output = llm.generate([{"prompt": prompt}], sampling_params=llm_sampling)
|
| 72 |
+
return output[0].outputs[0].text
|
| 73 |
+
|
| 74 |
+
##########################################
|
| 75 |
+
# Gradio part
|
| 76 |
+
##########################################
|
| 77 |
+
no_change_btn = gr.Button()
|
| 78 |
+
enable_btn = gr.Button(interactive=True)
|
| 79 |
+
disable_btn = gr.Button(interactive=False)
|
| 80 |
+
server_error_msg = "**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**"
|
| 81 |
+
server_oom_msg = "**OUT OF GPU MEMORY DETECTED. PLEASE DECREASE THE MAX OUTPUT TOKENS AND REGENERATE.**"
|
| 82 |
+
|
| 83 |
+
def load_demo_refresh_model_list():
|
| 84 |
+
logging.info(f"load_demo.")
|
| 85 |
+
state = default_conversation.copy()
|
| 86 |
+
return state
|
| 87 |
+
|
| 88 |
+
def regenerate(state, image_process_mode):
|
| 89 |
+
logging.info(f"regenerate.")
|
| 90 |
+
state.messages[-1][-1] = None
|
| 91 |
+
prev_human_msg = state.messages[-2]
|
| 92 |
+
if type(prev_human_msg[1]) in (tuple, list):
|
| 93 |
+
prev_human_msg[1] = (*prev_human_msg[1][:2], image_process_mode, *prev_human_msg[1][3:])
|
| 94 |
+
state.skip_next = False
|
| 95 |
+
return (state, state.to_gradio_chatbot_public(), "", None) + (disable_btn,) * 2
|
| 96 |
+
|
| 97 |
+
def clear_history():
|
| 98 |
+
logging.info(f"clear_history.")
|
| 99 |
+
state = default_conversation.copy()
|
| 100 |
+
return (state, state.to_gradio_chatbot_public(), "", None) + (disable_btn,) * 2
|
| 101 |
+
|
| 102 |
+
############
|
| 103 |
+
# Show prompt in the chatbot
|
| 104 |
+
# Input: [state, textbox, imagebox, image_process_mode]
|
| 105 |
+
# Return: [state, chatbot, textbox, imagebox] + btn_list
|
| 106 |
+
############
|
| 107 |
+
def add_text(state, text, image, image_process_mode):
|
| 108 |
+
# Input legality checking
|
| 109 |
+
logging.info(f"add_text. len: {len(text)}")
|
| 110 |
+
if len(text) <= 0 or image is None:
|
| 111 |
+
state.skip_next = True
|
| 112 |
+
return (state, state.to_gradio_chatbot_public(), "", None) + (no_change_btn,) * 2
|
| 113 |
+
|
| 114 |
+
# Deal with image inputs
|
| 115 |
+
if image is not None:
|
| 116 |
+
text = (text, image, image_process_mode, None)
|
| 117 |
+
|
| 118 |
+
# Single round only
|
| 119 |
+
state = default_conversation.copy()
|
| 120 |
+
state.append_message(state.roles[0], text)
|
| 121 |
+
state.skip_next = False
|
| 122 |
+
logging.info(str(state.messages))
|
| 123 |
+
return (state, state.to_gradio_chatbot_public(), "") + (disable_btn,) * 2
|
| 124 |
+
|
| 125 |
+
############
|
| 126 |
+
# Get response
|
| 127 |
+
# Input: [state]
|
| 128 |
+
# Return: [state, chatbot] + btn_list
|
| 129 |
+
############
|
| 130 |
+
@spaces.GPU
|
| 131 |
+
def http_bot(state):
|
| 132 |
+
logging.info(f"http_bot.")
|
| 133 |
+
|
| 134 |
+
if state.skip_next:
|
| 135 |
+
yield (state, state.to_gradio_chatbot_public()) + (no_change_btn,) * 2
|
| 136 |
+
return
|
| 137 |
+
|
| 138 |
+
# Retrive prompt
|
| 139 |
+
prompt = state.messages[-1][0][0]
|
| 140 |
+
all_images = state.get_images(return_pil=True)[0]
|
| 141 |
+
pload = {"prompt": prompt, "images": f'List of {len(state.get_images())} images: {all_images}'}
|
| 142 |
+
logging.info(f"==== request ====\n{pload}")
|
| 143 |
+
|
| 144 |
+
# Construct prompt
|
| 145 |
+
cap_msgs, qa_msgs = build_messages(all_images, prompt)
|
| 146 |
+
cap_prompt = processor.apply_chat_template([cap_msgs], tokenize=False, add_generation_prompt=True)
|
| 147 |
+
qa_prompt = processor.apply_chat_template([qa_msgs], tokenize=False, add_generation_prompt=True)
|
| 148 |
+
|
| 149 |
+
image_tensor, _ = process_vision_info(cap_msgs)
|
| 150 |
+
tentative_answer = run_mllm_tentative(image_tensor, cap_prompt, qa_prompt)
|
| 151 |
+
state.append_message(state.roles[1], "# Tentative Response\n\n" + tentative_answer)
|
| 152 |
+
logging.info("# Tentative Response\n\n" + tentative_answer)
|
| 153 |
+
yield (state, state.to_gradio_chatbot_public()) + (disable_btn,) * 2
|
| 154 |
+
|
| 155 |
+
caption_text = run_mllm_caption(image_tensor, cap_prompt, qa_prompt)
|
| 156 |
+
state.append_message(state.roles[1], "# Caption\n\n" + caption_text)
|
| 157 |
+
logging.info("# Caption\n\n" + caption_text)
|
| 158 |
+
yield (state, state.to_gradio_chatbot_public()) + (disable_btn,) * 2
|
| 159 |
+
|
| 160 |
+
final_answer = run_llm_reasoning(caption_text, QUESTION, tentative_answer)
|
| 161 |
+
state.append_message(state.roles[1], "# Final Response\n\n" + final_answer)
|
| 162 |
+
logging.info("# Final Response\n\n" + final_answer)
|
| 163 |
+
yield (state, state.to_gradio_chatbot_public()) + (enable_btn,) * 2
|
| 164 |
+
|
| 165 |
+
############
|
| 166 |
+
# Layout Markdown
|
| 167 |
+
############
|
| 168 |
+
title_markdown = ("""
|
| 169 |
+
<div style="display: flex; align-items: center; padding: 20px; border-radius: 10px; background-color: #f0f0f0;">
|
| 170 |
+
<div>
|
| 171 |
+
<h1 style="margin: 0;">RACRO: Perceptual Decoupling for Scalable Multi-modal Reasoning via Reward-Optimized Captioning</h1>
|
| 172 |
+
<h2 style="margin: 10px 0;">📃 <a href="https://www.arxiv.org/abs/2506.04559" style="font-weight: 400;">Paper</a> | 💻 <a href="https://github.com/gyhdog99/RACRO2" style="font-weight: 400;">Code</a> | 🤗 <a href="https://huggingface.co/collections/KaiChen1998/racro-6848ec8c65b3a0bf33d0fbdb" style="font-weight: 400;">HuggingFace</a></h2>
|
| 173 |
+
<p style="margin: 20px 0;">
|
| 174 |
+
<strong>1. RACRO is designed for multi-modal reasoning, and thus, image inputs are <mark>ALWAYS</mark> necessary!</strong><br/>
|
| 175 |
+
<strong>2. Models are deployed with vLLM, which unfortunately, still does not support streaming outputs for MLLMs.</strong>
|
| 176 |
+
</p>
|
| 177 |
+
</div>
|
| 178 |
+
</div>
|
| 179 |
+
""")
|
| 180 |
+
|
| 181 |
+
learn_more_markdown = ("""
|
| 182 |
+
## Citation
|
| 183 |
+
<pre><code>@article{gou2025perceptual,
|
| 184 |
+
author = {Gou, Yunhao and Chen, Kai and Liu, Zhili and Hong, Lanqing and Jin, Xin and Li, Zhenguo and Kwok, James T. and Zhang, Yu},
|
| 185 |
+
title = {Perceptual Decoupling for Scalable Multi-modal Reasoning via Reward-Optimized Captioning},
|
| 186 |
+
journal = {arXiv preprint arXiv:2506.04559},
|
| 187 |
+
year = {2025},
|
| 188 |
+
}</code></pre>
|
| 189 |
+
""")
|
| 190 |
+
|
| 191 |
+
block_css = """
|
| 192 |
+
#buttons button {
|
| 193 |
+
min-width: min(120px,100%);
|
| 194 |
+
}
|
| 195 |
+
.message-row img {
|
| 196 |
+
margin: 0px !important;
|
| 197 |
+
}
|
| 198 |
+
.avatar-container img {
|
| 199 |
+
padding: 0px !important;
|
| 200 |
+
}
|
| 201 |
+
"""
|
| 202 |
+
|
| 203 |
+
############
|
| 204 |
+
# Layout Demo
|
| 205 |
+
############
|
| 206 |
+
def build_demo(embed_mode):
|
| 207 |
+
textbox = gr.Textbox(label="Text", show_label=False, placeholder="Enter text and then click 💬 Chat to talk with me ^v^", container=False)
|
| 208 |
+
with gr.Blocks(title="RACRO", theme=gr.themes.Default(), css=block_css) as demo:
|
| 209 |
+
state = gr.State()
|
| 210 |
+
if not embed_mode:
|
| 211 |
+
gr.HTML(title_markdown)
|
| 212 |
+
|
| 213 |
+
##############
|
| 214 |
+
# Chatbot
|
| 215 |
+
##############
|
| 216 |
+
with gr.Row(equal_height=True):
|
| 217 |
+
with gr.Column(scale=1):
|
| 218 |
+
imagebox = gr.Image(type="pil", label="Image")
|
| 219 |
+
image_process_mode = gr.Radio(
|
| 220 |
+
["Crop", "Resize", "Pad", "Default"],
|
| 221 |
+
value="Default",
|
| 222 |
+
label="Preprocess for non-square image", visible=False)
|
| 223 |
+
|
| 224 |
+
gr.Examples(examples=[
|
| 225 |
+
["./examples/demo_example.png", "When the canister is momentarily stopped by the spring, by what distance $d$ is the spring compressed?"],
|
| 226 |
+
], inputs=[imagebox, textbox], label='Examples')
|
| 227 |
+
|
| 228 |
+
with gr.Column(scale=8):
|
| 229 |
+
chatbot = gr.Chatbot(
|
| 230 |
+
elem_id="chatbot",
|
| 231 |
+
label="RACRO Chatbot",
|
| 232 |
+
layout="bubble",
|
| 233 |
+
avatar_images=["examples/user_avator.png", "examples/icon_256.png"]
|
| 234 |
+
)
|
| 235 |
+
textbox.render()
|
| 236 |
+
with gr.Row(elem_id="buttons") as button_row:
|
| 237 |
+
submit_btn = gr.Button(value="💬 Chat", variant="primary")
|
| 238 |
+
# stop_btn = gr.Button(value="⏹️ Stop Generation", interactive=False)
|
| 239 |
+
regenerate_btn = gr.Button(value="🔄 Regenerate", interactive=False)
|
| 240 |
+
clear_btn = gr.Button(value="🗑️ Clear", interactive=False)
|
| 241 |
+
|
| 242 |
+
if not embed_mode:
|
| 243 |
+
gr.Markdown(learn_more_markdown)
|
| 244 |
+
|
| 245 |
+
# Register listeners
|
| 246 |
+
btn_list = [regenerate_btn, clear_btn]
|
| 247 |
+
regenerate_btn.click(
|
| 248 |
+
regenerate,
|
| 249 |
+
[state, image_process_mode],
|
| 250 |
+
[state, chatbot, textbox, imagebox] + btn_list
|
| 251 |
+
).then(
|
| 252 |
+
http_bot,
|
| 253 |
+
[state],
|
| 254 |
+
[state, chatbot] + btn_list,
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
clear_btn.click(
|
| 258 |
+
clear_history,
|
| 259 |
+
None,
|
| 260 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 261 |
+
queue=False
|
| 262 |
+
)
|
| 263 |
+
|
| 264 |
+
# probably mean press enter
|
| 265 |
+
textbox.submit(
|
| 266 |
+
add_text,
|
| 267 |
+
[state, textbox, imagebox, image_process_mode],
|
| 268 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 269 |
+
queue=False
|
| 270 |
+
).then(
|
| 271 |
+
http_bot,
|
| 272 |
+
[state],
|
| 273 |
+
[state, chatbot] + btn_list,
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
submit_btn.click(
|
| 277 |
+
add_text,
|
| 278 |
+
[state, textbox, imagebox, image_process_mode],
|
| 279 |
+
[state, chatbot, textbox, imagebox] + btn_list
|
| 280 |
+
).then(
|
| 281 |
+
http_bot,
|
| 282 |
+
[state],
|
| 283 |
+
[state, chatbot] + btn_list,
|
| 284 |
+
)
|
| 285 |
+
|
| 286 |
+
##############
|
| 287 |
+
# Demo loading
|
| 288 |
+
##############
|
| 289 |
+
demo.load(
|
| 290 |
+
load_demo_refresh_model_list,
|
| 291 |
+
None,
|
| 292 |
+
[state],
|
| 293 |
+
queue=False
|
| 294 |
+
)
|
| 295 |
+
return demo
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
parser = argparse.ArgumentParser()
|
| 299 |
+
parser.add_argument("--share", action="store_true")
|
| 300 |
+
parser.add_argument("--embed", action="store_true")
|
| 301 |
+
args = parser.parse_args()
|
| 302 |
+
|
| 303 |
+
demo = build_demo(args.embed)
|
| 304 |
+
demo.queue(
|
| 305 |
+
max_size=10,
|
| 306 |
+
api_open=False
|
| 307 |
+
).launch(
|
| 308 |
+
favicon_path="./examples/icon_256.png",
|
| 309 |
+
allowed_paths=["/"],
|
| 310 |
+
share=args.share
|
| 311 |
+
)
|
conversation_public.py
ADDED
|
@@ -0,0 +1,517 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import dataclasses
|
| 2 |
+
from enum import auto, Enum
|
| 3 |
+
from typing import List, Tuple
|
| 4 |
+
import base64
|
| 5 |
+
from io import BytesIO
|
| 6 |
+
from PIL import Image
|
| 7 |
+
|
| 8 |
+
import base64
|
| 9 |
+
tts_format = "Please synthesize the speech corresponding to the follwing text.\n"
|
| 10 |
+
|
| 11 |
+
class SeparatorStyle(Enum):
|
| 12 |
+
"""Different separator style."""
|
| 13 |
+
SINGLE = auto()
|
| 14 |
+
TWO = auto()
|
| 15 |
+
MPT = auto()
|
| 16 |
+
PLAIN = auto()
|
| 17 |
+
LLAMA_2 = auto()
|
| 18 |
+
GLM4 = auto()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@dataclasses.dataclass
|
| 22 |
+
class Conversation:
|
| 23 |
+
"""A class that keeps all conversation history."""
|
| 24 |
+
system: str
|
| 25 |
+
roles: List[str]
|
| 26 |
+
messages: List[List[str]]
|
| 27 |
+
offset: int
|
| 28 |
+
sep_style: SeparatorStyle = SeparatorStyle.SINGLE
|
| 29 |
+
sep: str = "###"
|
| 30 |
+
sep2: str = None
|
| 31 |
+
version: str = "Unknown"
|
| 32 |
+
|
| 33 |
+
skip_next: bool = False
|
| 34 |
+
|
| 35 |
+
def get_prompt(self):
|
| 36 |
+
messages = self.messages
|
| 37 |
+
if len(messages) > 0 and type(messages[0][1]) is tuple and messages[0][1][1] is not None:
|
| 38 |
+
messages = self.messages.copy()
|
| 39 |
+
init_role, init_msg = messages[0].copy()
|
| 40 |
+
init_msg = init_msg[0].replace("<image>", "").strip()
|
| 41 |
+
if 'mmtag' in self.version:
|
| 42 |
+
messages[0] = (init_role, init_msg)
|
| 43 |
+
messages.insert(0, (self.roles[0], "<Image><image></Image>"))
|
| 44 |
+
messages.insert(1, (self.roles[1], "Received."))
|
| 45 |
+
else:
|
| 46 |
+
messages[0] = (init_role, "<image>\n" + init_msg)
|
| 47 |
+
|
| 48 |
+
if self.sep_style == SeparatorStyle.SINGLE:
|
| 49 |
+
ret = self.system + self.sep
|
| 50 |
+
for role, message in messages:
|
| 51 |
+
if message:
|
| 52 |
+
if type(message) is tuple:
|
| 53 |
+
message, _, _ = message[:3]
|
| 54 |
+
ret += role + ": " + message + self.sep
|
| 55 |
+
else:
|
| 56 |
+
ret += role + ":"
|
| 57 |
+
elif self.sep_style == SeparatorStyle.TWO:
|
| 58 |
+
seps = [self.sep, self.sep2]
|
| 59 |
+
ret = self.system + seps[0]
|
| 60 |
+
for i, (role, message) in enumerate(messages):
|
| 61 |
+
if message:
|
| 62 |
+
if type(message) is tuple:
|
| 63 |
+
message, _, _ = message[:3]
|
| 64 |
+
ret += role + ": " + message + seps[i % 2]
|
| 65 |
+
else:
|
| 66 |
+
ret += role + ":"
|
| 67 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 68 |
+
ret = self.system + self.sep
|
| 69 |
+
for role, message in messages:
|
| 70 |
+
if message:
|
| 71 |
+
if type(message) is tuple:
|
| 72 |
+
message, _, _ = message[:3]
|
| 73 |
+
ret += role + message + self.sep
|
| 74 |
+
else:
|
| 75 |
+
ret += role
|
| 76 |
+
elif self.sep_style == SeparatorStyle.LLAMA_2:
|
| 77 |
+
wrap_sys = lambda msg: f"<<SYS>>\n{msg}\n<</SYS>>\n\n" if len(msg) > 0 else msg
|
| 78 |
+
wrap_inst = lambda msg: f"[INST] {msg} [/INST]"
|
| 79 |
+
ret = ""
|
| 80 |
+
|
| 81 |
+
for i, (role, message) in enumerate(messages):
|
| 82 |
+
if i == 0:
|
| 83 |
+
assert message, "first message should not be none"
|
| 84 |
+
assert role == self.roles[0], "first message should come from user"
|
| 85 |
+
if message:
|
| 86 |
+
if type(message) is tuple:
|
| 87 |
+
message, _, _ = message[:3]
|
| 88 |
+
if i == 0: message = wrap_sys(self.system) + message
|
| 89 |
+
if i % 2 == 0:
|
| 90 |
+
message = wrap_inst(message)
|
| 91 |
+
ret += self.sep + message
|
| 92 |
+
else:
|
| 93 |
+
ret += " " + message + " " + self.sep2
|
| 94 |
+
else:
|
| 95 |
+
ret += ""
|
| 96 |
+
ret = ret.lstrip(self.sep)
|
| 97 |
+
elif self.sep_style == SeparatorStyle.PLAIN:
|
| 98 |
+
seps = [self.sep, self.sep2]
|
| 99 |
+
ret = self.system
|
| 100 |
+
for i, (role, message) in enumerate(messages):
|
| 101 |
+
if message:
|
| 102 |
+
if type(message) is tuple:
|
| 103 |
+
message, _, _ = message[:3]
|
| 104 |
+
ret += message + seps[i % 2]
|
| 105 |
+
else:
|
| 106 |
+
ret += ""
|
| 107 |
+
elif self.sep_style == SeparatorStyle.GLM4:
|
| 108 |
+
role = ("<|user|>", "<|assistant|>")
|
| 109 |
+
ret = self.system + role[0]
|
| 110 |
+
for i, (role, message) in enumerate(messages):
|
| 111 |
+
if message:
|
| 112 |
+
if type(message) is tuple:
|
| 113 |
+
message, _, _ = message[:3]
|
| 114 |
+
ret += self.sep + message + role[(i+1) % 2]
|
| 115 |
+
else:
|
| 116 |
+
ret += ""
|
| 117 |
+
else:
|
| 118 |
+
raise ValueError(f"Invalid style: {self.sep_style}")
|
| 119 |
+
|
| 120 |
+
return ret
|
| 121 |
+
|
| 122 |
+
def append_message(self, role, message):
|
| 123 |
+
if isinstance(self.messages, tuple):
|
| 124 |
+
self.messages += ([role, message],)
|
| 125 |
+
else:
|
| 126 |
+
self.messages.append([role, message])
|
| 127 |
+
|
| 128 |
+
def process_image(self, image, image_process_mode, return_pil=False, image_format='PNG', max_len=1344, min_len=672):
|
| 129 |
+
if image_process_mode == "Pad":
|
| 130 |
+
def expand2square(pil_img, background_color=(122, 116, 104)):
|
| 131 |
+
width, height = pil_img.size
|
| 132 |
+
if width == height:
|
| 133 |
+
return pil_img
|
| 134 |
+
elif width > height:
|
| 135 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 136 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 137 |
+
return result
|
| 138 |
+
else:
|
| 139 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 140 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 141 |
+
return result
|
| 142 |
+
image = expand2square(image)
|
| 143 |
+
elif image_process_mode in ["Default", "Crop"]:
|
| 144 |
+
pass
|
| 145 |
+
elif image_process_mode == "Resize":
|
| 146 |
+
image = image.resize((336, 336))
|
| 147 |
+
else:
|
| 148 |
+
raise ValueError(f"Invalid image_process_mode: {image_process_mode}")
|
| 149 |
+
if max(image.size) > max_len:
|
| 150 |
+
max_hw, min_hw = max(image.size), min(image.size)
|
| 151 |
+
aspect_ratio = max_hw / min_hw
|
| 152 |
+
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
|
| 153 |
+
longest_edge = int(shortest_edge * aspect_ratio)
|
| 154 |
+
W, H = image.size
|
| 155 |
+
if H > W:
|
| 156 |
+
H, W = longest_edge, shortest_edge
|
| 157 |
+
else:
|
| 158 |
+
H, W = shortest_edge, longest_edge
|
| 159 |
+
image = image.resize((W, H))
|
| 160 |
+
if return_pil:
|
| 161 |
+
return image
|
| 162 |
+
else:
|
| 163 |
+
buffered = BytesIO()
|
| 164 |
+
image.save(buffered, format=image_format)
|
| 165 |
+
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
|
| 166 |
+
return img_b64_str
|
| 167 |
+
|
| 168 |
+
def get_images(self, return_pil=False):
|
| 169 |
+
images = []
|
| 170 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 171 |
+
if i % 2 == 0:
|
| 172 |
+
if type(msg) is tuple and msg[1] is not None:
|
| 173 |
+
msg, image, image_process_mode = msg[:3]
|
| 174 |
+
image = self.process_image(image, image_process_mode, return_pil=return_pil)
|
| 175 |
+
images.append(image)
|
| 176 |
+
return images
|
| 177 |
+
|
| 178 |
+
def to_gradio_chatbot(self):
|
| 179 |
+
ret = []
|
| 180 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 181 |
+
if i % 2 == 0:
|
| 182 |
+
if type(msg) is tuple:
|
| 183 |
+
msg, image, image_process_mode = msg
|
| 184 |
+
img_b64_str = self.process_image(
|
| 185 |
+
image, "Default", return_pil=False,
|
| 186 |
+
image_format='JPEG')
|
| 187 |
+
img_str = f'<img src="data:image/jpeg;base64,{img_b64_str}" alt="user upload image" />'
|
| 188 |
+
msg = img_str + msg.replace('<image>', '').strip()
|
| 189 |
+
ret.append([msg, None])
|
| 190 |
+
else:
|
| 191 |
+
ret.append([msg, None])
|
| 192 |
+
else:
|
| 193 |
+
ret[-1][-1] = msg
|
| 194 |
+
return ret
|
| 195 |
+
|
| 196 |
+
def to_gradio_chatbot_public(self):
|
| 197 |
+
ret = []
|
| 198 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 199 |
+
if i % 2 == 0:
|
| 200 |
+
if type(msg) is tuple:
|
| 201 |
+
msg, image, image_process_mode, audio_input = msg
|
| 202 |
+
ret_msg = ""
|
| 203 |
+
if image is not None:
|
| 204 |
+
img_b64_str = self.process_image(
|
| 205 |
+
image, "Default", return_pil=False,
|
| 206 |
+
image_format='JPEG')
|
| 207 |
+
img_str = f'<img src="data:image/jpeg;base64,{img_b64_str}" alt="user upload image" />'
|
| 208 |
+
ret_msg += img_str
|
| 209 |
+
if audio_input is not None:
|
| 210 |
+
audio_b64_str = base64.b64encode(open(audio_input, "rb").read()).decode("utf-8")
|
| 211 |
+
audio_str = f'<audio src="data:audio/wav;base64,{audio_b64_str}" controls ></audio>'
|
| 212 |
+
ret_msg += audio_str
|
| 213 |
+
else:
|
| 214 |
+
ret_msg += msg.replace('<image>', '').replace(tts_format, '').strip()
|
| 215 |
+
ret.append([ret_msg, None])
|
| 216 |
+
else:
|
| 217 |
+
ret.append([msg, None])
|
| 218 |
+
else:
|
| 219 |
+
if type(msg) is tuple:
|
| 220 |
+
audio_b64_str = base64.b64encode(open(msg[1], "rb").read()).decode("utf-8")
|
| 221 |
+
msg = f'<audio src="data:audio/wav;base64,{audio_b64_str}" controls autoplay></audio>'
|
| 222 |
+
ret[-1][-1] = msg
|
| 223 |
+
return ret
|
| 224 |
+
|
| 225 |
+
def copy(self):
|
| 226 |
+
return Conversation(
|
| 227 |
+
system=self.system,
|
| 228 |
+
roles=self.roles,
|
| 229 |
+
messages=[[x, y] for x, y in self.messages],
|
| 230 |
+
offset=self.offset,
|
| 231 |
+
sep_style=self.sep_style,
|
| 232 |
+
sep=self.sep,
|
| 233 |
+
sep2=self.sep2,
|
| 234 |
+
version=self.version)
|
| 235 |
+
|
| 236 |
+
def dict(self):
|
| 237 |
+
if len(self.get_images()) > 0:
|
| 238 |
+
return {
|
| 239 |
+
"system": self.system,
|
| 240 |
+
"roles": self.roles,
|
| 241 |
+
"messages": [[x, y[0] if type(y) is tuple else y] for x, y in self.messages],
|
| 242 |
+
"offset": self.offset,
|
| 243 |
+
"sep": self.sep,
|
| 244 |
+
"sep2": self.sep2,
|
| 245 |
+
}
|
| 246 |
+
return {
|
| 247 |
+
"system": self.system,
|
| 248 |
+
"roles": self.roles,
|
| 249 |
+
"messages": self.messages,
|
| 250 |
+
"offset": self.offset,
|
| 251 |
+
"sep": self.sep,
|
| 252 |
+
"sep2": self.sep2,
|
| 253 |
+
}
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
conv_vicuna_v0 = Conversation(
|
| 257 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 258 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 259 |
+
roles=("Human", "Assistant"),
|
| 260 |
+
messages=(
|
| 261 |
+
("Human", "What are the key differences between renewable and non-renewable energy sources?"),
|
| 262 |
+
("Assistant",
|
| 263 |
+
"Renewable energy sources are those that can be replenished naturally in a relatively "
|
| 264 |
+
"short amount of time, such as solar, wind, hydro, geothermal, and biomass. "
|
| 265 |
+
"Non-renewable energy sources, on the other hand, are finite and will eventually be "
|
| 266 |
+
"depleted, such as coal, oil, and natural gas. Here are some key differences between "
|
| 267 |
+
"renewable and non-renewable energy sources:\n"
|
| 268 |
+
"1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable "
|
| 269 |
+
"energy sources are finite and will eventually run out.\n"
|
| 270 |
+
"2. Environmental impact: Renewable energy sources have a much lower environmental impact "
|
| 271 |
+
"than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, "
|
| 272 |
+
"and other negative effects.\n"
|
| 273 |
+
"3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically "
|
| 274 |
+
"have lower operational costs than non-renewable sources.\n"
|
| 275 |
+
"4. Reliability: Renewable energy sources are often more reliable and can be used in more remote "
|
| 276 |
+
"locations than non-renewable sources.\n"
|
| 277 |
+
"5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different "
|
| 278 |
+
"situations and needs, while non-renewable sources are more rigid and inflexible.\n"
|
| 279 |
+
"6. Sustainability: Renewable energy sources are more sustainable over the long term, while "
|
| 280 |
+
"non-renewable sources are not, and their depletion can lead to economic and social instability.\n")
|
| 281 |
+
),
|
| 282 |
+
offset=2,
|
| 283 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 284 |
+
sep="###",
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
conv_vicuna_v1 = Conversation(
|
| 288 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 289 |
+
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
| 290 |
+
roles=("USER", "ASSISTANT"),
|
| 291 |
+
version="v1",
|
| 292 |
+
messages=(),
|
| 293 |
+
offset=0,
|
| 294 |
+
sep_style=SeparatorStyle.TWO,
|
| 295 |
+
sep=" ",
|
| 296 |
+
sep2="</s>",
|
| 297 |
+
)
|
| 298 |
+
|
| 299 |
+
conv_llama_2 = Conversation(
|
| 300 |
+
system="""You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
| 301 |
+
|
| 302 |
+
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""",
|
| 303 |
+
roles=("USER", "ASSISTANT"),
|
| 304 |
+
version="llama_v2",
|
| 305 |
+
messages=(),
|
| 306 |
+
offset=0,
|
| 307 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 308 |
+
sep="<s>",
|
| 309 |
+
sep2="</s>",
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
conv_llava_llama_2 = Conversation(
|
| 313 |
+
system="You are a helpful language and vision assistant. "
|
| 314 |
+
"You are able to understand the visual content that the user provides, "
|
| 315 |
+
"and assist the user with a variety of tasks using natural language.",
|
| 316 |
+
roles=("USER", "ASSISTANT"),
|
| 317 |
+
version="llama_v2",
|
| 318 |
+
messages=(),
|
| 319 |
+
offset=0,
|
| 320 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 321 |
+
sep="<s>",
|
| 322 |
+
sep2="</s>",
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
conv_mpt = Conversation(
|
| 326 |
+
system="""<|im_start|>system
|
| 327 |
+
A conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers.""",
|
| 328 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 329 |
+
version="mpt",
|
| 330 |
+
messages=(),
|
| 331 |
+
offset=0,
|
| 332 |
+
sep_style=SeparatorStyle.MPT,
|
| 333 |
+
sep="<|im_end|>",
|
| 334 |
+
)
|
| 335 |
+
|
| 336 |
+
conv_llava_plain = Conversation(
|
| 337 |
+
system="",
|
| 338 |
+
roles=("", ""),
|
| 339 |
+
messages=(),
|
| 340 |
+
offset=0,
|
| 341 |
+
sep_style=SeparatorStyle.PLAIN,
|
| 342 |
+
sep="\n",
|
| 343 |
+
)
|
| 344 |
+
|
| 345 |
+
conv_llava_v0 = Conversation(
|
| 346 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 347 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 348 |
+
roles=("Human", "Assistant"),
|
| 349 |
+
messages=(),
|
| 350 |
+
offset=0,
|
| 351 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 352 |
+
sep="###",
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
conv_llava_v0_mmtag = Conversation(
|
| 356 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 357 |
+
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
| 358 |
+
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
| 359 |
+
roles=("Human", "Assistant"),
|
| 360 |
+
messages=(
|
| 361 |
+
),
|
| 362 |
+
offset=0,
|
| 363 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 364 |
+
sep="###",
|
| 365 |
+
version="v0_mmtag",
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
conv_llava_v1 = Conversation(
|
| 369 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 370 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 371 |
+
roles=("USER", "ASSISTANT"),
|
| 372 |
+
version="v1",
|
| 373 |
+
messages=(),
|
| 374 |
+
offset=0,
|
| 375 |
+
sep_style=SeparatorStyle.TWO,
|
| 376 |
+
sep=" ",
|
| 377 |
+
sep2="</s>",
|
| 378 |
+
)
|
| 379 |
+
|
| 380 |
+
conv_llava_v1_mmtag = Conversation(
|
| 381 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 382 |
+
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
| 383 |
+
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
| 384 |
+
roles=("USER", "ASSISTANT"),
|
| 385 |
+
messages=(),
|
| 386 |
+
offset=0,
|
| 387 |
+
sep_style=SeparatorStyle.TWO,
|
| 388 |
+
sep=" ",
|
| 389 |
+
sep2="</s>",
|
| 390 |
+
version="v1_mmtag",
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
conv_mistral_instruct = Conversation(
|
| 394 |
+
system="",
|
| 395 |
+
roles=("USER", "ASSISTANT"),
|
| 396 |
+
version="llama_v2",
|
| 397 |
+
messages=(),
|
| 398 |
+
offset=0,
|
| 399 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 400 |
+
sep="",
|
| 401 |
+
sep2="</s>",
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
conv_chatml_direct = Conversation(
|
| 405 |
+
system="""<|im_start|>system
|
| 406 |
+
Answer the questions.""",
|
| 407 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 408 |
+
version="mpt",
|
| 409 |
+
messages=(),
|
| 410 |
+
offset=0,
|
| 411 |
+
sep_style=SeparatorStyle.MPT,
|
| 412 |
+
sep="<|im_end|>",
|
| 413 |
+
)
|
| 414 |
+
|
| 415 |
+
conv_llama3 = Conversation(
|
| 416 |
+
system="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.""",
|
| 417 |
+
roles=("<|start_header_id|>user<|end_header_id|>\n\n", "<|start_header_id|>assistant<|end_header_id|>\n\n"),
|
| 418 |
+
version="llama3",
|
| 419 |
+
messages=(),
|
| 420 |
+
offset=0,
|
| 421 |
+
sep_style=SeparatorStyle.MPT,
|
| 422 |
+
sep="<|eot_id|>",
|
| 423 |
+
)
|
| 424 |
+
|
| 425 |
+
conv_llama3_demo = Conversation(
|
| 426 |
+
system="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. Your name is emova, and you are purely developed by the emova Team.""",
|
| 427 |
+
roles=("<|start_header_id|>user<|end_header_id|>\n\n", "<|start_header_id|>assistant<|end_header_id|>\n\n"),
|
| 428 |
+
version="llama3_demo",
|
| 429 |
+
messages=(),
|
| 430 |
+
offset=0,
|
| 431 |
+
sep_style=SeparatorStyle.MPT,
|
| 432 |
+
sep="<|eot_id|>",
|
| 433 |
+
)
|
| 434 |
+
|
| 435 |
+
conv_llama3_without_system = Conversation(
|
| 436 |
+
system="",
|
| 437 |
+
roles=("<|start_header_id|>user<|end_header_id|>\n\n", "<|start_header_id|>assistant<|end_header_id|>\n\n"),
|
| 438 |
+
version="llama3_without_system",
|
| 439 |
+
messages=(),
|
| 440 |
+
offset=0,
|
| 441 |
+
sep_style=SeparatorStyle.MPT,
|
| 442 |
+
sep="<|eot_id|>",
|
| 443 |
+
)
|
| 444 |
+
|
| 445 |
+
conv_llama3_without_systemV2 = Conversation(
|
| 446 |
+
system="",
|
| 447 |
+
roles=("user:", "assistant:"),
|
| 448 |
+
version="llama3_without_systemv2",
|
| 449 |
+
messages=(),
|
| 450 |
+
offset=0,
|
| 451 |
+
sep_style=SeparatorStyle.MPT,
|
| 452 |
+
sep="\n\n",
|
| 453 |
+
)
|
| 454 |
+
|
| 455 |
+
conv_qwen2 = Conversation(
|
| 456 |
+
system='<|im_start|>system\nYou are a helpful assistant.',
|
| 457 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 458 |
+
version="qwen2",
|
| 459 |
+
messages=(),
|
| 460 |
+
offset=0,
|
| 461 |
+
sep_style=SeparatorStyle.MPT,
|
| 462 |
+
sep="<|im_end|>\n",
|
| 463 |
+
)
|
| 464 |
+
|
| 465 |
+
conv_qwen2_demo = Conversation(
|
| 466 |
+
system='<|im_start|>system\nYou are a helpful assistant. Your name is emova, and you are purely developed by the emova Team.',
|
| 467 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 468 |
+
version="qwen2_demo",
|
| 469 |
+
messages=(),
|
| 470 |
+
offset=0,
|
| 471 |
+
sep_style=SeparatorStyle.MPT,
|
| 472 |
+
sep="<|im_end|>\n",
|
| 473 |
+
)
|
| 474 |
+
|
| 475 |
+
conv_glm4 = Conversation(
|
| 476 |
+
system='[gMASK]<sop>',
|
| 477 |
+
roles=("<|user|>", "<|assistant|>"),
|
| 478 |
+
version="glm4",
|
| 479 |
+
messages=(),
|
| 480 |
+
offset=0,
|
| 481 |
+
sep_style=SeparatorStyle.GLM4,
|
| 482 |
+
sep="\n",
|
| 483 |
+
)
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
default_conversation = conv_vicuna_v1
|
| 487 |
+
conv_templates = {
|
| 488 |
+
"default": conv_vicuna_v0,
|
| 489 |
+
"v0": conv_vicuna_v0,
|
| 490 |
+
"v1": conv_vicuna_v1,
|
| 491 |
+
"vicuna_v1": conv_vicuna_v1,
|
| 492 |
+
"llama_2": conv_llama_2,
|
| 493 |
+
"mistral_instruct": conv_mistral_instruct,
|
| 494 |
+
"chatml_direct": conv_chatml_direct,
|
| 495 |
+
"mistral_direct": conv_chatml_direct,
|
| 496 |
+
|
| 497 |
+
"plain": conv_llava_plain,
|
| 498 |
+
"v0_plain": conv_llava_plain,
|
| 499 |
+
"llava_v0": conv_llava_v0,
|
| 500 |
+
"v0_mmtag": conv_llava_v0_mmtag,
|
| 501 |
+
"llava_v1": conv_llava_v1,
|
| 502 |
+
"v1_mmtag": conv_llava_v1_mmtag,
|
| 503 |
+
"llava_llama_2": conv_llava_llama_2,
|
| 504 |
+
"llama3": conv_llama3,
|
| 505 |
+
"llama3_demo": conv_llama3_demo,
|
| 506 |
+
"llama3_without_system": conv_llama3_without_system,
|
| 507 |
+
"conv_llama3_without_systemV2": conv_llama3_without_systemV2,
|
| 508 |
+
|
| 509 |
+
"mpt": conv_mpt,
|
| 510 |
+
"qwen2": conv_qwen2,
|
| 511 |
+
"qwen2_demo": conv_qwen2_demo,
|
| 512 |
+
"glm4": conv_glm4,
|
| 513 |
+
}
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
if __name__ == "__main__":
|
| 517 |
+
print(default_conversation.get_prompt())
|
examples/icon_256.png
ADDED
|
|
examples/image-text/demo_example.jpg
ADDED
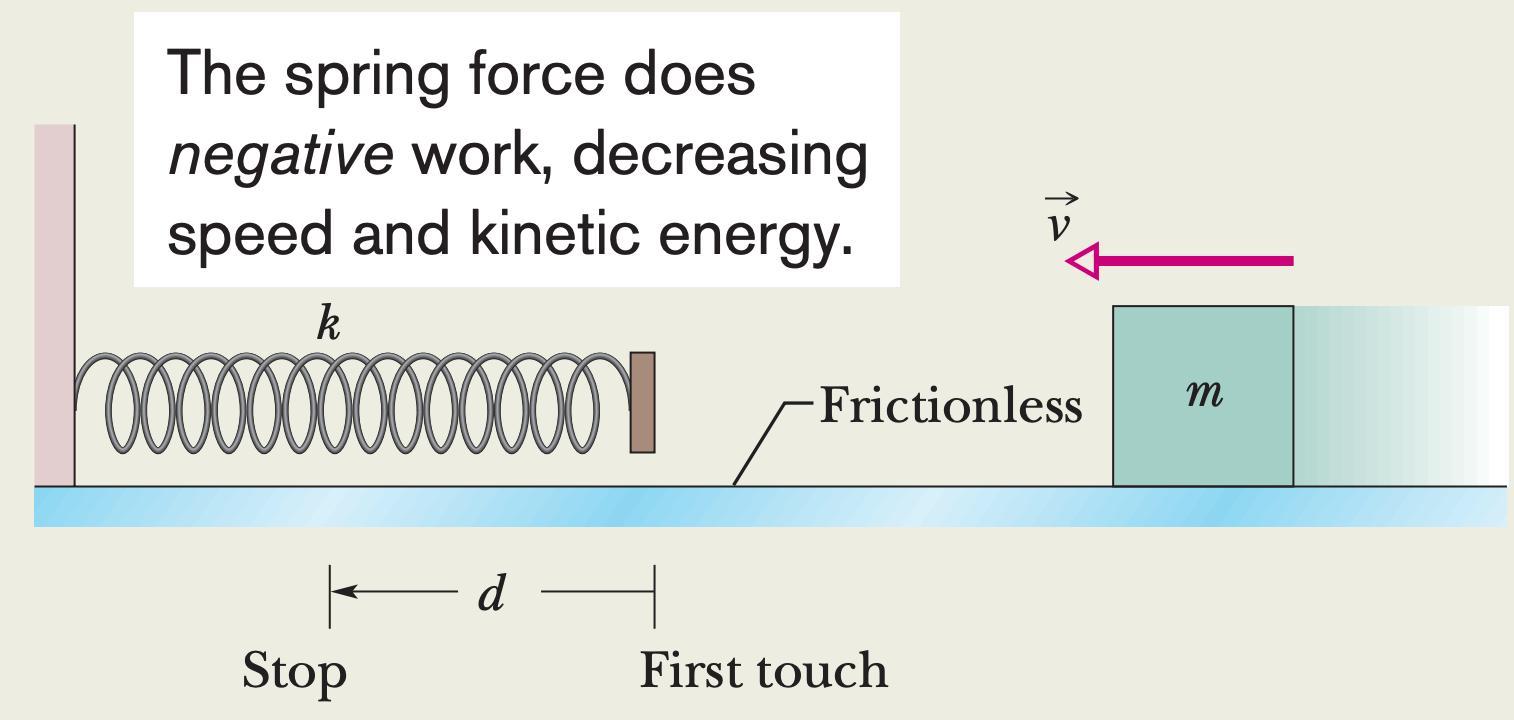
|
examples/user_avator.png
ADDED

|
gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__pycache__/
|
requirements.txt
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# requirements.txt records the full set of dependencies for development
|
| 2 |
+
torch==2.6.0
|
| 3 |
+
accelerate
|
| 4 |
+
codetiming
|
| 5 |
+
datasets
|
| 6 |
+
dill
|
| 7 |
+
# flash-attn
|
| 8 |
+
https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
|
| 9 |
+
hydra-core
|
| 10 |
+
liger-kernel
|
| 11 |
+
numpy
|
| 12 |
+
pandas
|
| 13 |
+
datasets
|
| 14 |
+
peft
|
| 15 |
+
pyarrow>=15.0.0
|
| 16 |
+
pybind11
|
| 17 |
+
pylatexenc
|
| 18 |
+
pylint==3.3.6
|
| 19 |
+
qwen_vl_utils
|
| 20 |
+
ray[default]
|
| 21 |
+
tensordict<=0.6.2
|
| 22 |
+
torchdata
|
| 23 |
+
transformers
|
| 24 |
+
vllm==0.8.2
|
| 25 |
+
wandb
|
| 26 |
+
word2number
|
| 27 |
+
math_verify
|
| 28 |
+
mathruler
|
| 29 |
+
tensorboard
|
| 30 |
+
transformers==4.51.0
|