Spaces:
Sleeping

Sleeping
Asaad Almutareb
commited on
Commit
·
f66560f
1
Parent(s):
8145c48
initial advanced rag chain
Browse files- .devcontainer/Dockerfile +15 -0
- .devcontainer/devcontainer.json +32 -0
- .github/dependabot.yml +12 -0
- .github/workflows/pylint.yml +23 -0
- CONTRIBUTION.md +21 -29
- Core_Advanced_RAG_components.ipynb +392 -0
- README.md +33 -32
- core-langchain-rag.py +267 -0
- docs/advanced_rag_architecture.drawio +115 -0
- docs/data_flow_diagram.drawio.png +0 -0
- docs/template.md +16 -0
- docs/workflow-advanced-rag.drawio +83 -0
- rag-system-anatomy/build_vector_store.py +46 -0
- rag-system-anatomy/create_embedding.py +48 -0
- rag-system-anatomy/get_db_retriever.py +29 -0
- rag-system-anatomy/load_data_from_urls.py +32 -0
- rag-system-anatomy/load_example_embeddings.py +37 -0
- requirements.txt +12 -0
- vectorstore/placeholder.txt +1 -0
.devcontainer/Dockerfile
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ARG VARIANT="3.10-bookworm"
|
| 2 |
+
FROM mcr.microsoft.com/devcontainers/python:1-${VARIANT}
|
| 3 |
+
#FROM langchain/langchain
|
| 4 |
+
|
| 5 |
+
# [Optional] Uncomment if you want to install an additional version of node using nvm
|
| 6 |
+
# ARG EXTRA_NODE_VERSION=10
|
| 7 |
+
# RUN su node -c "source /usr/local/share/nvm/nvm.sh && nvm install ${EXTRA_NODE_VERSION}"
|
| 8 |
+
|
| 9 |
+
# [Optional] Uncomment if you want to install more global node modules
|
| 10 |
+
# RUN su node -c "npm install -g <your-package-list-here>"
|
| 11 |
+
|
| 12 |
+
#COPY library-scripts/github-debian.sh /tmp/library-scripts/
|
| 13 |
+
RUN apt-get update && apt-get update
|
| 14 |
+
RUN pip install --upgrade pip
|
| 15 |
+
#RUN pip install -r requirements.txt
|
.devcontainer/devcontainer.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// For format details, see https://aka.ms/devcontainer.json. For config options, see the
|
| 2 |
+
// README at: https://github.com/devcontainers/templates/tree/main/src/python
|
| 3 |
+
{
|
| 4 |
+
"name": "Python 3.10",
|
| 5 |
+
// Or use a Dockerfile or Docker Compose file. More info: https://containers.dev/guide/dockerfile
|
| 6 |
+
//"image": "mcr.microsoft.com/devcontainers/python:1-3.10-bookworm"
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
// build config for the docker image instead:
|
| 10 |
+
"build": { "dockerfile": "Dockerfile" },
|
| 11 |
+
|
| 12 |
+
// Features to add to the dev container. More info: https://containers.dev/features.
|
| 13 |
+
// "features": {},
|
| 14 |
+
|
| 15 |
+
// Use 'forwardPorts' to make a list of ports inside the container available locally.
|
| 16 |
+
// "forwardPorts": [],
|
| 17 |
+
|
| 18 |
+
// Use 'postCreateCommand' to run commands after the container is created.
|
| 19 |
+
// "postCreateCommand": "pip3 install --user -r requirements.txt",
|
| 20 |
+
|
| 21 |
+
// Configure tool-specific properties.
|
| 22 |
+
"customizations": {
|
| 23 |
+
// Configure properties specific to VS Code.
|
| 24 |
+
"vscode": {
|
| 25 |
+
//Add the IDs of extensions you want installed when the container is created.
|
| 26 |
+
"extensions": ["ms-azuretools.vscode-docker", "ms-python.python", "qwtel.sqlite-viewer"]
|
| 27 |
+
}
|
| 28 |
+
}//,
|
| 29 |
+
|
| 30 |
+
// Uncomment to connect as root instead. More info: https://aka.ms/dev-containers-non-root.
|
| 31 |
+
// "remoteUser": "root"
|
| 32 |
+
}
|
.github/dependabot.yml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# To get started with Dependabot version updates, you'll need to specify which
|
| 2 |
+
# package ecosystems to update and where the package manifests are located.
|
| 3 |
+
# Please see the documentation for more information:
|
| 4 |
+
# https://docs.github.com/github/administering-a-repository/configuration-options-for-dependency-updates
|
| 5 |
+
# https://containers.dev/guide/dependabot
|
| 6 |
+
|
| 7 |
+
version: 2
|
| 8 |
+
updates:
|
| 9 |
+
- package-ecosystem: "devcontainers"
|
| 10 |
+
directory: "/"
|
| 11 |
+
schedule:
|
| 12 |
+
interval: weekly
|
.github/workflows/pylint.yml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Pylint
|
| 2 |
+
|
| 3 |
+
on: [push]
|
| 4 |
+
|
| 5 |
+
jobs:
|
| 6 |
+
build:
|
| 7 |
+
runs-on: ubuntu-latest
|
| 8 |
+
strategy:
|
| 9 |
+
matrix:
|
| 10 |
+
python-version: ["3.8", "3.9", "3.10"]
|
| 11 |
+
steps:
|
| 12 |
+
- uses: actions/checkout@v3
|
| 13 |
+
- name: Set up Python ${{ matrix.python-version }}
|
| 14 |
+
uses: actions/setup-python@v3
|
| 15 |
+
with:
|
| 16 |
+
python-version: ${{ matrix.python-version }}
|
| 17 |
+
- name: Install dependencies
|
| 18 |
+
run: |
|
| 19 |
+
python -m pip install --upgrade pip
|
| 20 |
+
pip install pylint
|
| 21 |
+
- name: Analysing the code with pylint
|
| 22 |
+
run: |
|
| 23 |
+
pylint $(git ls-files '*.py')
|
CONTRIBUTION.md
CHANGED
|
@@ -1,36 +1,28 @@
|
|
| 1 |
-
#
|
| 2 |
|
| 3 |
-
|
|
|
|
| 4 |
|
| 5 |
-
##
|
|
|
|
|
|
|
| 6 |
|
| 7 |
-
|
|
|
|
| 8 |
|
| 9 |
-
|
|
|
|
| 10 |
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
-
|
|
|
|
| 14 |
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
When reporting issues, please use the provided issue template. Your report should include:
|
| 20 |
-
|
| 21 |
-
- A clear, descriptive title
|
| 22 |
-
- A detailed description of the issue
|
| 23 |
-
- Steps to reproduce the issue
|
| 24 |
-
- Logs, if applicable
|
| 25 |
-
- Screenshots, if applicable
|
| 26 |
-
|
| 27 |
-
This information is crucial in diagnosing and fixing the issue you're experiencing.
|
| 28 |
-
|
| 29 |
-
### Suggestions
|
| 30 |
-
|
| 31 |
-
We're always looking for new ideas to improve our project. If you have a suggestion, please:
|
| 32 |
-
|
| 33 |
-
- Clearly describe your suggestion, including the purpose and intended outcome.
|
| 34 |
-
- Explain why you believe this change would be beneficial to the project.
|
| 35 |
-
|
| 36 |
-
We appreciate your contributions and look forward to collaborating with you!
|
|
|
|
| 1 |
+
# Pull Request Template
|
| 2 |
|
| 3 |
+
## Description
|
| 4 |
+
Please include a brief description of the changes introduced by this PR.
|
| 5 |
|
| 6 |
+
## Related Issue(s)
|
| 7 |
+
- If this PR addresses a particular issue, please reference it here using GitHub's linking syntax, e.g., "Fixes #123".
|
| 8 |
+
- If there's no related issue, briefly explain the motivation behind these changes.
|
| 9 |
|
| 10 |
+
## Changes Made
|
| 11 |
+
Please provide a list of the changes made in this PR.
|
| 12 |
|
| 13 |
+
## Screenshots (if applicable)
|
| 14 |
+
If the changes include UI updates or visual changes, please attach relevant screenshots here.
|
| 15 |
|
| 16 |
+
## Checklist
|
| 17 |
+
- [ ] I have tested my changes locally and ensured that they work as expected.
|
| 18 |
+
- [ ] I have updated the documentation (if applicable).
|
| 19 |
+
- [ ] My code follows the project's coding conventions and style guidelines.
|
| 20 |
+
- [ ] I have added appropriate test cases (if applicable).
|
| 21 |
+
- [ ] I have reviewed my own code to ensure its quality.
|
| 22 |
|
| 23 |
+
## Additional Notes
|
| 24 |
+
Add any additional notes or context about this PR here.
|
| 25 |
|
| 26 |
+
## Reviewer(s)
|
| 27 |
+
- @reviewer1
|
| 28 |
+
- @reviewer2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Core_Advanced_RAG_components.ipynb
ADDED
|
@@ -0,0 +1,392 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"nbformat": 4,
|
| 3 |
+
"nbformat_minor": 0,
|
| 4 |
+
"metadata": {
|
| 5 |
+
"colab": {
|
| 6 |
+
"provenance": [],
|
| 7 |
+
"gpuType": "T4",
|
| 8 |
+
"authorship_tag": "ABX9TyNTRxOWLfv3tkZHe66pK63p",
|
| 9 |
+
"include_colab_link": true
|
| 10 |
+
},
|
| 11 |
+
"kernelspec": {
|
| 12 |
+
"name": "python3",
|
| 13 |
+
"display_name": "Python 3"
|
| 14 |
+
},
|
| 15 |
+
"language_info": {
|
| 16 |
+
"name": "python"
|
| 17 |
+
},
|
| 18 |
+
"accelerator": "GPU"
|
| 19 |
+
},
|
| 20 |
+
"cells": [
|
| 21 |
+
{
|
| 22 |
+
"cell_type": "markdown",
|
| 23 |
+
"metadata": {
|
| 24 |
+
"id": "view-in-github",
|
| 25 |
+
"colab_type": "text"
|
| 26 |
+
},
|
| 27 |
+
"source": [
|
| 28 |
+
"<a href=\"https://colab.research.google.com/github/almutareb/advanced-rag-system-anatomy/blob/main/Core_Advanced_RAG_components.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
|
| 29 |
+
]
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
"cell_type": "markdown",
|
| 33 |
+
"source": [
|
| 34 |
+
"Install requirements"
|
| 35 |
+
],
|
| 36 |
+
"metadata": {
|
| 37 |
+
"id": "Hz8JZq6Ob8rt"
|
| 38 |
+
}
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"cell_type": "code",
|
| 42 |
+
"source": [
|
| 43 |
+
"import sys\n",
|
| 44 |
+
"import os\n",
|
| 45 |
+
"!pip install -qU langchain langchain-community --no-warn-script-location > /dev/null\n",
|
| 46 |
+
"!pip install -qU beautifulsoup4 --no-warn-script-location > /dev/null\n",
|
| 47 |
+
"!pip install -qU faiss-cpu --no-warn-script-location > /dev/null\n",
|
| 48 |
+
"# use the gpu optimized version of FAISS for better performance\n",
|
| 49 |
+
"#!pip install -qU faiss-gpu --no-warn-script-location > /dev/null\n",
|
| 50 |
+
"!pip install -qU chromadb --no-warn-script-location > /dev/null\n",
|
| 51 |
+
"!pip install -qU validators --no-warn-script-location > /dev/null\n",
|
| 52 |
+
"!pip install -qU sentence_transformers typing-extensions==4.8.0 unstructured --no-warn-script-location > /dev/null\n",
|
| 53 |
+
"!pip install -qU gradio==3.48.0 --no-warn-script-location > /dev/null"
|
| 54 |
+
],
|
| 55 |
+
"metadata": {
|
| 56 |
+
"id": "SXTdFuTvboyV"
|
| 57 |
+
},
|
| 58 |
+
"execution_count": null,
|
| 59 |
+
"outputs": []
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"cell_type": "markdown",
|
| 63 |
+
"source": [
|
| 64 |
+
"Download Documents"
|
| 65 |
+
],
|
| 66 |
+
"metadata": {
|
| 67 |
+
"id": "pETUBgFAk4Fx"
|
| 68 |
+
}
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"cell_type": "code",
|
| 72 |
+
"source": [
|
| 73 |
+
"from langchain.document_loaders.recursive_url_loader import RecursiveUrlLoader\n",
|
| 74 |
+
"from bs4 import BeautifulSoup as Soup\n",
|
| 75 |
+
"\n",
|
| 76 |
+
"# List of URLs to scrape\n",
|
| 77 |
+
"urls = [\"https://langchain-doc.readthedocs.io/en/latest\"\n",
|
| 78 |
+
" \"https://python.langchain.com/docs/get_started\"]\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"# Initialize an empty list to store the documents\n",
|
| 81 |
+
"docs = []\n",
|
| 82 |
+
"# Looping through each URL in the list - this could take some time!\n",
|
| 83 |
+
"for url in urls:\n",
|
| 84 |
+
" # max_depth set to 2 for demo purpose, should be increased for real scenario results, e.g. at least 5\n",
|
| 85 |
+
" loader = RecursiveUrlLoader(url=url, max_depth=4, extractor=lambda x: Soup(x, \"html.parser\").text)\n",
|
| 86 |
+
" docs.extend(loader.load())\n",
|
| 87 |
+
"print(f'Downloaded a total of {len(docs)} documents')"
|
| 88 |
+
],
|
| 89 |
+
"metadata": {
|
| 90 |
+
"id": "eVav9lGgk3X3"
|
| 91 |
+
},
|
| 92 |
+
"execution_count": null,
|
| 93 |
+
"outputs": []
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"cell_type": "markdown",
|
| 97 |
+
"source": [
|
| 98 |
+
"Chunking documents"
|
| 99 |
+
],
|
| 100 |
+
"metadata": {
|
| 101 |
+
"id": "0iurKj94w1jm"
|
| 102 |
+
}
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"cell_type": "code",
|
| 106 |
+
"source": [
|
| 107 |
+
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
|
| 108 |
+
"import time\n",
|
| 109 |
+
"\n",
|
| 110 |
+
"text_splitter = RecursiveCharacterTextSplitter(\n",
|
| 111 |
+
" chunk_size = 500, # The size of each text chunk\n",
|
| 112 |
+
" chunk_overlap = 50, # Overlap between chunks to ensure continuity\n",
|
| 113 |
+
")\n",
|
| 114 |
+
"\n",
|
| 115 |
+
"# Stage one: read all the docs, split them into chunks.\n",
|
| 116 |
+
"st = time.time() # Start time for performance measurement\n",
|
| 117 |
+
"print('Loading documents ...')\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"# Split each document into chunks using the configured text splitter\n",
|
| 120 |
+
"chunks = text_splitter.create_documents([doc.page_content for doc in docs], metadatas=[doc.metadata for doc in docs])\n",
|
| 121 |
+
"\n",
|
| 122 |
+
"et = time.time() - st # Calculate time taken for splitting\n",
|
| 123 |
+
"print(f'created {len(chunks)} chunks in {et} seconds.')"
|
| 124 |
+
],
|
| 125 |
+
"metadata": {
|
| 126 |
+
"id": "zSZJQeA_w2B3"
|
| 127 |
+
},
|
| 128 |
+
"execution_count": null,
|
| 129 |
+
"outputs": []
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "markdown",
|
| 133 |
+
"source": [
|
| 134 |
+
"Build VectorStore: Vectorization"
|
| 135 |
+
],
|
| 136 |
+
"metadata": {
|
| 137 |
+
"id": "oQGtHuTxkmFq"
|
| 138 |
+
}
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"cell_type": "code",
|
| 142 |
+
"source": [
|
| 143 |
+
"from langchain.vectorstores import FAISS\n",
|
| 144 |
+
"from langchain.vectorstores.utils import filter_complex_metadata\n",
|
| 145 |
+
"from langchain.embeddings import HuggingFaceEmbeddings\n",
|
| 146 |
+
"\n",
|
| 147 |
+
"# Path for saving the FAISS index\n",
|
| 148 |
+
"FAISS_INDEX_PATH = \"./vectorstore/lc-faiss-multi-mpnet-500\"\n",
|
| 149 |
+
"\n",
|
| 150 |
+
"\n",
|
| 151 |
+
"#Stage two: embed the docs.\n",
|
| 152 |
+
"# use multi-qa-mpnet-base-dot-v1 sentence transformer to convert pieces of text in vectors to store them in the vector store\n",
|
| 153 |
+
"model_name = \"sentence-transformers/multi-qa-mpnet-base-dot-v1\"\n",
|
| 154 |
+
"\n",
|
| 155 |
+
"# use the GPU for faster processing\n",
|
| 156 |
+
"#model_kwargs = {\"device\": \"cuda\"}\n",
|
| 157 |
+
"\n",
|
| 158 |
+
"# Initialize HuggingFace embeddings with the specified model\n",
|
| 159 |
+
"embeddings = HuggingFaceEmbeddings(\n",
|
| 160 |
+
" model_name=model_name,\n",
|
| 161 |
+
"# model_kwargs=model_kwargs # uncomment when using a GPU, like T4 - requires extended RAM!\n",
|
| 162 |
+
" )\n",
|
| 163 |
+
"\n",
|
| 164 |
+
"print(f'Loading chunks into vector store ...')\n",
|
| 165 |
+
"st = time.time() # Start time for performance measurement\n",
|
| 166 |
+
"\n",
|
| 167 |
+
"# Create a FAISS vector store from the document chunks and save it locally\n",
|
| 168 |
+
"db = FAISS.from_documents(filter_complex_metadata(chunks), embeddings)\n",
|
| 169 |
+
"# persist vectorstore\n",
|
| 170 |
+
"db.save_local(FAISS_INDEX_PATH)\n",
|
| 171 |
+
"\n",
|
| 172 |
+
"et = time.time() - st\n",
|
| 173 |
+
"print(f'Time taken: {et} seconds.')"
|
| 174 |
+
],
|
| 175 |
+
"metadata": {
|
| 176 |
+
"id": "qu6sDsq6c9fg"
|
| 177 |
+
},
|
| 178 |
+
"execution_count": null,
|
| 179 |
+
"outputs": []
|
| 180 |
+
},
|
| 181 |
+
{
|
| 182 |
+
"cell_type": "markdown",
|
| 183 |
+
"source": [
|
| 184 |
+
"Load LLM"
|
| 185 |
+
],
|
| 186 |
+
"metadata": {
|
| 187 |
+
"id": "updDdzwj0RdJ"
|
| 188 |
+
}
|
| 189 |
+
},
|
| 190 |
+
{
|
| 191 |
+
"cell_type": "code",
|
| 192 |
+
"source": [
|
| 193 |
+
"from dotenv import load_dotenv\n",
|
| 194 |
+
"# HF libraries\n",
|
| 195 |
+
"from langchain.llms import HuggingFaceHub\n",
|
| 196 |
+
"\n",
|
| 197 |
+
"# Load environment variables from a .env file\n",
|
| 198 |
+
"CONFIG = load_dotenv(\".env\")\n",
|
| 199 |
+
"\n",
|
| 200 |
+
"# Retrieve the Hugging Face API token from environment variables\n",
|
| 201 |
+
"HUGGINGFACEHUB_API_TOKEN = os.getenv('HUGGINGFACEHUB_API_TOKEN')\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"# load HF Token\n",
|
| 204 |
+
"HUGGINGFACEHUB_API_TOKEN=os.getenv('HUGGINGFACEHUB_API_TOKEN')\n",
|
| 205 |
+
"\n",
|
| 206 |
+
"# Load the model from the Hugging Face Hub\n",
|
| 207 |
+
"model_id = HuggingFaceHub(repo_id=\"mistralai/Mistral-7B-Instruct-v0.1\", model_kwargs={\n",
|
| 208 |
+
" \"temperature\":0.1,\n",
|
| 209 |
+
" \"max_new_tokens\":1024,\n",
|
| 210 |
+
" \"repetition_penalty\":1.2,\n",
|
| 211 |
+
" \"return_full_text\":False\n",
|
| 212 |
+
" })\n"
|
| 213 |
+
],
|
| 214 |
+
"metadata": {
|
| 215 |
+
"id": "GlnNrNdbg2E6"
|
| 216 |
+
},
|
| 217 |
+
"execution_count": null,
|
| 218 |
+
"outputs": []
|
| 219 |
+
},
|
| 220 |
+
{
|
| 221 |
+
"cell_type": "markdown",
|
| 222 |
+
"source": [
|
| 223 |
+
"Retriever"
|
| 224 |
+
],
|
| 225 |
+
"metadata": {
|
| 226 |
+
"id": "2m3BIm090jtr"
|
| 227 |
+
}
|
| 228 |
+
},
|
| 229 |
+
{
|
| 230 |
+
"cell_type": "code",
|
| 231 |
+
"source": [
|
| 232 |
+
"from langchain.embeddings import HuggingFaceHubEmbeddings\n",
|
| 233 |
+
"# vectorestore\n",
|
| 234 |
+
"from langchain.vectorstores import FAISS\n",
|
| 235 |
+
"\n",
|
| 236 |
+
"# Load and Initialize the vector store as a retriever for the RAG pipeline\n",
|
| 237 |
+
"db = FAISS.load_local(FAISS_INDEX_PATH, embeddings)\n",
|
| 238 |
+
"\n",
|
| 239 |
+
"retriever = db.as_retriever()"
|
| 240 |
+
],
|
| 241 |
+
"metadata": {
|
| 242 |
+
"id": "jzqPsuds0kSs"
|
| 243 |
+
},
|
| 244 |
+
"execution_count": null,
|
| 245 |
+
"outputs": []
|
| 246 |
+
},
|
| 247 |
+
{
|
| 248 |
+
"cell_type": "markdown",
|
| 249 |
+
"source": [
|
| 250 |
+
"Template and Chat logic"
|
| 251 |
+
],
|
| 252 |
+
"metadata": {
|
| 253 |
+
"id": "Bld8lOEv0Uq-"
|
| 254 |
+
}
|
| 255 |
+
},
|
| 256 |
+
{
|
| 257 |
+
"cell_type": "code",
|
| 258 |
+
"source": [
|
| 259 |
+
"# retrieval chain\n",
|
| 260 |
+
"from langchain.chains import RetrievalQA\n",
|
| 261 |
+
"# prompt template\n",
|
| 262 |
+
"from langchain.prompts import PromptTemplate\n",
|
| 263 |
+
"from langchain.memory import ConversationBufferMemory\n",
|
| 264 |
+
"\n",
|
| 265 |
+
"\n",
|
| 266 |
+
"global qa\n",
|
| 267 |
+
"template = \"\"\"\n",
|
| 268 |
+
"You are the friendly documentation buddy Arti, who helps novice programmers in using LangChain with simple explanations and examples.\\\n",
|
| 269 |
+
" Use the following context (delimited by <ctx></ctx>) and the chat history (delimited by <hs></hs>) to answer the question :\n",
|
| 270 |
+
"------\n",
|
| 271 |
+
"<ctx>\n",
|
| 272 |
+
"{context}\n",
|
| 273 |
+
"</ctx>\n",
|
| 274 |
+
"------\n",
|
| 275 |
+
"<hs>\n",
|
| 276 |
+
"{history}\n",
|
| 277 |
+
"</hs>\n",
|
| 278 |
+
"------\n",
|
| 279 |
+
"{question}\n",
|
| 280 |
+
"Answer:\n",
|
| 281 |
+
"\"\"\"\n",
|
| 282 |
+
"# Create a PromptTemplate object with specified input variables and the defined template\n",
|
| 283 |
+
"prompt = PromptTemplate.from_template(\n",
|
| 284 |
+
" template=template,\n",
|
| 285 |
+
")\n",
|
| 286 |
+
"prompt.format(context=\"context\", history=\"history\", question=\"question\")\n",
|
| 287 |
+
"\n",
|
| 288 |
+
"# Create a memory buffer to manage conversation history\n",
|
| 289 |
+
"memory = ConversationBufferMemory(memory_key=\"history\", input_key=\"question\")\n",
|
| 290 |
+
"\n",
|
| 291 |
+
"# Initialize the RetrievalQA object with the specified model,\n",
|
| 292 |
+
"# retriever, and additional configurations\n",
|
| 293 |
+
"qa = RetrievalQA.from_chain_type(llm=model_id, chain_type=\"stuff\", retriever=retriever, verbose=True, return_source_documents=True, chain_type_kwargs={\n",
|
| 294 |
+
" \"verbose\": True,\n",
|
| 295 |
+
" \"memory\": memory,\n",
|
| 296 |
+
" \"prompt\": prompt\n",
|
| 297 |
+
"}\n",
|
| 298 |
+
" )"
|
| 299 |
+
],
|
| 300 |
+
"metadata": {
|
| 301 |
+
"id": "K255Ldxq0Xg6"
|
| 302 |
+
},
|
| 303 |
+
"execution_count": null,
|
| 304 |
+
"outputs": []
|
| 305 |
+
},
|
| 306 |
+
{
|
| 307 |
+
"cell_type": "markdown",
|
| 308 |
+
"source": [
|
| 309 |
+
"UI - Gradio"
|
| 310 |
+
],
|
| 311 |
+
"metadata": {
|
| 312 |
+
"id": "pA5d0LL2kObx"
|
| 313 |
+
}
|
| 314 |
+
},
|
| 315 |
+
{
|
| 316 |
+
"cell_type": "code",
|
| 317 |
+
"source": [
|
| 318 |
+
"history=[]\n",
|
| 319 |
+
"query=\"draft a function to calculate a mxn matrix\"\n",
|
| 320 |
+
"question=query\n",
|
| 321 |
+
"response=qa({\"query\": query, \"history\": history, \"question\": question})\n",
|
| 322 |
+
"print(*response)"
|
| 323 |
+
],
|
| 324 |
+
"metadata": {
|
| 325 |
+
"id": "bKeoyhXPrQ2C"
|
| 326 |
+
},
|
| 327 |
+
"execution_count": null,
|
| 328 |
+
"outputs": []
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"cell_type": "code",
|
| 332 |
+
"source": [
|
| 333 |
+
"print(response['result'])"
|
| 334 |
+
],
|
| 335 |
+
"metadata": {
|
| 336 |
+
"id": "78wRMjjn0cl3"
|
| 337 |
+
},
|
| 338 |
+
"execution_count": null,
|
| 339 |
+
"outputs": []
|
| 340 |
+
},
|
| 341 |
+
{
|
| 342 |
+
"cell_type": "code",
|
| 343 |
+
"source": [
|
| 344 |
+
"import gradio as gr\n",
|
| 345 |
+
"\n",
|
| 346 |
+
"# Function to add a new input to the chat history\n",
|
| 347 |
+
"def add_text(history, text):\n",
|
| 348 |
+
" # Append the new text to the history with a placeholder for the response\n",
|
| 349 |
+
" history = history + [(text, None)]\n",
|
| 350 |
+
" return history, \"\"\n",
|
| 351 |
+
"\n",
|
| 352 |
+
"# Function representing the bot's response mechanism\n",
|
| 353 |
+
"def bot(history):\n",
|
| 354 |
+
" response = infer(history[-1][0], history)\n",
|
| 355 |
+
" history[-1][1] = response['result']\n",
|
| 356 |
+
" return history\n",
|
| 357 |
+
"\n",
|
| 358 |
+
"# Function to infer the response using the RAG model\n",
|
| 359 |
+
"def infer(question, history):\n",
|
| 360 |
+
" query = question\n",
|
| 361 |
+
" result = qa({\"query\": query, \"history\": history, \"question\": question})\n",
|
| 362 |
+
" return result\n",
|
| 363 |
+
"\n",
|
| 364 |
+
"# Building the Gradio interface\n",
|
| 365 |
+
"with gr.Blocks() as demo:\n",
|
| 366 |
+
" with gr.Column(elem_id=\"col-container\"):\n",
|
| 367 |
+
" chatbot = gr.Chatbot([], elem_id=\"chatbot\")\n",
|
| 368 |
+
" clear = gr.Button(\"Clear\")\n",
|
| 369 |
+
"\n",
|
| 370 |
+
" # Create a row for the question input\n",
|
| 371 |
+
" with gr.Row():\n",
|
| 372 |
+
" question = gr.Textbox(label=\"Question\", placeholder=\"Type your question and hit Enter \")\n",
|
| 373 |
+
"\n",
|
| 374 |
+
" # Define the action when the question is submitted\n",
|
| 375 |
+
" question.submit(add_text, [chatbot, question], [chatbot, question], queue=False).then(\n",
|
| 376 |
+
" bot, chatbot, chatbot\n",
|
| 377 |
+
" )\n",
|
| 378 |
+
"\n",
|
| 379 |
+
" # Define the action for the clear button\n",
|
| 380 |
+
" clear.click(lambda: None, None, chatbot, queue=False)\n",
|
| 381 |
+
"\n",
|
| 382 |
+
"# Launch the Gradio demo interface\n",
|
| 383 |
+
"demo.launch(share=False)"
|
| 384 |
+
],
|
| 385 |
+
"metadata": {
|
| 386 |
+
"id": "OHVkFa6MkCir"
|
| 387 |
+
},
|
| 388 |
+
"execution_count": null,
|
| 389 |
+
"outputs": []
|
| 390 |
+
}
|
| 391 |
+
]
|
| 392 |
+
}
|
README.md
CHANGED
|
@@ -1,32 +1,33 @@
|
|
| 1 |
-
#
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
-
|
| 9 |
-
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
-
|
| 25 |
-
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
|
|
|
|
|
| 1 |
+
# Anatomy of Advanced Enterprise Rag Systems
|
| 2 |
+
|
| 3 |
+
This repository accompanies the blog series "The Anatomy of Advanced Enterprise Rag Systems" and provides a hands-on learning experience for building sophisticated Rag systems. Dive deep into each component, from setup and evaluation to security and multi-agent interactions.
|
| 4 |
+
|
| 5 |
+
Explore these key topics:
|
| 6 |
+
|
| 7 |
+
- Test Setup and Evaluation Metrics: Learn how to assess the performance and effectiveness of your Rag system.
|
| 8 |
+
- Data Preparation and Management: Discover techniques for organizing and optimizing your knowledge base.
|
| 9 |
+
- User Input Processing: Understand how to handle diverse user queries and extract relevant information.
|
| 10 |
+
- Retrieval System: Unleash the power of retrieving relevant passages from your knowledge base.
|
| 11 |
+
- Information Processing and Generation: Craft accurate and informative responses using state-of-the-art techniques.
|
| 12 |
+
- Feedback and Continuous Improvement: Enhance your Rag system over time using user feedback and data analysis.
|
| 13 |
+
- Multi-agents and Agent-services: Explore advanced architectures for distributed and collaborative Rag systems.
|
| 14 |
+
- Monitoring and Security: Ensure the robustness and trustworthiness of your Rag system with proper monitoring and security practices.
|
| 15 |
+
|
| 16 |
+
What you'll find here:
|
| 17 |
+
|
| 18 |
+
- Code examples: Implementations of key concepts from each topic, ready to use and adapt.
|
| 19 |
+
- Data samples: Pre-prepared data sets for experimentation and testing.
|
| 20 |
+
- Additional resources: Links to relevant articles, libraries, and tools to deepen your understanding.
|
| 21 |
+
|
| 22 |
+
Getting started:
|
| 23 |
+
|
| 24 |
+
- Clone this repository: git clone https://github.com/<username>/advanced-enterprise-rag-systems.git
|
| 25 |
+
- Follow the instructions in each topic directory.
|
| 26 |
+
|
| 27 |
+
Contributing:
|
| 28 |
+
|
| 29 |
+
We welcome your contributions! Share your expertise, improve existing code examples, or add new ones. Submit a pull request to share your valuable additions.
|
| 30 |
+
|
| 31 |
+
License:
|
| 32 |
+
|
| 33 |
+
This project is licensed under the MIT License: LICENSE.
|
core-langchain-rag.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Importing necessary libraries
|
| 2 |
+
import sys
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
# # Importing RecursiveUrlLoader for web scraping and BeautifulSoup for HTML parsing
|
| 7 |
+
# from langchain.document_loaders.recursive_url_loader import RecursiveUrlLoader
|
| 8 |
+
# from bs4 import BeautifulSoup as Soup
|
| 9 |
+
# import mimetypes
|
| 10 |
+
|
| 11 |
+
# # List of URLs to scrape
|
| 12 |
+
# urls = ["https://langchain-doc.readthedocs.io/en/latest"]
|
| 13 |
+
|
| 14 |
+
# # Initialize an empty list to store the documents
|
| 15 |
+
# docs = []
|
| 16 |
+
|
| 17 |
+
# # Looping through each URL in the list - this could take some time!
|
| 18 |
+
# stf = time.time() # Start time for performance measurement
|
| 19 |
+
# for url in urls:
|
| 20 |
+
# try:
|
| 21 |
+
# st = time.time() # Start time for performance measurement
|
| 22 |
+
# # Create a RecursiveUrlLoader instance with a specified URL and depth
|
| 23 |
+
# # The extractor function uses BeautifulSoup to parse the HTML content and extract text
|
| 24 |
+
# loader = RecursiveUrlLoader(url=url, max_depth=5, extractor=lambda x: Soup(x, "html.parser").text)
|
| 25 |
+
|
| 26 |
+
# # Load the documents from the URL and extend the docs list
|
| 27 |
+
# docs.extend(loader.load())
|
| 28 |
+
|
| 29 |
+
# et = time.time() - st # Calculate time taken for splitting
|
| 30 |
+
# print(f'Time taken for downloading documents from {url}: {et} seconds.')
|
| 31 |
+
# except Exception as e:
|
| 32 |
+
# # Print an error message if there is an issue with loading or parsing the URL
|
| 33 |
+
# print(f"Failed to load or parse the URL {url}. Error: {e}", file=sys.stderr)
|
| 34 |
+
# etf = time.time() - stf # Calculate time taken for splitting
|
| 35 |
+
# print(f'Total time taken for downloading {len(docs)} documents: {etf} seconds.')
|
| 36 |
+
|
| 37 |
+
# # Import necessary modules for text splitting and vectorization
|
| 38 |
+
# from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 39 |
+
# import time
|
| 40 |
+
# from langchain_community.vectorstores import FAISS
|
| 41 |
+
# from langchain.vectorstores.utils import filter_complex_metadata
|
| 42 |
+
# from langchain_community.embeddings import HuggingFaceEmbeddings
|
| 43 |
+
|
| 44 |
+
# # Configure the text splitter
|
| 45 |
+
# text_splitter = RecursiveCharacterTextSplitter(
|
| 46 |
+
# separators=["\n\n", "\n", "(?<=\. )", " ", ""], # Define the separators for splitting text
|
| 47 |
+
# chunk_size=500, # The size of each text chunk
|
| 48 |
+
# chunk_overlap=50, # Overlap between chunks to ensure continuity
|
| 49 |
+
# length_function=len, # Function to determine the length of each chunk
|
| 50 |
+
# )
|
| 51 |
+
|
| 52 |
+
# try:
|
| 53 |
+
# # Stage one: Splitting the documents into chunks for vectorization
|
| 54 |
+
# st = time.time() # Start time for performance measurement
|
| 55 |
+
# print('Loading documents and creating chunks ...')
|
| 56 |
+
# # Split each document into chunks using the configured text splitter
|
| 57 |
+
# chunks = text_splitter.create_documents([doc.page_content for doc in docs], metadatas=[doc.metadata for doc in docs])
|
| 58 |
+
# et = time.time() - st # Calculate time taken for splitting
|
| 59 |
+
# print(f"created "+chunks+" chunks")
|
| 60 |
+
# print(f'Time taken for document chunking: {et} seconds.')
|
| 61 |
+
# except Exception as e:
|
| 62 |
+
# print(f"Error during document chunking: {e}", file=sys.stderr)
|
| 63 |
+
|
| 64 |
+
# # Path for saving the FAISS index
|
| 65 |
+
# FAISS_INDEX_PATH = "./vectorstore/lc-faiss-multi-mpnet-500"
|
| 66 |
+
|
| 67 |
+
# try:
|
| 68 |
+
# # Stage two: Vectorization of the document chunks
|
| 69 |
+
# model_name = "sentence-transformers/multi-qa-mpnet-base-dot-v1" # Model used for embedding
|
| 70 |
+
|
| 71 |
+
# # Initialize HuggingFace embeddings with the specified model
|
| 72 |
+
# embeddings = HuggingFaceEmbeddings(model_name=model_name)
|
| 73 |
+
|
| 74 |
+
# print(f'Loading chunks into vector store ...')
|
| 75 |
+
# st = time.time() # Start time for performance measurement
|
| 76 |
+
# # Create a FAISS vector store from the document chunks and save it locally
|
| 77 |
+
# db = FAISS.from_documents(filter_complex_metadata(chunks), embeddings)
|
| 78 |
+
# db.save_local(FAISS_INDEX_PATH)
|
| 79 |
+
# et = time.time() - st # Calculate time taken for vectorization
|
| 80 |
+
# print(f'Time taken for vectorization and saving: {et} seconds.')
|
| 81 |
+
# except Exception as e:
|
| 82 |
+
# print(f"Error during vectorization or FAISS index saving: {e}", file=sys.stderr)
|
| 83 |
+
|
| 84 |
+
# alternatively download a preparaed vectorized index from S3 and load the index into vectorstore
|
| 85 |
+
# Import necessary libraries for AWS S3 interaction, file handling, and FAISS vector stores
|
| 86 |
+
import boto3
|
| 87 |
+
from botocore import UNSIGNED
|
| 88 |
+
from botocore.client import Config
|
| 89 |
+
import zipfile
|
| 90 |
+
from langchain_community.vectorstores import FAISS
|
| 91 |
+
from langchain_huggingface import HuggingFaceEmbeddings
|
| 92 |
+
from dotenv import load_dotenv
|
| 93 |
+
|
| 94 |
+
# Load environment variables from a .env file
|
| 95 |
+
config = load_dotenv(".env")
|
| 96 |
+
|
| 97 |
+
# Retrieve the Hugging Face API token from environment variables
|
| 98 |
+
HUGGINGFACEHUB_API_TOKEN = os.getenv('HUGGINGFACEHUB_API_TOKEN')
|
| 99 |
+
S3_LOCATION = os.getenv("S3_LOCATION")
|
| 100 |
+
|
| 101 |
+
try:
|
| 102 |
+
# Initialize an S3 client with unsigned configuration for public access
|
| 103 |
+
s3 = boto3.client('s3', config=Config(signature_version=UNSIGNED))
|
| 104 |
+
|
| 105 |
+
# Define the FAISS index path and the destination for the downloaded file
|
| 106 |
+
FAISS_INDEX_PATH = './vectorstore/lc-faiss-multi-mpnet-500-markdown'
|
| 107 |
+
VS_DESTINATION = FAISS_INDEX_PATH + ".zip"
|
| 108 |
+
|
| 109 |
+
# Download the pre-prepared vectorized index from the S3 bucket
|
| 110 |
+
print("Downloading the pre-prepared vectorized index from S3...")
|
| 111 |
+
s3.download_file(S3_LOCATION, 'vectorstores/lc-faiss-multi-mpnet-500-markdown.zip', VS_DESTINATION)
|
| 112 |
+
|
| 113 |
+
# Extract the downloaded zip file
|
| 114 |
+
with zipfile.ZipFile(VS_DESTINATION, 'r') as zip_ref:
|
| 115 |
+
zip_ref.extractall('./vectorstore/')
|
| 116 |
+
print("Download and extraction completed.")
|
| 117 |
+
|
| 118 |
+
except Exception as e:
|
| 119 |
+
print(f"Error during downloading or extracting from S3: {e}", file=sys.stderr)
|
| 120 |
+
|
| 121 |
+
# Define the model name for embeddings
|
| 122 |
+
model_name = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
|
| 123 |
+
|
| 124 |
+
try:
|
| 125 |
+
# Initialize HuggingFace embeddings with the specified model
|
| 126 |
+
embeddings = HuggingFaceEmbeddings(model_name=model_name)
|
| 127 |
+
|
| 128 |
+
# Load the local FAISS index with the specified embeddings
|
| 129 |
+
db = FAISS.load_local(FAISS_INDEX_PATH, embeddings, allow_dangerous_deserialization=True)
|
| 130 |
+
print("FAISS index loaded successfully.")
|
| 131 |
+
except Exception as e:
|
| 132 |
+
print(f"Error during FAISS index loading: {e}", file=sys.stderr)
|
| 133 |
+
|
| 134 |
+
# Import necessary modules for environment variable management and HuggingFace integration
|
| 135 |
+
from langchain_huggingface import HuggingFaceEndpoint
|
| 136 |
+
|
| 137 |
+
# Initialize the vector store as a retriever for the RAG pipeline
|
| 138 |
+
retriever = db.as_retriever(search_type="mmr", search_kwargs={'k': 3, 'lambda_mult': 0.25})
|
| 139 |
+
|
| 140 |
+
try:
|
| 141 |
+
# Load the model from the Hugging Face Hub
|
| 142 |
+
model_id = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1",
|
| 143 |
+
temperature=0.1, # Controls randomness in response generation (lower value means less random)
|
| 144 |
+
max_new_tokens=1024, # Maximum number of new tokens to generate in responses
|
| 145 |
+
repetition_penalty=1.2, # Penalty for repeating the same words (higher value increases penalty)
|
| 146 |
+
return_full_text=False # If False, only the newly generated text is returned; if True, the input is included as well
|
| 147 |
+
)
|
| 148 |
+
print("Model loaded successfully from Hugging Face Hub.")
|
| 149 |
+
except Exception as e:
|
| 150 |
+
print(f"Error loading model from Hugging Face Hub: {e}", file=sys.stderr)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
# Importing necessary modules for retrieval-based question answering and prompt handling
|
| 155 |
+
from langchain.chains import RetrievalQA
|
| 156 |
+
from langchain.prompts import PromptTemplate
|
| 157 |
+
from langchain.memory import ConversationBufferMemory
|
| 158 |
+
|
| 159 |
+
# Declare a global variable 'qa' for the retrieval-based question answering system
|
| 160 |
+
global qa
|
| 161 |
+
|
| 162 |
+
# Define a prompt template for guiding the model's responses
|
| 163 |
+
template = """
|
| 164 |
+
You are the friendly documentation buddy Arti, if you don't know the answer say 'I don't know' and don't make things up.\
|
| 165 |
+
Use the following context (delimited by <ctx></ctx>) and the chat history (delimited by <hs></hs>) to answer the question :
|
| 166 |
+
------
|
| 167 |
+
<ctx>
|
| 168 |
+
{context}
|
| 169 |
+
</ctx>
|
| 170 |
+
------
|
| 171 |
+
<hs>
|
| 172 |
+
{history}
|
| 173 |
+
</hs>
|
| 174 |
+
------
|
| 175 |
+
{question}
|
| 176 |
+
Answer:
|
| 177 |
+
"""
|
| 178 |
+
|
| 179 |
+
# Create a PromptTemplate object with specified input variables and the defined template
|
| 180 |
+
prompt = PromptTemplate.from_template(
|
| 181 |
+
#input_variables=["history", "context", "question"], # Variables to be included in the prompt
|
| 182 |
+
template=template, # The prompt template as defined above
|
| 183 |
+
)
|
| 184 |
+
prompt.format(context="context", history="history", question="question")
|
| 185 |
+
# Create a memory buffer to manage conversation history
|
| 186 |
+
memory = ConversationBufferMemory(
|
| 187 |
+
memory_key="history", # Key for storing the conversation history
|
| 188 |
+
input_key="question" # Key for the input question
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
# Initialize the RetrievalQA object with the specified model, retriever, and additional configurations
|
| 192 |
+
qa = RetrievalQA.from_chain_type(
|
| 193 |
+
llm=model_id, # Language model loaded from Hugging Face Hub
|
| 194 |
+
retriever=retriever, # The vector store retriever initialized earlier
|
| 195 |
+
return_source_documents=True, # Option to return source documents along with responses
|
| 196 |
+
chain_type_kwargs={
|
| 197 |
+
"verbose": True, # Enables verbose output for debugging and analysis
|
| 198 |
+
"memory": memory, # Memory buffer for managing conversation history
|
| 199 |
+
"prompt": prompt # Prompt template for guiding the model's responses
|
| 200 |
+
}
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
# Import Gradio for UI, along with other necessary libraries
|
| 204 |
+
import gradio as gr
|
| 205 |
+
import random
|
| 206 |
+
import time
|
| 207 |
+
|
| 208 |
+
# Function to add a new input to the chat history
|
| 209 |
+
def add_text(history, text):
|
| 210 |
+
# Append the new text to the history with a placeholder for the response
|
| 211 |
+
history = history + [(text, None)]
|
| 212 |
+
return history, ""
|
| 213 |
+
|
| 214 |
+
# Function representing the bot's response mechanism
|
| 215 |
+
def bot(history):
|
| 216 |
+
# Obtain the response from the 'infer' function using the latest input
|
| 217 |
+
response = infer(history[-1][0], history)
|
| 218 |
+
sources = [doc.metadata.get("source") for doc in response['source_documents']]
|
| 219 |
+
src_list = '\n'.join(sources)
|
| 220 |
+
print_this = response['result'] + "\n\n\n Sources: \n\n\n" + src_list
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
history[-1][1] = print_this #response['answer']
|
| 224 |
+
# Update the history with the bot's response
|
| 225 |
+
#history[-1][1] = response['result']
|
| 226 |
+
return history
|
| 227 |
+
|
| 228 |
+
# Function to infer the response using the RAG model
|
| 229 |
+
def infer(question, history):
|
| 230 |
+
# Use the question and history to query the RAG model
|
| 231 |
+
result = qa({"query": question, "history": history, "question": question})
|
| 232 |
+
return result
|
| 233 |
+
|
| 234 |
+
# CSS styling for the Gradio interface
|
| 235 |
+
css = """
|
| 236 |
+
#col-container {max-width: 700px; margin-left: auto; margin-right: auto;}
|
| 237 |
+
"""
|
| 238 |
+
|
| 239 |
+
# HTML content for the Gradio interface title
|
| 240 |
+
title = """
|
| 241 |
+
<div style="text-align: center;max-width: 700px;">
|
| 242 |
+
<h1>Chat with your Documentation</h1>
|
| 243 |
+
<p style="text-align: center;">Chat with LangChain Documentation, <br />
|
| 244 |
+
You can ask questions about the LangChain docu ;)</p>
|
| 245 |
+
</div>
|
| 246 |
+
"""
|
| 247 |
+
|
| 248 |
+
# Building the Gradio interface
|
| 249 |
+
with gr.Blocks(css=css) as demo:
|
| 250 |
+
with gr.Column(elem_id="col-container"):
|
| 251 |
+
gr.HTML(title) # Add the HTML title to the interface
|
| 252 |
+
chatbot = gr.Chatbot([], elem_id="chatbot") # Initialize the chatbot component
|
| 253 |
+
clear = gr.Button("Clear") # Add a button to clear the chat
|
| 254 |
+
|
| 255 |
+
# Create a row for the question input
|
| 256 |
+
with gr.Row():
|
| 257 |
+
question = gr.Textbox(label="Question", placeholder="Type your question and hit Enter ")
|
| 258 |
+
|
| 259 |
+
# Define the action when the question is submitted
|
| 260 |
+
question.submit(add_text, [chatbot, question], [chatbot, question], queue=False).then(
|
| 261 |
+
bot, chatbot, chatbot
|
| 262 |
+
)
|
| 263 |
+
# Define the action for the clear button
|
| 264 |
+
clear.click(lambda: None, None, chatbot, queue=False)
|
| 265 |
+
|
| 266 |
+
# Launch the Gradio demo interface
|
| 267 |
+
demo.launch(share=False)
|
docs/advanced_rag_architecture.drawio
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<mxfile host="app.diagrams.net" modified="2024-02-02T10:57:09.662Z" agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:122.0) Gecko/20100101 Firefox/122.0" etag="jBjrxQrE8FMZUdqYmkDs" version="22.1.21" type="github">
|
| 2 |
+
<diagram id="C5RBs43oDa-KdzZeNtuy" name="Page-1">
|
| 3 |
+
<mxGraphModel dx="1434" dy="774" grid="1" gridSize="10" guides="1" tooltips="1" connect="1" arrows="1" fold="1" page="1" pageScale="1" pageWidth="827" pageHeight="1169" math="0" shadow="0">
|
| 4 |
+
<root>
|
| 5 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-0" />
|
| 6 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-1" parent="WIyWlLk6GJQsqaUBKTNV-0" />
|
| 7 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-59" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="7HGE-dyt3ShhVV6eNgTS-4" target="7HGE-dyt3ShhVV6eNgTS-22">
|
| 8 |
+
<mxGeometry relative="1" as="geometry" />
|
| 9 |
+
</mxCell>
|
| 10 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-4" value="Retrieval System" style="swimlane;whiteSpace=wrap;html=1;fillColor=#e1d5e7;strokeColor=#9673a6;startSize=23;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 11 |
+
<mxGeometry x="280" y="360" width="290" height="280" as="geometry" />
|
| 12 |
+
</mxCell>
|
| 13 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-7" value="<div>Indicies</div>" style="strokeWidth=2;html=1;shape=mxgraph.flowchart.database;whiteSpace=wrap;fillColor=#ffe6cc;strokeColor=#d79b00;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-4">
|
| 14 |
+
<mxGeometry x="44" y="40" width="60" height="60" as="geometry" />
|
| 15 |
+
</mxCell>
|
| 16 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-32" value="Re-ranking" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#e1d5e7;strokeColor=#9673a6;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-4">
|
| 17 |
+
<mxGeometry x="14" y="130" width="120" height="40" as="geometry" />
|
| 18 |
+
</mxCell>
|
| 19 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-34" value="Hypothetical Questions and HyDE" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#e1d5e7;strokeColor=#9673a6;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-4">
|
| 20 |
+
<mxGeometry x="160" y="130" width="120" height="40" as="geometry" />
|
| 21 |
+
</mxCell>
|
| 22 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-37" value="Fine-tuning Embeddings" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-4">
|
| 23 |
+
<mxGeometry x="14" y="195" width="120" height="40" as="geometry" />
|
| 24 |
+
</mxCell>
|
| 25 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-33" value="Hyperparamter Tuning" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-4">
|
| 26 |
+
<mxGeometry x="160" y="50" width="120" height="40" as="geometry" />
|
| 27 |
+
</mxCell>
|
| 28 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-56" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0;exitY=1;exitDx=0;exitDy=0;entryX=0;entryY=0;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="7HGE-dyt3ShhVV6eNgTS-14" target="7HGE-dyt3ShhVV6eNgTS-19">
|
| 29 |
+
<mxGeometry relative="1" as="geometry" />
|
| 30 |
+
</mxCell>
|
| 31 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-14" value="<div>Data Preparation and Management</div>" style="swimlane;whiteSpace=wrap;html=1;fillColor=#ffe6cc;strokeColor=#d79b00;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 32 |
+
<mxGeometry x="40" y="40" width="360" height="240" as="geometry">
|
| 33 |
+
<mxRectangle x="410" y="40" width="240" height="30" as="alternateBounds" />
|
| 34 |
+
</mxGeometry>
|
| 35 |
+
</mxCell>
|
| 36 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-23" value="Chunking &amp; Vectorization" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-14">
|
| 37 |
+
<mxGeometry x="14" y="50" width="120" height="40" as="geometry" />
|
| 38 |
+
</mxCell>
|
| 39 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-24" value="Metadata and Summaries" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#e1d5e7;strokeColor=#9673a6;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-14">
|
| 40 |
+
<mxGeometry x="161" y="50" width="120" height="40" as="geometry" />
|
| 41 |
+
</mxCell>
|
| 42 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-25" value="User Profile Management" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-14">
|
| 43 |
+
<mxGeometry x="14" y="190" width="120" height="40" as="geometry" />
|
| 44 |
+
</mxCell>
|
| 45 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-26" value="Data Cleaning" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-14">
|
| 46 |
+
<mxGeometry x="14" y="120" width="120" height="40" as="geometry" />
|
| 47 |
+
</mxCell>
|
| 48 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-31" value="Complex Formats Handling" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-14">
|
| 49 |
+
<mxGeometry x="161" y="120" width="120" height="40" as="geometry" />
|
| 50 |
+
</mxCell>
|
| 51 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-57" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="7HGE-dyt3ShhVV6eNgTS-19" target="7HGE-dyt3ShhVV6eNgTS-4">
|
| 52 |
+
<mxGeometry relative="1" as="geometry" />
|
| 53 |
+
</mxCell>
|
| 54 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-19" value="<div>User Input processing</div>" style="swimlane;horizontal=0;whiteSpace=wrap;html=1;fillColor=#d5e8d4;strokeColor=#82b366;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 55 |
+
<mxGeometry x="40" y="360" width="200" height="280" as="geometry" />
|
| 56 |
+
</mxCell>
|
| 57 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-3" value="User Authentication" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;" parent="7HGE-dyt3ShhVV6eNgTS-19" vertex="1">
|
| 58 |
+
<mxGeometry x="40" y="20" width="120" height="40" as="geometry" />
|
| 59 |
+
</mxCell>
|
| 60 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-7" value="Query Rewriter" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#e1d5e7;strokeColor=#9673a6;" parent="7HGE-dyt3ShhVV6eNgTS-19" vertex="1">
|
| 61 |
+
<mxGeometry x="40" y="80" width="120" height="40" as="geometry" />
|
| 62 |
+
</mxCell>
|
| 63 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-8" value="Input Guardrail" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#f8cecc;strokeColor=#b85450;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-19">
|
| 64 |
+
<mxGeometry x="40" y="140" width="120" height="40" as="geometry" />
|
| 65 |
+
</mxCell>
|
| 66 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-5" value="chat history&nbsp; " style="strokeWidth=2;html=1;shape=mxgraph.flowchart.multi-document;whiteSpace=wrap;fillColor=#ffe6cc;strokeColor=#d79b00;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-19">
|
| 67 |
+
<mxGeometry x="56" y="210" width="88" height="60" as="geometry" />
|
| 68 |
+
</mxCell>
|
| 69 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-60" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0;exitDx=0;exitDy=0;entryX=1;entryY=1;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="7HGE-dyt3ShhVV6eNgTS-22" target="7HGE-dyt3ShhVV6eNgTS-44">
|
| 70 |
+
<mxGeometry relative="1" as="geometry">
|
| 71 |
+
<mxPoint x="790" y="280" as="targetPoint" />
|
| 72 |
+
</mxGeometry>
|
| 73 |
+
</mxCell>
|
| 74 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-22" value="Information Processing and Generation" style="swimlane;horizontal=0;whiteSpace=wrap;html=1;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 75 |
+
<mxGeometry x="600" y="360" width="200" height="280" as="geometry" />
|
| 76 |
+
</mxCell>
|
| 77 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-9" value="Response Generation" style="rounded=1;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=2;fillColor=#e1d5e7;strokeColor=#9673a6;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-22">
|
| 78 |
+
<mxGeometry x="40" y="20" width="120" height="40" as="geometry" />
|
| 79 |
+
</mxCell>
|
| 80 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-28" value="Output Guardrails and Moderation" style="rounded=1;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=2;fillColor=#f8cecc;strokeColor=#b85450;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-22">
|
| 81 |
+
<mxGeometry x="40" y="80" width="120" height="40" as="geometry" />
|
| 82 |
+
</mxCell>
|
| 83 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-29" value="Caching" style="strokeWidth=2;html=1;shape=mxgraph.flowchart.multi-document;whiteSpace=wrap;fillColor=#ffe6cc;strokeColor=#d79b00;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-22">
|
| 84 |
+
<mxGeometry x="56" y="140" width="88" height="60" as="geometry" />
|
| 85 |
+
</mxCell>
|
| 86 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-30" value="Personalization and Customization" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-22">
|
| 87 |
+
<mxGeometry x="40" y="215" width="120" height="40" as="geometry" />
|
| 88 |
+
</mxCell>
|
| 89 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-61" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0;exitY=0;exitDx=0;exitDy=0;entryX=1;entryY=0;entryDx=0;entryDy=0;dashed=1;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="7HGE-dyt3ShhVV6eNgTS-44" target="7HGE-dyt3ShhVV6eNgTS-14">
|
| 90 |
+
<mxGeometry relative="1" as="geometry">
|
| 91 |
+
<Array as="points">
|
| 92 |
+
<mxPoint x="440" y="40" />
|
| 93 |
+
<mxPoint x="440" y="40" />
|
| 94 |
+
</Array>
|
| 95 |
+
</mxGeometry>
|
| 96 |
+
</mxCell>
|
| 97 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-44" value="Feedback and Continuous Improvement" style="swimlane;whiteSpace=wrap;html=1;startSize=23;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 98 |
+
<mxGeometry x="480" y="40" width="320" height="240" as="geometry" />
|
| 99 |
+
</mxCell>
|
| 100 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-46" value="Data Refinement" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#e1d5e7;strokeColor=#9673a6;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-44">
|
| 101 |
+
<mxGeometry x="170" y="50" width="120" height="40" as="geometry" />
|
| 102 |
+
</mxCell>
|
| 103 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-47" value="System Monitoring" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-44">
|
| 104 |
+
<mxGeometry x="170" y="120" width="120" height="40" as="geometry" />
|
| 105 |
+
</mxCell>
|
| 106 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-48" value="Generation Evaluation" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-44">
|
| 107 |
+
<mxGeometry x="20" y="120" width="120" height="40" as="geometry" />
|
| 108 |
+
</mxCell>
|
| 109 |
+
<mxCell id="7HGE-dyt3ShhVV6eNgTS-49" value="User Feedback" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;" vertex="1" parent="7HGE-dyt3ShhVV6eNgTS-44">
|
| 110 |
+
<mxGeometry x="20" y="50" width="120" height="40" as="geometry" />
|
| 111 |
+
</mxCell>
|
| 112 |
+
</root>
|
| 113 |
+
</mxGraphModel>
|
| 114 |
+
</diagram>
|
| 115 |
+
</mxfile>
|
docs/data_flow_diagram.drawio.png
ADDED
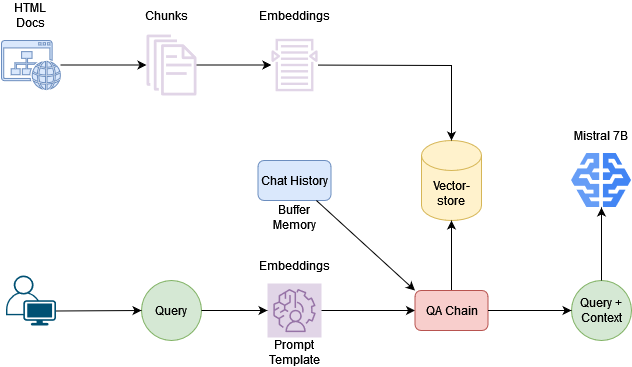
|
docs/template.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Template
|
| 2 |
+
|
| 3 |
+
1. **Architecture of advanced RAG**
|
| 4 |
+
2. **Test setup and Evaluation metrics**
|
| 5 |
+
3. **Data preparation (vectorization & chunking)**
|
| 6 |
+
4. **Search indexing**
|
| 7 |
+
5. **Query transformation**
|
| 8 |
+
6. **Chat logic and query routing**
|
| 9 |
+
7. **Multi agents and agent-services**
|
| 10 |
+
8. **Monitoring responses and adding security**
|
| 11 |
+
|
| 12 |
+
## Additional Resources
|
| 13 |
+
|
| 14 |
+
[Enterprise Rag](https://www.rungalileo.io/blog/mastering-rag-how-to-architect-an-enterprise-rag-systemhttps://www.rungalileo.io/blog/mastering-rag-how-to-architect-an-enterprise-rag-system)
|
| 15 |
+
|
| 16 |
+
[Advanced RAG](https://medium.com/towards-artificial-intelligence/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6)
|
docs/workflow-advanced-rag.drawio
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<mxfile host="app.diagrams.net" modified="2024-02-02T11:21:08.029Z" agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:122.0) Gecko/20100101 Firefox/122.0" etag="EvpGiXuqtWkE4FAqL8_g" version="22.1.21" type="github">
|
| 2 |
+
<diagram id="C5RBs43oDa-KdzZeNtuy" name="Page-1">
|
| 3 |
+
<mxGraphModel dx="1434" dy="774" grid="1" gridSize="10" guides="1" tooltips="1" connect="1" arrows="1" fold="1" page="1" pageScale="1" pageWidth="827" pageHeight="1169" math="0" shadow="0">
|
| 4 |
+
<root>
|
| 5 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-0" />
|
| 6 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-1" parent="WIyWlLk6GJQsqaUBKTNV-0" />
|
| 7 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-1" value="" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="WIyWlLk6GJQsqaUBKTNV-3" target="eFb6EC-VP60E3mpf6WAh-0">
|
| 8 |
+
<mxGeometry relative="1" as="geometry" />
|
| 9 |
+
</mxCell>
|
| 10 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-3" value="User Authentication and Input" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#d5e8d4;strokeColor=#82b366;" parent="WIyWlLk6GJQsqaUBKTNV-1" vertex="1">
|
| 11 |
+
<mxGeometry x="24" y="80" width="120" height="40" as="geometry" />
|
| 12 |
+
</mxCell>
|
| 13 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-12" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="WIyWlLk6GJQsqaUBKTNV-7" target="WIyWlLk6GJQsqaUBKTNV-11">
|
| 14 |
+
<mxGeometry relative="1" as="geometry" />
|
| 15 |
+
</mxCell>
|
| 16 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-7" value="Query Processing" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#d5e8d4;strokeColor=#82b366;" parent="WIyWlLk6GJQsqaUBKTNV-1" vertex="1">
|
| 17 |
+
<mxGeometry x="180" y="160" width="120" height="40" as="geometry" />
|
| 18 |
+
</mxCell>
|
| 19 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-13" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="WIyWlLk6GJQsqaUBKTNV-11" target="eFb6EC-VP60E3mpf6WAh-3">
|
| 20 |
+
<mxGeometry relative="1" as="geometry" />
|
| 21 |
+
</mxCell>
|
| 22 |
+
<mxCell id="WIyWlLk6GJQsqaUBKTNV-11" value="Data Preparation and Management" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#ffe6cc;strokeColor=#d79b00;" parent="WIyWlLk6GJQsqaUBKTNV-1" vertex="1">
|
| 23 |
+
<mxGeometry x="330" y="160" width="120" height="40" as="geometry" />
|
| 24 |
+
</mxCell>
|
| 25 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-11" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="eFb6EC-VP60E3mpf6WAh-0" target="WIyWlLk6GJQsqaUBKTNV-7">
|
| 26 |
+
<mxGeometry relative="1" as="geometry" />
|
| 27 |
+
</mxCell>
|
| 28 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-0" value="Input Guardrails" style="whiteSpace=wrap;html=1;rounded=1;glass=0;strokeWidth=1;shadow=0;fillColor=#f8cecc;strokeColor=#b85450;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 29 |
+
<mxGeometry x="24" y="160" width="120" height="40" as="geometry" />
|
| 30 |
+
</mxCell>
|
| 31 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-14" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="eFb6EC-VP60E3mpf6WAh-3" target="eFb6EC-VP60E3mpf6WAh-5">
|
| 32 |
+
<mxGeometry relative="1" as="geometry" />
|
| 33 |
+
</mxCell>
|
| 34 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-3" value="Retrieval System" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#e1d5e7;strokeColor=#9673a6;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 35 |
+
<mxGeometry x="480" y="160" width="120" height="40" as="geometry" />
|
| 36 |
+
</mxCell>
|
| 37 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-15" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0.5;exitY=0;exitDx=0;exitDy=0;entryX=0.5;entryY=1;entryDx=0;entryDy=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="eFb6EC-VP60E3mpf6WAh-5" target="eFb6EC-VP60E3mpf6WAh-9">
|
| 38 |
+
<mxGeometry relative="1" as="geometry" />
|
| 39 |
+
</mxCell>
|
| 40 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-18" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0;exitY=0;exitDx=0;exitDy=0;entryX=0.75;entryY=1;entryDx=0;entryDy=0;dashed=1;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="eFb6EC-VP60E3mpf6WAh-5" target="eFb6EC-VP60E3mpf6WAh-6">
|
| 41 |
+
<mxGeometry relative="1" as="geometry">
|
| 42 |
+
<Array as="points">
|
| 43 |
+
<mxPoint x="630" y="130" />
|
| 44 |
+
<mxPoint x="450" y="130" />
|
| 45 |
+
</Array>
|
| 46 |
+
</mxGeometry>
|
| 47 |
+
</mxCell>
|
| 48 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-5" value="Information Processing and Augmentation" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#fff2cc;strokeColor=#d6b656;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 49 |
+
<mxGeometry x="630" y="160" width="120" height="40" as="geometry" />
|
| 50 |
+
</mxCell>
|
| 51 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-6" value="Observability and Feedback" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 52 |
+
<mxGeometry x="360" y="40" width="120" height="40" as="geometry" />
|
| 53 |
+
</mxCell>
|
| 54 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-21" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0.98;exitY=0.02;exitDx=0;exitDy=0;exitPerimeter=0;entryX=0.575;entryY=1;entryDx=0;entryDy=0;dashed=1;entryPerimeter=0;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="eFb6EC-VP60E3mpf6WAh-8" target="eFb6EC-VP60E3mpf6WAh-3">
|
| 55 |
+
<mxGeometry relative="1" as="geometry" />
|
| 56 |
+
</mxCell>
|
| 57 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-8" value="Caching" style="strokeWidth=2;html=1;shape=mxgraph.flowchart.multi-document;whiteSpace=wrap;fillColor=#ffe6cc;strokeColor=#d79b00;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 58 |
+
<mxGeometry x="376" y="240" width="88" height="60" as="geometry" />
|
| 59 |
+
</mxCell>
|
| 60 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-16" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0;exitY=0;exitDx=0;exitDy=0;entryX=1;entryY=0.5;entryDx=0;entryDy=0;dashed=1;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="eFb6EC-VP60E3mpf6WAh-9" target="eFb6EC-VP60E3mpf6WAh-6">
|
| 61 |
+
<mxGeometry relative="1" as="geometry" />
|
| 62 |
+
</mxCell>
|
| 63 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-9" value="Output and Response" style="rounded=1;whiteSpace=wrap;html=1;fontSize=12;glass=0;strokeWidth=1;shadow=0;fillColor=#e1d5e7;strokeColor=#9673a6;" vertex="1" parent="WIyWlLk6GJQsqaUBKTNV-1">
|
| 64 |
+
<mxGeometry x="630" y="80" width="120" height="40" as="geometry" />
|
| 65 |
+
</mxCell>
|
| 66 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-17" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0;exitDx=0;exitDy=0;entryX=0.325;entryY=0.975;entryDx=0;entryDy=0;entryPerimeter=0;dashed=1;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="eFb6EC-VP60E3mpf6WAh-0" target="eFb6EC-VP60E3mpf6WAh-6">
|
| 67 |
+
<mxGeometry relative="1" as="geometry">
|
| 68 |
+
<Array as="points">
|
| 69 |
+
<mxPoint x="144" y="130" />
|
| 70 |
+
<mxPoint x="399" y="130" />
|
| 71 |
+
</Array>
|
| 72 |
+
</mxGeometry>
|
| 73 |
+
</mxCell>
|
| 74 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-19" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0.75;exitY=1;exitDx=0;exitDy=0;entryX=0;entryY=0.5;entryDx=0;entryDy=0;entryPerimeter=0;dashed=1;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="WIyWlLk6GJQsqaUBKTNV-7" target="eFb6EC-VP60E3mpf6WAh-8">
|
| 75 |
+
<mxGeometry relative="1" as="geometry" />
|
| 76 |
+
</mxCell>
|
| 77 |
+
<mxCell id="eFb6EC-VP60E3mpf6WAh-20" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=0.5;exitDx=0;exitDy=0;entryX=1;entryY=0.5;entryDx=0;entryDy=0;entryPerimeter=0;dashed=1;" edge="1" parent="WIyWlLk6GJQsqaUBKTNV-1" source="eFb6EC-VP60E3mpf6WAh-9" target="eFb6EC-VP60E3mpf6WAh-8">
|
| 78 |
+
<mxGeometry relative="1" as="geometry" />
|
| 79 |
+
</mxCell>
|
| 80 |
+
</root>
|
| 81 |
+
</mxGraphModel>
|
| 82 |
+
</diagram>
|
| 83 |
+
</mxfile>
|
rag-system-anatomy/build_vector_store.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# vectorization functions
|
| 2 |
+
from langchain.vectorstores import FAISS
|
| 3 |
+
from langchain.document_loaders import ReadTheDocsLoader
|
| 4 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 5 |
+
from langchain.embeddings import HuggingFaceEmbeddings
|
| 6 |
+
from create_embedding import create_embeddings
|
| 7 |
+
import time
|
| 8 |
+
|
| 9 |
+
def build_vector_store(
|
| 10 |
+
docs: list,
|
| 11 |
+
db_path: str,
|
| 12 |
+
embedding_model: str,
|
| 13 |
+
new_db:bool=False,
|
| 14 |
+
chunk_size:int=500,
|
| 15 |
+
chunk_overlap:int=50,
|
| 16 |
+
):
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
if db_path is None:
|
| 22 |
+
FAISS_INDEX_PATH = "./vectorstore/py-faiss-multi-mpnet-500"
|
| 23 |
+
else:
|
| 24 |
+
FAISS_INDEX_PATH = db_path
|
| 25 |
+
|
| 26 |
+
embeddings,chunks = create_embeddings(docs, embedding_model, chunk_size, chunk_overlap)
|
| 27 |
+
|
| 28 |
+
#load chunks into vector store
|
| 29 |
+
print(f'Loading chunks into faiss vector store ...')
|
| 30 |
+
st = time.time()
|
| 31 |
+
if new_db:
|
| 32 |
+
db_faiss = FAISS.from_documents(chunks, embeddings)
|
| 33 |
+
else:
|
| 34 |
+
db_faiss = FAISS.add_documents(chunks, embeddings)
|
| 35 |
+
db_faiss.save_local(FAISS_INDEX_PATH)
|
| 36 |
+
et = time.time() - st
|
| 37 |
+
print(f'Time taken: {et} seconds.')
|
| 38 |
+
|
| 39 |
+
#print(f'Loading chunks into chroma vector store ...')
|
| 40 |
+
#st = time.time()
|
| 41 |
+
#persist_directory='./vectorstore/py-chroma-multi-mpnet-500'
|
| 42 |
+
#db_chroma = Chroma.from_documents(chunks, embeddings, persist_directory=persist_directory)
|
| 43 |
+
#et = time.time() - st
|
| 44 |
+
#print(f'Time taken: {et} seconds.')
|
| 45 |
+
result = f"built vectore store at {FAISS_INDEX_PATH}"
|
| 46 |
+
return result
|
rag-system-anatomy/create_embedding.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# embeddings functions
|
| 2 |
+
from langchain.vectorstores import FAISS
|
| 3 |
+
from langchain.document_loaders import ReadTheDocsLoader
|
| 4 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 5 |
+
from langchain.embeddings import HuggingFaceEmbeddings
|
| 6 |
+
import time
|
| 7 |
+
from langchain_core.documents import Document
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def create_embeddings(
|
| 11 |
+
docs: list[Document],
|
| 12 |
+
chunk_size:int,
|
| 13 |
+
chunk_overlap:int,
|
| 14 |
+
embedding_model: str = "sentence-transformers/multi-qa-mpnet-base-dot-v1",
|
| 15 |
+
):
|
| 16 |
+
"""given a sequence of `Document` objects this fucntion will
|
| 17 |
+
generate embeddings for it.
|
| 18 |
+
|
| 19 |
+
## argument
|
| 20 |
+
:params docs (list[Document]) -> list of `list[Document]`
|
| 21 |
+
:params chunk_size (int) -> chunk size in which documents are chunks
|
| 22 |
+
:params chunk_overlap (int) -> the amount of token that will be overlapped between chunks
|
| 23 |
+
:params embedding_model (str) -> the huggingspace model that will embed the documents
|
| 24 |
+
## Return
|
| 25 |
+
Tuple of embedding and chunks
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 30 |
+
separators=["\n\n", "\n", "(?<=\. )", " ", ""],
|
| 31 |
+
chunk_size = chunk_size,
|
| 32 |
+
chunk_overlap = chunk_overlap,
|
| 33 |
+
length_function = len,
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
# Stage one: read all the docs, split them into chunks.
|
| 37 |
+
st = time.time()
|
| 38 |
+
print('Loading documents ...')
|
| 39 |
+
|
| 40 |
+
chunks = text_splitter.create_documents([doc.page_content for doc in docs], metadatas=[doc.metadata for doc in docs])
|
| 41 |
+
et = time.time() - st
|
| 42 |
+
print(f'Time taken: {et} seconds.')
|
| 43 |
+
|
| 44 |
+
#Stage two: embed the docs.
|
| 45 |
+
embeddings = HuggingFaceEmbeddings(model_name=embedding_model)
|
| 46 |
+
print(f"create a total of {len(chunks)}")
|
| 47 |
+
|
| 48 |
+
return embeddings,chunks
|
rag-system-anatomy/get_db_retriever.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# retriever and qa_chain function
|
| 2 |
+
|
| 3 |
+
# HF libraries
|
| 4 |
+
from langchain.llms import HuggingFaceHub
|
| 5 |
+
from langchain.embeddings import HuggingFaceHubEmbeddings
|
| 6 |
+
# vectorestore
|
| 7 |
+
from langchain.vectorstores import FAISS
|
| 8 |
+
# retrieval chain
|
| 9 |
+
from langchain.chains import RetrievalQA
|
| 10 |
+
# prompt template
|
| 11 |
+
from langchain.prompts import PromptTemplate
|
| 12 |
+
from langchain.memory import ConversationBufferMemory
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_db_retriever(vector_db:str=None):
|
| 16 |
+
model_name = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
|
| 17 |
+
embeddings = HuggingFaceHubEmbeddings(repo_id=model_name)
|
| 18 |
+
|
| 19 |
+
#db = Chroma(persist_directory="./vectorstore/lc-chroma-multi-mpnet-500", embedding_function=embeddings)
|
| 20 |
+
#db.get()
|
| 21 |
+
if not vector_db:
|
| 22 |
+
FAISS_INDEX_PATH='./vectorstore/py-faiss-multi-mpnet-500'
|
| 23 |
+
else:
|
| 24 |
+
FAISS_INDEX_PATH=vector_db
|
| 25 |
+
db = FAISS.load_local(FAISS_INDEX_PATH, embeddings)
|
| 26 |
+
|
| 27 |
+
retriever = db.as_retriever()
|
| 28 |
+
|
| 29 |
+
return retriever
|
rag-system-anatomy/load_data_from_urls.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# documents loader function
|
| 2 |
+
from langchain.document_loaders.recursive_url_loader import RecursiveUrlLoader
|
| 3 |
+
from bs4 import BeautifulSoup as Soup
|
| 4 |
+
from validators import url as url_validator
|
| 5 |
+
from langchain_core.documents import Document
|
| 6 |
+
|
| 7 |
+
def load_docs_from_urls(
|
| 8 |
+
urls: list = ["https://docs.python.org/3/"],
|
| 9 |
+
max_depth: int = 5,
|
| 10 |
+
) -> list[Document]:
|
| 11 |
+
"""
|
| 12 |
+
Load documents from a list of URLs.
|
| 13 |
+
|
| 14 |
+
## Args:
|
| 15 |
+
urls (list, optional): A list of URLs to load documents from. Defaults to ["https://docs.python.org/3/"].
|
| 16 |
+
max_depth (int, optional): Maximum depth to recursively load documents from each URL. Defaults to 5.
|
| 17 |
+
|
| 18 |
+
## Returns:
|
| 19 |
+
list: A list of documents loaded from the given URLs.
|
| 20 |
+
|
| 21 |
+
## Raises:
|
| 22 |
+
ValueError: If any URL in the provided list is invalid.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
docs = []
|
| 26 |
+
for url in urls:
|
| 27 |
+
if not url_validator(url):
|
| 28 |
+
raise ValueError(f"Invalid URL: {url}")
|
| 29 |
+
loader = RecursiveUrlLoader(url=url, max_depth=max_depth, extractor=lambda x: Soup(x, "html.parser").text)
|
| 30 |
+
docs.extend(loader.load())
|
| 31 |
+
print(f"loaded {len(docs)} pages")
|
| 32 |
+
return docs
|
rag-system-anatomy/load_example_embeddings.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# preprocessed vectorstore retrieval
|
| 2 |
+
import boto3
|
| 3 |
+
from botocore import UNSIGNED
|
| 4 |
+
from botocore.client import Config
|
| 5 |
+
import zipfile
|
| 6 |
+
from langchain.vectorstores import FAISS
|
| 7 |
+
from langchain.vectorstores import Chroma
|
| 8 |
+
from langchain.embeddings import HuggingFaceEmbeddings
|
| 9 |
+
|
| 10 |
+
# access .env file
|
| 11 |
+
|
| 12 |
+
s3 = boto3.client('s3', config=Config(signature_version=UNSIGNED))
|
| 13 |
+
|
| 14 |
+
model_name = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
|
| 15 |
+
#model_kwargs = {"device": "cuda"}
|
| 16 |
+
|
| 17 |
+
embeddings = HuggingFaceEmbeddings(
|
| 18 |
+
model_name=model_name,
|
| 19 |
+
# model_kwargs=model_kwargs
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
## FAISS
|
| 23 |
+
FAISS_INDEX_PATH='./vectorstore/lc-faiss-multi-mpnet-500-markdown'
|
| 24 |
+
VS_DESTINATION = FAISS_INDEX_PATH+".zip"
|
| 25 |
+
s3.download_file('rad-rag-demos', 'vectorstores/lc-faiss-multi-mpnet-500-markdown.zip', VS_DESTINATION)
|
| 26 |
+
with zipfile.ZipFile(VS_DESTINATION, 'r') as zip_ref:
|
| 27 |
+
zip_ref.extractall('./vectorstore/')
|
| 28 |
+
faissdb = FAISS.load_local(FAISS_INDEX_PATH, embeddings)
|
| 29 |
+
|
| 30 |
+
## Chroma DB
|
| 31 |
+
chroma_directory="./vectorstore/lc-chroma-multi-mpnet-500-markdown"
|
| 32 |
+
VS_DESTINATION = chroma_directory+".zip"
|
| 33 |
+
s3.download_file('rad-rag-demos', 'vectorstores/lc-chroma-multi-mpnet-500-markdown.zip', VS_DESTINATION)
|
| 34 |
+
with zipfile.ZipFile(VS_DESTINATION, 'r') as zip_ref:
|
| 35 |
+
zip_ref.extractall('./vectorstore/')
|
| 36 |
+
chromadb = Chroma(persist_directory=chroma_directory, embedding_function=embeddings)
|
| 37 |
+
chromadb.get()
|
requirements.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
langchain
|
| 2 |
+
langchain-community
|
| 3 |
+
langchain_huggingface
|
| 4 |
+
beautifulsoup4
|
| 5 |
+
faiss-cpu
|
| 6 |
+
chromadb
|
| 7 |
+
validators
|
| 8 |
+
sentence_transformers
|
| 9 |
+
typing-extensions
|
| 10 |
+
unstructured
|
| 11 |
+
gradio
|
| 12 |
+
boto3
|
vectorstore/placeholder.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
This file keeps the folder from being deleted for now
|