


Commit
·
b1f1770
1
Parent(s):
b7ea7c4
update sam2&&scripts
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- app_lhm.py +23 -22
- sam2_configs/__init__.py +0 -0
- sam2_configs/sam2.1_hiera_l.yaml +120 -0
- third_party/sam2/.clang-format +85 -0
- third_party/sam2/.github/workflows/check_fmt.yml +17 -0
- third_party/sam2/.gitignore +11 -0
- third_party/sam2/.watchmanconfig +1 -0
- third_party/sam2/CODE_OF_CONDUCT.md +80 -0
- third_party/sam2/CONTRIBUTING.md +31 -0
- third_party/sam2/INSTALL.md +189 -0
- third_party/sam2/LICENSE +201 -0
- third_party/sam2/LICENSE_cctorch +29 -0
- third_party/sam2/MANIFEST.in +7 -0
- third_party/sam2/README.md +224 -0
- third_party/sam2/RELEASE_NOTES.md +27 -0
- third_party/sam2/assets/model_diagram.png +0 -0
- third_party/sam2/assets/sa_v_dataset.jpg +0 -0
- third_party/sam2/backend.Dockerfile +64 -0
- third_party/sam2/checkpoints/download_ckpts.sh +59 -0
- third_party/sam2/docker-compose.yaml +42 -0
- third_party/sam2/pyproject.toml +6 -0
- third_party/sam2/sam2/__init__.py +11 -0
- third_party/sam2/sam2/automatic_mask_generator.py +454 -0
- third_party/sam2/sam2/benchmark.py +92 -0
- third_party/sam2/sam2/build_sam.py +174 -0
- third_party/sam2/sam2/configs/sam2.1/sam2.1_hiera_b+.yaml +116 -0
- third_party/sam2/sam2/configs/sam2.1/sam2.1_hiera_l.yaml +120 -0
- third_party/sam2/sam2/configs/sam2.1/sam2.1_hiera_s.yaml +119 -0
- third_party/sam2/sam2/configs/sam2.1/sam2.1_hiera_t.yaml +121 -0
- third_party/sam2/sam2/configs/sam2.1_training/sam2.1_hiera_b+_MOSE_finetune.yaml +339 -0
- third_party/sam2/sam2/configs/sam2/sam2_hiera_b+.yaml +113 -0
- third_party/sam2/sam2/configs/sam2/sam2_hiera_l.yaml +117 -0
- third_party/sam2/sam2/configs/sam2/sam2_hiera_s.yaml +116 -0
- third_party/sam2/sam2/configs/sam2/sam2_hiera_t.yaml +118 -0
- third_party/sam2/sam2/csrc/connected_components.cu +289 -0
- third_party/sam2/sam2/modeling/__init__.py +5 -0
- third_party/sam2/sam2/modeling/backbones/__init__.py +5 -0
- third_party/sam2/sam2/modeling/backbones/hieradet.py +317 -0
- third_party/sam2/sam2/modeling/backbones/image_encoder.py +134 -0
- third_party/sam2/sam2/modeling/backbones/utils.py +93 -0
- third_party/sam2/sam2/modeling/memory_attention.py +169 -0
- third_party/sam2/sam2/modeling/memory_encoder.py +181 -0
- third_party/sam2/sam2/modeling/position_encoding.py +239 -0
- third_party/sam2/sam2/modeling/sam/__init__.py +5 -0
- third_party/sam2/sam2/modeling/sam/mask_decoder.py +295 -0
- third_party/sam2/sam2/modeling/sam/prompt_encoder.py +202 -0
- third_party/sam2/sam2/modeling/sam/transformer.py +311 -0
- third_party/sam2/sam2/modeling/sam2_base.py +909 -0
- third_party/sam2/sam2/modeling/sam2_utils.py +323 -0
- third_party/sam2/sam2/sam2_hiera_b+.yaml +1 -0
app_lhm.py
CHANGED
|
@@ -22,24 +22,24 @@ import base64
|
|
| 22 |
import subprocess
|
| 23 |
import os
|
| 24 |
|
| 25 |
-
def install_cuda_toolkit():
|
| 26 |
-
# CUDA_TOOLKIT_URL = "https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run"
|
| 27 |
-
# # CUDA_TOOLKIT_URL = "https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run"
|
| 28 |
-
# CUDA_TOOLKIT_FILE = "/tmp/%s" % os.path.basename(CUDA_TOOLKIT_URL)
|
| 29 |
-
# subprocess.call(["wget", "-q", CUDA_TOOLKIT_URL, "-O", CUDA_TOOLKIT_FILE])
|
| 30 |
-
# subprocess.call(["chmod", "+x", CUDA_TOOLKIT_FILE])
|
| 31 |
-
# subprocess.call([CUDA_TOOLKIT_FILE, "--silent", "--toolkit"])
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
install_cuda_toolkit()
|
| 43 |
|
| 44 |
def launch_pretrained():
|
| 45 |
from huggingface_hub import snapshot_download, hf_hub_download
|
|
@@ -54,7 +54,8 @@ def launch_env_not_compile_with_cuda():
|
|
| 54 |
os.system("pip install chumpy")
|
| 55 |
os.system("pip uninstall -y basicsr")
|
| 56 |
os.system("pip install git+https://github.com/hitsz-zuoqi/BasicSR/")
|
| 57 |
-
os.system("pip install
|
|
|
|
| 58 |
# os.system("pip install git+https://github.com/ashawkey/diff-gaussian-rasterization/")
|
| 59 |
# os.system("pip install git+https://github.com/camenduru/simple-knn/")
|
| 60 |
os.system("pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/py310_cu121_pyt251/download.html")
|
|
@@ -78,8 +79,7 @@ def launch_env_not_compile_with_cuda():
|
|
| 78 |
# os.system("mv pytorch3d /usr/local/lib/python3.10/site-packages/")
|
| 79 |
# os.system("mv pytorch3d-0.7.8.dist-info /usr/local/lib/python3.10/site-packages/")
|
| 80 |
|
| 81 |
-
|
| 82 |
-
launch_env_not_compile_with_cuda()
|
| 83 |
# launch_env_compile_with_cuda()
|
| 84 |
|
| 85 |
def assert_input_image(input_image):
|
|
@@ -268,5 +268,6 @@ def launch_gradio_app():
|
|
| 268 |
|
| 269 |
|
| 270 |
if __name__ == '__main__':
|
| 271 |
-
|
|
|
|
| 272 |
launch_gradio_app()
|
|
|
|
| 22 |
import subprocess
|
| 23 |
import os
|
| 24 |
|
| 25 |
+
# def install_cuda_toolkit():
|
| 26 |
+
# # CUDA_TOOLKIT_URL = "https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run"
|
| 27 |
+
# # # CUDA_TOOLKIT_URL = "https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run"
|
| 28 |
+
# # CUDA_TOOLKIT_FILE = "/tmp/%s" % os.path.basename(CUDA_TOOLKIT_URL)
|
| 29 |
+
# # subprocess.call(["wget", "-q", CUDA_TOOLKIT_URL, "-O", CUDA_TOOLKIT_FILE])
|
| 30 |
+
# # subprocess.call(["chmod", "+x", CUDA_TOOLKIT_FILE])
|
| 31 |
+
# # subprocess.call([CUDA_TOOLKIT_FILE, "--silent", "--toolkit"])
|
| 32 |
+
|
| 33 |
+
# os.environ["CUDA_HOME"] = "/usr/local/cuda"
|
| 34 |
+
# os.environ["PATH"] = "%s/bin:%s" % (os.environ["CUDA_HOME"], os.environ["PATH"])
|
| 35 |
+
# os.environ["LD_LIBRARY_PATH"] = "%s/lib:%s" % (
|
| 36 |
+
# os.environ["CUDA_HOME"],
|
| 37 |
+
# "" if "LD_LIBRARY_PATH" not in os.environ else os.environ["LD_LIBRARY_PATH"],
|
| 38 |
+
# )
|
| 39 |
+
# # Fix: arch_list[-1] += '+PTX'; IndexError: list index out of range
|
| 40 |
+
# os.environ["TORCH_CUDA_ARCH_LIST"] = "8.0;8.6"
|
| 41 |
+
|
| 42 |
+
# install_cuda_toolkit()
|
| 43 |
|
| 44 |
def launch_pretrained():
|
| 45 |
from huggingface_hub import snapshot_download, hf_hub_download
|
|
|
|
| 54 |
os.system("pip install chumpy")
|
| 55 |
os.system("pip uninstall -y basicsr")
|
| 56 |
os.system("pip install git+https://github.com/hitsz-zuoqi/BasicSR/")
|
| 57 |
+
os.system("pip install -e ./third_party/sam2")
|
| 58 |
+
# os.system("pip install git+https://github.com/hitsz-zuoqi/sam2/")
|
| 59 |
# os.system("pip install git+https://github.com/ashawkey/diff-gaussian-rasterization/")
|
| 60 |
# os.system("pip install git+https://github.com/camenduru/simple-knn/")
|
| 61 |
os.system("pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/py310_cu121_pyt251/download.html")
|
|
|
|
| 79 |
# os.system("mv pytorch3d /usr/local/lib/python3.10/site-packages/")
|
| 80 |
# os.system("mv pytorch3d-0.7.8.dist-info /usr/local/lib/python3.10/site-packages/")
|
| 81 |
|
| 82 |
+
|
|
|
|
| 83 |
# launch_env_compile_with_cuda()
|
| 84 |
|
| 85 |
def assert_input_image(input_image):
|
|
|
|
| 268 |
|
| 269 |
|
| 270 |
if __name__ == '__main__':
|
| 271 |
+
launch_pretrained()
|
| 272 |
+
launch_env_not_compile_with_cuda()
|
| 273 |
launch_gradio_app()
|
sam2_configs/__init__.py
ADDED
|
File without changes
|
sam2_configs/sam2.1_hiera_l.yaml
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 144
|
| 12 |
+
num_heads: 2
|
| 13 |
+
stages: [2, 6, 36, 4]
|
| 14 |
+
global_att_blocks: [23, 33, 43]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
window_spec: [8, 4, 16, 8]
|
| 17 |
+
neck:
|
| 18 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 19 |
+
position_encoding:
|
| 20 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 21 |
+
num_pos_feats: 256
|
| 22 |
+
normalize: true
|
| 23 |
+
scale: null
|
| 24 |
+
temperature: 10000
|
| 25 |
+
d_model: 256
|
| 26 |
+
backbone_channel_list: [1152, 576, 288, 144]
|
| 27 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 28 |
+
fpn_interp_model: nearest
|
| 29 |
+
|
| 30 |
+
memory_attention:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 32 |
+
d_model: 256
|
| 33 |
+
pos_enc_at_input: true
|
| 34 |
+
layer:
|
| 35 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 36 |
+
activation: relu
|
| 37 |
+
dim_feedforward: 2048
|
| 38 |
+
dropout: 0.1
|
| 39 |
+
pos_enc_at_attn: false
|
| 40 |
+
self_attention:
|
| 41 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 42 |
+
rope_theta: 10000.0
|
| 43 |
+
feat_sizes: [32, 32]
|
| 44 |
+
embedding_dim: 256
|
| 45 |
+
num_heads: 1
|
| 46 |
+
downsample_rate: 1
|
| 47 |
+
dropout: 0.1
|
| 48 |
+
d_model: 256
|
| 49 |
+
pos_enc_at_cross_attn_keys: true
|
| 50 |
+
pos_enc_at_cross_attn_queries: false
|
| 51 |
+
cross_attention:
|
| 52 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 53 |
+
rope_theta: 10000.0
|
| 54 |
+
feat_sizes: [32, 32]
|
| 55 |
+
rope_k_repeat: True
|
| 56 |
+
embedding_dim: 256
|
| 57 |
+
num_heads: 1
|
| 58 |
+
downsample_rate: 1
|
| 59 |
+
dropout: 0.1
|
| 60 |
+
kv_in_dim: 64
|
| 61 |
+
num_layers: 4
|
| 62 |
+
|
| 63 |
+
memory_encoder:
|
| 64 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 65 |
+
out_dim: 64
|
| 66 |
+
position_encoding:
|
| 67 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 68 |
+
num_pos_feats: 64
|
| 69 |
+
normalize: true
|
| 70 |
+
scale: null
|
| 71 |
+
temperature: 10000
|
| 72 |
+
mask_downsampler:
|
| 73 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 74 |
+
kernel_size: 3
|
| 75 |
+
stride: 2
|
| 76 |
+
padding: 1
|
| 77 |
+
fuser:
|
| 78 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 79 |
+
layer:
|
| 80 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 81 |
+
dim: 256
|
| 82 |
+
kernel_size: 7
|
| 83 |
+
padding: 3
|
| 84 |
+
layer_scale_init_value: 1e-6
|
| 85 |
+
use_dwconv: True # depth-wise convs
|
| 86 |
+
num_layers: 2
|
| 87 |
+
|
| 88 |
+
num_maskmem: 7
|
| 89 |
+
image_size: 1024
|
| 90 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
no_obj_embed_spatial: true
|
| 97 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 98 |
+
use_high_res_features_in_sam: true
|
| 99 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 100 |
+
multimask_output_in_sam: true
|
| 101 |
+
# SAM heads
|
| 102 |
+
iou_prediction_use_sigmoid: True
|
| 103 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 104 |
+
use_obj_ptrs_in_encoder: true
|
| 105 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 106 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 107 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 108 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 109 |
+
# object occlusion prediction
|
| 110 |
+
pred_obj_scores: true
|
| 111 |
+
pred_obj_scores_mlp: true
|
| 112 |
+
fixed_no_obj_ptr: true
|
| 113 |
+
# multimask tracking settings
|
| 114 |
+
multimask_output_for_tracking: true
|
| 115 |
+
use_multimask_token_for_obj_ptr: true
|
| 116 |
+
multimask_min_pt_num: 0
|
| 117 |
+
multimask_max_pt_num: 1
|
| 118 |
+
use_mlp_for_obj_ptr_proj: true
|
| 119 |
+
# Compilation flag
|
| 120 |
+
compile_image_encoder: False
|
third_party/sam2/.clang-format
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
AccessModifierOffset: -1
|
| 2 |
+
AlignAfterOpenBracket: AlwaysBreak
|
| 3 |
+
AlignConsecutiveAssignments: false
|
| 4 |
+
AlignConsecutiveDeclarations: false
|
| 5 |
+
AlignEscapedNewlinesLeft: true
|
| 6 |
+
AlignOperands: false
|
| 7 |
+
AlignTrailingComments: false
|
| 8 |
+
AllowAllParametersOfDeclarationOnNextLine: false
|
| 9 |
+
AllowShortBlocksOnASingleLine: false
|
| 10 |
+
AllowShortCaseLabelsOnASingleLine: false
|
| 11 |
+
AllowShortFunctionsOnASingleLine: Empty
|
| 12 |
+
AllowShortIfStatementsOnASingleLine: false
|
| 13 |
+
AllowShortLoopsOnASingleLine: false
|
| 14 |
+
AlwaysBreakAfterReturnType: None
|
| 15 |
+
AlwaysBreakBeforeMultilineStrings: true
|
| 16 |
+
AlwaysBreakTemplateDeclarations: true
|
| 17 |
+
BinPackArguments: false
|
| 18 |
+
BinPackParameters: false
|
| 19 |
+
BraceWrapping:
|
| 20 |
+
AfterClass: false
|
| 21 |
+
AfterControlStatement: false
|
| 22 |
+
AfterEnum: false
|
| 23 |
+
AfterFunction: false
|
| 24 |
+
AfterNamespace: false
|
| 25 |
+
AfterObjCDeclaration: false
|
| 26 |
+
AfterStruct: false
|
| 27 |
+
AfterUnion: false
|
| 28 |
+
BeforeCatch: false
|
| 29 |
+
BeforeElse: false
|
| 30 |
+
IndentBraces: false
|
| 31 |
+
BreakBeforeBinaryOperators: None
|
| 32 |
+
BreakBeforeBraces: Attach
|
| 33 |
+
BreakBeforeTernaryOperators: true
|
| 34 |
+
BreakConstructorInitializersBeforeComma: false
|
| 35 |
+
BreakAfterJavaFieldAnnotations: false
|
| 36 |
+
BreakStringLiterals: false
|
| 37 |
+
ColumnLimit: 80
|
| 38 |
+
CommentPragmas: '^ IWYU pragma:'
|
| 39 |
+
ConstructorInitializerAllOnOneLineOrOnePerLine: true
|
| 40 |
+
ConstructorInitializerIndentWidth: 4
|
| 41 |
+
ContinuationIndentWidth: 4
|
| 42 |
+
Cpp11BracedListStyle: true
|
| 43 |
+
DerivePointerAlignment: false
|
| 44 |
+
DisableFormat: false
|
| 45 |
+
ForEachMacros: [ FOR_EACH, FOR_EACH_R, FOR_EACH_RANGE, ]
|
| 46 |
+
IncludeCategories:
|
| 47 |
+
- Regex: '^<.*\.h(pp)?>'
|
| 48 |
+
Priority: 1
|
| 49 |
+
- Regex: '^<.*'
|
| 50 |
+
Priority: 2
|
| 51 |
+
- Regex: '.*'
|
| 52 |
+
Priority: 3
|
| 53 |
+
IndentCaseLabels: true
|
| 54 |
+
IndentWidth: 2
|
| 55 |
+
IndentWrappedFunctionNames: false
|
| 56 |
+
KeepEmptyLinesAtTheStartOfBlocks: false
|
| 57 |
+
MacroBlockBegin: ''
|
| 58 |
+
MacroBlockEnd: ''
|
| 59 |
+
MaxEmptyLinesToKeep: 1
|
| 60 |
+
NamespaceIndentation: None
|
| 61 |
+
ObjCBlockIndentWidth: 2
|
| 62 |
+
ObjCSpaceAfterProperty: false
|
| 63 |
+
ObjCSpaceBeforeProtocolList: false
|
| 64 |
+
PenaltyBreakBeforeFirstCallParameter: 1
|
| 65 |
+
PenaltyBreakComment: 300
|
| 66 |
+
PenaltyBreakFirstLessLess: 120
|
| 67 |
+
PenaltyBreakString: 1000
|
| 68 |
+
PenaltyExcessCharacter: 1000000
|
| 69 |
+
PenaltyReturnTypeOnItsOwnLine: 200
|
| 70 |
+
PointerAlignment: Left
|
| 71 |
+
ReflowComments: true
|
| 72 |
+
SortIncludes: true
|
| 73 |
+
SpaceAfterCStyleCast: false
|
| 74 |
+
SpaceBeforeAssignmentOperators: true
|
| 75 |
+
SpaceBeforeParens: ControlStatements
|
| 76 |
+
SpaceInEmptyParentheses: false
|
| 77 |
+
SpacesBeforeTrailingComments: 1
|
| 78 |
+
SpacesInAngles: false
|
| 79 |
+
SpacesInContainerLiterals: true
|
| 80 |
+
SpacesInCStyleCastParentheses: false
|
| 81 |
+
SpacesInParentheses: false
|
| 82 |
+
SpacesInSquareBrackets: false
|
| 83 |
+
Standard: Cpp11
|
| 84 |
+
TabWidth: 8
|
| 85 |
+
UseTab: Never
|
third_party/sam2/.github/workflows/check_fmt.yml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: SAM2/fmt
|
| 2 |
+
on:
|
| 3 |
+
pull_request:
|
| 4 |
+
branches:
|
| 5 |
+
- main
|
| 6 |
+
jobs:
|
| 7 |
+
ufmt_check:
|
| 8 |
+
runs-on: ubuntu-latest
|
| 9 |
+
steps:
|
| 10 |
+
- name: Check formatting
|
| 11 |
+
uses: omnilib/ufmt@action-v1
|
| 12 |
+
with:
|
| 13 |
+
path: sam2 tools
|
| 14 |
+
version: "2.0.0b2"
|
| 15 |
+
python-version: "3.10"
|
| 16 |
+
black-version: "24.2.0"
|
| 17 |
+
usort-version: "1.0.2"
|
third_party/sam2/.gitignore
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.vscode/
|
| 2 |
+
.DS_Store
|
| 3 |
+
__pycache__/
|
| 4 |
+
*-checkpoint.ipynb
|
| 5 |
+
.venv
|
| 6 |
+
*.egg*
|
| 7 |
+
build/*
|
| 8 |
+
_C.*
|
| 9 |
+
outputs/*
|
| 10 |
+
checkpoints/*.pt
|
| 11 |
+
demo/backend/checkpoints/*.pt
|
third_party/sam2/.watchmanconfig
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{}
|
third_party/sam2/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
In the interest of fostering an open and welcoming environment, we as
|
| 6 |
+
contributors and maintainers pledge to make participation in our project and
|
| 7 |
+
our community a harassment-free experience for everyone, regardless of age, body
|
| 8 |
+
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
| 9 |
+
level of experience, education, socio-economic status, nationality, personal
|
| 10 |
+
appearance, race, religion, or sexual identity and orientation.
|
| 11 |
+
|
| 12 |
+
## Our Standards
|
| 13 |
+
|
| 14 |
+
Examples of behavior that contributes to creating a positive environment
|
| 15 |
+
include:
|
| 16 |
+
|
| 17 |
+
* Using welcoming and inclusive language
|
| 18 |
+
* Being respectful of differing viewpoints and experiences
|
| 19 |
+
* Gracefully accepting constructive criticism
|
| 20 |
+
* Focusing on what is best for the community
|
| 21 |
+
* Showing empathy towards other community members
|
| 22 |
+
|
| 23 |
+
Examples of unacceptable behavior by participants include:
|
| 24 |
+
|
| 25 |
+
* The use of sexualized language or imagery and unwelcome sexual attention or
|
| 26 |
+
advances
|
| 27 |
+
* Trolling, insulting/derogatory comments, and personal or political attacks
|
| 28 |
+
* Public or private harassment
|
| 29 |
+
* Publishing others' private information, such as a physical or electronic
|
| 30 |
+
address, without explicit permission
|
| 31 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 32 |
+
professional setting
|
| 33 |
+
|
| 34 |
+
## Our Responsibilities
|
| 35 |
+
|
| 36 |
+
Project maintainers are responsible for clarifying the standards of acceptable
|
| 37 |
+
behavior and are expected to take appropriate and fair corrective action in
|
| 38 |
+
response to any instances of unacceptable behavior.
|
| 39 |
+
|
| 40 |
+
Project maintainers have the right and responsibility to remove, edit, or
|
| 41 |
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
| 42 |
+
that are not aligned to this Code of Conduct, or to ban temporarily or
|
| 43 |
+
permanently any contributor for other behaviors that they deem inappropriate,
|
| 44 |
+
threatening, offensive, or harmful.
|
| 45 |
+
|
| 46 |
+
## Scope
|
| 47 |
+
|
| 48 |
+
This Code of Conduct applies within all project spaces, and it also applies when
|
| 49 |
+
an individual is representing the project or its community in public spaces.
|
| 50 |
+
Examples of representing a project or community include using an official
|
| 51 |
+
project e-mail address, posting via an official social media account, or acting
|
| 52 |
+
as an appointed representative at an online or offline event. Representation of
|
| 53 |
+
a project may be further defined and clarified by project maintainers.
|
| 54 |
+
|
| 55 |
+
This Code of Conduct also applies outside the project spaces when there is a
|
| 56 |
+
reasonable belief that an individual's behavior may have a negative impact on
|
| 57 |
+
the project or its community.
|
| 58 |
+
|
| 59 |
+
## Enforcement
|
| 60 |
+
|
| 61 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 62 |
+
reported by contacting the project team at <[email protected]>. All
|
| 63 |
+
complaints will be reviewed and investigated and will result in a response that
|
| 64 |
+
is deemed necessary and appropriate to the circumstances. The project team is
|
| 65 |
+
obligated to maintain confidentiality with regard to the reporter of an incident.
|
| 66 |
+
Further details of specific enforcement policies may be posted separately.
|
| 67 |
+
|
| 68 |
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
| 69 |
+
faith may face temporary or permanent repercussions as determined by other
|
| 70 |
+
members of the project's leadership.
|
| 71 |
+
|
| 72 |
+
## Attribution
|
| 73 |
+
|
| 74 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
| 75 |
+
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
| 76 |
+
|
| 77 |
+
[homepage]: https://www.contributor-covenant.org
|
| 78 |
+
|
| 79 |
+
For answers to common questions about this code of conduct, see
|
| 80 |
+
https://www.contributor-covenant.org/faq
|
third_party/sam2/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing to segment-anything
|
| 2 |
+
We want to make contributing to this project as easy and transparent as
|
| 3 |
+
possible.
|
| 4 |
+
|
| 5 |
+
## Pull Requests
|
| 6 |
+
We actively welcome your pull requests.
|
| 7 |
+
|
| 8 |
+
1. Fork the repo and create your branch from `main`.
|
| 9 |
+
2. If you've added code that should be tested, add tests.
|
| 10 |
+
3. If you've changed APIs, update the documentation.
|
| 11 |
+
4. Ensure the test suite passes.
|
| 12 |
+
5. Make sure your code lints, using the `ufmt format` command. Linting requires `black==24.2.0`, `usort==1.0.2`, and `ufmt==2.0.0b2`, which can be installed via `pip install -e ".[dev]"`.
|
| 13 |
+
6. If you haven't already, complete the Contributor License Agreement ("CLA").
|
| 14 |
+
|
| 15 |
+
## Contributor License Agreement ("CLA")
|
| 16 |
+
In order to accept your pull request, we need you to submit a CLA. You only need
|
| 17 |
+
to do this once to work on any of Facebook's open source projects.
|
| 18 |
+
|
| 19 |
+
Complete your CLA here: <https://code.facebook.com/cla>
|
| 20 |
+
|
| 21 |
+
## Issues
|
| 22 |
+
We use GitHub issues to track public bugs. Please ensure your description is
|
| 23 |
+
clear and has sufficient instructions to be able to reproduce the issue.
|
| 24 |
+
|
| 25 |
+
Facebook has a [bounty program](https://www.facebook.com/whitehat/) for the safe
|
| 26 |
+
disclosure of security bugs. In those cases, please go through the process
|
| 27 |
+
outlined on that page and do not file a public issue.
|
| 28 |
+
|
| 29 |
+
## License
|
| 30 |
+
By contributing to segment-anything, you agree that your contributions will be licensed
|
| 31 |
+
under the LICENSE file in the root directory of this source tree.
|
third_party/sam2/INSTALL.md
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Installation
|
| 2 |
+
|
| 3 |
+
### Requirements
|
| 4 |
+
|
| 5 |
+
- Linux with Python ≥ 3.10, PyTorch ≥ 2.5.1 and [torchvision](https://github.com/pytorch/vision/) that matches the PyTorch installation. Install them together at https://pytorch.org to ensure this.
|
| 6 |
+
* Note older versions of Python or PyTorch may also work. However, the versions above are strongly recommended to provide all features such as `torch.compile`.
|
| 7 |
+
- [CUDA toolkits](https://developer.nvidia.com/cuda-toolkit-archive) that match the CUDA version for your PyTorch installation. This should typically be CUDA 12.1 if you follow the default installation command.
|
| 8 |
+
- If you are installing on Windows, it's strongly recommended to use [Windows Subsystem for Linux (WSL)](https://learn.microsoft.com/en-us/windows/wsl/install) with Ubuntu.
|
| 9 |
+
|
| 10 |
+
Then, install SAM 2 from the root of this repository via
|
| 11 |
+
```bash
|
| 12 |
+
pip install -e ".[notebooks]"
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
Note that you may skip building the SAM 2 CUDA extension during installation via environment variable `SAM2_BUILD_CUDA=0`, as follows:
|
| 16 |
+
```bash
|
| 17 |
+
# skip the SAM 2 CUDA extension
|
| 18 |
+
SAM2_BUILD_CUDA=0 pip install -e ".[notebooks]"
|
| 19 |
+
```
|
| 20 |
+
This would also skip the post-processing step at runtime (removing small holes and sprinkles in the output masks, which requires the CUDA extension), but shouldn't affect the results in most cases.
|
| 21 |
+
|
| 22 |
+
### Building the SAM 2 CUDA extension
|
| 23 |
+
|
| 24 |
+
By default, we allow the installation to proceed even if the SAM 2 CUDA extension fails to build. (In this case, the build errors are hidden unless using `-v` for verbose output in `pip install`.)
|
| 25 |
+
|
| 26 |
+
If you see a message like `Skipping the post-processing step due to the error above` at runtime or `Failed to build the SAM 2 CUDA extension due to the error above` during installation, it indicates that the SAM 2 CUDA extension failed to build in your environment. In this case, **you can still use SAM 2 for both image and video applications**. The post-processing step (removing small holes and sprinkles in the output masks) will be skipped, but this shouldn't affect the results in most cases.
|
| 27 |
+
|
| 28 |
+
If you would like to enable this post-processing step, you can reinstall SAM 2 on a GPU machine with environment variable `SAM2_BUILD_ALLOW_ERRORS=0` to force building the CUDA extension (and raise errors if it fails to build), as follows
|
| 29 |
+
```bash
|
| 30 |
+
pip uninstall -y SAM-2 && \
|
| 31 |
+
rm -f ./sam2/*.so && \
|
| 32 |
+
SAM2_BUILD_ALLOW_ERRORS=0 pip install -v -e ".[notebooks]"
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
Note that PyTorch needs to be installed first before building the SAM 2 CUDA extension. It's also necessary to install [CUDA toolkits](https://developer.nvidia.com/cuda-toolkit-archive) that match the CUDA version for your PyTorch installation. (This should typically be CUDA 12.1 if you follow the default installation command.) After installing the CUDA toolkits, you can check its version via `nvcc --version`.
|
| 36 |
+
|
| 37 |
+
Please check the section below on common installation issues if the CUDA extension fails to build during installation or load at runtime.
|
| 38 |
+
|
| 39 |
+
### Common Installation Issues
|
| 40 |
+
|
| 41 |
+
Click each issue for its solutions:
|
| 42 |
+
|
| 43 |
+
<details>
|
| 44 |
+
<summary>
|
| 45 |
+
I got `ImportError: cannot import name '_C' from 'sam2'`
|
| 46 |
+
</summary>
|
| 47 |
+
<br/>
|
| 48 |
+
|
| 49 |
+
This is usually because you haven't run the `pip install -e ".[notebooks]"` step above or the installation failed. Please install SAM 2 first, and see the other issues if your installation fails.
|
| 50 |
+
|
| 51 |
+
In some systems, you may need to run `python setup.py build_ext --inplace` in the SAM 2 repo root as suggested in https://github.com/facebookresearch/sam2/issues/77.
|
| 52 |
+
</details>
|
| 53 |
+
|
| 54 |
+
<details>
|
| 55 |
+
<summary>
|
| 56 |
+
I got `MissingConfigException: Cannot find primary config 'configs/sam2.1/sam2.1_hiera_l.yaml'`
|
| 57 |
+
</summary>
|
| 58 |
+
<br/>
|
| 59 |
+
|
| 60 |
+
This is usually because you haven't run the `pip install -e .` step above, so `sam2` isn't in your Python's `sys.path`. Please run this installation step. In case it still fails after the installation step, you may try manually adding the root of this repo to `PYTHONPATH` via
|
| 61 |
+
```bash
|
| 62 |
+
export SAM2_REPO_ROOT=/path/to/sam2 # path to this repo
|
| 63 |
+
export PYTHONPATH="${SAM2_REPO_ROOT}:${PYTHONPATH}"
|
| 64 |
+
```
|
| 65 |
+
to manually add `sam2_configs` into your Python's `sys.path`.
|
| 66 |
+
|
| 67 |
+
</details>
|
| 68 |
+
|
| 69 |
+
<details>
|
| 70 |
+
<summary>
|
| 71 |
+
I got `RuntimeError: Error(s) in loading state_dict for SAM2Base` when loading the new SAM 2.1 checkpoints
|
| 72 |
+
</summary>
|
| 73 |
+
<br/>
|
| 74 |
+
|
| 75 |
+
This is likely because you have installed a previous version of this repo, which doesn't have the new modules to support the SAM 2.1 checkpoints yet. Please try the following steps:
|
| 76 |
+
|
| 77 |
+
1. pull the latest code from the `main` branch of this repo
|
| 78 |
+
2. run `pip uninstall -y SAM-2` to uninstall any previous installations
|
| 79 |
+
3. then install the latest repo again using `pip install -e ".[notebooks]"`
|
| 80 |
+
|
| 81 |
+
In case the steps above still don't resolve the error, please try running in your Python environment the following
|
| 82 |
+
```python
|
| 83 |
+
from sam2.modeling import sam2_base
|
| 84 |
+
|
| 85 |
+
print(sam2_base.__file__)
|
| 86 |
+
```
|
| 87 |
+
and check whether the content in the printed local path of `sam2/modeling/sam2_base.py` matches the latest one in https://github.com/facebookresearch/sam2/blob/main/sam2/modeling/sam2_base.py (e.g. whether your local file has `no_obj_embed_spatial`) to indentify if you're still using a previous installation.
|
| 88 |
+
|
| 89 |
+
</details>
|
| 90 |
+
|
| 91 |
+
<details>
|
| 92 |
+
<summary>
|
| 93 |
+
My installation failed with `CUDA_HOME environment variable is not set`
|
| 94 |
+
</summary>
|
| 95 |
+
<br/>
|
| 96 |
+
|
| 97 |
+
This usually happens because the installation step cannot find the CUDA toolkits (that contain the NVCC compiler) to build a custom CUDA kernel in SAM 2. Please install [CUDA toolkits](https://developer.nvidia.com/cuda-toolkit-archive) or the version that matches the CUDA version for your PyTorch installation. If the error persists after installing CUDA toolkits, you may explicitly specify `CUDA_HOME` via
|
| 98 |
+
```
|
| 99 |
+
export CUDA_HOME=/usr/local/cuda # change to your CUDA toolkit path
|
| 100 |
+
```
|
| 101 |
+
and rerun the installation.
|
| 102 |
+
|
| 103 |
+
Also, you should make sure
|
| 104 |
+
```
|
| 105 |
+
python -c 'import torch; from torch.utils.cpp_extension import CUDA_HOME; print(torch.cuda.is_available(), CUDA_HOME)'
|
| 106 |
+
```
|
| 107 |
+
print `(True, a directory with cuda)` to verify that the CUDA toolkits are correctly set up.
|
| 108 |
+
|
| 109 |
+
If you are still having problems after verifying that the CUDA toolkit is installed and the `CUDA_HOME` environment variable is set properly, you may have to add the `--no-build-isolation` flag to the pip command:
|
| 110 |
+
```
|
| 111 |
+
pip install --no-build-isolation -e .
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
</details>
|
| 115 |
+
|
| 116 |
+
<details>
|
| 117 |
+
<summary>
|
| 118 |
+
I got `undefined symbol: _ZN3c1015SmallVectorBaseIjE8grow_podEPKvmm` (or similar errors)
|
| 119 |
+
</summary>
|
| 120 |
+
<br/>
|
| 121 |
+
|
| 122 |
+
This usually happens because you have multiple versions of dependencies (PyTorch or CUDA) in your environment. During installation, the SAM 2 library is compiled against one version library while at run time it links against another version. This might be due to that you have different versions of PyTorch or CUDA installed separately via `pip` or `conda`. You may delete one of the duplicates to only keep a single PyTorch and CUDA version.
|
| 123 |
+
|
| 124 |
+
In particular, if you have a lower PyTorch version than 2.5.1, it's recommended to upgrade to PyTorch 2.5.1 or higher first. Otherwise, the installation script will try to upgrade to the latest PyTorch using `pip`, which could sometimes lead to duplicated PyTorch installation if you have previously installed another PyTorch version using `conda`.
|
| 125 |
+
|
| 126 |
+
We have been building SAM 2 against PyTorch 2.5.1 internally. However, a few user comments (e.g. https://github.com/facebookresearch/sam2/issues/22, https://github.com/facebookresearch/sam2/issues/14) suggested that downgrading to PyTorch 2.1.0 might resolve this problem. In case the error persists, you may try changing the restriction from `torch>=2.5.1` to `torch==2.1.0` in both [`pyproject.toml`](pyproject.toml) and [`setup.py`](setup.py) to allow PyTorch 2.1.0.
|
| 127 |
+
</details>
|
| 128 |
+
|
| 129 |
+
<details>
|
| 130 |
+
<summary>
|
| 131 |
+
I got `CUDA error: no kernel image is available for execution on the device`
|
| 132 |
+
</summary>
|
| 133 |
+
<br/>
|
| 134 |
+
|
| 135 |
+
A possible cause could be that the CUDA kernel is somehow not compiled towards your GPU's CUDA [capability](https://developer.nvidia.com/cuda-gpus). This could happen if the installation is done in an environment different from the runtime (e.g. in a slurm system).
|
| 136 |
+
|
| 137 |
+
You can try pulling the latest code from the SAM 2 repo and running the following
|
| 138 |
+
```
|
| 139 |
+
export TORCH_CUDA_ARCH_LIST=9.0 8.0 8.6 8.9 7.0 7.2 7.5 6.0`
|
| 140 |
+
```
|
| 141 |
+
to manually specify the CUDA capability in the compilation target that matches your GPU.
|
| 142 |
+
</details>
|
| 143 |
+
|
| 144 |
+
<details>
|
| 145 |
+
<summary>
|
| 146 |
+
I got `RuntimeError: No available kernel. Aborting execution.` (or similar errors)
|
| 147 |
+
</summary>
|
| 148 |
+
<br/>
|
| 149 |
+
|
| 150 |
+
This is probably because your machine doesn't have a GPU or a compatible PyTorch version for Flash Attention (see also https://discuss.pytorch.org/t/using-f-scaled-dot-product-attention-gives-the-error-runtimeerror-no-available-kernel-aborting-execution/180900 for a discussion in PyTorch forum). You may be able to resolve this error by replacing the line
|
| 151 |
+
```python
|
| 152 |
+
OLD_GPU, USE_FLASH_ATTN, MATH_KERNEL_ON = get_sdpa_settings()
|
| 153 |
+
```
|
| 154 |
+
in [`sam2/modeling/sam/transformer.py`](sam2/modeling/sam/transformer.py) with
|
| 155 |
+
```python
|
| 156 |
+
OLD_GPU, USE_FLASH_ATTN, MATH_KERNEL_ON = True, True, True
|
| 157 |
+
```
|
| 158 |
+
to relax the attention kernel setting and use other kernels than Flash Attention.
|
| 159 |
+
</details>
|
| 160 |
+
|
| 161 |
+
<details>
|
| 162 |
+
<summary>
|
| 163 |
+
I got `Error compiling objects for extension`
|
| 164 |
+
</summary>
|
| 165 |
+
<br/>
|
| 166 |
+
|
| 167 |
+
You may see error log of:
|
| 168 |
+
> unsupported Microsoft Visual Studio version! Only the versions between 2017 and 2022 (inclusive) are supported! The nvcc flag '-allow-unsupported-compiler' can be used to override this version check; however, using an unsupported host compiler may cause compilation failure or incorrect run time execution. Use at your own risk.
|
| 169 |
+
|
| 170 |
+
This is probably because your versions of CUDA and Visual Studio are incompatible. (see also https://stackoverflow.com/questions/78515942/cuda-compatibility-with-visual-studio-2022-version-17-10 for a discussion in stackoverflow).<br>
|
| 171 |
+
You may be able to fix this by adding the `-allow-unsupported-compiler` argument to `nvcc` after L48 in the [setup.py](https://github.com/facebookresearch/sam2/blob/main/setup.py). <br>
|
| 172 |
+
After adding the argument, `get_extension()` will look like this:
|
| 173 |
+
```python
|
| 174 |
+
def get_extensions():
|
| 175 |
+
srcs = ["sam2/csrc/connected_components.cu"]
|
| 176 |
+
compile_args = {
|
| 177 |
+
"cxx": [],
|
| 178 |
+
"nvcc": [
|
| 179 |
+
"-DCUDA_HAS_FP16=1",
|
| 180 |
+
"-D__CUDA_NO_HALF_OPERATORS__",
|
| 181 |
+
"-D__CUDA_NO_HALF_CONVERSIONS__",
|
| 182 |
+
"-D__CUDA_NO_HALF2_OPERATORS__",
|
| 183 |
+
"-allow-unsupported-compiler" # Add this argument
|
| 184 |
+
],
|
| 185 |
+
}
|
| 186 |
+
ext_modules = [CUDAExtension("sam2._C", srcs, extra_compile_args=compile_args)]
|
| 187 |
+
return ext_modules
|
| 188 |
+
```
|
| 189 |
+
</details>
|
third_party/sam2/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
third_party/sam2/LICENSE_cctorch
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2020, the respective contributors, as shown by the AUTHORS file.
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without
|
| 7 |
+
modification, are permitted provided that the following conditions are met:
|
| 8 |
+
|
| 9 |
+
1. Redistributions of source code must retain the above copyright notice, this
|
| 10 |
+
list of conditions and the following disclaimer.
|
| 11 |
+
|
| 12 |
+
2. Redistributions in binary form must reproduce the above copyright notice,
|
| 13 |
+
this list of conditions and the following disclaimer in the documentation
|
| 14 |
+
and/or other materials provided with the distribution.
|
| 15 |
+
|
| 16 |
+
3. Neither the name of the copyright holder nor the names of its
|
| 17 |
+
contributors may be used to endorse or promote products derived from
|
| 18 |
+
this software without specific prior written permission.
|
| 19 |
+
|
| 20 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 21 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 22 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 23 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 24 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 25 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 26 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 27 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 28 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 29 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
third_party/sam2/MANIFEST.in
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
recursive-include sam2 *.yaml #include all config files
|
third_party/sam2/README.md
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SAM 2: Segment Anything in Images and Videos
|
| 2 |
+
|
| 3 |
+
**[AI at Meta, FAIR](https://ai.meta.com/research/)**
|
| 4 |
+
|
| 5 |
+
[Nikhila Ravi](https://nikhilaravi.com/), [Valentin Gabeur](https://gabeur.github.io/), [Yuan-Ting Hu](https://scholar.google.com/citations?user=E8DVVYQAAAAJ&hl=en), [Ronghang Hu](https://ronghanghu.com/), [Chaitanya Ryali](https://scholar.google.com/citations?user=4LWx24UAAAAJ&hl=en), [Tengyu Ma](https://scholar.google.com/citations?user=VeTSl0wAAAAJ&hl=en), [Haitham Khedr](https://hkhedr.com/), [Roman Rädle](https://scholar.google.de/citations?user=Tpt57v0AAAAJ&hl=en), [Chloe Rolland](https://scholar.google.com/citations?hl=fr&user=n-SnMhoAAAAJ), [Laura Gustafson](https://scholar.google.com/citations?user=c8IpF9gAAAAJ&hl=en), [Eric Mintun](https://ericmintun.github.io/), [Junting Pan](https://junting.github.io/), [Kalyan Vasudev Alwala](https://scholar.google.co.in/citations?user=m34oaWEAAAAJ&hl=en), [Nicolas Carion](https://www.nicolascarion.com/), [Chao-Yuan Wu](https://chaoyuan.org/), [Ross Girshick](https://www.rossgirshick.info/), [Piotr Dollár](https://pdollar.github.io/), [Christoph Feichtenhofer](https://feichtenhofer.github.io/)
|
| 6 |
+
|
| 7 |
+
[[`Paper`](https://ai.meta.com/research/publications/sam-2-segment-anything-in-images-and-videos/)] [[`Project`](https://ai.meta.com/sam2)] [[`Demo`](https://sam2.metademolab.com/)] [[`Dataset`](https://ai.meta.com/datasets/segment-anything-video)] [[`Blog`](https://ai.meta.com/blog/segment-anything-2)] [[`BibTeX`](#citing-sam-2)]
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
**Segment Anything Model 2 (SAM 2)** is a foundation model towards solving promptable visual segmentation in images and videos. We extend SAM to video by considering images as a video with a single frame. The model design is a simple transformer architecture with streaming memory for real-time video processing. We build a model-in-the-loop data engine, which improves model and data via user interaction, to collect [**our SA-V dataset**](https://ai.meta.com/datasets/segment-anything-video), the largest video segmentation dataset to date. SAM 2 trained on our data provides strong performance across a wide range of tasks and visual domains.
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
## Latest updates
|
| 16 |
+
|
| 17 |
+
**12/11/2024 -- full model compilation for a major VOS speedup and a new `SAM2VideoPredictor` to better handle multi-object tracking**
|
| 18 |
+
|
| 19 |
+
- We now support `torch.compile` of the entire SAM 2 model on videos, which can be turned on by setting `vos_optimized=True` in `build_sam2_video_predictor`, leading to a major speedup for VOS inference.
|
| 20 |
+
- We update the implementation of `SAM2VideoPredictor` to support independent per-object inference, allowing us to relax the assumption of prompting for multi-object tracking and adding new objects after tracking starts.
|
| 21 |
+
- See [`RELEASE_NOTES.md`](RELEASE_NOTES.md) for full details.
|
| 22 |
+
|
| 23 |
+
**09/30/2024 -- SAM 2.1 Developer Suite (new checkpoints, training code, web demo) is released**
|
| 24 |
+
|
| 25 |
+
- A new suite of improved model checkpoints (denoted as **SAM 2.1**) are released. See [Model Description](#model-description) for details.
|
| 26 |
+
* To use the new SAM 2.1 checkpoints, you need the latest model code from this repo. If you have installed an earlier version of this repo, please first uninstall the previous version via `pip uninstall SAM-2`, pull the latest code from this repo (with `git pull`), and then reinstall the repo following [Installation](#installation) below.
|
| 27 |
+
- The training (and fine-tuning) code has been released. See [`training/README.md`](training/README.md) on how to get started.
|
| 28 |
+
- The frontend + backend code for the SAM 2 web demo has been released. See [`demo/README.md`](demo/README.md) for details.
|
| 29 |
+
|
| 30 |
+
## Installation
|
| 31 |
+
|
| 32 |
+
SAM 2 needs to be installed first before use. The code requires `python>=3.10`, as well as `torch>=2.5.1` and `torchvision>=0.20.1`. Please follow the instructions [here](https://pytorch.org/get-started/locally/) to install both PyTorch and TorchVision dependencies. You can install SAM 2 on a GPU machine using:
|
| 33 |
+
|
| 34 |
+
```bash
|
| 35 |
+
git clone https://github.com/facebookresearch/sam2.git && cd sam2
|
| 36 |
+
|
| 37 |
+
pip install -e .
|
| 38 |
+
```
|
| 39 |
+
If you are installing on Windows, it's strongly recommended to use [Windows Subsystem for Linux (WSL)](https://learn.microsoft.com/en-us/windows/wsl/install) with Ubuntu.
|
| 40 |
+
|
| 41 |
+
To use the SAM 2 predictor and run the example notebooks, `jupyter` and `matplotlib` are required and can be installed by:
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
pip install -e ".[notebooks]"
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Note:
|
| 48 |
+
1. It's recommended to create a new Python environment via [Anaconda](https://www.anaconda.com/) for this installation and install PyTorch 2.5.1 (or higher) via `pip` following https://pytorch.org/. If you have a PyTorch version lower than 2.5.1 in your current environment, the installation command above will try to upgrade it to the latest PyTorch version using `pip`.
|
| 49 |
+
2. The step above requires compiling a custom CUDA kernel with the `nvcc` compiler. If it isn't already available on your machine, please install the [CUDA toolkits](https://developer.nvidia.com/cuda-toolkit-archive) with a version that matches your PyTorch CUDA version.
|
| 50 |
+
3. If you see a message like `Failed to build the SAM 2 CUDA extension` during installation, you can ignore it and still use SAM 2 (some post-processing functionality may be limited, but it doesn't affect the results in most cases).
|
| 51 |
+
|
| 52 |
+
Please see [`INSTALL.md`](./INSTALL.md) for FAQs on potential issues and solutions.
|
| 53 |
+
|
| 54 |
+
## Getting Started
|
| 55 |
+
|
| 56 |
+
### Download Checkpoints
|
| 57 |
+
|
| 58 |
+
First, we need to download a model checkpoint. All the model checkpoints can be downloaded by running:
|
| 59 |
+
|
| 60 |
+
```bash
|
| 61 |
+
cd checkpoints && \
|
| 62 |
+
./download_ckpts.sh && \
|
| 63 |
+
cd ..
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
or individually from:
|
| 67 |
+
|
| 68 |
+
- [sam2.1_hiera_tiny.pt](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_tiny.pt)
|
| 69 |
+
- [sam2.1_hiera_small.pt](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_small.pt)
|
| 70 |
+
- [sam2.1_hiera_base_plus.pt](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_base_plus.pt)
|
| 71 |
+
- [sam2.1_hiera_large.pt](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_large.pt)
|
| 72 |
+
|
| 73 |
+
(note that these are the improved checkpoints denoted as SAM 2.1; see [Model Description](#model-description) for details.)
|
| 74 |
+
|
| 75 |
+
Then SAM 2 can be used in a few lines as follows for image and video prediction.
|
| 76 |
+
|
| 77 |
+
### Image prediction
|
| 78 |
+
|
| 79 |
+
SAM 2 has all the capabilities of [SAM](https://github.com/facebookresearch/segment-anything) on static images, and we provide image prediction APIs that closely resemble SAM for image use cases. The `SAM2ImagePredictor` class has an easy interface for image prompting.
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
import torch
|
| 83 |
+
from sam2.build_sam import build_sam2
|
| 84 |
+
from sam2.sam2_image_predictor import SAM2ImagePredictor
|
| 85 |
+
|
| 86 |
+
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
|
| 87 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
|
| 88 |
+
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
|
| 89 |
+
|
| 90 |
+
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
|
| 91 |
+
predictor.set_image(<your_image>)
|
| 92 |
+
masks, _, _ = predictor.predict(<input_prompts>)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
Please refer to the examples in [image_predictor_example.ipynb](./notebooks/image_predictor_example.ipynb) (also in Colab [here](https://colab.research.google.com/github/facebookresearch/sam2/blob/main/notebooks/image_predictor_example.ipynb)) for static image use cases.
|
| 96 |
+
|
| 97 |
+
SAM 2 also supports automatic mask generation on images just like SAM. Please see [automatic_mask_generator_example.ipynb](./notebooks/automatic_mask_generator_example.ipynb) (also in Colab [here](https://colab.research.google.com/github/facebookresearch/sam2/blob/main/notebooks/automatic_mask_generator_example.ipynb)) for automatic mask generation in images.
|
| 98 |
+
|
| 99 |
+
### Video prediction
|
| 100 |
+
|
| 101 |
+
For promptable segmentation and tracking in videos, we provide a video predictor with APIs for example to add prompts and propagate masklets throughout a video. SAM 2 supports video inference on multiple objects and uses an inference state to keep track of the interactions in each video.
|
| 102 |
+
|
| 103 |
+
```python
|
| 104 |
+
import torch
|
| 105 |
+
from sam2.build_sam import build_sam2_video_predictor
|
| 106 |
+
|
| 107 |
+
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
|
| 108 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
|
| 109 |
+
predictor = build_sam2_video_predictor(model_cfg, checkpoint)
|
| 110 |
+
|
| 111 |
+
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
|
| 112 |
+
state = predictor.init_state(<your_video>)
|
| 113 |
+
|
| 114 |
+
# add new prompts and instantly get the output on the same frame
|
| 115 |
+
frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>):
|
| 116 |
+
|
| 117 |
+
# propagate the prompts to get masklets throughout the video
|
| 118 |
+
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
|
| 119 |
+
...
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
Please refer to the examples in [video_predictor_example.ipynb](./notebooks/video_predictor_example.ipynb) (also in Colab [here](https://colab.research.google.com/github/facebookresearch/sam2/blob/main/notebooks/video_predictor_example.ipynb)) for details on how to add click or box prompts, make refinements, and track multiple objects in videos.
|
| 123 |
+
|
| 124 |
+
## Load from 🤗 Hugging Face
|
| 125 |
+
|
| 126 |
+
Alternatively, models can also be loaded from [Hugging Face](https://huggingface.co/models?search=facebook/sam2) (requires `pip install huggingface_hub`).
|
| 127 |
+
|
| 128 |
+
For image prediction:
|
| 129 |
+
|
| 130 |
+
```python
|
| 131 |
+
import torch
|
| 132 |
+
from sam2.sam2_image_predictor import SAM2ImagePredictor
|
| 133 |
+
|
| 134 |
+
predictor = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-large")
|
| 135 |
+
|
| 136 |
+
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
|
| 137 |
+
predictor.set_image(<your_image>)
|
| 138 |
+
masks, _, _ = predictor.predict(<input_prompts>)
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
For video prediction:
|
| 142 |
+
|
| 143 |
+
```python
|
| 144 |
+
import torch
|
| 145 |
+
from sam2.sam2_video_predictor import SAM2VideoPredictor
|
| 146 |
+
|
| 147 |
+
predictor = SAM2VideoPredictor.from_pretrained("facebook/sam2-hiera-large")
|
| 148 |
+
|
| 149 |
+
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
|
| 150 |
+
state = predictor.init_state(<your_video>)
|
| 151 |
+
|
| 152 |
+
# add new prompts and instantly get the output on the same frame
|
| 153 |
+
frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>):
|
| 154 |
+
|
| 155 |
+
# propagate the prompts to get masklets throughout the video
|
| 156 |
+
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
|
| 157 |
+
...
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
## Model Description
|
| 161 |
+
|
| 162 |
+
### SAM 2.1 checkpoints
|
| 163 |
+
|
| 164 |
+
The table below shows the improved SAM 2.1 checkpoints released on September 29, 2024.
|
| 165 |
+
| **Model** | **Size (M)** | **Speed (FPS)** | **SA-V test (J&F)** | **MOSE val (J&F)** | **LVOS v2 (J&F)** |
|
| 166 |
+
| :------------------: | :----------: | :--------------------: | :-----------------: | :----------------: | :---------------: |
|
| 167 |
+
| sam2.1_hiera_tiny <br /> ([config](sam2/configs/sam2.1/sam2.1_hiera_t.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_tiny.pt)) | 38.9 | 91.2 | 76.5 | 71.8 | 77.3 |
|
| 168 |
+
| sam2.1_hiera_small <br /> ([config](sam2/configs/sam2.1/sam2.1_hiera_s.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_small.pt)) | 46 | 84.8 | 76.6 | 73.5 | 78.3 |
|
| 169 |
+
| sam2.1_hiera_base_plus <br /> ([config](sam2/configs/sam2.1/sam2.1_hiera_b+.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_base_plus.pt)) | 80.8 | 64.1 | 78.2 | 73.7 | 78.2 |
|
| 170 |
+
| sam2.1_hiera_large <br /> ([config](sam2/configs/sam2.1/sam2.1_hiera_l.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_large.pt)) | 224.4 | 39.5 | 79.5 | 74.6 | 80.6 |
|
| 171 |
+
|
| 172 |
+
### SAM 2 checkpoints
|
| 173 |
+
|
| 174 |
+
The previous SAM 2 checkpoints released on July 29, 2024 can be found as follows:
|
| 175 |
+
|
| 176 |
+
| **Model** | **Size (M)** | **Speed (FPS)** | **SA-V test (J&F)** | **MOSE val (J&F)** | **LVOS v2 (J&F)** |
|
| 177 |
+
| :------------------: | :----------: | :--------------------: | :-----------------: | :----------------: | :---------------: |
|
| 178 |
+
| sam2_hiera_tiny <br /> ([config](sam2/configs/sam2/sam2_hiera_t.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_tiny.pt)) | 38.9 | 91.5 | 75.0 | 70.9 | 75.3 |
|
| 179 |
+
| sam2_hiera_small <br /> ([config](sam2/configs/sam2/sam2_hiera_s.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_small.pt)) | 46 | 85.6 | 74.9 | 71.5 | 76.4 |
|
| 180 |
+
| sam2_hiera_base_plus <br /> ([config](sam2/configs/sam2/sam2_hiera_b+.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_base_plus.pt)) | 80.8 | 64.8 | 74.7 | 72.8 | 75.8 |
|
| 181 |
+
| sam2_hiera_large <br /> ([config](sam2/configs/sam2/sam2_hiera_l.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.pt)) | 224.4 | 39.7 | 76.0 | 74.6 | 79.8 |
|
| 182 |
+
|
| 183 |
+
Speed measured on an A100 with `torch 2.5.1, cuda 12.4`. See `benchmark.py` for an example on benchmarking (compiling all the model components). Compiling only the image encoder can be more flexible and also provide (a smaller) speed-up (set `compile_image_encoder: True` in the config).
|
| 184 |
+
## Segment Anything Video Dataset
|
| 185 |
+
|
| 186 |
+
See [sav_dataset/README.md](sav_dataset/README.md) for details.
|
| 187 |
+
|
| 188 |
+
## Training SAM 2
|
| 189 |
+
|
| 190 |
+
You can train or fine-tune SAM 2 on custom datasets of images, videos, or both. Please check the training [README](training/README.md) on how to get started.
|
| 191 |
+
|
| 192 |
+
## Web demo for SAM 2
|
| 193 |
+
|
| 194 |
+
We have released the frontend + backend code for the SAM 2 web demo (a locally deployable version similar to https://sam2.metademolab.com/demo). Please see the web demo [README](demo/README.md) for details.
|
| 195 |
+
|
| 196 |
+
## License
|
| 197 |
+
|
| 198 |
+
The SAM 2 model checkpoints, SAM 2 demo code (front-end and back-end), and SAM 2 training code are licensed under [Apache 2.0](./LICENSE), however the [Inter Font](https://github.com/rsms/inter?tab=OFL-1.1-1-ov-file) and [Noto Color Emoji](https://github.com/googlefonts/noto-emoji) used in the SAM 2 demo code are made available under the [SIL Open Font License, version 1.1](https://openfontlicense.org/open-font-license-official-text/).
|
| 199 |
+
|
| 200 |
+
## Contributing
|
| 201 |
+
|
| 202 |
+
See [contributing](CONTRIBUTING.md) and the [code of conduct](CODE_OF_CONDUCT.md).
|
| 203 |
+
|
| 204 |
+
## Contributors
|
| 205 |
+
|
| 206 |
+
The SAM 2 project was made possible with the help of many contributors (alphabetical):
|
| 207 |
+
|
| 208 |
+
Karen Bergan, Daniel Bolya, Alex Bosenberg, Kai Brown, Vispi Cassod, Christopher Chedeau, Ida Cheng, Luc Dahlin, Shoubhik Debnath, Rene Martinez Doehner, Grant Gardner, Sahir Gomez, Rishi Godugu, Baishan Guo, Caleb Ho, Andrew Huang, Somya Jain, Bob Kamma, Amanda Kallet, Jake Kinney, Alexander Kirillov, Shiva Koduvayur, Devansh Kukreja, Robert Kuo, Aohan Lin, Parth Malani, Jitendra Malik, Mallika Malhotra, Miguel Martin, Alexander Miller, Sasha Mitts, William Ngan, George Orlin, Joelle Pineau, Kate Saenko, Rodrick Shepard, Azita Shokrpour, David Soofian, Jonathan Torres, Jenny Truong, Sagar Vaze, Meng Wang, Claudette Ward, Pengchuan Zhang.
|
| 209 |
+
|
| 210 |
+
Third-party code: we use a GPU-based connected component algorithm adapted from [`cc_torch`](https://github.com/zsef123/Connected_components_PyTorch) (with its license in [`LICENSE_cctorch`](./LICENSE_cctorch)) as an optional post-processing step for the mask predictions.
|
| 211 |
+
|
| 212 |
+
## Citing SAM 2
|
| 213 |
+
|
| 214 |
+
If you use SAM 2 or the SA-V dataset in your research, please use the following BibTeX entry.
|
| 215 |
+
|
| 216 |
+
```bibtex
|
| 217 |
+
@article{ravi2024sam2,
|
| 218 |
+
title={SAM 2: Segment Anything in Images and Videos},
|
| 219 |
+
author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph},
|
| 220 |
+
journal={arXiv preprint arXiv:2408.00714},
|
| 221 |
+
url={https://arxiv.org/abs/2408.00714},
|
| 222 |
+
year={2024}
|
| 223 |
+
}
|
| 224 |
+
```
|
third_party/sam2/RELEASE_NOTES.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## SAM 2 release notes
|
| 2 |
+
|
| 3 |
+
### 12/11/2024 -- full model compilation for a major VOS speedup and a new `SAM2VideoPredictor` to better handle multi-object tracking
|
| 4 |
+
|
| 5 |
+
- We now support `torch.compile` of the entire SAM 2 model on videos, which can be turned on by setting `vos_optimized=True` in `build_sam2_video_predictor` (it uses the new `SAM2VideoPredictorVOS` predictor class in `sam2/sam2_video_predictor.py`).
|
| 6 |
+
* Compared to the previous setting (which only compiles the image encoder backbone), the new full model compilation gives a major speedup in inference FPS.
|
| 7 |
+
* In the VOS prediction script `tools/vos_inference.py`, you can specify this option in `tools/vos_inference.py` via the `--use_vos_optimized_video_predictor` flag.
|
| 8 |
+
* Note that turning on this flag might introduce a small variance in the predictions due to numerical differences caused by `torch.compile` of the full model.
|
| 9 |
+
* **PyTorch 2.5.1 is the minimum version for full support of this feature**. (Earlier PyTorch versions might run into compilation errors in some cases.) Therefore, we have updated the minimum PyTorch version to 2.5.1 accordingly in the installation scripts.
|
| 10 |
+
- We also update the implementation of the `SAM2VideoPredictor` class for the SAM 2 video prediction in `sam2/sam2_video_predictor.py`, which allows for independent per-object inference. Specifically, in the new `SAM2VideoPredictor`:
|
| 11 |
+
* Now **we handle the inference of each object independently** (as if we are opening a separate session for each object) while sharing their backbone features.
|
| 12 |
+
* This change allows us to relax the assumption of prompting for multi-object tracking. Previously (due to the batching behavior in inference), if a video frame receives clicks for only a subset of objects, the rest of the (non-prompted) objects are assumed to be non-existent in this frame (i.e., in such frames, the user is telling SAM 2 that the rest of the objects don't appear). Now, if a frame receives clicks for only a subset of objects, we do not make any assumptions about the remaining (non-prompted) objects (i.e., now each object is handled independently and is not affected by how other objects are prompted). As a result, **we allow adding new objects after tracking starts** after this change (which was previously a restriction on usage).
|
| 13 |
+
* We believe that the new version is a more natural inference behavior and therefore switched to it as the default behavior. The previous implementation of `SAM2VideoPredictor` is backed up to in `sam2/sam2_video_predictor_legacy.py`. All the VOS inference results using `tools/vos_inference.py` should remain the same after this change to the `SAM2VideoPredictor` class.
|
| 14 |
+
|
| 15 |
+
### 09/30/2024 -- SAM 2.1 Developer Suite (new checkpoints, training code, web demo) is released
|
| 16 |
+
|
| 17 |
+
- A new suite of improved model checkpoints (denoted as **SAM 2.1**) are released. See [Model Description](#model-description) for details.
|
| 18 |
+
* To use the new SAM 2.1 checkpoints, you need the latest model code from this repo. If you have installed an earlier version of this repo, please first uninstall the previous version via `pip uninstall SAM-2`, pull the latest code from this repo (with `git pull`), and then reinstall the repo following [Installation](#installation) below.
|
| 19 |
+
- The training (and fine-tuning) code has been released. See [`training/README.md`](training/README.md) on how to get started.
|
| 20 |
+
- The frontend + backend code for the SAM 2 web demo has been released. See [`demo/README.md`](demo/README.md) for details.
|
| 21 |
+
|
| 22 |
+
### 07/29/2024 -- SAM 2 is released
|
| 23 |
+
|
| 24 |
+
- We release Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos.
|
| 25 |
+
* SAM 2 code: https://github.com/facebookresearch/sam2
|
| 26 |
+
* SAM 2 demo: https://sam2.metademolab.com/
|
| 27 |
+
* SAM 2 paper: https://arxiv.org/abs/2408.00714
|
third_party/sam2/assets/model_diagram.png
ADDED
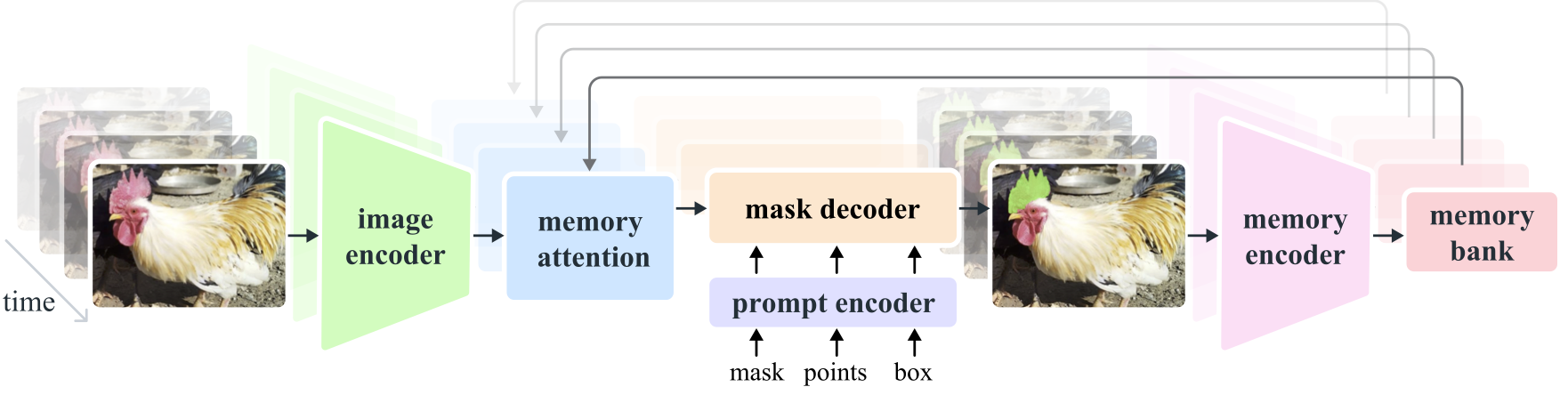
|
third_party/sam2/assets/sa_v_dataset.jpg
ADDED

|
third_party/sam2/backend.Dockerfile
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ARG BASE_IMAGE=pytorch/pytorch:2.5.1-cuda12.1-cudnn9-runtime
|
| 2 |
+
ARG MODEL_SIZE=base_plus
|
| 3 |
+
|
| 4 |
+
FROM ${BASE_IMAGE}
|
| 5 |
+
|
| 6 |
+
# Gunicorn environment variables
|
| 7 |
+
ENV GUNICORN_WORKERS=1
|
| 8 |
+
ENV GUNICORN_THREADS=2
|
| 9 |
+
ENV GUNICORN_PORT=5000
|
| 10 |
+
|
| 11 |
+
# SAM 2 environment variables
|
| 12 |
+
ENV APP_ROOT=/opt/sam2
|
| 13 |
+
ENV PYTHONUNBUFFERED=1
|
| 14 |
+
ENV SAM2_BUILD_CUDA=0
|
| 15 |
+
ENV MODEL_SIZE=${MODEL_SIZE}
|
| 16 |
+
|
| 17 |
+
# Install system requirements
|
| 18 |
+
RUN apt-get update && apt-get install -y --no-install-recommends \
|
| 19 |
+
ffmpeg \
|
| 20 |
+
libavutil-dev \
|
| 21 |
+
libavcodec-dev \
|
| 22 |
+
libavformat-dev \
|
| 23 |
+
libswscale-dev \
|
| 24 |
+
pkg-config \
|
| 25 |
+
build-essential \
|
| 26 |
+
libffi-dev
|
| 27 |
+
|
| 28 |
+
COPY setup.py .
|
| 29 |
+
COPY README.md .
|
| 30 |
+
|
| 31 |
+
RUN pip install --upgrade pip setuptools
|
| 32 |
+
RUN pip install -e ".[interactive-demo]"
|
| 33 |
+
|
| 34 |
+
# https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite/issues/69#issuecomment-1826764707
|
| 35 |
+
RUN rm /opt/conda/bin/ffmpeg && ln -s /bin/ffmpeg /opt/conda/bin/ffmpeg
|
| 36 |
+
|
| 37 |
+
# Make app directory. This directory will host all files required for the
|
| 38 |
+
# backend and SAM 2 inference files.
|
| 39 |
+
RUN mkdir ${APP_ROOT}
|
| 40 |
+
|
| 41 |
+
# Copy backend server files
|
| 42 |
+
COPY demo/backend/server ${APP_ROOT}/server
|
| 43 |
+
|
| 44 |
+
# Copy SAM 2 inference files
|
| 45 |
+
COPY sam2 ${APP_ROOT}/server/sam2
|
| 46 |
+
|
| 47 |
+
# Download SAM 2.1 checkpoints
|
| 48 |
+
ADD https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_tiny.pt ${APP_ROOT}/checkpoints/sam2.1_hiera_tiny.pt
|
| 49 |
+
ADD https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_small.pt ${APP_ROOT}/checkpoints/sam2.1_hiera_small.pt
|
| 50 |
+
ADD https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_base_plus.pt ${APP_ROOT}/checkpoints/sam2.1_hiera_base_plus.pt
|
| 51 |
+
ADD https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_large.pt ${APP_ROOT}/checkpoints/sam2.1_hiera_large.pt
|
| 52 |
+
|
| 53 |
+
WORKDIR ${APP_ROOT}/server
|
| 54 |
+
|
| 55 |
+
# https://pythonspeed.com/articles/gunicorn-in-docker/
|
| 56 |
+
CMD gunicorn --worker-tmp-dir /dev/shm \
|
| 57 |
+
--worker-class gthread app:app \
|
| 58 |
+
--log-level info \
|
| 59 |
+
--access-logfile /dev/stdout \
|
| 60 |
+
--log-file /dev/stderr \
|
| 61 |
+
--workers ${GUNICORN_WORKERS} \
|
| 62 |
+
--threads ${GUNICORN_THREADS} \
|
| 63 |
+
--bind 0.0.0.0:${GUNICORN_PORT} \
|
| 64 |
+
--timeout 60
|
third_party/sam2/checkpoints/download_ckpts.sh
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 4 |
+
# All rights reserved.
|
| 5 |
+
|
| 6 |
+
# This source code is licensed under the license found in the
|
| 7 |
+
# LICENSE file in the root directory of this source tree.
|
| 8 |
+
|
| 9 |
+
# Use either wget or curl to download the checkpoints
|
| 10 |
+
if command -v wget &> /dev/null; then
|
| 11 |
+
CMD="wget"
|
| 12 |
+
elif command -v curl &> /dev/null; then
|
| 13 |
+
CMD="curl -L -O"
|
| 14 |
+
else
|
| 15 |
+
echo "Please install wget or curl to download the checkpoints."
|
| 16 |
+
exit 1
|
| 17 |
+
fi
|
| 18 |
+
|
| 19 |
+
# Define the URLs for SAM 2 checkpoints
|
| 20 |
+
# SAM2_BASE_URL="https://dl.fbaipublicfiles.com/segment_anything_2/072824"
|
| 21 |
+
# sam2_hiera_t_url="${SAM2_BASE_URL}/sam2_hiera_tiny.pt"
|
| 22 |
+
# sam2_hiera_s_url="${SAM2_BASE_URL}/sam2_hiera_small.pt"
|
| 23 |
+
# sam2_hiera_b_plus_url="${SAM2_BASE_URL}/sam2_hiera_base_plus.pt"
|
| 24 |
+
# sam2_hiera_l_url="${SAM2_BASE_URL}/sam2_hiera_large.pt"
|
| 25 |
+
|
| 26 |
+
# Download each of the four checkpoints using wget
|
| 27 |
+
# echo "Downloading sam2_hiera_tiny.pt checkpoint..."
|
| 28 |
+
# $CMD $sam2_hiera_t_url || { echo "Failed to download checkpoint from $sam2_hiera_t_url"; exit 1; }
|
| 29 |
+
|
| 30 |
+
# echo "Downloading sam2_hiera_small.pt checkpoint..."
|
| 31 |
+
# $CMD $sam2_hiera_s_url || { echo "Failed to download checkpoint from $sam2_hiera_s_url"; exit 1; }
|
| 32 |
+
|
| 33 |
+
# echo "Downloading sam2_hiera_base_plus.pt checkpoint..."
|
| 34 |
+
# $CMD $sam2_hiera_b_plus_url || { echo "Failed to download checkpoint from $sam2_hiera_b_plus_url"; exit 1; }
|
| 35 |
+
|
| 36 |
+
# echo "Downloading sam2_hiera_large.pt checkpoint..."
|
| 37 |
+
# $CMD $sam2_hiera_l_url || { echo "Failed to download checkpoint from $sam2_hiera_l_url"; exit 1; }
|
| 38 |
+
|
| 39 |
+
# Define the URLs for SAM 2.1 checkpoints
|
| 40 |
+
SAM2p1_BASE_URL="https://dl.fbaipublicfiles.com/segment_anything_2/092824"
|
| 41 |
+
sam2p1_hiera_t_url="${SAM2p1_BASE_URL}/sam2.1_hiera_tiny.pt"
|
| 42 |
+
sam2p1_hiera_s_url="${SAM2p1_BASE_URL}/sam2.1_hiera_small.pt"
|
| 43 |
+
sam2p1_hiera_b_plus_url="${SAM2p1_BASE_URL}/sam2.1_hiera_base_plus.pt"
|
| 44 |
+
sam2p1_hiera_l_url="${SAM2p1_BASE_URL}/sam2.1_hiera_large.pt"
|
| 45 |
+
|
| 46 |
+
# SAM 2.1 checkpoints
|
| 47 |
+
echo "Downloading sam2.1_hiera_tiny.pt checkpoint..."
|
| 48 |
+
$CMD $sam2p1_hiera_t_url || { echo "Failed to download checkpoint from $sam2p1_hiera_t_url"; exit 1; }
|
| 49 |
+
|
| 50 |
+
echo "Downloading sam2.1_hiera_small.pt checkpoint..."
|
| 51 |
+
$CMD $sam2p1_hiera_s_url || { echo "Failed to download checkpoint from $sam2p1_hiera_s_url"; exit 1; }
|
| 52 |
+
|
| 53 |
+
echo "Downloading sam2.1_hiera_base_plus.pt checkpoint..."
|
| 54 |
+
$CMD $sam2p1_hiera_b_plus_url || { echo "Failed to download checkpoint from $sam2p1_hiera_b_plus_url"; exit 1; }
|
| 55 |
+
|
| 56 |
+
echo "Downloading sam2.1_hiera_large.pt checkpoint..."
|
| 57 |
+
$CMD $sam2p1_hiera_l_url || { echo "Failed to download checkpoint from $sam2p1_hiera_l_url"; exit 1; }
|
| 58 |
+
|
| 59 |
+
echo "All checkpoints are downloaded successfully."
|
third_party/sam2/docker-compose.yaml
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
services:
|
| 2 |
+
frontend:
|
| 3 |
+
image: sam2/frontend
|
| 4 |
+
build:
|
| 5 |
+
context: ./demo/frontend
|
| 6 |
+
dockerfile: frontend.Dockerfile
|
| 7 |
+
ports:
|
| 8 |
+
- 7262:80
|
| 9 |
+
|
| 10 |
+
backend:
|
| 11 |
+
image: sam2/backend
|
| 12 |
+
build:
|
| 13 |
+
context: .
|
| 14 |
+
dockerfile: backend.Dockerfile
|
| 15 |
+
ports:
|
| 16 |
+
- 7263:5000
|
| 17 |
+
volumes:
|
| 18 |
+
- ./demo/data/:/data/:rw
|
| 19 |
+
environment:
|
| 20 |
+
- SERVER_ENVIRONMENT=DEV
|
| 21 |
+
- GUNICORN_WORKERS=1
|
| 22 |
+
# Inference API needs to have at least 2 threads to handle an incoming
|
| 23 |
+
# parallel cancel propagation request
|
| 24 |
+
- GUNICORN_THREADS=2
|
| 25 |
+
- GUNICORN_PORT=5000
|
| 26 |
+
- API_URL=http://localhost:7263
|
| 27 |
+
- DEFAULT_VIDEO_PATH=gallery/05_default_juggle.mp4
|
| 28 |
+
# # ffmpeg/video encode settings
|
| 29 |
+
- FFMPEG_NUM_THREADS=1
|
| 30 |
+
- VIDEO_ENCODE_CODEC=libx264
|
| 31 |
+
- VIDEO_ENCODE_CRF=23
|
| 32 |
+
- VIDEO_ENCODE_FPS=24
|
| 33 |
+
- VIDEO_ENCODE_MAX_WIDTH=1280
|
| 34 |
+
- VIDEO_ENCODE_MAX_HEIGHT=720
|
| 35 |
+
- VIDEO_ENCODE_VERBOSE=False
|
| 36 |
+
deploy:
|
| 37 |
+
resources:
|
| 38 |
+
reservations:
|
| 39 |
+
devices:
|
| 40 |
+
- driver: nvidia
|
| 41 |
+
count: 1
|
| 42 |
+
capabilities: [gpu]
|
third_party/sam2/pyproject.toml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = [
|
| 3 |
+
"setuptools>=61.0",
|
| 4 |
+
"torch>=2.5.1",
|
| 5 |
+
]
|
| 6 |
+
build-backend = "setuptools.build_meta"
|
third_party/sam2/sam2/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from hydra import initialize_config_module
|
| 8 |
+
from hydra.core.global_hydra import GlobalHydra
|
| 9 |
+
|
| 10 |
+
if not GlobalHydra.instance().is_initialized():
|
| 11 |
+
initialize_config_module("sam2_configs", version_base="1.2")
|
third_party/sam2/sam2/automatic_mask_generator.py
ADDED
|
@@ -0,0 +1,454 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
# Adapted from https://github.com/facebookresearch/segment-anything/blob/main/segment_anything/automatic_mask_generator.py
|
| 8 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
from torchvision.ops.boxes import batched_nms, box_area # type: ignore
|
| 13 |
+
|
| 14 |
+
from sam2.modeling.sam2_base import SAM2Base
|
| 15 |
+
from sam2.sam2_image_predictor import SAM2ImagePredictor
|
| 16 |
+
from sam2.utils.amg import (
|
| 17 |
+
area_from_rle,
|
| 18 |
+
batch_iterator,
|
| 19 |
+
batched_mask_to_box,
|
| 20 |
+
box_xyxy_to_xywh,
|
| 21 |
+
build_all_layer_point_grids,
|
| 22 |
+
calculate_stability_score,
|
| 23 |
+
coco_encode_rle,
|
| 24 |
+
generate_crop_boxes,
|
| 25 |
+
is_box_near_crop_edge,
|
| 26 |
+
mask_to_rle_pytorch,
|
| 27 |
+
MaskData,
|
| 28 |
+
remove_small_regions,
|
| 29 |
+
rle_to_mask,
|
| 30 |
+
uncrop_boxes_xyxy,
|
| 31 |
+
uncrop_masks,
|
| 32 |
+
uncrop_points,
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class SAM2AutomaticMaskGenerator:
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
model: SAM2Base,
|
| 40 |
+
points_per_side: Optional[int] = 32,
|
| 41 |
+
points_per_batch: int = 64,
|
| 42 |
+
pred_iou_thresh: float = 0.8,
|
| 43 |
+
stability_score_thresh: float = 0.95,
|
| 44 |
+
stability_score_offset: float = 1.0,
|
| 45 |
+
mask_threshold: float = 0.0,
|
| 46 |
+
box_nms_thresh: float = 0.7,
|
| 47 |
+
crop_n_layers: int = 0,
|
| 48 |
+
crop_nms_thresh: float = 0.7,
|
| 49 |
+
crop_overlap_ratio: float = 512 / 1500,
|
| 50 |
+
crop_n_points_downscale_factor: int = 1,
|
| 51 |
+
point_grids: Optional[List[np.ndarray]] = None,
|
| 52 |
+
min_mask_region_area: int = 0,
|
| 53 |
+
output_mode: str = "binary_mask",
|
| 54 |
+
use_m2m: bool = False,
|
| 55 |
+
multimask_output: bool = True,
|
| 56 |
+
**kwargs,
|
| 57 |
+
) -> None:
|
| 58 |
+
"""
|
| 59 |
+
Using a SAM 2 model, generates masks for the entire image.
|
| 60 |
+
Generates a grid of point prompts over the image, then filters
|
| 61 |
+
low quality and duplicate masks. The default settings are chosen
|
| 62 |
+
for SAM 2 with a HieraL backbone.
|
| 63 |
+
|
| 64 |
+
Arguments:
|
| 65 |
+
model (Sam): The SAM 2 model to use for mask prediction.
|
| 66 |
+
points_per_side (int or None): The number of points to be sampled
|
| 67 |
+
along one side of the image. The total number of points is
|
| 68 |
+
points_per_side**2. If None, 'point_grids' must provide explicit
|
| 69 |
+
point sampling.
|
| 70 |
+
points_per_batch (int): Sets the number of points run simultaneously
|
| 71 |
+
by the model. Higher numbers may be faster but use more GPU memory.
|
| 72 |
+
pred_iou_thresh (float): A filtering threshold in [0,1], using the
|
| 73 |
+
model's predicted mask quality.
|
| 74 |
+
stability_score_thresh (float): A filtering threshold in [0,1], using
|
| 75 |
+
the stability of the mask under changes to the cutoff used to binarize
|
| 76 |
+
the model's mask predictions.
|
| 77 |
+
stability_score_offset (float): The amount to shift the cutoff when
|
| 78 |
+
calculated the stability score.
|
| 79 |
+
mask_threshold (float): Threshold for binarizing the mask logits
|
| 80 |
+
box_nms_thresh (float): The box IoU cutoff used by non-maximal
|
| 81 |
+
suppression to filter duplicate masks.
|
| 82 |
+
crop_n_layers (int): If >0, mask prediction will be run again on
|
| 83 |
+
crops of the image. Sets the number of layers to run, where each
|
| 84 |
+
layer has 2**i_layer number of image crops.
|
| 85 |
+
crop_nms_thresh (float): The box IoU cutoff used by non-maximal
|
| 86 |
+
suppression to filter duplicate masks between different crops.
|
| 87 |
+
crop_overlap_ratio (float): Sets the degree to which crops overlap.
|
| 88 |
+
In the first crop layer, crops will overlap by this fraction of
|
| 89 |
+
the image length. Later layers with more crops scale down this overlap.
|
| 90 |
+
crop_n_points_downscale_factor (int): The number of points-per-side
|
| 91 |
+
sampled in layer n is scaled down by crop_n_points_downscale_factor**n.
|
| 92 |
+
point_grids (list(np.ndarray) or None): A list over explicit grids
|
| 93 |
+
of points used for sampling, normalized to [0,1]. The nth grid in the
|
| 94 |
+
list is used in the nth crop layer. Exclusive with points_per_side.
|
| 95 |
+
min_mask_region_area (int): If >0, postprocessing will be applied
|
| 96 |
+
to remove disconnected regions and holes in masks with area smaller
|
| 97 |
+
than min_mask_region_area. Requires opencv.
|
| 98 |
+
output_mode (str): The form masks are returned in. Can be 'binary_mask',
|
| 99 |
+
'uncompressed_rle', or 'coco_rle'. 'coco_rle' requires pycocotools.
|
| 100 |
+
For large resolutions, 'binary_mask' may consume large amounts of
|
| 101 |
+
memory.
|
| 102 |
+
use_m2m (bool): Whether to add a one step refinement using previous mask predictions.
|
| 103 |
+
multimask_output (bool): Whether to output multimask at each point of the grid.
|
| 104 |
+
"""
|
| 105 |
+
|
| 106 |
+
assert (points_per_side is None) != (
|
| 107 |
+
point_grids is None
|
| 108 |
+
), "Exactly one of points_per_side or point_grid must be provided."
|
| 109 |
+
if points_per_side is not None:
|
| 110 |
+
self.point_grids = build_all_layer_point_grids(
|
| 111 |
+
points_per_side,
|
| 112 |
+
crop_n_layers,
|
| 113 |
+
crop_n_points_downscale_factor,
|
| 114 |
+
)
|
| 115 |
+
elif point_grids is not None:
|
| 116 |
+
self.point_grids = point_grids
|
| 117 |
+
else:
|
| 118 |
+
raise ValueError("Can't have both points_per_side and point_grid be None.")
|
| 119 |
+
|
| 120 |
+
assert output_mode in [
|
| 121 |
+
"binary_mask",
|
| 122 |
+
"uncompressed_rle",
|
| 123 |
+
"coco_rle",
|
| 124 |
+
], f"Unknown output_mode {output_mode}."
|
| 125 |
+
if output_mode == "coco_rle":
|
| 126 |
+
try:
|
| 127 |
+
from pycocotools import mask as mask_utils # type: ignore # noqa: F401
|
| 128 |
+
except ImportError as e:
|
| 129 |
+
print("Please install pycocotools")
|
| 130 |
+
raise e
|
| 131 |
+
|
| 132 |
+
self.predictor = SAM2ImagePredictor(
|
| 133 |
+
model,
|
| 134 |
+
max_hole_area=min_mask_region_area,
|
| 135 |
+
max_sprinkle_area=min_mask_region_area,
|
| 136 |
+
)
|
| 137 |
+
self.points_per_batch = points_per_batch
|
| 138 |
+
self.pred_iou_thresh = pred_iou_thresh
|
| 139 |
+
self.stability_score_thresh = stability_score_thresh
|
| 140 |
+
self.stability_score_offset = stability_score_offset
|
| 141 |
+
self.mask_threshold = mask_threshold
|
| 142 |
+
self.box_nms_thresh = box_nms_thresh
|
| 143 |
+
self.crop_n_layers = crop_n_layers
|
| 144 |
+
self.crop_nms_thresh = crop_nms_thresh
|
| 145 |
+
self.crop_overlap_ratio = crop_overlap_ratio
|
| 146 |
+
self.crop_n_points_downscale_factor = crop_n_points_downscale_factor
|
| 147 |
+
self.min_mask_region_area = min_mask_region_area
|
| 148 |
+
self.output_mode = output_mode
|
| 149 |
+
self.use_m2m = use_m2m
|
| 150 |
+
self.multimask_output = multimask_output
|
| 151 |
+
|
| 152 |
+
@classmethod
|
| 153 |
+
def from_pretrained(cls, model_id: str, **kwargs) -> "SAM2AutomaticMaskGenerator":
|
| 154 |
+
"""
|
| 155 |
+
Load a pretrained model from the Hugging Face hub.
|
| 156 |
+
|
| 157 |
+
Arguments:
|
| 158 |
+
model_id (str): The Hugging Face repository ID.
|
| 159 |
+
**kwargs: Additional arguments to pass to the model constructor.
|
| 160 |
+
|
| 161 |
+
Returns:
|
| 162 |
+
(SAM2AutomaticMaskGenerator): The loaded model.
|
| 163 |
+
"""
|
| 164 |
+
from sam2.build_sam import build_sam2_hf
|
| 165 |
+
|
| 166 |
+
sam_model = build_sam2_hf(model_id, **kwargs)
|
| 167 |
+
return cls(sam_model, **kwargs)
|
| 168 |
+
|
| 169 |
+
@torch.no_grad()
|
| 170 |
+
def generate(self, image: np.ndarray) -> List[Dict[str, Any]]:
|
| 171 |
+
"""
|
| 172 |
+
Generates masks for the given image.
|
| 173 |
+
|
| 174 |
+
Arguments:
|
| 175 |
+
image (np.ndarray): The image to generate masks for, in HWC uint8 format.
|
| 176 |
+
|
| 177 |
+
Returns:
|
| 178 |
+
list(dict(str, any)): A list over records for masks. Each record is
|
| 179 |
+
a dict containing the following keys:
|
| 180 |
+
segmentation (dict(str, any) or np.ndarray): The mask. If
|
| 181 |
+
output_mode='binary_mask', is an array of shape HW. Otherwise,
|
| 182 |
+
is a dictionary containing the RLE.
|
| 183 |
+
bbox (list(float)): The box around the mask, in XYWH format.
|
| 184 |
+
area (int): The area in pixels of the mask.
|
| 185 |
+
predicted_iou (float): The model's own prediction of the mask's
|
| 186 |
+
quality. This is filtered by the pred_iou_thresh parameter.
|
| 187 |
+
point_coords (list(list(float))): The point coordinates input
|
| 188 |
+
to the model to generate this mask.
|
| 189 |
+
stability_score (float): A measure of the mask's quality. This
|
| 190 |
+
is filtered on using the stability_score_thresh parameter.
|
| 191 |
+
crop_box (list(float)): The crop of the image used to generate
|
| 192 |
+
the mask, given in XYWH format.
|
| 193 |
+
"""
|
| 194 |
+
|
| 195 |
+
# Generate masks
|
| 196 |
+
mask_data = self._generate_masks(image)
|
| 197 |
+
|
| 198 |
+
# Encode masks
|
| 199 |
+
if self.output_mode == "coco_rle":
|
| 200 |
+
mask_data["segmentations"] = [
|
| 201 |
+
coco_encode_rle(rle) for rle in mask_data["rles"]
|
| 202 |
+
]
|
| 203 |
+
elif self.output_mode == "binary_mask":
|
| 204 |
+
mask_data["segmentations"] = [rle_to_mask(rle) for rle in mask_data["rles"]]
|
| 205 |
+
else:
|
| 206 |
+
mask_data["segmentations"] = mask_data["rles"]
|
| 207 |
+
|
| 208 |
+
# Write mask records
|
| 209 |
+
curr_anns = []
|
| 210 |
+
for idx in range(len(mask_data["segmentations"])):
|
| 211 |
+
ann = {
|
| 212 |
+
"segmentation": mask_data["segmentations"][idx],
|
| 213 |
+
"area": area_from_rle(mask_data["rles"][idx]),
|
| 214 |
+
"bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),
|
| 215 |
+
"predicted_iou": mask_data["iou_preds"][idx].item(),
|
| 216 |
+
"point_coords": [mask_data["points"][idx].tolist()],
|
| 217 |
+
"stability_score": mask_data["stability_score"][idx].item(),
|
| 218 |
+
"crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),
|
| 219 |
+
}
|
| 220 |
+
curr_anns.append(ann)
|
| 221 |
+
|
| 222 |
+
return curr_anns
|
| 223 |
+
|
| 224 |
+
def _generate_masks(self, image: np.ndarray) -> MaskData:
|
| 225 |
+
orig_size = image.shape[:2]
|
| 226 |
+
crop_boxes, layer_idxs = generate_crop_boxes(
|
| 227 |
+
orig_size, self.crop_n_layers, self.crop_overlap_ratio
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
# Iterate over image crops
|
| 231 |
+
data = MaskData()
|
| 232 |
+
for crop_box, layer_idx in zip(crop_boxes, layer_idxs):
|
| 233 |
+
crop_data = self._process_crop(image, crop_box, layer_idx, orig_size)
|
| 234 |
+
data.cat(crop_data)
|
| 235 |
+
|
| 236 |
+
# Remove duplicate masks between crops
|
| 237 |
+
if len(crop_boxes) > 1:
|
| 238 |
+
# Prefer masks from smaller crops
|
| 239 |
+
scores = 1 / box_area(data["crop_boxes"])
|
| 240 |
+
scores = scores.to(data["boxes"].device)
|
| 241 |
+
keep_by_nms = batched_nms(
|
| 242 |
+
data["boxes"].float(),
|
| 243 |
+
scores,
|
| 244 |
+
torch.zeros_like(data["boxes"][:, 0]), # categories
|
| 245 |
+
iou_threshold=self.crop_nms_thresh,
|
| 246 |
+
)
|
| 247 |
+
data.filter(keep_by_nms)
|
| 248 |
+
data.to_numpy()
|
| 249 |
+
return data
|
| 250 |
+
|
| 251 |
+
def _process_crop(
|
| 252 |
+
self,
|
| 253 |
+
image: np.ndarray,
|
| 254 |
+
crop_box: List[int],
|
| 255 |
+
crop_layer_idx: int,
|
| 256 |
+
orig_size: Tuple[int, ...],
|
| 257 |
+
) -> MaskData:
|
| 258 |
+
# Crop the image and calculate embeddings
|
| 259 |
+
x0, y0, x1, y1 = crop_box
|
| 260 |
+
cropped_im = image[y0:y1, x0:x1, :]
|
| 261 |
+
cropped_im_size = cropped_im.shape[:2]
|
| 262 |
+
self.predictor.set_image(cropped_im)
|
| 263 |
+
|
| 264 |
+
# Get points for this crop
|
| 265 |
+
points_scale = np.array(cropped_im_size)[None, ::-1]
|
| 266 |
+
points_for_image = self.point_grids[crop_layer_idx] * points_scale
|
| 267 |
+
|
| 268 |
+
# Generate masks for this crop in batches
|
| 269 |
+
data = MaskData()
|
| 270 |
+
for (points,) in batch_iterator(self.points_per_batch, points_for_image):
|
| 271 |
+
batch_data = self._process_batch(
|
| 272 |
+
points, cropped_im_size, crop_box, orig_size, normalize=True
|
| 273 |
+
)
|
| 274 |
+
data.cat(batch_data)
|
| 275 |
+
del batch_data
|
| 276 |
+
self.predictor.reset_predictor()
|
| 277 |
+
|
| 278 |
+
# Remove duplicates within this crop.
|
| 279 |
+
keep_by_nms = batched_nms(
|
| 280 |
+
data["boxes"].float(),
|
| 281 |
+
data["iou_preds"],
|
| 282 |
+
torch.zeros_like(data["boxes"][:, 0]), # categories
|
| 283 |
+
iou_threshold=self.box_nms_thresh,
|
| 284 |
+
)
|
| 285 |
+
data.filter(keep_by_nms)
|
| 286 |
+
|
| 287 |
+
# Return to the original image frame
|
| 288 |
+
data["boxes"] = uncrop_boxes_xyxy(data["boxes"], crop_box)
|
| 289 |
+
data["points"] = uncrop_points(data["points"], crop_box)
|
| 290 |
+
data["crop_boxes"] = torch.tensor([crop_box for _ in range(len(data["rles"]))])
|
| 291 |
+
|
| 292 |
+
return data
|
| 293 |
+
|
| 294 |
+
def _process_batch(
|
| 295 |
+
self,
|
| 296 |
+
points: np.ndarray,
|
| 297 |
+
im_size: Tuple[int, ...],
|
| 298 |
+
crop_box: List[int],
|
| 299 |
+
orig_size: Tuple[int, ...],
|
| 300 |
+
normalize=False,
|
| 301 |
+
) -> MaskData:
|
| 302 |
+
orig_h, orig_w = orig_size
|
| 303 |
+
|
| 304 |
+
# Run model on this batch
|
| 305 |
+
points = torch.as_tensor(
|
| 306 |
+
points, dtype=torch.float32, device=self.predictor.device
|
| 307 |
+
)
|
| 308 |
+
in_points = self.predictor._transforms.transform_coords(
|
| 309 |
+
points, normalize=normalize, orig_hw=im_size
|
| 310 |
+
)
|
| 311 |
+
in_labels = torch.ones(
|
| 312 |
+
in_points.shape[0], dtype=torch.int, device=in_points.device
|
| 313 |
+
)
|
| 314 |
+
masks, iou_preds, low_res_masks = self.predictor._predict(
|
| 315 |
+
in_points[:, None, :],
|
| 316 |
+
in_labels[:, None],
|
| 317 |
+
multimask_output=self.multimask_output,
|
| 318 |
+
return_logits=True,
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
# Serialize predictions and store in MaskData
|
| 322 |
+
data = MaskData(
|
| 323 |
+
masks=masks.flatten(0, 1),
|
| 324 |
+
iou_preds=iou_preds.flatten(0, 1),
|
| 325 |
+
points=points.repeat_interleave(masks.shape[1], dim=0),
|
| 326 |
+
low_res_masks=low_res_masks.flatten(0, 1),
|
| 327 |
+
)
|
| 328 |
+
del masks
|
| 329 |
+
|
| 330 |
+
if not self.use_m2m:
|
| 331 |
+
# Filter by predicted IoU
|
| 332 |
+
if self.pred_iou_thresh > 0.0:
|
| 333 |
+
keep_mask = data["iou_preds"] > self.pred_iou_thresh
|
| 334 |
+
data.filter(keep_mask)
|
| 335 |
+
|
| 336 |
+
# Calculate and filter by stability score
|
| 337 |
+
data["stability_score"] = calculate_stability_score(
|
| 338 |
+
data["masks"], self.mask_threshold, self.stability_score_offset
|
| 339 |
+
)
|
| 340 |
+
if self.stability_score_thresh > 0.0:
|
| 341 |
+
keep_mask = data["stability_score"] >= self.stability_score_thresh
|
| 342 |
+
data.filter(keep_mask)
|
| 343 |
+
else:
|
| 344 |
+
# One step refinement using previous mask predictions
|
| 345 |
+
in_points = self.predictor._transforms.transform_coords(
|
| 346 |
+
data["points"], normalize=normalize, orig_hw=im_size
|
| 347 |
+
)
|
| 348 |
+
labels = torch.ones(
|
| 349 |
+
in_points.shape[0], dtype=torch.int, device=in_points.device
|
| 350 |
+
)
|
| 351 |
+
masks, ious = self.refine_with_m2m(
|
| 352 |
+
in_points, labels, data["low_res_masks"], self.points_per_batch
|
| 353 |
+
)
|
| 354 |
+
data["masks"] = masks.squeeze(1)
|
| 355 |
+
data["iou_preds"] = ious.squeeze(1)
|
| 356 |
+
|
| 357 |
+
if self.pred_iou_thresh > 0.0:
|
| 358 |
+
keep_mask = data["iou_preds"] > self.pred_iou_thresh
|
| 359 |
+
data.filter(keep_mask)
|
| 360 |
+
|
| 361 |
+
data["stability_score"] = calculate_stability_score(
|
| 362 |
+
data["masks"], self.mask_threshold, self.stability_score_offset
|
| 363 |
+
)
|
| 364 |
+
if self.stability_score_thresh > 0.0:
|
| 365 |
+
keep_mask = data["stability_score"] >= self.stability_score_thresh
|
| 366 |
+
data.filter(keep_mask)
|
| 367 |
+
|
| 368 |
+
# Threshold masks and calculate boxes
|
| 369 |
+
data["masks"] = data["masks"] > self.mask_threshold
|
| 370 |
+
data["boxes"] = batched_mask_to_box(data["masks"])
|
| 371 |
+
|
| 372 |
+
# Filter boxes that touch crop boundaries
|
| 373 |
+
keep_mask = ~is_box_near_crop_edge(
|
| 374 |
+
data["boxes"], crop_box, [0, 0, orig_w, orig_h]
|
| 375 |
+
)
|
| 376 |
+
if not torch.all(keep_mask):
|
| 377 |
+
data.filter(keep_mask)
|
| 378 |
+
|
| 379 |
+
# Compress to RLE
|
| 380 |
+
data["masks"] = uncrop_masks(data["masks"], crop_box, orig_h, orig_w)
|
| 381 |
+
data["rles"] = mask_to_rle_pytorch(data["masks"])
|
| 382 |
+
del data["masks"]
|
| 383 |
+
|
| 384 |
+
return data
|
| 385 |
+
|
| 386 |
+
@staticmethod
|
| 387 |
+
def postprocess_small_regions(
|
| 388 |
+
mask_data: MaskData, min_area: int, nms_thresh: float
|
| 389 |
+
) -> MaskData:
|
| 390 |
+
"""
|
| 391 |
+
Removes small disconnected regions and holes in masks, then reruns
|
| 392 |
+
box NMS to remove any new duplicates.
|
| 393 |
+
|
| 394 |
+
Edits mask_data in place.
|
| 395 |
+
|
| 396 |
+
Requires open-cv as a dependency.
|
| 397 |
+
"""
|
| 398 |
+
if len(mask_data["rles"]) == 0:
|
| 399 |
+
return mask_data
|
| 400 |
+
|
| 401 |
+
# Filter small disconnected regions and holes
|
| 402 |
+
new_masks = []
|
| 403 |
+
scores = []
|
| 404 |
+
for rle in mask_data["rles"]:
|
| 405 |
+
mask = rle_to_mask(rle)
|
| 406 |
+
|
| 407 |
+
mask, changed = remove_small_regions(mask, min_area, mode="holes")
|
| 408 |
+
unchanged = not changed
|
| 409 |
+
mask, changed = remove_small_regions(mask, min_area, mode="islands")
|
| 410 |
+
unchanged = unchanged and not changed
|
| 411 |
+
|
| 412 |
+
new_masks.append(torch.as_tensor(mask).unsqueeze(0))
|
| 413 |
+
# Give score=0 to changed masks and score=1 to unchanged masks
|
| 414 |
+
# so NMS will prefer ones that didn't need postprocessing
|
| 415 |
+
scores.append(float(unchanged))
|
| 416 |
+
|
| 417 |
+
# Recalculate boxes and remove any new duplicates
|
| 418 |
+
masks = torch.cat(new_masks, dim=0)
|
| 419 |
+
boxes = batched_mask_to_box(masks)
|
| 420 |
+
keep_by_nms = batched_nms(
|
| 421 |
+
boxes.float(),
|
| 422 |
+
torch.as_tensor(scores),
|
| 423 |
+
torch.zeros_like(boxes[:, 0]), # categories
|
| 424 |
+
iou_threshold=nms_thresh,
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
# Only recalculate RLEs for masks that have changed
|
| 428 |
+
for i_mask in keep_by_nms:
|
| 429 |
+
if scores[i_mask] == 0.0:
|
| 430 |
+
mask_torch = masks[i_mask].unsqueeze(0)
|
| 431 |
+
mask_data["rles"][i_mask] = mask_to_rle_pytorch(mask_torch)[0]
|
| 432 |
+
mask_data["boxes"][i_mask] = boxes[i_mask] # update res directly
|
| 433 |
+
mask_data.filter(keep_by_nms)
|
| 434 |
+
|
| 435 |
+
return mask_data
|
| 436 |
+
|
| 437 |
+
def refine_with_m2m(self, points, point_labels, low_res_masks, points_per_batch):
|
| 438 |
+
new_masks = []
|
| 439 |
+
new_iou_preds = []
|
| 440 |
+
|
| 441 |
+
for cur_points, cur_point_labels, low_res_mask in batch_iterator(
|
| 442 |
+
points_per_batch, points, point_labels, low_res_masks
|
| 443 |
+
):
|
| 444 |
+
best_masks, best_iou_preds, _ = self.predictor._predict(
|
| 445 |
+
cur_points[:, None, :],
|
| 446 |
+
cur_point_labels[:, None],
|
| 447 |
+
mask_input=low_res_mask[:, None, :],
|
| 448 |
+
multimask_output=False,
|
| 449 |
+
return_logits=True,
|
| 450 |
+
)
|
| 451 |
+
new_masks.append(best_masks)
|
| 452 |
+
new_iou_preds.append(best_iou_preds)
|
| 453 |
+
masks = torch.cat(new_masks, dim=0)
|
| 454 |
+
return masks, torch.cat(new_iou_preds, dim=0)
|
third_party/sam2/sam2/benchmark.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import time
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
|
| 14 |
+
from sam2.build_sam import build_sam2_video_predictor
|
| 15 |
+
|
| 16 |
+
# Only cuda supported
|
| 17 |
+
assert torch.cuda.is_available()
|
| 18 |
+
device = torch.device("cuda")
|
| 19 |
+
|
| 20 |
+
torch.autocast(device_type="cuda", dtype=torch.bfloat16).__enter__()
|
| 21 |
+
if torch.cuda.get_device_properties(0).major >= 8:
|
| 22 |
+
# turn on tfloat32 for Ampere GPUs (https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)
|
| 23 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 24 |
+
torch.backends.cudnn.allow_tf32 = True
|
| 25 |
+
|
| 26 |
+
# Config and checkpoint
|
| 27 |
+
sam2_checkpoint = "checkpoints/sam2.1_hiera_base_plus.pt"
|
| 28 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_b+.yaml"
|
| 29 |
+
|
| 30 |
+
# Build video predictor with vos_optimized=True setting
|
| 31 |
+
predictor = build_sam2_video_predictor(
|
| 32 |
+
model_cfg, sam2_checkpoint, device=device, vos_optimized=True
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# Initialize with video
|
| 37 |
+
video_dir = "notebooks/videos/bedroom"
|
| 38 |
+
# scan all the JPEG frame names in this directory
|
| 39 |
+
frame_names = [
|
| 40 |
+
p
|
| 41 |
+
for p in os.listdir(video_dir)
|
| 42 |
+
if os.path.splitext(p)[-1] in [".jpg", ".jpeg", ".JPG", ".JPEG"]
|
| 43 |
+
]
|
| 44 |
+
frame_names.sort(key=lambda p: int(os.path.splitext(p)[0]))
|
| 45 |
+
inference_state = predictor.init_state(video_path=video_dir)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# Number of runs, warmup etc
|
| 49 |
+
warm_up, runs = 5, 25
|
| 50 |
+
verbose = True
|
| 51 |
+
num_frames = len(frame_names)
|
| 52 |
+
total, count = 0, 0
|
| 53 |
+
torch.cuda.empty_cache()
|
| 54 |
+
|
| 55 |
+
# We will select an object with a click.
|
| 56 |
+
# See video_predictor_example.ipynb for more detailed explanation
|
| 57 |
+
ann_frame_idx, ann_obj_id = 0, 1
|
| 58 |
+
# Add a positive click at (x, y) = (210, 350)
|
| 59 |
+
# For labels, `1` means positive click
|
| 60 |
+
points = np.array([[210, 350]], dtype=np.float32)
|
| 61 |
+
labels = np.array([1], np.int32)
|
| 62 |
+
|
| 63 |
+
_, out_obj_ids, out_mask_logits = predictor.add_new_points_or_box(
|
| 64 |
+
inference_state=inference_state,
|
| 65 |
+
frame_idx=ann_frame_idx,
|
| 66 |
+
obj_id=ann_obj_id,
|
| 67 |
+
points=points,
|
| 68 |
+
labels=labels,
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
# Warmup and then average FPS over several runs
|
| 72 |
+
with torch.autocast("cuda", torch.bfloat16):
|
| 73 |
+
with torch.inference_mode():
|
| 74 |
+
for i in tqdm(range(runs), disable=not verbose, desc="Benchmarking"):
|
| 75 |
+
start = time.time()
|
| 76 |
+
# Start tracking
|
| 77 |
+
for (
|
| 78 |
+
out_frame_idx,
|
| 79 |
+
out_obj_ids,
|
| 80 |
+
out_mask_logits,
|
| 81 |
+
) in predictor.propagate_in_video(inference_state):
|
| 82 |
+
pass
|
| 83 |
+
|
| 84 |
+
end = time.time()
|
| 85 |
+
total += end - start
|
| 86 |
+
count += 1
|
| 87 |
+
if i == warm_up - 1:
|
| 88 |
+
print("Warmup FPS: ", count * num_frames / total)
|
| 89 |
+
total = 0
|
| 90 |
+
count = 0
|
| 91 |
+
|
| 92 |
+
print("FPS: ", count * num_frames / total)
|
third_party/sam2/sam2/build_sam.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import logging
|
| 8 |
+
import os
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
from hydra import compose
|
| 12 |
+
from hydra.utils import instantiate
|
| 13 |
+
from omegaconf import OmegaConf
|
| 14 |
+
|
| 15 |
+
import sam2
|
| 16 |
+
|
| 17 |
+
# Check if the user is running Python from the parent directory of the sam2 repo
|
| 18 |
+
# (i.e. the directory where this repo is cloned into) -- this is not supported since
|
| 19 |
+
# it could shadow the sam2 package and cause issues.
|
| 20 |
+
if os.path.isdir(os.path.join(sam2.__path__[0], "sam2")):
|
| 21 |
+
# If the user has "sam2/sam2" in their path, they are likey importing the repo itself
|
| 22 |
+
# as "sam2" rather than importing the "sam2" python package (i.e. "sam2/sam2" directory).
|
| 23 |
+
# This typically happens because the user is running Python from the parent directory
|
| 24 |
+
# that contains the sam2 repo they cloned.
|
| 25 |
+
raise RuntimeError(
|
| 26 |
+
"You're likely running Python from the parent directory of the sam2 repository "
|
| 27 |
+
"(i.e. the directory where https://github.com/facebookresearch/sam2 is cloned into). "
|
| 28 |
+
"This is not supported since the `sam2` Python package could be shadowed by the "
|
| 29 |
+
"repository name (the repository is also named `sam2` and contains the Python package "
|
| 30 |
+
"in `sam2/sam2`). Please run Python from another directory (e.g. from the repo dir "
|
| 31 |
+
"rather than its parent dir, or from your home directory) after installing SAM 2."
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
HF_MODEL_ID_TO_FILENAMES = {
|
| 36 |
+
"facebook/sam2-hiera-tiny": (
|
| 37 |
+
"configs/sam2/sam2_hiera_t.yaml",
|
| 38 |
+
"sam2_hiera_tiny.pt",
|
| 39 |
+
),
|
| 40 |
+
"facebook/sam2-hiera-small": (
|
| 41 |
+
"configs/sam2/sam2_hiera_s.yaml",
|
| 42 |
+
"sam2_hiera_small.pt",
|
| 43 |
+
),
|
| 44 |
+
"facebook/sam2-hiera-base-plus": (
|
| 45 |
+
"configs/sam2/sam2_hiera_b+.yaml",
|
| 46 |
+
"sam2_hiera_base_plus.pt",
|
| 47 |
+
),
|
| 48 |
+
"facebook/sam2-hiera-large": (
|
| 49 |
+
"configs/sam2/sam2_hiera_l.yaml",
|
| 50 |
+
"sam2_hiera_large.pt",
|
| 51 |
+
),
|
| 52 |
+
"facebook/sam2.1-hiera-tiny": (
|
| 53 |
+
"configs/sam2.1/sam2.1_hiera_t.yaml",
|
| 54 |
+
"sam2.1_hiera_tiny.pt",
|
| 55 |
+
),
|
| 56 |
+
"facebook/sam2.1-hiera-small": (
|
| 57 |
+
"configs/sam2.1/sam2.1_hiera_s.yaml",
|
| 58 |
+
"sam2.1_hiera_small.pt",
|
| 59 |
+
),
|
| 60 |
+
"facebook/sam2.1-hiera-base-plus": (
|
| 61 |
+
"configs/sam2.1/sam2.1_hiera_b+.yaml",
|
| 62 |
+
"sam2.1_hiera_base_plus.pt",
|
| 63 |
+
),
|
| 64 |
+
"facebook/sam2.1-hiera-large": (
|
| 65 |
+
"configs/sam2.1/sam2.1_hiera_l.yaml",
|
| 66 |
+
"sam2.1_hiera_large.pt",
|
| 67 |
+
),
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def build_sam2(
|
| 72 |
+
config_file,
|
| 73 |
+
ckpt_path=None,
|
| 74 |
+
device="cuda",
|
| 75 |
+
mode="eval",
|
| 76 |
+
hydra_overrides_extra=[],
|
| 77 |
+
apply_postprocessing=True,
|
| 78 |
+
**kwargs,
|
| 79 |
+
):
|
| 80 |
+
|
| 81 |
+
if apply_postprocessing:
|
| 82 |
+
hydra_overrides_extra = hydra_overrides_extra.copy()
|
| 83 |
+
hydra_overrides_extra += [
|
| 84 |
+
# dynamically fall back to multi-mask if the single mask is not stable
|
| 85 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_via_stability=true",
|
| 86 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_stability_delta=0.05",
|
| 87 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_stability_thresh=0.98",
|
| 88 |
+
]
|
| 89 |
+
# Read config and init model
|
| 90 |
+
cfg = compose(config_name=config_file, overrides=hydra_overrides_extra)
|
| 91 |
+
OmegaConf.resolve(cfg)
|
| 92 |
+
model = instantiate(cfg.model, _recursive_=True)
|
| 93 |
+
_load_checkpoint(model, ckpt_path)
|
| 94 |
+
model = model.to(device)
|
| 95 |
+
if mode == "eval":
|
| 96 |
+
model.eval()
|
| 97 |
+
return model
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def build_sam2_video_predictor(
|
| 101 |
+
config_file,
|
| 102 |
+
ckpt_path=None,
|
| 103 |
+
device="cuda",
|
| 104 |
+
mode="eval",
|
| 105 |
+
hydra_overrides_extra=[],
|
| 106 |
+
apply_postprocessing=True,
|
| 107 |
+
vos_optimized=False,
|
| 108 |
+
**kwargs,
|
| 109 |
+
):
|
| 110 |
+
hydra_overrides = [
|
| 111 |
+
"++model._target_=sam2.sam2_video_predictor.SAM2VideoPredictor",
|
| 112 |
+
]
|
| 113 |
+
if vos_optimized:
|
| 114 |
+
hydra_overrides = [
|
| 115 |
+
"++model._target_=sam2.sam2_video_predictor.SAM2VideoPredictorVOS",
|
| 116 |
+
"++model.compile_image_encoder=True", # Let sam2_base handle this
|
| 117 |
+
]
|
| 118 |
+
|
| 119 |
+
if apply_postprocessing:
|
| 120 |
+
hydra_overrides_extra = hydra_overrides_extra.copy()
|
| 121 |
+
hydra_overrides_extra += [
|
| 122 |
+
# dynamically fall back to multi-mask if the single mask is not stable
|
| 123 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_via_stability=true",
|
| 124 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_stability_delta=0.05",
|
| 125 |
+
"++model.sam_mask_decoder_extra_args.dynamic_multimask_stability_thresh=0.98",
|
| 126 |
+
# the sigmoid mask logits on interacted frames with clicks in the memory encoder so that the encoded masks are exactly as what users see from clicking
|
| 127 |
+
"++model.binarize_mask_from_pts_for_mem_enc=true",
|
| 128 |
+
# fill small holes in the low-res masks up to `fill_hole_area` (before resizing them to the original video resolution)
|
| 129 |
+
"++model.fill_hole_area=8",
|
| 130 |
+
]
|
| 131 |
+
hydra_overrides.extend(hydra_overrides_extra)
|
| 132 |
+
|
| 133 |
+
# Read config and init model
|
| 134 |
+
cfg = compose(config_name=config_file, overrides=hydra_overrides)
|
| 135 |
+
OmegaConf.resolve(cfg)
|
| 136 |
+
model = instantiate(cfg.model, _recursive_=True)
|
| 137 |
+
_load_checkpoint(model, ckpt_path)
|
| 138 |
+
model = model.to(device)
|
| 139 |
+
if mode == "eval":
|
| 140 |
+
model.eval()
|
| 141 |
+
return model
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def _hf_download(model_id):
|
| 145 |
+
from huggingface_hub import hf_hub_download
|
| 146 |
+
|
| 147 |
+
config_name, checkpoint_name = HF_MODEL_ID_TO_FILENAMES[model_id]
|
| 148 |
+
ckpt_path = hf_hub_download(repo_id=model_id, filename=checkpoint_name)
|
| 149 |
+
return config_name, ckpt_path
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def build_sam2_hf(model_id, **kwargs):
|
| 153 |
+
config_name, ckpt_path = _hf_download(model_id)
|
| 154 |
+
return build_sam2(config_file=config_name, ckpt_path=ckpt_path, **kwargs)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def build_sam2_video_predictor_hf(model_id, **kwargs):
|
| 158 |
+
config_name, ckpt_path = _hf_download(model_id)
|
| 159 |
+
return build_sam2_video_predictor(
|
| 160 |
+
config_file=config_name, ckpt_path=ckpt_path, **kwargs
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def _load_checkpoint(model, ckpt_path):
|
| 165 |
+
if ckpt_path is not None:
|
| 166 |
+
sd = torch.load(ckpt_path, map_location="cpu", weights_only=True)["model"]
|
| 167 |
+
missing_keys, unexpected_keys = model.load_state_dict(sd)
|
| 168 |
+
if missing_keys:
|
| 169 |
+
logging.error(missing_keys)
|
| 170 |
+
raise RuntimeError()
|
| 171 |
+
if unexpected_keys:
|
| 172 |
+
logging.error(unexpected_keys)
|
| 173 |
+
raise RuntimeError()
|
| 174 |
+
logging.info("Loaded checkpoint sucessfully")
|
third_party/sam2/sam2/configs/sam2.1/sam2.1_hiera_b+.yaml
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 112
|
| 12 |
+
num_heads: 2
|
| 13 |
+
neck:
|
| 14 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 15 |
+
position_encoding:
|
| 16 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 17 |
+
num_pos_feats: 256
|
| 18 |
+
normalize: true
|
| 19 |
+
scale: null
|
| 20 |
+
temperature: 10000
|
| 21 |
+
d_model: 256
|
| 22 |
+
backbone_channel_list: [896, 448, 224, 112]
|
| 23 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 24 |
+
fpn_interp_model: nearest
|
| 25 |
+
|
| 26 |
+
memory_attention:
|
| 27 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 28 |
+
d_model: 256
|
| 29 |
+
pos_enc_at_input: true
|
| 30 |
+
layer:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 32 |
+
activation: relu
|
| 33 |
+
dim_feedforward: 2048
|
| 34 |
+
dropout: 0.1
|
| 35 |
+
pos_enc_at_attn: false
|
| 36 |
+
self_attention:
|
| 37 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 38 |
+
rope_theta: 10000.0
|
| 39 |
+
feat_sizes: [64, 64]
|
| 40 |
+
embedding_dim: 256
|
| 41 |
+
num_heads: 1
|
| 42 |
+
downsample_rate: 1
|
| 43 |
+
dropout: 0.1
|
| 44 |
+
d_model: 256
|
| 45 |
+
pos_enc_at_cross_attn_keys: true
|
| 46 |
+
pos_enc_at_cross_attn_queries: false
|
| 47 |
+
cross_attention:
|
| 48 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 49 |
+
rope_theta: 10000.0
|
| 50 |
+
feat_sizes: [64, 64]
|
| 51 |
+
rope_k_repeat: True
|
| 52 |
+
embedding_dim: 256
|
| 53 |
+
num_heads: 1
|
| 54 |
+
downsample_rate: 1
|
| 55 |
+
dropout: 0.1
|
| 56 |
+
kv_in_dim: 64
|
| 57 |
+
num_layers: 4
|
| 58 |
+
|
| 59 |
+
memory_encoder:
|
| 60 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 61 |
+
out_dim: 64
|
| 62 |
+
position_encoding:
|
| 63 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 64 |
+
num_pos_feats: 64
|
| 65 |
+
normalize: true
|
| 66 |
+
scale: null
|
| 67 |
+
temperature: 10000
|
| 68 |
+
mask_downsampler:
|
| 69 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 70 |
+
kernel_size: 3
|
| 71 |
+
stride: 2
|
| 72 |
+
padding: 1
|
| 73 |
+
fuser:
|
| 74 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 75 |
+
layer:
|
| 76 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 77 |
+
dim: 256
|
| 78 |
+
kernel_size: 7
|
| 79 |
+
padding: 3
|
| 80 |
+
layer_scale_init_value: 1e-6
|
| 81 |
+
use_dwconv: True # depth-wise convs
|
| 82 |
+
num_layers: 2
|
| 83 |
+
|
| 84 |
+
num_maskmem: 7
|
| 85 |
+
image_size: 1024
|
| 86 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 87 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 88 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 89 |
+
use_mask_input_as_output_without_sam: true
|
| 90 |
+
# Memory
|
| 91 |
+
directly_add_no_mem_embed: true
|
| 92 |
+
no_obj_embed_spatial: true
|
| 93 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 94 |
+
use_high_res_features_in_sam: true
|
| 95 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 96 |
+
multimask_output_in_sam: true
|
| 97 |
+
# SAM heads
|
| 98 |
+
iou_prediction_use_sigmoid: True
|
| 99 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 100 |
+
use_obj_ptrs_in_encoder: true
|
| 101 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 102 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 103 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 104 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 105 |
+
# object occlusion prediction
|
| 106 |
+
pred_obj_scores: true
|
| 107 |
+
pred_obj_scores_mlp: true
|
| 108 |
+
fixed_no_obj_ptr: true
|
| 109 |
+
# multimask tracking settings
|
| 110 |
+
multimask_output_for_tracking: true
|
| 111 |
+
use_multimask_token_for_obj_ptr: true
|
| 112 |
+
multimask_min_pt_num: 0
|
| 113 |
+
multimask_max_pt_num: 1
|
| 114 |
+
use_mlp_for_obj_ptr_proj: true
|
| 115 |
+
# Compilation flag
|
| 116 |
+
compile_image_encoder: False
|
third_party/sam2/sam2/configs/sam2.1/sam2.1_hiera_l.yaml
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 144
|
| 12 |
+
num_heads: 2
|
| 13 |
+
stages: [2, 6, 36, 4]
|
| 14 |
+
global_att_blocks: [23, 33, 43]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
window_spec: [8, 4, 16, 8]
|
| 17 |
+
neck:
|
| 18 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 19 |
+
position_encoding:
|
| 20 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 21 |
+
num_pos_feats: 256
|
| 22 |
+
normalize: true
|
| 23 |
+
scale: null
|
| 24 |
+
temperature: 10000
|
| 25 |
+
d_model: 256
|
| 26 |
+
backbone_channel_list: [1152, 576, 288, 144]
|
| 27 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 28 |
+
fpn_interp_model: nearest
|
| 29 |
+
|
| 30 |
+
memory_attention:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 32 |
+
d_model: 256
|
| 33 |
+
pos_enc_at_input: true
|
| 34 |
+
layer:
|
| 35 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 36 |
+
activation: relu
|
| 37 |
+
dim_feedforward: 2048
|
| 38 |
+
dropout: 0.1
|
| 39 |
+
pos_enc_at_attn: false
|
| 40 |
+
self_attention:
|
| 41 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 42 |
+
rope_theta: 10000.0
|
| 43 |
+
feat_sizes: [64, 64]
|
| 44 |
+
embedding_dim: 256
|
| 45 |
+
num_heads: 1
|
| 46 |
+
downsample_rate: 1
|
| 47 |
+
dropout: 0.1
|
| 48 |
+
d_model: 256
|
| 49 |
+
pos_enc_at_cross_attn_keys: true
|
| 50 |
+
pos_enc_at_cross_attn_queries: false
|
| 51 |
+
cross_attention:
|
| 52 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 53 |
+
rope_theta: 10000.0
|
| 54 |
+
feat_sizes: [64, 64]
|
| 55 |
+
rope_k_repeat: True
|
| 56 |
+
embedding_dim: 256
|
| 57 |
+
num_heads: 1
|
| 58 |
+
downsample_rate: 1
|
| 59 |
+
dropout: 0.1
|
| 60 |
+
kv_in_dim: 64
|
| 61 |
+
num_layers: 4
|
| 62 |
+
|
| 63 |
+
memory_encoder:
|
| 64 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 65 |
+
out_dim: 64
|
| 66 |
+
position_encoding:
|
| 67 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 68 |
+
num_pos_feats: 64
|
| 69 |
+
normalize: true
|
| 70 |
+
scale: null
|
| 71 |
+
temperature: 10000
|
| 72 |
+
mask_downsampler:
|
| 73 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 74 |
+
kernel_size: 3
|
| 75 |
+
stride: 2
|
| 76 |
+
padding: 1
|
| 77 |
+
fuser:
|
| 78 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 79 |
+
layer:
|
| 80 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 81 |
+
dim: 256
|
| 82 |
+
kernel_size: 7
|
| 83 |
+
padding: 3
|
| 84 |
+
layer_scale_init_value: 1e-6
|
| 85 |
+
use_dwconv: True # depth-wise convs
|
| 86 |
+
num_layers: 2
|
| 87 |
+
|
| 88 |
+
num_maskmem: 7
|
| 89 |
+
image_size: 1024
|
| 90 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
no_obj_embed_spatial: true
|
| 97 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 98 |
+
use_high_res_features_in_sam: true
|
| 99 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 100 |
+
multimask_output_in_sam: true
|
| 101 |
+
# SAM heads
|
| 102 |
+
iou_prediction_use_sigmoid: True
|
| 103 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 104 |
+
use_obj_ptrs_in_encoder: true
|
| 105 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 106 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 107 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 108 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 109 |
+
# object occlusion prediction
|
| 110 |
+
pred_obj_scores: true
|
| 111 |
+
pred_obj_scores_mlp: true
|
| 112 |
+
fixed_no_obj_ptr: true
|
| 113 |
+
# multimask tracking settings
|
| 114 |
+
multimask_output_for_tracking: true
|
| 115 |
+
use_multimask_token_for_obj_ptr: true
|
| 116 |
+
multimask_min_pt_num: 0
|
| 117 |
+
multimask_max_pt_num: 1
|
| 118 |
+
use_mlp_for_obj_ptr_proj: true
|
| 119 |
+
# Compilation flag
|
| 120 |
+
compile_image_encoder: False
|
third_party/sam2/sam2/configs/sam2.1/sam2.1_hiera_s.yaml
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 96
|
| 12 |
+
num_heads: 1
|
| 13 |
+
stages: [1, 2, 11, 2]
|
| 14 |
+
global_att_blocks: [7, 10, 13]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
neck:
|
| 17 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 18 |
+
position_encoding:
|
| 19 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 20 |
+
num_pos_feats: 256
|
| 21 |
+
normalize: true
|
| 22 |
+
scale: null
|
| 23 |
+
temperature: 10000
|
| 24 |
+
d_model: 256
|
| 25 |
+
backbone_channel_list: [768, 384, 192, 96]
|
| 26 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 27 |
+
fpn_interp_model: nearest
|
| 28 |
+
|
| 29 |
+
memory_attention:
|
| 30 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 31 |
+
d_model: 256
|
| 32 |
+
pos_enc_at_input: true
|
| 33 |
+
layer:
|
| 34 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 35 |
+
activation: relu
|
| 36 |
+
dim_feedforward: 2048
|
| 37 |
+
dropout: 0.1
|
| 38 |
+
pos_enc_at_attn: false
|
| 39 |
+
self_attention:
|
| 40 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 41 |
+
rope_theta: 10000.0
|
| 42 |
+
feat_sizes: [64, 64]
|
| 43 |
+
embedding_dim: 256
|
| 44 |
+
num_heads: 1
|
| 45 |
+
downsample_rate: 1
|
| 46 |
+
dropout: 0.1
|
| 47 |
+
d_model: 256
|
| 48 |
+
pos_enc_at_cross_attn_keys: true
|
| 49 |
+
pos_enc_at_cross_attn_queries: false
|
| 50 |
+
cross_attention:
|
| 51 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 52 |
+
rope_theta: 10000.0
|
| 53 |
+
feat_sizes: [64, 64]
|
| 54 |
+
rope_k_repeat: True
|
| 55 |
+
embedding_dim: 256
|
| 56 |
+
num_heads: 1
|
| 57 |
+
downsample_rate: 1
|
| 58 |
+
dropout: 0.1
|
| 59 |
+
kv_in_dim: 64
|
| 60 |
+
num_layers: 4
|
| 61 |
+
|
| 62 |
+
memory_encoder:
|
| 63 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 64 |
+
out_dim: 64
|
| 65 |
+
position_encoding:
|
| 66 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 67 |
+
num_pos_feats: 64
|
| 68 |
+
normalize: true
|
| 69 |
+
scale: null
|
| 70 |
+
temperature: 10000
|
| 71 |
+
mask_downsampler:
|
| 72 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 73 |
+
kernel_size: 3
|
| 74 |
+
stride: 2
|
| 75 |
+
padding: 1
|
| 76 |
+
fuser:
|
| 77 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 78 |
+
layer:
|
| 79 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 80 |
+
dim: 256
|
| 81 |
+
kernel_size: 7
|
| 82 |
+
padding: 3
|
| 83 |
+
layer_scale_init_value: 1e-6
|
| 84 |
+
use_dwconv: True # depth-wise convs
|
| 85 |
+
num_layers: 2
|
| 86 |
+
|
| 87 |
+
num_maskmem: 7
|
| 88 |
+
image_size: 1024
|
| 89 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 90 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 91 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 92 |
+
use_mask_input_as_output_without_sam: true
|
| 93 |
+
# Memory
|
| 94 |
+
directly_add_no_mem_embed: true
|
| 95 |
+
no_obj_embed_spatial: true
|
| 96 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 97 |
+
use_high_res_features_in_sam: true
|
| 98 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 99 |
+
multimask_output_in_sam: true
|
| 100 |
+
# SAM heads
|
| 101 |
+
iou_prediction_use_sigmoid: True
|
| 102 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 103 |
+
use_obj_ptrs_in_encoder: true
|
| 104 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 105 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 106 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 107 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 108 |
+
# object occlusion prediction
|
| 109 |
+
pred_obj_scores: true
|
| 110 |
+
pred_obj_scores_mlp: true
|
| 111 |
+
fixed_no_obj_ptr: true
|
| 112 |
+
# multimask tracking settings
|
| 113 |
+
multimask_output_for_tracking: true
|
| 114 |
+
use_multimask_token_for_obj_ptr: true
|
| 115 |
+
multimask_min_pt_num: 0
|
| 116 |
+
multimask_max_pt_num: 1
|
| 117 |
+
use_mlp_for_obj_ptr_proj: true
|
| 118 |
+
# Compilation flag
|
| 119 |
+
compile_image_encoder: False
|
third_party/sam2/sam2/configs/sam2.1/sam2.1_hiera_t.yaml
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 96
|
| 12 |
+
num_heads: 1
|
| 13 |
+
stages: [1, 2, 7, 2]
|
| 14 |
+
global_att_blocks: [5, 7, 9]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
neck:
|
| 17 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 18 |
+
position_encoding:
|
| 19 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 20 |
+
num_pos_feats: 256
|
| 21 |
+
normalize: true
|
| 22 |
+
scale: null
|
| 23 |
+
temperature: 10000
|
| 24 |
+
d_model: 256
|
| 25 |
+
backbone_channel_list: [768, 384, 192, 96]
|
| 26 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 27 |
+
fpn_interp_model: nearest
|
| 28 |
+
|
| 29 |
+
memory_attention:
|
| 30 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 31 |
+
d_model: 256
|
| 32 |
+
pos_enc_at_input: true
|
| 33 |
+
layer:
|
| 34 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 35 |
+
activation: relu
|
| 36 |
+
dim_feedforward: 2048
|
| 37 |
+
dropout: 0.1
|
| 38 |
+
pos_enc_at_attn: false
|
| 39 |
+
self_attention:
|
| 40 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 41 |
+
rope_theta: 10000.0
|
| 42 |
+
feat_sizes: [64, 64]
|
| 43 |
+
embedding_dim: 256
|
| 44 |
+
num_heads: 1
|
| 45 |
+
downsample_rate: 1
|
| 46 |
+
dropout: 0.1
|
| 47 |
+
d_model: 256
|
| 48 |
+
pos_enc_at_cross_attn_keys: true
|
| 49 |
+
pos_enc_at_cross_attn_queries: false
|
| 50 |
+
cross_attention:
|
| 51 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 52 |
+
rope_theta: 10000.0
|
| 53 |
+
feat_sizes: [64, 64]
|
| 54 |
+
rope_k_repeat: True
|
| 55 |
+
embedding_dim: 256
|
| 56 |
+
num_heads: 1
|
| 57 |
+
downsample_rate: 1
|
| 58 |
+
dropout: 0.1
|
| 59 |
+
kv_in_dim: 64
|
| 60 |
+
num_layers: 4
|
| 61 |
+
|
| 62 |
+
memory_encoder:
|
| 63 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 64 |
+
out_dim: 64
|
| 65 |
+
position_encoding:
|
| 66 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 67 |
+
num_pos_feats: 64
|
| 68 |
+
normalize: true
|
| 69 |
+
scale: null
|
| 70 |
+
temperature: 10000
|
| 71 |
+
mask_downsampler:
|
| 72 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 73 |
+
kernel_size: 3
|
| 74 |
+
stride: 2
|
| 75 |
+
padding: 1
|
| 76 |
+
fuser:
|
| 77 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 78 |
+
layer:
|
| 79 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 80 |
+
dim: 256
|
| 81 |
+
kernel_size: 7
|
| 82 |
+
padding: 3
|
| 83 |
+
layer_scale_init_value: 1e-6
|
| 84 |
+
use_dwconv: True # depth-wise convs
|
| 85 |
+
num_layers: 2
|
| 86 |
+
|
| 87 |
+
num_maskmem: 7
|
| 88 |
+
image_size: 1024
|
| 89 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 90 |
+
# SAM decoder
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
no_obj_embed_spatial: true
|
| 97 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 98 |
+
use_high_res_features_in_sam: true
|
| 99 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 100 |
+
multimask_output_in_sam: true
|
| 101 |
+
# SAM heads
|
| 102 |
+
iou_prediction_use_sigmoid: True
|
| 103 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 104 |
+
use_obj_ptrs_in_encoder: true
|
| 105 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 106 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 107 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 108 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 109 |
+
# object occlusion prediction
|
| 110 |
+
pred_obj_scores: true
|
| 111 |
+
pred_obj_scores_mlp: true
|
| 112 |
+
fixed_no_obj_ptr: true
|
| 113 |
+
# multimask tracking settings
|
| 114 |
+
multimask_output_for_tracking: true
|
| 115 |
+
use_multimask_token_for_obj_ptr: true
|
| 116 |
+
multimask_min_pt_num: 0
|
| 117 |
+
multimask_max_pt_num: 1
|
| 118 |
+
use_mlp_for_obj_ptr_proj: true
|
| 119 |
+
# Compilation flag
|
| 120 |
+
# HieraT does not currently support compilation, should always be set to False
|
| 121 |
+
compile_image_encoder: False
|
third_party/sam2/sam2/configs/sam2.1_training/sam2.1_hiera_b+_MOSE_finetune.yaml
ADDED
|
@@ -0,0 +1,339 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
scratch:
|
| 4 |
+
resolution: 1024
|
| 5 |
+
train_batch_size: 1
|
| 6 |
+
num_train_workers: 10
|
| 7 |
+
num_frames: 8
|
| 8 |
+
max_num_objects: 3
|
| 9 |
+
base_lr: 5.0e-6
|
| 10 |
+
vision_lr: 3.0e-06
|
| 11 |
+
phases_per_epoch: 1
|
| 12 |
+
num_epochs: 40
|
| 13 |
+
|
| 14 |
+
dataset:
|
| 15 |
+
# PATHS to Dataset
|
| 16 |
+
img_folder: null # PATH to MOSE JPEGImages folder
|
| 17 |
+
gt_folder: null # PATH to MOSE Annotations folder
|
| 18 |
+
file_list_txt: training/assets/MOSE_sample_train_list.txt # Optional PATH to filelist containing a subset of videos to be used for training
|
| 19 |
+
multiplier: 2
|
| 20 |
+
|
| 21 |
+
# Video transforms
|
| 22 |
+
vos:
|
| 23 |
+
train_transforms:
|
| 24 |
+
- _target_: training.dataset.transforms.ComposeAPI
|
| 25 |
+
transforms:
|
| 26 |
+
- _target_: training.dataset.transforms.RandomHorizontalFlip
|
| 27 |
+
consistent_transform: True
|
| 28 |
+
- _target_: training.dataset.transforms.RandomAffine
|
| 29 |
+
degrees: 25
|
| 30 |
+
shear: 20
|
| 31 |
+
image_interpolation: bilinear
|
| 32 |
+
consistent_transform: True
|
| 33 |
+
- _target_: training.dataset.transforms.RandomResizeAPI
|
| 34 |
+
sizes: ${scratch.resolution}
|
| 35 |
+
square: true
|
| 36 |
+
consistent_transform: True
|
| 37 |
+
- _target_: training.dataset.transforms.ColorJitter
|
| 38 |
+
consistent_transform: True
|
| 39 |
+
brightness: 0.1
|
| 40 |
+
contrast: 0.03
|
| 41 |
+
saturation: 0.03
|
| 42 |
+
hue: null
|
| 43 |
+
- _target_: training.dataset.transforms.RandomGrayscale
|
| 44 |
+
p: 0.05
|
| 45 |
+
consistent_transform: True
|
| 46 |
+
- _target_: training.dataset.transforms.ColorJitter
|
| 47 |
+
consistent_transform: False
|
| 48 |
+
brightness: 0.1
|
| 49 |
+
contrast: 0.05
|
| 50 |
+
saturation: 0.05
|
| 51 |
+
hue: null
|
| 52 |
+
- _target_: training.dataset.transforms.ToTensorAPI
|
| 53 |
+
- _target_: training.dataset.transforms.NormalizeAPI
|
| 54 |
+
mean: [0.485, 0.456, 0.406]
|
| 55 |
+
std: [0.229, 0.224, 0.225]
|
| 56 |
+
|
| 57 |
+
trainer:
|
| 58 |
+
_target_: training.trainer.Trainer
|
| 59 |
+
mode: train_only
|
| 60 |
+
max_epochs: ${times:${scratch.num_epochs},${scratch.phases_per_epoch}}
|
| 61 |
+
accelerator: cuda
|
| 62 |
+
seed_value: 123
|
| 63 |
+
|
| 64 |
+
model:
|
| 65 |
+
_target_: training.model.sam2.SAM2Train
|
| 66 |
+
image_encoder:
|
| 67 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 68 |
+
scalp: 1
|
| 69 |
+
trunk:
|
| 70 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 71 |
+
embed_dim: 112
|
| 72 |
+
num_heads: 2
|
| 73 |
+
drop_path_rate: 0.1
|
| 74 |
+
neck:
|
| 75 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 76 |
+
position_encoding:
|
| 77 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 78 |
+
num_pos_feats: 256
|
| 79 |
+
normalize: true
|
| 80 |
+
scale: null
|
| 81 |
+
temperature: 10000
|
| 82 |
+
d_model: 256
|
| 83 |
+
backbone_channel_list: [896, 448, 224, 112]
|
| 84 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 85 |
+
fpn_interp_model: nearest
|
| 86 |
+
|
| 87 |
+
memory_attention:
|
| 88 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 89 |
+
d_model: 256
|
| 90 |
+
pos_enc_at_input: true
|
| 91 |
+
layer:
|
| 92 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 93 |
+
activation: relu
|
| 94 |
+
dim_feedforward: 2048
|
| 95 |
+
dropout: 0.1
|
| 96 |
+
pos_enc_at_attn: false
|
| 97 |
+
self_attention:
|
| 98 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 99 |
+
rope_theta: 10000.0
|
| 100 |
+
feat_sizes: [64, 64]
|
| 101 |
+
embedding_dim: 256
|
| 102 |
+
num_heads: 1
|
| 103 |
+
downsample_rate: 1
|
| 104 |
+
dropout: 0.1
|
| 105 |
+
d_model: 256
|
| 106 |
+
pos_enc_at_cross_attn_keys: true
|
| 107 |
+
pos_enc_at_cross_attn_queries: false
|
| 108 |
+
cross_attention:
|
| 109 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 110 |
+
rope_theta: 10000.0
|
| 111 |
+
feat_sizes: [64, 64]
|
| 112 |
+
rope_k_repeat: True
|
| 113 |
+
embedding_dim: 256
|
| 114 |
+
num_heads: 1
|
| 115 |
+
downsample_rate: 1
|
| 116 |
+
dropout: 0.1
|
| 117 |
+
kv_in_dim: 64
|
| 118 |
+
num_layers: 4
|
| 119 |
+
|
| 120 |
+
memory_encoder:
|
| 121 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 122 |
+
out_dim: 64
|
| 123 |
+
position_encoding:
|
| 124 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 125 |
+
num_pos_feats: 64
|
| 126 |
+
normalize: true
|
| 127 |
+
scale: null
|
| 128 |
+
temperature: 10000
|
| 129 |
+
mask_downsampler:
|
| 130 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 131 |
+
kernel_size: 3
|
| 132 |
+
stride: 2
|
| 133 |
+
padding: 1
|
| 134 |
+
fuser:
|
| 135 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 136 |
+
layer:
|
| 137 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 138 |
+
dim: 256
|
| 139 |
+
kernel_size: 7
|
| 140 |
+
padding: 3
|
| 141 |
+
layer_scale_init_value: 1e-6
|
| 142 |
+
use_dwconv: True # depth-wise convs
|
| 143 |
+
num_layers: 2
|
| 144 |
+
|
| 145 |
+
num_maskmem: 7
|
| 146 |
+
image_size: ${scratch.resolution}
|
| 147 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 148 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 149 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 150 |
+
use_mask_input_as_output_without_sam: true
|
| 151 |
+
# Memory
|
| 152 |
+
directly_add_no_mem_embed: true
|
| 153 |
+
no_obj_embed_spatial: true
|
| 154 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 155 |
+
use_high_res_features_in_sam: true
|
| 156 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 157 |
+
multimask_output_in_sam: true
|
| 158 |
+
# SAM heads
|
| 159 |
+
iou_prediction_use_sigmoid: True
|
| 160 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 161 |
+
use_obj_ptrs_in_encoder: true
|
| 162 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 163 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 164 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 165 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 166 |
+
# object occlusion prediction
|
| 167 |
+
pred_obj_scores: true
|
| 168 |
+
pred_obj_scores_mlp: true
|
| 169 |
+
fixed_no_obj_ptr: true
|
| 170 |
+
# multimask tracking settings
|
| 171 |
+
multimask_output_for_tracking: true
|
| 172 |
+
use_multimask_token_for_obj_ptr: true
|
| 173 |
+
multimask_min_pt_num: 0
|
| 174 |
+
multimask_max_pt_num: 1
|
| 175 |
+
use_mlp_for_obj_ptr_proj: true
|
| 176 |
+
# Compilation flag
|
| 177 |
+
# compile_image_encoder: False
|
| 178 |
+
|
| 179 |
+
####### Training specific params #######
|
| 180 |
+
# box/point input and corrections
|
| 181 |
+
prob_to_use_pt_input_for_train: 0.5
|
| 182 |
+
prob_to_use_pt_input_for_eval: 0.0
|
| 183 |
+
prob_to_use_box_input_for_train: 0.5 # 0.5*0.5 = 0.25 prob to use box instead of points
|
| 184 |
+
prob_to_use_box_input_for_eval: 0.0
|
| 185 |
+
prob_to_sample_from_gt_for_train: 0.1 # with a small prob, sampling correction points from GT mask instead of prediction errors
|
| 186 |
+
num_frames_to_correct_for_train: 2 # iteratively sample on random 1~2 frames (always include the first frame)
|
| 187 |
+
num_frames_to_correct_for_eval: 1 # only iteratively sample on first frame
|
| 188 |
+
rand_frames_to_correct_for_train: True # random #init-cond-frame ~ 2
|
| 189 |
+
add_all_frames_to_correct_as_cond: True # when a frame receives a correction click, it becomes a conditioning frame (even if it's not initially a conditioning frame)
|
| 190 |
+
# maximum 2 initial conditioning frames
|
| 191 |
+
num_init_cond_frames_for_train: 2
|
| 192 |
+
rand_init_cond_frames_for_train: True # random 1~2
|
| 193 |
+
num_correction_pt_per_frame: 7
|
| 194 |
+
use_act_ckpt_iterative_pt_sampling: false
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
num_init_cond_frames_for_eval: 1 # only mask on the first frame
|
| 199 |
+
forward_backbone_per_frame_for_eval: True
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
data:
|
| 203 |
+
train:
|
| 204 |
+
_target_: training.dataset.sam2_datasets.TorchTrainMixedDataset
|
| 205 |
+
phases_per_epoch: ${scratch.phases_per_epoch}
|
| 206 |
+
batch_sizes:
|
| 207 |
+
- ${scratch.train_batch_size}
|
| 208 |
+
|
| 209 |
+
datasets:
|
| 210 |
+
- _target_: training.dataset.utils.RepeatFactorWrapper
|
| 211 |
+
dataset:
|
| 212 |
+
_target_: training.dataset.utils.ConcatDataset
|
| 213 |
+
datasets:
|
| 214 |
+
- _target_: training.dataset.vos_dataset.VOSDataset
|
| 215 |
+
transforms: ${vos.train_transforms}
|
| 216 |
+
training: true
|
| 217 |
+
video_dataset:
|
| 218 |
+
_target_: training.dataset.vos_raw_dataset.PNGRawDataset
|
| 219 |
+
img_folder: ${dataset.img_folder}
|
| 220 |
+
gt_folder: ${dataset.gt_folder}
|
| 221 |
+
file_list_txt: ${dataset.file_list_txt}
|
| 222 |
+
sampler:
|
| 223 |
+
_target_: training.dataset.vos_sampler.RandomUniformSampler
|
| 224 |
+
num_frames: ${scratch.num_frames}
|
| 225 |
+
max_num_objects: ${scratch.max_num_objects}
|
| 226 |
+
multiplier: ${dataset.multiplier}
|
| 227 |
+
shuffle: True
|
| 228 |
+
num_workers: ${scratch.num_train_workers}
|
| 229 |
+
pin_memory: True
|
| 230 |
+
drop_last: True
|
| 231 |
+
collate_fn:
|
| 232 |
+
_target_: training.utils.data_utils.collate_fn
|
| 233 |
+
_partial_: true
|
| 234 |
+
dict_key: all
|
| 235 |
+
|
| 236 |
+
optim:
|
| 237 |
+
amp:
|
| 238 |
+
enabled: True
|
| 239 |
+
amp_dtype: bfloat16
|
| 240 |
+
|
| 241 |
+
optimizer:
|
| 242 |
+
_target_: torch.optim.AdamW
|
| 243 |
+
|
| 244 |
+
gradient_clip:
|
| 245 |
+
_target_: training.optimizer.GradientClipper
|
| 246 |
+
max_norm: 0.1
|
| 247 |
+
norm_type: 2
|
| 248 |
+
|
| 249 |
+
param_group_modifiers:
|
| 250 |
+
- _target_: training.optimizer.layer_decay_param_modifier
|
| 251 |
+
_partial_: True
|
| 252 |
+
layer_decay_value: 0.9
|
| 253 |
+
apply_to: 'image_encoder.trunk'
|
| 254 |
+
overrides:
|
| 255 |
+
- pattern: '*pos_embed*'
|
| 256 |
+
value: 1.0
|
| 257 |
+
|
| 258 |
+
options:
|
| 259 |
+
lr:
|
| 260 |
+
- scheduler:
|
| 261 |
+
_target_: fvcore.common.param_scheduler.CosineParamScheduler
|
| 262 |
+
start_value: ${scratch.base_lr}
|
| 263 |
+
end_value: ${divide:${scratch.base_lr},10}
|
| 264 |
+
- scheduler:
|
| 265 |
+
_target_: fvcore.common.param_scheduler.CosineParamScheduler
|
| 266 |
+
start_value: ${scratch.vision_lr}
|
| 267 |
+
end_value: ${divide:${scratch.vision_lr},10}
|
| 268 |
+
param_names:
|
| 269 |
+
- 'image_encoder.*'
|
| 270 |
+
weight_decay:
|
| 271 |
+
- scheduler:
|
| 272 |
+
_target_: fvcore.common.param_scheduler.ConstantParamScheduler
|
| 273 |
+
value: 0.1
|
| 274 |
+
- scheduler:
|
| 275 |
+
_target_: fvcore.common.param_scheduler.ConstantParamScheduler
|
| 276 |
+
value: 0.0
|
| 277 |
+
param_names:
|
| 278 |
+
- '*bias*'
|
| 279 |
+
module_cls_names: ['torch.nn.LayerNorm']
|
| 280 |
+
|
| 281 |
+
loss:
|
| 282 |
+
all:
|
| 283 |
+
_target_: training.loss_fns.MultiStepMultiMasksAndIous
|
| 284 |
+
weight_dict:
|
| 285 |
+
loss_mask: 20
|
| 286 |
+
loss_dice: 1
|
| 287 |
+
loss_iou: 1
|
| 288 |
+
loss_class: 1
|
| 289 |
+
supervise_all_iou: true
|
| 290 |
+
iou_use_l1_loss: true
|
| 291 |
+
pred_obj_scores: true
|
| 292 |
+
focal_gamma_obj_score: 0.0
|
| 293 |
+
focal_alpha_obj_score: -1.0
|
| 294 |
+
|
| 295 |
+
distributed:
|
| 296 |
+
backend: nccl
|
| 297 |
+
find_unused_parameters: True
|
| 298 |
+
|
| 299 |
+
logging:
|
| 300 |
+
tensorboard_writer:
|
| 301 |
+
_target_: training.utils.logger.make_tensorboard_logger
|
| 302 |
+
log_dir: ${launcher.experiment_log_dir}/tensorboard
|
| 303 |
+
flush_secs: 120
|
| 304 |
+
should_log: True
|
| 305 |
+
log_dir: ${launcher.experiment_log_dir}/logs
|
| 306 |
+
log_freq: 10
|
| 307 |
+
|
| 308 |
+
# initialize from a SAM 2 checkpoint
|
| 309 |
+
checkpoint:
|
| 310 |
+
save_dir: ${launcher.experiment_log_dir}/checkpoints
|
| 311 |
+
save_freq: 0 # 0 only last checkpoint is saved.
|
| 312 |
+
model_weight_initializer:
|
| 313 |
+
_partial_: True
|
| 314 |
+
_target_: training.utils.checkpoint_utils.load_state_dict_into_model
|
| 315 |
+
strict: True
|
| 316 |
+
ignore_unexpected_keys: null
|
| 317 |
+
ignore_missing_keys: null
|
| 318 |
+
|
| 319 |
+
state_dict:
|
| 320 |
+
_target_: training.utils.checkpoint_utils.load_checkpoint_and_apply_kernels
|
| 321 |
+
checkpoint_path: ./checkpoints/sam2.1_hiera_base_plus.pt # PATH to SAM 2.1 checkpoint
|
| 322 |
+
ckpt_state_dict_keys: ['model']
|
| 323 |
+
|
| 324 |
+
launcher:
|
| 325 |
+
num_nodes: 1
|
| 326 |
+
gpus_per_node: 8
|
| 327 |
+
experiment_log_dir: null # Path to log directory, defaults to ./sam2_logs/${config_name}
|
| 328 |
+
|
| 329 |
+
# SLURM args if running on a cluster
|
| 330 |
+
submitit:
|
| 331 |
+
partition: null
|
| 332 |
+
account: null
|
| 333 |
+
qos: null
|
| 334 |
+
cpus_per_task: 10
|
| 335 |
+
use_cluster: false
|
| 336 |
+
timeout_hour: 24
|
| 337 |
+
name: null
|
| 338 |
+
port_range: [10000, 65000]
|
| 339 |
+
|
third_party/sam2/sam2/configs/sam2/sam2_hiera_b+.yaml
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 112
|
| 12 |
+
num_heads: 2
|
| 13 |
+
neck:
|
| 14 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 15 |
+
position_encoding:
|
| 16 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 17 |
+
num_pos_feats: 256
|
| 18 |
+
normalize: true
|
| 19 |
+
scale: null
|
| 20 |
+
temperature: 10000
|
| 21 |
+
d_model: 256
|
| 22 |
+
backbone_channel_list: [896, 448, 224, 112]
|
| 23 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 24 |
+
fpn_interp_model: nearest
|
| 25 |
+
|
| 26 |
+
memory_attention:
|
| 27 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 28 |
+
d_model: 256
|
| 29 |
+
pos_enc_at_input: true
|
| 30 |
+
layer:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 32 |
+
activation: relu
|
| 33 |
+
dim_feedforward: 2048
|
| 34 |
+
dropout: 0.1
|
| 35 |
+
pos_enc_at_attn: false
|
| 36 |
+
self_attention:
|
| 37 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 38 |
+
rope_theta: 10000.0
|
| 39 |
+
feat_sizes: [64, 64]
|
| 40 |
+
embedding_dim: 256
|
| 41 |
+
num_heads: 1
|
| 42 |
+
downsample_rate: 1
|
| 43 |
+
dropout: 0.1
|
| 44 |
+
d_model: 256
|
| 45 |
+
pos_enc_at_cross_attn_keys: true
|
| 46 |
+
pos_enc_at_cross_attn_queries: false
|
| 47 |
+
cross_attention:
|
| 48 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 49 |
+
rope_theta: 10000.0
|
| 50 |
+
feat_sizes: [64, 64]
|
| 51 |
+
rope_k_repeat: True
|
| 52 |
+
embedding_dim: 256
|
| 53 |
+
num_heads: 1
|
| 54 |
+
downsample_rate: 1
|
| 55 |
+
dropout: 0.1
|
| 56 |
+
kv_in_dim: 64
|
| 57 |
+
num_layers: 4
|
| 58 |
+
|
| 59 |
+
memory_encoder:
|
| 60 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 61 |
+
out_dim: 64
|
| 62 |
+
position_encoding:
|
| 63 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 64 |
+
num_pos_feats: 64
|
| 65 |
+
normalize: true
|
| 66 |
+
scale: null
|
| 67 |
+
temperature: 10000
|
| 68 |
+
mask_downsampler:
|
| 69 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 70 |
+
kernel_size: 3
|
| 71 |
+
stride: 2
|
| 72 |
+
padding: 1
|
| 73 |
+
fuser:
|
| 74 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 75 |
+
layer:
|
| 76 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 77 |
+
dim: 256
|
| 78 |
+
kernel_size: 7
|
| 79 |
+
padding: 3
|
| 80 |
+
layer_scale_init_value: 1e-6
|
| 81 |
+
use_dwconv: True # depth-wise convs
|
| 82 |
+
num_layers: 2
|
| 83 |
+
|
| 84 |
+
num_maskmem: 7
|
| 85 |
+
image_size: 1024
|
| 86 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 87 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 88 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 89 |
+
use_mask_input_as_output_without_sam: true
|
| 90 |
+
# Memory
|
| 91 |
+
directly_add_no_mem_embed: true
|
| 92 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 93 |
+
use_high_res_features_in_sam: true
|
| 94 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 95 |
+
multimask_output_in_sam: true
|
| 96 |
+
# SAM heads
|
| 97 |
+
iou_prediction_use_sigmoid: True
|
| 98 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 99 |
+
use_obj_ptrs_in_encoder: true
|
| 100 |
+
add_tpos_enc_to_obj_ptrs: false
|
| 101 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 102 |
+
# object occlusion prediction
|
| 103 |
+
pred_obj_scores: true
|
| 104 |
+
pred_obj_scores_mlp: true
|
| 105 |
+
fixed_no_obj_ptr: true
|
| 106 |
+
# multimask tracking settings
|
| 107 |
+
multimask_output_for_tracking: true
|
| 108 |
+
use_multimask_token_for_obj_ptr: true
|
| 109 |
+
multimask_min_pt_num: 0
|
| 110 |
+
multimask_max_pt_num: 1
|
| 111 |
+
use_mlp_for_obj_ptr_proj: true
|
| 112 |
+
# Compilation flag
|
| 113 |
+
compile_image_encoder: False
|
third_party/sam2/sam2/configs/sam2/sam2_hiera_l.yaml
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 144
|
| 12 |
+
num_heads: 2
|
| 13 |
+
stages: [2, 6, 36, 4]
|
| 14 |
+
global_att_blocks: [23, 33, 43]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
window_spec: [8, 4, 16, 8]
|
| 17 |
+
neck:
|
| 18 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 19 |
+
position_encoding:
|
| 20 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 21 |
+
num_pos_feats: 256
|
| 22 |
+
normalize: true
|
| 23 |
+
scale: null
|
| 24 |
+
temperature: 10000
|
| 25 |
+
d_model: 256
|
| 26 |
+
backbone_channel_list: [1152, 576, 288, 144]
|
| 27 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 28 |
+
fpn_interp_model: nearest
|
| 29 |
+
|
| 30 |
+
memory_attention:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 32 |
+
d_model: 256
|
| 33 |
+
pos_enc_at_input: true
|
| 34 |
+
layer:
|
| 35 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 36 |
+
activation: relu
|
| 37 |
+
dim_feedforward: 2048
|
| 38 |
+
dropout: 0.1
|
| 39 |
+
pos_enc_at_attn: false
|
| 40 |
+
self_attention:
|
| 41 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 42 |
+
rope_theta: 10000.0
|
| 43 |
+
feat_sizes: [64, 64]
|
| 44 |
+
embedding_dim: 256
|
| 45 |
+
num_heads: 1
|
| 46 |
+
downsample_rate: 1
|
| 47 |
+
dropout: 0.1
|
| 48 |
+
d_model: 256
|
| 49 |
+
pos_enc_at_cross_attn_keys: true
|
| 50 |
+
pos_enc_at_cross_attn_queries: false
|
| 51 |
+
cross_attention:
|
| 52 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 53 |
+
rope_theta: 10000.0
|
| 54 |
+
feat_sizes: [64, 64]
|
| 55 |
+
rope_k_repeat: True
|
| 56 |
+
embedding_dim: 256
|
| 57 |
+
num_heads: 1
|
| 58 |
+
downsample_rate: 1
|
| 59 |
+
dropout: 0.1
|
| 60 |
+
kv_in_dim: 64
|
| 61 |
+
num_layers: 4
|
| 62 |
+
|
| 63 |
+
memory_encoder:
|
| 64 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 65 |
+
out_dim: 64
|
| 66 |
+
position_encoding:
|
| 67 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 68 |
+
num_pos_feats: 64
|
| 69 |
+
normalize: true
|
| 70 |
+
scale: null
|
| 71 |
+
temperature: 10000
|
| 72 |
+
mask_downsampler:
|
| 73 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 74 |
+
kernel_size: 3
|
| 75 |
+
stride: 2
|
| 76 |
+
padding: 1
|
| 77 |
+
fuser:
|
| 78 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 79 |
+
layer:
|
| 80 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 81 |
+
dim: 256
|
| 82 |
+
kernel_size: 7
|
| 83 |
+
padding: 3
|
| 84 |
+
layer_scale_init_value: 1e-6
|
| 85 |
+
use_dwconv: True # depth-wise convs
|
| 86 |
+
num_layers: 2
|
| 87 |
+
|
| 88 |
+
num_maskmem: 7
|
| 89 |
+
image_size: 1024
|
| 90 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 97 |
+
use_high_res_features_in_sam: true
|
| 98 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 99 |
+
multimask_output_in_sam: true
|
| 100 |
+
# SAM heads
|
| 101 |
+
iou_prediction_use_sigmoid: True
|
| 102 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 103 |
+
use_obj_ptrs_in_encoder: true
|
| 104 |
+
add_tpos_enc_to_obj_ptrs: false
|
| 105 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 106 |
+
# object occlusion prediction
|
| 107 |
+
pred_obj_scores: true
|
| 108 |
+
pred_obj_scores_mlp: true
|
| 109 |
+
fixed_no_obj_ptr: true
|
| 110 |
+
# multimask tracking settings
|
| 111 |
+
multimask_output_for_tracking: true
|
| 112 |
+
use_multimask_token_for_obj_ptr: true
|
| 113 |
+
multimask_min_pt_num: 0
|
| 114 |
+
multimask_max_pt_num: 1
|
| 115 |
+
use_mlp_for_obj_ptr_proj: true
|
| 116 |
+
# Compilation flag
|
| 117 |
+
compile_image_encoder: False
|
third_party/sam2/sam2/configs/sam2/sam2_hiera_s.yaml
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 96
|
| 12 |
+
num_heads: 1
|
| 13 |
+
stages: [1, 2, 11, 2]
|
| 14 |
+
global_att_blocks: [7, 10, 13]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
neck:
|
| 17 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 18 |
+
position_encoding:
|
| 19 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 20 |
+
num_pos_feats: 256
|
| 21 |
+
normalize: true
|
| 22 |
+
scale: null
|
| 23 |
+
temperature: 10000
|
| 24 |
+
d_model: 256
|
| 25 |
+
backbone_channel_list: [768, 384, 192, 96]
|
| 26 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 27 |
+
fpn_interp_model: nearest
|
| 28 |
+
|
| 29 |
+
memory_attention:
|
| 30 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 31 |
+
d_model: 256
|
| 32 |
+
pos_enc_at_input: true
|
| 33 |
+
layer:
|
| 34 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 35 |
+
activation: relu
|
| 36 |
+
dim_feedforward: 2048
|
| 37 |
+
dropout: 0.1
|
| 38 |
+
pos_enc_at_attn: false
|
| 39 |
+
self_attention:
|
| 40 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 41 |
+
rope_theta: 10000.0
|
| 42 |
+
feat_sizes: [64, 64]
|
| 43 |
+
embedding_dim: 256
|
| 44 |
+
num_heads: 1
|
| 45 |
+
downsample_rate: 1
|
| 46 |
+
dropout: 0.1
|
| 47 |
+
d_model: 256
|
| 48 |
+
pos_enc_at_cross_attn_keys: true
|
| 49 |
+
pos_enc_at_cross_attn_queries: false
|
| 50 |
+
cross_attention:
|
| 51 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 52 |
+
rope_theta: 10000.0
|
| 53 |
+
feat_sizes: [64, 64]
|
| 54 |
+
rope_k_repeat: True
|
| 55 |
+
embedding_dim: 256
|
| 56 |
+
num_heads: 1
|
| 57 |
+
downsample_rate: 1
|
| 58 |
+
dropout: 0.1
|
| 59 |
+
kv_in_dim: 64
|
| 60 |
+
num_layers: 4
|
| 61 |
+
|
| 62 |
+
memory_encoder:
|
| 63 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 64 |
+
out_dim: 64
|
| 65 |
+
position_encoding:
|
| 66 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 67 |
+
num_pos_feats: 64
|
| 68 |
+
normalize: true
|
| 69 |
+
scale: null
|
| 70 |
+
temperature: 10000
|
| 71 |
+
mask_downsampler:
|
| 72 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 73 |
+
kernel_size: 3
|
| 74 |
+
stride: 2
|
| 75 |
+
padding: 1
|
| 76 |
+
fuser:
|
| 77 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 78 |
+
layer:
|
| 79 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 80 |
+
dim: 256
|
| 81 |
+
kernel_size: 7
|
| 82 |
+
padding: 3
|
| 83 |
+
layer_scale_init_value: 1e-6
|
| 84 |
+
use_dwconv: True # depth-wise convs
|
| 85 |
+
num_layers: 2
|
| 86 |
+
|
| 87 |
+
num_maskmem: 7
|
| 88 |
+
image_size: 1024
|
| 89 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 90 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 91 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 92 |
+
use_mask_input_as_output_without_sam: true
|
| 93 |
+
# Memory
|
| 94 |
+
directly_add_no_mem_embed: true
|
| 95 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 96 |
+
use_high_res_features_in_sam: true
|
| 97 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 98 |
+
multimask_output_in_sam: true
|
| 99 |
+
# SAM heads
|
| 100 |
+
iou_prediction_use_sigmoid: True
|
| 101 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 102 |
+
use_obj_ptrs_in_encoder: true
|
| 103 |
+
add_tpos_enc_to_obj_ptrs: false
|
| 104 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 105 |
+
# object occlusion prediction
|
| 106 |
+
pred_obj_scores: true
|
| 107 |
+
pred_obj_scores_mlp: true
|
| 108 |
+
fixed_no_obj_ptr: true
|
| 109 |
+
# multimask tracking settings
|
| 110 |
+
multimask_output_for_tracking: true
|
| 111 |
+
use_multimask_token_for_obj_ptr: true
|
| 112 |
+
multimask_min_pt_num: 0
|
| 113 |
+
multimask_max_pt_num: 1
|
| 114 |
+
use_mlp_for_obj_ptr_proj: true
|
| 115 |
+
# Compilation flag
|
| 116 |
+
compile_image_encoder: False
|
third_party/sam2/sam2/configs/sam2/sam2_hiera_t.yaml
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 96
|
| 12 |
+
num_heads: 1
|
| 13 |
+
stages: [1, 2, 7, 2]
|
| 14 |
+
global_att_blocks: [5, 7, 9]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
neck:
|
| 17 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 18 |
+
position_encoding:
|
| 19 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 20 |
+
num_pos_feats: 256
|
| 21 |
+
normalize: true
|
| 22 |
+
scale: null
|
| 23 |
+
temperature: 10000
|
| 24 |
+
d_model: 256
|
| 25 |
+
backbone_channel_list: [768, 384, 192, 96]
|
| 26 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 27 |
+
fpn_interp_model: nearest
|
| 28 |
+
|
| 29 |
+
memory_attention:
|
| 30 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 31 |
+
d_model: 256
|
| 32 |
+
pos_enc_at_input: true
|
| 33 |
+
layer:
|
| 34 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 35 |
+
activation: relu
|
| 36 |
+
dim_feedforward: 2048
|
| 37 |
+
dropout: 0.1
|
| 38 |
+
pos_enc_at_attn: false
|
| 39 |
+
self_attention:
|
| 40 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 41 |
+
rope_theta: 10000.0
|
| 42 |
+
feat_sizes: [64, 64]
|
| 43 |
+
embedding_dim: 256
|
| 44 |
+
num_heads: 1
|
| 45 |
+
downsample_rate: 1
|
| 46 |
+
dropout: 0.1
|
| 47 |
+
d_model: 256
|
| 48 |
+
pos_enc_at_cross_attn_keys: true
|
| 49 |
+
pos_enc_at_cross_attn_queries: false
|
| 50 |
+
cross_attention:
|
| 51 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 52 |
+
rope_theta: 10000.0
|
| 53 |
+
feat_sizes: [64, 64]
|
| 54 |
+
rope_k_repeat: True
|
| 55 |
+
embedding_dim: 256
|
| 56 |
+
num_heads: 1
|
| 57 |
+
downsample_rate: 1
|
| 58 |
+
dropout: 0.1
|
| 59 |
+
kv_in_dim: 64
|
| 60 |
+
num_layers: 4
|
| 61 |
+
|
| 62 |
+
memory_encoder:
|
| 63 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 64 |
+
out_dim: 64
|
| 65 |
+
position_encoding:
|
| 66 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 67 |
+
num_pos_feats: 64
|
| 68 |
+
normalize: true
|
| 69 |
+
scale: null
|
| 70 |
+
temperature: 10000
|
| 71 |
+
mask_downsampler:
|
| 72 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 73 |
+
kernel_size: 3
|
| 74 |
+
stride: 2
|
| 75 |
+
padding: 1
|
| 76 |
+
fuser:
|
| 77 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 78 |
+
layer:
|
| 79 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 80 |
+
dim: 256
|
| 81 |
+
kernel_size: 7
|
| 82 |
+
padding: 3
|
| 83 |
+
layer_scale_init_value: 1e-6
|
| 84 |
+
use_dwconv: True # depth-wise convs
|
| 85 |
+
num_layers: 2
|
| 86 |
+
|
| 87 |
+
num_maskmem: 7
|
| 88 |
+
image_size: 1024
|
| 89 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 90 |
+
# SAM decoder
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 97 |
+
use_high_res_features_in_sam: true
|
| 98 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 99 |
+
multimask_output_in_sam: true
|
| 100 |
+
# SAM heads
|
| 101 |
+
iou_prediction_use_sigmoid: True
|
| 102 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 103 |
+
use_obj_ptrs_in_encoder: true
|
| 104 |
+
add_tpos_enc_to_obj_ptrs: false
|
| 105 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 106 |
+
# object occlusion prediction
|
| 107 |
+
pred_obj_scores: true
|
| 108 |
+
pred_obj_scores_mlp: true
|
| 109 |
+
fixed_no_obj_ptr: true
|
| 110 |
+
# multimask tracking settings
|
| 111 |
+
multimask_output_for_tracking: true
|
| 112 |
+
use_multimask_token_for_obj_ptr: true
|
| 113 |
+
multimask_min_pt_num: 0
|
| 114 |
+
multimask_max_pt_num: 1
|
| 115 |
+
use_mlp_for_obj_ptr_proj: true
|
| 116 |
+
# Compilation flag
|
| 117 |
+
# HieraT does not currently support compilation, should always be set to False
|
| 118 |
+
compile_image_encoder: False
|
third_party/sam2/sam2/csrc/connected_components.cu
ADDED
|
@@ -0,0 +1,289 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
// All rights reserved.
|
| 3 |
+
|
| 4 |
+
// This source code is licensed under the license found in the
|
| 5 |
+
// LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
// adapted from https://github.com/zsef123/Connected_components_PyTorch
|
| 8 |
+
// with license found in the LICENSE_cctorch file in the root directory.
|
| 9 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 10 |
+
#include <cuda.h>
|
| 11 |
+
#include <cuda_runtime.h>
|
| 12 |
+
#include <torch/extension.h>
|
| 13 |
+
#include <torch/script.h>
|
| 14 |
+
#include <vector>
|
| 15 |
+
|
| 16 |
+
// 2d
|
| 17 |
+
#define BLOCK_ROWS 16
|
| 18 |
+
#define BLOCK_COLS 16
|
| 19 |
+
|
| 20 |
+
namespace cc2d {
|
| 21 |
+
|
| 22 |
+
template <typename T>
|
| 23 |
+
__device__ __forceinline__ unsigned char hasBit(T bitmap, unsigned char pos) {
|
| 24 |
+
return (bitmap >> pos) & 1;
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
__device__ int32_t find(const int32_t* s_buf, int32_t n) {
|
| 28 |
+
while (s_buf[n] != n)
|
| 29 |
+
n = s_buf[n];
|
| 30 |
+
return n;
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
__device__ int32_t find_n_compress(int32_t* s_buf, int32_t n) {
|
| 34 |
+
const int32_t id = n;
|
| 35 |
+
while (s_buf[n] != n) {
|
| 36 |
+
n = s_buf[n];
|
| 37 |
+
s_buf[id] = n;
|
| 38 |
+
}
|
| 39 |
+
return n;
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
__device__ void union_(int32_t* s_buf, int32_t a, int32_t b) {
|
| 43 |
+
bool done;
|
| 44 |
+
do {
|
| 45 |
+
a = find(s_buf, a);
|
| 46 |
+
b = find(s_buf, b);
|
| 47 |
+
|
| 48 |
+
if (a < b) {
|
| 49 |
+
int32_t old = atomicMin(s_buf + b, a);
|
| 50 |
+
done = (old == b);
|
| 51 |
+
b = old;
|
| 52 |
+
} else if (b < a) {
|
| 53 |
+
int32_t old = atomicMin(s_buf + a, b);
|
| 54 |
+
done = (old == a);
|
| 55 |
+
a = old;
|
| 56 |
+
} else
|
| 57 |
+
done = true;
|
| 58 |
+
|
| 59 |
+
} while (!done);
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
__global__ void
|
| 63 |
+
init_labeling(int32_t* label, const uint32_t W, const uint32_t H) {
|
| 64 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y) * 2;
|
| 65 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
|
| 66 |
+
const uint32_t idx = row * W + col;
|
| 67 |
+
|
| 68 |
+
if (row < H && col < W)
|
| 69 |
+
label[idx] = idx;
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
__global__ void
|
| 73 |
+
merge(uint8_t* img, int32_t* label, const uint32_t W, const uint32_t H) {
|
| 74 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y) * 2;
|
| 75 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
|
| 76 |
+
const uint32_t idx = row * W + col;
|
| 77 |
+
|
| 78 |
+
if (row >= H || col >= W)
|
| 79 |
+
return;
|
| 80 |
+
|
| 81 |
+
uint32_t P = 0;
|
| 82 |
+
|
| 83 |
+
if (img[idx])
|
| 84 |
+
P |= 0x777;
|
| 85 |
+
if (row + 1 < H && img[idx + W])
|
| 86 |
+
P |= 0x777 << 4;
|
| 87 |
+
if (col + 1 < W && img[idx + 1])
|
| 88 |
+
P |= 0x777 << 1;
|
| 89 |
+
|
| 90 |
+
if (col == 0)
|
| 91 |
+
P &= 0xEEEE;
|
| 92 |
+
if (col + 1 >= W)
|
| 93 |
+
P &= 0x3333;
|
| 94 |
+
else if (col + 2 >= W)
|
| 95 |
+
P &= 0x7777;
|
| 96 |
+
|
| 97 |
+
if (row == 0)
|
| 98 |
+
P &= 0xFFF0;
|
| 99 |
+
if (row + 1 >= H)
|
| 100 |
+
P &= 0xFF;
|
| 101 |
+
|
| 102 |
+
if (P > 0) {
|
| 103 |
+
// If need check about top-left pixel(if flag the first bit) and hit the
|
| 104 |
+
// top-left pixel
|
| 105 |
+
if (hasBit(P, 0) && img[idx - W - 1]) {
|
| 106 |
+
union_(label, idx, idx - 2 * W - 2); // top left block
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
if ((hasBit(P, 1) && img[idx - W]) || (hasBit(P, 2) && img[idx - W + 1]))
|
| 110 |
+
union_(label, idx, idx - 2 * W); // top bottom block
|
| 111 |
+
|
| 112 |
+
if (hasBit(P, 3) && img[idx + 2 - W])
|
| 113 |
+
union_(label, idx, idx - 2 * W + 2); // top right block
|
| 114 |
+
|
| 115 |
+
if ((hasBit(P, 4) && img[idx - 1]) || (hasBit(P, 8) && img[idx + W - 1]))
|
| 116 |
+
union_(label, idx, idx - 2); // just left block
|
| 117 |
+
}
|
| 118 |
+
}
|
| 119 |
+
|
| 120 |
+
__global__ void compression(int32_t* label, const int32_t W, const int32_t H) {
|
| 121 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y) * 2;
|
| 122 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
|
| 123 |
+
const uint32_t idx = row * W + col;
|
| 124 |
+
|
| 125 |
+
if (row < H && col < W)
|
| 126 |
+
find_n_compress(label, idx);
|
| 127 |
+
}
|
| 128 |
+
|
| 129 |
+
__global__ void final_labeling(
|
| 130 |
+
const uint8_t* img,
|
| 131 |
+
int32_t* label,
|
| 132 |
+
const int32_t W,
|
| 133 |
+
const int32_t H) {
|
| 134 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y) * 2;
|
| 135 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x) * 2;
|
| 136 |
+
const uint32_t idx = row * W + col;
|
| 137 |
+
|
| 138 |
+
if (row >= H || col >= W)
|
| 139 |
+
return;
|
| 140 |
+
|
| 141 |
+
int32_t y = label[idx] + 1;
|
| 142 |
+
|
| 143 |
+
if (img[idx])
|
| 144 |
+
label[idx] = y;
|
| 145 |
+
else
|
| 146 |
+
label[idx] = 0;
|
| 147 |
+
|
| 148 |
+
if (col + 1 < W) {
|
| 149 |
+
if (img[idx + 1])
|
| 150 |
+
label[idx + 1] = y;
|
| 151 |
+
else
|
| 152 |
+
label[idx + 1] = 0;
|
| 153 |
+
|
| 154 |
+
if (row + 1 < H) {
|
| 155 |
+
if (img[idx + W + 1])
|
| 156 |
+
label[idx + W + 1] = y;
|
| 157 |
+
else
|
| 158 |
+
label[idx + W + 1] = 0;
|
| 159 |
+
}
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
if (row + 1 < H) {
|
| 163 |
+
if (img[idx + W])
|
| 164 |
+
label[idx + W] = y;
|
| 165 |
+
else
|
| 166 |
+
label[idx + W] = 0;
|
| 167 |
+
}
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
__global__ void init_counting(
|
| 171 |
+
const int32_t* label,
|
| 172 |
+
int32_t* count_init,
|
| 173 |
+
const int32_t W,
|
| 174 |
+
const int32_t H) {
|
| 175 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y);
|
| 176 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x);
|
| 177 |
+
const uint32_t idx = row * W + col;
|
| 178 |
+
|
| 179 |
+
if (row >= H || col >= W)
|
| 180 |
+
return;
|
| 181 |
+
|
| 182 |
+
int32_t y = label[idx];
|
| 183 |
+
if (y > 0) {
|
| 184 |
+
int32_t count_idx = y - 1;
|
| 185 |
+
atomicAdd(count_init + count_idx, 1);
|
| 186 |
+
}
|
| 187 |
+
}
|
| 188 |
+
|
| 189 |
+
__global__ void final_counting(
|
| 190 |
+
const int32_t* label,
|
| 191 |
+
const int32_t* count_init,
|
| 192 |
+
int32_t* count_final,
|
| 193 |
+
const int32_t W,
|
| 194 |
+
const int32_t H) {
|
| 195 |
+
const uint32_t row = (blockIdx.y * blockDim.y + threadIdx.y);
|
| 196 |
+
const uint32_t col = (blockIdx.x * blockDim.x + threadIdx.x);
|
| 197 |
+
const uint32_t idx = row * W + col;
|
| 198 |
+
|
| 199 |
+
if (row >= H || col >= W)
|
| 200 |
+
return;
|
| 201 |
+
|
| 202 |
+
int32_t y = label[idx];
|
| 203 |
+
if (y > 0) {
|
| 204 |
+
int32_t count_idx = y - 1;
|
| 205 |
+
count_final[idx] = count_init[count_idx];
|
| 206 |
+
} else {
|
| 207 |
+
count_final[idx] = 0;
|
| 208 |
+
}
|
| 209 |
+
}
|
| 210 |
+
|
| 211 |
+
} // namespace cc2d
|
| 212 |
+
|
| 213 |
+
std::vector<torch::Tensor> get_connected_componnets(
|
| 214 |
+
const torch::Tensor& inputs) {
|
| 215 |
+
AT_ASSERTM(inputs.is_cuda(), "inputs must be a CUDA tensor");
|
| 216 |
+
AT_ASSERTM(inputs.ndimension() == 4, "inputs must be [N, 1, H, W] shape");
|
| 217 |
+
AT_ASSERTM(
|
| 218 |
+
inputs.scalar_type() == torch::kUInt8, "inputs must be a uint8 type");
|
| 219 |
+
|
| 220 |
+
const uint32_t N = inputs.size(0);
|
| 221 |
+
const uint32_t C = inputs.size(1);
|
| 222 |
+
const uint32_t H = inputs.size(2);
|
| 223 |
+
const uint32_t W = inputs.size(3);
|
| 224 |
+
|
| 225 |
+
AT_ASSERTM(C == 1, "inputs must be [N, 1, H, W] shape");
|
| 226 |
+
AT_ASSERTM((H % 2) == 0, "height must be an even number");
|
| 227 |
+
AT_ASSERTM((W % 2) == 0, "width must be an even number");
|
| 228 |
+
|
| 229 |
+
// label must be uint32_t
|
| 230 |
+
auto label_options =
|
| 231 |
+
torch::TensorOptions().dtype(torch::kInt32).device(inputs.device());
|
| 232 |
+
torch::Tensor labels = torch::zeros({N, C, H, W}, label_options);
|
| 233 |
+
torch::Tensor counts_init = torch::zeros({N, C, H, W}, label_options);
|
| 234 |
+
torch::Tensor counts_final = torch::zeros({N, C, H, W}, label_options);
|
| 235 |
+
|
| 236 |
+
dim3 grid = dim3(
|
| 237 |
+
((W + 1) / 2 + BLOCK_COLS - 1) / BLOCK_COLS,
|
| 238 |
+
((H + 1) / 2 + BLOCK_ROWS - 1) / BLOCK_ROWS);
|
| 239 |
+
dim3 block = dim3(BLOCK_COLS, BLOCK_ROWS);
|
| 240 |
+
dim3 grid_count =
|
| 241 |
+
dim3((W + BLOCK_COLS) / BLOCK_COLS, (H + BLOCK_ROWS) / BLOCK_ROWS);
|
| 242 |
+
dim3 block_count = dim3(BLOCK_COLS, BLOCK_ROWS);
|
| 243 |
+
cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 244 |
+
|
| 245 |
+
for (int n = 0; n < N; n++) {
|
| 246 |
+
uint32_t offset = n * H * W;
|
| 247 |
+
|
| 248 |
+
cc2d::init_labeling<<<grid, block, 0, stream>>>(
|
| 249 |
+
labels.data_ptr<int32_t>() + offset, W, H);
|
| 250 |
+
cc2d::merge<<<grid, block, 0, stream>>>(
|
| 251 |
+
inputs.data_ptr<uint8_t>() + offset,
|
| 252 |
+
labels.data_ptr<int32_t>() + offset,
|
| 253 |
+
W,
|
| 254 |
+
H);
|
| 255 |
+
cc2d::compression<<<grid, block, 0, stream>>>(
|
| 256 |
+
labels.data_ptr<int32_t>() + offset, W, H);
|
| 257 |
+
cc2d::final_labeling<<<grid, block, 0, stream>>>(
|
| 258 |
+
inputs.data_ptr<uint8_t>() + offset,
|
| 259 |
+
labels.data_ptr<int32_t>() + offset,
|
| 260 |
+
W,
|
| 261 |
+
H);
|
| 262 |
+
|
| 263 |
+
// get the counting of each pixel
|
| 264 |
+
cc2d::init_counting<<<grid_count, block_count, 0, stream>>>(
|
| 265 |
+
labels.data_ptr<int32_t>() + offset,
|
| 266 |
+
counts_init.data_ptr<int32_t>() + offset,
|
| 267 |
+
W,
|
| 268 |
+
H);
|
| 269 |
+
cc2d::final_counting<<<grid_count, block_count, 0, stream>>>(
|
| 270 |
+
labels.data_ptr<int32_t>() + offset,
|
| 271 |
+
counts_init.data_ptr<int32_t>() + offset,
|
| 272 |
+
counts_final.data_ptr<int32_t>() + offset,
|
| 273 |
+
W,
|
| 274 |
+
H);
|
| 275 |
+
}
|
| 276 |
+
|
| 277 |
+
// returned values are [labels, counts]
|
| 278 |
+
std::vector<torch::Tensor> outputs;
|
| 279 |
+
outputs.push_back(labels);
|
| 280 |
+
outputs.push_back(counts_final);
|
| 281 |
+
return outputs;
|
| 282 |
+
}
|
| 283 |
+
|
| 284 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 285 |
+
m.def(
|
| 286 |
+
"get_connected_componnets",
|
| 287 |
+
&get_connected_componnets,
|
| 288 |
+
"get_connected_componnets");
|
| 289 |
+
}
|
third_party/sam2/sam2/modeling/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
third_party/sam2/sam2/modeling/backbones/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
third_party/sam2/sam2/modeling/backbones/hieradet.py
ADDED
|
@@ -0,0 +1,317 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import logging
|
| 8 |
+
from functools import partial
|
| 9 |
+
from typing import List, Tuple, Union
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
from iopath.common.file_io import g_pathmgr
|
| 15 |
+
|
| 16 |
+
from sam2.modeling.backbones.utils import (
|
| 17 |
+
PatchEmbed,
|
| 18 |
+
window_partition,
|
| 19 |
+
window_unpartition,
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
from sam2.modeling.sam2_utils import DropPath, MLP
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def do_pool(x: torch.Tensor, pool: nn.Module, norm: nn.Module = None) -> torch.Tensor:
|
| 26 |
+
if pool is None:
|
| 27 |
+
return x
|
| 28 |
+
# (B, H, W, C) -> (B, C, H, W)
|
| 29 |
+
x = x.permute(0, 3, 1, 2)
|
| 30 |
+
x = pool(x)
|
| 31 |
+
# (B, C, H', W') -> (B, H', W', C)
|
| 32 |
+
x = x.permute(0, 2, 3, 1)
|
| 33 |
+
if norm:
|
| 34 |
+
x = norm(x)
|
| 35 |
+
|
| 36 |
+
return x
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class MultiScaleAttention(nn.Module):
|
| 40 |
+
def __init__(
|
| 41 |
+
self,
|
| 42 |
+
dim: int,
|
| 43 |
+
dim_out: int,
|
| 44 |
+
num_heads: int,
|
| 45 |
+
q_pool: nn.Module = None,
|
| 46 |
+
):
|
| 47 |
+
super().__init__()
|
| 48 |
+
|
| 49 |
+
self.dim = dim
|
| 50 |
+
self.dim_out = dim_out
|
| 51 |
+
self.num_heads = num_heads
|
| 52 |
+
self.q_pool = q_pool
|
| 53 |
+
self.qkv = nn.Linear(dim, dim_out * 3)
|
| 54 |
+
self.proj = nn.Linear(dim_out, dim_out)
|
| 55 |
+
|
| 56 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 57 |
+
B, H, W, _ = x.shape
|
| 58 |
+
# qkv with shape (B, H * W, 3, nHead, C)
|
| 59 |
+
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1)
|
| 60 |
+
# q, k, v with shape (B, H * W, nheads, C)
|
| 61 |
+
q, k, v = torch.unbind(qkv, 2)
|
| 62 |
+
|
| 63 |
+
# Q pooling (for downsample at stage changes)
|
| 64 |
+
if self.q_pool:
|
| 65 |
+
q = do_pool(q.reshape(B, H, W, -1), self.q_pool)
|
| 66 |
+
H, W = q.shape[1:3] # downsampled shape
|
| 67 |
+
q = q.reshape(B, H * W, self.num_heads, -1)
|
| 68 |
+
|
| 69 |
+
# Torch's SDPA expects [B, nheads, H*W, C] so we transpose
|
| 70 |
+
x = F.scaled_dot_product_attention(
|
| 71 |
+
q.transpose(1, 2),
|
| 72 |
+
k.transpose(1, 2),
|
| 73 |
+
v.transpose(1, 2),
|
| 74 |
+
)
|
| 75 |
+
# Transpose back
|
| 76 |
+
x = x.transpose(1, 2)
|
| 77 |
+
x = x.reshape(B, H, W, -1)
|
| 78 |
+
|
| 79 |
+
x = self.proj(x)
|
| 80 |
+
|
| 81 |
+
return x
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class MultiScaleBlock(nn.Module):
|
| 85 |
+
def __init__(
|
| 86 |
+
self,
|
| 87 |
+
dim: int,
|
| 88 |
+
dim_out: int,
|
| 89 |
+
num_heads: int,
|
| 90 |
+
mlp_ratio: float = 4.0,
|
| 91 |
+
drop_path: float = 0.0,
|
| 92 |
+
norm_layer: Union[nn.Module, str] = "LayerNorm",
|
| 93 |
+
q_stride: Tuple[int, int] = None,
|
| 94 |
+
act_layer: nn.Module = nn.GELU,
|
| 95 |
+
window_size: int = 0,
|
| 96 |
+
):
|
| 97 |
+
super().__init__()
|
| 98 |
+
|
| 99 |
+
if isinstance(norm_layer, str):
|
| 100 |
+
norm_layer = partial(getattr(nn, norm_layer), eps=1e-6)
|
| 101 |
+
|
| 102 |
+
self.dim = dim
|
| 103 |
+
self.dim_out = dim_out
|
| 104 |
+
self.norm1 = norm_layer(dim)
|
| 105 |
+
|
| 106 |
+
self.window_size = window_size
|
| 107 |
+
|
| 108 |
+
self.pool, self.q_stride = None, q_stride
|
| 109 |
+
if self.q_stride:
|
| 110 |
+
self.pool = nn.MaxPool2d(
|
| 111 |
+
kernel_size=q_stride, stride=q_stride, ceil_mode=False
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
self.attn = MultiScaleAttention(
|
| 115 |
+
dim,
|
| 116 |
+
dim_out,
|
| 117 |
+
num_heads=num_heads,
|
| 118 |
+
q_pool=self.pool,
|
| 119 |
+
)
|
| 120 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 121 |
+
|
| 122 |
+
self.norm2 = norm_layer(dim_out)
|
| 123 |
+
self.mlp = MLP(
|
| 124 |
+
dim_out,
|
| 125 |
+
int(dim_out * mlp_ratio),
|
| 126 |
+
dim_out,
|
| 127 |
+
num_layers=2,
|
| 128 |
+
activation=act_layer,
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
if dim != dim_out:
|
| 132 |
+
self.proj = nn.Linear(dim, dim_out)
|
| 133 |
+
|
| 134 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 135 |
+
shortcut = x # B, H, W, C
|
| 136 |
+
x = self.norm1(x)
|
| 137 |
+
|
| 138 |
+
# Skip connection
|
| 139 |
+
if self.dim != self.dim_out:
|
| 140 |
+
shortcut = do_pool(self.proj(x), self.pool)
|
| 141 |
+
|
| 142 |
+
# Window partition
|
| 143 |
+
window_size = self.window_size
|
| 144 |
+
if window_size > 0:
|
| 145 |
+
H, W = x.shape[1], x.shape[2]
|
| 146 |
+
x, pad_hw = window_partition(x, window_size)
|
| 147 |
+
|
| 148 |
+
# Window Attention + Q Pooling (if stage change)
|
| 149 |
+
x = self.attn(x)
|
| 150 |
+
if self.q_stride:
|
| 151 |
+
# Shapes have changed due to Q pooling
|
| 152 |
+
window_size = self.window_size // self.q_stride[0]
|
| 153 |
+
H, W = shortcut.shape[1:3]
|
| 154 |
+
|
| 155 |
+
pad_h = (window_size - H % window_size) % window_size
|
| 156 |
+
pad_w = (window_size - W % window_size) % window_size
|
| 157 |
+
pad_hw = (H + pad_h, W + pad_w)
|
| 158 |
+
|
| 159 |
+
# Reverse window partition
|
| 160 |
+
if self.window_size > 0:
|
| 161 |
+
x = window_unpartition(x, window_size, pad_hw, (H, W))
|
| 162 |
+
|
| 163 |
+
x = shortcut + self.drop_path(x)
|
| 164 |
+
# MLP
|
| 165 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 166 |
+
return x
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
class Hiera(nn.Module):
|
| 170 |
+
"""
|
| 171 |
+
Reference: https://arxiv.org/abs/2306.00989
|
| 172 |
+
"""
|
| 173 |
+
|
| 174 |
+
def __init__(
|
| 175 |
+
self,
|
| 176 |
+
embed_dim: int = 96, # initial embed dim
|
| 177 |
+
num_heads: int = 1, # initial number of heads
|
| 178 |
+
drop_path_rate: float = 0.0, # stochastic depth
|
| 179 |
+
q_pool: int = 3, # number of q_pool stages
|
| 180 |
+
q_stride: Tuple[int, int] = (2, 2), # downsample stride bet. stages
|
| 181 |
+
stages: Tuple[int, ...] = (2, 3, 16, 3), # blocks per stage
|
| 182 |
+
dim_mul: float = 2.0, # dim_mul factor at stage shift
|
| 183 |
+
head_mul: float = 2.0, # head_mul factor at stage shift
|
| 184 |
+
window_pos_embed_bkg_spatial_size: Tuple[int, int] = (14, 14),
|
| 185 |
+
# window size per stage, when not using global att.
|
| 186 |
+
window_spec: Tuple[int, ...] = (
|
| 187 |
+
8,
|
| 188 |
+
4,
|
| 189 |
+
14,
|
| 190 |
+
7,
|
| 191 |
+
),
|
| 192 |
+
# global attn in these blocks
|
| 193 |
+
global_att_blocks: Tuple[int, ...] = (
|
| 194 |
+
12,
|
| 195 |
+
16,
|
| 196 |
+
20,
|
| 197 |
+
),
|
| 198 |
+
weights_path=None,
|
| 199 |
+
return_interm_layers=True, # return feats from every stage
|
| 200 |
+
):
|
| 201 |
+
super().__init__()
|
| 202 |
+
|
| 203 |
+
assert len(stages) == len(window_spec)
|
| 204 |
+
self.window_spec = window_spec
|
| 205 |
+
|
| 206 |
+
depth = sum(stages)
|
| 207 |
+
self.q_stride = q_stride
|
| 208 |
+
self.stage_ends = [sum(stages[:i]) - 1 for i in range(1, len(stages) + 1)]
|
| 209 |
+
assert 0 <= q_pool <= len(self.stage_ends[:-1])
|
| 210 |
+
self.q_pool_blocks = [x + 1 for x in self.stage_ends[:-1]][:q_pool]
|
| 211 |
+
self.return_interm_layers = return_interm_layers
|
| 212 |
+
|
| 213 |
+
self.patch_embed = PatchEmbed(
|
| 214 |
+
embed_dim=embed_dim,
|
| 215 |
+
)
|
| 216 |
+
# Which blocks have global att?
|
| 217 |
+
self.global_att_blocks = global_att_blocks
|
| 218 |
+
|
| 219 |
+
# Windowed positional embedding (https://arxiv.org/abs/2311.05613)
|
| 220 |
+
self.window_pos_embed_bkg_spatial_size = window_pos_embed_bkg_spatial_size
|
| 221 |
+
self.pos_embed = nn.Parameter(
|
| 222 |
+
torch.zeros(1, embed_dim, *self.window_pos_embed_bkg_spatial_size)
|
| 223 |
+
)
|
| 224 |
+
self.pos_embed_window = nn.Parameter(
|
| 225 |
+
torch.zeros(1, embed_dim, self.window_spec[0], self.window_spec[0])
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
dpr = [
|
| 229 |
+
x.item() for x in torch.linspace(0, drop_path_rate, depth)
|
| 230 |
+
] # stochastic depth decay rule
|
| 231 |
+
|
| 232 |
+
cur_stage = 1
|
| 233 |
+
self.blocks = nn.ModuleList()
|
| 234 |
+
|
| 235 |
+
for i in range(depth):
|
| 236 |
+
dim_out = embed_dim
|
| 237 |
+
# lags by a block, so first block of
|
| 238 |
+
# next stage uses an initial window size
|
| 239 |
+
# of previous stage and final window size of current stage
|
| 240 |
+
window_size = self.window_spec[cur_stage - 1]
|
| 241 |
+
|
| 242 |
+
if self.global_att_blocks is not None:
|
| 243 |
+
window_size = 0 if i in self.global_att_blocks else window_size
|
| 244 |
+
|
| 245 |
+
if i - 1 in self.stage_ends:
|
| 246 |
+
dim_out = int(embed_dim * dim_mul)
|
| 247 |
+
num_heads = int(num_heads * head_mul)
|
| 248 |
+
cur_stage += 1
|
| 249 |
+
|
| 250 |
+
block = MultiScaleBlock(
|
| 251 |
+
dim=embed_dim,
|
| 252 |
+
dim_out=dim_out,
|
| 253 |
+
num_heads=num_heads,
|
| 254 |
+
drop_path=dpr[i],
|
| 255 |
+
q_stride=self.q_stride if i in self.q_pool_blocks else None,
|
| 256 |
+
window_size=window_size,
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
embed_dim = dim_out
|
| 260 |
+
self.blocks.append(block)
|
| 261 |
+
|
| 262 |
+
self.channel_list = (
|
| 263 |
+
[self.blocks[i].dim_out for i in self.stage_ends[::-1]]
|
| 264 |
+
if return_interm_layers
|
| 265 |
+
else [self.blocks[-1].dim_out]
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
if weights_path is not None:
|
| 269 |
+
with g_pathmgr.open(weights_path, "rb") as f:
|
| 270 |
+
chkpt = torch.load(f, map_location="cpu")
|
| 271 |
+
logging.info("loading Hiera", self.load_state_dict(chkpt, strict=False))
|
| 272 |
+
|
| 273 |
+
def _get_pos_embed(self, hw: Tuple[int, int]) -> torch.Tensor:
|
| 274 |
+
h, w = hw
|
| 275 |
+
window_embed = self.pos_embed_window
|
| 276 |
+
pos_embed = F.interpolate(self.pos_embed, size=(h, w), mode="bicubic")
|
| 277 |
+
pos_embed = pos_embed + window_embed.tile(
|
| 278 |
+
[x // y for x, y in zip(pos_embed.shape, window_embed.shape)]
|
| 279 |
+
)
|
| 280 |
+
pos_embed = pos_embed.permute(0, 2, 3, 1)
|
| 281 |
+
return pos_embed
|
| 282 |
+
|
| 283 |
+
def forward(self, x: torch.Tensor) -> List[torch.Tensor]:
|
| 284 |
+
x = self.patch_embed(x)
|
| 285 |
+
# x: (B, H, W, C)
|
| 286 |
+
|
| 287 |
+
# Add pos embed
|
| 288 |
+
x = x + self._get_pos_embed(x.shape[1:3])
|
| 289 |
+
|
| 290 |
+
outputs = []
|
| 291 |
+
for i, blk in enumerate(self.blocks):
|
| 292 |
+
x = blk(x)
|
| 293 |
+
if (i == self.stage_ends[-1]) or (
|
| 294 |
+
i in self.stage_ends and self.return_interm_layers
|
| 295 |
+
):
|
| 296 |
+
feats = x.permute(0, 3, 1, 2)
|
| 297 |
+
outputs.append(feats)
|
| 298 |
+
|
| 299 |
+
return outputs
|
| 300 |
+
|
| 301 |
+
def get_layer_id(self, layer_name):
|
| 302 |
+
# https://github.com/microsoft/unilm/blob/master/beit/optim_factory.py#L33
|
| 303 |
+
num_layers = self.get_num_layers()
|
| 304 |
+
|
| 305 |
+
if layer_name.find("rel_pos") != -1:
|
| 306 |
+
return num_layers + 1
|
| 307 |
+
elif layer_name.find("pos_embed") != -1:
|
| 308 |
+
return 0
|
| 309 |
+
elif layer_name.find("patch_embed") != -1:
|
| 310 |
+
return 0
|
| 311 |
+
elif layer_name.find("blocks") != -1:
|
| 312 |
+
return int(layer_name.split("blocks")[1].split(".")[1]) + 1
|
| 313 |
+
else:
|
| 314 |
+
return num_layers + 1
|
| 315 |
+
|
| 316 |
+
def get_num_layers(self) -> int:
|
| 317 |
+
return len(self.blocks)
|
third_party/sam2/sam2/modeling/backbones/image_encoder.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import List, Optional
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class ImageEncoder(nn.Module):
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
trunk: nn.Module,
|
| 18 |
+
neck: nn.Module,
|
| 19 |
+
scalp: int = 0,
|
| 20 |
+
):
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.trunk = trunk
|
| 23 |
+
self.neck = neck
|
| 24 |
+
self.scalp = scalp
|
| 25 |
+
assert (
|
| 26 |
+
self.trunk.channel_list == self.neck.backbone_channel_list
|
| 27 |
+
), f"Channel dims of trunk and neck do not match. Trunk: {self.trunk.channel_list}, neck: {self.neck.backbone_channel_list}"
|
| 28 |
+
|
| 29 |
+
def forward(self, sample: torch.Tensor):
|
| 30 |
+
# Forward through backbone
|
| 31 |
+
features, pos = self.neck(self.trunk(sample))
|
| 32 |
+
if self.scalp > 0:
|
| 33 |
+
# Discard the lowest resolution features
|
| 34 |
+
features, pos = features[: -self.scalp], pos[: -self.scalp]
|
| 35 |
+
|
| 36 |
+
src = features[-1]
|
| 37 |
+
output = {
|
| 38 |
+
"vision_features": src,
|
| 39 |
+
"vision_pos_enc": pos,
|
| 40 |
+
"backbone_fpn": features,
|
| 41 |
+
}
|
| 42 |
+
return output
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class FpnNeck(nn.Module):
|
| 46 |
+
"""
|
| 47 |
+
A modified variant of Feature Pyramid Network (FPN) neck
|
| 48 |
+
(we remove output conv and also do bicubic interpolation similar to ViT
|
| 49 |
+
pos embed interpolation)
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(
|
| 53 |
+
self,
|
| 54 |
+
position_encoding: nn.Module,
|
| 55 |
+
d_model: int,
|
| 56 |
+
backbone_channel_list: List[int],
|
| 57 |
+
kernel_size: int = 1,
|
| 58 |
+
stride: int = 1,
|
| 59 |
+
padding: int = 0,
|
| 60 |
+
fpn_interp_model: str = "bilinear",
|
| 61 |
+
fuse_type: str = "sum",
|
| 62 |
+
fpn_top_down_levels: Optional[List[int]] = None,
|
| 63 |
+
):
|
| 64 |
+
"""Initialize the neck
|
| 65 |
+
:param trunk: the backbone
|
| 66 |
+
:param position_encoding: the positional encoding to use
|
| 67 |
+
:param d_model: the dimension of the model
|
| 68 |
+
:param neck_norm: the normalization to use
|
| 69 |
+
"""
|
| 70 |
+
super().__init__()
|
| 71 |
+
self.position_encoding = position_encoding
|
| 72 |
+
self.convs = nn.ModuleList()
|
| 73 |
+
self.backbone_channel_list = backbone_channel_list
|
| 74 |
+
self.d_model = d_model
|
| 75 |
+
for dim in backbone_channel_list:
|
| 76 |
+
current = nn.Sequential()
|
| 77 |
+
current.add_module(
|
| 78 |
+
"conv",
|
| 79 |
+
nn.Conv2d(
|
| 80 |
+
in_channels=dim,
|
| 81 |
+
out_channels=d_model,
|
| 82 |
+
kernel_size=kernel_size,
|
| 83 |
+
stride=stride,
|
| 84 |
+
padding=padding,
|
| 85 |
+
),
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
self.convs.append(current)
|
| 89 |
+
self.fpn_interp_model = fpn_interp_model
|
| 90 |
+
assert fuse_type in ["sum", "avg"]
|
| 91 |
+
self.fuse_type = fuse_type
|
| 92 |
+
|
| 93 |
+
# levels to have top-down features in its outputs
|
| 94 |
+
# e.g. if fpn_top_down_levels is [2, 3], then only outputs of level 2 and 3
|
| 95 |
+
# have top-down propagation, while outputs of level 0 and level 1 have only
|
| 96 |
+
# lateral features from the same backbone level.
|
| 97 |
+
if fpn_top_down_levels is None:
|
| 98 |
+
# default is to have top-down features on all levels
|
| 99 |
+
fpn_top_down_levels = range(len(self.convs))
|
| 100 |
+
self.fpn_top_down_levels = list(fpn_top_down_levels)
|
| 101 |
+
|
| 102 |
+
def forward(self, xs: List[torch.Tensor]):
|
| 103 |
+
|
| 104 |
+
out = [None] * len(self.convs)
|
| 105 |
+
pos = [None] * len(self.convs)
|
| 106 |
+
assert len(xs) == len(self.convs)
|
| 107 |
+
# fpn forward pass
|
| 108 |
+
# see https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/fpn.py
|
| 109 |
+
prev_features = None
|
| 110 |
+
# forward in top-down order (from low to high resolution)
|
| 111 |
+
n = len(self.convs) - 1
|
| 112 |
+
for i in range(n, -1, -1):
|
| 113 |
+
x = xs[i]
|
| 114 |
+
lateral_features = self.convs[n - i](x)
|
| 115 |
+
if i in self.fpn_top_down_levels and prev_features is not None:
|
| 116 |
+
top_down_features = F.interpolate(
|
| 117 |
+
prev_features.to(dtype=torch.float32),
|
| 118 |
+
scale_factor=2.0,
|
| 119 |
+
mode=self.fpn_interp_model,
|
| 120 |
+
align_corners=(
|
| 121 |
+
None if self.fpn_interp_model == "nearest" else False
|
| 122 |
+
),
|
| 123 |
+
antialias=False,
|
| 124 |
+
)
|
| 125 |
+
prev_features = lateral_features + top_down_features
|
| 126 |
+
if self.fuse_type == "avg":
|
| 127 |
+
prev_features /= 2
|
| 128 |
+
else:
|
| 129 |
+
prev_features = lateral_features
|
| 130 |
+
x_out = prev_features
|
| 131 |
+
out[i] = x_out
|
| 132 |
+
pos[i] = self.position_encoding(x_out).to(x_out.dtype)
|
| 133 |
+
|
| 134 |
+
return out, pos
|
third_party/sam2/sam2/modeling/backbones/utils.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
"""Some utilities for backbones, in particular for windowing"""
|
| 8 |
+
|
| 9 |
+
from typing import Tuple
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def window_partition(x, window_size):
|
| 17 |
+
"""
|
| 18 |
+
Partition into non-overlapping windows with padding if needed.
|
| 19 |
+
Args:
|
| 20 |
+
x (tensor): input tokens with [B, H, W, C].
|
| 21 |
+
window_size (int): window size.
|
| 22 |
+
Returns:
|
| 23 |
+
windows: windows after partition with [B * num_windows, window_size, window_size, C].
|
| 24 |
+
(Hp, Wp): padded height and width before partition
|
| 25 |
+
"""
|
| 26 |
+
B, H, W, C = x.shape
|
| 27 |
+
|
| 28 |
+
pad_h = (window_size - H % window_size) % window_size
|
| 29 |
+
pad_w = (window_size - W % window_size) % window_size
|
| 30 |
+
if pad_h > 0 or pad_w > 0:
|
| 31 |
+
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
|
| 32 |
+
Hp, Wp = H + pad_h, W + pad_w
|
| 33 |
+
|
| 34 |
+
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
|
| 35 |
+
windows = x.permute(0, 1, 3, 2, 4, 5).reshape(-1, window_size, window_size, C)
|
| 36 |
+
return windows, (Hp, Wp)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def window_unpartition(windows, window_size, pad_hw, hw):
|
| 40 |
+
"""
|
| 41 |
+
Window unpartition into original sequences and removing padding.
|
| 42 |
+
Args:
|
| 43 |
+
x (tensor): input tokens with [B * num_windows, window_size, window_size, C].
|
| 44 |
+
window_size (int): window size.
|
| 45 |
+
pad_hw (Tuple): padded height and width (Hp, Wp).
|
| 46 |
+
hw (Tuple): original height and width (H, W) before padding.
|
| 47 |
+
Returns:
|
| 48 |
+
x: unpartitioned sequences with [B, H, W, C].
|
| 49 |
+
"""
|
| 50 |
+
Hp, Wp = pad_hw
|
| 51 |
+
H, W = hw
|
| 52 |
+
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
|
| 53 |
+
x = windows.reshape(
|
| 54 |
+
B, Hp // window_size, Wp // window_size, window_size, window_size, -1
|
| 55 |
+
)
|
| 56 |
+
x = x.permute(0, 1, 3, 2, 4, 5).reshape(B, Hp, Wp, -1)
|
| 57 |
+
|
| 58 |
+
if Hp > H or Wp > W:
|
| 59 |
+
x = x[:, :H, :W, :]
|
| 60 |
+
return x
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class PatchEmbed(nn.Module):
|
| 64 |
+
"""
|
| 65 |
+
Image to Patch Embedding.
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
def __init__(
|
| 69 |
+
self,
|
| 70 |
+
kernel_size: Tuple[int, ...] = (7, 7),
|
| 71 |
+
stride: Tuple[int, ...] = (4, 4),
|
| 72 |
+
padding: Tuple[int, ...] = (3, 3),
|
| 73 |
+
in_chans: int = 3,
|
| 74 |
+
embed_dim: int = 768,
|
| 75 |
+
):
|
| 76 |
+
"""
|
| 77 |
+
Args:
|
| 78 |
+
kernel_size (Tuple): kernel size of the projection layer.
|
| 79 |
+
stride (Tuple): stride of the projection layer.
|
| 80 |
+
padding (Tuple): padding size of the projection layer.
|
| 81 |
+
in_chans (int): Number of input image channels.
|
| 82 |
+
embed_dim (int): embed_dim (int): Patch embedding dimension.
|
| 83 |
+
"""
|
| 84 |
+
super().__init__()
|
| 85 |
+
self.proj = nn.Conv2d(
|
| 86 |
+
in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 90 |
+
x = self.proj(x)
|
| 91 |
+
# B C H W -> B H W C
|
| 92 |
+
x = x.permute(0, 2, 3, 1)
|
| 93 |
+
return x
|
third_party/sam2/sam2/modeling/memory_attention.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import Optional
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torch import nn, Tensor
|
| 11 |
+
|
| 12 |
+
from sam2.modeling.sam.transformer import RoPEAttention
|
| 13 |
+
|
| 14 |
+
from sam2.modeling.sam2_utils import get_activation_fn, get_clones
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class MemoryAttentionLayer(nn.Module):
|
| 18 |
+
|
| 19 |
+
def __init__(
|
| 20 |
+
self,
|
| 21 |
+
activation: str,
|
| 22 |
+
cross_attention: nn.Module,
|
| 23 |
+
d_model: int,
|
| 24 |
+
dim_feedforward: int,
|
| 25 |
+
dropout: float,
|
| 26 |
+
pos_enc_at_attn: bool,
|
| 27 |
+
pos_enc_at_cross_attn_keys: bool,
|
| 28 |
+
pos_enc_at_cross_attn_queries: bool,
|
| 29 |
+
self_attention: nn.Module,
|
| 30 |
+
):
|
| 31 |
+
super().__init__()
|
| 32 |
+
self.d_model = d_model
|
| 33 |
+
self.dim_feedforward = dim_feedforward
|
| 34 |
+
self.dropout_value = dropout
|
| 35 |
+
self.self_attn = self_attention
|
| 36 |
+
self.cross_attn_image = cross_attention
|
| 37 |
+
|
| 38 |
+
# Implementation of Feedforward model
|
| 39 |
+
self.linear1 = nn.Linear(d_model, dim_feedforward)
|
| 40 |
+
self.dropout = nn.Dropout(dropout)
|
| 41 |
+
self.linear2 = nn.Linear(dim_feedforward, d_model)
|
| 42 |
+
|
| 43 |
+
self.norm1 = nn.LayerNorm(d_model)
|
| 44 |
+
self.norm2 = nn.LayerNorm(d_model)
|
| 45 |
+
self.norm3 = nn.LayerNorm(d_model)
|
| 46 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 47 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 48 |
+
self.dropout3 = nn.Dropout(dropout)
|
| 49 |
+
|
| 50 |
+
self.activation_str = activation
|
| 51 |
+
self.activation = get_activation_fn(activation)
|
| 52 |
+
|
| 53 |
+
# Where to add pos enc
|
| 54 |
+
self.pos_enc_at_attn = pos_enc_at_attn
|
| 55 |
+
self.pos_enc_at_cross_attn_queries = pos_enc_at_cross_attn_queries
|
| 56 |
+
self.pos_enc_at_cross_attn_keys = pos_enc_at_cross_attn_keys
|
| 57 |
+
|
| 58 |
+
def _forward_sa(self, tgt, query_pos):
|
| 59 |
+
# Self-Attention
|
| 60 |
+
tgt2 = self.norm1(tgt)
|
| 61 |
+
q = k = tgt2 + query_pos if self.pos_enc_at_attn else tgt2
|
| 62 |
+
tgt2 = self.self_attn(q, k, v=tgt2)
|
| 63 |
+
tgt = tgt + self.dropout1(tgt2)
|
| 64 |
+
return tgt
|
| 65 |
+
|
| 66 |
+
def _forward_ca(self, tgt, memory, query_pos, pos, num_k_exclude_rope=0):
|
| 67 |
+
kwds = {}
|
| 68 |
+
if num_k_exclude_rope > 0:
|
| 69 |
+
assert isinstance(self.cross_attn_image, RoPEAttention)
|
| 70 |
+
kwds = {"num_k_exclude_rope": num_k_exclude_rope}
|
| 71 |
+
|
| 72 |
+
# Cross-Attention
|
| 73 |
+
tgt2 = self.norm2(tgt)
|
| 74 |
+
tgt2 = self.cross_attn_image(
|
| 75 |
+
q=tgt2 + query_pos if self.pos_enc_at_cross_attn_queries else tgt2,
|
| 76 |
+
k=memory + pos if self.pos_enc_at_cross_attn_keys else memory,
|
| 77 |
+
v=memory,
|
| 78 |
+
**kwds,
|
| 79 |
+
)
|
| 80 |
+
tgt = tgt + self.dropout2(tgt2)
|
| 81 |
+
return tgt
|
| 82 |
+
|
| 83 |
+
def forward(
|
| 84 |
+
self,
|
| 85 |
+
tgt,
|
| 86 |
+
memory,
|
| 87 |
+
pos: Optional[Tensor] = None,
|
| 88 |
+
query_pos: Optional[Tensor] = None,
|
| 89 |
+
num_k_exclude_rope: int = 0,
|
| 90 |
+
) -> torch.Tensor:
|
| 91 |
+
|
| 92 |
+
# Self-Attn, Cross-Attn
|
| 93 |
+
tgt = self._forward_sa(tgt, query_pos)
|
| 94 |
+
tgt = self._forward_ca(tgt, memory, query_pos, pos, num_k_exclude_rope)
|
| 95 |
+
# MLP
|
| 96 |
+
tgt2 = self.norm3(tgt)
|
| 97 |
+
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
|
| 98 |
+
tgt = tgt + self.dropout3(tgt2)
|
| 99 |
+
return tgt
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class MemoryAttention(nn.Module):
|
| 103 |
+
def __init__(
|
| 104 |
+
self,
|
| 105 |
+
d_model: int,
|
| 106 |
+
pos_enc_at_input: bool,
|
| 107 |
+
layer: nn.Module,
|
| 108 |
+
num_layers: int,
|
| 109 |
+
batch_first: bool = True, # Do layers expect batch first input?
|
| 110 |
+
):
|
| 111 |
+
super().__init__()
|
| 112 |
+
self.d_model = d_model
|
| 113 |
+
self.layers = get_clones(layer, num_layers)
|
| 114 |
+
self.num_layers = num_layers
|
| 115 |
+
self.norm = nn.LayerNorm(d_model)
|
| 116 |
+
self.pos_enc_at_input = pos_enc_at_input
|
| 117 |
+
self.batch_first = batch_first
|
| 118 |
+
|
| 119 |
+
def forward(
|
| 120 |
+
self,
|
| 121 |
+
curr: torch.Tensor, # self-attention inputs
|
| 122 |
+
memory: torch.Tensor, # cross-attention inputs
|
| 123 |
+
curr_pos: Optional[Tensor] = None, # pos_enc for self-attention inputs
|
| 124 |
+
memory_pos: Optional[Tensor] = None, # pos_enc for cross-attention inputs
|
| 125 |
+
num_obj_ptr_tokens: int = 0, # number of object pointer *tokens*
|
| 126 |
+
):
|
| 127 |
+
if isinstance(curr, list):
|
| 128 |
+
assert isinstance(curr_pos, list)
|
| 129 |
+
assert len(curr) == len(curr_pos) == 1
|
| 130 |
+
curr, curr_pos = (
|
| 131 |
+
curr[0],
|
| 132 |
+
curr_pos[0],
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
assert (
|
| 136 |
+
curr.shape[1] == memory.shape[1]
|
| 137 |
+
), "Batch size must be the same for curr and memory"
|
| 138 |
+
|
| 139 |
+
output = curr
|
| 140 |
+
if self.pos_enc_at_input and curr_pos is not None:
|
| 141 |
+
output = output + 0.1 * curr_pos
|
| 142 |
+
|
| 143 |
+
if self.batch_first:
|
| 144 |
+
# Convert to batch first
|
| 145 |
+
output = output.transpose(0, 1)
|
| 146 |
+
curr_pos = curr_pos.transpose(0, 1)
|
| 147 |
+
memory = memory.transpose(0, 1)
|
| 148 |
+
memory_pos = memory_pos.transpose(0, 1)
|
| 149 |
+
|
| 150 |
+
for layer in self.layers:
|
| 151 |
+
kwds = {}
|
| 152 |
+
if isinstance(layer.cross_attn_image, RoPEAttention):
|
| 153 |
+
kwds = {"num_k_exclude_rope": num_obj_ptr_tokens}
|
| 154 |
+
|
| 155 |
+
output = layer(
|
| 156 |
+
tgt=output,
|
| 157 |
+
memory=memory,
|
| 158 |
+
pos=memory_pos,
|
| 159 |
+
query_pos=curr_pos,
|
| 160 |
+
**kwds,
|
| 161 |
+
)
|
| 162 |
+
normed_output = self.norm(output)
|
| 163 |
+
|
| 164 |
+
if self.batch_first:
|
| 165 |
+
# Convert back to seq first
|
| 166 |
+
normed_output = normed_output.transpose(0, 1)
|
| 167 |
+
curr_pos = curr_pos.transpose(0, 1)
|
| 168 |
+
|
| 169 |
+
return normed_output
|
third_party/sam2/sam2/modeling/memory_encoder.py
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
from typing import Tuple
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
from sam2.modeling.sam2_utils import DropPath, get_clones, LayerNorm2d
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class MaskDownSampler(nn.Module):
|
| 18 |
+
"""
|
| 19 |
+
Progressively downsample a mask by total_stride, each time by stride.
|
| 20 |
+
Note that LayerNorm is applied per *token*, like in ViT.
|
| 21 |
+
|
| 22 |
+
With each downsample (by a factor stride**2), channel capacity increases by the same factor.
|
| 23 |
+
In the end, we linearly project to embed_dim channels.
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
def __init__(
|
| 27 |
+
self,
|
| 28 |
+
embed_dim=256,
|
| 29 |
+
kernel_size=4,
|
| 30 |
+
stride=4,
|
| 31 |
+
padding=0,
|
| 32 |
+
total_stride=16,
|
| 33 |
+
activation=nn.GELU,
|
| 34 |
+
):
|
| 35 |
+
super().__init__()
|
| 36 |
+
num_layers = int(math.log2(total_stride) // math.log2(stride))
|
| 37 |
+
assert stride**num_layers == total_stride
|
| 38 |
+
self.encoder = nn.Sequential()
|
| 39 |
+
mask_in_chans, mask_out_chans = 1, 1
|
| 40 |
+
for _ in range(num_layers):
|
| 41 |
+
mask_out_chans = mask_in_chans * (stride**2)
|
| 42 |
+
self.encoder.append(
|
| 43 |
+
nn.Conv2d(
|
| 44 |
+
mask_in_chans,
|
| 45 |
+
mask_out_chans,
|
| 46 |
+
kernel_size=kernel_size,
|
| 47 |
+
stride=stride,
|
| 48 |
+
padding=padding,
|
| 49 |
+
)
|
| 50 |
+
)
|
| 51 |
+
self.encoder.append(LayerNorm2d(mask_out_chans))
|
| 52 |
+
self.encoder.append(activation())
|
| 53 |
+
mask_in_chans = mask_out_chans
|
| 54 |
+
|
| 55 |
+
self.encoder.append(nn.Conv2d(mask_out_chans, embed_dim, kernel_size=1))
|
| 56 |
+
|
| 57 |
+
def forward(self, x):
|
| 58 |
+
return self.encoder(x)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# Lightly adapted from ConvNext (https://github.com/facebookresearch/ConvNeXt)
|
| 62 |
+
class CXBlock(nn.Module):
|
| 63 |
+
r"""ConvNeXt Block. There are two equivalent implementations:
|
| 64 |
+
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
|
| 65 |
+
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
|
| 66 |
+
We use (2) as we find it slightly faster in PyTorch
|
| 67 |
+
|
| 68 |
+
Args:
|
| 69 |
+
dim (int): Number of input channels.
|
| 70 |
+
drop_path (float): Stochastic depth rate. Default: 0.0
|
| 71 |
+
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
|
| 72 |
+
"""
|
| 73 |
+
|
| 74 |
+
def __init__(
|
| 75 |
+
self,
|
| 76 |
+
dim,
|
| 77 |
+
kernel_size=7,
|
| 78 |
+
padding=3,
|
| 79 |
+
drop_path=0.0,
|
| 80 |
+
layer_scale_init_value=1e-6,
|
| 81 |
+
use_dwconv=True,
|
| 82 |
+
):
|
| 83 |
+
super().__init__()
|
| 84 |
+
self.dwconv = nn.Conv2d(
|
| 85 |
+
dim,
|
| 86 |
+
dim,
|
| 87 |
+
kernel_size=kernel_size,
|
| 88 |
+
padding=padding,
|
| 89 |
+
groups=dim if use_dwconv else 1,
|
| 90 |
+
) # depthwise conv
|
| 91 |
+
self.norm = LayerNorm2d(dim, eps=1e-6)
|
| 92 |
+
self.pwconv1 = nn.Linear(
|
| 93 |
+
dim, 4 * dim
|
| 94 |
+
) # pointwise/1x1 convs, implemented with linear layers
|
| 95 |
+
self.act = nn.GELU()
|
| 96 |
+
self.pwconv2 = nn.Linear(4 * dim, dim)
|
| 97 |
+
self.gamma = (
|
| 98 |
+
nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
|
| 99 |
+
if layer_scale_init_value > 0
|
| 100 |
+
else None
|
| 101 |
+
)
|
| 102 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 103 |
+
|
| 104 |
+
def forward(self, x):
|
| 105 |
+
input = x
|
| 106 |
+
x = self.dwconv(x)
|
| 107 |
+
x = self.norm(x)
|
| 108 |
+
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
|
| 109 |
+
x = self.pwconv1(x)
|
| 110 |
+
x = self.act(x)
|
| 111 |
+
x = self.pwconv2(x)
|
| 112 |
+
if self.gamma is not None:
|
| 113 |
+
x = self.gamma * x
|
| 114 |
+
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
|
| 115 |
+
|
| 116 |
+
x = input + self.drop_path(x)
|
| 117 |
+
return x
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
class Fuser(nn.Module):
|
| 121 |
+
def __init__(self, layer, num_layers, dim=None, input_projection=False):
|
| 122 |
+
super().__init__()
|
| 123 |
+
self.proj = nn.Identity()
|
| 124 |
+
self.layers = get_clones(layer, num_layers)
|
| 125 |
+
|
| 126 |
+
if input_projection:
|
| 127 |
+
assert dim is not None
|
| 128 |
+
self.proj = nn.Conv2d(dim, dim, kernel_size=1)
|
| 129 |
+
|
| 130 |
+
def forward(self, x):
|
| 131 |
+
# normally x: (N, C, H, W)
|
| 132 |
+
x = self.proj(x)
|
| 133 |
+
for layer in self.layers:
|
| 134 |
+
x = layer(x)
|
| 135 |
+
return x
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class MemoryEncoder(nn.Module):
|
| 139 |
+
def __init__(
|
| 140 |
+
self,
|
| 141 |
+
out_dim,
|
| 142 |
+
mask_downsampler,
|
| 143 |
+
fuser,
|
| 144 |
+
position_encoding,
|
| 145 |
+
in_dim=256, # in_dim of pix_feats
|
| 146 |
+
):
|
| 147 |
+
super().__init__()
|
| 148 |
+
|
| 149 |
+
self.mask_downsampler = mask_downsampler
|
| 150 |
+
|
| 151 |
+
self.pix_feat_proj = nn.Conv2d(in_dim, in_dim, kernel_size=1)
|
| 152 |
+
self.fuser = fuser
|
| 153 |
+
self.position_encoding = position_encoding
|
| 154 |
+
self.out_proj = nn.Identity()
|
| 155 |
+
if out_dim != in_dim:
|
| 156 |
+
self.out_proj = nn.Conv2d(in_dim, out_dim, kernel_size=1)
|
| 157 |
+
|
| 158 |
+
def forward(
|
| 159 |
+
self,
|
| 160 |
+
pix_feat: torch.Tensor,
|
| 161 |
+
masks: torch.Tensor,
|
| 162 |
+
skip_mask_sigmoid: bool = False,
|
| 163 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 164 |
+
## Process masks
|
| 165 |
+
# sigmoid, so that less domain shift from gt masks which are bool
|
| 166 |
+
if not skip_mask_sigmoid:
|
| 167 |
+
masks = F.sigmoid(masks)
|
| 168 |
+
masks = self.mask_downsampler(masks)
|
| 169 |
+
|
| 170 |
+
## Fuse pix_feats and downsampled masks
|
| 171 |
+
# in case the visual features are on CPU, cast them to CUDA
|
| 172 |
+
pix_feat = pix_feat.to(masks.device)
|
| 173 |
+
|
| 174 |
+
x = self.pix_feat_proj(pix_feat)
|
| 175 |
+
x = x + masks
|
| 176 |
+
x = self.fuser(x)
|
| 177 |
+
x = self.out_proj(x)
|
| 178 |
+
|
| 179 |
+
pos = self.position_encoding(x).to(x.dtype)
|
| 180 |
+
|
| 181 |
+
return {"vision_features": x, "vision_pos_enc": [pos]}
|
third_party/sam2/sam2/modeling/position_encoding.py
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
from typing import Any, Optional, Tuple
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
from torch import nn
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class PositionEmbeddingSine(nn.Module):
|
| 17 |
+
"""
|
| 18 |
+
This is a more standard version of the position embedding, very similar to the one
|
| 19 |
+
used by the Attention Is All You Need paper, generalized to work on images.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
num_pos_feats,
|
| 25 |
+
temperature: int = 10000,
|
| 26 |
+
normalize: bool = True,
|
| 27 |
+
scale: Optional[float] = None,
|
| 28 |
+
# Following settings only relevant
|
| 29 |
+
# for warmping up cache for compilation
|
| 30 |
+
warmup_cache: bool = True,
|
| 31 |
+
image_size: int = 1024,
|
| 32 |
+
strides: Tuple[int] = (4, 8, 16, 32),
|
| 33 |
+
):
|
| 34 |
+
super().__init__()
|
| 35 |
+
assert num_pos_feats % 2 == 0, "Expecting even model width"
|
| 36 |
+
self.num_pos_feats = num_pos_feats // 2
|
| 37 |
+
self.temperature = temperature
|
| 38 |
+
self.normalize = normalize
|
| 39 |
+
if scale is not None and normalize is False:
|
| 40 |
+
raise ValueError("normalize should be True if scale is passed")
|
| 41 |
+
if scale is None:
|
| 42 |
+
scale = 2 * math.pi
|
| 43 |
+
self.scale = scale
|
| 44 |
+
|
| 45 |
+
self.cache = {}
|
| 46 |
+
if warmup_cache and torch.cuda.is_available():
|
| 47 |
+
# Warmup cache for cuda, to help with compilation
|
| 48 |
+
device = torch.device("cuda")
|
| 49 |
+
for stride in strides:
|
| 50 |
+
cache_key = (image_size // stride, image_size // stride)
|
| 51 |
+
self._pe(1, device, *cache_key)
|
| 52 |
+
|
| 53 |
+
def _encode_xy(self, x, y):
|
| 54 |
+
# The positions are expected to be normalized
|
| 55 |
+
assert len(x) == len(y) and x.ndim == y.ndim == 1
|
| 56 |
+
x_embed = x * self.scale
|
| 57 |
+
y_embed = y * self.scale
|
| 58 |
+
|
| 59 |
+
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
|
| 60 |
+
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
|
| 61 |
+
|
| 62 |
+
pos_x = x_embed[:, None] / dim_t
|
| 63 |
+
pos_y = y_embed[:, None] / dim_t
|
| 64 |
+
pos_x = torch.stack(
|
| 65 |
+
(pos_x[:, 0::2].sin(), pos_x[:, 1::2].cos()), dim=2
|
| 66 |
+
).flatten(1)
|
| 67 |
+
pos_y = torch.stack(
|
| 68 |
+
(pos_y[:, 0::2].sin(), pos_y[:, 1::2].cos()), dim=2
|
| 69 |
+
).flatten(1)
|
| 70 |
+
return pos_x, pos_y
|
| 71 |
+
|
| 72 |
+
@torch.no_grad()
|
| 73 |
+
def encode_boxes(self, x, y, w, h):
|
| 74 |
+
pos_x, pos_y = self._encode_xy(x, y)
|
| 75 |
+
pos = torch.cat((pos_y, pos_x, h[:, None], w[:, None]), dim=1)
|
| 76 |
+
return pos
|
| 77 |
+
|
| 78 |
+
encode = encode_boxes # Backwards compatibility
|
| 79 |
+
|
| 80 |
+
@torch.no_grad()
|
| 81 |
+
def encode_points(self, x, y, labels):
|
| 82 |
+
(bx, nx), (by, ny), (bl, nl) = x.shape, y.shape, labels.shape
|
| 83 |
+
assert bx == by and nx == ny and bx == bl and nx == nl
|
| 84 |
+
pos_x, pos_y = self._encode_xy(x.flatten(), y.flatten())
|
| 85 |
+
pos_x, pos_y = pos_x.reshape(bx, nx, -1), pos_y.reshape(by, ny, -1)
|
| 86 |
+
pos = torch.cat((pos_y, pos_x, labels[:, :, None]), dim=2)
|
| 87 |
+
return pos
|
| 88 |
+
|
| 89 |
+
@torch.no_grad()
|
| 90 |
+
def _pe(self, B, device, *cache_key):
|
| 91 |
+
H, W = cache_key
|
| 92 |
+
if cache_key in self.cache:
|
| 93 |
+
return self.cache[cache_key].to(device)[None].repeat(B, 1, 1, 1)
|
| 94 |
+
|
| 95 |
+
y_embed = (
|
| 96 |
+
torch.arange(1, H + 1, dtype=torch.float32, device=device)
|
| 97 |
+
.view(1, -1, 1)
|
| 98 |
+
.repeat(B, 1, W)
|
| 99 |
+
)
|
| 100 |
+
x_embed = (
|
| 101 |
+
torch.arange(1, W + 1, dtype=torch.float32, device=device)
|
| 102 |
+
.view(1, 1, -1)
|
| 103 |
+
.repeat(B, H, 1)
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
if self.normalize:
|
| 107 |
+
eps = 1e-6
|
| 108 |
+
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
|
| 109 |
+
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
|
| 110 |
+
|
| 111 |
+
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=device)
|
| 112 |
+
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
|
| 113 |
+
|
| 114 |
+
pos_x = x_embed[:, :, :, None] / dim_t
|
| 115 |
+
pos_y = y_embed[:, :, :, None] / dim_t
|
| 116 |
+
pos_x = torch.stack(
|
| 117 |
+
(pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4
|
| 118 |
+
).flatten(3)
|
| 119 |
+
pos_y = torch.stack(
|
| 120 |
+
(pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4
|
| 121 |
+
).flatten(3)
|
| 122 |
+
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
|
| 123 |
+
self.cache[cache_key] = pos[0]
|
| 124 |
+
return pos
|
| 125 |
+
|
| 126 |
+
@torch.no_grad()
|
| 127 |
+
def forward(self, x: torch.Tensor):
|
| 128 |
+
B = x.shape[0]
|
| 129 |
+
cache_key = (x.shape[-2], x.shape[-1])
|
| 130 |
+
return self._pe(B, x.device, *cache_key)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class PositionEmbeddingRandom(nn.Module):
|
| 134 |
+
"""
|
| 135 |
+
Positional encoding using random spatial frequencies.
|
| 136 |
+
"""
|
| 137 |
+
|
| 138 |
+
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
|
| 139 |
+
super().__init__()
|
| 140 |
+
if scale is None or scale <= 0.0:
|
| 141 |
+
scale = 1.0
|
| 142 |
+
self.register_buffer(
|
| 143 |
+
"positional_encoding_gaussian_matrix",
|
| 144 |
+
scale * torch.randn((2, num_pos_feats)),
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
|
| 148 |
+
"""Positionally encode points that are normalized to [0,1]."""
|
| 149 |
+
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
|
| 150 |
+
coords = 2 * coords - 1
|
| 151 |
+
coords = coords @ self.positional_encoding_gaussian_matrix
|
| 152 |
+
coords = 2 * np.pi * coords
|
| 153 |
+
# outputs d_1 x ... x d_n x C shape
|
| 154 |
+
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
|
| 155 |
+
|
| 156 |
+
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
|
| 157 |
+
"""Generate positional encoding for a grid of the specified size."""
|
| 158 |
+
h, w = size
|
| 159 |
+
device: Any = self.positional_encoding_gaussian_matrix.device
|
| 160 |
+
grid = torch.ones((h, w), device=device, dtype=torch.float32)
|
| 161 |
+
y_embed = grid.cumsum(dim=0) - 0.5
|
| 162 |
+
x_embed = grid.cumsum(dim=1) - 0.5
|
| 163 |
+
y_embed = y_embed / h
|
| 164 |
+
x_embed = x_embed / w
|
| 165 |
+
|
| 166 |
+
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
|
| 167 |
+
return pe.permute(2, 0, 1) # C x H x W
|
| 168 |
+
|
| 169 |
+
def forward_with_coords(
|
| 170 |
+
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
|
| 171 |
+
) -> torch.Tensor:
|
| 172 |
+
"""Positionally encode points that are not normalized to [0,1]."""
|
| 173 |
+
coords = coords_input.clone()
|
| 174 |
+
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
|
| 175 |
+
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
|
| 176 |
+
return self._pe_encoding(coords.to(torch.float)) # B x N x C
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
# Rotary Positional Encoding, adapted from:
|
| 180 |
+
# 1. https://github.com/meta-llama/codellama/blob/main/llama/model.py
|
| 181 |
+
# 2. https://github.com/naver-ai/rope-vit
|
| 182 |
+
# 3. https://github.com/lucidrains/rotary-embedding-torch
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def init_t_xy(end_x: int, end_y: int):
|
| 186 |
+
t = torch.arange(end_x * end_y, dtype=torch.float32)
|
| 187 |
+
t_x = (t % end_x).float()
|
| 188 |
+
t_y = torch.div(t, end_x, rounding_mode="floor").float()
|
| 189 |
+
return t_x, t_y
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def compute_axial_cis(dim: int, end_x: int, end_y: int, theta: float = 10000.0):
|
| 193 |
+
freqs_x = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim))
|
| 194 |
+
freqs_y = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim))
|
| 195 |
+
|
| 196 |
+
t_x, t_y = init_t_xy(end_x, end_y)
|
| 197 |
+
freqs_x = torch.outer(t_x, freqs_x)
|
| 198 |
+
freqs_y = torch.outer(t_y, freqs_y)
|
| 199 |
+
freqs_cis_x = torch.polar(torch.ones_like(freqs_x), freqs_x)
|
| 200 |
+
freqs_cis_y = torch.polar(torch.ones_like(freqs_y), freqs_y)
|
| 201 |
+
return torch.cat([freqs_cis_x, freqs_cis_y], dim=-1)
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
|
| 205 |
+
ndim = x.ndim
|
| 206 |
+
assert 0 <= 1 < ndim
|
| 207 |
+
assert freqs_cis.shape == (x.shape[-2], x.shape[-1])
|
| 208 |
+
shape = [d if i >= ndim - 2 else 1 for i, d in enumerate(x.shape)]
|
| 209 |
+
return freqs_cis.view(*shape)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def apply_rotary_enc(
|
| 213 |
+
xq: torch.Tensor,
|
| 214 |
+
xk: torch.Tensor,
|
| 215 |
+
freqs_cis: torch.Tensor,
|
| 216 |
+
repeat_freqs_k: bool = False,
|
| 217 |
+
):
|
| 218 |
+
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
|
| 219 |
+
xk_ = (
|
| 220 |
+
torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
|
| 221 |
+
if xk.shape[-2] != 0
|
| 222 |
+
else None
|
| 223 |
+
)
|
| 224 |
+
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
|
| 225 |
+
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
|
| 226 |
+
if xk_ is None:
|
| 227 |
+
# no keys to rotate, due to dropout
|
| 228 |
+
return xq_out.type_as(xq).to(xq.device), xk
|
| 229 |
+
# repeat freqs along seq_len dim to match k seq_len
|
| 230 |
+
if repeat_freqs_k:
|
| 231 |
+
r = xk_.shape[-2] // xq_.shape[-2]
|
| 232 |
+
if freqs_cis.is_cuda:
|
| 233 |
+
freqs_cis = freqs_cis.repeat(*([1] * (freqs_cis.ndim - 2)), r, 1)
|
| 234 |
+
else:
|
| 235 |
+
# torch.repeat on complex numbers may not be supported on non-CUDA devices
|
| 236 |
+
# (freqs_cis has 4 dims and we repeat on dim 2) so we use expand + flatten
|
| 237 |
+
freqs_cis = freqs_cis.unsqueeze(2).expand(-1, -1, r, -1, -1).flatten(2, 3)
|
| 238 |
+
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
|
| 239 |
+
return xq_out.type_as(xq).to(xq.device), xk_out.type_as(xk).to(xk.device)
|
third_party/sam2/sam2/modeling/sam/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
third_party/sam2/sam2/modeling/sam/mask_decoder.py
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import List, Optional, Tuple, Type
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torch import nn
|
| 11 |
+
|
| 12 |
+
from sam2.modeling.sam2_utils import LayerNorm2d, MLP
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class MaskDecoder(nn.Module):
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
*,
|
| 19 |
+
transformer_dim: int,
|
| 20 |
+
transformer: nn.Module,
|
| 21 |
+
num_multimask_outputs: int = 3,
|
| 22 |
+
activation: Type[nn.Module] = nn.GELU,
|
| 23 |
+
iou_head_depth: int = 3,
|
| 24 |
+
iou_head_hidden_dim: int = 256,
|
| 25 |
+
use_high_res_features: bool = False,
|
| 26 |
+
iou_prediction_use_sigmoid=False,
|
| 27 |
+
dynamic_multimask_via_stability=False,
|
| 28 |
+
dynamic_multimask_stability_delta=0.05,
|
| 29 |
+
dynamic_multimask_stability_thresh=0.98,
|
| 30 |
+
pred_obj_scores: bool = False,
|
| 31 |
+
pred_obj_scores_mlp: bool = False,
|
| 32 |
+
use_multimask_token_for_obj_ptr: bool = False,
|
| 33 |
+
) -> None:
|
| 34 |
+
"""
|
| 35 |
+
Predicts masks given an image and prompt embeddings, using a
|
| 36 |
+
transformer architecture.
|
| 37 |
+
|
| 38 |
+
Arguments:
|
| 39 |
+
transformer_dim (int): the channel dimension of the transformer
|
| 40 |
+
transformer (nn.Module): the transformer used to predict masks
|
| 41 |
+
num_multimask_outputs (int): the number of masks to predict
|
| 42 |
+
when disambiguating masks
|
| 43 |
+
activation (nn.Module): the type of activation to use when
|
| 44 |
+
upscaling masks
|
| 45 |
+
iou_head_depth (int): the depth of the MLP used to predict
|
| 46 |
+
mask quality
|
| 47 |
+
iou_head_hidden_dim (int): the hidden dimension of the MLP
|
| 48 |
+
used to predict mask quality
|
| 49 |
+
"""
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.transformer_dim = transformer_dim
|
| 52 |
+
self.transformer = transformer
|
| 53 |
+
|
| 54 |
+
self.num_multimask_outputs = num_multimask_outputs
|
| 55 |
+
|
| 56 |
+
self.iou_token = nn.Embedding(1, transformer_dim)
|
| 57 |
+
self.num_mask_tokens = num_multimask_outputs + 1
|
| 58 |
+
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
|
| 59 |
+
|
| 60 |
+
self.pred_obj_scores = pred_obj_scores
|
| 61 |
+
if self.pred_obj_scores:
|
| 62 |
+
self.obj_score_token = nn.Embedding(1, transformer_dim)
|
| 63 |
+
self.use_multimask_token_for_obj_ptr = use_multimask_token_for_obj_ptr
|
| 64 |
+
|
| 65 |
+
self.output_upscaling = nn.Sequential(
|
| 66 |
+
nn.ConvTranspose2d(
|
| 67 |
+
transformer_dim, transformer_dim // 4, kernel_size=2, stride=2
|
| 68 |
+
),
|
| 69 |
+
LayerNorm2d(transformer_dim // 4),
|
| 70 |
+
activation(),
|
| 71 |
+
nn.ConvTranspose2d(
|
| 72 |
+
transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2
|
| 73 |
+
),
|
| 74 |
+
activation(),
|
| 75 |
+
)
|
| 76 |
+
self.use_high_res_features = use_high_res_features
|
| 77 |
+
if use_high_res_features:
|
| 78 |
+
self.conv_s0 = nn.Conv2d(
|
| 79 |
+
transformer_dim, transformer_dim // 8, kernel_size=1, stride=1
|
| 80 |
+
)
|
| 81 |
+
self.conv_s1 = nn.Conv2d(
|
| 82 |
+
transformer_dim, transformer_dim // 4, kernel_size=1, stride=1
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
self.output_hypernetworks_mlps = nn.ModuleList(
|
| 86 |
+
[
|
| 87 |
+
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
|
| 88 |
+
for i in range(self.num_mask_tokens)
|
| 89 |
+
]
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
self.iou_prediction_head = MLP(
|
| 93 |
+
transformer_dim,
|
| 94 |
+
iou_head_hidden_dim,
|
| 95 |
+
self.num_mask_tokens,
|
| 96 |
+
iou_head_depth,
|
| 97 |
+
sigmoid_output=iou_prediction_use_sigmoid,
|
| 98 |
+
)
|
| 99 |
+
if self.pred_obj_scores:
|
| 100 |
+
self.pred_obj_score_head = nn.Linear(transformer_dim, 1)
|
| 101 |
+
if pred_obj_scores_mlp:
|
| 102 |
+
self.pred_obj_score_head = MLP(transformer_dim, transformer_dim, 1, 3)
|
| 103 |
+
|
| 104 |
+
# When outputting a single mask, optionally we can dynamically fall back to the best
|
| 105 |
+
# multimask output token if the single mask output token gives low stability scores.
|
| 106 |
+
self.dynamic_multimask_via_stability = dynamic_multimask_via_stability
|
| 107 |
+
self.dynamic_multimask_stability_delta = dynamic_multimask_stability_delta
|
| 108 |
+
self.dynamic_multimask_stability_thresh = dynamic_multimask_stability_thresh
|
| 109 |
+
|
| 110 |
+
def forward(
|
| 111 |
+
self,
|
| 112 |
+
image_embeddings: torch.Tensor,
|
| 113 |
+
image_pe: torch.Tensor,
|
| 114 |
+
sparse_prompt_embeddings: torch.Tensor,
|
| 115 |
+
dense_prompt_embeddings: torch.Tensor,
|
| 116 |
+
multimask_output: bool,
|
| 117 |
+
repeat_image: bool,
|
| 118 |
+
high_res_features: Optional[List[torch.Tensor]] = None,
|
| 119 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 120 |
+
"""
|
| 121 |
+
Predict masks given image and prompt embeddings.
|
| 122 |
+
|
| 123 |
+
Arguments:
|
| 124 |
+
image_embeddings (torch.Tensor): the embeddings from the image encoder
|
| 125 |
+
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
|
| 126 |
+
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
|
| 127 |
+
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
|
| 128 |
+
multimask_output (bool): Whether to return multiple masks or a single
|
| 129 |
+
mask.
|
| 130 |
+
|
| 131 |
+
Returns:
|
| 132 |
+
torch.Tensor: batched predicted masks
|
| 133 |
+
torch.Tensor: batched predictions of mask quality
|
| 134 |
+
torch.Tensor: batched SAM token for mask output
|
| 135 |
+
"""
|
| 136 |
+
masks, iou_pred, mask_tokens_out, object_score_logits = self.predict_masks(
|
| 137 |
+
image_embeddings=image_embeddings,
|
| 138 |
+
image_pe=image_pe,
|
| 139 |
+
sparse_prompt_embeddings=sparse_prompt_embeddings,
|
| 140 |
+
dense_prompt_embeddings=dense_prompt_embeddings,
|
| 141 |
+
repeat_image=repeat_image,
|
| 142 |
+
high_res_features=high_res_features,
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
# Select the correct mask or masks for output
|
| 146 |
+
if multimask_output:
|
| 147 |
+
masks = masks[:, 1:, :, :]
|
| 148 |
+
iou_pred = iou_pred[:, 1:]
|
| 149 |
+
elif self.dynamic_multimask_via_stability and not self.training:
|
| 150 |
+
masks, iou_pred = self._dynamic_multimask_via_stability(masks, iou_pred)
|
| 151 |
+
else:
|
| 152 |
+
masks = masks[:, 0:1, :, :]
|
| 153 |
+
iou_pred = iou_pred[:, 0:1]
|
| 154 |
+
|
| 155 |
+
if multimask_output and self.use_multimask_token_for_obj_ptr:
|
| 156 |
+
sam_tokens_out = mask_tokens_out[:, 1:] # [b, 3, c] shape
|
| 157 |
+
else:
|
| 158 |
+
# Take the mask output token. Here we *always* use the token for single mask output.
|
| 159 |
+
# At test time, even if we track after 1-click (and using multimask_output=True),
|
| 160 |
+
# we still take the single mask token here. The rationale is that we always track
|
| 161 |
+
# after multiple clicks during training, so the past tokens seen during training
|
| 162 |
+
# are always the single mask token (and we'll let it be the object-memory token).
|
| 163 |
+
sam_tokens_out = mask_tokens_out[:, 0:1] # [b, 1, c] shape
|
| 164 |
+
|
| 165 |
+
# Prepare output
|
| 166 |
+
return masks, iou_pred, sam_tokens_out, object_score_logits
|
| 167 |
+
|
| 168 |
+
def predict_masks(
|
| 169 |
+
self,
|
| 170 |
+
image_embeddings: torch.Tensor,
|
| 171 |
+
image_pe: torch.Tensor,
|
| 172 |
+
sparse_prompt_embeddings: torch.Tensor,
|
| 173 |
+
dense_prompt_embeddings: torch.Tensor,
|
| 174 |
+
repeat_image: bool,
|
| 175 |
+
high_res_features: Optional[List[torch.Tensor]] = None,
|
| 176 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 177 |
+
"""Predicts masks. See 'forward' for more details."""
|
| 178 |
+
# Concatenate output tokens
|
| 179 |
+
s = 0
|
| 180 |
+
if self.pred_obj_scores:
|
| 181 |
+
output_tokens = torch.cat(
|
| 182 |
+
[
|
| 183 |
+
self.obj_score_token.weight,
|
| 184 |
+
self.iou_token.weight,
|
| 185 |
+
self.mask_tokens.weight,
|
| 186 |
+
],
|
| 187 |
+
dim=0,
|
| 188 |
+
)
|
| 189 |
+
s = 1
|
| 190 |
+
else:
|
| 191 |
+
output_tokens = torch.cat(
|
| 192 |
+
[self.iou_token.weight, self.mask_tokens.weight], dim=0
|
| 193 |
+
)
|
| 194 |
+
output_tokens = output_tokens.unsqueeze(0).expand(
|
| 195 |
+
sparse_prompt_embeddings.size(0), -1, -1
|
| 196 |
+
)
|
| 197 |
+
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
|
| 198 |
+
|
| 199 |
+
# Expand per-image data in batch direction to be per-mask
|
| 200 |
+
if repeat_image:
|
| 201 |
+
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
|
| 202 |
+
else:
|
| 203 |
+
assert image_embeddings.shape[0] == tokens.shape[0]
|
| 204 |
+
src = image_embeddings
|
| 205 |
+
src = src + dense_prompt_embeddings
|
| 206 |
+
assert (
|
| 207 |
+
image_pe.size(0) == 1
|
| 208 |
+
), "image_pe should have size 1 in batch dim (from `get_dense_pe()`)"
|
| 209 |
+
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
|
| 210 |
+
b, c, h, w = src.shape
|
| 211 |
+
|
| 212 |
+
# Run the transformer
|
| 213 |
+
hs, src = self.transformer(src, pos_src, tokens)
|
| 214 |
+
iou_token_out = hs[:, s, :]
|
| 215 |
+
mask_tokens_out = hs[:, s + 1 : (s + 1 + self.num_mask_tokens), :]
|
| 216 |
+
|
| 217 |
+
# Upscale mask embeddings and predict masks using the mask tokens
|
| 218 |
+
src = src.transpose(1, 2).view(b, c, h, w)
|
| 219 |
+
if not self.use_high_res_features:
|
| 220 |
+
upscaled_embedding = self.output_upscaling(src)
|
| 221 |
+
else:
|
| 222 |
+
dc1, ln1, act1, dc2, act2 = self.output_upscaling
|
| 223 |
+
feat_s0, feat_s1 = high_res_features
|
| 224 |
+
upscaled_embedding = act1(ln1(dc1(src) + feat_s1))
|
| 225 |
+
upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0)
|
| 226 |
+
|
| 227 |
+
hyper_in_list: List[torch.Tensor] = []
|
| 228 |
+
for i in range(self.num_mask_tokens):
|
| 229 |
+
hyper_in_list.append(
|
| 230 |
+
self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])
|
| 231 |
+
)
|
| 232 |
+
hyper_in = torch.stack(hyper_in_list, dim=1)
|
| 233 |
+
b, c, h, w = upscaled_embedding.shape
|
| 234 |
+
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
|
| 235 |
+
|
| 236 |
+
# Generate mask quality predictions
|
| 237 |
+
iou_pred = self.iou_prediction_head(iou_token_out)
|
| 238 |
+
if self.pred_obj_scores:
|
| 239 |
+
assert s == 1
|
| 240 |
+
object_score_logits = self.pred_obj_score_head(hs[:, 0, :])
|
| 241 |
+
else:
|
| 242 |
+
# Obj scores logits - default to 10.0, i.e. assuming the object is present, sigmoid(10)=1
|
| 243 |
+
object_score_logits = 10.0 * iou_pred.new_ones(iou_pred.shape[0], 1)
|
| 244 |
+
|
| 245 |
+
return masks, iou_pred, mask_tokens_out, object_score_logits
|
| 246 |
+
|
| 247 |
+
def _get_stability_scores(self, mask_logits):
|
| 248 |
+
"""
|
| 249 |
+
Compute stability scores of the mask logits based on the IoU between upper and
|
| 250 |
+
lower thresholds.
|
| 251 |
+
"""
|
| 252 |
+
mask_logits = mask_logits.flatten(-2)
|
| 253 |
+
stability_delta = self.dynamic_multimask_stability_delta
|
| 254 |
+
area_i = torch.sum(mask_logits > stability_delta, dim=-1).float()
|
| 255 |
+
area_u = torch.sum(mask_logits > -stability_delta, dim=-1).float()
|
| 256 |
+
stability_scores = torch.where(area_u > 0, area_i / area_u, 1.0)
|
| 257 |
+
return stability_scores
|
| 258 |
+
|
| 259 |
+
def _dynamic_multimask_via_stability(self, all_mask_logits, all_iou_scores):
|
| 260 |
+
"""
|
| 261 |
+
When outputting a single mask, if the stability score from the current single-mask
|
| 262 |
+
output (based on output token 0) falls below a threshold, we instead select from
|
| 263 |
+
multi-mask outputs (based on output token 1~3) the mask with the highest predicted
|
| 264 |
+
IoU score. This is intended to ensure a valid mask for both clicking and tracking.
|
| 265 |
+
"""
|
| 266 |
+
# The best mask from multimask output tokens (1~3)
|
| 267 |
+
multimask_logits = all_mask_logits[:, 1:, :, :]
|
| 268 |
+
multimask_iou_scores = all_iou_scores[:, 1:]
|
| 269 |
+
best_scores_inds = torch.argmax(multimask_iou_scores, dim=-1)
|
| 270 |
+
batch_inds = torch.arange(
|
| 271 |
+
multimask_iou_scores.size(0), device=all_iou_scores.device
|
| 272 |
+
)
|
| 273 |
+
best_multimask_logits = multimask_logits[batch_inds, best_scores_inds]
|
| 274 |
+
best_multimask_logits = best_multimask_logits.unsqueeze(1)
|
| 275 |
+
best_multimask_iou_scores = multimask_iou_scores[batch_inds, best_scores_inds]
|
| 276 |
+
best_multimask_iou_scores = best_multimask_iou_scores.unsqueeze(1)
|
| 277 |
+
|
| 278 |
+
# The mask from singlemask output token 0 and its stability score
|
| 279 |
+
singlemask_logits = all_mask_logits[:, 0:1, :, :]
|
| 280 |
+
singlemask_iou_scores = all_iou_scores[:, 0:1]
|
| 281 |
+
stability_scores = self._get_stability_scores(singlemask_logits)
|
| 282 |
+
is_stable = stability_scores >= self.dynamic_multimask_stability_thresh
|
| 283 |
+
|
| 284 |
+
# Dynamically fall back to best multimask output upon low stability scores.
|
| 285 |
+
mask_logits_out = torch.where(
|
| 286 |
+
is_stable[..., None, None].expand_as(singlemask_logits),
|
| 287 |
+
singlemask_logits,
|
| 288 |
+
best_multimask_logits,
|
| 289 |
+
)
|
| 290 |
+
iou_scores_out = torch.where(
|
| 291 |
+
is_stable.expand_as(singlemask_iou_scores),
|
| 292 |
+
singlemask_iou_scores,
|
| 293 |
+
best_multimask_iou_scores,
|
| 294 |
+
)
|
| 295 |
+
return mask_logits_out, iou_scores_out
|
third_party/sam2/sam2/modeling/sam/prompt_encoder.py
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from typing import Optional, Tuple, Type
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torch import nn
|
| 11 |
+
|
| 12 |
+
from sam2.modeling.position_encoding import PositionEmbeddingRandom
|
| 13 |
+
|
| 14 |
+
from sam2.modeling.sam2_utils import LayerNorm2d
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class PromptEncoder(nn.Module):
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
embed_dim: int,
|
| 21 |
+
image_embedding_size: Tuple[int, int],
|
| 22 |
+
input_image_size: Tuple[int, int],
|
| 23 |
+
mask_in_chans: int,
|
| 24 |
+
activation: Type[nn.Module] = nn.GELU,
|
| 25 |
+
) -> None:
|
| 26 |
+
"""
|
| 27 |
+
Encodes prompts for input to SAM's mask decoder.
|
| 28 |
+
|
| 29 |
+
Arguments:
|
| 30 |
+
embed_dim (int): The prompts' embedding dimension
|
| 31 |
+
image_embedding_size (tuple(int, int)): The spatial size of the
|
| 32 |
+
image embedding, as (H, W).
|
| 33 |
+
input_image_size (int): The padded size of the image as input
|
| 34 |
+
to the image encoder, as (H, W).
|
| 35 |
+
mask_in_chans (int): The number of hidden channels used for
|
| 36 |
+
encoding input masks.
|
| 37 |
+
activation (nn.Module): The activation to use when encoding
|
| 38 |
+
input masks.
|
| 39 |
+
"""
|
| 40 |
+
super().__init__()
|
| 41 |
+
self.embed_dim = embed_dim
|
| 42 |
+
self.input_image_size = input_image_size
|
| 43 |
+
self.image_embedding_size = image_embedding_size
|
| 44 |
+
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
|
| 45 |
+
|
| 46 |
+
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners
|
| 47 |
+
point_embeddings = [
|
| 48 |
+
nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)
|
| 49 |
+
]
|
| 50 |
+
self.point_embeddings = nn.ModuleList(point_embeddings)
|
| 51 |
+
self.not_a_point_embed = nn.Embedding(1, embed_dim)
|
| 52 |
+
|
| 53 |
+
self.mask_input_size = (
|
| 54 |
+
4 * image_embedding_size[0],
|
| 55 |
+
4 * image_embedding_size[1],
|
| 56 |
+
)
|
| 57 |
+
self.mask_downscaling = nn.Sequential(
|
| 58 |
+
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
|
| 59 |
+
LayerNorm2d(mask_in_chans // 4),
|
| 60 |
+
activation(),
|
| 61 |
+
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
|
| 62 |
+
LayerNorm2d(mask_in_chans),
|
| 63 |
+
activation(),
|
| 64 |
+
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
|
| 65 |
+
)
|
| 66 |
+
self.no_mask_embed = nn.Embedding(1, embed_dim)
|
| 67 |
+
|
| 68 |
+
def get_dense_pe(self) -> torch.Tensor:
|
| 69 |
+
"""
|
| 70 |
+
Returns the positional encoding used to encode point prompts,
|
| 71 |
+
applied to a dense set of points the shape of the image encoding.
|
| 72 |
+
|
| 73 |
+
Returns:
|
| 74 |
+
torch.Tensor: Positional encoding with shape
|
| 75 |
+
1x(embed_dim)x(embedding_h)x(embedding_w)
|
| 76 |
+
"""
|
| 77 |
+
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
|
| 78 |
+
|
| 79 |
+
def _embed_points(
|
| 80 |
+
self,
|
| 81 |
+
points: torch.Tensor,
|
| 82 |
+
labels: torch.Tensor,
|
| 83 |
+
pad: bool,
|
| 84 |
+
) -> torch.Tensor:
|
| 85 |
+
"""Embeds point prompts."""
|
| 86 |
+
points = points + 0.5 # Shift to center of pixel
|
| 87 |
+
if pad:
|
| 88 |
+
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
|
| 89 |
+
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
|
| 90 |
+
points = torch.cat([points, padding_point], dim=1)
|
| 91 |
+
labels = torch.cat([labels, padding_label], dim=1)
|
| 92 |
+
point_embedding = self.pe_layer.forward_with_coords(
|
| 93 |
+
points, self.input_image_size
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
point_embedding = torch.where(
|
| 97 |
+
(labels == -1).unsqueeze(-1),
|
| 98 |
+
torch.zeros_like(point_embedding) + self.not_a_point_embed.weight,
|
| 99 |
+
point_embedding,
|
| 100 |
+
)
|
| 101 |
+
point_embedding = torch.where(
|
| 102 |
+
(labels == 0).unsqueeze(-1),
|
| 103 |
+
point_embedding + self.point_embeddings[0].weight,
|
| 104 |
+
point_embedding,
|
| 105 |
+
)
|
| 106 |
+
point_embedding = torch.where(
|
| 107 |
+
(labels == 1).unsqueeze(-1),
|
| 108 |
+
point_embedding + self.point_embeddings[1].weight,
|
| 109 |
+
point_embedding,
|
| 110 |
+
)
|
| 111 |
+
point_embedding = torch.where(
|
| 112 |
+
(labels == 2).unsqueeze(-1),
|
| 113 |
+
point_embedding + self.point_embeddings[2].weight,
|
| 114 |
+
point_embedding,
|
| 115 |
+
)
|
| 116 |
+
point_embedding = torch.where(
|
| 117 |
+
(labels == 3).unsqueeze(-1),
|
| 118 |
+
point_embedding + self.point_embeddings[3].weight,
|
| 119 |
+
point_embedding,
|
| 120 |
+
)
|
| 121 |
+
return point_embedding
|
| 122 |
+
|
| 123 |
+
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
|
| 124 |
+
"""Embeds box prompts."""
|
| 125 |
+
boxes = boxes + 0.5 # Shift to center of pixel
|
| 126 |
+
coords = boxes.reshape(-1, 2, 2)
|
| 127 |
+
corner_embedding = self.pe_layer.forward_with_coords(
|
| 128 |
+
coords, self.input_image_size
|
| 129 |
+
)
|
| 130 |
+
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
|
| 131 |
+
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
|
| 132 |
+
return corner_embedding
|
| 133 |
+
|
| 134 |
+
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
|
| 135 |
+
"""Embeds mask inputs."""
|
| 136 |
+
mask_embedding = self.mask_downscaling(masks)
|
| 137 |
+
return mask_embedding
|
| 138 |
+
|
| 139 |
+
def _get_batch_size(
|
| 140 |
+
self,
|
| 141 |
+
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
|
| 142 |
+
boxes: Optional[torch.Tensor],
|
| 143 |
+
masks: Optional[torch.Tensor],
|
| 144 |
+
) -> int:
|
| 145 |
+
"""
|
| 146 |
+
Gets the batch size of the output given the batch size of the input prompts.
|
| 147 |
+
"""
|
| 148 |
+
if points is not None:
|
| 149 |
+
return points[0].shape[0]
|
| 150 |
+
elif boxes is not None:
|
| 151 |
+
return boxes.shape[0]
|
| 152 |
+
elif masks is not None:
|
| 153 |
+
return masks.shape[0]
|
| 154 |
+
else:
|
| 155 |
+
return 1
|
| 156 |
+
|
| 157 |
+
def _get_device(self) -> torch.device:
|
| 158 |
+
return self.point_embeddings[0].weight.device
|
| 159 |
+
|
| 160 |
+
def forward(
|
| 161 |
+
self,
|
| 162 |
+
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
|
| 163 |
+
boxes: Optional[torch.Tensor],
|
| 164 |
+
masks: Optional[torch.Tensor],
|
| 165 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 166 |
+
"""
|
| 167 |
+
Embeds different types of prompts, returning both sparse and dense
|
| 168 |
+
embeddings.
|
| 169 |
+
|
| 170 |
+
Arguments:
|
| 171 |
+
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
|
| 172 |
+
and labels to embed.
|
| 173 |
+
boxes (torch.Tensor or none): boxes to embed
|
| 174 |
+
masks (torch.Tensor or none): masks to embed
|
| 175 |
+
|
| 176 |
+
Returns:
|
| 177 |
+
torch.Tensor: sparse embeddings for the points and boxes, with shape
|
| 178 |
+
BxNx(embed_dim), where N is determined by the number of input points
|
| 179 |
+
and boxes.
|
| 180 |
+
torch.Tensor: dense embeddings for the masks, in the shape
|
| 181 |
+
Bx(embed_dim)x(embed_H)x(embed_W)
|
| 182 |
+
"""
|
| 183 |
+
bs = self._get_batch_size(points, boxes, masks)
|
| 184 |
+
sparse_embeddings = torch.empty(
|
| 185 |
+
(bs, 0, self.embed_dim), device=self._get_device()
|
| 186 |
+
)
|
| 187 |
+
if points is not None:
|
| 188 |
+
coords, labels = points
|
| 189 |
+
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
|
| 190 |
+
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
|
| 191 |
+
if boxes is not None:
|
| 192 |
+
box_embeddings = self._embed_boxes(boxes)
|
| 193 |
+
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
|
| 194 |
+
|
| 195 |
+
if masks is not None:
|
| 196 |
+
dense_embeddings = self._embed_masks(masks)
|
| 197 |
+
else:
|
| 198 |
+
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
|
| 199 |
+
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
|
| 200 |
+
)
|
| 201 |
+
|
| 202 |
+
return sparse_embeddings, dense_embeddings
|
third_party/sam2/sam2/modeling/sam/transformer.py
ADDED
|
@@ -0,0 +1,311 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
from functools import partial
|
| 9 |
+
from typing import Tuple, Type
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
from torch import nn, Tensor
|
| 14 |
+
|
| 15 |
+
from sam2.modeling.position_encoding import apply_rotary_enc, compute_axial_cis
|
| 16 |
+
from sam2.modeling.sam2_utils import MLP
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class TwoWayTransformer(nn.Module):
|
| 20 |
+
def __init__(
|
| 21 |
+
self,
|
| 22 |
+
depth: int,
|
| 23 |
+
embedding_dim: int,
|
| 24 |
+
num_heads: int,
|
| 25 |
+
mlp_dim: int,
|
| 26 |
+
activation: Type[nn.Module] = nn.ReLU,
|
| 27 |
+
attention_downsample_rate: int = 2,
|
| 28 |
+
) -> None:
|
| 29 |
+
"""
|
| 30 |
+
A transformer decoder that attends to an input image using
|
| 31 |
+
queries whose positional embedding is supplied.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
depth (int): number of layers in the transformer
|
| 35 |
+
embedding_dim (int): the channel dimension for the input embeddings
|
| 36 |
+
num_heads (int): the number of heads for multihead attention. Must
|
| 37 |
+
divide embedding_dim
|
| 38 |
+
mlp_dim (int): the channel dimension internal to the MLP block
|
| 39 |
+
activation (nn.Module): the activation to use in the MLP block
|
| 40 |
+
"""
|
| 41 |
+
super().__init__()
|
| 42 |
+
self.depth = depth
|
| 43 |
+
self.embedding_dim = embedding_dim
|
| 44 |
+
self.num_heads = num_heads
|
| 45 |
+
self.mlp_dim = mlp_dim
|
| 46 |
+
self.layers = nn.ModuleList()
|
| 47 |
+
|
| 48 |
+
for i in range(depth):
|
| 49 |
+
self.layers.append(
|
| 50 |
+
TwoWayAttentionBlock(
|
| 51 |
+
embedding_dim=embedding_dim,
|
| 52 |
+
num_heads=num_heads,
|
| 53 |
+
mlp_dim=mlp_dim,
|
| 54 |
+
activation=activation,
|
| 55 |
+
attention_downsample_rate=attention_downsample_rate,
|
| 56 |
+
skip_first_layer_pe=(i == 0),
|
| 57 |
+
)
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
self.final_attn_token_to_image = Attention(
|
| 61 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 62 |
+
)
|
| 63 |
+
self.norm_final_attn = nn.LayerNorm(embedding_dim)
|
| 64 |
+
|
| 65 |
+
def forward(
|
| 66 |
+
self,
|
| 67 |
+
image_embedding: Tensor,
|
| 68 |
+
image_pe: Tensor,
|
| 69 |
+
point_embedding: Tensor,
|
| 70 |
+
) -> Tuple[Tensor, Tensor]:
|
| 71 |
+
"""
|
| 72 |
+
Args:
|
| 73 |
+
image_embedding (torch.Tensor): image to attend to. Should be shape
|
| 74 |
+
B x embedding_dim x h x w for any h and w.
|
| 75 |
+
image_pe (torch.Tensor): the positional encoding to add to the image. Must
|
| 76 |
+
have the same shape as image_embedding.
|
| 77 |
+
point_embedding (torch.Tensor): the embedding to add to the query points.
|
| 78 |
+
Must have shape B x N_points x embedding_dim for any N_points.
|
| 79 |
+
|
| 80 |
+
Returns:
|
| 81 |
+
torch.Tensor: the processed point_embedding
|
| 82 |
+
torch.Tensor: the processed image_embedding
|
| 83 |
+
"""
|
| 84 |
+
# BxCxHxW -> BxHWxC == B x N_image_tokens x C
|
| 85 |
+
bs, c, h, w = image_embedding.shape
|
| 86 |
+
image_embedding = image_embedding.flatten(2).permute(0, 2, 1)
|
| 87 |
+
image_pe = image_pe.flatten(2).permute(0, 2, 1)
|
| 88 |
+
|
| 89 |
+
# Prepare queries
|
| 90 |
+
queries = point_embedding
|
| 91 |
+
keys = image_embedding
|
| 92 |
+
|
| 93 |
+
# Apply transformer blocks and final layernorm
|
| 94 |
+
for layer in self.layers:
|
| 95 |
+
queries, keys = layer(
|
| 96 |
+
queries=queries,
|
| 97 |
+
keys=keys,
|
| 98 |
+
query_pe=point_embedding,
|
| 99 |
+
key_pe=image_pe,
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
# Apply the final attention layer from the points to the image
|
| 103 |
+
q = queries + point_embedding
|
| 104 |
+
k = keys + image_pe
|
| 105 |
+
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
|
| 106 |
+
queries = queries + attn_out
|
| 107 |
+
queries = self.norm_final_attn(queries)
|
| 108 |
+
|
| 109 |
+
return queries, keys
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class TwoWayAttentionBlock(nn.Module):
|
| 113 |
+
def __init__(
|
| 114 |
+
self,
|
| 115 |
+
embedding_dim: int,
|
| 116 |
+
num_heads: int,
|
| 117 |
+
mlp_dim: int = 2048,
|
| 118 |
+
activation: Type[nn.Module] = nn.ReLU,
|
| 119 |
+
attention_downsample_rate: int = 2,
|
| 120 |
+
skip_first_layer_pe: bool = False,
|
| 121 |
+
) -> None:
|
| 122 |
+
"""
|
| 123 |
+
A transformer block with four layers: (1) self-attention of sparse
|
| 124 |
+
inputs, (2) cross attention of sparse inputs to dense inputs, (3) mlp
|
| 125 |
+
block on sparse inputs, and (4) cross attention of dense inputs to sparse
|
| 126 |
+
inputs.
|
| 127 |
+
|
| 128 |
+
Arguments:
|
| 129 |
+
embedding_dim (int): the channel dimension of the embeddings
|
| 130 |
+
num_heads (int): the number of heads in the attention layers
|
| 131 |
+
mlp_dim (int): the hidden dimension of the mlp block
|
| 132 |
+
activation (nn.Module): the activation of the mlp block
|
| 133 |
+
skip_first_layer_pe (bool): skip the PE on the first layer
|
| 134 |
+
"""
|
| 135 |
+
super().__init__()
|
| 136 |
+
self.self_attn = Attention(embedding_dim, num_heads)
|
| 137 |
+
self.norm1 = nn.LayerNorm(embedding_dim)
|
| 138 |
+
|
| 139 |
+
self.cross_attn_token_to_image = Attention(
|
| 140 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 141 |
+
)
|
| 142 |
+
self.norm2 = nn.LayerNorm(embedding_dim)
|
| 143 |
+
|
| 144 |
+
self.mlp = MLP(
|
| 145 |
+
embedding_dim, mlp_dim, embedding_dim, num_layers=2, activation=activation
|
| 146 |
+
)
|
| 147 |
+
self.norm3 = nn.LayerNorm(embedding_dim)
|
| 148 |
+
|
| 149 |
+
self.norm4 = nn.LayerNorm(embedding_dim)
|
| 150 |
+
self.cross_attn_image_to_token = Attention(
|
| 151 |
+
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
self.skip_first_layer_pe = skip_first_layer_pe
|
| 155 |
+
|
| 156 |
+
def forward(
|
| 157 |
+
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
|
| 158 |
+
) -> Tuple[Tensor, Tensor]:
|
| 159 |
+
# Self attention block
|
| 160 |
+
if self.skip_first_layer_pe:
|
| 161 |
+
queries = self.self_attn(q=queries, k=queries, v=queries)
|
| 162 |
+
else:
|
| 163 |
+
q = queries + query_pe
|
| 164 |
+
attn_out = self.self_attn(q=q, k=q, v=queries)
|
| 165 |
+
queries = queries + attn_out
|
| 166 |
+
queries = self.norm1(queries)
|
| 167 |
+
|
| 168 |
+
# Cross attention block, tokens attending to image embedding
|
| 169 |
+
q = queries + query_pe
|
| 170 |
+
k = keys + key_pe
|
| 171 |
+
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
|
| 172 |
+
queries = queries + attn_out
|
| 173 |
+
queries = self.norm2(queries)
|
| 174 |
+
|
| 175 |
+
# MLP block
|
| 176 |
+
mlp_out = self.mlp(queries)
|
| 177 |
+
queries = queries + mlp_out
|
| 178 |
+
queries = self.norm3(queries)
|
| 179 |
+
|
| 180 |
+
# Cross attention block, image embedding attending to tokens
|
| 181 |
+
q = queries + query_pe
|
| 182 |
+
k = keys + key_pe
|
| 183 |
+
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
|
| 184 |
+
keys = keys + attn_out
|
| 185 |
+
keys = self.norm4(keys)
|
| 186 |
+
|
| 187 |
+
return queries, keys
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
class Attention(nn.Module):
|
| 191 |
+
"""
|
| 192 |
+
An attention layer that allows for downscaling the size of the embedding
|
| 193 |
+
after projection to queries, keys, and values.
|
| 194 |
+
"""
|
| 195 |
+
|
| 196 |
+
def __init__(
|
| 197 |
+
self,
|
| 198 |
+
embedding_dim: int,
|
| 199 |
+
num_heads: int,
|
| 200 |
+
downsample_rate: int = 1,
|
| 201 |
+
dropout: float = 0.0,
|
| 202 |
+
kv_in_dim: int = None,
|
| 203 |
+
) -> None:
|
| 204 |
+
super().__init__()
|
| 205 |
+
self.embedding_dim = embedding_dim
|
| 206 |
+
self.kv_in_dim = kv_in_dim if kv_in_dim is not None else embedding_dim
|
| 207 |
+
self.internal_dim = embedding_dim // downsample_rate
|
| 208 |
+
self.num_heads = num_heads
|
| 209 |
+
assert (
|
| 210 |
+
self.internal_dim % num_heads == 0
|
| 211 |
+
), "num_heads must divide embedding_dim."
|
| 212 |
+
|
| 213 |
+
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
|
| 214 |
+
self.k_proj = nn.Linear(self.kv_in_dim, self.internal_dim)
|
| 215 |
+
self.v_proj = nn.Linear(self.kv_in_dim, self.internal_dim)
|
| 216 |
+
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
|
| 217 |
+
|
| 218 |
+
self.dropout_p = dropout
|
| 219 |
+
|
| 220 |
+
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
|
| 221 |
+
b, n, c = x.shape
|
| 222 |
+
x = x.reshape(b, n, num_heads, c // num_heads)
|
| 223 |
+
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
|
| 224 |
+
|
| 225 |
+
def _recombine_heads(self, x: Tensor) -> Tensor:
|
| 226 |
+
b, n_heads, n_tokens, c_per_head = x.shape
|
| 227 |
+
x = x.transpose(1, 2)
|
| 228 |
+
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
|
| 229 |
+
|
| 230 |
+
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
|
| 231 |
+
# Input projections
|
| 232 |
+
q = self.q_proj(q)
|
| 233 |
+
k = self.k_proj(k)
|
| 234 |
+
v = self.v_proj(v)
|
| 235 |
+
|
| 236 |
+
# Separate into heads
|
| 237 |
+
q = self._separate_heads(q, self.num_heads)
|
| 238 |
+
k = self._separate_heads(k, self.num_heads)
|
| 239 |
+
v = self._separate_heads(v, self.num_heads)
|
| 240 |
+
|
| 241 |
+
dropout_p = self.dropout_p if self.training else 0.0
|
| 242 |
+
# Attention
|
| 243 |
+
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
|
| 244 |
+
|
| 245 |
+
out = self._recombine_heads(out)
|
| 246 |
+
out = self.out_proj(out)
|
| 247 |
+
|
| 248 |
+
return out
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
class RoPEAttention(Attention):
|
| 252 |
+
"""Attention with rotary position encoding."""
|
| 253 |
+
|
| 254 |
+
def __init__(
|
| 255 |
+
self,
|
| 256 |
+
*args,
|
| 257 |
+
rope_theta=10000.0,
|
| 258 |
+
# whether to repeat q rope to match k length
|
| 259 |
+
# this is needed for cross-attention to memories
|
| 260 |
+
rope_k_repeat=False,
|
| 261 |
+
feat_sizes=(64, 64), # [w, h] for stride 16 feats at 1024 resolution
|
| 262 |
+
**kwargs,
|
| 263 |
+
):
|
| 264 |
+
super().__init__(*args, **kwargs)
|
| 265 |
+
|
| 266 |
+
self.compute_cis = partial(
|
| 267 |
+
compute_axial_cis, dim=self.internal_dim // self.num_heads, theta=rope_theta
|
| 268 |
+
)
|
| 269 |
+
freqs_cis = self.compute_cis(end_x=feat_sizes[0], end_y=feat_sizes[1])
|
| 270 |
+
self.freqs_cis = (
|
| 271 |
+
freqs_cis.to("cuda") if torch.cuda.is_available() else freqs_cis
|
| 272 |
+
)
|
| 273 |
+
self.rope_k_repeat = rope_k_repeat
|
| 274 |
+
|
| 275 |
+
def forward(
|
| 276 |
+
self, q: Tensor, k: Tensor, v: Tensor, num_k_exclude_rope: int = 0
|
| 277 |
+
) -> Tensor:
|
| 278 |
+
# Input projections
|
| 279 |
+
q = self.q_proj(q)
|
| 280 |
+
k = self.k_proj(k)
|
| 281 |
+
v = self.v_proj(v)
|
| 282 |
+
|
| 283 |
+
# Separate into heads
|
| 284 |
+
q = self._separate_heads(q, self.num_heads)
|
| 285 |
+
k = self._separate_heads(k, self.num_heads)
|
| 286 |
+
v = self._separate_heads(v, self.num_heads)
|
| 287 |
+
|
| 288 |
+
# Apply rotary position encoding
|
| 289 |
+
w = h = math.sqrt(q.shape[-2])
|
| 290 |
+
self.freqs_cis = self.freqs_cis.to(q.device)
|
| 291 |
+
if self.freqs_cis.shape[0] != q.shape[-2]:
|
| 292 |
+
self.freqs_cis = self.compute_cis(end_x=w, end_y=h).to(q.device)
|
| 293 |
+
if q.shape[-2] != k.shape[-2]:
|
| 294 |
+
assert self.rope_k_repeat
|
| 295 |
+
|
| 296 |
+
num_k_rope = k.size(-2) - num_k_exclude_rope
|
| 297 |
+
q, k[:, :, :num_k_rope] = apply_rotary_enc(
|
| 298 |
+
q,
|
| 299 |
+
k[:, :, :num_k_rope],
|
| 300 |
+
freqs_cis=self.freqs_cis,
|
| 301 |
+
repeat_freqs_k=self.rope_k_repeat,
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
dropout_p = self.dropout_p if self.training else 0.0
|
| 305 |
+
# Attention
|
| 306 |
+
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
|
| 307 |
+
|
| 308 |
+
out = self._recombine_heads(out)
|
| 309 |
+
out = self.out_proj(out)
|
| 310 |
+
|
| 311 |
+
return out
|
third_party/sam2/sam2/modeling/sam2_base.py
ADDED
|
@@ -0,0 +1,909 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.distributed
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
from torch.nn.init import trunc_normal_
|
| 12 |
+
|
| 13 |
+
from sam2.modeling.sam.mask_decoder import MaskDecoder
|
| 14 |
+
from sam2.modeling.sam.prompt_encoder import PromptEncoder
|
| 15 |
+
from sam2.modeling.sam.transformer import TwoWayTransformer
|
| 16 |
+
from sam2.modeling.sam2_utils import get_1d_sine_pe, MLP, select_closest_cond_frames
|
| 17 |
+
|
| 18 |
+
# a large negative value as a placeholder score for missing objects
|
| 19 |
+
NO_OBJ_SCORE = -1024.0
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class SAM2Base(torch.nn.Module):
|
| 23 |
+
def __init__(
|
| 24 |
+
self,
|
| 25 |
+
image_encoder,
|
| 26 |
+
memory_attention,
|
| 27 |
+
memory_encoder,
|
| 28 |
+
num_maskmem=7, # default 1 input frame + 6 previous frames
|
| 29 |
+
image_size=512,
|
| 30 |
+
backbone_stride=16, # stride of the image backbone output
|
| 31 |
+
sigmoid_scale_for_mem_enc=1.0, # scale factor for mask sigmoid prob
|
| 32 |
+
sigmoid_bias_for_mem_enc=0.0, # bias factor for mask sigmoid prob
|
| 33 |
+
# During evaluation, whether to binarize the sigmoid mask logits on interacted frames with clicks
|
| 34 |
+
binarize_mask_from_pts_for_mem_enc=False,
|
| 35 |
+
use_mask_input_as_output_without_sam=False, # on frames with mask input, whether to directly output the input mask without using a SAM prompt encoder + mask decoder
|
| 36 |
+
# The maximum number of conditioning frames to participate in the memory attention (-1 means no limit; if there are more conditioning frames than this limit,
|
| 37 |
+
# we only cross-attend to the temporally closest `max_cond_frames_in_attn` conditioning frames in the encoder when tracking each frame). This gives the model
|
| 38 |
+
# a temporal locality when handling a large number of annotated frames (since closer frames should be more important) and also avoids GPU OOM.
|
| 39 |
+
max_cond_frames_in_attn=-1,
|
| 40 |
+
# on the first frame, whether to directly add the no-memory embedding to the image feature
|
| 41 |
+
# (instead of using the transformer encoder)
|
| 42 |
+
directly_add_no_mem_embed=False,
|
| 43 |
+
# whether to use high-resolution feature maps in the SAM mask decoder
|
| 44 |
+
use_high_res_features_in_sam=False,
|
| 45 |
+
# whether to output multiple (3) masks for the first click on initial conditioning frames
|
| 46 |
+
multimask_output_in_sam=False,
|
| 47 |
+
# the minimum and maximum number of clicks to use multimask_output_in_sam (only relevant when `multimask_output_in_sam=True`;
|
| 48 |
+
# default is 1 for both, meaning that only the first click gives multimask output; also note that a box counts as two points)
|
| 49 |
+
multimask_min_pt_num=1,
|
| 50 |
+
multimask_max_pt_num=1,
|
| 51 |
+
# whether to also use multimask output for tracking (not just for the first click on initial conditioning frames; only relevant when `multimask_output_in_sam=True`)
|
| 52 |
+
multimask_output_for_tracking=False,
|
| 53 |
+
# Whether to use multimask tokens for obj ptr; Only relevant when both
|
| 54 |
+
# use_obj_ptrs_in_encoder=True and multimask_output_for_tracking=True
|
| 55 |
+
use_multimask_token_for_obj_ptr: bool = False,
|
| 56 |
+
# whether to use sigmoid to restrict ious prediction to [0-1]
|
| 57 |
+
iou_prediction_use_sigmoid=False,
|
| 58 |
+
# The memory bank's temporal stride during evaluation (i.e. the `r` parameter in XMem and Cutie; XMem and Cutie use r=5).
|
| 59 |
+
# For r>1, the (self.num_maskmem - 1) non-conditioning memory frames consist of
|
| 60 |
+
# (self.num_maskmem - 2) nearest frames from every r-th frames, plus the last frame.
|
| 61 |
+
memory_temporal_stride_for_eval=1,
|
| 62 |
+
# whether to apply non-overlapping constraints on the object masks in the memory encoder during evaluation (to avoid/alleviate superposing masks)
|
| 63 |
+
non_overlap_masks_for_mem_enc=False,
|
| 64 |
+
# whether to cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 65 |
+
use_obj_ptrs_in_encoder=False,
|
| 66 |
+
# the maximum number of object pointers from other frames in encoder cross attention (only relevant when `use_obj_ptrs_in_encoder=True`)
|
| 67 |
+
max_obj_ptrs_in_encoder=16,
|
| 68 |
+
# whether to add temporal positional encoding to the object pointers in the encoder (only relevant when `use_obj_ptrs_in_encoder=True`)
|
| 69 |
+
add_tpos_enc_to_obj_ptrs=True,
|
| 70 |
+
# whether to add an extra linear projection layer for the temporal positional encoding in the object pointers to avoid potential interference
|
| 71 |
+
# with spatial positional encoding (only relevant when both `use_obj_ptrs_in_encoder=True` and `add_tpos_enc_to_obj_ptrs=True`)
|
| 72 |
+
proj_tpos_enc_in_obj_ptrs=False,
|
| 73 |
+
# whether to use signed distance (instead of unsigned absolute distance) in the temporal positional encoding in the object pointers
|
| 74 |
+
# (only relevant when both `use_obj_ptrs_in_encoder=True` and `add_tpos_enc_to_obj_ptrs=True`)
|
| 75 |
+
use_signed_tpos_enc_to_obj_ptrs=False,
|
| 76 |
+
# whether to only attend to object pointers in the past (before the current frame) in the encoder during evaluation
|
| 77 |
+
# (only relevant when `use_obj_ptrs_in_encoder=True`; this might avoid pointer information too far in the future to distract the initial tracking)
|
| 78 |
+
only_obj_ptrs_in_the_past_for_eval=False,
|
| 79 |
+
# Whether to predict if there is an object in the frame
|
| 80 |
+
pred_obj_scores: bool = False,
|
| 81 |
+
# Whether to use an MLP to predict object scores
|
| 82 |
+
pred_obj_scores_mlp: bool = False,
|
| 83 |
+
# Only relevant if pred_obj_scores=True and use_obj_ptrs_in_encoder=True;
|
| 84 |
+
# Whether to have a fixed no obj pointer when there is no object present
|
| 85 |
+
# or to use it as an additive embedding with obj_ptr produced by decoder
|
| 86 |
+
fixed_no_obj_ptr: bool = False,
|
| 87 |
+
# Soft no object, i.e. mix in no_obj_ptr softly,
|
| 88 |
+
# hope to make recovery easier if there is a mistake and mitigate accumulation of errors
|
| 89 |
+
soft_no_obj_ptr: bool = False,
|
| 90 |
+
use_mlp_for_obj_ptr_proj: bool = False,
|
| 91 |
+
# add no obj embedding to spatial frames
|
| 92 |
+
no_obj_embed_spatial: bool = False,
|
| 93 |
+
# extra arguments used to construct the SAM mask decoder; if not None, it should be a dict of kwargs to be passed into `MaskDecoder` class.
|
| 94 |
+
sam_mask_decoder_extra_args=None,
|
| 95 |
+
compile_image_encoder: bool = False,
|
| 96 |
+
):
|
| 97 |
+
super().__init__()
|
| 98 |
+
|
| 99 |
+
# Part 1: the image backbone
|
| 100 |
+
self.image_encoder = image_encoder
|
| 101 |
+
# Use level 0, 1, 2 for high-res setting, or just level 2 for the default setting
|
| 102 |
+
self.use_high_res_features_in_sam = use_high_res_features_in_sam
|
| 103 |
+
self.num_feature_levels = 3 if use_high_res_features_in_sam else 1
|
| 104 |
+
self.use_obj_ptrs_in_encoder = use_obj_ptrs_in_encoder
|
| 105 |
+
self.max_obj_ptrs_in_encoder = max_obj_ptrs_in_encoder
|
| 106 |
+
if use_obj_ptrs_in_encoder:
|
| 107 |
+
# A conv layer to downsample the mask prompt to stride 4 (the same stride as
|
| 108 |
+
# low-res SAM mask logits) and to change its scales from 0~1 to SAM logit scale,
|
| 109 |
+
# so that it can be fed into the SAM mask decoder to generate a pointer.
|
| 110 |
+
self.mask_downsample = torch.nn.Conv2d(1, 1, kernel_size=4, stride=4)
|
| 111 |
+
self.add_tpos_enc_to_obj_ptrs = add_tpos_enc_to_obj_ptrs
|
| 112 |
+
if proj_tpos_enc_in_obj_ptrs:
|
| 113 |
+
assert add_tpos_enc_to_obj_ptrs # these options need to be used together
|
| 114 |
+
self.proj_tpos_enc_in_obj_ptrs = proj_tpos_enc_in_obj_ptrs
|
| 115 |
+
self.use_signed_tpos_enc_to_obj_ptrs = use_signed_tpos_enc_to_obj_ptrs
|
| 116 |
+
self.only_obj_ptrs_in_the_past_for_eval = only_obj_ptrs_in_the_past_for_eval
|
| 117 |
+
|
| 118 |
+
# Part 2: memory attention to condition current frame's visual features
|
| 119 |
+
# with memories (and obj ptrs) from past frames
|
| 120 |
+
self.memory_attention = memory_attention
|
| 121 |
+
self.hidden_dim = image_encoder.neck.d_model
|
| 122 |
+
|
| 123 |
+
# Part 3: memory encoder for the previous frame's outputs
|
| 124 |
+
self.memory_encoder = memory_encoder
|
| 125 |
+
self.mem_dim = self.hidden_dim
|
| 126 |
+
if hasattr(self.memory_encoder, "out_proj") and hasattr(
|
| 127 |
+
self.memory_encoder.out_proj, "weight"
|
| 128 |
+
):
|
| 129 |
+
# if there is compression of memories along channel dim
|
| 130 |
+
self.mem_dim = self.memory_encoder.out_proj.weight.shape[0]
|
| 131 |
+
self.num_maskmem = num_maskmem # Number of memories accessible
|
| 132 |
+
# Temporal encoding of the memories
|
| 133 |
+
self.maskmem_tpos_enc = torch.nn.Parameter(
|
| 134 |
+
torch.zeros(num_maskmem, 1, 1, self.mem_dim)
|
| 135 |
+
)
|
| 136 |
+
trunc_normal_(self.maskmem_tpos_enc, std=0.02)
|
| 137 |
+
# a single token to indicate no memory embedding from previous frames
|
| 138 |
+
self.no_mem_embed = torch.nn.Parameter(torch.zeros(1, 1, self.hidden_dim))
|
| 139 |
+
self.no_mem_pos_enc = torch.nn.Parameter(torch.zeros(1, 1, self.hidden_dim))
|
| 140 |
+
trunc_normal_(self.no_mem_embed, std=0.02)
|
| 141 |
+
trunc_normal_(self.no_mem_pos_enc, std=0.02)
|
| 142 |
+
self.directly_add_no_mem_embed = directly_add_no_mem_embed
|
| 143 |
+
# Apply sigmoid to the output raw mask logits (to turn them from
|
| 144 |
+
# range (-inf, +inf) to range (0, 1)) before feeding them into the memory encoder
|
| 145 |
+
self.sigmoid_scale_for_mem_enc = sigmoid_scale_for_mem_enc
|
| 146 |
+
self.sigmoid_bias_for_mem_enc = sigmoid_bias_for_mem_enc
|
| 147 |
+
self.binarize_mask_from_pts_for_mem_enc = binarize_mask_from_pts_for_mem_enc
|
| 148 |
+
self.non_overlap_masks_for_mem_enc = non_overlap_masks_for_mem_enc
|
| 149 |
+
self.memory_temporal_stride_for_eval = memory_temporal_stride_for_eval
|
| 150 |
+
# On frames with mask input, whether to directly output the input mask without
|
| 151 |
+
# using a SAM prompt encoder + mask decoder
|
| 152 |
+
self.use_mask_input_as_output_without_sam = use_mask_input_as_output_without_sam
|
| 153 |
+
self.multimask_output_in_sam = multimask_output_in_sam
|
| 154 |
+
self.multimask_min_pt_num = multimask_min_pt_num
|
| 155 |
+
self.multimask_max_pt_num = multimask_max_pt_num
|
| 156 |
+
self.multimask_output_for_tracking = multimask_output_for_tracking
|
| 157 |
+
self.use_multimask_token_for_obj_ptr = use_multimask_token_for_obj_ptr
|
| 158 |
+
self.iou_prediction_use_sigmoid = iou_prediction_use_sigmoid
|
| 159 |
+
|
| 160 |
+
# Part 4: SAM-style prompt encoder (for both mask and point inputs)
|
| 161 |
+
# and SAM-style mask decoder for the final mask output
|
| 162 |
+
self.image_size = image_size
|
| 163 |
+
self.backbone_stride = backbone_stride
|
| 164 |
+
self.sam_mask_decoder_extra_args = sam_mask_decoder_extra_args
|
| 165 |
+
self.pred_obj_scores = pred_obj_scores
|
| 166 |
+
self.pred_obj_scores_mlp = pred_obj_scores_mlp
|
| 167 |
+
self.fixed_no_obj_ptr = fixed_no_obj_ptr
|
| 168 |
+
self.soft_no_obj_ptr = soft_no_obj_ptr
|
| 169 |
+
if self.fixed_no_obj_ptr:
|
| 170 |
+
assert self.pred_obj_scores
|
| 171 |
+
assert self.use_obj_ptrs_in_encoder
|
| 172 |
+
if self.pred_obj_scores and self.use_obj_ptrs_in_encoder:
|
| 173 |
+
self.no_obj_ptr = torch.nn.Parameter(torch.zeros(1, self.hidden_dim))
|
| 174 |
+
trunc_normal_(self.no_obj_ptr, std=0.02)
|
| 175 |
+
self.use_mlp_for_obj_ptr_proj = use_mlp_for_obj_ptr_proj
|
| 176 |
+
self.no_obj_embed_spatial = None
|
| 177 |
+
if no_obj_embed_spatial:
|
| 178 |
+
self.no_obj_embed_spatial = torch.nn.Parameter(torch.zeros(1, self.mem_dim))
|
| 179 |
+
trunc_normal_(self.no_obj_embed_spatial, std=0.02)
|
| 180 |
+
|
| 181 |
+
self._build_sam_heads()
|
| 182 |
+
self.max_cond_frames_in_attn = max_cond_frames_in_attn
|
| 183 |
+
|
| 184 |
+
# Model compilation
|
| 185 |
+
if compile_image_encoder:
|
| 186 |
+
# Compile the forward function (not the full module) to allow loading checkpoints.
|
| 187 |
+
print(
|
| 188 |
+
"Image encoder compilation is enabled. First forward pass will be slow."
|
| 189 |
+
)
|
| 190 |
+
self.image_encoder.forward = torch.compile(
|
| 191 |
+
self.image_encoder.forward,
|
| 192 |
+
mode="max-autotune",
|
| 193 |
+
fullgraph=True,
|
| 194 |
+
dynamic=False,
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
@property
|
| 198 |
+
def device(self):
|
| 199 |
+
return next(self.parameters()).device
|
| 200 |
+
|
| 201 |
+
def forward(self, *args, **kwargs):
|
| 202 |
+
raise NotImplementedError(
|
| 203 |
+
"Please use the corresponding methods in SAM2VideoPredictor for inference or SAM2Train for training/fine-tuning"
|
| 204 |
+
"See notebooks/video_predictor_example.ipynb for an inference example."
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
def _build_sam_heads(self):
|
| 208 |
+
"""Build SAM-style prompt encoder and mask decoder."""
|
| 209 |
+
self.sam_prompt_embed_dim = self.hidden_dim
|
| 210 |
+
self.sam_image_embedding_size = self.image_size // self.backbone_stride
|
| 211 |
+
|
| 212 |
+
# build PromptEncoder and MaskDecoder from SAM
|
| 213 |
+
# (their hyperparameters like `mask_in_chans=16` are from SAM code)
|
| 214 |
+
self.sam_prompt_encoder = PromptEncoder(
|
| 215 |
+
embed_dim=self.sam_prompt_embed_dim,
|
| 216 |
+
image_embedding_size=(
|
| 217 |
+
self.sam_image_embedding_size,
|
| 218 |
+
self.sam_image_embedding_size,
|
| 219 |
+
),
|
| 220 |
+
input_image_size=(self.image_size, self.image_size),
|
| 221 |
+
mask_in_chans=16,
|
| 222 |
+
)
|
| 223 |
+
self.sam_mask_decoder = MaskDecoder(
|
| 224 |
+
num_multimask_outputs=3,
|
| 225 |
+
transformer=TwoWayTransformer(
|
| 226 |
+
depth=2,
|
| 227 |
+
embedding_dim=self.sam_prompt_embed_dim,
|
| 228 |
+
mlp_dim=2048,
|
| 229 |
+
num_heads=8,
|
| 230 |
+
),
|
| 231 |
+
transformer_dim=self.sam_prompt_embed_dim,
|
| 232 |
+
iou_head_depth=3,
|
| 233 |
+
iou_head_hidden_dim=256,
|
| 234 |
+
use_high_res_features=self.use_high_res_features_in_sam,
|
| 235 |
+
iou_prediction_use_sigmoid=self.iou_prediction_use_sigmoid,
|
| 236 |
+
pred_obj_scores=self.pred_obj_scores,
|
| 237 |
+
pred_obj_scores_mlp=self.pred_obj_scores_mlp,
|
| 238 |
+
use_multimask_token_for_obj_ptr=self.use_multimask_token_for_obj_ptr,
|
| 239 |
+
**(self.sam_mask_decoder_extra_args or {}),
|
| 240 |
+
)
|
| 241 |
+
if self.use_obj_ptrs_in_encoder:
|
| 242 |
+
# a linear projection on SAM output tokens to turn them into object pointers
|
| 243 |
+
self.obj_ptr_proj = torch.nn.Linear(self.hidden_dim, self.hidden_dim)
|
| 244 |
+
if self.use_mlp_for_obj_ptr_proj:
|
| 245 |
+
self.obj_ptr_proj = MLP(
|
| 246 |
+
self.hidden_dim, self.hidden_dim, self.hidden_dim, 3
|
| 247 |
+
)
|
| 248 |
+
else:
|
| 249 |
+
self.obj_ptr_proj = torch.nn.Identity()
|
| 250 |
+
if self.proj_tpos_enc_in_obj_ptrs:
|
| 251 |
+
# a linear projection on temporal positional encoding in object pointers to
|
| 252 |
+
# avoid potential interference with spatial positional encoding
|
| 253 |
+
self.obj_ptr_tpos_proj = torch.nn.Linear(self.hidden_dim, self.mem_dim)
|
| 254 |
+
else:
|
| 255 |
+
self.obj_ptr_tpos_proj = torch.nn.Identity()
|
| 256 |
+
|
| 257 |
+
def _forward_sam_heads(
|
| 258 |
+
self,
|
| 259 |
+
backbone_features,
|
| 260 |
+
point_inputs=None,
|
| 261 |
+
mask_inputs=None,
|
| 262 |
+
high_res_features=None,
|
| 263 |
+
multimask_output=False,
|
| 264 |
+
):
|
| 265 |
+
"""
|
| 266 |
+
Forward SAM prompt encoders and mask heads.
|
| 267 |
+
|
| 268 |
+
Inputs:
|
| 269 |
+
- backbone_features: image features of [B, C, H, W] shape
|
| 270 |
+
- point_inputs: a dictionary with "point_coords" and "point_labels", where
|
| 271 |
+
1) "point_coords" has [B, P, 2] shape and float32 dtype and contains the
|
| 272 |
+
absolute pixel-unit coordinate in (x, y) format of the P input points
|
| 273 |
+
2) "point_labels" has shape [B, P] and int32 dtype, where 1 means
|
| 274 |
+
positive clicks, 0 means negative clicks, and -1 means padding
|
| 275 |
+
- mask_inputs: a mask of [B, 1, H*16, W*16] shape, float or bool, with the
|
| 276 |
+
same spatial size as the image.
|
| 277 |
+
- high_res_features: either 1) None or 2) or a list of length 2 containing
|
| 278 |
+
two feature maps of [B, C, 4*H, 4*W] and [B, C, 2*H, 2*W] shapes respectively,
|
| 279 |
+
which will be used as high-resolution feature maps for SAM decoder.
|
| 280 |
+
- multimask_output: if it's True, we output 3 candidate masks and their 3
|
| 281 |
+
corresponding IoU estimates, and if it's False, we output only 1 mask and
|
| 282 |
+
its corresponding IoU estimate.
|
| 283 |
+
|
| 284 |
+
Outputs:
|
| 285 |
+
- low_res_multimasks: [B, M, H*4, W*4] shape (where M = 3 if
|
| 286 |
+
`multimask_output=True` and M = 1 if `multimask_output=False`), the SAM
|
| 287 |
+
output mask logits (before sigmoid) for the low-resolution masks, with 4x
|
| 288 |
+
the resolution (1/4 stride) of the input backbone_features.
|
| 289 |
+
- high_res_multimasks: [B, M, H*16, W*16] shape (where M = 3
|
| 290 |
+
if `multimask_output=True` and M = 1 if `multimask_output=False`),
|
| 291 |
+
upsampled from the low-resolution masks, with shape size as the image
|
| 292 |
+
(stride is 1 pixel).
|
| 293 |
+
- ious, [B, M] shape, where (where M = 3 if `multimask_output=True` and M = 1
|
| 294 |
+
if `multimask_output=False`), the estimated IoU of each output mask.
|
| 295 |
+
- low_res_masks: [B, 1, H*4, W*4] shape, the best mask in `low_res_multimasks`.
|
| 296 |
+
If `multimask_output=True`, it's the mask with the highest IoU estimate.
|
| 297 |
+
If `multimask_output=False`, it's the same as `low_res_multimasks`.
|
| 298 |
+
- high_res_masks: [B, 1, H*16, W*16] shape, the best mask in `high_res_multimasks`.
|
| 299 |
+
If `multimask_output=True`, it's the mask with the highest IoU estimate.
|
| 300 |
+
If `multimask_output=False`, it's the same as `high_res_multimasks`.
|
| 301 |
+
- obj_ptr: [B, C] shape, the object pointer vector for the output mask, extracted
|
| 302 |
+
based on the output token from the SAM mask decoder.
|
| 303 |
+
"""
|
| 304 |
+
B = backbone_features.size(0)
|
| 305 |
+
device = backbone_features.device
|
| 306 |
+
assert backbone_features.size(1) == self.sam_prompt_embed_dim
|
| 307 |
+
assert backbone_features.size(2) == self.sam_image_embedding_size
|
| 308 |
+
assert backbone_features.size(3) == self.sam_image_embedding_size
|
| 309 |
+
|
| 310 |
+
# a) Handle point prompts
|
| 311 |
+
if point_inputs is not None:
|
| 312 |
+
sam_point_coords = point_inputs["point_coords"]
|
| 313 |
+
sam_point_labels = point_inputs["point_labels"]
|
| 314 |
+
assert sam_point_coords.size(0) == B and sam_point_labels.size(0) == B
|
| 315 |
+
else:
|
| 316 |
+
# If no points are provide, pad with an empty point (with label -1)
|
| 317 |
+
sam_point_coords = torch.zeros(B, 1, 2, device=device)
|
| 318 |
+
sam_point_labels = -torch.ones(B, 1, dtype=torch.int32, device=device)
|
| 319 |
+
|
| 320 |
+
# b) Handle mask prompts
|
| 321 |
+
if mask_inputs is not None:
|
| 322 |
+
# If mask_inputs is provided, downsize it into low-res mask input if needed
|
| 323 |
+
# and feed it as a dense mask prompt into the SAM mask encoder
|
| 324 |
+
assert len(mask_inputs.shape) == 4 and mask_inputs.shape[:2] == (B, 1)
|
| 325 |
+
if mask_inputs.shape[-2:] != self.sam_prompt_encoder.mask_input_size:
|
| 326 |
+
sam_mask_prompt = F.interpolate(
|
| 327 |
+
mask_inputs.float(),
|
| 328 |
+
size=self.sam_prompt_encoder.mask_input_size,
|
| 329 |
+
align_corners=False,
|
| 330 |
+
mode="bilinear",
|
| 331 |
+
antialias=True, # use antialias for downsampling
|
| 332 |
+
)
|
| 333 |
+
else:
|
| 334 |
+
sam_mask_prompt = mask_inputs
|
| 335 |
+
else:
|
| 336 |
+
# Otherwise, simply feed None (and SAM's prompt encoder will add
|
| 337 |
+
# a learned `no_mask_embed` to indicate no mask input in this case).
|
| 338 |
+
sam_mask_prompt = None
|
| 339 |
+
|
| 340 |
+
sparse_embeddings, dense_embeddings = self.sam_prompt_encoder(
|
| 341 |
+
points=(sam_point_coords, sam_point_labels),
|
| 342 |
+
boxes=None,
|
| 343 |
+
masks=sam_mask_prompt,
|
| 344 |
+
)
|
| 345 |
+
(
|
| 346 |
+
low_res_multimasks,
|
| 347 |
+
ious,
|
| 348 |
+
sam_output_tokens,
|
| 349 |
+
object_score_logits,
|
| 350 |
+
) = self.sam_mask_decoder(
|
| 351 |
+
image_embeddings=backbone_features,
|
| 352 |
+
image_pe=self.sam_prompt_encoder.get_dense_pe(),
|
| 353 |
+
sparse_prompt_embeddings=sparse_embeddings,
|
| 354 |
+
dense_prompt_embeddings=dense_embeddings,
|
| 355 |
+
multimask_output=multimask_output,
|
| 356 |
+
repeat_image=False, # the image is already batched
|
| 357 |
+
high_res_features=high_res_features,
|
| 358 |
+
)
|
| 359 |
+
if self.pred_obj_scores:
|
| 360 |
+
is_obj_appearing = object_score_logits > 0
|
| 361 |
+
|
| 362 |
+
# Mask used for spatial memories is always a *hard* choice between obj and no obj,
|
| 363 |
+
# consistent with the actual mask prediction
|
| 364 |
+
low_res_multimasks = torch.where(
|
| 365 |
+
is_obj_appearing[:, None, None],
|
| 366 |
+
low_res_multimasks,
|
| 367 |
+
NO_OBJ_SCORE,
|
| 368 |
+
)
|
| 369 |
+
|
| 370 |
+
# convert masks from possibly bfloat16 (or float16) to float32
|
| 371 |
+
# (older PyTorch versions before 2.1 don't support `interpolate` on bf16)
|
| 372 |
+
low_res_multimasks = low_res_multimasks.float()
|
| 373 |
+
high_res_multimasks = F.interpolate(
|
| 374 |
+
low_res_multimasks,
|
| 375 |
+
size=(self.image_size, self.image_size),
|
| 376 |
+
mode="bilinear",
|
| 377 |
+
align_corners=False,
|
| 378 |
+
)
|
| 379 |
+
|
| 380 |
+
sam_output_token = sam_output_tokens[:, 0]
|
| 381 |
+
if multimask_output:
|
| 382 |
+
# take the best mask prediction (with the highest IoU estimation)
|
| 383 |
+
best_iou_inds = torch.argmax(ious, dim=-1)
|
| 384 |
+
batch_inds = torch.arange(B, device=device)
|
| 385 |
+
low_res_masks = low_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1)
|
| 386 |
+
high_res_masks = high_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1)
|
| 387 |
+
if sam_output_tokens.size(1) > 1:
|
| 388 |
+
sam_output_token = sam_output_tokens[batch_inds, best_iou_inds]
|
| 389 |
+
else:
|
| 390 |
+
low_res_masks, high_res_masks = low_res_multimasks, high_res_multimasks
|
| 391 |
+
|
| 392 |
+
# Extract object pointer from the SAM output token (with occlusion handling)
|
| 393 |
+
obj_ptr = self.obj_ptr_proj(sam_output_token)
|
| 394 |
+
if self.pred_obj_scores:
|
| 395 |
+
# Allow *soft* no obj ptr, unlike for masks
|
| 396 |
+
if self.soft_no_obj_ptr:
|
| 397 |
+
lambda_is_obj_appearing = object_score_logits.sigmoid()
|
| 398 |
+
else:
|
| 399 |
+
lambda_is_obj_appearing = is_obj_appearing.float()
|
| 400 |
+
|
| 401 |
+
if self.fixed_no_obj_ptr:
|
| 402 |
+
obj_ptr = lambda_is_obj_appearing * obj_ptr
|
| 403 |
+
obj_ptr = obj_ptr + (1 - lambda_is_obj_appearing) * self.no_obj_ptr
|
| 404 |
+
|
| 405 |
+
return (
|
| 406 |
+
low_res_multimasks,
|
| 407 |
+
high_res_multimasks,
|
| 408 |
+
ious,
|
| 409 |
+
low_res_masks,
|
| 410 |
+
high_res_masks,
|
| 411 |
+
obj_ptr,
|
| 412 |
+
object_score_logits,
|
| 413 |
+
)
|
| 414 |
+
|
| 415 |
+
def _use_mask_as_output(self, backbone_features, high_res_features, mask_inputs):
|
| 416 |
+
"""
|
| 417 |
+
Directly turn binary `mask_inputs` into a output mask logits without using SAM.
|
| 418 |
+
(same input and output shapes as in _forward_sam_heads above).
|
| 419 |
+
"""
|
| 420 |
+
# Use -10/+10 as logits for neg/pos pixels (very close to 0/1 in prob after sigmoid).
|
| 421 |
+
out_scale, out_bias = 20.0, -10.0 # sigmoid(-10.0)=4.5398e-05
|
| 422 |
+
mask_inputs_float = mask_inputs.float()
|
| 423 |
+
high_res_masks = mask_inputs_float * out_scale + out_bias
|
| 424 |
+
low_res_masks = F.interpolate(
|
| 425 |
+
high_res_masks,
|
| 426 |
+
size=(high_res_masks.size(-2) // 4, high_res_masks.size(-1) // 4),
|
| 427 |
+
align_corners=False,
|
| 428 |
+
mode="bilinear",
|
| 429 |
+
antialias=True, # use antialias for downsampling
|
| 430 |
+
)
|
| 431 |
+
# a dummy IoU prediction of all 1's under mask input
|
| 432 |
+
ious = mask_inputs.new_ones(mask_inputs.size(0), 1).float()
|
| 433 |
+
if not self.use_obj_ptrs_in_encoder:
|
| 434 |
+
# all zeros as a dummy object pointer (of shape [B, C])
|
| 435 |
+
obj_ptr = torch.zeros(
|
| 436 |
+
mask_inputs.size(0), self.hidden_dim, device=mask_inputs.device
|
| 437 |
+
)
|
| 438 |
+
else:
|
| 439 |
+
# produce an object pointer using the SAM decoder from the mask input
|
| 440 |
+
_, _, _, _, _, obj_ptr, _ = self._forward_sam_heads(
|
| 441 |
+
backbone_features=backbone_features,
|
| 442 |
+
mask_inputs=self.mask_downsample(mask_inputs_float),
|
| 443 |
+
high_res_features=high_res_features,
|
| 444 |
+
)
|
| 445 |
+
# In this method, we are treating mask_input as output, e.g. using it directly to create spatial mem;
|
| 446 |
+
# Below, we follow the same design axiom to use mask_input to decide if obj appears or not instead of relying
|
| 447 |
+
# on the object_scores from the SAM decoder.
|
| 448 |
+
is_obj_appearing = torch.any(mask_inputs.flatten(1).float() > 0.0, dim=1)
|
| 449 |
+
is_obj_appearing = is_obj_appearing[..., None]
|
| 450 |
+
lambda_is_obj_appearing = is_obj_appearing.float()
|
| 451 |
+
object_score_logits = out_scale * lambda_is_obj_appearing + out_bias
|
| 452 |
+
if self.pred_obj_scores:
|
| 453 |
+
if self.fixed_no_obj_ptr:
|
| 454 |
+
obj_ptr = lambda_is_obj_appearing * obj_ptr
|
| 455 |
+
obj_ptr = obj_ptr + (1 - lambda_is_obj_appearing) * self.no_obj_ptr
|
| 456 |
+
|
| 457 |
+
return (
|
| 458 |
+
low_res_masks,
|
| 459 |
+
high_res_masks,
|
| 460 |
+
ious,
|
| 461 |
+
low_res_masks,
|
| 462 |
+
high_res_masks,
|
| 463 |
+
obj_ptr,
|
| 464 |
+
object_score_logits,
|
| 465 |
+
)
|
| 466 |
+
|
| 467 |
+
def forward_image(self, img_batch: torch.Tensor):
|
| 468 |
+
"""Get the image feature on the input batch."""
|
| 469 |
+
backbone_out = self.image_encoder(img_batch)
|
| 470 |
+
if self.use_high_res_features_in_sam:
|
| 471 |
+
# precompute projected level 0 and level 1 features in SAM decoder
|
| 472 |
+
# to avoid running it again on every SAM click
|
| 473 |
+
backbone_out["backbone_fpn"][0] = self.sam_mask_decoder.conv_s0(
|
| 474 |
+
backbone_out["backbone_fpn"][0]
|
| 475 |
+
)
|
| 476 |
+
backbone_out["backbone_fpn"][1] = self.sam_mask_decoder.conv_s1(
|
| 477 |
+
backbone_out["backbone_fpn"][1]
|
| 478 |
+
)
|
| 479 |
+
return backbone_out
|
| 480 |
+
|
| 481 |
+
def _prepare_backbone_features(self, backbone_out):
|
| 482 |
+
"""Prepare and flatten visual features."""
|
| 483 |
+
backbone_out = backbone_out.copy()
|
| 484 |
+
assert len(backbone_out["backbone_fpn"]) == len(backbone_out["vision_pos_enc"])
|
| 485 |
+
assert len(backbone_out["backbone_fpn"]) >= self.num_feature_levels
|
| 486 |
+
|
| 487 |
+
feature_maps = backbone_out["backbone_fpn"][-self.num_feature_levels :]
|
| 488 |
+
vision_pos_embeds = backbone_out["vision_pos_enc"][-self.num_feature_levels :]
|
| 489 |
+
|
| 490 |
+
feat_sizes = [(x.shape[-2], x.shape[-1]) for x in vision_pos_embeds]
|
| 491 |
+
# flatten NxCxHxW to HWxNxC
|
| 492 |
+
vision_feats = [x.flatten(2).permute(2, 0, 1) for x in feature_maps]
|
| 493 |
+
vision_pos_embeds = [x.flatten(2).permute(2, 0, 1) for x in vision_pos_embeds]
|
| 494 |
+
|
| 495 |
+
return backbone_out, vision_feats, vision_pos_embeds, feat_sizes
|
| 496 |
+
|
| 497 |
+
def _prepare_memory_conditioned_features(
|
| 498 |
+
self,
|
| 499 |
+
frame_idx,
|
| 500 |
+
is_init_cond_frame,
|
| 501 |
+
current_vision_feats,
|
| 502 |
+
current_vision_pos_embeds,
|
| 503 |
+
feat_sizes,
|
| 504 |
+
output_dict,
|
| 505 |
+
num_frames,
|
| 506 |
+
track_in_reverse=False, # tracking in reverse time order (for demo usage)
|
| 507 |
+
):
|
| 508 |
+
"""Fuse the current frame's visual feature map with previous memory."""
|
| 509 |
+
B = current_vision_feats[-1].size(1) # batch size on this frame
|
| 510 |
+
C = self.hidden_dim
|
| 511 |
+
H, W = feat_sizes[-1] # top-level (lowest-resolution) feature size
|
| 512 |
+
device = current_vision_feats[-1].device
|
| 513 |
+
# The case of `self.num_maskmem == 0` below is primarily used for reproducing SAM on images.
|
| 514 |
+
# In this case, we skip the fusion with any memory.
|
| 515 |
+
if self.num_maskmem == 0: # Disable memory and skip fusion
|
| 516 |
+
pix_feat = current_vision_feats[-1].permute(1, 2, 0).view(B, C, H, W)
|
| 517 |
+
return pix_feat
|
| 518 |
+
|
| 519 |
+
num_obj_ptr_tokens = 0
|
| 520 |
+
tpos_sign_mul = -1 if track_in_reverse else 1
|
| 521 |
+
# Step 1: condition the visual features of the current frame on previous memories
|
| 522 |
+
if not is_init_cond_frame:
|
| 523 |
+
# Retrieve the memories encoded with the maskmem backbone
|
| 524 |
+
to_cat_memory, to_cat_memory_pos_embed = [], []
|
| 525 |
+
# Add conditioning frames's output first (all cond frames have t_pos=0 for
|
| 526 |
+
# when getting temporal positional embedding below)
|
| 527 |
+
assert len(output_dict["cond_frame_outputs"]) > 0
|
| 528 |
+
# Select a maximum number of temporally closest cond frames for cross attention
|
| 529 |
+
cond_outputs = output_dict["cond_frame_outputs"]
|
| 530 |
+
selected_cond_outputs, unselected_cond_outputs = select_closest_cond_frames(
|
| 531 |
+
frame_idx, cond_outputs, self.max_cond_frames_in_attn
|
| 532 |
+
)
|
| 533 |
+
t_pos_and_prevs = [(0, out) for out in selected_cond_outputs.values()]
|
| 534 |
+
# Add last (self.num_maskmem - 1) frames before current frame for non-conditioning memory
|
| 535 |
+
# the earliest one has t_pos=1 and the latest one has t_pos=self.num_maskmem-1
|
| 536 |
+
# We also allow taking the memory frame non-consecutively (with stride>1), in which case
|
| 537 |
+
# we take (self.num_maskmem - 2) frames among every stride-th frames plus the last frame.
|
| 538 |
+
stride = 1 if self.training else self.memory_temporal_stride_for_eval
|
| 539 |
+
for t_pos in range(1, self.num_maskmem):
|
| 540 |
+
t_rel = self.num_maskmem - t_pos # how many frames before current frame
|
| 541 |
+
if t_rel == 1:
|
| 542 |
+
# for t_rel == 1, we take the last frame (regardless of r)
|
| 543 |
+
if not track_in_reverse:
|
| 544 |
+
# the frame immediately before this frame (i.e. frame_idx - 1)
|
| 545 |
+
prev_frame_idx = frame_idx - t_rel
|
| 546 |
+
else:
|
| 547 |
+
# the frame immediately after this frame (i.e. frame_idx + 1)
|
| 548 |
+
prev_frame_idx = frame_idx + t_rel
|
| 549 |
+
else:
|
| 550 |
+
# for t_rel >= 2, we take the memory frame from every r-th frames
|
| 551 |
+
if not track_in_reverse:
|
| 552 |
+
# first find the nearest frame among every r-th frames before this frame
|
| 553 |
+
# for r=1, this would be (frame_idx - 2)
|
| 554 |
+
prev_frame_idx = ((frame_idx - 2) // stride) * stride
|
| 555 |
+
# then seek further among every r-th frames
|
| 556 |
+
prev_frame_idx = prev_frame_idx - (t_rel - 2) * stride
|
| 557 |
+
else:
|
| 558 |
+
# first find the nearest frame among every r-th frames after this frame
|
| 559 |
+
# for r=1, this would be (frame_idx + 2)
|
| 560 |
+
prev_frame_idx = -(-(frame_idx + 2) // stride) * stride
|
| 561 |
+
# then seek further among every r-th frames
|
| 562 |
+
prev_frame_idx = prev_frame_idx + (t_rel - 2) * stride
|
| 563 |
+
out = output_dict["non_cond_frame_outputs"].get(prev_frame_idx, None)
|
| 564 |
+
if out is None:
|
| 565 |
+
# If an unselected conditioning frame is among the last (self.num_maskmem - 1)
|
| 566 |
+
# frames, we still attend to it as if it's a non-conditioning frame.
|
| 567 |
+
out = unselected_cond_outputs.get(prev_frame_idx, None)
|
| 568 |
+
t_pos_and_prevs.append((t_pos, out))
|
| 569 |
+
|
| 570 |
+
for t_pos, prev in t_pos_and_prevs:
|
| 571 |
+
if prev is None:
|
| 572 |
+
continue # skip padding frames
|
| 573 |
+
# "maskmem_features" might have been offloaded to CPU in demo use cases,
|
| 574 |
+
# so we load it back to GPU (it's a no-op if it's already on GPU).
|
| 575 |
+
feats = prev["maskmem_features"].to(device, non_blocking=True)
|
| 576 |
+
to_cat_memory.append(feats.flatten(2).permute(2, 0, 1))
|
| 577 |
+
# Spatial positional encoding (it might have been offloaded to CPU in eval)
|
| 578 |
+
maskmem_enc = prev["maskmem_pos_enc"][-1].to(device)
|
| 579 |
+
maskmem_enc = maskmem_enc.flatten(2).permute(2, 0, 1)
|
| 580 |
+
# Temporal positional encoding
|
| 581 |
+
maskmem_enc = (
|
| 582 |
+
maskmem_enc + self.maskmem_tpos_enc[self.num_maskmem - t_pos - 1]
|
| 583 |
+
)
|
| 584 |
+
to_cat_memory_pos_embed.append(maskmem_enc)
|
| 585 |
+
|
| 586 |
+
# Construct the list of past object pointers
|
| 587 |
+
if self.use_obj_ptrs_in_encoder:
|
| 588 |
+
max_obj_ptrs_in_encoder = min(num_frames, self.max_obj_ptrs_in_encoder)
|
| 589 |
+
# First add those object pointers from selected conditioning frames
|
| 590 |
+
# (optionally, only include object pointers in the past during evaluation)
|
| 591 |
+
if not self.training and self.only_obj_ptrs_in_the_past_for_eval:
|
| 592 |
+
ptr_cond_outputs = {
|
| 593 |
+
t: out
|
| 594 |
+
for t, out in selected_cond_outputs.items()
|
| 595 |
+
if (t >= frame_idx if track_in_reverse else t <= frame_idx)
|
| 596 |
+
}
|
| 597 |
+
else:
|
| 598 |
+
ptr_cond_outputs = selected_cond_outputs
|
| 599 |
+
pos_and_ptrs = [
|
| 600 |
+
# Temporal pos encoding contains how far away each pointer is from current frame
|
| 601 |
+
(
|
| 602 |
+
(
|
| 603 |
+
(frame_idx - t) * tpos_sign_mul
|
| 604 |
+
if self.use_signed_tpos_enc_to_obj_ptrs
|
| 605 |
+
else abs(frame_idx - t)
|
| 606 |
+
),
|
| 607 |
+
out["obj_ptr"],
|
| 608 |
+
)
|
| 609 |
+
for t, out in ptr_cond_outputs.items()
|
| 610 |
+
]
|
| 611 |
+
# Add up to (max_obj_ptrs_in_encoder - 1) non-conditioning frames before current frame
|
| 612 |
+
for t_diff in range(1, max_obj_ptrs_in_encoder):
|
| 613 |
+
t = frame_idx + t_diff if track_in_reverse else frame_idx - t_diff
|
| 614 |
+
if t < 0 or (num_frames is not None and t >= num_frames):
|
| 615 |
+
break
|
| 616 |
+
out = output_dict["non_cond_frame_outputs"].get(
|
| 617 |
+
t, unselected_cond_outputs.get(t, None)
|
| 618 |
+
)
|
| 619 |
+
if out is not None:
|
| 620 |
+
pos_and_ptrs.append((t_diff, out["obj_ptr"]))
|
| 621 |
+
# If we have at least one object pointer, add them to the across attention
|
| 622 |
+
if len(pos_and_ptrs) > 0:
|
| 623 |
+
pos_list, ptrs_list = zip(*pos_and_ptrs)
|
| 624 |
+
# stack object pointers along dim=0 into [ptr_seq_len, B, C] shape
|
| 625 |
+
obj_ptrs = torch.stack(ptrs_list, dim=0)
|
| 626 |
+
# a temporal positional embedding based on how far each object pointer is from
|
| 627 |
+
# the current frame (sine embedding normalized by the max pointer num).
|
| 628 |
+
if self.add_tpos_enc_to_obj_ptrs:
|
| 629 |
+
t_diff_max = max_obj_ptrs_in_encoder - 1
|
| 630 |
+
tpos_dim = C if self.proj_tpos_enc_in_obj_ptrs else self.mem_dim
|
| 631 |
+
obj_pos = torch.tensor(pos_list).to(
|
| 632 |
+
device=device, non_blocking=True
|
| 633 |
+
)
|
| 634 |
+
obj_pos = get_1d_sine_pe(obj_pos / t_diff_max, dim=tpos_dim)
|
| 635 |
+
obj_pos = self.obj_ptr_tpos_proj(obj_pos)
|
| 636 |
+
obj_pos = obj_pos.unsqueeze(1).expand(-1, B, self.mem_dim)
|
| 637 |
+
else:
|
| 638 |
+
obj_pos = obj_ptrs.new_zeros(len(pos_list), B, self.mem_dim)
|
| 639 |
+
if self.mem_dim < C:
|
| 640 |
+
# split a pointer into (C // self.mem_dim) tokens for self.mem_dim < C
|
| 641 |
+
obj_ptrs = obj_ptrs.reshape(
|
| 642 |
+
-1, B, C // self.mem_dim, self.mem_dim
|
| 643 |
+
)
|
| 644 |
+
obj_ptrs = obj_ptrs.permute(0, 2, 1, 3).flatten(0, 1)
|
| 645 |
+
obj_pos = obj_pos.repeat_interleave(C // self.mem_dim, dim=0)
|
| 646 |
+
to_cat_memory.append(obj_ptrs)
|
| 647 |
+
to_cat_memory_pos_embed.append(obj_pos)
|
| 648 |
+
num_obj_ptr_tokens = obj_ptrs.shape[0]
|
| 649 |
+
else:
|
| 650 |
+
num_obj_ptr_tokens = 0
|
| 651 |
+
else:
|
| 652 |
+
# for initial conditioning frames, encode them without using any previous memory
|
| 653 |
+
if self.directly_add_no_mem_embed:
|
| 654 |
+
# directly add no-mem embedding (instead of using the transformer encoder)
|
| 655 |
+
pix_feat_with_mem = current_vision_feats[-1] + self.no_mem_embed
|
| 656 |
+
pix_feat_with_mem = pix_feat_with_mem.permute(1, 2, 0).view(B, C, H, W)
|
| 657 |
+
return pix_feat_with_mem
|
| 658 |
+
|
| 659 |
+
# Use a dummy token on the first frame (to avoid empty memory input to tranformer encoder)
|
| 660 |
+
to_cat_memory = [self.no_mem_embed.expand(1, B, self.mem_dim)]
|
| 661 |
+
to_cat_memory_pos_embed = [self.no_mem_pos_enc.expand(1, B, self.mem_dim)]
|
| 662 |
+
|
| 663 |
+
# Step 2: Concatenate the memories and forward through the transformer encoder
|
| 664 |
+
memory = torch.cat(to_cat_memory, dim=0)
|
| 665 |
+
memory_pos_embed = torch.cat(to_cat_memory_pos_embed, dim=0)
|
| 666 |
+
|
| 667 |
+
pix_feat_with_mem = self.memory_attention(
|
| 668 |
+
curr=current_vision_feats,
|
| 669 |
+
curr_pos=current_vision_pos_embeds,
|
| 670 |
+
memory=memory,
|
| 671 |
+
memory_pos=memory_pos_embed,
|
| 672 |
+
num_obj_ptr_tokens=num_obj_ptr_tokens,
|
| 673 |
+
)
|
| 674 |
+
# reshape the output (HW)BC => BCHW
|
| 675 |
+
pix_feat_with_mem = pix_feat_with_mem.permute(1, 2, 0).view(B, C, H, W)
|
| 676 |
+
return pix_feat_with_mem
|
| 677 |
+
|
| 678 |
+
def _encode_new_memory(
|
| 679 |
+
self,
|
| 680 |
+
current_vision_feats,
|
| 681 |
+
feat_sizes,
|
| 682 |
+
pred_masks_high_res,
|
| 683 |
+
object_score_logits,
|
| 684 |
+
is_mask_from_pts,
|
| 685 |
+
):
|
| 686 |
+
"""Encode the current image and its prediction into a memory feature."""
|
| 687 |
+
B = current_vision_feats[-1].size(1) # batch size on this frame
|
| 688 |
+
C = self.hidden_dim
|
| 689 |
+
H, W = feat_sizes[-1] # top-level (lowest-resolution) feature size
|
| 690 |
+
# top-level feature, (HW)BC => BCHW
|
| 691 |
+
pix_feat = current_vision_feats[-1].permute(1, 2, 0).view(B, C, H, W)
|
| 692 |
+
if self.non_overlap_masks_for_mem_enc and not self.training:
|
| 693 |
+
# optionally, apply non-overlapping constraints to the masks (it's applied
|
| 694 |
+
# in the batch dimension and should only be used during eval, where all
|
| 695 |
+
# the objects come from the same video under batch size 1).
|
| 696 |
+
pred_masks_high_res = self._apply_non_overlapping_constraints(
|
| 697 |
+
pred_masks_high_res
|
| 698 |
+
)
|
| 699 |
+
# scale the raw mask logits with a temperature before applying sigmoid
|
| 700 |
+
binarize = self.binarize_mask_from_pts_for_mem_enc and is_mask_from_pts
|
| 701 |
+
if binarize and not self.training:
|
| 702 |
+
mask_for_mem = (pred_masks_high_res > 0).float()
|
| 703 |
+
else:
|
| 704 |
+
# apply sigmoid on the raw mask logits to turn them into range (0, 1)
|
| 705 |
+
mask_for_mem = torch.sigmoid(pred_masks_high_res)
|
| 706 |
+
# apply scale and bias terms to the sigmoid probabilities
|
| 707 |
+
if self.sigmoid_scale_for_mem_enc != 1.0:
|
| 708 |
+
mask_for_mem = mask_for_mem * self.sigmoid_scale_for_mem_enc
|
| 709 |
+
if self.sigmoid_bias_for_mem_enc != 0.0:
|
| 710 |
+
mask_for_mem = mask_for_mem + self.sigmoid_bias_for_mem_enc
|
| 711 |
+
maskmem_out = self.memory_encoder(
|
| 712 |
+
pix_feat, mask_for_mem, skip_mask_sigmoid=True # sigmoid already applied
|
| 713 |
+
)
|
| 714 |
+
maskmem_features = maskmem_out["vision_features"]
|
| 715 |
+
maskmem_pos_enc = maskmem_out["vision_pos_enc"]
|
| 716 |
+
# add a no-object embedding to the spatial memory to indicate that the frame
|
| 717 |
+
# is predicted to be occluded (i.e. no object is appearing in the frame)
|
| 718 |
+
if self.no_obj_embed_spatial is not None:
|
| 719 |
+
is_obj_appearing = (object_score_logits > 0).float()
|
| 720 |
+
maskmem_features += (
|
| 721 |
+
1 - is_obj_appearing[..., None, None]
|
| 722 |
+
) * self.no_obj_embed_spatial[..., None, None].expand(
|
| 723 |
+
*maskmem_features.shape
|
| 724 |
+
)
|
| 725 |
+
|
| 726 |
+
return maskmem_features, maskmem_pos_enc
|
| 727 |
+
|
| 728 |
+
def _track_step(
|
| 729 |
+
self,
|
| 730 |
+
frame_idx,
|
| 731 |
+
is_init_cond_frame,
|
| 732 |
+
current_vision_feats,
|
| 733 |
+
current_vision_pos_embeds,
|
| 734 |
+
feat_sizes,
|
| 735 |
+
point_inputs,
|
| 736 |
+
mask_inputs,
|
| 737 |
+
output_dict,
|
| 738 |
+
num_frames,
|
| 739 |
+
track_in_reverse,
|
| 740 |
+
prev_sam_mask_logits,
|
| 741 |
+
):
|
| 742 |
+
current_out = {"point_inputs": point_inputs, "mask_inputs": mask_inputs}
|
| 743 |
+
# High-resolution feature maps for the SAM head, reshape (HW)BC => BCHW
|
| 744 |
+
if len(current_vision_feats) > 1:
|
| 745 |
+
high_res_features = [
|
| 746 |
+
x.permute(1, 2, 0).view(x.size(1), x.size(2), *s)
|
| 747 |
+
for x, s in zip(current_vision_feats[:-1], feat_sizes[:-1])
|
| 748 |
+
]
|
| 749 |
+
else:
|
| 750 |
+
high_res_features = None
|
| 751 |
+
if mask_inputs is not None and self.use_mask_input_as_output_without_sam:
|
| 752 |
+
# When use_mask_input_as_output_without_sam=True, we directly output the mask input
|
| 753 |
+
# (see it as a GT mask) without using a SAM prompt encoder + mask decoder.
|
| 754 |
+
pix_feat = current_vision_feats[-1].permute(1, 2, 0)
|
| 755 |
+
pix_feat = pix_feat.view(-1, self.hidden_dim, *feat_sizes[-1])
|
| 756 |
+
sam_outputs = self._use_mask_as_output(
|
| 757 |
+
pix_feat, high_res_features, mask_inputs
|
| 758 |
+
)
|
| 759 |
+
else:
|
| 760 |
+
# fused the visual feature with previous memory features in the memory bank
|
| 761 |
+
pix_feat = self._prepare_memory_conditioned_features(
|
| 762 |
+
frame_idx=frame_idx,
|
| 763 |
+
is_init_cond_frame=is_init_cond_frame,
|
| 764 |
+
current_vision_feats=current_vision_feats[-1:],
|
| 765 |
+
current_vision_pos_embeds=current_vision_pos_embeds[-1:],
|
| 766 |
+
feat_sizes=feat_sizes[-1:],
|
| 767 |
+
output_dict=output_dict,
|
| 768 |
+
num_frames=num_frames,
|
| 769 |
+
track_in_reverse=track_in_reverse,
|
| 770 |
+
)
|
| 771 |
+
# apply SAM-style segmentation head
|
| 772 |
+
# here we might feed previously predicted low-res SAM mask logits into the SAM mask decoder,
|
| 773 |
+
# e.g. in demo where such logits come from earlier interaction instead of correction sampling
|
| 774 |
+
# (in this case, any `mask_inputs` shouldn't reach here as they are sent to _use_mask_as_output instead)
|
| 775 |
+
if prev_sam_mask_logits is not None:
|
| 776 |
+
assert point_inputs is not None and mask_inputs is None
|
| 777 |
+
mask_inputs = prev_sam_mask_logits
|
| 778 |
+
multimask_output = self._use_multimask(is_init_cond_frame, point_inputs)
|
| 779 |
+
sam_outputs = self._forward_sam_heads(
|
| 780 |
+
backbone_features=pix_feat,
|
| 781 |
+
point_inputs=point_inputs,
|
| 782 |
+
mask_inputs=mask_inputs,
|
| 783 |
+
high_res_features=high_res_features,
|
| 784 |
+
multimask_output=multimask_output,
|
| 785 |
+
)
|
| 786 |
+
|
| 787 |
+
return current_out, sam_outputs, high_res_features, pix_feat
|
| 788 |
+
|
| 789 |
+
def _encode_memory_in_output(
|
| 790 |
+
self,
|
| 791 |
+
current_vision_feats,
|
| 792 |
+
feat_sizes,
|
| 793 |
+
point_inputs,
|
| 794 |
+
run_mem_encoder,
|
| 795 |
+
high_res_masks,
|
| 796 |
+
object_score_logits,
|
| 797 |
+
current_out,
|
| 798 |
+
):
|
| 799 |
+
if run_mem_encoder and self.num_maskmem > 0:
|
| 800 |
+
high_res_masks_for_mem_enc = high_res_masks
|
| 801 |
+
maskmem_features, maskmem_pos_enc = self._encode_new_memory(
|
| 802 |
+
current_vision_feats=current_vision_feats,
|
| 803 |
+
feat_sizes=feat_sizes,
|
| 804 |
+
pred_masks_high_res=high_res_masks_for_mem_enc,
|
| 805 |
+
object_score_logits=object_score_logits,
|
| 806 |
+
is_mask_from_pts=(point_inputs is not None),
|
| 807 |
+
)
|
| 808 |
+
current_out["maskmem_features"] = maskmem_features
|
| 809 |
+
current_out["maskmem_pos_enc"] = maskmem_pos_enc
|
| 810 |
+
else:
|
| 811 |
+
current_out["maskmem_features"] = None
|
| 812 |
+
current_out["maskmem_pos_enc"] = None
|
| 813 |
+
|
| 814 |
+
def track_step(
|
| 815 |
+
self,
|
| 816 |
+
frame_idx,
|
| 817 |
+
is_init_cond_frame,
|
| 818 |
+
current_vision_feats,
|
| 819 |
+
current_vision_pos_embeds,
|
| 820 |
+
feat_sizes,
|
| 821 |
+
point_inputs,
|
| 822 |
+
mask_inputs,
|
| 823 |
+
output_dict,
|
| 824 |
+
num_frames,
|
| 825 |
+
track_in_reverse=False, # tracking in reverse time order (for demo usage)
|
| 826 |
+
# Whether to run the memory encoder on the predicted masks. Sometimes we might want
|
| 827 |
+
# to skip the memory encoder with `run_mem_encoder=False`. For example,
|
| 828 |
+
# in demo we might call `track_step` multiple times for each user click,
|
| 829 |
+
# and only encode the memory when the user finalizes their clicks. And in ablation
|
| 830 |
+
# settings like SAM training on static images, we don't need the memory encoder.
|
| 831 |
+
run_mem_encoder=True,
|
| 832 |
+
# The previously predicted SAM mask logits (which can be fed together with new clicks in demo).
|
| 833 |
+
prev_sam_mask_logits=None,
|
| 834 |
+
):
|
| 835 |
+
current_out, sam_outputs, _, _ = self._track_step(
|
| 836 |
+
frame_idx,
|
| 837 |
+
is_init_cond_frame,
|
| 838 |
+
current_vision_feats,
|
| 839 |
+
current_vision_pos_embeds,
|
| 840 |
+
feat_sizes,
|
| 841 |
+
point_inputs,
|
| 842 |
+
mask_inputs,
|
| 843 |
+
output_dict,
|
| 844 |
+
num_frames,
|
| 845 |
+
track_in_reverse,
|
| 846 |
+
prev_sam_mask_logits,
|
| 847 |
+
)
|
| 848 |
+
|
| 849 |
+
(
|
| 850 |
+
_,
|
| 851 |
+
_,
|
| 852 |
+
_,
|
| 853 |
+
low_res_masks,
|
| 854 |
+
high_res_masks,
|
| 855 |
+
obj_ptr,
|
| 856 |
+
object_score_logits,
|
| 857 |
+
) = sam_outputs
|
| 858 |
+
|
| 859 |
+
current_out["pred_masks"] = low_res_masks
|
| 860 |
+
current_out["pred_masks_high_res"] = high_res_masks
|
| 861 |
+
current_out["obj_ptr"] = obj_ptr
|
| 862 |
+
if not self.training:
|
| 863 |
+
# Only add this in inference (to avoid unused param in activation checkpointing;
|
| 864 |
+
# it's mainly used in the demo to encode spatial memories w/ consolidated masks)
|
| 865 |
+
current_out["object_score_logits"] = object_score_logits
|
| 866 |
+
|
| 867 |
+
# Finally run the memory encoder on the predicted mask to encode
|
| 868 |
+
# it into a new memory feature (that can be used in future frames)
|
| 869 |
+
self._encode_memory_in_output(
|
| 870 |
+
current_vision_feats,
|
| 871 |
+
feat_sizes,
|
| 872 |
+
point_inputs,
|
| 873 |
+
run_mem_encoder,
|
| 874 |
+
high_res_masks,
|
| 875 |
+
object_score_logits,
|
| 876 |
+
current_out,
|
| 877 |
+
)
|
| 878 |
+
|
| 879 |
+
return current_out
|
| 880 |
+
|
| 881 |
+
def _use_multimask(self, is_init_cond_frame, point_inputs):
|
| 882 |
+
"""Whether to use multimask output in the SAM head."""
|
| 883 |
+
num_pts = 0 if point_inputs is None else point_inputs["point_labels"].size(1)
|
| 884 |
+
multimask_output = (
|
| 885 |
+
self.multimask_output_in_sam
|
| 886 |
+
and (is_init_cond_frame or self.multimask_output_for_tracking)
|
| 887 |
+
and (self.multimask_min_pt_num <= num_pts <= self.multimask_max_pt_num)
|
| 888 |
+
)
|
| 889 |
+
return multimask_output
|
| 890 |
+
|
| 891 |
+
def _apply_non_overlapping_constraints(self, pred_masks):
|
| 892 |
+
"""
|
| 893 |
+
Apply non-overlapping constraints to the object scores in pred_masks. Here we
|
| 894 |
+
keep only the highest scoring object at each spatial location in pred_masks.
|
| 895 |
+
"""
|
| 896 |
+
batch_size = pred_masks.size(0)
|
| 897 |
+
if batch_size == 1:
|
| 898 |
+
return pred_masks
|
| 899 |
+
|
| 900 |
+
device = pred_masks.device
|
| 901 |
+
# "max_obj_inds": object index of the object with the highest score at each location
|
| 902 |
+
max_obj_inds = torch.argmax(pred_masks, dim=0, keepdim=True)
|
| 903 |
+
# "batch_obj_inds": object index of each object slice (along dim 0) in `pred_masks`
|
| 904 |
+
batch_obj_inds = torch.arange(batch_size, device=device)[:, None, None, None]
|
| 905 |
+
keep = max_obj_inds == batch_obj_inds
|
| 906 |
+
# suppress overlapping regions' scores below -10.0 so that the foreground regions
|
| 907 |
+
# don't overlap (here sigmoid(-10.0)=4.5398e-05)
|
| 908 |
+
pred_masks = torch.where(keep, pred_masks, torch.clamp(pred_masks, max=-10.0))
|
| 909 |
+
return pred_masks
|
third_party/sam2/sam2/modeling/sam2_utils.py
ADDED
|
@@ -0,0 +1,323 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import copy
|
| 9 |
+
from typing import Tuple
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
import torch.nn as nn
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
|
| 16 |
+
from sam2.utils.misc import mask_to_box
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def select_closest_cond_frames(frame_idx, cond_frame_outputs, max_cond_frame_num):
|
| 20 |
+
"""
|
| 21 |
+
Select up to `max_cond_frame_num` conditioning frames from `cond_frame_outputs`
|
| 22 |
+
that are temporally closest to the current frame at `frame_idx`. Here, we take
|
| 23 |
+
- a) the closest conditioning frame before `frame_idx` (if any);
|
| 24 |
+
- b) the closest conditioning frame after `frame_idx` (if any);
|
| 25 |
+
- c) any other temporally closest conditioning frames until reaching a total
|
| 26 |
+
of `max_cond_frame_num` conditioning frames.
|
| 27 |
+
|
| 28 |
+
Outputs:
|
| 29 |
+
- selected_outputs: selected items (keys & values) from `cond_frame_outputs`.
|
| 30 |
+
- unselected_outputs: items (keys & values) not selected in `cond_frame_outputs`.
|
| 31 |
+
"""
|
| 32 |
+
if max_cond_frame_num == -1 or len(cond_frame_outputs) <= max_cond_frame_num:
|
| 33 |
+
selected_outputs = cond_frame_outputs
|
| 34 |
+
unselected_outputs = {}
|
| 35 |
+
else:
|
| 36 |
+
assert max_cond_frame_num >= 2, "we should allow using 2+ conditioning frames"
|
| 37 |
+
selected_outputs = {}
|
| 38 |
+
|
| 39 |
+
# the closest conditioning frame before `frame_idx` (if any)
|
| 40 |
+
idx_before = max((t for t in cond_frame_outputs if t < frame_idx), default=None)
|
| 41 |
+
if idx_before is not None:
|
| 42 |
+
selected_outputs[idx_before] = cond_frame_outputs[idx_before]
|
| 43 |
+
|
| 44 |
+
# the closest conditioning frame after `frame_idx` (if any)
|
| 45 |
+
idx_after = min((t for t in cond_frame_outputs if t >= frame_idx), default=None)
|
| 46 |
+
if idx_after is not None:
|
| 47 |
+
selected_outputs[idx_after] = cond_frame_outputs[idx_after]
|
| 48 |
+
|
| 49 |
+
# add other temporally closest conditioning frames until reaching a total
|
| 50 |
+
# of `max_cond_frame_num` conditioning frames.
|
| 51 |
+
num_remain = max_cond_frame_num - len(selected_outputs)
|
| 52 |
+
inds_remain = sorted(
|
| 53 |
+
(t for t in cond_frame_outputs if t not in selected_outputs),
|
| 54 |
+
key=lambda x: abs(x - frame_idx),
|
| 55 |
+
)[:num_remain]
|
| 56 |
+
selected_outputs.update((t, cond_frame_outputs[t]) for t in inds_remain)
|
| 57 |
+
unselected_outputs = {
|
| 58 |
+
t: v for t, v in cond_frame_outputs.items() if t not in selected_outputs
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
return selected_outputs, unselected_outputs
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def get_1d_sine_pe(pos_inds, dim, temperature=10000):
|
| 65 |
+
"""
|
| 66 |
+
Get 1D sine positional embedding as in the original Transformer paper.
|
| 67 |
+
"""
|
| 68 |
+
pe_dim = dim // 2
|
| 69 |
+
dim_t = torch.arange(pe_dim, dtype=torch.float32, device=pos_inds.device)
|
| 70 |
+
dim_t = temperature ** (2 * (dim_t // 2) / pe_dim)
|
| 71 |
+
|
| 72 |
+
pos_embed = pos_inds.unsqueeze(-1) / dim_t
|
| 73 |
+
pos_embed = torch.cat([pos_embed.sin(), pos_embed.cos()], dim=-1)
|
| 74 |
+
return pos_embed
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def get_activation_fn(activation):
|
| 78 |
+
"""Return an activation function given a string"""
|
| 79 |
+
if activation == "relu":
|
| 80 |
+
return F.relu
|
| 81 |
+
if activation == "gelu":
|
| 82 |
+
return F.gelu
|
| 83 |
+
if activation == "glu":
|
| 84 |
+
return F.glu
|
| 85 |
+
raise RuntimeError(f"activation should be relu/gelu, not {activation}.")
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def get_clones(module, N):
|
| 89 |
+
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class DropPath(nn.Module):
|
| 93 |
+
# adapted from https://github.com/huggingface/pytorch-image-models/blob/main/timm/layers/drop.py
|
| 94 |
+
def __init__(self, drop_prob=0.0, scale_by_keep=True):
|
| 95 |
+
super(DropPath, self).__init__()
|
| 96 |
+
self.drop_prob = drop_prob
|
| 97 |
+
self.scale_by_keep = scale_by_keep
|
| 98 |
+
|
| 99 |
+
def forward(self, x):
|
| 100 |
+
if self.drop_prob == 0.0 or not self.training:
|
| 101 |
+
return x
|
| 102 |
+
keep_prob = 1 - self.drop_prob
|
| 103 |
+
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
|
| 104 |
+
random_tensor = x.new_empty(shape).bernoulli_(keep_prob)
|
| 105 |
+
if keep_prob > 0.0 and self.scale_by_keep:
|
| 106 |
+
random_tensor.div_(keep_prob)
|
| 107 |
+
return x * random_tensor
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
# Lightly adapted from
|
| 111 |
+
# https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/transformer/transformer_predictor.py # noqa
|
| 112 |
+
class MLP(nn.Module):
|
| 113 |
+
def __init__(
|
| 114 |
+
self,
|
| 115 |
+
input_dim: int,
|
| 116 |
+
hidden_dim: int,
|
| 117 |
+
output_dim: int,
|
| 118 |
+
num_layers: int,
|
| 119 |
+
activation: nn.Module = nn.ReLU,
|
| 120 |
+
sigmoid_output: bool = False,
|
| 121 |
+
) -> None:
|
| 122 |
+
super().__init__()
|
| 123 |
+
self.num_layers = num_layers
|
| 124 |
+
h = [hidden_dim] * (num_layers - 1)
|
| 125 |
+
self.layers = nn.ModuleList(
|
| 126 |
+
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
|
| 127 |
+
)
|
| 128 |
+
self.sigmoid_output = sigmoid_output
|
| 129 |
+
self.act = activation()
|
| 130 |
+
|
| 131 |
+
def forward(self, x):
|
| 132 |
+
for i, layer in enumerate(self.layers):
|
| 133 |
+
x = self.act(layer(x)) if i < self.num_layers - 1 else layer(x)
|
| 134 |
+
if self.sigmoid_output:
|
| 135 |
+
x = F.sigmoid(x)
|
| 136 |
+
return x
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
# From https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py # noqa
|
| 140 |
+
# Itself from https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa
|
| 141 |
+
class LayerNorm2d(nn.Module):
|
| 142 |
+
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
|
| 143 |
+
super().__init__()
|
| 144 |
+
self.weight = nn.Parameter(torch.ones(num_channels))
|
| 145 |
+
self.bias = nn.Parameter(torch.zeros(num_channels))
|
| 146 |
+
self.eps = eps
|
| 147 |
+
|
| 148 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 149 |
+
u = x.mean(1, keepdim=True)
|
| 150 |
+
s = (x - u).pow(2).mean(1, keepdim=True)
|
| 151 |
+
x = (x - u) / torch.sqrt(s + self.eps)
|
| 152 |
+
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
| 153 |
+
return x
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def sample_box_points(
|
| 157 |
+
masks: torch.Tensor,
|
| 158 |
+
noise: float = 0.1, # SAM default
|
| 159 |
+
noise_bound: int = 20, # SAM default
|
| 160 |
+
top_left_label: int = 2,
|
| 161 |
+
bottom_right_label: int = 3,
|
| 162 |
+
) -> Tuple[np.array, np.array]:
|
| 163 |
+
"""
|
| 164 |
+
Sample a noised version of the top left and bottom right corners of a given `bbox`
|
| 165 |
+
|
| 166 |
+
Inputs:
|
| 167 |
+
- masks: [B, 1, H,W] boxes, dtype=torch.Tensor
|
| 168 |
+
- noise: noise as a fraction of box width and height, dtype=float
|
| 169 |
+
- noise_bound: maximum amount of noise (in pure pixesl), dtype=int
|
| 170 |
+
|
| 171 |
+
Returns:
|
| 172 |
+
- box_coords: [B, num_pt, 2], contains (x, y) coordinates of top left and bottom right box corners, dtype=torch.float
|
| 173 |
+
- box_labels: [B, num_pt], label 2 is reserverd for top left and 3 for bottom right corners, dtype=torch.int32
|
| 174 |
+
"""
|
| 175 |
+
device = masks.device
|
| 176 |
+
box_coords = mask_to_box(masks)
|
| 177 |
+
B, _, H, W = masks.shape
|
| 178 |
+
box_labels = torch.tensor(
|
| 179 |
+
[top_left_label, bottom_right_label], dtype=torch.int, device=device
|
| 180 |
+
).repeat(B)
|
| 181 |
+
if noise > 0.0:
|
| 182 |
+
if not isinstance(noise_bound, torch.Tensor):
|
| 183 |
+
noise_bound = torch.tensor(noise_bound, device=device)
|
| 184 |
+
bbox_w = box_coords[..., 2] - box_coords[..., 0]
|
| 185 |
+
bbox_h = box_coords[..., 3] - box_coords[..., 1]
|
| 186 |
+
max_dx = torch.min(bbox_w * noise, noise_bound)
|
| 187 |
+
max_dy = torch.min(bbox_h * noise, noise_bound)
|
| 188 |
+
box_noise = 2 * torch.rand(B, 1, 4, device=device) - 1
|
| 189 |
+
box_noise = box_noise * torch.stack((max_dx, max_dy, max_dx, max_dy), dim=-1)
|
| 190 |
+
|
| 191 |
+
box_coords = box_coords + box_noise
|
| 192 |
+
img_bounds = (
|
| 193 |
+
torch.tensor([W, H, W, H], device=device) - 1
|
| 194 |
+
) # uncentered pixel coords
|
| 195 |
+
box_coords.clamp_(torch.zeros_like(img_bounds), img_bounds) # In place clamping
|
| 196 |
+
|
| 197 |
+
box_coords = box_coords.reshape(-1, 2, 2) # always 2 points
|
| 198 |
+
box_labels = box_labels.reshape(-1, 2)
|
| 199 |
+
return box_coords, box_labels
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def sample_random_points_from_errors(gt_masks, pred_masks, num_pt=1):
|
| 203 |
+
"""
|
| 204 |
+
Sample `num_pt` random points (along with their labels) independently from the error regions.
|
| 205 |
+
|
| 206 |
+
Inputs:
|
| 207 |
+
- gt_masks: [B, 1, H_im, W_im] masks, dtype=torch.bool
|
| 208 |
+
- pred_masks: [B, 1, H_im, W_im] masks, dtype=torch.bool or None
|
| 209 |
+
- num_pt: int, number of points to sample independently for each of the B error maps
|
| 210 |
+
|
| 211 |
+
Outputs:
|
| 212 |
+
- points: [B, num_pt, 2], dtype=torch.float, contains (x, y) coordinates of each sampled point
|
| 213 |
+
- labels: [B, num_pt], dtype=torch.int32, where 1 means positive clicks and 0 means
|
| 214 |
+
negative clicks
|
| 215 |
+
"""
|
| 216 |
+
if pred_masks is None: # if pred_masks is not provided, treat it as empty
|
| 217 |
+
pred_masks = torch.zeros_like(gt_masks)
|
| 218 |
+
assert gt_masks.dtype == torch.bool and gt_masks.size(1) == 1
|
| 219 |
+
assert pred_masks.dtype == torch.bool and pred_masks.shape == gt_masks.shape
|
| 220 |
+
assert num_pt >= 0
|
| 221 |
+
|
| 222 |
+
B, _, H_im, W_im = gt_masks.shape
|
| 223 |
+
device = gt_masks.device
|
| 224 |
+
|
| 225 |
+
# false positive region, a new point sampled in this region should have
|
| 226 |
+
# negative label to correct the FP error
|
| 227 |
+
fp_masks = ~gt_masks & pred_masks
|
| 228 |
+
# false negative region, a new point sampled in this region should have
|
| 229 |
+
# positive label to correct the FN error
|
| 230 |
+
fn_masks = gt_masks & ~pred_masks
|
| 231 |
+
# whether the prediction completely match the ground-truth on each mask
|
| 232 |
+
all_correct = torch.all((gt_masks == pred_masks).flatten(2), dim=2)
|
| 233 |
+
all_correct = all_correct[..., None, None]
|
| 234 |
+
|
| 235 |
+
# channel 0 is FP map, while channel 1 is FN map
|
| 236 |
+
pts_noise = torch.rand(B, num_pt, H_im, W_im, 2, device=device)
|
| 237 |
+
# sample a negative new click from FP region or a positive new click
|
| 238 |
+
# from FN region, depend on where the maximum falls,
|
| 239 |
+
# and in case the predictions are all correct (no FP or FN), we just
|
| 240 |
+
# sample a negative click from the background region
|
| 241 |
+
pts_noise[..., 0] *= fp_masks | (all_correct & ~gt_masks)
|
| 242 |
+
pts_noise[..., 1] *= fn_masks
|
| 243 |
+
pts_idx = pts_noise.flatten(2).argmax(dim=2)
|
| 244 |
+
labels = (pts_idx % 2).to(torch.int32)
|
| 245 |
+
pts_idx = pts_idx // 2
|
| 246 |
+
pts_x = pts_idx % W_im
|
| 247 |
+
pts_y = pts_idx // W_im
|
| 248 |
+
points = torch.stack([pts_x, pts_y], dim=2).to(torch.float)
|
| 249 |
+
return points, labels
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
def sample_one_point_from_error_center(gt_masks, pred_masks, padding=True):
|
| 253 |
+
"""
|
| 254 |
+
Sample 1 random point (along with its label) from the center of each error region,
|
| 255 |
+
that is, the point with the largest distance to the boundary of each error region.
|
| 256 |
+
This is the RITM sampling method from https://github.com/saic-vul/ritm_interactive_segmentation/blob/master/isegm/inference/clicker.py
|
| 257 |
+
|
| 258 |
+
Inputs:
|
| 259 |
+
- gt_masks: [B, 1, H_im, W_im] masks, dtype=torch.bool
|
| 260 |
+
- pred_masks: [B, 1, H_im, W_im] masks, dtype=torch.bool or None
|
| 261 |
+
- padding: if True, pad with boundary of 1 px for distance transform
|
| 262 |
+
|
| 263 |
+
Outputs:
|
| 264 |
+
- points: [B, 1, 2], dtype=torch.float, contains (x, y) coordinates of each sampled point
|
| 265 |
+
- labels: [B, 1], dtype=torch.int32, where 1 means positive clicks and 0 means negative clicks
|
| 266 |
+
"""
|
| 267 |
+
import cv2
|
| 268 |
+
|
| 269 |
+
if pred_masks is None:
|
| 270 |
+
pred_masks = torch.zeros_like(gt_masks)
|
| 271 |
+
assert gt_masks.dtype == torch.bool and gt_masks.size(1) == 1
|
| 272 |
+
assert pred_masks.dtype == torch.bool and pred_masks.shape == gt_masks.shape
|
| 273 |
+
|
| 274 |
+
B, _, _, W_im = gt_masks.shape
|
| 275 |
+
device = gt_masks.device
|
| 276 |
+
|
| 277 |
+
# false positive region, a new point sampled in this region should have
|
| 278 |
+
# negative label to correct the FP error
|
| 279 |
+
fp_masks = ~gt_masks & pred_masks
|
| 280 |
+
# false negative region, a new point sampled in this region should have
|
| 281 |
+
# positive label to correct the FN error
|
| 282 |
+
fn_masks = gt_masks & ~pred_masks
|
| 283 |
+
|
| 284 |
+
fp_masks = fp_masks.cpu().numpy()
|
| 285 |
+
fn_masks = fn_masks.cpu().numpy()
|
| 286 |
+
points = torch.zeros(B, 1, 2, dtype=torch.float)
|
| 287 |
+
labels = torch.ones(B, 1, dtype=torch.int32)
|
| 288 |
+
for b in range(B):
|
| 289 |
+
fn_mask = fn_masks[b, 0]
|
| 290 |
+
fp_mask = fp_masks[b, 0]
|
| 291 |
+
if padding:
|
| 292 |
+
fn_mask = np.pad(fn_mask, ((1, 1), (1, 1)), "constant")
|
| 293 |
+
fp_mask = np.pad(fp_mask, ((1, 1), (1, 1)), "constant")
|
| 294 |
+
# compute the distance of each point in FN/FP region to its boundary
|
| 295 |
+
fn_mask_dt = cv2.distanceTransform(fn_mask.astype(np.uint8), cv2.DIST_L2, 0)
|
| 296 |
+
fp_mask_dt = cv2.distanceTransform(fp_mask.astype(np.uint8), cv2.DIST_L2, 0)
|
| 297 |
+
if padding:
|
| 298 |
+
fn_mask_dt = fn_mask_dt[1:-1, 1:-1]
|
| 299 |
+
fp_mask_dt = fp_mask_dt[1:-1, 1:-1]
|
| 300 |
+
|
| 301 |
+
# take the point in FN/FP region with the largest distance to its boundary
|
| 302 |
+
fn_mask_dt_flat = fn_mask_dt.reshape(-1)
|
| 303 |
+
fp_mask_dt_flat = fp_mask_dt.reshape(-1)
|
| 304 |
+
fn_argmax = np.argmax(fn_mask_dt_flat)
|
| 305 |
+
fp_argmax = np.argmax(fp_mask_dt_flat)
|
| 306 |
+
is_positive = fn_mask_dt_flat[fn_argmax] > fp_mask_dt_flat[fp_argmax]
|
| 307 |
+
pt_idx = fn_argmax if is_positive else fp_argmax
|
| 308 |
+
points[b, 0, 0] = pt_idx % W_im # x
|
| 309 |
+
points[b, 0, 1] = pt_idx // W_im # y
|
| 310 |
+
labels[b, 0] = int(is_positive)
|
| 311 |
+
|
| 312 |
+
points = points.to(device)
|
| 313 |
+
labels = labels.to(device)
|
| 314 |
+
return points, labels
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
def get_next_point(gt_masks, pred_masks, method):
|
| 318 |
+
if method == "uniform":
|
| 319 |
+
return sample_random_points_from_errors(gt_masks, pred_masks)
|
| 320 |
+
elif method == "center":
|
| 321 |
+
return sample_one_point_from_error_center(gt_masks, pred_masks)
|
| 322 |
+
else:
|
| 323 |
+
raise ValueError(f"unknown sampling method {method}")
|
third_party/sam2/sam2/sam2_hiera_b+.yaml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
configs/sam2/sam2_hiera_b+.yaml
|