

Updated to latest FastSD
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +2 -1
- LICENSE +21 -0
- README.md +723 -13
- THIRD-PARTY-LICENSES +143 -0
- app.py +0 -196
- benchmark-openvino.bat +23 -0
- benchmark.bat +23 -0
- configs/lcm-lora-models.txt +2 -1
- configs/lcm-models.txt +3 -0
- configs/openvino-lcm-models.txt +6 -1
- controlnet_models/Readme.txt +3 -0
- docs/images/2steps-inference.jpg +3 -0
- docs/images/ARCGPU.png +3 -0
- docs/images/fastcpu-cli.png +3 -0
- docs/images/fastcpu-webui.png +3 -0
- docs/images/fastsdcpu-android-termux-pixel7.png +3 -0
- docs/images/fastsdcpu-api.png +3 -0
- docs/images/fastsdcpu-gui.jpg +3 -0
- docs/images/fastsdcpu-mac-gui.jpg +3 -0
- docs/images/fastsdcpu-screenshot.png +3 -0
- docs/images/fastsdcpu-webui.png +3 -0
- docs/images/fastsdcpu_claude.jpg +3 -0
- docs/images/fastsdcpu_flux_on_cpu.png +3 -0
- docs/images/openwebui-fastsd.jpg +3 -0
- docs/images/openwebui-settings.png +3 -0
- frontend/webui/hf_demo.py +6 -6
- install-mac.sh +36 -0
- install.bat +38 -0
- install.sh +44 -0
- lora_models/Readme.txt +3 -0
- models/gguf/clip/readme.txt +1 -0
- models/gguf/diffusion/readme.txt +1 -0
- models/gguf/t5xxl/readme.txt +1 -0
- models/gguf/vae/readme.txt +1 -0
- requirements.txt +15 -11
- src/__init__.py +0 -0
- src/app.py +554 -0
- src/app_settings.py +124 -0
- src/backend/__init__.py +0 -0
- src/backend/annotators/canny_control.py +15 -0
- src/backend/annotators/control_interface.py +12 -0
- src/backend/annotators/depth_control.py +15 -0
- src/backend/annotators/image_control_factory.py +31 -0
- src/backend/annotators/lineart_control.py +11 -0
- src/backend/annotators/mlsd_control.py +10 -0
- src/backend/annotators/normal_control.py +10 -0
- src/backend/annotators/pose_control.py +10 -0
- src/backend/annotators/shuffle_control.py +10 -0
- src/backend/annotators/softedge_control.py +10 -0
- src/backend/api/mcp_server.py +97 -0
.gitignore
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
env
|
|
|
|
| 2 |
*.bak
|
| 3 |
*.pyc
|
| 4 |
__pycache__
|
| 5 |
results
|
| 6 |
# excluding user settings for the GUI frontend
|
| 7 |
-
configs/settings.yaml
|
|
|
|
| 1 |
env
|
| 2 |
+
env_old
|
| 3 |
*.bak
|
| 4 |
*.pyc
|
| 5 |
__pycache__
|
| 6 |
results
|
| 7 |
# excluding user settings for the GUI frontend
|
| 8 |
+
configs/settings.yaml
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Rupesh Sreeraman
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,13 +1,723 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FastSD CPU :sparkles:[](https://github.com/openvinotoolkit/awesome-openvino)
|
| 2 |
+
|
| 3 |
+
<div align="center">
|
| 4 |
+
<a href="https://trendshift.io/repositories/3957" target="_blank"><img src="https://trendshift.io/api/badge/repositories/3957" alt="rupeshs%2Ffastsdcpu | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
|
| 5 |
+
</div>
|
| 6 |
+
|
| 7 |
+
## 📰 News
|
| 8 |
+
|
| 9 |
+
- **2024-11-03** - Added Intel Core Ultra Series 2 (Lunar Lake) NPU support
|
| 10 |
+
- **2024-10-02** - Added GGUF diffusion model(Flux) support
|
| 11 |
+
- **2024-09-03** – Added Intel AI PC GPU, NPU support 🚀
|
| 12 |
+
|
| 13 |
+
FastSD CPU is a faster version of Stable Diffusion on CPU. Based on [Latent Consistency Models](https://github.com/luosiallen/latent-consistency-model) and
|
| 14 |
+
[Adversarial Diffusion Distillation](https://nolowiz.com/fast-stable-diffusion-on-cpu-using-fastsd-cpu-and-openvino/).
|
| 15 |
+
|
| 16 |
+
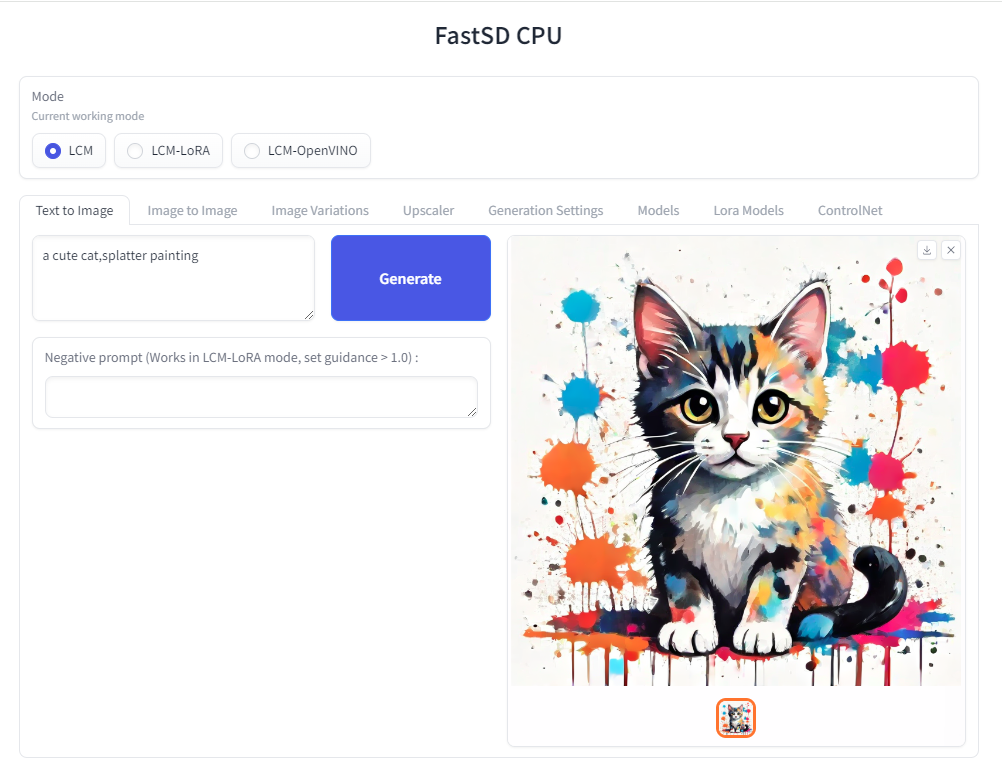
|
| 17 |
+
The following interfaces are available :
|
| 18 |
+
|
| 19 |
+
- Desktop GUI, basic text to image generation (Qt,faster)
|
| 20 |
+
- WebUI (Advanced features,Lora,controlnet etc)
|
| 21 |
+
- CLI (CommandLine Interface)
|
| 22 |
+
|
| 23 |
+
🚀 Using **OpenVINO(SDXS-512-0.9)**, it took **0.82 seconds** (**820 milliseconds**) to create a single 512x512 image on a **Core i7-12700**.
|
| 24 |
+
|
| 25 |
+
## Table of Contents 👇
|
| 26 |
+
|
| 27 |
+
- [Supported Platforms](#Supported platforms)
|
| 28 |
+
- [Dependencies](#dependencies)
|
| 29 |
+
- [Memory requirements](#memory-requirements)
|
| 30 |
+
- [Features](#features)
|
| 31 |
+
- [Benchmarks](#fast-inference-benchmarks)
|
| 32 |
+
- [OpenVINO Support](#openvino)
|
| 33 |
+
- [Installation](#installation)
|
| 34 |
+
- [Real-time text to image (EXPERIMENTAL)](#real-time-text-to-image)
|
| 35 |
+
- [Models](#models)
|
| 36 |
+
- [How to use Lora models](#useloramodels)
|
| 37 |
+
- [How to use controlnet](#usecontrolnet)
|
| 38 |
+
- [Android](#android)
|
| 39 |
+
- [Raspberry Pi 4](#raspberry)
|
| 40 |
+
- [API Support](#apisupport)
|
| 41 |
+
- [GGUF support (Flux)](#gguf-support)
|
| 42 |
+
- [AI PC Support - OpenVINO](#ai-pc-support)
|
| 43 |
+
- [MCP Server Support](#mcpsupport)
|
| 44 |
+
- [Open WebUI Support](#openwebuisupport)
|
| 45 |
+
- [License](#license)
|
| 46 |
+
- [Contributors](#contributors)
|
| 47 |
+
|
| 48 |
+
## Supported platforms⚡️
|
| 49 |
+
|
| 50 |
+
FastSD CPU works on the following platforms:
|
| 51 |
+
|
| 52 |
+
- Windows
|
| 53 |
+
- Linux
|
| 54 |
+
- Mac
|
| 55 |
+
- Android + Termux
|
| 56 |
+
- Raspberry PI 4
|
| 57 |
+
|
| 58 |
+
## Dependencies 📦
|
| 59 |
+
|
| 60 |
+
- Python 3.10 or Python 3.11 (Please ensure that you have a working Python 3.10 or Python 3.11 installation available on the system)
|
| 61 |
+
|
| 62 |
+
## Memory requirements
|
| 63 |
+
|
| 64 |
+
Minimum system RAM requirement for FastSD CPU.
|
| 65 |
+
|
| 66 |
+
Model (LCM,OpenVINO): SD Turbo, 1 step, 512 x 512
|
| 67 |
+
|
| 68 |
+
Model (LCM-LoRA): Dreamshaper v8, 3 step, 512 x 512
|
| 69 |
+
|
| 70 |
+
| Mode | Min RAM |
|
| 71 |
+
| --------------------- | ------------- |
|
| 72 |
+
| LCM | 2 GB |
|
| 73 |
+
| LCM-LoRA | 4 GB |
|
| 74 |
+
| OpenVINO | 11 GB |
|
| 75 |
+
|
| 76 |
+
If we enable Tiny decoder(TAESD) we can save some memory(2GB approx) for example in OpenVINO mode memory usage will become 9GB.
|
| 77 |
+
|
| 78 |
+
:exclamation: Please note that guidance scale >1 increases RAM usage and slow inference speed.
|
| 79 |
+
|
| 80 |
+
## Features ✨
|
| 81 |
+
|
| 82 |
+
- Desktop GUI, web UI and CLI
|
| 83 |
+
- Supports 256,512,768,1024 image sizes
|
| 84 |
+
- Supports Windows,Linux,Mac
|
| 85 |
+
- Saves images and diffusion setting used to generate the image
|
| 86 |
+
- Settings to control,steps,guidance and seed
|
| 87 |
+
- Added safety checker setting
|
| 88 |
+
- Maximum inference steps increased to 25
|
| 89 |
+
- Added [OpenVINO](https://github.com/openvinotoolkit/openvino) support
|
| 90 |
+
- Fixed OpenVINO image reproducibility issue
|
| 91 |
+
- Fixed OpenVINO high RAM usage,thanks [deinferno](https://github.com/deinferno)
|
| 92 |
+
- Added multiple image generation support
|
| 93 |
+
- Application settings
|
| 94 |
+
- Added Tiny Auto Encoder for SD (TAESD) support, 1.4x speed boost (Fast,moderate quality)
|
| 95 |
+
- Safety checker disabled by default
|
| 96 |
+
- Added SDXL,SSD1B - 1B LCM models
|
| 97 |
+
- Added LCM-LoRA support, works well for fine-tuned Stable Diffusion model 1.5 or SDXL models
|
| 98 |
+
- Added negative prompt support in LCM-LoRA mode
|
| 99 |
+
- LCM-LoRA models can be configured using text configuration file
|
| 100 |
+
- Added support for custom models for OpenVINO (LCM-LoRA baked)
|
| 101 |
+
- OpenVINO models now supports negative prompt (Set guidance >1.0)
|
| 102 |
+
- Real-time inference support,generates images while you type (experimental)
|
| 103 |
+
- Fast 2,3 steps inference
|
| 104 |
+
- Lcm-Lora fused models for faster inference
|
| 105 |
+
- Supports integrated GPU(iGPU) using OpenVINO (export DEVICE=GPU)
|
| 106 |
+
- 5.7x speed using OpenVINO(steps: 2,tiny autoencoder)
|
| 107 |
+
- Image to Image support (Use Web UI)
|
| 108 |
+
- OpenVINO image to image support
|
| 109 |
+
- Fast 1 step inference (SDXL Turbo)
|
| 110 |
+
- Added SD Turbo support
|
| 111 |
+
- Added image to image support for Turbo models (Pytorch and OpenVINO)
|
| 112 |
+
- Added image variations support
|
| 113 |
+
- Added 2x upscaler (EDSR and Tiled SD upscale (experimental)),thanks [monstruosoft](https://github.com/monstruosoft) for SD upscale
|
| 114 |
+
- Works on Android + Termux + PRoot
|
| 115 |
+
- Added interactive CLI,thanks [monstruosoft](https://github.com/monstruosoft)
|
| 116 |
+
- Added basic lora support to CLI and WebUI
|
| 117 |
+
- ONNX EDSR 2x upscale
|
| 118 |
+
- Add SDXL-Lightning support
|
| 119 |
+
- Add SDXL-Lightning OpenVINO support (int8)
|
| 120 |
+
- Add multilora support,thanks [monstruosoft](https://github.com/monstruosoft)
|
| 121 |
+
- Add basic ControlNet v1.1 support(LCM-LoRA mode),thanks [monstruosoft](https://github.com/monstruosoft)
|
| 122 |
+
- Add ControlNet annotators(Canny,Depth,LineArt,MLSD,NormalBAE,Pose,SoftEdge,Shuffle)
|
| 123 |
+
- Add SDXS-512 0.9 support
|
| 124 |
+
- Add SDXS-512 0.9 OpenVINO,fast 1 step inference (0.8 seconds to generate 512x512 image)
|
| 125 |
+
- Default model changed to SDXS-512-0.9
|
| 126 |
+
- Faster realtime image generation
|
| 127 |
+
- Add NPU device check
|
| 128 |
+
- Revert default model to SDTurbo
|
| 129 |
+
- Update realtime UI
|
| 130 |
+
- Add hypersd support
|
| 131 |
+
- 1 step fast inference support for SDXL and SD1.5
|
| 132 |
+
- Experimental support for single file Safetensors SD 1.5 models(Civitai models), simply add local model path to configs/stable-diffusion-models.txt file.
|
| 133 |
+
- Add REST API support
|
| 134 |
+
- Add Aura SR (4x)/GigaGAN based upscaler support
|
| 135 |
+
- Add Aura SR v2 upscaler support
|
| 136 |
+
- Add FLUX.1 schnell OpenVINO int 4 support
|
| 137 |
+
- Add CLIP skip support
|
| 138 |
+
- Add token merging support
|
| 139 |
+
- Add Intel AI PC support
|
| 140 |
+
- AI PC NPU(Power efficient inference using OpenVINO) supports, text to image ,image to image and image variations support
|
| 141 |
+
- Add [TAEF1 (Tiny autoencoder for FLUX.1) openvino](https://huggingface.co/rupeshs/taef1-openvino) support
|
| 142 |
+
- Add Image to Image and Image Variations Qt GUI support,thanks [monstruosoft](https://github.com/monstruosoft)
|
| 143 |
+
|
| 144 |
+
<a id="fast-inference-benchmarks"></a>
|
| 145 |
+
|
| 146 |
+
## Fast Inference Benchmarks
|
| 147 |
+
|
| 148 |
+
### 🚀 Fast 1 step inference with Hyper-SD
|
| 149 |
+
|
| 150 |
+
#### Stable diffuion 1.5
|
| 151 |
+
|
| 152 |
+
Works with LCM-LoRA mode.
|
| 153 |
+
Fast 1 step inference supported on `runwayml/stable-diffusion-v1-5` model,select `rupeshs/hypersd-sd1-5-1-step-lora` lcm_lora model from the settings.
|
| 154 |
+
|
| 155 |
+
#### Stable diffuion XL
|
| 156 |
+
|
| 157 |
+
Works with LCM and LCM-OpenVINO mode.
|
| 158 |
+
|
| 159 |
+
- *Hyper-SD SDXL 1 step* - [rupeshs/hyper-sd-sdxl-1-step](https://huggingface.co/rupeshs/hyper-sd-sdxl-1-step)
|
| 160 |
+
|
| 161 |
+
- *Hyper-SD SDXL 1 step OpenVINO* - [rupeshs/hyper-sd-sdxl-1-step-openvino-int8](https://huggingface.co/rupeshs/hyper-sd-sdxl-1-step-openvino-int8)
|
| 162 |
+
|
| 163 |
+
#### Inference Speed
|
| 164 |
+
|
| 165 |
+
Tested on Core i7-12700 to generate **768x768** image(1 step).
|
| 166 |
+
|
| 167 |
+
| Diffusion Pipeline | Latency |
|
| 168 |
+
| --------------------- | ------------- |
|
| 169 |
+
| Pytorch | 19s |
|
| 170 |
+
| OpenVINO | 13s |
|
| 171 |
+
| OpenVINO + TAESDXL | 6.3s |
|
| 172 |
+
|
| 173 |
+
### Fastest 1 step inference (SDXS-512-0.9)
|
| 174 |
+
|
| 175 |
+
:exclamation:This is an experimental model, only text to image workflow is supported.
|
| 176 |
+
|
| 177 |
+
#### Inference Speed
|
| 178 |
+
|
| 179 |
+
Tested on Core i7-12700 to generate **512x512** image(1 step).
|
| 180 |
+
|
| 181 |
+
**SDXS-512-0.9**
|
| 182 |
+
|
| 183 |
+
| Diffusion Pipeline | Latency |
|
| 184 |
+
| --------------------- | ------------- |
|
| 185 |
+
| Pytorch | 4.8s |
|
| 186 |
+
| OpenVINO | 3.8s |
|
| 187 |
+
| OpenVINO + TAESD | **0.82s** |
|
| 188 |
+
|
| 189 |
+
### 🚀 Fast 1 step inference (SD/SDXL Turbo - Adversarial Diffusion Distillation,ADD)
|
| 190 |
+
|
| 191 |
+
Added support for ultra fast 1 step inference using [sdxl-turbo](https://huggingface.co/stabilityai/sdxl-turbo) model
|
| 192 |
+
|
| 193 |
+
:exclamation: These SD turbo models are intended for research purpose only.
|
| 194 |
+
|
| 195 |
+
#### Inference Speed
|
| 196 |
+
|
| 197 |
+
Tested on Core i7-12700 to generate **512x512** image(1 step).
|
| 198 |
+
|
| 199 |
+
**SD Turbo**
|
| 200 |
+
|
| 201 |
+
| Diffusion Pipeline | Latency |
|
| 202 |
+
| --------------------- | ------------- |
|
| 203 |
+
| Pytorch | 7.8s |
|
| 204 |
+
| OpenVINO | 5s |
|
| 205 |
+
| OpenVINO + TAESD | 1.7s |
|
| 206 |
+
|
| 207 |
+
**SDXL Turbo**
|
| 208 |
+
|
| 209 |
+
| Diffusion Pipeline | Latency |
|
| 210 |
+
| --------------------- | ------------- |
|
| 211 |
+
| Pytorch | 10s |
|
| 212 |
+
| OpenVINO | 5.6s |
|
| 213 |
+
| OpenVINO + TAESDXL | 2.5s |
|
| 214 |
+
|
| 215 |
+
### 🚀 Fast 2 step inference (SDXL-Lightning - Adversarial Diffusion Distillation)
|
| 216 |
+
|
| 217 |
+
SDXL-Lightning works with LCM and LCM-OpenVINO mode.You can select these models from app settings.
|
| 218 |
+
|
| 219 |
+
Tested on Core i7-12700 to generate **768x768** image(2 steps).
|
| 220 |
+
|
| 221 |
+
| Diffusion Pipeline | Latency |
|
| 222 |
+
| --------------------- | ------------- |
|
| 223 |
+
| Pytorch | 18s |
|
| 224 |
+
| OpenVINO | 12s |
|
| 225 |
+
| OpenVINO + TAESDXL | 10s |
|
| 226 |
+
|
| 227 |
+
- *SDXL-Lightning* - [rupeshs/SDXL-Lightning-2steps](https://huggingface.co/rupeshs/SDXL-Lightning-2steps)
|
| 228 |
+
|
| 229 |
+
- *SDXL-Lightning OpenVINO* - [rupeshs/SDXL-Lightning-2steps-openvino-int8](https://huggingface.co/rupeshs/SDXL-Lightning-2steps-openvino-int8)
|
| 230 |
+
|
| 231 |
+
### 2 Steps fast inference (LCM)
|
| 232 |
+
|
| 233 |
+
FastSD CPU supports 2 to 3 steps fast inference using LCM-LoRA workflow. It works well with SD 1.5 models.
|
| 234 |
+
|
| 235 |
+

|
| 236 |
+
|
| 237 |
+
### FLUX.1-schnell OpenVINO support
|
| 238 |
+
|
| 239 |
+
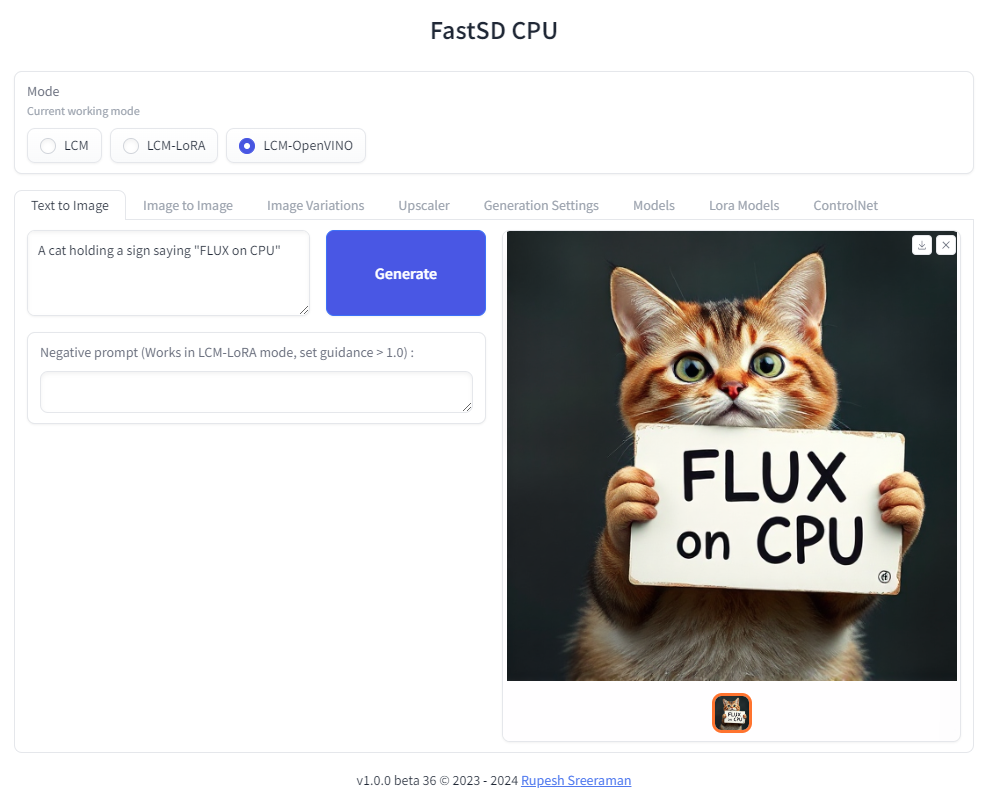
|
| 240 |
+
|
| 241 |
+
:exclamation: Important - Please note the following points with FLUX workflow
|
| 242 |
+
|
| 243 |
+
- As of now only text to image generation mode is supported
|
| 244 |
+
- Use OpenVINO mode
|
| 245 |
+
- Use int4 model - *rupeshs/FLUX.1-schnell-openvino-int4*
|
| 246 |
+
- 512x512 image generation needs around **30GB** system RAM
|
| 247 |
+
|
| 248 |
+
Tested on Intel Core i7-12700 to generate **512x512** image(3 steps).
|
| 249 |
+
|
| 250 |
+
| Diffusion Pipeline | Latency |
|
| 251 |
+
| --------------------- | ------------- |
|
| 252 |
+
| OpenVINO | 4 min 30sec |
|
| 253 |
+
|
| 254 |
+
### Benchmark scripts
|
| 255 |
+
|
| 256 |
+
To benchmark run the following batch file on Windows:
|
| 257 |
+
|
| 258 |
+
- `benchmark.bat` - To benchmark Pytorch
|
| 259 |
+
- `benchmark-openvino.bat` - To benchmark OpenVINO
|
| 260 |
+
|
| 261 |
+
Alternatively you can run benchmarks by passing `-b` command line argument in CLI mode.
|
| 262 |
+
<a id="openvino"></a>
|
| 263 |
+
|
| 264 |
+
## OpenVINO support
|
| 265 |
+
|
| 266 |
+
Fast SD CPU utilizes [OpenVINO](https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html) to speed up the inference speed.
|
| 267 |
+
Thanks [deinferno](https://github.com/deinferno) for the OpenVINO model contribution.
|
| 268 |
+
We can get 2x speed improvement when using OpenVINO.
|
| 269 |
+
Thanks [Disty0](https://github.com/Disty0) for the conversion script.
|
| 270 |
+
|
| 271 |
+
### OpenVINO SDXL models
|
| 272 |
+
|
| 273 |
+
These are models converted to use directly use it with FastSD CPU. These models are compressed to int8 to reduce the file size (10GB to 4.4 GB) using [NNCF](https://github.com/openvinotoolkit/nncf)
|
| 274 |
+
|
| 275 |
+
- Hyper-SD SDXL 1 step - [rupeshs/hyper-sd-sdxl-1-step-openvino-int8](https://huggingface.co/rupeshs/hyper-sd-sdxl-1-step-openvino-int8)
|
| 276 |
+
- SDXL Lightning 2 steps - [rupeshs/SDXL-Lightning-2steps-openvino-int8](https://huggingface.co/rupeshs/SDXL-Lightning-2steps-openvino-int8)
|
| 277 |
+
|
| 278 |
+
### OpenVINO SD Turbo models
|
| 279 |
+
|
| 280 |
+
We have converted SD/SDXL Turbo models to OpenVINO for fast inference on CPU. These models are intended for research purpose only. Also we converted TAESDXL MODEL to OpenVINO and
|
| 281 |
+
|
| 282 |
+
- *SD Turbo OpenVINO* - [rupeshs/sd-turbo-openvino](https://huggingface.co/rupeshs/sd-turbo-openvino)
|
| 283 |
+
- *SDXL Turbo OpenVINO int8* - [rupeshs/sdxl-turbo-openvino-int8](https://huggingface.co/rupeshs/sdxl-turbo-openvino-int8)
|
| 284 |
+
- *TAESDXL OpenVINO* - [rupeshs/taesdxl-openvino](https://huggingface.co/rupeshs/taesdxl-openvino)
|
| 285 |
+
|
| 286 |
+
You can directly use these models in FastSD CPU.
|
| 287 |
+
|
| 288 |
+
### Convert SD 1.5 models to OpenVINO LCM-LoRA fused models
|
| 289 |
+
|
| 290 |
+
We first creates LCM-LoRA baked in model,replaces the scheduler with LCM and then converts it into OpenVINO model. For more details check [LCM OpenVINO Converter](https://github.com/rupeshs/lcm-openvino-converter), you can use this tools to convert any StableDiffusion 1.5 fine tuned models to OpenVINO.
|
| 291 |
+
|
| 292 |
+
<a id="real-time-text-to-image"></a>
|
| 293 |
+
|
| 294 |
+
## Real-time text to image (EXPERIMENTAL)
|
| 295 |
+
|
| 296 |
+
We can generate real-time text to images using FastSD CPU.
|
| 297 |
+
|
| 298 |
+
**CPU (OpenVINO)**
|
| 299 |
+
|
| 300 |
+
Near real-time inference on CPU using OpenVINO, run the `start-realtime.bat` batch file and open the link in browser (Resolution : 512x512,Latency : 0.82s on Intel Core i7)
|
| 301 |
+
|
| 302 |
+
Watch YouTube video :
|
| 303 |
+
|
| 304 |
+
[](https://www.youtube.com/watch?v=0XMiLc_vsyI)
|
| 305 |
+
|
| 306 |
+
## Models
|
| 307 |
+
|
| 308 |
+
To use single file [Safetensors](https://huggingface.co/docs/safetensors/en/index) SD 1.5 models(Civit AI) follow this [YouTube tutorial](https://www.youtube.com/watch?v=zZTfUZnXJVk). Use LCM-LoRA Mode for single file safetensors.
|
| 309 |
+
|
| 310 |
+
Fast SD supports LCM models and LCM-LoRA models.
|
| 311 |
+
|
| 312 |
+
### LCM Models
|
| 313 |
+
|
| 314 |
+
These models can be configured in `configs/lcm-models.txt` file.
|
| 315 |
+
|
| 316 |
+
### OpenVINO models
|
| 317 |
+
|
| 318 |
+
These are LCM-LoRA baked in models. These models can be configured in `configs/openvino-lcm-models.txt` file
|
| 319 |
+
|
| 320 |
+
### LCM-LoRA models
|
| 321 |
+
|
| 322 |
+
These models can be configured in `configs/lcm-lora-models.txt` file.
|
| 323 |
+
|
| 324 |
+
- *lcm-lora-sdv1-5* - distilled consistency adapter for [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
|
| 325 |
+
- *lcm-lora-sdxl* - Distilled consistency adapter for [stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
|
| 326 |
+
- *lcm-lora-ssd-1b* - Distilled consistency adapter for [segmind/SSD-1B](https://huggingface.co/segmind/SSD-1B)
|
| 327 |
+
|
| 328 |
+
These models are used with Stablediffusion base models `configs/stable-diffusion-models.txt`.
|
| 329 |
+
|
| 330 |
+
:exclamation: Currently no support for OpenVINO LCM-LoRA models.
|
| 331 |
+
|
| 332 |
+
### How to add new LCM-LoRA models
|
| 333 |
+
|
| 334 |
+
To add new model follow the steps:
|
| 335 |
+
For example we will add `wavymulder/collage-diffusion`, you can give Stable diffusion 1.5 Or SDXL,SSD-1B fine tuned models.
|
| 336 |
+
|
| 337 |
+
1. Open `configs/stable-diffusion-models.txt` file in text editor.
|
| 338 |
+
2. Add the model ID `wavymulder/collage-diffusion` or locally cloned path.
|
| 339 |
+
|
| 340 |
+
Updated file as shown below :
|
| 341 |
+
|
| 342 |
+
```Lykon/dreamshaper-8
|
| 343 |
+
Fictiverse/Stable_Diffusion_PaperCut_Model
|
| 344 |
+
stabilityai/stable-diffusion-xl-base-1.0
|
| 345 |
+
runwayml/stable-diffusion-v1-5
|
| 346 |
+
segmind/SSD-1B
|
| 347 |
+
stablediffusionapi/anything-v5
|
| 348 |
+
wavymulder/collage-diffusion
|
| 349 |
+
```
|
| 350 |
+
|
| 351 |
+
Similarly we can update `configs/lcm-lora-models.txt` file with lcm-lora ID.
|
| 352 |
+
|
| 353 |
+
### How to use LCM-LoRA models offline
|
| 354 |
+
|
| 355 |
+
Please follow the steps to run LCM-LoRA models offline :
|
| 356 |
+
|
| 357 |
+
- In the settings ensure that "Use locally cached model" setting is ticked.
|
| 358 |
+
- Download the model for example `latent-consistency/lcm-lora-sdv1-5`
|
| 359 |
+
Run the following commands:
|
| 360 |
+
|
| 361 |
+
```
|
| 362 |
+
git lfs install
|
| 363 |
+
git clone https://huggingface.co/latent-consistency/lcm-lora-sdv1-5
|
| 364 |
+
```
|
| 365 |
+
|
| 366 |
+
Copy the cloned model folder path for example "D:\demo\lcm-lora-sdv1-5" and update the `configs/lcm-lora-models.txt` file as shown below :
|
| 367 |
+
|
| 368 |
+
```
|
| 369 |
+
D:\demo\lcm-lora-sdv1-5
|
| 370 |
+
latent-consistency/lcm-lora-sdxl
|
| 371 |
+
latent-consistency/lcm-lora-ssd-1b
|
| 372 |
+
```
|
| 373 |
+
|
| 374 |
+
- Open the app and select the newly added local folder in the combo box menu.
|
| 375 |
+
- That's all!
|
| 376 |
+
<a id="useloramodels"></a>
|
| 377 |
+
|
| 378 |
+
## How to use Lora models
|
| 379 |
+
|
| 380 |
+
Place your lora models in "lora_models" folder. Use LCM or LCM-Lora mode.
|
| 381 |
+
You can download lora model (.safetensors/Safetensor) from [Civitai](https://civitai.com/) or [Hugging Face](https://huggingface.co/)
|
| 382 |
+
E.g: [cutecartoonredmond](https://civitai.com/models/207984/cutecartoonredmond-15v-cute-cartoon-lora-for-liberteredmond-sd-15?modelVersionId=234192)
|
| 383 |
+
<a id="usecontrolnet"></a>
|
| 384 |
+
|
| 385 |
+
## ControlNet support
|
| 386 |
+
|
| 387 |
+
We can use ControlNet in LCM-LoRA mode.
|
| 388 |
+
|
| 389 |
+
Download ControlNet models from [ControlNet-v1-1](https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main).Download and place controlnet models in "controlnet_models" folder.
|
| 390 |
+
|
| 391 |
+
Use the medium size models (723 MB)(For example : <https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/blob/main/control_v11p_sd15_canny_fp16.safetensors>)
|
| 392 |
+
|
| 393 |
+
## Installation
|
| 394 |
+
|
| 395 |
+
### FastSD CPU on Windows
|
| 396 |
+
|
| 397 |
+
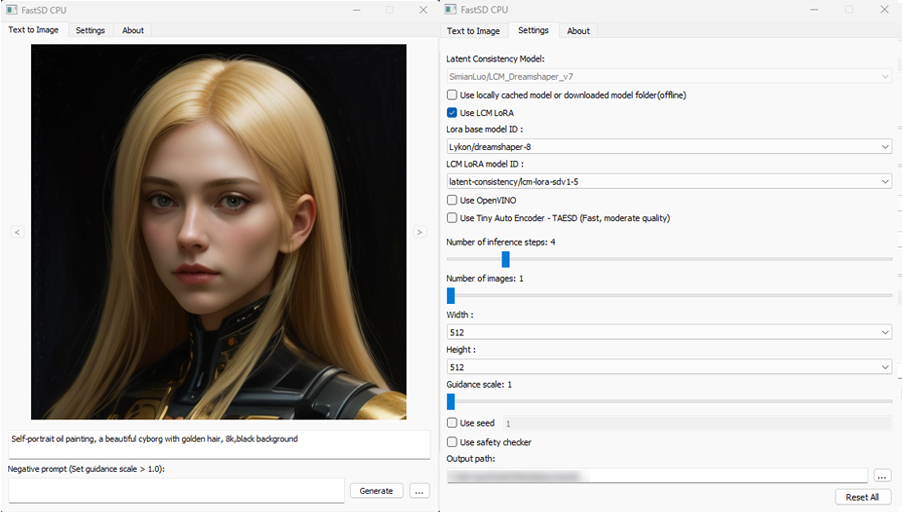
|
| 398 |
+
|
| 399 |
+
:exclamation:**You must have a working Python installation.(Recommended : Python 3.10 or 3.11 )**
|
| 400 |
+
|
| 401 |
+
To install FastSD CPU on Windows run the following steps :
|
| 402 |
+
|
| 403 |
+
- Clone/download this repo or download [release](https://github.com/rupeshs/fastsdcpu/releases).
|
| 404 |
+
- Double click `install.bat` (It will take some time to install,depending on your internet speed.)
|
| 405 |
+
- You can run in desktop GUI mode or web UI mode.
|
| 406 |
+
|
| 407 |
+
#### Desktop GUI
|
| 408 |
+
|
| 409 |
+
- To start desktop GUI double click `start.bat`
|
| 410 |
+
|
| 411 |
+
#### Web UI
|
| 412 |
+
|
| 413 |
+
- To start web UI double click `start-webui.bat`
|
| 414 |
+
|
| 415 |
+
### FastSD CPU on Linux
|
| 416 |
+
|
| 417 |
+
:exclamation:**Ensure that you have Python 3.9 or 3.10 or 3.11 version installed.**
|
| 418 |
+
|
| 419 |
+
- Clone/download this repo or download [release](https://github.com/rupeshs/fastsdcpu/releases).
|
| 420 |
+
- In the terminal, enter into fastsdcpu directory
|
| 421 |
+
- Run the following command
|
| 422 |
+
|
| 423 |
+
`chmod +x install.sh`
|
| 424 |
+
|
| 425 |
+
`./install.sh`
|
| 426 |
+
|
| 427 |
+
#### To start Desktop GUI
|
| 428 |
+
|
| 429 |
+
`./start.sh`
|
| 430 |
+
|
| 431 |
+
#### To start Web UI
|
| 432 |
+
|
| 433 |
+
`./start-webui.sh`
|
| 434 |
+
|
| 435 |
+
### FastSD CPU on Mac
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
:exclamation:**Ensure that you have Python 3.9 or 3.10 or 3.11 version installed.**
|
| 440 |
+
|
| 441 |
+
Run the following commands to install FastSD CPU on Mac :
|
| 442 |
+
|
| 443 |
+
- Clone/download this repo or download [release](https://github.com/rupeshs/fastsdcpu/releases).
|
| 444 |
+
- In the terminal, enter into fastsdcpu directory
|
| 445 |
+
- Run the following command
|
| 446 |
+
|
| 447 |
+
`chmod +x install-mac.sh`
|
| 448 |
+
|
| 449 |
+
`./install-mac.sh`
|
| 450 |
+
|
| 451 |
+
#### To start Desktop GUI
|
| 452 |
+
|
| 453 |
+
`./start.sh`
|
| 454 |
+
|
| 455 |
+
#### To start Web UI
|
| 456 |
+
|
| 457 |
+
`./start-webui.sh`
|
| 458 |
+
|
| 459 |
+
Thanks [Autantpourmoi](https://github.com/Autantpourmoi) for Mac testing.
|
| 460 |
+
|
| 461 |
+
:exclamation:We don't support OpenVINO on Mac (M1/M2/M3 chips, but *does* work on Intel chips).
|
| 462 |
+
|
| 463 |
+
If you want to increase image generation speed on Mac(M1/M2 chip) try this:
|
| 464 |
+
|
| 465 |
+
`export DEVICE=mps` and start app `start.sh`
|
| 466 |
+
|
| 467 |
+
#### Web UI screenshot
|
| 468 |
+
|
| 469 |
+
|
| 470 |
+
|
| 471 |
+
### Google Colab
|
| 472 |
+
|
| 473 |
+
Due to the limitation of using CPU/OpenVINO inside colab, we are using GPU with colab.
|
| 474 |
+
[](https://colab.research.google.com/drive/1SuAqskB-_gjWLYNRFENAkIXZ1aoyINqL?usp=sharing)
|
| 475 |
+
|
| 476 |
+
### CLI mode (Advanced users)
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
|
| 480 |
+
Open the terminal and enter into fastsdcpu folder.
|
| 481 |
+
Activate virtual environment using the command:
|
| 482 |
+
|
| 483 |
+
##### Windows users
|
| 484 |
+
|
| 485 |
+
(Suppose FastSD CPU available in the directory "D:\fastsdcpu")
|
| 486 |
+
`D:\fastsdcpu\env\Scripts\activate.bat`
|
| 487 |
+
|
| 488 |
+
##### Linux users
|
| 489 |
+
|
| 490 |
+
`source env/bin/activate`
|
| 491 |
+
|
| 492 |
+
Start CLI `src/app.py -h`
|
| 493 |
+
|
| 494 |
+
<a id="android"></a>
|
| 495 |
+
|
| 496 |
+
## Android (Termux + PRoot)
|
| 497 |
+
|
| 498 |
+
FastSD CPU running on Google Pixel 7 Pro.
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
|
| 502 |
+
### Install FastSD CPU on Android
|
| 503 |
+
|
| 504 |
+
Follow this guide to install FastSD CPU on Android + Termux [How To Install and Run FastSD CPU on Android + Temux – Step By Step Guide [Updated]](https://nolowiz.com/how-to-install-and-run-fastsd-cpu-on-android-temux-step-by-step-guide/)
|
| 505 |
+
|
| 506 |
+
<a id="raspberry"></a>
|
| 507 |
+
|
| 508 |
+
## Raspberry PI 4 support
|
| 509 |
+
|
| 510 |
+
Thanks [WGNW_MGM] for Raspberry PI 4 testing.FastSD CPU worked without problems.
|
| 511 |
+
System configuration - Raspberry Pi 4 with 4GB RAM, 8GB of SWAP memory.
|
| 512 |
+
|
| 513 |
+
<a id="apisupport"></a>
|
| 514 |
+
|
| 515 |
+
## API support
|
| 516 |
+
|
| 517 |
+
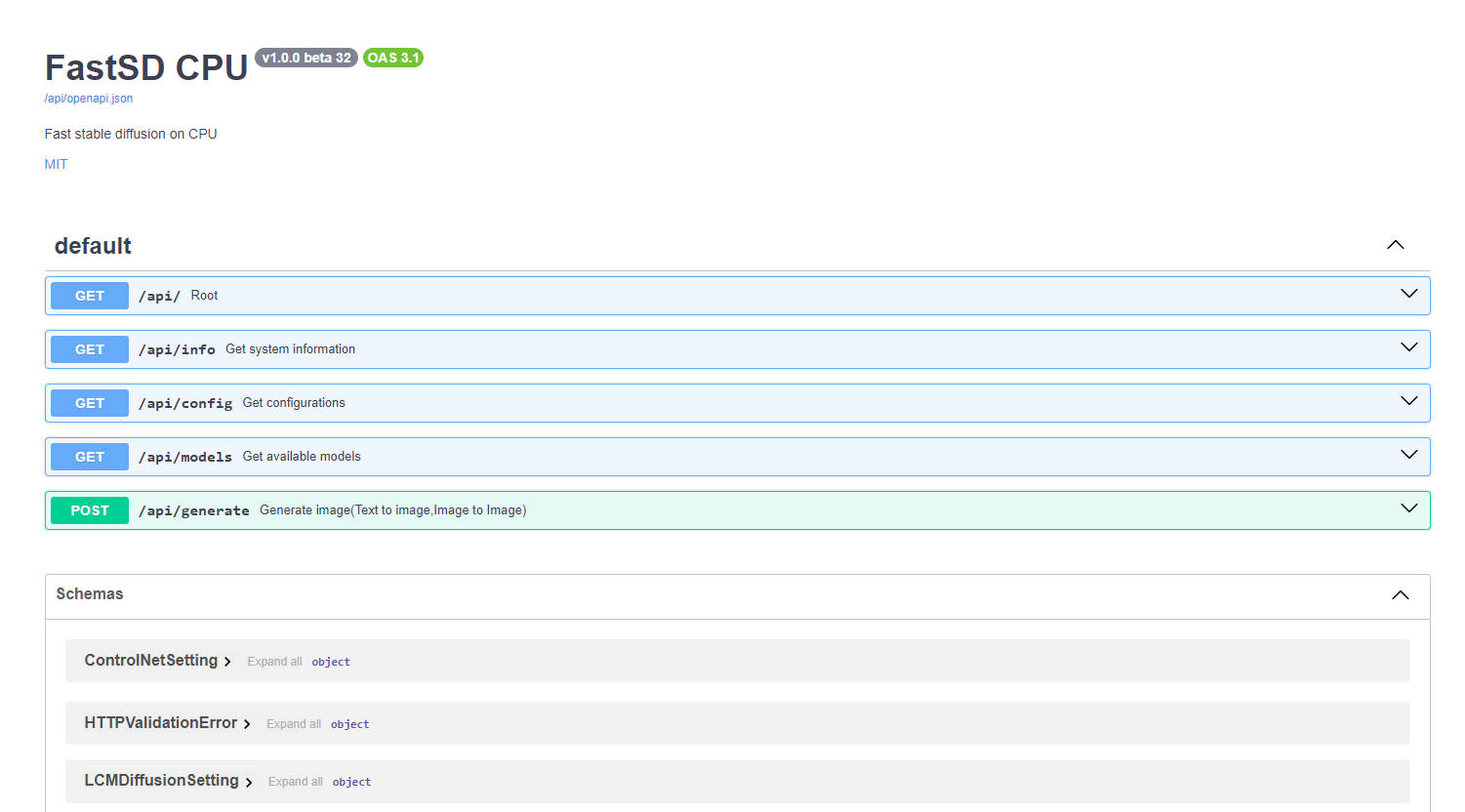
|
| 518 |
+
|
| 519 |
+
FastSD CPU supports basic API endpoints. Following API endpoints are available :
|
| 520 |
+
|
| 521 |
+
- /api/info - To get system information
|
| 522 |
+
- /api/config - Get configuration
|
| 523 |
+
- /api/models - List all available models
|
| 524 |
+
- /api/generate - Generate images (Text to image,image to image)
|
| 525 |
+
|
| 526 |
+
To start FastAPI in webserver mode run:
|
| 527 |
+
``python src/app.py --api``
|
| 528 |
+
|
| 529 |
+
or use `start-webserver.sh` for Linux and `start-webserver.bat` for Windows.
|
| 530 |
+
|
| 531 |
+
Access API documentation locally at <http://localhost:8000/api/docs> .
|
| 532 |
+
|
| 533 |
+
Generated image is JPEG image encoded as base64 string.
|
| 534 |
+
In the image-to-image mode input image should be encoded as base64 string.
|
| 535 |
+
|
| 536 |
+
To generate an image a minimal request `POST /api/generate` with body :
|
| 537 |
+
|
| 538 |
+
```
|
| 539 |
+
{
|
| 540 |
+
"prompt": "a cute cat",
|
| 541 |
+
"use_openvino": true
|
| 542 |
+
}
|
| 543 |
+
```
|
| 544 |
+
|
| 545 |
+
<a id="gguf-support"></a>
|
| 546 |
+
|
| 547 |
+
## GGUF support - Flux
|
| 548 |
+
|
| 549 |
+
[GGUF](https://github.com/ggerganov/ggml/blob/master/docs/gguf.md) Flux model supported via [stablediffusion.cpp](https://github.com/leejet/stable-diffusion.cpp) shared library. Currently Flux Schenell model supported.
|
| 550 |
+
|
| 551 |
+
To use GGUF model use web UI and select GGUF mode.
|
| 552 |
+
|
| 553 |
+
Tested on Windows and Linux.
|
| 554 |
+
|
| 555 |
+
:exclamation: Main advantage here we reduced minimum system RAM required for Flux workflow to around **12 GB**.
|
| 556 |
+
|
| 557 |
+
Supported mode - Text to image
|
| 558 |
+
|
| 559 |
+
### How to run Flux GGUF model
|
| 560 |
+
|
| 561 |
+
- Download stablediffusion.cpp prebuilt shared library and place it inside fastsdcpu folder
|
| 562 |
+
For Windows users, download [stable-diffusion.dll](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/stable-diffusion.dll)
|
| 563 |
+
|
| 564 |
+
For Linux users download [libstable-diffusion.so](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/libstable-diffusion.so)
|
| 565 |
+
|
| 566 |
+
You can also build the library manully by following the guide *"Build stablediffusion.cpp shared library for GGUF flux model support"*
|
| 567 |
+
|
| 568 |
+
- Download **diffusion model** from [flux1-schnell-q4_0.gguf](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/flux1-schnell-q4_0.gguf) and place it inside `models/gguf/diffusion` directory
|
| 569 |
+
- Download **clip model** from [clip_l_q4_0.gguf](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/clip_l_q4_0.gguf) and place it inside `models/gguf/clip` directory
|
| 570 |
+
- Download **T5-XXL model** from [t5xxl_q4_0.gguf](https://huggingface.co/rupeshs/FastSD-Flux-GGUF/blob/main/t5xxl_q4_0.gguf) and place it inside `models/gguf/t5xxl` directory
|
| 571 |
+
- Download **VAE model** from [ae.safetensors](https://huggingface.co/black-forest-labs/FLUX.1-schnell/blob/main/ae.safetensors) and place it inside `models/gguf/vae` directory
|
| 572 |
+
- Start web UI and select GGUF mode
|
| 573 |
+
- Select the models settings tab and select GGUF diffusion,clip_l,t5xxl and VAE models.
|
| 574 |
+
- Enter your prompt and generate image
|
| 575 |
+
|
| 576 |
+
### Build stablediffusion.cpp shared library for GGUF flux model support(Optional)
|
| 577 |
+
|
| 578 |
+
To build the stablediffusion.cpp library follow these steps
|
| 579 |
+
|
| 580 |
+
- `git clone https://github.com/leejet/stable-diffusion.cpp`
|
| 581 |
+
- `cd stable-diffusion.cpp`
|
| 582 |
+
- `git pull origin master`
|
| 583 |
+
- `git submodule init`
|
| 584 |
+
- `git submodule update`
|
| 585 |
+
- `git checkout 14206fd48832ab600d9db75f15acb5062ae2c296`
|
| 586 |
+
- `cmake . -DSD_BUILD_SHARED_LIBS=ON`
|
| 587 |
+
- `cmake --build . --config Release`
|
| 588 |
+
- Copy the stablediffusion dll/so file to fastsdcpu folder
|
| 589 |
+
|
| 590 |
+
<a id="ai-pc-support"></a>
|
| 591 |
+
|
| 592 |
+
## Intel AI PC support - OpenVINO (CPU, GPU, NPU)
|
| 593 |
+
|
| 594 |
+
Fast SD now supports AI PC with Intel® Core™ Ultra Processors. [To learn more about AI PC and OpenVINO](https://nolowiz.com/ai-pc-and-openvino-quick-and-simple-guide/).
|
| 595 |
+
|
| 596 |
+
### GPU
|
| 597 |
+
|
| 598 |
+
For GPU mode `set device=GPU` and run webui. FastSD GPU benchmark on AI PC as shown below.
|
| 599 |
+
|
| 600 |
+
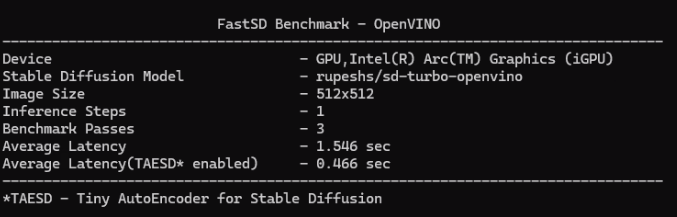
|
| 601 |
+
|
| 602 |
+
### NPU
|
| 603 |
+
|
| 604 |
+
FastSD CPU now supports power efficient NPU (Neural Processing Unit) that comes with Intel Core Ultra processors.
|
| 605 |
+
|
| 606 |
+
FastSD tested with following Intel processor's NPUs:
|
| 607 |
+
|
| 608 |
+
- Intel Core Ultra Series 1 (Meteor Lake)
|
| 609 |
+
- Intel Core Ultra Series 2 (Lunar Lake)
|
| 610 |
+
|
| 611 |
+
Currently FastSD support this model for NPU [rupeshs/sd15-lcm-square-openvino-int8](https://huggingface.co/rupeshs/sd15-lcm-square-openvino-int8).
|
| 612 |
+
|
| 613 |
+
Supports following modes on NPU :
|
| 614 |
+
|
| 615 |
+
- Text to image
|
| 616 |
+
- Image to image
|
| 617 |
+
- Image variations
|
| 618 |
+
|
| 619 |
+
To run model in NPU follow these steps (Please make sure that your AI PC's NPU driver is the latest):
|
| 620 |
+
|
| 621 |
+
- Start webui
|
| 622 |
+
- Select LCM-OpenVINO mode
|
| 623 |
+
- Select the models settings tab and select OpenVINO model `rupeshs/sd15-lcm-square-openvino-int8`
|
| 624 |
+
- Set device envionment variable `set DEVICE=NPU`
|
| 625 |
+
- Now it will run on the NPU
|
| 626 |
+
|
| 627 |
+
This is heterogeneous computing since text encoder and Unet will use NPU and VAE will use GPU for processing. Thanks to OpenVINO.
|
| 628 |
+
|
| 629 |
+
Please note that tiny auto encoder will not work in NPU mode.
|
| 630 |
+
|
| 631 |
+
*Thanks to Intel for providing AI PC dev kit and Tiber cloud access to test FastSD, special thanks to [Pooja Baraskar](https://github.com/Pooja-B),[Dmitriy Pastushenkov](https://github.com/DimaPastushenkov).*
|
| 632 |
+
|
| 633 |
+
<a id="mcpsupport"></a>
|
| 634 |
+
|
| 635 |
+
## MCP Server Support
|
| 636 |
+
|
| 637 |
+
FastSDCPU now supports [MCP(Model Context Protocol)](https://modelcontextprotocol.io/introduction) server.
|
| 638 |
+
|
| 639 |
+
To start FastAPI in MCP server mode run:
|
| 640 |
+
``python src/app.py --mcp``
|
| 641 |
+
|
| 642 |
+
or use `start-mcpserver.sh` for Linux and `start-mcpserver.bat` for Windows.
|
| 643 |
+
|
| 644 |
+
FastSDCPU MCP server will be running at <http://127.0.0.1:8000/mcp>
|
| 645 |
+
|
| 646 |
+
It can be used with AI apps that support MCP protocol for example [Claude desktop](https://claude.ai/download)
|
| 647 |
+
|
| 648 |
+
Note: OpenWebUI not directly using MCP protocol it is based on OpenAPI protocol.
|
| 649 |
+
|
| 650 |
+
### Claude desktop
|
| 651 |
+
|
| 652 |
+
To connect with FastSD MCP server first configure Claude desktop :
|
| 653 |
+
|
| 654 |
+
- First configure Claude desktop,open File - >Settings -> Developer - Edit config
|
| 655 |
+
- Add below config(Also ensure that node.js installed on your machine)
|
| 656 |
+
|
| 657 |
+
```json
|
| 658 |
+
{
|
| 659 |
+
"mcpServers": {
|
| 660 |
+
"fastsdcpu": {
|
| 661 |
+
"command": "npx",
|
| 662 |
+
"args": [
|
| 663 |
+
"mcp-remote",
|
| 664 |
+
"http://127.0.0.1:8000/mcp"
|
| 665 |
+
]
|
| 666 |
+
}
|
| 667 |
+
}
|
| 668 |
+
}
|
| 669 |
+
```
|
| 670 |
+
|
| 671 |
+
- Restart Claude desktop
|
| 672 |
+
- Give a sample prompt to generate image "create image of a cat"
|
| 673 |
+
|
| 674 |
+
Screenshot of Claude desktop accessing **Intel AI PC NPU** to generate an image using the FastSD MCP server
|
| 675 |
+
|
| 676 |
+
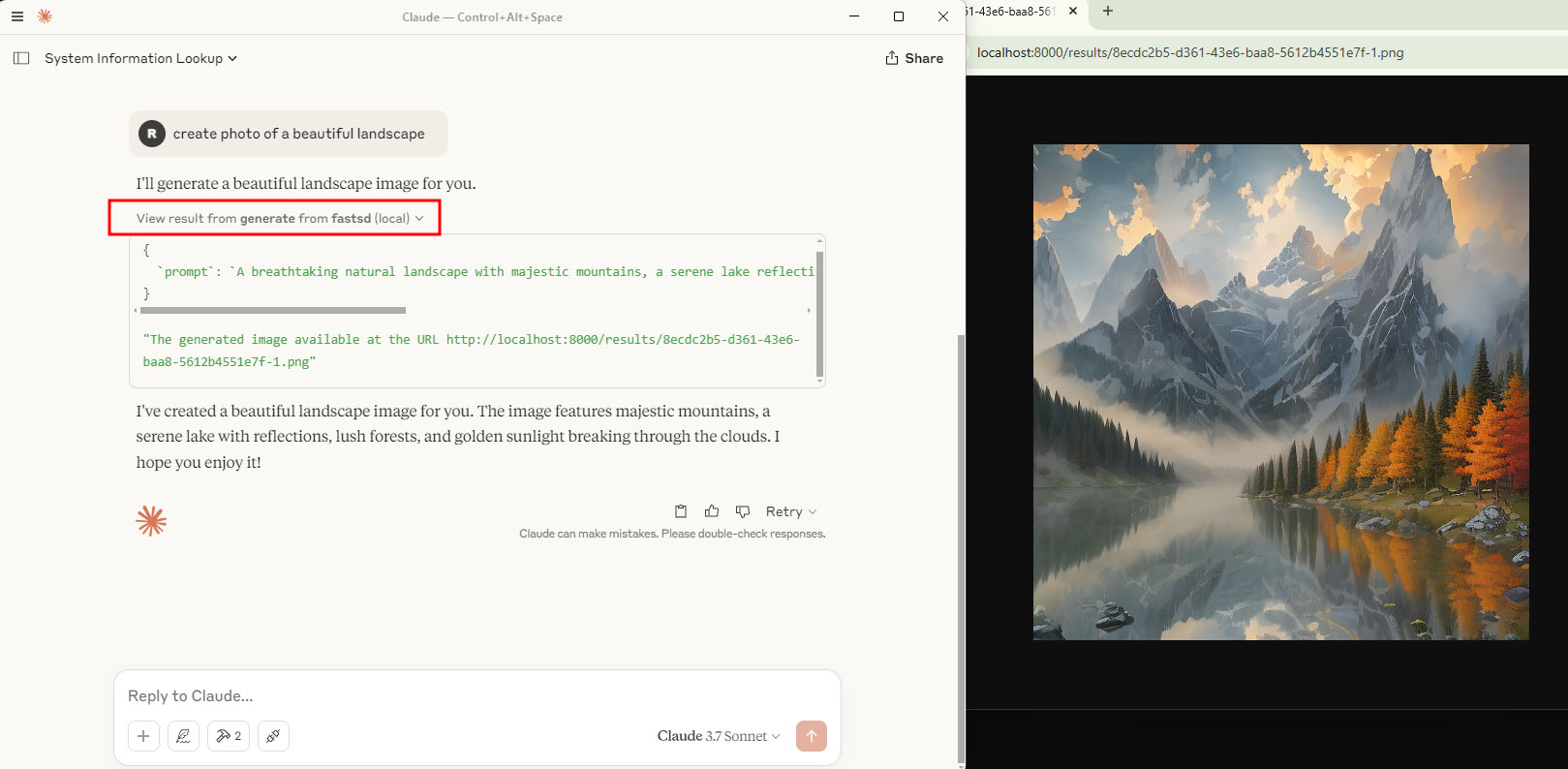
|
| 677 |
+
|
| 678 |
+
<a id="openwebuisupport"></a>
|
| 679 |
+
|
| 680 |
+
## Open WebUI Support
|
| 681 |
+
|
| 682 |
+
The FastSDCPU can be used with [OpenWebUI](https://github.com/open-webui/open-webui) for local image generation using LLM and tool calling.
|
| 683 |
+
|
| 684 |
+
Follow the below steps to FastSD to use with Open WebUI.
|
| 685 |
+
|
| 686 |
+
- First start FastAPI in MCP server:
|
| 687 |
+
``python src/app.py --mcp``
|
| 688 |
+
|
| 689 |
+
or use `start-mcpserver.sh` for Linux and `start-mcpserver.bat` for Windows.
|
| 690 |
+
|
| 691 |
+
- Update server URL in the settings page as shown below
|
| 692 |
+
|
| 693 |
+
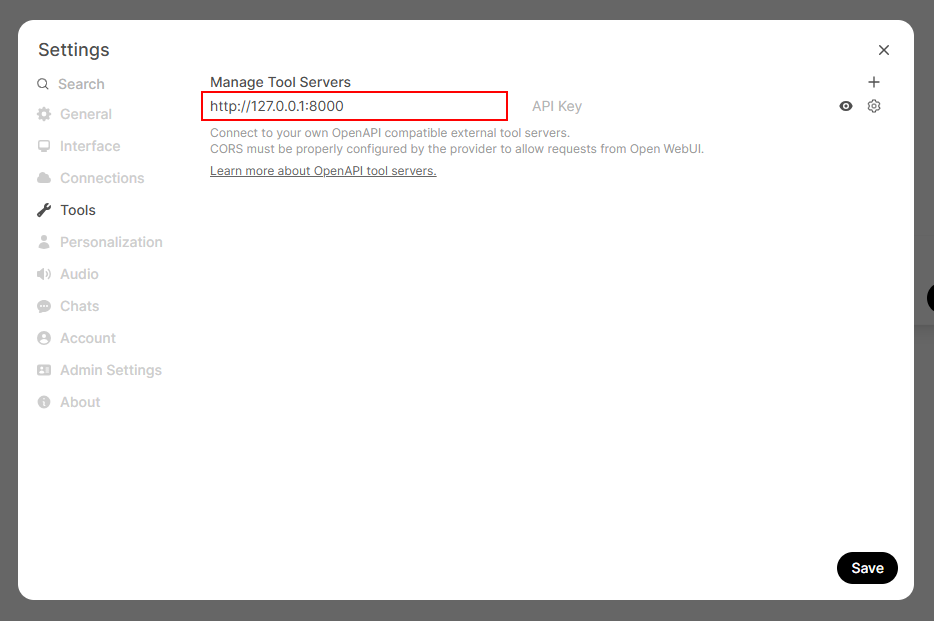
|
| 694 |
+
|
| 695 |
+
- Change chat controls setting "Function Calling" to "Native"
|
| 696 |
+
|
| 697 |
+
- Generate image using text prompt (Qwen 2.5 7B model used for the demo)
|
| 698 |
+
|
| 699 |
+
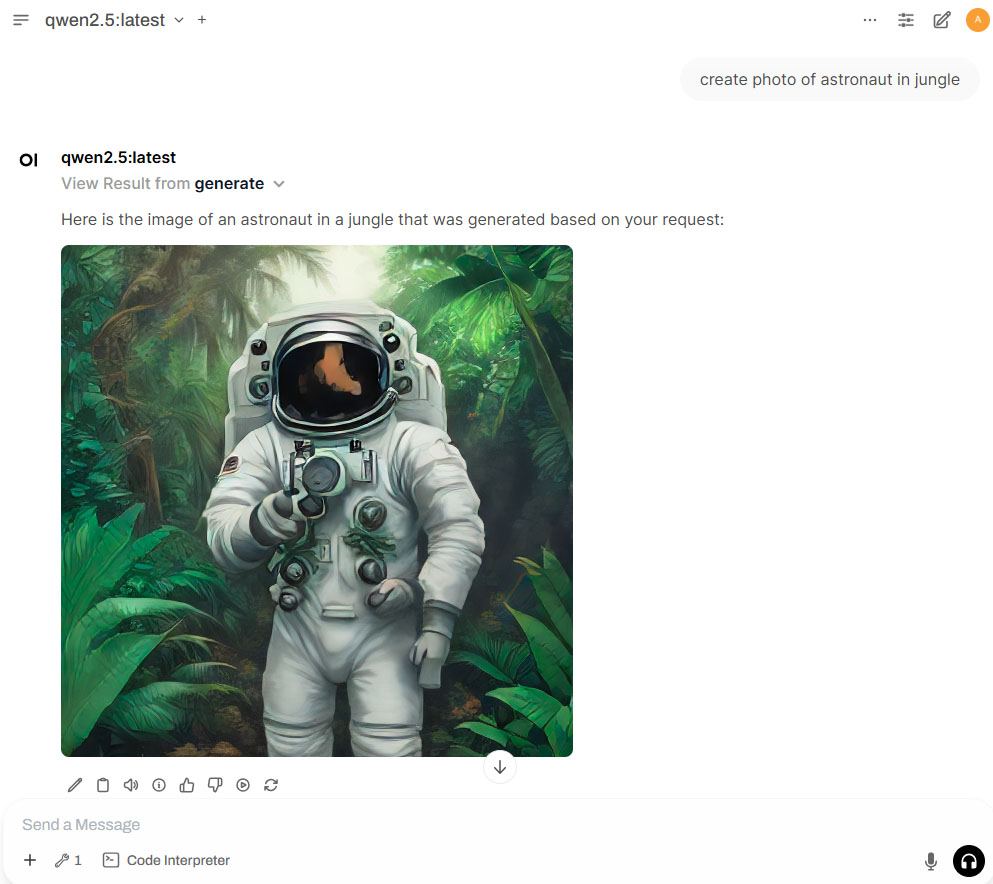
|
| 700 |
+
|
| 701 |
+
## Known issues
|
| 702 |
+
|
| 703 |
+
- TAESD will not work with OpenVINO image to image workflow
|
| 704 |
+
|
| 705 |
+
## License
|
| 706 |
+
|
| 707 |
+
The fastsdcpu project is available as open source under the terms of the [MIT license](https://github.com/rupeshs/fastsdcpu/blob/main/LICENSE)
|
| 708 |
+
|
| 709 |
+
## Disclaimer
|
| 710 |
+
|
| 711 |
+
Users are granted the freedom to create images using this tool, but they are obligated to comply with local laws and utilize it responsibly. The developers will not assume any responsibility for potential misuse by users.
|
| 712 |
+
|
| 713 |
+
<a id="contributors"></a>
|
| 714 |
+
|
| 715 |
+
## Thanks to all our contributors
|
| 716 |
+
|
| 717 |
+
Original Author & Maintainer - [Rupesh Sreeraman](https://github.com/rupeshs)
|
| 718 |
+
|
| 719 |
+
We thank all contributors for their time and hard work!
|
| 720 |
+
|
| 721 |
+
<a href="https://github.com/rupeshs/fastsdcpu/graphs/contributors">
|
| 722 |
+
<img src="https://contrib.rocks/image?repo=rupeshs/fastsdcpu" />
|
| 723 |
+
</a>
|
THIRD-PARTY-LICENSES
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
stablediffusion.cpp - MIT
|
| 2 |
+
|
| 3 |
+
OpenVINO stablediffusion engine - Apache 2
|
| 4 |
+
|
| 5 |
+
SD Turbo - STABILITY AI NON-COMMERCIAL RESEARCH COMMUNITY LICENSE AGREEMENT
|
| 6 |
+
|
| 7 |
+
MIT License
|
| 8 |
+
|
| 9 |
+
Copyright (c) 2023 leejet
|
| 10 |
+
|
| 11 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 12 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 13 |
+
in the Software without restriction, including without limitation the rights
|
| 14 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 15 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 16 |
+
furnished to do so, subject to the following conditions:
|
| 17 |
+
|
| 18 |
+
The above copyright notice and this permission notice shall be included in all
|
| 19 |
+
copies or substantial portions of the Software.
|
| 20 |
+
|
| 21 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 22 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 23 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 24 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 25 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 26 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 27 |
+
SOFTWARE.
|
| 28 |
+
|
| 29 |
+
ERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 30 |
+
|
| 31 |
+
Definitions.
|
| 32 |
+
|
| 33 |
+
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
|
| 34 |
+
|
| 35 |
+
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
|
| 36 |
+
|
| 37 |
+
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
|
| 38 |
+
|
| 39 |
+
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
|
| 40 |
+
|
| 41 |
+
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
|
| 42 |
+
|
| 43 |
+
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
|
| 44 |
+
|
| 45 |
+
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
|
| 46 |
+
|
| 47 |
+
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
|
| 48 |
+
|
| 49 |
+
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
|
| 50 |
+
|
| 51 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
|
| 52 |
+
|
| 53 |
+
Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
|
| 54 |
+
|
| 55 |
+
Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
|
| 56 |
+
|
| 57 |
+
Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
|
| 58 |
+
|
| 59 |
+
(a) You must give any other recipients of the Work or Derivative Works a copy of this License; and
|
| 60 |
+
|
| 61 |
+
(b) You must cause any modified files to carry prominent notices stating that You changed the files; and
|
| 62 |
+
|
| 63 |
+
(c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
|
| 64 |
+
|
| 65 |
+
(d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
|
| 66 |
+
|
| 67 |
+
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
|
| 68 |
+
|
| 69 |
+
Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
|
| 70 |
+
|
| 71 |
+
Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
|
| 72 |
+
|
| 73 |
+
Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
|
| 74 |
+
|
| 75 |
+
Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
|
| 76 |
+
|
| 77 |
+
Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
|
| 78 |
+
|
| 79 |
+
END OF TERMS AND CONDITIONS
|
| 80 |
+
|
| 81 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 82 |
+
|
| 83 |
+
To apply the Apache License to your work, attach the following
|
| 84 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 85 |
+
replaced with your own identifying information. (Don't include
|
| 86 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 87 |
+
comment syntax for the file format. We also recommend that a
|
| 88 |
+
file or class name and description of purpose be included on the
|
| 89 |
+
same "printed page" as the copyright notice for easier
|
| 90 |
+
identification within third-party archives.
|
| 91 |
+
Copyright [yyyy] [name of copyright owner]
|
| 92 |
+
|
| 93 |
+
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
|
| 94 |
+
|
| 95 |
+
<http://www.apache.org/licenses/LICENSE-2.0>
|
| 96 |
+
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
|
| 97 |
+
|
| 98 |
+
STABILITY AI NON-COMMERCIAL RESEARCH COMMUNITY LICENSE AGREEMENT
|
| 99 |
+
Dated: November 28, 2023
|
| 100 |
+
|
| 101 |
+
By using or distributing any portion or element of the Models, Software, Software Products or Derivative Works, you agree to be bound by this Agreement.
|
| 102 |
+
|
| 103 |
+
"Agreement" means this Stable Non-Commercial Research Community License Agreement.
|
| 104 |
+
|
| 105 |
+
“AUP” means the Stability AI Acceptable Use Policy available at <https://stability.ai/use-policy>, as may be updated from time to time.
|
| 106 |
+
|
| 107 |
+
"Derivative Work(s)” means (a) any derivative work of the Software Products as recognized by U.S. copyright laws and (b) any modifications to a Model, and any other model created which is based on or derived from the Model or the Model’s output. For clarity, Derivative Works do not include the output of any Model.
|
| 108 |
+
|
| 109 |
+
“Documentation” means any specifications, manuals, documentation, and other written information provided by Stability AI related to the Software.
|
| 110 |
+
|
| 111 |
+
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity's behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
|
| 112 |
+
|
| 113 |
+
“Model(s)" means, collectively, Stability AI’s proprietary models and algorithms, including machine-learning models, trained model weights and other elements of the foregoing, made available under this Agreement.
|
| 114 |
+
|
| 115 |
+
“Non-Commercial Uses” means exercising any of the rights granted herein for the purpose of research or non-commercial purposes. Non-Commercial Uses does not include any production use of the Software Products or any Derivative Works.
|
| 116 |
+
|
| 117 |
+
"Stability AI" or "we" means Stability AI Ltd. and its affiliates.
|
| 118 |
+
|
| 119 |
+
"Software" means Stability AI’s proprietary software made available under this Agreement.
|
| 120 |
+
|
| 121 |
+
“Software Products” means the Models, Software and Documentation, individually or in any combination.
|
| 122 |
+
|
| 123 |
+
1. License Rights and Redistribution.
|
| 124 |
+
|
| 125 |
+
a. Subject to your compliance with this Agreement, the AUP (which is hereby incorporated herein by reference), and the Documentation, Stability AI grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty free and limited license under Stability AI’s intellectual property or other rights owned or controlled by Stability AI embodied in the Software Products to use, reproduce, distribute, and create Derivative Works of, the Software Products, in each case for Non-Commercial Uses only.
|
| 126 |
+
|
| 127 |
+
b. You may not use the Software Products or Derivative Works to enable third parties to use the Software Products or Derivative Works as part of your hosted service or via your APIs, whether you are adding substantial additional functionality thereto or not. Merely distributing the Software Products or Derivative Works for download online without offering any related service (ex. by distributing the Models on HuggingFace) is not a violation of this subsection. If you wish to use the Software Products or any Derivative Works for commercial or production use or you wish to make the Software Products or any Derivative Works available to third parties via your hosted service or your APIs, contact Stability AI at <https://stability.ai/contact>.
|
| 128 |
+
|
| 129 |
+
c. If you distribute or make the Software Products, or any Derivative Works thereof, available to a third party, the Software Products, Derivative Works, or any portion thereof, respectively, will remain subject to this Agreement and you must (i) provide a copy of this Agreement to such third party, and (ii) retain the following attribution notice within a "Notice" text file distributed as a part of such copies: "This Stability AI Model is licensed under the Stability AI Non-Commercial Research Community License, Copyright (c) Stability AI Ltd. All Rights Reserved.” If you create a Derivative Work of a Software Product, you may add your own attribution notices to the Notice file included with the Software Product, provided that you clearly indicate which attributions apply to the Software Product and you must state in the NOTICE file that you changed the Software Product and how it was modified.
|
| 130 |
+
|
| 131 |
+
2. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE SOFTWARE PRODUCTS AND ANY OUTPUT AND RESULTS THERE FROM ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE SOFTWARE PRODUCTS, DERIVATIVE WORKS OR ANY OUTPUT OR RESULTS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE SOFTWARE PRODUCTS, DERIVATIVE WORKS AND ANY OUTPUT AND RESULTS.
|
| 132 |
+
|
| 133 |
+
3. Limitation of Liability. IN NO EVENT WILL STABILITY AI OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY DIRECT, INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF STABILITY AI OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
|
| 134 |
+
|
| 135 |
+
4. Intellectual Property.
|
| 136 |
+
|
| 137 |
+
a. No trademark licenses are granted under this Agreement, and in connection with the Software Products or Derivative Works, neither Stability AI nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Software Products or Derivative Works.
|
| 138 |
+
|
| 139 |
+
b. Subject to Stability AI’s ownership of the Software Products and Derivative Works made by or for Stability AI, with respect to any Derivative Works that are made by you, as between you and Stability AI, you are and will be the owner of such Derivative Works
|
| 140 |
+
|
| 141 |
+
c. If you institute litigation or other proceedings against Stability AI (including a cross-claim or counterclaim in a lawsuit) alleging that the Software Products, Derivative Works or associated outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Stability AI from and against any claim by any third party arising out of or related to your use or distribution of the Software Products or Derivative Works in violation of this Agreement.
|
| 142 |
+
|
| 143 |
+
5. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Software Products and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Stability AI may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of any Software Products or Derivative Works. Sections 2-4 shall survive the termination of this Agreement.
|
app.py
CHANGED
|
@@ -1,199 +1,3 @@
|
|
| 1 |
-
from app_settings import AppSettings
|
| 2 |
-
from utils import show_system_info
|
| 3 |
-
from PIL import Image
|
| 4 |
-
from backend.models.lcmdiffusion_setting import DiffusionTask
|
| 5 |
-
import constants
|
| 6 |
-
from argparse import ArgumentParser
|
| 7 |
-
|
| 8 |
-
from constants import APP_VERSION, LCM_DEFAULT_MODEL_OPENVINO
|
| 9 |
-
from models.interface_types import InterfaceType
|
| 10 |
-
from constants import DEVICE
|
| 11 |
-
from state import get_settings, get_context
|
| 12 |
-
|
| 13 |
-
parser = ArgumentParser(description=f"FAST SD CPU {constants.APP_VERSION}")
|
| 14 |
-
parser.add_argument(
|
| 15 |
-
"-s",
|
| 16 |
-
"--share",
|
| 17 |
-
action="store_true",
|
| 18 |
-
help="Create sharable link(Web UI)",
|
| 19 |
-
required=False,
|
| 20 |
-
)
|
| 21 |
-
group = parser.add_mutually_exclusive_group(required=False)
|
| 22 |
-
group.add_argument(
|
| 23 |
-
"-g",
|
| 24 |
-
"--gui",
|
| 25 |
-
action="store_true",
|
| 26 |
-
help="Start desktop GUI",
|
| 27 |
-
)
|
| 28 |
-
group.add_argument(
|
| 29 |
-
"-w",
|
| 30 |
-
"--webui",
|
| 31 |
-
action="store_true",
|
| 32 |
-
help="Start Web UI",
|
| 33 |
-
)
|
| 34 |
-
group.add_argument(
|
| 35 |
-
"-r",
|
| 36 |
-
"--realtime",
|
| 37 |
-
action="store_true",
|
| 38 |
-
help="Start realtime inference UI(experimental)",
|
| 39 |
-
)
|
| 40 |
-
group.add_argument(
|
| 41 |
-
"-v",
|
| 42 |
-
"--version",
|
| 43 |
-
action="store_true",
|
| 44 |
-
help="Version",
|
| 45 |
-
)
|
| 46 |
-
parser.add_argument(
|
| 47 |
-
"--lcm_model_id",
|
| 48 |
-
type=str,
|
| 49 |
-
help="Model ID or path,Default SimianLuo/LCM_Dreamshaper_v7",
|
| 50 |
-
default="SimianLuo/LCM_Dreamshaper_v7",
|
| 51 |
-
)
|
| 52 |
-
parser.add_argument(
|
| 53 |
-
"--prompt",
|
| 54 |
-
type=str,
|
| 55 |
-
help="Describe the image you want to generate",
|
| 56 |
-
)
|
| 57 |
-
parser.add_argument(
|
| 58 |
-
"--image_height",
|
| 59 |
-
type=int,
|
| 60 |
-
help="Height of the image",
|
| 61 |
-
default=512,
|
| 62 |
-
)
|
| 63 |
-
parser.add_argument(
|
| 64 |
-
"--image_width",
|
| 65 |
-
type=int,
|
| 66 |
-
help="Width of the image",
|
| 67 |
-
default=512,
|
| 68 |
-
)
|
| 69 |
-
parser.add_argument(
|
| 70 |
-
"--inference_steps",
|
| 71 |
-
type=int,
|
| 72 |
-
help="Number of steps,default : 4",
|
| 73 |
-
default=4,
|
| 74 |
-
)
|
| 75 |
-
parser.add_argument(
|
| 76 |
-
"--guidance_scale",
|
| 77 |
-
type=int,
|
| 78 |
-
help="Guidance scale,default : 1.0",
|
| 79 |
-
default=1.0,
|
| 80 |
-
)
|
| 81 |
-
|
| 82 |
-
parser.add_argument(
|
| 83 |
-
"--number_of_images",
|
| 84 |
-
type=int,
|
| 85 |
-
help="Number of images to generate ,default : 1",
|
| 86 |
-
default=1,
|
| 87 |
-
)
|
| 88 |
-
parser.add_argument(
|
| 89 |
-
"--seed",
|
| 90 |
-
type=int,
|
| 91 |
-
help="Seed,default : -1 (disabled) ",
|
| 92 |
-
default=-1,
|
| 93 |
-
)
|
| 94 |
-
parser.add_argument(
|
| 95 |
-
"--use_openvino",
|
| 96 |
-
action="store_true",
|
| 97 |
-
help="Use OpenVINO model",
|
| 98 |
-
)
|
| 99 |
-
|
| 100 |
-
parser.add_argument(
|
| 101 |
-
"--use_offline_model",
|
| 102 |
-
action="store_true",
|
| 103 |
-
help="Use offline model",
|
| 104 |
-
)
|
| 105 |
-
parser.add_argument(
|
| 106 |
-
"--use_safety_checker",
|
| 107 |
-
action="store_false",
|
| 108 |
-
help="Use safety checker",
|
| 109 |
-
)
|
| 110 |
-
parser.add_argument(
|
| 111 |
-
"--use_lcm_lora",
|
| 112 |
-
action="store_true",
|
| 113 |
-
help="Use LCM-LoRA",
|
| 114 |
-
)
|
| 115 |
-
parser.add_argument(
|
| 116 |
-
"--base_model_id",
|
| 117 |
-
type=str,
|
| 118 |
-
help="LCM LoRA base model ID,Default Lykon/dreamshaper-8",
|
| 119 |
-
default="Lykon/dreamshaper-8",
|
| 120 |
-
)
|
| 121 |
-
parser.add_argument(
|
| 122 |
-
"--lcm_lora_id",
|
| 123 |
-
type=str,
|
| 124 |
-
help="LCM LoRA model ID,Default latent-consistency/lcm-lora-sdv1-5",
|
| 125 |
-
default="latent-consistency/lcm-lora-sdv1-5",
|
| 126 |
-
)
|
| 127 |
-
parser.add_argument(
|
| 128 |
-
"-i",
|
| 129 |
-
"--interactive",
|
| 130 |
-
action="store_true",
|
| 131 |
-
help="Interactive CLI mode",
|
| 132 |
-
)
|
| 133 |
-
parser.add_argument(
|
| 134 |
-
"-t",
|
| 135 |
-
"--use_tiny_auto_encoder",
|
| 136 |
-
action="store_true",
|
| 137 |
-
help="Use tiny auto encoder for SD (TAESD)",
|
| 138 |
-
)
|
| 139 |
-
parser.add_argument(
|
| 140 |
-
"-f",
|
| 141 |
-
"--file",
|
| 142 |
-
type=str,
|
| 143 |
-
help="Input image for img2img mode",
|
| 144 |
-
default="",
|
| 145 |
-
)
|
| 146 |
-
parser.add_argument(
|
| 147 |
-
"--img2img",
|
| 148 |
-
action="store_true",
|
| 149 |
-
help="img2img mode; requires input file via -f argument",
|
| 150 |
-
)
|
| 151 |
-
args = parser.parse_args()
|
| 152 |
-
|
| 153 |
-
if args.version:
|
| 154 |
-
print(APP_VERSION)
|
| 155 |
-
exit()
|
| 156 |
-
|
| 157 |
-
# parser.print_help()
|
| 158 |
-
show_system_info()
|
| 159 |
-
print(f"Using device : {constants.DEVICE}")
|
| 160 |
-
if args.webui:
|
| 161 |
-
app_settings = get_settings()
|
| 162 |
-
else:
|
| 163 |
-
app_settings = get_settings()
|
| 164 |
-
|
| 165 |
-
print(f"Found {len(app_settings.lcm_models)} LCM models in config/lcm-models.txt")
|
| 166 |
-
print(
|
| 167 |
-
f"Found {len(app_settings.stable_diffsuion_models)} stable diffusion models in config/stable-diffusion-models.txt"
|
| 168 |
-
)
|
| 169 |
-
print(
|
| 170 |
-
f"Found {len(app_settings.lcm_lora_models)} LCM-LoRA models in config/lcm-lora-models.txt"
|
| 171 |
-
)
|
| 172 |
-
print(
|
| 173 |
-
f"Found {len(app_settings.openvino_lcm_models)} OpenVINO LCM models in config/openvino-lcm-models.txt"
|
| 174 |
-
)
|
| 175 |
-
if args.gui:
|
| 176 |
-
from frontend.gui.ui import start_gui
|
| 177 |
-
|
| 178 |
-
print("Starting desktop GUI mode(Qt)")
|
| 179 |
-
start_gui(
|
| 180 |
-
[],
|
| 181 |
-
app_settings,
|
| 182 |
-
)
|
| 183 |
-
elif args.webui:
|
| 184 |
-
from frontend.webui.ui import start_webui
|
| 185 |
-
|
| 186 |
-
print("Starting web UI mode")
|
| 187 |
-
start_webui(
|
| 188 |
-
args.share,
|
| 189 |
-
)
|
| 190 |
-
elif args.realtime:
|
| 191 |
-
from frontend.webui.realtime_ui import start_realtime_text_to_image
|
| 192 |
-
|
| 193 |
-
print("Starting realtime text to image(EXPERIMENTAL)")
|
| 194 |
-
start_realtime_text_to_image(args.share)
|
| 195 |
-
|
| 196 |
-
|
| 197 |
from frontend.webui.hf_demo import start_demo_text_to_image
|
| 198 |
|
| 199 |
print("Starting HF demo text to image")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
from frontend.webui.hf_demo import start_demo_text_to_image
|
| 2 |
|
| 3 |
print("Starting HF demo text to image")
|
benchmark-openvino.bat
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
@echo off
|
| 2 |
+
setlocal
|
| 3 |
+
|
| 4 |
+
set "PYTHON_COMMAND=python"
|
| 5 |
+
|
| 6 |
+
call python --version > nul 2>&1
|
| 7 |
+
if %errorlevel% equ 0 (
|
| 8 |
+
echo Python command check :OK
|
| 9 |
+
) else (
|
| 10 |
+
echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
|
| 11 |
+
pause
|
| 12 |
+
exit /b 1
|
| 13 |
+
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
:check_python_version
|
| 17 |
+
for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
|
| 18 |
+
set "python_version=%%I"
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
echo Python version: %python_version%
|
| 22 |
+
|
| 23 |
+
call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% src/app.py -b --use_openvino --openvino_lcm_model_id "rupeshs/sd-turbo-openvino"
|
benchmark.bat
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
@echo off
|
| 2 |
+
setlocal
|
| 3 |
+
|
| 4 |
+
set "PYTHON_COMMAND=python"
|
| 5 |
+
|
| 6 |
+
call python --version > nul 2>&1
|
| 7 |
+
if %errorlevel% equ 0 (
|
| 8 |
+
echo Python command check :OK
|
| 9 |
+
) else (
|
| 10 |
+
echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
|
| 11 |
+
pause
|
| 12 |
+
exit /b 1
|
| 13 |
+
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
:check_python_version
|
| 17 |
+
for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
|
| 18 |
+
set "python_version=%%I"
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
echo Python version: %python_version%
|
| 22 |
+
|
| 23 |
+
call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% src/app.py -b
|
configs/lcm-lora-models.txt
CHANGED
|
@@ -1,3 +1,4 @@
|
|
| 1 |
latent-consistency/lcm-lora-sdv1-5
|
| 2 |
latent-consistency/lcm-lora-sdxl
|
| 3 |
-
latent-consistency/lcm-lora-ssd-1b
|
|
|
|
|
|
| 1 |
latent-consistency/lcm-lora-sdv1-5
|
| 2 |
latent-consistency/lcm-lora-sdxl
|
| 3 |
+
latent-consistency/lcm-lora-ssd-1b
|
| 4 |
+
rupeshs/hypersd-sd1-5-1-step-lora
|
configs/lcm-models.txt
CHANGED
|
@@ -1,4 +1,7 @@
|
|
| 1 |
stabilityai/sd-turbo
|
|
|
|
|
|
|
|
|
|
| 2 |
stabilityai/sdxl-turbo
|
| 3 |
SimianLuo/LCM_Dreamshaper_v7
|
| 4 |
latent-consistency/lcm-sdxl
|
|
|
|
| 1 |
stabilityai/sd-turbo
|
| 2 |
+
rupeshs/sdxs-512-0.9-orig-vae
|
| 3 |
+
rupeshs/hyper-sd-sdxl-1-step
|
| 4 |
+
rupeshs/SDXL-Lightning-2steps
|
| 5 |
stabilityai/sdxl-turbo
|
| 6 |
SimianLuo/LCM_Dreamshaper_v7
|
| 7 |
latent-consistency/lcm-sdxl
|
configs/openvino-lcm-models.txt
CHANGED
|
@@ -1,4 +1,9 @@
|
|
| 1 |
rupeshs/sd-turbo-openvino
|
|
|
|
|
|
|
|
|
|
| 2 |
rupeshs/sdxl-turbo-openvino-int8
|
| 3 |
rupeshs/LCM-dreamshaper-v7-openvino
|
| 4 |
-
Disty0/LCM_SoteMix
|
|
|
|
|
|
|
|
|
| 1 |
rupeshs/sd-turbo-openvino
|
| 2 |
+
rupeshs/sdxs-512-0.9-openvino
|
| 3 |
+
rupeshs/hyper-sd-sdxl-1-step-openvino-int8
|
| 4 |
+
rupeshs/SDXL-Lightning-2steps-openvino-int8
|
| 5 |
rupeshs/sdxl-turbo-openvino-int8
|
| 6 |
rupeshs/LCM-dreamshaper-v7-openvino
|
| 7 |
+
Disty0/LCM_SoteMix
|
| 8 |
+
rupeshs/FLUX.1-schnell-openvino-int4
|
| 9 |
+
rupeshs/sd15-lcm-square-openvino-int8
|
controlnet_models/Readme.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Place your ControlNet models in this folder.
|
| 2 |
+
You can download controlnet model (.safetensors) from https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main
|
| 3 |
+
E.g: https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/blob/main/control_v11p_sd15_canny_fp16.safetensors
|
docs/images/2steps-inference.jpg
ADDED

|
Git LFS Details
|
docs/images/ARCGPU.png
ADDED

|
Git LFS Details
|
docs/images/fastcpu-cli.png
ADDED

|
Git LFS Details
|
docs/images/fastcpu-webui.png
ADDED

|
Git LFS Details
|
docs/images/fastsdcpu-android-termux-pixel7.png
ADDED
|
|
Git LFS Details
|
docs/images/fastsdcpu-api.png
ADDED

|
Git LFS Details
|
docs/images/fastsdcpu-gui.jpg
ADDED

|
Git LFS Details
|
docs/images/fastsdcpu-mac-gui.jpg
ADDED

|
Git LFS Details
|
docs/images/fastsdcpu-screenshot.png
ADDED

|
Git LFS Details
|
docs/images/fastsdcpu-webui.png
ADDED

|
Git LFS Details
|
docs/images/fastsdcpu_claude.jpg
ADDED

|
Git LFS Details
|
docs/images/fastsdcpu_flux_on_cpu.png
ADDED

|
Git LFS Details
|
docs/images/openwebui-fastsd.jpg
ADDED

|
Git LFS Details
|
docs/images/openwebui-settings.png
ADDED

|
Git LFS Details
|
frontend/webui/hf_demo.py
CHANGED
|
@@ -42,8 +42,8 @@ def predict(
|
|
| 42 |
print(f"prompt - {prompt}")
|
| 43 |
lcm_diffusion_setting = LCMDiffusionSetting()
|
| 44 |
lcm_diffusion_setting.diffusion_task = DiffusionTask.text_to_image.value
|
| 45 |
-
lcm_diffusion_setting.openvino_lcm_model_id = "rupeshs/
|
| 46 |
-
lcm_diffusion_setting.use_lcm_lora =
|
| 47 |
lcm_diffusion_setting.prompt = prompt
|
| 48 |
lcm_diffusion_setting.guidance_scale = 1.0
|
| 49 |
lcm_diffusion_setting.inference_steps = steps
|
|
@@ -53,8 +53,8 @@ def predict(
|
|
| 53 |
lcm_diffusion_setting.use_tiny_auto_encoder = True
|
| 54 |
# lcm_diffusion_setting.image_width = 320 if is_openvino_device() else 512
|
| 55 |
# lcm_diffusion_setting.image_height = 320 if is_openvino_device() else 512
|
| 56 |
-
lcm_diffusion_setting.image_width =
|
| 57 |
-
lcm_diffusion_setting.image_height =
|
| 58 |
lcm_diffusion_setting.use_openvino = False
|
| 59 |
lcm_diffusion_setting.use_tiny_auto_encoder = True
|
| 60 |
pprint(lcm_diffusion_setting.model_dump())
|
|
@@ -133,9 +133,9 @@ with gr.Blocks(css=css) as demo:
|
|
| 133 |
with gr.Accordion("Advanced options", open=False):
|
| 134 |
steps = gr.Slider(
|
| 135 |
label="Steps",
|
| 136 |
-
value=
|
| 137 |
minimum=1,
|
| 138 |
-
maximum=
|
| 139 |
step=1,
|
| 140 |
)
|
| 141 |
seed = gr.Slider(
|
|
|
|
| 42 |
print(f"prompt - {prompt}")
|
| 43 |
lcm_diffusion_setting = LCMDiffusionSetting()
|
| 44 |
lcm_diffusion_setting.diffusion_task = DiffusionTask.text_to_image.value
|
| 45 |
+
lcm_diffusion_setting.openvino_lcm_model_id = "rupeshs/hyper-sd-sdxl-1-step"
|
| 46 |
+
lcm_diffusion_setting.use_lcm_lora = False
|
| 47 |
lcm_diffusion_setting.prompt = prompt
|
| 48 |
lcm_diffusion_setting.guidance_scale = 1.0
|
| 49 |
lcm_diffusion_setting.inference_steps = steps
|
|
|
|
| 53 |
lcm_diffusion_setting.use_tiny_auto_encoder = True
|
| 54 |
# lcm_diffusion_setting.image_width = 320 if is_openvino_device() else 512
|
| 55 |
# lcm_diffusion_setting.image_height = 320 if is_openvino_device() else 512
|
| 56 |
+
lcm_diffusion_setting.image_width = 768
|
| 57 |
+
lcm_diffusion_setting.image_height = 768
|
| 58 |
lcm_diffusion_setting.use_openvino = False
|
| 59 |
lcm_diffusion_setting.use_tiny_auto_encoder = True
|
| 60 |
pprint(lcm_diffusion_setting.model_dump())
|
|
|
|
| 133 |
with gr.Accordion("Advanced options", open=False):
|
| 134 |
steps = gr.Slider(
|
| 135 |
label="Steps",
|
| 136 |
+
value=1,
|
| 137 |
minimum=1,
|
| 138 |
+
maximum=3,
|
| 139 |
step=1,
|
| 140 |
)
|
| 141 |
seed = gr.Slider(
|
install-mac.sh
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
echo Starting FastSD CPU env installation...
|
| 3 |
+
set -e
|
| 4 |
+
PYTHON_COMMAND="python3"
|
| 5 |
+
|
| 6 |
+
if ! command -v python3 &>/dev/null; then
|
| 7 |
+
if ! command -v python &>/dev/null; then
|
| 8 |
+
echo "Error: Python not found, please install python 3.8 or higher and try again"
|
| 9 |
+
exit 1
|
| 10 |
+
fi
|
| 11 |
+
fi
|
| 12 |
+
|
| 13 |
+
if command -v python &>/dev/null; then
|
| 14 |
+
PYTHON_COMMAND="python"
|
| 15 |
+
fi
|
| 16 |
+
|
| 17 |
+
echo "Found $PYTHON_COMMAND command"
|
| 18 |
+
|
| 19 |
+
python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
|
| 20 |
+
echo "Python version : $python_version"
|
| 21 |
+
|
| 22 |
+
if ! command -v uv &>/dev/null; then
|
| 23 |
+
echo "Error: uv command not found,please install https://docs.astral.sh/uv/getting-started/installation/#__tabbed_1_1 ,for termux "pkg install uv" and try again."
|
| 24 |
+
exit 1
|
| 25 |
+
fi
|
| 26 |
+
|
| 27 |
+
BASEDIR=$(pwd)
|
| 28 |
+
|
| 29 |
+
uv venv --python 3.11.6 "$BASEDIR/env"
|
| 30 |
+
# shellcheck disable=SC1091
|
| 31 |
+
source "$BASEDIR/env/bin/activate"
|
| 32 |
+
uv pip install torch
|
| 33 |
+
uv pip install -r "$BASEDIR/requirements.txt"
|
| 34 |
+
chmod +x "start.sh"
|
| 35 |
+
chmod +x "start-webui.sh"
|
| 36 |
+
read -n1 -r -p "FastSD CPU installation completed,press any key to continue..." key
|
install.bat
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
@echo off
|
| 3 |
+
setlocal
|
| 4 |
+
echo Starting FastSD CPU env installation...
|
| 5 |
+
|
| 6 |
+
set "PYTHON_COMMAND=python"
|
| 7 |
+
|
| 8 |
+
call python --version > nul 2>&1
|
| 9 |
+
if %errorlevel% equ 0 (
|
| 10 |
+
echo Python command check :OK
|
| 11 |
+
) else (
|
| 12 |
+
echo "Error: Python command not found,please install Python(Recommended : Python 3.10 or Python 3.11) and try again."
|
| 13 |
+
pause
|
| 14 |
+
exit /b 1
|
| 15 |
+
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
call uv --version > nul 2>&1
|
| 19 |
+
if %errorlevel% equ 0 (
|
| 20 |
+
echo uv command check :OK
|
| 21 |
+
) else (
|
| 22 |
+
echo "Error: uv command not found,please install it using "pip install uv" command,for termux "pkg install uv" and try again."
|
| 23 |
+
pause
|
| 24 |
+
exit /b 1
|
| 25 |
+
|
| 26 |
+
)
|
| 27 |
+
:check_python_version
|
| 28 |
+
for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
|
| 29 |
+
set "python_version=%%I"
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
echo Python version: %python_version%
|
| 33 |
+
|
| 34 |
+
uv venv --python 3.11.6 "%~dp0env"
|
| 35 |
+
call "%~dp0env\Scripts\activate.bat" && uv pip install torch --index-url https://download.pytorch.org/whl/cpu
|
| 36 |
+
call "%~dp0env\Scripts\activate.bat" && uv pip install -r "%~dp0requirements.txt"
|
| 37 |
+
echo FastSD CPU env installation completed.
|
| 38 |
+
pause
|
install.sh
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
echo Starting FastSD CPU env installation...
|
| 3 |
+
set -e
|
| 4 |
+
PYTHON_COMMAND="python3"
|
| 5 |
+
|
| 6 |
+
if ! command -v python3 &>/dev/null; then
|
| 7 |
+
if ! command -v python &>/dev/null; then
|
| 8 |
+
echo "Error: Python not found, please install python 3.8 or higher and try again"
|
| 9 |
+
exit 1
|
| 10 |
+
fi
|
| 11 |
+
fi
|
| 12 |
+
|
| 13 |
+
if command -v python &>/dev/null; then
|
| 14 |
+
PYTHON_COMMAND="python"
|
| 15 |
+
fi
|
| 16 |
+
|
| 17 |
+
echo "Found $PYTHON_COMMAND command"
|
| 18 |
+
|
| 19 |
+
python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
|
| 20 |
+
echo "Python version : $python_version"
|
| 21 |
+
|
| 22 |
+
if ! command -v uv &>/dev/null; then
|
| 23 |
+
echo "Error: uv command not found,please install https://docs.astral.sh/uv/getting-started/installation/#__tabbed_1_1 ,for termux "pkg install uv" and try again."
|
| 24 |
+
exit 1
|
| 25 |
+
fi
|
| 26 |
+
|
| 27 |
+
BASEDIR=$(pwd)
|
| 28 |
+
|
| 29 |
+
uv venv --python 3.11.6 "$BASEDIR/env"
|
| 30 |
+
# shellcheck disable=SC1091
|
| 31 |
+
source "$BASEDIR/env/bin/activate"
|
| 32 |
+
uv pip install torch==2.2.2 --index-url https://download.pytorch.org/whl/cpu
|
| 33 |
+
if [[ "$1" == "--disable-gui" ]]; then
|
| 34 |
+
#! For termux , we don't need Qt based GUI
|
| 35 |
+
packages="$(grep -v "^ *#\|^PyQt5" requirements.txt | grep .)"
|
| 36 |
+
# shellcheck disable=SC2086
|
| 37 |
+
uv pip install $packages
|
| 38 |
+
else
|
| 39 |
+
uv pip install -r "$BASEDIR/requirements.txt"
|
| 40 |
+
fi
|
| 41 |
+
|
| 42 |
+
chmod +x "start.sh"
|
| 43 |
+
chmod +x "start-webui.sh"
|
| 44 |
+
read -n1 -r -p "FastSD CPU installation completed,press any key to continue..." key
|
lora_models/Readme.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Place your lora models in this folder.
|
| 2 |
+
You can download lora model (.safetensors/Safetensor) from Civitai (https://civitai.com/) or Hugging Face(https://huggingface.co/)
|
| 3 |
+
E.g: https://civitai.com/models/207984/cutecartoonredmond-15v-cute-cartoon-lora-for-liberteredmond-sd-15?modelVersionId=234192
|
models/gguf/clip/readme.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Place CLIP model files here"
|
models/gguf/diffusion/readme.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Place your diffusion gguf model files here
|
models/gguf/t5xxl/readme.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Place T5-XXL model files here
|
models/gguf/vae/readme.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Place VAE model files here
|
requirements.txt
CHANGED
|
@@ -1,16 +1,20 @@
|
|
| 1 |
-
accelerate==0.
|
| 2 |
-
diffusers==0.
|
| 3 |
-
transformers==4.
|
| 4 |
PyQt5
|
| 5 |
Pillow==9.4.0
|
| 6 |
-
openvino==
|
| 7 |
-
optimum==1.
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
pydantic==2.4.2
|
| 12 |
typing-extensions==4.8.0
|
| 13 |
pyyaml==6.0.1
|
| 14 |
-
gradio==
|
| 15 |
peft==0.6.1
|
| 16 |
-
opencv-python==4.8.1.78
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate==0.33.0
|
| 2 |
+
diffusers==0.30.0
|
| 3 |
+
transformers==4.41.2
|
| 4 |
PyQt5
|
| 5 |
Pillow==9.4.0
|
| 6 |
+
openvino==2024.4.0
|
| 7 |
+
optimum-intel==1.18.2
|
| 8 |
+
onnx==1.16.0
|
| 9 |
+
onnxruntime==1.17.3
|
| 10 |
+
pydantic
|
|
|
|
| 11 |
typing-extensions==4.8.0
|
| 12 |
pyyaml==6.0.1
|
| 13 |
+
gradio==5.6.0
|
| 14 |
peft==0.6.1
|
| 15 |
+
opencv-python==4.8.1.78
|
| 16 |
+
omegaconf==2.3.0
|
| 17 |
+
controlnet-aux==0.0.7
|
| 18 |
+
mediapipe>=0.10.9
|
| 19 |
+
tomesd==0.1.3
|
| 20 |
+
fastapi-mcp
|
src/__init__.py
ADDED
|
File without changes
|
src/app.py
ADDED
|
@@ -0,0 +1,554 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from argparse import ArgumentParser
|
| 3 |
+
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
import constants
|
| 7 |
+
from backend.controlnet import controlnet_settings_from_dict
|
| 8 |
+
from backend.device import get_device_name
|
| 9 |
+
from backend.models.gen_images import ImageFormat
|
| 10 |
+
from backend.models.lcmdiffusion_setting import DiffusionTask
|
| 11 |
+
from backend.upscale.tiled_upscale import generate_upscaled_image
|
| 12 |
+
from constants import APP_VERSION, DEVICE
|
| 13 |
+
from frontend.webui.image_variations_ui import generate_image_variations
|
| 14 |
+
from models.interface_types import InterfaceType
|
| 15 |
+
from paths import FastStableDiffusionPaths, ensure_path
|
| 16 |
+
from state import get_context, get_settings
|
| 17 |
+
from utils import show_system_info
|
| 18 |
+
|
| 19 |
+
parser = ArgumentParser(description=f"FAST SD CPU {constants.APP_VERSION}")
|
| 20 |
+
parser.add_argument(
|
| 21 |
+
"-s",
|
| 22 |
+
"--share",
|
| 23 |
+
action="store_true",
|
| 24 |
+
help="Create sharable link(Web UI)",
|
| 25 |
+
required=False,
|
| 26 |
+
)
|
| 27 |
+
group = parser.add_mutually_exclusive_group(required=False)
|
| 28 |
+
group.add_argument(
|
| 29 |
+
"-g",
|
| 30 |
+
"--gui",
|
| 31 |
+
action="store_true",
|
| 32 |
+
help="Start desktop GUI",
|
| 33 |
+
)
|
| 34 |
+
group.add_argument(
|
| 35 |
+
"-w",
|
| 36 |
+
"--webui",
|
| 37 |
+
action="store_true",
|
| 38 |
+
help="Start Web UI",
|
| 39 |
+
)
|
| 40 |
+
group.add_argument(
|
| 41 |
+
"-a",
|
| 42 |
+
"--api",
|
| 43 |
+
action="store_true",
|
| 44 |
+
help="Start Web API server",
|
| 45 |
+
)
|
| 46 |
+
group.add_argument(
|
| 47 |
+
"-m",
|
| 48 |
+
"--mcp",
|
| 49 |
+
action="store_true",
|
| 50 |
+
help="Start MCP(Model Context Protocol) server",
|
| 51 |
+
)
|
| 52 |
+
group.add_argument(
|
| 53 |
+
"-r",
|
| 54 |
+
"--realtime",
|
| 55 |
+
action="store_true",
|
| 56 |
+
help="Start realtime inference UI(experimental)",
|
| 57 |
+
)
|
| 58 |
+
group.add_argument(
|
| 59 |
+
"-v",
|
| 60 |
+
"--version",
|
| 61 |
+
action="store_true",
|
| 62 |
+
help="Version",
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
parser.add_argument(
|
| 66 |
+
"-b",
|
| 67 |
+
"--benchmark",
|
| 68 |
+
action="store_true",
|
| 69 |
+
help="Run inference benchmark on the selected device",
|
| 70 |
+
)
|
| 71 |
+
parser.add_argument(
|
| 72 |
+
"--lcm_model_id",
|
| 73 |
+
type=str,
|
| 74 |
+
help="Model ID or path,Default stabilityai/sd-turbo",
|
| 75 |
+
default="stabilityai/sd-turbo",
|
| 76 |
+
)
|
| 77 |
+
parser.add_argument(
|
| 78 |
+
"--openvino_lcm_model_id",
|
| 79 |
+
type=str,
|
| 80 |
+
help="OpenVINO Model ID or path,Default rupeshs/sd-turbo-openvino",
|
| 81 |
+
default="rupeshs/sd-turbo-openvino",
|
| 82 |
+
)
|
| 83 |
+
parser.add_argument(
|
| 84 |
+
"--prompt",
|
| 85 |
+
type=str,
|
| 86 |
+
help="Describe the image you want to generate",
|
| 87 |
+
default="",
|
| 88 |
+
)
|
| 89 |
+
parser.add_argument(
|
| 90 |
+
"--negative_prompt",
|
| 91 |
+
type=str,
|
| 92 |
+
help="Describe what you want to exclude from the generation",
|
| 93 |
+
default="",
|
| 94 |
+
)
|
| 95 |
+
parser.add_argument(
|
| 96 |
+
"--image_height",
|
| 97 |
+
type=int,
|
| 98 |
+
help="Height of the image",
|
| 99 |
+
default=512,
|
| 100 |
+
)
|
| 101 |
+
parser.add_argument(
|
| 102 |
+
"--image_width",
|
| 103 |
+
type=int,
|
| 104 |
+
help="Width of the image",
|
| 105 |
+
default=512,
|
| 106 |
+
)
|
| 107 |
+
parser.add_argument(
|
| 108 |
+
"--inference_steps",
|
| 109 |
+
type=int,
|
| 110 |
+
help="Number of steps,default : 1",
|
| 111 |
+
default=1,
|
| 112 |
+
)
|
| 113 |
+
parser.add_argument(
|
| 114 |
+
"--guidance_scale",
|
| 115 |
+
type=float,
|
| 116 |
+
help="Guidance scale,default : 1.0",
|
| 117 |
+
default=1.0,
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
parser.add_argument(
|
| 121 |
+
"--number_of_images",
|
| 122 |
+
type=int,
|
| 123 |
+
help="Number of images to generate ,default : 1",
|
| 124 |
+
default=1,
|
| 125 |
+
)
|
| 126 |
+
parser.add_argument(
|
| 127 |
+
"--seed",
|
| 128 |
+
type=int,
|
| 129 |
+
help="Seed,default : -1 (disabled) ",
|
| 130 |
+
default=-1,
|
| 131 |
+
)
|
| 132 |
+
parser.add_argument(
|
| 133 |
+
"--use_openvino",
|
| 134 |
+
action="store_true",
|
| 135 |
+
help="Use OpenVINO model",
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
parser.add_argument(
|
| 139 |
+
"--use_offline_model",
|
| 140 |
+
action="store_true",
|
| 141 |
+
help="Use offline model",
|
| 142 |
+
)
|
| 143 |
+
parser.add_argument(
|
| 144 |
+
"--clip_skip",
|
| 145 |
+
type=int,
|
| 146 |
+
help="CLIP Skip (1-12), default : 1 (disabled) ",
|
| 147 |
+
default=1,
|
| 148 |
+
)
|
| 149 |
+
parser.add_argument(
|
| 150 |
+
"--token_merging",
|
| 151 |
+
type=float,
|
| 152 |
+
help="Token merging scale, 0.0 - 1.0, default : 0.0",
|
| 153 |
+
default=0.0,
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
parser.add_argument(
|
| 157 |
+
"--use_safety_checker",
|
| 158 |
+
action="store_true",
|
| 159 |
+
help="Use safety checker",
|
| 160 |
+
)
|
| 161 |
+
parser.add_argument(
|
| 162 |
+
"--use_lcm_lora",
|
| 163 |
+
action="store_true",
|
| 164 |
+
help="Use LCM-LoRA",
|
| 165 |
+
)
|
| 166 |
+
parser.add_argument(
|
| 167 |
+
"--base_model_id",
|
| 168 |
+
type=str,
|
| 169 |
+
help="LCM LoRA base model ID,Default Lykon/dreamshaper-8",
|
| 170 |
+
default="Lykon/dreamshaper-8",
|
| 171 |
+
)
|
| 172 |
+
parser.add_argument(
|
| 173 |
+
"--lcm_lora_id",
|
| 174 |
+
type=str,
|
| 175 |
+
help="LCM LoRA model ID,Default latent-consistency/lcm-lora-sdv1-5",
|
| 176 |
+
default="latent-consistency/lcm-lora-sdv1-5",
|
| 177 |
+
)
|
| 178 |
+
parser.add_argument(
|
| 179 |
+
"-i",
|
| 180 |
+
"--interactive",
|
| 181 |
+
action="store_true",
|
| 182 |
+
help="Interactive CLI mode",
|
| 183 |
+
)
|
| 184 |
+
parser.add_argument(
|
| 185 |
+
"-t",
|
| 186 |
+
"--use_tiny_auto_encoder",
|
| 187 |
+
action="store_true",
|
| 188 |
+
help="Use tiny auto encoder for SD (TAESD)",
|
| 189 |
+
)
|
| 190 |
+
parser.add_argument(
|
| 191 |
+
"-f",
|
| 192 |
+
"--file",
|
| 193 |
+
type=str,
|
| 194 |
+
help="Input image for img2img mode",
|
| 195 |
+
default="",
|
| 196 |
+
)
|
| 197 |
+
parser.add_argument(
|
| 198 |
+
"--img2img",
|
| 199 |
+
action="store_true",
|
| 200 |
+
help="img2img mode; requires input file via -f argument",
|
| 201 |
+
)
|
| 202 |
+
parser.add_argument(
|
| 203 |
+
"--batch_count",
|
| 204 |
+
type=int,
|
| 205 |
+
help="Number of sequential generations",
|
| 206 |
+
default=1,
|
| 207 |
+
)
|
| 208 |
+
parser.add_argument(
|
| 209 |
+
"--strength",
|
| 210 |
+
type=float,
|
| 211 |
+
help="Denoising strength for img2img and Image variations",
|
| 212 |
+
default=0.3,
|
| 213 |
+
)
|
| 214 |
+
parser.add_argument(
|
| 215 |
+
"--sdupscale",
|
| 216 |
+
action="store_true",
|
| 217 |
+
help="Tiled SD upscale,works only for the resolution 512x512,(2x upscale)",
|
| 218 |
+
)
|
| 219 |
+
parser.add_argument(
|
| 220 |
+
"--upscale",
|
| 221 |
+
action="store_true",
|
| 222 |
+
help="EDSR SD upscale ",
|
| 223 |
+
)
|
| 224 |
+
parser.add_argument(
|
| 225 |
+
"--custom_settings",
|
| 226 |
+
type=str,
|
| 227 |
+
help="JSON file containing custom generation settings",
|
| 228 |
+
default=None,
|
| 229 |
+
)
|
| 230 |
+
parser.add_argument(
|
| 231 |
+
"--usejpeg",
|
| 232 |
+
action="store_true",
|
| 233 |
+
help="Images will be saved as JPEG format",
|
| 234 |
+
)
|
| 235 |
+
parser.add_argument(
|
| 236 |
+
"--noimagesave",
|
| 237 |
+
action="store_true",
|
| 238 |
+
help="Disable image saving",
|
| 239 |
+
)
|
| 240 |
+
parser.add_argument(
|
| 241 |
+
"--imagequality", type=int, help="Output image quality [0 to 100]", default=90
|
| 242 |
+
)
|
| 243 |
+
parser.add_argument(
|
| 244 |
+
"--lora",
|
| 245 |
+
type=str,
|
| 246 |
+
help="LoRA model full path e.g D:\lora_models\CuteCartoon15V-LiberteRedmodModel-Cartoon-CuteCartoonAF.safetensors",
|
| 247 |
+
default=None,
|
| 248 |
+
)
|
| 249 |
+
parser.add_argument(
|
| 250 |
+
"--lora_weight",
|
| 251 |
+
type=float,
|
| 252 |
+
help="LoRA adapter weight [0 to 1.0]",
|
| 253 |
+
default=0.5,
|
| 254 |
+
)
|
| 255 |
+
parser.add_argument(
|
| 256 |
+
"--port",
|
| 257 |
+
type=int,
|
| 258 |
+
help="Web server port",
|
| 259 |
+
default=8000,
|
| 260 |
+
)
|
| 261 |
+
|
| 262 |
+
args = parser.parse_args()
|
| 263 |
+
|
| 264 |
+
if args.version:
|
| 265 |
+
print(APP_VERSION)
|
| 266 |
+
exit()
|
| 267 |
+
|
| 268 |
+
# parser.print_help()
|
| 269 |
+
print("FastSD CPU - ", APP_VERSION)
|
| 270 |
+
show_system_info()
|
| 271 |
+
print(f"Using device : {constants.DEVICE}")
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
if args.webui:
|
| 275 |
+
app_settings = get_settings()
|
| 276 |
+
else:
|
| 277 |
+
app_settings = get_settings()
|
| 278 |
+
|
| 279 |
+
print(f"Output path : {app_settings.settings.generated_images.path}")
|
| 280 |
+
ensure_path(app_settings.settings.generated_images.path)
|
| 281 |
+
|
| 282 |
+
print(f"Found {len(app_settings.lcm_models)} LCM models in config/lcm-models.txt")
|
| 283 |
+
print(
|
| 284 |
+
f"Found {len(app_settings.stable_diffsuion_models)} stable diffusion models in config/stable-diffusion-models.txt"
|
| 285 |
+
)
|
| 286 |
+
print(
|
| 287 |
+
f"Found {len(app_settings.lcm_lora_models)} LCM-LoRA models in config/lcm-lora-models.txt"
|
| 288 |
+
)
|
| 289 |
+
print(
|
| 290 |
+
f"Found {len(app_settings.openvino_lcm_models)} OpenVINO LCM models in config/openvino-lcm-models.txt"
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
if args.noimagesave:
|
| 294 |
+
app_settings.settings.generated_images.save_image = False
|
| 295 |
+
else:
|
| 296 |
+
app_settings.settings.generated_images.save_image = True
|
| 297 |
+
|
| 298 |
+
app_settings.settings.generated_images.save_image_quality = args.imagequality
|
| 299 |
+
|
| 300 |
+
if not args.realtime:
|
| 301 |
+
# To minimize realtime mode dependencies
|
| 302 |
+
from backend.upscale.upscaler import upscale_image
|
| 303 |
+
from frontend.cli_interactive import interactive_mode
|
| 304 |
+
|
| 305 |
+
if args.gui:
|
| 306 |
+
from frontend.gui.ui import start_gui
|
| 307 |
+
|
| 308 |
+
print("Starting desktop GUI mode(Qt)")
|
| 309 |
+
start_gui(
|
| 310 |
+
[],
|
| 311 |
+
app_settings,
|
| 312 |
+
)
|
| 313 |
+
elif args.webui:
|
| 314 |
+
from frontend.webui.ui import start_webui
|
| 315 |
+
|
| 316 |
+
print("Starting web UI mode")
|
| 317 |
+
start_webui(
|
| 318 |
+
args.share,
|
| 319 |
+
)
|
| 320 |
+
elif args.realtime:
|
| 321 |
+
from frontend.webui.realtime_ui import start_realtime_text_to_image
|
| 322 |
+
|
| 323 |
+
print("Starting realtime text to image(EXPERIMENTAL)")
|
| 324 |
+
start_realtime_text_to_image(args.share)
|
| 325 |
+
elif args.api:
|
| 326 |
+
from backend.api.web import start_web_server
|
| 327 |
+
|
| 328 |
+
start_web_server(args.port)
|
| 329 |
+
elif args.mcp:
|
| 330 |
+
from backend.api.mcp_server import start_mcp_server
|
| 331 |
+
|
| 332 |
+
start_mcp_server(args.port)
|
| 333 |
+
else:
|
| 334 |
+
context = get_context(InterfaceType.CLI)
|
| 335 |
+
config = app_settings.settings
|
| 336 |
+
|
| 337 |
+
if args.use_openvino:
|
| 338 |
+
config.lcm_diffusion_setting.openvino_lcm_model_id = args.openvino_lcm_model_id
|
| 339 |
+
else:
|
| 340 |
+
config.lcm_diffusion_setting.lcm_model_id = args.lcm_model_id
|
| 341 |
+
|
| 342 |
+
config.lcm_diffusion_setting.prompt = args.prompt
|
| 343 |
+
config.lcm_diffusion_setting.negative_prompt = args.negative_prompt
|
| 344 |
+
config.lcm_diffusion_setting.image_height = args.image_height
|
| 345 |
+
config.lcm_diffusion_setting.image_width = args.image_width
|
| 346 |
+
config.lcm_diffusion_setting.guidance_scale = args.guidance_scale
|
| 347 |
+
config.lcm_diffusion_setting.number_of_images = args.number_of_images
|
| 348 |
+
config.lcm_diffusion_setting.inference_steps = args.inference_steps
|
| 349 |
+
config.lcm_diffusion_setting.strength = args.strength
|
| 350 |
+
config.lcm_diffusion_setting.seed = args.seed
|
| 351 |
+
config.lcm_diffusion_setting.use_openvino = args.use_openvino
|
| 352 |
+
config.lcm_diffusion_setting.use_tiny_auto_encoder = args.use_tiny_auto_encoder
|
| 353 |
+
config.lcm_diffusion_setting.use_lcm_lora = args.use_lcm_lora
|
| 354 |
+
config.lcm_diffusion_setting.lcm_lora.base_model_id = args.base_model_id
|
| 355 |
+
config.lcm_diffusion_setting.lcm_lora.lcm_lora_id = args.lcm_lora_id
|
| 356 |
+
config.lcm_diffusion_setting.diffusion_task = DiffusionTask.text_to_image.value
|
| 357 |
+
config.lcm_diffusion_setting.lora.enabled = False
|
| 358 |
+
config.lcm_diffusion_setting.lora.path = args.lora
|
| 359 |
+
config.lcm_diffusion_setting.lora.weight = args.lora_weight
|
| 360 |
+
config.lcm_diffusion_setting.lora.fuse = True
|
| 361 |
+
if config.lcm_diffusion_setting.lora.path:
|
| 362 |
+
config.lcm_diffusion_setting.lora.enabled = True
|
| 363 |
+
if args.usejpeg:
|
| 364 |
+
config.generated_images.format = ImageFormat.JPEG.value.upper()
|
| 365 |
+
if args.seed > -1:
|
| 366 |
+
config.lcm_diffusion_setting.use_seed = True
|
| 367 |
+
else:
|
| 368 |
+
config.lcm_diffusion_setting.use_seed = False
|
| 369 |
+
config.lcm_diffusion_setting.use_offline_model = args.use_offline_model
|
| 370 |
+
config.lcm_diffusion_setting.clip_skip = args.clip_skip
|
| 371 |
+
config.lcm_diffusion_setting.token_merging = args.token_merging
|
| 372 |
+
config.lcm_diffusion_setting.use_safety_checker = args.use_safety_checker
|
| 373 |
+
|
| 374 |
+
# Read custom settings from JSON file
|
| 375 |
+
custom_settings = {}
|
| 376 |
+
if args.custom_settings:
|
| 377 |
+
with open(args.custom_settings) as f:
|
| 378 |
+
custom_settings = json.load(f)
|
| 379 |
+
|
| 380 |
+
# Basic ControlNet settings; if ControlNet is enabled, an image is
|
| 381 |
+
# required even in txt2img mode
|
| 382 |
+
config.lcm_diffusion_setting.controlnet = None
|
| 383 |
+
controlnet_settings_from_dict(
|
| 384 |
+
config.lcm_diffusion_setting,
|
| 385 |
+
custom_settings,
|
| 386 |
+
)
|
| 387 |
+
|
| 388 |
+
# Interactive mode
|
| 389 |
+
if args.interactive:
|
| 390 |
+
# wrapper(interactive_mode, config, context)
|
| 391 |
+
config.lcm_diffusion_setting.lora.fuse = False
|
| 392 |
+
interactive_mode(config, context)
|
| 393 |
+
|
| 394 |
+
# Start of non-interactive CLI image generation
|
| 395 |
+
if args.img2img and args.file != "":
|
| 396 |
+
config.lcm_diffusion_setting.init_image = Image.open(args.file)
|
| 397 |
+
config.lcm_diffusion_setting.diffusion_task = DiffusionTask.image_to_image.value
|
| 398 |
+
elif args.img2img and args.file == "":
|
| 399 |
+
print("Error : You need to specify a file in img2img mode")
|
| 400 |
+
exit()
|
| 401 |
+
elif args.upscale and args.file == "" and args.custom_settings == None:
|
| 402 |
+
print("Error : You need to specify a file in SD upscale mode")
|
| 403 |
+
exit()
|
| 404 |
+
elif (
|
| 405 |
+
args.prompt == ""
|
| 406 |
+
and args.file == ""
|
| 407 |
+
and args.custom_settings == None
|
| 408 |
+
and not args.benchmark
|
| 409 |
+
):
|
| 410 |
+
print("Error : You need to provide a prompt")
|
| 411 |
+
exit()
|
| 412 |
+
|
| 413 |
+
if args.upscale:
|
| 414 |
+
# image = Image.open(args.file)
|
| 415 |
+
output_path = FastStableDiffusionPaths.get_upscale_filepath(
|
| 416 |
+
args.file,
|
| 417 |
+
2,
|
| 418 |
+
config.generated_images.format,
|
| 419 |
+
)
|
| 420 |
+
result = upscale_image(
|
| 421 |
+
context,
|
| 422 |
+
args.file,
|
| 423 |
+
output_path,
|
| 424 |
+
2,
|
| 425 |
+
)
|
| 426 |
+
# Perform Tiled SD upscale (EXPERIMENTAL)
|
| 427 |
+
elif args.sdupscale:
|
| 428 |
+
if args.use_openvino:
|
| 429 |
+
config.lcm_diffusion_setting.strength = 0.3
|
| 430 |
+
upscale_settings = None
|
| 431 |
+
if custom_settings != {}:
|
| 432 |
+
upscale_settings = custom_settings
|
| 433 |
+
filepath = args.file
|
| 434 |
+
output_format = config.generated_images.format
|
| 435 |
+
if upscale_settings:
|
| 436 |
+
filepath = upscale_settings["source_file"]
|
| 437 |
+
output_format = upscale_settings["output_format"].upper()
|
| 438 |
+
output_path = FastStableDiffusionPaths.get_upscale_filepath(
|
| 439 |
+
filepath,
|
| 440 |
+
2,
|
| 441 |
+
output_format,
|
| 442 |
+
)
|
| 443 |
+
|
| 444 |
+
generate_upscaled_image(
|
| 445 |
+
config,
|
| 446 |
+
filepath,
|
| 447 |
+
config.lcm_diffusion_setting.strength,
|
| 448 |
+
upscale_settings=upscale_settings,
|
| 449 |
+
context=context,
|
| 450 |
+
tile_overlap=32 if config.lcm_diffusion_setting.use_openvino else 16,
|
| 451 |
+
output_path=output_path,
|
| 452 |
+
image_format=output_format,
|
| 453 |
+
)
|
| 454 |
+
exit()
|
| 455 |
+
# If img2img argument is set and prompt is empty, use image variations mode
|
| 456 |
+
elif args.img2img and args.prompt == "":
|
| 457 |
+
for i in range(0, args.batch_count):
|
| 458 |
+
generate_image_variations(
|
| 459 |
+
config.lcm_diffusion_setting.init_image, args.strength
|
| 460 |
+
)
|
| 461 |
+
else:
|
| 462 |
+
if args.benchmark:
|
| 463 |
+
print("Initializing benchmark...")
|
| 464 |
+
bench_lcm_setting = config.lcm_diffusion_setting
|
| 465 |
+
bench_lcm_setting.prompt = "a cat"
|
| 466 |
+
bench_lcm_setting.use_tiny_auto_encoder = False
|
| 467 |
+
context.generate_text_to_image(
|
| 468 |
+
settings=config,
|
| 469 |
+
device=DEVICE,
|
| 470 |
+
)
|
| 471 |
+
|
| 472 |
+
latencies = []
|
| 473 |
+
|
| 474 |
+
print("Starting benchmark please wait...")
|
| 475 |
+
for _ in range(3):
|
| 476 |
+
context.generate_text_to_image(
|
| 477 |
+
settings=config,
|
| 478 |
+
device=DEVICE,
|
| 479 |
+
)
|
| 480 |
+
latencies.append(context.latency)
|
| 481 |
+
|
| 482 |
+
avg_latency = sum(latencies) / 3
|
| 483 |
+
|
| 484 |
+
bench_lcm_setting.use_tiny_auto_encoder = True
|
| 485 |
+
|
| 486 |
+
context.generate_text_to_image(
|
| 487 |
+
settings=config,
|
| 488 |
+
device=DEVICE,
|
| 489 |
+
)
|
| 490 |
+
latencies = []
|
| 491 |
+
for _ in range(3):
|
| 492 |
+
context.generate_text_to_image(
|
| 493 |
+
settings=config,
|
| 494 |
+
device=DEVICE,
|
| 495 |
+
)
|
| 496 |
+
latencies.append(context.latency)
|
| 497 |
+
|
| 498 |
+
avg_latency_taesd = sum(latencies) / 3
|
| 499 |
+
|
| 500 |
+
benchmark_name = ""
|
| 501 |
+
|
| 502 |
+
if config.lcm_diffusion_setting.use_openvino:
|
| 503 |
+
benchmark_name = "OpenVINO"
|
| 504 |
+
else:
|
| 505 |
+
benchmark_name = "PyTorch"
|
| 506 |
+
|
| 507 |
+
bench_model_id = ""
|
| 508 |
+
if bench_lcm_setting.use_openvino:
|
| 509 |
+
bench_model_id = bench_lcm_setting.openvino_lcm_model_id
|
| 510 |
+
elif bench_lcm_setting.use_lcm_lora:
|
| 511 |
+
bench_model_id = bench_lcm_setting.lcm_lora.base_model_id
|
| 512 |
+
else:
|
| 513 |
+
bench_model_id = bench_lcm_setting.lcm_model_id
|
| 514 |
+
|
| 515 |
+
benchmark_result = [
|
| 516 |
+
["Device", f"{DEVICE.upper()},{get_device_name()}"],
|
| 517 |
+
["Stable Diffusion Model", bench_model_id],
|
| 518 |
+
[
|
| 519 |
+
"Image Size ",
|
| 520 |
+
f"{bench_lcm_setting.image_width}x{bench_lcm_setting.image_height}",
|
| 521 |
+
],
|
| 522 |
+
[
|
| 523 |
+
"Inference Steps",
|
| 524 |
+
f"{bench_lcm_setting.inference_steps}",
|
| 525 |
+
],
|
| 526 |
+
[
|
| 527 |
+
"Benchmark Passes",
|
| 528 |
+
3,
|
| 529 |
+
],
|
| 530 |
+
[
|
| 531 |
+
"Average Latency",
|
| 532 |
+
f"{round(avg_latency, 3)} sec",
|
| 533 |
+
],
|
| 534 |
+
[
|
| 535 |
+
"Average Latency(TAESD* enabled)",
|
| 536 |
+
f"{round(avg_latency_taesd, 3)} sec",
|
| 537 |
+
],
|
| 538 |
+
]
|
| 539 |
+
print()
|
| 540 |
+
print(
|
| 541 |
+
f" FastSD Benchmark - {benchmark_name:8} "
|
| 542 |
+
)
|
| 543 |
+
print(f"-" * 80)
|
| 544 |
+
for benchmark in benchmark_result:
|
| 545 |
+
print(f"{benchmark[0]:35} - {benchmark[1]}")
|
| 546 |
+
print(f"-" * 80)
|
| 547 |
+
print("*TAESD - Tiny AutoEncoder for Stable Diffusion")
|
| 548 |
+
|
| 549 |
+
else:
|
| 550 |
+
for i in range(0, args.batch_count):
|
| 551 |
+
context.generate_text_to_image(
|
| 552 |
+
settings=config,
|
| 553 |
+
device=DEVICE,
|
| 554 |
+
)
|
src/app_settings.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from copy import deepcopy
|
| 2 |
+
from os import makedirs, path
|
| 3 |
+
|
| 4 |
+
import yaml
|
| 5 |
+
from constants import (
|
| 6 |
+
LCM_LORA_MODELS_FILE,
|
| 7 |
+
LCM_MODELS_FILE,
|
| 8 |
+
OPENVINO_LCM_MODELS_FILE,
|
| 9 |
+
SD_MODELS_FILE,
|
| 10 |
+
)
|
| 11 |
+
from paths import FastStableDiffusionPaths, join_paths
|
| 12 |
+
from utils import get_files_in_dir, get_models_from_text_file
|
| 13 |
+
|
| 14 |
+
from models.settings import Settings
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class AppSettings:
|
| 18 |
+
def __init__(self):
|
| 19 |
+
self.config_path = FastStableDiffusionPaths().get_app_settings_path()
|
| 20 |
+
self._stable_diffsuion_models = get_models_from_text_file(
|
| 21 |
+
FastStableDiffusionPaths().get_models_config_path(SD_MODELS_FILE)
|
| 22 |
+
)
|
| 23 |
+
self._lcm_lora_models = get_models_from_text_file(
|
| 24 |
+
FastStableDiffusionPaths().get_models_config_path(LCM_LORA_MODELS_FILE)
|
| 25 |
+
)
|
| 26 |
+
self._openvino_lcm_models = get_models_from_text_file(
|
| 27 |
+
FastStableDiffusionPaths().get_models_config_path(OPENVINO_LCM_MODELS_FILE)
|
| 28 |
+
)
|
| 29 |
+
self._lcm_models = get_models_from_text_file(
|
| 30 |
+
FastStableDiffusionPaths().get_models_config_path(LCM_MODELS_FILE)
|
| 31 |
+
)
|
| 32 |
+
self._gguf_diffusion_models = get_files_in_dir(
|
| 33 |
+
join_paths(FastStableDiffusionPaths().get_gguf_models_path(), "diffusion")
|
| 34 |
+
)
|
| 35 |
+
self._gguf_clip_models = get_files_in_dir(
|
| 36 |
+
join_paths(FastStableDiffusionPaths().get_gguf_models_path(), "clip")
|
| 37 |
+
)
|
| 38 |
+
self._gguf_vae_models = get_files_in_dir(
|
| 39 |
+
join_paths(FastStableDiffusionPaths().get_gguf_models_path(), "vae")
|
| 40 |
+
)
|
| 41 |
+
self._gguf_t5xxl_models = get_files_in_dir(
|
| 42 |
+
join_paths(FastStableDiffusionPaths().get_gguf_models_path(), "t5xxl")
|
| 43 |
+
)
|
| 44 |
+
self._config = None
|
| 45 |
+
|
| 46 |
+
@property
|
| 47 |
+
def settings(self):
|
| 48 |
+
return self._config
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
def stable_diffsuion_models(self):
|
| 52 |
+
return self._stable_diffsuion_models
|
| 53 |
+
|
| 54 |
+
@property
|
| 55 |
+
def openvino_lcm_models(self):
|
| 56 |
+
return self._openvino_lcm_models
|
| 57 |
+
|
| 58 |
+
@property
|
| 59 |
+
def lcm_models(self):
|
| 60 |
+
return self._lcm_models
|
| 61 |
+
|
| 62 |
+
@property
|
| 63 |
+
def lcm_lora_models(self):
|
| 64 |
+
return self._lcm_lora_models
|
| 65 |
+
|
| 66 |
+
@property
|
| 67 |
+
def gguf_diffusion_models(self):
|
| 68 |
+
return self._gguf_diffusion_models
|
| 69 |
+
|
| 70 |
+
@property
|
| 71 |
+
def gguf_clip_models(self):
|
| 72 |
+
return self._gguf_clip_models
|
| 73 |
+
|
| 74 |
+
@property
|
| 75 |
+
def gguf_vae_models(self):
|
| 76 |
+
return self._gguf_vae_models
|
| 77 |
+
|
| 78 |
+
@property
|
| 79 |
+
def gguf_t5xxl_models(self):
|
| 80 |
+
return self._gguf_t5xxl_models
|
| 81 |
+
|
| 82 |
+
def load(self, skip_file=False):
|
| 83 |
+
if skip_file:
|
| 84 |
+
print("Skipping config file")
|
| 85 |
+
settings_dict = self._load_default()
|
| 86 |
+
self._config = Settings.model_validate(settings_dict)
|
| 87 |
+
else:
|
| 88 |
+
if not path.exists(self.config_path):
|
| 89 |
+
base_dir = path.dirname(self.config_path)
|
| 90 |
+
if not path.exists(base_dir):
|
| 91 |
+
makedirs(base_dir)
|
| 92 |
+
try:
|
| 93 |
+
print("Settings not found creating default settings")
|
| 94 |
+
with open(self.config_path, "w") as file:
|
| 95 |
+
yaml.dump(
|
| 96 |
+
self._load_default(),
|
| 97 |
+
file,
|
| 98 |
+
)
|
| 99 |
+
except Exception as ex:
|
| 100 |
+
print(f"Error in creating settings : {ex}")
|
| 101 |
+
exit()
|
| 102 |
+
try:
|
| 103 |
+
with open(self.config_path) as file:
|
| 104 |
+
settings_dict = yaml.safe_load(file)
|
| 105 |
+
self._config = Settings.model_validate(settings_dict)
|
| 106 |
+
except Exception as ex:
|
| 107 |
+
print(f"Error in loading settings : {ex}")
|
| 108 |
+
|
| 109 |
+
def save(self):
|
| 110 |
+
try:
|
| 111 |
+
with open(self.config_path, "w") as file:
|
| 112 |
+
tmp_cfg = deepcopy(self._config)
|
| 113 |
+
tmp_cfg.lcm_diffusion_setting.init_image = None
|
| 114 |
+
configurations = tmp_cfg.model_dump(
|
| 115 |
+
exclude=["init_image"],
|
| 116 |
+
)
|
| 117 |
+
if configurations:
|
| 118 |
+
yaml.dump(configurations, file)
|
| 119 |
+
except Exception as ex:
|
| 120 |
+
print(f"Error in saving settings : {ex}")
|
| 121 |
+
|
| 122 |
+
def _load_default(self) -> dict:
|
| 123 |
+
default_config = Settings()
|
| 124 |
+
return default_config.model_dump()
|
src/backend/__init__.py
ADDED
|
File without changes
|
src/backend/annotators/canny_control.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from backend.annotators.control_interface import ControlInterface
|
| 3 |
+
from cv2 import Canny
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class CannyControl(ControlInterface):
|
| 8 |
+
def get_control_image(self, image: Image) -> Image:
|
| 9 |
+
low_threshold = 100
|
| 10 |
+
high_threshold = 200
|
| 11 |
+
image = np.array(image)
|
| 12 |
+
image = Canny(image, low_threshold, high_threshold)
|
| 13 |
+
image = image[:, :, None]
|
| 14 |
+
image = np.concatenate([image, image, image], axis=2)
|
| 15 |
+
return Image.fromarray(image)
|
src/backend/annotators/control_interface.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class ControlInterface(ABC):
|
| 7 |
+
@abstractmethod
|
| 8 |
+
def get_control_image(
|
| 9 |
+
self,
|
| 10 |
+
image: Image,
|
| 11 |
+
) -> Image:
|
| 12 |
+
pass
|
src/backend/annotators/depth_control.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from backend.annotators.control_interface import ControlInterface
|
| 3 |
+
from PIL import Image
|
| 4 |
+
from transformers import pipeline
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class DepthControl(ControlInterface):
|
| 8 |
+
def get_control_image(self, image: Image) -> Image:
|
| 9 |
+
depth_estimator = pipeline("depth-estimation")
|
| 10 |
+
image = depth_estimator(image)["depth"]
|
| 11 |
+
image = np.array(image)
|
| 12 |
+
image = image[:, :, None]
|
| 13 |
+
image = np.concatenate([image, image, image], axis=2)
|
| 14 |
+
image = Image.fromarray(image)
|
| 15 |
+
return image
|
src/backend/annotators/image_control_factory.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from backend.annotators.canny_control import CannyControl
|
| 2 |
+
from backend.annotators.depth_control import DepthControl
|
| 3 |
+
from backend.annotators.lineart_control import LineArtControl
|
| 4 |
+
from backend.annotators.mlsd_control import MlsdControl
|
| 5 |
+
from backend.annotators.normal_control import NormalControl
|
| 6 |
+
from backend.annotators.pose_control import PoseControl
|
| 7 |
+
from backend.annotators.shuffle_control import ShuffleControl
|
| 8 |
+
from backend.annotators.softedge_control import SoftEdgeControl
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class ImageControlFactory:
|
| 12 |
+
def create_control(self, controlnet_type: str):
|
| 13 |
+
if controlnet_type == "Canny":
|
| 14 |
+
return CannyControl()
|
| 15 |
+
elif controlnet_type == "Pose":
|
| 16 |
+
return PoseControl()
|
| 17 |
+
elif controlnet_type == "MLSD":
|
| 18 |
+
return MlsdControl()
|
| 19 |
+
elif controlnet_type == "Depth":
|
| 20 |
+
return DepthControl()
|
| 21 |
+
elif controlnet_type == "LineArt":
|
| 22 |
+
return LineArtControl()
|
| 23 |
+
elif controlnet_type == "Shuffle":
|
| 24 |
+
return ShuffleControl()
|
| 25 |
+
elif controlnet_type == "NormalBAE":
|
| 26 |
+
return NormalControl()
|
| 27 |
+
elif controlnet_type == "SoftEdge":
|
| 28 |
+
return SoftEdgeControl()
|
| 29 |
+
else:
|
| 30 |
+
print("Error: Control type not implemented!")
|
| 31 |
+
raise Exception("Error: Control type not implemented!")
|
src/backend/annotators/lineart_control.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from backend.annotators.control_interface import ControlInterface
|
| 3 |
+
from controlnet_aux import LineartDetector
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class LineArtControl(ControlInterface):
|
| 8 |
+
def get_control_image(self, image: Image) -> Image:
|
| 9 |
+
processor = LineartDetector.from_pretrained("lllyasviel/Annotators")
|
| 10 |
+
control_image = processor(image)
|
| 11 |
+
return control_image
|
src/backend/annotators/mlsd_control.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from backend.annotators.control_interface import ControlInterface
|
| 2 |
+
from controlnet_aux import MLSDdetector
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class MlsdControl(ControlInterface):
|
| 7 |
+
def get_control_image(self, image: Image) -> Image:
|
| 8 |
+
mlsd = MLSDdetector.from_pretrained("lllyasviel/ControlNet")
|
| 9 |
+
image = mlsd(image)
|
| 10 |
+
return image
|
src/backend/annotators/normal_control.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from backend.annotators.control_interface import ControlInterface
|
| 2 |
+
from controlnet_aux import NormalBaeDetector
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class NormalControl(ControlInterface):
|
| 7 |
+
def get_control_image(self, image: Image) -> Image:
|
| 8 |
+
processor = NormalBaeDetector.from_pretrained("lllyasviel/Annotators")
|
| 9 |
+
control_image = processor(image)
|
| 10 |
+
return control_image
|
src/backend/annotators/pose_control.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from backend.annotators.control_interface import ControlInterface
|
| 2 |
+
from controlnet_aux import OpenposeDetector
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class PoseControl(ControlInterface):
|
| 7 |
+
def get_control_image(self, image: Image) -> Image:
|
| 8 |
+
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
|
| 9 |
+
image = openpose(image)
|
| 10 |
+
return image
|
src/backend/annotators/shuffle_control.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from backend.annotators.control_interface import ControlInterface
|
| 2 |
+
from controlnet_aux import ContentShuffleDetector
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class ShuffleControl(ControlInterface):
|
| 7 |
+
def get_control_image(self, image: Image) -> Image:
|
| 8 |
+
shuffle_processor = ContentShuffleDetector()
|
| 9 |
+
image = shuffle_processor(image)
|
| 10 |
+
return image
|
src/backend/annotators/softedge_control.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from backend.annotators.control_interface import ControlInterface
|
| 2 |
+
from controlnet_aux import PidiNetDetector
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class SoftEdgeControl(ControlInterface):
|
| 7 |
+
def get_control_image(self, image: Image) -> Image:
|
| 8 |
+
processor = PidiNetDetector.from_pretrained("lllyasviel/Annotators")
|
| 9 |
+
control_image = processor(image)
|
| 10 |
+
return control_image
|
src/backend/api/mcp_server.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import platform
|
| 2 |
+
|
| 3 |
+
import uvicorn
|
| 4 |
+
from backend.device import get_device_name
|
| 5 |
+
from backend.models.device import DeviceInfo
|
| 6 |
+
from constants import APP_VERSION, DEVICE
|
| 7 |
+
from context import Context
|
| 8 |
+
from fastapi import FastAPI, Request
|
| 9 |
+
from fastapi_mcp import FastApiMCP
|
| 10 |
+
from state import get_settings
|
| 11 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 12 |
+
from models.interface_types import InterfaceType
|
| 13 |
+
from fastapi.staticfiles import StaticFiles
|
| 14 |
+
|
| 15 |
+
app_settings = get_settings()
|
| 16 |
+
app = FastAPI(
|
| 17 |
+
title="FastSD CPU",
|
| 18 |
+
description="Fast stable diffusion on CPU",
|
| 19 |
+
version=APP_VERSION,
|
| 20 |
+
license_info={
|
| 21 |
+
"name": "MIT",
|
| 22 |
+
"identifier": "MIT",
|
| 23 |
+
},
|
| 24 |
+
describe_all_responses=True,
|
| 25 |
+
describe_full_response_schema=True,
|
| 26 |
+
)
|
| 27 |
+
origins = ["*"]
|
| 28 |
+
|
| 29 |
+
app.add_middleware(
|
| 30 |
+
CORSMiddleware,
|
| 31 |
+
allow_origins=origins,
|
| 32 |
+
allow_credentials=True,
|
| 33 |
+
allow_methods=["*"],
|
| 34 |
+
allow_headers=["*"],
|
| 35 |
+
)
|
| 36 |
+
print(app_settings.settings.lcm_diffusion_setting)
|
| 37 |
+
|
| 38 |
+
context = Context(InterfaceType.API_SERVER)
|
| 39 |
+
app.mount("/results", StaticFiles(directory="results"), name="results")
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
@app.get(
|
| 43 |
+
"/info",
|
| 44 |
+
description="Get system information",
|
| 45 |
+
summary="Get system information",
|
| 46 |
+
operation_id="get_system_info",
|
| 47 |
+
)
|
| 48 |
+
async def info() -> dict:
|
| 49 |
+
device_info = DeviceInfo(
|
| 50 |
+
device_type=DEVICE,
|
| 51 |
+
device_name=get_device_name(),
|
| 52 |
+
os=platform.system(),
|
| 53 |
+
platform=platform.platform(),
|
| 54 |
+
processor=platform.processor(),
|
| 55 |
+
)
|
| 56 |
+
return device_info.model_dump()
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
@app.post(
|
| 60 |
+
"/generate",
|
| 61 |
+
description="Generate image from text prompt",
|
| 62 |
+
summary="Text to image generation",
|
| 63 |
+
operation_id="generate",
|
| 64 |
+
)
|
| 65 |
+
async def generate(
|
| 66 |
+
prompt: str,
|
| 67 |
+
request: Request,
|
| 68 |
+
) -> str:
|
| 69 |
+
"""
|
| 70 |
+
Returns URL of the generated image for text prompt
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
app_settings.settings.lcm_diffusion_setting.prompt = prompt
|
| 74 |
+
images = context.generate_text_to_image(app_settings.settings)
|
| 75 |
+
image_names = context.save_images(
|
| 76 |
+
images,
|
| 77 |
+
app_settings.settings,
|
| 78 |
+
)
|
| 79 |
+
url = request.url_for("results", path=image_names[0])
|
| 80 |
+
image_url = f"The generated image available at the URL {url}"
|
| 81 |
+
return image_url
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def start_mcp_server(port: int = 8000):
|
| 85 |
+
mcp = FastApiMCP(
|
| 86 |
+
app,
|
| 87 |
+
name="FastSDCPU MCP",
|
| 88 |
+
description="MCP server for FastSD CPU API",
|
| 89 |
+
base_url=f"http://localhost:{port}",
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
mcp.mount()
|
| 93 |
+
uvicorn.run(
|
| 94 |
+
app,
|
| 95 |
+
host="0.0.0.0",
|
| 96 |
+
port=port,
|
| 97 |
+
)
|