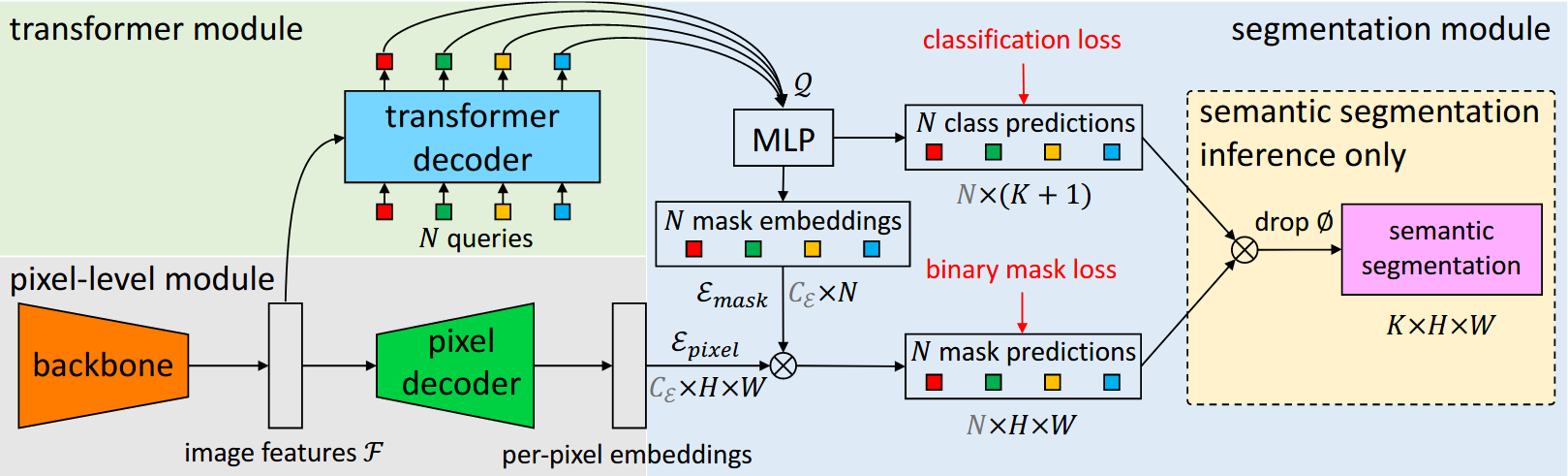
# MaskFormer
> [MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278)
## Introduction
Official Repo
Code Snippet
## Abstract
Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.
### Usage
- MaskFormer model needs to install [MMDetection](https://github.com/open-mmlab/mmdetection) first.
```shell
pip install "mmdet>=3.0.0rc4"
```
## Results and models
### ADE20K
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
| ---------- | --------- | --------- | ------- | -------- | -------------- | ------ | ----- | ------------- | ----------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| MaskFormer | R-50-D32 | 512x512 | 160000 | 3.29 | A100 | 42.20 | 44.29 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/maskformer/maskformer_r50-d32_8xb2-160k_ade20k-512x512.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/maskformer/maskformer_r50-d32_8xb2-160k_ade20k-512x512/maskformer_r50-d32_8xb2-160k_ade20k-512x512_20221030_182724-3a9cfe45.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/maskformer/maskformer_r50-d32_8xb2-160k_ade20k-512x512/maskformer_r50-d32_8xb2-160k_ade20k-512x512_20221030_182724.json) |
| MaskFormer | R-101-D32 | 512x512 | 160000 | 4.12 | A100 | 34.90 | 45.11 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/maskformer/maskformer_r101-d32_8xb2-160k_ade20k-512x512.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/maskformer/maskformer_r101-d32_8xb2-160k_ade20k-512x512/maskformer_r101-d32_8xb2-160k_ade20k-512x512_20221031_223053-84adbfcb.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/maskformer/maskformer_r101-d32_8xb2-160k_ade20k-512x512/maskformer_r101-d32_8xb2-160k_ade20k-512x512_20221031_223053.json) |
| MaskFormer | Swin-T | 512x512 | 160000 | 3.73 | A100 | 40.53 | 46.69 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/maskformer/maskformer_swin-t_upernet_8xb2-160k_ade20k-512x512.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/maskformer/maskformer_swin-t_upernet_8xb2-160k_ade20k-512x512/maskformer_swin-t_upernet_8xb2-160k_ade20k-512x512_20221114_232813-f14e7ce0.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/maskformer/maskformer_swin-t_upernet_8xb2-160k_ade20k-512x512/maskformer_swin-t_upernet_8xb2-160k_ade20k-512x512_20221114_232813.json) |
| MaskFormer | Swin-S | 512x512 | 160000 | 5.33 | A100 | 26.98 | 49.36 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/maskformer/maskformer_swin-s_upernet_8xb2-160k_ade20k-512x512.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/maskformer/maskformer_swin-s_upernet_8xb2-160k_ade20k-512x512/maskformer_swin-s_upernet_8xb2-160k_ade20k-512x512_20221115_114710-723512c7.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/maskformer/maskformer_swin-s_upernet_8xb2-160k_ade20k-512x512/maskformer_swin-s_upernet_8xb2-160k_ade20k-512x512_20221115_114710.json) |
Note:
- All experiments of MaskFormer are implemented with 8 V100 (32G) GPUs with 2 samplers per GPU.
- The results of MaskFormer are relatively not stable. The accuracy (mIoU) of model with `R-101-D32` is from 44.7 to 46.0, and with `Swin-S` is from 49.0 to 49.8.
- The ResNet backbones utilized in MaskFormer models are standard `ResNet` rather than `ResNetV1c`.
- Test time augmentation is not supported in MMSegmentation 1.x version yet, we would add "ms+flip" results as soon as possible.
## Citation
```bibtex
@article{cheng2021per,
title={Per-pixel classification is not all you need for semantic segmentation},
author={Cheng, Bowen and Schwing, Alex and Kirillov, Alexander},
journal={Advances in Neural Information Processing Systems},
volume={34},
pages={17864--17875},
year={2021}
}
```