
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- a_mllm_notebooks/.ipynb_checkpoints/serve-checkpoint.sh +30 -0
- a_mllm_notebooks/langchain/image.jpg +3 -0
- a_mllm_notebooks/lmdeploy/api_server.ipynb +568 -0
- a_mllm_notebooks/lmdeploy/api_server.md +265 -0
- a_mllm_notebooks/lmdeploy/api_server_vl.ipynb +199 -0
- a_mllm_notebooks/lmdeploy/api_server_vl.md +155 -0
- a_mllm_notebooks/lmdeploy/download_md.ipynb +211 -0
- a_mllm_notebooks/lmdeploy/get_started_vl.ipynb +517 -0
- a_mllm_notebooks/lmdeploy/get_started_vl.md +204 -0
- a_mllm_notebooks/lmdeploy/internvl_25.ipynb +355 -0
- a_mllm_notebooks/lmdeploy/kv_quant.ipynb +114 -0
- a_mllm_notebooks/lmdeploy/kv_quant.md +82 -0
- a_mllm_notebooks/lmdeploy/links.txt +8 -0
- a_mllm_notebooks/lmdeploy/lmdeploy_deepseek_vl.ipynb +665 -0
- a_mllm_notebooks/lmdeploy/lmdeploy_info.ipynb +132 -0
- a_mllm_notebooks/lmdeploy/lmdeploy_serve.sh +47 -0
- a_mllm_notebooks/lmdeploy/long_context.ipynb +169 -0
- a_mllm_notebooks/lmdeploy/long_context.md +119 -0
- a_mllm_notebooks/lmdeploy/pipeline.ipynb +570 -0
- a_mllm_notebooks/lmdeploy/pipeline.md +205 -0
- a_mllm_notebooks/lmdeploy/proxy_server.ipynb +248 -0
- a_mllm_notebooks/lmdeploy/proxy_server.md +97 -0
- a_mllm_notebooks/lmdeploy/pytorch_new_model.ipynb +261 -0
- a_mllm_notebooks/lmdeploy/pytorch_new_model.md +181 -0
- a_mllm_notebooks/lmdeploy/tiger.jpeg +0 -0
- a_mllm_notebooks/lmdeploy/turbomind.ipynb +88 -0
- a_mllm_notebooks/lmdeploy/turbomind.md +68 -0
- a_mllm_notebooks/lmdeploy/w4a16.ipynb +174 -0
- a_mllm_notebooks/lmdeploy/w4a16.md +130 -0
- a_mllm_notebooks/lmdeploy/w8a8.ipynb +75 -0
- a_mllm_notebooks/lmdeploy/w8a8.md +55 -0
- a_mllm_notebooks/openai/.ipynb_checkpoints/infer-checkpoint.py +167 -0
- a_mllm_notebooks/openai/.ipynb_checkpoints/langchain_openai_api-checkpoint.ipynb +0 -0
- a_mllm_notebooks/openai/.ipynb_checkpoints/load_synth_pedes-checkpoint.ipynb +96 -0
- a_mllm_notebooks/openai/.ipynb_checkpoints/openai_api-checkpoint.ipynb +408 -0
- a_mllm_notebooks/openai/.ipynb_checkpoints/ping_server-checkpoint.ipynb +292 -0
- a_mllm_notebooks/openai/.ipynb_checkpoints/serve-checkpoint.sh +60 -0
- a_mllm_notebooks/openai/.ipynb_checkpoints/temp-checkpoint.sh +25 -0
- a_mllm_notebooks/openai/combine_chinese_output.ipynb +526 -0
- a_mllm_notebooks/openai/openai_api.ipynb +408 -0
- a_mllm_notebooks/tensorrt-llm/bert/.gitignore +2 -0
- a_mllm_notebooks/tensorrt-llm/bert/README.md +79 -0
- a_mllm_notebooks/tensorrt-llm/bert/base_benchmark/config.json +22 -0
- a_mllm_notebooks/tensorrt-llm/bert/base_with_attention_plugin_benchmark/config.json +22 -0
- a_mllm_notebooks/tensorrt-llm/bert/build.py +354 -0
- a_mllm_notebooks/tensorrt-llm/bert/large_benchmark/config.json +22 -0
- a_mllm_notebooks/tensorrt-llm/bert/large_with_attention_plugin_benchmark/config.json +22 -0
- a_mllm_notebooks/tensorrt-llm/bert/run.py +128 -0
- a_mllm_notebooks/tensorrt-llm/bert/run_remove_input_padding.py +153 -0
.gitattributes
CHANGED
|
@@ -452,3 +452,5 @@ recognize-anything/images/demo/.ipynb_checkpoints/demo4-checkpoint.jpg filter=lf
|
|
| 452 |
recognize-anything/images/demo/.ipynb_checkpoints/demo2-checkpoint.jpg filter=lfs diff=lfs merge=lfs -text
|
| 453 |
a_mllm_notebooks/vllm/cat.jpg filter=lfs diff=lfs merge=lfs -text
|
| 454 |
a_mllm_notebooks/openai/image.jpg filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 452 |
recognize-anything/images/demo/.ipynb_checkpoints/demo2-checkpoint.jpg filter=lfs diff=lfs merge=lfs -text
|
| 453 |
a_mllm_notebooks/vllm/cat.jpg filter=lfs diff=lfs merge=lfs -text
|
| 454 |
a_mllm_notebooks/openai/image.jpg filter=lfs diff=lfs merge=lfs -text
|
| 455 |
+
a_mllm_notebooks/langchain/image.jpg filter=lfs diff=lfs merge=lfs -text
|
| 456 |
+
a_mllm_notebooks/vllm/.ipynb_checkpoints/cat-checkpoint.jpg filter=lfs diff=lfs merge=lfs -text
|
a_mllm_notebooks/.ipynb_checkpoints/serve-checkpoint.sh
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
eval "$(conda shell.bash hook)"
|
| 2 |
+
conda activate lmdeploy
|
| 3 |
+
|
| 4 |
+
MODEL_NAME=Qwen/Qwen2.5-1.5B-Instruct-AWQ
|
| 5 |
+
# PORT_LIST=(2020 2021 2022 2023 2024 2025 2026 2027 2028 2029 2030 2031)
|
| 6 |
+
|
| 7 |
+
# PORT_LIST from 3063 to 3099
|
| 8 |
+
PORT_LIST=( $(seq 19500 1 19590) )
|
| 9 |
+
# PORT_LIST=(9898)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# PROXY_URL=0.0.0.0
|
| 13 |
+
# lmdeploy serve proxy --server-name $PROXY_URL --server-port 8080 --strategy \
|
| 14 |
+
# min_observed_latency &
|
| 15 |
+
# "min_expected_latency" \
|
| 16 |
+
# &
|
| 17 |
+
|
| 18 |
+
for PORT in "${PORT_LIST[@]}"; do
|
| 19 |
+
# get random device id from 0 to 3
|
| 20 |
+
# RANDOM_DEVICE_ID=$((RANDOM % 3))
|
| 21 |
+
RANDOM_DEVICE_ID=1
|
| 22 |
+
# CUDA_VISIBLE_DEVICES=$RANDOM_DEVICE_ID \
|
| 23 |
+
# CUDA_VISIBLE_DEVICES=0,1 \
|
| 24 |
+
# CUDA_VISIBLE_DEVICES=2,3 \
|
| 25 |
+
lmdeploy serve api_server $MODEL_NAME \
|
| 26 |
+
--server-port $PORT \
|
| 27 |
+
--backend turbomind \
|
| 28 |
+
--dtype float16 --proxy-url http://0.0.0.0:8080 \
|
| 29 |
+
--cache-max-entry-count 0.1 --tp 1 &
|
| 30 |
+
done
|
a_mllm_notebooks/langchain/image.jpg
ADDED

|
Git LFS Details
|
a_mllm_notebooks/lmdeploy/api_server.ipynb
ADDED
|
@@ -0,0 +1,568 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "c1639fe1",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# OpenAI Compatible Server\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"This article primarily discusses the deployment of a single LLM model across multiple GPUs on a single node, providing a service that is compatible with the OpenAI interface, as well as the usage of the service API.\n",
|
| 11 |
+
"For the sake of convenience, we refer to this service as `api_server`. Regarding parallel services with multiple models, please refer to the guide about [Request Distribution Server](proxy_server.md).\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"In the following sections, we will first introduce methods for starting the service, choosing the appropriate one based on your application scenario.\n",
|
| 14 |
+
"\n",
|
| 15 |
+
"Next, we focus on the definition of the service's RESTful API, explore the various ways to interact with the interface, and demonstrate how to try the service through the Swagger UI or LMDeploy CLI tools.\n",
|
| 16 |
+
"\n",
|
| 17 |
+
"Finally, we showcase how to integrate the service into a WebUI, providing you with a reference to easily set up a demonstration demo.\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"## Launch Service\n",
|
| 20 |
+
"\n",
|
| 21 |
+
"Take the [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) model hosted on huggingface hub as an example, you can choose one the following methods to start the service.\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"### Option 1: Launching with lmdeploy CLI\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"```shell\n",
|
| 26 |
+
"lmdeploy serve api_server internlm/internlm2_5-7b-chat --server-port 23333\n",
|
| 27 |
+
"```\n",
|
| 28 |
+
"\n",
|
| 29 |
+
"The arguments of `api_server` can be viewed through the command `lmdeploy serve api_server -h`, for instance, `--tp` to set tensor parallelism, `--session-len` to specify the max length of the context window, `--cache-max-entry-count` to adjust the GPU mem ratio for k/v cache etc.\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"### Option 2: Deploying with docker\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"With LMDeploy [official docker image](https://hub.docker.com/r/openmmlab/lmdeploy/tags), you can run OpenAI compatible server as follows:\n",
|
| 34 |
+
"\n",
|
| 35 |
+
"```shell\n",
|
| 36 |
+
"docker run --runtime nvidia --gpus all \\\n",
|
| 37 |
+
" -v ~/.cache/huggingface:/root/.cache/huggingface \\\n",
|
| 38 |
+
" --env \"HUGGING_FACE_HUB_TOKEN=<secret>\" \\\n",
|
| 39 |
+
" -p 23333:23333 \\\n",
|
| 40 |
+
" --ipc=host \\\n",
|
| 41 |
+
" openmmlab/lmdeploy:latest \\\n",
|
| 42 |
+
" lmdeploy serve api_server internlm/internlm2_5-7b-chat\n",
|
| 43 |
+
"```\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"The parameters of `api_server` are the same with that mentioned in \"[option 1](#option-1-launching-with-lmdeploy-cli)\" section\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"### Option 3: Deploying to Kubernetes cluster\n",
|
| 48 |
+
"\n",
|
| 49 |
+
"Connect to a running Kubernetes cluster and deploy the internlm2_5-7b-chat model service with [kubectl](https://kubernetes.io/docs/reference/kubectl/) command-line tool (replace `<your token>` with your huggingface hub token):\n",
|
| 50 |
+
"\n",
|
| 51 |
+
"```shell\n",
|
| 52 |
+
"sed 's/{{HUGGING_FACE_HUB_TOKEN}}/<your token>/' k8s/deployment.yaml | kubectl create -f - \\\n",
|
| 53 |
+
" && kubectl create -f k8s/service.yaml\n",
|
| 54 |
+
"```\n",
|
| 55 |
+
"\n",
|
| 56 |
+
"In the example above the model data is placed on the local disk of the node (hostPath). Consider replacing it with high-availability shared storage if multiple replicas are desired, and the storage can be mounted into container using [PersistentVolume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/).\n",
|
| 57 |
+
"\n",
|
| 58 |
+
"## RESTful API\n",
|
| 59 |
+
"\n",
|
| 60 |
+
"LMDeploy's RESTful API is compatible with the following three OpenAI interfaces:\n",
|
| 61 |
+
"\n",
|
| 62 |
+
"- /v1/chat/completions\n",
|
| 63 |
+
"- /v1/models\n",
|
| 64 |
+
"- /v1/completions\n",
|
| 65 |
+
"\n",
|
| 66 |
+
"Additionally, LMDeploy also defines `/v1/chat/interactive` to support interactive inference. The feature of interactive inference is that there's no need to pass the user conversation history as required by `v1/chat/completions`, since the conversation history will be cached on the server side. This method boasts excellent performance during multi-turn long context inference.\n",
|
| 67 |
+
"\n",
|
| 68 |
+
"You can overview and try out the offered RESTful APIs by the website `http://0.0.0.0:23333` as shown in the below image after launching the service successfully.\n",
|
| 69 |
+
"\n",
|
| 70 |
+
"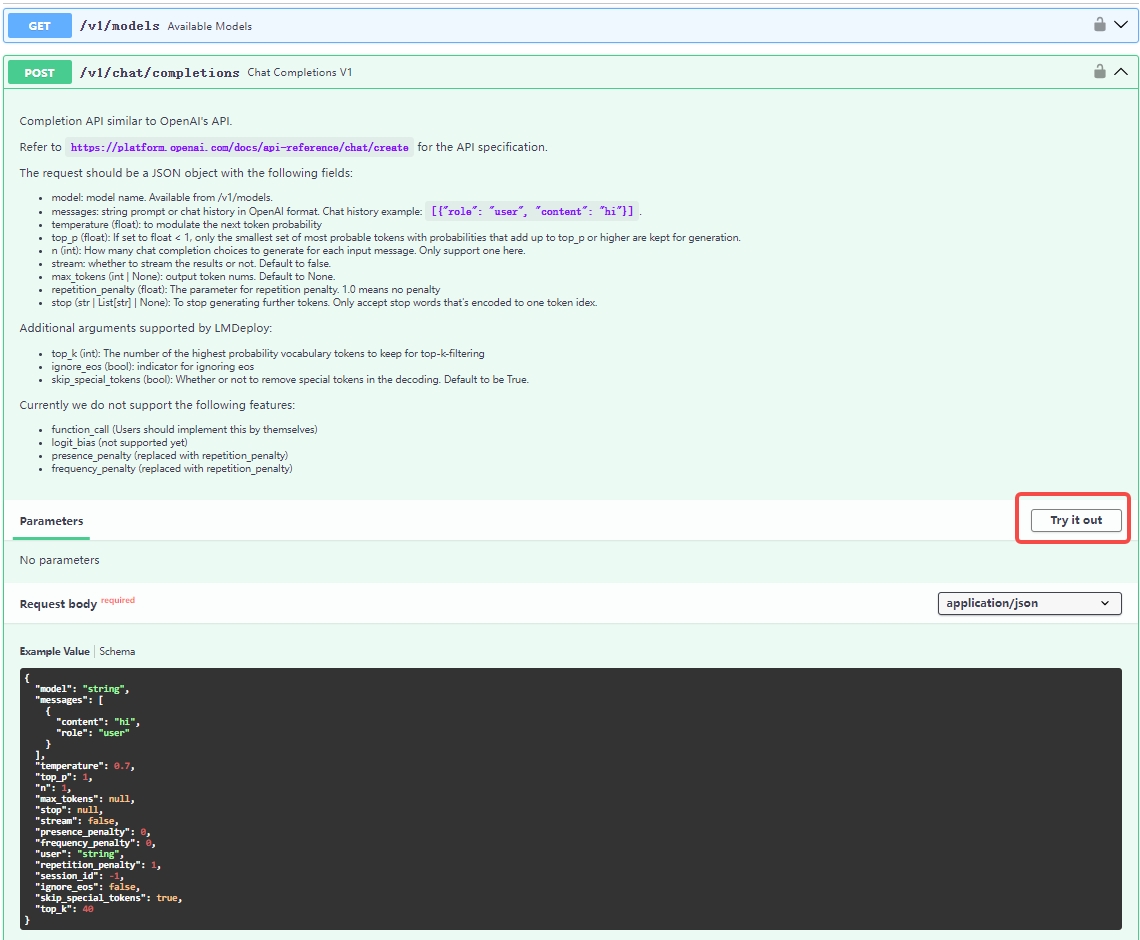\n",
|
| 71 |
+
"\n",
|
| 72 |
+
"Or, you can use the LMDeploy's built-in CLI tool to verify the service correctness right from the console.\n",
|
| 73 |
+
"\n",
|
| 74 |
+
"```shell\n",
|
| 75 |
+
"# restful_api_url is what printed in api_server.py, e.g. http://localhost:23333\n",
|
| 76 |
+
"lmdeploy serve api_client ${api_server_url}\n",
|
| 77 |
+
"```\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"If you need to integrate the service into your own projects or products, we recommend the following approach:\n",
|
| 80 |
+
"\n",
|
| 81 |
+
"### Integrate with `OpenAI`\n",
|
| 82 |
+
"\n",
|
| 83 |
+
"Here is an example of interaction with the endpoint `v1/chat/completions` service via the openai package.\n",
|
| 84 |
+
"Before running it, please install the openai package by `pip install openai`"
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"cell_type": "code",
|
| 89 |
+
"execution_count": 1,
|
| 90 |
+
"id": "be8a8067",
|
| 91 |
+
"metadata": {},
|
| 92 |
+
"outputs": [
|
| 93 |
+
{
|
| 94 |
+
"data": {
|
| 95 |
+
"text/plain": [
|
| 96 |
+
"0"
|
| 97 |
+
]
|
| 98 |
+
},
|
| 99 |
+
"execution_count": 1,
|
| 100 |
+
"metadata": {},
|
| 101 |
+
"output_type": "execute_result"
|
| 102 |
+
},
|
| 103 |
+
{
|
| 104 |
+
"name": "stderr",
|
| 105 |
+
"output_type": "stream",
|
| 106 |
+
"text": [
|
| 107 |
+
"Fetching 32 files: 100%|██████████████████████████████████████| 32/32 [00:00<00:00, 8631.92it/s]\n",
|
| 108 |
+
"InternLM2ForCausalLM has generative capabilities, as `prepare_inputs_for_generation` is explicitly overwritten. However, it doesn't directly inherit from `GenerationMixin`. From 👉v4.50👈 onwards, `PreTrainedModel` will NOT inherit from `GenerationMixin`, and this model will lose the ability to call `generate` and other related functions.\n",
|
| 109 |
+
" - If you're using `trust_remote_code=True`, you can get rid of this warning by loading the model with an auto class. See https://huggingface.co/docs/transformers/en/model_doc/auto#auto-classes\n",
|
| 110 |
+
" - If you are the owner of the model architecture code, please modify your model class such that it inherits from `GenerationMixin` (after `PreTrainedModel`, otherwise you'll get an exception).\n",
|
| 111 |
+
" - If you are not the owner of the model architecture class, please contact the model code owner to update it.\n",
|
| 112 |
+
"Convert to turbomind format: 0%| | 0/48 [00:00<?, ?it/s]"
|
| 113 |
+
]
|
| 114 |
+
}
|
| 115 |
+
],
|
| 116 |
+
"source": [
|
| 117 |
+
"command = '''lmdeploy serve api_server \\\n",
|
| 118 |
+
"OpenGVLab/InternVL2_5-26B-AWQ \\\n",
|
| 119 |
+
"--server-port 23333 \\\n",
|
| 120 |
+
"--model-format awq \\\n",
|
| 121 |
+
"--backend turbomind \\\n",
|
| 122 |
+
"--tp 4 \\\n",
|
| 123 |
+
"--dtype float16 \\\n",
|
| 124 |
+
"&\n",
|
| 125 |
+
"'''\n",
|
| 126 |
+
"\n",
|
| 127 |
+
"import os\n",
|
| 128 |
+
"os.system(command)"
|
| 129 |
+
]
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "code",
|
| 133 |
+
"execution_count": 1,
|
| 134 |
+
"id": "063f3c9f",
|
| 135 |
+
"metadata": {},
|
| 136 |
+
"outputs": [],
|
| 137 |
+
"source": [
|
| 138 |
+
"# kill all the process having lmdeploy in the name\n",
|
| 139 |
+
"# !ps aux|grep 'lmdeploy' | awk '{print $2}'| xargs kill -9"
|
| 140 |
+
]
|
| 141 |
+
},
|
| 142 |
+
{
|
| 143 |
+
"cell_type": "code",
|
| 144 |
+
"execution_count": 1,
|
| 145 |
+
"id": "63db3f55",
|
| 146 |
+
"metadata": {},
|
| 147 |
+
"outputs": [
|
| 148 |
+
{
|
| 149 |
+
"name": "stdout",
|
| 150 |
+
"output_type": "stream",
|
| 151 |
+
"text": [
|
| 152 |
+
"Fri Dec 20 08:33:19 2024 \n",
|
| 153 |
+
"+---------------------------------------------------------------------------------------+\n",
|
| 154 |
+
"| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |\n",
|
| 155 |
+
"|-----------------------------------------+----------------------+----------------------+\n",
|
| 156 |
+
"| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |\n",
|
| 157 |
+
"| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |\n",
|
| 158 |
+
"| | | MIG M. |\n",
|
| 159 |
+
"|=========================================+======================+======================|\n",
|
| 160 |
+
"| 0 NVIDIA A100-PCIE-40GB Off | 00000000:14:00.0 Off | 0 |\n",
|
| 161 |
+
"| N/A 32C P0 36W / 250W | 33714MiB / 40960MiB | 0% Default |\n",
|
| 162 |
+
"| | | Disabled |\n",
|
| 163 |
+
"+-----------------------------------------+----------------------+----------------------+\n",
|
| 164 |
+
"| 1 NVIDIA A100-PCIE-40GB Off | 00000000:15:00.0 Off | 0 |\n",
|
| 165 |
+
"| N/A 33C P0 38W / 250W | 33934MiB / 40960MiB | 0% Default |\n",
|
| 166 |
+
"| | | Disabled |\n",
|
| 167 |
+
"+-----------------------------------------+----------------------+----------------------+\n",
|
| 168 |
+
"| 2 NVIDIA A100-PCIE-40GB Off | 00000000:39:00.0 Off | 0 |\n",
|
| 169 |
+
"| N/A 32C P0 36W / 250W | 33934MiB / 40960MiB | 0% Default |\n",
|
| 170 |
+
"| | | Disabled |\n",
|
| 171 |
+
"+-----------------------------------------+----------------------+----------------------+\n",
|
| 172 |
+
"| 3 NVIDIA A100-PCIE-40GB Off | 00000000:3A:00.0 Off | 0 |\n",
|
| 173 |
+
"| N/A 33C P0 39W / 250W | 34604MiB / 40960MiB | 0% Default |\n",
|
| 174 |
+
"| | | Disabled |\n",
|
| 175 |
+
"+-----------------------------------------+----------------------+----------------------+\n",
|
| 176 |
+
" \n",
|
| 177 |
+
"+---------------------------------------------------------------------------------------+\n",
|
| 178 |
+
"| Processes: |\n",
|
| 179 |
+
"| GPU GI CI PID Type Process name GPU Memory |\n",
|
| 180 |
+
"| ID ID Usage |\n",
|
| 181 |
+
"|=======================================================================================|\n",
|
| 182 |
+
"+---------------------------------------------------------------------------------------+\n"
|
| 183 |
+
]
|
| 184 |
+
}
|
| 185 |
+
],
|
| 186 |
+
"source": [
|
| 187 |
+
"!nvidia-smi"
|
| 188 |
+
]
|
| 189 |
+
},
|
| 190 |
+
{
|
| 191 |
+
"cell_type": "code",
|
| 192 |
+
"execution_count": 4,
|
| 193 |
+
"id": "0d54a9a2",
|
| 194 |
+
"metadata": {},
|
| 195 |
+
"outputs": [
|
| 196 |
+
{
|
| 197 |
+
"name": "stdout",
|
| 198 |
+
"output_type": "stream",
|
| 199 |
+
"text": [
|
| 200 |
+
"INFO: 127.0.0.1:43526 - \"GET /v1/models HTTP/1.1\" 200 OK\n",
|
| 201 |
+
"INFO: 127.0.0.1:43526 - \"POST /v1/chat/completions HTTP/1.1\" 200 OK\n",
|
| 202 |
+
"ChatCompletion(id='1', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='1. Prioritize tasks: Make a list of tasks you need to complete and prioritize them based on their importance and urgency. This will help you focus on the most critical tasks first and ensure that you complete them on time.\\n\\n2. Set realistic deadlines: Set realistic deadlines for each task based on the time required to complete it. This will help you avoid procrastination and ensure that you complete tasks on time.\\n\\n3. Use time management tools: Use time management tools like calendars, to-do lists, and time-tracking apps to help you manage your time more effectively. These tools can help you stay organized, focused, and on track with your tasks and deadlines.', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1734683216, model='OpenGVLab/InternVL2_5-26B-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=138, prompt_tokens=27, total_tokens=165, completion_tokens_details=None))\n"
|
| 203 |
+
]
|
| 204 |
+
}
|
| 205 |
+
],
|
| 206 |
+
"source": [
|
| 207 |
+
"from openai import OpenAI\n",
|
| 208 |
+
"\n",
|
| 209 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:23333/v1\")\n",
|
| 210 |
+
"model_name = client.models.list().data[0].id\n",
|
| 211 |
+
"response = client.chat.completions.create(\n",
|
| 212 |
+
" model=model_name,\n",
|
| 213 |
+
" messages=[\n",
|
| 214 |
+
" {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
|
| 215 |
+
" {\"role\": \"user\", \"content\": \" provide three suggestions about time management\"},\n",
|
| 216 |
+
" ],\n",
|
| 217 |
+
" temperature=0.8,\n",
|
| 218 |
+
" top_p=0.8,\n",
|
| 219 |
+
")\n",
|
| 220 |
+
"print(response)"
|
| 221 |
+
]
|
| 222 |
+
},
|
| 223 |
+
{
|
| 224 |
+
"cell_type": "markdown",
|
| 225 |
+
"id": "6cad3dc4",
|
| 226 |
+
"metadata": {},
|
| 227 |
+
"source": [
|
| 228 |
+
"If you want to use async functions, may try the following example:"
|
| 229 |
+
]
|
| 230 |
+
},
|
| 231 |
+
{
|
| 232 |
+
"cell_type": "code",
|
| 233 |
+
"execution_count": null,
|
| 234 |
+
"id": "056d55bf",
|
| 235 |
+
"metadata": {},
|
| 236 |
+
"outputs": [],
|
| 237 |
+
"source": [
|
| 238 |
+
"import asyncio\n",
|
| 239 |
+
"from openai import AsyncOpenAI\n",
|
| 240 |
+
"\n",
|
| 241 |
+
"\n",
|
| 242 |
+
"async def main():\n",
|
| 243 |
+
" client = AsyncOpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:23333/v1\")\n",
|
| 244 |
+
" model_cards = await client.models.list()._get_page()\n",
|
| 245 |
+
" response = await client.chat.completions.create(\n",
|
| 246 |
+
" model=model_cards.data[0].id,\n",
|
| 247 |
+
" messages=[\n",
|
| 248 |
+
" {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
|
| 249 |
+
" {\n",
|
| 250 |
+
" \"role\": \"user\",\n",
|
| 251 |
+
" \"content\": \" provide three suggestions about time management\",\n",
|
| 252 |
+
" },\n",
|
| 253 |
+
" ],\n",
|
| 254 |
+
" temperature=0.8,\n",
|
| 255 |
+
" top_p=0.8,\n",
|
| 256 |
+
" )\n",
|
| 257 |
+
" print(response)\n",
|
| 258 |
+
"\n",
|
| 259 |
+
"\n",
|
| 260 |
+
"asyncio.run(main())"
|
| 261 |
+
]
|
| 262 |
+
},
|
| 263 |
+
{
|
| 264 |
+
"cell_type": "markdown",
|
| 265 |
+
"id": "1bb5033b",
|
| 266 |
+
"metadata": {},
|
| 267 |
+
"source": [
|
| 268 |
+
"You can invoke other OpenAI interfaces using similar methods. For more detailed information, please refer to the [OpenAI API guide](https://platform.openai.com/docs/guides/text-generation)\n",
|
| 269 |
+
"\n",
|
| 270 |
+
"### Integrate with lmdeploy `APIClient`\n",
|
| 271 |
+
"\n",
|
| 272 |
+
"Below are some examples demonstrating how to visit the service through `APIClient`\n",
|
| 273 |
+
"\n",
|
| 274 |
+
"If you want to use the `/v1/chat/completions` endpoint, you can try the following code:"
|
| 275 |
+
]
|
| 276 |
+
},
|
| 277 |
+
{
|
| 278 |
+
"cell_type": "code",
|
| 279 |
+
"execution_count": 6,
|
| 280 |
+
"id": "cc032c11",
|
| 281 |
+
"metadata": {},
|
| 282 |
+
"outputs": [],
|
| 283 |
+
"source": [
|
| 284 |
+
"server_ip = \"0.0.0.0\"\n",
|
| 285 |
+
"server_port = 23333"
|
| 286 |
+
]
|
| 287 |
+
},
|
| 288 |
+
{
|
| 289 |
+
"cell_type": "code",
|
| 290 |
+
"execution_count": 8,
|
| 291 |
+
"id": "85a8aca4",
|
| 292 |
+
"metadata": {},
|
| 293 |
+
"outputs": [
|
| 294 |
+
{
|
| 295 |
+
"name": "stdout",
|
| 296 |
+
"output_type": "stream",
|
| 297 |
+
"text": [
|
| 298 |
+
"INFO: 127.0.0.1:48416 - \"GET /v1/models HTTP/1.1\" 200 OK\n",
|
| 299 |
+
"INFO: 127.0.0.1:48426 - \"POST /v1/chat/completions HTTP/1.1\" 200 OK\n",
|
| 300 |
+
"{'id': '2', 'object': 'chat.completion', 'created': 1734683311, 'model': 'OpenGVLab/InternVL2_5-26B-AWQ', 'choices': [{'index': 0, 'message': {'role': 'assistant', 'content': \"Hello! It looks like you're testing out the system. How can I assist you today? If you have any questions or need help with something specific, feel free to ask!\", 'tool_calls': None}, 'logprobs': None, 'finish_reason': 'stop'}], 'usage': {'prompt_tokens': 53, 'total_tokens': 90, 'completion_tokens': 37}}\n"
|
| 301 |
+
]
|
| 302 |
+
}
|
| 303 |
+
],
|
| 304 |
+
"source": [
|
| 305 |
+
"from lmdeploy.serve.openai.api_client import APIClient\n",
|
| 306 |
+
"\n",
|
| 307 |
+
"api_client = APIClient(f\"http://{server_ip}:{server_port}\")\n",
|
| 308 |
+
"model_name = api_client.available_models[0]\n",
|
| 309 |
+
"messages = [{\"role\": \"user\", \"content\": \"Say this is a test!\"}]\n",
|
| 310 |
+
"for item in api_client.chat_completions_v1(model=model_name, messages=messages):\n",
|
| 311 |
+
" print(item)"
|
| 312 |
+
]
|
| 313 |
+
},
|
| 314 |
+
{
|
| 315 |
+
"cell_type": "markdown",
|
| 316 |
+
"id": "a3f47b52",
|
| 317 |
+
"metadata": {},
|
| 318 |
+
"source": [
|
| 319 |
+
"For the `/v1/completions` endpoint, you can try:"
|
| 320 |
+
]
|
| 321 |
+
},
|
| 322 |
+
{
|
| 323 |
+
"cell_type": "code",
|
| 324 |
+
"execution_count": 9,
|
| 325 |
+
"id": "4095a0e2",
|
| 326 |
+
"metadata": {},
|
| 327 |
+
"outputs": [
|
| 328 |
+
{
|
| 329 |
+
"name": "stdout",
|
| 330 |
+
"output_type": "stream",
|
| 331 |
+
"text": [
|
| 332 |
+
"INFO: 127.0.0.1:45650 - \"GET /v1/models HTTP/1.1\" 200 OK\n",
|
| 333 |
+
"INFO: 127.0.0.1:45660 - \"POST /v1/completions HTTP/1.1\" 200 OK\n",
|
| 334 |
+
"{'id': '3', 'object': 'text_completion', 'created': 1734683319, 'model': 'OpenGVLab/InternVL2_5-26B-AWQ', 'choices': [{'index': 0, 'text': '. I need help with a math problem. \\n\\nFind the smallest value of 2', 'logprobs': None, 'finish_reason': 'length'}], 'usage': {'prompt_tokens': 2, 'total_tokens': 19, 'completion_tokens': 17}}\n"
|
| 335 |
+
]
|
| 336 |
+
}
|
| 337 |
+
],
|
| 338 |
+
"source": [
|
| 339 |
+
"from lmdeploy.serve.openai.api_client import APIClient\n",
|
| 340 |
+
"\n",
|
| 341 |
+
"api_client = APIClient(f\"http://{server_ip}:{server_port}\")\n",
|
| 342 |
+
"model_name = api_client.available_models[0]\n",
|
| 343 |
+
"for item in api_client.completions_v1(model=model_name, prompt=\"hi\"):\n",
|
| 344 |
+
" print(item)"
|
| 345 |
+
]
|
| 346 |
+
},
|
| 347 |
+
{
|
| 348 |
+
"cell_type": "markdown",
|
| 349 |
+
"id": "d7ac9e5f",
|
| 350 |
+
"metadata": {},
|
| 351 |
+
"source": [
|
| 352 |
+
"As for `/v1/chat/interactive`,we disable the feature by default. Please open it by setting `interactive_mode = True`. If you don't, it falls back to openai compatible interfaces.\n",
|
| 353 |
+
"\n",
|
| 354 |
+
"Keep in mind that `session_id` indicates an identical sequence and all requests belonging to the same sequence must share the same `session_id`.\n",
|
| 355 |
+
"For instance, in a sequence with 10 rounds of chatting requests, the `session_id` in each request should be the same."
|
| 356 |
+
]
|
| 357 |
+
},
|
| 358 |
+
{
|
| 359 |
+
"cell_type": "code",
|
| 360 |
+
"execution_count": 10,
|
| 361 |
+
"id": "4b7c4695",
|
| 362 |
+
"metadata": {},
|
| 363 |
+
"outputs": [
|
| 364 |
+
{
|
| 365 |
+
"name": "stdout",
|
| 366 |
+
"output_type": "stream",
|
| 367 |
+
"text": [
|
| 368 |
+
"INFO: 127.0.0.1:52202 - \"POST /v1/chat/interactive HTTP/1.1\" 200 OK\n",
|
| 369 |
+
"{'text': \"Hello! I'm an AI assistant, here to help you with any questions or tasks you have. How can I assist you today?\", 'tokens': 28, 'input_tokens': 54, 'history_tokens': 0, 'finish_reason': 'stop'}\n",
|
| 370 |
+
"INFO: 127.0.0.1:52218 - \"POST /v1/chat/interactive HTTP/1.1\" 200 OK\n",
|
| 371 |
+
"{'text': 'I was developed by SenseTime, a leading artificial intelligence company. SenseTime focuses on developing advanced AI technologies and applications across various industries. If you have any specific questions or need assistance with something, feel free to ask!', 'tokens': 45, 'input_tokens': 14, 'history_tokens': 82, 'finish_reason': 'stop'}\n",
|
| 372 |
+
"INFO: 127.0.0.1:52228 - \"POST /v1/chat/interactive HTTP/1.1\" 200 OK\n",
|
| 373 |
+
"{'text': \"SenseTime is a prominent artificial intelligence company based in China, known for its cutting-edge research and development in AI technologies. Here are some key points about SenseTime:\\n\\n1. **Founding and Growth**:\\n - SenseTime was founded in 2014 and has since grown to become one of the leading AI companies globally.\\n - It has a significant presence in China and has expanded its operations internationally.\\n\\n2. **Research and Development**:\\n - SenseTime is at the forefront of AI research, focusing on areas such as computer vision, deep learning, and natural language processing.\\n - The company has developed various AI applications, including facial recognition, augmented reality, and autonomous driving technologies.\\n\\n3. **Industry Applications**:\\n - SenseTime's AI technologies are applied across various industries, including healthcare, education, finance, and entertainment.\\n - For example, in healthcare, their AI solutions help in medical imaging and diagnostics.\\n\\n4. **Partnerships and Collaborations**:\\n - SenseTime collaborates with numerous academic institutions, research labs, and industry partners to advance AI technologies.\\n - They have partnerships with major tech companies and organizations to integrate their AI solutions into broader ecosystems.\\n\\n5. **Innovation and Impact**:\\n - SenseTime is committed to driving innovation in AI and making it accessible to a wide range of users.\\n - Their work has a significant impact on improving efficiency, accuracy, and decision-making in various fields.\\n\\n6. **Awards and Recognition**:\\n - SenseTime has received numerous awards and recognitions for its contributions to AI and technology.\\n - The company is often cited in media and industry reports for its advancements and leadership in AI.\\n\\nIf you have any specific questions about SenseTime or need more detailed information, feel free to ask!\", 'tokens': 365, 'input_tokens': 16, 'history_tokens': 141, 'finish_reason': 'stop'}\n",
|
| 374 |
+
"INFO: 127.0.0.1:52230 - \"POST /v1/chat/interactive HTTP/1.1\" 200 OK\n",
|
| 375 |
+
"{'text': \"Certainly! Here's a summary of our conversation so far:\\n\\n1. **Introduction**:\\n - I am an AI assistant developed by SenseTime, a leading AI company.\\n\\n2. **About SenseTime**:\\n - SenseTime is a prominent AI company based in China, founded in 2014.\\n - It focuses on advanced AI technologies, including computer vision, deep learning, and natural language processing.\\n - The company develops AI applications for various industries such as healthcare, education, finance, and entertainment.\\n - SenseTime collaborates with academic institutions, research labs, and industry partners to advance AI technologies.\\n - They have received numerous awards and recognitions for their contributions to AI and technology.\\n\\nIf you need more specific information or have any other questions, feel free to ask!\", 'tokens': 163, 'input_tokens': 20, 'history_tokens': 522, 'finish_reason': 'stop'}\n"
|
| 376 |
+
]
|
| 377 |
+
}
|
| 378 |
+
],
|
| 379 |
+
"source": [
|
| 380 |
+
"from lmdeploy.serve.openai.api_client import APIClient\n",
|
| 381 |
+
"\n",
|
| 382 |
+
"api_client = APIClient(f\"http://{server_ip}:{server_port}\")\n",
|
| 383 |
+
"messages = [\n",
|
| 384 |
+
" \"hi, what's your name?\",\n",
|
| 385 |
+
" \"who developed you?\",\n",
|
| 386 |
+
" \"Tell me more about your developers\",\n",
|
| 387 |
+
" \"Summarize the information we've talked so far\",\n",
|
| 388 |
+
"]\n",
|
| 389 |
+
"for message in messages:\n",
|
| 390 |
+
" for item in api_client.chat_interactive_v1(\n",
|
| 391 |
+
" prompt=message, session_id=1, interactive_mode=True, stream=False\n",
|
| 392 |
+
" ):\n",
|
| 393 |
+
" print(item)"
|
| 394 |
+
]
|
| 395 |
+
},
|
| 396 |
+
{
|
| 397 |
+
"cell_type": "markdown",
|
| 398 |
+
"id": "278265b6",
|
| 399 |
+
"metadata": {},
|
| 400 |
+
"source": [
|
| 401 |
+
"### Tools\n",
|
| 402 |
+
"\n",
|
| 403 |
+
"May refer to [api_server_tools](./api_server_tools.md).\n",
|
| 404 |
+
"\n",
|
| 405 |
+
"### Integrate with Java/Golang/Rust\n",
|
| 406 |
+
"\n",
|
| 407 |
+
"May use [openapi-generator-cli](https://github.com/OpenAPITools/openapi-generator-cli) to convert `http://{server_ip}:{server_port}/openapi.json` to java/rust/golang client.\n",
|
| 408 |
+
"Here is an example:\n",
|
| 409 |
+
"\n",
|
| 410 |
+
"```shell\n",
|
| 411 |
+
"$ docker run -it --rm -v ${PWD}:/local openapitools/openapi-generator-cli generate -i /local/openapi.json -g rust -o /local/rust\n",
|
| 412 |
+
"\n",
|
| 413 |
+
"$ ls rust/*\n",
|
| 414 |
+
"rust/Cargo.toml rust/git_push.sh rust/README.md\n",
|
| 415 |
+
"\n",
|
| 416 |
+
"rust/docs:\n",
|
| 417 |
+
"ChatCompletionRequest.md EmbeddingsRequest.md HttpValidationError.md LocationInner.md Prompt.md\n",
|
| 418 |
+
"DefaultApi.md GenerateRequest.md Input.md Messages.md ValidationError.md\n",
|
| 419 |
+
"\n",
|
| 420 |
+
"rust/src:\n",
|
| 421 |
+
"apis lib.rs models\n",
|
| 422 |
+
"```\n",
|
| 423 |
+
"\n",
|
| 424 |
+
"### Integrate with cURL\n",
|
| 425 |
+
"\n",
|
| 426 |
+
"cURL is a tool for observing the output of the RESTful APIs.\n",
|
| 427 |
+
"\n",
|
| 428 |
+
"- list served models `v1/models`"
|
| 429 |
+
]
|
| 430 |
+
},
|
| 431 |
+
{
|
| 432 |
+
"cell_type": "code",
|
| 433 |
+
"execution_count": 12,
|
| 434 |
+
"id": "a1411963",
|
| 435 |
+
"metadata": {},
|
| 436 |
+
"outputs": [
|
| 437 |
+
{
|
| 438 |
+
"name": "stdout",
|
| 439 |
+
"output_type": "stream",
|
| 440 |
+
"text": [
|
| 441 |
+
"INFO: 127.0.0.1:41826 - \"GET /v1/models HTTP/1.1\" 200 OK\n",
|
| 442 |
+
"{\"object\":\"list\",\"data\":[{\"id\":\"OpenGVLab/InternVL2_5-26B-AWQ\",\"object\":\"model\",\"created\":1734683385,\"owned_by\":\"lmdeploy\",\"root\":\"OpenGVLab/InternVL2_5-26B-AWQ\",\"parent\":null,\"permission\":[{\"id\":\"modelperm-iFPz3naHoQtF4of9cmFLoL\",\"object\":\"model_permission\",\"created\":1734683385,\"allow_create_engine\":false,\"allow_sampling\":true,\"allow_logprobs\":true,\"allow_search_indices\":true,\"allow_view\":true,\"allow_fine_tuning\":false,\"organization\":\"*\",\"group\":null,\"is_blocking\":false}]}]}"
|
| 443 |
+
]
|
| 444 |
+
}
|
| 445 |
+
],
|
| 446 |
+
"source": [
|
| 447 |
+
"# %%bash\n",
|
| 448 |
+
"!curl http://{server_ip}:{server_port}/v1/models"
|
| 449 |
+
]
|
| 450 |
+
},
|
| 451 |
+
{
|
| 452 |
+
"cell_type": "markdown",
|
| 453 |
+
"id": "ce68340d",
|
| 454 |
+
"metadata": {},
|
| 455 |
+
"source": [
|
| 456 |
+
"- chat `v1/chat/completions`"
|
| 457 |
+
]
|
| 458 |
+
},
|
| 459 |
+
{
|
| 460 |
+
"cell_type": "code",
|
| 461 |
+
"execution_count": null,
|
| 462 |
+
"id": "8bc660df",
|
| 463 |
+
"metadata": {},
|
| 464 |
+
"outputs": [],
|
| 465 |
+
"source": [
|
| 466 |
+
"%%bash\n",
|
| 467 |
+
"curl http://{server_ip}:{server_port}/v1/chat/completions \\\n",
|
| 468 |
+
" -H \"Content-Type: application/json\" \\\n",
|
| 469 |
+
" -d '{\n",
|
| 470 |
+
" \"model\": \"internlm-chat-7b\",\n",
|
| 471 |
+
" \"messages\": [{\"role\": \"user\", \"content\": \"Hello! How are you?\"}]\n",
|
| 472 |
+
" }'"
|
| 473 |
+
]
|
| 474 |
+
},
|
| 475 |
+
{
|
| 476 |
+
"cell_type": "markdown",
|
| 477 |
+
"id": "1d5552dd",
|
| 478 |
+
"metadata": {},
|
| 479 |
+
"source": [
|
| 480 |
+
"- text completions `v1/completions`\n",
|
| 481 |
+
"\n",
|
| 482 |
+
"```shell\n",
|
| 483 |
+
"curl http://{server_ip}:{server_port}/v1/completions \\\n",
|
| 484 |
+
" -H 'Content-Type: application/json' \\\n",
|
| 485 |
+
" -d '{\n",
|
| 486 |
+
" \"model\": \"llama\",\n",
|
| 487 |
+
" \"prompt\": \"two steps to build a house:\"\n",
|
| 488 |
+
"}'\n",
|
| 489 |
+
"```\n",
|
| 490 |
+
"\n",
|
| 491 |
+
"- interactive chat `v1/chat/interactive`"
|
| 492 |
+
]
|
| 493 |
+
},
|
| 494 |
+
{
|
| 495 |
+
"cell_type": "code",
|
| 496 |
+
"execution_count": null,
|
| 497 |
+
"id": "082c7709",
|
| 498 |
+
"metadata": {},
|
| 499 |
+
"outputs": [],
|
| 500 |
+
"source": [
|
| 501 |
+
"%%bash\n",
|
| 502 |
+
"curl http://{server_ip}:{server_port}/v1/chat/interactive \\\n",
|
| 503 |
+
" -H \"Content-Type: application/json\" \\\n",
|
| 504 |
+
" -d '{\n",
|
| 505 |
+
" \"prompt\": \"Hello! How are you?\",\n",
|
| 506 |
+
" \"session_id\": 1,\n",
|
| 507 |
+
" \"interactive_mode\": true\n",
|
| 508 |
+
" }'"
|
| 509 |
+
]
|
| 510 |
+
},
|
| 511 |
+
{
|
| 512 |
+
"cell_type": "markdown",
|
| 513 |
+
"id": "ec3c5eca",
|
| 514 |
+
"metadata": {},
|
| 515 |
+
"source": [
|
| 516 |
+
"## Integrate with WebUI\n",
|
| 517 |
+
"\n",
|
| 518 |
+
"```shell\n",
|
| 519 |
+
"# api_server_url is what printed in api_server.py, e.g. http://localhost:23333\n",
|
| 520 |
+
"# server_ip and server_port here are for gradio ui\n",
|
| 521 |
+
"# example: lmdeploy serve gradio http://localhost:23333 --server-name localhost --server-port 6006\n",
|
| 522 |
+
"lmdeploy serve gradio api_server_url --server-name ${gradio_ui_ip} --server-port ${gradio_ui_port}\n",
|
| 523 |
+
"```\n",
|
| 524 |
+
"\n",
|
| 525 |
+
"## FAQ\n",
|
| 526 |
+
"\n",
|
| 527 |
+
"1. When user got `\"finish_reason\":\"length\"`, it means the session is too long to be continued. The session length can be\n",
|
| 528 |
+
" modified by passing `--session_len` to api_server.\n",
|
| 529 |
+
"\n",
|
| 530 |
+
"2. When OOM appeared at the server side, please reduce the `cache_max_entry_count` of `backend_config` when launching the service.\n",
|
| 531 |
+
"\n",
|
| 532 |
+
"3. When the request with the same `session_id` to `/v1/chat/interactive` got a empty return value and a negative `tokens`, please consider setting `interactive_mode=false` to restart the session.\n",
|
| 533 |
+
"\n",
|
| 534 |
+
"4. The `/v1/chat/interactive` api disables engaging in multiple rounds of conversation by default. The input argument `prompt` consists of either single strings or entire chat histories.\n",
|
| 535 |
+
"\n",
|
| 536 |
+
"5. Regarding the stop words, we only support characters that encode into a single index. Furthermore, there may be multiple indexes that decode into results containing the stop word. In such cases, if the number of these indexes is too large, we will only use the index encoded by the tokenizer. If you want use a stop symbol that encodes into multiple indexes, you may consider performing string matching on the streaming client side. Once a successful match is found, you can then break out of the streaming loop.\n",
|
| 537 |
+
"\n",
|
| 538 |
+
"6. To customize a chat template, please refer to [chat_template.md](../advance/chat_template.md)."
|
| 539 |
+
]
|
| 540 |
+
}
|
| 541 |
+
],
|
| 542 |
+
"metadata": {
|
| 543 |
+
"jupytext": {
|
| 544 |
+
"cell_metadata_filter": "-all",
|
| 545 |
+
"main_language": "python",
|
| 546 |
+
"notebook_metadata_filter": "-all"
|
| 547 |
+
},
|
| 548 |
+
"kernelspec": {
|
| 549 |
+
"display_name": "lmdeploy",
|
| 550 |
+
"language": "python",
|
| 551 |
+
"name": "python3"
|
| 552 |
+
},
|
| 553 |
+
"language_info": {
|
| 554 |
+
"codemirror_mode": {
|
| 555 |
+
"name": "ipython",
|
| 556 |
+
"version": 3
|
| 557 |
+
},
|
| 558 |
+
"file_extension": ".py",
|
| 559 |
+
"mimetype": "text/x-python",
|
| 560 |
+
"name": "python",
|
| 561 |
+
"nbconvert_exporter": "python",
|
| 562 |
+
"pygments_lexer": "ipython3",
|
| 563 |
+
"version": "3.8.19"
|
| 564 |
+
}
|
| 565 |
+
},
|
| 566 |
+
"nbformat": 4,
|
| 567 |
+
"nbformat_minor": 5
|
| 568 |
+
}
|
a_mllm_notebooks/lmdeploy/api_server.md
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenAI Compatible Server
|
| 2 |
+
|
| 3 |
+
This article primarily discusses the deployment of a single LLM model across multiple GPUs on a single node, providing a service that is compatible with the OpenAI interface, as well as the usage of the service API.
|
| 4 |
+
For the sake of convenience, we refer to this service as `api_server`. Regarding parallel services with multiple models, please refer to the guide about [Request Distribution Server](proxy_server.md).
|
| 5 |
+
|
| 6 |
+
In the following sections, we will first introduce methods for starting the service, choosing the appropriate one based on your application scenario.
|
| 7 |
+
|
| 8 |
+
Next, we focus on the definition of the service's RESTful API, explore the various ways to interact with the interface, and demonstrate how to try the service through the Swagger UI or LMDeploy CLI tools.
|
| 9 |
+
|
| 10 |
+
Finally, we showcase how to integrate the service into a WebUI, providing you with a reference to easily set up a demonstration demo.
|
| 11 |
+
|
| 12 |
+
## Launch Service
|
| 13 |
+
|
| 14 |
+
Take the [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) model hosted on huggingface hub as an example, you can choose one the following methods to start the service.
|
| 15 |
+
|
| 16 |
+
### Option 1: Launching with lmdeploy CLI
|
| 17 |
+
|
| 18 |
+
```shell
|
| 19 |
+
lmdeploy serve api_server internlm/internlm2_5-7b-chat --server-port 23333
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
The arguments of `api_server` can be viewed through the command `lmdeploy serve api_server -h`, for instance, `--tp` to set tensor parallelism, `--session-len` to specify the max length of the context window, `--cache-max-entry-count` to adjust the GPU mem ratio for k/v cache etc.
|
| 23 |
+
|
| 24 |
+
### Option 2: Deploying with docker
|
| 25 |
+
|
| 26 |
+
With LMDeploy [official docker image](https://hub.docker.com/r/openmmlab/lmdeploy/tags), you can run OpenAI compatible server as follows:
|
| 27 |
+
|
| 28 |
+
```shell
|
| 29 |
+
docker run --runtime nvidia --gpus all \
|
| 30 |
+
-v ~/.cache/huggingface:/root/.cache/huggingface \
|
| 31 |
+
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
|
| 32 |
+
-p 23333:23333 \
|
| 33 |
+
--ipc=host \
|
| 34 |
+
openmmlab/lmdeploy:latest \
|
| 35 |
+
lmdeploy serve api_server internlm/internlm2_5-7b-chat
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
The parameters of `api_server` are the same with that mentioned in "[option 1](#option-1-launching-with-lmdeploy-cli)" section
|
| 39 |
+
|
| 40 |
+
### Option 3: Deploying to Kubernetes cluster
|
| 41 |
+
|
| 42 |
+
Connect to a running Kubernetes cluster and deploy the internlm2_5-7b-chat model service with [kubectl](https://kubernetes.io/docs/reference/kubectl/) command-line tool (replace `<your token>` with your huggingface hub token):
|
| 43 |
+
|
| 44 |
+
```shell
|
| 45 |
+
sed 's/{{HUGGING_FACE_HUB_TOKEN}}/<your token>/' k8s/deployment.yaml | kubectl create -f - \
|
| 46 |
+
&& kubectl create -f k8s/service.yaml
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
In the example above the model data is placed on the local disk of the node (hostPath). Consider replacing it with high-availability shared storage if multiple replicas are desired, and the storage can be mounted into container using [PersistentVolume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/).
|
| 50 |
+
|
| 51 |
+
## RESTful API
|
| 52 |
+
|
| 53 |
+
LMDeploy's RESTful API is compatible with the following three OpenAI interfaces:
|
| 54 |
+
|
| 55 |
+
- /v1/chat/completions
|
| 56 |
+
- /v1/models
|
| 57 |
+
- /v1/completions
|
| 58 |
+
|
| 59 |
+
Additionally, LMDeploy also defines `/v1/chat/interactive` to support interactive inference. The feature of interactive inference is that there's no need to pass the user conversation history as required by `v1/chat/completions`, since the conversation history will be cached on the server side. This method boasts excellent performance during multi-turn long context inference.
|
| 60 |
+
|
| 61 |
+
You can overview and try out the offered RESTful APIs by the website `http://0.0.0.0:23333` as shown in the below image after launching the service successfully.
|
| 62 |
+
|
| 63 |
+

|
| 64 |
+
|
| 65 |
+
Or, you can use the LMDeploy's built-in CLI tool to verify the service correctness right from the console.
|
| 66 |
+
|
| 67 |
+
```shell
|
| 68 |
+
# restful_api_url is what printed in api_server.py, e.g. http://localhost:23333
|
| 69 |
+
lmdeploy serve api_client ${api_server_url}
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
If you need to integrate the service into your own projects or products, we recommend the following approach:
|
| 73 |
+
|
| 74 |
+
### Integrate with `OpenAI`
|
| 75 |
+
|
| 76 |
+
Here is an example of interaction with the endpoint `v1/chat/completions` service via the openai package.
|
| 77 |
+
Before running it, please install the openai package by `pip install openai`
|
| 78 |
+
|
| 79 |
+
```python
|
| 80 |
+
from openai import OpenAI
|
| 81 |
+
client = OpenAI(
|
| 82 |
+
api_key='YOUR_API_KEY',
|
| 83 |
+
base_url="http://0.0.0.0:23333/v1"
|
| 84 |
+
)
|
| 85 |
+
model_name = client.models.list().data[0].id
|
| 86 |
+
response = client.chat.completions.create(
|
| 87 |
+
model=model_name,
|
| 88 |
+
messages=[
|
| 89 |
+
{"role": "system", "content": "You are a helpful assistant."},
|
| 90 |
+
{"role": "user", "content": " provide three suggestions about time management"},
|
| 91 |
+
],
|
| 92 |
+
temperature=0.8,
|
| 93 |
+
top_p=0.8
|
| 94 |
+
)
|
| 95 |
+
print(response)
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
If you want to use async functions, may try the following example:
|
| 99 |
+
|
| 100 |
+
```python
|
| 101 |
+
import asyncio
|
| 102 |
+
from openai import AsyncOpenAI
|
| 103 |
+
|
| 104 |
+
async def main():
|
| 105 |
+
client = AsyncOpenAI(api_key='YOUR_API_KEY',
|
| 106 |
+
base_url='http://0.0.0.0:23333/v1')
|
| 107 |
+
model_cards = await client.models.list()._get_page()
|
| 108 |
+
response = await client.chat.completions.create(
|
| 109 |
+
model=model_cards.data[0].id,
|
| 110 |
+
messages=[
|
| 111 |
+
{
|
| 112 |
+
'role': 'system',
|
| 113 |
+
'content': 'You are a helpful assistant.'
|
| 114 |
+
},
|
| 115 |
+
{
|
| 116 |
+
'role': 'user',
|
| 117 |
+
'content': ' provide three suggestions about time management'
|
| 118 |
+
},
|
| 119 |
+
],
|
| 120 |
+
temperature=0.8,
|
| 121 |
+
top_p=0.8)
|
| 122 |
+
print(response)
|
| 123 |
+
|
| 124 |
+
asyncio.run(main())
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
You can invoke other OpenAI interfaces using similar methods. For more detailed information, please refer to the [OpenAI API guide](https://platform.openai.com/docs/guides/text-generation)
|
| 128 |
+
|
| 129 |
+
### Integrate with lmdeploy `APIClient`
|
| 130 |
+
|
| 131 |
+
Below are some examples demonstrating how to visit the service through `APIClient`
|
| 132 |
+
|
| 133 |
+
If you want to use the `/v1/chat/completions` endpoint, you can try the following code:
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
from lmdeploy.serve.openai.api_client import APIClient
|
| 137 |
+
api_client = APIClient('http://{server_ip}:{server_port}')
|
| 138 |
+
model_name = api_client.available_models[0]
|
| 139 |
+
messages = [{"role": "user", "content": "Say this is a test!"}]
|
| 140 |
+
for item in api_client.chat_completions_v1(model=model_name, messages=messages):
|
| 141 |
+
print(item)
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
For the `/v1/completions` endpoint, you can try:
|
| 145 |
+
|
| 146 |
+
```python
|
| 147 |
+
from lmdeploy.serve.openai.api_client import APIClient
|
| 148 |
+
api_client = APIClient('http://{server_ip}:{server_port}')
|
| 149 |
+
model_name = api_client.available_models[0]
|
| 150 |
+
for item in api_client.completions_v1(model=model_name, prompt='hi'):
|
| 151 |
+
print(item)
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
As for `/v1/chat/interactive`,we disable the feature by default. Please open it by setting `interactive_mode = True`. If you don't, it falls back to openai compatible interfaces.
|
| 155 |
+
|
| 156 |
+
Keep in mind that `session_id` indicates an identical sequence and all requests belonging to the same sequence must share the same `session_id`.
|
| 157 |
+
For instance, in a sequence with 10 rounds of chatting requests, the `session_id` in each request should be the same.
|
| 158 |
+
|
| 159 |
+
```python
|
| 160 |
+
from lmdeploy.serve.openai.api_client import APIClient
|
| 161 |
+
api_client = APIClient(f'http://{server_ip}:{server_port}')
|
| 162 |
+
messages = [
|
| 163 |
+
"hi, what's your name?",
|
| 164 |
+
"who developed you?",
|
| 165 |
+
"Tell me more about your developers",
|
| 166 |
+
"Summarize the information we've talked so far"
|
| 167 |
+
]
|
| 168 |
+
for message in messages:
|
| 169 |
+
for item in api_client.chat_interactive_v1(prompt=message,
|
| 170 |
+
session_id=1,
|
| 171 |
+
interactive_mode=True,
|
| 172 |
+
stream=False):
|
| 173 |
+
print(item)
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
### Tools
|
| 177 |
+
|
| 178 |
+
May refer to [api_server_tools](./api_server_tools.md).
|
| 179 |
+
|
| 180 |
+
### Integrate with Java/Golang/Rust
|
| 181 |
+
|
| 182 |
+
May use [openapi-generator-cli](https://github.com/OpenAPITools/openapi-generator-cli) to convert `http://{server_ip}:{server_port}/openapi.json` to java/rust/golang client.
|
| 183 |
+
Here is an example:
|
| 184 |
+
|
| 185 |
+
```shell
|
| 186 |
+
$ docker run -it --rm -v ${PWD}:/local openapitools/openapi-generator-cli generate -i /local/openapi.json -g rust -o /local/rust
|
| 187 |
+
|
| 188 |
+
$ ls rust/*
|
| 189 |
+
rust/Cargo.toml rust/git_push.sh rust/README.md
|
| 190 |
+
|
| 191 |
+
rust/docs:
|
| 192 |
+
ChatCompletionRequest.md EmbeddingsRequest.md HttpValidationError.md LocationInner.md Prompt.md
|
| 193 |
+
DefaultApi.md GenerateRequest.md Input.md Messages.md ValidationError.md
|
| 194 |
+
|
| 195 |
+
rust/src:
|
| 196 |
+
apis lib.rs models
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
### Integrate with cURL
|
| 200 |
+
|
| 201 |
+
cURL is a tool for observing the output of the RESTful APIs.
|
| 202 |
+
|
| 203 |
+
- list served models `v1/models`
|
| 204 |
+
|
| 205 |
+
```bash
|
| 206 |
+
curl http://{server_ip}:{server_port}/v1/models
|
| 207 |
+
```
|
| 208 |
+
|
| 209 |
+
- chat `v1/chat/completions`
|
| 210 |
+
|
| 211 |
+
```bash
|
| 212 |
+
curl http://{server_ip}:{server_port}/v1/chat/completions \
|
| 213 |
+
-H "Content-Type: application/json" \
|
| 214 |
+
-d '{
|
| 215 |
+
"model": "internlm-chat-7b",
|
| 216 |
+
"messages": [{"role": "user", "content": "Hello! How are you?"}]
|
| 217 |
+
}'
|
| 218 |
+
```
|
| 219 |
+
|
| 220 |
+
- text completions `v1/completions`
|
| 221 |
+
|
| 222 |
+
```shell
|
| 223 |
+
curl http://{server_ip}:{server_port}/v1/completions \
|
| 224 |
+
-H 'Content-Type: application/json' \
|
| 225 |
+
-d '{
|
| 226 |
+
"model": "llama",
|
| 227 |
+
"prompt": "two steps to build a house:"
|
| 228 |
+
}'
|
| 229 |
+
```
|
| 230 |
+
|
| 231 |
+
- interactive chat `v1/chat/interactive`
|
| 232 |
+
|
| 233 |
+
```bash
|
| 234 |
+
curl http://{server_ip}:{server_port}/v1/chat/interactive \
|
| 235 |
+
-H "Content-Type: application/json" \
|
| 236 |
+
-d '{
|
| 237 |
+
"prompt": "Hello! How are you?",
|
| 238 |
+
"session_id": 1,
|
| 239 |
+
"interactive_mode": true
|
| 240 |
+
}'
|
| 241 |
+
```
|
| 242 |
+
|
| 243 |
+
## Integrate with WebUI
|
| 244 |
+
|
| 245 |
+
```shell
|
| 246 |
+
# api_server_url is what printed in api_server.py, e.g. http://localhost:23333
|
| 247 |
+
# server_ip and server_port here are for gradio ui
|
| 248 |
+
# example: lmdeploy serve gradio http://localhost:23333 --server-name localhost --server-port 6006
|
| 249 |
+
lmdeploy serve gradio api_server_url --server-name ${gradio_ui_ip} --server-port ${gradio_ui_port}
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
## FAQ
|
| 253 |
+
|
| 254 |
+
1. When user got `"finish_reason":"length"`, it means the session is too long to be continued. The session length can be
|
| 255 |
+
modified by passing `--session_len` to api_server.
|
| 256 |
+
|
| 257 |
+
2. When OOM appeared at the server side, please reduce the `cache_max_entry_count` of `backend_config` when launching the service.
|
| 258 |
+
|
| 259 |
+
3. When the request with the same `session_id` to `/v1/chat/interactive` got a empty return value and a negative `tokens`, please consider setting `interactive_mode=false` to restart the session.
|
| 260 |
+
|
| 261 |
+
4. The `/v1/chat/interactive` api disables engaging in multiple rounds of conversation by default. The input argument `prompt` consists of either single strings or entire chat histories.
|
| 262 |
+
|
| 263 |
+
5. Regarding the stop words, we only support characters that encode into a single index. Furthermore, there may be multiple indexes that decode into results containing the stop word. In such cases, if the number of these indexes is too large, we will only use the index encoded by the tokenizer. If you want use a stop symbol that encodes into multiple indexes, you may consider performing string matching on the streaming client side. Once a successful match is found, you can then break out of the streaming loop.
|
| 264 |
+
|
| 265 |
+
6. To customize a chat template, please refer to [chat_template.md](../advance/chat_template.md).
|
a_mllm_notebooks/lmdeploy/api_server_vl.ipynb
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "bce4dd82",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# OpenAI Compatible Server\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"This article primarily discusses the deployment of a single large vision language model across multiple GPUs on a single node, providing a service that is compatible with the OpenAI interface, as well as the usage of the service API.\n",
|
| 11 |
+
"For the sake of convenience, we refer to this service as `api_server`. Regarding parallel services with multiple models, please refer to the guide about [Request Distribution Server](../llm/proxy_server.md).\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"In the following sections, we will first introduce two methods for starting the service, choosing the appropriate one based on your application scenario.\n",
|
| 14 |
+
"\n",
|
| 15 |
+
"Next, we focus on the definition of the service's RESTful API, explore the various ways to interact with the interface, and demonstrate how to try the service through the Swagger UI or LMDeploy CLI tools.\n",
|
| 16 |
+
"\n",
|
| 17 |
+
"Finally, we showcase how to integrate the service into a WebUI, providing you with a reference to easily set up a demonstration demo.\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"## Launch Service\n",
|
| 20 |
+
"\n",
|
| 21 |
+
"Take the [llava-v1.6-vicuna-7b](https://huggingface.co/liuhaotian/llava-v1.6-vicuna-7b) model hosted on huggingface hub as an example, you can choose one the following methods to start the service.\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"### Option 1: Launching with lmdeploy CLI\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"```shell\n",
|
| 26 |
+
"lmdeploy serve api_server liuhaotian/llava-v1.6-vicuna-7b --server-port 23333\n",
|
| 27 |
+
"```\n",
|
| 28 |
+
"\n",
|
| 29 |
+
"The arguments of `api_server` can be viewed through the command `lmdeploy serve api_server -h`, for instance, `--tp` to set tensor parallelism, `--session-len` to specify the max length of the context window, `--cache-max-entry-count` to adjust the GPU mem ratio for k/v cache etc.\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"### Option 2: Deploying with docker\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"With LMDeploy [official docker image](https://hub.docker.com/r/openmmlab/lmdeploy/tags), you can run OpenAI compatible server as follows:\n",
|
| 34 |
+
"\n",
|
| 35 |
+
"```shell\n",
|
| 36 |
+
"docker run --runtime nvidia --gpus all \\\n",
|
| 37 |
+
" -v ~/.cache/huggingface:/root/.cache/huggingface \\\n",
|
| 38 |
+
" --env \"HUGGING_FACE_HUB_TOKEN=<secret>\" \\\n",
|
| 39 |
+
" -p 23333:23333 \\\n",
|
| 40 |
+
" --ipc=host \\\n",
|
| 41 |
+
" openmmlab/lmdeploy:latest \\\n",
|
| 42 |
+
" lmdeploy serve api_server liuhaotian/llava-v1.6-vicuna-7b\n",
|
| 43 |
+
"```\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"The parameters of `api_server` are the same with that mentioned in \"[option 1](#option-1-launching-with-lmdeploy-cli)\" section\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"Each model may require specific dependencies not included in the Docker image. If you run into issues, you may need to install those yourself\n",
|
| 48 |
+
"on a case-by-case basis. If in doubt, refer to the specific model's project for documentation.\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"For example, for Llava:\n",
|
| 51 |
+
"\n",
|
| 52 |
+
"```\n",
|
| 53 |
+
"FROM openmmlab/lmdeploy:latest\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"RUN apt-get update && apt-get install -y python3 python3-pip git\n",
|
| 56 |
+
"\n",
|
| 57 |
+
"WORKDIR /app\n",
|
| 58 |
+
"\n",
|
| 59 |
+
"RUN pip3 install --upgrade pip\n",
|
| 60 |
+
"RUN pip3 install timm\n",
|
| 61 |
+
"RUN pip3 install git+https://github.com/haotian-liu/LLaVA.git --no-deps\n",
|
| 62 |
+
"\n",
|
| 63 |
+
"COPY . .\n",
|
| 64 |
+
"\n",
|
| 65 |
+
"CMD [\"lmdeploy\", \"serve\", \"api_server\", \"liuhaotian/llava-v1.6-34b\"]\n",
|
| 66 |
+
"```\n",
|
| 67 |
+
"\n",
|
| 68 |
+
"## RESTful API\n",
|
| 69 |
+
"\n",
|
| 70 |
+
"LMDeploy's RESTful API is compatible with the following three OpenAI interfaces:\n",
|
| 71 |
+
"\n",
|
| 72 |
+
"- /v1/chat/completions\n",
|
| 73 |
+
"- /v1/models\n",
|
| 74 |
+
"- /v1/completions\n",
|
| 75 |
+
"\n",
|
| 76 |
+
"The interface for image interaction is `/v1/chat/completions`, which is consistent with OpenAI.\n",
|
| 77 |
+
"\n",
|
| 78 |
+
"You can overview and try out the offered RESTful APIs by the website `http://0.0.0.0:23333` as shown in the below image after launching the service successfully.\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"If you need to integrate the service into your own projects or products, we recommend the following approach:\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"### Integrate with `OpenAI`\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"Here is an example of interaction with the endpoint `v1/chat/completions` service via the openai package.\n",
|
| 87 |
+
"Before running it, please install the openai package by `pip install openai`"
|
| 88 |
+
]
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"cell_type": "code",
|
| 92 |
+
"execution_count": null,
|
| 93 |
+
"id": "c5e123fd",
|
| 94 |
+
"metadata": {},
|
| 95 |
+
"outputs": [],
|
| 96 |
+
"source": [
|
| 97 |
+
"from openai import OpenAI\n",
|
| 98 |
+
"\n",
|
| 99 |
+
"client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')\n",
|
| 100 |
+
"model_name = client.models.list().data[0].id\n",
|
| 101 |
+
"response = client.chat.completions.create(\n",
|
| 102 |
+
" model=model_name,\n",
|
| 103 |
+
" messages=[{\n",
|
| 104 |
+
" 'role':\n",
|
| 105 |
+
" 'user',\n",
|
| 106 |
+
" 'content': [{\n",
|
| 107 |
+
" 'type': 'text',\n",
|
| 108 |
+
" 'text': 'Describe the image please',\n",
|
| 109 |
+
" }, {\n",
|
| 110 |
+
" 'type': 'image_url',\n",
|
| 111 |
+
" 'image_url': {\n",
|
| 112 |
+
" 'url':\n",
|
| 113 |
+
" 'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',\n",
|
| 114 |
+
" },\n",
|
| 115 |
+
" }],\n",
|
| 116 |
+
" }],\n",
|
| 117 |
+
" temperature=0.8,\n",
|
| 118 |
+
" top_p=0.8)\n",
|
| 119 |
+
"print(response)"
|
| 120 |
+
]
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"cell_type": "markdown",
|
| 124 |
+
"id": "f1478f29",
|
| 125 |
+
"metadata": {},
|
| 126 |
+
"source": [
|
| 127 |
+
"### Integrate with lmdeploy `APIClient`\n",
|
| 128 |
+
"\n",
|
| 129 |
+
"Below are some examples demonstrating how to visit the service through `APIClient`\n",
|
| 130 |
+
"\n",
|
| 131 |
+
"If you want to use the `/v1/chat/completions` endpoint, you can try the following code:"
|
| 132 |
+
]
|
| 133 |
+
},
|
| 134 |
+
{
|
| 135 |
+
"cell_type": "code",
|
| 136 |
+
"execution_count": null,
|
| 137 |
+
"id": "01388ff3",
|
| 138 |
+
"metadata": {},
|
| 139 |
+
"outputs": [],
|
| 140 |
+
"source": [
|
| 141 |
+
"from lmdeploy.serve.openai.api_client import APIClient\n",
|
| 142 |
+
"\n",
|
| 143 |
+
"api_client = APIClient(f'http://0.0.0.0:23333')\n",
|
| 144 |
+
"model_name = api_client.available_models[0]\n",
|
| 145 |
+
"messages = [{\n",
|
| 146 |
+
" 'role':\n",
|
| 147 |
+
" 'user',\n",
|
| 148 |
+
" 'content': [{\n",
|
| 149 |
+
" 'type': 'text',\n",
|
| 150 |
+
" 'text': 'Describe the image please',\n",
|
| 151 |
+
" }, {\n",
|
| 152 |
+
" 'type': 'image_url',\n",
|
| 153 |
+
" 'image_url': {\n",
|
| 154 |
+
" 'url':\n",
|
| 155 |
+
" 'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',\n",
|
| 156 |
+
" },\n",
|
| 157 |
+
" }]\n",
|
| 158 |
+
"}]\n",
|
| 159 |
+
"for item in api_client.chat_completions_v1(model=model_name,\n",
|
| 160 |
+
" messages=messages):\n",
|
| 161 |
+
" print(item)"
|
| 162 |
+
]
|
| 163 |
+
},
|
| 164 |
+
{
|
| 165 |
+
"cell_type": "markdown",
|
| 166 |
+
"id": "39cd5080",
|
| 167 |
+
"metadata": {},
|
| 168 |
+
"source": [
|
| 169 |
+
"### Integrate with Java/Golang/Rust\n",
|
| 170 |
+
"\n",
|
| 171 |
+
"May use [openapi-generator-cli](https://github.com/OpenAPITools/openapi-generator-cli) to convert `http://{server_ip}:{server_port}/openapi.json` to java/rust/golang client.\n",
|
| 172 |
+
"Here is an example:\n",
|
| 173 |
+
"\n",
|
| 174 |
+
"```shell\n",
|
| 175 |
+
"$ docker run -it --rm -v ${PWD}:/local openapitools/openapi-generator-cli generate -i /local/openapi.json -g rust -o /local/rust\n",
|
| 176 |
+
"\n",
|
| 177 |
+
"$ ls rust/*\n",
|
| 178 |
+
"rust/Cargo.toml rust/git_push.sh rust/README.md\n",
|
| 179 |
+
"\n",
|
| 180 |
+
"rust/docs:\n",
|
| 181 |
+
"ChatCompletionRequest.md EmbeddingsRequest.md HttpValidationError.md LocationInner.md Prompt.md\n",
|
| 182 |
+
"DefaultApi.md GenerateRequest.md Input.md Messages.md ValidationError.md\n",
|
| 183 |
+
"\n",
|
| 184 |
+
"rust/src:\n",
|
| 185 |
+
"apis lib.rs models\n",
|
| 186 |
+
"```"
|
| 187 |
+
]
|
| 188 |
+
}
|
| 189 |
+
],
|
| 190 |
+
"metadata": {
|
| 191 |
+
"jupytext": {
|
| 192 |
+
"cell_metadata_filter": "-all",
|
| 193 |
+
"main_language": "python",
|
| 194 |
+
"notebook_metadata_filter": "-all"
|
| 195 |
+
}
|
| 196 |
+
},
|
| 197 |
+
"nbformat": 4,
|
| 198 |
+
"nbformat_minor": 5
|
| 199 |
+
}
|
a_mllm_notebooks/lmdeploy/api_server_vl.md
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenAI Compatible Server
|
| 2 |
+
|
| 3 |
+
This article primarily discusses the deployment of a single large vision language model across multiple GPUs on a single node, providing a service that is compatible with the OpenAI interface, as well as the usage of the service API.
|
| 4 |
+
For the sake of convenience, we refer to this service as `api_server`. Regarding parallel services with multiple models, please refer to the guide about [Request Distribution Server](../llm/proxy_server.md).
|
| 5 |
+
|
| 6 |
+
In the following sections, we will first introduce two methods for starting the service, choosing the appropriate one based on your application scenario.
|
| 7 |
+
|
| 8 |
+
Next, we focus on the definition of the service's RESTful API, explore the various ways to interact with the interface, and demonstrate how to try the service through the Swagger UI or LMDeploy CLI tools.
|
| 9 |
+
|
| 10 |
+
Finally, we showcase how to integrate the service into a WebUI, providing you with a reference to easily set up a demonstration demo.
|
| 11 |
+
|
| 12 |
+
## Launch Service
|
| 13 |
+
|
| 14 |
+
Take the [llava-v1.6-vicuna-7b](https://huggingface.co/liuhaotian/llava-v1.6-vicuna-7b) model hosted on huggingface hub as an example, you can choose one the following methods to start the service.
|
| 15 |
+
|
| 16 |
+
### Option 1: Launching with lmdeploy CLI
|
| 17 |
+
|
| 18 |
+
```shell
|
| 19 |
+
lmdeploy serve api_server liuhaotian/llava-v1.6-vicuna-7b --server-port 23333
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
The arguments of `api_server` can be viewed through the command `lmdeploy serve api_server -h`, for instance, `--tp` to set tensor parallelism, `--session-len` to specify the max length of the context window, `--cache-max-entry-count` to adjust the GPU mem ratio for k/v cache etc.
|
| 23 |
+
|
| 24 |
+
### Option 2: Deploying with docker
|
| 25 |
+
|
| 26 |
+
With LMDeploy [official docker image](https://hub.docker.com/r/openmmlab/lmdeploy/tags), you can run OpenAI compatible server as follows:
|
| 27 |
+
|
| 28 |
+
```shell
|
| 29 |
+
docker run --runtime nvidia --gpus all \
|
| 30 |
+
-v ~/.cache/huggingface:/root/.cache/huggingface \
|
| 31 |
+
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
|
| 32 |
+
-p 23333:23333 \
|
| 33 |
+
--ipc=host \
|
| 34 |
+
openmmlab/lmdeploy:latest \
|
| 35 |
+
lmdeploy serve api_server liuhaotian/llava-v1.6-vicuna-7b
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
The parameters of `api_server` are the same with that mentioned in "[option 1](#option-1-launching-with-lmdeploy-cli)" section
|
| 39 |
+
|
| 40 |
+
Each model may require specific dependencies not included in the Docker image. If you run into issues, you may need to install those yourself
|
| 41 |
+
on a case-by-case basis. If in doubt, refer to the specific model's project for documentation.
|
| 42 |
+
|
| 43 |
+
For example, for Llava:
|
| 44 |
+
|
| 45 |
+
```
|
| 46 |
+
FROM openmmlab/lmdeploy:latest
|
| 47 |
+
|
| 48 |
+
RUN apt-get update && apt-get install -y python3 python3-pip git
|
| 49 |
+
|
| 50 |
+
WORKDIR /app
|
| 51 |
+
|
| 52 |
+
RUN pip3 install --upgrade pip
|
| 53 |
+
RUN pip3 install timm
|
| 54 |
+
RUN pip3 install git+https://github.com/haotian-liu/LLaVA.git --no-deps
|
| 55 |
+
|
| 56 |
+
COPY . .
|
| 57 |
+
|
| 58 |
+
CMD ["lmdeploy", "serve", "api_server", "liuhaotian/llava-v1.6-34b"]
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
## RESTful API
|
| 62 |
+
|
| 63 |
+
LMDeploy's RESTful API is compatible with the following three OpenAI interfaces:
|
| 64 |
+
|
| 65 |
+
- /v1/chat/completions
|
| 66 |
+
- /v1/models
|
| 67 |
+
- /v1/completions
|
| 68 |
+
|
| 69 |
+
The interface for image interaction is `/v1/chat/completions`, which is consistent with OpenAI.
|
| 70 |
+
|
| 71 |
+
You can overview and try out the offered RESTful APIs by the website `http://0.0.0.0:23333` as shown in the below image after launching the service successfully.
|
| 72 |
+
|
| 73 |
+

|
| 74 |
+
|
| 75 |
+
If you need to integrate the service into your own projects or products, we recommend the following approach:
|
| 76 |
+
|
| 77 |
+
### Integrate with `OpenAI`
|
| 78 |
+
|
| 79 |
+
Here is an example of interaction with the endpoint `v1/chat/completions` service via the openai package.
|
| 80 |
+
Before running it, please install the openai package by `pip install openai`
|
| 81 |
+
|
| 82 |
+
```python
|
| 83 |
+
from openai import OpenAI
|
| 84 |
+
|
| 85 |
+
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
|
| 86 |
+
model_name = client.models.list().data[0].id
|
| 87 |
+
response = client.chat.completions.create(
|
| 88 |
+
model=model_name,
|
| 89 |
+
messages=[{
|
| 90 |
+
'role':
|
| 91 |
+
'user',
|
| 92 |
+
'content': [{
|
| 93 |
+
'type': 'text',
|
| 94 |
+
'text': 'Describe the image please',
|
| 95 |
+
}, {
|
| 96 |
+
'type': 'image_url',
|
| 97 |
+
'image_url': {
|
| 98 |
+
'url':
|
| 99 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',
|
| 100 |
+
},
|
| 101 |
+
}],
|
| 102 |
+
}],
|
| 103 |
+
temperature=0.8,
|
| 104 |
+
top_p=0.8)
|
| 105 |
+
print(response)
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
### Integrate with lmdeploy `APIClient`
|
| 109 |
+
|
| 110 |
+
Below are some examples demonstrating how to visit the service through `APIClient`
|
| 111 |
+
|
| 112 |
+
If you want to use the `/v1/chat/completions` endpoint, you can try the following code:
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
from lmdeploy.serve.openai.api_client import APIClient
|
| 116 |
+
|
| 117 |
+
api_client = APIClient(f'http://0.0.0.0:23333')
|
| 118 |
+
model_name = api_client.available_models[0]
|
| 119 |
+
messages = [{
|
| 120 |
+
'role':
|
| 121 |
+
'user',
|
| 122 |
+
'content': [{
|
| 123 |
+
'type': 'text',
|
| 124 |
+
'text': 'Describe the image please',
|
| 125 |
+
}, {
|
| 126 |
+
'type': 'image_url',
|
| 127 |
+
'image_url': {
|
| 128 |
+
'url':
|
| 129 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',
|
| 130 |
+
},
|
| 131 |
+
}]
|
| 132 |
+
}]
|
| 133 |
+
for item in api_client.chat_completions_v1(model=model_name,
|
| 134 |
+
messages=messages):
|
| 135 |
+
print(item)
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
### Integrate with Java/Golang/Rust
|
| 139 |
+
|
| 140 |
+
May use [openapi-generator-cli](https://github.com/OpenAPITools/openapi-generator-cli) to convert `http://{server_ip}:{server_port}/openapi.json` to java/rust/golang client.
|
| 141 |
+
Here is an example:
|
| 142 |
+
|
| 143 |
+
```shell
|
| 144 |
+
$ docker run -it --rm -v ${PWD}:/local openapitools/openapi-generator-cli generate -i /local/openapi.json -g rust -o /local/rust
|
| 145 |
+
|
| 146 |
+
$ ls rust/*
|
| 147 |
+
rust/Cargo.toml rust/git_push.sh rust/README.md
|
| 148 |
+
|
| 149 |
+
rust/docs:
|
| 150 |
+
ChatCompletionRequest.md EmbeddingsRequest.md HttpValidationError.md LocationInner.md Prompt.md
|
| 151 |
+
DefaultApi.md GenerateRequest.md Input.md Messages.md ValidationError.md
|
| 152 |
+
|
| 153 |
+
rust/src:
|
| 154 |
+
apis lib.rs models
|
| 155 |
+
```
|
a_mllm_notebooks/lmdeploy/download_md.ipynb
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 17,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"# https://github.com/InternLM/lmdeploy/blob/main/docs/en/llm/pipeline.md\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"# download then convert to jupyter notebook\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"import os\n",
|
| 14 |
+
"import sys\n",
|
| 15 |
+
"import json\n",
|
| 16 |
+
"import requests\n",
|
| 17 |
+
"# import jupyter_text\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"def download_markdown_and_save(url, filename):\n",
|
| 21 |
+
" # remove existing file\n",
|
| 22 |
+
" if os.path.exists(filename):\n",
|
| 23 |
+
" os.remove(filename)\n",
|
| 24 |
+
" \n",
|
| 25 |
+
" import wget \n",
|
| 26 |
+
" # preprocess url to downloadable url\n",
|
| 27 |
+
" url = url.replace(\"github.com\", \"raw.githubusercontent.com\")\n",
|
| 28 |
+
" url = url.replace(\"blob/\", \"\")\n",
|
| 29 |
+
" print(f\"Downloading {url}\")\n",
|
| 30 |
+
" wget.download(url, filename)\n",
|
| 31 |
+
" print(f\"Downloaded {filename}\")\n",
|
| 32 |
+
" \n",
|
| 33 |
+
" \n",
|
| 34 |
+
" \n",
|
| 35 |
+
"# !jupytext --to notebook your_markdown_file.md\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"def convert_markdown_to_jupyter_notebook(filename):\n",
|
| 38 |
+
" os.system(f\"jupytext --to notebook {filename}\")\n",
|
| 39 |
+
" print(f\"Converted {filename} to jupyter notebook.\")\n",
|
| 40 |
+
" \n",
|
| 41 |
+
" \n",
|
| 42 |
+
"def markdown2jupyter(url, filename):\n",
|
| 43 |
+
" download_markdown_and_save(url, filename)\n",
|
| 44 |
+
" convert_markdown_to_jupyter_notebook(filename)\n",
|
| 45 |
+
"\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"# def main():\n",
|
| 48 |
+
"# url = \"https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/llm/pipeline.md\"\n",
|
| 49 |
+
"# filename = \"pipeline.md\"\n",
|
| 50 |
+
"# download_markdown_and_save(url, filename)\n",
|
| 51 |
+
"# convert_markdown_to_jupyter_notebook(filename)\n",
|
| 52 |
+
" \n",
|
| 53 |
+
" \n",
|
| 54 |
+
"# if __name__ == \"__main__\":\n",
|
| 55 |
+
"# main()\n",
|
| 56 |
+
" "
|
| 57 |
+
]
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"cell_type": "code",
|
| 61 |
+
"execution_count": 20,
|
| 62 |
+
"metadata": {},
|
| 63 |
+
"outputs": [
|
| 64 |
+
{
|
| 65 |
+
"name": "stdout",
|
| 66 |
+
"output_type": "stream",
|
| 67 |
+
"text": [
|
| 68 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/get_started/get_started.md\n",
|
| 69 |
+
"Downloaded get_started_vl.md\n",
|
| 70 |
+
"[jupytext] Reading get_started_vl.md in format md\n",
|
| 71 |
+
"[jupytext] Writing get_started_vl.ipynb\n",
|
| 72 |
+
"Converted get_started_vl.md to jupyter notebook.\n"
|
| 73 |
+
]
|
| 74 |
+
}
|
| 75 |
+
],
|
| 76 |
+
"source": [
|
| 77 |
+
"markdown2jupyter(\n",
|
| 78 |
+
" 'https://github.com/InternLM/lmdeploy/blob/main/docs/en/get_started/get_started.md',\n",
|
| 79 |
+
" 'get_started_vl.md'\n",
|
| 80 |
+
")"
|
| 81 |
+
]
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"cell_type": "code",
|
| 85 |
+
"execution_count": 30,
|
| 86 |
+
"metadata": {},
|
| 87 |
+
"outputs": [
|
| 88 |
+
{
|
| 89 |
+
"name": "stdout",
|
| 90 |
+
"output_type": "stream",
|
| 91 |
+
"text": [
|
| 92 |
+
"Overwriting links.txt\n"
|
| 93 |
+
]
|
| 94 |
+
}
|
| 95 |
+
],
|
| 96 |
+
"source": [
|
| 97 |
+
"%%writefile links.txt\n",
|
| 98 |
+
"'https://github.com/InternLM/lmdeploy/blob/main/docs/en/quantization/kv_quant.md'\n",
|
| 99 |
+
"'https://github.com/InternLM/lmdeploy/blob/main/docs/en/advance/pytorch_new_model.md'\n",
|
| 100 |
+
"'https://github.com/InternLM/lmdeploy/blob/main/docs/en/inference/turbomind.md'\n",
|
| 101 |
+
"'https://github.com/InternLM/lmdeploy/blob/main/docs/en/multi_modal/api_server_vl.md'\n",
|
| 102 |
+
"'https://github.com/InternLM/lmdeploy/blob/main/docs/en/quantization/w4a16.md'\n",
|
| 103 |
+
"'https://github.com/InternLM/lmdeploy/blob/main/docs/en/quantization/w8a8.md'\n",
|
| 104 |
+
"'https://github.com/InternLM/lmdeploy/blob/main/docs/en/llm/proxy_server.md'\n",
|
| 105 |
+
"'https://github.com/InternLM/lmdeploy/blob/main/docs/en/advance/long_context.md'"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "code",
|
| 110 |
+
"execution_count": 31,
|
| 111 |
+
"metadata": {},
|
| 112 |
+
"outputs": [],
|
| 113 |
+
"source": [
|
| 114 |
+
"list_url = []\n",
|
| 115 |
+
"with open('links.txt') as f:\n",
|
| 116 |
+
" list_url = f.readlines()\n",
|
| 117 |
+
"for i in range(len(list_url)):\n",
|
| 118 |
+
" list_url[i] = eval(list_url[i])"
|
| 119 |
+
]
|
| 120 |
+
},
|
| 121 |
+
{
|
| 122 |
+
"cell_type": "code",
|
| 123 |
+
"execution_count": 35,
|
| 124 |
+
"metadata": {},
|
| 125 |
+
"outputs": [
|
| 126 |
+
{
|
| 127 |
+
"name": "stdout",
|
| 128 |
+
"output_type": "stream",
|
| 129 |
+
"text": [
|
| 130 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/quantization/kv_quant.md\n",
|
| 131 |
+
"Downloaded kv_quant.md\n",
|
| 132 |
+
"[jupytext] Reading kv_quant.md in format md\n",
|
| 133 |
+
"[jupytext] Writing kv_quant.ipynb (destination file replaced [use --update to preserve cell outputs and ids])\n",
|
| 134 |
+
"Converted kv_quant.md to jupyter notebook.\n",
|
| 135 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/advance/pytorch_new_model.md\n",
|
| 136 |
+
"Downloaded pytorch_new_model.md\n",
|
| 137 |
+
"[jupytext] Reading pytorch_new_model.md in format md\n",
|
| 138 |
+
"[jupytext] Writing pytorch_new_model.ipynb (destination file replaced [use --update to preserve cell outputs and ids])\n",
|
| 139 |
+
"Converted pytorch_new_model.md to jupyter notebook.\n",
|
| 140 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/inference/turbomind.md\n",
|
| 141 |
+
"Downloaded turbomind.md\n",
|
| 142 |
+
"[jupytext] Reading turbomind.md in format md\n",
|
| 143 |
+
"[jupytext] Writing turbomind.ipynb (destination file replaced [use --update to preserve cell outputs and ids])\n",
|
| 144 |
+
"Converted turbomind.md to jupyter notebook.\n",
|
| 145 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/multi_modal/api_server_vl.md\n",
|
| 146 |
+
"Downloaded api_server_vl.md\n",
|
| 147 |
+
"[jupytext] Reading api_server_vl.md in format md\n",
|
| 148 |
+
"[jupytext] Writing api_server_vl.ipynb (destination file replaced [use --update to preserve cell outputs and ids])\n",
|
| 149 |
+
"Converted api_server_vl.md to jupyter notebook.\n",
|
| 150 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/quantization/w4a16.md\n",
|
| 151 |
+
"Downloaded w4a16.md\n",
|
| 152 |
+
"[jupytext] Reading w4a16.md in format md\n",
|
| 153 |
+
"[jupytext] Writing w4a16.ipynb (destination file replaced [use --update to preserve cell outputs and ids])\n",
|
| 154 |
+
"Converted w4a16.md to jupyter notebook.\n",
|
| 155 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/quantization/w8a8.md\n",
|
| 156 |
+
"Downloaded w8a8.md\n",
|
| 157 |
+
"[jupytext] Reading w8a8.md in format md\n",
|
| 158 |
+
"[jupytext] Writing w8a8.ipynb (destination file replaced [use --update to preserve cell outputs and ids])\n",
|
| 159 |
+
"Converted w8a8.md to jupyter notebook.\n",
|
| 160 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/llm/proxy_server.md\n",
|
| 161 |
+
"Downloaded proxy_server.md\n",
|
| 162 |
+
"[jupytext] Reading proxy_server.md in format md\n",
|
| 163 |
+
"[jupytext] Writing proxy_server.ipynb (destination file replaced [use --update to preserve cell outputs and ids])\n",
|
| 164 |
+
"Converted proxy_server.md to jupyter notebook.\n",
|
| 165 |
+
"Downloading https://raw.githubusercontent.com/InternLM/lmdeploy/main/docs/en/advance/long_context.md\n",
|
| 166 |
+
"Downloaded long_context.md\n",
|
| 167 |
+
"[jupytext] Reading long_context.md in format md\n",
|
| 168 |
+
"[jupytext] Writing long_context.ipynb (destination file replaced [use --update to preserve cell outputs and ids])\n",
|
| 169 |
+
"Converted long_context.md to jupyter notebook.\n"
|
| 170 |
+
]
|
| 171 |
+
}
|
| 172 |
+
],
|
| 173 |
+
"source": [
|
| 174 |
+
"for i in range(len(list_url)):\n",
|
| 175 |
+
" url = list_url[i]\n",
|
| 176 |
+
" name = url.split('/')[-1]\n",
|
| 177 |
+
" markdown2jupyter(url, name)\n",
|
| 178 |
+
" \n",
|
| 179 |
+
"# delete all file{i}.md"
|
| 180 |
+
]
|
| 181 |
+
},
|
| 182 |
+
{
|
| 183 |
+
"cell_type": "code",
|
| 184 |
+
"execution_count": null,
|
| 185 |
+
"metadata": {},
|
| 186 |
+
"outputs": [],
|
| 187 |
+
"source": []
|
| 188 |
+
}
|
| 189 |
+
],
|
| 190 |
+
"metadata": {
|
| 191 |
+
"kernelspec": {
|
| 192 |
+
"display_name": "base",
|
| 193 |
+
"language": "python",
|
| 194 |
+
"name": "python3"
|
| 195 |
+
},
|
| 196 |
+
"language_info": {
|
| 197 |
+
"codemirror_mode": {
|
| 198 |
+
"name": "ipython",
|
| 199 |
+
"version": 3
|
| 200 |
+
},
|
| 201 |
+
"file_extension": ".py",
|
| 202 |
+
"mimetype": "text/x-python",
|
| 203 |
+
"name": "python",
|
| 204 |
+
"nbconvert_exporter": "python",
|
| 205 |
+
"pygments_lexer": "ipython3",
|
| 206 |
+
"version": "3.8.18"
|
| 207 |
+
}
|
| 208 |
+
},
|
| 209 |
+
"nbformat": 4,
|
| 210 |
+
"nbformat_minor": 2
|
| 211 |
+
}
|
a_mllm_notebooks/lmdeploy/get_started_vl.ipynb
ADDED
|
@@ -0,0 +1,517 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "a210e718",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Quick Start\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"This tutorial shows the usage of LMDeploy on CUDA platform:\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"- Offline inference of LLM model and VLM model\n",
|
| 13 |
+
"- Serve a LLM or VLM model by the OpenAI compatible server\n",
|
| 14 |
+
"- Console CLI to interactively chat with LLM model\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"Before reading further, please ensure that you have installed lmdeploy as outlined in the [installation guide](installation.md)\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"## Offline batch inference\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"### LLM inference"
|
| 21 |
+
]
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"cell_type": "code",
|
| 25 |
+
"execution_count": null,
|
| 26 |
+
"id": "1e86fd28",
|
| 27 |
+
"metadata": {},
|
| 28 |
+
"outputs": [],
|
| 29 |
+
"source": [
|
| 30 |
+
"from lmdeploy import pipeline\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"pipe = pipeline(\"internlm/internlm2_5-7b-chat\")\n",
|
| 33 |
+
"response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"])\n",
|
| 34 |
+
"print(response)"
|
| 35 |
+
]
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"cell_type": "markdown",
|
| 39 |
+
"id": "b3c14b37",
|
| 40 |
+
"metadata": {},
|
| 41 |
+
"source": [
|
| 42 |
+
"When constructing the `pipeline`, if an inference engine is not designated between the TurboMind Engine and the PyTorch Engine, LMDeploy will automatically assign one based on [their respective capabilities](../supported_models/supported_models.md), with the TurboMind Engine taking precedence by default.\n",
|
| 43 |
+
"\n",
|
| 44 |
+
"However, you have the option to manually select an engine. For instance,"
|
| 45 |
+
]
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"cell_type": "code",
|
| 49 |
+
"execution_count": null,
|
| 50 |
+
"id": "2b71c8bb",
|
| 51 |
+
"metadata": {},
|
| 52 |
+
"outputs": [],
|
| 53 |
+
"source": [
|
| 54 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 55 |
+
"\n",
|
| 56 |
+
"pipe = pipeline(\n",
|
| 57 |
+
" \"internlm/internlm2_5-7b-chat\",\n",
|
| 58 |
+
" backend_config=TurbomindEngineConfig(\n",
|
| 59 |
+
" max_batch_size=32,\n",
|
| 60 |
+
" enable_prefix_caching=True,\n",
|
| 61 |
+
" cache_max_entry_count=0.8,\n",
|
| 62 |
+
" session_len=8192,\n",
|
| 63 |
+
" ),\n",
|
| 64 |
+
")"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "markdown",
|
| 69 |
+
"id": "c34d729a",
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"source": [
|
| 72 |
+
"or,"
|
| 73 |
+
]
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"cell_type": "code",
|
| 77 |
+
"execution_count": null,
|
| 78 |
+
"id": "4878141f",
|
| 79 |
+
"metadata": {},
|
| 80 |
+
"outputs": [],
|
| 81 |
+
"source": [
|
| 82 |
+
"from lmdeploy import pipeline, PytorchEngineConfig\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"pipe = pipeline(\n",
|
| 85 |
+
" \"internlm/internlm2_5-7b-chat\",\n",
|
| 86 |
+
" backend_config=PytorchEngineConfig(\n",
|
| 87 |
+
" max_batch_size=32,\n",
|
| 88 |
+
" enable_prefix_caching=True,\n",
|
| 89 |
+
" cache_max_entry_count=0.8,\n",
|
| 90 |
+
" session_len=8192,\n",
|
| 91 |
+
" ),\n",
|
| 92 |
+
")"
|
| 93 |
+
]
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"cell_type": "markdown",
|
| 97 |
+
"id": "ca986d53",
|
| 98 |
+
"metadata": {},
|
| 99 |
+
"source": [
|
| 100 |
+
"```{note}\n",
|
| 101 |
+
"The parameter \"cache_max_entry_count\" significantly influences the GPU memory usage.\n",
|
| 102 |
+
"It means the proportion of FREE GPU memory occupied by the K/V cache after the model weights are loaded.\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"The default value is 0.8. The K/V cache memory is allocated once and reused repeatedly, which is why it is observed that the built pipeline and the \"api_server\" mentioned later in the next consumes a substantial amount of GPU memory.\n",
|
| 105 |
+
"\n",
|
| 106 |
+
"If you encounter an Out-of-Memory(OOM) error, you may need to consider lowering the value of \"cache_max_entry_count\".\n",
|
| 107 |
+
"```\n",
|
| 108 |
+
"\n",
|
| 109 |
+
"When use the callable `pipe()` to perform token generation with given prompts, you can set the sampling parameters via `GenerationConfig` as below:"
|
| 110 |
+
]
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"cell_type": "code",
|
| 114 |
+
"execution_count": null,
|
| 115 |
+
"id": "bd007ca1",
|
| 116 |
+
"metadata": {},
|
| 117 |
+
"outputs": [],
|
| 118 |
+
"source": [
|
| 119 |
+
"from lmdeploy import GenerationConfig, pipeline\n",
|
| 120 |
+
"\n",
|
| 121 |
+
"pipe = pipeline(\"internlm/internlm2_5-7b-chat\")\n",
|
| 122 |
+
"prompts = [\"Hi, pls intro yourself\", \"Shanghai is\"]\n",
|
| 123 |
+
"response = pipe(\n",
|
| 124 |
+
" prompts,\n",
|
| 125 |
+
" gen_config=GenerationConfig(\n",
|
| 126 |
+
" max_new_tokens=1024, top_p=0.8, top_k=40, temperature=0.6\n",
|
| 127 |
+
" ),\n",
|
| 128 |
+
")"
|
| 129 |
+
]
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "markdown",
|
| 133 |
+
"id": "c4b9ce5d",
|
| 134 |
+
"metadata": {},
|
| 135 |
+
"source": [
|
| 136 |
+
"In the `GenerationConfig`, `top_k=1` or `temperature=0.0` indicates greedy search.\n",
|
| 137 |
+
"\n",
|
| 138 |
+
"For more information about pipeline, please read the [detailed tutorial](../llm/pipeline.md)\n",
|
| 139 |
+
"\n",
|
| 140 |
+
"### VLM inference\n",
|
| 141 |
+
"\n",
|
| 142 |
+
"The usage of VLM inference pipeline is akin to that of LLMs, with the additional capability of processing image data with the pipeline.\n",
|
| 143 |
+
"For example, you can utilize the following code snippet to perform the inference with an InternVL model:"
|
| 144 |
+
]
|
| 145 |
+
},
|
| 146 |
+
{
|
| 147 |
+
"cell_type": "code",
|
| 148 |
+
"execution_count": null,
|
| 149 |
+
"id": "926fad07",
|
| 150 |
+
"metadata": {},
|
| 151 |
+
"outputs": [],
|
| 152 |
+
"source": [
|
| 153 |
+
"from lmdeploy import pipeline\n",
|
| 154 |
+
"from lmdeploy.vl import load_image\n",
|
| 155 |
+
"\n",
|
| 156 |
+
"pipe = pipeline(\"OpenGVLab/InternVL2-8B\")\n",
|
| 157 |
+
"\n",
|
| 158 |
+
"image = load_image(\n",
|
| 159 |
+
" \"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg\"\n",
|
| 160 |
+
")\n",
|
| 161 |
+
"response = pipe((\"describe this image\", image))\n",
|
| 162 |
+
"print(response)"
|
| 163 |
+
]
|
| 164 |
+
},
|
| 165 |
+
{
|
| 166 |
+
"cell_type": "markdown",
|
| 167 |
+
"id": "b3f0a6a0",
|
| 168 |
+
"metadata": {},
|
| 169 |
+
"source": [
|
| 170 |
+
"In VLM pipeline, the default image processing batch size is 1. This can be adjusted by `VisionConfig`. For instance, you might set it like this:"
|
| 171 |
+
]
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"cell_type": "code",
|
| 175 |
+
"execution_count": null,
|
| 176 |
+
"id": "0fcd88e9",
|
| 177 |
+
"metadata": {},
|
| 178 |
+
"outputs": [
|
| 179 |
+
{
|
| 180 |
+
"name": "stderr",
|
| 181 |
+
"output_type": "stream",
|
| 182 |
+
"text": [
|
| 183 |
+
"/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
|
| 184 |
+
" from .autonotebook import tqdm as notebook_tqdm\n"
|
| 185 |
+
]
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"ename": "",
|
| 189 |
+
"evalue": "",
|
| 190 |
+
"output_type": "error",
|
| 191 |
+
"traceback": [
|
| 192 |
+
"\u001b[1;31mThe Kernel crashed while executing code in the current cell or a previous cell. \n",
|
| 193 |
+
"\u001b[1;31mPlease review the code in the cell(s) to identify a possible cause of the failure. \n",
|
| 194 |
+
"\u001b[1;31mClick <a href='https://aka.ms/vscodeJupyterKernelCrash'>here</a> for more info. \n",
|
| 195 |
+
"\u001b[1;31mView Jupyter <a href='command:jupyter.viewOutput'>log</a> for further details."
|
| 196 |
+
]
|
| 197 |
+
}
|
| 198 |
+
],
|
| 199 |
+
"source": [
|
| 200 |
+
"# %pip install nest_asyncio\n",
|
| 201 |
+
"import nest_asyncio\n",
|
| 202 |
+
"nest_asyncio.apply()\n",
|
| 203 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig\n",
|
| 204 |
+
"# backend_config = TurbomindEngineConfig(tp=4, cache_max_entry_count=0.2)"
|
| 205 |
+
]
|
| 206 |
+
},
|
| 207 |
+
{
|
| 208 |
+
"cell_type": "code",
|
| 209 |
+
"execution_count": null,
|
| 210 |
+
"id": "b12e46c5",
|
| 211 |
+
"metadata": {},
|
| 212 |
+
"outputs": [
|
| 213 |
+
{
|
| 214 |
+
"name": "stderr",
|
| 215 |
+
"output_type": "stream",
|
| 216 |
+
"text": [
|
| 217 |
+
"Fetching 32 files: 100%|█████████████████████████████████████| 32/32 [00:00<00:00, 27296.67it/s]\n",
|
| 218 |
+
"InternLM2ForCausalLM has generative capabilities, as `prepare_inputs_for_generation` is explicitly overwritten. However, it doesn't directly inherit from `GenerationMixin`. From 👉v4.50👈 onwards, `PreTrainedModel` will NOT inherit from `GenerationMixin`, and this model will lose the ability to call `generate` and other related functions.\n",
|
| 219 |
+
" - If you're using `trust_remote_code=True`, you can get rid of this warning by loading the model with an auto class. See https://huggingface.co/docs/transformers/en/model_doc/auto#auto-classes\n",
|
| 220 |
+
" - If you are the owner of the model architecture code, please modify your model class such that it inherits from `GenerationMixin` (after `PreTrainedModel`, otherwise you'll get an exception).\n",
|
| 221 |
+
" - If you are not the owner of the model architecture class, please contact the model code owner to update it.\n"
|
| 222 |
+
]
|
| 223 |
+
},
|
| 224 |
+
{
|
| 225 |
+
"name": "stdout",
|
| 226 |
+
"output_type": "stream",
|
| 227 |
+
"text": [
|
| 228 |
+
"2024-12-20 09:07:32,076 - lmdeploy - \u001b[33mWARNING\u001b[0m - tokenizer.py:243 - The current version of `transformers` is transformers==4.46.3, which is lower than the required version transformers==4.47.0. Please upgrade to the required version.\n",
|
| 229 |
+
"2024-12-20 09:07:34,912 - lmdeploy - \u001b[33mWARNING\u001b[0m - turbomind.py:231 - get 2985 model params\n"
|
| 230 |
+
]
|
| 231 |
+
},
|
| 232 |
+
{
|
| 233 |
+
"name": "stderr",
|
| 234 |
+
"output_type": "stream",
|
| 235 |
+
"text": [
|
| 236 |
+
"[TM][WARNING] [LlamaTritonModel] `max_context_token_num` is not set, default to 32768.\n",
|
| 237 |
+
"[TM][WARNING] pad vocab size from 92553 to 92556\n",
|
| 238 |
+
"[TM][WARNING] pad embed size from 92556 to 92556\n",
|
| 239 |
+
"[TM][WARNING] pad vocab size from 92553 to 92556\n",
|
| 240 |
+
"[TM][WARNING] pad embed size from 92556 to 92556\n",
|
| 241 |
+
"[TM][WARNING] pad vocab size from 92553 to 92556\n",
|
| 242 |
+
"[TM][WARNING] pad embed size from 92556 to 92556\n",
|
| 243 |
+
"[TM][WARNING] pad vocab size from 92553 to 92556\n",
|
| 244 |
+
"[TM][WARNING] pad embed size from 92556 to 92556\n",
|
| 245 |
+
" \r"
|
| 246 |
+
]
|
| 247 |
+
},
|
| 248 |
+
{
|
| 249 |
+
"name": "stdout",
|
| 250 |
+
"output_type": "stream",
|
| 251 |
+
"text": [
|
| 252 |
+
"[WARNING] gemm_config.in is not found; using default GEMM algo\n",
|
| 253 |
+
"[WARNING] gemm_config.in is not found; using default GEMM algo\n",
|
| 254 |
+
"[WARNING] gemm_config.in is not found; using default GEMM algo\n",
|
| 255 |
+
"[WARNING] gemm_config.in is not found; using default GEMM algo\n",
|
| 256 |
+
"2024-12-20 09:08:10,327 - lmdeploy - \u001b[33mWARNING\u001b[0m - async_engine.py:505 - GenerationConfig: GenerationConfig(n=1, max_new_tokens=256, do_sample=False, top_p=0.8, top_k=40, min_p=0.0, temperature=0.8, repetition_penalty=1.0, ignore_eos=False, random_seed=None, stop_words=None, bad_words=None, stop_token_ids=[92542, 92540], bad_token_ids=None, min_new_tokens=None, skip_special_tokens=True, logprobs=None, response_format=None, logits_processors=None)\n",
|
| 257 |
+
"2024-12-20 09:08:10,328 - lmdeploy - \u001b[33mWARNING\u001b[0m - async_engine.py:506 - Since v0.6.0, lmdeploy add `do_sample` in GenerationConfig. It defaults to False, meaning greedy decoding. Please set `do_sample=True` if sampling decoding is needed\n"
|
| 258 |
+
]
|
| 259 |
+
}
|
| 260 |
+
],
|
| 261 |
+
"source": [
|
| 262 |
+
"from lmdeploy import pipeline, VisionConfig\n",
|
| 263 |
+
"from lmdeploy.vl import load_image\n",
|
| 264 |
+
"gen_config = GenerationConfig(top_p=0.8, top_k=40, temperature=0.8, max_new_tokens=256)\n",
|
| 265 |
+
"\n",
|
| 266 |
+
"pipe = pipeline(\n",
|
| 267 |
+
" \"OpenGVLab/InternVL2_5-26B-AWQ\", vision_config=VisionConfig(max_batch_size=1),\n",
|
| 268 |
+
" backend_config=TurbomindEngineConfig(tp=4, cache_max_entry_count=0.4),\n",
|
| 269 |
+
")\n",
|
| 270 |
+
"\n",
|
| 271 |
+
"image = load_image(\n",
|
| 272 |
+
" \"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg\"\n",
|
| 273 |
+
")\n",
|
| 274 |
+
"response = pipe((\"describe this image\", image), gen_config=gen_config)\n",
|
| 275 |
+
"print(response)"
|
| 276 |
+
]
|
| 277 |
+
},
|
| 278 |
+
{
|
| 279 |
+
"cell_type": "markdown",
|
| 280 |
+
"id": "8b83a357",
|
| 281 |
+
"metadata": {},
|
| 282 |
+
"source": [
|
| 283 |
+
"However, the larger the image batch size, the greater risk of an OOM error, because the LLM component within the VLM model pre-allocates a massive amount of memory in advance.\n",
|
| 284 |
+
"\n",
|
| 285 |
+
"We encourage you to manually choose between the TurboMind Engine and the PyTorch Engine based on their respective capabilities, as detailed in [the supported-models matrix](../supported_models/supported_models.md).\n",
|
| 286 |
+
"Additionally, follow the instructions in [LLM Inference](#llm-inference) section to reduce the values of memory-related parameters\n",
|
| 287 |
+
"\n",
|
| 288 |
+
"## Serving\n",
|
| 289 |
+
"\n",
|
| 290 |
+
"As demonstrated in the previous [offline batch inference](#offline-batch-inference) section, this part presents the respective serving methods for LLMs and VLMs.\n",
|
| 291 |
+
"\n",
|
| 292 |
+
"### Serve a LLM model\n",
|
| 293 |
+
"\n",
|
| 294 |
+
"```shell\n",
|
| 295 |
+
"lmdeploy serve api_server internlm/internlm2_5-7b-chat\n",
|
| 296 |
+
"```\n",
|
| 297 |
+
"\n",
|
| 298 |
+
"This command will launch an OpenAI-compatible server on the localhost at port `23333`. You can specify a different server port by using the `--server-port` option.\n",
|
| 299 |
+
"For more options, consult the help documentation by running `lmdeploy serve api_server --help`. Most of these options align with the engine configuration.\n",
|
| 300 |
+
"\n",
|
| 301 |
+
"To access the service, you can utilize the official OpenAI Python package `pip install openai`. Below is an example demonstrating how to use the entrypoint `v1/chat/completions`"
|
| 302 |
+
]
|
| 303 |
+
},
|
| 304 |
+
{
|
| 305 |
+
"cell_type": "code",
|
| 306 |
+
"execution_count": null,
|
| 307 |
+
"id": "3e625411",
|
| 308 |
+
"metadata": {},
|
| 309 |
+
"outputs": [],
|
| 310 |
+
"source": [
|
| 311 |
+
"from openai import OpenAI\n",
|
| 312 |
+
"\n",
|
| 313 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:23333/v1\")\n",
|
| 314 |
+
"model_name = client.models.list().data[0].id\n",
|
| 315 |
+
"response = client.chat.completions.create(\n",
|
| 316 |
+
" model=model_name,\n",
|
| 317 |
+
" messages=[\n",
|
| 318 |
+
" {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"},\n",
|
| 319 |
+
" {\"role\": \"user\", \"content\": \" provide three suggestions about time management\"},\n",
|
| 320 |
+
" ],\n",
|
| 321 |
+
" temperature=0.8,\n",
|
| 322 |
+
" top_p=0.8,\n",
|
| 323 |
+
")\n",
|
| 324 |
+
"print(response)"
|
| 325 |
+
]
|
| 326 |
+
},
|
| 327 |
+
{
|
| 328 |
+
"cell_type": "markdown",
|
| 329 |
+
"id": "24be9e23",
|
| 330 |
+
"metadata": {},
|
| 331 |
+
"source": [
|
| 332 |
+
"We encourage you to refer to the detailed guide for more comprehensive information about [serving with Docker](../llm/api_server.md), [function calls](../llm/api_server_tools.md) and other topics\n",
|
| 333 |
+
"\n",
|
| 334 |
+
"### Serve a VLM model\n",
|
| 335 |
+
"\n",
|
| 336 |
+
"```shell\n",
|
| 337 |
+
"lmdeploy serve api_server OpenGVLab/InternVL2-8B\n",
|
| 338 |
+
"```\n",
|
| 339 |
+
"\n",
|
| 340 |
+
"```{note}\n",
|
| 341 |
+
"LMDeploy reuses the vision component from upstream VLM repositories. Each upstream VLM model may have different dependencies.\n",
|
| 342 |
+
"Consequently, LMDeploy has decided not to include the dependencies of the upstream VLM repositories in its own dependency list.\n",
|
| 343 |
+
"If you encounter an \"ImportError\" when using LMDeploy for inference with VLM models, please install the relevant dependencies yourself.\n",
|
| 344 |
+
"```\n",
|
| 345 |
+
"\n",
|
| 346 |
+
"After the service is launched successfully, you can access the VLM service in a manner similar to how you would access the `gptv4` service by modifying the `api_key` and `base_url` parameters:"
|
| 347 |
+
]
|
| 348 |
+
},
|
| 349 |
+
{
|
| 350 |
+
"cell_type": "code",
|
| 351 |
+
"execution_count": 5,
|
| 352 |
+
"id": "02236cc9",
|
| 353 |
+
"metadata": {},
|
| 354 |
+
"outputs": [
|
| 355 |
+
{
|
| 356 |
+
"name": "stdout",
|
| 357 |
+
"output_type": "stream",
|
| 358 |
+
"text": [
|
| 359 |
+
"--2024-12-20 08:55:15-- https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg\n",
|
| 360 |
+
"Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.111.133, 185.199.108.133, ...\n",
|
| 361 |
+
"Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected.\n",
|
| 362 |
+
"HTTP request sent, awaiting response... 200 OK\n",
|
| 363 |
+
"Length: 13929 (14K) [image/jpeg]\n",
|
| 364 |
+
"Saving to: ‘tiger.jpeg’\n",
|
| 365 |
+
"\n",
|
| 366 |
+
"tiger.jpeg 100%[===================>] 13.60K --.-KB/s in 0.003s \n",
|
| 367 |
+
"\n",
|
| 368 |
+
"2024-12-20 08:55:16 (3.97 MB/s) - ‘tiger.jpeg’ saved [13929/13929]\n",
|
| 369 |
+
"\n"
|
| 370 |
+
]
|
| 371 |
+
}
|
| 372 |
+
],
|
| 373 |
+
"source": [
|
| 374 |
+
"# download \"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg\" to local\n",
|
| 375 |
+
"!wget https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg"
|
| 376 |
+
]
|
| 377 |
+
},
|
| 378 |
+
{
|
| 379 |
+
"cell_type": "code",
|
| 380 |
+
"execution_count": 6,
|
| 381 |
+
"id": "df43b1ea",
|
| 382 |
+
"metadata": {},
|
| 383 |
+
"outputs": [
|
| 384 |
+
{
|
| 385 |
+
"ename": "APIConnectionError",
|
| 386 |
+
"evalue": "Connection error.",
|
| 387 |
+
"output_type": "error",
|
| 388 |
+
"traceback": [
|
| 389 |
+
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 390 |
+
"\u001b[0;31mConnectError\u001b[0m Traceback (most recent call last)",
|
| 391 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpx/_transports/default.py:72\u001b[0m, in \u001b[0;36mmap_httpcore_exceptions\u001b[0;34m()\u001b[0m\n\u001b[1;32m 71\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m---> 72\u001b[0m \u001b[38;5;28;01myield\u001b[39;00m\n\u001b[1;32m 73\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m \u001b[38;5;167;01mException\u001b[39;00m \u001b[38;5;28;01mas\u001b[39;00m exc:\n",
|
| 392 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpx/_transports/default.py:236\u001b[0m, in \u001b[0;36mHTTPTransport.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 235\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m map_httpcore_exceptions():\n\u001b[0;32m--> 236\u001b[0m resp \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_pool\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mhandle_request\u001b[49m\u001b[43m(\u001b[49m\u001b[43mreq\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 238\u001b[0m \u001b[38;5;28;01massert\u001b[39;00m \u001b[38;5;28misinstance\u001b[39m(resp\u001b[38;5;241m.\u001b[39mstream, typing\u001b[38;5;241m.\u001b[39mIterable)\n",
|
| 393 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpcore/_sync/connection_pool.py:216\u001b[0m, in \u001b[0;36mConnectionPool.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 215\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_close_connections(closing)\n\u001b[0;32m--> 216\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m exc \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m\n\u001b[1;32m 218\u001b[0m \u001b[38;5;66;03m# Return the response. Note that in this case we still have to manage\u001b[39;00m\n\u001b[1;32m 219\u001b[0m \u001b[38;5;66;03m# the point at which the response is closed.\u001b[39;00m\n",
|
| 394 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpcore/_sync/connection_pool.py:196\u001b[0m, in \u001b[0;36mConnectionPool.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 194\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[1;32m 195\u001b[0m \u001b[38;5;66;03m# Send the request on the assigned connection.\u001b[39;00m\n\u001b[0;32m--> 196\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[43mconnection\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mhandle_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 197\u001b[0m \u001b[43m \u001b[49m\u001b[43mpool_request\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mrequest\u001b[49m\n\u001b[1;32m 198\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 199\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m ConnectionNotAvailable:\n\u001b[1;32m 200\u001b[0m \u001b[38;5;66;03m# In some cases a connection may initially be available to\u001b[39;00m\n\u001b[1;32m 201\u001b[0m \u001b[38;5;66;03m# handle a request, but then become unavailable.\u001b[39;00m\n\u001b[1;32m 202\u001b[0m \u001b[38;5;66;03m#\u001b[39;00m\n\u001b[1;32m 203\u001b[0m \u001b[38;5;66;03m# In this case we clear the connection and try again.\u001b[39;00m\n",
|
| 395 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpcore/_sync/connection.py:99\u001b[0m, in \u001b[0;36mHTTPConnection.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 98\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_connect_failed \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;01mTrue\u001b[39;00m\n\u001b[0;32m---> 99\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m exc\n\u001b[1;32m 101\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_connection\u001b[38;5;241m.\u001b[39mhandle_request(request)\n",
|
| 396 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpcore/_sync/connection.py:76\u001b[0m, in \u001b[0;36mHTTPConnection.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 75\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_connection \u001b[38;5;129;01mis\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m:\n\u001b[0;32m---> 76\u001b[0m stream \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_connect\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 78\u001b[0m ssl_object \u001b[38;5;241m=\u001b[39m stream\u001b[38;5;241m.\u001b[39mget_extra_info(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mssl_object\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n",
|
| 397 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpcore/_sync/connection.py:122\u001b[0m, in \u001b[0;36mHTTPConnection._connect\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 121\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m Trace(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mconnect_tcp\u001b[39m\u001b[38;5;124m\"\u001b[39m, logger, request, kwargs) \u001b[38;5;28;01mas\u001b[39;00m trace:\n\u001b[0;32m--> 122\u001b[0m stream \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_network_backend\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mconnect_tcp\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;241;43m*\u001b[39;49m\u001b[38;5;241;43m*\u001b[39;49m\u001b[43mkwargs\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 123\u001b[0m trace\u001b[38;5;241m.\u001b[39mreturn_value \u001b[38;5;241m=\u001b[39m stream\n",
|
| 398 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpcore/_backends/sync.py:213\u001b[0m, in \u001b[0;36mSyncBackend.connect_tcp\u001b[0;34m(self, host, port, timeout, local_address, socket_options)\u001b[0m\n\u001b[1;32m 212\u001b[0m sock\u001b[38;5;241m.\u001b[39msetsockopt(\u001b[38;5;241m*\u001b[39moption) \u001b[38;5;66;03m# pragma: no cover\u001b[39;00m\n\u001b[0;32m--> 213\u001b[0m sock\u001b[38;5;241m.\u001b[39msetsockopt(socket\u001b[38;5;241m.\u001b[39mIPPROTO_TCP, socket\u001b[38;5;241m.\u001b[39mTCP_NODELAY, \u001b[38;5;241m1\u001b[39m)\n\u001b[1;32m 214\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m SyncStream(sock)\n",
|
| 399 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/contextlib.py:131\u001b[0m, in \u001b[0;36m_GeneratorContextManager.__exit__\u001b[0;34m(self, type, value, traceback)\u001b[0m\n\u001b[1;32m 130\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m--> 131\u001b[0m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mgen\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mthrow\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;28;43mtype\u001b[39;49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mvalue\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mtraceback\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 132\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m \u001b[38;5;167;01mStopIteration\u001b[39;00m \u001b[38;5;28;01mas\u001b[39;00m exc:\n\u001b[1;32m 133\u001b[0m \u001b[38;5;66;03m# Suppress StopIteration *unless* it's the same exception that\u001b[39;00m\n\u001b[1;32m 134\u001b[0m \u001b[38;5;66;03m# was passed to throw(). This prevents a StopIteration\u001b[39;00m\n\u001b[1;32m 135\u001b[0m \u001b[38;5;66;03m# raised inside the \"with\" statement from being suppressed.\u001b[39;00m\n",
|
| 400 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpcore/_exceptions.py:14\u001b[0m, in \u001b[0;36mmap_exceptions\u001b[0;34m(map)\u001b[0m\n\u001b[1;32m 13\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28misinstance\u001b[39m(exc, from_exc):\n\u001b[0;32m---> 14\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m to_exc(exc) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01mexc\u001b[39;00m\n\u001b[1;32m 15\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m\n",
|
| 401 |
+
"\u001b[0;31mConnectError\u001b[0m: [Errno 111] Connection refused",
|
| 402 |
+
"\nThe above exception was the direct cause of the following exception:\n",
|
| 403 |
+
"\u001b[0;31mConnectError\u001b[0m Traceback (most recent call last)",
|
| 404 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:981\u001b[0m, in \u001b[0;36mSyncAPIClient._request\u001b[0;34m(self, cast_to, options, retries_taken, stream, stream_cls)\u001b[0m\n\u001b[1;32m 980\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m--> 981\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_client\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43msend\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 982\u001b[0m \u001b[43m \u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 983\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;129;43;01mor\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_should_stream_response_body\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrequest\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mrequest\u001b[49m\u001b[43m)\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 984\u001b[0m \u001b[43m \u001b[49m\u001b[38;5;241;43m*\u001b[39;49m\u001b[38;5;241;43m*\u001b[39;49m\u001b[43mkwargs\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 985\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 986\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m httpx\u001b[38;5;241m.\u001b[39mTimeoutException \u001b[38;5;28;01mas\u001b[39;00m err:\n",
|
| 405 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpx/_client.py:926\u001b[0m, in \u001b[0;36mClient.send\u001b[0;34m(self, request, stream, auth, follow_redirects)\u001b[0m\n\u001b[1;32m 924\u001b[0m auth \u001b[38;5;241m=\u001b[39m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_build_request_auth(request, auth)\n\u001b[0;32m--> 926\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_send_handling_auth\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 927\u001b[0m \u001b[43m \u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 928\u001b[0m \u001b[43m \u001b[49m\u001b[43mauth\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mauth\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 929\u001b[0m \u001b[43m \u001b[49m\u001b[43mfollow_redirects\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mfollow_redirects\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 930\u001b[0m \u001b[43m \u001b[49m\u001b[43mhistory\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43m[\u001b[49m\u001b[43m]\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 931\u001b[0m \u001b[43m\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 932\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n",
|
| 406 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpx/_client.py:954\u001b[0m, in \u001b[0;36mClient._send_handling_auth\u001b[0;34m(self, request, auth, follow_redirects, history)\u001b[0m\n\u001b[1;32m 953\u001b[0m \u001b[38;5;28;01mwhile\u001b[39;00m \u001b[38;5;28;01mTrue\u001b[39;00m:\n\u001b[0;32m--> 954\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_send_handling_redirects\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 955\u001b[0m \u001b[43m \u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 956\u001b[0m \u001b[43m \u001b[49m\u001b[43mfollow_redirects\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mfollow_redirects\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 957\u001b[0m \u001b[43m \u001b[49m\u001b[43mhistory\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mhistory\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 958\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 959\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n",
|
| 407 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpx/_client.py:991\u001b[0m, in \u001b[0;36mClient._send_handling_redirects\u001b[0;34m(self, request, follow_redirects, history)\u001b[0m\n\u001b[1;32m 989\u001b[0m hook(request)\n\u001b[0;32m--> 991\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_send_single_request\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 992\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n",
|
| 408 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpx/_client.py:1027\u001b[0m, in \u001b[0;36mClient._send_single_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 1026\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m request_context(request\u001b[38;5;241m=\u001b[39mrequest):\n\u001b[0;32m-> 1027\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[43mtransport\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mhandle_request\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 1029\u001b[0m \u001b[38;5;28;01massert\u001b[39;00m \u001b[38;5;28misinstance\u001b[39m(response\u001b[38;5;241m.\u001b[39mstream, SyncByteStream)\n",
|
| 409 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpx/_transports/default.py:236\u001b[0m, in \u001b[0;36mHTTPTransport.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 235\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m map_httpcore_exceptions():\n\u001b[0;32m--> 236\u001b[0m resp \u001b[38;5;241m=\u001b[39m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_pool\u001b[38;5;241m.\u001b[39mhandle_request(req)\n\u001b[1;32m 238\u001b[0m \u001b[38;5;28;01massert\u001b[39;00m \u001b[38;5;28misinstance\u001b[39m(resp\u001b[38;5;241m.\u001b[39mstream, typing\u001b[38;5;241m.\u001b[39mIterable)\n",
|
| 410 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/contextlib.py:131\u001b[0m, in \u001b[0;36m_GeneratorContextManager.__exit__\u001b[0;34m(self, type, value, traceback)\u001b[0m\n\u001b[1;32m 130\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m--> 131\u001b[0m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mgen\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mthrow\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;28;43mtype\u001b[39;49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mvalue\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mtraceback\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 132\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m \u001b[38;5;167;01mStopIteration\u001b[39;00m \u001b[38;5;28;01mas\u001b[39;00m exc:\n\u001b[1;32m 133\u001b[0m \u001b[38;5;66;03m# Suppress StopIteration *unless* it's the same exception that\u001b[39;00m\n\u001b[1;32m 134\u001b[0m \u001b[38;5;66;03m# was passed to throw(). This prevents a StopIteration\u001b[39;00m\n\u001b[1;32m 135\u001b[0m \u001b[38;5;66;03m# raised inside the \"with\" statement from being suppressed.\u001b[39;00m\n",
|
| 411 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/httpx/_transports/default.py:89\u001b[0m, in \u001b[0;36mmap_httpcore_exceptions\u001b[0;34m()\u001b[0m\n\u001b[1;32m 88\u001b[0m message \u001b[38;5;241m=\u001b[39m \u001b[38;5;28mstr\u001b[39m(exc)\n\u001b[0;32m---> 89\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m mapped_exc(message) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01mexc\u001b[39;00m\n",
|
| 412 |
+
"\u001b[0;31mConnectError\u001b[0m: [Errno 111] Connection refused",
|
| 413 |
+
"\nThe above exception was the direct cause of the following exception:\n",
|
| 414 |
+
"\u001b[0;31mAPIConnectionError\u001b[0m Traceback (most recent call last)",
|
| 415 |
+
"Cell \u001b[0;32mIn[6], line 4\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01mopenai\u001b[39;00m \u001b[38;5;28;01mimport\u001b[39;00m OpenAI\n\u001b[1;32m 3\u001b[0m client \u001b[38;5;241m=\u001b[39m OpenAI(api_key\u001b[38;5;241m=\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mYOUR_API_KEY\u001b[39m\u001b[38;5;124m\"\u001b[39m, base_url\u001b[38;5;241m=\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mhttp://0.0.0.0:23333/v1\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[0;32m----> 4\u001b[0m model_name \u001b[38;5;241m=\u001b[39m \u001b[43mclient\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mmodels\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mlist\u001b[49m\u001b[43m(\u001b[49m\u001b[43m)\u001b[49m\u001b[38;5;241m.\u001b[39mdata[\u001b[38;5;241m0\u001b[39m]\u001b[38;5;241m.\u001b[39mid\n\u001b[1;32m 5\u001b[0m response \u001b[38;5;241m=\u001b[39m client\u001b[38;5;241m.\u001b[39mchat\u001b[38;5;241m.\u001b[39mcompletions\u001b[38;5;241m.\u001b[39mcreate(\n\u001b[1;32m 6\u001b[0m model\u001b[38;5;241m=\u001b[39mmodel_name,\n\u001b[1;32m 7\u001b[0m messages\u001b[38;5;241m=\u001b[39m[\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 25\u001b[0m top_p\u001b[38;5;241m=\u001b[39m\u001b[38;5;241m0.8\u001b[39m,\n\u001b[1;32m 26\u001b[0m )\n\u001b[1;32m 27\u001b[0m \u001b[38;5;28mprint\u001b[39m(response)\n",
|
| 416 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/resources/models.py:91\u001b[0m, in \u001b[0;36mModels.list\u001b[0;34m(self, extra_headers, extra_query, extra_body, timeout)\u001b[0m\n\u001b[1;32m 77\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mlist\u001b[39m(\n\u001b[1;32m 78\u001b[0m \u001b[38;5;28mself\u001b[39m,\n\u001b[1;32m 79\u001b[0m \u001b[38;5;241m*\u001b[39m,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 85\u001b[0m timeout: \u001b[38;5;28mfloat\u001b[39m \u001b[38;5;241m|\u001b[39m httpx\u001b[38;5;241m.\u001b[39mTimeout \u001b[38;5;241m|\u001b[39m \u001b[38;5;28;01mNone\u001b[39;00m \u001b[38;5;241m|\u001b[39m NotGiven \u001b[38;5;241m=\u001b[39m NOT_GIVEN,\n\u001b[1;32m 86\u001b[0m ) \u001b[38;5;241m-\u001b[39m\u001b[38;5;241m>\u001b[39m SyncPage[Model]:\n\u001b[1;32m 87\u001b[0m \u001b[38;5;250m \u001b[39m\u001b[38;5;124;03m\"\"\"\u001b[39;00m\n\u001b[1;32m 88\u001b[0m \u001b[38;5;124;03m Lists the currently available models, and provides basic information about each\u001b[39;00m\n\u001b[1;32m 89\u001b[0m \u001b[38;5;124;03m one such as the owner and availability.\u001b[39;00m\n\u001b[1;32m 90\u001b[0m \u001b[38;5;124;03m \"\"\"\u001b[39;00m\n\u001b[0;32m---> 91\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_get_api_list\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 92\u001b[0m \u001b[43m \u001b[49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[38;5;124;43m/models\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[43m,\u001b[49m\n\u001b[1;32m 93\u001b[0m \u001b[43m \u001b[49m\u001b[43mpage\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mSyncPage\u001b[49m\u001b[43m[\u001b[49m\u001b[43mModel\u001b[49m\u001b[43m]\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 94\u001b[0m \u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mmake_request_options\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 95\u001b[0m \u001b[43m \u001b[49m\u001b[43mextra_headers\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mextra_headers\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mextra_query\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mextra_query\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mextra_body\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mextra_body\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mtimeout\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mtimeout\u001b[49m\n\u001b[1;32m 96\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 97\u001b[0m \u001b[43m \u001b[49m\u001b[43mmodel\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mModel\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 98\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n",
|
| 417 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:1317\u001b[0m, in \u001b[0;36mSyncAPIClient.get_api_list\u001b[0;34m(self, path, model, page, body, options, method)\u001b[0m\n\u001b[1;32m 1306\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mget_api_list\u001b[39m(\n\u001b[1;32m 1307\u001b[0m \u001b[38;5;28mself\u001b[39m,\n\u001b[1;32m 1308\u001b[0m path: \u001b[38;5;28mstr\u001b[39m,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 1314\u001b[0m method: \u001b[38;5;28mstr\u001b[39m \u001b[38;5;241m=\u001b[39m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mget\u001b[39m\u001b[38;5;124m\"\u001b[39m,\n\u001b[1;32m 1315\u001b[0m ) \u001b[38;5;241m-\u001b[39m\u001b[38;5;241m>\u001b[39m SyncPageT:\n\u001b[1;32m 1316\u001b[0m opts \u001b[38;5;241m=\u001b[39m FinalRequestOptions\u001b[38;5;241m.\u001b[39mconstruct(method\u001b[38;5;241m=\u001b[39mmethod, url\u001b[38;5;241m=\u001b[39mpath, json_data\u001b[38;5;241m=\u001b[39mbody, \u001b[38;5;241m*\u001b[39m\u001b[38;5;241m*\u001b[39moptions)\n\u001b[0;32m-> 1317\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_request_api_list\u001b[49m\u001b[43m(\u001b[49m\u001b[43mmodel\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mpage\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mopts\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 418 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:1168\u001b[0m, in \u001b[0;36mSyncAPIClient._request_api_list\u001b[0;34m(self, model, page, options)\u001b[0m\n\u001b[1;32m 1164\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m resp\n\u001b[1;32m 1166\u001b[0m options\u001b[38;5;241m.\u001b[39mpost_parser \u001b[38;5;241m=\u001b[39m _parser\n\u001b[0;32m-> 1168\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mrequest\u001b[49m\u001b[43m(\u001b[49m\u001b[43mpage\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43;01mFalse\u001b[39;49;00m\u001b[43m)\u001b[49m\n",
|
| 419 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:945\u001b[0m, in \u001b[0;36mSyncAPIClient.request\u001b[0;34m(self, cast_to, options, remaining_retries, stream, stream_cls)\u001b[0m\n\u001b[1;32m 942\u001b[0m \u001b[38;5;28;01melse\u001b[39;00m:\n\u001b[1;32m 943\u001b[0m retries_taken \u001b[38;5;241m=\u001b[39m \u001b[38;5;241m0\u001b[39m\n\u001b[0;32m--> 945\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 946\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 947\u001b[0m \u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43moptions\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 948\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 949\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 950\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 951\u001b[0m \u001b[43m\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 420 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:1005\u001b[0m, in \u001b[0;36mSyncAPIClient._request\u001b[0;34m(self, cast_to, options, retries_taken, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1002\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mEncountered Exception\u001b[39m\u001b[38;5;124m\"\u001b[39m, exc_info\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mTrue\u001b[39;00m)\n\u001b[1;32m 1004\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m remaining_retries \u001b[38;5;241m>\u001b[39m \u001b[38;5;241m0\u001b[39m:\n\u001b[0;32m-> 1005\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_retry_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1006\u001b[0m \u001b[43m \u001b[49m\u001b[43minput_options\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1007\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1008\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1009\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1010\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1011\u001b[0m \u001b[43m \u001b[49m\u001b[43mresponse_headers\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43;01mNone\u001b[39;49;00m\u001b[43m,\u001b[49m\n\u001b[1;32m 1012\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 1014\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRaising connection error\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[1;32m 1015\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m APIConnectionError(request\u001b[38;5;241m=\u001b[39mrequest) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01merr\u001b[39;00m\n",
|
| 421 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:1083\u001b[0m, in \u001b[0;36mSyncAPIClient._retry_request\u001b[0;34m(self, options, cast_to, retries_taken, response_headers, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1079\u001b[0m \u001b[38;5;66;03m# In a synchronous context we are blocking the entire thread. Up to the library user to run the client in a\u001b[39;00m\n\u001b[1;32m 1080\u001b[0m \u001b[38;5;66;03m# different thread if necessary.\u001b[39;00m\n\u001b[1;32m 1081\u001b[0m time\u001b[38;5;241m.\u001b[39msleep(timeout)\n\u001b[0;32m-> 1083\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1084\u001b[0m \u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43moptions\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1085\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1086\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;241;43m+\u001b[39;49m\u001b[43m \u001b[49m\u001b[38;5;241;43m1\u001b[39;49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1087\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1088\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1089\u001b[0m \u001b[43m\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 422 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:1005\u001b[0m, in \u001b[0;36mSyncAPIClient._request\u001b[0;34m(self, cast_to, options, retries_taken, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1002\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mEncountered Exception\u001b[39m\u001b[38;5;124m\"\u001b[39m, exc_info\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mTrue\u001b[39;00m)\n\u001b[1;32m 1004\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m remaining_retries \u001b[38;5;241m>\u001b[39m \u001b[38;5;241m0\u001b[39m:\n\u001b[0;32m-> 1005\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_retry_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1006\u001b[0m \u001b[43m \u001b[49m\u001b[43minput_options\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1007\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1008\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1009\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1010\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1011\u001b[0m \u001b[43m \u001b[49m\u001b[43mresponse_headers\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43;01mNone\u001b[39;49;00m\u001b[43m,\u001b[49m\n\u001b[1;32m 1012\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 1014\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRaising connection error\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[1;32m 1015\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m APIConnectionError(request\u001b[38;5;241m=\u001b[39mrequest) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01merr\u001b[39;00m\n",
|
| 423 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:1083\u001b[0m, in \u001b[0;36mSyncAPIClient._retry_request\u001b[0;34m(self, options, cast_to, retries_taken, response_headers, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1079\u001b[0m \u001b[38;5;66;03m# In a synchronous context we are blocking the entire thread. Up to the library user to run the client in a\u001b[39;00m\n\u001b[1;32m 1080\u001b[0m \u001b[38;5;66;03m# different thread if necessary.\u001b[39;00m\n\u001b[1;32m 1081\u001b[0m time\u001b[38;5;241m.\u001b[39msleep(timeout)\n\u001b[0;32m-> 1083\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1084\u001b[0m \u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43moptions\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1085\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1086\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;241;43m+\u001b[39;49m\u001b[43m \u001b[49m\u001b[38;5;241;43m1\u001b[39;49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1087\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1088\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1089\u001b[0m \u001b[43m\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 424 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/openai/_base_client.py:1015\u001b[0m, in \u001b[0;36mSyncAPIClient._request\u001b[0;34m(self, cast_to, options, retries_taken, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1005\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_retry_request(\n\u001b[1;32m 1006\u001b[0m input_options,\n\u001b[1;32m 1007\u001b[0m cast_to,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 1011\u001b[0m response_headers\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mNone\u001b[39;00m,\n\u001b[1;32m 1012\u001b[0m )\n\u001b[1;32m 1014\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRaising connection error\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[0;32m-> 1015\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m APIConnectionError(request\u001b[38;5;241m=\u001b[39mrequest) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01merr\u001b[39;00m\n\u001b[1;32m 1017\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\n\u001b[1;32m 1018\u001b[0m \u001b[38;5;124m'\u001b[39m\u001b[38;5;124mHTTP Response: \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m \u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;132;01m%i\u001b[39;00m\u001b[38;5;124m \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124m \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m'\u001b[39m,\n\u001b[1;32m 1019\u001b[0m request\u001b[38;5;241m.\u001b[39mmethod,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 1023\u001b[0m response\u001b[38;5;241m.\u001b[39mheaders,\n\u001b[1;32m 1024\u001b[0m )\n\u001b[1;32m 1025\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mrequest_id: \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m\"\u001b[39m, response\u001b[38;5;241m.\u001b[39mheaders\u001b[38;5;241m.\u001b[39mget(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mx-request-id\u001b[39m\u001b[38;5;124m\"\u001b[39m))\n",
|
| 425 |
+
"\u001b[0;31mAPIConnectionError\u001b[0m: Connection error."
|
| 426 |
+
]
|
| 427 |
+
},
|
| 428 |
+
{
|
| 429 |
+
"ename": "",
|
| 430 |
+
"evalue": "",
|
| 431 |
+
"output_type": "error",
|
| 432 |
+
"traceback": [
|
| 433 |
+
"\u001b[1;31mThe Kernel crashed while executing code in the current cell or a previous cell. \n",
|
| 434 |
+
"\u001b[1;31mPlease review the code in the cell(s) to identify a possible cause of the failure. \n",
|
| 435 |
+
"\u001b[1;31mClick <a href='https://aka.ms/vscodeJupyterKernelCrash'>here</a> for more info. \n",
|
| 436 |
+
"\u001b[1;31mView Jupyter <a href='command:jupyter.viewOutput'>log</a> for further details."
|
| 437 |
+
]
|
| 438 |
+
}
|
| 439 |
+
],
|
| 440 |
+
"source": [
|
| 441 |
+
"from openai import OpenAI\n",
|
| 442 |
+
"\n",
|
| 443 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:23333/v1\")\n",
|
| 444 |
+
"model_name = client.models.list().data[0].id\n",
|
| 445 |
+
"response = client.chat.completions.create(\n",
|
| 446 |
+
" model=model_name,\n",
|
| 447 |
+
" messages=[\n",
|
| 448 |
+
" {\n",
|
| 449 |
+
" \"role\": \"user\",\n",
|
| 450 |
+
" \"content\": [\n",
|
| 451 |
+
" {\n",
|
| 452 |
+
" \"type\": \"text\",\n",
|
| 453 |
+
" \"text\": \"Describe the image please\",\n",
|
| 454 |
+
" },\n",
|
| 455 |
+
" {\n",
|
| 456 |
+
" \"type\": \"image_url\",\n",
|
| 457 |
+
" \"image_url\": {\n",
|
| 458 |
+
" \"url\": \"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg\",\n",
|
| 459 |
+
" },\n",
|
| 460 |
+
" },\n",
|
| 461 |
+
" ],\n",
|
| 462 |
+
" }\n",
|
| 463 |
+
" ],\n",
|
| 464 |
+
" temperature=0.8,\n",
|
| 465 |
+
" top_p=0.8,\n",
|
| 466 |
+
")\n",
|
| 467 |
+
"print(response)"
|
| 468 |
+
]
|
| 469 |
+
},
|
| 470 |
+
{
|
| 471 |
+
"cell_type": "markdown",
|
| 472 |
+
"id": "545bbd85",
|
| 473 |
+
"metadata": {},
|
| 474 |
+
"source": [
|
| 475 |
+
"## Inference with Command line Interface\n",
|
| 476 |
+
"\n",
|
| 477 |
+
"LMDeploy offers a very convenient CLI tool for users to chat with the LLM model locally. For example:\n",
|
| 478 |
+
"\n",
|
| 479 |
+
"```shell\n",
|
| 480 |
+
"lmdeploy chat internlm/internlm2_5-7b-chat --backend turbomind\n",
|
| 481 |
+
"```\n",
|
| 482 |
+
"\n",
|
| 483 |
+
"It is designed to assist users in checking and verifying whether LMDeploy supports their model, whether the chat template is applied correctly, and whether the inference results are delivered smoothly.\n",
|
| 484 |
+
"\n",
|
| 485 |
+
"Another tool, `lmdeploy check_env`, aims to gather the essential environment information. It is crucial when reporting an issue to us, as it helps us diagnose and resolve the problem more effectively.\n",
|
| 486 |
+
"\n",
|
| 487 |
+
"If you have any doubt about their usage, you can try using the `--help` option to obtain detailed information."
|
| 488 |
+
]
|
| 489 |
+
}
|
| 490 |
+
],
|
| 491 |
+
"metadata": {
|
| 492 |
+
"jupytext": {
|
| 493 |
+
"cell_metadata_filter": "-all",
|
| 494 |
+
"main_language": "python",
|
| 495 |
+
"notebook_metadata_filter": "-all"
|
| 496 |
+
},
|
| 497 |
+
"kernelspec": {
|
| 498 |
+
"display_name": "lmdeploy",
|
| 499 |
+
"language": "python",
|
| 500 |
+
"name": "python3"
|
| 501 |
+
},
|
| 502 |
+
"language_info": {
|
| 503 |
+
"codemirror_mode": {
|
| 504 |
+
"name": "ipython",
|
| 505 |
+
"version": 3
|
| 506 |
+
},
|
| 507 |
+
"file_extension": ".py",
|
| 508 |
+
"mimetype": "text/x-python",
|
| 509 |
+
"name": "python",
|
| 510 |
+
"nbconvert_exporter": "python",
|
| 511 |
+
"pygments_lexer": "ipython3",
|
| 512 |
+
"version": "3.8.19"
|
| 513 |
+
}
|
| 514 |
+
},
|
| 515 |
+
"nbformat": 4,
|
| 516 |
+
"nbformat_minor": 5
|
| 517 |
+
}
|
a_mllm_notebooks/lmdeploy/get_started_vl.md
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Quick Start
|
| 2 |
+
|
| 3 |
+
This tutorial shows the usage of LMDeploy on CUDA platform:
|
| 4 |
+
|
| 5 |
+
- Offline inference of LLM model and VLM model
|
| 6 |
+
- Serve a LLM or VLM model by the OpenAI compatible server
|
| 7 |
+
- Console CLI to interactively chat with LLM model
|
| 8 |
+
|
| 9 |
+
Before reading further, please ensure that you have installed lmdeploy as outlined in the [installation guide](installation.md)
|
| 10 |
+
|
| 11 |
+
## Offline batch inference
|
| 12 |
+
|
| 13 |
+
### LLM inference
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
from lmdeploy import pipeline
|
| 17 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat')
|
| 18 |
+
response = pipe(['Hi, pls intro yourself', 'Shanghai is'])
|
| 19 |
+
print(response)
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
When constructing the `pipeline`, if an inference engine is not designated between the TurboMind Engine and the PyTorch Engine, LMDeploy will automatically assign one based on [their respective capabilities](../supported_models/supported_models.md), with the TurboMind Engine taking precedence by default.
|
| 23 |
+
|
| 24 |
+
However, you have the option to manually select an engine. For instance,
|
| 25 |
+
|
| 26 |
+
```python
|
| 27 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 28 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat',
|
| 29 |
+
backend_config=TurbomindEngineConfig(
|
| 30 |
+
max_batch_size=32,
|
| 31 |
+
enable_prefix_caching=True,
|
| 32 |
+
cache_max_entry_count=0.8,
|
| 33 |
+
session_len=8192,
|
| 34 |
+
))
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
or,
|
| 38 |
+
|
| 39 |
+
```python
|
| 40 |
+
from lmdeploy import pipeline, PytorchEngineConfig
|
| 41 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat',
|
| 42 |
+
backend_config=PytorchEngineConfig(
|
| 43 |
+
max_batch_size=32,
|
| 44 |
+
enable_prefix_caching=True,
|
| 45 |
+
cache_max_entry_count=0.8,
|
| 46 |
+
session_len=8192,
|
| 47 |
+
))
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
```{note}
|
| 51 |
+
The parameter "cache_max_entry_count" significantly influences the GPU memory usage.
|
| 52 |
+
It means the proportion of FREE GPU memory occupied by the K/V cache after the model weights are loaded.
|
| 53 |
+
|
| 54 |
+
The default value is 0.8. The K/V cache memory is allocated once and reused repeatedly, which is why it is observed that the built pipeline and the "api_server" mentioned later in the next consumes a substantial amount of GPU memory.
|
| 55 |
+
|
| 56 |
+
If you encounter an Out-of-Memory(OOM) error, you may need to consider lowering the value of "cache_max_entry_count".
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
When use the callable `pipe()` to perform token generation with given prompts, you can set the sampling parameters via `GenerationConfig` as below:
|
| 60 |
+
|
| 61 |
+
```python
|
| 62 |
+
from lmdeploy import GenerationConfig, pipeline
|
| 63 |
+
|
| 64 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat')
|
| 65 |
+
prompts = ['Hi, pls intro yourself', 'Shanghai is']
|
| 66 |
+
response = pipe(prompts,
|
| 67 |
+
gen_config=GenerationConfig(
|
| 68 |
+
max_new_tokens=1024,
|
| 69 |
+
top_p=0.8,
|
| 70 |
+
top_k=40,
|
| 71 |
+
temperature=0.6
|
| 72 |
+
))
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
In the `GenerationConfig`, `top_k=1` or `temperature=0.0` indicates greedy search.
|
| 76 |
+
|
| 77 |
+
For more information about pipeline, please read the [detailed tutorial](../llm/pipeline.md)
|
| 78 |
+
|
| 79 |
+
### VLM inference
|
| 80 |
+
|
| 81 |
+
The usage of VLM inference pipeline is akin to that of LLMs, with the additional capability of processing image data with the pipeline.
|
| 82 |
+
For example, you can utilize the following code snippet to perform the inference with an InternVL model:
|
| 83 |
+
|
| 84 |
+
```python
|
| 85 |
+
from lmdeploy import pipeline
|
| 86 |
+
from lmdeploy.vl import load_image
|
| 87 |
+
|
| 88 |
+
pipe = pipeline('OpenGVLab/InternVL2-8B')
|
| 89 |
+
|
| 90 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
|
| 91 |
+
response = pipe(('describe this image', image))
|
| 92 |
+
print(response)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
In VLM pipeline, the default image processing batch size is 1. This can be adjusted by `VisionConfig`. For instance, you might set it like this:
|
| 96 |
+
|
| 97 |
+
```python
|
| 98 |
+
from lmdeploy import pipeline, VisionConfig
|
| 99 |
+
from lmdeploy.vl import load_image
|
| 100 |
+
|
| 101 |
+
pipe = pipeline('OpenGVLab/InternVL2-8B',
|
| 102 |
+
vision_config=VisionConfig(
|
| 103 |
+
max_batch_size=8
|
| 104 |
+
))
|
| 105 |
+
|
| 106 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
|
| 107 |
+
response = pipe(('describe this image', image))
|
| 108 |
+
print(response)
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
However, the larger the image batch size, the greater risk of an OOM error, because the LLM component within the VLM model pre-allocates a massive amount of memory in advance.
|
| 112 |
+
|
| 113 |
+
We encourage you to manually choose between the TurboMind Engine and the PyTorch Engine based on their respective capabilities, as detailed in [the supported-models matrix](../supported_models/supported_models.md).
|
| 114 |
+
Additionally, follow the instructions in [LLM Inference](#llm-inference) section to reduce the values of memory-related parameters
|
| 115 |
+
|
| 116 |
+
## Serving
|
| 117 |
+
|
| 118 |
+
As demonstrated in the previous [offline batch inference](#offline-batch-inference) section, this part presents the respective serving methods for LLMs and VLMs.
|
| 119 |
+
|
| 120 |
+
### Serve a LLM model
|
| 121 |
+
|
| 122 |
+
```shell
|
| 123 |
+
lmdeploy serve api_server internlm/internlm2_5-7b-chat
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
This command will launch an OpenAI-compatible server on the localhost at port `23333`. You can specify a different server port by using the `--server-port` option.
|
| 127 |
+
For more options, consult the help documentation by running `lmdeploy serve api_server --help`. Most of these options align with the engine configuration.
|
| 128 |
+
|
| 129 |
+
To access the service, you can utilize the official OpenAI Python package `pip install openai`. Below is an example demonstrating how to use the entrypoint `v1/chat/completions`
|
| 130 |
+
|
| 131 |
+
```python
|
| 132 |
+
from openai import OpenAI
|
| 133 |
+
client = OpenAI(
|
| 134 |
+
api_key='YOUR_API_KEY',
|
| 135 |
+
base_url="http://0.0.0.0:23333/v1"
|
| 136 |
+
)
|
| 137 |
+
model_name = client.models.list().data[0].id
|
| 138 |
+
response = client.chat.completions.create(
|
| 139 |
+
model=model_name,
|
| 140 |
+
messages=[
|
| 141 |
+
{"role": "system", "content": "You are a helpful assistant."},
|
| 142 |
+
{"role": "user", "content": " provide three suggestions about time management"},
|
| 143 |
+
],
|
| 144 |
+
temperature=0.8,
|
| 145 |
+
top_p=0.8
|
| 146 |
+
)
|
| 147 |
+
print(response)
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
We encourage you to refer to the detailed guide for more comprehensive information about [serving with Docker](../llm/api_server.md), [function calls](../llm/api_server_tools.md) and other topics
|
| 151 |
+
|
| 152 |
+
### Serve a VLM model
|
| 153 |
+
|
| 154 |
+
```shell
|
| 155 |
+
lmdeploy serve api_server OpenGVLab/InternVL2-8B
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
```{note}
|
| 159 |
+
LMDeploy reuses the vision component from upstream VLM repositories. Each upstream VLM model may have different dependencies.
|
| 160 |
+
Consequently, LMDeploy has decided not to include the dependencies of the upstream VLM repositories in its own dependency list.
|
| 161 |
+
If you encounter an "ImportError" when using LMDeploy for inference with VLM models, please install the relevant dependencies yourself.
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
After the service is launched successfully, you can access the VLM service in a manner similar to how you would access the `gptv4` service by modifying the `api_key` and `base_url` parameters:
|
| 165 |
+
|
| 166 |
+
```python
|
| 167 |
+
from openai import OpenAI
|
| 168 |
+
|
| 169 |
+
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
|
| 170 |
+
model_name = client.models.list().data[0].id
|
| 171 |
+
response = client.chat.completions.create(
|
| 172 |
+
model=model_name,
|
| 173 |
+
messages=[{
|
| 174 |
+
'role':
|
| 175 |
+
'user',
|
| 176 |
+
'content': [{
|
| 177 |
+
'type': 'text',
|
| 178 |
+
'text': 'Describe the image please',
|
| 179 |
+
}, {
|
| 180 |
+
'type': 'image_url',
|
| 181 |
+
'image_url': {
|
| 182 |
+
'url':
|
| 183 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',
|
| 184 |
+
},
|
| 185 |
+
}],
|
| 186 |
+
}],
|
| 187 |
+
temperature=0.8,
|
| 188 |
+
top_p=0.8)
|
| 189 |
+
print(response)
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
## Inference with Command line Interface
|
| 193 |
+
|
| 194 |
+
LMDeploy offers a very convenient CLI tool for users to chat with the LLM model locally. For example:
|
| 195 |
+
|
| 196 |
+
```shell
|
| 197 |
+
lmdeploy chat internlm/internlm2_5-7b-chat --backend turbomind
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
It is designed to assist users in checking and verifying whether LMDeploy supports their model, whether the chat template is applied correctly, and whether the inference results are delivered smoothly.
|
| 201 |
+
|
| 202 |
+
Another tool, `lmdeploy check_env`, aims to gather the essential environment information. It is crucial when reporting an issue to us, as it helps us diagnose and resolve the problem more effectively.
|
| 203 |
+
|
| 204 |
+
If you have any doubt about their usage, you can try using the `--help` option to obtain detailed information.
|
a_mllm_notebooks/lmdeploy/internvl_25.ipynb
ADDED
|
@@ -0,0 +1,355 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [
|
| 8 |
+
{
|
| 9 |
+
"name": "stdout",
|
| 10 |
+
"output_type": "stream",
|
| 11 |
+
"text": [
|
| 12 |
+
"/dscilab_dungvo/workspace/huggingface_cache\n",
|
| 13 |
+
"models--AIDC-AI--Ovis1.6-Gemma2-27B\n",
|
| 14 |
+
"models--FoundationVision--groma-7b-pretrain\n",
|
| 15 |
+
"models--MBZUAI--GLaMM-FullScope\n",
|
| 16 |
+
"models--OpenGVLab--InternVL2_5-26B-AWQ\n",
|
| 17 |
+
"models--OpenGVLab--InternVL2_5-38B-AWQ\n",
|
| 18 |
+
"models--OpenGVLab--InternVL2_5-78B-AWQ\n",
|
| 19 |
+
"models--Qwen--Qwen2-VL-2B-Instruct\n",
|
| 20 |
+
"models--Qwen--Qwen2-VL-72B-Instruct-AWQ\n",
|
| 21 |
+
"models--Qwen--Qwen2-VL-7B-Instruct\n",
|
| 22 |
+
"models--Qwen--Qwen2.5-7B-Instruct\n",
|
| 23 |
+
"models--meta-llama--Llama-3.2-90B-Vision-Instruct\n",
|
| 24 |
+
"models--opengvlab--internvl2_5-26B-AWQ\n",
|
| 25 |
+
"models--opengvlab--internvl2_5-38B-AWQ\n",
|
| 26 |
+
"models--vinai--phobert-base-v2\n",
|
| 27 |
+
"version.txt\n"
|
| 28 |
+
]
|
| 29 |
+
}
|
| 30 |
+
],
|
| 31 |
+
"source": [
|
| 32 |
+
"!echo $HF_HOME\n",
|
| 33 |
+
"!ls $HF_HOME/hub"
|
| 34 |
+
]
|
| 35 |
+
},
|
| 36 |
+
{
|
| 37 |
+
"cell_type": "markdown",
|
| 38 |
+
"metadata": {},
|
| 39 |
+
"source": []
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"cell_type": "code",
|
| 43 |
+
"execution_count": 4,
|
| 44 |
+
"metadata": {},
|
| 45 |
+
"outputs": [
|
| 46 |
+
{
|
| 47 |
+
"name": "stdout",
|
| 48 |
+
"output_type": "stream",
|
| 49 |
+
"text": [
|
| 50 |
+
"The supported chat template names are:\n",
|
| 51 |
+
"baichuan2\n",
|
| 52 |
+
"base\n",
|
| 53 |
+
"chatglm\n",
|
| 54 |
+
"chatglm3\n",
|
| 55 |
+
"codegeex4\n",
|
| 56 |
+
"codellama\n",
|
| 57 |
+
"cogvlm\n",
|
| 58 |
+
"cogvlm2\n",
|
| 59 |
+
"dbrx\n",
|
| 60 |
+
"deepseek\n",
|
| 61 |
+
"deepseek-coder\n",
|
| 62 |
+
"deepseek-vl\n",
|
| 63 |
+
"falcon\n",
|
| 64 |
+
"gemma\n",
|
| 65 |
+
"glm4\n",
|
| 66 |
+
"internlm\n",
|
| 67 |
+
"internlm-xcomposer2\n",
|
| 68 |
+
"internlm-xcomposer2d5\n",
|
| 69 |
+
"internlm2\n",
|
| 70 |
+
"internvl-internlm2\n",
|
| 71 |
+
"internvl-phi3\n",
|
| 72 |
+
"internvl-zh\n",
|
| 73 |
+
"internvl-zh-hermes2\n",
|
| 74 |
+
"internvl2-internlm2\n",
|
| 75 |
+
"internvl2-phi3\n",
|
| 76 |
+
"internvl2_5\n",
|
| 77 |
+
"llama\n",
|
| 78 |
+
"llama2\n",
|
| 79 |
+
"llama3\n",
|
| 80 |
+
"llama3_1\n",
|
| 81 |
+
"llama3_2\n",
|
| 82 |
+
"llava-chatml\n",
|
| 83 |
+
"llava-v1\n",
|
| 84 |
+
"mini-gemini-vicuna\n",
|
| 85 |
+
"minicpm3\n",
|
| 86 |
+
"minicpmv-2d6\n",
|
| 87 |
+
"mistral\n",
|
| 88 |
+
"mixtral\n",
|
| 89 |
+
"molmo\n",
|
| 90 |
+
"phi-3\n",
|
| 91 |
+
"puyu\n",
|
| 92 |
+
"qwen\n",
|
| 93 |
+
"qwen2d5\n",
|
| 94 |
+
"solar\n",
|
| 95 |
+
"ultracm\n",
|
| 96 |
+
"ultralm\n",
|
| 97 |
+
"vicuna\n",
|
| 98 |
+
"wizardlm\n",
|
| 99 |
+
"yi\n",
|
| 100 |
+
"yi-vl\n"
|
| 101 |
+
]
|
| 102 |
+
}
|
| 103 |
+
],
|
| 104 |
+
"source": [
|
| 105 |
+
"!lmdeploy list"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "code",
|
| 110 |
+
"execution_count": 5,
|
| 111 |
+
"metadata": {},
|
| 112 |
+
"outputs": [
|
| 113 |
+
{
|
| 114 |
+
"name": "stdout",
|
| 115 |
+
"output_type": "stream",
|
| 116 |
+
"text": [
|
| 117 |
+
"usage: lmdeploy lite [-h] {auto_awq,auto_gptq,calibrate,smooth_quant} ...\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"Compressing and accelerating LLMs with lmdeploy.lite module\n",
|
| 120 |
+
"\n",
|
| 121 |
+
"optional arguments:\n",
|
| 122 |
+
" -h, --help show this help message and exit\n",
|
| 123 |
+
"\n",
|
| 124 |
+
"Commands:\n",
|
| 125 |
+
" This group has the following commands:\n",
|
| 126 |
+
"\n",
|
| 127 |
+
" {auto_awq,auto_gptq,calibrate,smooth_quant}\n",
|
| 128 |
+
" auto_awq Perform weight quantization using AWQ algorithm.\n",
|
| 129 |
+
" auto_gptq Perform weight quantization using GPTQ algorithm.\n",
|
| 130 |
+
" calibrate Perform calibration on a given dataset.\n",
|
| 131 |
+
" smooth_quant Perform w8a8 quantization using SmoothQuant.\n"
|
| 132 |
+
]
|
| 133 |
+
}
|
| 134 |
+
],
|
| 135 |
+
"source": [
|
| 136 |
+
"!lmdeploy lite --help"
|
| 137 |
+
]
|
| 138 |
+
},
|
| 139 |
+
{
|
| 140 |
+
"cell_type": "code",
|
| 141 |
+
"execution_count": 8,
|
| 142 |
+
"metadata": {},
|
| 143 |
+
"outputs": [
|
| 144 |
+
{
|
| 145 |
+
"name": "stdout",
|
| 146 |
+
"output_type": "stream",
|
| 147 |
+
"text": [
|
| 148 |
+
"models--opengvlab--internvl2_5-26B-AWQ\n",
|
| 149 |
+
"/dscilab_dungvo/workspace/huggingface_cache/hub/models--opengvlab--internvl2_5-26B-AWQ\n"
|
| 150 |
+
]
|
| 151 |
+
}
|
| 152 |
+
],
|
| 153 |
+
"source": [
|
| 154 |
+
"model_name = \"OpenGVLab/InternVL2_5-26B-AWQ\"\n",
|
| 155 |
+
"\n",
|
| 156 |
+
"def convertname2path(name):\n",
|
| 157 |
+
" name = \"models/\" + name\n",
|
| 158 |
+
" name = name.lower()\n",
|
| 159 |
+
" name = name.replace(\"b-\", \"B-\")\n",
|
| 160 |
+
" name = name.replace(\"-awq\", \"-AWQ\")\n",
|
| 161 |
+
" name = name.replace(\"/\", \"--\")\n",
|
| 162 |
+
" import os\n",
|
| 163 |
+
" HF_HOME = os.environ.get(\"HF_HOME\")\n",
|
| 164 |
+
" print(name)\n",
|
| 165 |
+
" return f\"{HF_HOME}/hub/{name}\"\n",
|
| 166 |
+
"\n",
|
| 167 |
+
"model_path = convertname2path(model_name)\n",
|
| 168 |
+
"print(model_path)"
|
| 169 |
+
]
|
| 170 |
+
},
|
| 171 |
+
{
|
| 172 |
+
"cell_type": "code",
|
| 173 |
+
"execution_count": 9,
|
| 174 |
+
"metadata": {},
|
| 175 |
+
"outputs": [
|
| 176 |
+
{
|
| 177 |
+
"name": "stderr",
|
| 178 |
+
"output_type": "stream",
|
| 179 |
+
"text": [
|
| 180 |
+
"The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is ignored.\n"
|
| 181 |
+
]
|
| 182 |
+
},
|
| 183 |
+
{
|
| 184 |
+
"name": "stdout",
|
| 185 |
+
"output_type": "stream",
|
| 186 |
+
"text": [
|
| 187 |
+
"models--opengvlab--internvl2_5-26B-AWQ\n"
|
| 188 |
+
]
|
| 189 |
+
},
|
| 190 |
+
{
|
| 191 |
+
"ename": "RuntimeError",
|
| 192 |
+
"evalue": "Could not find model architecture from config: {'return_dict': True, 'output_hidden_states': False, 'output_attentions': False, 'torchscript': False, 'torch_dtype': None, 'use_bfloat16': False, 'tf_legacy_loss': False, 'pruned_heads': {}, 'tie_word_embeddings': True, 'chunk_size_feed_forward': 0, 'is_encoder_decoder': False, 'is_decoder': False, 'cross_attention_hidden_size': None, 'add_cross_attention': False, 'tie_encoder_decoder': False, 'max_length': 20, 'min_length': 0, 'do_sample': False, 'early_stopping': False, 'num_beams': 1, 'num_beam_groups': 1, 'diversity_penalty': 0.0, 'temperature': 1.0, 'top_k': 50, 'top_p': 1.0, 'typical_p': 1.0, 'repetition_penalty': 1.0, 'length_penalty': 1.0, 'no_repeat_ngram_size': 0, 'encoder_no_repeat_ngram_size': 0, 'bad_words_ids': None, 'num_return_sequences': 1, 'output_scores': False, 'return_dict_in_generate': False, 'forced_bos_token_id': None, 'forced_eos_token_id': None, 'remove_invalid_values': False, 'exponential_decay_length_penalty': None, 'suppress_tokens': None, 'begin_suppress_tokens': None, 'architectures': None, 'finetuning_task': None, 'id2label': {0: 'LABEL_0', 1: 'LABEL_1'}, 'label2id': {'LABEL_0': 0, 'LABEL_1': 1}, 'tokenizer_class': None, 'prefix': None, 'bos_token_id': None, 'pad_token_id': None, 'eos_token_id': None, 'sep_token_id': None, 'decoder_start_token_id': None, 'task_specific_params': None, 'problem_type': None, '_name_or_path': '', '_attn_implementation_autoset': False, 'transformers_version': '4.46.3', 'model_type': ''}",
|
| 193 |
+
"output_type": "error",
|
| 194 |
+
"traceback": [
|
| 195 |
+
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 196 |
+
"\u001b[0;31mRuntimeError\u001b[0m Traceback (most recent call last)",
|
| 197 |
+
"Cell \u001b[0;32mIn[9], line 6\u001b[0m\n\u001b[1;32m 3\u001b[0m model_path \u001b[38;5;241m=\u001b[39m convertname2path(model_name)\n\u001b[1;32m 4\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m pipeline(model_path)\n\u001b[0;32m----> 6\u001b[0m pipe \u001b[38;5;241m=\u001b[39m \u001b[43mget_pipe\u001b[49m\u001b[43m(\u001b[49m\u001b[43mmodel_name\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 7\u001b[0m \u001b[38;5;66;03m# response = pipe(['Hi, pls intro yourself', 'Shanghai is'])\u001b[39;00m\n\u001b[1;32m 8\u001b[0m \u001b[38;5;66;03m# print(response)\u001b[39;00m\n",
|
| 198 |
+
"Cell \u001b[0;32mIn[9], line 4\u001b[0m, in \u001b[0;36mget_pipe\u001b[0;34m(model_name)\u001b[0m\n\u001b[1;32m 2\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mget_pipe\u001b[39m(model_name):\n\u001b[1;32m 3\u001b[0m model_path \u001b[38;5;241m=\u001b[39m convertname2path(model_name)\n\u001b[0;32m----> 4\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[43mpipeline\u001b[49m\u001b[43m(\u001b[49m\u001b[43mmodel_path\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 199 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/lmdeploy/api.py:72\u001b[0m, in \u001b[0;36mpipeline\u001b[0;34m(model_path, backend_config, chat_template_config, log_level, max_log_len, **kwargs)\u001b[0m\n\u001b[1;32m 68\u001b[0m revision \u001b[38;5;241m=\u001b[39m backend_config\u001b[38;5;241m.\u001b[39mrevision \\\n\u001b[1;32m 69\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m backend_config \u001b[38;5;129;01mis\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m \u001b[38;5;28;01melse\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m\n\u001b[1;32m 70\u001b[0m model_path \u001b[38;5;241m=\u001b[39m get_model(model_path, download_dir, revision)\n\u001b[0;32m---> 72\u001b[0m task, pipeline_class \u001b[38;5;241m=\u001b[39m \u001b[43mget_task\u001b[49m\u001b[43m(\u001b[49m\u001b[43mmodel_path\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 73\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m task \u001b[38;5;241m==\u001b[39m \u001b[38;5;124m'\u001b[39m\u001b[38;5;124mvlm\u001b[39m\u001b[38;5;124m'\u001b[39m:\n\u001b[1;32m 74\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m backend_config \u001b[38;5;129;01mand\u001b[39;00m backend_config\u001b[38;5;241m.\u001b[39menable_prefix_caching:\n",
|
| 200 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/lmdeploy/archs.py:145\u001b[0m, in \u001b[0;36mget_task\u001b[0;34m(model_path)\u001b[0m\n\u001b[1;32m 142\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m os\u001b[38;5;241m.\u001b[39mpath\u001b[38;5;241m.\u001b[39mexists(os\u001b[38;5;241m.\u001b[39mpath\u001b[38;5;241m.\u001b[39mjoin(model_path, \u001b[38;5;124m'\u001b[39m\u001b[38;5;124mtriton_models\u001b[39m\u001b[38;5;124m'\u001b[39m, \u001b[38;5;124m'\u001b[39m\u001b[38;5;124mweights\u001b[39m\u001b[38;5;124m'\u001b[39m)):\n\u001b[1;32m 143\u001b[0m \u001b[38;5;66;03m# workspace model\u001b[39;00m\n\u001b[1;32m 144\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;124m'\u001b[39m\u001b[38;5;124mllm\u001b[39m\u001b[38;5;124m'\u001b[39m, AsyncEngine\n\u001b[0;32m--> 145\u001b[0m _, config \u001b[38;5;241m=\u001b[39m \u001b[43mget_model_arch\u001b[49m\u001b[43m(\u001b[49m\u001b[43mmodel_path\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 146\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m check_vl_llm(config\u001b[38;5;241m.\u001b[39mto_dict()):\n\u001b[1;32m 147\u001b[0m \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01mlmdeploy\u001b[39;00m\u001b[38;5;21;01m.\u001b[39;00m\u001b[38;5;21;01mserve\u001b[39;00m\u001b[38;5;21;01m.\u001b[39;00m\u001b[38;5;21;01mvl_async_engine\u001b[39;00m \u001b[38;5;28;01mimport\u001b[39;00m VLAsyncEngine\n",
|
| 201 |
+
"File \u001b[0;32m/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/lmdeploy/archs.py:193\u001b[0m, in \u001b[0;36mget_model_arch\u001b[0;34m(model_path)\u001b[0m\n\u001b[1;32m 191\u001b[0m arch \u001b[38;5;241m=\u001b[39m _cfg[\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mauto_map\u001b[39m\u001b[38;5;124m'\u001b[39m][\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mAutoModelForCausalLM\u001b[39m\u001b[38;5;124m'\u001b[39m]\u001b[38;5;241m.\u001b[39msplit(\u001b[38;5;124m'\u001b[39m\u001b[38;5;124m.\u001b[39m\u001b[38;5;124m'\u001b[39m)[\u001b[38;5;241m-\u001b[39m\u001b[38;5;241m1\u001b[39m]\n\u001b[1;32m 192\u001b[0m \u001b[38;5;28;01melse\u001b[39;00m:\n\u001b[0;32m--> 193\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m \u001b[38;5;167;01mRuntimeError\u001b[39;00m(\n\u001b[1;32m 194\u001b[0m \u001b[38;5;124mf\u001b[39m\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mCould not find model architecture from config: \u001b[39m\u001b[38;5;132;01m{\u001b[39;00m_cfg\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m'\u001b[39m)\n\u001b[1;32m 195\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m arch, cfg\n",
|
| 202 |
+
"\u001b[0;31mRuntimeError\u001b[0m: Could not find model architecture from config: {'return_dict': True, 'output_hidden_states': False, 'output_attentions': False, 'torchscript': False, 'torch_dtype': None, 'use_bfloat16': False, 'tf_legacy_loss': False, 'pruned_heads': {}, 'tie_word_embeddings': True, 'chunk_size_feed_forward': 0, 'is_encoder_decoder': False, 'is_decoder': False, 'cross_attention_hidden_size': None, 'add_cross_attention': False, 'tie_encoder_decoder': False, 'max_length': 20, 'min_length': 0, 'do_sample': False, 'early_stopping': False, 'num_beams': 1, 'num_beam_groups': 1, 'diversity_penalty': 0.0, 'temperature': 1.0, 'top_k': 50, 'top_p': 1.0, 'typical_p': 1.0, 'repetition_penalty': 1.0, 'length_penalty': 1.0, 'no_repeat_ngram_size': 0, 'encoder_no_repeat_ngram_size': 0, 'bad_words_ids': None, 'num_return_sequences': 1, 'output_scores': False, 'return_dict_in_generate': False, 'forced_bos_token_id': None, 'forced_eos_token_id': None, 'remove_invalid_values': False, 'exponential_decay_length_penalty': None, 'suppress_tokens': None, 'begin_suppress_tokens': None, 'architectures': None, 'finetuning_task': None, 'id2label': {0: 'LABEL_0', 1: 'LABEL_1'}, 'label2id': {'LABEL_0': 0, 'LABEL_1': 1}, 'tokenizer_class': None, 'prefix': None, 'bos_token_id': None, 'pad_token_id': None, 'eos_token_id': None, 'sep_token_id': None, 'decoder_start_token_id': None, 'task_specific_params': None, 'problem_type': None, '_name_or_path': '', '_attn_implementation_autoset': False, 'transformers_version': '4.46.3', 'model_type': ''}"
|
| 203 |
+
]
|
| 204 |
+
}
|
| 205 |
+
],
|
| 206 |
+
"source": [
|
| 207 |
+
"from lmdeploy import pipeline\n",
|
| 208 |
+
"def get_pipe(model_name):\n",
|
| 209 |
+
" model_path = convertname2path(model_name)\n",
|
| 210 |
+
" return pipeline(model_path)\n",
|
| 211 |
+
"\n",
|
| 212 |
+
"pipe = get_pipe(model_name)\n",
|
| 213 |
+
"# response = pipe(['Hi, pls intro yourself', 'Shanghai is'])\n",
|
| 214 |
+
"# print(response)\n"
|
| 215 |
+
]
|
| 216 |
+
},
|
| 217 |
+
{
|
| 218 |
+
"cell_type": "code",
|
| 219 |
+
"execution_count": 2,
|
| 220 |
+
"metadata": {},
|
| 221 |
+
"outputs": [
|
| 222 |
+
{
|
| 223 |
+
"name": "stdout",
|
| 224 |
+
"output_type": "stream",
|
| 225 |
+
"text": [
|
| 226 |
+
"\u001b[0;31mSignature:\u001b[0m\n",
|
| 227 |
+
"\u001b[0mpipeline\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 228 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmodel_path\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mstr\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 229 |
+
"\u001b[0;34m\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mUnion\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mlmdeploy\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mmessages\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mTurbomindEngineConfig\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mlmdeploy\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mmessages\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mPytorchEngineConfig\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mNoneType\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 230 |
+
"\u001b[0;34m\u001b[0m \u001b[0mchat_template_config\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mUnion\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mlmdeploy\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mmodel\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mChatTemplateConfig\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mNoneType\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 231 |
+
"\u001b[0;34m\u001b[0m \u001b[0mlog_level\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mstr\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m'WARNING'\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 232 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_log_len\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 233 |
+
"\u001b[0;34m\u001b[0m \u001b[0;34m**\u001b[0m\u001b[0mkwargs\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 234 |
+
"\u001b[0;34m\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
|
| 235 |
+
"\u001b[0;31mSource:\u001b[0m \n",
|
| 236 |
+
"\u001b[0;32mdef\u001b[0m \u001b[0mpipeline\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmodel_path\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mstr\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 237 |
+
"\u001b[0;34m\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mOptional\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mUnion\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mTurbomindEngineConfig\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 238 |
+
"\u001b[0;34m\u001b[0m \u001b[0mPytorchEngineConfig\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 239 |
+
"\u001b[0;34m\u001b[0m \u001b[0mchat_template_config\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mOptional\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mChatTemplateConfig\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 240 |
+
"\u001b[0;34m\u001b[0m \u001b[0mlog_level\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mstr\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m'WARNING'\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 241 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_log_len\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 242 |
+
"\u001b[0;34m\u001b[0m \u001b[0;34m**\u001b[0m\u001b[0mkwargs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 243 |
+
"\u001b[0;34m\u001b[0m \u001b[0;34m\"\"\"\u001b[0m\n",
|
| 244 |
+
"\u001b[0;34m Args:\u001b[0m\n",
|
| 245 |
+
"\u001b[0;34m model_path (str): the path of a model.\u001b[0m\n",
|
| 246 |
+
"\u001b[0;34m It could be one of the following options:\u001b[0m\n",
|
| 247 |
+
"\u001b[0;34m - i) A local directory path of a turbomind model which is\u001b[0m\n",
|
| 248 |
+
"\u001b[0;34m converted by `lmdeploy convert` command or download from\u001b[0m\n",
|
| 249 |
+
"\u001b[0;34m ii) and iii).\u001b[0m\n",
|
| 250 |
+
"\u001b[0;34m - ii) The model_id of a lmdeploy-quantized model hosted\u001b[0m\n",
|
| 251 |
+
"\u001b[0;34m inside a model repo on huggingface.co, such as\u001b[0m\n",
|
| 252 |
+
"\u001b[0;34m \"InternLM/internlm-chat-20b-4bit\",\u001b[0m\n",
|
| 253 |
+
"\u001b[0;34m \"lmdeploy/llama2-chat-70b-4bit\", etc.\u001b[0m\n",
|
| 254 |
+
"\u001b[0;34m - iii) The model_id of a model hosted inside a model repo\u001b[0m\n",
|
| 255 |
+
"\u001b[0;34m on huggingface.co, such as \"internlm/internlm-chat-7b\",\u001b[0m\n",
|
| 256 |
+
"\u001b[0;34m \"Qwen/Qwen-7B-Chat \", \"baichuan-inc/Baichuan2-7B-Chat\"\u001b[0m\n",
|
| 257 |
+
"\u001b[0;34m and so on.\u001b[0m\n",
|
| 258 |
+
"\u001b[0;34m backend_config (TurbomindEngineConfig | PytorchEngineConfig): backend\u001b[0m\n",
|
| 259 |
+
"\u001b[0;34m config instance. Default to None.\u001b[0m\n",
|
| 260 |
+
"\u001b[0;34m chat_template_config (ChatTemplateConfig): chat template configuration.\u001b[0m\n",
|
| 261 |
+
"\u001b[0;34m Default to None.\u001b[0m\n",
|
| 262 |
+
"\u001b[0;34m log_level(str): set log level whose value among [CRITICAL, ERROR,\u001b[0m\n",
|
| 263 |
+
"\u001b[0;34m WARNING, INFO, DEBUG]\u001b[0m\n",
|
| 264 |
+
"\u001b[0;34m max_log_len(int): Max number of prompt characters or prompt tokens\u001b[0m\n",
|
| 265 |
+
"\u001b[0;34m being printed in log\u001b[0m\n",
|
| 266 |
+
"\u001b[0;34m\u001b[0m\n",
|
| 267 |
+
"\u001b[0;34m Examples:\u001b[0m\n",
|
| 268 |
+
"\u001b[0;34m >>> # LLM\u001b[0m\n",
|
| 269 |
+
"\u001b[0;34m >>> import lmdeploy\u001b[0m\n",
|
| 270 |
+
"\u001b[0;34m >>> pipe = lmdeploy.pipeline('internlm/internlm-chat-7b')\u001b[0m\n",
|
| 271 |
+
"\u001b[0;34m >>> response = pipe(['hi','say this is a test'])\u001b[0m\n",
|
| 272 |
+
"\u001b[0;34m >>> print(response)\u001b[0m\n",
|
| 273 |
+
"\u001b[0;34m >>>\u001b[0m\n",
|
| 274 |
+
"\u001b[0;34m >>> # VLM\u001b[0m\n",
|
| 275 |
+
"\u001b[0;34m >>> from lmdeploy.vl import load_image\u001b[0m\n",
|
| 276 |
+
"\u001b[0;34m >>> from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig\u001b[0m\n",
|
| 277 |
+
"\u001b[0;34m >>> pipe = pipeline('liuhaotian/llava-v1.5-7b',\u001b[0m\n",
|
| 278 |
+
"\u001b[0;34m ... backend_config=TurbomindEngineConfig(session_len=8192),\u001b[0m\n",
|
| 279 |
+
"\u001b[0;34m ... chat_template_config=ChatTemplateConfig(model_name='vicuna'))\u001b[0m\n",
|
| 280 |
+
"\u001b[0;34m >>> im = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')\u001b[0m\n",
|
| 281 |
+
"\u001b[0;34m >>> response = pipe([('describe this image', [im])])\u001b[0m\n",
|
| 282 |
+
"\u001b[0;34m >>> print(response)\u001b[0m\n",
|
| 283 |
+
"\u001b[0;34m \"\"\"\u001b[0m \u001b[0;31m# noqa E501\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 284 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mos\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mgetenv\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'TM_LOG_LEVEL'\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;32mis\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 285 |
+
"\u001b[0;34m\u001b[0m \u001b[0mos\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0menviron\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m'TM_LOG_LEVEL'\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mlog_level\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 286 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32mfrom\u001b[0m \u001b[0mlmdeploy\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mutils\u001b[0m \u001b[0;32mimport\u001b[0m \u001b[0mget_logger\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mget_model\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 287 |
+
"\u001b[0;34m\u001b[0m \u001b[0mlogger\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mget_logger\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'lmdeploy'\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 288 |
+
"\u001b[0;34m\u001b[0m \u001b[0mlogger\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0msetLevel\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlog_level\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 289 |
+
"\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 290 |
+
"\u001b[0;34m\u001b[0m \u001b[0;31m# model_path is not local path.\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 291 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0;32mnot\u001b[0m \u001b[0mos\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mpath\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mexists\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmodel_path\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 292 |
+
"\u001b[0;34m\u001b[0m \u001b[0mdownload_dir\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdownload_dir\u001b[0m \\\n",
|
| 293 |
+
" \u001b[0;32mif\u001b[0m \u001b[0mbackend_config\u001b[0m \u001b[0;32mis\u001b[0m \u001b[0;32mnot\u001b[0m \u001b[0;32mNone\u001b[0m \u001b[0;32melse\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 294 |
+
"\u001b[0;34m\u001b[0m \u001b[0mrevision\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mrevision\u001b[0m \\\n",
|
| 295 |
+
" \u001b[0;32mif\u001b[0m \u001b[0mbackend_config\u001b[0m \u001b[0;32mis\u001b[0m \u001b[0;32mnot\u001b[0m \u001b[0;32mNone\u001b[0m \u001b[0;32melse\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 296 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmodel_path\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mget_model\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmodel_path\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mdownload_dir\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mrevision\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 297 |
+
"\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 298 |
+
"\u001b[0;34m\u001b[0m \u001b[0mtask\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mpipeline_class\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mget_task\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmodel_path\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 299 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mtask\u001b[0m \u001b[0;34m==\u001b[0m \u001b[0;34m'vlm'\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 300 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mbackend_config\u001b[0m \u001b[0;32mand\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0menable_prefix_caching\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 301 |
+
"\u001b[0;34m\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0menable_prefix_caching\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mFalse\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 302 |
+
"\u001b[0;34m\u001b[0m \u001b[0mlogger\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mwarning\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m'VLM does not support prefix caching.'\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 303 |
+
"\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 304 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mtype\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mbackend_config\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;32mis\u001b[0m \u001b[0;32mnot\u001b[0m \u001b[0mPytorchEngineConfig\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 305 |
+
"\u001b[0;34m\u001b[0m \u001b[0;31m# set auto backend mode\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 306 |
+
"\u001b[0;34m\u001b[0m \u001b[0mbackend_config\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mautoget_backend_config\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmodel_path\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 307 |
+
"\u001b[0;34m\u001b[0m \u001b[0mbackend\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m'pytorch'\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mtype\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 308 |
+
"\u001b[0;34m\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;32mis\u001b[0m \u001b[0mPytorchEngineConfig\u001b[0m \u001b[0;32melse\u001b[0m \u001b[0;34m'turbomind'\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 309 |
+
"\u001b[0;34m\u001b[0m \u001b[0mlogger\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0minfo\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34mf'Using {backend} engine'\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 310 |
+
"\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 311 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32mreturn\u001b[0m \u001b[0mpipeline_class\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmodel_path\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 312 |
+
"\u001b[0;34m\u001b[0m \u001b[0mbackend\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mbackend\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 313 |
+
"\u001b[0;34m\u001b[0m \u001b[0mbackend_config\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mbackend_config\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 314 |
+
"\u001b[0;34m\u001b[0m \u001b[0mchat_template_config\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mchat_template_config\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 315 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_log_len\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mmax_log_len\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 316 |
+
"\u001b[0;34m\u001b[0m \u001b[0;34m**\u001b[0m\u001b[0mkwargs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
|
| 317 |
+
"\u001b[0;31mFile:\u001b[0m /dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/lmdeploy/api.py\n",
|
| 318 |
+
"\u001b[0;31mType:\u001b[0m function"
|
| 319 |
+
]
|
| 320 |
+
}
|
| 321 |
+
],
|
| 322 |
+
"source": [
|
| 323 |
+
"pipeline??"
|
| 324 |
+
]
|
| 325 |
+
},
|
| 326 |
+
{
|
| 327 |
+
"cell_type": "code",
|
| 328 |
+
"execution_count": null,
|
| 329 |
+
"metadata": {},
|
| 330 |
+
"outputs": [],
|
| 331 |
+
"source": []
|
| 332 |
+
}
|
| 333 |
+
],
|
| 334 |
+
"metadata": {
|
| 335 |
+
"kernelspec": {
|
| 336 |
+
"display_name": "lmdeploy",
|
| 337 |
+
"language": "python",
|
| 338 |
+
"name": "python3"
|
| 339 |
+
},
|
| 340 |
+
"language_info": {
|
| 341 |
+
"codemirror_mode": {
|
| 342 |
+
"name": "ipython",
|
| 343 |
+
"version": 3
|
| 344 |
+
},
|
| 345 |
+
"file_extension": ".py",
|
| 346 |
+
"mimetype": "text/x-python",
|
| 347 |
+
"name": "python",
|
| 348 |
+
"nbconvert_exporter": "python",
|
| 349 |
+
"pygments_lexer": "ipython3",
|
| 350 |
+
"version": "3.8.19"
|
| 351 |
+
}
|
| 352 |
+
},
|
| 353 |
+
"nbformat": 4,
|
| 354 |
+
"nbformat_minor": 2
|
| 355 |
+
}
|
a_mllm_notebooks/lmdeploy/kv_quant.ipynb
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "7fece453",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# INT4/INT8 KV Cache\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"Since v0.4.0, LMDeploy has supported **online** key-value (kv) cache quantization with int4 and int8 numerical precision, utilizing an asymmetric quantization method that is applied on a per-head, per-token basis. The original kv offline quantization method has been removed.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"Intuitively, quantization is beneficial for increasing the number of kv block. Compared to fp16, the number of kv block for int4/int8 kv can be increased by 4 times and 2 times respectively. This means that under the same memory conditions, the system can support a significantly increased number of concurrent operations after kv quantization, thereby ultimately enhancing throughput.\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"However, quantization typically brings in some loss of model accuracy. We have used OpenCompass to evaluate the accuracy of several models after applying int4/int8 quantization. int8 kv keeps the accuracy while int4 kv has slight loss. The detailed results are presented in the [Evaluation](#evaluation) section. You can refer to the information and choose wisely based on your requirements.\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"LMDeploy inference with quantized kv supports the following NVIDIA GPU models:\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"- Volta architecture (sm70): V100\n",
|
| 19 |
+
"- Turing architecture (sm75): 20 series, T4\n",
|
| 20 |
+
"- Ampere architecture (sm80, sm86): 30 series, A10, A16, A30, A100\n",
|
| 21 |
+
"- Ada Lovelace architecture (sm89): 40 series\n",
|
| 22 |
+
"- Hopper architecture (sm90): H100, H200\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"In summary, LMDeploy kv quantization has the following advantages:\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"1. data-free online quantization\n",
|
| 27 |
+
"2. Supports all nvidia GPU models with Volta architecture (sm70) and above\n",
|
| 28 |
+
"3. KV int8 quantization has almost lossless accuracy, and KV int4 quantization accuracy is within an acceptable range\n",
|
| 29 |
+
"4. Efficient inference, with int8/int4 kv quantization applied to llama2-7b, RPS is improved by round 30% and 40% respectively compared to fp16\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"In the next section, we will take `internlm2-chat-7b` model as an example, introducing the usage of kv quantization and inference of lmdeploy. But before that, please ensure that lmdeploy is installed.\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"```shell\n",
|
| 34 |
+
"pip install lmdeploy\n",
|
| 35 |
+
"```\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"## Usage\n",
|
| 38 |
+
"\n",
|
| 39 |
+
"Applying kv quantization and inference via LMDeploy is quite straightforward. Simply set the `quant_policy` parameter.\n",
|
| 40 |
+
"\n",
|
| 41 |
+
"**LMDeploy specifies that `quant_policy=4` stands for 4-bit kv, whereas `quant_policy=8` indicates 8-bit kv.**\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"### Offline inference"
|
| 44 |
+
]
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"cell_type": "code",
|
| 48 |
+
"execution_count": null,
|
| 49 |
+
"id": "fae395aa",
|
| 50 |
+
"metadata": {},
|
| 51 |
+
"outputs": [],
|
| 52 |
+
"source": [
|
| 53 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 54 |
+
"engine_config = TurbomindEngineConfig(quant_policy=8)\n",
|
| 55 |
+
"pipe = pipeline(\"internlm/internlm2_5-7b-chat\", backend_config=engine_config)\n",
|
| 56 |
+
"response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"])\n",
|
| 57 |
+
"print(response)"
|
| 58 |
+
]
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"cell_type": "markdown",
|
| 62 |
+
"id": "b1e29acd",
|
| 63 |
+
"metadata": {},
|
| 64 |
+
"source": [
|
| 65 |
+
"### Serving\n",
|
| 66 |
+
"\n",
|
| 67 |
+
"```shell\n",
|
| 68 |
+
"lmdeploy serve api_server internlm/internlm2_5-7b-chat --quant-policy 8\n",
|
| 69 |
+
"```\n",
|
| 70 |
+
"\n",
|
| 71 |
+
"## Evaluation\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"We apply kv quantization of LMDeploy to several LLM models and utilize OpenCompass to evaluate the inference accuracy. The results are shown in the table below:\n",
|
| 74 |
+
"\n",
|
| 75 |
+
"| - | - | - | llama2-7b-chat | - | - | internlm2-chat-7b | - | - | internlm2.5-chat-7b | - | - | qwen1.5-7b-chat | - | - |\n",
|
| 76 |
+
"| ----------- | ------- | ------------- | -------------- | ------- | ------- | ----------------- | ------- | ------- | ------------------- | ------- | ------- | --------------- | ------- | ------- |\n",
|
| 77 |
+
"| dataset | version | metric | kv fp16 | kv int8 | kv int4 | kv fp16 | kv int8 | kv int4 | kv fp16 | kv int8 | kv int4 | fp16 | kv int8 | kv int4 |\n",
|
| 78 |
+
"| ceval | - | naive_average | 28.42 | 27.96 | 27.58 | 60.45 | 60.88 | 60.28 | 78.06 | 77.87 | 77.05 | 70.56 | 70.49 | 68.62 |\n",
|
| 79 |
+
"| mmlu | - | naive_average | 35.64 | 35.58 | 34.79 | 63.91 | 64 | 62.36 | 72.30 | 72.27 | 71.17 | 61.48 | 61.56 | 60.65 |\n",
|
| 80 |
+
"| triviaqa | 2121ce | score | 56.09 | 56.13 | 53.71 | 58.73 | 58.7 | 58.18 | 65.09 | 64.87 | 63.28 | 44.62 | 44.77 | 44.04 |\n",
|
| 81 |
+
"| gsm8k | 1d7fe4 | accuracy | 28.2 | 28.05 | 27.37 | 70.13 | 69.75 | 66.87 | 85.67 | 85.44 | 83.78 | 54.97 | 56.41 | 54.74 |\n",
|
| 82 |
+
"| race-middle | 9a54b6 | accuracy | 41.57 | 41.78 | 41.23 | 88.93 | 88.93 | 88.93 | 92.76 | 92.83 | 92.55 | 87.33 | 87.26 | 86.28 |\n",
|
| 83 |
+
"| race-high | 9a54b6 | accuracy | 39.65 | 39.77 | 40.77 | 85.33 | 85.31 | 84.62 | 90.51 | 90.42 | 90.42 | 82.53 | 82.59 | 82.02 |\n",
|
| 84 |
+
"\n",
|
| 85 |
+
"For detailed evaluation methods, please refer to [this](../benchmark/evaluate_with_opencompass.md) guide. Remember to pass `quant_policy` to the inference engine in the config file.\n",
|
| 86 |
+
"\n",
|
| 87 |
+
"## Performance\n",
|
| 88 |
+
"\n",
|
| 89 |
+
"| model | kv type | test settings | RPS | v.s. kv fp16 |\n",
|
| 90 |
+
"| ----------------- | ------- | ---------------------------------------- | ----- | ------------ |\n",
|
| 91 |
+
"| llama2-chat-7b | fp16 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 14.98 | 1.0 |\n",
|
| 92 |
+
"| - | int8 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 19.01 | 1.27 |\n",
|
| 93 |
+
"| - | int4 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 20.81 | 1.39 |\n",
|
| 94 |
+
"| llama2-chat-13b | fp16 | tp1 / ratio 0.9 / bs 128 / prompts 10000 | 8.55 | 1.0 |\n",
|
| 95 |
+
"| - | int8 | tp1 / ratio 0.9 / bs 256 / prompts 10000 | 10.96 | 1.28 |\n",
|
| 96 |
+
"| - | int4 | tp1 / ratio 0.9 / bs 256 / prompts 10000 | 11.91 | 1.39 |\n",
|
| 97 |
+
"| internlm2-chat-7b | fp16 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 24.13 | 1.0 |\n",
|
| 98 |
+
"| - | int8 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 25.28 | 1.05 |\n",
|
| 99 |
+
"| - | int4 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 25.80 | 1.07 |\n",
|
| 100 |
+
"\n",
|
| 101 |
+
"The performance data is obtained by `benchmark/profile_throughput.py`"
|
| 102 |
+
]
|
| 103 |
+
}
|
| 104 |
+
],
|
| 105 |
+
"metadata": {
|
| 106 |
+
"jupytext": {
|
| 107 |
+
"cell_metadata_filter": "-all",
|
| 108 |
+
"main_language": "python",
|
| 109 |
+
"notebook_metadata_filter": "-all"
|
| 110 |
+
}
|
| 111 |
+
},
|
| 112 |
+
"nbformat": 4,
|
| 113 |
+
"nbformat_minor": 5
|
| 114 |
+
}
|
a_mllm_notebooks/lmdeploy/kv_quant.md
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# INT4/INT8 KV Cache
|
| 2 |
+
|
| 3 |
+
Since v0.4.0, LMDeploy has supported **online** key-value (kv) cache quantization with int4 and int8 numerical precision, utilizing an asymmetric quantization method that is applied on a per-head, per-token basis. The original kv offline quantization method has been removed.
|
| 4 |
+
|
| 5 |
+
Intuitively, quantization is beneficial for increasing the number of kv block. Compared to fp16, the number of kv block for int4/int8 kv can be increased by 4 times and 2 times respectively. This means that under the same memory conditions, the system can support a significantly increased number of concurrent operations after kv quantization, thereby ultimately enhancing throughput.
|
| 6 |
+
|
| 7 |
+
However, quantization typically brings in some loss of model accuracy. We have used OpenCompass to evaluate the accuracy of several models after applying int4/int8 quantization. int8 kv keeps the accuracy while int4 kv has slight loss. The detailed results are presented in the [Evaluation](#evaluation) section. You can refer to the information and choose wisely based on your requirements.
|
| 8 |
+
|
| 9 |
+
LMDeploy inference with quantized kv supports the following NVIDIA GPU models:
|
| 10 |
+
|
| 11 |
+
- Volta architecture (sm70): V100
|
| 12 |
+
- Turing architecture (sm75): 20 series, T4
|
| 13 |
+
- Ampere architecture (sm80, sm86): 30 series, A10, A16, A30, A100
|
| 14 |
+
- Ada Lovelace architecture (sm89): 40 series
|
| 15 |
+
- Hopper architecture (sm90): H100, H200
|
| 16 |
+
|
| 17 |
+
In summary, LMDeploy kv quantization has the following advantages:
|
| 18 |
+
|
| 19 |
+
1. data-free online quantization
|
| 20 |
+
2. Supports all nvidia GPU models with Volta architecture (sm70) and above
|
| 21 |
+
3. KV int8 quantization has almost lossless accuracy, and KV int4 quantization accuracy is within an acceptable range
|
| 22 |
+
4. Efficient inference, with int8/int4 kv quantization applied to llama2-7b, RPS is improved by round 30% and 40% respectively compared to fp16
|
| 23 |
+
|
| 24 |
+
In the next section, we will take `internlm2-chat-7b` model as an example, introducing the usage of kv quantization and inference of lmdeploy. But before that, please ensure that lmdeploy is installed.
|
| 25 |
+
|
| 26 |
+
```shell
|
| 27 |
+
pip install lmdeploy
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
## Usage
|
| 31 |
+
|
| 32 |
+
Applying kv quantization and inference via LMDeploy is quite straightforward. Simply set the `quant_policy` parameter.
|
| 33 |
+
|
| 34 |
+
**LMDeploy specifies that `quant_policy=4` stands for 4-bit kv, whereas `quant_policy=8` indicates 8-bit kv.**
|
| 35 |
+
|
| 36 |
+
### Offline inference
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 40 |
+
engine_config = TurbomindEngineConfig(quant_policy=8)
|
| 41 |
+
pipe = pipeline("internlm/internlm2_5-7b-chat", backend_config=engine_config)
|
| 42 |
+
response = pipe(["Hi, pls intro yourself", "Shanghai is"])
|
| 43 |
+
print(response)
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
### Serving
|
| 47 |
+
|
| 48 |
+
```shell
|
| 49 |
+
lmdeploy serve api_server internlm/internlm2_5-7b-chat --quant-policy 8
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
## Evaluation
|
| 53 |
+
|
| 54 |
+
We apply kv quantization of LMDeploy to several LLM models and utilize OpenCompass to evaluate the inference accuracy. The results are shown in the table below:
|
| 55 |
+
|
| 56 |
+
| - | - | - | llama2-7b-chat | - | - | internlm2-chat-7b | - | - | internlm2.5-chat-7b | - | - | qwen1.5-7b-chat | - | - |
|
| 57 |
+
| ----------- | ------- | ------------- | -------------- | ------- | ------- | ----------------- | ------- | ------- | ------------------- | ------- | ------- | --------------- | ------- | ------- |
|
| 58 |
+
| dataset | version | metric | kv fp16 | kv int8 | kv int4 | kv fp16 | kv int8 | kv int4 | kv fp16 | kv int8 | kv int4 | fp16 | kv int8 | kv int4 |
|
| 59 |
+
| ceval | - | naive_average | 28.42 | 27.96 | 27.58 | 60.45 | 60.88 | 60.28 | 78.06 | 77.87 | 77.05 | 70.56 | 70.49 | 68.62 |
|
| 60 |
+
| mmlu | - | naive_average | 35.64 | 35.58 | 34.79 | 63.91 | 64 | 62.36 | 72.30 | 72.27 | 71.17 | 61.48 | 61.56 | 60.65 |
|
| 61 |
+
| triviaqa | 2121ce | score | 56.09 | 56.13 | 53.71 | 58.73 | 58.7 | 58.18 | 65.09 | 64.87 | 63.28 | 44.62 | 44.77 | 44.04 |
|
| 62 |
+
| gsm8k | 1d7fe4 | accuracy | 28.2 | 28.05 | 27.37 | 70.13 | 69.75 | 66.87 | 85.67 | 85.44 | 83.78 | 54.97 | 56.41 | 54.74 |
|
| 63 |
+
| race-middle | 9a54b6 | accuracy | 41.57 | 41.78 | 41.23 | 88.93 | 88.93 | 88.93 | 92.76 | 92.83 | 92.55 | 87.33 | 87.26 | 86.28 |
|
| 64 |
+
| race-high | 9a54b6 | accuracy | 39.65 | 39.77 | 40.77 | 85.33 | 85.31 | 84.62 | 90.51 | 90.42 | 90.42 | 82.53 | 82.59 | 82.02 |
|
| 65 |
+
|
| 66 |
+
For detailed evaluation methods, please refer to [this](../benchmark/evaluate_with_opencompass.md) guide. Remember to pass `quant_policy` to the inference engine in the config file.
|
| 67 |
+
|
| 68 |
+
## Performance
|
| 69 |
+
|
| 70 |
+
| model | kv type | test settings | RPS | v.s. kv fp16 |
|
| 71 |
+
| ----------------- | ------- | ---------------------------------------- | ----- | ------------ |
|
| 72 |
+
| llama2-chat-7b | fp16 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 14.98 | 1.0 |
|
| 73 |
+
| - | int8 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 19.01 | 1.27 |
|
| 74 |
+
| - | int4 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 20.81 | 1.39 |
|
| 75 |
+
| llama2-chat-13b | fp16 | tp1 / ratio 0.9 / bs 128 / prompts 10000 | 8.55 | 1.0 |
|
| 76 |
+
| - | int8 | tp1 / ratio 0.9 / bs 256 / prompts 10000 | 10.96 | 1.28 |
|
| 77 |
+
| - | int4 | tp1 / ratio 0.9 / bs 256 / prompts 10000 | 11.91 | 1.39 |
|
| 78 |
+
| internlm2-chat-7b | fp16 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 24.13 | 1.0 |
|
| 79 |
+
| - | int8 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 25.28 | 1.05 |
|
| 80 |
+
| - | int4 | tp1 / ratio 0.8 / bs 256 / prompts 10000 | 25.80 | 1.07 |
|
| 81 |
+
|
| 82 |
+
The performance data is obtained by `benchmark/profile_throughput.py`
|
a_mllm_notebooks/lmdeploy/links.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'https://github.com/InternLM/lmdeploy/blob/main/docs/en/quantization/kv_quant.md'
|
| 2 |
+
'https://github.com/InternLM/lmdeploy/blob/main/docs/en/advance/pytorch_new_model.md'
|
| 3 |
+
'https://github.com/InternLM/lmdeploy/blob/main/docs/en/inference/turbomind.md'
|
| 4 |
+
'https://github.com/InternLM/lmdeploy/blob/main/docs/en/multi_modal/api_server_vl.md'
|
| 5 |
+
'https://github.com/InternLM/lmdeploy/blob/main/docs/en/quantization/w4a16.md'
|
| 6 |
+
'https://github.com/InternLM/lmdeploy/blob/main/docs/en/quantization/w8a8.md'
|
| 7 |
+
'https://github.com/InternLM/lmdeploy/blob/main/docs/en/llm/proxy_server.md'
|
| 8 |
+
'https://github.com/InternLM/lmdeploy/blob/main/docs/en/advance/long_context.md'
|
a_mllm_notebooks/lmdeploy/lmdeploy_deepseek_vl.ipynb
ADDED
|
@@ -0,0 +1,665 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"nbformat": 4,
|
| 3 |
+
"nbformat_minor": 0,
|
| 4 |
+
"metadata": {
|
| 5 |
+
"colab": {
|
| 6 |
+
"provenance": [],
|
| 7 |
+
"gpuType": "T4"
|
| 8 |
+
},
|
| 9 |
+
"kernelspec": {
|
| 10 |
+
"name": "python3",
|
| 11 |
+
"display_name": "Python 3"
|
| 12 |
+
},
|
| 13 |
+
"language_info": {
|
| 14 |
+
"name": "python"
|
| 15 |
+
},
|
| 16 |
+
"accelerator": "GPU",
|
| 17 |
+
"widgets": {
|
| 18 |
+
"application/vnd.jupyter.widget-state+json": {
|
| 19 |
+
"998fbdaa144d466b8973bda101228f84": {
|
| 20 |
+
"model_module": "@jupyter-widgets/controls",
|
| 21 |
+
"model_name": "HBoxModel",
|
| 22 |
+
"model_module_version": "1.5.0",
|
| 23 |
+
"state": {
|
| 24 |
+
"_dom_classes": [],
|
| 25 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 26 |
+
"_model_module_version": "1.5.0",
|
| 27 |
+
"_model_name": "HBoxModel",
|
| 28 |
+
"_view_count": null,
|
| 29 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 30 |
+
"_view_module_version": "1.5.0",
|
| 31 |
+
"_view_name": "HBoxView",
|
| 32 |
+
"box_style": "",
|
| 33 |
+
"children": [
|
| 34 |
+
"IPY_MODEL_3628d06a3bcb451aa7866b52dd553dc4",
|
| 35 |
+
"IPY_MODEL_4690b670bfae4dc0b81c08c774bfbd9a",
|
| 36 |
+
"IPY_MODEL_d2430af0eaa4457491a294e252104c11"
|
| 37 |
+
],
|
| 38 |
+
"layout": "IPY_MODEL_88e413f539ac4bfa95d2954178a8df00"
|
| 39 |
+
}
|
| 40 |
+
},
|
| 41 |
+
"3628d06a3bcb451aa7866b52dd553dc4": {
|
| 42 |
+
"model_module": "@jupyter-widgets/controls",
|
| 43 |
+
"model_name": "HTMLModel",
|
| 44 |
+
"model_module_version": "1.5.0",
|
| 45 |
+
"state": {
|
| 46 |
+
"_dom_classes": [],
|
| 47 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 48 |
+
"_model_module_version": "1.5.0",
|
| 49 |
+
"_model_name": "HTMLModel",
|
| 50 |
+
"_view_count": null,
|
| 51 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 52 |
+
"_view_module_version": "1.5.0",
|
| 53 |
+
"_view_name": "HTMLView",
|
| 54 |
+
"description": "",
|
| 55 |
+
"description_tooltip": null,
|
| 56 |
+
"layout": "IPY_MODEL_79d4ad1a55e64291b67f7a2ed2e82bfc",
|
| 57 |
+
"placeholder": "",
|
| 58 |
+
"style": "IPY_MODEL_0d32734804454f3fa1511a8be9facd5b",
|
| 59 |
+
"value": "Fetching 9 files: 100%"
|
| 60 |
+
}
|
| 61 |
+
},
|
| 62 |
+
"4690b670bfae4dc0b81c08c774bfbd9a": {
|
| 63 |
+
"model_module": "@jupyter-widgets/controls",
|
| 64 |
+
"model_name": "FloatProgressModel",
|
| 65 |
+
"model_module_version": "1.5.0",
|
| 66 |
+
"state": {
|
| 67 |
+
"_dom_classes": [],
|
| 68 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 69 |
+
"_model_module_version": "1.5.0",
|
| 70 |
+
"_model_name": "FloatProgressModel",
|
| 71 |
+
"_view_count": null,
|
| 72 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 73 |
+
"_view_module_version": "1.5.0",
|
| 74 |
+
"_view_name": "ProgressView",
|
| 75 |
+
"bar_style": "success",
|
| 76 |
+
"description": "",
|
| 77 |
+
"description_tooltip": null,
|
| 78 |
+
"layout": "IPY_MODEL_5250b56c84e34862ac892d395730218f",
|
| 79 |
+
"max": 9,
|
| 80 |
+
"min": 0,
|
| 81 |
+
"orientation": "horizontal",
|
| 82 |
+
"style": "IPY_MODEL_5bf6228dfb8f4cc1a542590545f68338",
|
| 83 |
+
"value": 9
|
| 84 |
+
}
|
| 85 |
+
},
|
| 86 |
+
"d2430af0eaa4457491a294e252104c11": {
|
| 87 |
+
"model_module": "@jupyter-widgets/controls",
|
| 88 |
+
"model_name": "HTMLModel",
|
| 89 |
+
"model_module_version": "1.5.0",
|
| 90 |
+
"state": {
|
| 91 |
+
"_dom_classes": [],
|
| 92 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 93 |
+
"_model_module_version": "1.5.0",
|
| 94 |
+
"_model_name": "HTMLModel",
|
| 95 |
+
"_view_count": null,
|
| 96 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 97 |
+
"_view_module_version": "1.5.0",
|
| 98 |
+
"_view_name": "HTMLView",
|
| 99 |
+
"description": "",
|
| 100 |
+
"description_tooltip": null,
|
| 101 |
+
"layout": "IPY_MODEL_f05724a0721f4321ac7f41129682e232",
|
| 102 |
+
"placeholder": "",
|
| 103 |
+
"style": "IPY_MODEL_20029df435c44a44a6b1c61552cf8a25",
|
| 104 |
+
"value": " 9/9 [00:00<00:00, 141.93it/s]"
|
| 105 |
+
}
|
| 106 |
+
},
|
| 107 |
+
"88e413f539ac4bfa95d2954178a8df00": {
|
| 108 |
+
"model_module": "@jupyter-widgets/base",
|
| 109 |
+
"model_name": "LayoutModel",
|
| 110 |
+
"model_module_version": "1.2.0",
|
| 111 |
+
"state": {
|
| 112 |
+
"_model_module": "@jupyter-widgets/base",
|
| 113 |
+
"_model_module_version": "1.2.0",
|
| 114 |
+
"_model_name": "LayoutModel",
|
| 115 |
+
"_view_count": null,
|
| 116 |
+
"_view_module": "@jupyter-widgets/base",
|
| 117 |
+
"_view_module_version": "1.2.0",
|
| 118 |
+
"_view_name": "LayoutView",
|
| 119 |
+
"align_content": null,
|
| 120 |
+
"align_items": null,
|
| 121 |
+
"align_self": null,
|
| 122 |
+
"border": null,
|
| 123 |
+
"bottom": null,
|
| 124 |
+
"display": null,
|
| 125 |
+
"flex": null,
|
| 126 |
+
"flex_flow": null,
|
| 127 |
+
"grid_area": null,
|
| 128 |
+
"grid_auto_columns": null,
|
| 129 |
+
"grid_auto_flow": null,
|
| 130 |
+
"grid_auto_rows": null,
|
| 131 |
+
"grid_column": null,
|
| 132 |
+
"grid_gap": null,
|
| 133 |
+
"grid_row": null,
|
| 134 |
+
"grid_template_areas": null,
|
| 135 |
+
"grid_template_columns": null,
|
| 136 |
+
"grid_template_rows": null,
|
| 137 |
+
"height": null,
|
| 138 |
+
"justify_content": null,
|
| 139 |
+
"justify_items": null,
|
| 140 |
+
"left": null,
|
| 141 |
+
"margin": null,
|
| 142 |
+
"max_height": null,
|
| 143 |
+
"max_width": null,
|
| 144 |
+
"min_height": null,
|
| 145 |
+
"min_width": null,
|
| 146 |
+
"object_fit": null,
|
| 147 |
+
"object_position": null,
|
| 148 |
+
"order": null,
|
| 149 |
+
"overflow": null,
|
| 150 |
+
"overflow_x": null,
|
| 151 |
+
"overflow_y": null,
|
| 152 |
+
"padding": null,
|
| 153 |
+
"right": null,
|
| 154 |
+
"top": null,
|
| 155 |
+
"visibility": null,
|
| 156 |
+
"width": null
|
| 157 |
+
}
|
| 158 |
+
},
|
| 159 |
+
"79d4ad1a55e64291b67f7a2ed2e82bfc": {
|
| 160 |
+
"model_module": "@jupyter-widgets/base",
|
| 161 |
+
"model_name": "LayoutModel",
|
| 162 |
+
"model_module_version": "1.2.0",
|
| 163 |
+
"state": {
|
| 164 |
+
"_model_module": "@jupyter-widgets/base",
|
| 165 |
+
"_model_module_version": "1.2.0",
|
| 166 |
+
"_model_name": "LayoutModel",
|
| 167 |
+
"_view_count": null,
|
| 168 |
+
"_view_module": "@jupyter-widgets/base",
|
| 169 |
+
"_view_module_version": "1.2.0",
|
| 170 |
+
"_view_name": "LayoutView",
|
| 171 |
+
"align_content": null,
|
| 172 |
+
"align_items": null,
|
| 173 |
+
"align_self": null,
|
| 174 |
+
"border": null,
|
| 175 |
+
"bottom": null,
|
| 176 |
+
"display": null,
|
| 177 |
+
"flex": null,
|
| 178 |
+
"flex_flow": null,
|
| 179 |
+
"grid_area": null,
|
| 180 |
+
"grid_auto_columns": null,
|
| 181 |
+
"grid_auto_flow": null,
|
| 182 |
+
"grid_auto_rows": null,
|
| 183 |
+
"grid_column": null,
|
| 184 |
+
"grid_gap": null,
|
| 185 |
+
"grid_row": null,
|
| 186 |
+
"grid_template_areas": null,
|
| 187 |
+
"grid_template_columns": null,
|
| 188 |
+
"grid_template_rows": null,
|
| 189 |
+
"height": null,
|
| 190 |
+
"justify_content": null,
|
| 191 |
+
"justify_items": null,
|
| 192 |
+
"left": null,
|
| 193 |
+
"margin": null,
|
| 194 |
+
"max_height": null,
|
| 195 |
+
"max_width": null,
|
| 196 |
+
"min_height": null,
|
| 197 |
+
"min_width": null,
|
| 198 |
+
"object_fit": null,
|
| 199 |
+
"object_position": null,
|
| 200 |
+
"order": null,
|
| 201 |
+
"overflow": null,
|
| 202 |
+
"overflow_x": null,
|
| 203 |
+
"overflow_y": null,
|
| 204 |
+
"padding": null,
|
| 205 |
+
"right": null,
|
| 206 |
+
"top": null,
|
| 207 |
+
"visibility": null,
|
| 208 |
+
"width": null
|
| 209 |
+
}
|
| 210 |
+
},
|
| 211 |
+
"0d32734804454f3fa1511a8be9facd5b": {
|
| 212 |
+
"model_module": "@jupyter-widgets/controls",
|
| 213 |
+
"model_name": "DescriptionStyleModel",
|
| 214 |
+
"model_module_version": "1.5.0",
|
| 215 |
+
"state": {
|
| 216 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 217 |
+
"_model_module_version": "1.5.0",
|
| 218 |
+
"_model_name": "DescriptionStyleModel",
|
| 219 |
+
"_view_count": null,
|
| 220 |
+
"_view_module": "@jupyter-widgets/base",
|
| 221 |
+
"_view_module_version": "1.2.0",
|
| 222 |
+
"_view_name": "StyleView",
|
| 223 |
+
"description_width": ""
|
| 224 |
+
}
|
| 225 |
+
},
|
| 226 |
+
"5250b56c84e34862ac892d395730218f": {
|
| 227 |
+
"model_module": "@jupyter-widgets/base",
|
| 228 |
+
"model_name": "LayoutModel",
|
| 229 |
+
"model_module_version": "1.2.0",
|
| 230 |
+
"state": {
|
| 231 |
+
"_model_module": "@jupyter-widgets/base",
|
| 232 |
+
"_model_module_version": "1.2.0",
|
| 233 |
+
"_model_name": "LayoutModel",
|
| 234 |
+
"_view_count": null,
|
| 235 |
+
"_view_module": "@jupyter-widgets/base",
|
| 236 |
+
"_view_module_version": "1.2.0",
|
| 237 |
+
"_view_name": "LayoutView",
|
| 238 |
+
"align_content": null,
|
| 239 |
+
"align_items": null,
|
| 240 |
+
"align_self": null,
|
| 241 |
+
"border": null,
|
| 242 |
+
"bottom": null,
|
| 243 |
+
"display": null,
|
| 244 |
+
"flex": null,
|
| 245 |
+
"flex_flow": null,
|
| 246 |
+
"grid_area": null,
|
| 247 |
+
"grid_auto_columns": null,
|
| 248 |
+
"grid_auto_flow": null,
|
| 249 |
+
"grid_auto_rows": null,
|
| 250 |
+
"grid_column": null,
|
| 251 |
+
"grid_gap": null,
|
| 252 |
+
"grid_row": null,
|
| 253 |
+
"grid_template_areas": null,
|
| 254 |
+
"grid_template_columns": null,
|
| 255 |
+
"grid_template_rows": null,
|
| 256 |
+
"height": null,
|
| 257 |
+
"justify_content": null,
|
| 258 |
+
"justify_items": null,
|
| 259 |
+
"left": null,
|
| 260 |
+
"margin": null,
|
| 261 |
+
"max_height": null,
|
| 262 |
+
"max_width": null,
|
| 263 |
+
"min_height": null,
|
| 264 |
+
"min_width": null,
|
| 265 |
+
"object_fit": null,
|
| 266 |
+
"object_position": null,
|
| 267 |
+
"order": null,
|
| 268 |
+
"overflow": null,
|
| 269 |
+
"overflow_x": null,
|
| 270 |
+
"overflow_y": null,
|
| 271 |
+
"padding": null,
|
| 272 |
+
"right": null,
|
| 273 |
+
"top": null,
|
| 274 |
+
"visibility": null,
|
| 275 |
+
"width": null
|
| 276 |
+
}
|
| 277 |
+
},
|
| 278 |
+
"5bf6228dfb8f4cc1a542590545f68338": {
|
| 279 |
+
"model_module": "@jupyter-widgets/controls",
|
| 280 |
+
"model_name": "ProgressStyleModel",
|
| 281 |
+
"model_module_version": "1.5.0",
|
| 282 |
+
"state": {
|
| 283 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 284 |
+
"_model_module_version": "1.5.0",
|
| 285 |
+
"_model_name": "ProgressStyleModel",
|
| 286 |
+
"_view_count": null,
|
| 287 |
+
"_view_module": "@jupyter-widgets/base",
|
| 288 |
+
"_view_module_version": "1.2.0",
|
| 289 |
+
"_view_name": "StyleView",
|
| 290 |
+
"bar_color": null,
|
| 291 |
+
"description_width": ""
|
| 292 |
+
}
|
| 293 |
+
},
|
| 294 |
+
"f05724a0721f4321ac7f41129682e232": {
|
| 295 |
+
"model_module": "@jupyter-widgets/base",
|
| 296 |
+
"model_name": "LayoutModel",
|
| 297 |
+
"model_module_version": "1.2.0",
|
| 298 |
+
"state": {
|
| 299 |
+
"_model_module": "@jupyter-widgets/base",
|
| 300 |
+
"_model_module_version": "1.2.0",
|
| 301 |
+
"_model_name": "LayoutModel",
|
| 302 |
+
"_view_count": null,
|
| 303 |
+
"_view_module": "@jupyter-widgets/base",
|
| 304 |
+
"_view_module_version": "1.2.0",
|
| 305 |
+
"_view_name": "LayoutView",
|
| 306 |
+
"align_content": null,
|
| 307 |
+
"align_items": null,
|
| 308 |
+
"align_self": null,
|
| 309 |
+
"border": null,
|
| 310 |
+
"bottom": null,
|
| 311 |
+
"display": null,
|
| 312 |
+
"flex": null,
|
| 313 |
+
"flex_flow": null,
|
| 314 |
+
"grid_area": null,
|
| 315 |
+
"grid_auto_columns": null,
|
| 316 |
+
"grid_auto_flow": null,
|
| 317 |
+
"grid_auto_rows": null,
|
| 318 |
+
"grid_column": null,
|
| 319 |
+
"grid_gap": null,
|
| 320 |
+
"grid_row": null,
|
| 321 |
+
"grid_template_areas": null,
|
| 322 |
+
"grid_template_columns": null,
|
| 323 |
+
"grid_template_rows": null,
|
| 324 |
+
"height": null,
|
| 325 |
+
"justify_content": null,
|
| 326 |
+
"justify_items": null,
|
| 327 |
+
"left": null,
|
| 328 |
+
"margin": null,
|
| 329 |
+
"max_height": null,
|
| 330 |
+
"max_width": null,
|
| 331 |
+
"min_height": null,
|
| 332 |
+
"min_width": null,
|
| 333 |
+
"object_fit": null,
|
| 334 |
+
"object_position": null,
|
| 335 |
+
"order": null,
|
| 336 |
+
"overflow": null,
|
| 337 |
+
"overflow_x": null,
|
| 338 |
+
"overflow_y": null,
|
| 339 |
+
"padding": null,
|
| 340 |
+
"right": null,
|
| 341 |
+
"top": null,
|
| 342 |
+
"visibility": null,
|
| 343 |
+
"width": null
|
| 344 |
+
}
|
| 345 |
+
},
|
| 346 |
+
"20029df435c44a44a6b1c61552cf8a25": {
|
| 347 |
+
"model_module": "@jupyter-widgets/controls",
|
| 348 |
+
"model_name": "DescriptionStyleModel",
|
| 349 |
+
"model_module_version": "1.5.0",
|
| 350 |
+
"state": {
|
| 351 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 352 |
+
"_model_module_version": "1.5.0",
|
| 353 |
+
"_model_name": "DescriptionStyleModel",
|
| 354 |
+
"_view_count": null,
|
| 355 |
+
"_view_module": "@jupyter-widgets/base",
|
| 356 |
+
"_view_module_version": "1.2.0",
|
| 357 |
+
"_view_name": "StyleView",
|
| 358 |
+
"description_width": ""
|
| 359 |
+
}
|
| 360 |
+
}
|
| 361 |
+
}
|
| 362 |
+
}
|
| 363 |
+
},
|
| 364 |
+
"cells": [
|
| 365 |
+
{
|
| 366 |
+
"cell_type": "markdown",
|
| 367 |
+
"source": [
|
| 368 |
+
"# Install lmdeploy\n",
|
| 369 |
+
"Below, we will introduce how to use LMDeploy to run the inference of deepseek-ai/deepseek-vl-1.3b-chat model on a T4 GPU."
|
| 370 |
+
],
|
| 371 |
+
"metadata": {
|
| 372 |
+
"id": "LvQjS_1PHeSh"
|
| 373 |
+
}
|
| 374 |
+
},
|
| 375 |
+
{
|
| 376 |
+
"cell_type": "code",
|
| 377 |
+
"execution_count": null,
|
| 378 |
+
"metadata": {
|
| 379 |
+
"colab": {
|
| 380 |
+
"base_uri": "https://localhost:8080/"
|
| 381 |
+
},
|
| 382 |
+
"id": "myQIIbTXkXxm",
|
| 383 |
+
"outputId": "4c6ff0ff-3572-4757-ecdd-a742fda07ff2"
|
| 384 |
+
},
|
| 385 |
+
"outputs": [
|
| 386 |
+
{
|
| 387 |
+
"output_type": "stream",
|
| 388 |
+
"name": "stdout",
|
| 389 |
+
"text": [
|
| 390 |
+
"Requirement already satisfied: lmdeploy in /usr/local/lib/python3.10/dist-packages (0.4.0)\n",
|
| 391 |
+
"Requirement already satisfied: einops in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.7.0)\n",
|
| 392 |
+
"Requirement already satisfied: fastapi in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.110.2)\n",
|
| 393 |
+
"Requirement already satisfied: fire in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.6.0)\n",
|
| 394 |
+
"Requirement already satisfied: mmengine-lite in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.10.4)\n",
|
| 395 |
+
"Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (1.25.2)\n",
|
| 396 |
+
"Requirement already satisfied: peft<=0.9.0 in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.9.0)\n",
|
| 397 |
+
"Requirement already satisfied: pillow in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (9.4.0)\n",
|
| 398 |
+
"Requirement already satisfied: protobuf in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (3.20.3)\n",
|
| 399 |
+
"Requirement already satisfied: pydantic>2.0.0 in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (2.7.0)\n",
|
| 400 |
+
"Requirement already satisfied: pynvml in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (11.5.0)\n",
|
| 401 |
+
"Requirement already satisfied: safetensors in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.4.3)\n",
|
| 402 |
+
"Requirement already satisfied: sentencepiece in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.1.99)\n",
|
| 403 |
+
"Requirement already satisfied: shortuuid in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (1.0.13)\n",
|
| 404 |
+
"Requirement already satisfied: tiktoken in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.6.0)\n",
|
| 405 |
+
"Requirement already satisfied: torch<=2.2.2,>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (2.2.1+cu121)\n",
|
| 406 |
+
"Requirement already satisfied: transformers in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (4.40.0)\n",
|
| 407 |
+
"Requirement already satisfied: triton<=2.2.0,>=2.1.0 in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (2.2.0)\n",
|
| 408 |
+
"Requirement already satisfied: uvicorn in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (0.29.0)\n",
|
| 409 |
+
"Requirement already satisfied: nvidia-nccl-cu12 in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (2.19.3)\n",
|
| 410 |
+
"Requirement already satisfied: nvidia-cuda-runtime-cu12 in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (12.1.105)\n",
|
| 411 |
+
"Requirement already satisfied: nvidia-cublas-cu12 in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (12.1.3.1)\n",
|
| 412 |
+
"Requirement already satisfied: nvidia-curand-cu12 in /usr/local/lib/python3.10/dist-packages (from lmdeploy) (10.3.2.106)\n",
|
| 413 |
+
"Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from peft<=0.9.0->lmdeploy) (24.0)\n",
|
| 414 |
+
"Requirement already satisfied: psutil in /usr/local/lib/python3.10/dist-packages (from peft<=0.9.0->lmdeploy) (5.9.5)\n",
|
| 415 |
+
"Requirement already satisfied: pyyaml in /usr/local/lib/python3.10/dist-packages (from peft<=0.9.0->lmdeploy) (6.0.1)\n",
|
| 416 |
+
"Requirement already satisfied: tqdm in /usr/local/lib/python3.10/dist-packages (from peft<=0.9.0->lmdeploy) (4.66.2)\n",
|
| 417 |
+
"Requirement already satisfied: accelerate>=0.21.0 in /usr/local/lib/python3.10/dist-packages (from peft<=0.9.0->lmdeploy) (0.29.3)\n",
|
| 418 |
+
"Requirement already satisfied: huggingface-hub>=0.17.0 in /usr/local/lib/python3.10/dist-packages (from peft<=0.9.0->lmdeploy) (0.20.3)\n",
|
| 419 |
+
"Requirement already satisfied: annotated-types>=0.4.0 in /usr/local/lib/python3.10/dist-packages (from pydantic>2.0.0->lmdeploy) (0.6.0)\n",
|
| 420 |
+
"Requirement already satisfied: pydantic-core==2.18.1 in /usr/local/lib/python3.10/dist-packages (from pydantic>2.0.0->lmdeploy) (2.18.1)\n",
|
| 421 |
+
"Requirement already satisfied: typing-extensions>=4.6.1 in /usr/local/lib/python3.10/dist-packages (from pydantic>2.0.0->lmdeploy) (4.11.0)\n",
|
| 422 |
+
"Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (3.13.4)\n",
|
| 423 |
+
"Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (1.12)\n",
|
| 424 |
+
"Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (3.3)\n",
|
| 425 |
+
"Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (3.1.3)\n",
|
| 426 |
+
"Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (2023.6.0)\n",
|
| 427 |
+
"Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (12.1.105)\n",
|
| 428 |
+
"Requirement already satisfied: nvidia-cuda-cupti-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (12.1.105)\n",
|
| 429 |
+
"Requirement already satisfied: nvidia-cudnn-cu12==8.9.2.26 in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (8.9.2.26)\n",
|
| 430 |
+
"Requirement already satisfied: nvidia-cufft-cu12==11.0.2.54 in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (11.0.2.54)\n",
|
| 431 |
+
"Requirement already satisfied: nvidia-cusolver-cu12==11.4.5.107 in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (11.4.5.107)\n",
|
| 432 |
+
"Requirement already satisfied: nvidia-cusparse-cu12==12.1.0.106 in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (12.1.0.106)\n",
|
| 433 |
+
"Requirement already satisfied: nvidia-nvtx-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch<=2.2.2,>=2.0.0->lmdeploy) (12.1.105)\n",
|
| 434 |
+
"Requirement already satisfied: nvidia-nvjitlink-cu12 in /usr/local/lib/python3.10/dist-packages (from nvidia-cusolver-cu12==11.4.5.107->torch<=2.2.2,>=2.0.0->lmdeploy) (12.4.127)\n",
|
| 435 |
+
"Requirement already satisfied: starlette<0.38.0,>=0.37.2 in /usr/local/lib/python3.10/dist-packages (from fastapi->lmdeploy) (0.37.2)\n",
|
| 436 |
+
"Requirement already satisfied: six in /usr/local/lib/python3.10/dist-packages (from fire->lmdeploy) (1.16.0)\n",
|
| 437 |
+
"Requirement already satisfied: termcolor in /usr/local/lib/python3.10/dist-packages (from fire->lmdeploy) (2.4.0)\n",
|
| 438 |
+
"Requirement already satisfied: addict in /usr/local/lib/python3.10/dist-packages (from mmengine-lite->lmdeploy) (2.4.0)\n",
|
| 439 |
+
"Requirement already satisfied: rich in /usr/local/lib/python3.10/dist-packages (from mmengine-lite->lmdeploy) (13.7.1)\n",
|
| 440 |
+
"Requirement already satisfied: yapf in /usr/local/lib/python3.10/dist-packages (from mmengine-lite->lmdeploy) (0.40.2)\n",
|
| 441 |
+
"Requirement already satisfied: regex>=2022.1.18 in /usr/local/lib/python3.10/dist-packages (from tiktoken->lmdeploy) (2023.12.25)\n",
|
| 442 |
+
"Requirement already satisfied: requests>=2.26.0 in /usr/local/lib/python3.10/dist-packages (from tiktoken->lmdeploy) (2.31.0)\n",
|
| 443 |
+
"Requirement already satisfied: tokenizers<0.20,>=0.19 in /usr/local/lib/python3.10/dist-packages (from transformers->lmdeploy) (0.19.1)\n",
|
| 444 |
+
"Requirement already satisfied: click>=7.0 in /usr/local/lib/python3.10/dist-packages (from uvicorn->lmdeploy) (8.1.7)\n",
|
| 445 |
+
"Requirement already satisfied: h11>=0.8 in /usr/local/lib/python3.10/dist-packages (from uvicorn->lmdeploy) (0.14.0)\n",
|
| 446 |
+
"Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests>=2.26.0->tiktoken->lmdeploy) (3.3.2)\n",
|
| 447 |
+
"Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests>=2.26.0->tiktoken->lmdeploy) (3.7)\n",
|
| 448 |
+
"Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests>=2.26.0->tiktoken->lmdeploy) (2.0.7)\n",
|
| 449 |
+
"Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests>=2.26.0->tiktoken->lmdeploy) (2024.2.2)\n",
|
| 450 |
+
"Requirement already satisfied: anyio<5,>=3.4.0 in /usr/local/lib/python3.10/dist-packages (from starlette<0.38.0,>=0.37.2->fastapi->lmdeploy) (3.7.1)\n",
|
| 451 |
+
"Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch<=2.2.2,>=2.0.0->lmdeploy) (2.1.5)\n",
|
| 452 |
+
"Requirement already satisfied: markdown-it-py>=2.2.0 in /usr/local/lib/python3.10/dist-packages (from rich->mmengine-lite->lmdeploy) (3.0.0)\n",
|
| 453 |
+
"Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /usr/local/lib/python3.10/dist-packages (from rich->mmengine-lite->lmdeploy) (2.16.1)\n",
|
| 454 |
+
"Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch<=2.2.2,>=2.0.0->lmdeploy) (1.3.0)\n",
|
| 455 |
+
"Requirement already satisfied: importlib-metadata>=6.6.0 in /usr/local/lib/python3.10/dist-packages (from yapf->mmengine-lite->lmdeploy) (7.1.0)\n",
|
| 456 |
+
"Requirement already satisfied: platformdirs>=3.5.1 in /usr/local/lib/python3.10/dist-packages (from yapf->mmengine-lite->lmdeploy) (4.2.0)\n",
|
| 457 |
+
"Requirement already satisfied: tomli>=2.0.1 in /usr/local/lib/python3.10/dist-packages (from yapf->mmengine-lite->lmdeploy) (2.0.1)\n",
|
| 458 |
+
"Requirement already satisfied: sniffio>=1.1 in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.4.0->starlette<0.38.0,>=0.37.2->fastapi->lmdeploy) (1.3.1)\n",
|
| 459 |
+
"Requirement already satisfied: exceptiongroup in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.4.0->starlette<0.38.0,>=0.37.2->fastapi->lmdeploy) (1.2.1)\n",
|
| 460 |
+
"Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.10/dist-packages (from importlib-metadata>=6.6.0->yapf->mmengine-lite->lmdeploy) (3.18.1)\n",
|
| 461 |
+
"Requirement already satisfied: mdurl~=0.1 in /usr/local/lib/python3.10/dist-packages (from markdown-it-py>=2.2.0->rich->mmengine-lite->lmdeploy) (0.1.2)\n"
|
| 462 |
+
]
|
| 463 |
+
}
|
| 464 |
+
],
|
| 465 |
+
"source": [
|
| 466 |
+
"!pip install lmdeploy"
|
| 467 |
+
]
|
| 468 |
+
},
|
| 469 |
+
{
|
| 470 |
+
"cell_type": "markdown",
|
| 471 |
+
"source": [
|
| 472 |
+
"# Install vl package"
|
| 473 |
+
],
|
| 474 |
+
"metadata": {
|
| 475 |
+
"id": "YZmonXZI_L3d"
|
| 476 |
+
}
|
| 477 |
+
},
|
| 478 |
+
{
|
| 479 |
+
"cell_type": "code",
|
| 480 |
+
"source": [
|
| 481 |
+
"!pip install git+https://github.com/deepseek-ai/DeepSeek-VL.git"
|
| 482 |
+
],
|
| 483 |
+
"metadata": {
|
| 484 |
+
"colab": {
|
| 485 |
+
"base_uri": "https://localhost:8080/"
|
| 486 |
+
},
|
| 487 |
+
"id": "N_usa-tMlg44",
|
| 488 |
+
"outputId": "9c4165f0-6b68-4c33-9d80-ccd417380bee"
|
| 489 |
+
},
|
| 490 |
+
"execution_count": null,
|
| 491 |
+
"outputs": [
|
| 492 |
+
{
|
| 493 |
+
"output_type": "stream",
|
| 494 |
+
"name": "stdout",
|
| 495 |
+
"text": [
|
| 496 |
+
"Collecting git+https://github.com/deepseek-ai/DeepSeek-VL.git\n",
|
| 497 |
+
" Cloning https://github.com/deepseek-ai/DeepSeek-VL.git to /tmp/pip-req-build-_b9wee4w\n",
|
| 498 |
+
" Running command git clone --filter=blob:none --quiet https://github.com/deepseek-ai/DeepSeek-VL.git /tmp/pip-req-build-_b9wee4w\n",
|
| 499 |
+
" Resolved https://github.com/deepseek-ai/DeepSeek-VL.git to commit 37fcec4806394573f3268d9cf0c2f9669aa7993a\n",
|
| 500 |
+
" Installing build dependencies ... \u001b[?25l\u001b[?25hdone\n",
|
| 501 |
+
" Getting requirements to build wheel ... \u001b[?25l\u001b[?25hdone\n",
|
| 502 |
+
" Preparing metadata (pyproject.toml) ... \u001b[?25l\u001b[?25hdone\n",
|
| 503 |
+
"Requirement already satisfied: torch>=2.0.1 in /usr/local/lib/python3.10/dist-packages (from deepseek_vl==1.0.0) (2.2.1+cu121)\n",
|
| 504 |
+
"Requirement already satisfied: transformers>=4.38.2 in /usr/local/lib/python3.10/dist-packages (from deepseek_vl==1.0.0) (4.40.0)\n",
|
| 505 |
+
"Requirement already satisfied: timm>=0.9.16 in /usr/local/lib/python3.10/dist-packages (from deepseek_vl==1.0.0) (0.9.16)\n",
|
| 506 |
+
"Requirement already satisfied: accelerate in /usr/local/lib/python3.10/dist-packages (from deepseek_vl==1.0.0) (0.29.3)\n",
|
| 507 |
+
"Requirement already satisfied: sentencepiece in /usr/local/lib/python3.10/dist-packages (from deepseek_vl==1.0.0) (0.1.99)\n",
|
| 508 |
+
"Requirement already satisfied: attrdict in /usr/local/lib/python3.10/dist-packages (from deepseek_vl==1.0.0) (2.0.1)\n",
|
| 509 |
+
"Requirement already satisfied: einops in /usr/local/lib/python3.10/dist-packages (from deepseek_vl==1.0.0) (0.7.0)\n",
|
| 510 |
+
"Requirement already satisfied: torchvision in /usr/local/lib/python3.10/dist-packages (from timm>=0.9.16->deepseek_vl==1.0.0) (0.17.1+cu121)\n",
|
| 511 |
+
"Requirement already satisfied: pyyaml in /usr/local/lib/python3.10/dist-packages (from timm>=0.9.16->deepseek_vl==1.0.0) (6.0.1)\n",
|
| 512 |
+
"Requirement already satisfied: huggingface_hub in /usr/local/lib/python3.10/dist-packages (from timm>=0.9.16->deepseek_vl==1.0.0) (0.20.3)\n",
|
| 513 |
+
"Requirement already satisfied: safetensors in /usr/local/lib/python3.10/dist-packages (from timm>=0.9.16->deepseek_vl==1.0.0) (0.4.3)\n",
|
| 514 |
+
"Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (3.13.4)\n",
|
| 515 |
+
"Requirement already satisfied: typing-extensions>=4.8.0 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (4.11.0)\n",
|
| 516 |
+
"Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (1.12)\n",
|
| 517 |
+
"Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (3.3)\n",
|
| 518 |
+
"Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (3.1.3)\n",
|
| 519 |
+
"Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (2023.6.0)\n",
|
| 520 |
+
"Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (12.1.105)\n",
|
| 521 |
+
"Requirement already satisfied: nvidia-cuda-runtime-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (12.1.105)\n",
|
| 522 |
+
"Requirement already satisfied: nvidia-cuda-cupti-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (12.1.105)\n",
|
| 523 |
+
"Requirement already satisfied: nvidia-cudnn-cu12==8.9.2.26 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (8.9.2.26)\n",
|
| 524 |
+
"Requirement already satisfied: nvidia-cublas-cu12==12.1.3.1 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (12.1.3.1)\n",
|
| 525 |
+
"Requirement already satisfied: nvidia-cufft-cu12==11.0.2.54 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (11.0.2.54)\n",
|
| 526 |
+
"Requirement already satisfied: nvidia-curand-cu12==10.3.2.106 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (10.3.2.106)\n",
|
| 527 |
+
"Requirement already satisfied: nvidia-cusolver-cu12==11.4.5.107 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (11.4.5.107)\n",
|
| 528 |
+
"Requirement already satisfied: nvidia-cusparse-cu12==12.1.0.106 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (12.1.0.106)\n",
|
| 529 |
+
"Requirement already satisfied: nvidia-nccl-cu12==2.19.3 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (2.19.3)\n",
|
| 530 |
+
"Requirement already satisfied: nvidia-nvtx-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (12.1.105)\n",
|
| 531 |
+
"Requirement already satisfied: triton==2.2.0 in /usr/local/lib/python3.10/dist-packages (from torch>=2.0.1->deepseek_vl==1.0.0) (2.2.0)\n",
|
| 532 |
+
"Requirement already satisfied: nvidia-nvjitlink-cu12 in /usr/local/lib/python3.10/dist-packages (from nvidia-cusolver-cu12==11.4.5.107->torch>=2.0.1->deepseek_vl==1.0.0) (12.4.127)\n",
|
| 533 |
+
"Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.38.2->deepseek_vl==1.0.0) (1.25.2)\n",
|
| 534 |
+
"Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.38.2->deepseek_vl==1.0.0) (24.0)\n",
|
| 535 |
+
"Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.38.2->deepseek_vl==1.0.0) (2023.12.25)\n",
|
| 536 |
+
"Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers>=4.38.2->deepseek_vl==1.0.0) (2.31.0)\n",
|
| 537 |
+
"Requirement already satisfied: tokenizers<0.20,>=0.19 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.38.2->deepseek_vl==1.0.0) (0.19.1)\n",
|
| 538 |
+
"Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers>=4.38.2->deepseek_vl==1.0.0) (4.66.2)\n",
|
| 539 |
+
"Requirement already satisfied: psutil in /usr/local/lib/python3.10/dist-packages (from accelerate->deepseek_vl==1.0.0) (5.9.5)\n",
|
| 540 |
+
"Requirement already satisfied: six in /usr/local/lib/python3.10/dist-packages (from attrdict->deepseek_vl==1.0.0) (1.16.0)\n",
|
| 541 |
+
"Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch>=2.0.1->deepseek_vl==1.0.0) (2.1.5)\n",
|
| 542 |
+
"Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->transformers>=4.38.2->deepseek_vl==1.0.0) (3.3.2)\n",
|
| 543 |
+
"Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers>=4.38.2->deepseek_vl==1.0.0) (3.7)\n",
|
| 544 |
+
"Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers>=4.38.2->deepseek_vl==1.0.0) (2.0.7)\n",
|
| 545 |
+
"Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers>=4.38.2->deepseek_vl==1.0.0) (2024.2.2)\n",
|
| 546 |
+
"Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch>=2.0.1->deepseek_vl==1.0.0) (1.3.0)\n",
|
| 547 |
+
"Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.10/dist-packages (from torchvision->timm>=0.9.16->deepseek_vl==1.0.0) (9.4.0)\n"
|
| 548 |
+
]
|
| 549 |
+
}
|
| 550 |
+
]
|
| 551 |
+
},
|
| 552 |
+
{
|
| 553 |
+
"cell_type": "code",
|
| 554 |
+
"source": [
|
| 555 |
+
"!pip install nest_asyncio\n",
|
| 556 |
+
"import nest_asyncio\n",
|
| 557 |
+
"nest_asyncio.apply()"
|
| 558 |
+
],
|
| 559 |
+
"metadata": {
|
| 560 |
+
"colab": {
|
| 561 |
+
"base_uri": "https://localhost:8080/"
|
| 562 |
+
},
|
| 563 |
+
"id": "FNWeAUaZn3JB",
|
| 564 |
+
"outputId": "ec9edb83-981d-47cf-c803-5bfa9b265862"
|
| 565 |
+
},
|
| 566 |
+
"execution_count": null,
|
| 567 |
+
"outputs": [
|
| 568 |
+
{
|
| 569 |
+
"output_type": "stream",
|
| 570 |
+
"name": "stdout",
|
| 571 |
+
"text": [
|
| 572 |
+
"Requirement already satisfied: nest_asyncio in /usr/local/lib/python3.10/dist-packages (1.6.0)\n"
|
| 573 |
+
]
|
| 574 |
+
}
|
| 575 |
+
]
|
| 576 |
+
},
|
| 577 |
+
{
|
| 578 |
+
"cell_type": "code",
|
| 579 |
+
"source": [
|
| 580 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 581 |
+
"from lmdeploy.vl import load_image\n",
|
| 582 |
+
"\n",
|
| 583 |
+
"engine_config = TurbomindEngineConfig(cache_max_entry_count=0.3)\n",
|
| 584 |
+
"pipe = pipeline('deepseek-ai/deepseek-vl-1.3b-chat', backend_config=engine_config)\n",
|
| 585 |
+
"\n",
|
| 586 |
+
"image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')\n",
|
| 587 |
+
"response = pipe(('describe this image', image))\n",
|
| 588 |
+
"print(response)"
|
| 589 |
+
],
|
| 590 |
+
"metadata": {
|
| 591 |
+
"colab": {
|
| 592 |
+
"base_uri": "https://localhost:8080/",
|
| 593 |
+
"height": 260,
|
| 594 |
+
"referenced_widgets": [
|
| 595 |
+
"998fbdaa144d466b8973bda101228f84",
|
| 596 |
+
"3628d06a3bcb451aa7866b52dd553dc4",
|
| 597 |
+
"4690b670bfae4dc0b81c08c774bfbd9a",
|
| 598 |
+
"d2430af0eaa4457491a294e252104c11",
|
| 599 |
+
"88e413f539ac4bfa95d2954178a8df00",
|
| 600 |
+
"79d4ad1a55e64291b67f7a2ed2e82bfc",
|
| 601 |
+
"0d32734804454f3fa1511a8be9facd5b",
|
| 602 |
+
"5250b56c84e34862ac892d395730218f",
|
| 603 |
+
"5bf6228dfb8f4cc1a542590545f68338",
|
| 604 |
+
"f05724a0721f4321ac7f41129682e232",
|
| 605 |
+
"20029df435c44a44a6b1c61552cf8a25"
|
| 606 |
+
]
|
| 607 |
+
},
|
| 608 |
+
"id": "3nGUWZi-lqb-",
|
| 609 |
+
"outputId": "2054d9dc-53c1-4f1e-b858-6810c0c61cbb"
|
| 610 |
+
},
|
| 611 |
+
"execution_count": null,
|
| 612 |
+
"outputs": [
|
| 613 |
+
{
|
| 614 |
+
"output_type": "stream",
|
| 615 |
+
"name": "stderr",
|
| 616 |
+
"text": [
|
| 617 |
+
"/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_token.py:88: UserWarning: \n",
|
| 618 |
+
"The secret `HF_TOKEN` does not exist in your Colab secrets.\n",
|
| 619 |
+
"To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.\n",
|
| 620 |
+
"You will be able to reuse this secret in all of your notebooks.\n",
|
| 621 |
+
"Please note that authentication is recommended but still optional to access public models or datasets.\n",
|
| 622 |
+
" warnings.warn(\n"
|
| 623 |
+
]
|
| 624 |
+
},
|
| 625 |
+
{
|
| 626 |
+
"output_type": "display_data",
|
| 627 |
+
"data": {
|
| 628 |
+
"text/plain": [
|
| 629 |
+
"Fetching 9 files: 0%| | 0/9 [00:00<?, ?it/s]"
|
| 630 |
+
],
|
| 631 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 632 |
+
"version_major": 2,
|
| 633 |
+
"version_minor": 0,
|
| 634 |
+
"model_id": "998fbdaa144d466b8973bda101228f84"
|
| 635 |
+
}
|
| 636 |
+
},
|
| 637 |
+
"metadata": {}
|
| 638 |
+
},
|
| 639 |
+
{
|
| 640 |
+
"output_type": "stream",
|
| 641 |
+
"name": "stdout",
|
| 642 |
+
"text": [
|
| 643 |
+
"Python version is above 3.10, patching the collections module.\n"
|
| 644 |
+
]
|
| 645 |
+
},
|
| 646 |
+
{
|
| 647 |
+
"output_type": "stream",
|
| 648 |
+
"name": "stderr",
|
| 649 |
+
"text": [
|
| 650 |
+
"Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.\n",
|
| 651 |
+
"Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.\n",
|
| 652 |
+
"Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.\n"
|
| 653 |
+
]
|
| 654 |
+
},
|
| 655 |
+
{
|
| 656 |
+
"output_type": "stream",
|
| 657 |
+
"name": "stdout",
|
| 658 |
+
"text": [
|
| 659 |
+
"Response(text=\"\\n\\nThis is a vivid, color photograph of a tiger resting in a grassy field. The tiger, with its distinctive orange and black stripes, is lying on its side, its body facing the camera. Its eyes are wide open, and it appears to be gazing directly at the camera, creating a sense of connection between the viewer and the subject. The tiger's tail is curled around its body, adding to the relaxed posture. The background is a lush green field, suggesting a natural, outdoor setting. There are no other animals visible in the image. The tiger's position and the open field provide a sense of tranquility and freedom.\", generate_token_len=130, input_token_len=625, session_id=0, finish_reason='stop', token_ids=[185, 185, 1567, 317, 245, 26206, 11, 3042, 14537, 280, 245, 42901, 28459, 279, 245, 69139, 2021, 13, 429, 42901, 11, 366, 895, 30372, 16639, 285, 3438, 45138, 11, 317, 13595, 331, 895, 2387, 11, 895, 3123, 14087, 254, 8603, 13, 9904, 3545, 418, 5505, 1721, 11, 285, 359, 6266, 276, 330, 36545, 4723, 430, 254, 8603, 11, 6817, 245, 3078, 280, 4714, 1439, 254, 32975, 285, 254, 3605, 13, 429, 42901, 6, 82, 9960, 317, 61867, 1983, 895, 3123, 11, 7227, 276, 254, 23450, 43891, 13, 429, 4140, 317, 245, 50461, 5575, 2021, 11, 23473, 245, 3892, 11, 13022, 5007, 13, 2071, 418, 642, 750, 8466, 9200, 279, 254, 3324, 13, 429, 42901, 6, 82, 3299, 285, 254, 1721, 2021, 2774, 245, 3078, 280, 28036, 1242, 285, 10264, 13], logprobs=None)\n"
|
| 660 |
+
]
|
| 661 |
+
}
|
| 662 |
+
]
|
| 663 |
+
}
|
| 664 |
+
]
|
| 665 |
+
}
|
a_mllm_notebooks/lmdeploy/lmdeploy_info.ipynb
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [
|
| 8 |
+
{
|
| 9 |
+
"name": "stdout",
|
| 10 |
+
"output_type": "stream",
|
| 11 |
+
"text": [
|
| 12 |
+
"/dscilab_dungvo/workspace/huggingface_cache\n",
|
| 13 |
+
"models--AIDC-AI--Ovis1.6-Gemma2-27B\n",
|
| 14 |
+
"models--FoundationVision--groma-7b-pretrain\n",
|
| 15 |
+
"models--MBZUAI--GLaMM-FullScope\n",
|
| 16 |
+
"models--OpenGVLab--InternVL2_5-26B-AWQ\n",
|
| 17 |
+
"models--OpenGVLab--InternVL2_5-38B-AWQ\n",
|
| 18 |
+
"models--OpenGVLab--InternVL2_5-78B-AWQ\n",
|
| 19 |
+
"models--Qwen--Qwen2-VL-2B-Instruct\n",
|
| 20 |
+
"models--Qwen--Qwen2-VL-72B-Instruct-AWQ\n",
|
| 21 |
+
"models--Qwen--Qwen2-VL-7B-Instruct\n",
|
| 22 |
+
"models--Qwen--Qwen2.5-7B-Instruct\n",
|
| 23 |
+
"models--meta-llama--Llama-3.2-90B-Vision-Instruct\n",
|
| 24 |
+
"models--opengvlab--internvl2_5-26B-AWQ\n",
|
| 25 |
+
"models--opengvlab--internvl2_5-38B-AWQ\n",
|
| 26 |
+
"models--vinai--phobert-base-v2\n",
|
| 27 |
+
"version.txt\n"
|
| 28 |
+
]
|
| 29 |
+
}
|
| 30 |
+
],
|
| 31 |
+
"source": [
|
| 32 |
+
"!echo $HF_HOME\n",
|
| 33 |
+
"!ls $HF_HOME/hub"
|
| 34 |
+
]
|
| 35 |
+
},
|
| 36 |
+
{
|
| 37 |
+
"cell_type": "code",
|
| 38 |
+
"execution_count": 2,
|
| 39 |
+
"metadata": {},
|
| 40 |
+
"outputs": [
|
| 41 |
+
{
|
| 42 |
+
"name": "stdout",
|
| 43 |
+
"output_type": "stream",
|
| 44 |
+
"text": [
|
| 45 |
+
"The supported chat template names are:\n",
|
| 46 |
+
"baichuan2\n",
|
| 47 |
+
"base\n",
|
| 48 |
+
"chatglm\n",
|
| 49 |
+
"chatglm3\n",
|
| 50 |
+
"codegeex4\n",
|
| 51 |
+
"codellama\n",
|
| 52 |
+
"cogvlm\n",
|
| 53 |
+
"cogvlm2\n",
|
| 54 |
+
"dbrx\n",
|
| 55 |
+
"deepseek\n",
|
| 56 |
+
"deepseek-coder\n",
|
| 57 |
+
"deepseek-vl\n",
|
| 58 |
+
"falcon\n",
|
| 59 |
+
"gemma\n",
|
| 60 |
+
"glm4\n",
|
| 61 |
+
"internlm\n",
|
| 62 |
+
"internlm-xcomposer2\n",
|
| 63 |
+
"internlm-xcomposer2d5\n",
|
| 64 |
+
"internlm2\n",
|
| 65 |
+
"internvl-internlm2\n",
|
| 66 |
+
"internvl-phi3\n",
|
| 67 |
+
"internvl-zh\n",
|
| 68 |
+
"internvl-zh-hermes2\n",
|
| 69 |
+
"internvl2-internlm2\n",
|
| 70 |
+
"internvl2-phi3\n",
|
| 71 |
+
"internvl2_5\n",
|
| 72 |
+
"llama\n",
|
| 73 |
+
"llama2\n",
|
| 74 |
+
"llama3\n",
|
| 75 |
+
"llama3_1\n",
|
| 76 |
+
"llama3_2\n",
|
| 77 |
+
"llava-chatml\n",
|
| 78 |
+
"llava-v1\n",
|
| 79 |
+
"mini-gemini-vicuna\n",
|
| 80 |
+
"minicpm3\n",
|
| 81 |
+
"minicpmv-2d6\n",
|
| 82 |
+
"mistral\n",
|
| 83 |
+
"mixtral\n",
|
| 84 |
+
"molmo\n",
|
| 85 |
+
"phi-3\n",
|
| 86 |
+
"puyu\n",
|
| 87 |
+
"qwen\n",
|
| 88 |
+
"qwen2d5\n",
|
| 89 |
+
"solar\n",
|
| 90 |
+
"ultracm\n",
|
| 91 |
+
"ultralm\n",
|
| 92 |
+
"vicuna\n",
|
| 93 |
+
"wizardlm\n",
|
| 94 |
+
"yi\n",
|
| 95 |
+
"yi-vl\n"
|
| 96 |
+
]
|
| 97 |
+
}
|
| 98 |
+
],
|
| 99 |
+
"source": [
|
| 100 |
+
"!lmdeploy list"
|
| 101 |
+
]
|
| 102 |
+
},
|
| 103 |
+
{
|
| 104 |
+
"cell_type": "code",
|
| 105 |
+
"execution_count": null,
|
| 106 |
+
"metadata": {},
|
| 107 |
+
"outputs": [],
|
| 108 |
+
"source": []
|
| 109 |
+
}
|
| 110 |
+
],
|
| 111 |
+
"metadata": {
|
| 112 |
+
"kernelspec": {
|
| 113 |
+
"display_name": "lmdeploy",
|
| 114 |
+
"language": "python",
|
| 115 |
+
"name": "python3"
|
| 116 |
+
},
|
| 117 |
+
"language_info": {
|
| 118 |
+
"codemirror_mode": {
|
| 119 |
+
"name": "ipython",
|
| 120 |
+
"version": 3
|
| 121 |
+
},
|
| 122 |
+
"file_extension": ".py",
|
| 123 |
+
"mimetype": "text/x-python",
|
| 124 |
+
"name": "python",
|
| 125 |
+
"nbconvert_exporter": "python",
|
| 126 |
+
"pygments_lexer": "ipython3",
|
| 127 |
+
"version": "3.8.19"
|
| 128 |
+
}
|
| 129 |
+
},
|
| 130 |
+
"nbformat": 4,
|
| 131 |
+
"nbformat_minor": 2
|
| 132 |
+
}
|
a_mllm_notebooks/lmdeploy/lmdeploy_serve.sh
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
eval "$(conda shell.bash hook)"
|
| 2 |
+
conda activate lmdeploy
|
| 3 |
+
|
| 4 |
+
# MODEL_NAME=OpenGVLab/InternVL2_5-1B
|
| 5 |
+
# MODEL_NAME=OpenGVLab/InternVL2_5-26B-AWQ
|
| 6 |
+
MODEL_NAME=OpenGVLab/InternVL2_5-26B-MPO-AWQ
|
| 7 |
+
# MODEL_NAME=Qwen/Qwen2-VL-7B-Instruct-AWQ
|
| 8 |
+
|
| 9 |
+
# PROXY_URL=0.0.0.0
|
| 10 |
+
# lmdeploy serve proxy --server-name $PROXY_URL --server-port 8080 --strategy "min_expected_latency" &
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
CUDA_VISIBLE_DEVICES=2 \
|
| 14 |
+
lmdeploy serve api_server \
|
| 15 |
+
$MODEL_NAME \
|
| 16 |
+
--server-port 2002 \
|
| 17 |
+
--tp 1 \
|
| 18 |
+
--dtype float16 \
|
| 19 |
+
--cache-max-entry-count 0.05 \
|
| 20 |
+
--proxy-url http://0.0.0.0:8082 &
|
| 21 |
+
# --backend turbomind \
|
| 22 |
+
# --model-format awq \
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
# lmdeploy serve api_server [-h] [--server-name SERVER_NAME] [--server-port SERVER_PORT]
|
| 29 |
+
# [--allow-origins ALLOW_ORIGINS [ALLOW_ORIGINS ...]] [--allow-credentials]
|
| 30 |
+
# [--allow-methods ALLOW_METHODS [ALLOW_METHODS ...]]
|
| 31 |
+
# [--allow-headers ALLOW_HEADERS [ALLOW_HEADERS ...]] [--proxy-url PROXY_URL]
|
| 32 |
+
# [--backend {pytorch,turbomind}]
|
| 33 |
+
# [--log-level {CRITICAL,FATAL,ERROR,WARN,WARNING,INFO,DEBUG,NOTSET}]
|
| 34 |
+
# [--api-keys [API_KEYS [API_KEYS ...]]] [--ssl] [--model-name MODEL_NAME]
|
| 35 |
+
# [--max-log-len MAX_LOG_LEN] [--disable-fastapi-docs]
|
| 36 |
+
# [--chat-template CHAT_TEMPLATE] [--revision REVISION]
|
| 37 |
+
# [--download-dir DOWNLOAD_DIR] [--adapters [ADAPTERS [ADAPTERS ...]]]
|
| 38 |
+
# [--device {cuda,ascend,maca}] [--eager-mode] [--dtype {auto,float16,bfloat16}]
|
| 39 |
+
# [--tp TP] [--session-len SESSION_LEN] [--max-batch-size MAX_BATCH_SIZE]
|
| 40 |
+
# [--cache-max-entry-count CACHE_MAX_ENTRY_COUNT]
|
| 41 |
+
# [--cache-block-seq-len CACHE_BLOCK_SEQ_LEN] [--enable-prefix-caching]
|
| 42 |
+
# [--max-prefill-token-num MAX_PREFILL_TOKEN_NUM] [--quant-policy {0,4,8}]
|
| 43 |
+
# [--model-format {hf,llama,awq,gptq}] [--rope-scaling-factor ROPE_SCALING_FACTOR]
|
| 44 |
+
# [--num-tokens-per-iter NUM_TOKENS_PER_ITER]
|
| 45 |
+
# [--max-prefill-iters MAX_PREFILL_ITERS]
|
| 46 |
+
# [--vision-max-batch-size VISION_MAX_BATCH_SIZE]
|
| 47 |
+
# model_path
|
a_mllm_notebooks/lmdeploy/long_context.ipynb
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "a674e57f",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Context length extrapolation\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"Long text extrapolation refers to the ability of LLM to handle data longer than the training text during inference. TurboMind engine now support [LlamaDynamicNTKScalingRotaryEmbedding](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py#L178) and the implementation is consistent with huggingface.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"## Usage\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"You can enable the context length extrapolation abality by modifying the TurbomindEngineConfig. Edit the `session_len` to the expected length and change `rope_scaling_factor` to a number no less than 1.0.\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"Take `internlm2_5-7b-chat-1m` as an example, which supports a context length of up to **1 million tokens**:"
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "code",
|
| 21 |
+
"execution_count": null,
|
| 22 |
+
"id": "c4781275",
|
| 23 |
+
"metadata": {},
|
| 24 |
+
"outputs": [],
|
| 25 |
+
"source": [
|
| 26 |
+
"from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"backend_config = TurbomindEngineConfig(\n",
|
| 29 |
+
" rope_scaling_factor=2.5,\n",
|
| 30 |
+
" session_len=1000000,\n",
|
| 31 |
+
" max_batch_size=1,\n",
|
| 32 |
+
" cache_max_entry_count=0.7,\n",
|
| 33 |
+
" tp=4)\n",
|
| 34 |
+
"pipe = pipeline('internlm/internlm2_5-7b-chat-1m', backend_config=backend_config)\n",
|
| 35 |
+
"prompt = 'Use a long prompt to replace this sentence'\n",
|
| 36 |
+
"gen_config = GenerationConfig(top_p=0.8,\n",
|
| 37 |
+
" top_k=40,\n",
|
| 38 |
+
" temperature=0.8,\n",
|
| 39 |
+
" max_new_tokens=1024)\n",
|
| 40 |
+
"response = pipe(prompt, gen_config=gen_config)\n",
|
| 41 |
+
"print(response)"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "markdown",
|
| 46 |
+
"id": "dbd245e2",
|
| 47 |
+
"metadata": {},
|
| 48 |
+
"source": [
|
| 49 |
+
"## Evaluation\n",
|
| 50 |
+
"\n",
|
| 51 |
+
"We use several methods to evaluate the long-context-length inference ability of LMDeploy, including [passkey retrieval](#passkey-retrieval), [needle in a haystack](#needle-in-a-haystack) and computing [perplexity](#perplexity)\n",
|
| 52 |
+
"\n",
|
| 53 |
+
"### Passkey Retrieval\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"You can try the following code to test how many times LMDeploy can retrieval the special key."
|
| 56 |
+
]
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"cell_type": "code",
|
| 60 |
+
"execution_count": null,
|
| 61 |
+
"id": "2de48014",
|
| 62 |
+
"metadata": {},
|
| 63 |
+
"outputs": [],
|
| 64 |
+
"source": [
|
| 65 |
+
"import numpy as np\n",
|
| 66 |
+
"from lmdeploy import pipeline\n",
|
| 67 |
+
"from lmdeploy import TurbomindEngineConfig\n",
|
| 68 |
+
"import time\n",
|
| 69 |
+
"\n",
|
| 70 |
+
"session_len = 1000000\n",
|
| 71 |
+
"backend_config = TurbomindEngineConfig(\n",
|
| 72 |
+
" rope_scaling_factor=2.5,\n",
|
| 73 |
+
" session_len=session_len,\n",
|
| 74 |
+
" max_batch_size=1,\n",
|
| 75 |
+
" cache_max_entry_count=0.7,\n",
|
| 76 |
+
" tp=4)\n",
|
| 77 |
+
"pipe = pipeline('internlm/internlm2_5-7b-chat-1m', backend_config=backend_config)\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"def passkey_retrieval(session_len, n_round=5):\n",
|
| 81 |
+
" # create long context input\n",
|
| 82 |
+
" tok = pipe.tokenizer\n",
|
| 83 |
+
" task_description = 'There is an important info hidden inside a lot of irrelevant text. Find it and memorize them. I will quiz you about the important information there.'\n",
|
| 84 |
+
" garbage = 'The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again.'\n",
|
| 85 |
+
"\n",
|
| 86 |
+
" for _ in range(n_round):\n",
|
| 87 |
+
" start = time.perf_counter()\n",
|
| 88 |
+
" n_times = (session_len - 1000) // len(tok.encode(garbage))\n",
|
| 89 |
+
" n_garbage_prefix = np.random.randint(0, n_times)\n",
|
| 90 |
+
" n_garbage_suffix = n_times - n_garbage_prefix\n",
|
| 91 |
+
" garbage_prefix = ' '.join([garbage] * n_garbage_prefix)\n",
|
| 92 |
+
" garbage_suffix = ' '.join([garbage] * n_garbage_suffix)\n",
|
| 93 |
+
" pass_key = np.random.randint(1, 50000)\n",
|
| 94 |
+
" information_line = f'The pass key is {pass_key}. Remember it. {pass_key} is the pass key.' # noqa: E501\n",
|
| 95 |
+
" final_question = 'What is the pass key? The pass key is'\n",
|
| 96 |
+
" lines = [\n",
|
| 97 |
+
" task_description,\n",
|
| 98 |
+
" garbage_prefix,\n",
|
| 99 |
+
" information_line,\n",
|
| 100 |
+
" garbage_suffix,\n",
|
| 101 |
+
" final_question,\n",
|
| 102 |
+
" ]\n",
|
| 103 |
+
"\n",
|
| 104 |
+
" # inference\n",
|
| 105 |
+
" prompt = ' '.join(lines)\n",
|
| 106 |
+
" response = pipe([prompt])\n",
|
| 107 |
+
" print(pass_key, response)\n",
|
| 108 |
+
" end = time.perf_counter()\n",
|
| 109 |
+
" print(f'duration: {end - start} s')\n",
|
| 110 |
+
"\n",
|
| 111 |
+
"passkey_retrieval(session_len, 5)"
|
| 112 |
+
]
|
| 113 |
+
},
|
| 114 |
+
{
|
| 115 |
+
"cell_type": "markdown",
|
| 116 |
+
"id": "4c33e786",
|
| 117 |
+
"metadata": {},
|
| 118 |
+
"source": [
|
| 119 |
+
"This test takes approximately 364 seconds per round when conducted on A100-80G GPUs\n",
|
| 120 |
+
"\n",
|
| 121 |
+
"### Needle In A Haystack\n",
|
| 122 |
+
"\n",
|
| 123 |
+
"[OpenCompass](https://github.com/open-compass/opencompass) offers very useful tools to perform needle-in-a-haystack evaluation. For specific instructions, please refer to the [guide](https://github.com/open-compass/opencompass/blob/main/docs/en/advanced_guides/needleinahaystack_eval.md).\n",
|
| 124 |
+
"\n",
|
| 125 |
+
"### Perplexity\n",
|
| 126 |
+
"\n",
|
| 127 |
+
"The following codes demonstrate how to use LMDeploy to calculate perplexity."
|
| 128 |
+
]
|
| 129 |
+
},
|
| 130 |
+
{
|
| 131 |
+
"cell_type": "code",
|
| 132 |
+
"execution_count": null,
|
| 133 |
+
"id": "3b9a97ec",
|
| 134 |
+
"metadata": {},
|
| 135 |
+
"outputs": [],
|
| 136 |
+
"source": [
|
| 137 |
+
"from transformers import AutoTokenizer\n",
|
| 138 |
+
"from lmdeploy import TurbomindEngineConfig, pipeline\n",
|
| 139 |
+
"import numpy as np\n",
|
| 140 |
+
"\n",
|
| 141 |
+
"# load model and tokenizer\n",
|
| 142 |
+
"model_repoid_or_path = 'internlm/internlm2_5-7b-chat-1m'\n",
|
| 143 |
+
"backend_config = TurbomindEngineConfig(\n",
|
| 144 |
+
" rope_scaling_factor=2.5,\n",
|
| 145 |
+
" session_len=1000000,\n",
|
| 146 |
+
" max_batch_size=1,\n",
|
| 147 |
+
" cache_max_entry_count=0.7,\n",
|
| 148 |
+
" tp=4)\n",
|
| 149 |
+
"pipe = pipeline(model_repoid_or_path, backend_config=backend_config)\n",
|
| 150 |
+
"tokenizer = AutoTokenizer.from_pretrained(model_repoid_or_path, trust_remote_code=True)\n",
|
| 151 |
+
"\n",
|
| 152 |
+
"# get perplexity\n",
|
| 153 |
+
"text = 'Use a long prompt to replace this sentence'\n",
|
| 154 |
+
"input_ids = tokenizer.encode(text)\n",
|
| 155 |
+
"ppl = pipe.get_ppl(input_ids)[0]\n",
|
| 156 |
+
"print(ppl)"
|
| 157 |
+
]
|
| 158 |
+
}
|
| 159 |
+
],
|
| 160 |
+
"metadata": {
|
| 161 |
+
"jupytext": {
|
| 162 |
+
"cell_metadata_filter": "-all",
|
| 163 |
+
"main_language": "python",
|
| 164 |
+
"notebook_metadata_filter": "-all"
|
| 165 |
+
}
|
| 166 |
+
},
|
| 167 |
+
"nbformat": 4,
|
| 168 |
+
"nbformat_minor": 5
|
| 169 |
+
}
|
a_mllm_notebooks/lmdeploy/long_context.md
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Context length extrapolation
|
| 2 |
+
|
| 3 |
+
Long text extrapolation refers to the ability of LLM to handle data longer than the training text during inference. TurboMind engine now support [LlamaDynamicNTKScalingRotaryEmbedding](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py#L178) and the implementation is consistent with huggingface.
|
| 4 |
+
|
| 5 |
+
## Usage
|
| 6 |
+
|
| 7 |
+
You can enable the context length extrapolation abality by modifying the TurbomindEngineConfig. Edit the `session_len` to the expected length and change `rope_scaling_factor` to a number no less than 1.0.
|
| 8 |
+
|
| 9 |
+
Take `internlm2_5-7b-chat-1m` as an example, which supports a context length of up to **1 million tokens**:
|
| 10 |
+
|
| 11 |
+
```python
|
| 12 |
+
from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig
|
| 13 |
+
|
| 14 |
+
backend_config = TurbomindEngineConfig(
|
| 15 |
+
rope_scaling_factor=2.5,
|
| 16 |
+
session_len=1000000,
|
| 17 |
+
max_batch_size=1,
|
| 18 |
+
cache_max_entry_count=0.7,
|
| 19 |
+
tp=4)
|
| 20 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat-1m', backend_config=backend_config)
|
| 21 |
+
prompt = 'Use a long prompt to replace this sentence'
|
| 22 |
+
gen_config = GenerationConfig(top_p=0.8,
|
| 23 |
+
top_k=40,
|
| 24 |
+
temperature=0.8,
|
| 25 |
+
max_new_tokens=1024)
|
| 26 |
+
response = pipe(prompt, gen_config=gen_config)
|
| 27 |
+
print(response)
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
## Evaluation
|
| 31 |
+
|
| 32 |
+
We use several methods to evaluate the long-context-length inference ability of LMDeploy, including [passkey retrieval](#passkey-retrieval), [needle in a haystack](#needle-in-a-haystack) and computing [perplexity](#perplexity)
|
| 33 |
+
|
| 34 |
+
### Passkey Retrieval
|
| 35 |
+
|
| 36 |
+
You can try the following code to test how many times LMDeploy can retrieval the special key.
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
import numpy as np
|
| 40 |
+
from lmdeploy import pipeline
|
| 41 |
+
from lmdeploy import TurbomindEngineConfig
|
| 42 |
+
import time
|
| 43 |
+
|
| 44 |
+
session_len = 1000000
|
| 45 |
+
backend_config = TurbomindEngineConfig(
|
| 46 |
+
rope_scaling_factor=2.5,
|
| 47 |
+
session_len=session_len,
|
| 48 |
+
max_batch_size=1,
|
| 49 |
+
cache_max_entry_count=0.7,
|
| 50 |
+
tp=4)
|
| 51 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat-1m', backend_config=backend_config)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def passkey_retrieval(session_len, n_round=5):
|
| 55 |
+
# create long context input
|
| 56 |
+
tok = pipe.tokenizer
|
| 57 |
+
task_description = 'There is an important info hidden inside a lot of irrelevant text. Find it and memorize them. I will quiz you about the important information there.'
|
| 58 |
+
garbage = 'The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again.'
|
| 59 |
+
|
| 60 |
+
for _ in range(n_round):
|
| 61 |
+
start = time.perf_counter()
|
| 62 |
+
n_times = (session_len - 1000) // len(tok.encode(garbage))
|
| 63 |
+
n_garbage_prefix = np.random.randint(0, n_times)
|
| 64 |
+
n_garbage_suffix = n_times - n_garbage_prefix
|
| 65 |
+
garbage_prefix = ' '.join([garbage] * n_garbage_prefix)
|
| 66 |
+
garbage_suffix = ' '.join([garbage] * n_garbage_suffix)
|
| 67 |
+
pass_key = np.random.randint(1, 50000)
|
| 68 |
+
information_line = f'The pass key is {pass_key}. Remember it. {pass_key} is the pass key.' # noqa: E501
|
| 69 |
+
final_question = 'What is the pass key? The pass key is'
|
| 70 |
+
lines = [
|
| 71 |
+
task_description,
|
| 72 |
+
garbage_prefix,
|
| 73 |
+
information_line,
|
| 74 |
+
garbage_suffix,
|
| 75 |
+
final_question,
|
| 76 |
+
]
|
| 77 |
+
|
| 78 |
+
# inference
|
| 79 |
+
prompt = ' '.join(lines)
|
| 80 |
+
response = pipe([prompt])
|
| 81 |
+
print(pass_key, response)
|
| 82 |
+
end = time.perf_counter()
|
| 83 |
+
print(f'duration: {end - start} s')
|
| 84 |
+
|
| 85 |
+
passkey_retrieval(session_len, 5)
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
This test takes approximately 364 seconds per round when conducted on A100-80G GPUs
|
| 89 |
+
|
| 90 |
+
### Needle In A Haystack
|
| 91 |
+
|
| 92 |
+
[OpenCompass](https://github.com/open-compass/opencompass) offers very useful tools to perform needle-in-a-haystack evaluation. For specific instructions, please refer to the [guide](https://github.com/open-compass/opencompass/blob/main/docs/en/advanced_guides/needleinahaystack_eval.md).
|
| 93 |
+
|
| 94 |
+
### Perplexity
|
| 95 |
+
|
| 96 |
+
The following codes demonstrate how to use LMDeploy to calculate perplexity.
|
| 97 |
+
|
| 98 |
+
```python
|
| 99 |
+
from transformers import AutoTokenizer
|
| 100 |
+
from lmdeploy import TurbomindEngineConfig, pipeline
|
| 101 |
+
import numpy as np
|
| 102 |
+
|
| 103 |
+
# load model and tokenizer
|
| 104 |
+
model_repoid_or_path = 'internlm/internlm2_5-7b-chat-1m'
|
| 105 |
+
backend_config = TurbomindEngineConfig(
|
| 106 |
+
rope_scaling_factor=2.5,
|
| 107 |
+
session_len=1000000,
|
| 108 |
+
max_batch_size=1,
|
| 109 |
+
cache_max_entry_count=0.7,
|
| 110 |
+
tp=4)
|
| 111 |
+
pipe = pipeline(model_repoid_or_path, backend_config=backend_config)
|
| 112 |
+
tokenizer = AutoTokenizer.from_pretrained(model_repoid_or_path, trust_remote_code=True)
|
| 113 |
+
|
| 114 |
+
# get perplexity
|
| 115 |
+
text = 'Use a long prompt to replace this sentence'
|
| 116 |
+
input_ids = tokenizer.encode(text)
|
| 117 |
+
ppl = pipe.get_ppl(input_ids)[0]
|
| 118 |
+
print(ppl)
|
| 119 |
+
```
|
a_mllm_notebooks/lmdeploy/pipeline.ipynb
ADDED
|
@@ -0,0 +1,570 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "d3f6f4c5",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Offline Inference Pipeline\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"In this tutorial, We will present a list of examples to introduce the usage of `lmdeploy.pipeline`.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"You can overview the detailed pipeline API in [this](https://lmdeploy.readthedocs.io/en/latest/api/pipeline.html) guide.\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"## Usage\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"- **An example using default parameters:**"
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "code",
|
| 21 |
+
"execution_count": 1,
|
| 22 |
+
"id": "3ff6970a",
|
| 23 |
+
"metadata": {},
|
| 24 |
+
"outputs": [
|
| 25 |
+
{
|
| 26 |
+
"name": "stderr",
|
| 27 |
+
"output_type": "stream",
|
| 28 |
+
"text": [
|
| 29 |
+
"/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
|
| 30 |
+
" from .autonotebook import tqdm as notebook_tqdm\n"
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"name": "stdout",
|
| 35 |
+
"output_type": "stream",
|
| 36 |
+
"text": [
|
| 37 |
+
"\u001b[0;31mInit signature:\u001b[0m\n",
|
| 38 |
+
"\u001b[0mTurbomindEngineConfig\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 39 |
+
"\u001b[0;34m\u001b[0m \u001b[0mdtype\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mstr\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m'auto'\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 40 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmodel_format\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mUnion\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mNoneType\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 41 |
+
"\u001b[0;34m\u001b[0m \u001b[0mtp\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 42 |
+
"\u001b[0;34m\u001b[0m \u001b[0msession_len\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mUnion\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mint\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mNoneType\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 43 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_batch_size\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 44 |
+
"\u001b[0;34m\u001b[0m \u001b[0mcache_max_entry_count\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mfloat\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0.8\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 45 |
+
"\u001b[0;34m\u001b[0m \u001b[0mcache_chunk_size\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m-\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 46 |
+
"\u001b[0;34m\u001b[0m \u001b[0mcache_block_seq_len\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m64\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 47 |
+
"\u001b[0;34m\u001b[0m \u001b[0menable_prefix_caching\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mbool\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mFalse\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 48 |
+
"\u001b[0;34m\u001b[0m \u001b[0mquant_policy\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 49 |
+
"\u001b[0;34m\u001b[0m \u001b[0mrope_scaling_factor\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mfloat\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0.0\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 50 |
+
"\u001b[0;34m\u001b[0m \u001b[0muse_logn_attn\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mbool\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mFalse\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 51 |
+
"\u001b[0;34m\u001b[0m \u001b[0mdownload_dir\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mUnion\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mNoneType\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 52 |
+
"\u001b[0;34m\u001b[0m \u001b[0mrevision\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mUnion\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mNoneType\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 53 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_prefill_token_num\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m8192\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 54 |
+
"\u001b[0;34m\u001b[0m \u001b[0mnum_tokens_per_iter\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 55 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_prefill_iters\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 56 |
+
"\u001b[0;34m\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;34m->\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
|
| 57 |
+
"\u001b[0;31mSource:\u001b[0m \n",
|
| 58 |
+
"\u001b[0;32mclass\u001b[0m \u001b[0mTurbomindEngineConfig\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 59 |
+
"\u001b[0;34m\u001b[0m \u001b[0;34m\"\"\"TurboMind Engine config.\u001b[0m\n",
|
| 60 |
+
"\u001b[0;34m\u001b[0m\n",
|
| 61 |
+
"\u001b[0;34m Args:\u001b[0m\n",
|
| 62 |
+
"\u001b[0;34m dtype (str): data type for model weights and activations. It can be\u001b[0m\n",
|
| 63 |
+
"\u001b[0;34m one of the following values, ['auto', 'float16', 'bfloat16']\u001b[0m\n",
|
| 64 |
+
"\u001b[0;34m The `auto` option will use FP16 precision for FP32 and FP16\u001b[0m\n",
|
| 65 |
+
"\u001b[0;34m models, and BF16 precision for BF16 models.\u001b[0m\n",
|
| 66 |
+
"\u001b[0;34m model_format (str): the layout of the deployed model. It can be one\u001b[0m\n",
|
| 67 |
+
"\u001b[0;34m of the following values [hf, meta_llama, awq, gptq],`hf` meaning\u001b[0m\n",
|
| 68 |
+
"\u001b[0;34m huggingface model(.bin, .safetensors), `meta_llama` being\u001b[0m\n",
|
| 69 |
+
"\u001b[0;34m meta llama's format(.pth), `awq` and `gptq` meaning the quantized\u001b[0m\n",
|
| 70 |
+
"\u001b[0;34m model by AWQ and GPTQ, respectively. If it is not specified,\u001b[0m\n",
|
| 71 |
+
"\u001b[0;34m i.e. None, it will be extracted from the input model\u001b[0m\n",
|
| 72 |
+
"\u001b[0;34m tp (int): the number of GPU cards used in tensor parallelism,\u001b[0m\n",
|
| 73 |
+
"\u001b[0;34m default to 1\u001b[0m\n",
|
| 74 |
+
"\u001b[0;34m session_len (int): the max session length of a sequence, default to\u001b[0m\n",
|
| 75 |
+
"\u001b[0;34m None\u001b[0m\n",
|
| 76 |
+
"\u001b[0;34m max_batch_size (int): the max batch size during inference. If it is\u001b[0m\n",
|
| 77 |
+
"\u001b[0;34m not specified, the engine will automatically set it according to\u001b[0m\n",
|
| 78 |
+
"\u001b[0;34m the device\u001b[0m\n",
|
| 79 |
+
"\u001b[0;34m cache_max_entry_count (float): the percentage of gpu memory occupied\u001b[0m\n",
|
| 80 |
+
"\u001b[0;34m by the k/v cache.\u001b[0m\n",
|
| 81 |
+
"\u001b[0;34m For versions of lmdeploy between `v0.2.0` and `v0.2.1`, it\u001b[0m\n",
|
| 82 |
+
"\u001b[0;34m defaults to 0.5, depicting the percentage of TOTAL GPU memory to\u001b[0m\n",
|
| 83 |
+
"\u001b[0;34m be allocated to the k/v cache.\u001b[0m\n",
|
| 84 |
+
"\u001b[0;34m For lmdeploy versions greater than `v0.2.1`, it defaults to 0.8,\u001b[0m\n",
|
| 85 |
+
"\u001b[0;34m signifying the percentage of FREE GPU memory to be reserved for\u001b[0m\n",
|
| 86 |
+
"\u001b[0;34m the k/v cache\u001b[0m\n",
|
| 87 |
+
"\u001b[0;34m cache_chunk_size (int): The policy to apply for KV block from\u001b[0m\n",
|
| 88 |
+
"\u001b[0;34m the block manager, default to -1.\u001b[0m\n",
|
| 89 |
+
"\u001b[0;34m cache_block_seq_len (int): the length of the token sequence in\u001b[0m\n",
|
| 90 |
+
"\u001b[0;34m a k/v block, default to 64\u001b[0m\n",
|
| 91 |
+
"\u001b[0;34m enable_prefix_caching (bool): enable cache prompts for block reuse,\u001b[0m\n",
|
| 92 |
+
"\u001b[0;34m default to False\u001b[0m\n",
|
| 93 |
+
"\u001b[0;34m quant_policy (int): default to 0. When k/v is quantized into 4 or 8\u001b[0m\n",
|
| 94 |
+
"\u001b[0;34m bit, set it to 4 or 8, respectively\u001b[0m\n",
|
| 95 |
+
"\u001b[0;34m rope_scaling_factor (float): scaling factor used for dynamic ntk,\u001b[0m\n",
|
| 96 |
+
"\u001b[0;34m default to 0. TurboMind follows the implementation of transformer\u001b[0m\n",
|
| 97 |
+
"\u001b[0;34m LlamaAttention\u001b[0m\n",
|
| 98 |
+
"\u001b[0;34m use_logn_attn (bool): whether or not to use log attn: default to False\u001b[0m\n",
|
| 99 |
+
"\u001b[0;34m download_dir (str): Directory to download and load the weights,\u001b[0m\n",
|
| 100 |
+
"\u001b[0;34m default to the default cache directory of huggingface.\u001b[0m\n",
|
| 101 |
+
"\u001b[0;34m revision (str): The specific model version to use. It can be a branch\u001b[0m\n",
|
| 102 |
+
"\u001b[0;34m name, a tag name, or a commit id. If unspecified, will use the\u001b[0m\n",
|
| 103 |
+
"\u001b[0;34m default version.\u001b[0m\n",
|
| 104 |
+
"\u001b[0;34m max_prefill_token_num(int): the number of tokens each iteration during\u001b[0m\n",
|
| 105 |
+
"\u001b[0;34m prefill, default to 8192\u001b[0m\n",
|
| 106 |
+
"\u001b[0;34m num_tokens_per_iter(int): the number of tokens processed in each\u001b[0m\n",
|
| 107 |
+
"\u001b[0;34m forward pass. Working with `max_prefill_iters` enables the\u001b[0m\n",
|
| 108 |
+
"\u001b[0;34m \"Dynamic SplitFuse\"-like scheduling\u001b[0m\n",
|
| 109 |
+
"\u001b[0;34m max_prefill_iters(int): the max number of forward pass during prefill\u001b[0m\n",
|
| 110 |
+
"\u001b[0;34m stage\u001b[0m\n",
|
| 111 |
+
"\u001b[0;34m \"\"\"\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 112 |
+
"\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 113 |
+
"\u001b[0;34m\u001b[0m \u001b[0mdtype\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mstr\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m'auto'\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 114 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmodel_format\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mOptional\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 115 |
+
"\u001b[0;34m\u001b[0m \u001b[0mtp\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 116 |
+
"\u001b[0;34m\u001b[0m \u001b[0msession_len\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mOptional\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mint\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 117 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_batch_size\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 118 |
+
"\u001b[0;34m\u001b[0m \u001b[0mcache_max_entry_count\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mfloat\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0.8\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 119 |
+
"\u001b[0;34m\u001b[0m \u001b[0mcache_chunk_size\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m-\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 120 |
+
"\u001b[0;34m\u001b[0m \u001b[0mcache_block_seq_len\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m64\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 121 |
+
"\u001b[0;34m\u001b[0m \u001b[0menable_prefix_caching\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mbool\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mFalse\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 122 |
+
"\u001b[0;34m\u001b[0m \u001b[0mquant_policy\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 123 |
+
"\u001b[0;34m\u001b[0m \u001b[0mrope_scaling_factor\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mfloat\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0.0\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 124 |
+
"\u001b[0;34m\u001b[0m \u001b[0muse_logn_attn\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mbool\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mFalse\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 125 |
+
"\u001b[0;34m\u001b[0m \u001b[0mdownload_dir\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mOptional\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 126 |
+
"\u001b[0;34m\u001b[0m \u001b[0mrevision\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mOptional\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mstr\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;32mNone\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 127 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_prefill_token_num\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m8192\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 128 |
+
"\u001b[0;34m\u001b[0m \u001b[0mnum_tokens_per_iter\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 129 |
+
"\u001b[0;34m\u001b[0m \u001b[0mmax_prefill_iters\u001b[0m\u001b[0;34m:\u001b[0m \u001b[0mint\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 130 |
+
"\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 131 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0m__post_init__\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mself\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 132 |
+
"\u001b[0;34m\u001b[0m \u001b[0;34m\"\"\"Check input validation.\"\"\"\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 133 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32massert\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdtype\u001b[0m \u001b[0;32min\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0;34m'auto'\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m'float16'\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m'bfloat16'\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 134 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32massert\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtp\u001b[0m \u001b[0;34m>=\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m'tp must be a positive integer'\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 135 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32massert\u001b[0m \u001b[0;36m0\u001b[0m \u001b[0;34m<\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mcache_max_entry_count\u001b[0m \u001b[0;34m<\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m,\u001b[0m \\\n",
|
| 136 |
+
" \u001b[0;34m'invalid cache_max_entry_count'\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 137 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32massert\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mquant_policy\u001b[0m \u001b[0;32min\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0;36m0\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m4\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;36m8\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m'invalid quant_policy'\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 138 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32massert\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mrope_scaling_factor\u001b[0m \u001b[0;34m>=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m'invalid rope_scaling_factor'\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 139 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32massert\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mmax_prefill_token_num\u001b[0m \u001b[0;34m>=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m,\u001b[0m \\\n",
|
| 140 |
+
" \u001b[0;34m'invalid max_prefill_token_num'\u001b[0m\u001b[0;34m\u001b[0m\n",
|
| 141 |
+
"\u001b[0;34m\u001b[0m \u001b[0;32massert\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mnum_tokens_per_iter\u001b[0m \u001b[0;34m>=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m'invalid num_tokens_per_iter'\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
|
| 142 |
+
"\u001b[0;31mFile:\u001b[0m /dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/lmdeploy/messages.py\n",
|
| 143 |
+
"\u001b[0;31mType:\u001b[0m type\n",
|
| 144 |
+
"\u001b[0;31mSubclasses:\u001b[0m "
|
| 145 |
+
]
|
| 146 |
+
}
|
| 147 |
+
],
|
| 148 |
+
"source": [
|
| 149 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 150 |
+
"TurbomindEngineConfig??"
|
| 151 |
+
]
|
| 152 |
+
},
|
| 153 |
+
{
|
| 154 |
+
"cell_type": "code",
|
| 155 |
+
"execution_count": 2,
|
| 156 |
+
"id": "346a051f",
|
| 157 |
+
"metadata": {},
|
| 158 |
+
"outputs": [
|
| 159 |
+
{
|
| 160 |
+
"name": "stderr",
|
| 161 |
+
"output_type": "stream",
|
| 162 |
+
"text": [
|
| 163 |
+
"Fetching 14 files: 100%|█████████████████████████████████████| 14/14 [00:00<00:00, 84855.86it/s]\n"
|
| 164 |
+
]
|
| 165 |
+
},
|
| 166 |
+
{
|
| 167 |
+
"name": "stdout",
|
| 168 |
+
"output_type": "stream",
|
| 169 |
+
"text": [
|
| 170 |
+
"2024-12-20 08:11:58,360 - lmdeploy - \u001b[33mWARNING\u001b[0m - turbomind.py:231 - get 849 model params\n"
|
| 171 |
+
]
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"name": "stderr",
|
| 175 |
+
"output_type": "stream",
|
| 176 |
+
"text": [
|
| 177 |
+
"[TM][WARNING] [LlamaTritonModel] `max_context_token_num` is not set, default to 32768.\n",
|
| 178 |
+
" \r"
|
| 179 |
+
]
|
| 180 |
+
},
|
| 181 |
+
{
|
| 182 |
+
"name": "stdout",
|
| 183 |
+
"output_type": "stream",
|
| 184 |
+
"text": [
|
| 185 |
+
"[WARNING] gemm_config.in is not found; using default GEMM algo\n",
|
| 186 |
+
"[WARNING] gemm_config.in is not found; using default GEMM algo\n",
|
| 187 |
+
"[WARNING] gemm_config.in is not found; using default GEMM algo\n",
|
| 188 |
+
"[WARNING] gemm_config.in is not found; using default GEMM algo\n",
|
| 189 |
+
"2024-12-20 08:12:08,076 - lmdeploy - \u001b[33mWARNING\u001b[0m - async_engine.py:505 - GenerationConfig: GenerationConfig(n=1, max_new_tokens=512, do_sample=False, top_p=1.0, top_k=50, min_p=0.0, temperature=0.8, repetition_penalty=1.0, ignore_eos=False, random_seed=None, stop_words=None, bad_words=None, stop_token_ids=[151645], bad_token_ids=None, min_new_tokens=None, skip_special_tokens=True, logprobs=None, response_format=None, logits_processors=None)\n",
|
| 190 |
+
"2024-12-20 08:12:08,077 - lmdeploy - \u001b[33mWARNING\u001b[0m - async_engine.py:506 - Since v0.6.0, lmdeploy add `do_sample` in GenerationConfig. It defaults to False, meaning greedy decoding. Please set `do_sample=True` if sampling decoding is needed\n",
|
| 191 |
+
"[Response(text=\"Hello! I'm Qwen, an AI assistant created by Alibaba Cloud. I'm here to help with a wide variety of tasks, from answering questions and providing information on various topics to assisting with writing, translating, and more. How can I assist you today?\", generate_token_len=53, input_token_len=34, session_id=0, finish_reason='stop', token_ids=[9707, 0, 358, 2776, 1207, 16948, 11, 458, 15235, 17847, 3465, 553, 54364, 14817, 13, 358, 2776, 1588, 311, 1492, 448, 264, 6884, 8045, 315, 9079, 11, 504, 35764, 4755, 323, 8241, 1995, 389, 5257, 13347, 311, 45827, 448, 4378, 11, 66271, 11, 323, 803, 13, 2585, 646, 358, 7789, 498, 3351, 30], logprobs=None, index=0), Response(text='Shanghai is a major city located in the eastern part of China, at the mouth of the Yangtze River. It is the largest city in China and one of the largest cities in the world by population. Shanghai is known for its blend of traditional and modern architecture, vibrant economy, and cultural diversity. It is a global financial hub and a major center for commerce, fashion, technology, and transportation. Some notable features of Shanghai include the Shanghai Tower, the Bund, and the ancient city walls of the Huangpu District.', generate_token_len=106, input_token_len=32, session_id=1, finish_reason='stop', token_ids=[2016, 30070, 374, 264, 3598, 3283, 7407, 304, 279, 23149, 949, 315, 5616, 11, 518, 279, 10780, 315, 279, 24474, 83, 2986, 10948, 13, 1084, 374, 279, 7772, 3283, 304, 5616, 323, 825, 315, 279, 7772, 9720, 304, 279, 1879, 553, 7042, 13, 37047, 374, 3881, 369, 1181, 20334, 315, 8606, 323, 6481, 17646, 11, 32976, 8584, 11, 323, 12752, 19492, 13, 1084, 374, 264, 3644, 5896, 18719, 323, 264, 3598, 4126, 369, 35654, 11, 11153, 11, 5440, 11, 323, 17903, 13, 4329, 27190, 4419, 315, 37047, 2924, 279, 37047, 21938, 11, 279, 29608, 11, 323, 279, 13833, 3283, 14285, 315, 279, 58409, 5584, 10942, 13], logprobs=None, index=1)]\n"
|
| 192 |
+
]
|
| 193 |
+
}
|
| 194 |
+
],
|
| 195 |
+
"source": [
|
| 196 |
+
"# %pip install nest_asyncio\n",
|
| 197 |
+
"import nest_asyncio\n",
|
| 198 |
+
"nest_asyncio.apply()\n",
|
| 199 |
+
"\n",
|
| 200 |
+
"\n",
|
| 201 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"backend_config = TurbomindEngineConfig(tp=4, cache_max_entry_count=0.2)\n",
|
| 204 |
+
"\n",
|
| 205 |
+
"\n",
|
| 206 |
+
"# pipe = pipeline('internlm/internlm2_5-7b-chat')\n",
|
| 207 |
+
"# models--Qwen--Qwen2.5-7B-Instruct\n",
|
| 208 |
+
"if __name__ == \"__main__\":\n",
|
| 209 |
+
" pipe = pipeline(\"Qwen/Qwen2.5-7B-Instruct\", backend_config=backend_config)\n",
|
| 210 |
+
" response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"])\n",
|
| 211 |
+
" print(response)"
|
| 212 |
+
]
|
| 213 |
+
},
|
| 214 |
+
{
|
| 215 |
+
"cell_type": "code",
|
| 216 |
+
"execution_count": null,
|
| 217 |
+
"id": "2abce346",
|
| 218 |
+
"metadata": {},
|
| 219 |
+
"outputs": [],
|
| 220 |
+
"source": [
|
| 221 |
+
"response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"])"
|
| 222 |
+
]
|
| 223 |
+
},
|
| 224 |
+
{
|
| 225 |
+
"cell_type": "markdown",
|
| 226 |
+
"id": "82167998",
|
| 227 |
+
"metadata": {},
|
| 228 |
+
"source": [
|
| 229 |
+
"In this example, the pipeline by default allocates a predetermined percentage of GPU memory for storing k/v cache. The ratio is dictated by the parameter `TurbomindEngineConfig.cache_max_entry_count`.\n",
|
| 230 |
+
"\n",
|
| 231 |
+
"There have been alterations to the strategy for setting the k/v cache ratio throughout the evolution of LMDeploy. The following are the change histories:\n",
|
| 232 |
+
"\n",
|
| 233 |
+
"1. `v0.2.0 <= lmdeploy <= v0.2.1`\n",
|
| 234 |
+
"\n",
|
| 235 |
+
" `TurbomindEngineConfig.cache_max_entry_count` defaults to 0.5, indicating 50% GPU **total memory** allocated for k/v cache. Out Of Memory (OOM) errors may occur if a 7B model is deployed on a GPU with memory less than 40G. If you encounter an OOM error, please decrease the ratio of the k/v cache occupation as follows:\n",
|
| 236 |
+
"\n",
|
| 237 |
+
" ```python\n",
|
| 238 |
+
" from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 239 |
+
"\n",
|
| 240 |
+
" # decrease the ratio of the k/v cache occupation to 20%\n",
|
| 241 |
+
" backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)\n",
|
| 242 |
+
"\n",
|
| 243 |
+
" pipe = pipeline('internlm/internlm2_5-7b-chat',\n",
|
| 244 |
+
" backend_config=backend_config)\n",
|
| 245 |
+
" response = pipe(['Hi, pls intro yourself', 'Shanghai is'])\n",
|
| 246 |
+
" print(response)\n",
|
| 247 |
+
" ```\n",
|
| 248 |
+
"\n",
|
| 249 |
+
"2. `lmdeploy > v0.2.1`\n",
|
| 250 |
+
"\n",
|
| 251 |
+
" The allocation strategy for k/v cache is changed to reserve space from the **GPU free memory** proportionally. The ratio `TurbomindEngineConfig.cache_max_entry_count` has been adjusted to 0.8 by default. If OOM error happens, similar to the method mentioned above, please consider reducing the ratio value to decrease the memory usage of the k/v cache.\n",
|
| 252 |
+
"\n",
|
| 253 |
+
"- **An example showing how to set tensor parallel num**:"
|
| 254 |
+
]
|
| 255 |
+
},
|
| 256 |
+
{
|
| 257 |
+
"cell_type": "code",
|
| 258 |
+
"execution_count": null,
|
| 259 |
+
"id": "7f51b276",
|
| 260 |
+
"metadata": {},
|
| 261 |
+
"outputs": [],
|
| 262 |
+
"source": [
|
| 263 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 264 |
+
"\n",
|
| 265 |
+
"model_path = \"Qwen/Qwen2.5-7B-Instruct\"\n",
|
| 266 |
+
"backend_config = TurbomindEngineConfig(tp=2, cache_max_entry_count=0.2)\n",
|
| 267 |
+
"pipe = pipeline(model_path, backend_config=backend_config)\n",
|
| 268 |
+
"response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"])\n",
|
| 269 |
+
"print(response)"
|
| 270 |
+
]
|
| 271 |
+
},
|
| 272 |
+
{
|
| 273 |
+
"cell_type": "markdown",
|
| 274 |
+
"id": "662e7b9b",
|
| 275 |
+
"metadata": {},
|
| 276 |
+
"source": [
|
| 277 |
+
"- **An example for setting sampling parameters:**"
|
| 278 |
+
]
|
| 279 |
+
},
|
| 280 |
+
{
|
| 281 |
+
"cell_type": "code",
|
| 282 |
+
"execution_count": 4,
|
| 283 |
+
"id": "ee7ffc98",
|
| 284 |
+
"metadata": {},
|
| 285 |
+
"outputs": [],
|
| 286 |
+
"source": [
|
| 287 |
+
"from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig\n",
|
| 288 |
+
"\n",
|
| 289 |
+
"backend_config = TurbomindEngineConfig(tp=2)\n",
|
| 290 |
+
"gen_config = GenerationConfig(top_p=0.8, top_k=40, temperature=0.8, max_new_tokens=1024)"
|
| 291 |
+
]
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"cell_type": "code",
|
| 295 |
+
"execution_count": null,
|
| 296 |
+
"id": "72358f97",
|
| 297 |
+
"metadata": {},
|
| 298 |
+
"outputs": [],
|
| 299 |
+
"source": [
|
| 300 |
+
"pipe = pipeline(\"internlm/internlm2_5-7b-chat\", backend_config=backend_config)"
|
| 301 |
+
]
|
| 302 |
+
},
|
| 303 |
+
{
|
| 304 |
+
"cell_type": "code",
|
| 305 |
+
"execution_count": 5,
|
| 306 |
+
"id": "af76389b",
|
| 307 |
+
"metadata": {},
|
| 308 |
+
"outputs": [
|
| 309 |
+
{
|
| 310 |
+
"name": "stdout",
|
| 311 |
+
"output_type": "stream",
|
| 312 |
+
"text": [
|
| 313 |
+
"2024-12-20 08:10:41,524 - lmdeploy - \u001b[33mWARNING\u001b[0m - async_engine.py:505 - GenerationConfig: GenerationConfig(n=1, max_new_tokens=1024, do_sample=False, top_p=0.8, top_k=40, min_p=0.0, temperature=0.8, repetition_penalty=1.0, ignore_eos=False, random_seed=None, stop_words=None, bad_words=None, stop_token_ids=[151645], bad_token_ids=None, min_new_tokens=None, skip_special_tokens=True, logprobs=None, response_format=None, logits_processors=None)\n",
|
| 314 |
+
"[Response(text=\"Hello! I'm Qwen, an AI assistant created by Alibaba Cloud. I'm here to help with a wide variety of tasks, from answering questions and providing information on various topics to assisting with writing, translating, and more. How can I assist you today?\", generate_token_len=53, input_token_len=34, session_id=4, finish_reason='stop', token_ids=[9707, 0, 358, 2776, 1207, 16948, 11, 458, 15235, 17847, 3465, 553, 54364, 14817, 13, 358, 2776, 1588, 311, 1492, 448, 264, 6884, 8045, 315, 9079, 11, 504, 35764, 4755, 323, 8241, 1995, 389, 5257, 13347, 311, 45827, 448, 4378, 11, 66271, 11, 323, 803, 13, 2585, 646, 358, 7789, 498, 3351, 30], logprobs=None, index=0), Response(text='Shanghai is a major city located in the eastern part of China, at the mouth of the Yangtze River. It is the largest city in China and one of the largest cities in the world by population. Shanghai is known for its blend of traditional and modern architecture, vibrant economy, and cultural diversity. It is a global financial hub and a major center for commerce, fashion, technology, and transportation. Some notable features of Shanghai include the Shanghai Tower, the Bund, and the ancient city walls of the Huangpu District.', generate_token_len=106, input_token_len=32, session_id=5, finish_reason='stop', token_ids=[2016, 30070, 374, 264, 3598, 3283, 7407, 304, 279, 23149, 949, 315, 5616, 11, 518, 279, 10780, 315, 279, 24474, 83, 2986, 10948, 13, 1084, 374, 279, 7772, 3283, 304, 5616, 323, 825, 315, 279, 7772, 9720, 304, 279, 1879, 553, 7042, 13, 37047, 374, 3881, 369, 1181, 20334, 315, 8606, 323, 6481, 17646, 11, 32976, 8584, 11, 323, 12752, 19492, 13, 1084, 374, 264, 3644, 5896, 18719, 323, 264, 3598, 4126, 369, 35654, 11, 11153, 11, 5440, 11, 323, 17903, 13, 4329, 27190, 4419, 315, 37047, 2924, 279, 37047, 21938, 11, 279, 29608, 11, 323, 279, 13833, 3283, 14285, 315, 279, 58409, 5584, 10942, 13], logprobs=None, index=1)]\n"
|
| 315 |
+
]
|
| 316 |
+
}
|
| 317 |
+
],
|
| 318 |
+
"source": [
|
| 319 |
+
"response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"], gen_config=gen_config)\n",
|
| 320 |
+
"print(response)"
|
| 321 |
+
]
|
| 322 |
+
},
|
| 323 |
+
{
|
| 324 |
+
"cell_type": "markdown",
|
| 325 |
+
"id": "06a02f9d",
|
| 326 |
+
"metadata": {},
|
| 327 |
+
"source": [
|
| 328 |
+
"- **An example for OpenAI format prompt input:**"
|
| 329 |
+
]
|
| 330 |
+
},
|
| 331 |
+
{
|
| 332 |
+
"cell_type": "code",
|
| 333 |
+
"execution_count": null,
|
| 334 |
+
"id": "b6e03be1",
|
| 335 |
+
"metadata": {},
|
| 336 |
+
"outputs": [
|
| 337 |
+
{
|
| 338 |
+
"name": "stderr",
|
| 339 |
+
"output_type": "stream",
|
| 340 |
+
"text": [
|
| 341 |
+
"Fetching 20 files: 25%|██████████▎ | 5/20 [00:09<00:28, 1.89s/it]\n"
|
| 342 |
+
]
|
| 343 |
+
}
|
| 344 |
+
],
|
| 345 |
+
"source": [
|
| 346 |
+
"from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig\n",
|
| 347 |
+
"\n",
|
| 348 |
+
"backend_config = TurbomindEngineConfig(tp=2)\n",
|
| 349 |
+
"gen_config = GenerationConfig(top_p=0.8, top_k=40, temperature=0.8, max_new_tokens=1024)\n",
|
| 350 |
+
"# pipe = pipeline(\"internlm/internlm2_5-7b-chat\", backend_config=backend_config)\n",
|
| 351 |
+
"prompts = [\n",
|
| 352 |
+
" [{\"role\": \"user\", \"content\": \"Hi, pls intro yourself\"}],\n",
|
| 353 |
+
" [{\"role\": \"user\", \"content\": \"Shanghai is\"}],\n",
|
| 354 |
+
"]\n",
|
| 355 |
+
"response = pipe(prompts, gen_config=gen_config)\n",
|
| 356 |
+
"print(response)"
|
| 357 |
+
]
|
| 358 |
+
},
|
| 359 |
+
{
|
| 360 |
+
"cell_type": "markdown",
|
| 361 |
+
"id": "dc8ef83f",
|
| 362 |
+
"metadata": {},
|
| 363 |
+
"source": [
|
| 364 |
+
"- **An example for streaming mode:**"
|
| 365 |
+
]
|
| 366 |
+
},
|
| 367 |
+
{
|
| 368 |
+
"cell_type": "code",
|
| 369 |
+
"execution_count": 7,
|
| 370 |
+
"id": "197a2719",
|
| 371 |
+
"metadata": {},
|
| 372 |
+
"outputs": [
|
| 373 |
+
{
|
| 374 |
+
"name": "stdout",
|
| 375 |
+
"output_type": "stream",
|
| 376 |
+
"text": [
|
| 377 |
+
"Hello!Sh Ianghai is'm Q a majorwen, city located an in AI assistant the eastern created by part of Alibaba Cloud China,. I at the'm here mouth of to help the Yang with at wideze variety River of. tasks It, is from the answering largest questions city and in providing China information and on one various of topics the to largest assisting cities with in writing the, world translating by, population and. more Shanghai. is How known can for I its assist blend you of today traditional? and modern architecture, vibrant economy, and cultural diversity. It is a global financial hub and a major center for commerce, fashion, technology, and transportation. Some notable features of Shanghai include the Shanghai Tower, the Bund, and the ancient city walls of the Huangpu District."
|
| 378 |
+
]
|
| 379 |
+
}
|
| 380 |
+
],
|
| 381 |
+
"source": [
|
| 382 |
+
"from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig\n",
|
| 383 |
+
"\n",
|
| 384 |
+
"backend_config = TurbomindEngineConfig(tp=2)\n",
|
| 385 |
+
"gen_config = GenerationConfig(top_p=0.8, top_k=40, temperature=0.8, max_new_tokens=1024)\n",
|
| 386 |
+
"# pipe = pipeline(\"internlm/internlm2_5-7b-chat\", backend_config=backend_config)\n",
|
| 387 |
+
"prompts = [\n",
|
| 388 |
+
" [{\"role\": \"user\", \"content\": \"Hi, pls intro yourself\"}],\n",
|
| 389 |
+
" [{\"role\": \"user\", \"content\": \"Shanghai is\"}],\n",
|
| 390 |
+
"]\n",
|
| 391 |
+
"for item in pipe.stream_infer(prompts, gen_config=gen_config):\n",
|
| 392 |
+
" # print(item.text)\n",
|
| 393 |
+
" # echo item.text incrementally\n",
|
| 394 |
+
" print(item.text, end=\"\")"
|
| 395 |
+
]
|
| 396 |
+
},
|
| 397 |
+
{
|
| 398 |
+
"cell_type": "code",
|
| 399 |
+
"execution_count": null,
|
| 400 |
+
"id": "77228bf3",
|
| 401 |
+
"metadata": {},
|
| 402 |
+
"outputs": [
|
| 403 |
+
{
|
| 404 |
+
"name": "stderr",
|
| 405 |
+
"output_type": "stream",
|
| 406 |
+
"text": [
|
| 407 |
+
"Fetching 20 files: 25%|██████████▎ | 5/20 [00:06<00:18, 1.26s/it]\n"
|
| 408 |
+
]
|
| 409 |
+
}
|
| 410 |
+
],
|
| 411 |
+
"source": [
|
| 412 |
+
"from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig\n",
|
| 413 |
+
"\n",
|
| 414 |
+
"backend_config = TurbomindEngineConfig(tp=2)\n",
|
| 415 |
+
"gen_config = GenerationConfig(top_p=0.8, top_k=40, temperature=0.8, max_new_tokens=1024)\n",
|
| 416 |
+
"pipe = pipeline(\"internlm/internlm2_5-7b-chat\", backend_config=backend_config)\n",
|
| 417 |
+
"prompts = [\n",
|
| 418 |
+
" [{\"role\": \"user\", \"content\": \"Hi, pls intro yourself\"}],\n",
|
| 419 |
+
" [{\"role\": \"user\", \"content\": \"Shanghai is\" * 10}],\n",
|
| 420 |
+
"]\n",
|
| 421 |
+
"for item in pipe.stream_infer(prompts, gen_config=gen_config):\n",
|
| 422 |
+
" print(item)"
|
| 423 |
+
]
|
| 424 |
+
},
|
| 425 |
+
{
|
| 426 |
+
"cell_type": "markdown",
|
| 427 |
+
"id": "fb2782c8",
|
| 428 |
+
"metadata": {},
|
| 429 |
+
"source": [
|
| 430 |
+
"- **An example to cauculate logits & ppl:**"
|
| 431 |
+
]
|
| 432 |
+
},
|
| 433 |
+
{
|
| 434 |
+
"cell_type": "code",
|
| 435 |
+
"execution_count": null,
|
| 436 |
+
"id": "841c67c9",
|
| 437 |
+
"metadata": {},
|
| 438 |
+
"outputs": [],
|
| 439 |
+
"source": [
|
| 440 |
+
"from transformers import AutoTokenizer\n",
|
| 441 |
+
"from lmdeploy import pipeline\n",
|
| 442 |
+
"\n",
|
| 443 |
+
"model_repoid_or_path = \"internlm/internlm2_5-7b-chat\"\n",
|
| 444 |
+
"pipe = pipeline(model_repoid_or_path)\n",
|
| 445 |
+
"tokenizer = AutoTokenizer.from_pretrained(model_repoid_or_path, trust_remote_code=True)\n",
|
| 446 |
+
"\n",
|
| 447 |
+
"# logits\n",
|
| 448 |
+
"messages = [\n",
|
| 449 |
+
" {\"role\": \"user\", \"content\": \"Hello, how are you?\"},\n",
|
| 450 |
+
"]\n",
|
| 451 |
+
"input_ids = tokenizer.apply_chat_template(messages)\n",
|
| 452 |
+
"logits = pipe.get_logits(input_ids)\n",
|
| 453 |
+
"\n",
|
| 454 |
+
"# ppl\n",
|
| 455 |
+
"ppl = pipe.get_ppl(input_ids)"
|
| 456 |
+
]
|
| 457 |
+
},
|
| 458 |
+
{
|
| 459 |
+
"cell_type": "markdown",
|
| 460 |
+
"id": "68025eb2",
|
| 461 |
+
"metadata": {},
|
| 462 |
+
"source": [
|
| 463 |
+
"```{note}\n",
|
| 464 |
+
"get_ppl returns the cross entropy loss without applying the exponential operation afterwards\n",
|
| 465 |
+
"```\n",
|
| 466 |
+
"\n",
|
| 467 |
+
"- **Below is an example for pytorch backend. Please install triton first.**\n",
|
| 468 |
+
"\n",
|
| 469 |
+
"```shell\n",
|
| 470 |
+
"pip install triton>=2.1.0\n",
|
| 471 |
+
"```"
|
| 472 |
+
]
|
| 473 |
+
},
|
| 474 |
+
{
|
| 475 |
+
"cell_type": "code",
|
| 476 |
+
"execution_count": null,
|
| 477 |
+
"id": "b3535249",
|
| 478 |
+
"metadata": {},
|
| 479 |
+
"outputs": [],
|
| 480 |
+
"source": [
|
| 481 |
+
"from lmdeploy import pipeline, GenerationConfig, PytorchEngineConfig\n",
|
| 482 |
+
"\n",
|
| 483 |
+
"backend_config = PytorchEngineConfig(session_len=2048)\n",
|
| 484 |
+
"gen_config = GenerationConfig(top_p=0.8, top_k=40, temperature=0.8, max_new_tokens=1024)\n",
|
| 485 |
+
"pipe = pipeline(\"internlm/internlm2_5-7b-chat\", backend_config=backend_config)\n",
|
| 486 |
+
"prompts = [\n",
|
| 487 |
+
" [{\"role\": \"user\", \"content\": \"Hi, pls intro yourself\"}],\n",
|
| 488 |
+
" [{\"role\": \"user\", \"content\": \"Shanghai is\"}],\n",
|
| 489 |
+
"]\n",
|
| 490 |
+
"response = pipe(prompts, gen_config=gen_config)\n",
|
| 491 |
+
"print(response)"
|
| 492 |
+
]
|
| 493 |
+
},
|
| 494 |
+
{
|
| 495 |
+
"cell_type": "markdown",
|
| 496 |
+
"id": "06883551",
|
| 497 |
+
"metadata": {},
|
| 498 |
+
"source": [
|
| 499 |
+
"- **An example for lora.**"
|
| 500 |
+
]
|
| 501 |
+
},
|
| 502 |
+
{
|
| 503 |
+
"cell_type": "code",
|
| 504 |
+
"execution_count": null,
|
| 505 |
+
"id": "85d5f9a2",
|
| 506 |
+
"metadata": {},
|
| 507 |
+
"outputs": [],
|
| 508 |
+
"source": [
|
| 509 |
+
"from lmdeploy import pipeline, GenerationConfig, PytorchEngineConfig\n",
|
| 510 |
+
"\n",
|
| 511 |
+
"backend_config = PytorchEngineConfig(\n",
|
| 512 |
+
" session_len=2048, adapters=dict(lora_name_1=\"chenchi/lora-chatglm2-6b-guodegang\")\n",
|
| 513 |
+
")\n",
|
| 514 |
+
"gen_config = GenerationConfig(top_p=0.8, top_k=40, temperature=0.8, max_new_tokens=1024)\n",
|
| 515 |
+
"pipe = pipeline(\"THUDM/chatglm2-6b\", backend_config=backend_config)\n",
|
| 516 |
+
"prompts = [[{\"role\": \"user\", \"content\": \"您猜怎么着\"}]]\n",
|
| 517 |
+
"response = pipe(prompts, gen_config=gen_config, adapter_name=\"lora_name_1\")\n",
|
| 518 |
+
"print(response)"
|
| 519 |
+
]
|
| 520 |
+
},
|
| 521 |
+
{
|
| 522 |
+
"cell_type": "markdown",
|
| 523 |
+
"id": "2991899f",
|
| 524 |
+
"metadata": {},
|
| 525 |
+
"source": [
|
| 526 |
+
"## FAQs\n",
|
| 527 |
+
"\n",
|
| 528 |
+
"- **RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase**.\n",
|
| 529 |
+
"\n",
|
| 530 |
+
" If you got this for tp>1 in pytorch backend. Please make sure the python script has following\n",
|
| 531 |
+
"\n",
|
| 532 |
+
" ```python\n",
|
| 533 |
+
" if __name__ == '__main__':\n",
|
| 534 |
+
" ```\n",
|
| 535 |
+
"\n",
|
| 536 |
+
" Generally, in the context of multi-threading or multi-processing, it might be necessary to ensure that initialization code is executed only once. In this case, `if __name__ == '__main__':` can help to ensure that these initialization codes are run only in the main program, and not repeated in each newly created process or thread.\n",
|
| 537 |
+
"\n",
|
| 538 |
+
"- To customize a chat template, please refer to [chat_template.md](../advance/chat_template.md).\n",
|
| 539 |
+
"\n",
|
| 540 |
+
"- If the weight of lora has a corresponding chat template, you can first register the chat template to lmdeploy, and then use the chat template name as the adapter name."
|
| 541 |
+
]
|
| 542 |
+
}
|
| 543 |
+
],
|
| 544 |
+
"metadata": {
|
| 545 |
+
"jupytext": {
|
| 546 |
+
"cell_metadata_filter": "-all",
|
| 547 |
+
"main_language": "python",
|
| 548 |
+
"notebook_metadata_filter": "-all"
|
| 549 |
+
},
|
| 550 |
+
"kernelspec": {
|
| 551 |
+
"display_name": "lmdeploy",
|
| 552 |
+
"language": "python",
|
| 553 |
+
"name": "python3"
|
| 554 |
+
},
|
| 555 |
+
"language_info": {
|
| 556 |
+
"codemirror_mode": {
|
| 557 |
+
"name": "ipython",
|
| 558 |
+
"version": 3
|
| 559 |
+
},
|
| 560 |
+
"file_extension": ".py",
|
| 561 |
+
"mimetype": "text/x-python",
|
| 562 |
+
"name": "python",
|
| 563 |
+
"nbconvert_exporter": "python",
|
| 564 |
+
"pygments_lexer": "ipython3",
|
| 565 |
+
"version": "3.8.19"
|
| 566 |
+
}
|
| 567 |
+
},
|
| 568 |
+
"nbformat": 4,
|
| 569 |
+
"nbformat_minor": 5
|
| 570 |
+
}
|
a_mllm_notebooks/lmdeploy/pipeline.md
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Offline Inference Pipeline
|
| 2 |
+
|
| 3 |
+
In this tutorial, We will present a list of examples to introduce the usage of `lmdeploy.pipeline`.
|
| 4 |
+
|
| 5 |
+
You can overview the detailed pipeline API in [this](https://lmdeploy.readthedocs.io/en/latest/api/pipeline.html) guide.
|
| 6 |
+
|
| 7 |
+
## Usage
|
| 8 |
+
|
| 9 |
+
- **An example using default parameters:**
|
| 10 |
+
|
| 11 |
+
```python
|
| 12 |
+
from lmdeploy import pipeline
|
| 13 |
+
|
| 14 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat')
|
| 15 |
+
response = pipe(['Hi, pls intro yourself', 'Shanghai is'])
|
| 16 |
+
print(response)
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
In this example, the pipeline by default allocates a predetermined percentage of GPU memory for storing k/v cache. The ratio is dictated by the parameter `TurbomindEngineConfig.cache_max_entry_count`.
|
| 20 |
+
|
| 21 |
+
There have been alterations to the strategy for setting the k/v cache ratio throughout the evolution of LMDeploy. The following are the change histories:
|
| 22 |
+
|
| 23 |
+
1. `v0.2.0 <= lmdeploy <= v0.2.1`
|
| 24 |
+
|
| 25 |
+
`TurbomindEngineConfig.cache_max_entry_count` defaults to 0.5, indicating 50% GPU **total memory** allocated for k/v cache. Out Of Memory (OOM) errors may occur if a 7B model is deployed on a GPU with memory less than 40G. If you encounter an OOM error, please decrease the ratio of the k/v cache occupation as follows:
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 29 |
+
|
| 30 |
+
# decrease the ratio of the k/v cache occupation to 20%
|
| 31 |
+
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)
|
| 32 |
+
|
| 33 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat',
|
| 34 |
+
backend_config=backend_config)
|
| 35 |
+
response = pipe(['Hi, pls intro yourself', 'Shanghai is'])
|
| 36 |
+
print(response)
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
2. `lmdeploy > v0.2.1`
|
| 40 |
+
|
| 41 |
+
The allocation strategy for k/v cache is changed to reserve space from the **GPU free memory** proportionally. The ratio `TurbomindEngineConfig.cache_max_entry_count` has been adjusted to 0.8 by default. If OOM error happens, similar to the method mentioned above, please consider reducing the ratio value to decrease the memory usage of the k/v cache.
|
| 42 |
+
|
| 43 |
+
- **An example showing how to set tensor parallel num**:
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 47 |
+
|
| 48 |
+
backend_config = TurbomindEngineConfig(tp=2)
|
| 49 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat',
|
| 50 |
+
backend_config=backend_config)
|
| 51 |
+
response = pipe(['Hi, pls intro yourself', 'Shanghai is'])
|
| 52 |
+
print(response)
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
- **An example for setting sampling parameters:**
|
| 56 |
+
|
| 57 |
+
```python
|
| 58 |
+
from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig
|
| 59 |
+
|
| 60 |
+
backend_config = TurbomindEngineConfig(tp=2)
|
| 61 |
+
gen_config = GenerationConfig(top_p=0.8,
|
| 62 |
+
top_k=40,
|
| 63 |
+
temperature=0.8,
|
| 64 |
+
max_new_tokens=1024)
|
| 65 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat',
|
| 66 |
+
backend_config=backend_config)
|
| 67 |
+
response = pipe(['Hi, pls intro yourself', 'Shanghai is'],
|
| 68 |
+
gen_config=gen_config)
|
| 69 |
+
print(response)
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
- **An example for OpenAI format prompt input:**
|
| 73 |
+
|
| 74 |
+
```python
|
| 75 |
+
from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig
|
| 76 |
+
|
| 77 |
+
backend_config = TurbomindEngineConfig(tp=2)
|
| 78 |
+
gen_config = GenerationConfig(top_p=0.8,
|
| 79 |
+
top_k=40,
|
| 80 |
+
temperature=0.8,
|
| 81 |
+
max_new_tokens=1024)
|
| 82 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat',
|
| 83 |
+
backend_config=backend_config)
|
| 84 |
+
prompts = [[{
|
| 85 |
+
'role': 'user',
|
| 86 |
+
'content': 'Hi, pls intro yourself'
|
| 87 |
+
}], [{
|
| 88 |
+
'role': 'user',
|
| 89 |
+
'content': 'Shanghai is'
|
| 90 |
+
}]]
|
| 91 |
+
response = pipe(prompts,
|
| 92 |
+
gen_config=gen_config)
|
| 93 |
+
print(response)
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
- **An example for streaming mode:**
|
| 97 |
+
|
| 98 |
+
```python
|
| 99 |
+
from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig
|
| 100 |
+
|
| 101 |
+
backend_config = TurbomindEngineConfig(tp=2)
|
| 102 |
+
gen_config = GenerationConfig(top_p=0.8,
|
| 103 |
+
top_k=40,
|
| 104 |
+
temperature=0.8,
|
| 105 |
+
max_new_tokens=1024)
|
| 106 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat',
|
| 107 |
+
backend_config=backend_config)
|
| 108 |
+
prompts = [[{
|
| 109 |
+
'role': 'user',
|
| 110 |
+
'content': 'Hi, pls intro yourself'
|
| 111 |
+
}], [{
|
| 112 |
+
'role': 'user',
|
| 113 |
+
'content': 'Shanghai is'
|
| 114 |
+
}]]
|
| 115 |
+
for item in pipe.stream_infer(prompts, gen_config=gen_config):
|
| 116 |
+
print(item)
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
- **An example to cauculate logits & ppl:**
|
| 120 |
+
|
| 121 |
+
```python
|
| 122 |
+
from transformers import AutoTokenizer
|
| 123 |
+
from lmdeploy import pipeline
|
| 124 |
+
model_repoid_or_path='internlm/internlm2_5-7b-chat'
|
| 125 |
+
pipe = pipeline(model_repoid_or_path)
|
| 126 |
+
tokenizer = AutoTokenizer.from_pretrained(model_repoid_or_path, trust_remote_code=True)
|
| 127 |
+
|
| 128 |
+
# logits
|
| 129 |
+
messages = [
|
| 130 |
+
{"role": "user", "content": "Hello, how are you?"},
|
| 131 |
+
]
|
| 132 |
+
input_ids = tokenizer.apply_chat_template(messages)
|
| 133 |
+
logits = pipe.get_logits(input_ids)
|
| 134 |
+
|
| 135 |
+
# ppl
|
| 136 |
+
ppl = pipe.get_ppl(input_ids)
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
```{note}
|
| 140 |
+
get_ppl returns the cross entropy loss without applying the exponential operation afterwards
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
- **Below is an example for pytorch backend. Please install triton first.**
|
| 144 |
+
|
| 145 |
+
```shell
|
| 146 |
+
pip install triton>=2.1.0
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
```python
|
| 150 |
+
from lmdeploy import pipeline, GenerationConfig, PytorchEngineConfig
|
| 151 |
+
|
| 152 |
+
backend_config = PytorchEngineConfig(session_len=2048)
|
| 153 |
+
gen_config = GenerationConfig(top_p=0.8,
|
| 154 |
+
top_k=40,
|
| 155 |
+
temperature=0.8,
|
| 156 |
+
max_new_tokens=1024)
|
| 157 |
+
pipe = pipeline('internlm/internlm2_5-7b-chat',
|
| 158 |
+
backend_config=backend_config)
|
| 159 |
+
prompts = [[{
|
| 160 |
+
'role': 'user',
|
| 161 |
+
'content': 'Hi, pls intro yourself'
|
| 162 |
+
}], [{
|
| 163 |
+
'role': 'user',
|
| 164 |
+
'content': 'Shanghai is'
|
| 165 |
+
}]]
|
| 166 |
+
response = pipe(prompts, gen_config=gen_config)
|
| 167 |
+
print(response)
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
- **An example for lora.**
|
| 171 |
+
|
| 172 |
+
```python
|
| 173 |
+
from lmdeploy import pipeline, GenerationConfig, PytorchEngineConfig
|
| 174 |
+
|
| 175 |
+
backend_config = PytorchEngineConfig(session_len=2048,
|
| 176 |
+
adapters=dict(lora_name_1='chenchi/lora-chatglm2-6b-guodegang'))
|
| 177 |
+
gen_config = GenerationConfig(top_p=0.8,
|
| 178 |
+
top_k=40,
|
| 179 |
+
temperature=0.8,
|
| 180 |
+
max_new_tokens=1024)
|
| 181 |
+
pipe = pipeline('THUDM/chatglm2-6b',
|
| 182 |
+
backend_config=backend_config)
|
| 183 |
+
prompts = [[{
|
| 184 |
+
'role': 'user',
|
| 185 |
+
'content': '您猜怎么着'
|
| 186 |
+
}]]
|
| 187 |
+
response = pipe(prompts, gen_config=gen_config, adapter_name='lora_name_1')
|
| 188 |
+
print(response)
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
## FAQs
|
| 192 |
+
|
| 193 |
+
- **RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase**.
|
| 194 |
+
|
| 195 |
+
If you got this for tp>1 in pytorch backend. Please make sure the python script has following
|
| 196 |
+
|
| 197 |
+
```python
|
| 198 |
+
if __name__ == '__main__':
|
| 199 |
+
```
|
| 200 |
+
|
| 201 |
+
Generally, in the context of multi-threading or multi-processing, it might be necessary to ensure that initialization code is executed only once. In this case, `if __name__ == '__main__':` can help to ensure that these initialization codes are run only in the main program, and not repeated in each newly created process or thread.
|
| 202 |
+
|
| 203 |
+
- To customize a chat template, please refer to [chat_template.md](../advance/chat_template.md).
|
| 204 |
+
|
| 205 |
+
- If the weight of lora has a corresponding chat template, you can first register the chat template to lmdeploy, and then use the chat template name as the adapter name.
|
a_mllm_notebooks/lmdeploy/proxy_server.ipynb
ADDED
|
@@ -0,0 +1,248 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "219e5106",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Request Distributor Server\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"The request distributor service can parallelize multiple api_server services. Users only need to access the proxy URL, and they can indirectly access different api_server services. The proxy service will automatically distribute requests internally, achieving load balancing.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"## Startup\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"Start the proxy service:\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"```shell\n",
|
| 17 |
+
"lmdeploy serve proxy --server-name {server_name} --server-port {server_port} --strategy \"min_expected_latency\"\n",
|
| 18 |
+
"```\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"After startup is successful, the URL of the proxy service will also be printed by the script. Access this URL in your browser to open the Swagger UI.\n",
|
| 21 |
+
"Subsequently, users can add it directly to the proxy service when starting the `api_server` service by using the `--proxy-url` command. For example:\n",
|
| 22 |
+
"`lmdeploy serve api_server InternLM/internlm2-chat-1_8b --proxy-url http://0.0.0.0:8000`。\n",
|
| 23 |
+
"In this way, users can access the services of the `api_server` through the proxy node, and the usage of the proxy node is exactly the same as that of the `api_server`, both of which are compatible with the OpenAI format.\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"- /v1/models\n",
|
| 26 |
+
"- /v1/chat/completions\n",
|
| 27 |
+
"- /v1/completions\n",
|
| 28 |
+
"\n",
|
| 29 |
+
"## Node Management\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"Through Swagger UI, we can see multiple APIs. Those related to api_server node management include:\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"- /nodes/status\n",
|
| 34 |
+
"- /nodes/add\n",
|
| 35 |
+
"- /nodes/remove\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"They respectively represent viewing all api_server service nodes, adding a certain node, and deleting a certain node.\n",
|
| 38 |
+
"\n",
|
| 39 |
+
"### Node Management through curl\n",
|
| 40 |
+
"\n",
|
| 41 |
+
"```shell\n",
|
| 42 |
+
"curl -X 'GET' \\\n",
|
| 43 |
+
" 'http://localhost:8000/nodes/status' \\\n",
|
| 44 |
+
" -H 'accept: application/json'\n",
|
| 45 |
+
"```\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"```shell\n",
|
| 48 |
+
"curl -X 'POST' \\\n",
|
| 49 |
+
" 'http://localhost:8000/nodes/add' \\\n",
|
| 50 |
+
" -H 'accept: application/json' \\\n",
|
| 51 |
+
" -H 'Content-Type: application/json' \\\n",
|
| 52 |
+
" -d '{\n",
|
| 53 |
+
" \"url\": \"http://0.0.0.0:23333\"\n",
|
| 54 |
+
"}'\n",
|
| 55 |
+
"```\n",
|
| 56 |
+
"\n",
|
| 57 |
+
"```shell\n",
|
| 58 |
+
"curl -X 'POST' \\\n",
|
| 59 |
+
" 'http://localhost:8000/nodes/remove?node_url=http://0.0.0.0:23333' \\\n",
|
| 60 |
+
" -H 'accept: application/json' \\\n",
|
| 61 |
+
" -d ''\n",
|
| 62 |
+
"```\n",
|
| 63 |
+
"\n",
|
| 64 |
+
"### Node Management through python"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "code",
|
| 69 |
+
"execution_count": 3,
|
| 70 |
+
"id": "e4582e32",
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"outputs": [
|
| 73 |
+
{
|
| 74 |
+
"data": {
|
| 75 |
+
"text/plain": [
|
| 76 |
+
"'OpenGVLab/InternVL2_5-1B'"
|
| 77 |
+
]
|
| 78 |
+
},
|
| 79 |
+
"execution_count": 3,
|
| 80 |
+
"metadata": {},
|
| 81 |
+
"output_type": "execute_result"
|
| 82 |
+
}
|
| 83 |
+
],
|
| 84 |
+
"source": [
|
| 85 |
+
"from openai import OpenAI\n",
|
| 86 |
+
"\n",
|
| 87 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:23333/v1\")\n",
|
| 88 |
+
"model_name = client.models.list().data[0].id\n",
|
| 89 |
+
"\n",
|
| 90 |
+
"\n",
|
| 91 |
+
"server_port = 8080\n",
|
| 92 |
+
"model_name"
|
| 93 |
+
]
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"cell_type": "code",
|
| 97 |
+
"execution_count": 7,
|
| 98 |
+
"id": "a169c92b",
|
| 99 |
+
"metadata": {},
|
| 100 |
+
"outputs": [
|
| 101 |
+
{
|
| 102 |
+
"name": "stdout",
|
| 103 |
+
"output_type": "stream",
|
| 104 |
+
"text": [
|
| 105 |
+
"usage: lmdeploy serve proxy [-h] [--server-name SERVER_NAME] [--server-port SERVER_PORT]\n",
|
| 106 |
+
" [--strategy {random,min_expected_latency,min_observed_latency}]\n",
|
| 107 |
+
" [--api-keys [API_KEYS [API_KEYS ...]]] [--ssl]\n",
|
| 108 |
+
"\n",
|
| 109 |
+
"Proxy server that manages distributed api_server nodes.\n",
|
| 110 |
+
"\n",
|
| 111 |
+
"optional arguments:\n",
|
| 112 |
+
" -h, --help show this help message and exit\n",
|
| 113 |
+
" --server-name SERVER_NAME\n",
|
| 114 |
+
" Host ip for proxy serving. Default: 0.0.0.0. Type: str\n",
|
| 115 |
+
" --server-port SERVER_PORT\n",
|
| 116 |
+
" Server port of the proxy. Default: 8000. Type: int\n",
|
| 117 |
+
" --strategy {random,min_expected_latency,min_observed_latency}\n",
|
| 118 |
+
" the strategy to dispatch requests to nodes. Default:\n",
|
| 119 |
+
" min_expected_latency. Type: str\n",
|
| 120 |
+
" --api-keys [API_KEYS [API_KEYS ...]]\n",
|
| 121 |
+
" Optional list of space separated API keys. Default: None. Type: str\n",
|
| 122 |
+
" --ssl Enable SSL. Requires OS Environment variables 'SSL_KEYFILE' and\n",
|
| 123 |
+
" 'SSL_CERTFILE'. Default: False\n"
|
| 124 |
+
]
|
| 125 |
+
}
|
| 126 |
+
],
|
| 127 |
+
"source": [
|
| 128 |
+
"!lmdeploy serve proxy --help"
|
| 129 |
+
]
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "code",
|
| 133 |
+
"execution_count": 9,
|
| 134 |
+
"id": "7f7b4e5b",
|
| 135 |
+
"metadata": {},
|
| 136 |
+
"outputs": [
|
| 137 |
+
{
|
| 138 |
+
"name": "stdout",
|
| 139 |
+
"output_type": "stream",
|
| 140 |
+
"text": [
|
| 141 |
+
"\u001b[32mINFO\u001b[0m: Started server process [\u001b[36m72836\u001b[0m]\n",
|
| 142 |
+
"\u001b[32mINFO\u001b[0m: Waiting for application startup.\n",
|
| 143 |
+
"\u001b[32mINFO\u001b[0m: Application startup complete.\n",
|
| 144 |
+
"\u001b[32mINFO\u001b[0m: Uvicorn running on \u001b[1mhttp://0.0.0.0:8080\u001b[0m (Press CTRL+C to quit)\n",
|
| 145 |
+
"^C\n",
|
| 146 |
+
"\u001b[32mINFO\u001b[0m: Shutting down\n",
|
| 147 |
+
"\u001b[32mINFO\u001b[0m: Waiting for application shutdown.\n",
|
| 148 |
+
"\u001b[32mINFO\u001b[0m: Application shutdown complete.\n",
|
| 149 |
+
"\u001b[32mINFO\u001b[0m: Finished server process [\u001b[36m72836\u001b[0m]\n"
|
| 150 |
+
]
|
| 151 |
+
}
|
| 152 |
+
],
|
| 153 |
+
"source": [
|
| 154 |
+
"!lmdeploy serve proxy --server-name 0.0.0.0 --server-port {server_port} --strategy \"min_expected_latency\""
|
| 155 |
+
]
|
| 156 |
+
},
|
| 157 |
+
{
|
| 158 |
+
"cell_type": "code",
|
| 159 |
+
"execution_count": null,
|
| 160 |
+
"id": "e86af8a2",
|
| 161 |
+
"metadata": {},
|
| 162 |
+
"outputs": [],
|
| 163 |
+
"source": [
|
| 164 |
+
"# query all nodes\n",
|
| 165 |
+
"import requests\n",
|
| 166 |
+
"url = 'http://localhost:8000/nodes/status'\n",
|
| 167 |
+
"headers = {'accept': 'application/json'}\n",
|
| 168 |
+
"response = requests.get(url, headers=headers)\n",
|
| 169 |
+
"print(response.text)"
|
| 170 |
+
]
|
| 171 |
+
},
|
| 172 |
+
{
|
| 173 |
+
"cell_type": "code",
|
| 174 |
+
"execution_count": null,
|
| 175 |
+
"id": "dc76e33b",
|
| 176 |
+
"metadata": {},
|
| 177 |
+
"outputs": [],
|
| 178 |
+
"source": [
|
| 179 |
+
"# add a new node\n",
|
| 180 |
+
"import requests\n",
|
| 181 |
+
"url = 'http://localhost:8000/nodes/add'\n",
|
| 182 |
+
"headers = {\n",
|
| 183 |
+
" 'accept': 'application/json',\n",
|
| 184 |
+
" 'Content-Type': 'application/json'\n",
|
| 185 |
+
"}\n",
|
| 186 |
+
"data = {\"url\": \"http://0.0.0.0:23333\"}\n",
|
| 187 |
+
"response = requests.post(url, headers=headers, json=data)\n",
|
| 188 |
+
"print(response.text)"
|
| 189 |
+
]
|
| 190 |
+
},
|
| 191 |
+
{
|
| 192 |
+
"cell_type": "code",
|
| 193 |
+
"execution_count": null,
|
| 194 |
+
"id": "1c675bc1",
|
| 195 |
+
"metadata": {},
|
| 196 |
+
"outputs": [],
|
| 197 |
+
"source": [
|
| 198 |
+
"# delete a node\n",
|
| 199 |
+
"import requests\n",
|
| 200 |
+
"url = 'http://localhost:8000/nodes/remove'\n",
|
| 201 |
+
"headers = {'accept': 'application/json',}\n",
|
| 202 |
+
"params = {'node_url': 'http://0.0.0.0:23333',}\n",
|
| 203 |
+
"response = requests.post(url, headers=headers, data='', params=params)\n",
|
| 204 |
+
"print(response.text)"
|
| 205 |
+
]
|
| 206 |
+
},
|
| 207 |
+
{
|
| 208 |
+
"cell_type": "markdown",
|
| 209 |
+
"id": "2a6bf84e",
|
| 210 |
+
"metadata": {},
|
| 211 |
+
"source": [
|
| 212 |
+
"## Dispatch Strategy\n",
|
| 213 |
+
"\n",
|
| 214 |
+
"The current distribution strategies of the proxy service are as follows:\n",
|
| 215 |
+
"\n",
|
| 216 |
+
"- random: dispatches based on the ability of each api_server node provided by the user to process requests. The greater the request throughput, the more likely it is to be allocated. Nodes that do not provide throughput are treated according to the average throughput of other nodes.\n",
|
| 217 |
+
"- min_expected_latency: allocates based on the number of requests currently waiting to be processed on each node, and the throughput capability of each node, calculating the expected time required to complete the response. The shortest one gets allocated. Nodes that do not provide throughput are treated similarly.\n",
|
| 218 |
+
"- min_observed_latency: allocates based on the average time required to handle a certain number of past requests on each node. The one with the shortest time gets allocated."
|
| 219 |
+
]
|
| 220 |
+
}
|
| 221 |
+
],
|
| 222 |
+
"metadata": {
|
| 223 |
+
"jupytext": {
|
| 224 |
+
"cell_metadata_filter": "-all",
|
| 225 |
+
"main_language": "python",
|
| 226 |
+
"notebook_metadata_filter": "-all"
|
| 227 |
+
},
|
| 228 |
+
"kernelspec": {
|
| 229 |
+
"display_name": "lmdeploy",
|
| 230 |
+
"language": "python",
|
| 231 |
+
"name": "python3"
|
| 232 |
+
},
|
| 233 |
+
"language_info": {
|
| 234 |
+
"codemirror_mode": {
|
| 235 |
+
"name": "ipython",
|
| 236 |
+
"version": 3
|
| 237 |
+
},
|
| 238 |
+
"file_extension": ".py",
|
| 239 |
+
"mimetype": "text/x-python",
|
| 240 |
+
"name": "python",
|
| 241 |
+
"nbconvert_exporter": "python",
|
| 242 |
+
"pygments_lexer": "ipython3",
|
| 243 |
+
"version": "3.8.19"
|
| 244 |
+
}
|
| 245 |
+
},
|
| 246 |
+
"nbformat": 4,
|
| 247 |
+
"nbformat_minor": 5
|
| 248 |
+
}
|
a_mllm_notebooks/lmdeploy/proxy_server.md
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Request Distributor Server
|
| 2 |
+
|
| 3 |
+
The request distributor service can parallelize multiple api_server services. Users only need to access the proxy URL, and they can indirectly access different api_server services. The proxy service will automatically distribute requests internally, achieving load balancing.
|
| 4 |
+
|
| 5 |
+
## Startup
|
| 6 |
+
|
| 7 |
+
Start the proxy service:
|
| 8 |
+
|
| 9 |
+
```shell
|
| 10 |
+
lmdeploy serve proxy --server-name {server_name} --server-port {server_port} --strategy "min_expected_latency"
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
After startup is successful, the URL of the proxy service will also be printed by the script. Access this URL in your browser to open the Swagger UI.
|
| 14 |
+
Subsequently, users can add it directly to the proxy service when starting the `api_server` service by using the `--proxy-url` command. For example:
|
| 15 |
+
`lmdeploy serve api_server InternLM/internlm2-chat-1_8b --proxy-url http://0.0.0.0:8000`。
|
| 16 |
+
In this way, users can access the services of the `api_server` through the proxy node, and the usage of the proxy node is exactly the same as that of the `api_server`, both of which are compatible with the OpenAI format.
|
| 17 |
+
|
| 18 |
+
- /v1/models
|
| 19 |
+
- /v1/chat/completions
|
| 20 |
+
- /v1/completions
|
| 21 |
+
|
| 22 |
+
## Node Management
|
| 23 |
+
|
| 24 |
+
Through Swagger UI, we can see multiple APIs. Those related to api_server node management include:
|
| 25 |
+
|
| 26 |
+
- /nodes/status
|
| 27 |
+
- /nodes/add
|
| 28 |
+
- /nodes/remove
|
| 29 |
+
|
| 30 |
+
They respectively represent viewing all api_server service nodes, adding a certain node, and deleting a certain node.
|
| 31 |
+
|
| 32 |
+
### Node Management through curl
|
| 33 |
+
|
| 34 |
+
```shell
|
| 35 |
+
curl -X 'GET' \
|
| 36 |
+
'http://localhost:8000/nodes/status' \
|
| 37 |
+
-H 'accept: application/json'
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
```shell
|
| 41 |
+
curl -X 'POST' \
|
| 42 |
+
'http://localhost:8000/nodes/add' \
|
| 43 |
+
-H 'accept: application/json' \
|
| 44 |
+
-H 'Content-Type: application/json' \
|
| 45 |
+
-d '{
|
| 46 |
+
"url": "http://0.0.0.0:23333"
|
| 47 |
+
}'
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
```shell
|
| 51 |
+
curl -X 'POST' \
|
| 52 |
+
'http://localhost:8000/nodes/remove?node_url=http://0.0.0.0:23333' \
|
| 53 |
+
-H 'accept: application/json' \
|
| 54 |
+
-d ''
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
### Node Management through python
|
| 58 |
+
|
| 59 |
+
```python
|
| 60 |
+
# query all nodes
|
| 61 |
+
import requests
|
| 62 |
+
url = 'http://localhost:8000/nodes/status'
|
| 63 |
+
headers = {'accept': 'application/json'}
|
| 64 |
+
response = requests.get(url, headers=headers)
|
| 65 |
+
print(response.text)
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
```python
|
| 69 |
+
# add a new node
|
| 70 |
+
import requests
|
| 71 |
+
url = 'http://localhost:8000/nodes/add'
|
| 72 |
+
headers = {
|
| 73 |
+
'accept': 'application/json',
|
| 74 |
+
'Content-Type': 'application/json'
|
| 75 |
+
}
|
| 76 |
+
data = {"url": "http://0.0.0.0:23333"}
|
| 77 |
+
response = requests.post(url, headers=headers, json=data)
|
| 78 |
+
print(response.text)
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
# delete a node
|
| 83 |
+
import requests
|
| 84 |
+
url = 'http://localhost:8000/nodes/remove'
|
| 85 |
+
headers = {'accept': 'application/json',}
|
| 86 |
+
params = {'node_url': 'http://0.0.0.0:23333',}
|
| 87 |
+
response = requests.post(url, headers=headers, data='', params=params)
|
| 88 |
+
print(response.text)
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
## Dispatch Strategy
|
| 92 |
+
|
| 93 |
+
The current distribution strategies of the proxy service are as follows:
|
| 94 |
+
|
| 95 |
+
- random: dispatches based on the ability of each api_server node provided by the user to process requests. The greater the request throughput, the more likely it is to be allocated. Nodes that do not provide throughput are treated according to the average throughput of other nodes.
|
| 96 |
+
- min_expected_latency: allocates based on the number of requests currently waiting to be processed on each node, and the throughput capability of each node, calculating the expected time required to complete the response. The shortest one gets allocated. Nodes that do not provide throughput are treated similarly.
|
| 97 |
+
- min_observed_latency: allocates based on the average time required to handle a certain number of past requests on each node. The one with the shortest time gets allocated.
|
a_mllm_notebooks/lmdeploy/pytorch_new_model.ipynb
ADDED
|
@@ -0,0 +1,261 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "8e7fb7ca",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# lmdeploy.pytorch New Model Support\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"lmdeploy.pytorch is designed to simplify the support for new models and the development of prototypes. Users can adapt new models according to their own needs.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"## Model Support\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"### Configuration Loading (Optional)\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"lmdeploy.pytorch initializes the engine based on the model's config file. If the parameter naming of the model to be integrated differs from common models in transformers, parsing errors may occur. A custom ConfigBuilder can be added to parse the configuration."
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "code",
|
| 21 |
+
"execution_count": null,
|
| 22 |
+
"id": "8e2aaf0c",
|
| 23 |
+
"metadata": {},
|
| 24 |
+
"outputs": [],
|
| 25 |
+
"source": [
|
| 26 |
+
"# lmdeploy/pytorch/configurations/gemma.py\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"from lmdeploy.pytorch.config import ModelConfig\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"from .builder import AutoModelConfigBuilder\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"class GemmaModelConfigBuilder(AutoModelConfigBuilder):\n",
|
| 34 |
+
"\n",
|
| 35 |
+
" @classmethod\n",
|
| 36 |
+
" def condition(cls, hf_config):\n",
|
| 37 |
+
" # Check if hf_config is suitable for this builder\n",
|
| 38 |
+
" return hf_config.model_type in ['gemma', 'gemma2']\n",
|
| 39 |
+
"\n",
|
| 40 |
+
" @classmethod\n",
|
| 41 |
+
" def build(cls, hf_config, model_path: str = None):\n",
|
| 42 |
+
" # Use the hf_config loaded by transformers\n",
|
| 43 |
+
" # Construct the ModelConfig for the pytorch engine\n",
|
| 44 |
+
" return ModelConfig(hidden_size=hf_config.hidden_size,\n",
|
| 45 |
+
" num_layers=hf_config.num_hidden_layers,\n",
|
| 46 |
+
" num_attention_heads=hf_config.num_attention_heads,\n",
|
| 47 |
+
" num_key_value_heads=hf_config.num_key_value_heads,\n",
|
| 48 |
+
" bos_token_id=hf_config.bos_token_id,\n",
|
| 49 |
+
" eos_token_id=hf_config.eos_token_id,\n",
|
| 50 |
+
" head_dim=hf_config.head_dim,\n",
|
| 51 |
+
" vocab_size=hf_config.vocab_size)"
|
| 52 |
+
]
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"cell_type": "markdown",
|
| 56 |
+
"id": "a5493f54",
|
| 57 |
+
"metadata": {},
|
| 58 |
+
"source": [
|
| 59 |
+
"The `lmdeploy.pytorch.check_env.check_model` function can be used to verify if the configuration can be parsed correctly.\n",
|
| 60 |
+
"\n",
|
| 61 |
+
"### Implementing the Model\n",
|
| 62 |
+
"\n",
|
| 63 |
+
"After ensuring that the configuration can be parsed correctly, you can start implementing the model logic. Taking the implementation of llama as an example, we need to create the model using the configuration file from transformers."
|
| 64 |
+
]
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"cell_type": "code",
|
| 68 |
+
"execution_count": null,
|
| 69 |
+
"id": "e49b0483",
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"outputs": [],
|
| 72 |
+
"source": [
|
| 73 |
+
"class LlamaForCausalLM(nn.Module):\n",
|
| 74 |
+
"\n",
|
| 75 |
+
" # Constructor, builds the model with the given config\n",
|
| 76 |
+
" # ctx_mgr is the context manager, which can be used to pass engine configurations or additional parameters\n",
|
| 77 |
+
" def __init__(self,\n",
|
| 78 |
+
" config: LlamaConfig,\n",
|
| 79 |
+
" ctx_mgr: StepContextManager,\n",
|
| 80 |
+
" dtype: torch.dtype = None,\n",
|
| 81 |
+
" device: torch.device = None):\n",
|
| 82 |
+
" super().__init__()\n",
|
| 83 |
+
" self.config = config\n",
|
| 84 |
+
" self.ctx_mgr = ctx_mgr\n",
|
| 85 |
+
" # build LLamaModel\n",
|
| 86 |
+
" self.model = LlamaModel(config, dtype=dtype, device=device)\n",
|
| 87 |
+
" # build lm_head\n",
|
| 88 |
+
" self.lm_head = build_rowwise_linear(config.hidden_size,\n",
|
| 89 |
+
" config.vocab_size,\n",
|
| 90 |
+
" bias=False,\n",
|
| 91 |
+
" dtype=dtype,\n",
|
| 92 |
+
" device=device)\n",
|
| 93 |
+
"\n",
|
| 94 |
+
" # Model inference function\n",
|
| 95 |
+
" # It is recommended to use the same parameters as below\n",
|
| 96 |
+
" def forward(\n",
|
| 97 |
+
" self,\n",
|
| 98 |
+
" input_ids: torch.Tensor,\n",
|
| 99 |
+
" position_ids: torch.Tensor,\n",
|
| 100 |
+
" past_key_values: List[List[torch.Tensor]],\n",
|
| 101 |
+
" attn_metadata: Any = None,\n",
|
| 102 |
+
" inputs_embeds: torch.Tensor = None,\n",
|
| 103 |
+
" **kwargs,\n",
|
| 104 |
+
" ):\n",
|
| 105 |
+
" hidden_states = self.model(\n",
|
| 106 |
+
" input_ids=input_ids,\n",
|
| 107 |
+
" position_ids=position_ids,\n",
|
| 108 |
+
" past_key_values=past_key_values,\n",
|
| 109 |
+
" attn_metadata=attn_metadata,\n",
|
| 110 |
+
" inputs_embeds=inputs_embeds,\n",
|
| 111 |
+
" )\n",
|
| 112 |
+
"\n",
|
| 113 |
+
" logits = self.lm_head(hidden_states)\n",
|
| 114 |
+
" logits = logits.float()\n",
|
| 115 |
+
" return logits"
|
| 116 |
+
]
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"cell_type": "markdown",
|
| 120 |
+
"id": "ce1f7780",
|
| 121 |
+
"metadata": {},
|
| 122 |
+
"source": [
|
| 123 |
+
"In addition to these, the following content needs to be added:"
|
| 124 |
+
]
|
| 125 |
+
},
|
| 126 |
+
{
|
| 127 |
+
"cell_type": "code",
|
| 128 |
+
"execution_count": null,
|
| 129 |
+
"id": "b240132b",
|
| 130 |
+
"metadata": {},
|
| 131 |
+
"outputs": [],
|
| 132 |
+
"source": [
|
| 133 |
+
"class LlamaForCausalLM(nn.Module):\n",
|
| 134 |
+
"\n",
|
| 135 |
+
" ...\n",
|
| 136 |
+
"\n",
|
| 137 |
+
" # Indicates whether the model supports cudagraph\n",
|
| 138 |
+
" # Can be a callable object, receiving forward inputs\n",
|
| 139 |
+
" # Dynamically determines if cudagraph is supported\n",
|
| 140 |
+
" support_cuda_graph = True\n",
|
| 141 |
+
"\n",
|
| 142 |
+
" # Builds model inputs\n",
|
| 143 |
+
" # Returns a dictionary, the keys of which must be inputs to forward\n",
|
| 144 |
+
" def prepare_inputs_for_generation(\n",
|
| 145 |
+
" self,\n",
|
| 146 |
+
" past_key_values: List[List[torch.Tensor]],\n",
|
| 147 |
+
" inputs_embeds: Optional[torch.Tensor] = None,\n",
|
| 148 |
+
" context: StepContext = None,\n",
|
| 149 |
+
" ):\n",
|
| 150 |
+
" ...\n",
|
| 151 |
+
"\n",
|
| 152 |
+
" # Loads weights\n",
|
| 153 |
+
" # The model's inputs are key-value pairs of the state dict\n",
|
| 154 |
+
" def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]):\n",
|
| 155 |
+
" ..."
|
| 156 |
+
]
|
| 157 |
+
},
|
| 158 |
+
{
|
| 159 |
+
"cell_type": "markdown",
|
| 160 |
+
"id": "ffa21e47",
|
| 161 |
+
"metadata": {},
|
| 162 |
+
"source": [
|
| 163 |
+
"We have encapsulated many fused operators to simplify the model construction. These operators better support various functions such as tensor parallelism and quantization. We encourage developers to use these ops as much as possible."
|
| 164 |
+
]
|
| 165 |
+
},
|
| 166 |
+
{
|
| 167 |
+
"cell_type": "code",
|
| 168 |
+
"execution_count": null,
|
| 169 |
+
"id": "70668060",
|
| 170 |
+
"metadata": {},
|
| 171 |
+
"outputs": [],
|
| 172 |
+
"source": [
|
| 173 |
+
"# Using predefined build_merged_colwise_linear, SiluAndMul, build_rowwise_linear\n",
|
| 174 |
+
"# Helps us build the model faster and without worrying about tensor concurrency, quantization, etc.\n",
|
| 175 |
+
"class LlamaMLP(nn.Module):\n",
|
| 176 |
+
"\n",
|
| 177 |
+
" def __init__(self,\n",
|
| 178 |
+
" config: LlamaConfig,\n",
|
| 179 |
+
" dtype: torch.dtype = None,\n",
|
| 180 |
+
" device: torch.device = None):\n",
|
| 181 |
+
" super().__init__()\n",
|
| 182 |
+
" quantization_config = getattr(config, 'quantization_config', None)\n",
|
| 183 |
+
" # gate up\n",
|
| 184 |
+
" self.gate_up_proj = build_merged_colwise_linear(\n",
|
| 185 |
+
" config.hidden_size,\n",
|
| 186 |
+
" [config.intermediate_size, config.intermediate_size],\n",
|
| 187 |
+
" bias=config.mlp_bias,\n",
|
| 188 |
+
" dtype=dtype,\n",
|
| 189 |
+
" device=device,\n",
|
| 190 |
+
" quant_config=quantization_config,\n",
|
| 191 |
+
" is_tp=True,\n",
|
| 192 |
+
" )\n",
|
| 193 |
+
"\n",
|
| 194 |
+
" # silu and mul\n",
|
| 195 |
+
" self.act_fn = SiluAndMul(inplace=True)\n",
|
| 196 |
+
"\n",
|
| 197 |
+
" # down\n",
|
| 198 |
+
" self.down_proj = build_rowwise_linear(config.intermediate_size,\n",
|
| 199 |
+
" config.hidden_size,\n",
|
| 200 |
+
" bias=config.mlp_bias,\n",
|
| 201 |
+
" quant_config=quantization_config,\n",
|
| 202 |
+
" dtype=dtype,\n",
|
| 203 |
+
" device=device,\n",
|
| 204 |
+
" is_tp=True)\n",
|
| 205 |
+
"\n",
|
| 206 |
+
" def forward(self, x):\n",
|
| 207 |
+
" \"\"\"forward.\"\"\"\n",
|
| 208 |
+
" gate_up = self.gate_up_proj(x)\n",
|
| 209 |
+
" act = self.act_fn(gate_up)\n",
|
| 210 |
+
" return self.down_proj(act)"
|
| 211 |
+
]
|
| 212 |
+
},
|
| 213 |
+
{
|
| 214 |
+
"cell_type": "markdown",
|
| 215 |
+
"id": "b1701d22",
|
| 216 |
+
"metadata": {},
|
| 217 |
+
"source": [
|
| 218 |
+
"### Model Registration\n",
|
| 219 |
+
"\n",
|
| 220 |
+
"To ensure that the developed model implementation can be used normally, we also need to register the model in `lmdeploy/pytorch/models/module_map.py`"
|
| 221 |
+
]
|
| 222 |
+
},
|
| 223 |
+
{
|
| 224 |
+
"cell_type": "code",
|
| 225 |
+
"execution_count": null,
|
| 226 |
+
"id": "966830a0",
|
| 227 |
+
"metadata": {},
|
| 228 |
+
"outputs": [],
|
| 229 |
+
"source": [
|
| 230 |
+
"MODULE_MAP.update({\n",
|
| 231 |
+
" 'LlamaForCausalLM':\n",
|
| 232 |
+
" f'{LMDEPLOY_PYTORCH_MODEL_PATH}.llama.LlamaForCausalLM',\n",
|
| 233 |
+
"})"
|
| 234 |
+
]
|
| 235 |
+
},
|
| 236 |
+
{
|
| 237 |
+
"cell_type": "markdown",
|
| 238 |
+
"id": "5eee6ab5",
|
| 239 |
+
"metadata": {},
|
| 240 |
+
"source": [
|
| 241 |
+
"If you do not wish to modify the model source code, you can also pass a custom module map from the outside, making it easier to integrate into other projects.\n",
|
| 242 |
+
"\n",
|
| 243 |
+
"```\n",
|
| 244 |
+
"from lmdeploy import PytorchEngineConfig, pipeline\n",
|
| 245 |
+
"\n",
|
| 246 |
+
"backend_config = PytorchEngineConfig(custom_module_map='/path/to/custom/module_map.py')\n",
|
| 247 |
+
"generator = pipeline(model_path, backend_config=backend_config)\n",
|
| 248 |
+
"```"
|
| 249 |
+
]
|
| 250 |
+
}
|
| 251 |
+
],
|
| 252 |
+
"metadata": {
|
| 253 |
+
"jupytext": {
|
| 254 |
+
"cell_metadata_filter": "-all",
|
| 255 |
+
"main_language": "python",
|
| 256 |
+
"notebook_metadata_filter": "-all"
|
| 257 |
+
}
|
| 258 |
+
},
|
| 259 |
+
"nbformat": 4,
|
| 260 |
+
"nbformat_minor": 5
|
| 261 |
+
}
|
a_mllm_notebooks/lmdeploy/pytorch_new_model.md
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# lmdeploy.pytorch New Model Support
|
| 2 |
+
|
| 3 |
+
lmdeploy.pytorch is designed to simplify the support for new models and the development of prototypes. Users can adapt new models according to their own needs.
|
| 4 |
+
|
| 5 |
+
## Model Support
|
| 6 |
+
|
| 7 |
+
### Configuration Loading (Optional)
|
| 8 |
+
|
| 9 |
+
lmdeploy.pytorch initializes the engine based on the model's config file. If the parameter naming of the model to be integrated differs from common models in transformers, parsing errors may occur. A custom ConfigBuilder can be added to parse the configuration.
|
| 10 |
+
|
| 11 |
+
```python
|
| 12 |
+
# lmdeploy/pytorch/configurations/gemma.py
|
| 13 |
+
|
| 14 |
+
from lmdeploy.pytorch.config import ModelConfig
|
| 15 |
+
|
| 16 |
+
from .builder import AutoModelConfigBuilder
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class GemmaModelConfigBuilder(AutoModelConfigBuilder):
|
| 20 |
+
|
| 21 |
+
@classmethod
|
| 22 |
+
def condition(cls, hf_config):
|
| 23 |
+
# Check if hf_config is suitable for this builder
|
| 24 |
+
return hf_config.model_type in ['gemma', 'gemma2']
|
| 25 |
+
|
| 26 |
+
@classmethod
|
| 27 |
+
def build(cls, hf_config, model_path: str = None):
|
| 28 |
+
# Use the hf_config loaded by transformers
|
| 29 |
+
# Construct the ModelConfig for the pytorch engine
|
| 30 |
+
return ModelConfig(hidden_size=hf_config.hidden_size,
|
| 31 |
+
num_layers=hf_config.num_hidden_layers,
|
| 32 |
+
num_attention_heads=hf_config.num_attention_heads,
|
| 33 |
+
num_key_value_heads=hf_config.num_key_value_heads,
|
| 34 |
+
bos_token_id=hf_config.bos_token_id,
|
| 35 |
+
eos_token_id=hf_config.eos_token_id,
|
| 36 |
+
head_dim=hf_config.head_dim,
|
| 37 |
+
vocab_size=hf_config.vocab_size)
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
The `lmdeploy.pytorch.check_env.check_model` function can be used to verify if the configuration can be parsed correctly.
|
| 41 |
+
|
| 42 |
+
### Implementing the Model
|
| 43 |
+
|
| 44 |
+
After ensuring that the configuration can be parsed correctly, you can start implementing the model logic. Taking the implementation of llama as an example, we need to create the model using the configuration file from transformers.
|
| 45 |
+
|
| 46 |
+
```python
|
| 47 |
+
class LlamaForCausalLM(nn.Module):
|
| 48 |
+
|
| 49 |
+
# Constructor, builds the model with the given config
|
| 50 |
+
# ctx_mgr is the context manager, which can be used to pass engine configurations or additional parameters
|
| 51 |
+
def __init__(self,
|
| 52 |
+
config: LlamaConfig,
|
| 53 |
+
ctx_mgr: StepContextManager,
|
| 54 |
+
dtype: torch.dtype = None,
|
| 55 |
+
device: torch.device = None):
|
| 56 |
+
super().__init__()
|
| 57 |
+
self.config = config
|
| 58 |
+
self.ctx_mgr = ctx_mgr
|
| 59 |
+
# build LLamaModel
|
| 60 |
+
self.model = LlamaModel(config, dtype=dtype, device=device)
|
| 61 |
+
# build lm_head
|
| 62 |
+
self.lm_head = build_rowwise_linear(config.hidden_size,
|
| 63 |
+
config.vocab_size,
|
| 64 |
+
bias=False,
|
| 65 |
+
dtype=dtype,
|
| 66 |
+
device=device)
|
| 67 |
+
|
| 68 |
+
# Model inference function
|
| 69 |
+
# It is recommended to use the same parameters as below
|
| 70 |
+
def forward(
|
| 71 |
+
self,
|
| 72 |
+
input_ids: torch.Tensor,
|
| 73 |
+
position_ids: torch.Tensor,
|
| 74 |
+
past_key_values: List[List[torch.Tensor]],
|
| 75 |
+
attn_metadata: Any = None,
|
| 76 |
+
inputs_embeds: torch.Tensor = None,
|
| 77 |
+
**kwargs,
|
| 78 |
+
):
|
| 79 |
+
hidden_states = self.model(
|
| 80 |
+
input_ids=input_ids,
|
| 81 |
+
position_ids=position_ids,
|
| 82 |
+
past_key_values=past_key_values,
|
| 83 |
+
attn_metadata=attn_metadata,
|
| 84 |
+
inputs_embeds=inputs_embeds,
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
logits = self.lm_head(hidden_states)
|
| 88 |
+
logits = logits.float()
|
| 89 |
+
return logits
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
In addition to these, the following content needs to be added:
|
| 93 |
+
|
| 94 |
+
```python
|
| 95 |
+
class LlamaForCausalLM(nn.Module):
|
| 96 |
+
|
| 97 |
+
...
|
| 98 |
+
|
| 99 |
+
# Indicates whether the model supports cudagraph
|
| 100 |
+
# Can be a callable object, receiving forward inputs
|
| 101 |
+
# Dynamically determines if cudagraph is supported
|
| 102 |
+
support_cuda_graph = True
|
| 103 |
+
|
| 104 |
+
# Builds model inputs
|
| 105 |
+
# Returns a dictionary, the keys of which must be inputs to forward
|
| 106 |
+
def prepare_inputs_for_generation(
|
| 107 |
+
self,
|
| 108 |
+
past_key_values: List[List[torch.Tensor]],
|
| 109 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 110 |
+
context: StepContext = None,
|
| 111 |
+
):
|
| 112 |
+
...
|
| 113 |
+
|
| 114 |
+
# Loads weights
|
| 115 |
+
# The model's inputs are key-value pairs of the state dict
|
| 116 |
+
def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]):
|
| 117 |
+
...
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
We have encapsulated many fused operators to simplify the model construction. These operators better support various functions such as tensor parallelism and quantization. We encourage developers to use these ops as much as possible.
|
| 121 |
+
|
| 122 |
+
```python
|
| 123 |
+
# Using predefined build_merged_colwise_linear, SiluAndMul, build_rowwise_linear
|
| 124 |
+
# Helps us build the model faster and without worrying about tensor concurrency, quantization, etc.
|
| 125 |
+
class LlamaMLP(nn.Module):
|
| 126 |
+
|
| 127 |
+
def __init__(self,
|
| 128 |
+
config: LlamaConfig,
|
| 129 |
+
dtype: torch.dtype = None,
|
| 130 |
+
device: torch.device = None):
|
| 131 |
+
super().__init__()
|
| 132 |
+
quantization_config = getattr(config, 'quantization_config', None)
|
| 133 |
+
# gate up
|
| 134 |
+
self.gate_up_proj = build_merged_colwise_linear(
|
| 135 |
+
config.hidden_size,
|
| 136 |
+
[config.intermediate_size, config.intermediate_size],
|
| 137 |
+
bias=config.mlp_bias,
|
| 138 |
+
dtype=dtype,
|
| 139 |
+
device=device,
|
| 140 |
+
quant_config=quantization_config,
|
| 141 |
+
is_tp=True,
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
# silu and mul
|
| 145 |
+
self.act_fn = SiluAndMul(inplace=True)
|
| 146 |
+
|
| 147 |
+
# down
|
| 148 |
+
self.down_proj = build_rowwise_linear(config.intermediate_size,
|
| 149 |
+
config.hidden_size,
|
| 150 |
+
bias=config.mlp_bias,
|
| 151 |
+
quant_config=quantization_config,
|
| 152 |
+
dtype=dtype,
|
| 153 |
+
device=device,
|
| 154 |
+
is_tp=True)
|
| 155 |
+
|
| 156 |
+
def forward(self, x):
|
| 157 |
+
"""forward."""
|
| 158 |
+
gate_up = self.gate_up_proj(x)
|
| 159 |
+
act = self.act_fn(gate_up)
|
| 160 |
+
return self.down_proj(act)
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
### Model Registration
|
| 164 |
+
|
| 165 |
+
To ensure that the developed model implementation can be used normally, we also need to register the model in `lmdeploy/pytorch/models/module_map.py`
|
| 166 |
+
|
| 167 |
+
```python
|
| 168 |
+
MODULE_MAP.update({
|
| 169 |
+
'LlamaForCausalLM':
|
| 170 |
+
f'{LMDEPLOY_PYTORCH_MODEL_PATH}.llama.LlamaForCausalLM',
|
| 171 |
+
})
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
If you do not wish to modify the model source code, you can also pass a custom module map from the outside, making it easier to integrate into other projects.
|
| 175 |
+
|
| 176 |
+
```
|
| 177 |
+
from lmdeploy import PytorchEngineConfig, pipeline
|
| 178 |
+
|
| 179 |
+
backend_config = PytorchEngineConfig(custom_module_map='/path/to/custom/module_map.py')
|
| 180 |
+
generator = pipeline(model_path, backend_config=backend_config)
|
| 181 |
+
```
|
a_mllm_notebooks/lmdeploy/tiger.jpeg
ADDED

|
a_mllm_notebooks/lmdeploy/turbomind.ipynb
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "0b726f14",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Architecture of TurboMind\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"TurboMind is an inference engine that supports high throughput inference for conversational LLMs. It's based on NVIDIA's [FasterTransformer](https://github.com/NVIDIA/FasterTransformer). Major features of TurboMind include an efficient LLaMa implementation, the persistent batch inference model and an extendable KV cache manager.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"## High level overview of TurboMind\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"```\n",
|
| 15 |
+
" +--------------------+\n",
|
| 16 |
+
" | API |\n",
|
| 17 |
+
" +--------------------+\n",
|
| 18 |
+
" | ^\n",
|
| 19 |
+
" request | | stream callback\n",
|
| 20 |
+
" v |\n",
|
| 21 |
+
" +--------------------+ fetch +-------------------+\n",
|
| 22 |
+
" | Persistent Batch | <-------> | KV Cache Manager |\n",
|
| 23 |
+
" +--------------------+ update +-------------------+\n",
|
| 24 |
+
" ^\n",
|
| 25 |
+
" |\n",
|
| 26 |
+
" v\n",
|
| 27 |
+
"+------------------------+\n",
|
| 28 |
+
"| LLaMA implementation |\n",
|
| 29 |
+
"+------------------------+\n",
|
| 30 |
+
"| FT kernels & utilities |\n",
|
| 31 |
+
"+------------------------+\n",
|
| 32 |
+
"```\n",
|
| 33 |
+
"\n",
|
| 34 |
+
"## Persistent Batch\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"You may recognize this feature as \"continuous batching\" in other repos. But during the concurrent development of the feature, we modeled the inference of a conversational LLM as a persistently running batch whose lifetime spans the entire serving process, hence the name \"persistent batch\". To put it simply\n",
|
| 37 |
+
"\n",
|
| 38 |
+
"- The persistent batch as N pre-configured batch slots.\n",
|
| 39 |
+
"- Requests join the batch when there are free slots available. A batch slot is released and can be reused once the generation of the requested tokens is finished.\n",
|
| 40 |
+
"- __On cache-hits (see below), history tokens don't need to be decoded in every round of a conversation; generation of response tokens will start instantly.__\n",
|
| 41 |
+
"- The batch grows or shrinks automatically to minimize unnecessary computations.\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"## KV Cache Manager\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"The [KV cache manager](https://github.com/InternLM/lmdeploy/blob/main/src/turbomind/models/llama/SequenceManager.h) of TurboMind is a memory-pool-liked object that also implements LRU policy so that it can be viewed as a form of __cache of KV caches__. It works in the following way\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"- All device memory required for KV cache is allocated by the manager. A fixed number of slots is pre-configured to match the memory size of the system. Each slot corresponds to the memory required by the KV cache of a single sequence. Allocation chunk-size can be configure to implement pre-allocate/on-demand style allocation policy (or something in-between).\n",
|
| 48 |
+
"- When space for the KV cache of a new sequence is requested but no free slots left in the pool, the least recently used sequence is evicted from the cache and its device memory is directly reused by the new sequence. However, this is not the end of the story.\n",
|
| 49 |
+
"- Fetching sequence currently resides in one of the slots resembles a _cache-hit_, the history KV cache is returned directly and no context decoding is needed.\n",
|
| 50 |
+
"- Victim (evicted) sequences are not erased entirely but converted to its most compact form, i.e. token IDs. When the same sequence id is fetched later (_cache-miss_) the token IDs will be decoded by FMHA backed context decoder and converted back to KV cache.\n",
|
| 51 |
+
"- The eviction and conversion are handled automatically inside TurboMind and thus transparent to the users. __From the user's aspect, system that use TurboMind has access to infinite device memory.__\n",
|
| 52 |
+
"\n",
|
| 53 |
+
"## LLaMa implementation\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"Our implementation of the LLaMa family models is modified from Gpt-NeoX model in FasterTransformer. In addition to basic refactoring and modifications to support the LLaMa family, we made some improvements to enable high performance inference of conversational models, most importantly:\n",
|
| 56 |
+
"\n",
|
| 57 |
+
"- To support fast context decoding in multi-round conversations. We replaced the attention implementation in context decoder with a [cutlass](https://github.com/NVIDIA/cutlass)-based FMHA implementation that supports mismatched Q/K lengths.\n",
|
| 58 |
+
"- We introduced indirect buffer pointers in both context FMHA and generation FMHA to support the discontinuity in KV cache within the batch.\n",
|
| 59 |
+
"- To support concurrent inference with persistent batch, new synchronization mechanism was designed to orchestrate the worker threads running in tensor parallel mode.\n",
|
| 60 |
+
"- To maximize the throughput, we implement INT8 KV cache support to increase the max batch size. It's effective because in real-world serving scenarios, KV cache costs more memory and consumes more memory bandwidth than weights or other activations.\n",
|
| 61 |
+
"- We resolved an NCCL hang issue when running multiple model instances in TP mode within a single process, NCCL APIs are now guarded by host-side synchronization barriers.\n",
|
| 62 |
+
"\n",
|
| 63 |
+
"## API\n",
|
| 64 |
+
"\n",
|
| 65 |
+
"TurboMind supports a Python API that enables streaming output and tensor parallel mode.\n",
|
| 66 |
+
"\n",
|
| 67 |
+
"## Difference between FasterTransformer and TurboMind\n",
|
| 68 |
+
"\n",
|
| 69 |
+
"Apart of the features described above, there are still many minor differences that we don't cover in this document. Notably, many capabilities of FT are dropped in TurboMind because of the difference in objectives (e.g. prefix prompt, beam search, context embedding, sparse GEMM, GPT/T5/other model families, etc)\n",
|
| 70 |
+
"\n",
|
| 71 |
+
"## FAQ\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"### Supporting Huggingface models\n",
|
| 74 |
+
"\n",
|
| 75 |
+
"For historical reasons, TurboMind's weight layout is based on [the original LLaMa implementation](https://github.com/facebookresearch/llama) (differ only by a transpose). The implementation in huggingface transformers uses a [different layout](https://github.com/huggingface/transformers/blob/45025d92f815675e483f32812caa28cce3a960e7/src/transformers/models/llama/convert_llama_weights_to_hf.py#L123C76-L123C76) for `W_q` and `W_k` which is handled in [deploy.py](https://github.com/InternLM/lmdeploy/blob/ff4648a1d09e5aec74cf70efef35bfaeeac552e0/lmdeploy/serve/turbomind/deploy.py#L398)."
|
| 76 |
+
]
|
| 77 |
+
}
|
| 78 |
+
],
|
| 79 |
+
"metadata": {
|
| 80 |
+
"jupytext": {
|
| 81 |
+
"cell_metadata_filter": "-all",
|
| 82 |
+
"main_language": "python",
|
| 83 |
+
"notebook_metadata_filter": "-all"
|
| 84 |
+
}
|
| 85 |
+
},
|
| 86 |
+
"nbformat": 4,
|
| 87 |
+
"nbformat_minor": 5
|
| 88 |
+
}
|
a_mllm_notebooks/lmdeploy/turbomind.md
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Architecture of TurboMind
|
| 2 |
+
|
| 3 |
+
TurboMind is an inference engine that supports high throughput inference for conversational LLMs. It's based on NVIDIA's [FasterTransformer](https://github.com/NVIDIA/FasterTransformer). Major features of TurboMind include an efficient LLaMa implementation, the persistent batch inference model and an extendable KV cache manager.
|
| 4 |
+
|
| 5 |
+
## High level overview of TurboMind
|
| 6 |
+
|
| 7 |
+
```
|
| 8 |
+
+--------------------+
|
| 9 |
+
| API |
|
| 10 |
+
+--------------------+
|
| 11 |
+
| ^
|
| 12 |
+
request | | stream callback
|
| 13 |
+
v |
|
| 14 |
+
+--------------------+ fetch +-------------------+
|
| 15 |
+
| Persistent Batch | <-------> | KV Cache Manager |
|
| 16 |
+
+--------------------+ update +-------------------+
|
| 17 |
+
^
|
| 18 |
+
|
|
| 19 |
+
v
|
| 20 |
+
+------------------------+
|
| 21 |
+
| LLaMA implementation |
|
| 22 |
+
+------------------------+
|
| 23 |
+
| FT kernels & utilities |
|
| 24 |
+
+------------------------+
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
## Persistent Batch
|
| 28 |
+
|
| 29 |
+
You may recognize this feature as "continuous batching" in other repos. But during the concurrent development of the feature, we modeled the inference of a conversational LLM as a persistently running batch whose lifetime spans the entire serving process, hence the name "persistent batch". To put it simply
|
| 30 |
+
|
| 31 |
+
- The persistent batch as N pre-configured batch slots.
|
| 32 |
+
- Requests join the batch when there are free slots available. A batch slot is released and can be reused once the generation of the requested tokens is finished.
|
| 33 |
+
- __On cache-hits (see below), history tokens don't need to be decoded in every round of a conversation; generation of response tokens will start instantly.__
|
| 34 |
+
- The batch grows or shrinks automatically to minimize unnecessary computations.
|
| 35 |
+
|
| 36 |
+
## KV Cache Manager
|
| 37 |
+
|
| 38 |
+
The [KV cache manager](https://github.com/InternLM/lmdeploy/blob/main/src/turbomind/models/llama/SequenceManager.h) of TurboMind is a memory-pool-liked object that also implements LRU policy so that it can be viewed as a form of __cache of KV caches__. It works in the following way
|
| 39 |
+
|
| 40 |
+
- All device memory required for KV cache is allocated by the manager. A fixed number of slots is pre-configured to match the memory size of the system. Each slot corresponds to the memory required by the KV cache of a single sequence. Allocation chunk-size can be configure to implement pre-allocate/on-demand style allocation policy (or something in-between).
|
| 41 |
+
- When space for the KV cache of a new sequence is requested but no free slots left in the pool, the least recently used sequence is evicted from the cache and its device memory is directly reused by the new sequence. However, this is not the end of the story.
|
| 42 |
+
- Fetching sequence currently resides in one of the slots resembles a _cache-hit_, the history KV cache is returned directly and no context decoding is needed.
|
| 43 |
+
- Victim (evicted) sequences are not erased entirely but converted to its most compact form, i.e. token IDs. When the same sequence id is fetched later (_cache-miss_) the token IDs will be decoded by FMHA backed context decoder and converted back to KV cache.
|
| 44 |
+
- The eviction and conversion are handled automatically inside TurboMind and thus transparent to the users. __From the user's aspect, system that use TurboMind has access to infinite device memory.__
|
| 45 |
+
|
| 46 |
+
## LLaMa implementation
|
| 47 |
+
|
| 48 |
+
Our implementation of the LLaMa family models is modified from Gpt-NeoX model in FasterTransformer. In addition to basic refactoring and modifications to support the LLaMa family, we made some improvements to enable high performance inference of conversational models, most importantly:
|
| 49 |
+
|
| 50 |
+
- To support fast context decoding in multi-round conversations. We replaced the attention implementation in context decoder with a [cutlass](https://github.com/NVIDIA/cutlass)-based FMHA implementation that supports mismatched Q/K lengths.
|
| 51 |
+
- We introduced indirect buffer pointers in both context FMHA and generation FMHA to support the discontinuity in KV cache within the batch.
|
| 52 |
+
- To support concurrent inference with persistent batch, new synchronization mechanism was designed to orchestrate the worker threads running in tensor parallel mode.
|
| 53 |
+
- To maximize the throughput, we implement INT8 KV cache support to increase the max batch size. It's effective because in real-world serving scenarios, KV cache costs more memory and consumes more memory bandwidth than weights or other activations.
|
| 54 |
+
- We resolved an NCCL hang issue when running multiple model instances in TP mode within a single process, NCCL APIs are now guarded by host-side synchronization barriers.
|
| 55 |
+
|
| 56 |
+
## API
|
| 57 |
+
|
| 58 |
+
TurboMind supports a Python API that enables streaming output and tensor parallel mode.
|
| 59 |
+
|
| 60 |
+
## Difference between FasterTransformer and TurboMind
|
| 61 |
+
|
| 62 |
+
Apart of the features described above, there are still many minor differences that we don't cover in this document. Notably, many capabilities of FT are dropped in TurboMind because of the difference in objectives (e.g. prefix prompt, beam search, context embedding, sparse GEMM, GPT/T5/other model families, etc)
|
| 63 |
+
|
| 64 |
+
## FAQ
|
| 65 |
+
|
| 66 |
+
### Supporting Huggingface models
|
| 67 |
+
|
| 68 |
+
For historical reasons, TurboMind's weight layout is based on [the original LLaMa implementation](https://github.com/facebookresearch/llama) (differ only by a transpose). The implementation in huggingface transformers uses a [different layout](https://github.com/huggingface/transformers/blob/45025d92f815675e483f32812caa28cce3a960e7/src/transformers/models/llama/convert_llama_weights_to_hf.py#L123C76-L123C76) for `W_q` and `W_k` which is handled in [deploy.py](https://github.com/InternLM/lmdeploy/blob/ff4648a1d09e5aec74cf70efef35bfaeeac552e0/lmdeploy/serve/turbomind/deploy.py#L398).
|
a_mllm_notebooks/lmdeploy/w4a16.ipynb
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "76ea6484",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# AWQ/GPTQ\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"LMDeploy TurboMind engine supports the inference of 4bit quantized models that are quantized both by [AWQ](https://arxiv.org/abs/2306.00978) and [GPTQ](https://github.com/AutoGPTQ/AutoGPTQ), but its quantization module only supports the AWQ quantization algorithm.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"The following NVIDIA GPUs are available for AWQ/GPTQ INT4 inference:\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"- V100(sm70): V100\n",
|
| 15 |
+
"- Turing(sm75): 20 series, T4\n",
|
| 16 |
+
"- Ampere(sm80,sm86): 30 series, A10, A16, A30, A100\n",
|
| 17 |
+
"- Ada Lovelace(sm89): 40 series\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"Before proceeding with the quantization and inference, please ensure that lmdeploy is installed by following the [installation guide](../get_started/installation.md)\n",
|
| 20 |
+
"\n",
|
| 21 |
+
"The remainder of this article is structured into the following sections:\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"<!-- toc -->\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"- [Quantization](#quantization)\n",
|
| 26 |
+
"- [Evaluation](#evaluation)\n",
|
| 27 |
+
"- [Inference](#inference)\n",
|
| 28 |
+
"- [Service](#service)\n",
|
| 29 |
+
"- [Performance](#performance)\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"<!-- tocstop -->\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"## Quantization\n",
|
| 34 |
+
"\n",
|
| 35 |
+
"A single command execution is all it takes to quantize the model. The resulting quantized weights are then stored in the $WORK_DIR directory.\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"```shell\n",
|
| 38 |
+
"export HF_MODEL=internlm/internlm2_5-7b-chat\n",
|
| 39 |
+
"export WORK_DIR=internlm/internlm2_5-7b-chat-4bit\n",
|
| 40 |
+
"\n",
|
| 41 |
+
"lmdeploy lite auto_awq \\\n",
|
| 42 |
+
" $HF_MODEL \\\n",
|
| 43 |
+
" --calib-dataset 'ptb' \\\n",
|
| 44 |
+
" --calib-samples 128 \\\n",
|
| 45 |
+
" --calib-seqlen 2048 \\\n",
|
| 46 |
+
" --w-bits 4 \\\n",
|
| 47 |
+
" --w-group-size 128 \\\n",
|
| 48 |
+
" --batch-size 1 \\\n",
|
| 49 |
+
" --work-dir $WORK_DIR\n",
|
| 50 |
+
"```\n",
|
| 51 |
+
"\n",
|
| 52 |
+
"Typically, the above command doesn't require filling in optional parameters, as the defaults usually suffice. For instance, when quantizing the [internlm/internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) model, the command can be condensed as:\n",
|
| 53 |
+
"\n",
|
| 54 |
+
"```shell\n",
|
| 55 |
+
"lmdeploy lite auto_awq internlm/internlm2_5-7b-chat --work-dir internlm2_5-7b-chat-4bit\n",
|
| 56 |
+
"```\n",
|
| 57 |
+
"\n",
|
| 58 |
+
"**Note:**\n",
|
| 59 |
+
"\n",
|
| 60 |
+
"- We recommend that you specify the --work-dir parameter, including the model name as demonstrated in the example above. This facilitates LMDeploy in fuzzy matching the --work-dir with an appropriate built-in chat template. Otherwise, you will have to designate the chat template during inference.\n",
|
| 61 |
+
"- If the quantized model’s accuracy is compromised, it is recommended to enable --search-scale for re-quantization and increase the --batch-size, for example, to 8. When search_scale is enabled, the quantization process will take more time. The --batch-size affects the amount of memory used, which can be adjusted according to actual conditions as needed.\n",
|
| 62 |
+
"\n",
|
| 63 |
+
"Upon completing quantization, you can engage with the model efficiently using a variety of handy tools.\n",
|
| 64 |
+
"For example, you can initiate a conversation with it via the command line:\n",
|
| 65 |
+
"\n",
|
| 66 |
+
"```shell\n",
|
| 67 |
+
"lmdeploy chat ./internlm2_5-7b-chat-4bit --model-format awq\n",
|
| 68 |
+
"```\n",
|
| 69 |
+
"\n",
|
| 70 |
+
"Alternatively, you can start the gradio server and interact with the model through the web at `http://{ip_addr}:{port`\n",
|
| 71 |
+
"\n",
|
| 72 |
+
"```shell\n",
|
| 73 |
+
"lmdeploy serve gradio ./internlm2_5-7b-chat-4bit --server_name {ip_addr} --server_port {port} --model-format awq\n",
|
| 74 |
+
"```\n",
|
| 75 |
+
"\n",
|
| 76 |
+
"## Evaluation\n",
|
| 77 |
+
"\n",
|
| 78 |
+
"Please refer to [OpenCompass](https://opencompass.readthedocs.io/en/latest/index.html) about model evaluation with LMDeploy. Here is the [guide](https://opencompass.readthedocs.io/en/latest/advanced_guides/evaluation_lmdeploy.html)\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"## Inference\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"Trying the following codes, you can perform the batched offline inference with the quantized model:"
|
| 83 |
+
]
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"cell_type": "code",
|
| 87 |
+
"execution_count": null,
|
| 88 |
+
"id": "4ee45c86",
|
| 89 |
+
"metadata": {},
|
| 90 |
+
"outputs": [],
|
| 91 |
+
"source": [
|
| 92 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 93 |
+
"engine_config = TurbomindEngineConfig(model_format='awq')\n",
|
| 94 |
+
"pipe = pipeline(\"./internlm2_5-7b-chat-4bit\", backend_config=engine_config)\n",
|
| 95 |
+
"response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"])\n",
|
| 96 |
+
"print(response)"
|
| 97 |
+
]
|
| 98 |
+
},
|
| 99 |
+
{
|
| 100 |
+
"cell_type": "markdown",
|
| 101 |
+
"id": "0743ccb8",
|
| 102 |
+
"metadata": {},
|
| 103 |
+
"source": [
|
| 104 |
+
"For more information about the pipeline parameters, please refer to [here](../llm/pipeline.md).\n",
|
| 105 |
+
"\n",
|
| 106 |
+
"In addition to performing inference with the quantized model on localhost, LMDeploy can also execute inference for the 4bit quantized model derived from AWQ algorithm available on Huggingface Hub, such as models from the [lmdeploy space](https://huggingface.co/lmdeploy) and [TheBloke space](https://huggingface.co/TheBloke)"
|
| 107 |
+
]
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"cell_type": "code",
|
| 111 |
+
"execution_count": null,
|
| 112 |
+
"id": "a522e026",
|
| 113 |
+
"metadata": {},
|
| 114 |
+
"outputs": [],
|
| 115 |
+
"source": [
|
| 116 |
+
"# inference with models from lmdeploy space\n",
|
| 117 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig\n",
|
| 118 |
+
"pipe = pipeline(\"lmdeploy/llama2-chat-70b-4bit\",\n",
|
| 119 |
+
" backend_config=TurbomindEngineConfig(model_format='awq', tp=4))\n",
|
| 120 |
+
"response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"])\n",
|
| 121 |
+
"print(response)\n",
|
| 122 |
+
"\n",
|
| 123 |
+
"# inference with models from thebloke space\n",
|
| 124 |
+
"from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig\n",
|
| 125 |
+
"pipe = pipeline(\"TheBloke/LLaMA2-13B-Tiefighter-AWQ\",\n",
|
| 126 |
+
" backend_config=TurbomindEngineConfig(model_format='awq'),\n",
|
| 127 |
+
" chat_template_config=ChatTemplateConfig(model_name='llama2')\n",
|
| 128 |
+
" )\n",
|
| 129 |
+
"response = pipe([\"Hi, pls intro yourself\", \"Shanghai is\"])\n",
|
| 130 |
+
"print(response)"
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"cell_type": "markdown",
|
| 135 |
+
"id": "a75d4d9e",
|
| 136 |
+
"metadata": {},
|
| 137 |
+
"source": [
|
| 138 |
+
"## Service\n",
|
| 139 |
+
"\n",
|
| 140 |
+
"LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:\n",
|
| 141 |
+
"\n",
|
| 142 |
+
"```shell\n",
|
| 143 |
+
"lmdeploy serve api_server ./internlm2_5-7b-chat-4bit --backend turbomind --model-format awq\n",
|
| 144 |
+
"```\n",
|
| 145 |
+
"\n",
|
| 146 |
+
"The default port of `api_server` is `23333`. After the server is launched, you can communicate with server on terminal through `api_client`:\n",
|
| 147 |
+
"\n",
|
| 148 |
+
"```shell\n",
|
| 149 |
+
"lmdeploy serve api_client http://0.0.0.0:23333\n",
|
| 150 |
+
"```\n",
|
| 151 |
+
"\n",
|
| 152 |
+
"You can overview and try out `api_server` APIs online by swagger UI at `http://0.0.0.0:23333`, or you can also read the API specification from [here](../llm/api_server.md).\n",
|
| 153 |
+
"\n",
|
| 154 |
+
"## Performance\n",
|
| 155 |
+
"\n",
|
| 156 |
+
"We benchmarked the Llama-2-7B-chat and Llama-2-13B-chat models with 4-bit quantization on NVIDIA GeForce RTX 4090 using [profile_generation.py](https://github.com/InternLM/lmdeploy/blob/main/benchmark/profile_generation.py). And we measure the token generation throughput (tokens/s) by setting a single prompt token and generating 512 tokens. All the results are measured for single batch inference.\n",
|
| 157 |
+
"\n",
|
| 158 |
+
"| model | llm-awq | mlc-llm | turbomind |\n",
|
| 159 |
+
"| ---------------- | ------- | ------- | --------- |\n",
|
| 160 |
+
"| Llama-2-7B-chat | 112.9 | 159.4 | 206.4 |\n",
|
| 161 |
+
"| Llama-2-13B-chat | N/A | 90.7 | 115.8 |"
|
| 162 |
+
]
|
| 163 |
+
}
|
| 164 |
+
],
|
| 165 |
+
"metadata": {
|
| 166 |
+
"jupytext": {
|
| 167 |
+
"cell_metadata_filter": "-all",
|
| 168 |
+
"main_language": "python",
|
| 169 |
+
"notebook_metadata_filter": "-all"
|
| 170 |
+
}
|
| 171 |
+
},
|
| 172 |
+
"nbformat": 4,
|
| 173 |
+
"nbformat_minor": 5
|
| 174 |
+
}
|
a_mllm_notebooks/lmdeploy/w4a16.md
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AWQ/GPTQ
|
| 2 |
+
|
| 3 |
+
LMDeploy TurboMind engine supports the inference of 4bit quantized models that are quantized both by [AWQ](https://arxiv.org/abs/2306.00978) and [GPTQ](https://github.com/AutoGPTQ/AutoGPTQ), but its quantization module only supports the AWQ quantization algorithm.
|
| 4 |
+
|
| 5 |
+
The following NVIDIA GPUs are available for AWQ/GPTQ INT4 inference:
|
| 6 |
+
|
| 7 |
+
- V100(sm70): V100
|
| 8 |
+
- Turing(sm75): 20 series, T4
|
| 9 |
+
- Ampere(sm80,sm86): 30 series, A10, A16, A30, A100
|
| 10 |
+
- Ada Lovelace(sm89): 40 series
|
| 11 |
+
|
| 12 |
+
Before proceeding with the quantization and inference, please ensure that lmdeploy is installed by following the [installation guide](../get_started/installation.md)
|
| 13 |
+
|
| 14 |
+
The remainder of this article is structured into the following sections:
|
| 15 |
+
|
| 16 |
+
<!-- toc -->
|
| 17 |
+
|
| 18 |
+
- [Quantization](#quantization)
|
| 19 |
+
- [Evaluation](#evaluation)
|
| 20 |
+
- [Inference](#inference)
|
| 21 |
+
- [Service](#service)
|
| 22 |
+
- [Performance](#performance)
|
| 23 |
+
|
| 24 |
+
<!-- tocstop -->
|
| 25 |
+
|
| 26 |
+
## Quantization
|
| 27 |
+
|
| 28 |
+
A single command execution is all it takes to quantize the model. The resulting quantized weights are then stored in the $WORK_DIR directory.
|
| 29 |
+
|
| 30 |
+
```shell
|
| 31 |
+
export HF_MODEL=internlm/internlm2_5-7b-chat
|
| 32 |
+
export WORK_DIR=internlm/internlm2_5-7b-chat-4bit
|
| 33 |
+
|
| 34 |
+
lmdeploy lite auto_awq \
|
| 35 |
+
$HF_MODEL \
|
| 36 |
+
--calib-dataset 'ptb' \
|
| 37 |
+
--calib-samples 128 \
|
| 38 |
+
--calib-seqlen 2048 \
|
| 39 |
+
--w-bits 4 \
|
| 40 |
+
--w-group-size 128 \
|
| 41 |
+
--batch-size 1 \
|
| 42 |
+
--work-dir $WORK_DIR
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
Typically, the above command doesn't require filling in optional parameters, as the defaults usually suffice. For instance, when quantizing the [internlm/internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) model, the command can be condensed as:
|
| 46 |
+
|
| 47 |
+
```shell
|
| 48 |
+
lmdeploy lite auto_awq internlm/internlm2_5-7b-chat --work-dir internlm2_5-7b-chat-4bit
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
**Note:**
|
| 52 |
+
|
| 53 |
+
- We recommend that you specify the --work-dir parameter, including the model name as demonstrated in the example above. This facilitates LMDeploy in fuzzy matching the --work-dir with an appropriate built-in chat template. Otherwise, you will have to designate the chat template during inference.
|
| 54 |
+
- If the quantized model’s accuracy is compromised, it is recommended to enable --search-scale for re-quantization and increase the --batch-size, for example, to 8. When search_scale is enabled, the quantization process will take more time. The --batch-size affects the amount of memory used, which can be adjusted according to actual conditions as needed.
|
| 55 |
+
|
| 56 |
+
Upon completing quantization, you can engage with the model efficiently using a variety of handy tools.
|
| 57 |
+
For example, you can initiate a conversation with it via the command line:
|
| 58 |
+
|
| 59 |
+
```shell
|
| 60 |
+
lmdeploy chat ./internlm2_5-7b-chat-4bit --model-format awq
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
Alternatively, you can start the gradio server and interact with the model through the web at `http://{ip_addr}:{port`
|
| 64 |
+
|
| 65 |
+
```shell
|
| 66 |
+
lmdeploy serve gradio ./internlm2_5-7b-chat-4bit --server_name {ip_addr} --server_port {port} --model-format awq
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
## Evaluation
|
| 70 |
+
|
| 71 |
+
Please refer to [OpenCompass](https://opencompass.readthedocs.io/en/latest/index.html) about model evaluation with LMDeploy. Here is the [guide](https://opencompass.readthedocs.io/en/latest/advanced_guides/evaluation_lmdeploy.html)
|
| 72 |
+
|
| 73 |
+
## Inference
|
| 74 |
+
|
| 75 |
+
Trying the following codes, you can perform the batched offline inference with the quantized model:
|
| 76 |
+
|
| 77 |
+
```python
|
| 78 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 79 |
+
engine_config = TurbomindEngineConfig(model_format='awq')
|
| 80 |
+
pipe = pipeline("./internlm2_5-7b-chat-4bit", backend_config=engine_config)
|
| 81 |
+
response = pipe(["Hi, pls intro yourself", "Shanghai is"])
|
| 82 |
+
print(response)
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
For more information about the pipeline parameters, please refer to [here](../llm/pipeline.md).
|
| 86 |
+
|
| 87 |
+
In addition to performing inference with the quantized model on localhost, LMDeploy can also execute inference for the 4bit quantized model derived from AWQ algorithm available on Huggingface Hub, such as models from the [lmdeploy space](https://huggingface.co/lmdeploy) and [TheBloke space](https://huggingface.co/TheBloke)
|
| 88 |
+
|
| 89 |
+
```python
|
| 90 |
+
# inference with models from lmdeploy space
|
| 91 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 92 |
+
pipe = pipeline("lmdeploy/llama2-chat-70b-4bit",
|
| 93 |
+
backend_config=TurbomindEngineConfig(model_format='awq', tp=4))
|
| 94 |
+
response = pipe(["Hi, pls intro yourself", "Shanghai is"])
|
| 95 |
+
print(response)
|
| 96 |
+
|
| 97 |
+
# inference with models from thebloke space
|
| 98 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
| 99 |
+
pipe = pipeline("TheBloke/LLaMA2-13B-Tiefighter-AWQ",
|
| 100 |
+
backend_config=TurbomindEngineConfig(model_format='awq'),
|
| 101 |
+
chat_template_config=ChatTemplateConfig(model_name='llama2')
|
| 102 |
+
)
|
| 103 |
+
response = pipe(["Hi, pls intro yourself", "Shanghai is"])
|
| 104 |
+
print(response)
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
## Service
|
| 108 |
+
|
| 109 |
+
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
|
| 110 |
+
|
| 111 |
+
```shell
|
| 112 |
+
lmdeploy serve api_server ./internlm2_5-7b-chat-4bit --backend turbomind --model-format awq
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
The default port of `api_server` is `23333`. After the server is launched, you can communicate with server on terminal through `api_client`:
|
| 116 |
+
|
| 117 |
+
```shell
|
| 118 |
+
lmdeploy serve api_client http://0.0.0.0:23333
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
You can overview and try out `api_server` APIs online by swagger UI at `http://0.0.0.0:23333`, or you can also read the API specification from [here](../llm/api_server.md).
|
| 122 |
+
|
| 123 |
+
## Performance
|
| 124 |
+
|
| 125 |
+
We benchmarked the Llama-2-7B-chat and Llama-2-13B-chat models with 4-bit quantization on NVIDIA GeForce RTX 4090 using [profile_generation.py](https://github.com/InternLM/lmdeploy/blob/main/benchmark/profile_generation.py). And we measure the token generation throughput (tokens/s) by setting a single prompt token and generating 512 tokens. All the results are measured for single batch inference.
|
| 126 |
+
|
| 127 |
+
| model | llm-awq | mlc-llm | turbomind |
|
| 128 |
+
| ---------------- | ------- | ------- | --------- |
|
| 129 |
+
| Llama-2-7B-chat | 112.9 | 159.4 | 206.4 |
|
| 130 |
+
| Llama-2-13B-chat | N/A | 90.7 | 115.8 |
|
a_mllm_notebooks/lmdeploy/w8a8.ipynb
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "dce2a8a7",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# SmoothQuant\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"LMDeploy provides functions for quantization and inference of large language models using 8-bit integers.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"Before starting inference, ensure that lmdeploy and openai/triton are correctly installed. Execute the following commands to install these:\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"```shell\n",
|
| 15 |
+
"pip install lmdeploy\n",
|
| 16 |
+
"pip install triton>=2.1.0\n",
|
| 17 |
+
"```\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"## 8-bit Weight Model Inference\n",
|
| 20 |
+
"\n",
|
| 21 |
+
"For performing 8-bit weight model inference, you can directly download the pre-quantized 8-bit weight models from LMDeploy's [model zoo](https://huggingface.co/lmdeploy). For instance, the 8-bit Internlm-chat-7B model is available for direct download from the model zoo:\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"```shell\n",
|
| 24 |
+
"git-lfs install\n",
|
| 25 |
+
"git clone https://huggingface.co/lmdeploy/internlm-chat-7b-w8 (coming soon)\n",
|
| 26 |
+
"```\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"Alternatively, you can manually convert original 16-bit weights into 8-bit by referring to the content under the [\"8bit Weight Quantization\"](#8bit-weight-quantization) section. Save them in the internlm-chat-7b-w8 directory, using the command below:\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"```shell\n",
|
| 31 |
+
"lmdeploy lite smooth_quant internlm/internlm-chat-7b --work-dir ./internlm-chat-7b-w8\n",
|
| 32 |
+
"```\n",
|
| 33 |
+
"\n",
|
| 34 |
+
"Afterwards, use the following command to interact with the model via the terminal:\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"```shell\n",
|
| 37 |
+
"lmdeploy chat ./internlm-chat-7b-w8 --backend pytorch\n",
|
| 38 |
+
"```\n",
|
| 39 |
+
"\n",
|
| 40 |
+
"## Launching gradio service\n",
|
| 41 |
+
"\n",
|
| 42 |
+
"Coming soon...\n",
|
| 43 |
+
"\n",
|
| 44 |
+
"## Inference Speed\n",
|
| 45 |
+
"\n",
|
| 46 |
+
"Coming soon...\n",
|
| 47 |
+
"\n",
|
| 48 |
+
"## 8bit Weight Quantization\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"Performing 8bit weight quantization involves three steps:\n",
|
| 51 |
+
"\n",
|
| 52 |
+
"1. **Smooth Weights**: Start by smoothing the weights of the Language Model (LLM). This process makes the weights more amenable to quantizing.\n",
|
| 53 |
+
"2. **Replace Modules**: Locate DecoderLayers and replace the modules RSMNorm and nn.Linear with QRSMNorm and QLinear modules respectively. These 'Q' modules are available in the lmdeploy/pytorch/models/q_modules.py file.\n",
|
| 54 |
+
"3. **Save the Quantized Model**: Once you've made the necessary replacements, save the new quantized model.\n",
|
| 55 |
+
"\n",
|
| 56 |
+
"The script `lmdeploy/lite/apis/smooth_quant.py` accomplishes all three tasks detailed above. For example, you can obtain the model weights of the quantized Internlm-chat-7B model by running the following command:\n",
|
| 57 |
+
"\n",
|
| 58 |
+
"```shell\n",
|
| 59 |
+
"lmdeploy lite smooth_quant internlm/internlm-chat-7b --work-dir ./internlm-chat-7b-w8\n",
|
| 60 |
+
"```\n",
|
| 61 |
+
"\n",
|
| 62 |
+
"After saving, you can instantiate your quantized model by calling the from_pretrained interface."
|
| 63 |
+
]
|
| 64 |
+
}
|
| 65 |
+
],
|
| 66 |
+
"metadata": {
|
| 67 |
+
"jupytext": {
|
| 68 |
+
"cell_metadata_filter": "-all",
|
| 69 |
+
"main_language": "python",
|
| 70 |
+
"notebook_metadata_filter": "-all"
|
| 71 |
+
}
|
| 72 |
+
},
|
| 73 |
+
"nbformat": 4,
|
| 74 |
+
"nbformat_minor": 5
|
| 75 |
+
}
|
a_mllm_notebooks/lmdeploy/w8a8.md
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SmoothQuant
|
| 2 |
+
|
| 3 |
+
LMDeploy provides functions for quantization and inference of large language models using 8-bit integers.
|
| 4 |
+
|
| 5 |
+
Before starting inference, ensure that lmdeploy and openai/triton are correctly installed. Execute the following commands to install these:
|
| 6 |
+
|
| 7 |
+
```shell
|
| 8 |
+
pip install lmdeploy
|
| 9 |
+
pip install triton>=2.1.0
|
| 10 |
+
```
|
| 11 |
+
|
| 12 |
+
## 8-bit Weight Model Inference
|
| 13 |
+
|
| 14 |
+
For performing 8-bit weight model inference, you can directly download the pre-quantized 8-bit weight models from LMDeploy's [model zoo](https://huggingface.co/lmdeploy). For instance, the 8-bit Internlm-chat-7B model is available for direct download from the model zoo:
|
| 15 |
+
|
| 16 |
+
```shell
|
| 17 |
+
git-lfs install
|
| 18 |
+
git clone https://huggingface.co/lmdeploy/internlm-chat-7b-w8 (coming soon)
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
Alternatively, you can manually convert original 16-bit weights into 8-bit by referring to the content under the ["8bit Weight Quantization"](#8bit-weight-quantization) section. Save them in the internlm-chat-7b-w8 directory, using the command below:
|
| 22 |
+
|
| 23 |
+
```shell
|
| 24 |
+
lmdeploy lite smooth_quant internlm/internlm-chat-7b --work-dir ./internlm-chat-7b-w8
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
Afterwards, use the following command to interact with the model via the terminal:
|
| 28 |
+
|
| 29 |
+
```shell
|
| 30 |
+
lmdeploy chat ./internlm-chat-7b-w8 --backend pytorch
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## Launching gradio service
|
| 34 |
+
|
| 35 |
+
Coming soon...
|
| 36 |
+
|
| 37 |
+
## Inference Speed
|
| 38 |
+
|
| 39 |
+
Coming soon...
|
| 40 |
+
|
| 41 |
+
## 8bit Weight Quantization
|
| 42 |
+
|
| 43 |
+
Performing 8bit weight quantization involves three steps:
|
| 44 |
+
|
| 45 |
+
1. **Smooth Weights**: Start by smoothing the weights of the Language Model (LLM). This process makes the weights more amenable to quantizing.
|
| 46 |
+
2. **Replace Modules**: Locate DecoderLayers and replace the modules RSMNorm and nn.Linear with QRSMNorm and QLinear modules respectively. These 'Q' modules are available in the lmdeploy/pytorch/models/q_modules.py file.
|
| 47 |
+
3. **Save the Quantized Model**: Once you've made the necessary replacements, save the new quantized model.
|
| 48 |
+
|
| 49 |
+
The script `lmdeploy/lite/apis/smooth_quant.py` accomplishes all three tasks detailed above. For example, you can obtain the model weights of the quantized Internlm-chat-7B model by running the following command:
|
| 50 |
+
|
| 51 |
+
```shell
|
| 52 |
+
lmdeploy lite smooth_quant internlm/internlm-chat-7b --work-dir ./internlm-chat-7b-w8
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
After saving, you can instantiate your quantized model by calling the from_pretrained interface.
|
a_mllm_notebooks/openai/.ipynb_checkpoints/infer-checkpoint.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# !pip install openai
|
| 2 |
+
from openai import OpenAI
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
client = OpenAI(api_key="YOUR_API_KEY", base_url="http://0.0.0.0:8082/v1")
|
| 5 |
+
model_name = client.models.list().data[0].id
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
NUM_MODEL = len(client.models.list().data)
|
| 10 |
+
NUM_THREAD = min(int(NUM_MODEL * 1.5), 32)
|
| 11 |
+
|
| 12 |
+
import datasets, huggingface_hub
|
| 13 |
+
disk_path ='/dscilab_dungvo/workspace/BA-PRE_THESIS/dataset_pretraining/SYNTH-PEDES/annotation_english_vietnamese_processed'
|
| 14 |
+
dataset = datasets.load_from_disk(disk_path)
|
| 15 |
+
|
| 16 |
+
# Dataset({
|
| 17 |
+
# features: ['image_name', 'person_id', 'caption_0', 'caption_1', 'attributes', 'prompt_caption', 'image', 'viet_captions', 'viet_prompt_caption'],
|
| 18 |
+
# num_rows: 4791127
|
| 19 |
+
# })
|
| 20 |
+
|
| 21 |
+
# {'image_name': 'Part1/1/0.jpg',
|
| 22 |
+
# 'person_id': 1,
|
| 23 |
+
# 'caption_0': 'A woman with black hair and she is wearing a black jacket with blue jeans paired with black shoes.',
|
| 24 |
+
# 'caption_1': '',
|
| 25 |
+
# 'attributes': 'woman,short hair,black jacket,blue denim jeans,black sneakers,black backpack',
|
| 26 |
+
# 'prompt_caption': 'The woman has short hair. She is wearing a black jacket, blue denim jeans and black sneakers. She is carrying a black backpack. ',
|
| 27 |
+
# 'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=59x129>,
|
| 28 |
+
# 'viet_captions': ['Một người phụ nữ với mái tóc đen và cô ấy đang mặc một chiếc áo khoác màu đen với quần jean màu xanh kết hợp với giày đen.'],
|
| 29 |
+
# 'viet_prompt_caption': ['Người phụ nữ có mái tóc ngắn. Cô đang mặc một chiếc áo khoác màu đen, quần jean denim màu xanh và giày thể thao màu đen. Cô đang mang theo một ba lô màu đen.']}
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def get_output(english_text):
|
| 34 |
+
response = client.chat.completions.create(
|
| 35 |
+
model=model_name,
|
| 36 |
+
messages=[
|
| 37 |
+
{
|
| 38 |
+
"role": "system",
|
| 39 |
+
"content": "You are a helpful assistant who is proficient in translating English to Chinese.",
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"role": "user",
|
| 43 |
+
"content": "Please translate and paraphrase the following sentence into natural, fluent Chinese: " + english_text,
|
| 44 |
+
},
|
| 45 |
+
],
|
| 46 |
+
temperature=0.7,
|
| 47 |
+
top_p=0.9,
|
| 48 |
+
)
|
| 49 |
+
return response.choices[0].message.content
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
output_root_folder = './output_chinese'
|
| 53 |
+
import os
|
| 54 |
+
# make dir
|
| 55 |
+
os.makedirs(output_root_folder, exist_ok=True)
|
| 56 |
+
|
| 57 |
+
# multithread: NUM_THREAD threads
|
| 58 |
+
|
| 59 |
+
import threading
|
| 60 |
+
import time
|
| 61 |
+
|
| 62 |
+
# def get_list_partition_index(n, num_partition):
|
| 63 |
+
# partition_size = n // num_partition
|
| 64 |
+
# partition_index = []
|
| 65 |
+
# for i in range(num_partition):
|
| 66 |
+
# if i == num_partition - 1:
|
| 67 |
+
# partition_index.append((i * partition_size, n))
|
| 68 |
+
# else:
|
| 69 |
+
# partition_index.append((i * partition_size, (i + 1) * partition_size))
|
| 70 |
+
# return partition_index
|
| 71 |
+
|
| 72 |
+
# /dscilab_dungvo/workspace/vlm_clone/a_mllm_notebooks/openai/output_chinese/thread_32/4509280.json
|
| 73 |
+
def get_uninferenced_indices(total_indices, output_dir):
|
| 74 |
+
inferenced_indices = set()
|
| 75 |
+
for thread_folder in os.listdir(output_dir):
|
| 76 |
+
if 'thread' not in thread_folder:
|
| 77 |
+
continue
|
| 78 |
+
thread_path = os.path.join(output_dir, thread_folder)
|
| 79 |
+
if os.path.isdir(thread_path):
|
| 80 |
+
for json_file in os.listdir(thread_path):
|
| 81 |
+
try:
|
| 82 |
+
index = json_file.split('.')[0]
|
| 83 |
+
index = int(index)
|
| 84 |
+
except:
|
| 85 |
+
print(f"Error: {json_file}")
|
| 86 |
+
continue
|
| 87 |
+
inferenced_indices.add(index)
|
| 88 |
+
uninferenced_indices = [index for index in total_indices if index not in inferenced_indices]
|
| 89 |
+
return uninferenced_indices
|
| 90 |
+
|
| 91 |
+
total_indices = list(range(len(dataset)))
|
| 92 |
+
REMAIN_INDEXES = get_uninferenced_indices(total_indices, output_root_folder)
|
| 93 |
+
|
| 94 |
+
def get_list_partition_from_list_index(list_index, num_partition):
|
| 95 |
+
n = len(list_index)
|
| 96 |
+
partition_size = n // num_partition
|
| 97 |
+
partition_index = []
|
| 98 |
+
for i in range(num_partition):
|
| 99 |
+
if i == num_partition - 1:
|
| 100 |
+
partition_index.append(list_index[i * partition_size:])
|
| 101 |
+
else:
|
| 102 |
+
partition_index.append(list_index[i * partition_size:(i + 1) * partition_size])
|
| 103 |
+
return partition_index
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
# LIST_PARTITION_INDEX is list of list of index
|
| 107 |
+
LIST_PARTITION_INDEX = get_list_partition_from_list_index(REMAIN_INDEXES, NUM_THREAD)
|
| 108 |
+
import json
|
| 109 |
+
|
| 110 |
+
# Each thread do a loop in its partition index. for each index, get the chinese translation for: prompt_caption, caption_0, caption_1
|
| 111 |
+
|
| 112 |
+
def thread_function(thread_id):
|
| 113 |
+
# make output folder for this thread
|
| 114 |
+
os.makedirs(os.path.join(output_root_folder, f"thread_{thread_id}"), exist_ok=True)
|
| 115 |
+
|
| 116 |
+
list_index = LIST_PARTITION_INDEX[thread_id]
|
| 117 |
+
|
| 118 |
+
for i in tqdm(range(len(list_index))):
|
| 119 |
+
if i % 1000 == 0:
|
| 120 |
+
print(f"Thread {thread_id}: {i}/{len(list_index)}")
|
| 121 |
+
|
| 122 |
+
index = list_index[i]
|
| 123 |
+
item = dataset[index]
|
| 124 |
+
dump_item = {}
|
| 125 |
+
|
| 126 |
+
for key in ['prompt_caption', 'caption_0', 'caption_1']:
|
| 127 |
+
english_text = item[key]
|
| 128 |
+
|
| 129 |
+
if english_text == '':
|
| 130 |
+
chinese_text = ''
|
| 131 |
+
else:
|
| 132 |
+
chinese_text = get_output(english_text)
|
| 133 |
+
dump_item[key + '_chinese'] = chinese_text
|
| 134 |
+
|
| 135 |
+
# dump to json file
|
| 136 |
+
with open(os.path.join(output_root_folder, f"thread_{thread_id}", f"{index}.json"), 'w') as f:
|
| 137 |
+
json.dump(dump_item, f)
|
| 138 |
+
|
| 139 |
+
print(f"Thread {thread_id}: Done")
|
| 140 |
+
|
| 141 |
+
threads = []
|
| 142 |
+
# for i, (start, end) in enumerate(LIST_PARTITION_INDEX):
|
| 143 |
+
for i in range(NUM_THREAD):
|
| 144 |
+
x = threading.Thread(target=thread_function, args=(i,))
|
| 145 |
+
threads.append(x)
|
| 146 |
+
x.start()
|
| 147 |
+
time.sleep(1)
|
| 148 |
+
|
| 149 |
+
for thread in threads:
|
| 150 |
+
thread.join()
|
| 151 |
+
|
| 152 |
+
print("Done")
|
| 153 |
+
|
| 154 |
+
# # Combine all json files in each thread folder to a single json file
|
| 155 |
+
# import os
|
| 156 |
+
# import json
|
| 157 |
+
# list_json_files = []
|
| 158 |
+
# for thread_folder in os.listdir(output_file):
|
| 159 |
+
# for json_file in os.listdir(os.path.join(output_file, thread_folder)):
|
| 160 |
+
# list_json_files.append(os.path.join(output_file, thread_folder, json_file))
|
| 161 |
+
|
| 162 |
+
# output_json_file = './output_chinese.json'
|
| 163 |
+
# with open(output_json_file, 'w') as f:
|
| 164 |
+
# for json_file in list_json_files:
|
| 165 |
+
# with open(json_file, 'r') as f_json:
|
| 166 |
+
# json.dump(json.load(f_json), f)
|
| 167 |
+
# f.write('\n')
|
a_mllm_notebooks/openai/.ipynb_checkpoints/langchain_openai_api-checkpoint.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
a_mllm_notebooks/openai/.ipynb_checkpoints/load_synth_pedes-checkpoint.ipynb
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import datasets, huggingface_hub\n",
|
| 10 |
+
"# huggingface_hub.login(token=\"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\")\n",
|
| 11 |
+
"disk_path ='/dscilab_dungvo/workspace/BA-PRE_THESIS/dataset_pretraining/SYNTH-PEDES/annotation_english_vietnamese_processed'\n",
|
| 12 |
+
"dataset = datasets.load_from_disk(disk_path)\n",
|
| 13 |
+
"# dataset = dataset.cast_column('image', datasets.Image(decode=True))"
|
| 14 |
+
]
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"cell_type": "code",
|
| 18 |
+
"execution_count": 5,
|
| 19 |
+
"metadata": {},
|
| 20 |
+
"outputs": [
|
| 21 |
+
{
|
| 22 |
+
"data": {
|
| 23 |
+
"text/plain": [
|
| 24 |
+
"Dataset({\n",
|
| 25 |
+
" features: ['image_name', 'person_id', 'caption_0', 'caption_1', 'attributes', 'prompt_caption', 'image', 'viet_captions', 'viet_prompt_caption'],\n",
|
| 26 |
+
" num_rows: 4791127\n",
|
| 27 |
+
"})"
|
| 28 |
+
]
|
| 29 |
+
},
|
| 30 |
+
"execution_count": 5,
|
| 31 |
+
"metadata": {},
|
| 32 |
+
"output_type": "execute_result"
|
| 33 |
+
}
|
| 34 |
+
],
|
| 35 |
+
"source": [
|
| 36 |
+
"dataset"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "code",
|
| 41 |
+
"execution_count": 4,
|
| 42 |
+
"metadata": {},
|
| 43 |
+
"outputs": [
|
| 44 |
+
{
|
| 45 |
+
"data": {
|
| 46 |
+
"text/plain": [
|
| 47 |
+
"{'image_name': 'Part1/1/0.jpg',\n",
|
| 48 |
+
" 'person_id': 1,\n",
|
| 49 |
+
" 'caption_0': 'A woman with black hair and she is wearing a black jacket with blue jeans paired with black shoes.',\n",
|
| 50 |
+
" 'caption_1': '',\n",
|
| 51 |
+
" 'attributes': 'woman,short hair,black jacket,blue denim jeans,black sneakers,black backpack',\n",
|
| 52 |
+
" 'prompt_caption': 'The woman has short hair. She is wearing a black jacket, blue denim jeans and black sneakers. She is carrying a black backpack. ',\n",
|
| 53 |
+
" 'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=59x129>,\n",
|
| 54 |
+
" 'viet_captions': ['Một người phụ nữ với mái tóc đen và cô ấy đang mặc một chiếc áo khoác màu đen với quần jean màu xanh kết hợp với giày đen.'],\n",
|
| 55 |
+
" 'viet_prompt_caption': ['Người phụ nữ có mái tóc ngắn. Cô đang mặc một chiếc áo khoác màu đen, quần jean denim màu xanh và giày thể thao màu đen. Cô đang mang theo một ba lô màu đen.']}"
|
| 56 |
+
]
|
| 57 |
+
},
|
| 58 |
+
"execution_count": 4,
|
| 59 |
+
"metadata": {},
|
| 60 |
+
"output_type": "execute_result"
|
| 61 |
+
}
|
| 62 |
+
],
|
| 63 |
+
"source": [
|
| 64 |
+
"dataset[0]"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "code",
|
| 69 |
+
"execution_count": null,
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"outputs": [],
|
| 72 |
+
"source": []
|
| 73 |
+
}
|
| 74 |
+
],
|
| 75 |
+
"metadata": {
|
| 76 |
+
"kernelspec": {
|
| 77 |
+
"display_name": "lmdeploy",
|
| 78 |
+
"language": "python",
|
| 79 |
+
"name": "python3"
|
| 80 |
+
},
|
| 81 |
+
"language_info": {
|
| 82 |
+
"codemirror_mode": {
|
| 83 |
+
"name": "ipython",
|
| 84 |
+
"version": 3
|
| 85 |
+
},
|
| 86 |
+
"file_extension": ".py",
|
| 87 |
+
"mimetype": "text/x-python",
|
| 88 |
+
"name": "python",
|
| 89 |
+
"nbconvert_exporter": "python",
|
| 90 |
+
"pygments_lexer": "ipython3",
|
| 91 |
+
"version": "3.8.19"
|
| 92 |
+
}
|
| 93 |
+
},
|
| 94 |
+
"nbformat": 4,
|
| 95 |
+
"nbformat_minor": 2
|
| 96 |
+
}
|
a_mllm_notebooks/openai/.ipynb_checkpoints/openai_api-checkpoint.ipynb
ADDED
|
@@ -0,0 +1,408 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "65815b1f",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Image URL"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"cell_type": "code",
|
| 13 |
+
"execution_count": 1,
|
| 14 |
+
"id": "d606605d-b949-4b3d-b582-9316734320f1",
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"outputs": [
|
| 17 |
+
{
|
| 18 |
+
"name": "stdout",
|
| 19 |
+
"output_type": "stream",
|
| 20 |
+
"text": [
|
| 21 |
+
"ChatCompletion(id='1831', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on a grassy surface. The tiger is positioned with its front legs extended forward and its head slightly raised, giving it a relaxed appearance. The tiger's distinctive orange fur with black stripes is clearly visible, and it is surrounded by green grass, suggesting a natural or zoo-like environment. The lighting is bright, indicating a sunny day. The tiger's expression is calm and focused.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735906949, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=82, prompt_tokens=1843, total_tokens=1925, completion_tokens_details=None))\n"
|
| 22 |
+
]
|
| 23 |
+
}
|
| 24 |
+
],
|
| 25 |
+
"source": [
|
| 26 |
+
"from openai import OpenAI\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:8081/v1\")\n",
|
| 29 |
+
"model_name = client.models.list().data[0].id\n",
|
| 30 |
+
"response = client.chat.completions.create(\n",
|
| 31 |
+
" model=model_name,\n",
|
| 32 |
+
" messages=[\n",
|
| 33 |
+
" {\n",
|
| 34 |
+
" \"role\": \"user\",\n",
|
| 35 |
+
" \"content\": [\n",
|
| 36 |
+
" {\n",
|
| 37 |
+
" \"type\": \"text\",\n",
|
| 38 |
+
" \"text\": \"describe this image\",\n",
|
| 39 |
+
" },\n",
|
| 40 |
+
" {\n",
|
| 41 |
+
" \"type\": \"image_url\",\n",
|
| 42 |
+
" \"image_url\": {\n",
|
| 43 |
+
" \"url\": \"https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg\",\n",
|
| 44 |
+
" },\n",
|
| 45 |
+
" },\n",
|
| 46 |
+
" ],\n",
|
| 47 |
+
" }\n",
|
| 48 |
+
" ],\n",
|
| 49 |
+
" temperature=0.5,\n",
|
| 50 |
+
" top_p=0.8,\n",
|
| 51 |
+
")\n",
|
| 52 |
+
"print(response)"
|
| 53 |
+
]
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"cell_type": "code",
|
| 57 |
+
"execution_count": 2,
|
| 58 |
+
"id": "370fea1d",
|
| 59 |
+
"metadata": {},
|
| 60 |
+
"outputs": [],
|
| 61 |
+
"source": [
|
| 62 |
+
"# ChatCompletion(id='6', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on a grassy area. The tiger has distinct orange fur with black stripes and is resting \n",
|
| 63 |
+
"text = response.choices[0].message.content"
|
| 64 |
+
]
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"cell_type": "code",
|
| 68 |
+
"execution_count": 3,
|
| 69 |
+
"id": "46de478b",
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"outputs": [
|
| 72 |
+
{
|
| 73 |
+
"data": {
|
| 74 |
+
"text/plain": [
|
| 75 |
+
"\"The image shows a tiger lying on a grassy surface. The tiger is relaxed, with its front legs stretched out and its head slightly raised, giving a clear view of its face and stripes. The background consists of lush green grass, and the tiger's distinctive orange, black, and white fur is prominently displayed. The lighting suggests a bright, sunny day.\""
|
| 76 |
+
]
|
| 77 |
+
},
|
| 78 |
+
"execution_count": 3,
|
| 79 |
+
"metadata": {},
|
| 80 |
+
"output_type": "execute_result"
|
| 81 |
+
}
|
| 82 |
+
],
|
| 83 |
+
"source": [
|
| 84 |
+
"text"
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"cell_type": "code",
|
| 89 |
+
"execution_count": 2,
|
| 90 |
+
"id": "f60099ff-ca4c-46f1-9dcd-3a4fb776ea4d",
|
| 91 |
+
"metadata": {},
|
| 92 |
+
"outputs": [
|
| 93 |
+
{
|
| 94 |
+
"data": {
|
| 95 |
+
"text/plain": [
|
| 96 |
+
"5"
|
| 97 |
+
]
|
| 98 |
+
},
|
| 99 |
+
"execution_count": 2,
|
| 100 |
+
"metadata": {},
|
| 101 |
+
"output_type": "execute_result"
|
| 102 |
+
}
|
| 103 |
+
],
|
| 104 |
+
"source": [
|
| 105 |
+
"len(client.models.list().data)"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "code",
|
| 110 |
+
"execution_count": 23,
|
| 111 |
+
"id": "e51e6cd6-9ca3-4082-8a8c-f1668f0de5c9",
|
| 112 |
+
"metadata": {},
|
| 113 |
+
"outputs": [
|
| 114 |
+
{
|
| 115 |
+
"name": "stdout",
|
| 116 |
+
"output_type": "stream",
|
| 117 |
+
"text": [
|
| 118 |
+
"ChatCompletion(id='1', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image features a tiger lying down on a grassy surface. The tiger is positioned with its front legs stretched forward and its head slightly raised, giving it a relaxed posture. The background is lush and green, suggesting a natural, outdoor setting. The tiger's distinctive orange, black, and white stripes are clearly visible, making it a striking and recognizable subject. The lighting highlights the tiger's fur, creating a vivid and clear image of the animal.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640960, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=90, prompt_tokens=1843, total_tokens=1933, completion_tokens_details=None))\n",
|
| 119 |
+
"ChatCompletion(id='1', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on a grassy surface. The tiger is relaxed, with its front paws stretched out and its head slightly tilted. The stripes on the tiger's fur are prominent and characteristic of the species. The background consists of lush green grass, and the lighting suggests a bright, sunny day. The tiger appears calm and comfortable in its environment.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640964, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=73, prompt_tokens=1843, total_tokens=1916, completion_tokens_details=None))\n",
|
| 120 |
+
"ChatCompletion(id='2', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='The image shows a tiger lying down on green grass. The tiger has a striking orange coat with black stripes and a white underbelly. It is looking directly at the camera, giving a calm and composed expression. The background consists of lush, green foliage, providing a natural and serene setting for the animal.', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640967, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=62, prompt_tokens=1843, total_tokens=1905, completion_tokens_details=None))\n",
|
| 121 |
+
"ChatCompletion(id='1', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image features a tiger lying down on a lush, green grassy area. The tiger is relaxed, with its front legs stretched out, and its distinctive orange fur with black stripes is clearly visible. The background consists of well-maintained grass, creating a serene and natural setting. The lighting suggests a bright, sunny day, enhancing the vivid colors of the tiger's coat. The tiger's facial expression is calm, adding to the tranquil atmosphere of the scene.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640969, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=93, prompt_tokens=1843, total_tokens=1936, completion_tokens_details=None))\n",
|
| 122 |
+
"ChatCompletion(id='2', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on green grass. The tiger is relaxed, with its front paws stretched out and its head turned slightly to the side, giving a direct and calm gaze towards the camera. The tiger's distinctive orange fur with black stripes is clearly visible, and the background is lush and green, suggesting a natural or well-maintained habitat. The lighting is bright, indicating a sunny day.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640973, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=82, prompt_tokens=1843, total_tokens=1925, completion_tokens_details=None))\n",
|
| 123 |
+
"ChatCompletion(id='2', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='The image shows a tiger lying down on a lush green lawn. The tiger has striking orange fur with black stripes and a white underbelly. It is looking directly at the camera with a relaxed posture. The surrounding grass is vibrant and well-maintained, creating a peaceful and natural setting.', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640977, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=59, prompt_tokens=1843, total_tokens=1902, completion_tokens_details=None))\n",
|
| 124 |
+
"ChatCompletion(id='3', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image features a tiger lying on green grass. The tiger is in a relaxed position, with its front paws stretched out in front of it. The background consists of lush, green foliage, and the tiger's distinctive orange and black stripes are clearly visible. The lighting suggests it's a bright, sunny day. The tiger appears calm and at ease in its environment.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640979, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=74, prompt_tokens=1843, total_tokens=1917, completion_tokens_details=None))\n",
|
| 125 |
+
"ChatCompletion(id='3', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on a grassy surface. The tiger has its front paws stretched forward, with the rest of its body relaxed. The background consists of lush green grass, and the tiger's distinctive orange, black, and white stripes are clearly visible. The animal's expression is calm, and it is looking directly at the camera. The lighting in the image is bright, highlighting the tiger's features and the vivid colors of its fur.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640981, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=91, prompt_tokens=1843, total_tokens=1934, completion_tokens_details=None))\n",
|
| 126 |
+
"2.86 s ± 846 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\n"
|
| 127 |
+
]
|
| 128 |
+
}
|
| 129 |
+
],
|
| 130 |
+
"source": [
|
| 131 |
+
"%%timeit\n",
|
| 132 |
+
"response = client.chat.completions.create(\n",
|
| 133 |
+
" model=model_name,\n",
|
| 134 |
+
" messages=[{\n",
|
| 135 |
+
" 'role':\n",
|
| 136 |
+
" 'user',\n",
|
| 137 |
+
" 'content': [{\n",
|
| 138 |
+
" 'type': 'text',\n",
|
| 139 |
+
" 'text': 'describe this image',\n",
|
| 140 |
+
" }, {\n",
|
| 141 |
+
" 'type': 'image_url',\n",
|
| 142 |
+
" 'image_url': {\n",
|
| 143 |
+
" 'url':\n",
|
| 144 |
+
" 'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',\n",
|
| 145 |
+
" },\n",
|
| 146 |
+
" }],\n",
|
| 147 |
+
" }],\n",
|
| 148 |
+
" temperature=0.8,\n",
|
| 149 |
+
" top_p=0.8)\n",
|
| 150 |
+
"print(response)"
|
| 151 |
+
]
|
| 152 |
+
},
|
| 153 |
+
{
|
| 154 |
+
"cell_type": "code",
|
| 155 |
+
"execution_count": null,
|
| 156 |
+
"id": "094bec32-0324-486a-809e-d919891c2167",
|
| 157 |
+
"metadata": {},
|
| 158 |
+
"outputs": [],
|
| 159 |
+
"source": [
|
| 160 |
+
"# !ps aux|grep lmdeploy |grep -v grep | awk '{print $2}'|xargs kill -9"
|
| 161 |
+
]
|
| 162 |
+
},
|
| 163 |
+
{
|
| 164 |
+
"cell_type": "markdown",
|
| 165 |
+
"id": "07a1fb36-e361-4d59-870e-0a8a3f15e5d5",
|
| 166 |
+
"metadata": {},
|
| 167 |
+
"source": [
|
| 168 |
+
"# PIL Image"
|
| 169 |
+
]
|
| 170 |
+
},
|
| 171 |
+
{
|
| 172 |
+
"cell_type": "code",
|
| 173 |
+
"execution_count": 2,
|
| 174 |
+
"id": "e56e3874",
|
| 175 |
+
"metadata": {},
|
| 176 |
+
"outputs": [
|
| 177 |
+
{
|
| 178 |
+
"name": "stderr",
|
| 179 |
+
"output_type": "stream",
|
| 180 |
+
"text": [
|
| 181 |
+
"/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
|
| 182 |
+
" from .autonotebook import tqdm as notebook_tqdm\n"
|
| 183 |
+
]
|
| 184 |
+
}
|
| 185 |
+
],
|
| 186 |
+
"source": [
|
| 187 |
+
"\n",
|
| 188 |
+
"import datasets, huggingface_hub\n",
|
| 189 |
+
"\n",
|
| 190 |
+
"disk_path = \"/dscilab_dungvo/workspace/BA-PRE_THESIS/dataset_pretraining/SYNTH-PEDES/annotation_english_vietnamese_processed\"\n",
|
| 191 |
+
"dataset = datasets.load_from_disk(disk_path)\n",
|
| 192 |
+
"\n",
|
| 193 |
+
"image = dataset[110]['image']"
|
| 194 |
+
]
|
| 195 |
+
},
|
| 196 |
+
{
|
| 197 |
+
"cell_type": "code",
|
| 198 |
+
"execution_count": 35,
|
| 199 |
+
"id": "c0c2b27d",
|
| 200 |
+
"metadata": {},
|
| 201 |
+
"outputs": [],
|
| 202 |
+
"source": [
|
| 203 |
+
"from PIL import Image\n",
|
| 204 |
+
"import io\n",
|
| 205 |
+
"import base64\n",
|
| 206 |
+
"import uuid\n",
|
| 207 |
+
"# {\"url\": 'data:image/jpeg;base64,' + img_str}}\n",
|
| 208 |
+
"\n",
|
| 209 |
+
"def pil_to_url(pil_image):\n",
|
| 210 |
+
" buffered = io.BytesIO()\n",
|
| 211 |
+
" pil_image.save(buffered, format=\"JPEG\")\n",
|
| 212 |
+
" img_str = base64.b64encode(buffered.getvalue()).decode()\n",
|
| 213 |
+
" return f\"data:image/jpeg;base64,{img_str}\"\n",
|
| 214 |
+
" \n",
|
| 215 |
+
" \n",
|
| 216 |
+
"\n",
|
| 217 |
+
"def generate_content(image, prompt):\n",
|
| 218 |
+
"\n",
|
| 219 |
+
" # image is a PIL image\n",
|
| 220 |
+
" messages = (\n",
|
| 221 |
+
" [\n",
|
| 222 |
+
" {\n",
|
| 223 |
+
" \"role\": \"user\",\n",
|
| 224 |
+
" \"content\": [\n",
|
| 225 |
+
" {\n",
|
| 226 |
+
" \"type\": \"text\",\n",
|
| 227 |
+
" \"text\": prompt,\n",
|
| 228 |
+
" },\n",
|
| 229 |
+
" \n",
|
| 230 |
+
" {\n",
|
| 231 |
+
" \"type\": \"image_url\",\n",
|
| 232 |
+
" \"image_url\": {\n",
|
| 233 |
+
" \"url\": pil_to_url(image),\n",
|
| 234 |
+
" },\n",
|
| 235 |
+
" },\n",
|
| 236 |
+
" ],\n",
|
| 237 |
+
" }\n",
|
| 238 |
+
" ],\n",
|
| 239 |
+
" )\n",
|
| 240 |
+
"\n",
|
| 241 |
+
" # send message to the model\n",
|
| 242 |
+
" response = client.chat.completions.create(\n",
|
| 243 |
+
" model=model_name, messages=messages, temperature=0.5, top_p=0.8\n",
|
| 244 |
+
" )\n",
|
| 245 |
+
"\n",
|
| 246 |
+
" return response\n",
|
| 247 |
+
"\n",
|
| 248 |
+
"# print(generate_content(image=dataset[110][\"image\"], prompt=\"describe this image\"))"
|
| 249 |
+
]
|
| 250 |
+
},
|
| 251 |
+
{
|
| 252 |
+
"cell_type": "code",
|
| 253 |
+
"execution_count": 26,
|
| 254 |
+
"id": "cbf16d3e",
|
| 255 |
+
"metadata": {},
|
| 256 |
+
"outputs": [
|
| 257 |
+
{
|
| 258 |
+
"data": {
|
| 259 |
+
"image/jpeg": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAD0AFcDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwDm/FehWvh2yjjt2kLMQpJHWsLSG1a0k3Wds8hc+nBr0zxTb2V3aRT3Um1c5U4zx61PY6poFno3nC6gKoOSCMk/SuZXZo7Hn2ua79vtGtrzTvIvFA+YelcjKo5rV8R60uravLdRJti+6vGCRWKzk1rFXJsaVrOF3KJHCH+Dcdv5Vo22oFZ45I40DxcodgOTjHNc5EWLda7rwhpEV3cKZeR71UtEOEbsrT+LNaWbzQY42IxlExTLbXNSuSy3L+ZGzbiWGea19Z8K6hJfyNZxq8WeBmp7DwhqCxZljRSe2ayvc2cLHKzRl3dlBA9NxqnDIEm2+prrZ/D95FK6NH+VZR8NXrT5ChRnvWhDZVvLK2kMeWILDkg0VpT6JcqmW29cUUhaCXfiD7d4RSynceeuFBJ5wO1Y/h7w3deI7oLFlIFb55COPoKf4X0SHWb7NzKwiX7wHU17Fp32LTbWO1tLfbGowAOKl6Eo5Hxh4esdI8Hhba2XzIQP3nc+teWumUDDvXsfj66aXw7LGEOGryTTYTczCDIyQcZpxK6lSEESDPrXs/gjSRLp4mzjcMdK86i8OzSMp29SOte/eGtITTvDsKkcqmSampK+htTjbU47VfEEXh+Z/tMTMd+BisxvijaH5VsZGP1pnjFhdTyb/mCuQo9BXCPbhHzjinBKxNWXY6O78czTSM6WYGTwCelV18Z3DZzap+dYpi3DoaRYMZ4qjE0rnxPdznAiVRn1orNMOT0ooHcPB+rJpWvxSz827nZIPb1r6IsLeynhSVEQqwypHcV8z6jp8+malJayrhkP5+9dhpPjzVNK0pLNCrhU2qx6j/GqUeYzPTvHCWI0CeJmjUFDgAjJNeH6cP7OkL7FZ+xPan32rXOoy+ZczM7e54FVfN962jTQrs6a08QvG43ouK9H0XxyJ7b7K5jXK4FeJiXnrT47qSNso7KfUGk6UWUqkj07VtL3iSdP9IVm3bVPIrh55zbXoDWcg9NycCrFn4kngiVGkY4HepZ/EAucb0VvcrR7KwOdyB3W4beYtgqMxAHipZdUjlkjjKbTgKDV6OFSucUnASkYbqQx+XNFbxtkx0FFZ8pVzd+IfhpLmxGqwp++iX95gdRXlQfK17x4vuhB4WuJOoMXT8K8DViRnGM9qumybDyaTNNzRnmtRDt1LuqPNGaaYiUvjvU0E+4gVTY5FOt8q4Ip8wWuaUwztYHkc11Glv5tpGWPPSudiTz4iO9bulkQQrGxHHepdmK1jXEYA6cUVYQBl4orKxVx3ijWrfVvDS2dq3mSbVV1Jx0HUV5hNY3NsAZYiAe46V3SabcWTDzoSorI13iFVHc1kpWZuoXicoaSpZIyrYNR4rpTuYNWENFLSUxAa19EsYb1nEjEbegFY/etbw/NtvtvrUT2NKe51kPhuOW0kNvIRMBkAnAqnFaTW0gSQDf1OK6LTbtYnOaoXZvJtRElvbSGNR1AyDXNGbub1Ka5blm2kCoA5waKzpxNDcLNMrrnIAxRXQcg46rdXTH7TMT6ADP9aytRU3FzGvQZ71GsdzbSMsgPBPJH69afcTAukhwBuycVyXuzuinaxj6vB5VyfQiszNbevDf5Uo6Fe1YmOK66exz1FZiZopKUVoZC4qxpjGHUIjngnmol5qSMBZVb0NKSuhwdmd3a3QwMDnNb1hb6pdqGN5HDbE8KMZ/+tXH2Mm6JSDUXiV7i3hjljuJUBwAqtgdK4npI7WnKI3xdrQ+3m1tZDL5BKmUnqc+lFceGZiSeT6nmiuuOxxSjqe0abp8V7ZSCaMMx7kcjiuI1W0NpPJCQcIcDNd/p10scuxAArVjeJrNJ1aVfvfzrD2dkdkXdnCXNwk2nRox/eIT+VZZxVq7jZHKgVUEbVtT2MKu4hopdho8s46VoY2YBtpp/mZWnR25cgYrSi0h5oDjg/SndWKUWXNEkDxFCelavia1+0WFqmeS3H5VgaWr2l0Y3GCOoNad1evPdQxFsheg9K4ai947YP3dTm9R0iXTJFMhBVhwc4orsvFGnpLo0UuBvBHJFFbxloc7Wps2U4+0IrdCat6hEJUKntWTZzQeeqsw3A8VrPJvJPrWn2QTszkNQ0XfLuU4Unmqo0Be8uK6m7XEbVml651OzOynSjNXZkjQI+8p69hViLRbRSNxZvarRcik8wjkiq5zZUIIt21lZxsNsK10dg9nGjf6OuSPSuWjnAYDNXY7kBcA0uZsPZxsUvEkEceoJcxIFDDaxFZToqalAx+6w7VoavI8kQDN8gOax7qUmWAoeQaTOeorbHYaxG0+joqDJAWirOmTLcWao+CQBndRSRlyM5WyV5JwMV1MKsQKwNLRjehx90dfautiUFBxzXXBXOaTKl1DvhJAycVzUsrxuflGAe9dr5WVII4rlbyDZPIpHRjXPUp2Z3YapdWMr+1ERyHXFOW/S4IWMgZ9arX1spBPTFZ1jlb0L2NZ2Ou50BiwM7sn2p8MTs4LHC+lEcLKPvVKFYnAOKpFDNSRTZSe1cxFP506D+62K6icFo9h5BqjPpEcd0kqDaG5IFU1ocVR2kW7bUBZXphZyAy5HpRXP+JJtl6iR53KuDRWVi+aJv2+uWumllkhdjnkrWlD4y0ogFlmQ+myuNvCHmf8A3jUCxgkV2RdjzG7nqNt4g0u5iDJcAcdG4rFv5Y5buR4mDI3ORXO6dDZglrjp6CtdzCT/AKOu2MDpU1Hc6sL8RRvvukAdaraJpsup6mYIiocLu+arN1V7wEwj8ZRMf4lwAehrA7puxKyGCRon+8hKn6igeoq94hi8jXbpQMAtkVmgkUJlQleJJ5bysFjXc3pXTR+Ho59JW5lISVEz1rl4rkxzKR1B7V1omaXTi28gFOhrZK6POxE7SPJ9cVptWbYkjDHZSaK9ssI7S3tIyLWLfjJZlBJoqeUi9zxOTmQn3pAQKfdRmOVvTNV8nNXc51sWFcqeDWxYzb49vcVz8jMgyK19CbzN5f8ACom9DooO0i1d4APrWt4JtN+tx3POY6zL1ecjvXVeBYGE7NsOMZJrnudtSd0Q+LiW1xjtwMfnWE8oRctxXTeL5rca4sSgl9vzHHFc1fIrRkCmmTCdkZtvqLyXhVF6HjPeu10WK61O1kZvljThie4rzaW4ayvhIg5Wu48Ia/eapO8WxI4VXJCjk11QehxVdZHS398mmWiF1LDgYFFWjGsnDoCPcUVVi01Y8WuL9bqZht2sCeDTAcVBqkH2HX7qEdFkP86nU8is0cyHuu6M+wrR0YbImPrVL+E/Sr2nMFgOfWpqbG9HVlud9zKvcnivZvCumRWumRuVUEpzjv3rxOSQNLHjruFe56bMYvDQk6FUJ/8AHa5zebPJPEN+L7xnfmMnYjkL9M1DMSyfhWPbXBm1i9l6lpm/nWo7/KabLprQopo41SZ137SBya2/AVqbW6vY2O5kbbkVU0aXF6y56itTwp+71LUR6yf41vS1OaroztFI70VCGIPWiurlMOY8V8XSbvFV6c8mQ5/OmQkGJTUPiNH/ALeu3b+Jyc/jS2jZhHrWHUSLqHjmpIJdoKioQpPNV4Zv9IZfepnsa0XZmzbAvdxem8V7VeXa2vhCRjgYiPP/AAGvErWTZNG3vXpOp3Et54Slij+8YR39ua50tTpnseP2Nywv2OeXYn9a6IMWSuTtz5V2d38LEV1cHzRD3FORVLYn0z5NQX3rc0MbNZvAO+01gQt5Vwr/AN081saLcBtVmI48wDr7CtqTsc9VanYA5Wis+fUILP8A10ir7Zorb2hlyHlXia7ju7lZVUAkc1RsmLKRS6rbSRTtnoCcVFablJqGxJGqvC1lozC8xV0N8vWqYGbpD6mpbKgtTWSQrtr0XQbpbvR3hkbohFefm3Plg9sVraTqj2kTxgHkYyDWKWp0yehyWpRi31m5jByBIcfnXR2J3QL/ALtczqRMmqyOTnLZrrrGDbbJhSAVHX6UpoKDH20QebnpVDXZjbzRi3ZkYkcqaukvBNkdKzNXy80D+4qovQKi1IdRVnt4mcu5IBJJzzRVu6g862Reneii5CidlqfhuyvlYiLBb0FYo8CNuOxjjPetvUtbktmxDgY61iz+Jr5xjzNuPSqVyNBf+EBnJ/4+EUfWsnVfCraQi3LXSSAHgD1qZ9cvPmPnvz1way727muVwzsw9zVJE7EP26TdtzlfStHT0MwfA5rGSB2kHB610ulwiEZHUjmqsgu2crf2k6Xju0bAZ610Vjq/k2cSSIWKrjrV7UIvMgckc44rmlhuixUROfTAqGkyoya2Ne51S3mQjYyn61lTSNNNGQxKg9Kli0TU7ogR278nqRWvYeDNXaQMUC49anRA5yZUv7pTbx+UNhAANFdRF4BvJxiQc+1FToaRloZeqZ89uaymA20UVujGIxUG6nmNPSiigaFjjXeOK6PT4I9i8daKKmRSN6HTraZPnTNamm6XZozbYh+VFFZvYZvQWduBkRr+VXUhjC8ItFFYlvYUnavAH5UUUVSJP//Z",
|
| 260 |
+
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAFcAAAD0CAIAAABhIi17AAB85UlEQVR4AbXdWXdj2XUneMwgwSnmiJwlWUrL8rJ79epV7vL3f/SL+8FV1pDKlHKOgQxOAAiAQP/++wAMpjJtl6pXn4y8vLj3DHve+4y3+5tfvtjb2xtWevDg2P3V1cV0Or2aTW9vbzudzsnJyd/88tMXL14Mh+PJZDIejkej0enp6RdffHF+cfX69euzi/P5fH677mw2m26no1Ruut31cuW+Pxqq85OPf97r9d774P3FYvHVn7+qmjdq66036/V6dn15dXX1f/4f//jzn//8/fffl/PV9y/Pz8/39ke/+tWvTg4PgXG7Wv35z39eLJfeqvC3v/3tcrm8uHx7fX66XC46nX5n01uuN/3eQOPgXyxWMoAEtKPx/mAw6PcHnV7vtru+WS1vlzdavL6+Ho/HQBqsViuVHh8f7++PNTAD0eXlzc3N6nblNWRkkPvt27fHxw+kRw8fHh4eHRwc9Ab9s9NzReYBojObL+CDCveT4oh4cXHx2WefodTnf/pCQ511B/6gQtnNciXP7PoAWf18/vz5o0ePPOluOvhydX3x5ZdffrVeq3M+m3399de9fv9pJdBLEOysN999/c3p6RtIDsf7nU4PiVXQ7/fB1vihuJvNZu1Jv9ff7/WWvQ5o5ZTcDH7+ycfvvfcesPqDLlSvry6gvd6sNrfJ2e0Nlb68uFjc3Jydnl5dnq8++STY9ntPnz5Bi6vZ1Vff4u2y1+900GBNCjbuJE1q/ujwZIGkt7cyew7W8d4IZ7xdLlfzq6vAenuL4liN/4eTA/XPZjNP5tMrOUHrydXl5dnZGdKcv3376tUrrFIhLg8HkweP3uv1j1ar215vgP+97u1oNLhZLrq9Dey1udmoYdPvB77hIGK/XPaH/UGv08VgMA/+6Z/+6emzx5rBf0Cfn5/1uhuEgHxIuLolOciCtH7iBhXAjOOTh1Kn18cNgHrVUkO+FKK77ob2hNPD/f19Erdapx4/teWqqu7tmjyPh6nnu++++/bbb9ehWIiyul3cLpYKdrsdP4eDwjDSOht++61GHz9+vL9/uJxTwxFakN1bcPbG3c56tVxREIyAv3+lo6jQx5a90fjo5BiC6HWwP5kdzmA6+Kf/9n9BhNDiw/nZqZxaHfb7S3KIqrepfFpyi1J+np6+hs/Jg0dPnjwZ7u2Tcyh5VZIQZndV0CiInJsOoAcDKAyJHuqQi+64v+n0NuuNBke9/s3NfPTg+MWz59eXF5i8vJlFOojvcrVaLG+6dLmEvARMQ8iKHnRT5fMZ7e/OZii5Ds/DigghqNUg3XZid7p0gUyQ4E0f/oNev9vvzKez9WrR72729vcGh4cTbXk3v5lNZ9enb94ADqXDVcDGonRXy+AfSRoOqT5pnM5ucLI/imaig8zd0oJ2bRBstL7pEFSQBaDb28nBUbtxz9p1CEKfxGzOTy8gPOh1S1UwP1p1OxzN+4V/hPmdkiMKQycLZhJxVEDfwbDX68bGqR+6t2vmrNkCD1CfsvQgpdlU3u0Ouj1UxkI0wtTB7ZLg3QwJC3lCnAVjp/W98Xi/PxiwQDCnwCWBTycHB7PFzdn524vzK/Zss1iqYl0+oRf1o0Jd9C9zFhKUTG5I92ZDttbDEaMYgXUP5wVzoobhEFg4sz8eoml3M9iwR2uAk6t9urC+XbI4dFj14OkNBxzBoBc1xKgecaK4q5vbzXIwjtKjxWrTXxC9XjQ6ZCgQ6QXA2DvmJuLWiQf0ltEYUIdOZxTmNGs5GDQd3t8/YN4fPX58eHjItGj+2bMX+5PJ9Gb+/auXf/7TV7PZDbkYDkarmNuqLsx3r2L1R7Ogp21taVWKtq9WdCb3kUYIIMpmOO5N9kYYjhlMmOeqwGqZIb9cbFSfygZ9Vhx4LH1poMqXG9anT+A10R2NGK9wfjjqzVm5+JatRACrQebKImJqaLXBoQVrwAKvZCdiyIuok/GINT86OoIz+/f0yTNGaLQ3hs/e3gSz2PvDo5OL8+ne3rd0gQnrD0naan1LgfvaSMsdxrkHbqKJInCmHeSCiWFk0Yr/5YCQjF2UO9Zx0Nfo3miInXCjletepzfsr28Hm2VvWACwAWynJrgGlbrZG+8vbhFrwxihenmBTm/QI980n/D0Ov3bJQPnR7eJwpJS9Pvz6RSVUQHpgS7GqAiHCSlL/uzZs8lsXpx/xhc8f/aCHRIoeSujBtkCVhzEcL6ZL+EwuCVTSB7k74SieJAinjfSqIF0tIbZJBmIQXfTG48Gk73x4WT/0YOThw+OB5vu2ZvTy9vNanaDUSjIqqMgkDBwhCFD7nGE9KqFTzXKbPmVVK3gaBLpBlN74hoJbHa3xNUTKh+g+QgOyR+vSf6Dx48up9eb3qUMRP3o8PjRk6cQVrsaS1RX0/ni+nK6mC/wkskSH5D5OOIVKaCIYsZgp/a656madLTfaSiWw9V/fTreYw6ODw8enBw9f/Lw6ePH3dV6NZ+96rAGN8wGF6oVFiLa2+35FztZpg7Yqo4DWm1WkM2bYMVykqK98YR4yuMJGNy4Yvtefy+iQUyQBYipZR2KupEEIZiPmUdHV0o+evjIk3iF4TAYNMQWN9PXp7/73e/EgtRpuQxp4pZgvcEWtI9KV9ORDrKQsu23u13iuij/ZG//YDyiBQeTvaePHz19/BA5RJNHB4f0gkWA82J+Q3RJAKMxHI+VGvYS8PiHmURwnShHqyiFDMXbHh33doVYBD4IrktQN4mDmjkIU2O3Eu97MhBUy6qSvYPJA36x0zs4PCZHYmWmiHrHw8cox4KyiK5vXr06ffX6ZjqraIpFG+LJbTyiVO1taRF64Hk9j2QWF13UR2j7+3ujg/29o4M9GvHg8ODR8bHAcbVYHR8dPDo5ZrBmQujrq4Seqy6rJeacTPYmh5PR/gRvBn3tbnqDm+LBUv3CEteGOTXV+rCTWAvMFIQDUop+gQBpZFOnYEeGAZ/J2w0HiN2/upqen19eXU+rwLXc5Eq9aqaib968+dOf/vQv//Iv//7v/34zX6i3QmTs2PD2HSrKNW2pEPx3KbJQlVRFvFsxuTETWAK4vYqECQX818v19PL4448+fPL08duzc0EXHDCJ5z6gtMcnk8PDAeuIMf0h/K9n07cJ+a6ro1UCUtZnsphQdmTCajg3xwdHigwOTwJ/J/2uUOHqcjoe6YR0UOX07dmr16/fvj2Xr9P56mBy9N4HH37wwQdMMaNNEf7t3/7tD5/9XtQUPiSVtJfAl0neeojiPqGIDWwJIdzw0elrVAKEqImnYB2JUxLfsb7lGQ4PJoPnL2A+fy/hMS13r/RI8DIGy34vfoRx4S+j6g+uL96eXYZe6t/0yhrECuAc7SdTwGJc+8NxXEX0dMPqNJHRLMQHr1+fPnj0mF2Z3QgFluzWxdXlV19+c3l5jVHPn7/34YcfEmExkjhfUjVdhkPg6PRKzbSVTlfZ4/jIkghwJ2yBxIopqn/uPY1IxPfjREwSgQJK9XSYxWu2ZUxhxHPD4aOTBzRHJo4ptoxV63RYB2qWjiyihQrLTY/DGszmkwKGRyxX1Q1fI63pB8QjbjjP0D0G8XblAYt2K4/r4M9ffvPehx/v7x2S08Pj429fvTl9e/HyzWkINp1fTW8++/wLwabmOV4FCMCTR091gWkN2SFRJVTe3LLJcYxpJXCUJih1y5aFJAKT7hAcoUXCxc0+IeT/eh12gUTczOaIOtk7WCxuEhqmks24H6fYHY4Go6HwSLG4oA1KxexJ4cXCwEJaQ02CEFQrdfdGwE6RYSQxssi6FnyMrLIETeXDzWjwh88+//Rv/47ww0HAoQf5+s2ZogP5oj76fEtUCNSQ9HwwMPLx61//2kiBrsRvfx9/MZud40ZPDJ0oroSixk9CFCnBk6LAYSHyP1D8VZVxFFYJFQ72x8E77jBBLoM22jsAM+Jy6+JKvjv+MmIWLaE/8cdrcI5uO1NwshTIJqzSYAWfqT/84L0SUkEmHiHglOMnOFBjFtPfOzs7/5//87ebXl+8JCapKJYgK6wftEqcPujjn6hTTfqRv/jFL/77//3fPvroI1r65Mkj/VADIUiftqUyv+49AYHkWa4kIKodjkHFQ64Q8iziHonYG/GaqBArW1CKtPt5s8ey98fUYYCQqYLkpKH0fDUAq83ihjMVxcC2eAa7SC6cBXshi6pCxHKZqLBObE4RXGk3vBAijuQPf/hDABmNgAh6YYLhFuUloYUa09hmo0/x93//97/5zW9+9rOfyaOKeJ7hUAirUt48jTUuFPKNEOU0CvmQgTj6HxM3JEdZRossSAzfiDxzfx3aQqiSMtozX9xy5gIMBQXUMaEBSVSsp+SNjt033319eX5B/2FocGV5s1imZ61bEe+OoBpqclEAbGSAOcQRCBaug7cXV0cnD6+vZl9/9e1iOf/+++8Xs7nIRCahC6CRDFPee/H817/69B//8R+Jw/5ohA/GBfwTH6tqRZPjq0UpJbQhmjelDlv7EEGBSyixNvYnaNmMhn0RwrOKl06OjnSOqfTF+TURxVsG//zi+uzy6nI21zGmjgovO+uF7mbZIBBKV7PLs/NzzCV1BYrYc4XReACkxj8yTnqAxAZz70tegJrvwkUQJR+pMMijGM7I2vgjH2hgInb66IOP/u7v/u5vf/mr9z94gW9bfreOjcE+Etv4HIVIuMY3qLYIb1SUFgeBKEIMVFnptd6UCKO7L146OWJiSMNIWI/Pm/73r94sL6+vXr25mM5enp6/PjtbbjrXgnYsWeu+RUjVzrKsEkNThJgtzYEZY0PtskftIZDIVIhf3fkMOFZ3u731PPQ6OXmgyNQAy/W1gT3kwF05GLDp1TV1ff/Fe7/59ad/++kv33/x4mByUGKfztpoPNhPMJKhNA2E82zgJv1i8avaW0DNv7ljaIEmrgIhddAEhpJgGdkdYw2hUZneA5HTwcHl9fTN29ffvXzz7avXXxNPQXC3J1ZGAeMOQYDNTMSstXSIBRxhdVRym4DkiR8expSCIRFJ8SQPkuRpGQaaxPMWCGDg2dnpZG9P3xZR6ZVg4R/+4R9+/emnXCOEY8QNBwwFbam9JbKAnMpKbJCHBEDSgCf+Iih5DnF14RMDpW8NfsxvcufKY0EhEWGnO9rbf/Dw8fXNsv/m7eIm8jtkhkLidIpr2CkxophY+IcKMc3F7ab81Whab1RwAxgQlluJv5ChPQzzCk59ys2Njvtq/c13pAB2nfObG01xxLTgn//7P/3yl798/OBhxB6fqw/DI5M9QDNpBEFFTQM9BJmfomP8LmdcvTXeSxdagTgIcrxkSbnD46PDhw9PEJcxJ1FahwvDNt7fO+72zy6vwWik9OlmM2X2Q4UQMuaV+Qw3w1PuORazn65BnGG8aIS/eS3AxC4hUyll5DJYhEvytBvEGnAHaOPRYmEMm13NoBXI3n/x/J//+Z//8R/+nrCI/LSJpApEHZlpg0X6T7HA8W1eJsYpt+QVeqMLBhhEjlUgu0pQixJI1gtKfOTh/t6JHtQR4dvTxybuqr+9uZ3F8Ka/jzqZ1BFQs5TzuYhPI1HxYoYemfiznEaeaTddmrIIDaS7KxEL/CUUwPdcNvlbZs8HM8gXSTOeF2kcv3j27OOPP/77v/vbv/mbvzGrQ1i40dSRJqJp+bPpEFRdTC4nPwJLJ4M2u7AEFbiYGwE7P0RqtVqjAwYUkF6MpBONAmRB2tfPozWVzDAJ4S8urq5msxpSGRlIVMteZ9QxoLrMgI7mQusifmiBuuGx53FO5MG/hFYN7bLZ8pd/qkksAN/9axpRTIuQkPn90dAE0d//5te/+tUvnz99qhvLPiifKvB5fUuT42PDky4KYBotaDDJ02RKVfL4OREKjMc8PDBZQ+aABFNoIFClhr8hHLkM5EFJqfWNgdauPsLF1TUlFVeKq0aCvJs1Cb1lGBJ/hRMZjk0Q2eHUg3WTU8izHYV2iFUYugYBkkKb3nHRbVLLo6+SOint3v7+48cP/+bTX/3qbz998ugRZDKIok9iTPp0qgBCCG2g7caYgu6DnrhuePXfVaehVIUWgMH/g8kkVna+GQsMjAMYBfEiI4c3J8dH7714ZnzNtCA2JEQmL/pms+X1/CaKoaoSY/0C9cojbGFYhgKne35ec9Do8DYQDgli19gPv4lcXjVCEP6AFmJVF28rC1U4BWv0rgw+p22syYirJq+mU/aXDdQwtPECUVQzJ+fDhJhCBpbo2rREzWjxJtPpPPQuqyPsZ03MODKEF3E6ukx9Q6yueEX2kZvQaYsBUnOrvLPsofiMiqldPWKkjAOJAiPnakYp5DTmgxBSngTZQqmwBWHpO7zeGQj4A0zyqmFf2ZRLne5dDXYyqjGuRA7oHulQudcplQPorjSaXTPCJ65hJuTJUF51tFIZb7wzP/erZmj3DvfYAdOJ6lCRcQTOUsUPHzxAAoMmqIDo5ESVIMn0j4pNyd3qCwRDBIIA7EyXJUc8I/eFlk28Na7LHGSkALZ9bran/dq+Illqo9ZFCbfvSKDgQLPYzMgRbzzWaoYRu+Y1+mw3Y2R6CZZAFfWnlkz2dfRzD8xcz2bHhidfvuLpZr0lTcQg+ie8uyAn8wXTcMzXTTJgxUckOipgzGsQn2HGKUaGTJiOgNwNheckb3U7XywpnYEJwKLRYD3gVjg3InhLdQrV0nEcDAVTf0liQ88TpIuhrJRXfjKsCWXz8I5kbiSRx5iD8VjgeHp29t4HL/jusAfra6COQrplp+KVSy1Lag5pynB/QtJfvzn/4k9fU3dFTGugAjP7+MnTvcnRaHJE4nvrW+aQHCD3SBzf6yBgxhr6IyFYp8dNjvjq7jBTcTOuR6S0NCHYS4gWBt6SQk43ckEdbswjqIpLG1G6GqDpG/7SLyKSrBKsOFwFS/6aSJRZ4EL6EWFUcJUh6lkJ5OlK6BaqxbjTbHpjcO/o6EBdQOc4FCCNWCd/4MC+oDTgJgejieHY4wcPMxYwumYWZdifxCI8evx0cvRA1jLlt6hNJQCO6mDY9A2LjparzXy11k/Sf6dxAsNbg87rzdU1AynKCScOjg7X11MG31AN0hAWuYadcQu00yMd7MFGuyGEUdrSizIBWwwDNgsoRbE2t4ndog7kumRCiW5IIJEWYw6nBlhOTzHLTIxIRtUNeU/w3xUzEcUr8+qElgQRV3OwJvLfnl+a4iS+htf9EypeYevNam8gDF3SD7Zxb4/vM8s+2PTXby/n3cH54rYXZxnpMyJiNAY5dH7W8BVE6XsfEsL9wwQMq5Xurxse1HwU8UQC2NB/14xFiN+IA5NVQWB6LRSnhEKGok6MY5x2gqutxa3YopvxBblDj4Hx6Jvvvn355vWZEVciJ6vkOXLIgArBOuB22Q56qz8xCec51idffvk1nbegQRdhect93NwsbjmFeIUMVTFvBhNHBwLGvb3Dhdnb169Or46Pz48fnBwc7DPMar64vDK48vDx09v0gBOkSJNRXwRhOgj+eodYzH1aAmQUAeQmLxDITbsC1b2yrnjOkojY3Tcq1JM8lzwsV5K/MVj+mN9lC+BsfOHzzz//5GcfJapVl66bOLaMfLIjA7zSDMHu13iftSnmL/f2J0fD0Sp2rtefzvT3tz2WMJeP7ne4z/FKj8As4/JyurqYpbd2cDF9eH1z8sAQR8ZC5tOb/njy/sc/P3rwVB9PN/f16Rurp+bmJFarq5s56lfM3p3e6GelX9fpoHfNzBTyw3jZAFlE1HOFaabJA3z0goeqHkeUI4TIlUWr1yGVgu4vL68MPelK8mFZg1QChjoKFzlV4Rkp7DPo4iXzovP5Yjabi/c5I5DorVg+EEji1EivsrHjOGL0gyFgiK5mq6NFRi5MOa86F0hjPkOHgsEzhgu3k0f7G+NdzMn1/PuXp5aaSQkoF7en529VC5+aVD4QvopmB0R5PBhHDI3lN86DMyyGb5d2tJApUiJ83ZoMEXBkK1SIZ8byeDB4mrD66quv/vVf//X4wZF+BOujSdGLZqgAxeI15QSFWfvhYH9lwdF1bNzB0cPoT/pltI5tCwOy6GzACzBFylS3Thyttludjumq05/f3r69ut4/v2RlHj56YEkJXLhnhBiOD07GBwbh1xWnZrFPb4jthp4kxAobOPLFylqSqKclToMxemorYMIdqXBbiBEpKB3h6ZMSx5fSIA6kN81RB38OyTXKeXFhDuq3v33GRlJXmiaYk7WoYd3VFUKQArrz1TfffvbZ5yzC5UV6wdRKDd6qih6oVOvV+wkV8qJUMq3wq0AFyBWCrk1Yc3JmmbI8YZwuJt8kIQUz8d4HH+uzHD94/PL1K1R48PixMfvpfIZ5EpwODib4bQw82CZ+L5TBYjQj8EQeWo8rvzJEEk7R6PykI4nuM6qbNWtGnEO8CHX3anr9+99/9uTJMxM2bDgvV8FVT2T13cvTt2/NBZ1/8813f/zjF99/9yrDm4QxNUagCAKQwgoK2hV01ugCyVBFBhnSyXZHsXVn48NMmnn3snM02Y8IDMcPTzJRTCXVVayD3dC4y/7hEXe4f3Q8vTRPYkUjbQtKf/vrT81nnl2csUbGrBUheF5VhBK2B7aKD4ajrMIEQF/MTARiSjWS8ZGouqF68IVE8b0DDfzxj3/85JOf/fzN2Wq5WRxEV70SUPzut3/87ruX/mW53cV1TAwPnkFqVKBvIUQEMsqpjTIRASE1Z1xBwBMnJU9dk62ruXOzfrqHAtbRweXjue62+Fol2mVEkQ6grI2FpyfdvtnTSc2kCXNoRyRcXNUfLtvsXPXDtJC4MhhHXngqjbvRFwmvwREBiQeBdYyKR/wlTHgA99o24kL2zNP927/9T4s9wQSU69nNV19984fff04iptcmMyyNMvORMX9xAWeiIB6UULiQhWhJRtfi0RO05Vk6x6ERM1EtBj1CakC8e5N7M2/d/nixWmsO0J5IasuV5GSUg7sQ3BDBEJ97EqpzorFtNX9rZFbDmdFiFRPjZL6IAdgCgC8FHBj8pQacxG45lNHrmxsjDIBTe6awe0MKL4yjES9evE9jr6azb7+1pumsQofwDUFTN01siIWCQdSvRs0gq8ZQAWCR/EBQmaMJlSpnUx/USSTC7PN/JFROsqChQBwXFh4KdGFv4UarxxwfDfWEcuBueg+ZqQSeeQ1DbYQh8tBexRjGSkI9SQ0IbYx68MknH5lcqqWZMarpdQC705uw0HuHwH7z5u3L78+MgPASENaYt5JmK2eqC0Vi7sLzQi2X/EhLSLV9Dn1Ve1h5cvVezamCLREMRWOW/bkVCxmH8JQIlEYUyTLKIkvJQI2mkA7MQ9yqoSrUZ0sR9igaQS1CkjiKYBe0Q02mSGNREDAYMB6YbhKcEMiodLRaX4DmuLFCVYQS+PzM0PFtZBiLwo/qtKCx1+4Lq9S4Sw2g/Cr4chMwYjgjDn5GhOK9Wv2eBEJtAYCZoKGu3qGv1JiWUikaQsAcRNCoqCSr1RSR3NDf/slR4sHUidv+VPv5zQgm9mm/240ig/fe++BnP/uFxWrT2TetmFlc+mhhRQKEmkMALmpnknxp+tDDyD2PnU4QoFo3DliFiiuVd20pchA2QD6ZgVUjQ7lVJUSa9AAFgTzFSWqPsjEE6egrFZwNi2pT8VAhZrgE0nxelkvqfdKTNftgCpKjXa32DYEiUawCKmRdQEhepdHOj/AvzK2U1cSmHkWpzL5i4ZD6BcKWQ8SYZ/ElcN17ATKRWghcMWWrAogRhwx3B0nX4lh7mWvEHP8STATZlgEBCxs08UITHkdLm5SlWDURnpfAiJIUlwFwBb03MQQGZoxIp96qosYuV2b4rE5DwnA/RkEdkWF/qoYmodsiwBo8evSA4jGEX3/5jUgAtEGloungllmS0vB4j6TwLv9RnAhEq7cAShuZf9ulRhEW2IOEC/zxHXmisUEueVnYdkOHK1THUGWbeKdYOIqbDZWySqFXXFLeRmOF89EwRv16TbsXoqzhjVGcLJzwRnFNZ9wegPqUqGchZJxIyQJPR6KMiNuecfrm7e8/++zN6/OqnY8pghWEqBJwi9UKooX7e9dCpjI0nCMXTGJmJAFdqGt3+67kRYkCoNVzVx5YQWyX3IfwmW0RU0Nb49tiHsscdiWu3RVIdTrm6fVbnm3B1H5nP/6A9DQh8rpnoISnaMVTUvH0rCnSRx9/bCTVbPHUKqnsAyjnD1tSG3ErkxYzKYEysLlr13roknzb+1CKCKQ4SN/l3EpAdKPVU9q6LdSKlyfbkRizCWfVwfjI1zfjL8yLLJZpLIV3G4KwOLLWcBPHMev3Jjf760ysFtjRI1xJv+qOA1QsxcSOqqbtDx+dcJmvM8pyfnp2WRZBSykf4PyXVNWV58/DeylV/eBJQ35bw13GbR5/ykvVz8DxLkMEJ7p396SATOu45SGquELVE3KOwQHOk0oJDGMs47aYWKpBiMrK5rVs8jcbrXiVqIIoEBOQJflDw/Cffvrp2zN7ZT5HC+EZG4nwCjewSIT7n0qR3NbMT729V0NBzOrJDIwCpWxCWexWg7pKTFpNMIx3hT0/4RH6BPpUkCQz+Mtcpk9gTwUqqJYrlRnh0EKnTM5WXagWEkchPCkzy8RYhq9MNaz38t57L37xNz87PX1rwZIIQscmbk34WUKhrqqiVZhr+/kXD+9e//j5Hd9a2XcZivl+VhPNHW6r8dBLEMbRFNoQcwOfuIBIR1KYHFT9zaCGjqJ7m8TcpwISxk5RHO4ypmprS6pIYAm3i5zJUYR47/0X33/xxz8tZglFJOtO1KgANmxB+xH+slG5u7fbm7KjWzXaFUmb5VNJRGlaMNFEagiIFbhVTWl7S50id4APG2J1BQAmv1qbGROJQCWz4QxzCxnQSYUhQRxTRiKxMjMd1c8L8i1wqlKazPBee6iU/qUFOx99/MGT3z0y11TeqUi4Q1/VIUel+zjXw0hsGriX8vzeT+Xq17tn7cndczCgUti1KZa23BiRVLpQrVe8kJ9MXXJv4fEgKbslhMXlxP0KIQoo8sDe8Y8whrW6K7QP+TJDR5esBtGrpGK6X6ZSzCS/Hp8aaKZaogltccd6jTJHrMK0hm0wbzjEBZPPLZ4F/vayxXmH6jZXUJAqXoRz5U1tEkwyv+NV2UJoaJ7PUZFXQUBbkfIax+A4Ci+vAI/teK8882jBEPWxo1K5xJH+aTQuR3NhpwJqFherM9KusGvBANrck4usEC3GQ769LUwbxJV3R4Ltj//vf4ooIJD+orIowC5xAulYZcun7Y7w0T0CfKaIa8C8tAzEFCeyExwQQmk3eXwvNfQz84VyCRn9J37HfZtJE2KnMAvkSr34G3xWPDnfJVU32nn0rrF373P3Tl5+/DxiJd2TiILYJWlXNR5gbgx11AVKpMOw42oR51FRoCr4uvBaDG5WRI5M9kTmm9iH282CahDZ8LNogTJZW9D4LAf0SURGNrM5MOPg5VuJDJucYajMC0VeGhV+IBEQAfTdNYilrWDRnteDH1x2z1Oq5WyvE2Heo/MPqwWwSpGVtlvSobNDJiyAM7tHU403RU9ME1akBMKyGAnhSce2oVDgh0m7ZmsTlCGhsVsKlgUH19PLt+fXF5eTo+NWjfCE/BVvSpkD71aHG+h3V23s0PPsLvP9h9u8P8B8K/9N9ZPhrhI3xK9kINCD0FuEEORkWYh+un4BdosbIgoRnzEyHNhhNrC2OiTDwExtmbYSU4xiFWJZlJG56IF++N9a9aANFxhOs4tb4GX0UyWNMQWWJiDfpKA9DrdbUryB7mb3LI2o4w6lu+dudg+3LPqpV/ef5V5tLTUIYh1rz01BSTQoLwwhb09edmaWDSAP9DyeEfLRK3Ohle5qV2f6ESFWlq1kFJRdmF1PSYSBcCUSPu4mc8KDwLKVgqCxte2twrzdMrUeFLlzp+YdzvXiv7o0SgfhKosPubVjUC8gkT8+uGSJUNhktIUR02eKjgAWw/OgdR/KV4SRCf2MTd6YgGnBQUFbBYCT4WYg8ijcjIUk9ilJKrOXSb+qNyZUneXGZMZQZc3xKvYjEmx5e58K95H9awnxF2XzM1RJAptAhvU3GOIasxUXqKedRQ6j7F5OdGTmVxGjeJml66yXvfRELL057h1boqES6a4VmyuyEkfCeVLk+ub1a+Ighw56JrPpXC9GNKKU0ZfSoOLHfQ6z4vdSGmjOpHVf/ITA/fy7zJGsH9Bu5988LTC3Lz2WUSVIILyBJumGSPoPDPdSdLg22Niz5MQ6sAyTxrXK3t8MV8a+LC8bZBkZY6DTHLGqzXkBw/iC+b8GnAag6qdxCdOP4337jphfQmApdWYlK1X/Vu20ITL1nydYbNXnP8/3H729TzV8QsZGW/QhoiURfHlCm1o01VsvLLub2VICSvPHOLpe9C319j6yIfSqsFpV7vOzxEG9A/Og7RH+c49sqTV4/tlQnlGGzKGgiu4HlYhJQOGtXlRMC4EmBTHju8Qu5/nu51/7N8hXZa0G7Kka1JkbIYzlktnJwLFhqdlJnLIQdzgiHkavbZcwV1N+w14rW20yYFTg0aCQMfKdMChtpHLjC20k2wpUQ99vpq/NPqKFbtXrs1ML6g1Z6YRG90xuxb5k7sGQqQooxn8kEe8o9dcSYJe/gbglxhZWv9h6+8D2s1Tm5ND6QbqABrC0pPzk8Gi4P5rNb7797uXsq69tKjfVPMkKoiDKV9rMILfpDSKwrX+nihnt14/eHD8kESLHs7M3b05f2UahePlYC7t0QITlN+Si4NluQkJFlTRB2AG/o0umQ8hDU4fGybss/9VNbH/6CHf5NKGK4FKcs6vSsnlL5Bhu+zJqd+7AFixbLfi1q+n8+upy325zg27dPUuqLFK2+WmwN0l/MxsLFyM+Jt7GHBbXEw9kedLMSS+H4+zTtPHGHJTJKJqDOhwH3luwZvckQaKLw+5Q/xRQOm3wjJ38UfqPBORHGX/6QePSj95VF4hmlsVEf80Tb36c+UeeDBZtLM3tPnt8ghamJE7P3lqIR9LPrSqPyvTkYxZ40VZ54oCQNU5n8Pkfv4C/7aqu4gxPnj9/enm5F3pVl/Z6Oj87u7DujL01q13djpT+C3BDm3CseNgsZx781UnNKfNOFLY1aM4L1yzAMnU/n/UthrJi3JIx8g5dm28sRxz1Hx5PBsNnIkjaaxUCey+wpBgRJ+rTT0DRdCSbdmtXVdbEa4eumDE27rY/thJ4HwkYIQ7WmvRHjzoH+4evT0/tKqJcKMlf7RRqC+KP/9xFFj9+9b/3pFEBjfAQyk6uGff2s3JY7MR/EZIIIY+4tJTOhJLwmYNbZIO+BdQ1PcNO7o08xGq1laQnzIKpqCkLivyQ2kAlKEkUp0OKdEz4SDb55sAOaLt15lGI6GjcauxCbtPXalLQJCI9tko42jRcq/eRD0qN5/efbssUz1tx1SXbu7Isf6ar53PqLb5hedK1SBcCQLfpWRR0/MXByJJVu+e6jq1wFgj8+3uHo8mB5TV1FFVHp7Gt8nXGRHarZMOSfgYzaGKOULmxUjPzVBmuCIFjSKydzd5/Lkc4hAPgy7xdielfwLpF5x6GDec7WrSf997/9O29bMjabG06RwkE/Cv/j86qlfKznoAQmHGjXat8LD62Gm7eXwwmIqakqJVuswUhCOFe9DxAXRPRHGKsZcJNQUh6AI47YRsl3jXzx21FSi12L+uQRQIRrYK/VLnxP7DuePcO9IblPax+Gu2UrcLbev8il0lDHCcO4rmsY4G1/DgSChGDUAectuL3Y90BznpaNGuTeO9mwTrY+5c42ODMfGYBiOppgCs7muMVWI10yzs9myIty0RAkWgxe5moPAeOZE9johRWWeym5ZCg6UF69SosduVO0cLFvX87mnhxL91RBDfuPf7p28oTbkfubRXJGo6Msq87WaDPHvjfW1uuY+0MUkPWbvNsrLBdeUaDIMgbYr3Vt5m8YSgpQO3pVJh9iamAjSEE3jQSLsDMAF1QiOMmJTAxWergq+hfhZC6LA1pfkSfFq5ArFQUyeU/Ry6A79L9+x+XS7hA6jPlEepqh6mKE2cUM3rQiT2oWTwkgDZfRpstR3CuyNnbN27Qh0E3U7Oeza22Fm5yJZ3Ofi0E6yDo4GF2EhrxzaCvOMn0JnJrjFZphBPKgvwE0bELvA0CpspsXkC1mIiSAXKzxSkL9RFIPU0i3iG7Q/p/428xR+gLVNofRZXKChggA4YVUwOrUDt18Bx69QZWHBkmOT97O7u6RKlgYK19tvjphscPmOnOki1damHHzz75OLJkOa2NsvPlenGzcQIazA09ZT2WG6YhA5I0MGvelRYtYYczp6KMOq+oshUECAJhh+Z/LRG7nO/+Novwk6QDAAQRn503Pn5nF7K8h/rTlZrXyPaf2lInSDg8PLDE/5bE7++v+2Pm0jw/mvCHoeOVs3qmODmwadrQ3cJE7dXl7XQ+vbyYX2V4xpJNGDWYUInkRUsy1JkrnqQWsXnmusxgpZfWQCdHHjUj8Q65H939UAvevUa5nzSN8ktaQXEprVeycSrPIw4W3WY1dDSC+dp0BcFHtqYdHppush/vhlUf7TluwYJqRbJ6qncq/AL4wArtxXzNJAoevHQVPt0IS0MBqGZIOoZY45vbdmSTUyAoYL8rAoXvQL0aZkXqyhyUL1LE26jVOwzv392PvsF0ZyzlQYj7he6IAnnNNBIowjJE78qRx8jX0Av4mX2QHEwwv/v0vReTBycGCOaO5bNFuTdcXE91Q6xVur6evXzpFMlLq3YG1vtGKhZLiuD0GZsZrbpDEocuaAlMrhp2owFb/rRn+i89NegSQoYicIvpoFLUSoktFnc39/H/i/uWx3VLCBW7R8pdiqGt1B4UZUsSYx4BtyU6GOI3kwhDNN/0o+Wrl8Jtpw1k6+PqyjZzkDpRcm4tYQKnOA6bYb/485cO00MF/S3kHMVDUPguiWhU55EaFdAYIURZBmvcgEbiNaUdwPn7X3qH+5l/fP8XtclQDI+kJUXkejTRHpWb/SxjsoCVUfKvpmAyGZn1a7c9IwPLzfrt1cWNhd6j8Y2tF6zCwXEn27n2LG6+uLJjN+vyX52eDpwtaXxFOD7JTtYeQoz7g4Ps8DEFbml1pmlQIRvHamkAGluax2WSBrRgDEKG0spyoSTjr06F3V+WunuY6smGHlBGSVA89sDwKMBIQ9bcY7WBBnOTpCahVOaqbam4nE2ZvyvjT5v1wcmj588e7x89sAPIIkprFV69+vLly9disG++/i5j0NiLCgzig8OjD54/U5mTfyI7cU3onlkequB4HIcd1SxY1gFRCoZBKVoYa5MExq0S/SVOP/69E/k7bNvN9nH98USl2+fp+FScyPBVmJAerMM9jTBmybPAbxlKSToUfXs3FroJ16uZw50+/uCDZ+87aejQKMPzjz6xfv3/+dd/+x//4384e4laE4escEI+XKUCin02nRGHmtdNQEnzVCsPEdDdPDywVH9AYWwcKSOU8XtlhZMIUS4zBvP/j6S5RCBkIt4fe5Deju2V3jB5rRg2KxkNvfFjINYzftjr/vrj3zx+/sw2i5Fhp/EBKsxn8y//9BUNOHv9BjUhSODDVQJWKBE5z/3jIR1Fmp6Cn0wNcnilJWsdrK1lM+bjjNz3O6tSAPhvE6IQh4q4fmgtdhnu/m598I5kCt69uruJdCWpD/6EIrzGowQz5J41d35hDgaJ82C+MDTrxyMyMZ/2PX340YeTkyOugS/P0vf+4Jtvv/3sd7837iCDStJzMECbVjIoJ9QwCpUxPM5Au+yCTOBAIIKgjHtPEkOnAxpLGdrFMDTTnJoCd9ns/PhrkoKNEO2aekoGq44QSIQQcWC8Iw9ueISsR9CzCm+qafwLzBCWEgkaHzrTqejYf+eEE0Nlg/GfPv/i97/93emFJfj7BEcMRq51sJZOS9OtRgIrq9uKddWItZmMhj8g7gihR2GdsZ+aBhkLbvVQjhG6z8vS50Jge2lYtR/32Y5Bdz/D71qE4kkhfPcKziTBITFbd4EP+B9PYQTM4N8YvNmOQo5xRqBT0p1H39nH8sXnBMEM041hw97g33/3R9sr5FgJQU3HZQdTZ8CILmZTB3yOR9k6S+BTzXpteBMhHUQKAjDRwIhQTn8Fa3qWIQSeIGZZbZC5+V9JKHKH+Y/z371qN3UNdeqGoioLqUwOkf6KafUdjUEDKeCovEjA2WXr/9n5m6+/+ebNxcXbCycSoVV/ltOnHIF9sNJLX29EQI6bGLw9e2OprH0B1oyyf3sH+6hm6M2OeiO8MQcEEKYhdZP86IV7bQpkWRLwYWOI8aP0HyH8Hz1XQbMX8A6xGYTIWFHBqGAWx/nBRVvzqA6nIDr407wZzA0BRRnBFoPHta/7wqUrexMd8n01NbBs6MTQG7+Zza/WhoayA1kj8j3jEukY5QxpXan0plYi5T0beTVeC8JDXfViPigROF2HCiVdQRlyJFz2S/KngL7n5NqL//L6H5GmCKFSTVTfLVyhI+k0EVDroG1exKMYMVnLwIGJ8ab2jgt8cHwCC93HqWG61dp6pWkNPDgJkyG1Aw9ugw/efyGc9u7Rw5Ob65uAkr1UzHGJQHovwa9AiV7ocxv2RhFHVkgL86DlWnRPK0/T7vj5tiEDbf9z/Bvyd9fWlp9uXIJXlQcQ6qs3vEkmr4yGZXc6QOQPp3hJolsJ2/y15xQJxuNL/QVbf0nvjUnKyHE/s4/OYef+YHxyMDnt3IqyzpD1ZoGETv91FiTjr1qQqEshzSCB3vg+jatT4TyUCsJGo3b77qpgQ+bdox/etbd32fx0L8u9Uq2G3XOYI4kAIe4sWwZKSBVq65e2ChsbKoSuno7IocbQcjaaYVuhQUaUSBXJIT6Ww9nyb7jgwdHhJx99aKNqzlA7mCAP3BWo83oTTJWAl75pc6oOkzPo27ZdxyTV3HFkMmjs8Gz45FqsdHMPt22mlmdX4if+3tHFu8ZbdsOt55I/gteMfsSLx4TEizJgceeZeQCb/7Pwi1CtczwMihiCZSD9LrEKpzMmYy+nIUvGIWZDOB4XXH3v9LKzdpbiSIVGDrEnR6Y+HEhEHZgPOmaABkxkFAUbGcDid7NzRYSfwPB//ZGmq/U77Uh4kDHjGLeNzccmZJxfmfPWEv7QItBaiLCcCBmHOUiJ2EO3SBchwBF8tKdVDXlFwSHhCDEUHQ54kmze0l1brK90sTb9rGgwYYG6BKRIjkDZ1JyoudbN0xG7WLp2CkdYd/8Hlp3B1O8MM6Li9zFP1h+lcDirVZIzl4rH/PXE1AkYsL8eN3I7m9zss2MoZ6hwMM4mnvwXeV8ZEqPxgju9RG1BTdlEoQEzshC7wfWbYbD+17YSkmP45MWLR/uTY4O7hh9ECn/8w+fpqChEqu7ArQ00xjPta4y21Aa3eEsSGRbE8DRj2JB8pyF3NfyVN2FgWBAQ3CKB+llHIpmwyS/KazohTIpqZFwUHTMqz/yNa0VSLGZGAoyELOukTMwWNSXkY2LseBY11XlNw1HnyGkSD57YOr6/j9u945O305mxtwQK0T3awznkFIGV+QxnItiMrjNawpLxmBiIXdqJQXiYV2HF7t1/9TeOoExRu6Zfg2sgaAMajZupsP4XQXqFOlvx8Tepggaavc70dMxjpifI642O+I3Az2reoYk2OGVGPgeTm6CMC+CJsmnM7P7BZHRzuHr27PmbN2IM6zqyyr4hydGCyRCNSOOgBl0iDjlhtMZCKraPDys07uMLssD916SWP/OPyhItIlcWMHpX3SlCkh3gtTAPYBLHrwVGgaDAXEFgp39sk5kZVx1N8jtK7ETn6XScfhlRTp5gOzTA9IZ+NLJ1Tdcer7sn1zNnMZsWNY0hj5kQYhCT14wz71xmk14UHaMU93G8+/HX4g/tqPYuBf9IUgRN/6msRpR6S9PqZEI/px+MrODOaSmYn34OsHV/sTXzR5EF/c7RpHd0/MQA5KvXb23cNIRirMbalIGgKgdv951RoyUSoZwww+EYR9ArgwSMdGU1LF9CJCsaZjN6YTyimczAxI2roBC4h8UOm7/y7xbJoJ71rJQqdnObKElAwpJ4TQMOUdn4f8a+lkSHXGAIg8S1SFd7dH1jgTl7+PTps+H45Pj8+5y+cm1Xap2OkKM2JrVpnj7sldQJDUd1xsOJ4zAyJRjjh0Xxl+CCeTaimvwVnNfyt9Aoghq25VJ/E7xEeHJtWLVre56nP5UyqKaOKhtrGD4UTtGzSHhZv3ofb0lWzCETmEytZc4KqDHXXH5MlYTjwNNpzuTcvnNKRw+fPjuYnPRMaq++vb3IkjejLDGk2o0h5jRYU6cPjXr7e5PHDx77wghFMNUHf5Vxk+oFpRsm2CJRSwUabjDKTRDYmgA/i2pbXO+y/RTu757dZaubjGyrOOoWE5CmUykscSMkSgRobaoDYK9nHWeEOUdKNiOyOa8n2yC5kvgOUqNcrGB9q0E1TDuj5vhAQzU6VQHalD33wk1m2LVv9MkKOaeQGWE7mE4PSAErEPEqR6B8CO/UwvRegVG0R8doRMAruQgjpe0wVGRoS52GsUbdNDLFp9RPT9S1pV2Kuw91y9JlcBV+0fR2nGIMRUZbyb6rMWFj0iYdHc3hXi9LLGMtRyK9GhzVAh2BeaIJBtCAyq7TYVfpYyJKBUANJePvUaV8eiCHVk/2EWKqB+tsfNywqm5oYgdgeqkBb5simEnp3xPgUoIg61H+7NJf/NxiW2+35FCFMLjcXsuc+6hjDD2jjgQBPeaJR4gw8JRGT2C3Gaeikp3E9+ZsbPfRFfD5F07N+GFUlnXJB5l6vh72ZDBy2o08L1+fOg/8gaNAVEybrBS0fIEpEajJTrL29vaPjx6YFWQLqYbj4XOSG3WEXQL2xF5MQqqPTkWHtUYO8yfKgVj16IeC0PAM1JXiB9pNSkQG7nqifrD0rBXsvcrIITJkkMXe4sxPcwSGfLyNvKbHJBF8vM5XgDx0SLKlWZlJKt3lctWknsPR+NHjB8evDx0hPEBGYaiwKpM1N4tR9t8Mx85Ui8o5oN5B/YK01eHVFVjn8ykX5KTzmqKMvrWh5zKOAElglxSabKU9IVP82fZnvS5cI/pb29kebq9R/LLRjRxBPuMq6oAuIpgCINjOH1pA3ioGG51Qh1jU1pnObc4xCX+6nWmmoBemp6oTALYCoyKohBH5PolTTceiiYGcvI1/WLxkCxFkkOPrMpXvfdrN8VlcBjrTMbKXQZUCMRIgFYZYhDo4B2QPtig1TO5+7tBtgVXy7TLu3uRJ+JvxjXjCmCIpHI9K68Zlbsm4s2+y5VNM3evLhJdyI4yHfIP+sWPT49tjzXgAw0bNm2gvEahJFSEFaJ1fzPCp0KcC2gfkMFZdQq7bseU8uB31ZpAy0qcPbln0nrNfrq+zD2HdzvrVPWe8qSn5zYgw0HVhIg5lzBtiMe/3UmEe1D2NiN97mT5OHhbSJS46fTXWHbtMSa1OZ9adVeaINGrBvS90JH1NZH4Nklg64o4K+VBZ95YVwVeTV2aWWQVKKvSo74hpllhxruR64hsePop3bZlLRqyyuUDETTTidXVO0BD+IR6z7FB40xwWuh2trnyFRVt237UtqbECbFpGYcPAMueeEMuyCO7uiOAhQJsckQ83YGk/S6RcBGYhTuEf5fQzKxolJwAihC+K9A2hW+FHwvtZ4bheXfe7vrmQ9RcYGXQZgNLZGhaiDgbVojOENP8iMWkpxg070aIXjSBwDG6aZ3RWOQQDkWJ6uCGqnhA+SsBMxEpV0n9XW1iU6mCvypAjCkGPkrZ+Uc13VIgMyBVYwADVKpmsIVjzrJQwSCQGdGJ8bKHBYbrgY0x1jToc6v5UFNvVGR70rof9i7e906nNLct0DPSmIMVNiGhsgKrRc2XToMP/owAOlewPEgMWROKu7CNIo5TLQ8Nq+ZgAnUJUEEBBBiaQ9SAluhgExT9Hk6LUHgs0X9DAOr4DpUotQo/yF9ALt6OTgHNfLKBCIRdq1FqhcMVbNbixLc4J2wZv3OsgO5GIDpN/EYqE6JDx1kdY6jMsOjibm/n01FfAlqvZxRlIcp7+yiwMRQEOuzfe9Cyw6PhCQ0Sdz7p1Dq0jx4J3pGDAa+5V1LRVZE2H1W2eAVMxEVqkgMp4E3aBeJfck9+MXibSQUL548C1JG35L3/t5omnEAHiBYlTzgoj832iD/TQiD1wxn/8FrHSvH0H6eH/di0mtPct9B7tW4+JCsjhKCdWDVGIvGUHB7Z+kmBLFa4ugnyCF2v4x6E+XTDJJgAoA8NxeCVBk0eFG8qk3fRDwAqBjfAj62DtyItTQqsMv5LfWszENGWTbTYs17rTLKW2UN40f1ZkE+oc1an5oF9UeGcOPODdPNeQV6QCs9BF66xbNJPkOycSspLFNbQ9lit+AYW162Mb4jfWwFM/eW9UYJymJo75un5v/mR2+uqVT0loIm6y1BCZ5NeiTjcRUFulfA1SxBAVjEEDVY6xpvwkK2rv0CYlVaEwicz4BaZ6RDOdKXlwOIj4618zIkmmsggzwIi4npmsKoEt3U4bqkUgzLkNcSX3mtPTJ+cWRDCBhSk6BNyaJgqx0np8DwlUxZrTM9g22Jietm3SOgUr1Zab2xsz1qZRMpNi/YnvNhEhG0UwlUMoAU4XMX1qQeWlahn4uIOMIS64CJi5D6BmOjE8zaUg1juvaiQa5xI8ibMkQyUOlEofizNhk8l9GSsjMvnYDBHlRMz7wcU/tGfaonUxLIazgZvxS9nghi0l18EcZM1HyC2lXOQ5+Luml4D+RoMwFuC8/8jOBIMklrPlVAp50qHIFEnGok3A2EBjDBKh8Ult+KQB1FdNMkdN0yh4ooFIHCpHLjWRAq5ycKu0RYue5CElieUunwfMAZlfRKWHgz1fh6O68t84yk48h94694xAG+1JcR4LLbCJBCbwy9Cf6DwdlkyI1ocuiAOoWk554BPrHyMSSug78ohZj87Ym5e16sg00GpuAk1lbAxvgyBG1jhqK0wkvYFUXnohB7xCYFOQS12GKYpQuTzZfSCRXkdA1IHqzi2DAFKggvVOIqhYgSz2QwNSVlgpmtMN8oU8OOuR9w87i/6cnhkDx0pPi3Sxf+EmAGGFjjGLFqjGUkS0MhvsoGP8q9XmQZkgYgvfleYS44SRaMgjsznxfaEidtBHSKsjMheDvYgwG/hZ+p6dtfuXl70V4bNRholNloSJJDFLk/KZzFQPDA3CX5XQNATfZCHPiR9NJrG2VLrWmb/BJcIQWYrYwpVqiEcztmH1/N44GxDnCwJHkOBQ5lHYFgCCTnayZsAb4Wh8+oHFHDbVjTXdGUyspAl1aiF/q//HaMSXmFpldQSjAuE4QtEdwtr9hQzp1qFIDDy2DfIZM+JghoI42+nTo0Faz5KMTK9qsT4WFk7nPgu1xsICHieTtkGRCoUOPQumIKD7KN+WneFhtEgGJam/gD3dG5N8AprNWlhihBtvU0UCrUSyKhFcyoMFnsOQjaStTIW6dP2TgchHOmqEQlnllI2gceZxPBV8ZiCDDsqvHBi13FCSn1gQBLAK/REQCYQW17ORJV/UCK15MYhQBJ9YxRKJn+EZcjqqCm996mqydM6XH8gvoRqiWyDvXtUIpowqYFAQZhpGu2bPIxOMSDQlJGPnLeXgcYJPAI9n2AaDmU9vFEwlKCmbv+Qk7A3TPSxJCznyPxFRZxhQkZtnSVFKFYX+4ZDpFRLJqUVYohFeo4jOHimQnZyrBAp6U8DHPM15ay0TfghAsmRPLOqFv1RGC/CWKVltIHCzPS4zeq0BEAX8yEKuMjgjq+2dCI0wP0MbMS65QARnCqNUnPvAKFySp1KUpXxBZC332+HMor4WFCDDTRILMJVArAm2IqrM/yFCTAQimCLh7ml+vmeRyYLmqtOzak2GUgaHTN+TK2t70NEpypnRU4nRlPLMYAYNSiBOzMko3/pTcZAMG9I0BYxUJx4gsRHa+gfDkMc9sGO1oRHhiS3BURh6rAr9OwY0GVv2FPMwDWi8/UgB6lJ56l1ssldEyzW9HMl8UiiVV9WoCmOadJlqjjXCJaXC0Cvwu4lMlF1Qe6Yzbbmd39QnGtNViq0TzdPLDN4mMFlaD2lcQRloqzfcIn9IoLZyBEihFlWDg44HHKbcrJVNKvKVU0YFuhcKRJ5KnAO02yJSxGaLRmqDaiEYciiOEKml8AdhwIuoCkxKHACDF3kSuBuPQIQwPAulDQ+NF6Z/RBiie02UKoI0aKzfMbu+Us5mmM4mXjN9hsSIvuGxWeo59pe3piU0ZltWDHzYWkEWRQBX7FrNWgYFv1m9pthwCyL0vP6CD6D5PxwpJIN9lkDBIBhTokToEYcUi6y0FFlIgfamhKfkNEKhytQKPP9HiKJNTiXKmvAQBSIlgblvcuJ9TTLLmYUpriiMWxwEirGfVoD4dANjQFaIE8aXqyQ3qTQfN7eDICwNJQIhQgTFWDV+Vv1N+AKKJhMOJE9BjxYNwxSgJZGHAjrK3mojDrK7b3LOk5UhwFzYqAUeasYJV5ITdwLz2BPHEImkZUgMRm2zkC+S4X8xRTrWPsxGP7L8rI60Jdcq5ATpP7uoCtsDeZ18NX2jrylKXiWoNr3FVSO0gUXlI3PdzmT/oGhcZ8dFcD0DOvfnyyZkCV4W2udsRXFJ1jrZmBDmIzIJCRrFLE4Ptn74GTeHplqvn7mJPoTPyV/rZ91GiPNHCkO0mms0wHPY1sQ0vDyLzuoKcDcRzeqHlqXLvAnRi8JWzFLRjha04cMmIUSNoew5udcIjADf7qJIf7hi3Nbm85lGSYSf8TfkrQDimpCgwgpi5RugGZmKUJGCHDLZosAgTkgSOoCgHcQN7EKyMMG0SKYWQ4hKEEZSNcfwxyQLK8hJCFokLQ/EbPlKR6U04ZzgWKVa3mc+TW2RhYgEzAVRkQUy4/NE5UqLtOlxiSk0QTpWvZvpdWIHXQ+1ZjV44GBLIovitHINlLpSmmxsKYHEGO6UM8lDYuAg3qhkvCyalwyBTqEAlKgtLlW1JRo7HOpVqr3Dyk2ji2sKh4CeyfIuT4bMKnlI5qpRjiOfaFImSlegxN8bpSaf9Tmk7CVC4uqLYI+wQXTAXV7MfdTeN3L2Dvcn2kvPWr5oAxSRspIXAUFAXY8jxxGWIhVg0gcQNKfvFEtopCJyQSCyNqTYzDBExrOFB2t2yFHlQiQX7VQTuYjPmjNLMzEyhCFqHwdWeXPJwwQISUaAMwyXWebUA776rw1UtI4DiaYvpPwH1ESrtJCDfUzqWQR7WaN5iefVnm5LYn6Rdo5LFW+DM2RI+xG/pET04ax88ti1puPvaE0aWSaQnJVqZwGhQtFt2ciCJsCaauva8HetuhPbTHNCVBYK4aRQRlOV0UBW9nryVWpo3ArNQBUDzb9lxKXGGQXRzcnmuUQMfYaUaUEcOpEZJo9AnwixaxjCHCa6i6C0C6rWm0KgMF0DrsH3LtGz1EXukNzaiEhN6WzshsgNi267c2YFl/I1LjM8xLkWfhBTqBoLh4CaGyGqt1/0rVYaLVqGhpWBo7RYS1cIFPyVbVdAtUrgqR755ZSKnGSPanhvDWjMNDsvCKohsy3U6knHLOTIYs8s3FquHEe/MZbX4IO6CqQiZcRM7VtSxOps26OPeUxfUsCszdDSDyOczMvagoiMFMS2K67a0tYgyCCjSz3JPgtN3BFZTvgo4qFXUpZh0KeSoDibYkzLH6hIaeEvP1jzFpnibGJS1SO1zAjnK0eU1nRrqU28XOqPOdO7Xflm2HUbRmVIGtqojITJZICqUpqhmFlJWwqSkCkihuJCtZBUrIPu4qjx7R6yz5aOOmJn0FvCvp1CRr7AhBBcj1dIfY8KOQO9pRjTGHCWHBkSG6TBECgsiR4Uk4xWZwaeQqkYTOKbCjrcVgIioFJBuhQMmO/ZZISiqEM8LWkaONuURt9Or2dvh2f5KqSkRm2EvQxSEcIYnnHENFZUcm1wAMbwEuqUgUjr0RMjaQZdruf94QwtvcvAX3weRdD21ihEqrOwjLnamlB14i7i0FCUR3dn3+vwIzy7WC029gIQIUI7DxsFIby73ZKUYUB4lCsBorWRR1AkNMjizAyCtbZQplXlp+Uob8fnoQL44gAynxP4GiEymooJiTxjbMCRTJvEZOkjMUrUcZPvJ/Ghvu7DEoraTaYKo6GDSzqnKix5jxy5LylIsJCfdcWFOJZbH6TKxHuzVekTpA9ND3eaGPyDbcIBlxg5j4K0IENcED8fnUiKTJvF6xzMfb/lNmdypa3IVMmgAVHjpHPRKO1d+5b561NeLuFK0p3nh7aoQ+87YcAw/Q38VldRPyNOZULJY8J/VDCbadJMeIqFgYS9MByU0TCcw58Ap7AmyAbyuy9oS5zLT0OpZdBQMjQSQyvcrVpSUwq1sqjmRmckFNGPxZ34qe1bUJuFPTw6Ics2W9/4XnqogKiGlnP2X/Anxo7o6/hCqVU5t8YRPY3XxxJjUSFHNQh5BFJjSUF6bMgZQsRRxAHlZ1hh1mM05DbznWD8zOZtTsWCYxSQ0FsZ/2LICiVKm+g2Q/41MFDuoyQjKCNXdu2pXTchizJJFvbGSYUMRQhuJ1QjRXAxwyXwM+aVnmXMEZ3esyfg5MjBLTben7/tG0pFBA4m9M33v3zzK7MxVjo5mN85FPERabA6KvF1re+xZX4oLlUMg3yBIy44oUd6t+Ep0aU4UI/sOOuNk6q19zLE25Hq8FNKRSVv1ka4xc9IR13bTd6bm/V9hnSZYhFRqmDb3rRK1KvVetvIG6iURcfWkfYTIQQ+k8lhbI210tFr48m+Nzx2zBe4RIP1LxiHcCESPGPW4hQ0rJaWqurCgbhUKvzDFyPqBJLwexFdqmlthMAg5VsPOyWyuyWJOGJaPvobVYmuMlqwlZK9jlRwr3VfffOWXklwSOGy2xHjeoEInuV98xTiPU2WZ00oXUJV5In3Yb0Pbw8x3oFGFkRPDvJpLDKY45fYDLYz4W6dfqtS3ojwW+nnUpBVS5Aushfpo5e4FT30eMuloABiEmENlDFfLA6U/g8iJObOsG+jJpUklNud6QyXoASLSrkHCTHLBE9S+JFALHraiJAn9Yq+UpVoChyrb+ENVFJfdDDbRZ1wpzyX48OX7B3wwWEgYWrZnpkXwhguFhWqcKa0983BjTNuKdXDXO/S9qFWtqyKm2459EJ94VbEs3S+VSkxVcgIVn33pMRbmb9M1U4uTG50DAFBRBDwjuSAoRWqdlpmchfBKp/lokZZdvXkBn1IPzJ5RRbog1ElcxEZQMkHkrP5waeBnVnnXPysc5E1AVHN3iIKX2Xi0zfiBGWhWRLb1GxaZBWoxRxtpLkQCqdjmln1xDIwj62ODMgSISE88sUgb41DCIGxzEHuCoHUDJ8y3Z402wGqO+mQAZmSW85EgPF5kJUzLheEbGPB28DKgJKgSHahbT5CgxAQgilHHvevIPRN+RkLBbhwPN1QdQsqjMMUIfJ1aU+5GXYoLqmQVidGBRSgR38Ybtjmw5qhqG4sKzEQQ8Ijygy4AjyIhiyuxaiqAGUQWiUmPsVHFms4VicSY1ZJc7H2tYc0HoolzsQM2GsRos50OhcVWIay9g4NRO6aK9JECIpVqs/YlPl3NZtUsCTKcwlsZE7/By3SnBkWFPWU5JBn03UJ4AQgKtRREedmbOueNkYyQojmLACaWAEt4etTiVkzlVX16f7W8KS6Zc8k5Q9TYK9qw0byVIvWVKp2LxhtYLgVULYAHkNCFGFJOhhlh0hElcVMXi3yFuxjtjJyVAftYJozaMxjG3U3qGiaSqyCfV5HibAwpfINK0qzpQISSDEnGVPM3BW6wJfeEAcFNUegkBIbLK4hosoLM9LPxruwLIIKvUhyzBmYNVCRebBLgnODvhFCnlC0EphiFsoKtrLhWrP50bCqwZ/c5NrqAQ1U8rqeaNhNxTkRCeI8Ppw8m4x8JuR2NZ9eXES46Uh8dQ18lP6pIvHCroqsDqPWXKyodDYzw7MXocA34hOLo34xLRZrPMeOxup6ZWZZmXzwOClZg7Y4JtN8ZUXiDiU/pdai2igsb8tckXcr14hANNEKlSzFiRVCGqzFY6W1GFeUawupCnM4RzGj+SF9HFAGLLLl08Vk7NiCzQedxw+t/bJ/9uri3NqXDIhk9TjuVUAWP1/W0eyVwt3+dQyI0VrLBHp2HR/4DqnlG4gakiNkhj+j91oHOrKALGY6uGWVWGBq2MZINiaFPTGPeS7jlo3Igb5aBzM1PHl4bK7VT18W5Ei1nsgwh3AlZdax4a6M+lxLIlCkxkU1VPmY8o21BPnsLbYD38pdV1AOu2vbe779umOlqznisDGxQcQ+/Q6u2+rQ1dJHX7MHAIX0hoANhXwU1dGilljVF1W1DMOjyeGJr9MfHzvPxilpkQiDhLerfTpB/kuGK3YJaTRVilx887qSH/IJ6ZkAiyUsFDveO/7k5z/3WXljHl9/+WdbxCOq7KBoilxUNIVzqQU3FPdH9UWIPGzJqyxeHjL1/Gy+n2aNlLWJJydj9opN6fVOT09p90yrOrLOBnSTz2HW0RpEUjhtVteney1ksxQKLaLcQQq/0v3GpfrRNXr59Mkj32eyssgAbg7HxC8Gxs77zALW7twCKJIcMY2/Bafi7eoGQFr0k6/RWzBy4ovBvneH6s8/fP/b778zo8h3xdplU/jSSKnQg6iVIIbcamz/0jiD7KfctT7OoqfuZGw5iI+oZtDG/g+rcBgG3fpO1+jepXXRGfnxfSr+QRAwiizQTP9QPz41wWY6/Y303BOg8TNrSTIcOpg6WHV5Y5OdL0n6Bm2+3i5m2KyZdf1KV8cQ67xBOoSslZJ3yKvhLqGeSNYSa/1fPMFYAdt4Mh454CI+OWtWeR+0gC4go/2FuxpUGJwR2a2H8cKehmkMGfbYC0MWWgQoOqLsom03UJeDEzh5+NgyFNXm/uRhxQUlcgxVVaWJ3MRVkzot1IMmCwk4aADVyQlf0+klK8Ih+iZtz7d8bsc+q5xPHwPR0mx/1CMBgnaEKEEjUw9xOlmzYaVKiMspXl1dHB6D/0Cn/uHTxy+/+Q4hK8CJ3WFyhWaxXHhEqeMXARbYVELP46JiWGOV8DnrF2mFD21ezzZXVyJoS4fNaF/Pb5yoYDFdloJlMV3unNeTEZgYrJiv9LrBFqzTRiNwo0KeAddjtlP2ph8EQVVjR7MPuyd7E19/NtljuC+4xiyoa1uPnzH78dNinqhoIzqgoT1bzGAMomfPnzs+bHJ4gKWZTym49MECG/qXOLgnZmABrWrVADDAuUcmnWz7e3qWMIkNZrN1Lz03rdn84puKxP7o8OT502e+sogcSEAkrSrNBGBRMuGlajJeDVW031av8m1LnjMyiZIqUMNSIcbDkyOnaqLCQ1Zzf29hTwLTkAB5C2LqKRFIRZUAHbgzEhdW1n1eWOCji0uMrfxMIMbpiJes4qFwUbqQZJsynEBl6QLBLEkwZMI96DkudZxuNvMZ/2AWQKipIUW9on64y+I/ffb8g/c/AjwkYxBufEe3ak8DwZINwK4MV0Ddr9ZqQwMDw0O6l0WEPLFo5PjEJ3fZNJ+4sqfZSFFlIb2NOa3gDvZQM08CVcQF/rIb/0JGBsBBhGjoSZZLmdTKopQUIaoJzKSSMaDmIZqwCnoEujFpzNVGIFEAcb41YqXLTDCpK92QPZ6Ww+rq91oEb9whxwOvLODKTpusWRP4IGh5hbg1TQX5IMwol/9rELe+bgyDCNtGBd0O6yxrXBFYjG62VxjVKdpRB+5Jvymo7FLCPFqNDPShVMY0TghR51uQZ1GU2GGk1vGg1rHCNSjAu84mVyg0aPUVgWiXECi+CBUSMpkmYtoXNz0fHeUFoysJaxOEFUbZA7dYnV9cwqx1XVeLyEJ6eKjAMhcJ0kSVLGLUfXuiFqkExvuojOluW2hsqDImEaM4vdZ3MeqWbOFe1VNGUeYGuqv7ljSQnDGfKyfS4p97j+haIy43GQWVcphO5lQaJKyCWnbxV+wa0hJ4nWcT5zcG/abd1ehydDixIjYDqNUrzSnJem7UPZ0Uhpa0x0Rb++Qz2KYJM+gIMijn/7I6jeQN+OLuFnr3+IzewccSspzIfmv2FhUEfYeJgWl31CpUrbTDOoQonAoZ4hlbm4QJDlAiTW4CMWD3snjXXKtfIOMv0lygKdUImDGXGggXQ8cs2beIUgHGkPiLIHNMh61/6fPToDAbawwLEg3agXSixJhUo69qQcWoRNrwLhYBrNEGTRUad5fgU9SI1BH3ZU/0he2jnrMH1nafc4mCoazYxytSQFXVdC+xKZ6XsECsoZQaOUutyEgKSAI35sZCLI+iswbFQoeYOlF13RKHcCf0YOS0BM8of+ass9J6knhcW2q2xhDd7ARpTVBHFNlCQoh8O4OJ4MTYA2inheKW3JCIvBYKfkrCelC2aEqbwimzEuZB+aTYa4YqZp0TS3czApxp3Wg1mkRz0yeOUfDQcTo2pYKDsPLaKEodYq5ER0Muc8RZivmsrQDIuAbRdEEaPUlqKQNCp1FuM8G1RQd2vOBfRi1GzsRmsplwY3Irw19FP/bP15ePxiacmFQisAK5K9Ac0McmhSeRhJj2uotehABF7qJBkdxd+FD3cAIIUqCN+ywHC+nj14oo6XiR+tCuRCruHSohb1Kqou+SlrtZmAkBsb3hG/16mBQphbGmYIJsCtg+mG1tbqvLr1FETsThxKauYFENwDDipjbSzlpnZY5QpZwR/kM4Ts7P4IEvqTWjGHlXANXVRQrPmyYq4nd+JuyJjmSGIFyI/wafl576l7FuOuJpZEQTeRfKFlXTOIaVtVCbDMENXeJwjGXYx5tPyQMGRbkMqamqEtUKTPCoSqm2YrwoHIUXa9tik32dhnoYEavFZ1aor6Y3Vj/qRzj2VMMEzRJhZ54TEGFIQOZQcDDB0o4K0LufAKpJKSiXsQwh6hE0JXT01v+YXdDQNFY6XsoSYcN+Cb1JUlFBvuCNHv7fMiNSphaY63QcnOj5HTMHUGrICyjV1KjfiqatcEap6GrardrTNVw4xFPoYznFeJMVXZ0r66AnCcb1FZgYfCb5ewfDw6MjQZlyEUY8S7iwzLqmO+F0UwZHnnApf/zDWgiVLBQc4UORJ5cShuhlxndt1Vh0HalpxmdUY5oKRWyaLKRqnOQ28i+aofMboWMF9o4enOAYeUYCzZmwzclhtDdjqGmExDCQaRJEqmJHyhgwhznN8vrq3GIE9nRiuRlakZrsoaDU2Se9Nzo5PPbhjaPJQXbcV1gcA8ReLhYXjkq+nm7npkiy+pEh7e5SI8Tu1/Yv8xkmVFPwRKQCE4iGsaihlVWDxHChY6TGBHTmqnlytI/K5F/hEIaUMRsaCBnZMca+rmw7GJFehr0IWCKZGCshIfzScoSB/EepjTteT6fn11cX09moN+lUd7SGDIXiAwtkxAi6CS+eOefzialxRjirY8h3RGHtm0q+IHL6+g1rXSmin4Fp9ItfCk22b9rrJg4lkoEkOioVovkjEXYeK+G61hjdGAE9GvZNTfjZpB0+/rlnWBQTKaa7jkWi5vSwSgEZSCtTh8N5t1blEGB2MU48MCEGm+ZABItVMPxyPm3DAiyhkNHIqVFgEwp8rOxIYCjk/fffe/r4MWwpj1AvDMp4U6Ieg2xClfQp79CFquRnNRfU2s39qwg/JjCSXpwJVNDJMoSgrZtcgzRQzGhFbAqcRTW1qyey00xF0RsFYFuJX8wEfEKmWuCvt5cNShVC8QusJspXs6CPWtlSa+mS7ZKLGwOCw+5YH255u9jrH40i96OMjPR6es360TwikcTdchOmquylLJryQNWCt3HuRQoyh0KaiiyEHK3ZIOtf7BIcRLuxl3mmplBKSsZcy9/0Ro3b4gE3TTOCAnGrfxGkmE4BA+Va6zWM921nSW8C4eiIf4rxdhEQUwp2PRuF0K0JbCAQoYlGIkvhvzmoPQfuEASdUmNdN8fWb9l8eHgk15PHT1XL0DjiFZ88SV9jZpVrTJOe1YcffvzsyfN0kRomYa1cQWdLAlRvGAaE3BXWIUjLSFfdsBIMPtGAs8NI6TrPY5IQMjJGYvLIlTA38nkc1lawUAuxU2H9hDl4dPt1eyMapCkVGzCJwkXsIoJWG9Pb9Bcp1Lg/zrSvDL3OomP2bWq198HRof7DyaPHdmGqnBe4Wl5ZB08o0haISwYQSHDFQtC+9DHxB3ZESkO4V4wNunmaP8X00gBkghCTGHrlkr/MP2LUmHmHqQ7utEGTiFISlDKJIyNl6qIf+aM3aVdqRjYytAUNLXthsNcYpG67oy8MZQKB2OpKQLZayyi6FhDOP8X0tLgFN+pn9n1T0bE5e/uX6Phy+pIWPDp6aFuQ/VFGnAAeD6h1NwnYQVmGidOO8fbGWAQmFeI/eUnbJQdFmWBF1VKWoqRycXh/5dst4llxP4MGbG+pQO5Bae6IRlkDGQgkTYNeQg0/1WcvT35mNYQT2ym/tULZahk1YnEYiFIulSErwhmRqgqE7hn41USdnLM21tb96kujbGKjhyePfvGLXzjlUHABAdSOvYpCEzQkwQzEEMRayhuSxwJ5mdpgkLvQpCSB3IeGYPVEXQpX6BaXQyoqDtdIvZUpppKAqSmniqFJ1ugTrWhHygMkWeRBJ5TxXgOBLpsc0hcoVU35jKNZQBfv5q1U1ceOMILm35izqoTFlHnD5q9MQ718rWxmoPf3DydHMiuoKjABLhh5XVXFWzdCuobMhQOsit8N97R6P6niTlHkRxf5VBguoJIaGq+iI15B3J7INKuJvNUwOyeTuyhNxu807ZpXlRgzn0D7wx//+O3XX1sO4LDO5GnMwZdQUt64YtS1fX5h56Maio76uhheE3BRbpxlKXkKo4zqViRd8VLUMIhrK9vHjmUWg05rCOMj4PVCmTRV1zIasesQIU6eby8lGoG8frdmXNUQuHiMIqhJG+2GU+oLAYoc2fXq1Pk4iIw9Hxxgl4Ik/Pzy4vWpE2tzqszwIHGdqkq9yhL7vUsAiT+MxKK1rlTgVTs1A2x0plJcxv5+4ASbN8USFErZUIZGOEDA0elldwIpFlbSgBqKZcFaKjnKu/YzT9JcOuDqxvb7BUMDMVTmeFvVKs6NPFp1Z+CH8huzEzs/fPzo5NFDVDBTZDyItYa/bNy+/CmZ9ZNRPRTULnumj0F75NEXcI1WdxeRdp2YsCTnx5tLEgjoRKlZBrW5Rn2rhtBJPmO2cspk5BxbfFokHW8uXPToOKtYeNmKtoVfQ/4OEzWgE+CK3EFPtJH1oC1fKaFAkTXkneTJxcMSNNJgUmRvcnBw8uDJ8+eHvqR3cggZR4GIERhP7EAIkm16XORrXFc5yMNcgyAsfGrNPUY44nI8dCq+AWDxoJPqGBGbKQl85KISCpYA+xlVCJCBSVnWyFhWWBr+aMMoRehuOiTWTA31El5b/jfVLXkOqkWbiEPQi1KE+XnqinskCRXkVmkkI7k8b9a0o+/w6MkTh5gfPDjm3g2Qg9aZQPtHR6JaE4rGo40RL6y4NH/bpKARmJeGErlVYRkdrAZ/rSvOhy1ufC8mC4vyoUb2MWJQYUKDDYoBgzg0PxGw62iVEt6MoKWqKuAeuUIzKOW/d6mhvv2dgCYin0Gm6EWo2TIoG1gzyRMqpEKpXuaHsZDBQFDw5NlTQ4zOVsjaPGNlqa8Pfw5fLnJKh6WUbUQsG5EaoiV5WHM3lg449Hg/9pk5Fkv1TQLHmoCH3tEFzeFXLOOOe0hY3IVhtgglmcxs7FJ7cIo1qjCrCNEgaAKxu29yggzmcsqWEL8igWtaCoShu8pottsQtMwSEpBELkwk42gwvtqVN2XR5aO7Qt3pFa9/fTg+cC9ZsZcD6ln8qniHSX6ycAjFtImRLIQwB8s+HW863758c3MlqmQ1ou9NXuAFjJLcCggJZhFl8N133yG89fKBOR8SoiZxxUU1zUWAgwCVbqFOrEUGsyUylVeFdn7v1CFVVSxFFjIapKxHYWOIrBqDo1HNGp5qNhKYpEATWCI6cLCYf0e+HMekZWQzDhX4oWCz7QLHvu/RptYyk06wtKLTeOO++QyB1mRy/Nmf/owzcJH02V1TSa3iATRgw6xcewNfJ5PqZJC2wiihL35qLe0WtgonhRn1MEFbMbyokHOHi89g1VJ7laxhbVLuKglv/RARHoxHz9978ey9FycPHhyeHOs2wF/d9sB+8fmfBQuUAi0UDCShKdqj5zaiaVzx1qsSumZ1Vwfjo2fvPe+PJ3T74PDYR1VMh8d71ISwT0TowoYn4CltiNmOgGZ9ODfZZZC0Zz0CzkS5rGXPwRKkINiKSMAYeWjlY1cqlWNWUAIiKtA/IlomJdhjlD8NaBDTOvcIIr8BVkeCIac1WOrWIpUyLsIu4goHIWdCIYwqa4UUcVdF08hEE8yaW0dWI0wEzTiqhRv0gguhLEAsCoYZ7sPkBIfKgjY2AQlKyrOrrPAERUUm2uZfmwRuMS0kcrmLkdqPqtptQmW1F99abWmVec1SiGRKnpqGcIPnEYuaQcDgjCmV8/NEC3rK1PPi7VtGoZlZXAEMQ5j2pUb8uiK3d1nGWzbYjgXhATYZfBmOJo4h1GiLOGRv9eQgCgMNkYdtWNSqzNRoaLmLZNGCRalWthcoJQQuZGSTlFQEa6S83aX2k1LoCRWmsYhAoV2ySWoR3aZQKUtqqAw10EfyfVw9hweSBZmVUtxNgyPglo9Us5tqC+Vz1lxQqggio3uO+re0sVoMRSqmQguZoKYSQzSlRkTSM6ROvNF7+vSpeklgKivH7qYkedu8n1KA2F3v3+RdJRnuJ4win1sDs8vjb4hRyX3oExEIqhGKmM/6DmktFPdcHiCBu+XJ/S4Jx6qad0DWAFocihuvFMUdTcBWtelmJDJOs962ajxuN4PDg2Oj9FclnBgjB4C0mu9bAlqpXRJWbW8pfjQ2KEVK/Al5xXZthiWvGg7lImLHW7fPTSvlxgSCx36SHT4e9IaEKcKlVUfXiRotZCBTjf9lmavaqkGNqZ9ElHSoLXgZTKwTBgTJJBf+as60WREXtm40WTYLyFpGYn9iIRJU6GkIWnZUzt+ClbwlpYkqpOG0XenuJq/igKVQUGr1pDlxTQlXKizWVbZcZHOFeauuyjkWbTG78sWP7K1URBOemzGQLaykIlWqZZbh/s96mJVBjb1+NjVNJWkj5jCLKuLjG7RbvNSiqt4HH30obqHnxjBjEmoyugGaAkVv1y2mXtxPGUbbJu1JEYL4tK3Uobayjee7jO/+xnEGzwRskQiz5yZWK4FMgpXU+qftiasifGYLQwJh2mraHoXypKVM0mfMb8u29lDb29cVcIm5EChyo+NtTSD5kSOKWixq1UVadqkVLqwDh9TQvrtPDX7s1JVXJH9bzpREpM5SQ7nUGvzmGR1CJva2GbbSCEuCss9Wha0J17RS+Af9Sg2ulsE9dyNpQorklSFsSLUieUgYWrC0qzcFiayngDECSS+aFCiJ3u63VL9XQHYPq3lXElvKWb/luvPPBU74l0rC5i17i8cmEKrbWqLVoFS28AoOCZwvLslIKtwGZgQsHGrwtJx+umFrPKzBAH/TuyJJfpLrslqho5ScO/MhG2EtWjT8a2jCb937NghhYkQeVhVFkEbhlhtAhelWlhrQnrjJvZeowTImoqF94XNsQlLGF4FVElByDfISIkrrGy4Si5tSOQQhs5KhmfCpkjlYs2+mK7d1FuY6kcm/S5mjlard4rZW/AhgNGVrGlrBusrbKicC6mlJ/QOeMrO6tGt1a+BHNTVikxX0vG/GC0KFIkR6ym4IaqJO9I5x1QcHJ5tyY4VqhtB0Z/LFBaMN1mNnFEPD/o9vb63iTwYDa5UdTw5tsAGdUdCHMNESfe6JI53mPCE5aMEpsfzCUu2qBjhKaSgk3yX9MQM+wAZt09fjybFTN0LXbBFLwCovGKgae9AYEpBgKQua8e0I4V4+ph0SRWIZwMN/hgplifIcHWRupEmOiupUAlV1EkgtG8MLl0thQ4XSapWoOWJ6LyEECJ3VK0/grf0OippxZiBmw7lzTc1SgKB4HDsdHjReRg7LfNAaQIbDBSFeoUoFeAWFS8aqEKDKQTMUIVnF17WetQnS6nAU5sG2BKDBDejAXXEEDNDZ80IkalBUD4XkIQ4O9YlOsu2hFJuH3uEyatMLgEgAbRQAoptUnpSDUaihJbr2PoNAThTxxHOSsLRgTisRvvjlet+qS4WtkibrSqWVUCGq7VWDuXKHerFmqSMSirvKe5rZKyWLTHGqhWairvvcK2UvVBulqspgfi9FZu1FKjsEENCKTeHv/8a2LRwFlrItFaqEeHPtSxWZsM+EiqZRWt1k/l2CGAQMTYSQ7qNjLakKzo0tDWw/yaURB6+25AfKNgYBXUlAGXQ10u2sGEZyjbUacZFGoEL7mSyhrJ/+RpAacXcobTUNx2OLtWQVO/Jm4UwMEOOVbWwhQyQmxN+lBq524xftac4hOaGCq9xMTfB0HFWGf6K22mYtsAnKEf0SQM17nipd6iY5d1GDGMSbQFX62IBQK4RSQ4lR6qn41SckVB6eyd2Qd1XmXWrCUA/bq7RbPzPbHwn1Mxgq0pqERgKbqiJtVn7G0w0SS97Uw1Cv3Jyv+vhOw7XinqcSg8qS7V8xHPnZKgvU9zBHErNDqq81StVlCBVkzrb5vAgXk8LRIpbS2BFmM4vZ7JbRV1sV4p+RUMZk37ZXjbYneSqFq3JK7XdsC/DKXLpXOf03dRx2QYSS6MZmWUTKNqFVlhWoqC4kqkpbmLw22uhfiZtS4QdLGTkt42om05NqGgxl2xqwjSJaLLKi150NQmuNUqKWWnMBOGSLw2C4SoSdtl7nNaWwPg191pevqAkht2QAa8MjN1v8GyFkoHUe0VMfXMF8C5vgn+UA2X2RYd54mV0NSiWppiDDm5JfVjCzrCxCvqZc0tsQNowPlrSC02x2ItstAFvMwpl3D9V9H2GOz5Psb9u9EGlHPdUaTsS/+QHEfF4ByZs4hJ0RoTD8jgS5uZOqaqS9LXDDsWBcGYSoHJ2FpZoN4xqI5dtjiSQYlulWpcU/GhWfwdy+92JG7AKLKAQ00qX+cMKRGjra+ZbUTgQynRTljQmMMr6DjoghqxgsEpQeTDjaJIJUDayBS7U5qUYwVmODlNGqsFrhoIzcgAZnAV9iEux3wlRP7y7teXvfKIJpaJdKyJT/szg+6hpFKKOwY1LctIJgJeuozzQakwIuGKyy8sSrqrlc61bao60lFD68mk1dDZJY/xIq+SPhmF5DKSrg6co4pK0w1QgtIWKsHebNDASv2HqfngAzrdjKQr1I5SGEHwVotb21l/VsK3vu5XTd6mdEPpJGIeOfWNmslronnGI1wrB7puBW4SsiuN3MbFPzhEagRQEQPIHX5i/ApEh+ajH8j5LJRrRKwrwP2DFFZu4AXXTM6zIuFeugomDGxh7mE7BlToWK8eYGHTvZN7VFfkf4QjCttoa1vcMoillWUPGkbYnAZuoxzlURtNCjI69GyD0N90BetG2KBUrhEXdgGc5tb7xYzZ1fIX4n+dCkC/M6mkD9EaZwLXXSlDInuJKGvAn3+diEdAVIZVWqUdkxd2hldsOEpVUsOTbauNHaorfaFJZ1JCoqyHlKZWlOcyoNrdBWg5XeEUK+NO1fOBTipz137HDgKBGMOAB46GwMIFgMnINgohNRX9TknchQVsGt3r59i/njW/Ou6YV7UoNDAIn3ogOlz2QrHVyLE7k1wtAAox1aL28SMLiCGtIsoGqdWcRqsTEVjFK+J3E9vdRX6h9EUQyqqtKCkEzx1yyRGkIFDQs2FYjVhFsQTgpjK7EffoIhmBQFqkEh8lZFGYKW05XAQcxJ6jEJxbeqbHtRgzzw0gwitqeEHQCW5ElXl1N50LIYE/9PTSxYclB6MA7yAeP+vSf1vJxxJyZmeWHzuwOksq/eVAsyG8dar0/Ge8yxECQDxOJ1C2KZUf8HPf0Zndz0avLtnhDhfhualDwsQWjt1a9dtrwtVbeoBOG2dqWKhLIFdytQNW2pgFxMowXsej1ZvGRarZK+JvzVo4j8CBSqxdiXXQhksUepNn9QWuvJGfjqactak48zFdjmF7KLUHkHtESVoS6PlY7XWSBgLZivOgPUQKsZU5vhFuV4HKWvCQKZOiul9tw3/SdR0UkAxOZ5HlgzjiOF/9W1jKNyxrapGot38yZK43/gwiqIVeycBQyjHEpsqQGhNXNp6hY/2AjLn/jJWMMihyKNEEG64CpzmG9PRgkTs5ckhzbep1GdSupCMpxy2uk8ZEFIhGerm9vzi7OX333v877SlVWfosgXL16Yp/TR1vOzHJIb/4+lsaD64XoUd32K8DJmwJNEYHQmax8FJyQ43TVWIHOtTpjMaSCGBhx2l1kXmSLC1fWOGYonhpXo4OjkIcNCKkeGNkxSW4GQmVXBF3oFf0k/1Zk6mXKo9fHRtGJP4MuYWGY7Q4AEfKyJNnHI8HMMP/4AhjH+9ps/z67Pc+rxaHBhz/l1BMHEh+2xRDKdcOOO86troujr3g64Drw7QYh0lSgWPKWTRL5wYqxCd7BGSghwUIsBi8fKRJhtpZRTxKcEonkshsh0X5FAtCZhuYlAzZGu1m4GoHZ9uWo0HsLitgYGg5Bh9kppumSMidn6YTZYPaEAdEPWRe2S89ny65eX33ytBeDRithBNKIPAkaWJ6dcapWENxuZLaHFBRe1RHRzeENS6giSZA17twISQEKCJG8V8SciKv4Jz2sqPKziKlK65VEtDmAIYz6cmEzyrdHMrx8e5iMa1SWXMfoQhat/FU5tjYVXdxbHvabB1hI4M8NI+8dxEFP7S2cJKDVUiPji4thxDFrBg7hq+4FJjkVUsKMg6qo1mJnHgAwJCGbVSfNDjdD0e9ta/c37kGAba8qmPcwucmW0ItXEyMRFujZ/2bKhvsWI5uP2jg4sgrBUnTqYv5YwSsXQQ9FoeSWlPJHiXKrB9hwEBViygQ2civsiE85m3rJFWWFAnBcZ4QaQQBb6KD+qyTN4+fI7QpgAvsadG4hpbNu8B+FAQ95NSa6fGLUlSkHTSBbQ05VgOur0ODYyYMdsoEikMUCLt7MoK50XEuGmmtsiYFUeKM0v56O0CQy0FUMryebJjsapLIO3IGO2QQsbw54oWsOucloSKliySDyDHYrWmDWo/aPOLWRSBhV7zEPW1N1My3Fu53Zak4Xe9tKoEPksCSyQ3Eqai9JuybTTDsCma3EnrlsxKI8XkUGtbSzASscjFC3AxGnQTYkiMH1FxJA4LcWk5L765oDf8iZ02N3jPQ6JZJBO1CwipdMaVBDa1LpV5WcrpV1SmRE3bTc4Qj/V+F9EvJN/xVoq0Yyh25qGQhybU12ipMCkYA0EbKU3P5PAFDEoJOARWtIdSevXV9ORaGZ/T75QVEqlhN7PGr1NKA2eTJSjtwP4qtpWMx6nVvKW3nz8RJr0hL1MVWLSxbK+BZExlHQZcvp5nFY0xk8bERhT+ANJn5bzRBVZVQEa1kxq+HuyIwWaxxD4GY1AgRrvS9ZkLiKiNxgqATd/2zBnHpZk1ytDzLa5GXOlFI0HWgzcFRfIgg3IkS4qOx1j5QfqoXVRASkrpV0PE0OHEIGq5D/fKa/+baQ/a/BZCQzartdQlEWIARErOvECCa7NEadznUF7nXP1bqFXvKEDBk4wXiJtR1tDLCs6E3qGP7XLWSnyIa9MGs6uwiJolpbqzyaGZyOz1j8udIczElh3E6NkqabvnsxnOQamhuRUaNxRdGbTo6Af0I0f4BNVIA+GYwpgNBoKBV+zX3pzuswQCaghSxLTkPjQAai22dRuw2xoz0eZlzfRQILgBUFILZU0VngG+dolGfqEBAkrSwVKvFFA9sqUDIxQ9A7/Y5BTkSIwadeIAbnGH0WiE3ibVQJsAkK0bx4IY9hpD9WmighV6lFHVRJ73lxujE7VEWkMYIDgnjKXYQVQeIPmab7A4K4aDHfAEITkrwQSZ/0N367S62AnwsLUHmkrw1wU5uVyDhqZS5VxHfVavcx92lNN9DB00oxdmrZ9t/rzU+AqcABq3H/0R+a8tXLFsth8O9FMnD2QAhxfXZ1fO0CkCAaddDYjz1rMpksL3B1xQFAIi0pFiUAgQhnbRISmAZEJcJlJyJcDkC2WIuY0+tjkXX0RcaqVNUFZ/VsHyHvk4Ra63NdtkSOVxkxI6qpWtzfJVzmTeecaMocWQ4hO4UQTnLoR8yFsGJcK/c8FZLhRADfnu40rsALNRlTFVVyLFS9rmgJneVbpc9WbyLp6xuTFY6y1zjODSrHrhtEyC1c2oRBQhElwhUgArkQiYhf030Tu/hkR4Va9D5RZehQgwkbsdVv6xvAQScJaDwvRWLsop2pLvLbGL2VixpJonMa4KJhoXNbAEJrW5mafe7nus8m2hcoRk1kWOpjEkdfwWJHC0hYdUCTMnrv0ClWSiJwJVO+OQ2FYiXpcQJxNjF3sHUiyV62sY8SimAvFfEXC/0ImAZulBOqlo1YOxBIX/+P7in6qaOU8Tw0/Sg2zHYqFfzCIOY9ZJnaAgn0tC8AMgMams6q3OfFW16mb3cBDxtPIR2hWLVY7Qdw/gaakaidNtW9GBLzCX9VKaMjPEN//jdm8anaSOEYoqgHIZgtUHoC54xpbsWdP031xtSMgmbQ53S0bEIqWkmMqLjbXmo5ALf9HiEI7ShTcAmYeARrw6FYhoyx5gkuwIhBpu6IBew29ykAlUctHIaMh5QoTVUoRZiqP0eBRcfsnHLU7uM7a0oROWs5xLF1HO0HWXpco+TRbwabKtpMohxAkgYGhlwCf8CkBSLyh545hp2nrvdFAd9rhUwaOlxFbmY1UZrB3S4IY5xKCaGIIKUdwruHNoIsQgT00wOoidov0Qh8/46xDnrY6M1olVFUXthE9Gpw8Ue51Th8rUd6RNaoEVssdjpxltGfgaIlyabqGNaO2MRZZHZLGuFzAqLRMADFB2sYM9fC1rTYVNs0BAW0ZPDw5tgRB1U67QRG1M6/8qAK8EUpE2BKmp29TtA/9NFhwZyQiCgoSfsEgn9UHkXWeLIudwwQ9Ah5STXWMs+ciGL0DXMZDMxhErUVojCVKo5YJCaCHQvGAaQGV/SE7RmVYBUfT5TseHlgcxyUa3Yv01PyNVVwInEGz7E7lOllf7i/FyWYu+Z630pQF1t4CcvD+s6fnJG04mB4e6Nzo7dqArR/KxTJUyiBeY1SYb+tdguuQ++6hPGmjmnEP5GSrsMxGC+KfHgp04/yJMolJlIftgKIbQgxkBROeEQIpCl+q6z7sNdFgT9j19PTtuZGlAzt7cryKOsL9RE2qcWCYIVXCiAIb5zHoQcXYo6DZ8BabqpOYasiIljhoNjXAWVOhTiN/8vhRDqzb30MV/W34n+3ti16MDzQqApGPDkdQoQ5ratRRaXQ43q8Mj61XbnY0IkIstFhouE7Ap9UsjnGm/H4GUfBKhWQBnPFp+eaLo9aiufLeCTASMByl/l4GHjFFzkxTMP4rksj8OuyN5lI6H+VzNLG+aMygw+mc9WtBxNzJZQ78zal11EfX2vG24nbjCyBBiNn13GrwYceO/NoooYyN+v7p3kLVigJXuAELdV0ZOUBezcwsh+GhQhmYoJnjpXEhM04BoewzFY/ChMl4FHclPmWORLmBQAyh8piqJMVlaJ28oEcGQ5DohQQRB7Hpf8Ztb/IdRpQDXluoycYkKLMU2tDC/q1tiBxKhnoSt+cfXiFB2jISlzVH4SoTglUGR3Pou0+DDoWQg94ip3g6cHK4dDhmhoOCEigU0R5QBmNGpSPAc4UGoAmYxRIyFIeNOcq4tHh1amCv6K0e8hxRr2E420S3qwqArYJmEkh2OC4SCFkjDvnNaEZDWqSndbJwOeUx5+QKnJrWYSx+oh8SpNtC4qyDQnF0iYLobmAzXlAbTmRzezmbDt6eW65VZ/oZmNWZzHdlbjSsDa2jbscpDaXVnti1UNVHFrATczTMlqCftsO9aINdalkyIsG/ZlyWr16++fLLL1+9epUdn3UINsK7wUWcjBakLxTsCIA6qIZ6WrIzmvXKqSqZKpApSTXCDsH16PKaV4u41eFOqA8koEtYHYtbh4dqIy6rtRFC6ODkRFHwCNJvN2/ytYTajsC6ZCygRrGDucRZYgqfwELFjZY5VFhqaJPf3GejQfUmy1Py3MpqmEIpAbLL63yoqA7fBn9CfVDFVlVsCjN0jMa7aa4HKD7hqsXu+uD4iPLbYYfzbVkol2aiBPnZD2yJKBt9r809YJtnxDeaEyvDOJZDqSfpFjG7UQcoCFjYrDr9ioxzQgwtKkFHfRBopAye6THWkdrBu4biwwipxA+mKpS4Q/N+Hifksv2xFmYBWkoY1O2afTN+FaLoFFfXrQQBFSBupUcEt2dTfsw4AgUH9eRIaVtNHzxyz4xnhHqWb0rzXO4FSSyiXh1/E+joKc7HwsZ6BCy6jaw7VyWPmtPRkofmtoMeco6PQTlep3S8PtCViewgQyKIq1PIhjXgY894i5FKFtRlCiVWL1PNLF88sMkveXI+QoL/rMFwMprnaE6SX758HcGrL5/G60eESiO4aRpA57PfTu2JspkA/xCdcyULvij7cPRoUj7bxJGahzNs23aEM79rWqWZza3EO/qJZME/oxaagzak/A6lmMGyPWIShHBCK8IzVC28dfSYFqEfYVYEMqiA5Lmvg4EhgyeFlSMNpkwdWyqPmyRThxiItF3TgemV+4iLx2F1jiO7UhV6xbMKGMKfLc/VgKw0sDXauloqkTyR8rakA2wZhk1UGB8JQjVn0AURK6KQzRMF1Bmhgx6rUHJxV10Jd/Sd+KuQURNUNefOhFhJGefS4yMShyJldzZfXJ5n0J5dCc8X8ZGK2+7rzEEYNuC8QiBjMvlZ0bSQLdTVRyxJcQ2VYtvATzlbZ7ZQbJcEqVv/oqcDOM1EVOofwQ5WJaFZGdTtIgGVNHqoFa+CUnVT5UFOEVlRAc2jFB42WiAJ+JGLqCEg5cNTFMtxdpqXjD6Ia52TYMNVyKlL48yei6vTs9ObWRrL/qJdDOMnnGhMtRoQA4tYMU9iFMOOkCROzvNUWMLFAgHC06BXyoWqbgJBjflZhL5n3FU3OdFLalaZSnaZy4FEn2KzEFeeVrncnGXL5tqkgTuWN78K8ixHbhqXAQEnIXtDEVY2uCUaqPB+L/tPE+8P5qKdXnd2NXt7cU4c5jWBGcIm9okhA5Zr6q4uoVYrKav1GuooJAuIxFE0mRSQTQVhyJpFYohsOtfBsEmmaM2cVHaD6shFxuNFoFBESOCcHmW6McQmX9wzJ6pwRizRMSeFxX/DgMzlVaKiEFxF7GgYXfjBkhZwvc73MB8DHqf2ZO7Kzj3fSKhdt8ksxsCEC5HzdM78JuavU3w0V0TAxvAeGcoHgTOMBW9oS7eK8HlS3qH9jKRUEZkjk+Fn/K1MEipwiyUBBJ5hjNjLSTJTcULKoghEIwRJMriqU4plrDyBRByB4cKPfCeF5Gf8BboOaebv1UrfDNM51oCJkWCuHpAgMcpmsr4ODxR+xeCRCPgLkxl8MBQ8uTb0IxQVNcHWw0CMJl6yzGSgSWQbbbon+fIhXsxSPER8G1z8ryNAEPCl3F3GV8FUVj9Kh+EBsz0QbkeIHNMwdqqKVoHKTyOjimR27F3iht5GT8g5DnoK+odOtjl54AgW08D2Kw+cEBhUVVHbQBpNCZIWSATSEIXs3KqPUtLufAYhhono7oxCwMr4fyKfNmBARgu7MBhKvLKOtfCfKTAqIX+xsFjMKERkCjecktJBzXD4eJT+Czji2VIekfIvFVYcmbzZ9YHziWiFk/qy5Dn8MA1MiOuTmweH+4l6uhunTGTtg1Ejp/aMx0cHkwASPHPAubMetKtUhlrLLWkIYKCQ2NoBy4f9Iu+pnlfWmQZhSp0TeYszriyIYKrGx9hGiIVXnosBDXtjlh4+wRSJ5KFScKsEEz8T2Ia68cce6xImzBCGZ/UVdvX2DXll9f+2b5IiJV/a9fXuYXdi54YaFIKkzt6Rg2bqOw9KGY5MOOIVhMlGTK2pSkC5izfxKoysznsYDJ1SCplB517Nvn6RZSXl1ULogOtvdRYVKFxdVRWMinUhw12K35Ec71mS3DhPXe+oQIHcR+6LHO4RLFfi6js2Zbn03wqwUBdwrawruoEnYGWYI0BAjAyfHCGCr12Igpj/hFxecbgeBJgdNWEoYEk9pYlI4j6eK4bGJY5J7vTO3f1F0rgnjds7KuSvAlBxR9sLxGRLZbXoQn4/XYJt7EpQbTXnpipqVyKgKhpdlpvthk5IGdMv5WVeS/jZGlKbZt0zaZTcSfBl1Uz4O7JBATgFLVRoAFQVuTQqxPIUD1wpkJzpwzF14k3IxMT+VEp5fuudLASJ0LSsPeTcwDCVlr65QZJ6W7eEZpdne1NUoKpeowI48Lwl960SCHnCfXqin8qes/xuG4BF/Kxfp8kTZ9TTZ9KR5UaRhUaFir/StAobeO3aRNq9FGEHrKkmZiwhIu++/n8BM287HyfWqUIAAAAASUVORK5CYII=",
|
| 261 |
+
"text/plain": [
|
| 262 |
+
"<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=87x244>"
|
| 263 |
+
]
|
| 264 |
+
},
|
| 265 |
+
"execution_count": 26,
|
| 266 |
+
"metadata": {},
|
| 267 |
+
"output_type": "execute_result"
|
| 268 |
+
}
|
| 269 |
+
],
|
| 270 |
+
"source": [
|
| 271 |
+
"dataset[110][\"image\"]"
|
| 272 |
+
]
|
| 273 |
+
},
|
| 274 |
+
{
|
| 275 |
+
"cell_type": "code",
|
| 276 |
+
"execution_count": 36,
|
| 277 |
+
"id": "bb86837f",
|
| 278 |
+
"metadata": {},
|
| 279 |
+
"outputs": [
|
| 280 |
+
{
|
| 281 |
+
"data": {
|
| 282 |
+
"text/plain": [
|
| 283 |
+
"'data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAD0AFcDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwDm/FehWvh2yjjt2kLMQpJHWsLSG1a0k3Wds8hc+nBr0zxTb2V3aRT3Um1c5U4zx61PY6poFno3nC6gKoOSCMk/SuZXZo7Hn2ua79vtGtrzTvIvFA+YelcjKo5rV8R60uravLdRJti+6vGCRWKzk1rFXJsaVrOF3KJHCH+Dcdv5Vo22oFZ45I40DxcodgOTjHNc5EWLda7rwhpEV3cKZeR71UtEOEbsrT+LNaWbzQY42IxlExTLbXNSuSy3L+ZGzbiWGea19Z8K6hJfyNZxq8WeBmp7DwhqCxZljRSe2ayvc2cLHKzRl3dlBA9NxqnDIEm2+prrZ/D95FK6NH+VZR8NXrT5ChRnvWhDZVvLK2kMeWILDkg0VpT6JcqmW29cUUhaCXfiD7d4RSynceeuFBJ5wO1Y/h7w3deI7oLFlIFb55COPoKf4X0SHWb7NzKwiX7wHU17Fp32LTbWO1tLfbGowAOKl6Eo5Hxh4esdI8Hhba2XzIQP3nc+teWumUDDvXsfj66aXw7LGEOGryTTYTczCDIyQcZpxK6lSEESDPrXs/gjSRLp4mzjcMdK86i8OzSMp29SOte/eGtITTvDsKkcqmSampK+htTjbU47VfEEXh+Z/tMTMd+BisxvijaH5VsZGP1pnjFhdTyb/mCuQo9BXCPbhHzjinBKxNWXY6O78czTSM6WYGTwCelV18Z3DZzap+dYpi3DoaRYMZ4qjE0rnxPdznAiVRn1orNMOT0ooHcPB+rJpWvxSz827nZIPb1r6IsLeynhSVEQqwypHcV8z6jp8+malJayrhkP5+9dhpPjzVNK0pLNCrhU2qx6j/GqUeYzPTvHCWI0CeJmjUFDgAjJNeH6cP7OkL7FZ+xPan32rXOoy+ZczM7e54FVfN962jTQrs6a08QvG43ouK9H0XxyJ7b7K5jXK4FeJiXnrT47qSNso7KfUGk6UWUqkj07VtL3iSdP9IVm3bVPIrh55zbXoDWcg9NycCrFn4kngiVGkY4HepZ/EAucb0VvcrR7KwOdyB3W4beYtgqMxAHipZdUjlkjjKbTgKDV6OFSucUnASkYbqQx+XNFbxtkx0FFZ8pVzd+IfhpLmxGqwp++iX95gdRXlQfK17x4vuhB4WuJOoMXT8K8DViRnGM9qumybDyaTNNzRnmtRDt1LuqPNGaaYiUvjvU0E+4gVTY5FOt8q4Ip8wWuaUwztYHkc11Glv5tpGWPPSudiTz4iO9bulkQQrGxHHepdmK1jXEYA6cUVYQBl4orKxVx3ijWrfVvDS2dq3mSbVV1Jx0HUV5hNY3NsAZYiAe46V3SabcWTDzoSorI13iFVHc1kpWZuoXicoaSpZIyrYNR4rpTuYNWENFLSUxAa19EsYb1nEjEbegFY/etbw/NtvtvrUT2NKe51kPhuOW0kNvIRMBkAnAqnFaTW0gSQDf1OK6LTbtYnOaoXZvJtRElvbSGNR1AyDXNGbub1Ka5blm2kCoA5waKzpxNDcLNMrrnIAxRXQcg46rdXTH7TMT6ADP9aytRU3FzGvQZ71GsdzbSMsgPBPJH69afcTAukhwBuycVyXuzuinaxj6vB5VyfQiszNbevDf5Uo6Fe1YmOK66exz1FZiZopKUVoZC4qxpjGHUIjngnmol5qSMBZVb0NKSuhwdmd3a3QwMDnNb1hb6pdqGN5HDbE8KMZ/+tXH2Mm6JSDUXiV7i3hjljuJUBwAqtgdK4npI7WnKI3xdrQ+3m1tZDL5BKmUnqc+lFceGZiSeT6nmiuuOxxSjqe0abp8V7ZSCaMMx7kcjiuI1W0NpPJCQcIcDNd/p10scuxAArVjeJrNJ1aVfvfzrD2dkdkXdnCXNwk2nRox/eIT+VZZxVq7jZHKgVUEbVtT2MKu4hopdho8s46VoY2YBtpp/mZWnR25cgYrSi0h5oDjg/SndWKUWXNEkDxFCelavia1+0WFqmeS3H5VgaWr2l0Y3GCOoNad1evPdQxFsheg9K4ai947YP3dTm9R0iXTJFMhBVhwc4orsvFGnpLo0UuBvBHJFFbxloc7Wps2U4+0IrdCat6hEJUKntWTZzQeeqsw3A8VrPJvJPrWn2QTszkNQ0XfLuU4Unmqo0Be8uK6m7XEbVml651OzOynSjNXZkjQI+8p69hViLRbRSNxZvarRcik8wjkiq5zZUIIt21lZxsNsK10dg9nGjf6OuSPSuWjnAYDNXY7kBcA0uZsPZxsUvEkEceoJcxIFDDaxFZToqalAx+6w7VoavI8kQDN8gOax7qUmWAoeQaTOeorbHYaxG0+joqDJAWirOmTLcWao+CQBndRSRlyM5WyV5JwMV1MKsQKwNLRjehx90dfautiUFBxzXXBXOaTKl1DvhJAycVzUsrxuflGAe9dr5WVII4rlbyDZPIpHRjXPUp2Z3YapdWMr+1ERyHXFOW/S4IWMgZ9arX1spBPTFZ1jlb0L2NZ2Ou50BiwM7sn2p8MTs4LHC+lEcLKPvVKFYnAOKpFDNSRTZSe1cxFP506D+62K6icFo9h5BqjPpEcd0kqDaG5IFU1ocVR2kW7bUBZXphZyAy5HpRXP+JJtl6iR53KuDRWVi+aJv2+uWumllkhdjnkrWlD4y0ogFlmQ+myuNvCHmf8A3jUCxgkV2RdjzG7nqNt4g0u5iDJcAcdG4rFv5Y5buR4mDI3ORXO6dDZglrjp6CtdzCT/AKOu2MDpU1Hc6sL8RRvvukAdaraJpsup6mYIiocLu+arN1V7wEwj8ZRMf4lwAehrA7puxKyGCRon+8hKn6igeoq94hi8jXbpQMAtkVmgkUJlQleJJ5bysFjXc3pXTR+Ho59JW5lISVEz1rl4rkxzKR1B7V1omaXTi28gFOhrZK6POxE7SPJ9cVptWbYkjDHZSaK9ssI7S3tIyLWLfjJZlBJoqeUi9zxOTmQn3pAQKfdRmOVvTNV8nNXc51sWFcqeDWxYzb49vcVz8jMgyK19CbzN5f8ACom9DooO0i1d4APrWt4JtN+tx3POY6zL1ecjvXVeBYGE7NsOMZJrnudtSd0Q+LiW1xjtwMfnWE8oRctxXTeL5rca4sSgl9vzHHFc1fIrRkCmmTCdkZtvqLyXhVF6HjPeu10WK61O1kZvljThie4rzaW4ayvhIg5Wu48Ia/eapO8WxI4VXJCjk11QehxVdZHS398mmWiF1LDgYFFWjGsnDoCPcUVVi01Y8WuL9bqZht2sCeDTAcVBqkH2HX7qEdFkP86nU8is0cyHuu6M+wrR0YbImPrVL+E/Sr2nMFgOfWpqbG9HVlud9zKvcnivZvCumRWumRuVUEpzjv3rxOSQNLHjruFe56bMYvDQk6FUJ/8AHa5zebPJPEN+L7xnfmMnYjkL9M1DMSyfhWPbXBm1i9l6lpm/nWo7/KabLprQopo41SZ137SBya2/AVqbW6vY2O5kbbkVU0aXF6y56itTwp+71LUR6yf41vS1OaroztFI70VCGIPWiurlMOY8V8XSbvFV6c8mQ5/OmQkGJTUPiNH/ALeu3b+Jyc/jS2jZhHrWHUSLqHjmpIJdoKioQpPNV4Zv9IZfepnsa0XZmzbAvdxem8V7VeXa2vhCRjgYiPP/AAGvErWTZNG3vXpOp3Et54Slij+8YR39ua50tTpnseP2Nywv2OeXYn9a6IMWSuTtz5V2d38LEV1cHzRD3FORVLYn0z5NQX3rc0MbNZvAO+01gQt5Vwr/AN081saLcBtVmI48wDr7CtqTsc9VanYA5Wis+fUILP8A10ir7Zorb2hlyHlXia7ju7lZVUAkc1RsmLKRS6rbSRTtnoCcVFablJqGxJGqvC1lozC8xV0N8vWqYGbpD6mpbKgtTWSQrtr0XQbpbvR3hkbohFefm3Plg9sVraTqj2kTxgHkYyDWKWp0yehyWpRi31m5jByBIcfnXR2J3QL/ALtczqRMmqyOTnLZrrrGDbbJhSAVHX6UpoKDH20QebnpVDXZjbzRi3ZkYkcqaukvBNkdKzNXy80D+4qovQKi1IdRVnt4mcu5IBJJzzRVu6g862Reneii5CidlqfhuyvlYiLBb0FYo8CNuOxjjPetvUtbktmxDgY61iz+Jr5xjzNuPSqVyNBf+EBnJ/4+EUfWsnVfCraQi3LXSSAHgD1qZ9cvPmPnvz1way727muVwzsw9zVJE7EP26TdtzlfStHT0MwfA5rGSB2kHB610ulwiEZHUjmqsgu2crf2k6Xju0bAZ610Vjq/k2cSSIWKrjrV7UIvMgckc44rmlhuixUROfTAqGkyoya2Ne51S3mQjYyn61lTSNNNGQxKg9Kli0TU7ogR278nqRWvYeDNXaQMUC49anRA5yZUv7pTbx+UNhAANFdRF4BvJxiQc+1FToaRloZeqZ89uaymA20UVujGIxUG6nmNPSiigaFjjXeOK6PT4I9i8daKKmRSN6HTraZPnTNamm6XZozbYh+VFFZvYZvQWduBkRr+VXUhjC8ItFFYlvYUnavAH5UUUVSJP//Z'"
|
| 284 |
+
]
|
| 285 |
+
},
|
| 286 |
+
"execution_count": 36,
|
| 287 |
+
"metadata": {},
|
| 288 |
+
"output_type": "execute_result"
|
| 289 |
+
}
|
| 290 |
+
],
|
| 291 |
+
"source": [
|
| 292 |
+
"pil_to_url(dataset[110]['image'])"
|
| 293 |
+
]
|
| 294 |
+
},
|
| 295 |
+
{
|
| 296 |
+
"cell_type": "code",
|
| 297 |
+
"execution_count": null,
|
| 298 |
+
"id": "ce9be966",
|
| 299 |
+
"metadata": {},
|
| 300 |
+
"outputs": [
|
| 301 |
+
{
|
| 302 |
+
"data": {
|
| 303 |
+
"text/plain": [
|
| 304 |
+
"'The image shows a person from behind, wearing a dark blue t-shirt and pink shorts. They are standing among a group of people, and the setting appears to be outdoors.'"
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
"execution_count": 38,
|
| 308 |
+
"metadata": {},
|
| 309 |
+
"output_type": "execute_result"
|
| 310 |
+
}
|
| 311 |
+
],
|
| 312 |
+
"source": [
|
| 313 |
+
"from openai import OpenAI\n",
|
| 314 |
+
"\n",
|
| 315 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:8082/v1\")\n",
|
| 316 |
+
"model_name = client.models.list().data[0].id\n",
|
| 317 |
+
"\n",
|
| 318 |
+
"def generate_content(image, prompt):\n",
|
| 319 |
+
" \n",
|
| 320 |
+
" url_of_pil_image = pil_to_url(image)\n",
|
| 321 |
+
" \n",
|
| 322 |
+
" response = client.chat.completions.create(\n",
|
| 323 |
+
" model=model_name,\n",
|
| 324 |
+
" messages=[\n",
|
| 325 |
+
" {\n",
|
| 326 |
+
" \"role\": \"user\",\n",
|
| 327 |
+
" \"content\": [\n",
|
| 328 |
+
" {\n",
|
| 329 |
+
" \"type\": \"text\",\n",
|
| 330 |
+
" \"text\": prompt,\n",
|
| 331 |
+
" },\n",
|
| 332 |
+
" {\n",
|
| 333 |
+
" \"type\": \"image_url\",\n",
|
| 334 |
+
" \"image_url\": {\n",
|
| 335 |
+
" \"url\": url_of_pil_image,\n",
|
| 336 |
+
" },\n",
|
| 337 |
+
" },\n",
|
| 338 |
+
" ],\n",
|
| 339 |
+
" }\n",
|
| 340 |
+
" ],\n",
|
| 341 |
+
" temperature=0.5,\n",
|
| 342 |
+
" top_p=0.8,\n",
|
| 343 |
+
" )\n",
|
| 344 |
+
" return response.choices[0].message.content\n",
|
| 345 |
+
"\n",
|
| 346 |
+
"generate_content(image=dataset[110][\"image\"], prompt=\"describe this image\")"
|
| 347 |
+
]
|
| 348 |
+
},
|
| 349 |
+
{
|
| 350 |
+
"cell_type": "code",
|
| 351 |
+
"execution_count": null,
|
| 352 |
+
"id": "8ebeb3b6",
|
| 353 |
+
"metadata": {},
|
| 354 |
+
"outputs": [],
|
| 355 |
+
"source": [
|
| 356 |
+
"PROMPT = '''\n",
|
| 357 |
+
"You are an AI assistant that helps users describe a given person from an image in detail. The image is taken from a surveillance camera and focuses on one person. Your caption must focus on the person and cover the following aspects:\n",
|
| 358 |
+
"\n",
|
| 359 |
+
"- Gender, age, and pose of the person\n",
|
| 360 |
+
"- Upper body clothing such as shirt, jacket, etc.\n",
|
| 361 |
+
"- Lower body clothing such as pants, skirt, etc.\n",
|
| 362 |
+
"- Accessories on head/face such as hat, glasses, etc.\n",
|
| 363 |
+
"- Accessories on body such as bag, watch, book, etc.\n",
|
| 364 |
+
"- Accessories on feet such as shoes, sandals, etc.\n",
|
| 365 |
+
"- Activities and interactions with other objects such as holding a phone, sitting on a bench, etc.\n",
|
| 366 |
+
"- Transportation such as car, bicycle, etc.\n",
|
| 367 |
+
"\n",
|
| 368 |
+
"Here are two example captions. \n",
|
| 369 |
+
"{EXAMPLE}\n",
|
| 370 |
+
"Please mimic the style, expression, and sentence structure of the examples without copying the specific details. If the example is unusual, please ignore it. \n",
|
| 371 |
+
"You must describe the person in your input image truthfully and in detail.\n",
|
| 372 |
+
"'''\n",
|
| 373 |
+
"\n",
|
| 374 |
+
"def make_prompt(prompt, example):\n",
|
| 375 |
+
" return prompt.format(EXAMPLE=example)\n"
|
| 376 |
+
]
|
| 377 |
+
},
|
| 378 |
+
{
|
| 379 |
+
"cell_type": "code",
|
| 380 |
+
"execution_count": null,
|
| 381 |
+
"id": "76cd677f",
|
| 382 |
+
"metadata": {},
|
| 383 |
+
"outputs": [],
|
| 384 |
+
"source": []
|
| 385 |
+
}
|
| 386 |
+
],
|
| 387 |
+
"metadata": {
|
| 388 |
+
"kernelspec": {
|
| 389 |
+
"display_name": "lmdeploy",
|
| 390 |
+
"language": "python",
|
| 391 |
+
"name": "lmdeploy"
|
| 392 |
+
},
|
| 393 |
+
"language_info": {
|
| 394 |
+
"codemirror_mode": {
|
| 395 |
+
"name": "ipython",
|
| 396 |
+
"version": 3
|
| 397 |
+
},
|
| 398 |
+
"file_extension": ".py",
|
| 399 |
+
"mimetype": "text/x-python",
|
| 400 |
+
"name": "python",
|
| 401 |
+
"nbconvert_exporter": "python",
|
| 402 |
+
"pygments_lexer": "ipython3",
|
| 403 |
+
"version": "3.8.19"
|
| 404 |
+
}
|
| 405 |
+
},
|
| 406 |
+
"nbformat": 4,
|
| 407 |
+
"nbformat_minor": 5
|
| 408 |
+
}
|
a_mllm_notebooks/openai/.ipynb_checkpoints/ping_server-checkpoint.ipynb
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 6,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"# !pip install openai\n",
|
| 10 |
+
"from openai import OpenAI\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:8082/v1\")\n",
|
| 13 |
+
"model_name = client.models.list().data[0].id\n",
|
| 14 |
+
"# response = client.chat.completions.create(\n",
|
| 15 |
+
"# model=model_name,\n",
|
| 16 |
+
"# messages=[\n",
|
| 17 |
+
"# {\n",
|
| 18 |
+
"# \"role\": \"system\",\n",
|
| 19 |
+
"# \"content\": \"You are a helpful assistant who is proficient in translating English to Chinese.\",\n",
|
| 20 |
+
"# },\n",
|
| 21 |
+
"# {\n",
|
| 22 |
+
"# \"role\": \"user\",\n",
|
| 23 |
+
"# \"content\": \"Please translate and paraphrase the following sentence into natural, fluent Chinese: \",\n",
|
| 24 |
+
"# },\n",
|
| 25 |
+
"# ],\n",
|
| 26 |
+
"# temperature=0.8,\n",
|
| 27 |
+
"# top_p=0.9,\n",
|
| 28 |
+
"# )\n",
|
| 29 |
+
"# print(response)"
|
| 30 |
+
]
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"cell_type": "code",
|
| 34 |
+
"execution_count": 8,
|
| 35 |
+
"metadata": {},
|
| 36 |
+
"outputs": [
|
| 37 |
+
{
|
| 38 |
+
"data": {
|
| 39 |
+
"text/plain": [
|
| 40 |
+
"24"
|
| 41 |
+
]
|
| 42 |
+
},
|
| 43 |
+
"execution_count": 8,
|
| 44 |
+
"metadata": {},
|
| 45 |
+
"output_type": "execute_result"
|
| 46 |
+
}
|
| 47 |
+
],
|
| 48 |
+
"source": [
|
| 49 |
+
"len(client.models.list().data)"
|
| 50 |
+
]
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"cell_type": "code",
|
| 54 |
+
"execution_count": 2,
|
| 55 |
+
"metadata": {},
|
| 56 |
+
"outputs": [
|
| 57 |
+
{
|
| 58 |
+
"data": {
|
| 59 |
+
"text/plain": [
|
| 60 |
+
"'这个男人穿着红色的衬衫和蓝色的牛仔裤。'"
|
| 61 |
+
]
|
| 62 |
+
},
|
| 63 |
+
"execution_count": 2,
|
| 64 |
+
"metadata": {},
|
| 65 |
+
"output_type": "execute_result"
|
| 66 |
+
}
|
| 67 |
+
],
|
| 68 |
+
"source": [
|
| 69 |
+
"def get_output(english_text):\n",
|
| 70 |
+
" response = client.chat.completions.create(\n",
|
| 71 |
+
" model=model_name,\n",
|
| 72 |
+
" messages=[\n",
|
| 73 |
+
" {\n",
|
| 74 |
+
" \"role\": \"system\",\n",
|
| 75 |
+
" \"content\": \"You are a helpful assistant who is proficient in translating English to Chinese.\",\n",
|
| 76 |
+
" },\n",
|
| 77 |
+
" {\n",
|
| 78 |
+
" \"role\": \"user\",\n",
|
| 79 |
+
" \"content\": \"Please translate and paraphrase the following sentence into natural, fluent Chinese: \" + english_text,\n",
|
| 80 |
+
" },\n",
|
| 81 |
+
" ],\n",
|
| 82 |
+
" temperature=0.7,\n",
|
| 83 |
+
" top_p=0.9,\n",
|
| 84 |
+
" )\n",
|
| 85 |
+
" return response.choices[0].message.content\n",
|
| 86 |
+
"\n",
|
| 87 |
+
"o = get_output(\"The man is wearing a red shirt and blue jeans.\" * 5)\n",
|
| 88 |
+
"o"
|
| 89 |
+
]
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"cell_type": "code",
|
| 93 |
+
"execution_count": 5,
|
| 94 |
+
"metadata": {},
|
| 95 |
+
"outputs": [
|
| 96 |
+
{
|
| 97 |
+
"data": {
|
| 98 |
+
"text/plain": [
|
| 99 |
+
"21"
|
| 100 |
+
]
|
| 101 |
+
},
|
| 102 |
+
"execution_count": 5,
|
| 103 |
+
"metadata": {},
|
| 104 |
+
"output_type": "execute_result"
|
| 105 |
+
}
|
| 106 |
+
],
|
| 107 |
+
"source": []
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"cell_type": "code",
|
| 111 |
+
"execution_count": 1,
|
| 112 |
+
"metadata": {},
|
| 113 |
+
"outputs": [],
|
| 114 |
+
"source": [
|
| 115 |
+
"# !ps aux|grep infer|grep -v grep | awk '{print $2}'|xargs kill -9"
|
| 116 |
+
]
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"cell_type": "code",
|
| 120 |
+
"execution_count": 5,
|
| 121 |
+
"metadata": {},
|
| 122 |
+
"outputs": [
|
| 123 |
+
{
|
| 124 |
+
"ename": "APIConnectionError",
|
| 125 |
+
"evalue": "Connection error.",
|
| 126 |
+
"output_type": "error",
|
| 127 |
+
"traceback": [
|
| 128 |
+
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 129 |
+
"\u001b[0;31mConnectError\u001b[0m Traceback (most recent call last)",
|
| 130 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpx/_transports/default.py:101\u001b[0m, in \u001b[0;36mmap_httpcore_exceptions\u001b[0;34m()\u001b[0m\n\u001b[1;32m 100\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m--> 101\u001b[0m \u001b[38;5;28;01myield\u001b[39;00m\n\u001b[1;32m 102\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m \u001b[38;5;167;01mException\u001b[39;00m \u001b[38;5;28;01mas\u001b[39;00m exc:\n",
|
| 131 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpx/_transports/default.py:250\u001b[0m, in \u001b[0;36mHTTPTransport.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 249\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m map_httpcore_exceptions():\n\u001b[0;32m--> 250\u001b[0m resp \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_pool\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mhandle_request\u001b[49m\u001b[43m(\u001b[49m\u001b[43mreq\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 252\u001b[0m \u001b[38;5;28;01massert\u001b[39;00m \u001b[38;5;28misinstance\u001b[39m(resp\u001b[38;5;241m.\u001b[39mstream, typing\u001b[38;5;241m.\u001b[39mIterable)\n",
|
| 132 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpcore/_sync/connection_pool.py:256\u001b[0m, in \u001b[0;36mConnectionPool.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 255\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_close_connections(closing)\n\u001b[0;32m--> 256\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m exc \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m\n\u001b[1;32m 258\u001b[0m \u001b[38;5;66;03m# Return the response. Note that in this case we still have to manage\u001b[39;00m\n\u001b[1;32m 259\u001b[0m \u001b[38;5;66;03m# the point at which the response is closed.\u001b[39;00m\n",
|
| 133 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpcore/_sync/connection_pool.py:236\u001b[0m, in \u001b[0;36mConnectionPool.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 234\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[1;32m 235\u001b[0m \u001b[38;5;66;03m# Send the request on the assigned connection.\u001b[39;00m\n\u001b[0;32m--> 236\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[43mconnection\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mhandle_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 237\u001b[0m \u001b[43m \u001b[49m\u001b[43mpool_request\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mrequest\u001b[49m\n\u001b[1;32m 238\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 239\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m ConnectionNotAvailable:\n\u001b[1;32m 240\u001b[0m \u001b[38;5;66;03m# In some cases a connection may initially be available to\u001b[39;00m\n\u001b[1;32m 241\u001b[0m \u001b[38;5;66;03m# handle a request, but then become unavailable.\u001b[39;00m\n\u001b[1;32m 242\u001b[0m \u001b[38;5;66;03m#\u001b[39;00m\n\u001b[1;32m 243\u001b[0m \u001b[38;5;66;03m# In this case we clear the connection and try again.\u001b[39;00m\n",
|
| 134 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpcore/_sync/connection.py:101\u001b[0m, in \u001b[0;36mHTTPConnection.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 100\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_connect_failed \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;01mTrue\u001b[39;00m\n\u001b[0;32m--> 101\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m exc\n\u001b[1;32m 103\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_connection\u001b[38;5;241m.\u001b[39mhandle_request(request)\n",
|
| 135 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpcore/_sync/connection.py:78\u001b[0m, in \u001b[0;36mHTTPConnection.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 77\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_connection \u001b[38;5;129;01mis\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m:\n\u001b[0;32m---> 78\u001b[0m stream \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_connect\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 80\u001b[0m ssl_object \u001b[38;5;241m=\u001b[39m stream\u001b[38;5;241m.\u001b[39mget_extra_info(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mssl_object\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n",
|
| 136 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpcore/_sync/connection.py:124\u001b[0m, in \u001b[0;36mHTTPConnection._connect\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 123\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m Trace(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mconnect_tcp\u001b[39m\u001b[38;5;124m\"\u001b[39m, logger, request, kwargs) \u001b[38;5;28;01mas\u001b[39;00m trace:\n\u001b[0;32m--> 124\u001b[0m stream \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_network_backend\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mconnect_tcp\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;241;43m*\u001b[39;49m\u001b[38;5;241;43m*\u001b[39;49m\u001b[43mkwargs\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 125\u001b[0m trace\u001b[38;5;241m.\u001b[39mreturn_value \u001b[38;5;241m=\u001b[39m stream\n",
|
| 137 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpcore/_backends/sync.py:207\u001b[0m, in \u001b[0;36mSyncBackend.connect_tcp\u001b[0;34m(self, host, port, timeout, local_address, socket_options)\u001b[0m\n\u001b[1;32m 202\u001b[0m exc_map: ExceptionMapping \u001b[38;5;241m=\u001b[39m {\n\u001b[1;32m 203\u001b[0m socket\u001b[38;5;241m.\u001b[39mtimeout: ConnectTimeout,\n\u001b[1;32m 204\u001b[0m \u001b[38;5;167;01mOSError\u001b[39;00m: ConnectError,\n\u001b[1;32m 205\u001b[0m }\n\u001b[0;32m--> 207\u001b[0m \u001b[43m\u001b[49m\u001b[38;5;28;43;01mwith\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[43mmap_exceptions\u001b[49m\u001b[43m(\u001b[49m\u001b[43mexc_map\u001b[49m\u001b[43m)\u001b[49m\u001b[43m:\u001b[49m\n\u001b[1;32m 208\u001b[0m \u001b[43m \u001b[49m\u001b[43msock\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43m \u001b[49m\u001b[43msocket\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mcreate_connection\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 209\u001b[0m \u001b[43m \u001b[49m\u001b[43maddress\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 210\u001b[0m \u001b[43m \u001b[49m\u001b[43mtimeout\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 211\u001b[0m \u001b[43m \u001b[49m\u001b[43msource_address\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43msource_address\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 212\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n",
|
| 138 |
+
"File \u001b[0;32m/usr/lib/python3.11/contextlib.py:155\u001b[0m, in \u001b[0;36m_GeneratorContextManager.__exit__\u001b[0;34m(self, typ, value, traceback)\u001b[0m\n\u001b[1;32m 154\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m--> 155\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39mgen\u001b[38;5;241m.\u001b[39mthrow(typ, value, traceback)\n\u001b[1;32m 156\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m \u001b[38;5;167;01mStopIteration\u001b[39;00m \u001b[38;5;28;01mas\u001b[39;00m exc:\n\u001b[1;32m 157\u001b[0m \u001b[38;5;66;03m# Suppress StopIteration *unless* it's the same exception that\u001b[39;00m\n\u001b[1;32m 158\u001b[0m \u001b[38;5;66;03m# was passed to throw(). This prevents a StopIteration\u001b[39;00m\n\u001b[1;32m 159\u001b[0m \u001b[38;5;66;03m# raised inside the \"with\" statement from being suppressed.\u001b[39;00m\n",
|
| 139 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpcore/_exceptions.py:14\u001b[0m, in \u001b[0;36mmap_exceptions\u001b[0;34m(map)\u001b[0m\n\u001b[1;32m 13\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28misinstance\u001b[39m(exc, from_exc):\n\u001b[0;32m---> 14\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m to_exc(exc) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01mexc\u001b[39;00m\n\u001b[1;32m 15\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m\n",
|
| 140 |
+
"\u001b[0;31mConnectError\u001b[0m: [Errno 111] Connection refused",
|
| 141 |
+
"\nThe above exception was the direct cause of the following exception:\n",
|
| 142 |
+
"\u001b[0;31mConnectError\u001b[0m Traceback (most recent call last)",
|
| 143 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:993\u001b[0m, in \u001b[0;36mSyncAPIClient._request\u001b[0;34m(self, cast_to, options, retries_taken, stream, stream_cls)\u001b[0m\n\u001b[1;32m 992\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m--> 993\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_client\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43msend\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 994\u001b[0m \u001b[43m \u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 995\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;129;43;01mor\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_should_stream_response_body\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrequest\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mrequest\u001b[49m\u001b[43m)\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 996\u001b[0m \u001b[43m \u001b[49m\u001b[38;5;241;43m*\u001b[39;49m\u001b[38;5;241;43m*\u001b[39;49m\u001b[43mkwargs\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 997\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 998\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m httpx\u001b[38;5;241m.\u001b[39mTimeoutException \u001b[38;5;28;01mas\u001b[39;00m err:\n",
|
| 144 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpx/_client.py:914\u001b[0m, in \u001b[0;36mClient.send\u001b[0;34m(self, request, stream, auth, follow_redirects)\u001b[0m\n\u001b[1;32m 912\u001b[0m auth \u001b[38;5;241m=\u001b[39m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_build_request_auth(request, auth)\n\u001b[0;32m--> 914\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_send_handling_auth\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 915\u001b[0m \u001b[43m \u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 916\u001b[0m \u001b[43m \u001b[49m\u001b[43mauth\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mauth\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 917\u001b[0m \u001b[43m \u001b[49m\u001b[43mfollow_redirects\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mfollow_redirects\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 918\u001b[0m \u001b[43m \u001b[49m\u001b[43mhistory\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43m[\u001b[49m\u001b[43m]\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 919\u001b[0m \u001b[43m\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 920\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n",
|
| 145 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpx/_client.py:942\u001b[0m, in \u001b[0;36mClient._send_handling_auth\u001b[0;34m(self, request, auth, follow_redirects, history)\u001b[0m\n\u001b[1;32m 941\u001b[0m \u001b[38;5;28;01mwhile\u001b[39;00m \u001b[38;5;28;01mTrue\u001b[39;00m:\n\u001b[0;32m--> 942\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_send_handling_redirects\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 943\u001b[0m \u001b[43m \u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 944\u001b[0m \u001b[43m \u001b[49m\u001b[43mfollow_redirects\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mfollow_redirects\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 945\u001b[0m \u001b[43m \u001b[49m\u001b[43mhistory\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mhistory\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 946\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 947\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n",
|
| 146 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpx/_client.py:979\u001b[0m, in \u001b[0;36mClient._send_handling_redirects\u001b[0;34m(self, request, follow_redirects, history)\u001b[0m\n\u001b[1;32m 977\u001b[0m hook(request)\n\u001b[0;32m--> 979\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_send_single_request\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 980\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n",
|
| 147 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpx/_client.py:1014\u001b[0m, in \u001b[0;36mClient._send_single_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 1013\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m request_context(request\u001b[38;5;241m=\u001b[39mrequest):\n\u001b[0;32m-> 1014\u001b[0m response \u001b[38;5;241m=\u001b[39m \u001b[43mtransport\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mhandle_request\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrequest\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 1016\u001b[0m \u001b[38;5;28;01massert\u001b[39;00m \u001b[38;5;28misinstance\u001b[39m(response\u001b[38;5;241m.\u001b[39mstream, SyncByteStream)\n",
|
| 148 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpx/_transports/default.py:249\u001b[0m, in \u001b[0;36mHTTPTransport.handle_request\u001b[0;34m(self, request)\u001b[0m\n\u001b[1;32m 237\u001b[0m req \u001b[38;5;241m=\u001b[39m httpcore\u001b[38;5;241m.\u001b[39mRequest(\n\u001b[1;32m 238\u001b[0m method\u001b[38;5;241m=\u001b[39mrequest\u001b[38;5;241m.\u001b[39mmethod,\n\u001b[1;32m 239\u001b[0m url\u001b[38;5;241m=\u001b[39mhttpcore\u001b[38;5;241m.\u001b[39mURL(\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 247\u001b[0m extensions\u001b[38;5;241m=\u001b[39mrequest\u001b[38;5;241m.\u001b[39mextensions,\n\u001b[1;32m 248\u001b[0m )\n\u001b[0;32m--> 249\u001b[0m \u001b[43m\u001b[49m\u001b[38;5;28;43;01mwith\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[43mmap_httpcore_exceptions\u001b[49m\u001b[43m(\u001b[49m\u001b[43m)\u001b[49m\u001b[43m:\u001b[49m\n\u001b[1;32m 250\u001b[0m \u001b[43m \u001b[49m\u001b[43mresp\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43m \u001b[49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_pool\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mhandle_request\u001b[49m\u001b[43m(\u001b[49m\u001b[43mreq\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 149 |
+
"File \u001b[0;32m/usr/lib/python3.11/contextlib.py:155\u001b[0m, in \u001b[0;36m_GeneratorContextManager.__exit__\u001b[0;34m(self, typ, value, traceback)\u001b[0m\n\u001b[1;32m 154\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m--> 155\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39mgen\u001b[38;5;241m.\u001b[39mthrow(typ, value, traceback)\n\u001b[1;32m 156\u001b[0m \u001b[38;5;28;01mexcept\u001b[39;00m \u001b[38;5;167;01mStopIteration\u001b[39;00m \u001b[38;5;28;01mas\u001b[39;00m exc:\n\u001b[1;32m 157\u001b[0m \u001b[38;5;66;03m# Suppress StopIteration *unless* it's the same exception that\u001b[39;00m\n\u001b[1;32m 158\u001b[0m \u001b[38;5;66;03m# was passed to throw(). This prevents a StopIteration\u001b[39;00m\n\u001b[1;32m 159\u001b[0m \u001b[38;5;66;03m# raised inside the \"with\" statement from being suppressed.\u001b[39;00m\n",
|
| 150 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/httpx/_transports/default.py:118\u001b[0m, in \u001b[0;36mmap_httpcore_exceptions\u001b[0;34m()\u001b[0m\n\u001b[1;32m 117\u001b[0m message \u001b[38;5;241m=\u001b[39m \u001b[38;5;28mstr\u001b[39m(exc)\n\u001b[0;32m--> 118\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m mapped_exc(message) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01mexc\u001b[39;00m\n",
|
| 151 |
+
"\u001b[0;31mConnectError\u001b[0m: [Errno 111] Connection refused",
|
| 152 |
+
"\nThe above exception was the direct cause of the following exception:\n",
|
| 153 |
+
"\u001b[0;31mAPIConnectionError\u001b[0m Traceback (most recent call last)",
|
| 154 |
+
"Cell \u001b[0;32mIn[5], line 6\u001b[0m\n\u001b[1;32m 3\u001b[0m port \u001b[38;5;241m=\u001b[39m \u001b[38;5;241m2000\u001b[39m\n\u001b[1;32m 5\u001b[0m client \u001b[38;5;241m=\u001b[39m OpenAI(api_key\u001b[38;5;241m=\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mYOUR_API_KEY\u001b[39m\u001b[38;5;124m\"\u001b[39m, base_url\u001b[38;5;241m=\u001b[39m\u001b[38;5;124mf\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mhttp://0.0.0.0:\u001b[39m\u001b[38;5;132;01m{\u001b[39;00mport\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m/v1\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[0;32m----> 6\u001b[0m model_name \u001b[38;5;241m=\u001b[39m \u001b[43mclient\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mmodels\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mlist\u001b[49m\u001b[43m(\u001b[49m\u001b[43m)\u001b[49m\u001b[38;5;241m.\u001b[39mdata[\u001b[38;5;241m0\u001b[39m]\u001b[38;5;241m.\u001b[39mid\n\u001b[1;32m 7\u001b[0m response \u001b[38;5;241m=\u001b[39m client\u001b[38;5;241m.\u001b[39mchat\u001b[38;5;241m.\u001b[39mcompletions\u001b[38;5;241m.\u001b[39mcreate(\n\u001b[1;32m 8\u001b[0m model\u001b[38;5;241m=\u001b[39mmodel_name,\n\u001b[1;32m 9\u001b[0m messages\u001b[38;5;241m=\u001b[39m[\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 27\u001b[0m top_p\u001b[38;5;241m=\u001b[39m\u001b[38;5;241m0.8\u001b[39m,\n\u001b[1;32m 28\u001b[0m )\n\u001b[1;32m 29\u001b[0m \u001b[38;5;28mprint\u001b[39m(response)\n",
|
| 155 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/resources/models.py:91\u001b[0m, in \u001b[0;36mModels.list\u001b[0;34m(self, extra_headers, extra_query, extra_body, timeout)\u001b[0m\n\u001b[1;32m 77\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mlist\u001b[39m(\n\u001b[1;32m 78\u001b[0m \u001b[38;5;28mself\u001b[39m,\n\u001b[1;32m 79\u001b[0m \u001b[38;5;241m*\u001b[39m,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 85\u001b[0m timeout: \u001b[38;5;28mfloat\u001b[39m \u001b[38;5;241m|\u001b[39m httpx\u001b[38;5;241m.\u001b[39mTimeout \u001b[38;5;241m|\u001b[39m \u001b[38;5;28;01mNone\u001b[39;00m \u001b[38;5;241m|\u001b[39m NotGiven \u001b[38;5;241m=\u001b[39m NOT_GIVEN,\n\u001b[1;32m 86\u001b[0m ) \u001b[38;5;241m-\u001b[39m\u001b[38;5;241m>\u001b[39m SyncPage[Model]:\n\u001b[1;32m 87\u001b[0m \u001b[38;5;250m \u001b[39m\u001b[38;5;124;03m\"\"\"\u001b[39;00m\n\u001b[1;32m 88\u001b[0m \u001b[38;5;124;03m Lists the currently available models, and provides basic information about each\u001b[39;00m\n\u001b[1;32m 89\u001b[0m \u001b[38;5;124;03m one such as the owner and availability.\u001b[39;00m\n\u001b[1;32m 90\u001b[0m \u001b[38;5;124;03m \"\"\"\u001b[39;00m\n\u001b[0;32m---> 91\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_get_api_list\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 92\u001b[0m \u001b[43m \u001b[49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[38;5;124;43m/models\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[43m,\u001b[49m\n\u001b[1;32m 93\u001b[0m \u001b[43m \u001b[49m\u001b[43mpage\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mSyncPage\u001b[49m\u001b[43m[\u001b[49m\u001b[43mModel\u001b[49m\u001b[43m]\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 94\u001b[0m \u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mmake_request_options\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 95\u001b[0m \u001b[43m \u001b[49m\u001b[43mextra_headers\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mextra_headers\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mextra_query\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mextra_query\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mextra_body\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mextra_body\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mtimeout\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mtimeout\u001b[49m\n\u001b[1;32m 96\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 97\u001b[0m \u001b[43m \u001b[49m\u001b[43mmodel\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mModel\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 98\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n",
|
| 156 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:1329\u001b[0m, in \u001b[0;36mSyncAPIClient.get_api_list\u001b[0;34m(self, path, model, page, body, options, method)\u001b[0m\n\u001b[1;32m 1318\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mget_api_list\u001b[39m(\n\u001b[1;32m 1319\u001b[0m \u001b[38;5;28mself\u001b[39m,\n\u001b[1;32m 1320\u001b[0m path: \u001b[38;5;28mstr\u001b[39m,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 1326\u001b[0m method: \u001b[38;5;28mstr\u001b[39m \u001b[38;5;241m=\u001b[39m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mget\u001b[39m\u001b[38;5;124m\"\u001b[39m,\n\u001b[1;32m 1327\u001b[0m ) \u001b[38;5;241m-\u001b[39m\u001b[38;5;241m>\u001b[39m SyncPageT:\n\u001b[1;32m 1328\u001b[0m opts \u001b[38;5;241m=\u001b[39m FinalRequestOptions\u001b[38;5;241m.\u001b[39mconstruct(method\u001b[38;5;241m=\u001b[39mmethod, url\u001b[38;5;241m=\u001b[39mpath, json_data\u001b[38;5;241m=\u001b[39mbody, \u001b[38;5;241m*\u001b[39m\u001b[38;5;241m*\u001b[39moptions)\n\u001b[0;32m-> 1329\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_request_api_list\u001b[49m\u001b[43m(\u001b[49m\u001b[43mmodel\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mpage\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mopts\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 157 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:1180\u001b[0m, in \u001b[0;36mSyncAPIClient._request_api_list\u001b[0;34m(self, model, page, options)\u001b[0m\n\u001b[1;32m 1176\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m resp\n\u001b[1;32m 1178\u001b[0m options\u001b[38;5;241m.\u001b[39mpost_parser \u001b[38;5;241m=\u001b[39m _parser\n\u001b[0;32m-> 1180\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mrequest\u001b[49m\u001b[43m(\u001b[49m\u001b[43mpage\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43;01mFalse\u001b[39;49;00m\u001b[43m)\u001b[49m\n",
|
| 158 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:957\u001b[0m, in \u001b[0;36mSyncAPIClient.request\u001b[0;34m(self, cast_to, options, remaining_retries, stream, stream_cls)\u001b[0m\n\u001b[1;32m 954\u001b[0m \u001b[38;5;28;01melse\u001b[39;00m:\n\u001b[1;32m 955\u001b[0m retries_taken \u001b[38;5;241m=\u001b[39m \u001b[38;5;241m0\u001b[39m\n\u001b[0;32m--> 957\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 958\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 959\u001b[0m \u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43moptions\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 960\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 961\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 962\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 963\u001b[0m \u001b[43m\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 159 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:1017\u001b[0m, in \u001b[0;36mSyncAPIClient._request\u001b[0;34m(self, cast_to, options, retries_taken, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1014\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mEncountered Exception\u001b[39m\u001b[38;5;124m\"\u001b[39m, exc_info\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mTrue\u001b[39;00m)\n\u001b[1;32m 1016\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m remaining_retries \u001b[38;5;241m>\u001b[39m \u001b[38;5;241m0\u001b[39m:\n\u001b[0;32m-> 1017\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_retry_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1018\u001b[0m \u001b[43m \u001b[49m\u001b[43minput_options\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1019\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1020\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1021\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1022\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1023\u001b[0m \u001b[43m \u001b[49m\u001b[43mresponse_headers\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43;01mNone\u001b[39;49;00m\u001b[43m,\u001b[49m\n\u001b[1;32m 1024\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 1026\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRaising connection error\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[1;32m 1027\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m APIConnectionError(request\u001b[38;5;241m=\u001b[39mrequest) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01merr\u001b[39;00m\n",
|
| 160 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:1095\u001b[0m, in \u001b[0;36mSyncAPIClient._retry_request\u001b[0;34m(self, options, cast_to, retries_taken, response_headers, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1091\u001b[0m \u001b[38;5;66;03m# In a synchronous context we are blocking the entire thread. Up to the library user to run the client in a\u001b[39;00m\n\u001b[1;32m 1092\u001b[0m \u001b[38;5;66;03m# different thread if necessary.\u001b[39;00m\n\u001b[1;32m 1093\u001b[0m time\u001b[38;5;241m.\u001b[39msleep(timeout)\n\u001b[0;32m-> 1095\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1096\u001b[0m \u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43moptions\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1097\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1098\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;241;43m+\u001b[39;49m\u001b[43m \u001b[49m\u001b[38;5;241;43m1\u001b[39;49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1099\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1100\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1101\u001b[0m \u001b[43m\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 161 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:1017\u001b[0m, in \u001b[0;36mSyncAPIClient._request\u001b[0;34m(self, cast_to, options, retries_taken, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1014\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mEncountered Exception\u001b[39m\u001b[38;5;124m\"\u001b[39m, exc_info\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mTrue\u001b[39;00m)\n\u001b[1;32m 1016\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m remaining_retries \u001b[38;5;241m>\u001b[39m \u001b[38;5;241m0\u001b[39m:\n\u001b[0;32m-> 1017\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_retry_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1018\u001b[0m \u001b[43m \u001b[49m\u001b[43minput_options\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1019\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1020\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1021\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1022\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1023\u001b[0m \u001b[43m \u001b[49m\u001b[43mresponse_headers\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43;01mNone\u001b[39;49;00m\u001b[43m,\u001b[49m\n\u001b[1;32m 1024\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 1026\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRaising connection error\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[1;32m 1027\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m APIConnectionError(request\u001b[38;5;241m=\u001b[39mrequest) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01merr\u001b[39;00m\n",
|
| 162 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:1095\u001b[0m, in \u001b[0;36mSyncAPIClient._retry_request\u001b[0;34m(self, options, cast_to, retries_taken, response_headers, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1091\u001b[0m \u001b[38;5;66;03m# In a synchronous context we are blocking the entire thread. Up to the library user to run the client in a\u001b[39;00m\n\u001b[1;32m 1092\u001b[0m \u001b[38;5;66;03m# different thread if necessary.\u001b[39;00m\n\u001b[1;32m 1093\u001b[0m time\u001b[38;5;241m.\u001b[39msleep(timeout)\n\u001b[0;32m-> 1095\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_request\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 1096\u001b[0m \u001b[43m \u001b[49m\u001b[43moptions\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43moptions\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1097\u001b[0m \u001b[43m \u001b[49m\u001b[43mcast_to\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mcast_to\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1098\u001b[0m \u001b[43m \u001b[49m\u001b[43mretries_taken\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mretries_taken\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;241;43m+\u001b[39;49m\u001b[43m \u001b[49m\u001b[38;5;241;43m1\u001b[39;49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1099\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1100\u001b[0m \u001b[43m \u001b[49m\u001b[43mstream_cls\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mstream_cls\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 1101\u001b[0m \u001b[43m\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 163 |
+
"File \u001b[0;32m/usr/local/lib/python3.11/dist-packages/openai/_base_client.py:1027\u001b[0m, in \u001b[0;36mSyncAPIClient._request\u001b[0;34m(self, cast_to, options, retries_taken, stream, stream_cls)\u001b[0m\n\u001b[1;32m 1017\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_retry_request(\n\u001b[1;32m 1018\u001b[0m input_options,\n\u001b[1;32m 1019\u001b[0m cast_to,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 1023\u001b[0m response_headers\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mNone\u001b[39;00m,\n\u001b[1;32m 1024\u001b[0m )\n\u001b[1;32m 1026\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRaising connection error\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[0;32m-> 1027\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m APIConnectionError(request\u001b[38;5;241m=\u001b[39mrequest) \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01merr\u001b[39;00m\n\u001b[1;32m 1029\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\n\u001b[1;32m 1030\u001b[0m \u001b[38;5;124m'\u001b[39m\u001b[38;5;124mHTTP Response: \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m \u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;132;01m%i\u001b[39;00m\u001b[38;5;124m \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124m \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m'\u001b[39m,\n\u001b[1;32m 1031\u001b[0m request\u001b[38;5;241m.\u001b[39mmethod,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 1035\u001b[0m response\u001b[38;5;241m.\u001b[39mheaders,\n\u001b[1;32m 1036\u001b[0m )\n\u001b[1;32m 1037\u001b[0m log\u001b[38;5;241m.\u001b[39mdebug(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mrequest_id: \u001b[39m\u001b[38;5;132;01m%s\u001b[39;00m\u001b[38;5;124m\"\u001b[39m, response\u001b[38;5;241m.\u001b[39mheaders\u001b[38;5;241m.\u001b[39mget(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mx-request-id\u001b[39m\u001b[38;5;124m\"\u001b[39m))\n",
|
| 164 |
+
"\u001b[0;31mAPIConnectionError\u001b[0m: Connection error."
|
| 165 |
+
]
|
| 166 |
+
}
|
| 167 |
+
],
|
| 168 |
+
"source": [
|
| 169 |
+
"from openai import OpenAI\n",
|
| 170 |
+
"\n",
|
| 171 |
+
"port = 2000\n",
|
| 172 |
+
"\n",
|
| 173 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=f\"http://0.0.0.0:{port}/v1\")\n",
|
| 174 |
+
"model_name = client.models.list().data[0].id\n",
|
| 175 |
+
"response = client.chat.completions.create(\n",
|
| 176 |
+
" model=model_name,\n",
|
| 177 |
+
" messages=[\n",
|
| 178 |
+
" {\n",
|
| 179 |
+
" \"role\": \"user\",\n",
|
| 180 |
+
" \"content\": [\n",
|
| 181 |
+
" {\n",
|
| 182 |
+
" \"type\": \"text\",\n",
|
| 183 |
+
" \"text\": \"Miêu tả bức tranh giùm coi\",\n",
|
| 184 |
+
" },\n",
|
| 185 |
+
" {\n",
|
| 186 |
+
" \"type\": \"image_url\",\n",
|
| 187 |
+
" \"image_url\": {\n",
|
| 188 |
+
" \"url\": \"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg\",\n",
|
| 189 |
+
" },\n",
|
| 190 |
+
" },\n",
|
| 191 |
+
" ],\n",
|
| 192 |
+
" }\n",
|
| 193 |
+
" ],\n",
|
| 194 |
+
" temperature=0.8,\n",
|
| 195 |
+
" top_p=0.8,\n",
|
| 196 |
+
")\n",
|
| 197 |
+
"print(response)"
|
| 198 |
+
]
|
| 199 |
+
},
|
| 200 |
+
{
|
| 201 |
+
"cell_type": "code",
|
| 202 |
+
"execution_count": null,
|
| 203 |
+
"metadata": {},
|
| 204 |
+
"outputs": [],
|
| 205 |
+
"source": [
|
| 206 |
+
"model_name"
|
| 207 |
+
]
|
| 208 |
+
},
|
| 209 |
+
{
|
| 210 |
+
"cell_type": "code",
|
| 211 |
+
"execution_count": null,
|
| 212 |
+
"metadata": {},
|
| 213 |
+
"outputs": [],
|
| 214 |
+
"source": [
|
| 215 |
+
"response.choices[0].message.content"
|
| 216 |
+
]
|
| 217 |
+
},
|
| 218 |
+
{
|
| 219 |
+
"cell_type": "code",
|
| 220 |
+
"execution_count": null,
|
| 221 |
+
"metadata": {},
|
| 222 |
+
"outputs": [],
|
| 223 |
+
"source": []
|
| 224 |
+
},
|
| 225 |
+
{
|
| 226 |
+
"cell_type": "code",
|
| 227 |
+
"execution_count": 12,
|
| 228 |
+
"metadata": {},
|
| 229 |
+
"outputs": [
|
| 230 |
+
{
|
| 231 |
+
"name": "stderr",
|
| 232 |
+
"output_type": "stream",
|
| 233 |
+
"text": [
|
| 234 |
+
" % Total % Received % Xferd Average Speed Time Time Time Current\n",
|
| 235 |
+
" Dload Upload Total Spent Left Speed\n",
|
| 236 |
+
"100 617 100 404 100 213 5970 3147 --:--:-- --:--:-- --:--:-- 9208\n"
|
| 237 |
+
]
|
| 238 |
+
},
|
| 239 |
+
{
|
| 240 |
+
"name": "stdout",
|
| 241 |
+
"output_type": "stream",
|
| 242 |
+
"text": [
|
| 243 |
+
"{\"id\":\"chatcmpl-8b3b1360415d4805a44f33bd81fc3447\",\"object\":\"chat.completion\",\"created\":1734879441,\"model\":\"Qwen/Qwen2.5-1.5B-Instruct\",\"choices\":[{\"index\":0,\"message\":{\"role\":\"assistant\",\"content\":\"巴黎\",\"tool_calls\":[]},\"logprobs\":null,\"finish_reason\":\"stop\",\"stop_reason\":null}],\"usage\":{\"prompt_tokens\":48,\"total_tokens\":50,\"completion_tokens\":2,\"prompt_tokens_details\":null},\"prompt_logprobs\":null}"
|
| 244 |
+
]
|
| 245 |
+
}
|
| 246 |
+
],
|
| 247 |
+
"source": [
|
| 248 |
+
"%%bash\n",
|
| 249 |
+
"# Call the server using curl:\n",
|
| 250 |
+
"curl -X POST \"http://localhost:8000/v1/chat/completions\" \\\n",
|
| 251 |
+
"\t-H \"Content-Type: application/json\" \\\n",
|
| 252 |
+
"\t--data '{\n",
|
| 253 |
+
"\t\t\"model\": \"Qwen/Qwen2.5-1.5B-Instruct\",\n",
|
| 254 |
+
"\t\t\"messages\": [\n",
|
| 255 |
+
"\t\t\t{\n",
|
| 256 |
+
"\t\t\t\t\"role\": \"user\",\n",
|
| 257 |
+
"\t\t\t\t\"content\": \"What is the capital of France? You must answer in Chinese without adding any comment or explanation.\"\n",
|
| 258 |
+
"\t\t\t}\n",
|
| 259 |
+
"\t\t]\n",
|
| 260 |
+
"\t}'"
|
| 261 |
+
]
|
| 262 |
+
},
|
| 263 |
+
{
|
| 264 |
+
"cell_type": "code",
|
| 265 |
+
"execution_count": null,
|
| 266 |
+
"metadata": {},
|
| 267 |
+
"outputs": [],
|
| 268 |
+
"source": []
|
| 269 |
+
}
|
| 270 |
+
],
|
| 271 |
+
"metadata": {
|
| 272 |
+
"kernelspec": {
|
| 273 |
+
"display_name": "lmdeploy",
|
| 274 |
+
"language": "python",
|
| 275 |
+
"name": "lmdeploy"
|
| 276 |
+
},
|
| 277 |
+
"language_info": {
|
| 278 |
+
"codemirror_mode": {
|
| 279 |
+
"name": "ipython",
|
| 280 |
+
"version": 3
|
| 281 |
+
},
|
| 282 |
+
"file_extension": ".py",
|
| 283 |
+
"mimetype": "text/x-python",
|
| 284 |
+
"name": "python",
|
| 285 |
+
"nbconvert_exporter": "python",
|
| 286 |
+
"pygments_lexer": "ipython3",
|
| 287 |
+
"version": "3.8.19"
|
| 288 |
+
}
|
| 289 |
+
},
|
| 290 |
+
"nbformat": 4,
|
| 291 |
+
"nbformat_minor": 4
|
| 292 |
+
}
|
a_mllm_notebooks/openai/.ipynb_checkpoints/serve-checkpoint.sh
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
eval "$(conda shell.bash hook)"
|
| 2 |
+
conda activate lmdeploy
|
| 3 |
+
# # MODEL_NAME=OpenGVLab/InternVL2_5-8B-AWQ
|
| 4 |
+
MODEL_NAME=OpenGVLab/InternVL2_5-4B-MPO-AWQ
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
PORT_LIST=( $(seq 5911 1 5911) )
|
| 8 |
+
for PORT in "${PORT_LIST[@]}"; do
|
| 9 |
+
# get random device id from 0 to 3
|
| 10 |
+
# RANDOM_DEVICE_ID=$((RANDOM % 3))
|
| 11 |
+
# RANDOM_DEVICE_ID=3
|
| 12 |
+
# CUDA_VISIBLE_DEVICES=0,1 \
|
| 13 |
+
# CUDA_VISIBLE_DEVICES=2,3 \
|
| 14 |
+
CUDA_VISIBLE_DEVICES=1 \
|
| 15 |
+
lmdeploy serve api_server $MODEL_NAME \
|
| 16 |
+
--server-port $PORT \
|
| 17 |
+
--backend turbomind \
|
| 18 |
+
--dtype float16 --proxy-url http://0.0.0.0:7089 \
|
| 19 |
+
--vision-max-batch-size 64 &
|
| 20 |
+
# --cache-max-entry-count 0.4 &
|
| 21 |
+
# --tp 1 &
|
| 22 |
+
# &
|
| 23 |
+
done
|
| 24 |
+
|
| 25 |
+
PORT_LIST=( $(seq 5972 1 5972) )
|
| 26 |
+
for PORT in "${PORT_LIST[@]}"; do
|
| 27 |
+
# get random device id from 0 to 3
|
| 28 |
+
# RANDOM_DEVICE_ID=$((RANDOM % 3))
|
| 29 |
+
# RANDOM_DEVICE_ID=3
|
| 30 |
+
# CUDA_VISIBLE_DEVICES=0,1 \
|
| 31 |
+
# CUDA_VISIBLE_DEVICES=2,3 \
|
| 32 |
+
CUDA_VISIBLE_DEVICES=2 \
|
| 33 |
+
lmdeploy serve api_server $MODEL_NAME \
|
| 34 |
+
--server-port $PORT \
|
| 35 |
+
--backend turbomind \
|
| 36 |
+
--dtype float16 --proxy-url http://0.0.0.0:7089 \
|
| 37 |
+
--vision-max-batch-size 64 &
|
| 38 |
+
# --cache-max-entry-count 0.4 &
|
| 39 |
+
# --tp 1 &
|
| 40 |
+
# &
|
| 41 |
+
done
|
| 42 |
+
|
| 43 |
+
PORT_LIST=( $(seq 5171 1 5171) )
|
| 44 |
+
for PORT in "${PORT_LIST[@]}"; do
|
| 45 |
+
# get random device id from 0 to 3
|
| 46 |
+
# RANDOM_DEVICE_ID=$((RANDOM % 3))
|
| 47 |
+
# RANDOM_DEVICE_ID=3
|
| 48 |
+
# CUDA_VISIBLE_DEVICES=0,1 \
|
| 49 |
+
# CUDA_VISIBLE_DEVICES=2,3 \
|
| 50 |
+
CUDA_VISIBLE_DEVICES=1 \
|
| 51 |
+
lmdeploy serve api_server $MODEL_NAME \
|
| 52 |
+
--server-port $PORT \
|
| 53 |
+
--backend turbomind \
|
| 54 |
+
--dtype float16 --proxy-url http://0.0.0.0:7089 \
|
| 55 |
+
--vision-max-batch-size 64 &
|
| 56 |
+
# --cache-max-entry-count 0.4 &
|
| 57 |
+
# --tp 1 &
|
| 58 |
+
# &
|
| 59 |
+
done
|
| 60 |
+
|
a_mllm_notebooks/openai/.ipynb_checkpoints/temp-checkpoint.sh
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
eval "$(conda shell.bash hook)"
|
| 2 |
+
conda activate lmdeploy
|
| 3 |
+
MODEL_NAME=Qwen/Qwen2.5-1.5B-Instruct-AWQ
|
| 4 |
+
PORT_LIST=( $(seq 3162 1 3162) )
|
| 5 |
+
for PORT in "${PORT_LIST[@]}"; do
|
| 6 |
+
CUDA_VISIBLE_DEVICES=0,1,2,3 \
|
| 7 |
+
lmdeploy serve api_server $MODEL_NAME \
|
| 8 |
+
--server-port $PORT \
|
| 9 |
+
--backend turbomind \
|
| 10 |
+
--dtype float16 --proxy-url http://0.0.0.0:8082 \
|
| 11 |
+
--cache-max-entry-count 0.0075 --tp 3 &
|
| 12 |
+
done
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# # PORT_LIST from 3063 to 3099
|
| 16 |
+
# PORT_LIST=( $(seq 9000 1 9000) )
|
| 17 |
+
# # PORT_LIST=(9898)
|
| 18 |
+
# for PORT in "${PORT_LIST[@]}"; do
|
| 19 |
+
# CUDA_VISIBLE_DEVICES=3 \
|
| 20 |
+
# lmdeploy serve api_server $MODEL_NAME \
|
| 21 |
+
# --server-port $PORT \
|
| 22 |
+
# --backend turbomind \
|
| 23 |
+
# --dtype float16 --proxy-url http://0.0.0.0:8082 \
|
| 24 |
+
# --cache-max-entry-count 0.025 --tp 1 &
|
| 25 |
+
# done
|
a_mllm_notebooks/openai/combine_chinese_output.ipynb
ADDED
|
@@ -0,0 +1,526 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": []
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"cell_type": "code",
|
| 12 |
+
"execution_count": 2,
|
| 13 |
+
"metadata": {},
|
| 14 |
+
"outputs": [
|
| 15 |
+
{
|
| 16 |
+
"name": "stdout",
|
| 17 |
+
"output_type": "stream",
|
| 18 |
+
"text": [
|
| 19 |
+
"thread_0 thread_18 thread_27 thread_36 thread_45 thread_54 thread_63\n",
|
| 20 |
+
"thread_1 thread_19 thread_28 thread_37 thread_46 thread_55 thread_7\n",
|
| 21 |
+
"thread_10 thread_2 thread_29 thread_38 thread_47 thread_56 thread_8\n",
|
| 22 |
+
"thread_11 thread_20 thread_3\t thread_39 thread_48 thread_57 thread_9\n",
|
| 23 |
+
"thread_12 thread_21 thread_30 thread_4 thread_49 thread_58 thread_92\n",
|
| 24 |
+
"thread_13 thread_22 thread_31 thread_40 thread_5 thread_59\n",
|
| 25 |
+
"thread_14 thread_23 thread_32 thread_41 thread_50 thread_6\n",
|
| 26 |
+
"thread_15 thread_24 thread_33 thread_42 thread_51 thread_60\n",
|
| 27 |
+
"thread_16 thread_25 thread_34 thread_43 thread_52 thread_61\n",
|
| 28 |
+
"thread_17 thread_26 thread_35 thread_44 thread_53 thread_62\n"
|
| 29 |
+
]
|
| 30 |
+
}
|
| 31 |
+
],
|
| 32 |
+
"source": [
|
| 33 |
+
"!ls output_chinese\n",
|
| 34 |
+
"# thread_0 thread_18 thread_27 thread_36 thread_45 thread_54 thread_63\n",
|
| 35 |
+
"# thread_1 thread_19 thread_28 thread_37 thread_46 thread_55 thread_7\n",
|
| 36 |
+
"# thread_10 thread_2 thread_29 thread_38 thread_47 thread_56 thread_8\n",
|
| 37 |
+
"# thread_11 thread_20 thread_3\t thread_39 thread_48 thread_57 thread_9\n",
|
| 38 |
+
"# thread_12 thread_21 thread_30 thread_4 thread_49 thread_58 thread_92\n",
|
| 39 |
+
"# thread_13 thread_22 thread_31 thread_40 thread_5 thread_59\n",
|
| 40 |
+
"# thread_14 thread_23 thread_32 thread_41 thread_50 thread_6\n",
|
| 41 |
+
"# thread_15 thread_24 thread_33 thread_42 thread_51 thread_60\n",
|
| 42 |
+
"# thread_16 thread_25 thread_34 thread_43 thread_52 thread_61\n",
|
| 43 |
+
"# thread_17 thread_26 thread_35 thread_44 thread_53 thread_62\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"# json files in thread_x are i.txt, which i the id of instance"
|
| 46 |
+
]
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"cell_type": "code",
|
| 50 |
+
"execution_count": null,
|
| 51 |
+
"metadata": {},
|
| 52 |
+
"outputs": [],
|
| 53 |
+
"source": [
|
| 54 |
+
"# /dscilab_dungvo/workspace/vlm_clone/a_mllm_notebooks/openai/output_chinese/thread_63/4752443.json"
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"cell_type": "code",
|
| 59 |
+
"execution_count": 2,
|
| 60 |
+
"metadata": {},
|
| 61 |
+
"outputs": [],
|
| 62 |
+
"source": [
|
| 63 |
+
"# help me write a function to get all the json files in the output_chinese folder. sorted by the id of instance\n",
|
| 64 |
+
"\n",
|
| 65 |
+
"import os\n",
|
| 66 |
+
"import re\n",
|
| 67 |
+
"\n",
|
| 68 |
+
"def get_all_json_files(folder):\n",
|
| 69 |
+
" json_files = []\n",
|
| 70 |
+
" for root, dirs, files in os.walk(folder):\n",
|
| 71 |
+
" for file in files:\n",
|
| 72 |
+
" if file.endswith(\".json\") and 'checkpoint' not in file:\n",
|
| 73 |
+
" json_files.append(os.path.join(root, file))\n",
|
| 74 |
+
" # json_files.sort(key=lambda x: int(re.search(r'\\d+', x).group()))\n",
|
| 75 |
+
" return json_files\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"json_files = get_all_json_files('output_chinese')"
|
| 78 |
+
]
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"cell_type": "code",
|
| 82 |
+
"execution_count": 4,
|
| 83 |
+
"metadata": {},
|
| 84 |
+
"outputs": [],
|
| 85 |
+
"source": [
|
| 86 |
+
"# json_files[0]\n",
|
| 87 |
+
"# 'output_chinese/thread_0/59266.json'\n"
|
| 88 |
+
]
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"cell_type": "code",
|
| 92 |
+
"execution_count": 5,
|
| 93 |
+
"metadata": {},
|
| 94 |
+
"outputs": [
|
| 95 |
+
{
|
| 96 |
+
"data": {
|
| 97 |
+
"text/plain": [
|
| 98 |
+
"'output_chinese/thread_0/59266.json'"
|
| 99 |
+
]
|
| 100 |
+
},
|
| 101 |
+
"execution_count": 5,
|
| 102 |
+
"metadata": {},
|
| 103 |
+
"output_type": "execute_result"
|
| 104 |
+
}
|
| 105 |
+
],
|
| 106 |
+
"source": [
|
| 107 |
+
"json_files[0]"
|
| 108 |
+
]
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"cell_type": "code",
|
| 112 |
+
"execution_count": 6,
|
| 113 |
+
"metadata": {},
|
| 114 |
+
"outputs": [
|
| 115 |
+
{
|
| 116 |
+
"name": "stdout",
|
| 117 |
+
"output_type": "stream",
|
| 118 |
+
"text": [
|
| 119 |
+
"{\"prompt_caption_chinese\": \"\\u4e00\\u4f4d\\u7559\\u7740\\u9ed1\\u8272\\u5934\\u53d1\\u7684\\u7537\\u5b50\\u7a7f\\u7740\\u4e00\\u4ef6\\u7070\\u8272\\u7684\\u6c57\\u886b\\u548c\\u9ed1\\u8272\\u7684\\u88e4\\u5b50\\u3002\\u4ed6\\u8fd8\\u5728\\u80a9\\u8180\\u4e0a\\u80cc\\u7740\\u4e00\\u4e2a\\u9ed1\\u8272\\u7684\\u80cc\\u5305\\u3002\", \"caption_0_chinese\": \"\\u4e00\\u4e2a\\u7559\\u7740\\u77ed\\u9ed1\\u53d1\\u7684\\u7537\\u5b50\\u7a7f\\u7740\\u4e00\\u4ef6\\u7070\\u8272\\u957f\\u8896\\u4e0a\\u8863\\uff0c\\u9ed1\\u8272\\u957f\\u88e4\\u548c\\u4e00\\u53cc\\u7070\\u8272\\u7684\\u978b\\u5b50\\u3002\\u4ed6\\u80cc\\u7740\\u4e00\\u4e2a\\u9ed1\\u8272\\u80cc\\u5305\\u3002\", \"caption_1_chinese\": \"\\u8fd9\\u4e2a\\u7537\\u4eba\\u7a7f\\u7740\\u4e00\\u4ef6\\u9ed1\\u8272\\u957f\\u8896\\u886c\\u886b\\uff0c\\u9ed1\\u8272\\u88e4\\u5b50\\u548c\\u7070\\u8272\\u7684\\u978b\\u5b50\\u3002\\u4ed6\\u8fd8\\u80cc\\u7740\\u4e00\\u4e2a\\u7070\\u8272\\u7684\\u80cc\\u5305\\u3002\"}"
|
| 120 |
+
]
|
| 121 |
+
}
|
| 122 |
+
],
|
| 123 |
+
"source": [
|
| 124 |
+
"!cat output_chinese/thread_0/59266.json"
|
| 125 |
+
]
|
| 126 |
+
},
|
| 127 |
+
{
|
| 128 |
+
"cell_type": "code",
|
| 129 |
+
"execution_count": 7,
|
| 130 |
+
"metadata": {},
|
| 131 |
+
"outputs": [
|
| 132 |
+
{
|
| 133 |
+
"data": {
|
| 134 |
+
"text/plain": [
|
| 135 |
+
"4791127"
|
| 136 |
+
]
|
| 137 |
+
},
|
| 138 |
+
"execution_count": 7,
|
| 139 |
+
"metadata": {},
|
| 140 |
+
"output_type": "execute_result"
|
| 141 |
+
}
|
| 142 |
+
],
|
| 143 |
+
"source": [
|
| 144 |
+
"len(json_files)"
|
| 145 |
+
]
|
| 146 |
+
},
|
| 147 |
+
{
|
| 148 |
+
"cell_type": "code",
|
| 149 |
+
"execution_count": 8,
|
| 150 |
+
"metadata": {},
|
| 151 |
+
"outputs": [],
|
| 152 |
+
"source": [
|
| 153 |
+
"# sort by the id of instance\n",
|
| 154 |
+
"\n",
|
| 155 |
+
"json_files = sorted(json_files, key=lambda x: int(x.split('/')[-1].split('.')[0]))"
|
| 156 |
+
]
|
| 157 |
+
},
|
| 158 |
+
{
|
| 159 |
+
"cell_type": "code",
|
| 160 |
+
"execution_count": 9,
|
| 161 |
+
"metadata": {},
|
| 162 |
+
"outputs": [
|
| 163 |
+
{
|
| 164 |
+
"data": {
|
| 165 |
+
"text/plain": [
|
| 166 |
+
"'output_chinese/thread_31/4791126.json'"
|
| 167 |
+
]
|
| 168 |
+
},
|
| 169 |
+
"execution_count": 9,
|
| 170 |
+
"metadata": {},
|
| 171 |
+
"output_type": "execute_result"
|
| 172 |
+
}
|
| 173 |
+
],
|
| 174 |
+
"source": [
|
| 175 |
+
"json_files[-1]"
|
| 176 |
+
]
|
| 177 |
+
},
|
| 178 |
+
{
|
| 179 |
+
"cell_type": "code",
|
| 180 |
+
"execution_count": 10,
|
| 181 |
+
"metadata": {},
|
| 182 |
+
"outputs": [],
|
| 183 |
+
"source": [
|
| 184 |
+
"# check if the json files are sorted by the id of instance\n"
|
| 185 |
+
]
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"cell_type": "code",
|
| 189 |
+
"execution_count": 11,
|
| 190 |
+
"metadata": {},
|
| 191 |
+
"outputs": [],
|
| 192 |
+
"source": [
|
| 193 |
+
"import json\n",
|
| 194 |
+
"\n",
|
| 195 |
+
"data_list = []\n",
|
| 196 |
+
"error_files = []\n",
|
| 197 |
+
"for json_file in json_files:\n",
|
| 198 |
+
" with open(json_file) as f:\n",
|
| 199 |
+
" try:\n",
|
| 200 |
+
" data = json.load(f)\n",
|
| 201 |
+
" data_list.append(data)\n",
|
| 202 |
+
" except:\n",
|
| 203 |
+
" print(json_file)\n",
|
| 204 |
+
" data_list.append({})\n",
|
| 205 |
+
" error_files.append(json_file)\n",
|
| 206 |
+
" \n",
|
| 207 |
+
"for error_file in error_files:\n",
|
| 208 |
+
" os.remove(error_file)"
|
| 209 |
+
]
|
| 210 |
+
},
|
| 211 |
+
{
|
| 212 |
+
"cell_type": "code",
|
| 213 |
+
"execution_count": 22,
|
| 214 |
+
"metadata": {},
|
| 215 |
+
"outputs": [
|
| 216 |
+
{
|
| 217 |
+
"data": {
|
| 218 |
+
"text/plain": [
|
| 219 |
+
"'output_chinese/thread_31/4791126.json'"
|
| 220 |
+
]
|
| 221 |
+
},
|
| 222 |
+
"execution_count": 22,
|
| 223 |
+
"metadata": {},
|
| 224 |
+
"output_type": "execute_result"
|
| 225 |
+
}
|
| 226 |
+
],
|
| 227 |
+
"source": [
|
| 228 |
+
"json_files[-1]"
|
| 229 |
+
]
|
| 230 |
+
},
|
| 231 |
+
{
|
| 232 |
+
"cell_type": "code",
|
| 233 |
+
"execution_count": 14,
|
| 234 |
+
"metadata": {},
|
| 235 |
+
"outputs": [
|
| 236 |
+
{
|
| 237 |
+
"data": {
|
| 238 |
+
"text/plain": [
|
| 239 |
+
"0"
|
| 240 |
+
]
|
| 241 |
+
},
|
| 242 |
+
"execution_count": 14,
|
| 243 |
+
"metadata": {},
|
| 244 |
+
"output_type": "execute_result"
|
| 245 |
+
}
|
| 246 |
+
],
|
| 247 |
+
"source": [
|
| 248 |
+
"len(error_files)"
|
| 249 |
+
]
|
| 250 |
+
},
|
| 251 |
+
{
|
| 252 |
+
"cell_type": "code",
|
| 253 |
+
"execution_count": 16,
|
| 254 |
+
"metadata": {},
|
| 255 |
+
"outputs": [],
|
| 256 |
+
"source": [
|
| 257 |
+
"import datasets\n",
|
| 258 |
+
"\n",
|
| 259 |
+
"dataset = datasets.Dataset.from_list(data_list)"
|
| 260 |
+
]
|
| 261 |
+
},
|
| 262 |
+
{
|
| 263 |
+
"cell_type": "code",
|
| 264 |
+
"execution_count": 19,
|
| 265 |
+
"metadata": {},
|
| 266 |
+
"outputs": [
|
| 267 |
+
{
|
| 268 |
+
"data": {
|
| 269 |
+
"text/plain": [
|
| 270 |
+
"{'prompt_caption_chinese': '穿着黑色夹克和蓝色牛仔裤的黑色鞋子的女孩。',\n",
|
| 271 |
+
" 'caption_0_chinese': '她穿着一件黑色夹克,外面罩着一件灰色上衣,搭配一条蓝色牛仔裤和一双黑色皮鞋。',\n",
|
| 272 |
+
" 'caption_1_chinese': ''}"
|
| 273 |
+
]
|
| 274 |
+
},
|
| 275 |
+
"execution_count": 19,
|
| 276 |
+
"metadata": {},
|
| 277 |
+
"output_type": "execute_result"
|
| 278 |
+
}
|
| 279 |
+
],
|
| 280 |
+
"source": [
|
| 281 |
+
"dataset[1]"
|
| 282 |
+
]
|
| 283 |
+
},
|
| 284 |
+
{
|
| 285 |
+
"cell_type": "code",
|
| 286 |
+
"execution_count": 23,
|
| 287 |
+
"metadata": {},
|
| 288 |
+
"outputs": [],
|
| 289 |
+
"source": [
|
| 290 |
+
"list_ids = [int(json_file.split('/')[-1].split('.')[0]) for json_file in json_files]"
|
| 291 |
+
]
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"cell_type": "code",
|
| 295 |
+
"execution_count": 26,
|
| 296 |
+
"metadata": {},
|
| 297 |
+
"outputs": [],
|
| 298 |
+
"source": [
|
| 299 |
+
"list_ids[0]\n",
|
| 300 |
+
"# append the id of instance to the dataset\n",
|
| 301 |
+
"\n",
|
| 302 |
+
"dataset = dataset.add_column('id', list_ids)"
|
| 303 |
+
]
|
| 304 |
+
},
|
| 305 |
+
{
|
| 306 |
+
"cell_type": "code",
|
| 307 |
+
"execution_count": 35,
|
| 308 |
+
"metadata": {},
|
| 309 |
+
"outputs": [
|
| 310 |
+
{
|
| 311 |
+
"data": {
|
| 312 |
+
"text/plain": [
|
| 313 |
+
"{'prompt_caption_chinese': '这人穿着一件蓝色上衣和一条黑色裤子,脚上穿着白色鞋子。他的头发是黑色的。',\n",
|
| 314 |
+
" 'caption_0_chinese': '一位穿着蓝色衬衫、黑色裤子和白色鞋子的男士。',\n",
|
| 315 |
+
" 'caption_1_chinese': '',\n",
|
| 316 |
+
" 'id': 4791118}"
|
| 317 |
+
]
|
| 318 |
+
},
|
| 319 |
+
"execution_count": 35,
|
| 320 |
+
"metadata": {},
|
| 321 |
+
"output_type": "execute_result"
|
| 322 |
+
}
|
| 323 |
+
],
|
| 324 |
+
"source": [
|
| 325 |
+
"dataset[-9]"
|
| 326 |
+
]
|
| 327 |
+
},
|
| 328 |
+
{
|
| 329 |
+
"cell_type": "code",
|
| 330 |
+
"execution_count": null,
|
| 331 |
+
"metadata": {},
|
| 332 |
+
"outputs": [],
|
| 333 |
+
"source": [
|
| 334 |
+
"# dump the data_list to a json file\n",
|
| 335 |
+
"# 一位穿着蓝色衬衫、黑色裤子和白色鞋子的男士。 nghĩa là"
|
| 336 |
+
]
|
| 337 |
+
},
|
| 338 |
+
{
|
| 339 |
+
"cell_type": "code",
|
| 340 |
+
"execution_count": null,
|
| 341 |
+
"metadata": {},
|
| 342 |
+
"outputs": [],
|
| 343 |
+
"source": [
|
| 344 |
+
"# /dscilab_dungvo/workspace/BA-PRE_THESIS/dataset_pretraining/SYNTH-PEDES"
|
| 345 |
+
]
|
| 346 |
+
},
|
| 347 |
+
{
|
| 348 |
+
"cell_type": "code",
|
| 349 |
+
"execution_count": 36,
|
| 350 |
+
"metadata": {},
|
| 351 |
+
"outputs": [
|
| 352 |
+
{
|
| 353 |
+
"data": {
|
| 354 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 355 |
+
"model_id": "1bd1611110ff416e8556f83bcbf014dd",
|
| 356 |
+
"version_major": 2,
|
| 357 |
+
"version_minor": 0
|
| 358 |
+
},
|
| 359 |
+
"text/plain": [
|
| 360 |
+
"Saving the dataset (0/4 shards): 0%| | 0/4791127 [00:00<?, ? examples/s]"
|
| 361 |
+
]
|
| 362 |
+
},
|
| 363 |
+
"metadata": {},
|
| 364 |
+
"output_type": "display_data"
|
| 365 |
+
}
|
| 366 |
+
],
|
| 367 |
+
"source": [
|
| 368 |
+
"# dump dataset to above path\n",
|
| 369 |
+
"\n",
|
| 370 |
+
"dataset.save_to_disk('/dscilab_dungvo/workspace/BA-PRE_THESIS/dataset_pretraining/SYNTH-PEDES/chinese_translated_annotations')"
|
| 371 |
+
]
|
| 372 |
+
},
|
| 373 |
+
{
|
| 374 |
+
"cell_type": "code",
|
| 375 |
+
"execution_count": 42,
|
| 376 |
+
"metadata": {},
|
| 377 |
+
"outputs": [],
|
| 378 |
+
"source": [
|
| 379 |
+
"import datasets\n",
|
| 380 |
+
"\n",
|
| 381 |
+
"new_dataset = datasets.load_from_disk('/dscilab_dungvo/workspace/BA-PRE_THESIS/dataset_pretraining/SYNTH-PEDES/chinese_translated_annotations')"
|
| 382 |
+
]
|
| 383 |
+
},
|
| 384 |
+
{
|
| 385 |
+
"cell_type": "code",
|
| 386 |
+
"execution_count": 43,
|
| 387 |
+
"metadata": {},
|
| 388 |
+
"outputs": [
|
| 389 |
+
{
|
| 390 |
+
"data": {
|
| 391 |
+
"text/plain": [
|
| 392 |
+
"{'prompt_caption_chinese': '他有一头黑发,穿着一件蓝色的上衣和黑色的裤子,还穿着白色的鞋子。',\n",
|
| 393 |
+
" 'caption_0_chinese': '一个中年男子,短发,黑色,穿着一件浅蓝色衬衫和黑色裤子,手里拿着一件紫色大衣,穿着白色鞋子。',\n",
|
| 394 |
+
" 'caption_1_chinese': '一个中年男子,短发,黑色,穿着一件浅蓝色衬衫和一条黑色裤子。他手里拿着一个粉红色的瓶子,穿着白色的鞋子。',\n",
|
| 395 |
+
" 'id': 4791107}"
|
| 396 |
+
]
|
| 397 |
+
},
|
| 398 |
+
"execution_count": 43,
|
| 399 |
+
"metadata": {},
|
| 400 |
+
"output_type": "execute_result"
|
| 401 |
+
}
|
| 402 |
+
],
|
| 403 |
+
"source": [
|
| 404 |
+
"new_dataset[-20]"
|
| 405 |
+
]
|
| 406 |
+
},
|
| 407 |
+
{
|
| 408 |
+
"cell_type": "code",
|
| 409 |
+
"execution_count": 44,
|
| 410 |
+
"metadata": {},
|
| 411 |
+
"outputs": [
|
| 412 |
+
{
|
| 413 |
+
"data": {
|
| 414 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 415 |
+
"model_id": "dbaf83950bda495f9ac2373748da7646",
|
| 416 |
+
"version_major": 2,
|
| 417 |
+
"version_minor": 0
|
| 418 |
+
},
|
| 419 |
+
"text/plain": [
|
| 420 |
+
"Uploading the dataset shards: 0%| | 0/4 [00:00<?, ?it/s]"
|
| 421 |
+
]
|
| 422 |
+
},
|
| 423 |
+
"metadata": {},
|
| 424 |
+
"output_type": "display_data"
|
| 425 |
+
},
|
| 426 |
+
{
|
| 427 |
+
"data": {
|
| 428 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 429 |
+
"model_id": "9a7ae97afb0549e9b9fe9638e8f0be48",
|
| 430 |
+
"version_major": 2,
|
| 431 |
+
"version_minor": 0
|
| 432 |
+
},
|
| 433 |
+
"text/plain": [
|
| 434 |
+
"Creating parquet from Arrow format: 0%| | 0/1198 [00:00<?, ?ba/s]"
|
| 435 |
+
]
|
| 436 |
+
},
|
| 437 |
+
"metadata": {},
|
| 438 |
+
"output_type": "display_data"
|
| 439 |
+
},
|
| 440 |
+
{
|
| 441 |
+
"data": {
|
| 442 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 443 |
+
"model_id": "ac4f5b0cf06647dd9132725fd813d2a8",
|
| 444 |
+
"version_major": 2,
|
| 445 |
+
"version_minor": 0
|
| 446 |
+
},
|
| 447 |
+
"text/plain": [
|
| 448 |
+
"Creating parquet from Arrow format: 0%| | 0/1198 [00:00<?, ?ba/s]"
|
| 449 |
+
]
|
| 450 |
+
},
|
| 451 |
+
"metadata": {},
|
| 452 |
+
"output_type": "display_data"
|
| 453 |
+
},
|
| 454 |
+
{
|
| 455 |
+
"data": {
|
| 456 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 457 |
+
"model_id": "3353dc46907841ee8bb0d62b50531229",
|
| 458 |
+
"version_major": 2,
|
| 459 |
+
"version_minor": 0
|
| 460 |
+
},
|
| 461 |
+
"text/plain": [
|
| 462 |
+
"Creating parquet from Arrow format: 0%| | 0/1198 [00:00<?, ?ba/s]"
|
| 463 |
+
]
|
| 464 |
+
},
|
| 465 |
+
"metadata": {},
|
| 466 |
+
"output_type": "display_data"
|
| 467 |
+
},
|
| 468 |
+
{
|
| 469 |
+
"data": {
|
| 470 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 471 |
+
"model_id": "5a2e8418bd9e4b30a6cc404731354691",
|
| 472 |
+
"version_major": 2,
|
| 473 |
+
"version_minor": 0
|
| 474 |
+
},
|
| 475 |
+
"text/plain": [
|
| 476 |
+
"Creating parquet from Arrow format: 0%| | 0/1198 [00:00<?, ?ba/s]"
|
| 477 |
+
]
|
| 478 |
+
},
|
| 479 |
+
"metadata": {},
|
| 480 |
+
"output_type": "display_data"
|
| 481 |
+
},
|
| 482 |
+
{
|
| 483 |
+
"data": {
|
| 484 |
+
"text/plain": [
|
| 485 |
+
"CommitInfo(commit_url='https://huggingface.co/datasets/tuandunghcmut/synthpedes-chinese-translated-annotations/commit/0a6b1aa1c1aa34ff201543ba4ad2a2abddf5204e', commit_message='Upload dataset', commit_description='', oid='0a6b1aa1c1aa34ff201543ba4ad2a2abddf5204e', pr_url=None, pr_revision=None, pr_num=None)"
|
| 486 |
+
]
|
| 487 |
+
},
|
| 488 |
+
"execution_count": 44,
|
| 489 |
+
"metadata": {},
|
| 490 |
+
"output_type": "execute_result"
|
| 491 |
+
}
|
| 492 |
+
],
|
| 493 |
+
"source": [
|
| 494 |
+
"new_dataset.push_to_hub('tuandunghcmut/synthpedes-chinese-translated-annotations')"
|
| 495 |
+
]
|
| 496 |
+
},
|
| 497 |
+
{
|
| 498 |
+
"cell_type": "code",
|
| 499 |
+
"execution_count": null,
|
| 500 |
+
"metadata": {},
|
| 501 |
+
"outputs": [],
|
| 502 |
+
"source": []
|
| 503 |
+
}
|
| 504 |
+
],
|
| 505 |
+
"metadata": {
|
| 506 |
+
"kernelspec": {
|
| 507 |
+
"display_name": "tbps",
|
| 508 |
+
"language": "python",
|
| 509 |
+
"name": "python3"
|
| 510 |
+
},
|
| 511 |
+
"language_info": {
|
| 512 |
+
"codemirror_mode": {
|
| 513 |
+
"name": "ipython",
|
| 514 |
+
"version": 3
|
| 515 |
+
},
|
| 516 |
+
"file_extension": ".py",
|
| 517 |
+
"mimetype": "text/x-python",
|
| 518 |
+
"name": "python",
|
| 519 |
+
"nbconvert_exporter": "python",
|
| 520 |
+
"pygments_lexer": "ipython3",
|
| 521 |
+
"version": "3.9.18"
|
| 522 |
+
}
|
| 523 |
+
},
|
| 524 |
+
"nbformat": 4,
|
| 525 |
+
"nbformat_minor": 2
|
| 526 |
+
}
|
a_mllm_notebooks/openai/openai_api.ipynb
ADDED
|
@@ -0,0 +1,408 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "65815b1f",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Image URL"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"cell_type": "code",
|
| 13 |
+
"execution_count": 1,
|
| 14 |
+
"id": "d606605d-b949-4b3d-b582-9316734320f1",
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"outputs": [
|
| 17 |
+
{
|
| 18 |
+
"name": "stdout",
|
| 19 |
+
"output_type": "stream",
|
| 20 |
+
"text": [
|
| 21 |
+
"ChatCompletion(id='1831', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on a grassy surface. The tiger is positioned with its front legs extended forward and its head slightly raised, giving it a relaxed appearance. The tiger's distinctive orange fur with black stripes is clearly visible, and it is surrounded by green grass, suggesting a natural or zoo-like environment. The lighting is bright, indicating a sunny day. The tiger's expression is calm and focused.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735906949, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=82, prompt_tokens=1843, total_tokens=1925, completion_tokens_details=None))\n"
|
| 22 |
+
]
|
| 23 |
+
}
|
| 24 |
+
],
|
| 25 |
+
"source": [
|
| 26 |
+
"from openai import OpenAI\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:8081/v1\")\n",
|
| 29 |
+
"model_name = client.models.list().data[0].id\n",
|
| 30 |
+
"response = client.chat.completions.create(\n",
|
| 31 |
+
" model=model_name,\n",
|
| 32 |
+
" messages=[\n",
|
| 33 |
+
" {\n",
|
| 34 |
+
" \"role\": \"user\",\n",
|
| 35 |
+
" \"content\": [\n",
|
| 36 |
+
" {\n",
|
| 37 |
+
" \"type\": \"text\",\n",
|
| 38 |
+
" \"text\": \"describe this image\",\n",
|
| 39 |
+
" },\n",
|
| 40 |
+
" {\n",
|
| 41 |
+
" \"type\": \"image_url\",\n",
|
| 42 |
+
" \"image_url\": {\n",
|
| 43 |
+
" \"url\": \"https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg\",\n",
|
| 44 |
+
" },\n",
|
| 45 |
+
" },\n",
|
| 46 |
+
" ],\n",
|
| 47 |
+
" }\n",
|
| 48 |
+
" ],\n",
|
| 49 |
+
" temperature=0.5,\n",
|
| 50 |
+
" top_p=0.8,\n",
|
| 51 |
+
")\n",
|
| 52 |
+
"print(response)"
|
| 53 |
+
]
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"cell_type": "code",
|
| 57 |
+
"execution_count": 2,
|
| 58 |
+
"id": "370fea1d",
|
| 59 |
+
"metadata": {},
|
| 60 |
+
"outputs": [],
|
| 61 |
+
"source": [
|
| 62 |
+
"# ChatCompletion(id='6', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on a grassy area. The tiger has distinct orange fur with black stripes and is resting \n",
|
| 63 |
+
"text = response.choices[0].message.content"
|
| 64 |
+
]
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"cell_type": "code",
|
| 68 |
+
"execution_count": 3,
|
| 69 |
+
"id": "46de478b",
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"outputs": [
|
| 72 |
+
{
|
| 73 |
+
"data": {
|
| 74 |
+
"text/plain": [
|
| 75 |
+
"\"The image shows a tiger lying on a grassy surface. The tiger is relaxed, with its front legs stretched out and its head slightly raised, giving a clear view of its face and stripes. The background consists of lush green grass, and the tiger's distinctive orange, black, and white fur is prominently displayed. The lighting suggests a bright, sunny day.\""
|
| 76 |
+
]
|
| 77 |
+
},
|
| 78 |
+
"execution_count": 3,
|
| 79 |
+
"metadata": {},
|
| 80 |
+
"output_type": "execute_result"
|
| 81 |
+
}
|
| 82 |
+
],
|
| 83 |
+
"source": [
|
| 84 |
+
"text"
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"cell_type": "code",
|
| 89 |
+
"execution_count": 2,
|
| 90 |
+
"id": "f60099ff-ca4c-46f1-9dcd-3a4fb776ea4d",
|
| 91 |
+
"metadata": {},
|
| 92 |
+
"outputs": [
|
| 93 |
+
{
|
| 94 |
+
"data": {
|
| 95 |
+
"text/plain": [
|
| 96 |
+
"5"
|
| 97 |
+
]
|
| 98 |
+
},
|
| 99 |
+
"execution_count": 2,
|
| 100 |
+
"metadata": {},
|
| 101 |
+
"output_type": "execute_result"
|
| 102 |
+
}
|
| 103 |
+
],
|
| 104 |
+
"source": [
|
| 105 |
+
"len(client.models.list().data)"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "code",
|
| 110 |
+
"execution_count": 23,
|
| 111 |
+
"id": "e51e6cd6-9ca3-4082-8a8c-f1668f0de5c9",
|
| 112 |
+
"metadata": {},
|
| 113 |
+
"outputs": [
|
| 114 |
+
{
|
| 115 |
+
"name": "stdout",
|
| 116 |
+
"output_type": "stream",
|
| 117 |
+
"text": [
|
| 118 |
+
"ChatCompletion(id='1', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image features a tiger lying down on a grassy surface. The tiger is positioned with its front legs stretched forward and its head slightly raised, giving it a relaxed posture. The background is lush and green, suggesting a natural, outdoor setting. The tiger's distinctive orange, black, and white stripes are clearly visible, making it a striking and recognizable subject. The lighting highlights the tiger's fur, creating a vivid and clear image of the animal.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640960, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=90, prompt_tokens=1843, total_tokens=1933, completion_tokens_details=None))\n",
|
| 119 |
+
"ChatCompletion(id='1', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on a grassy surface. The tiger is relaxed, with its front paws stretched out and its head slightly tilted. The stripes on the tiger's fur are prominent and characteristic of the species. The background consists of lush green grass, and the lighting suggests a bright, sunny day. The tiger appears calm and comfortable in its environment.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640964, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=73, prompt_tokens=1843, total_tokens=1916, completion_tokens_details=None))\n",
|
| 120 |
+
"ChatCompletion(id='2', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='The image shows a tiger lying down on green grass. The tiger has a striking orange coat with black stripes and a white underbelly. It is looking directly at the camera, giving a calm and composed expression. The background consists of lush, green foliage, providing a natural and serene setting for the animal.', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640967, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=62, prompt_tokens=1843, total_tokens=1905, completion_tokens_details=None))\n",
|
| 121 |
+
"ChatCompletion(id='1', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image features a tiger lying down on a lush, green grassy area. The tiger is relaxed, with its front legs stretched out, and its distinctive orange fur with black stripes is clearly visible. The background consists of well-maintained grass, creating a serene and natural setting. The lighting suggests a bright, sunny day, enhancing the vivid colors of the tiger's coat. The tiger's facial expression is calm, adding to the tranquil atmosphere of the scene.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640969, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=93, prompt_tokens=1843, total_tokens=1936, completion_tokens_details=None))\n",
|
| 122 |
+
"ChatCompletion(id='2', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on green grass. The tiger is relaxed, with its front paws stretched out and its head turned slightly to the side, giving a direct and calm gaze towards the camera. The tiger's distinctive orange fur with black stripes is clearly visible, and the background is lush and green, suggesting a natural or well-maintained habitat. The lighting is bright, indicating a sunny day.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640973, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=82, prompt_tokens=1843, total_tokens=1925, completion_tokens_details=None))\n",
|
| 123 |
+
"ChatCompletion(id='2', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='The image shows a tiger lying down on a lush green lawn. The tiger has striking orange fur with black stripes and a white underbelly. It is looking directly at the camera with a relaxed posture. The surrounding grass is vibrant and well-maintained, creating a peaceful and natural setting.', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640977, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=59, prompt_tokens=1843, total_tokens=1902, completion_tokens_details=None))\n",
|
| 124 |
+
"ChatCompletion(id='3', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image features a tiger lying on green grass. The tiger is in a relaxed position, with its front paws stretched out in front of it. The background consists of lush, green foliage, and the tiger's distinctive orange and black stripes are clearly visible. The lighting suggests it's a bright, sunny day. The tiger appears calm and at ease in its environment.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640979, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=74, prompt_tokens=1843, total_tokens=1917, completion_tokens_details=None))\n",
|
| 125 |
+
"ChatCompletion(id='3', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content=\"The image shows a tiger lying on a grassy surface. The tiger has its front paws stretched forward, with the rest of its body relaxed. The background consists of lush green grass, and the tiger's distinctive orange, black, and white stripes are clearly visible. The animal's expression is calm, and it is looking directly at the camera. The lighting in the image is bright, highlighting the tiger's features and the vivid colors of its fur.\", refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1735640981, model='OpenGVLab/InternVL2_5-4B-MPO-AWQ', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=91, prompt_tokens=1843, total_tokens=1934, completion_tokens_details=None))\n",
|
| 126 |
+
"2.86 s ± 846 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\n"
|
| 127 |
+
]
|
| 128 |
+
}
|
| 129 |
+
],
|
| 130 |
+
"source": [
|
| 131 |
+
"%%timeit\n",
|
| 132 |
+
"response = client.chat.completions.create(\n",
|
| 133 |
+
" model=model_name,\n",
|
| 134 |
+
" messages=[{\n",
|
| 135 |
+
" 'role':\n",
|
| 136 |
+
" 'user',\n",
|
| 137 |
+
" 'content': [{\n",
|
| 138 |
+
" 'type': 'text',\n",
|
| 139 |
+
" 'text': 'describe this image',\n",
|
| 140 |
+
" }, {\n",
|
| 141 |
+
" 'type': 'image_url',\n",
|
| 142 |
+
" 'image_url': {\n",
|
| 143 |
+
" 'url':\n",
|
| 144 |
+
" 'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',\n",
|
| 145 |
+
" },\n",
|
| 146 |
+
" }],\n",
|
| 147 |
+
" }],\n",
|
| 148 |
+
" temperature=0.8,\n",
|
| 149 |
+
" top_p=0.8)\n",
|
| 150 |
+
"print(response)"
|
| 151 |
+
]
|
| 152 |
+
},
|
| 153 |
+
{
|
| 154 |
+
"cell_type": "code",
|
| 155 |
+
"execution_count": null,
|
| 156 |
+
"id": "094bec32-0324-486a-809e-d919891c2167",
|
| 157 |
+
"metadata": {},
|
| 158 |
+
"outputs": [],
|
| 159 |
+
"source": [
|
| 160 |
+
"# !ps aux|grep lmdeploy |grep -v grep | awk '{print $2}'|xargs kill -9"
|
| 161 |
+
]
|
| 162 |
+
},
|
| 163 |
+
{
|
| 164 |
+
"cell_type": "markdown",
|
| 165 |
+
"id": "07a1fb36-e361-4d59-870e-0a8a3f15e5d5",
|
| 166 |
+
"metadata": {},
|
| 167 |
+
"source": [
|
| 168 |
+
"# PIL Image"
|
| 169 |
+
]
|
| 170 |
+
},
|
| 171 |
+
{
|
| 172 |
+
"cell_type": "code",
|
| 173 |
+
"execution_count": 2,
|
| 174 |
+
"id": "e56e3874",
|
| 175 |
+
"metadata": {},
|
| 176 |
+
"outputs": [
|
| 177 |
+
{
|
| 178 |
+
"name": "stderr",
|
| 179 |
+
"output_type": "stream",
|
| 180 |
+
"text": [
|
| 181 |
+
"/dscilab_dungvo/workspace/bin/envs/lmdeploy/lib/python3.8/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
|
| 182 |
+
" from .autonotebook import tqdm as notebook_tqdm\n"
|
| 183 |
+
]
|
| 184 |
+
}
|
| 185 |
+
],
|
| 186 |
+
"source": [
|
| 187 |
+
"\n",
|
| 188 |
+
"import datasets, huggingface_hub\n",
|
| 189 |
+
"\n",
|
| 190 |
+
"disk_path = \"/dscilab_dungvo/workspace/BA-PRE_THESIS/dataset_pretraining/SYNTH-PEDES/annotation_english_vietnamese_processed\"\n",
|
| 191 |
+
"dataset = datasets.load_from_disk(disk_path)\n",
|
| 192 |
+
"\n",
|
| 193 |
+
"image = dataset[110]['image']"
|
| 194 |
+
]
|
| 195 |
+
},
|
| 196 |
+
{
|
| 197 |
+
"cell_type": "code",
|
| 198 |
+
"execution_count": 35,
|
| 199 |
+
"id": "c0c2b27d",
|
| 200 |
+
"metadata": {},
|
| 201 |
+
"outputs": [],
|
| 202 |
+
"source": [
|
| 203 |
+
"from PIL import Image\n",
|
| 204 |
+
"import io\n",
|
| 205 |
+
"import base64\n",
|
| 206 |
+
"import uuid\n",
|
| 207 |
+
"# {\"url\": 'data:image/jpeg;base64,' + img_str}}\n",
|
| 208 |
+
"\n",
|
| 209 |
+
"def pil_to_url(pil_image):\n",
|
| 210 |
+
" buffered = io.BytesIO()\n",
|
| 211 |
+
" pil_image.save(buffered, format=\"JPEG\")\n",
|
| 212 |
+
" img_str = base64.b64encode(buffered.getvalue()).decode()\n",
|
| 213 |
+
" return f\"data:image/jpeg;base64,{img_str}\"\n",
|
| 214 |
+
" \n",
|
| 215 |
+
" \n",
|
| 216 |
+
"\n",
|
| 217 |
+
"def generate_content(image, prompt):\n",
|
| 218 |
+
"\n",
|
| 219 |
+
" # image is a PIL image\n",
|
| 220 |
+
" messages = (\n",
|
| 221 |
+
" [\n",
|
| 222 |
+
" {\n",
|
| 223 |
+
" \"role\": \"user\",\n",
|
| 224 |
+
" \"content\": [\n",
|
| 225 |
+
" {\n",
|
| 226 |
+
" \"type\": \"text\",\n",
|
| 227 |
+
" \"text\": prompt,\n",
|
| 228 |
+
" },\n",
|
| 229 |
+
" \n",
|
| 230 |
+
" {\n",
|
| 231 |
+
" \"type\": \"image_url\",\n",
|
| 232 |
+
" \"image_url\": {\n",
|
| 233 |
+
" \"url\": pil_to_url(image),\n",
|
| 234 |
+
" },\n",
|
| 235 |
+
" },\n",
|
| 236 |
+
" ],\n",
|
| 237 |
+
" }\n",
|
| 238 |
+
" ],\n",
|
| 239 |
+
" )\n",
|
| 240 |
+
"\n",
|
| 241 |
+
" # send message to the model\n",
|
| 242 |
+
" response = client.chat.completions.create(\n",
|
| 243 |
+
" model=model_name, messages=messages, temperature=0.5, top_p=0.8\n",
|
| 244 |
+
" )\n",
|
| 245 |
+
"\n",
|
| 246 |
+
" return response\n",
|
| 247 |
+
"\n",
|
| 248 |
+
"# print(generate_content(image=dataset[110][\"image\"], prompt=\"describe this image\"))"
|
| 249 |
+
]
|
| 250 |
+
},
|
| 251 |
+
{
|
| 252 |
+
"cell_type": "code",
|
| 253 |
+
"execution_count": 26,
|
| 254 |
+
"id": "cbf16d3e",
|
| 255 |
+
"metadata": {},
|
| 256 |
+
"outputs": [
|
| 257 |
+
{
|
| 258 |
+
"data": {
|
| 259 |
+
"image/jpeg": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAD0AFcDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwDm/FehWvh2yjjt2kLMQpJHWsLSG1a0k3Wds8hc+nBr0zxTb2V3aRT3Um1c5U4zx61PY6poFno3nC6gKoOSCMk/SuZXZo7Hn2ua79vtGtrzTvIvFA+YelcjKo5rV8R60uravLdRJti+6vGCRWKzk1rFXJsaVrOF3KJHCH+Dcdv5Vo22oFZ45I40DxcodgOTjHNc5EWLda7rwhpEV3cKZeR71UtEOEbsrT+LNaWbzQY42IxlExTLbXNSuSy3L+ZGzbiWGea19Z8K6hJfyNZxq8WeBmp7DwhqCxZljRSe2ayvc2cLHKzRl3dlBA9NxqnDIEm2+prrZ/D95FK6NH+VZR8NXrT5ChRnvWhDZVvLK2kMeWILDkg0VpT6JcqmW29cUUhaCXfiD7d4RSynceeuFBJ5wO1Y/h7w3deI7oLFlIFb55COPoKf4X0SHWb7NzKwiX7wHU17Fp32LTbWO1tLfbGowAOKl6Eo5Hxh4esdI8Hhba2XzIQP3nc+teWumUDDvXsfj66aXw7LGEOGryTTYTczCDIyQcZpxK6lSEESDPrXs/gjSRLp4mzjcMdK86i8OzSMp29SOte/eGtITTvDsKkcqmSampK+htTjbU47VfEEXh+Z/tMTMd+BisxvijaH5VsZGP1pnjFhdTyb/mCuQo9BXCPbhHzjinBKxNWXY6O78czTSM6WYGTwCelV18Z3DZzap+dYpi3DoaRYMZ4qjE0rnxPdznAiVRn1orNMOT0ooHcPB+rJpWvxSz827nZIPb1r6IsLeynhSVEQqwypHcV8z6jp8+malJayrhkP5+9dhpPjzVNK0pLNCrhU2qx6j/GqUeYzPTvHCWI0CeJmjUFDgAjJNeH6cP7OkL7FZ+xPan32rXOoy+ZczM7e54FVfN962jTQrs6a08QvG43ouK9H0XxyJ7b7K5jXK4FeJiXnrT47qSNso7KfUGk6UWUqkj07VtL3iSdP9IVm3bVPIrh55zbXoDWcg9NycCrFn4kngiVGkY4HepZ/EAucb0VvcrR7KwOdyB3W4beYtgqMxAHipZdUjlkjjKbTgKDV6OFSucUnASkYbqQx+XNFbxtkx0FFZ8pVzd+IfhpLmxGqwp++iX95gdRXlQfK17x4vuhB4WuJOoMXT8K8DViRnGM9qumybDyaTNNzRnmtRDt1LuqPNGaaYiUvjvU0E+4gVTY5FOt8q4Ip8wWuaUwztYHkc11Glv5tpGWPPSudiTz4iO9bulkQQrGxHHepdmK1jXEYA6cUVYQBl4orKxVx3ijWrfVvDS2dq3mSbVV1Jx0HUV5hNY3NsAZYiAe46V3SabcWTDzoSorI13iFVHc1kpWZuoXicoaSpZIyrYNR4rpTuYNWENFLSUxAa19EsYb1nEjEbegFY/etbw/NtvtvrUT2NKe51kPhuOW0kNvIRMBkAnAqnFaTW0gSQDf1OK6LTbtYnOaoXZvJtRElvbSGNR1AyDXNGbub1Ka5blm2kCoA5waKzpxNDcLNMrrnIAxRXQcg46rdXTH7TMT6ADP9aytRU3FzGvQZ71GsdzbSMsgPBPJH69afcTAukhwBuycVyXuzuinaxj6vB5VyfQiszNbevDf5Uo6Fe1YmOK66exz1FZiZopKUVoZC4qxpjGHUIjngnmol5qSMBZVb0NKSuhwdmd3a3QwMDnNb1hb6pdqGN5HDbE8KMZ/+tXH2Mm6JSDUXiV7i3hjljuJUBwAqtgdK4npI7WnKI3xdrQ+3m1tZDL5BKmUnqc+lFceGZiSeT6nmiuuOxxSjqe0abp8V7ZSCaMMx7kcjiuI1W0NpPJCQcIcDNd/p10scuxAArVjeJrNJ1aVfvfzrD2dkdkXdnCXNwk2nRox/eIT+VZZxVq7jZHKgVUEbVtT2MKu4hopdho8s46VoY2YBtpp/mZWnR25cgYrSi0h5oDjg/SndWKUWXNEkDxFCelavia1+0WFqmeS3H5VgaWr2l0Y3GCOoNad1evPdQxFsheg9K4ai947YP3dTm9R0iXTJFMhBVhwc4orsvFGnpLo0UuBvBHJFFbxloc7Wps2U4+0IrdCat6hEJUKntWTZzQeeqsw3A8VrPJvJPrWn2QTszkNQ0XfLuU4Unmqo0Be8uK6m7XEbVml651OzOynSjNXZkjQI+8p69hViLRbRSNxZvarRcik8wjkiq5zZUIIt21lZxsNsK10dg9nGjf6OuSPSuWjnAYDNXY7kBcA0uZsPZxsUvEkEceoJcxIFDDaxFZToqalAx+6w7VoavI8kQDN8gOax7qUmWAoeQaTOeorbHYaxG0+joqDJAWirOmTLcWao+CQBndRSRlyM5WyV5JwMV1MKsQKwNLRjehx90dfautiUFBxzXXBXOaTKl1DvhJAycVzUsrxuflGAe9dr5WVII4rlbyDZPIpHRjXPUp2Z3YapdWMr+1ERyHXFOW/S4IWMgZ9arX1spBPTFZ1jlb0L2NZ2Ou50BiwM7sn2p8MTs4LHC+lEcLKPvVKFYnAOKpFDNSRTZSe1cxFP506D+62K6icFo9h5BqjPpEcd0kqDaG5IFU1ocVR2kW7bUBZXphZyAy5HpRXP+JJtl6iR53KuDRWVi+aJv2+uWumllkhdjnkrWlD4y0ogFlmQ+myuNvCHmf8A3jUCxgkV2RdjzG7nqNt4g0u5iDJcAcdG4rFv5Y5buR4mDI3ORXO6dDZglrjp6CtdzCT/AKOu2MDpU1Hc6sL8RRvvukAdaraJpsup6mYIiocLu+arN1V7wEwj8ZRMf4lwAehrA7puxKyGCRon+8hKn6igeoq94hi8jXbpQMAtkVmgkUJlQleJJ5bysFjXc3pXTR+Ho59JW5lISVEz1rl4rkxzKR1B7V1omaXTi28gFOhrZK6POxE7SPJ9cVptWbYkjDHZSaK9ssI7S3tIyLWLfjJZlBJoqeUi9zxOTmQn3pAQKfdRmOVvTNV8nNXc51sWFcqeDWxYzb49vcVz8jMgyK19CbzN5f8ACom9DooO0i1d4APrWt4JtN+tx3POY6zL1ecjvXVeBYGE7NsOMZJrnudtSd0Q+LiW1xjtwMfnWE8oRctxXTeL5rca4sSgl9vzHHFc1fIrRkCmmTCdkZtvqLyXhVF6HjPeu10WK61O1kZvljThie4rzaW4ayvhIg5Wu48Ia/eapO8WxI4VXJCjk11QehxVdZHS398mmWiF1LDgYFFWjGsnDoCPcUVVi01Y8WuL9bqZht2sCeDTAcVBqkH2HX7qEdFkP86nU8is0cyHuu6M+wrR0YbImPrVL+E/Sr2nMFgOfWpqbG9HVlud9zKvcnivZvCumRWumRuVUEpzjv3rxOSQNLHjruFe56bMYvDQk6FUJ/8AHa5zebPJPEN+L7xnfmMnYjkL9M1DMSyfhWPbXBm1i9l6lpm/nWo7/KabLprQopo41SZ137SBya2/AVqbW6vY2O5kbbkVU0aXF6y56itTwp+71LUR6yf41vS1OaroztFI70VCGIPWiurlMOY8V8XSbvFV6c8mQ5/OmQkGJTUPiNH/ALeu3b+Jyc/jS2jZhHrWHUSLqHjmpIJdoKioQpPNV4Zv9IZfepnsa0XZmzbAvdxem8V7VeXa2vhCRjgYiPP/AAGvErWTZNG3vXpOp3Et54Slij+8YR39ua50tTpnseP2Nywv2OeXYn9a6IMWSuTtz5V2d38LEV1cHzRD3FORVLYn0z5NQX3rc0MbNZvAO+01gQt5Vwr/AN081saLcBtVmI48wDr7CtqTsc9VanYA5Wis+fUILP8A10ir7Zorb2hlyHlXia7ju7lZVUAkc1RsmLKRS6rbSRTtnoCcVFablJqGxJGqvC1lozC8xV0N8vWqYGbpD6mpbKgtTWSQrtr0XQbpbvR3hkbohFefm3Plg9sVraTqj2kTxgHkYyDWKWp0yehyWpRi31m5jByBIcfnXR2J3QL/ALtczqRMmqyOTnLZrrrGDbbJhSAVHX6UpoKDH20QebnpVDXZjbzRi3ZkYkcqaukvBNkdKzNXy80D+4qovQKi1IdRVnt4mcu5IBJJzzRVu6g862Reneii5CidlqfhuyvlYiLBb0FYo8CNuOxjjPetvUtbktmxDgY61iz+Jr5xjzNuPSqVyNBf+EBnJ/4+EUfWsnVfCraQi3LXSSAHgD1qZ9cvPmPnvz1way727muVwzsw9zVJE7EP26TdtzlfStHT0MwfA5rGSB2kHB610ulwiEZHUjmqsgu2crf2k6Xju0bAZ610Vjq/k2cSSIWKrjrV7UIvMgckc44rmlhuixUROfTAqGkyoya2Ne51S3mQjYyn61lTSNNNGQxKg9Kli0TU7ogR278nqRWvYeDNXaQMUC49anRA5yZUv7pTbx+UNhAANFdRF4BvJxiQc+1FToaRloZeqZ89uaymA20UVujGIxUG6nmNPSiigaFjjXeOK6PT4I9i8daKKmRSN6HTraZPnTNamm6XZozbYh+VFFZvYZvQWduBkRr+VXUhjC8ItFFYlvYUnavAH5UUUVSJP//Z",
|
| 260 |
+
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAFcAAAD0CAIAAABhIi17AAB85UlEQVR4AbXdWXdj2XUneMwgwSnmiJwlWUrL8rJ79epV7vL3f/SL+8FV1pDKlHKOgQxOAAiAQP/++wAMpjJtl6pXn4y8vLj3DHve+4y3+5tfvtjb2xtWevDg2P3V1cV0Or2aTW9vbzudzsnJyd/88tMXL14Mh+PJZDIejkej0enp6RdffHF+cfX69euzi/P5fH677mw2m26no1Ruut31cuW+Pxqq85OPf97r9d774P3FYvHVn7+qmjdq66036/V6dn15dXX1f/4f//jzn//8/fffl/PV9y/Pz8/39ke/+tWvTg4PgXG7Wv35z39eLJfeqvC3v/3tcrm8uHx7fX66XC46nX5n01uuN/3eQOPgXyxWMoAEtKPx/mAw6PcHnV7vtru+WS1vlzdavL6+Ho/HQBqsViuVHh8f7++PNTAD0eXlzc3N6nblNWRkkPvt27fHxw+kRw8fHh4eHRwc9Ab9s9NzReYBojObL+CDCveT4oh4cXHx2WefodTnf/pCQ511B/6gQtnNciXP7PoAWf18/vz5o0ePPOluOvhydX3x5ZdffrVeq3M+m3399de9fv9pJdBLEOysN999/c3p6RtIDsf7nU4PiVXQ7/fB1vihuJvNZu1Jv9ff7/WWvQ5o5ZTcDH7+ycfvvfcesPqDLlSvry6gvd6sNrfJ2e0Nlb68uFjc3Jydnl5dnq8++STY9ntPnz5Bi6vZ1Vff4u2y1+900GBNCjbuJE1q/ujwZIGkt7cyew7W8d4IZ7xdLlfzq6vAenuL4liN/4eTA/XPZjNP5tMrOUHrydXl5dnZGdKcv3376tUrrFIhLg8HkweP3uv1j1ar215vgP+97u1oNLhZLrq9Dey1udmoYdPvB77hIGK/XPaH/UGv08VgMA/+6Z/+6emzx5rBf0Cfn5/1uhuEgHxIuLolOciCtH7iBhXAjOOTh1Kn18cNgHrVUkO+FKK77ob2hNPD/f19Erdapx4/teWqqu7tmjyPh6nnu++++/bbb9ehWIiyul3cLpYKdrsdP4eDwjDSOht++61GHz9+vL9/uJxTwxFakN1bcPbG3c56tVxREIyAv3+lo6jQx5a90fjo5BiC6HWwP5kdzmA6+Kf/9n9BhNDiw/nZqZxaHfb7S3KIqrepfFpyi1J+np6+hs/Jg0dPnjwZ7u2Tcyh5VZIQZndV0CiInJsOoAcDKAyJHuqQi+64v+n0NuuNBke9/s3NfPTg+MWz59eXF5i8vJlFOojvcrVaLG+6dLmEvARMQ8iKHnRT5fMZ7e/OZii5Ds/DigghqNUg3XZid7p0gUyQ4E0f/oNev9vvzKez9WrR72729vcGh4cTbXk3v5lNZ9enb94ADqXDVcDGonRXy+AfSRoOqT5pnM5ucLI/imaig8zd0oJ2bRBstL7pEFSQBaDb28nBUbtxz9p1CEKfxGzOTy8gPOh1S1UwP1p1OxzN+4V/hPmdkiMKQycLZhJxVEDfwbDX68bGqR+6t2vmrNkCD1CfsvQgpdlU3u0Ouj1UxkI0wtTB7ZLg3QwJC3lCnAVjp/W98Xi/PxiwQDCnwCWBTycHB7PFzdn524vzK/Zss1iqYl0+oRf1o0Jd9C9zFhKUTG5I92ZDttbDEaMYgXUP5wVzoobhEFg4sz8eoml3M9iwR2uAk6t9urC+XbI4dFj14OkNBxzBoBc1xKgecaK4q5vbzXIwjtKjxWrTXxC9XjQ6ZCgQ6QXA2DvmJuLWiQf0ltEYUIdOZxTmNGs5GDQd3t8/YN4fPX58eHjItGj+2bMX+5PJ9Gb+/auXf/7TV7PZDbkYDkarmNuqLsx3r2L1R7Ogp21taVWKtq9WdCb3kUYIIMpmOO5N9kYYjhlMmOeqwGqZIb9cbFSfygZ9Vhx4LH1poMqXG9anT+A10R2NGK9wfjjqzVm5+JatRACrQebKImJqaLXBoQVrwAKvZCdiyIuok/GINT86OoIz+/f0yTNGaLQ3hs/e3gSz2PvDo5OL8+ne3rd0gQnrD0naan1LgfvaSMsdxrkHbqKJInCmHeSCiWFk0Yr/5YCQjF2UO9Zx0Nfo3miInXCjletepzfsr28Hm2VvWACwAWynJrgGlbrZG+8vbhFrwxihenmBTm/QI980n/D0Ov3bJQPnR7eJwpJS9Pvz6RSVUQHpgS7GqAiHCSlL/uzZs8lsXpx/xhc8f/aCHRIoeSujBtkCVhzEcL6ZL+EwuCVTSB7k74SieJAinjfSqIF0tIbZJBmIQXfTG48Gk73x4WT/0YOThw+OB5vu2ZvTy9vNanaDUSjIqqMgkDBwhCFD7nGE9KqFTzXKbPmVVK3gaBLpBlN74hoJbHa3xNUTKh+g+QgOyR+vSf6Dx48up9eb3qUMRP3o8PjRk6cQVrsaS1RX0/ni+nK6mC/wkskSH5D5OOIVKaCIYsZgp/a656madLTfaSiWw9V/fTreYw6ODw8enBw9f/Lw6ePH3dV6NZ+96rAGN8wGF6oVFiLa2+35FztZpg7Yqo4DWm1WkM2bYMVykqK98YR4yuMJGNy4Yvtefy+iQUyQBYipZR2KupEEIZiPmUdHV0o+evjIk3iF4TAYNMQWN9PXp7/73e/EgtRpuQxp4pZgvcEWtI9KV9ORDrKQsu23u13iuij/ZG//YDyiBQeTvaePHz19/BA5RJNHB4f0gkWA82J+Q3RJAKMxHI+VGvYS8PiHmURwnShHqyiFDMXbHh33doVYBD4IrktQN4mDmjkIU2O3Eu97MhBUy6qSvYPJA36x0zs4PCZHYmWmiHrHw8cox4KyiK5vXr06ffX6ZjqraIpFG+LJbTyiVO1taRF64Hk9j2QWF13UR2j7+3ujg/29o4M9GvHg8ODR8bHAcbVYHR8dPDo5ZrBmQujrq4Seqy6rJeacTPYmh5PR/gRvBn3tbnqDm+LBUv3CEteGOTXV+rCTWAvMFIQDUop+gQBpZFOnYEeGAZ/J2w0HiN2/upqen19eXU+rwLXc5Eq9aqaib968+dOf/vQv//Iv//7v/34zX6i3QmTs2PD2HSrKNW2pEPx3KbJQlVRFvFsxuTETWAK4vYqECQX818v19PL4448+fPL08duzc0EXHDCJ5z6gtMcnk8PDAeuIMf0h/K9n07cJ+a6ro1UCUtZnsphQdmTCajg3xwdHigwOTwJ/J/2uUOHqcjoe6YR0UOX07dmr16/fvj2Xr9P56mBy9N4HH37wwQdMMaNNEf7t3/7tD5/9XtQUPiSVtJfAl0neeojiPqGIDWwJIdzw0elrVAKEqImnYB2JUxLfsb7lGQ4PJoPnL2A+fy/hMS13r/RI8DIGy34vfoRx4S+j6g+uL96eXYZe6t/0yhrECuAc7SdTwGJc+8NxXEX0dMPqNJHRLMQHr1+fPnj0mF2Z3QgFluzWxdXlV19+c3l5jVHPn7/34YcfEmExkjhfUjVdhkPg6PRKzbSVTlfZ4/jIkghwJ2yBxIopqn/uPY1IxPfjREwSgQJK9XSYxWu2ZUxhxHPD4aOTBzRHJo4ptoxV63RYB2qWjiyihQrLTY/DGszmkwKGRyxX1Q1fI63pB8QjbjjP0D0G8XblAYt2K4/r4M9ffvPehx/v7x2S08Pj429fvTl9e/HyzWkINp1fTW8++/wLwabmOV4FCMCTR091gWkN2SFRJVTe3LLJcYxpJXCUJih1y5aFJAKT7hAcoUXCxc0+IeT/eh12gUTczOaIOtk7WCxuEhqmks24H6fYHY4Go6HwSLG4oA1KxexJ4cXCwEJaQ02CEFQrdfdGwE6RYSQxssi6FnyMrLIETeXDzWjwh88+//Rv/47ww0HAoQf5+s2ZogP5oj76fEtUCNSQ9HwwMPLx61//2kiBrsRvfx9/MZud40ZPDJ0oroSixk9CFCnBk6LAYSHyP1D8VZVxFFYJFQ72x8E77jBBLoM22jsAM+Jy6+JKvjv+MmIWLaE/8cdrcI5uO1NwshTIJqzSYAWfqT/84L0SUkEmHiHglOMnOFBjFtPfOzs7/5//87ebXl+8JCapKJYgK6wftEqcPujjn6hTTfqRv/jFL/77//3fPvroI1r65Mkj/VADIUiftqUyv+49AYHkWa4kIKodjkHFQ64Q8iziHonYG/GaqBArW1CKtPt5s8ey98fUYYCQqYLkpKH0fDUAq83ihjMVxcC2eAa7SC6cBXshi6pCxHKZqLBObE4RXGk3vBAijuQPf/hDABmNgAh6YYLhFuUloYUa09hmo0/x93//97/5zW9+9rOfyaOKeJ7hUAirUt48jTUuFPKNEOU0CvmQgTj6HxM3JEdZRossSAzfiDxzfx3aQqiSMtozX9xy5gIMBQXUMaEBSVSsp+SNjt033319eX5B/2FocGV5s1imZ61bEe+OoBpqclEAbGSAOcQRCBaug7cXV0cnD6+vZl9/9e1iOf/+++8Xs7nIRCahC6CRDFPee/H817/69B//8R+Jw/5ohA/GBfwTH6tqRZPjq0UpJbQhmjelDlv7EEGBSyixNvYnaNmMhn0RwrOKl06OjnSOqfTF+TURxVsG//zi+uzy6nI21zGmjgovO+uF7mbZIBBKV7PLs/NzzCV1BYrYc4XReACkxj8yTnqAxAZz70tegJrvwkUQJR+pMMijGM7I2vgjH2hgInb66IOP/u7v/u5vf/mr9z94gW9bfreOjcE+Etv4HIVIuMY3qLYIb1SUFgeBKEIMVFnptd6UCKO7L146OWJiSMNIWI/Pm/73r94sL6+vXr25mM5enp6/PjtbbjrXgnYsWeu+RUjVzrKsEkNThJgtzYEZY0PtskftIZDIVIhf3fkMOFZ3u731PPQ6OXmgyNQAy/W1gT3kwF05GLDp1TV1ff/Fe7/59ad/++kv33/x4mByUGKfztpoPNhPMJKhNA2E82zgJv1i8avaW0DNv7ljaIEmrgIhddAEhpJgGdkdYw2hUZneA5HTwcHl9fTN29ffvXzz7avXXxNPQXC3J1ZGAeMOQYDNTMSstXSIBRxhdVRym4DkiR8expSCIRFJ8SQPkuRpGQaaxPMWCGDg2dnpZG9P3xZR6ZVg4R/+4R9+/emnXCOEY8QNBwwFbam9JbKAnMpKbJCHBEDSgCf+Iih5DnF14RMDpW8NfsxvcufKY0EhEWGnO9rbf/Dw8fXNsv/m7eIm8jtkhkLidIpr2CkxophY+IcKMc3F7ab81Whab1RwAxgQlluJv5ChPQzzCk59ys2Njvtq/c13pAB2nfObG01xxLTgn//7P/3yl798/OBhxB6fqw/DI5M9QDNpBEFFTQM9BJmfomP8LmdcvTXeSxdagTgIcrxkSbnD46PDhw9PEJcxJ1FahwvDNt7fO+72zy6vwWik9OlmM2X2Q4UQMuaV+Qw3w1PuORazn65BnGG8aIS/eS3AxC4hUyll5DJYhEvytBvEGnAHaOPRYmEMm13NoBXI3n/x/J//+Z//8R/+nrCI/LSJpApEHZlpg0X6T7HA8W1eJsYpt+QVeqMLBhhEjlUgu0pQixJI1gtKfOTh/t6JHtQR4dvTxybuqr+9uZ3F8Ka/jzqZ1BFQs5TzuYhPI1HxYoYemfiznEaeaTddmrIIDaS7KxEL/CUUwPdcNvlbZs8HM8gXSTOeF2kcv3j27OOPP/77v/vbv/mbvzGrQ1i40dSRJqJp+bPpEFRdTC4nPwJLJ4M2u7AEFbiYGwE7P0RqtVqjAwYUkF6MpBONAmRB2tfPozWVzDAJ4S8urq5msxpSGRlIVMteZ9QxoLrMgI7mQusifmiBuuGx53FO5MG/hFYN7bLZ8pd/qkksAN/9axpRTIuQkPn90dAE0d//5te/+tUvnz99qhvLPiifKvB5fUuT42PDky4KYBotaDDJ02RKVfL4OREKjMc8PDBZQ+aABFNoIFClhr8hHLkM5EFJqfWNgdauPsLF1TUlFVeKq0aCvJs1Cb1lGBJ/hRMZjk0Q2eHUg3WTU8izHYV2iFUYugYBkkKb3nHRbVLLo6+SOint3v7+48cP/+bTX/3qbz998ugRZDKIok9iTPp0qgBCCG2g7caYgu6DnrhuePXfVaehVIUWgMH/g8kkVna+GQsMjAMYBfEiI4c3J8dH7714ZnzNtCA2JEQmL/pms+X1/CaKoaoSY/0C9cojbGFYhgKne35ec9Do8DYQDgli19gPv4lcXjVCEP6AFmJVF28rC1U4BWv0rgw+p22syYirJq+mU/aXDdQwtPECUVQzJ+fDhJhCBpbo2rREzWjxJtPpPPQuqyPsZ03MODKEF3E6ukx9Q6yueEX2kZvQaYsBUnOrvLPsofiMiqldPWKkjAOJAiPnakYp5DTmgxBSngTZQqmwBWHpO7zeGQj4A0zyqmFf2ZRLne5dDXYyqjGuRA7oHulQudcplQPorjSaXTPCJ65hJuTJUF51tFIZb7wzP/erZmj3DvfYAdOJ6lCRcQTOUsUPHzxAAoMmqIDo5ESVIMn0j4pNyd3qCwRDBIIA7EyXJUc8I/eFlk28Na7LHGSkALZ9bran/dq+Illqo9ZFCbfvSKDgQLPYzMgRbzzWaoYRu+Y1+mw3Y2R6CZZAFfWnlkz2dfRzD8xcz2bHhidfvuLpZr0lTcQg+ie8uyAn8wXTcMzXTTJgxUckOipgzGsQn2HGKUaGTJiOgNwNheckb3U7XywpnYEJwKLRYD3gVjg3InhLdQrV0nEcDAVTf0liQ88TpIuhrJRXfjKsCWXz8I5kbiSRx5iD8VjgeHp29t4HL/jusAfra6COQrplp+KVSy1Lag5pynB/QtJfvzn/4k9fU3dFTGugAjP7+MnTvcnRaHJE4nvrW+aQHCD3SBzf6yBgxhr6IyFYp8dNjvjq7jBTcTOuR6S0NCHYS4gWBt6SQk43ckEdbswjqIpLG1G6GqDpG/7SLyKSrBKsOFwFS/6aSJRZ4EL6EWFUcJUh6lkJ5OlK6BaqxbjTbHpjcO/o6EBdQOc4FCCNWCd/4MC+oDTgJgejieHY4wcPMxYwumYWZdifxCI8evx0cvRA1jLlt6hNJQCO6mDY9A2LjparzXy11k/Sf6dxAsNbg87rzdU1AynKCScOjg7X11MG31AN0hAWuYadcQu00yMd7MFGuyGEUdrSizIBWwwDNgsoRbE2t4ndog7kumRCiW5IIJEWYw6nBlhOTzHLTIxIRtUNeU/w3xUzEcUr8+qElgQRV3OwJvLfnl+a4iS+htf9EypeYevNam8gDF3SD7Zxb4/vM8s+2PTXby/n3cH54rYXZxnpMyJiNAY5dH7W8BVE6XsfEsL9wwQMq5Xurxse1HwU8UQC2NB/14xFiN+IA5NVQWB6LRSnhEKGok6MY5x2gqutxa3YopvxBblDj4Hx6Jvvvn355vWZEVciJ6vkOXLIgArBOuB22Q56qz8xCec51idffvk1nbegQRdhect93NwsbjmFeIUMVTFvBhNHBwLGvb3Dhdnb169Or46Pz48fnBwc7DPMar64vDK48vDx09v0gBOkSJNRXwRhOgj+eodYzH1aAmQUAeQmLxDITbsC1b2yrnjOkojY3Tcq1JM8lzwsV5K/MVj+mN9lC+BsfOHzzz//5GcfJapVl66bOLaMfLIjA7zSDMHu13iftSnmL/f2J0fD0Sp2rtefzvT3tz2WMJeP7ne4z/FKj8As4/JyurqYpbd2cDF9eH1z8sAQR8ZC5tOb/njy/sc/P3rwVB9PN/f16Rurp+bmJFarq5s56lfM3p3e6GelX9fpoHfNzBTyw3jZAFlE1HOFaabJA3z0goeqHkeUI4TIlUWr1yGVgu4vL68MPelK8mFZg1QChjoKFzlV4Rkp7DPo4iXzovP5Yjabi/c5I5DorVg+EEji1EivsrHjOGL0gyFgiK5mq6NFRi5MOa86F0hjPkOHgsEzhgu3k0f7G+NdzMn1/PuXp5aaSQkoF7en529VC5+aVD4QvopmB0R5PBhHDI3lN86DMyyGb5d2tJApUiJ83ZoMEXBkK1SIZ8byeDB4mrD66quv/vVf//X4wZF+BOujSdGLZqgAxeI15QSFWfvhYH9lwdF1bNzB0cPoT/pltI5tCwOy6GzACzBFylS3Thyttludjumq05/f3r69ut4/v2RlHj56YEkJXLhnhBiOD07GBwbh1xWnZrFPb4jthp4kxAobOPLFylqSqKclToMxemorYMIdqXBbiBEpKB3h6ZMSx5fSIA6kN81RB38OyTXKeXFhDuq3v33GRlJXmiaYk7WoYd3VFUKQArrz1TfffvbZ5yzC5UV6wdRKDd6qih6oVOvV+wkV8qJUMq3wq0AFyBWCrk1Yc3JmmbI8YZwuJt8kIQUz8d4HH+uzHD94/PL1K1R48PixMfvpfIZ5EpwODib4bQw82CZ+L5TBYjQj8EQeWo8rvzJEEk7R6PykI4nuM6qbNWtGnEO8CHX3anr9+99/9uTJMxM2bDgvV8FVT2T13cvTt2/NBZ1/8813f/zjF99/9yrDm4QxNUagCAKQwgoK2hV01ugCyVBFBhnSyXZHsXVn48NMmnn3snM02Y8IDMcPTzJRTCXVVayD3dC4y/7hEXe4f3Q8vTRPYkUjbQtKf/vrT81nnl2csUbGrBUheF5VhBK2B7aKD4ajrMIEQF/MTARiSjWS8ZGouqF68IVE8b0DDfzxj3/85JOf/fzN2Wq5WRxEV70SUPzut3/87ruX/mW53cV1TAwPnkFqVKBvIUQEMsqpjTIRASE1Z1xBwBMnJU9dk62ruXOzfrqHAtbRweXjue62+Fol2mVEkQ6grI2FpyfdvtnTSc2kCXNoRyRcXNUfLtvsXPXDtJC4MhhHXngqjbvRFwmvwREBiQeBdYyKR/wlTHgA99o24kL2zNP927/9T4s9wQSU69nNV19984fff04iptcmMyyNMvORMX9xAWeiIB6UULiQhWhJRtfi0RO05Vk6x6ERM1EtBj1CakC8e5N7M2/d/nixWmsO0J5IasuV5GSUg7sQ3BDBEJ97EqpzorFtNX9rZFbDmdFiFRPjZL6IAdgCgC8FHBj8pQacxG45lNHrmxsjDIBTe6awe0MKL4yjES9evE9jr6azb7+1pumsQofwDUFTN01siIWCQdSvRs0gq8ZQAWCR/EBQmaMJlSpnUx/USSTC7PN/JFROsqChQBwXFh4KdGFv4UarxxwfDfWEcuBueg+ZqQSeeQ1DbYQh8tBexRjGSkI9SQ0IbYx68MknH5lcqqWZMarpdQC705uw0HuHwH7z5u3L78+MgPASENaYt5JmK2eqC0Vi7sLzQi2X/EhLSLV9Dn1Ve1h5cvVezamCLREMRWOW/bkVCxmH8JQIlEYUyTLKIkvJQI2mkA7MQ9yqoSrUZ0sR9igaQS1CkjiKYBe0Q02mSGNREDAYMB6YbhKcEMiodLRaX4DmuLFCVYQS+PzM0PFtZBiLwo/qtKCx1+4Lq9S4Sw2g/Cr4chMwYjgjDn5GhOK9Wv2eBEJtAYCZoKGu3qGv1JiWUikaQsAcRNCoqCSr1RSR3NDf/slR4sHUidv+VPv5zQgm9mm/240ig/fe++BnP/uFxWrT2TetmFlc+mhhRQKEmkMALmpnknxp+tDDyD2PnU4QoFo3DliFiiuVd20pchA2QD6ZgVUjQ7lVJUSa9AAFgTzFSWqPsjEE6egrFZwNi2pT8VAhZrgE0nxelkvqfdKTNftgCpKjXa32DYEiUawCKmRdQEhepdHOj/AvzK2U1cSmHkWpzL5i4ZD6BcKWQ8SYZ/ElcN17ATKRWghcMWWrAogRhwx3B0nX4lh7mWvEHP8STATZlgEBCxs08UITHkdLm5SlWDURnpfAiJIUlwFwBb03MQQGZoxIp96qosYuV2b4rE5DwnA/RkEdkWF/qoYmodsiwBo8evSA4jGEX3/5jUgAtEGloungllmS0vB4j6TwLv9RnAhEq7cAShuZf9ulRhEW2IOEC/zxHXmisUEueVnYdkOHK1THUGWbeKdYOIqbDZWySqFXXFLeRmOF89EwRv16TbsXoqzhjVGcLJzwRnFNZ9wegPqUqGchZJxIyQJPR6KMiNuecfrm7e8/++zN6/OqnY8pghWEqBJwi9UKooX7e9dCpjI0nCMXTGJmJAFdqGt3+67kRYkCoNVzVx5YQWyX3IfwmW0RU0Nb49tiHsscdiWu3RVIdTrm6fVbnm3B1H5nP/6A9DQh8rpnoISnaMVTUvH0rCnSRx9/bCTVbPHUKqnsAyjnD1tSG3ErkxYzKYEysLlr13roknzb+1CKCKQ4SN/l3EpAdKPVU9q6LdSKlyfbkRizCWfVwfjI1zfjL8yLLJZpLIV3G4KwOLLWcBPHMev3Jjf760ysFtjRI1xJv+qOA1QsxcSOqqbtDx+dcJmvM8pyfnp2WRZBSykf4PyXVNWV58/DeylV/eBJQ35bw13GbR5/ykvVz8DxLkMEJ7p396SATOu45SGquELVE3KOwQHOk0oJDGMs47aYWKpBiMrK5rVs8jcbrXiVqIIoEBOQJflDw/Cffvrp2zN7ZT5HC+EZG4nwCjewSIT7n0qR3NbMT729V0NBzOrJDIwCpWxCWexWg7pKTFpNMIx3hT0/4RH6BPpUkCQz+Mtcpk9gTwUqqJYrlRnh0EKnTM5WXagWEkchPCkzy8RYhq9MNaz38t57L37xNz87PX1rwZIIQscmbk34WUKhrqqiVZhr+/kXD+9e//j5Hd9a2XcZivl+VhPNHW6r8dBLEMbRFNoQcwOfuIBIR1KYHFT9zaCGjqJ7m8TcpwISxk5RHO4ypmprS6pIYAm3i5zJUYR47/0X33/xxz8tZglFJOtO1KgANmxB+xH+slG5u7fbm7KjWzXaFUmb5VNJRGlaMNFEagiIFbhVTWl7S50id4APG2J1BQAmv1qbGROJQCWz4QxzCxnQSYUhQRxTRiKxMjMd1c8L8i1wqlKazPBee6iU/qUFOx99/MGT3z0y11TeqUi4Q1/VIUel+zjXw0hsGriX8vzeT+Xq17tn7cndczCgUti1KZa23BiRVLpQrVe8kJ9MXXJv4fEgKbslhMXlxP0KIQoo8sDe8Y8whrW6K7QP+TJDR5esBtGrpGK6X6ZSzCS/Hp8aaKZaogltccd6jTJHrMK0hm0wbzjEBZPPLZ4F/vayxXmH6jZXUJAqXoRz5U1tEkwyv+NV2UJoaJ7PUZFXQUBbkfIax+A4Ci+vAI/teK8882jBEPWxo1K5xJH+aTQuR3NhpwJqFherM9KusGvBANrck4usEC3GQ769LUwbxJV3R4Ltj//vf4ooIJD+orIowC5xAulYZcun7Y7w0T0CfKaIa8C8tAzEFCeyExwQQmk3eXwvNfQz84VyCRn9J37HfZtJE2KnMAvkSr34G3xWPDnfJVU32nn0rrF373P3Tl5+/DxiJd2TiILYJWlXNR5gbgx11AVKpMOw42oR51FRoCr4uvBaDG5WRI5M9kTmm9iH282CahDZ8LNogTJZW9D4LAf0SURGNrM5MOPg5VuJDJucYajMC0VeGhV+IBEQAfTdNYilrWDRnteDH1x2z1Oq5WyvE2Heo/MPqwWwSpGVtlvSobNDJiyAM7tHU403RU9ME1akBMKyGAnhSce2oVDgh0m7ZmsTlCGhsVsKlgUH19PLt+fXF5eTo+NWjfCE/BVvSpkD71aHG+h3V23s0PPsLvP9h9u8P8B8K/9N9ZPhrhI3xK9kINCD0FuEEORkWYh+un4BdosbIgoRnzEyHNhhNrC2OiTDwExtmbYSU4xiFWJZlJG56IF++N9a9aANFxhOs4tb4GX0UyWNMQWWJiDfpKA9DrdbUryB7mb3LI2o4w6lu+dudg+3LPqpV/ef5V5tLTUIYh1rz01BSTQoLwwhb09edmaWDSAP9DyeEfLRK3Ohle5qV2f6ESFWlq1kFJRdmF1PSYSBcCUSPu4mc8KDwLKVgqCxte2twrzdMrUeFLlzp+YdzvXiv7o0SgfhKosPubVjUC8gkT8+uGSJUNhktIUR02eKjgAWw/OgdR/KV4SRCf2MTd6YgGnBQUFbBYCT4WYg8ijcjIUk9ilJKrOXSb+qNyZUneXGZMZQZc3xKvYjEmx5e58K95H9awnxF2XzM1RJAptAhvU3GOIasxUXqKedRQ6j7F5OdGTmVxGjeJml66yXvfRELL057h1boqES6a4VmyuyEkfCeVLk+ub1a+Ighw56JrPpXC9GNKKU0ZfSoOLHfQ6z4vdSGmjOpHVf/ITA/fy7zJGsH9Bu5988LTC3Lz2WUSVIILyBJumGSPoPDPdSdLg22Niz5MQ6sAyTxrXK3t8MV8a+LC8bZBkZY6DTHLGqzXkBw/iC+b8GnAag6qdxCdOP4337jphfQmApdWYlK1X/Vu20ITL1nydYbNXnP8/3H729TzV8QsZGW/QhoiURfHlCm1o01VsvLLub2VICSvPHOLpe9C319j6yIfSqsFpV7vOzxEG9A/Og7RH+c49sqTV4/tlQnlGGzKGgiu4HlYhJQOGtXlRMC4EmBTHju8Qu5/nu51/7N8hXZa0G7Kka1JkbIYzlktnJwLFhqdlJnLIQdzgiHkavbZcwV1N+w14rW20yYFTg0aCQMfKdMChtpHLjC20k2wpUQ99vpq/NPqKFbtXrs1ML6g1Z6YRG90xuxb5k7sGQqQooxn8kEe8o9dcSYJe/gbglxhZWv9h6+8D2s1Tm5ND6QbqABrC0pPzk8Gi4P5rNb7797uXsq69tKjfVPMkKoiDKV9rMILfpDSKwrX+nihnt14/eHD8kESLHs7M3b05f2UahePlYC7t0QITlN+Si4NluQkJFlTRB2AG/o0umQ8hDU4fGybss/9VNbH/6CHf5NKGK4FKcs6vSsnlL5Bhu+zJqd+7AFixbLfi1q+n8+upy325zg27dPUuqLFK2+WmwN0l/MxsLFyM+Jt7GHBbXEw9kedLMSS+H4+zTtPHGHJTJKJqDOhwH3luwZvckQaKLw+5Q/xRQOm3wjJ38UfqPBORHGX/6QePSj95VF4hmlsVEf80Tb36c+UeeDBZtLM3tPnt8ghamJE7P3lqIR9LPrSqPyvTkYxZ40VZ54oCQNU5n8Pkfv4C/7aqu4gxPnj9/enm5F3pVl/Z6Oj87u7DujL01q13djpT+C3BDm3CseNgsZx781UnNKfNOFLY1aM4L1yzAMnU/n/UthrJi3JIx8g5dm28sRxz1Hx5PBsNnIkjaaxUCey+wpBgRJ+rTT0DRdCSbdmtXVdbEa4eumDE27rY/thJ4HwkYIQ7WmvRHjzoH+4evT0/tKqJcKMlf7RRqC+KP/9xFFj9+9b/3pFEBjfAQyk6uGff2s3JY7MR/EZIIIY+4tJTOhJLwmYNbZIO+BdQ1PcNO7o08xGq1laQnzIKpqCkLivyQ2kAlKEkUp0OKdEz4SDb55sAOaLt15lGI6GjcauxCbtPXalLQJCI9tko42jRcq/eRD0qN5/efbssUz1tx1SXbu7Isf6ar53PqLb5hedK1SBcCQLfpWRR0/MXByJJVu+e6jq1wFgj8+3uHo8mB5TV1FFVHp7Gt8nXGRHarZMOSfgYzaGKOULmxUjPzVBmuCIFjSKydzd5/Lkc4hAPgy7xdielfwLpF5x6GDec7WrSf997/9O29bMjabG06RwkE/Cv/j86qlfKznoAQmHGjXat8LD62Gm7eXwwmIqakqJVuswUhCOFe9DxAXRPRHGKsZcJNQUh6AI47YRsl3jXzx21FSi12L+uQRQIRrYK/VLnxP7DuePcO9IblPax+Gu2UrcLbev8il0lDHCcO4rmsY4G1/DgSChGDUAectuL3Y90BznpaNGuTeO9mwTrY+5c42ODMfGYBiOppgCs7muMVWI10yzs9myIty0RAkWgxe5moPAeOZE9johRWWeym5ZCg6UF69SosduVO0cLFvX87mnhxL91RBDfuPf7p28oTbkfubRXJGo6Msq87WaDPHvjfW1uuY+0MUkPWbvNsrLBdeUaDIMgbYr3Vt5m8YSgpQO3pVJh9iamAjSEE3jQSLsDMAF1QiOMmJTAxWergq+hfhZC6LA1pfkSfFq5ArFQUyeU/Ry6A79L9+x+XS7hA6jPlEepqh6mKE2cUM3rQiT2oWTwkgDZfRpstR3CuyNnbN27Qh0E3U7Oeza22Fm5yJZ3Ofi0E6yDo4GF2EhrxzaCvOMn0JnJrjFZphBPKgvwE0bELvA0CpspsXkC1mIiSAXKzxSkL9RFIPU0i3iG7Q/p/428xR+gLVNofRZXKChggA4YVUwOrUDt18Bx69QZWHBkmOT97O7u6RKlgYK19tvjphscPmOnOki1damHHzz75OLJkOa2NsvPlenGzcQIazA09ZT2WG6YhA5I0MGvelRYtYYczp6KMOq+oshUECAJhh+Z/LRG7nO/+Novwk6QDAAQRn503Pn5nF7K8h/rTlZrXyPaf2lInSDg8PLDE/5bE7++v+2Pm0jw/mvCHoeOVs3qmODmwadrQ3cJE7dXl7XQ+vbyYX2V4xpJNGDWYUInkRUsy1JkrnqQWsXnmusxgpZfWQCdHHjUj8Q65H939UAvevUa5nzSN8ktaQXEprVeycSrPIw4W3WY1dDSC+dp0BcFHtqYdHppush/vhlUf7TluwYJqRbJ6qncq/AL4wArtxXzNJAoevHQVPt0IS0MBqGZIOoZY45vbdmSTUyAoYL8rAoXvQL0aZkXqyhyUL1LE26jVOwzv392PvsF0ZyzlQYj7he6IAnnNNBIowjJE78qRx8jX0Av4mX2QHEwwv/v0vReTBycGCOaO5bNFuTdcXE91Q6xVur6evXzpFMlLq3YG1vtGKhZLiuD0GZsZrbpDEocuaAlMrhp2owFb/rRn+i89NegSQoYicIvpoFLUSoktFnc39/H/i/uWx3VLCBW7R8pdiqGt1B4UZUsSYx4BtyU6GOI3kwhDNN/0o+Wrl8Jtpw1k6+PqyjZzkDpRcm4tYQKnOA6bYb/485cO00MF/S3kHMVDUPguiWhU55EaFdAYIURZBmvcgEbiNaUdwPn7X3qH+5l/fP8XtclQDI+kJUXkejTRHpWb/SxjsoCVUfKvpmAyGZn1a7c9IwPLzfrt1cWNhd6j8Y2tF6zCwXEn27n2LG6+uLJjN+vyX52eDpwtaXxFOD7JTtYeQoz7g4Ps8DEFbml1pmlQIRvHamkAGluax2WSBrRgDEKG0spyoSTjr06F3V+WunuY6smGHlBGSVA89sDwKMBIQ9bcY7WBBnOTpCahVOaqbam4nE2ZvyvjT5v1wcmj588e7x89sAPIIkprFV69+vLly9disG++/i5j0NiLCgzig8OjD54/U5mTfyI7cU3onlkequB4HIcd1SxY1gFRCoZBKVoYa5MExq0S/SVOP/69E/k7bNvN9nH98USl2+fp+FScyPBVmJAerMM9jTBmybPAbxlKSToUfXs3FroJ16uZw50+/uCDZ+87aejQKMPzjz6xfv3/+dd/+x//4384e4laE4escEI+XKUCin02nRGHmtdNQEnzVCsPEdDdPDywVH9AYWwcKSOU8XtlhZMIUS4zBvP/j6S5RCBkIt4fe5Deju2V3jB5rRg2KxkNvfFjINYzftjr/vrj3zx+/sw2i5Fhp/EBKsxn8y//9BUNOHv9BjUhSODDVQJWKBE5z/3jIR1Fmp6Cn0wNcnilJWsdrK1lM+bjjNz3O6tSAPhvE6IQh4q4fmgtdhnu/m598I5kCt69uruJdCWpD/6EIrzGowQz5J41d35hDgaJ82C+MDTrxyMyMZ/2PX340YeTkyOugS/P0vf+4Jtvv/3sd7837iCDStJzMECbVjIoJ9QwCpUxPM5Au+yCTOBAIIKgjHtPEkOnAxpLGdrFMDTTnJoCd9ns/PhrkoKNEO2aekoGq44QSIQQcWC8Iw9ueISsR9CzCm+qafwLzBCWEgkaHzrTqejYf+eEE0Nlg/GfPv/i97/93emFJfj7BEcMRq51sJZOS9OtRgIrq9uKddWItZmMhj8g7gihR2GdsZ+aBhkLbvVQjhG6z8vS50Jge2lYtR/32Y5Bdz/D71qE4kkhfPcKziTBITFbd4EP+B9PYQTM4N8YvNmOQo5xRqBT0p1H39nH8sXnBMEM041hw97g33/3R9sr5FgJQU3HZQdTZ8CILmZTB3yOR9k6S+BTzXpteBMhHUQKAjDRwIhQTn8Fa3qWIQSeIGZZbZC5+V9JKHKH+Y/z371qN3UNdeqGoioLqUwOkf6KafUdjUEDKeCovEjA2WXr/9n5m6+/+ebNxcXbCycSoVV/ltOnHIF9sNJLX29EQI6bGLw9e2OprH0B1oyyf3sH+6hm6M2OeiO8MQcEEKYhdZP86IV7bQpkWRLwYWOI8aP0HyH8Hz1XQbMX8A6xGYTIWFHBqGAWx/nBRVvzqA6nIDr407wZzA0BRRnBFoPHta/7wqUrexMd8n01NbBs6MTQG7+Zza/WhoayA1kj8j3jEukY5QxpXan0plYi5T0beTVeC8JDXfViPigROF2HCiVdQRlyJFz2S/KngL7n5NqL//L6H5GmCKFSTVTfLVyhI+k0EVDroG1exKMYMVnLwIGJ8ab2jgt8cHwCC93HqWG61dp6pWkNPDgJkyG1Aw9ugw/efyGc9u7Rw5Ob65uAkr1UzHGJQHovwa9AiV7ocxv2RhFHVkgL86DlWnRPK0/T7vj5tiEDbf9z/Bvyd9fWlp9uXIJXlQcQ6qs3vEkmr4yGZXc6QOQPp3hJolsJ2/y15xQJxuNL/QVbf0nvjUnKyHE/s4/OYef+YHxyMDnt3IqyzpD1ZoGETv91FiTjr1qQqEshzSCB3vg+jatT4TyUCsJGo3b77qpgQ+bdox/etbd32fx0L8u9Uq2G3XOYI4kAIe4sWwZKSBVq65e2ChsbKoSuno7IocbQcjaaYVuhQUaUSBXJIT6Ww9nyb7jgwdHhJx99aKNqzlA7mCAP3BWo83oTTJWAl75pc6oOkzPo27ZdxyTV3HFkMmjs8Gz45FqsdHMPt22mlmdX4if+3tHFu8ZbdsOt55I/gteMfsSLx4TEizJgceeZeQCb/7Pwi1CtczwMihiCZSD9LrEKpzMmYy+nIUvGIWZDOB4XXH3v9LKzdpbiSIVGDrEnR6Y+HEhEHZgPOmaABkxkFAUbGcDid7NzRYSfwPB//ZGmq/U77Uh4kDHjGLeNzccmZJxfmfPWEv7QItBaiLCcCBmHOUiJ2EO3SBchwBF8tKdVDXlFwSHhCDEUHQ54kmze0l1brK90sTb9rGgwYYG6BKRIjkDZ1JyoudbN0xG7WLp2CkdYd/8Hlp3B1O8MM6Li9zFP1h+lcDirVZIzl4rH/PXE1AkYsL8eN3I7m9zss2MoZ6hwMM4mnvwXeV8ZEqPxgju9RG1BTdlEoQEzshC7wfWbYbD+17YSkmP45MWLR/uTY4O7hh9ECn/8w+fpqChEqu7ArQ00xjPta4y21Aa3eEsSGRbE8DRj2JB8pyF3NfyVN2FgWBAQ3CKB+llHIpmwyS/KazohTIpqZFwUHTMqz/yNa0VSLGZGAoyELOukTMwWNSXkY2LseBY11XlNw1HnyGkSD57YOr6/j9u945O305mxtwQK0T3awznkFIGV+QxnItiMrjNawpLxmBiIXdqJQXiYV2HF7t1/9TeOoExRu6Zfg2sgaAMajZupsP4XQXqFOlvx8Tepggaavc70dMxjpifI642O+I3Az2reoYk2OGVGPgeTm6CMC+CJsmnM7P7BZHRzuHr27PmbN2IM6zqyyr4hydGCyRCNSOOgBl0iDjlhtMZCKraPDys07uMLssD916SWP/OPyhItIlcWMHpX3SlCkh3gtTAPYBLHrwVGgaDAXEFgp39sk5kZVx1N8jtK7ETn6XScfhlRTp5gOzTA9IZ+NLJ1Tdcer7sn1zNnMZsWNY0hj5kQYhCT14wz71xmk14UHaMU93G8+/HX4g/tqPYuBf9IUgRN/6msRpR6S9PqZEI/px+MrODOaSmYn34OsHV/sTXzR5EF/c7RpHd0/MQA5KvXb23cNIRirMbalIGgKgdv951RoyUSoZwww+EYR9ArgwSMdGU1LF9CJCsaZjN6YTyimczAxI2roBC4h8UOm7/y7xbJoJ71rJQqdnObKElAwpJ4TQMOUdn4f8a+lkSHXGAIg8S1SFd7dH1jgTl7+PTps+H45Pj8+5y+cm1Xap2OkKM2JrVpnj7sldQJDUd1xsOJ4zAyJRjjh0Xxl+CCeTaimvwVnNfyt9Aoghq25VJ/E7xEeHJtWLVre56nP5UyqKaOKhtrGD4UTtGzSHhZv3ofb0lWzCETmEytZc4KqDHXXH5MlYTjwNNpzuTcvnNKRw+fPjuYnPRMaq++vb3IkjejLDGk2o0h5jRYU6cPjXr7e5PHDx77wghFMNUHf5Vxk+oFpRsm2CJRSwUabjDKTRDYmgA/i2pbXO+y/RTu757dZaubjGyrOOoWE5CmUykscSMkSgRobaoDYK9nHWeEOUdKNiOyOa8n2yC5kvgOUqNcrGB9q0E1TDuj5vhAQzU6VQHalD33wk1m2LVv9MkKOaeQGWE7mE4PSAErEPEqR6B8CO/UwvRegVG0R8doRMAruQgjpe0wVGRoS52GsUbdNDLFp9RPT9S1pV2Kuw91y9JlcBV+0fR2nGIMRUZbyb6rMWFj0iYdHc3hXi9LLGMtRyK9GhzVAh2BeaIJBtCAyq7TYVfpYyJKBUANJePvUaV8eiCHVk/2EWKqB+tsfNywqm5oYgdgeqkBb5simEnp3xPgUoIg61H+7NJf/NxiW2+35FCFMLjcXsuc+6hjDD2jjgQBPeaJR4gw8JRGT2C3Gaeikp3E9+ZsbPfRFfD5F07N+GFUlnXJB5l6vh72ZDBy2o08L1+fOg/8gaNAVEybrBS0fIEpEajJTrL29vaPjx6YFWQLqYbj4XOSG3WEXQL2xF5MQqqPTkWHtUYO8yfKgVj16IeC0PAM1JXiB9pNSkQG7nqifrD0rBXsvcrIITJkkMXe4sxPcwSGfLyNvKbHJBF8vM5XgDx0SLKlWZlJKt3lctWknsPR+NHjB8evDx0hPEBGYaiwKpM1N4tR9t8Mx85Ui8o5oN5B/YK01eHVFVjn8ykX5KTzmqKMvrWh5zKOAElglxSabKU9IVP82fZnvS5cI/pb29kebq9R/LLRjRxBPuMq6oAuIpgCINjOH1pA3ioGG51Qh1jU1pnObc4xCX+6nWmmoBemp6oTALYCoyKohBH5PolTTceiiYGcvI1/WLxkCxFkkOPrMpXvfdrN8VlcBjrTMbKXQZUCMRIgFYZYhDo4B2QPtig1TO5+7tBtgVXy7TLu3uRJ+JvxjXjCmCIpHI9K68Zlbsm4s2+y5VNM3evLhJdyI4yHfIP+sWPT49tjzXgAw0bNm2gvEahJFSEFaJ1fzPCp0KcC2gfkMFZdQq7bseU8uB31ZpAy0qcPbln0nrNfrq+zD2HdzvrVPWe8qSn5zYgw0HVhIg5lzBtiMe/3UmEe1D2NiN97mT5OHhbSJS46fTXWHbtMSa1OZ9adVeaINGrBvS90JH1NZH4Nklg64o4K+VBZ95YVwVeTV2aWWQVKKvSo74hpllhxruR64hsePop3bZlLRqyyuUDETTTidXVO0BD+IR6z7FB40xwWuh2trnyFRVt237UtqbECbFpGYcPAMueeEMuyCO7uiOAhQJsckQ83YGk/S6RcBGYhTuEf5fQzKxolJwAihC+K9A2hW+FHwvtZ4bheXfe7vrmQ9RcYGXQZgNLZGhaiDgbVojOENP8iMWkpxg070aIXjSBwDG6aZ3RWOQQDkWJ6uCGqnhA+SsBMxEpV0n9XW1iU6mCvypAjCkGPkrZ+Uc13VIgMyBVYwADVKpmsIVjzrJQwSCQGdGJ8bKHBYbrgY0x1jToc6v5UFNvVGR70rof9i7e906nNLct0DPSmIMVNiGhsgKrRc2XToMP/owAOlewPEgMWROKu7CNIo5TLQ8Nq+ZgAnUJUEEBBBiaQ9SAluhgExT9Hk6LUHgs0X9DAOr4DpUotQo/yF9ALt6OTgHNfLKBCIRdq1FqhcMVbNbixLc4J2wZv3OsgO5GIDpN/EYqE6JDx1kdY6jMsOjibm/n01FfAlqvZxRlIcp7+yiwMRQEOuzfe9Cyw6PhCQ0Sdz7p1Dq0jx4J3pGDAa+5V1LRVZE2H1W2eAVMxEVqkgMp4E3aBeJfck9+MXibSQUL548C1JG35L3/t5omnEAHiBYlTzgoj832iD/TQiD1wxn/8FrHSvH0H6eH/di0mtPct9B7tW4+JCsjhKCdWDVGIvGUHB7Z+kmBLFa4ugnyCF2v4x6E+XTDJJgAoA8NxeCVBk0eFG8qk3fRDwAqBjfAj62DtyItTQqsMv5LfWszENGWTbTYs17rTLKW2UN40f1ZkE+oc1an5oF9UeGcOPODdPNeQV6QCs9BF66xbNJPkOycSspLFNbQ9lit+AYW162Mb4jfWwFM/eW9UYJymJo75un5v/mR2+uqVT0loIm6y1BCZ5NeiTjcRUFulfA1SxBAVjEEDVY6xpvwkK2rv0CYlVaEwicz4BaZ6RDOdKXlwOIj4618zIkmmsggzwIi4npmsKoEt3U4bqkUgzLkNcSX3mtPTJ+cWRDCBhSk6BNyaJgqx0np8DwlUxZrTM9g22Jietm3SOgUr1Zab2xsz1qZRMpNi/YnvNhEhG0UwlUMoAU4XMX1qQeWlahn4uIOMIS64CJi5D6BmOjE8zaUg1juvaiQa5xI8ibMkQyUOlEofizNhk8l9GSsjMvnYDBHlRMz7wcU/tGfaonUxLIazgZvxS9nghi0l18EcZM1HyC2lXOQ5+Luml4D+RoMwFuC8/8jOBIMklrPlVAp50qHIFEnGok3A2EBjDBKh8Ult+KQB1FdNMkdN0yh4ooFIHCpHLjWRAq5ycKu0RYue5CElieUunwfMAZlfRKWHgz1fh6O68t84yk48h94694xAG+1JcR4LLbCJBCbwy9Cf6DwdlkyI1ocuiAOoWk554BPrHyMSSug78ohZj87Ym5e16sg00GpuAk1lbAxvgyBG1jhqK0wkvYFUXnohB7xCYFOQS12GKYpQuTzZfSCRXkdA1IHqzi2DAFKggvVOIqhYgSz2QwNSVlgpmtMN8oU8OOuR9w87i/6cnhkDx0pPi3Sxf+EmAGGFjjGLFqjGUkS0MhvsoGP8q9XmQZkgYgvfleYS44SRaMgjsznxfaEidtBHSKsjMheDvYgwG/hZ+p6dtfuXl70V4bNRholNloSJJDFLk/KZzFQPDA3CX5XQNATfZCHPiR9NJrG2VLrWmb/BJcIQWYrYwpVqiEcztmH1/N44GxDnCwJHkOBQ5lHYFgCCTnayZsAb4Wh8+oHFHDbVjTXdGUyspAl1aiF/q//HaMSXmFpldQSjAuE4QtEdwtr9hQzp1qFIDDy2DfIZM+JghoI42+nTo0Faz5KMTK9qsT4WFk7nPgu1xsICHieTtkGRCoUOPQumIKD7KN+WneFhtEgGJam/gD3dG5N8AprNWlhihBtvU0UCrUSyKhFcyoMFnsOQjaStTIW6dP2TgchHOmqEQlnllI2gceZxPBV8ZiCDDsqvHBi13FCSn1gQBLAK/REQCYQW17ORJV/UCK15MYhQBJ9YxRKJn+EZcjqqCm996mqydM6XH8gvoRqiWyDvXtUIpowqYFAQZhpGu2bPIxOMSDQlJGPnLeXgcYJPAI9n2AaDmU9vFEwlKCmbv+Qk7A3TPSxJCznyPxFRZxhQkZtnSVFKFYX+4ZDpFRLJqUVYohFeo4jOHimQnZyrBAp6U8DHPM15ay0TfghAsmRPLOqFv1RGC/CWKVltIHCzPS4zeq0BEAX8yEKuMjgjq+2dCI0wP0MbMS65QARnCqNUnPvAKFySp1KUpXxBZC332+HMor4WFCDDTRILMJVArAm2IqrM/yFCTAQimCLh7ml+vmeRyYLmqtOzak2GUgaHTN+TK2t70NEpypnRU4nRlPLMYAYNSiBOzMko3/pTcZAMG9I0BYxUJx4gsRHa+gfDkMc9sGO1oRHhiS3BURh6rAr9OwY0GVv2FPMwDWi8/UgB6lJ56l1ssldEyzW9HMl8UiiVV9WoCmOadJlqjjXCJaXC0Cvwu4lMlF1Qe6Yzbbmd39QnGtNViq0TzdPLDN4mMFlaD2lcQRloqzfcIn9IoLZyBEihFlWDg44HHKbcrJVNKvKVU0YFuhcKRJ5KnAO02yJSxGaLRmqDaiEYciiOEKml8AdhwIuoCkxKHACDF3kSuBuPQIQwPAulDQ+NF6Z/RBiie02UKoI0aKzfMbu+Us5mmM4mXjN9hsSIvuGxWeo59pe3piU0ZltWDHzYWkEWRQBX7FrNWgYFv1m9pthwCyL0vP6CD6D5PxwpJIN9lkDBIBhTokToEYcUi6y0FFlIgfamhKfkNEKhytQKPP9HiKJNTiXKmvAQBSIlgblvcuJ9TTLLmYUpriiMWxwEirGfVoD4dANjQFaIE8aXqyQ3qTQfN7eDICwNJQIhQgTFWDV+Vv1N+AKKJhMOJE9BjxYNwxSgJZGHAjrK3mojDrK7b3LOk5UhwFzYqAUeasYJV5ITdwLz2BPHEImkZUgMRm2zkC+S4X8xRTrWPsxGP7L8rI60Jdcq5ATpP7uoCtsDeZ18NX2jrylKXiWoNr3FVSO0gUXlI3PdzmT/oGhcZ8dFcD0DOvfnyyZkCV4W2udsRXFJ1jrZmBDmIzIJCRrFLE4Ptn74GTeHplqvn7mJPoTPyV/rZ91GiPNHCkO0mms0wHPY1sQ0vDyLzuoKcDcRzeqHlqXLvAnRi8JWzFLRjha04cMmIUSNoew5udcIjADf7qJIf7hi3Nbm85lGSYSf8TfkrQDimpCgwgpi5RugGZmKUJGCHDLZosAgTkgSOoCgHcQN7EKyMMG0SKYWQ4hKEEZSNcfwxyQLK8hJCFokLQ/EbPlKR6U04ZzgWKVa3mc+TW2RhYgEzAVRkQUy4/NE5UqLtOlxiSk0QTpWvZvpdWIHXQ+1ZjV44GBLIovitHINlLpSmmxsKYHEGO6UM8lDYuAg3qhkvCyalwyBTqEAlKgtLlW1JRo7HOpVqr3Dyk2ji2sKh4CeyfIuT4bMKnlI5qpRjiOfaFImSlegxN8bpSaf9Tmk7CVC4uqLYI+wQXTAXV7MfdTeN3L2Dvcn2kvPWr5oAxSRspIXAUFAXY8jxxGWIhVg0gcQNKfvFEtopCJyQSCyNqTYzDBExrOFB2t2yFHlQiQX7VQTuYjPmjNLMzEyhCFqHwdWeXPJwwQISUaAMwyXWebUA776rw1UtI4DiaYvpPwH1ESrtJCDfUzqWQR7WaN5iefVnm5LYn6Rdo5LFW+DM2RI+xG/pET04ax88ti1puPvaE0aWSaQnJVqZwGhQtFt2ciCJsCaauva8HetuhPbTHNCVBYK4aRQRlOV0UBW9nryVWpo3ArNQBUDzb9lxKXGGQXRzcnmuUQMfYaUaUEcOpEZJo9AnwixaxjCHCa6i6C0C6rWm0KgMF0DrsH3LtGz1EXukNzaiEhN6WzshsgNi267c2YFl/I1LjM8xLkWfhBTqBoLh4CaGyGqt1/0rVYaLVqGhpWBo7RYS1cIFPyVbVdAtUrgqR755ZSKnGSPanhvDWjMNDsvCKohsy3U6knHLOTIYs8s3FquHEe/MZbX4IO6CqQiZcRM7VtSxOps26OPeUxfUsCszdDSDyOczMvagoiMFMS2K67a0tYgyCCjSz3JPgtN3BFZTvgo4qFXUpZh0KeSoDibYkzLH6hIaeEvP1jzFpnibGJS1SO1zAjnK0eU1nRrqU28XOqPOdO7Xflm2HUbRmVIGtqojITJZICqUpqhmFlJWwqSkCkihuJCtZBUrIPu4qjx7R6yz5aOOmJn0FvCvp1CRr7AhBBcj1dIfY8KOQO9pRjTGHCWHBkSG6TBECgsiR4Uk4xWZwaeQqkYTOKbCjrcVgIioFJBuhQMmO/ZZISiqEM8LWkaONuURt9Or2dvh2f5KqSkRm2EvQxSEcIYnnHENFZUcm1wAMbwEuqUgUjr0RMjaQZdruf94QwtvcvAX3weRdD21ihEqrOwjLnamlB14i7i0FCUR3dn3+vwIzy7WC029gIQIUI7DxsFIby73ZKUYUB4lCsBorWRR1AkNMjizAyCtbZQplXlp+Uob8fnoQL44gAynxP4GiEymooJiTxjbMCRTJvEZOkjMUrUcZPvJ/Ghvu7DEoraTaYKo6GDSzqnKix5jxy5LylIsJCfdcWFOJZbH6TKxHuzVekTpA9ND3eaGPyDbcIBlxg5j4K0IENcED8fnUiKTJvF6xzMfb/lNmdypa3IVMmgAVHjpHPRKO1d+5b561NeLuFK0p3nh7aoQ+87YcAw/Q38VldRPyNOZULJY8J/VDCbadJMeIqFgYS9MByU0TCcw58Ap7AmyAbyuy9oS5zLT0OpZdBQMjQSQyvcrVpSUwq1sqjmRmckFNGPxZ34qe1bUJuFPTw6Ics2W9/4XnqogKiGlnP2X/Anxo7o6/hCqVU5t8YRPY3XxxJjUSFHNQh5BFJjSUF6bMgZQsRRxAHlZ1hh1mM05DbznWD8zOZtTsWCYxSQ0FsZ/2LICiVKm+g2Q/41MFDuoyQjKCNXdu2pXTchizJJFvbGSYUMRQhuJ1QjRXAxwyXwM+aVnmXMEZ3esyfg5MjBLTben7/tG0pFBA4m9M33v3zzK7MxVjo5mN85FPERabA6KvF1re+xZX4oLlUMg3yBIy44oUd6t+Ep0aU4UI/sOOuNk6q19zLE25Hq8FNKRSVv1ka4xc9IR13bTd6bm/V9hnSZYhFRqmDb3rRK1KvVetvIG6iURcfWkfYTIQQ+k8lhbI210tFr48m+Nzx2zBe4RIP1LxiHcCESPGPW4hQ0rJaWqurCgbhUKvzDFyPqBJLwexFdqmlthMAg5VsPOyWyuyWJOGJaPvobVYmuMlqwlZK9jlRwr3VfffOWXklwSOGy2xHjeoEInuV98xTiPU2WZ00oXUJV5In3Yb0Pbw8x3oFGFkRPDvJpLDKY45fYDLYz4W6dfqtS3ojwW+nnUpBVS5Aushfpo5e4FT30eMuloABiEmENlDFfLA6U/g8iJObOsG+jJpUklNud6QyXoASLSrkHCTHLBE9S+JFALHraiJAn9Yq+UpVoChyrb+ENVFJfdDDbRZ1wpzyX48OX7B3wwWEgYWrZnpkXwhguFhWqcKa0983BjTNuKdXDXO/S9qFWtqyKm2459EJ94VbEs3S+VSkxVcgIVn33pMRbmb9M1U4uTG50DAFBRBDwjuSAoRWqdlpmchfBKp/lokZZdvXkBn1IPzJ5RRbog1ElcxEZQMkHkrP5waeBnVnnXPysc5E1AVHN3iIKX2Xi0zfiBGWhWRLb1GxaZBWoxRxtpLkQCqdjmln1xDIwj62ODMgSISE88sUgb41DCIGxzEHuCoHUDJ8y3Z402wGqO+mQAZmSW85EgPF5kJUzLheEbGPB28DKgJKgSHahbT5CgxAQgilHHvevIPRN+RkLBbhwPN1QdQsqjMMUIfJ1aU+5GXYoLqmQVidGBRSgR38Ybtjmw5qhqG4sKzEQQ8Ijygy4AjyIhiyuxaiqAGUQWiUmPsVHFms4VicSY1ZJc7H2tYc0HoolzsQM2GsRos50OhcVWIay9g4NRO6aK9JECIpVqs/YlPl3NZtUsCTKcwlsZE7/By3SnBkWFPWU5JBn03UJ4AQgKtRREedmbOueNkYyQojmLACaWAEt4etTiVkzlVX16f7W8KS6Zc8k5Q9TYK9qw0byVIvWVKp2LxhtYLgVULYAHkNCFGFJOhhlh0hElcVMXi3yFuxjtjJyVAftYJozaMxjG3U3qGiaSqyCfV5HibAwpfINK0qzpQISSDEnGVPM3BW6wJfeEAcFNUegkBIbLK4hosoLM9LPxruwLIIKvUhyzBmYNVCRebBLgnODvhFCnlC0EphiFsoKtrLhWrP50bCqwZ/c5NrqAQ1U8rqeaNhNxTkRCeI8Ppw8m4x8JuR2NZ9eXES46Uh8dQ18lP6pIvHCroqsDqPWXKyodDYzw7MXocA34hOLo34xLRZrPMeOxup6ZWZZmXzwOClZg7Y4JtN8ZUXiDiU/pdai2igsb8tckXcr14hANNEKlSzFiRVCGqzFY6W1GFeUawupCnM4RzGj+SF9HFAGLLLl08Vk7NiCzQedxw+t/bJ/9uri3NqXDIhk9TjuVUAWP1/W0eyVwt3+dQyI0VrLBHp2HR/4DqnlG4gakiNkhj+j91oHOrKALGY6uGWVWGBq2MZINiaFPTGPeS7jlo3Igb5aBzM1PHl4bK7VT18W5Ei1nsgwh3AlZdax4a6M+lxLIlCkxkU1VPmY8o21BPnsLbYD38pdV1AOu2vbe779umOlqznisDGxQcQ+/Q6u2+rQ1dJHX7MHAIX0hoANhXwU1dGilljVF1W1DMOjyeGJr9MfHzvPxilpkQiDhLerfTpB/kuGK3YJaTRVilx887qSH/IJ6ZkAiyUsFDveO/7k5z/3WXljHl9/+WdbxCOq7KBoilxUNIVzqQU3FPdH9UWIPGzJqyxeHjL1/Gy+n2aNlLWJJydj9opN6fVOT09p90yrOrLOBnSTz2HW0RpEUjhtVteney1ksxQKLaLcQQq/0v3GpfrRNXr59Mkj32eyssgAbg7HxC8Gxs77zALW7twCKJIcMY2/Bafi7eoGQFr0k6/RWzBy4ovBvneH6s8/fP/b778zo8h3xdplU/jSSKnQg6iVIIbcamz/0jiD7KfctT7OoqfuZGw5iI+oZtDG/g+rcBgG3fpO1+jepXXRGfnxfSr+QRAwiizQTP9QPz41wWY6/Y303BOg8TNrSTIcOpg6WHV5Y5OdL0n6Bm2+3i5m2KyZdf1KV8cQ67xBOoSslZJ3yKvhLqGeSNYSa/1fPMFYAdt4Mh454CI+OWtWeR+0gC4go/2FuxpUGJwR2a2H8cKehmkMGfbYC0MWWgQoOqLsom03UJeDEzh5+NgyFNXm/uRhxQUlcgxVVaWJ3MRVkzot1IMmCwk4aADVyQlf0+klK8Ih+iZtz7d8bsc+q5xPHwPR0mx/1CMBgnaEKEEjUw9xOlmzYaVKiMspXl1dHB6D/0Cn/uHTxy+/+Q4hK8CJ3WFyhWaxXHhEqeMXARbYVELP46JiWGOV8DnrF2mFD21ezzZXVyJoS4fNaF/Pb5yoYDFdloJlMV3unNeTEZgYrJiv9LrBFqzTRiNwo0KeAddjtlP2ph8EQVVjR7MPuyd7E19/NtljuC+4xiyoa1uPnzH78dNinqhoIzqgoT1bzGAMomfPnzs+bHJ4gKWZTym49MECG/qXOLgnZmABrWrVADDAuUcmnWz7e3qWMIkNZrN1Lz03rdn84puKxP7o8OT502e+sogcSEAkrSrNBGBRMuGlajJeDVW031av8m1LnjMyiZIqUMNSIcbDkyOnaqLCQ1Zzf29hTwLTkAB5C2LqKRFIRZUAHbgzEhdW1n1eWOCji0uMrfxMIMbpiJes4qFwUbqQZJsynEBl6QLBLEkwZMI96DkudZxuNvMZ/2AWQKipIUW9on64y+I/ffb8g/c/AjwkYxBufEe3ak8DwZINwK4MV0Ddr9ZqQwMDw0O6l0WEPLFo5PjEJ3fZNJ+4sqfZSFFlIb2NOa3gDvZQM08CVcQF/rIb/0JGBsBBhGjoSZZLmdTKopQUIaoJzKSSMaDmIZqwCnoEujFpzNVGIFEAcb41YqXLTDCpK92QPZ6Ww+rq91oEb9whxwOvLODKTpusWRP4IGh5hbg1TQX5IMwol/9rELe+bgyDCNtGBd0O6yxrXBFYjG62VxjVKdpRB+5Jvymo7FLCPFqNDPShVMY0TghR51uQZ1GU2GGk1vGg1rHCNSjAu84mVyg0aPUVgWiXECi+CBUSMpkmYtoXNz0fHeUFoysJaxOEFUbZA7dYnV9cwqx1XVeLyEJ6eKjAMhcJ0kSVLGLUfXuiFqkExvuojOluW2hsqDImEaM4vdZ3MeqWbOFe1VNGUeYGuqv7ljSQnDGfKyfS4p97j+haIy43GQWVcphO5lQaJKyCWnbxV+wa0hJ4nWcT5zcG/abd1ehydDixIjYDqNUrzSnJem7UPZ0Uhpa0x0Rb++Qz2KYJM+gIMijn/7I6jeQN+OLuFnr3+IzewccSspzIfmv2FhUEfYeJgWl31CpUrbTDOoQonAoZ4hlbm4QJDlAiTW4CMWD3snjXXKtfIOMv0lygKdUImDGXGggXQ8cs2beIUgHGkPiLIHNMh61/6fPToDAbawwLEg3agXSixJhUo69qQcWoRNrwLhYBrNEGTRUad5fgU9SI1BH3ZU/0he2jnrMH1nafc4mCoazYxytSQFXVdC+xKZ6XsECsoZQaOUutyEgKSAI35sZCLI+iswbFQoeYOlF13RKHcCf0YOS0BM8of+ass9J6knhcW2q2xhDd7ARpTVBHFNlCQoh8O4OJ4MTYA2inheKW3JCIvBYKfkrCelC2aEqbwimzEuZB+aTYa4YqZp0TS3czApxp3Wg1mkRz0yeOUfDQcTo2pYKDsPLaKEodYq5ER0Muc8RZivmsrQDIuAbRdEEaPUlqKQNCp1FuM8G1RQd2vOBfRi1GzsRmsplwY3Irw19FP/bP15ePxiacmFQisAK5K9Ac0McmhSeRhJj2uotehABF7qJBkdxd+FD3cAIIUqCN+ywHC+nj14oo6XiR+tCuRCruHSohb1Kqou+SlrtZmAkBsb3hG/16mBQphbGmYIJsCtg+mG1tbqvLr1FETsThxKauYFENwDDipjbSzlpnZY5QpZwR/kM4Ts7P4IEvqTWjGHlXANXVRQrPmyYq4nd+JuyJjmSGIFyI/wafl576l7FuOuJpZEQTeRfKFlXTOIaVtVCbDMENXeJwjGXYx5tPyQMGRbkMqamqEtUKTPCoSqm2YrwoHIUXa9tik32dhnoYEavFZ1aor6Y3Vj/qRzj2VMMEzRJhZ54TEGFIQOZQcDDB0o4K0LufAKpJKSiXsQwh6hE0JXT01v+YXdDQNFY6XsoSYcN+Cb1JUlFBvuCNHv7fMiNSphaY63QcnOj5HTMHUGrICyjV1KjfiqatcEap6GrardrTNVw4xFPoYznFeJMVXZ0r66AnCcb1FZgYfCb5ewfDw6MjQZlyEUY8S7iwzLqmO+F0UwZHnnApf/zDWgiVLBQc4UORJ5cShuhlxndt1Vh0HalpxmdUY5oKRWyaLKRqnOQ28i+aofMboWMF9o4enOAYeUYCzZmwzclhtDdjqGmExDCQaRJEqmJHyhgwhznN8vrq3GIE9nRiuRlakZrsoaDU2Se9Nzo5PPbhjaPJQXbcV1gcA8ReLhYXjkq+nm7npkiy+pEh7e5SI8Tu1/Yv8xkmVFPwRKQCE4iGsaihlVWDxHChY6TGBHTmqnlytI/K5F/hEIaUMRsaCBnZMca+rmw7GJFehr0IWCKZGCshIfzScoSB/EepjTteT6fn11cX09moN+lUd7SGDIXiAwtkxAi6CS+eOefzialxRjirY8h3RGHtm0q+IHL6+g1rXSmin4Fp9ItfCk22b9rrJg4lkoEkOioVovkjEXYeK+G61hjdGAE9GvZNTfjZpB0+/rlnWBQTKaa7jkWi5vSwSgEZSCtTh8N5t1blEGB2MU48MCEGm+ZABItVMPxyPm3DAiyhkNHIqVFgEwp8rOxIYCjk/fffe/r4MWwpj1AvDMp4U6Ieg2xClfQp79CFquRnNRfU2s39qwg/JjCSXpwJVNDJMoSgrZtcgzRQzGhFbAqcRTW1qyey00xF0RsFYFuJX8wEfEKmWuCvt5cNShVC8QusJspXs6CPWtlSa+mS7ZKLGwOCw+5YH255u9jrH40i96OMjPR6es360TwikcTdchOmquylLJryQNWCt3HuRQoyh0KaiiyEHK3ZIOtf7BIcRLuxl3mmplBKSsZcy9/0Ro3b4gE3TTOCAnGrfxGkmE4BA+Va6zWM921nSW8C4eiIf4rxdhEQUwp2PRuF0K0JbCAQoYlGIkvhvzmoPQfuEASdUmNdN8fWb9l8eHgk15PHT1XL0DjiFZ88SV9jZpVrTJOe1YcffvzsyfN0kRomYa1cQWdLAlRvGAaE3BXWIUjLSFfdsBIMPtGAs8NI6TrPY5IQMjJGYvLIlTA38nkc1lawUAuxU2H9hDl4dPt1eyMapCkVGzCJwkXsIoJWG9Pb9Bcp1Lg/zrSvDL3OomP2bWq198HRof7DyaPHdmGqnBe4Wl5ZB08o0haISwYQSHDFQtC+9DHxB3ZESkO4V4wNunmaP8X00gBkghCTGHrlkr/MP2LUmHmHqQ7utEGTiFISlDKJIyNl6qIf+aM3aVdqRjYytAUNLXthsNcYpG67oy8MZQKB2OpKQLZayyi6FhDOP8X0tLgFN+pn9n1T0bE5e/uX6Phy+pIWPDp6aFuQ/VFGnAAeD6h1NwnYQVmGidOO8fbGWAQmFeI/eUnbJQdFmWBF1VKWoqRycXh/5dst4llxP4MGbG+pQO5Bae6IRlkDGQgkTYNeQg0/1WcvT35mNYQT2ym/tULZahk1YnEYiFIulSErwhmRqgqE7hn41USdnLM21tb96kujbGKjhyePfvGLXzjlUHABAdSOvYpCEzQkwQzEEMRayhuSxwJ5mdpgkLvQpCSB3IeGYPVEXQpX6BaXQyoqDtdIvZUpppKAqSmniqFJ1ugTrWhHygMkWeRBJ5TxXgOBLpsc0hcoVU35jKNZQBfv5q1U1ceOMILm35izqoTFlHnD5q9MQ718rWxmoPf3DydHMiuoKjABLhh5XVXFWzdCuobMhQOsit8N97R6P6niTlHkRxf5VBguoJIaGq+iI15B3J7INKuJvNUwOyeTuyhNxu807ZpXlRgzn0D7wx//+O3XX1sO4LDO5GnMwZdQUt64YtS1fX5h56Maio76uhheE3BRbpxlKXkKo4zqViRd8VLUMIhrK9vHjmUWg05rCOMj4PVCmTRV1zIasesQIU6eby8lGoG8frdmXNUQuHiMIqhJG+2GU+oLAYoc2fXq1Pk4iIw9Hxxgl4Ik/Pzy4vWpE2tzqszwIHGdqkq9yhL7vUsAiT+MxKK1rlTgVTs1A2x0plJcxv5+4ASbN8USFErZUIZGOEDA0elldwIpFlbSgBqKZcFaKjnKu/YzT9JcOuDqxvb7BUMDMVTmeFvVKs6NPFp1Z+CH8huzEzs/fPzo5NFDVDBTZDyItYa/bNy+/CmZ9ZNRPRTULnumj0F75NEXcI1WdxeRdp2YsCTnx5tLEgjoRKlZBrW5Rn2rhtBJPmO2cspk5BxbfFokHW8uXPToOKtYeNmKtoVfQ/4OEzWgE+CK3EFPtJH1oC1fKaFAkTXkneTJxcMSNNJgUmRvcnBw8uDJ8+eHvqR3cggZR4GIERhP7EAIkm16XORrXFc5yMNcgyAsfGrNPUY44nI8dCq+AWDxoJPqGBGbKQl85KISCpYA+xlVCJCBSVnWyFhWWBr+aMMoRehuOiTWTA31El5b/jfVLXkOqkWbiEPQi1KE+XnqinskCRXkVmkkI7k8b9a0o+/w6MkTh5gfPDjm3g2Qg9aZQPtHR6JaE4rGo40RL6y4NH/bpKARmJeGErlVYRkdrAZ/rSvOhy1ufC8mC4vyoUb2MWJQYUKDDYoBgzg0PxGw62iVEt6MoKWqKuAeuUIzKOW/d6mhvv2dgCYin0Gm6EWo2TIoG1gzyRMqpEKpXuaHsZDBQFDw5NlTQ4zOVsjaPGNlqa8Pfw5fLnJKh6WUbUQsG5EaoiV5WHM3lg449Hg/9pk5Fkv1TQLHmoCH3tEFzeFXLOOOe0hY3IVhtgglmcxs7FJ7cIo1qjCrCNEgaAKxu29yggzmcsqWEL8igWtaCoShu8pottsQtMwSEpBELkwk42gwvtqVN2XR5aO7Qt3pFa9/fTg+cC9ZsZcD6ln8qniHSX6ycAjFtImRLIQwB8s+HW863758c3MlqmQ1ou9NXuAFjJLcCggJZhFl8N133yG89fKBOR8SoiZxxUU1zUWAgwCVbqFOrEUGsyUylVeFdn7v1CFVVSxFFjIapKxHYWOIrBqDo1HNGp5qNhKYpEATWCI6cLCYf0e+HMekZWQzDhX4oWCz7QLHvu/RptYyk06wtKLTeOO++QyB1mRy/Nmf/owzcJH02V1TSa3iATRgw6xcewNfJ5PqZJC2wiihL35qLe0WtgonhRn1MEFbMbyokHOHi89g1VJ7laxhbVLuKglv/RARHoxHz9978ey9FycPHhyeHOs2wF/d9sB+8fmfBQuUAi0UDCShKdqj5zaiaVzx1qsSumZ1Vwfjo2fvPe+PJ3T74PDYR1VMh8d71ISwT0TowoYn4CltiNmOgGZ9ODfZZZC0Zz0CzkS5rGXPwRKkINiKSMAYeWjlY1cqlWNWUAIiKtA/IlomJdhjlD8NaBDTOvcIIr8BVkeCIac1WOrWIpUyLsIu4goHIWdCIYwqa4UUcVdF08hEE8yaW0dWI0wEzTiqhRv0gguhLEAsCoYZ7sPkBIfKgjY2AQlKyrOrrPAERUUm2uZfmwRuMS0kcrmLkdqPqtptQmW1F99abWmVec1SiGRKnpqGcIPnEYuaQcDgjCmV8/NEC3rK1PPi7VtGoZlZXAEMQ5j2pUb8uiK3d1nGWzbYjgXhATYZfBmOJo4h1GiLOGRv9eQgCgMNkYdtWNSqzNRoaLmLZNGCRalWthcoJQQuZGSTlFQEa6S83aX2k1LoCRWmsYhAoV2ySWoR3aZQKUtqqAw10EfyfVw9hweSBZmVUtxNgyPglo9Us5tqC+Vz1lxQqggio3uO+re0sVoMRSqmQguZoKYSQzSlRkTSM6ROvNF7+vSpeklgKivH7qYkedu8n1KA2F3v3+RdJRnuJ4win1sDs8vjb4hRyX3oExEIqhGKmM/6DmktFPdcHiCBu+XJ/S4Jx6qad0DWAFocihuvFMUdTcBWtelmJDJOs962ajxuN4PDg2Oj9FclnBgjB4C0mu9bAlqpXRJWbW8pfjQ2KEVK/Al5xXZthiWvGg7lImLHW7fPTSvlxgSCx36SHT4e9IaEKcKlVUfXiRotZCBTjf9lmavaqkGNqZ9ElHSoLXgZTKwTBgTJJBf+as60WREXtm40WTYLyFpGYn9iIRJU6GkIWnZUzt+ClbwlpYkqpOG0XenuJq/igKVQUGr1pDlxTQlXKizWVbZcZHOFeauuyjkWbTG78sWP7K1URBOemzGQLaykIlWqZZbh/s96mJVBjb1+NjVNJWkj5jCLKuLjG7RbvNSiqt4HH30obqHnxjBjEmoyugGaAkVv1y2mXtxPGUbbJu1JEYL4tK3Uobayjee7jO/+xnEGzwRskQiz5yZWK4FMgpXU+qftiasifGYLQwJh2mraHoXypKVM0mfMb8u29lDb29cVcIm5EChyo+NtTSD5kSOKWixq1UVadqkVLqwDh9TQvrtPDX7s1JVXJH9bzpREpM5SQ7nUGvzmGR1CJva2GbbSCEuCss9Wha0J17RS+Af9Sg2ulsE9dyNpQorklSFsSLUieUgYWrC0qzcFiayngDECSS+aFCiJ3u63VL9XQHYPq3lXElvKWb/luvPPBU74l0rC5i17i8cmEKrbWqLVoFS28AoOCZwvLslIKtwGZgQsHGrwtJx+umFrPKzBAH/TuyJJfpLrslqho5ScO/MhG2EtWjT8a2jCb937NghhYkQeVhVFkEbhlhtAhelWlhrQnrjJvZeowTImoqF94XNsQlLGF4FVElByDfISIkrrGy4Si5tSOQQhs5KhmfCpkjlYs2+mK7d1FuY6kcm/S5mjlard4rZW/AhgNGVrGlrBusrbKicC6mlJ/QOeMrO6tGt1a+BHNTVikxX0vG/GC0KFIkR6ym4IaqJO9I5x1QcHJ5tyY4VqhtB0Z/LFBaMN1mNnFEPD/o9vb63iTwYDa5UdTw5tsAGdUdCHMNESfe6JI53mPCE5aMEpsfzCUu2qBjhKaSgk3yX9MQM+wAZt09fjybFTN0LXbBFLwCovGKgae9AYEpBgKQua8e0I4V4+ph0SRWIZwMN/hgplifIcHWRupEmOiupUAlV1EkgtG8MLl0thQ4XSapWoOWJ6LyEECJ3VK0/grf0OippxZiBmw7lzTc1SgKB4HDsdHjReRg7LfNAaQIbDBSFeoUoFeAWFS8aqEKDKQTMUIVnF17WetQnS6nAU5sG2BKDBDejAXXEEDNDZ80IkalBUD4XkIQ4O9YlOsu2hFJuH3uEyatMLgEgAbRQAoptUnpSDUaihJbr2PoNAThTxxHOSsLRgTisRvvjlet+qS4WtkibrSqWVUCGq7VWDuXKHerFmqSMSirvKe5rZKyWLTHGqhWairvvcK2UvVBulqspgfi9FZu1FKjsEENCKTeHv/8a2LRwFlrItFaqEeHPtSxWZsM+EiqZRWt1k/l2CGAQMTYSQ7qNjLakKzo0tDWw/yaURB6+25AfKNgYBXUlAGXQ10u2sGEZyjbUacZFGoEL7mSyhrJ/+RpAacXcobTUNx2OLtWQVO/Jm4UwMEOOVbWwhQyQmxN+lBq524xftac4hOaGCq9xMTfB0HFWGf6K22mYtsAnKEf0SQM17nipd6iY5d1GDGMSbQFX62IBQK4RSQ4lR6qn41SckVB6eyd2Qd1XmXWrCUA/bq7RbPzPbHwn1Mxgq0pqERgKbqiJtVn7G0w0SS97Uw1Cv3Jyv+vhOw7XinqcSg8qS7V8xHPnZKgvU9zBHErNDqq81StVlCBVkzrb5vAgXk8LRIpbS2BFmM4vZ7JbRV1sV4p+RUMZk37ZXjbYneSqFq3JK7XdsC/DKXLpXOf03dRx2QYSS6MZmWUTKNqFVlhWoqC4kqkpbmLw22uhfiZtS4QdLGTkt42om05NqGgxl2xqwjSJaLLKi150NQmuNUqKWWnMBOGSLw2C4SoSdtl7nNaWwPg191pevqAkht2QAa8MjN1v8GyFkoHUe0VMfXMF8C5vgn+UA2X2RYd54mV0NSiWppiDDm5JfVjCzrCxCvqZc0tsQNowPlrSC02x2ItstAFvMwpl3D9V9H2GOz5Psb9u9EGlHPdUaTsS/+QHEfF4ByZs4hJ0RoTD8jgS5uZOqaqS9LXDDsWBcGYSoHJ2FpZoN4xqI5dtjiSQYlulWpcU/GhWfwdy+92JG7AKLKAQ00qX+cMKRGjra+ZbUTgQynRTljQmMMr6DjoghqxgsEpQeTDjaJIJUDayBS7U5qUYwVmODlNGqsFrhoIzcgAZnAV9iEux3wlRP7y7teXvfKIJpaJdKyJT/szg+6hpFKKOwY1LctIJgJeuozzQakwIuGKyy8sSrqrlc61bao60lFD68mk1dDZJY/xIq+SPhmF5DKSrg6co4pK0w1QgtIWKsHebNDASv2HqfngAzrdjKQr1I5SGEHwVotb21l/VsK3vu5XTd6mdEPpJGIeOfWNmslronnGI1wrB7puBW4SsiuN3MbFPzhEagRQEQPIHX5i/ApEh+ajH8j5LJRrRKwrwP2DFFZu4AXXTM6zIuFeugomDGxh7mE7BlToWK8eYGHTvZN7VFfkf4QjCttoa1vcMoillWUPGkbYnAZuoxzlURtNCjI69GyD0N90BetG2KBUrhEXdgGc5tb7xYzZ1fIX4n+dCkC/M6mkD9EaZwLXXSlDInuJKGvAn3+diEdAVIZVWqUdkxd2hldsOEpVUsOTbauNHaorfaFJZ1JCoqyHlKZWlOcyoNrdBWg5XeEUK+NO1fOBTipz137HDgKBGMOAB46GwMIFgMnINgohNRX9TknchQVsGt3r59i/njW/Ou6YV7UoNDAIn3ogOlz2QrHVyLE7k1wtAAox1aL28SMLiCGtIsoGqdWcRqsTEVjFK+J3E9vdRX6h9EUQyqqtKCkEzx1yyRGkIFDQs2FYjVhFsQTgpjK7EffoIhmBQFqkEh8lZFGYKW05XAQcxJ6jEJxbeqbHtRgzzw0gwitqeEHQCW5ElXl1N50LIYE/9PTSxYclB6MA7yAeP+vSf1vJxxJyZmeWHzuwOksq/eVAsyG8dar0/Ge8yxECQDxOJ1C2KZUf8HPf0Zndz0avLtnhDhfhualDwsQWjt1a9dtrwtVbeoBOG2dqWKhLIFdytQNW2pgFxMowXsej1ZvGRarZK+JvzVo4j8CBSqxdiXXQhksUepNn9QWuvJGfjqactak48zFdjmF7KLUHkHtESVoS6PlY7XWSBgLZivOgPUQKsZU5vhFuV4HKWvCQKZOiul9tw3/SdR0UkAxOZ5HlgzjiOF/9W1jKNyxrapGot38yZK43/gwiqIVeycBQyjHEpsqQGhNXNp6hY/2AjLn/jJWMMihyKNEEG64CpzmG9PRgkTs5ckhzbep1GdSupCMpxy2uk8ZEFIhGerm9vzi7OX333v877SlVWfosgXL16Yp/TR1vOzHJIb/4+lsaD64XoUd32K8DJmwJNEYHQmax8FJyQ43TVWIHOtTpjMaSCGBhx2l1kXmSLC1fWOGYonhpXo4OjkIcNCKkeGNkxSW4GQmVXBF3oFf0k/1Zk6mXKo9fHRtGJP4MuYWGY7Q4AEfKyJNnHI8HMMP/4AhjH+9ps/z67Pc+rxaHBhz/l1BMHEh+2xRDKdcOOO86troujr3g64Drw7QYh0lSgWPKWTRL5wYqxCd7BGSghwUIsBi8fKRJhtpZRTxKcEonkshsh0X5FAtCZhuYlAzZGu1m4GoHZ9uWo0HsLitgYGg5Bh9kppumSMidn6YTZYPaEAdEPWRe2S89ny65eX33ytBeDRithBNKIPAkaWJ6dcapWENxuZLaHFBRe1RHRzeENS6giSZA17twISQEKCJG8V8SciKv4Jz2sqPKziKlK65VEtDmAIYz6cmEzyrdHMrx8e5iMa1SWXMfoQhat/FU5tjYVXdxbHvabB1hI4M8NI+8dxEFP7S2cJKDVUiPji4thxDFrBg7hq+4FJjkVUsKMg6qo1mJnHgAwJCGbVSfNDjdD0e9ta/c37kGAba8qmPcwucmW0ItXEyMRFujZ/2bKhvsWI5uP2jg4sgrBUnTqYv5YwSsXQQ9FoeSWlPJHiXKrB9hwEBViygQ2civsiE85m3rJFWWFAnBcZ4QaQQBb6KD+qyTN4+fI7QpgAvsadG4hpbNu8B+FAQ95NSa6fGLUlSkHTSBbQ05VgOur0ODYyYMdsoEikMUCLt7MoK50XEuGmmtsiYFUeKM0v56O0CQy0FUMryebJjsapLIO3IGO2QQsbw54oWsOucloSKliySDyDHYrWmDWo/aPOLWRSBhV7zEPW1N1My3Fu53Zak4Xe9tKoEPksCSyQ3Eqai9JuybTTDsCma3EnrlsxKI8XkUGtbSzASscjFC3AxGnQTYkiMH1FxJA4LcWk5L765oDf8iZ02N3jPQ6JZJBO1CwipdMaVBDa1LpV5WcrpV1SmRE3bTc4Qj/V+F9EvJN/xVoq0Yyh25qGQhybU12ipMCkYA0EbKU3P5PAFDEoJOARWtIdSevXV9ORaGZ/T75QVEqlhN7PGr1NKA2eTJSjtwP4qtpWMx6nVvKW3nz8RJr0hL1MVWLSxbK+BZExlHQZcvp5nFY0xk8bERhT+ANJn5bzRBVZVQEa1kxq+HuyIwWaxxD4GY1AgRrvS9ZkLiKiNxgqATd/2zBnHpZk1ytDzLa5GXOlFI0HWgzcFRfIgg3IkS4qOx1j5QfqoXVRASkrpV0PE0OHEIGq5D/fKa/+baQ/a/BZCQzartdQlEWIARErOvECCa7NEadznUF7nXP1bqFXvKEDBk4wXiJtR1tDLCs6E3qGP7XLWSnyIa9MGs6uwiJolpbqzyaGZyOz1j8udIczElh3E6NkqabvnsxnOQamhuRUaNxRdGbTo6Af0I0f4BNVIA+GYwpgNBoKBV+zX3pzuswQCaghSxLTkPjQAai22dRuw2xoz0eZlzfRQILgBUFILZU0VngG+dolGfqEBAkrSwVKvFFA9sqUDIxQ9A7/Y5BTkSIwadeIAbnGH0WiE3ibVQJsAkK0bx4IY9hpD9WmighV6lFHVRJ73lxujE7VEWkMYIDgnjKXYQVQeIPmab7A4K4aDHfAEITkrwQSZ/0N367S62AnwsLUHmkrw1wU5uVyDhqZS5VxHfVavcx92lNN9DB00oxdmrZ9t/rzU+AqcABq3H/0R+a8tXLFsth8O9FMnD2QAhxfXZ1fO0CkCAaddDYjz1rMpksL3B1xQFAIi0pFiUAgQhnbRISmAZEJcJlJyJcDkC2WIuY0+tjkXX0RcaqVNUFZ/VsHyHvk4Ra63NdtkSOVxkxI6qpWtzfJVzmTeecaMocWQ4hO4UQTnLoR8yFsGJcK/c8FZLhRADfnu40rsALNRlTFVVyLFS9rmgJneVbpc9WbyLp6xuTFY6y1zjODSrHrhtEyC1c2oRBQhElwhUgArkQiYhf030Tu/hkR4Va9D5RZehQgwkbsdVv6xvAQScJaDwvRWLsop2pLvLbGL2VixpJonMa4KJhoXNbAEJrW5mafe7nus8m2hcoRk1kWOpjEkdfwWJHC0hYdUCTMnrv0ClWSiJwJVO+OQ2FYiXpcQJxNjF3sHUiyV62sY8SimAvFfEXC/0ImAZulBOqlo1YOxBIX/+P7in6qaOU8Tw0/Sg2zHYqFfzCIOY9ZJnaAgn0tC8AMgMams6q3OfFW16mb3cBDxtPIR2hWLVY7Qdw/gaakaidNtW9GBLzCX9VKaMjPEN//jdm8anaSOEYoqgHIZgtUHoC54xpbsWdP031xtSMgmbQ53S0bEIqWkmMqLjbXmo5ALf9HiEI7ShTcAmYeARrw6FYhoyx5gkuwIhBpu6IBew29ykAlUctHIaMh5QoTVUoRZiqP0eBRcfsnHLU7uM7a0oROWs5xLF1HO0HWXpco+TRbwabKtpMohxAkgYGhlwCf8CkBSLyh545hp2nrvdFAd9rhUwaOlxFbmY1UZrB3S4IY5xKCaGIIKUdwruHNoIsQgT00wOoidov0Qh8/46xDnrY6M1olVFUXthE9Gpw8Ue51Th8rUd6RNaoEVssdjpxltGfgaIlyabqGNaO2MRZZHZLGuFzAqLRMADFB2sYM9fC1rTYVNs0BAW0ZPDw5tgRB1U67QRG1M6/8qAK8EUpE2BKmp29TtA/9NFhwZyQiCgoSfsEgn9UHkXWeLIudwwQ9Ah5STXWMs+ciGL0DXMZDMxhErUVojCVKo5YJCaCHQvGAaQGV/SE7RmVYBUfT5TseHlgcxyUa3Yv01PyNVVwInEGz7E7lOllf7i/FyWYu+Z630pQF1t4CcvD+s6fnJG04mB4e6Nzo7dqArR/KxTJUyiBeY1SYb+tdguuQ++6hPGmjmnEP5GSrsMxGC+KfHgp04/yJMolJlIftgKIbQgxkBROeEQIpCl+q6z7sNdFgT9j19PTtuZGlAzt7cryKOsL9RE2qcWCYIVXCiAIb5zHoQcXYo6DZ8BabqpOYasiIljhoNjXAWVOhTiN/8vhRDqzb30MV/W34n+3ti16MDzQqApGPDkdQoQ5ratRRaXQ43q8Mj61XbnY0IkIstFhouE7Ap9UsjnGm/H4GUfBKhWQBnPFp+eaLo9aiufLeCTASMByl/l4GHjFFzkxTMP4rksj8OuyN5lI6H+VzNLG+aMygw+mc9WtBxNzJZQ78zal11EfX2vG24nbjCyBBiNn13GrwYceO/NoooYyN+v7p3kLVigJXuAELdV0ZOUBezcwsh+GhQhmYoJnjpXEhM04BoewzFY/ChMl4FHclPmWORLmBQAyh8piqJMVlaJ28oEcGQ5DohQQRB7Hpf8Ztb/IdRpQDXluoycYkKLMU2tDC/q1tiBxKhnoSt+cfXiFB2jISlzVH4SoTglUGR3Pou0+DDoWQg94ip3g6cHK4dDhmhoOCEigU0R5QBmNGpSPAc4UGoAmYxRIyFIeNOcq4tHh1amCv6K0e8hxRr2E420S3qwqArYJmEkh2OC4SCFkjDvnNaEZDWqSndbJwOeUx5+QKnJrWYSx+oh8SpNtC4qyDQnF0iYLobmAzXlAbTmRzezmbDt6eW65VZ/oZmNWZzHdlbjSsDa2jbscpDaXVnti1UNVHFrATczTMlqCftsO9aINdalkyIsG/ZlyWr16++fLLL1+9epUdn3UINsK7wUWcjBakLxTsCIA6qIZ6WrIzmvXKqSqZKpApSTXCDsH16PKaV4u41eFOqA8koEtYHYtbh4dqIy6rtRFC6ODkRFHwCNJvN2/ytYTajsC6ZCygRrGDucRZYgqfwELFjZY5VFhqaJPf3GejQfUmy1Py3MpqmEIpAbLL63yoqA7fBn9CfVDFVlVsCjN0jMa7aa4HKD7hqsXu+uD4iPLbYYfzbVkol2aiBPnZD2yJKBt9r809YJtnxDeaEyvDOJZDqSfpFjG7UQcoCFjYrDr9ioxzQgwtKkFHfRBopAye6THWkdrBu4biwwipxA+mKpS4Q/N+Hifksv2xFmYBWkoY1O2afTN+FaLoFFfXrQQBFSBupUcEt2dTfsw4AgUH9eRIaVtNHzxyz4xnhHqWb0rzXO4FSSyiXh1/E+joKc7HwsZ6BCy6jaw7VyWPmtPRkofmtoMeco6PQTlep3S8PtCViewgQyKIq1PIhjXgY894i5FKFtRlCiVWL1PNLF88sMkveXI+QoL/rMFwMprnaE6SX758HcGrL5/G60eESiO4aRpA57PfTu2JspkA/xCdcyULvij7cPRoUj7bxJGahzNs23aEM79rWqWZza3EO/qJZME/oxaagzak/A6lmMGyPWIShHBCK8IzVC28dfSYFqEfYVYEMqiA5Lmvg4EhgyeFlSMNpkwdWyqPmyRThxiItF3TgemV+4iLx2F1jiO7UhV6xbMKGMKfLc/VgKw0sDXauloqkTyR8rakA2wZhk1UGB8JQjVn0AURK6KQzRMF1Bmhgx6rUHJxV10Jd/Sd+KuQURNUNefOhFhJGefS4yMShyJldzZfXJ5n0J5dCc8X8ZGK2+7rzEEYNuC8QiBjMvlZ0bSQLdTVRyxJcQ2VYtvATzlbZ7ZQbJcEqVv/oqcDOM1EVOofwQ5WJaFZGdTtIgGVNHqoFa+CUnVT5UFOEVlRAc2jFB42WiAJ+JGLqCEg5cNTFMtxdpqXjD6Ia52TYMNVyKlL48yei6vTs9ObWRrL/qJdDOMnnGhMtRoQA4tYMU9iFMOOkCROzvNUWMLFAgHC06BXyoWqbgJBjflZhL5n3FU3OdFLalaZSnaZy4FEn2KzEFeeVrncnGXL5tqkgTuWN78K8ixHbhqXAQEnIXtDEVY2uCUaqPB+L/tPE+8P5qKdXnd2NXt7cU4c5jWBGcIm9okhA5Zr6q4uoVYrKav1GuooJAuIxFE0mRSQTQVhyJpFYohsOtfBsEmmaM2cVHaD6shFxuNFoFBESOCcHmW6McQmX9wzJ6pwRizRMSeFxX/DgMzlVaKiEFxF7GgYXfjBkhZwvc73MB8DHqf2ZO7Kzj3fSKhdt8ksxsCEC5HzdM78JuavU3w0V0TAxvAeGcoHgTOMBW9oS7eK8HlS3qH9jKRUEZkjk+Fn/K1MEipwiyUBBJ5hjNjLSTJTcULKoghEIwRJMriqU4plrDyBRByB4cKPfCeF5Gf8BboOaebv1UrfDNM51oCJkWCuHpAgMcpmsr4ODxR+xeCRCPgLkxl8MBQ8uTb0IxQVNcHWw0CMJl6yzGSgSWQbbbon+fIhXsxSPER8G1z8ryNAEPCl3F3GV8FUVj9Kh+EBsz0QbkeIHNMwdqqKVoHKTyOjimR27F3iht5GT8g5DnoK+odOtjl54AgW08D2Kw+cEBhUVVHbQBpNCZIWSATSEIXs3KqPUtLufAYhhono7oxCwMr4fyKfNmBARgu7MBhKvLKOtfCfKTAqIX+xsFjMKERkCjecktJBzXD4eJT+Czji2VIekfIvFVYcmbzZ9YHziWiFk/qy5Dn8MA1MiOuTmweH+4l6uhunTGTtg1Ejp/aMx0cHkwASPHPAubMetKtUhlrLLWkIYKCQ2NoBy4f9Iu+pnlfWmQZhSp0TeYszriyIYKrGx9hGiIVXnosBDXtjlh4+wRSJ5KFScKsEEz8T2Ia68cce6xImzBCGZ/UVdvX2DXll9f+2b5IiJV/a9fXuYXdi54YaFIKkzt6Rg2bqOw9KGY5MOOIVhMlGTK2pSkC5izfxKoysznsYDJ1SCplB517Nvn6RZSXl1ULogOtvdRYVKFxdVRWMinUhw12K35Ec71mS3DhPXe+oQIHcR+6LHO4RLFfi6js2Zbn03wqwUBdwrawruoEnYGWYI0BAjAyfHCGCr12Igpj/hFxecbgeBJgdNWEoYEk9pYlI4j6eK4bGJY5J7vTO3f1F0rgnjds7KuSvAlBxR9sLxGRLZbXoQn4/XYJt7EpQbTXnpipqVyKgKhpdlpvthk5IGdMv5WVeS/jZGlKbZt0zaZTcSfBl1Uz4O7JBATgFLVRoAFQVuTQqxPIUD1wpkJzpwzF14k3IxMT+VEp5fuudLASJ0LSsPeTcwDCVlr65QZJ6W7eEZpdne1NUoKpeowI48Lwl960SCHnCfXqin8qes/xuG4BF/Kxfp8kTZ9TTZ9KR5UaRhUaFir/StAobeO3aRNq9FGEHrKkmZiwhIu++/n8BM287HyfWqUIAAAAASUVORK5CYII=",
|
| 261 |
+
"text/plain": [
|
| 262 |
+
"<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=87x244>"
|
| 263 |
+
]
|
| 264 |
+
},
|
| 265 |
+
"execution_count": 26,
|
| 266 |
+
"metadata": {},
|
| 267 |
+
"output_type": "execute_result"
|
| 268 |
+
}
|
| 269 |
+
],
|
| 270 |
+
"source": [
|
| 271 |
+
"dataset[110][\"image\"]"
|
| 272 |
+
]
|
| 273 |
+
},
|
| 274 |
+
{
|
| 275 |
+
"cell_type": "code",
|
| 276 |
+
"execution_count": 36,
|
| 277 |
+
"id": "bb86837f",
|
| 278 |
+
"metadata": {},
|
| 279 |
+
"outputs": [
|
| 280 |
+
{
|
| 281 |
+
"data": {
|
| 282 |
+
"text/plain": [
|
| 283 |
+
"'data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAD0AFcDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwDm/FehWvh2yjjt2kLMQpJHWsLSG1a0k3Wds8hc+nBr0zxTb2V3aRT3Um1c5U4zx61PY6poFno3nC6gKoOSCMk/SuZXZo7Hn2ua79vtGtrzTvIvFA+YelcjKo5rV8R60uravLdRJti+6vGCRWKzk1rFXJsaVrOF3KJHCH+Dcdv5Vo22oFZ45I40DxcodgOTjHNc5EWLda7rwhpEV3cKZeR71UtEOEbsrT+LNaWbzQY42IxlExTLbXNSuSy3L+ZGzbiWGea19Z8K6hJfyNZxq8WeBmp7DwhqCxZljRSe2ayvc2cLHKzRl3dlBA9NxqnDIEm2+prrZ/D95FK6NH+VZR8NXrT5ChRnvWhDZVvLK2kMeWILDkg0VpT6JcqmW29cUUhaCXfiD7d4RSynceeuFBJ5wO1Y/h7w3deI7oLFlIFb55COPoKf4X0SHWb7NzKwiX7wHU17Fp32LTbWO1tLfbGowAOKl6Eo5Hxh4esdI8Hhba2XzIQP3nc+teWumUDDvXsfj66aXw7LGEOGryTTYTczCDIyQcZpxK6lSEESDPrXs/gjSRLp4mzjcMdK86i8OzSMp29SOte/eGtITTvDsKkcqmSampK+htTjbU47VfEEXh+Z/tMTMd+BisxvijaH5VsZGP1pnjFhdTyb/mCuQo9BXCPbhHzjinBKxNWXY6O78czTSM6WYGTwCelV18Z3DZzap+dYpi3DoaRYMZ4qjE0rnxPdznAiVRn1orNMOT0ooHcPB+rJpWvxSz827nZIPb1r6IsLeynhSVEQqwypHcV8z6jp8+malJayrhkP5+9dhpPjzVNK0pLNCrhU2qx6j/GqUeYzPTvHCWI0CeJmjUFDgAjJNeH6cP7OkL7FZ+xPan32rXOoy+ZczM7e54FVfN962jTQrs6a08QvG43ouK9H0XxyJ7b7K5jXK4FeJiXnrT47qSNso7KfUGk6UWUqkj07VtL3iSdP9IVm3bVPIrh55zbXoDWcg9NycCrFn4kngiVGkY4HepZ/EAucb0VvcrR7KwOdyB3W4beYtgqMxAHipZdUjlkjjKbTgKDV6OFSucUnASkYbqQx+XNFbxtkx0FFZ8pVzd+IfhpLmxGqwp++iX95gdRXlQfK17x4vuhB4WuJOoMXT8K8DViRnGM9qumybDyaTNNzRnmtRDt1LuqPNGaaYiUvjvU0E+4gVTY5FOt8q4Ip8wWuaUwztYHkc11Glv5tpGWPPSudiTz4iO9bulkQQrGxHHepdmK1jXEYA6cUVYQBl4orKxVx3ijWrfVvDS2dq3mSbVV1Jx0HUV5hNY3NsAZYiAe46V3SabcWTDzoSorI13iFVHc1kpWZuoXicoaSpZIyrYNR4rpTuYNWENFLSUxAa19EsYb1nEjEbegFY/etbw/NtvtvrUT2NKe51kPhuOW0kNvIRMBkAnAqnFaTW0gSQDf1OK6LTbtYnOaoXZvJtRElvbSGNR1AyDXNGbub1Ka5blm2kCoA5waKzpxNDcLNMrrnIAxRXQcg46rdXTH7TMT6ADP9aytRU3FzGvQZ71GsdzbSMsgPBPJH69afcTAukhwBuycVyXuzuinaxj6vB5VyfQiszNbevDf5Uo6Fe1YmOK66exz1FZiZopKUVoZC4qxpjGHUIjngnmol5qSMBZVb0NKSuhwdmd3a3QwMDnNb1hb6pdqGN5HDbE8KMZ/+tXH2Mm6JSDUXiV7i3hjljuJUBwAqtgdK4npI7WnKI3xdrQ+3m1tZDL5BKmUnqc+lFceGZiSeT6nmiuuOxxSjqe0abp8V7ZSCaMMx7kcjiuI1W0NpPJCQcIcDNd/p10scuxAArVjeJrNJ1aVfvfzrD2dkdkXdnCXNwk2nRox/eIT+VZZxVq7jZHKgVUEbVtT2MKu4hopdho8s46VoY2YBtpp/mZWnR25cgYrSi0h5oDjg/SndWKUWXNEkDxFCelavia1+0WFqmeS3H5VgaWr2l0Y3GCOoNad1evPdQxFsheg9K4ai947YP3dTm9R0iXTJFMhBVhwc4orsvFGnpLo0UuBvBHJFFbxloc7Wps2U4+0IrdCat6hEJUKntWTZzQeeqsw3A8VrPJvJPrWn2QTszkNQ0XfLuU4Unmqo0Be8uK6m7XEbVml651OzOynSjNXZkjQI+8p69hViLRbRSNxZvarRcik8wjkiq5zZUIIt21lZxsNsK10dg9nGjf6OuSPSuWjnAYDNXY7kBcA0uZsPZxsUvEkEceoJcxIFDDaxFZToqalAx+6w7VoavI8kQDN8gOax7qUmWAoeQaTOeorbHYaxG0+joqDJAWirOmTLcWao+CQBndRSRlyM5WyV5JwMV1MKsQKwNLRjehx90dfautiUFBxzXXBXOaTKl1DvhJAycVzUsrxuflGAe9dr5WVII4rlbyDZPIpHRjXPUp2Z3YapdWMr+1ERyHXFOW/S4IWMgZ9arX1spBPTFZ1jlb0L2NZ2Ou50BiwM7sn2p8MTs4LHC+lEcLKPvVKFYnAOKpFDNSRTZSe1cxFP506D+62K6icFo9h5BqjPpEcd0kqDaG5IFU1ocVR2kW7bUBZXphZyAy5HpRXP+JJtl6iR53KuDRWVi+aJv2+uWumllkhdjnkrWlD4y0ogFlmQ+myuNvCHmf8A3jUCxgkV2RdjzG7nqNt4g0u5iDJcAcdG4rFv5Y5buR4mDI3ORXO6dDZglrjp6CtdzCT/AKOu2MDpU1Hc6sL8RRvvukAdaraJpsup6mYIiocLu+arN1V7wEwj8ZRMf4lwAehrA7puxKyGCRon+8hKn6igeoq94hi8jXbpQMAtkVmgkUJlQleJJ5bysFjXc3pXTR+Ho59JW5lISVEz1rl4rkxzKR1B7V1omaXTi28gFOhrZK6POxE7SPJ9cVptWbYkjDHZSaK9ssI7S3tIyLWLfjJZlBJoqeUi9zxOTmQn3pAQKfdRmOVvTNV8nNXc51sWFcqeDWxYzb49vcVz8jMgyK19CbzN5f8ACom9DooO0i1d4APrWt4JtN+tx3POY6zL1ecjvXVeBYGE7NsOMZJrnudtSd0Q+LiW1xjtwMfnWE8oRctxXTeL5rca4sSgl9vzHHFc1fIrRkCmmTCdkZtvqLyXhVF6HjPeu10WK61O1kZvljThie4rzaW4ayvhIg5Wu48Ia/eapO8WxI4VXJCjk11QehxVdZHS398mmWiF1LDgYFFWjGsnDoCPcUVVi01Y8WuL9bqZht2sCeDTAcVBqkH2HX7qEdFkP86nU8is0cyHuu6M+wrR0YbImPrVL+E/Sr2nMFgOfWpqbG9HVlud9zKvcnivZvCumRWumRuVUEpzjv3rxOSQNLHjruFe56bMYvDQk6FUJ/8AHa5zebPJPEN+L7xnfmMnYjkL9M1DMSyfhWPbXBm1i9l6lpm/nWo7/KabLprQopo41SZ137SBya2/AVqbW6vY2O5kbbkVU0aXF6y56itTwp+71LUR6yf41vS1OaroztFI70VCGIPWiurlMOY8V8XSbvFV6c8mQ5/OmQkGJTUPiNH/ALeu3b+Jyc/jS2jZhHrWHUSLqHjmpIJdoKioQpPNV4Zv9IZfepnsa0XZmzbAvdxem8V7VeXa2vhCRjgYiPP/AAGvErWTZNG3vXpOp3Et54Slij+8YR39ua50tTpnseP2Nywv2OeXYn9a6IMWSuTtz5V2d38LEV1cHzRD3FORVLYn0z5NQX3rc0MbNZvAO+01gQt5Vwr/AN081saLcBtVmI48wDr7CtqTsc9VanYA5Wis+fUILP8A10ir7Zorb2hlyHlXia7ju7lZVUAkc1RsmLKRS6rbSRTtnoCcVFablJqGxJGqvC1lozC8xV0N8vWqYGbpD6mpbKgtTWSQrtr0XQbpbvR3hkbohFefm3Plg9sVraTqj2kTxgHkYyDWKWp0yehyWpRi31m5jByBIcfnXR2J3QL/ALtczqRMmqyOTnLZrrrGDbbJhSAVHX6UpoKDH20QebnpVDXZjbzRi3ZkYkcqaukvBNkdKzNXy80D+4qovQKi1IdRVnt4mcu5IBJJzzRVu6g862Reneii5CidlqfhuyvlYiLBb0FYo8CNuOxjjPetvUtbktmxDgY61iz+Jr5xjzNuPSqVyNBf+EBnJ/4+EUfWsnVfCraQi3LXSSAHgD1qZ9cvPmPnvz1way727muVwzsw9zVJE7EP26TdtzlfStHT0MwfA5rGSB2kHB610ulwiEZHUjmqsgu2crf2k6Xju0bAZ610Vjq/k2cSSIWKrjrV7UIvMgckc44rmlhuixUROfTAqGkyoya2Ne51S3mQjYyn61lTSNNNGQxKg9Kli0TU7ogR278nqRWvYeDNXaQMUC49anRA5yZUv7pTbx+UNhAANFdRF4BvJxiQc+1FToaRloZeqZ89uaymA20UVujGIxUG6nmNPSiigaFjjXeOK6PT4I9i8daKKmRSN6HTraZPnTNamm6XZozbYh+VFFZvYZvQWduBkRr+VXUhjC8ItFFYlvYUnavAH5UUUVSJP//Z'"
|
| 284 |
+
]
|
| 285 |
+
},
|
| 286 |
+
"execution_count": 36,
|
| 287 |
+
"metadata": {},
|
| 288 |
+
"output_type": "execute_result"
|
| 289 |
+
}
|
| 290 |
+
],
|
| 291 |
+
"source": [
|
| 292 |
+
"pil_to_url(dataset[110]['image'])"
|
| 293 |
+
]
|
| 294 |
+
},
|
| 295 |
+
{
|
| 296 |
+
"cell_type": "code",
|
| 297 |
+
"execution_count": null,
|
| 298 |
+
"id": "ce9be966",
|
| 299 |
+
"metadata": {},
|
| 300 |
+
"outputs": [
|
| 301 |
+
{
|
| 302 |
+
"data": {
|
| 303 |
+
"text/plain": [
|
| 304 |
+
"'The image shows a person from behind, wearing a dark blue t-shirt and pink shorts. They are standing among a group of people, and the setting appears to be outdoors.'"
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
"execution_count": 38,
|
| 308 |
+
"metadata": {},
|
| 309 |
+
"output_type": "execute_result"
|
| 310 |
+
}
|
| 311 |
+
],
|
| 312 |
+
"source": [
|
| 313 |
+
"from openai import OpenAI\n",
|
| 314 |
+
"\n",
|
| 315 |
+
"client = OpenAI(api_key=\"YOUR_API_KEY\", base_url=\"http://0.0.0.0:8082/v1\")\n",
|
| 316 |
+
"model_name = client.models.list().data[0].id\n",
|
| 317 |
+
"\n",
|
| 318 |
+
"def generate_content(image, prompt):\n",
|
| 319 |
+
" \n",
|
| 320 |
+
" url_of_pil_image = pil_to_url(image)\n",
|
| 321 |
+
" \n",
|
| 322 |
+
" response = client.chat.completions.create(\n",
|
| 323 |
+
" model=model_name,\n",
|
| 324 |
+
" messages=[\n",
|
| 325 |
+
" {\n",
|
| 326 |
+
" \"role\": \"user\",\n",
|
| 327 |
+
" \"content\": [\n",
|
| 328 |
+
" {\n",
|
| 329 |
+
" \"type\": \"text\",\n",
|
| 330 |
+
" \"text\": prompt,\n",
|
| 331 |
+
" },\n",
|
| 332 |
+
" {\n",
|
| 333 |
+
" \"type\": \"image_url\",\n",
|
| 334 |
+
" \"image_url\": {\n",
|
| 335 |
+
" \"url\": url_of_pil_image,\n",
|
| 336 |
+
" },\n",
|
| 337 |
+
" },\n",
|
| 338 |
+
" ],\n",
|
| 339 |
+
" }\n",
|
| 340 |
+
" ],\n",
|
| 341 |
+
" temperature=0.5,\n",
|
| 342 |
+
" top_p=0.8,\n",
|
| 343 |
+
" )\n",
|
| 344 |
+
" return response.choices[0].message.content\n",
|
| 345 |
+
"\n",
|
| 346 |
+
"generate_content(image=dataset[110][\"image\"], prompt=\"describe this image\")"
|
| 347 |
+
]
|
| 348 |
+
},
|
| 349 |
+
{
|
| 350 |
+
"cell_type": "code",
|
| 351 |
+
"execution_count": null,
|
| 352 |
+
"id": "8ebeb3b6",
|
| 353 |
+
"metadata": {},
|
| 354 |
+
"outputs": [],
|
| 355 |
+
"source": [
|
| 356 |
+
"PROMPT = '''\n",
|
| 357 |
+
"You are an AI assistant that helps users describe a given person from an image in detail. The image is taken from a surveillance camera and focuses on one person. Your caption must focus on the person and cover the following aspects:\n",
|
| 358 |
+
"\n",
|
| 359 |
+
"- Gender, age, and pose of the person\n",
|
| 360 |
+
"- Upper body clothing such as shirt, jacket, etc.\n",
|
| 361 |
+
"- Lower body clothing such as pants, skirt, etc.\n",
|
| 362 |
+
"- Accessories on head/face such as hat, glasses, etc.\n",
|
| 363 |
+
"- Accessories on body such as bag, watch, book, etc.\n",
|
| 364 |
+
"- Accessories on feet such as shoes, sandals, etc.\n",
|
| 365 |
+
"- Activities and interactions with other objects such as holding a phone, sitting on a bench, etc.\n",
|
| 366 |
+
"- Transportation such as car, bicycle, etc.\n",
|
| 367 |
+
"\n",
|
| 368 |
+
"Here are two example captions. \n",
|
| 369 |
+
"{EXAMPLE}\n",
|
| 370 |
+
"Please mimic the style, expression, and sentence structure of the examples without copying the specific details. If the example is unusual, please ignore it. \n",
|
| 371 |
+
"You must describe the person in your input image truthfully and in detail.\n",
|
| 372 |
+
"'''\n",
|
| 373 |
+
"\n",
|
| 374 |
+
"def make_prompt(prompt, example):\n",
|
| 375 |
+
" return prompt.format(EXAMPLE=example)\n"
|
| 376 |
+
]
|
| 377 |
+
},
|
| 378 |
+
{
|
| 379 |
+
"cell_type": "code",
|
| 380 |
+
"execution_count": null,
|
| 381 |
+
"id": "76cd677f",
|
| 382 |
+
"metadata": {},
|
| 383 |
+
"outputs": [],
|
| 384 |
+
"source": []
|
| 385 |
+
}
|
| 386 |
+
],
|
| 387 |
+
"metadata": {
|
| 388 |
+
"kernelspec": {
|
| 389 |
+
"display_name": "lmdeploy",
|
| 390 |
+
"language": "python",
|
| 391 |
+
"name": "python3"
|
| 392 |
+
},
|
| 393 |
+
"language_info": {
|
| 394 |
+
"codemirror_mode": {
|
| 395 |
+
"name": "ipython",
|
| 396 |
+
"version": 3
|
| 397 |
+
},
|
| 398 |
+
"file_extension": ".py",
|
| 399 |
+
"mimetype": "text/x-python",
|
| 400 |
+
"name": "python",
|
| 401 |
+
"nbconvert_exporter": "python",
|
| 402 |
+
"pygments_lexer": "ipython3",
|
| 403 |
+
"version": "3.8.19"
|
| 404 |
+
}
|
| 405 |
+
},
|
| 406 |
+
"nbformat": 4,
|
| 407 |
+
"nbformat_minor": 5
|
| 408 |
+
}
|
a_mllm_notebooks/tensorrt-llm/bert/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
bert*
|
| 2 |
+
*.log
|
a_mllm_notebooks/tensorrt-llm/bert/README.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# BERT and BERT Variants
|
| 2 |
+
|
| 3 |
+
This document explains how to build the BERT family, specifically [BERT](https://huggingface.co/docs/transformers/model_doc/bert) and [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta) model using TensorRT-LLM. It also describes how to run on a single GPU and two GPUs.
|
| 4 |
+
|
| 5 |
+
## Overview
|
| 6 |
+
|
| 7 |
+
The TensorRT-LLM BERT family implementation can be found in [`tensorrt_llm/models/bert/model.py`](../../tensorrt_llm/models/bert/model.py). The TensorRT-LLM BERT family example
|
| 8 |
+
code is located in [`examples/bert`](./). There are two main files in that folder:
|
| 9 |
+
|
| 10 |
+
* [`build.py`](./build.py) to build the [TensorRT](https://developer.nvidia.com/tensorrt) engine(s) needed to run the model,
|
| 11 |
+
* [`run.py`](./run.py) to run the inference on an input text,
|
| 12 |
+
|
| 13 |
+
## Build and run on a single GPU
|
| 14 |
+
|
| 15 |
+
TensorRT-LLM converts HuggingFace BERT family models into TensorRT engine(s).
|
| 16 |
+
To build the TensorRT engine, use:
|
| 17 |
+
|
| 18 |
+
```bash
|
| 19 |
+
python3 build.py [--model <model_name> --dtype <data_type> ...]
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
Supported `model_name` options include: BertModel, BertForQuestionAnswering, BertForSequenceClassification, RobertaModel, RobertaForQuestionAnswering, and RobertaForSequenceClassification, with `BertModel` as the default.
|
| 23 |
+
|
| 24 |
+
Some examples are as follows:
|
| 25 |
+
|
| 26 |
+
```bash
|
| 27 |
+
# Build BertModel
|
| 28 |
+
python3 build.py --model BertModel --dtype=float16 --log_level=verbose
|
| 29 |
+
|
| 30 |
+
# Build RobertaModel
|
| 31 |
+
python3 build.py --model RobertaModel --dtype=float16 --log_level=verbose
|
| 32 |
+
|
| 33 |
+
# Build BertModel with TensorRT-LLM BERT Attention plugin for enhanced runtime performance
|
| 34 |
+
python3 build.py --dtype=float16 --log_level=verbose --use_bert_attention_plugin float16
|
| 35 |
+
|
| 36 |
+
# Build BertForSequenceClassification with TensorRT-LLM remove input padding knob for enhanced runtime performance
|
| 37 |
+
python3 build.py --model BertForSequenceClassification --remove_input_padding --use_bert_attention_plugin float16
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
The following command can be used to run the model on a single GPU:
|
| 41 |
+
|
| 42 |
+
```bash
|
| 43 |
+
python3 run.py
|
| 44 |
+
|
| 45 |
+
```
|
| 46 |
+
If the model built with **--remove_input_padding** knob, please run the model with below command
|
| 47 |
+
```bash
|
| 48 |
+
python3 run_remove_input_padding.py
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
#### Fused MultiHead Attention (FMHA)
|
| 52 |
+
|
| 53 |
+
You can enable the FMHA kernels for BERT by adding `--enable_context_fmha` to the invocation of `build.py`. Note that it is disabled by default because of possible accuracy issues due to the use of Flash Attention.
|
| 54 |
+
|
| 55 |
+
If you find that the default fp16 accumulation (`--enable_context_fmha`) cannot meet the requirement, you can try to enable fp32 accumulation by adding `--enable_context_fmha_fp32_acc`. However, it is expected to see performance drop.
|
| 56 |
+
|
| 57 |
+
Note `--enable_context_fmha` / `--enable_context_fmha_fp32_acc` has to be used together with `--use_bert_attention_plugin float16`.
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
#### Remove input padding
|
| 61 |
+
The remove input padding feature is enabled by adding `--remove_input_padding` into build command.
|
| 62 |
+
When input padding is removed, the different tokens are packed together. It reduces both the amount of computations and memory consumption. For more details, see this [Document](https://nvidia.github.io/TensorRT-LLM/advanced/gpt-attention.md#padded-and-packed-tensors).
|
| 63 |
+
|
| 64 |
+
Currently, this feature only enables for BertForSequenceClassification model.
|
| 65 |
+
|
| 66 |
+
## Build and run on two GPUs
|
| 67 |
+
|
| 68 |
+
The following two commands can be used to build TensorRT engines to run BERT on two GPUs. The first command builds one engine for the first GPU. The second command builds another engine for the second GPU. For example, to build `BertForQuestionAnswering` with two GPUs, run:
|
| 69 |
+
|
| 70 |
+
```bash
|
| 71 |
+
python3 build.py --model BertForQuestionAnswering --world_size=2 --rank=0
|
| 72 |
+
python3 build.py --model BertForQuestionAnswering --world_size=2 --rank=1
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
The following command can be used to run the inference on 2 GPUs. It uses MPI with `mpirun`.
|
| 76 |
+
|
| 77 |
+
```bash
|
| 78 |
+
mpirun -n 2 python3 run.py
|
| 79 |
+
```
|
a_mllm_notebooks/tensorrt-llm/bert/base_benchmark/config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"builder_config": {
|
| 3 |
+
"max_batch_size": 256,
|
| 4 |
+
"max_input_len": 512,
|
| 5 |
+
"name": "bert",
|
| 6 |
+
"precision": "float16",
|
| 7 |
+
"tensor_parallel": 1,
|
| 8 |
+
"use_refit": false
|
| 9 |
+
},
|
| 10 |
+
"plugin_config": {
|
| 11 |
+
"bert_attention_plugin": "float16",
|
| 12 |
+
"context_fmha_enabled": true,
|
| 13 |
+
"gemm_plugin": "float16",
|
| 14 |
+
"gpt_attention_plugin": false,
|
| 15 |
+
"identity_plugin": false,
|
| 16 |
+
"layernorm_plugin": false,
|
| 17 |
+
"layernorm_quantization_plugin": false,
|
| 18 |
+
"nccl_plugin": false,
|
| 19 |
+
"smooth_quant_gemm_plugin": false,
|
| 20 |
+
"weight_only_quant_matmul_plugin": false
|
| 21 |
+
}
|
| 22 |
+
}
|
a_mllm_notebooks/tensorrt-llm/bert/base_with_attention_plugin_benchmark/config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"builder_config": {
|
| 3 |
+
"max_batch_size": 256,
|
| 4 |
+
"max_input_len": 512,
|
| 5 |
+
"name": "bert",
|
| 6 |
+
"precision": "float16",
|
| 7 |
+
"tensor_parallel": 1,
|
| 8 |
+
"use_refit": false
|
| 9 |
+
},
|
| 10 |
+
"plugin_config": {
|
| 11 |
+
"bert_attention_plugin": "float16",
|
| 12 |
+
"context_fmha_enabled": true,
|
| 13 |
+
"gemm_plugin": "float16",
|
| 14 |
+
"gpt_attention_plugin": false,
|
| 15 |
+
"identity_plugin": false,
|
| 16 |
+
"layernorm_plugin": false,
|
| 17 |
+
"layernorm_quantization_plugin": false,
|
| 18 |
+
"nccl_plugin": false,
|
| 19 |
+
"smooth_quant_gemm_plugin": false,
|
| 20 |
+
"weight_only_quant_matmul_plugin": false
|
| 21 |
+
}
|
| 22 |
+
}
|
a_mllm_notebooks/tensorrt-llm/bert/build.py
ADDED
|
@@ -0,0 +1,354 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2022-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
import argparse
|
| 16 |
+
import os
|
| 17 |
+
from collections import OrderedDict
|
| 18 |
+
|
| 19 |
+
# isort: off
|
| 20 |
+
import torch
|
| 21 |
+
import tensorrt as trt
|
| 22 |
+
# isort: on
|
| 23 |
+
|
| 24 |
+
from transformers import BertConfig, BertForQuestionAnswering, BertForSequenceClassification, BertModel # isort:skip
|
| 25 |
+
from transformers import RobertaConfig, RobertaForQuestionAnswering, RobertaForSequenceClassification, RobertaModel # isort:skip
|
| 26 |
+
|
| 27 |
+
from weight import (load_from_hf_cls_model, load_from_hf_model,
|
| 28 |
+
load_from_hf_qa_model)
|
| 29 |
+
|
| 30 |
+
import tensorrt_llm
|
| 31 |
+
from tensorrt_llm.builder import Builder
|
| 32 |
+
from tensorrt_llm.mapping import Mapping
|
| 33 |
+
from tensorrt_llm.network import net_guard
|
| 34 |
+
from tensorrt_llm.plugin.plugin import ContextFMHAType
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def get_engine_name(model, dtype, tp_size, rank):
|
| 38 |
+
return '{}_{}_tp{}_rank{}.engine'.format(model, dtype, tp_size, rank)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def parse_arguments():
|
| 42 |
+
parser = argparse.ArgumentParser()
|
| 43 |
+
parser.add_argument('--world_size',
|
| 44 |
+
type=int,
|
| 45 |
+
default=1,
|
| 46 |
+
help='Tensor parallelism size')
|
| 47 |
+
parser.add_argument('--rank', type=int, default=0)
|
| 48 |
+
parser.add_argument('--dtype',
|
| 49 |
+
type=str,
|
| 50 |
+
default='float16',
|
| 51 |
+
choices=['float16', 'float32'])
|
| 52 |
+
parser.add_argument('--timing_cache', type=str, default='model.cache')
|
| 53 |
+
parser.add_argument(
|
| 54 |
+
'--profiling_verbosity',
|
| 55 |
+
type=str,
|
| 56 |
+
default='layer_names_only',
|
| 57 |
+
choices=['layer_names_only', 'detailed', 'none'],
|
| 58 |
+
help=
|
| 59 |
+
'The profiling verbosity for the generated TRT engine. Set to detailed can inspect tactic choices and kernel parameters.'
|
| 60 |
+
)
|
| 61 |
+
parser.add_argument('--log_level', type=str, default='info')
|
| 62 |
+
parser.add_argument('--vocab_size', type=int, default=51200)
|
| 63 |
+
parser.add_argument('--n_labels', type=int, default=2)
|
| 64 |
+
parser.add_argument('--n_layer', type=int, default=24)
|
| 65 |
+
parser.add_argument('--n_positions', type=int, default=1024)
|
| 66 |
+
parser.add_argument('--n_embd', type=int, default=1024)
|
| 67 |
+
parser.add_argument('--n_head', type=int, default=16)
|
| 68 |
+
parser.add_argument('--hidden_act', type=str, default='gelu')
|
| 69 |
+
parser.add_argument('--max_batch_size', type=int, default=256)
|
| 70 |
+
parser.add_argument('--max_input_len', type=int, default=512)
|
| 71 |
+
parser.add_argument('--gpus_per_node', type=int, default=8)
|
| 72 |
+
parser.add_argument('--output_dir', type=str, default='bert_outputs')
|
| 73 |
+
|
| 74 |
+
parser.add_argument('--remove_input_padding',
|
| 75 |
+
default=False,
|
| 76 |
+
action='store_true')
|
| 77 |
+
parser.add_argument('--use_bert_attention_plugin',
|
| 78 |
+
nargs='?',
|
| 79 |
+
const='float16',
|
| 80 |
+
type=str,
|
| 81 |
+
default=False,
|
| 82 |
+
choices=['float16', 'float32'])
|
| 83 |
+
parser.add_argument('--use_gemm_plugin',
|
| 84 |
+
nargs='?',
|
| 85 |
+
const='float16',
|
| 86 |
+
type=str,
|
| 87 |
+
default=False,
|
| 88 |
+
choices=['float16', 'float32'])
|
| 89 |
+
parser.add_argument('--enable_context_fmha',
|
| 90 |
+
default=False,
|
| 91 |
+
action='store_true')
|
| 92 |
+
parser.add_argument('--enable_context_fmha_fp32_acc',
|
| 93 |
+
default=False,
|
| 94 |
+
action='store_true')
|
| 95 |
+
parser.add_argument('--model',
|
| 96 |
+
default='BertModel',
|
| 97 |
+
choices=[
|
| 98 |
+
'BertModel',
|
| 99 |
+
'BertForQuestionAnswering',
|
| 100 |
+
'BertForSequenceClassification',
|
| 101 |
+
'RobertaModel',
|
| 102 |
+
'RobertaForQuestionAnswering',
|
| 103 |
+
'RobertaForSequenceClassification',
|
| 104 |
+
])
|
| 105 |
+
parser.add_argument('--model_dir', type=str, required=False)
|
| 106 |
+
return parser.parse_args()
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def prepare_inputs():
|
| 110 |
+
# opt_shape is set to half of max batch_size and seq_len by default
|
| 111 |
+
# tune this according to real data distribution
|
| 112 |
+
bs_range = [1, (args.max_batch_size + 1) // 2, args.max_batch_size]
|
| 113 |
+
inlen_range = [1, (args.max_input_len + 1) // 2, args.max_input_len]
|
| 114 |
+
num_tokens_range = [
|
| 115 |
+
1,
|
| 116 |
+
(args.max_input_len * args.max_batch_size + 1) // 2,
|
| 117 |
+
args.max_input_len * args.max_batch_size,
|
| 118 |
+
]
|
| 119 |
+
if not args.remove_input_padding:
|
| 120 |
+
input_ids = tensorrt_llm.Tensor(
|
| 121 |
+
name='input_ids',
|
| 122 |
+
dtype=trt.int32,
|
| 123 |
+
shape=[-1, -1],
|
| 124 |
+
dim_range=OrderedDict([('batch_size', [bs_range]),
|
| 125 |
+
('input_len', [inlen_range])]),
|
| 126 |
+
)
|
| 127 |
+
# also called segment_ids
|
| 128 |
+
token_type_ids = tensorrt_llm.Tensor(
|
| 129 |
+
name='token_type_ids',
|
| 130 |
+
dtype=trt.int32,
|
| 131 |
+
shape=[-1, -1],
|
| 132 |
+
dim_range=OrderedDict([('batch_size', [bs_range]),
|
| 133 |
+
('input_len', [inlen_range])]),
|
| 134 |
+
)
|
| 135 |
+
else:
|
| 136 |
+
input_ids = tensorrt_llm.Tensor(
|
| 137 |
+
name="input_ids",
|
| 138 |
+
dtype=trt.int32,
|
| 139 |
+
shape=[-1],
|
| 140 |
+
dim_range=OrderedDict([("num_tokens", [num_tokens_range])]),
|
| 141 |
+
)
|
| 142 |
+
token_type_ids = tensorrt_llm.Tensor(
|
| 143 |
+
name='token_type_ids',
|
| 144 |
+
dtype=trt.int32,
|
| 145 |
+
shape=[-1],
|
| 146 |
+
dim_range=OrderedDict([('num_tokens', [num_tokens_range])]),
|
| 147 |
+
)
|
| 148 |
+
position_ids = tensorrt_llm.Tensor(
|
| 149 |
+
name='position_ids',
|
| 150 |
+
dtype=trt.int32,
|
| 151 |
+
shape=[-1],
|
| 152 |
+
dim_range=OrderedDict([('num_tokens', [num_tokens_range])]),
|
| 153 |
+
)
|
| 154 |
+
max_input_length = tensorrt_llm.Tensor(
|
| 155 |
+
name="max_input_length",
|
| 156 |
+
dtype=trt.int32,
|
| 157 |
+
shape=[-1],
|
| 158 |
+
dim_range=OrderedDict([("max_input_length", [inlen_range])]),
|
| 159 |
+
)
|
| 160 |
+
input_lengths = tensorrt_llm.Tensor(name='input_lengths',
|
| 161 |
+
dtype=trt.int32,
|
| 162 |
+
shape=[-1],
|
| 163 |
+
dim_range=OrderedDict([('batch_size',
|
| 164 |
+
[bs_range])]))
|
| 165 |
+
|
| 166 |
+
inputs = {
|
| 167 |
+
'input_ids': input_ids,
|
| 168 |
+
'input_lengths': input_lengths,
|
| 169 |
+
'token_type_ids': token_type_ids,
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
if args.remove_input_padding:
|
| 173 |
+
inputs['position_ids'] = position_ids
|
| 174 |
+
inputs['max_input_length'] = max_input_length
|
| 175 |
+
|
| 176 |
+
return inputs
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
if __name__ == '__main__':
|
| 180 |
+
args = parse_arguments()
|
| 181 |
+
tensorrt_llm.logger.set_level(args.log_level)
|
| 182 |
+
if not os.path.exists(args.output_dir):
|
| 183 |
+
os.makedirs(args.output_dir)
|
| 184 |
+
|
| 185 |
+
torch_dtype = torch.float16 if args.dtype == 'float16' else torch.float32
|
| 186 |
+
trt_dtype = trt.float16 if args.dtype == 'float16' else trt.float32
|
| 187 |
+
|
| 188 |
+
builder = Builder()
|
| 189 |
+
builder_config = builder.create_builder_config(
|
| 190 |
+
name=args.model,
|
| 191 |
+
precision=args.dtype,
|
| 192 |
+
timing_cache=args.timing_cache,
|
| 193 |
+
profiling_verbosity=args.profiling_verbosity,
|
| 194 |
+
tensor_parallel=args.world_size, # TP only
|
| 195 |
+
max_batch_size=args.max_batch_size,
|
| 196 |
+
max_input_len=args.max_input_len,
|
| 197 |
+
)
|
| 198 |
+
# Initialize model
|
| 199 |
+
if 'Roberta' in args.model:
|
| 200 |
+
model_type = 'Roberta'
|
| 201 |
+
else:
|
| 202 |
+
model_type = 'Bert'
|
| 203 |
+
|
| 204 |
+
# initialize config with input arguments and update from json
|
| 205 |
+
config_cls = globals()[f'{model_type}Config']
|
| 206 |
+
config = dict(
|
| 207 |
+
vocab_size=args.vocab_size,
|
| 208 |
+
num_labels=args.n_labels,
|
| 209 |
+
num_hidden_layers=args.n_layer,
|
| 210 |
+
max_position_embeddings=args.n_positions,
|
| 211 |
+
hidden_size=args.n_embd,
|
| 212 |
+
num_attention_heads=args.n_head,
|
| 213 |
+
intermediate_size=4 * args.n_embd if args.n_embd else None,
|
| 214 |
+
hidden_act=args.hidden_act,
|
| 215 |
+
torch_dtype=torch_dtype,
|
| 216 |
+
)
|
| 217 |
+
if args.model_dir is not None:
|
| 218 |
+
json_config = config_cls.get_config_dict(args.model_dir)[0]
|
| 219 |
+
config.update((k, v) for k, v in json_config.items() if v is not None)
|
| 220 |
+
bert_config = config_cls.from_dict(config)
|
| 221 |
+
|
| 222 |
+
output_name = 'hidden_states'
|
| 223 |
+
if args.model == 'BertModel' or args.model == 'RobertaModel':
|
| 224 |
+
hf_bert = globals()[f'{model_type}Model'](bert_config,
|
| 225 |
+
add_pooling_layer=False)
|
| 226 |
+
tensorrt_llm_bert = tensorrt_llm.models.BertModel(
|
| 227 |
+
num_layers=bert_config.num_hidden_layers,
|
| 228 |
+
num_heads=bert_config.num_attention_heads,
|
| 229 |
+
hidden_size=bert_config.hidden_size,
|
| 230 |
+
vocab_size=bert_config.vocab_size,
|
| 231 |
+
hidden_act=bert_config.hidden_act,
|
| 232 |
+
max_position_embeddings=bert_config.max_position_embeddings,
|
| 233 |
+
type_vocab_size=bert_config.type_vocab_size,
|
| 234 |
+
pad_token_id=bert_config.pad_token_id,
|
| 235 |
+
is_roberta=(model_type == 'Roberta'),
|
| 236 |
+
mapping=Mapping(world_size=args.world_size,
|
| 237 |
+
rank=args.rank,
|
| 238 |
+
tp_size=args.world_size), # TP only
|
| 239 |
+
dtype=trt_dtype)
|
| 240 |
+
load_from_hf_model(
|
| 241 |
+
tensorrt_llm_bert,
|
| 242 |
+
hf_bert,
|
| 243 |
+
bert_config,
|
| 244 |
+
rank=args.rank,
|
| 245 |
+
tensor_parallel=args.world_size,
|
| 246 |
+
fp16=(args.dtype == 'float16'),
|
| 247 |
+
)
|
| 248 |
+
|
| 249 |
+
elif args.model == 'BertForQuestionAnswering' or args.model == 'RobertaForQuestionAnswering':
|
| 250 |
+
hf_bert = globals()[f'{model_type}ForQuestionAnswering'](bert_config)
|
| 251 |
+
tensorrt_llm_bert = tensorrt_llm.models.BertForQuestionAnswering(
|
| 252 |
+
num_layers=bert_config.num_hidden_layers,
|
| 253 |
+
num_heads=bert_config.num_attention_heads,
|
| 254 |
+
hidden_size=bert_config.hidden_size,
|
| 255 |
+
vocab_size=bert_config.vocab_size,
|
| 256 |
+
hidden_act=bert_config.hidden_act,
|
| 257 |
+
max_position_embeddings=bert_config.max_position_embeddings,
|
| 258 |
+
type_vocab_size=bert_config.type_vocab_size,
|
| 259 |
+
pad_token_id=bert_config.pad_token_id,
|
| 260 |
+
is_roberta=(model_type == 'Roberta'),
|
| 261 |
+
num_labels=args.
|
| 262 |
+
n_labels, # TODO: this might just need to be a constant
|
| 263 |
+
mapping=Mapping(world_size=args.world_size,
|
| 264 |
+
rank=args.rank,
|
| 265 |
+
tp_size=args.world_size), # TP only
|
| 266 |
+
dtype=trt_dtype)
|
| 267 |
+
load_from_hf_qa_model(
|
| 268 |
+
tensorrt_llm_bert,
|
| 269 |
+
hf_bert,
|
| 270 |
+
bert_config,
|
| 271 |
+
rank=args.rank,
|
| 272 |
+
tensor_parallel=args.world_size,
|
| 273 |
+
fp16=(args.dtype == 'float16'),
|
| 274 |
+
)
|
| 275 |
+
output_name = 'logits'
|
| 276 |
+
elif args.model == 'BertForSequenceClassification' or args.model == 'RobertaForSequenceClassification':
|
| 277 |
+
hf_bert = globals()[f'{model_type}ForSequenceClassification'](
|
| 278 |
+
config=bert_config)
|
| 279 |
+
if args.model_dir is not None and os.path.exist(
|
| 280 |
+
os.path.join(args.model_dir, "pytorch_model.bin")):
|
| 281 |
+
state_dict = torch.load(
|
| 282 |
+
os.path.join(args.model_dir, "pytorch_model.bin"))
|
| 283 |
+
hf_bert.load_state_dict(state_dict, strict=False)
|
| 284 |
+
|
| 285 |
+
tensorrt_llm_bert = tensorrt_llm.models.BertForSequenceClassification(
|
| 286 |
+
num_layers=bert_config.num_hidden_layers,
|
| 287 |
+
num_heads=bert_config.num_attention_heads,
|
| 288 |
+
hidden_size=bert_config.hidden_size,
|
| 289 |
+
vocab_size=bert_config.vocab_size,
|
| 290 |
+
hidden_act=bert_config.hidden_act,
|
| 291 |
+
max_position_embeddings=bert_config.max_position_embeddings,
|
| 292 |
+
type_vocab_size=bert_config.type_vocab_size,
|
| 293 |
+
pad_token_id=bert_config.pad_token_id,
|
| 294 |
+
is_roberta=(model_type == 'Roberta'),
|
| 295 |
+
num_labels=bert_config.num_labels,
|
| 296 |
+
mapping=Mapping(world_size=args.world_size,
|
| 297 |
+
rank=args.rank,
|
| 298 |
+
tp_size=args.world_size), # TP only
|
| 299 |
+
dtype=trt_dtype)
|
| 300 |
+
load_from_hf_cls_model(
|
| 301 |
+
tensorrt_llm_bert,
|
| 302 |
+
hf_bert,
|
| 303 |
+
bert_config,
|
| 304 |
+
rank=args.rank,
|
| 305 |
+
tensor_parallel=args.world_size,
|
| 306 |
+
fp16=(args.dtype == 'float16'),
|
| 307 |
+
)
|
| 308 |
+
output_name = 'logits'
|
| 309 |
+
else:
|
| 310 |
+
assert False, f"Unknown BERT model {args.model}"
|
| 311 |
+
|
| 312 |
+
# Module -> Network
|
| 313 |
+
network = builder.create_network()
|
| 314 |
+
network.plugin_config.to_legacy_setting()
|
| 315 |
+
if args.remove_input_padding:
|
| 316 |
+
assert args.model == "BertForSequenceClassification", \
|
| 317 |
+
"remove_input_padding is only supported for BertForSequenceClassification models"
|
| 318 |
+
network.plugin_config.remove_input_padding = True
|
| 319 |
+
if args.use_bert_attention_plugin:
|
| 320 |
+
network.plugin_config.bert_attention_plugin = args.use_bert_attention_plugin
|
| 321 |
+
if args.use_gemm_plugin:
|
| 322 |
+
network.plugin_config.gemm_plugin = args.use_gemm_plugin
|
| 323 |
+
assert not (args.enable_context_fmha and args.enable_context_fmha_fp32_acc)
|
| 324 |
+
if args.enable_context_fmha:
|
| 325 |
+
network.plugin_config.set_context_fmha(ContextFMHAType.enabled)
|
| 326 |
+
if args.enable_context_fmha_fp32_acc:
|
| 327 |
+
network.plugin_config.set_context_fmha(
|
| 328 |
+
ContextFMHAType.enabled_with_fp32_acc)
|
| 329 |
+
if args.world_size > 1:
|
| 330 |
+
network.plugin_config.set_nccl_plugin(args.dtype)
|
| 331 |
+
with net_guard(network):
|
| 332 |
+
# Prepare
|
| 333 |
+
network.set_named_parameters(tensorrt_llm_bert.named_parameters())
|
| 334 |
+
|
| 335 |
+
# Forward
|
| 336 |
+
inputs = prepare_inputs()
|
| 337 |
+
|
| 338 |
+
# logits for QA BERT, or hidden_state for vanilla BERT
|
| 339 |
+
output = tensorrt_llm_bert(**inputs)
|
| 340 |
+
|
| 341 |
+
# Mark outputs
|
| 342 |
+
output_dtype = trt.float16 if args.dtype == 'float16' else trt.float32
|
| 343 |
+
output.mark_output(output_name, output_dtype)
|
| 344 |
+
|
| 345 |
+
# Network -> Engine
|
| 346 |
+
engine = builder.build_engine(network, builder_config)
|
| 347 |
+
assert engine is not None, 'Failed to build engine.'
|
| 348 |
+
engine_file = os.path.join(
|
| 349 |
+
args.output_dir,
|
| 350 |
+
get_engine_name(args.model, args.dtype, args.world_size, args.rank))
|
| 351 |
+
with open(engine_file, 'wb') as f:
|
| 352 |
+
f.write(engine)
|
| 353 |
+
builder.save_config(builder_config,
|
| 354 |
+
os.path.join(args.output_dir, 'config.json'))
|
a_mllm_notebooks/tensorrt-llm/bert/large_benchmark/config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"builder_config": {
|
| 3 |
+
"max_batch_size": 256,
|
| 4 |
+
"max_input_len": 512,
|
| 5 |
+
"name": "bert",
|
| 6 |
+
"precision": "float16",
|
| 7 |
+
"tensor_parallel": 1,
|
| 8 |
+
"use_refit": false
|
| 9 |
+
},
|
| 10 |
+
"plugin_config": {
|
| 11 |
+
"bert_attention_plugin": false,
|
| 12 |
+
"context_fmha_enabled": false,
|
| 13 |
+
"gemm_plugin": false,
|
| 14 |
+
"gpt_attention_plugin": false,
|
| 15 |
+
"identity_plugin": false,
|
| 16 |
+
"layernorm_plugin": false,
|
| 17 |
+
"layernorm_quantization_plugin": false,
|
| 18 |
+
"nccl_plugin": false,
|
| 19 |
+
"smooth_quant_gemm_plugin": false,
|
| 20 |
+
"weight_only_quant_matmul_plugin": false
|
| 21 |
+
}
|
| 22 |
+
}
|
a_mllm_notebooks/tensorrt-llm/bert/large_with_attention_plugin_benchmark/config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"builder_config": {
|
| 3 |
+
"max_batch_size": 256,
|
| 4 |
+
"max_input_len": 512,
|
| 5 |
+
"name": "bert",
|
| 6 |
+
"precision": "float16",
|
| 7 |
+
"tensor_parallel": 1,
|
| 8 |
+
"use_refit": false
|
| 9 |
+
},
|
| 10 |
+
"plugin_config": {
|
| 11 |
+
"bert_attention_plugin": "float16",
|
| 12 |
+
"context_fmha_enabled": true,
|
| 13 |
+
"gemm_plugin": "float16",
|
| 14 |
+
"gpt_attention_plugin": false,
|
| 15 |
+
"identity_plugin": false,
|
| 16 |
+
"layernorm_plugin": false,
|
| 17 |
+
"layernorm_quantization_plugin": false,
|
| 18 |
+
"nccl_plugin": false,
|
| 19 |
+
"smooth_quant_gemm_plugin": false,
|
| 20 |
+
"weight_only_quant_matmul_plugin": false
|
| 21 |
+
}
|
| 22 |
+
}
|
a_mllm_notebooks/tensorrt-llm/bert/run.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2022-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
import argparse
|
| 16 |
+
import json
|
| 17 |
+
import os
|
| 18 |
+
|
| 19 |
+
# isort: off
|
| 20 |
+
import torch
|
| 21 |
+
import tensorrt as trt
|
| 22 |
+
# isort: on
|
| 23 |
+
|
| 24 |
+
import tensorrt_llm
|
| 25 |
+
from tensorrt_llm import logger
|
| 26 |
+
from tensorrt_llm.runtime import Session, TensorInfo
|
| 27 |
+
|
| 28 |
+
from build import get_engine_name # isort:skip
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def trt_dtype_to_torch(dtype):
|
| 32 |
+
if dtype == trt.float16:
|
| 33 |
+
return torch.float16
|
| 34 |
+
elif dtype == trt.float32:
|
| 35 |
+
return torch.float32
|
| 36 |
+
elif dtype == trt.int32:
|
| 37 |
+
return torch.int32
|
| 38 |
+
else:
|
| 39 |
+
raise TypeError("%s is not supported" % dtype)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def parse_arguments():
|
| 43 |
+
parser = argparse.ArgumentParser()
|
| 44 |
+
parser.add_argument('--log_level', type=str, default='info')
|
| 45 |
+
parser.add_argument('--engine_dir', type=str, default='bert_outputs')
|
| 46 |
+
|
| 47 |
+
return parser.parse_args()
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
if __name__ == '__main__':
|
| 51 |
+
args = parse_arguments()
|
| 52 |
+
|
| 53 |
+
tensorrt_llm.logger.set_level(args.log_level)
|
| 54 |
+
|
| 55 |
+
config_path = os.path.join(args.engine_dir, 'config.json')
|
| 56 |
+
with open(config_path, 'r') as f:
|
| 57 |
+
config = json.load(f)
|
| 58 |
+
|
| 59 |
+
assert config["plugin_config"]["remove_input_padding"] == False, \
|
| 60 |
+
"Please refer to run_remove_input_padding.py for running BERT models with remove_input_padding enabled"
|
| 61 |
+
|
| 62 |
+
dtype = config['builder_config']['precision']
|
| 63 |
+
world_size = config['builder_config']['tensor_parallel']
|
| 64 |
+
assert world_size == tensorrt_llm.mpi_world_size(), \
|
| 65 |
+
f'Engine world size ({world_size}) != Runtime world size ({tensorrt_llm.mpi_world_size()})'
|
| 66 |
+
|
| 67 |
+
model_name = config['builder_config']['name']
|
| 68 |
+
runtime_rank = tensorrt_llm.mpi_rank() if world_size > 1 else 0
|
| 69 |
+
|
| 70 |
+
runtime_mapping = tensorrt_llm.Mapping(world_size,
|
| 71 |
+
runtime_rank,
|
| 72 |
+
tp_size=world_size)
|
| 73 |
+
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
| 74 |
+
|
| 75 |
+
serialize_path = get_engine_name(model_name, dtype, world_size,
|
| 76 |
+
runtime_rank)
|
| 77 |
+
serialize_path = os.path.join(args.engine_dir, serialize_path)
|
| 78 |
+
|
| 79 |
+
stream = torch.cuda.current_stream().cuda_stream
|
| 80 |
+
logger.info(f'Loading engine from {serialize_path}')
|
| 81 |
+
with open(serialize_path, 'rb') as f:
|
| 82 |
+
engine_buffer = f.read()
|
| 83 |
+
logger.info(f'Creating session from engine')
|
| 84 |
+
session = Session.from_serialized_engine(engine_buffer)
|
| 85 |
+
|
| 86 |
+
for i in range(3):
|
| 87 |
+
batch_size = (i + 1) * 4
|
| 88 |
+
seq_len = (i + 1) * 32
|
| 89 |
+
input_ids = torch.randint(100, (batch_size, seq_len)).int().cuda()
|
| 90 |
+
input_lengths = seq_len * torch.ones(
|
| 91 |
+
(batch_size, ), dtype=torch.int32, device='cuda')
|
| 92 |
+
token_type_ids = torch.randint(100, (batch_size, seq_len)).int().cuda()
|
| 93 |
+
|
| 94 |
+
inputs = {
|
| 95 |
+
'input_ids': input_ids,
|
| 96 |
+
'input_lengths': input_lengths,
|
| 97 |
+
'token_type_ids': token_type_ids
|
| 98 |
+
}
|
| 99 |
+
output_info = session.infer_shapes([
|
| 100 |
+
TensorInfo('input_ids', trt.DataType.INT32, input_ids.shape),
|
| 101 |
+
TensorInfo('input_lengths', trt.DataType.INT32,
|
| 102 |
+
input_lengths.shape),
|
| 103 |
+
TensorInfo('token_type_ids', trt.DataType.INT32,
|
| 104 |
+
token_type_ids.shape),
|
| 105 |
+
])
|
| 106 |
+
outputs = {
|
| 107 |
+
t.name: torch.empty(tuple(t.shape),
|
| 108 |
+
dtype=trt_dtype_to_torch(t.dtype),
|
| 109 |
+
device='cuda')
|
| 110 |
+
for t in output_info
|
| 111 |
+
}
|
| 112 |
+
if (model_name == 'BertModel' or model_name == 'RobertaModel'):
|
| 113 |
+
output_name = 'hidden_states'
|
| 114 |
+
elif (model_name == 'BertForQuestionAnswering'
|
| 115 |
+
or model_name == 'RobertaForQuestionAnswering'):
|
| 116 |
+
output_name = 'logits'
|
| 117 |
+
elif (model_name == 'BertForSequenceClassification'
|
| 118 |
+
or model_name == 'RobertaForSequenceClassification'):
|
| 119 |
+
output_name = 'logits'
|
| 120 |
+
else:
|
| 121 |
+
assert False, f"Unknown BERT model {model_name}"
|
| 122 |
+
|
| 123 |
+
assert output_name in outputs, f'{output_name} not found in outputs, check if build.py set the name correctly'
|
| 124 |
+
|
| 125 |
+
ok = session.run(inputs, outputs, stream)
|
| 126 |
+
assert ok, "Runtime execution failed"
|
| 127 |
+
torch.cuda.synchronize()
|
| 128 |
+
res = outputs[output_name]
|
a_mllm_notebooks/tensorrt-llm/bert/run_remove_input_padding.py
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-FileCopyrightText: Copyright (c) 2022-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
import argparse
|
| 16 |
+
import json
|
| 17 |
+
import os
|
| 18 |
+
import random
|
| 19 |
+
from typing import List
|
| 20 |
+
|
| 21 |
+
# isort: off
|
| 22 |
+
import torch
|
| 23 |
+
import tensorrt as trt
|
| 24 |
+
# isort: on
|
| 25 |
+
|
| 26 |
+
import tensorrt_llm
|
| 27 |
+
from tensorrt_llm import logger
|
| 28 |
+
from tensorrt_llm.runtime import Session, TensorInfo
|
| 29 |
+
|
| 30 |
+
from build import get_engine_name # isort:skip
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def trt_dtype_to_torch(dtype):
|
| 34 |
+
if dtype == trt.float16:
|
| 35 |
+
return torch.float16
|
| 36 |
+
elif dtype == trt.float32:
|
| 37 |
+
return torch.float32
|
| 38 |
+
elif dtype == trt.int32:
|
| 39 |
+
return torch.int32
|
| 40 |
+
else:
|
| 41 |
+
raise TypeError("%s is not supported" % dtype)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def parse_arguments():
|
| 45 |
+
parser = argparse.ArgumentParser()
|
| 46 |
+
parser.add_argument("--log_level", type=str, default="info")
|
| 47 |
+
parser.add_argument("--engine_dir", type=str, default='bert_outputs')
|
| 48 |
+
|
| 49 |
+
return parser.parse_args()
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def process_input(input_ids_list: List[torch.Tensor],
|
| 53 |
+
token_type_ids_list: List[torch.Tensor]):
|
| 54 |
+
input_lengths = []
|
| 55 |
+
position_ids_list = []
|
| 56 |
+
max_input_length = 0
|
| 57 |
+
for i, input_ids in enumerate(input_ids_list):
|
| 58 |
+
input_len = len(input_ids)
|
| 59 |
+
assert input_len == len(token_type_ids_list[i]), f"sample {i}: len(input_ids)={len(input_ids)}, " \
|
| 60 |
+
f"len(token_type_ids)={len(token_type_ids_list[i])}, not equal"
|
| 61 |
+
input_lengths.append(input_len)
|
| 62 |
+
position_ids_list.append(torch.arange(0, input_len, dtype=torch.int32))
|
| 63 |
+
max_input_length = max(max_input_length, input_len)
|
| 64 |
+
|
| 65 |
+
# [num_tokens]
|
| 66 |
+
input_ids = torch.concat(input_ids_list).int().cuda()
|
| 67 |
+
token_type_ids = torch.concat(token_type_ids_list).int().cuda()
|
| 68 |
+
position_ids = torch.concat(position_ids_list).int().cuda()
|
| 69 |
+
|
| 70 |
+
input_lengths = torch.tensor(input_lengths).int().cuda() # [batch_size]
|
| 71 |
+
max_input_length = torch.empty((max_input_length, )).int().cuda()
|
| 72 |
+
return input_ids, input_lengths, token_type_ids, position_ids, max_input_length
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
if __name__ == '__main__':
|
| 76 |
+
args = parse_arguments()
|
| 77 |
+
|
| 78 |
+
tensorrt_llm.logger.set_level(args.log_level)
|
| 79 |
+
|
| 80 |
+
config_path = os.path.join(args.engine_dir, 'config.json')
|
| 81 |
+
with open(config_path, 'r') as f:
|
| 82 |
+
config = json.load(f)
|
| 83 |
+
dtype = config['builder_config']['precision']
|
| 84 |
+
world_size = config['builder_config']['tensor_parallel']
|
| 85 |
+
assert world_size == tensorrt_llm.mpi_world_size(), \
|
| 86 |
+
f'Engine world size ({world_size}) != Runtime world size ({tensorrt_llm.mpi_world_size()})'
|
| 87 |
+
|
| 88 |
+
model_name = config['builder_config']['name']
|
| 89 |
+
runtime_rank = tensorrt_llm.mpi_rank() if world_size > 1 else 0
|
| 90 |
+
|
| 91 |
+
runtime_mapping = tensorrt_llm.Mapping(world_size,
|
| 92 |
+
runtime_rank,
|
| 93 |
+
tp_size=world_size)
|
| 94 |
+
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
| 95 |
+
|
| 96 |
+
serialize_path = get_engine_name(model_name, dtype, world_size,
|
| 97 |
+
runtime_rank)
|
| 98 |
+
serialize_path = os.path.join(args.engine_dir, serialize_path)
|
| 99 |
+
|
| 100 |
+
stream = torch.cuda.current_stream().cuda_stream
|
| 101 |
+
logger.info(f'Loading engine from {serialize_path}')
|
| 102 |
+
with open(serialize_path, 'rb') as f:
|
| 103 |
+
engine_buffer = f.read()
|
| 104 |
+
logger.info(f'Creating session from engine')
|
| 105 |
+
session = Session.from_serialized_engine(engine_buffer)
|
| 106 |
+
|
| 107 |
+
remove_input_padding = config["plugin_config"]["remove_input_padding"]
|
| 108 |
+
assert remove_input_padding, "This is a demo for BERT models with remove_input_padding enabled"
|
| 109 |
+
|
| 110 |
+
for i in range(3):
|
| 111 |
+
batch_size = (i + 1) * 4
|
| 112 |
+
# use list of tensor to represent unpadded samples
|
| 113 |
+
input_ids = []
|
| 114 |
+
token_type_ids = []
|
| 115 |
+
for _ in range(batch_size):
|
| 116 |
+
seq_len = random.randint(64, 128)
|
| 117 |
+
input_ids.append(torch.randint(100, size=(seq_len, )).int().cuda())
|
| 118 |
+
token_type_ids.append(
|
| 119 |
+
torch.randint(0, 1, size=(seq_len, )).int().cuda())
|
| 120 |
+
|
| 121 |
+
input_ids, input_lengths, token_type_ids, position_ids, max_input_length = \
|
| 122 |
+
process_input(input_ids, token_type_ids)
|
| 123 |
+
inputs = {
|
| 124 |
+
"input_ids": input_ids,
|
| 125 |
+
"input_lengths": input_lengths,
|
| 126 |
+
"token_type_ids": token_type_ids,
|
| 127 |
+
"position_ids": position_ids,
|
| 128 |
+
"max_input_length": max_input_length
|
| 129 |
+
}
|
| 130 |
+
output_info = session.infer_shapes([
|
| 131 |
+
TensorInfo("input_ids", trt.DataType.INT32, input_ids.shape),
|
| 132 |
+
TensorInfo("input_lengths", trt.DataType.INT32,
|
| 133 |
+
input_lengths.shape),
|
| 134 |
+
TensorInfo("token_type_ids", trt.DataType.INT32,
|
| 135 |
+
token_type_ids.shape),
|
| 136 |
+
TensorInfo("position_ids", trt.DataType.INT32, position_ids.shape),
|
| 137 |
+
TensorInfo("max_input_length", trt.DataType.INT32,
|
| 138 |
+
max_input_length.shape)
|
| 139 |
+
])
|
| 140 |
+
outputs = {
|
| 141 |
+
t.name: torch.empty(tuple(t.shape),
|
| 142 |
+
dtype=trt_dtype_to_torch(t.dtype),
|
| 143 |
+
device='cuda')
|
| 144 |
+
for t in output_info
|
| 145 |
+
}
|
| 146 |
+
output_name = "logits"
|
| 147 |
+
assert output_name in outputs, f'{output_name} not found in outputs, check if build.py set output name correctly'
|
| 148 |
+
|
| 149 |
+
ok = session.run(inputs, outputs, stream)
|
| 150 |
+
assert ok, "Runtime execution failed"
|
| 151 |
+
torch.cuda.synchronize()
|
| 152 |
+
res = outputs[output_name]
|
| 153 |
+
print(res)
|