
Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese
Paper • 2408.12480 • Published • 26
We are excited to introduce Vintern-1B-v2 the Vietnamese 🇻🇳 multimodal model that combines the advanced Vietnamese language model Qwen2-0.5B-Instruct[1] with the latest visual model, InternViT-300M-448px[2], CVPR 2024. This model excels in tasks such as OCR-VQA, Doc-VQA, and Chart-VQA,... With only 1 billion parameters, it is 4096 context length finetuned from the Viet-InternVL2-1B model on over 3 million specialized image-question-answer pairs for optical character recognition 🔍, text recognition 🔤, document extraction 📑, and general VQA. The model can be integrated into various on-device applications 📱, demonstrating its versatility and robust capabilities.
The special thing is that our model can be easily finetuned with a T4 GPU on Google Colab by following the instructions provided at the end of this section.
| Model Name | Vision Part | Language Part |
|---|---|---|
| Vintern-1B-v2 | InternViT-300M-448px | Qwen2-0.5B-Instruct |
Vintern-1B-v2 is a multimodal large language model series, featuring models of various sizes. For each size, we release instruction-tuned models optimized for multimodal tasks. Vintern-1B-v2 consists of InternViT-300M-448px, an MLP projector, and Qwen2-0.5B-Instruct.
The fine-tuning dataset was meticulously sampled in part from the following datasets:
Viet-OCR-VQA 📚, Viet-Doc-VQA 📄, Viet-Doc-VQA-II 📑, Vista 🖼️, Viet-Receipt-VQA 🧾, Viet-Sketches-VQA ✏️, Viet-Geometry-VQA 📐, Viet-Wiki-Handwriting ✍️, Viet-ComputerScience-VQA 💻, Viet-Handwriting-gemini-VQA 🖋️, Viet-Menu-gemini-VQA 🍽️, Viet-Vintext-gemini-VQA 📜, Viet-OpenViVQA-gemini-VQA 🧠, Viet-Resume-VQA 📃, Viet-ViTextVQA-gemini-VQA 📑
Since there are still many different metrics that need to be tested, we chose a quick and simple metric first to guide the development of our model. Our metric is inspired by Lavy[4]. For the time being, we are using GPT-4 to evaluate the quality of answers on two datasets: OpenViVQA and ViTextVQA. Detailed results can be found at the provided here. The inputs are images, questions, labels, and predicted answers. The model will return a score from 0 to 10 for the corresponding answer quality. The results table is shown below.
| Model | gpt4o-score | |
| OpenViVQA-dev | ViTextVQA-dev | |
| Vintern-1B | 7.1/10 | 7.6/10 |
| Vintern-1B-v2 | 7.7/10 | 7.7/10 |
The benchmark result in MTVQA
| Models | Open-Source | Vietnamese Score |
|---|---|---|
| Qwen2-VL 72B (Top 1) | ✗ | 41.6 |
| GPT-4o (Top 2) | ✗ | 34.2 |
| Vintern-1B-V2 (Top 3) | ✓ | 31.7 |
| Qwen2-VL 7B | ✓ | 30.0 |
| Claude3 Opus | ✗ | 29.1 |
| GPT-4o mini | ✗ | 29.1 |
| GPT-4V | ✗ | 28.9 |
| Gemini Ultra | ✗ | 28.6 |
| InternVL2 76B | ✓ | 26.9 |
| QwenVL Max | ✗ | 23.5 |
| Claude3 Sonnet | ✗ | 20.8 |
| QwenVL Plus | ✗ | 18.1 |
| MiniCPM-V2.5 | ✓ | 15.3 |
| InternVL-V1.5 | ✗ | 12.4 |

User: <image>
Mô tả hình ảnh một cách chi tiết.
Assistant: Bức ảnh là một trang giấy kẻ ô vuông với dòng chữ viết tay bằng mực đen. Bố cục đơn giản, chỉ có nội dung văn bản được viết theo chiều dọc từ trên xuống dưới. Các dòng chữ được sắp xếp theo thứ tự từ trên xuống dưới như sau:
- Nghe thầy đọc thơ
- Em nghe thầy đọc bao ngày
- Tiếng thơ đỏ nắng xanh cây quanh nhà
- Mái chèo nghe vọng sông xa
- Em êm nghe tiếng của bà năm xưa
- Nghe trăng thở động tàu dừa
- Rào rào nghe chuyển con mưa giữa trời
- Thêm yêu tiếng hát nụ cười
- Nghe thơ em thấy đất trời đẹp ra.
- Trần Đăng Khoa
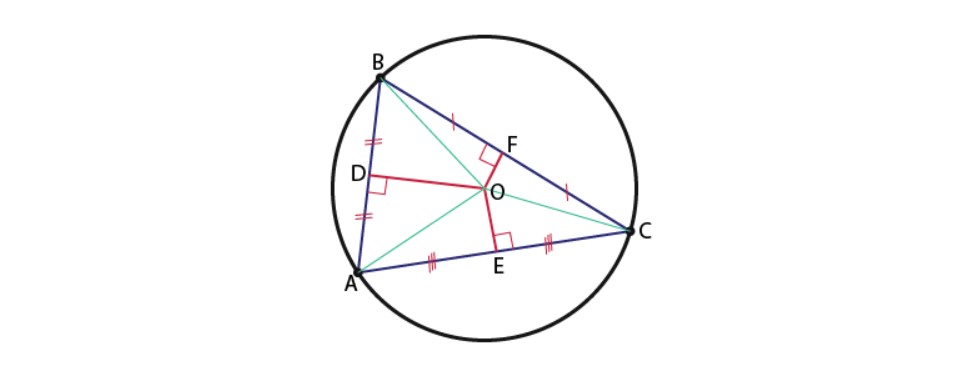
User: <image>
Tam giác ABC là gì của đường tròn tâm O ?
Assistant: Tam giác ABC là tam giác nội tiếp của đường tròn tâm O.

User: <image>
Mô tả hình ảnh một cách chi tiết.
Assistant: Bức ảnh chụp một con sông ở Việt Nam với những ngôi nhà cổ kính được sơn màu vàng nhạt. Phía trước là một con thuyền nhỏ màu đỏ và một chiếc thuyền lớn màu xanh dương.
Trên thuyền có một người đàn ông đang chèo thuyền. Hai bên bờ sông là những hàng cây xanh mát. Bầu trời trong xanh và có một vài đám mây trắng.
Ở góc dưới bên trái của bức ảnh có dòng chữ "VNEXPRESS".

User: <image>
Mô tả hình ảnh một cách chi tiết.
Assistant: Bức ảnh là một thông báo tuyển dụng của công ty Mobifone. Bố cục được chia thành 3 phần chính:
- Phần đầu tiên là tiêu đề "TUYỂN DỤNG" được in chữ màu đỏ đậm, cỡ chữ lớn, nằm ở vị trí trung tâm phía trên cùng của bức ảnh.
- Phần thứ hai là phần giới thiệu về vị trí và yêu cầu của ứng viên. Phần này được trình bày theo dạng liệt kê các mục:
- Vị trí: Nhân viên kinh doanh
- Địa điểm: Thành phố và các huyện Yên Sơn, Sơn Dương, Hàm Yên, Chiêm Hóa
- Yêu cầu: Trình độ: Tốt nghiệp Trung cấp trở lên, Độ tuổi: Không quá 35 tuổi
- Phần thứ ba là phần giới thiệu về chế độ đãi ngộ. Phần này được trình bày theo dạng liệt kê các mục:
- Chế độ đãi ngộ:
- Mức lương: 7.000.000đ - 17.000.000đ
- Thưởng thi đua hàng tháng, quý: Thưởng theo doanh số
- Chế độ bảo hiểm theo quy định
- Được trau dồi các kỹ năng: Giao tiếp, thuyết phục, chăm sóc khách hàng...
Phần cuối cùng là phần "NỘP HỒ SƠ" với thông tin liên lạc của người nộp hồ sơ. Phần này được trình bày theo dạng liệt kê các mục:
- Người nhận: Trần Thị Thúy
- Địa chỉ: 547 đường Quang Trung, Tổ 25, Phường Phan Thiết, TP Tuyên Quang
- Điện thoại liên hệ: 0901.452.888
- Email nhận hồ sơ: thuy.tranthi.kd@mobifone.vn
- Thời hạn nộp hồ sơ: đến hết ngày 28/5/2021

User: <image>
Con nào sẽ thắng ?
Assistant: Con thỏ sẽ thắng.

User: <image>
Mô tả chi tiết hình ảnh.
Assistant: Bức ảnh hiển thị một đoạn mã nguồn được viết bằng ngôn ngữ lập trình Python. Đoạn mã này bao gồm hai phần:
Phần đầu: Nêu tiêu đề "Example of avoiding complex expressions" (Mô tả ví dụ về việc tránh các hàm phức tạp).
Phần chính: Bao gồm hai hàm square_numbers và main().
Hàm square_numbers nhận một tham số là danh sách số từ 1 đến 4. Hàm này sử dụng vòng lặp for để duyệt qua mỗi số trong danh sách và thêm nó vào danh sách squares. Sau đó, hàm trả về danh sách squares.
Hàm main() tạo một biến numbers với giá trị [1, 2, 3, 4], sau đó gọi hàm square_numbers và ghi kết quả vào biến result. Cuối cùng, hàm print(result) sẽ in ra kết quả của hàm main().
Here provides a code snippet to show you how to load the tokenizer and model and how to generate contents.
To run inference using the model, follow the steps outlined in our Colab inference notebook
![]()
import numpy as np
import torch
import torchvision.transforms as T
# from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
model = AutoModel.from_pretrained(
"5CD-AI/Vintern-1B-v2",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained("5CD-AI/Vintern-1B-v2", trust_remote_code=True, use_fast=False)
test_image = 'test-image.jpg'
pixel_values = load_image(test_image, max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens= 1024, do_sample=False, num_beams = 3, repetition_penalty=2.5)
question = '<image>\nMô tả hình ảnh một cách chi tiết.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
#question = "Câu hỏi khác ......"
#response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
#print(f'User: {question}\nAssistant: {response}')
![]()
@misc{doan2024vintern1befficientmultimodallarge,
title={Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese},
author={Khang T. Doan and Bao G. Huynh and Dung T. Hoang and Thuc D. Pham and Nhat H. Pham and Quan T. M. Nguyen and Bang Q. Vo and Suong N. Hoang},
year={2024},
eprint={2408.12480},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2408.12480},
}
[1] Yang, An, et al. "Qwen2 technical report." arXiv preprint arXiv:2407.10671 (2024).
[2] Chen, Zhe, et al. "Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[3] Chen, Zhe, et al. "How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites." arXiv preprint arXiv:2404.16821 (2024).
[4] Tran, Chi, and Huong Le Thanh. "LaVy: Vietnamese Multimodal Large Language Model." arXiv preprint arXiv:2404.07922 (2024).