
Mirage
Collection
Mirage family of small language, multi-modal and reasoning models trained through supervised fine-tuning (SFT)
•
11 items
•
Updated
•
1
The Solana Vanguard Challenge dataset, comprising 1,000 diverse and in-depth questions, offers full-spectrum coverage of the Solana ecosystem. It spans fundamental blockchain concepts, advanced on-chain programming in Rust and the Anchor framework, client-side integration in TypeScript, detailed security strategies, and performance as well as regulatory considerations.
Mirage OpenReasoning Nemotron 7B is in active development with additional fine-tuning sessions, & benchmark statistics coming soon!
| Link | Type | Size/GB | Notes |
|---|---|---|---|
| GGUF | Q4_K_S | 4 | fast, recommended |
| GGUF | Q5_K-S | 5 | |
| GGUF | Q6_K | 6 | very good quality |
| GGUF | Q8_0 | 8 | fast, best quality |
| GGUF | F16 | 15 | 16 bpw, highest quality |
To run inference on coding problems:
import transformers
import torch
model_id = "Bifrost-AI/Mirage-OpenReasoning-Nemotron-7B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
# Code generation prompt
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
Please use python programming language only.
You must use ```python for just the final solution code block with the following format:
```python
# Your code here
```
{user}
"""
# Math generation prompt
# prompt = """Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.
#
# {user}
# """
# Science generation prompt
# You can refer to prompts here -
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/generic/hle.yaml (HLE)
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-4choices-boxed.yaml (for GPQA)
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-10choices-boxed.yaml (MMLU-Pro)
messages = [
{
"role": "user",
"content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")},
]
outputs = pipeline(
messages,
max_new_tokens=64000,
)
print(outputs[0]["generated_text"][-1]['content'])
OpenReasoning-Nemotron-7B is a large language model (LLM) which is a derivative of Qwen2.5-7B-Instruct (AKA the reference model). It is a reasoning model that is post-trained for reasoning about math, code and science solution generation. We evaluated this model with up to 64K output tokens. The OpenReasoning model is available in the following sizes: 1.5B, 7B and 14B and 32B.
This model is ready for commercial/non-commercial research use.
GOVERNING TERMS: Use of the models listed above are governed by the Creative Commons Attribution 4.0 International License (CC-BY-4.0). ADDITIONAL INFORMATION: Apache 2.0 License
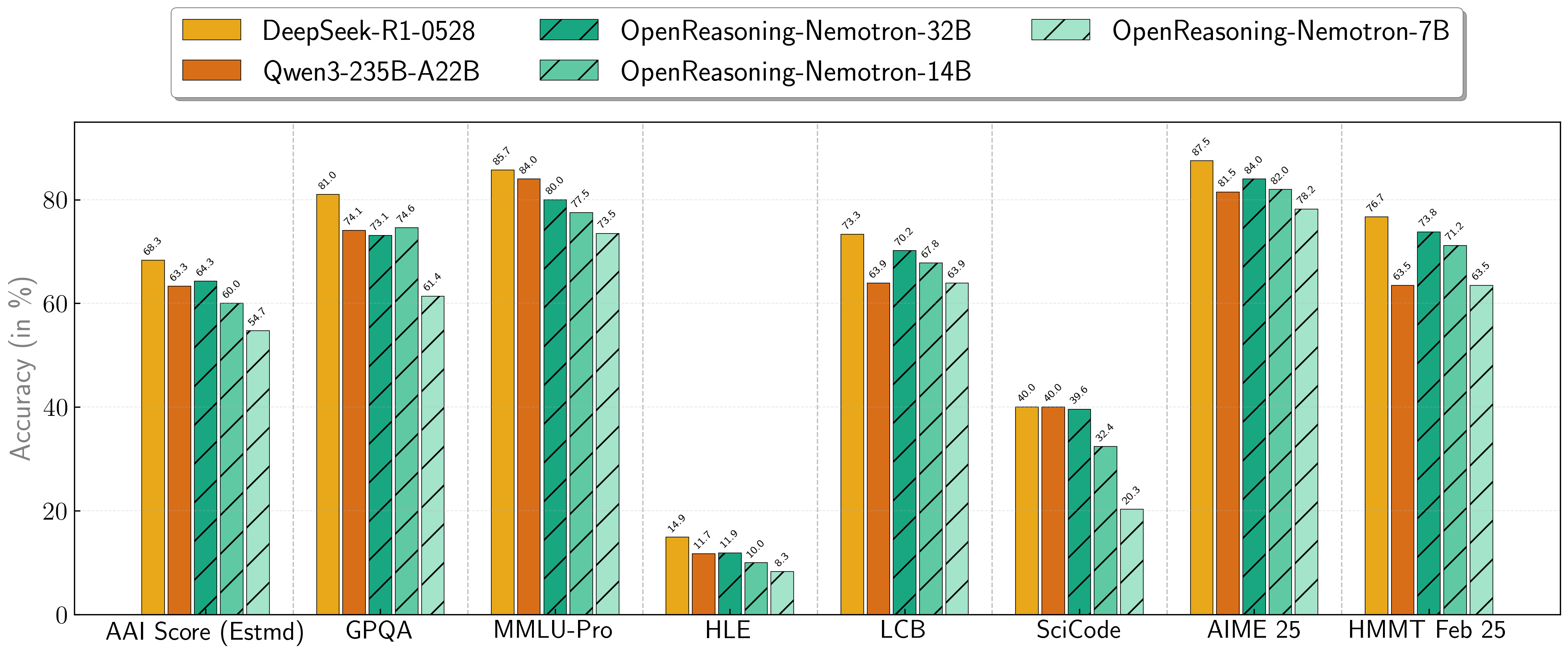
Our models demonstrate exceptional performance across a suite of challenging reasoning benchmarks. The 7B, 14B, and 32B models consistently set new state-of-the-art records for their size classes.
| Model | AritificalAnalysisIndex* | GPQA | MMLU-PRO | HLE | LiveCodeBench* | SciCode | AIME24 | AIME25 | HMMT FEB 25 |
|---|---|---|---|---|---|---|---|---|---|
| 1.5B | 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
| 7B | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
| 14B | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
| 32B | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
* This is our estimation of the Artificial Analysis Intelligence Index, not an official score.
* LiveCodeBench version 6, date range 2408-2505.
OpenReasoning-Nemotron models can be used in a "heavy" mode by starting multiple parallel generations and combining them together via generative solution selection (GenSelect). To add this "skill" we follow the original GenSelect training pipeline except we do not train on the selection summary but use the full reasoning trace of DeepSeek R1 0528 671B instead. We only train models to select the best solution for math problems but surprisingly find that this capability directly generalizes to code and science questions! With this "heavy" GenSelect inference mode, OpenReasoning-Nemotron-32B model surpasses O3 (High) on math and coding benchmarks.
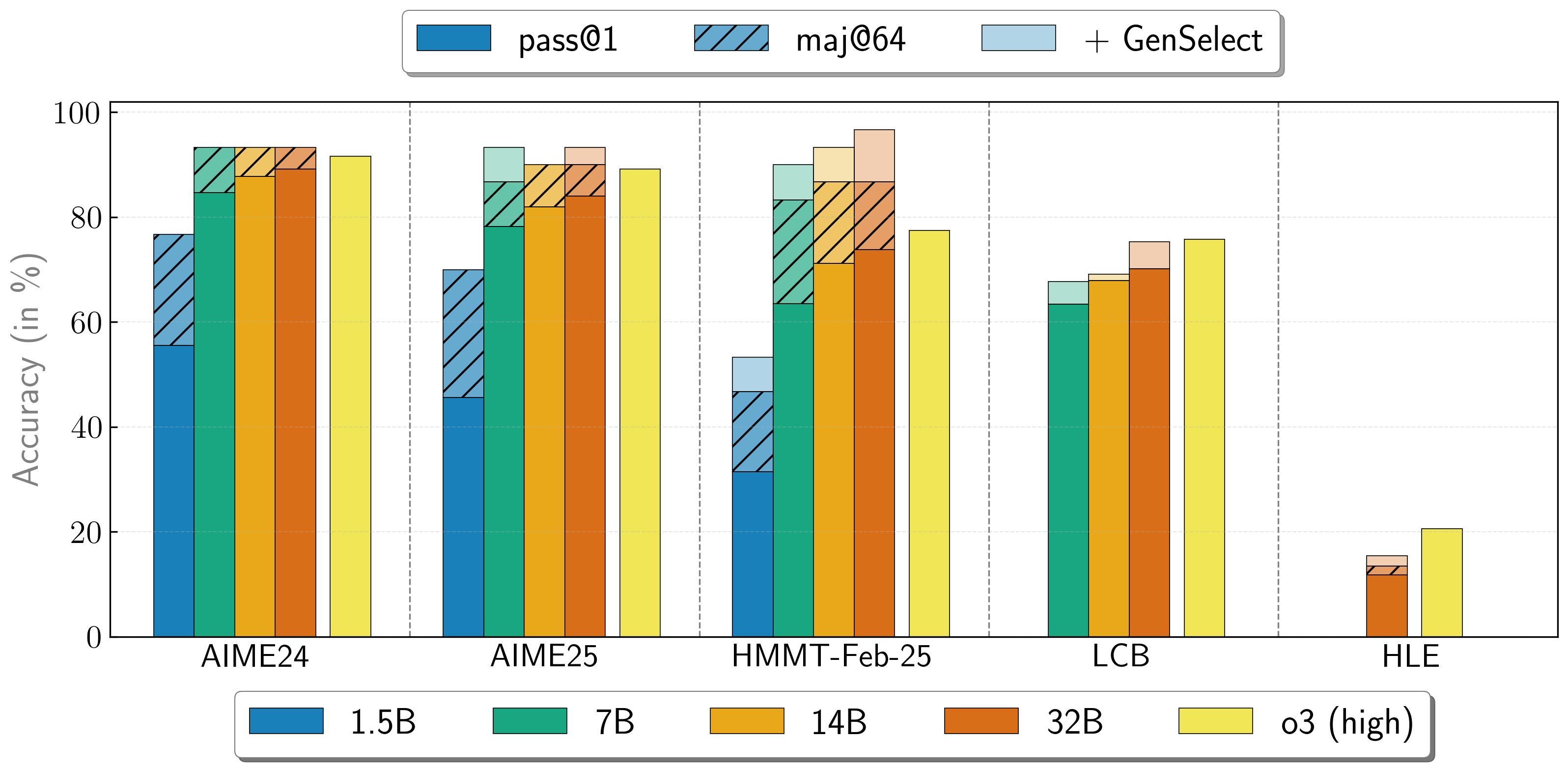
| Model | Pass@1 (Avg@64) | Majority@64 | GenSelect |
|---|---|---|---|
| 1.5B | |||
| AIME24 | 55.5 | 76.7 | 76.7 |
| AIME25 | 45.6 | 70.0 | 70.0 |
| HMMT Feb 25 | 31.5 | 46.7 | 53.3 |
| 7B | |||
| AIME24 | 84.7 | 93.3 | 93.3 |
| AIME25 | 78.2 | 86.7 | 93.3 |
| HMMT Feb 25 | 63.5 | 83.3 | 90.0 |
| LCB v6 2408-2505 | 63.4 | n/a | 67.7 |
| 14B | |||
| AIME24 | 87.8 | 93.3 | 93.3 |
| AIME25 | 82.0 | 90.0 | 90.0 |
| HMMT Feb 25 | 71.2 | 86.7 | 93.3 |
| LCB v6 2408-2505 | 67.9 | n/a | 69.1 |
| 32B | |||
| AIME24 | 89.2 | 93.3 | 93.3 |
| AIME25 | 84.0 | 90.0 | 93.3 |
| HMMT Feb 25 | 73.8 | 86.7 | 96.7 |
| LCB v6 2408-2505 | 70.2 | n/a | 75.3 |
| HLE | 11.8 | 13.4 | 15.5 |
16-bit
Base model
Qwen/Qwen2.5-7B