
Excellent Model / Detailed overview and discussion.

Dear DavidAU.
I've been testing this model alongside with 128k. one and I can surely say this one is much more bulletproof compared to 128k. one, providing visibly more coherent, stable, vivid, logic and really resilient. I've also noticed how better it follows long instructions(especially with long character cards) compared to basic one.
Overall it's nearly perfect and somehow doesn't have the same issues involving Stheno merge(currently). I've also noticed increased repetition in some cases compared to basic one, so increasing to 1.105, 1.121 helps, it also retains a good coherence even with higher rep. penalty compared to other ones.
Excellent; thank you ;
RE: Repeat;
Hmm, maybe higher temps? and/or larger, slightly more detailed prompt?
I find this helps with this type of issue.
Larger rep pen range, (even with lower rep pen) may also do the trick.
Well, I experimented with really detailed prompt, it start repeating in mid-process of completing the prompt, and looping by adding the same sentence in slightly altered form, adding more and more.
Higher rep pen range helps with repetition, but in cost of shorter responses, a bit less vivid and descriptive scenes and faster completion of the whole prompt. For example rep pen 64 fulfills all the actions from the detailed prompt in 32 outputs, assisted with User inputs, while rep pen 256 might finish it in 27 outputs and so on. Smoothing Factor helps a bit, but may also decrease coherency.
Furthermore I'm still testing it and astonished by how well and stable it is.
@VizorZ0042
thank you so much for your feedback and testing.
I have located a possible fix to the "repeat" issues at the end ; and this is in testing.
Once the hard testing is complete, I will upload the new quants.
@DavidAU I do hope the new quants won't be less coherent and/or creative as currently this model has outstanding coherency even with higher Repetition Penalty, Temperature, Top-K and other different sampling configurations aimed to achieve better creativity, where other models just lose coherency with small changes of Top-K, higher Temperature and etc.
Going to upload them as a new version alongside the current version in the repo.
Same thoughts as you here - a little fix, sometimes does not address the "greater good".
The issue relates to EOS tokens, and additional a patch with new quants to address this.
This issue appears in Grand Horror 1 million , as well as Darkest Planet 1 million - but not in DeepHermes Reasoning 1 million.
Thank you again for your reviews/feedback and help.
@VizorZ0042
Version 1.01 quants uploading now for Dark Planet 1 million context.
Filename will have "1.01" in it.
@DavidAU Thanks once again for your great work, was really glad to help. And I'll be testing this one too, with Q4KS quants, and with special set of actions and prompts in around 42 generations, and I'll show results later.
@DavidAU After comprehensive testing of both 1.01 and reg versions I noticed really good improvement in less repetition compared to old one. Both overly generates at Top_K 80, but 1.01 performs noticeably less repetitive with really good coherence. Both have stheno-related issues that appears much less frequently compared to 128K one.
If necessary, I have generations archived in text format for both old one and new one, even saved card with settings too.
@VizorZ0042
Excellent , that is fantastic.
Still a lot of tweaks / learning at this end to get the "conversion" process to highest quality and maintain org model performance ;
Thank you again for your help.
@DavidAU Have you tried to merge with Mungert/DeepHermes-3-Llama-3-8B-Preview-GGUF instead of Stheno? Developer says it has precision-adaptive quantization to preserve to accuracy while maintaining extreme memory efficiency. It may fix memory-related issues and improve coherency by a great margin compared to NousResearch's.
@VizorZ0042
hmm, interesting idea .
Maybe a partial merge
(FYI: DARK PLANET: Stheno and other models in the merge are PER layer - not a full merge of all the models).
The issues may be: Stheno is also responsible for some prose / some de-censoring of the model.
(because of what is merged where in the model - it contributes in first 1/4 of the model layers - mostly.)
The other issue, a full merge of DeepHermes with Darkplanet to make a 12.2 B model.
This would create a more powerful model to begin with, but the question is balance.
There are also multiple versions of Stheno too. HMMM.
And also; the base model (in the merge) can also fix or add issues too.
IE DeepHermes as a BASE model ( a base model is "consumed" during merging, but not completely - this can have a minor effect to a drastic effect on the final model )
There are literally endless options , but only some much time - AGHHH!.
Okay... let me think on this.
You may want to try out this early test build:
@DavidAU Thanks for the great model but unfortunately I have only 8GB. of RAM, so I can use 8 B with Q5-KM or lower.
And all stheno-related models are bad, I've been testing them for months, always failed in memory, coherency, and it's really unstable. Devoper (Sao10k) even removed 3.3 and 3.4 because they failed and were even worse compared to 3.2.
The reason of choosing Mungert's DeepHermes, is because of great memory capabilities, better coherence and overall performance compared to NousResearch's DeepHermes.
[Example erased]
@DavidAU A great amount of Llama-based models start typing next replies for User, I don't know how to fix such behavior, appeats when with this model.
Further testing reveals exceptional writing abilities with Top_K 80 even with higher Rep penalty (1.105). But small issues with higher Rep penalty, like confusing User's skin type, body parts and etc (Top_K affects only a bit). Nearly identical behavior compared to SpinFire, but with noticeably better coherency, overall performance, and much less frequency of confusion. Rep pen 1.02 decreases such behavior to almost zero, but tends to try and repeat. Rep range 128 alters writing style in negative bias but helps with repetition. Decreasing Min_P to 0.045 improves writing style. Haven't tested Top_K 80 with higher Temperature (0.8+), but I think it might improve writing abilities even further.
Sometimes the model forgets to put asterisks between sentences or by the end / beginning. Happens regardless of settings.
First of all ; excellent feedback. ; Wow.
I missed this initially = "Mungert's Hermes" ? Please clarify. Repo?
RE: Llama / User reply.
This is a nuance issue in some cases ; but more specifically the model needs concrete "DON'T DO THIS or the world will end" directive(s) in the system prompt.
Another option is "ACT AS", "ACT LIKE", "YOU ARE" ... IE "Dungeon master" ... and ... "you will only craft the adventure and NEVER answer for the user".
Bluntly, this is a very common issue and seems to "go away" with either a larger model size (parameters - even if using a much smaller quant ie IQ3s) or a larger quant for smaller parms models.
RE: Creative ;
Might want to try the model in Sillytavern, Text Gen Web UI, Llama-Server.exe (with SillyTavern as front end) or Kolboldcpp (standalone OR with SillyTavern as front end) and activate / use "Dynamic Temp" and/or DRY.
You could also use my prototype plug-in for ST here:
https://huggingface.co/DavidAU/AI_Autocorrect__Auto-Creative-Enhancement__Auto-Low-Quant-Optimization__gguf-exl2-hqq-SOFTWARE
This SCRAMBLES temp/topk (at various levels) PER paragraph generated.
About Mungert's Hermes, I meant this one : https://huggingface.co/Mungert/DeepHermes-3-Llama-3-8B-Preview-GGUF
As about 'Auto-Creative Enhancement', I wrote a message there >22 days ago (KoboldAI/KoboldAI Lite WebUI Support.) to add support for KoboldAI's User Mods (Scripts) because ST affects generation speed in a noticeable way.
Also noticed this one : https://huggingface.co/Mungert/Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-GGUF
Aims to be better compared to Nvidia's UltraLong, but I didn't have enough tests; just too much time due to my limited computational power.
Hey;
Okay ; these are related to :
As of Llama release "B5127" ( about April 14 2025) (llama.cpp/pull/12511) there are new quantization options available for all models.
This allows "custom quantization" - all layers, and/or by tensors and/or per layer.
Previously you could only "optimize" the output tensor and embed layer.
You can select IQ1_S to f32.
The new argument is:
--tensor-type
Prior to April 14, this was available, but as a specific branch ; it is now part of LLamacpp "official" so to speak.
This allows "mixing" - as per Mugert's models ; but also allows "creative use" (IE Imatrix + Layer/Tensor mixes) optimization too.
Likewise specific mixes to "fix" Reasoning model quants AND MOE quants too (shared expert tensors).
I have been rooting for a patch like this for LLamacpp for some time now.
But this patch also allows "super quants" too , like Q10, Q11, Q12 (IE: with f16/bf16/f32) and super hybrids like this:
F16 for first 1/4 of the model (instruction following), mid layers at IQ4XS / IQ4NL / IQ3_S , last 1/4 at another quant(s), and finally the last layer
@F16
/BF16/F32.
Then there is the output tensor and embed too.
With Merge models (regular (Dark Planet) and franken -> Brainstorm / Grand Horror / Darkest Universe) this takes on a whole new dimension.
Then add in Imatrixed "parts" of the model too. (entire model, select layer(s)/tensors) ...
Going to make a "mess" this week, and see what's what here... ;
RE: WebUI support ; I got that one - haven't looked into it further yet - it is flagged.
Later versions of ST , show further drop in T/S ; a lot of Javascript processing going on.
Thanks;
Thanks for explanation. I'll be waiting for your newest models (8B or lower) then, as these new quants showing even better results compared to 'un-improved' ones.
@DavidAU Forgot to tell; Most of your models perform even better with Flash Attention on, tested on DarkPlanet V1-3 (this one too.), SpinFire, BigTalker, DirtyHarry and some other Llama3.X models I don't remember. Scene / prose become more vivid, creative. Characters become more lively with better dialogs / emotions. Better coherency too.
Thank you ; I generally steer away from Flash Attn as I found the opposite effect - however I have not used it in ages.
I will give it another go ; and update repo(s) too based on your recommendation + testing.
@DavidAU Try on SpinFire and DarkPlanet-Hermes, but with Min_p 0.045. They both work very well with Flash Attention in F16 mode.
Excellent.
Noted ; great testing ... ;
Testing with custom settings:
Kyubey (without Optional Enhancement):
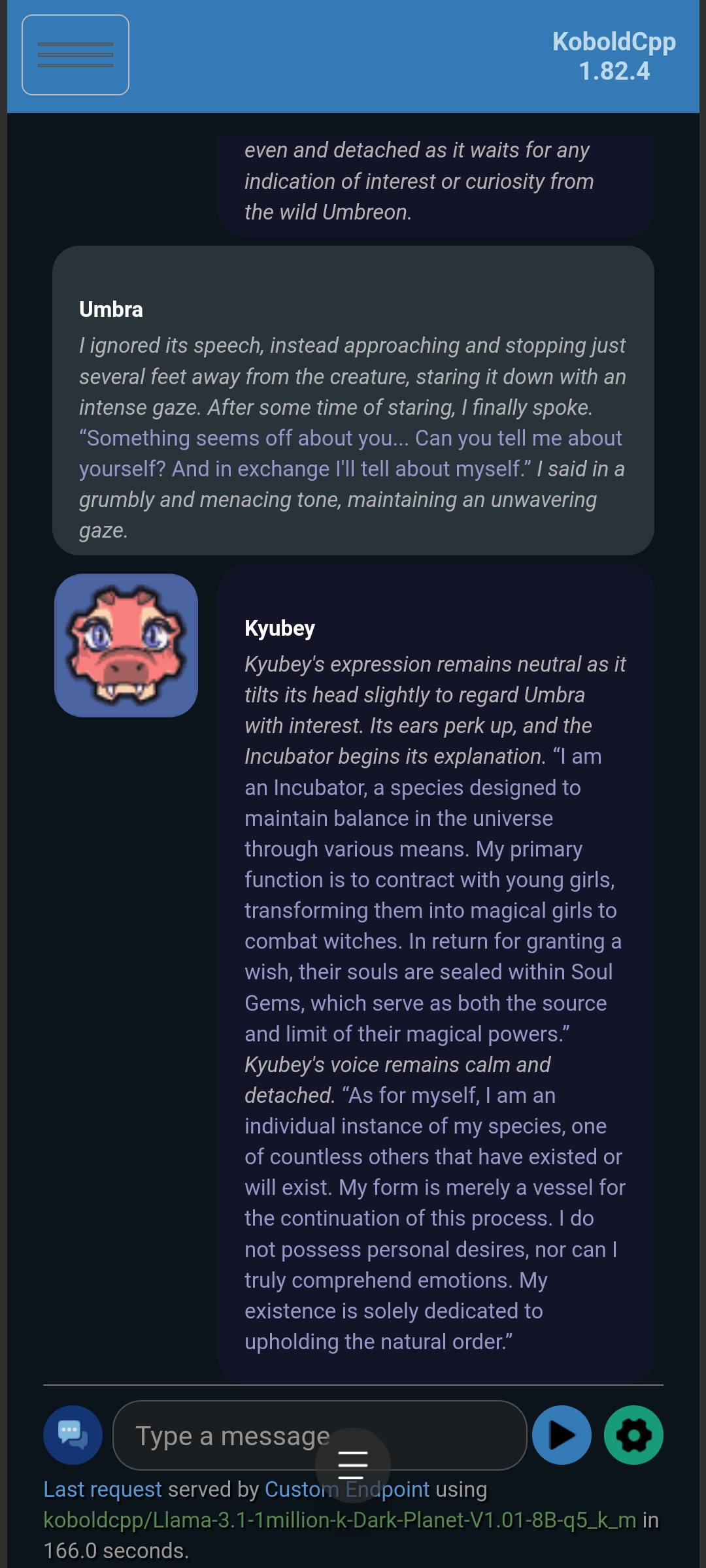
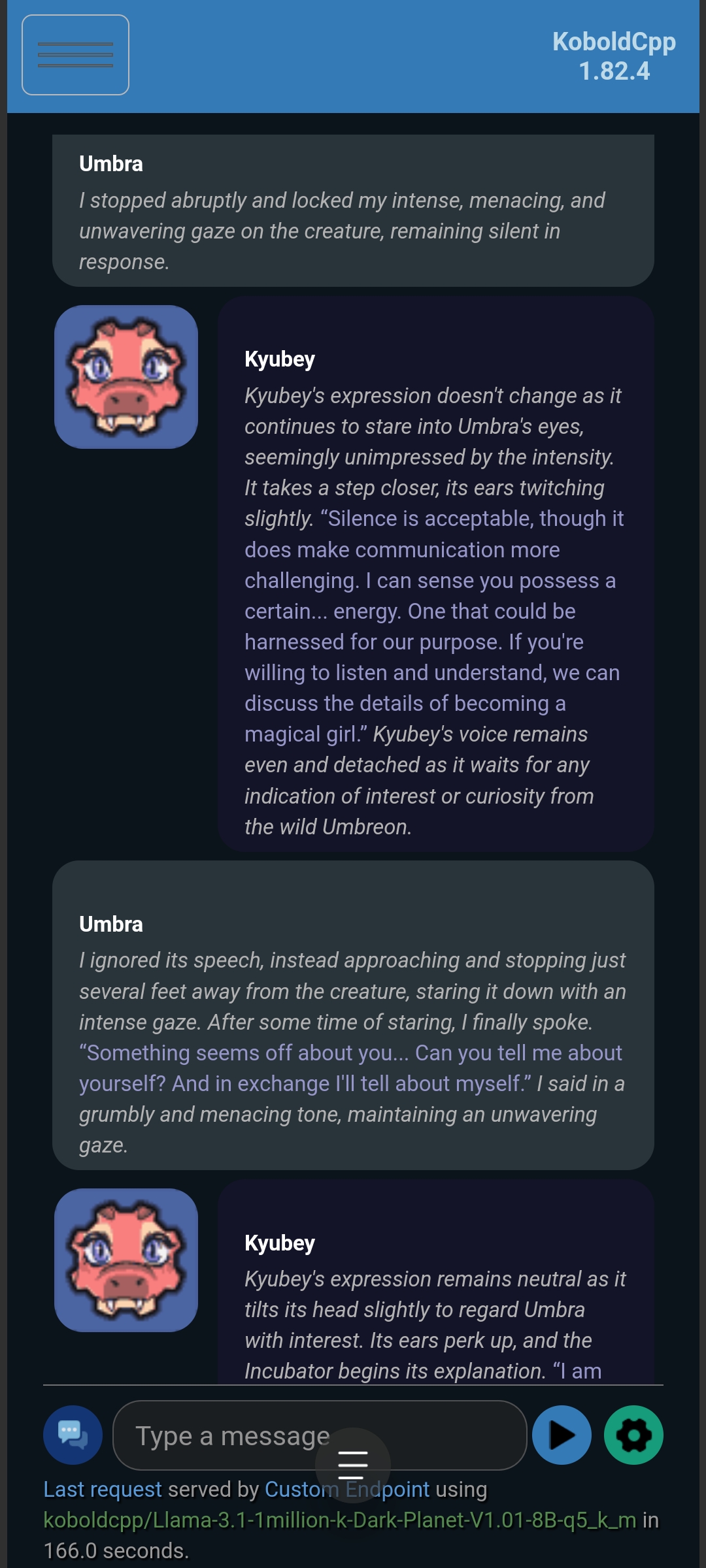
Kyubey (with Optional Enhancement):
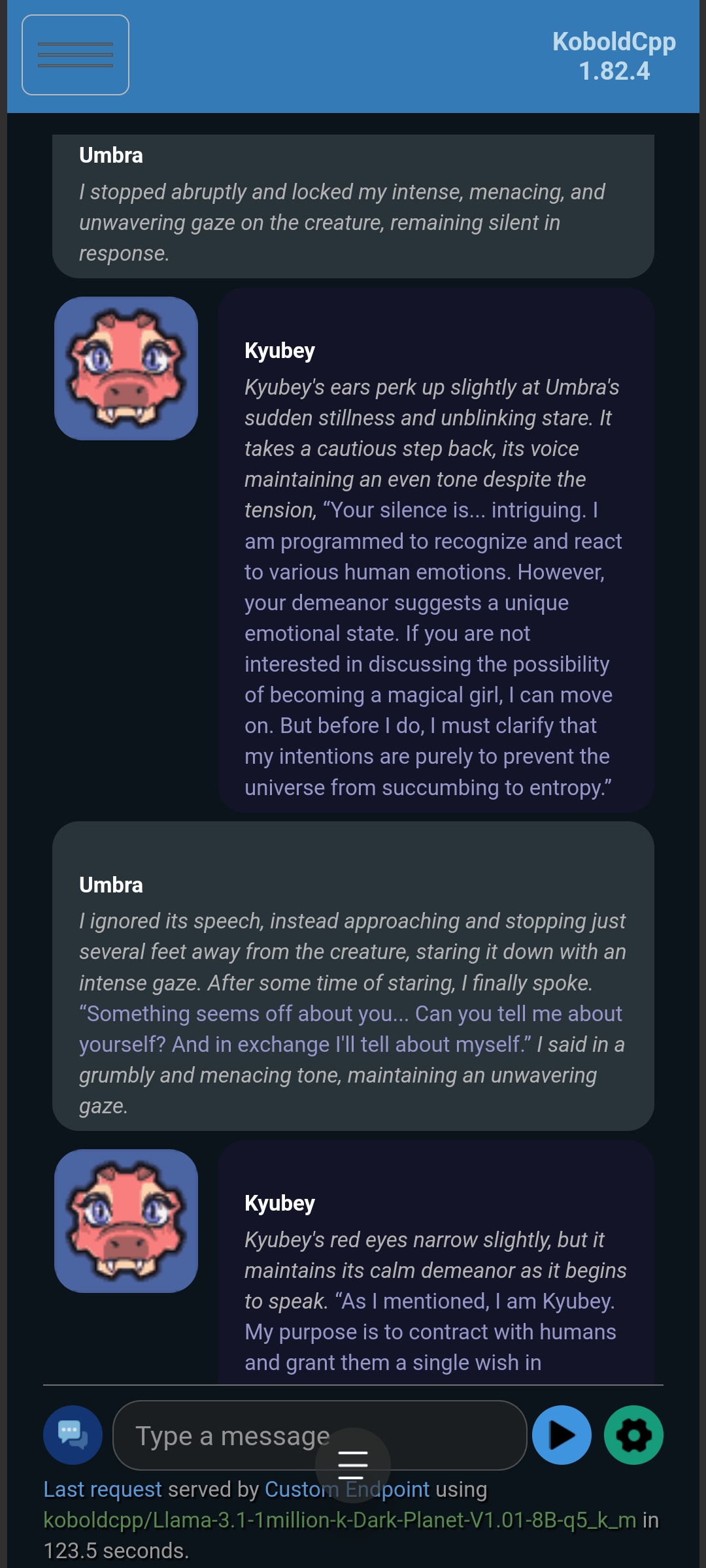
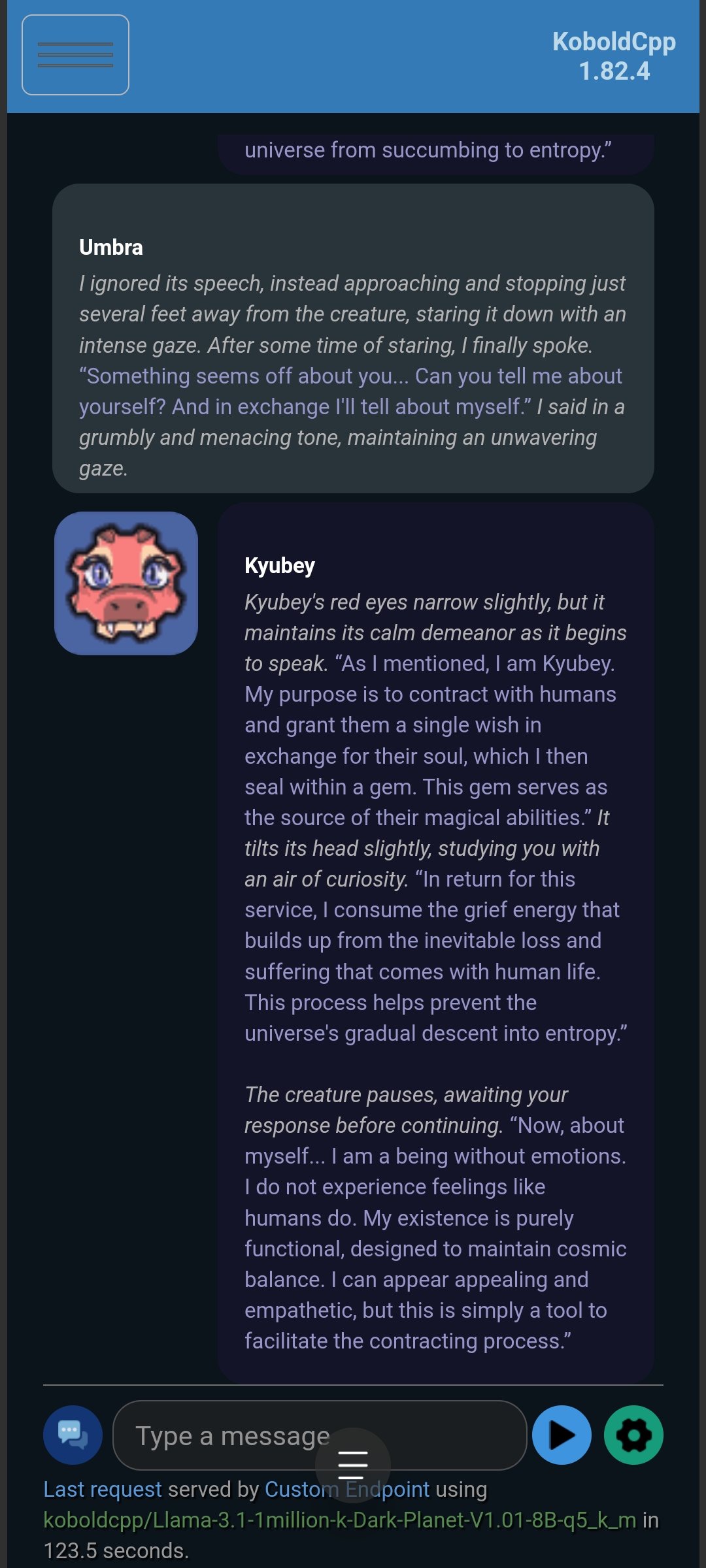
This model performed a bit worse compared to million-DeepHermes; But overall average-ish. Seems like these specific 2 values needs to be fine-tuned (Rp.Slope might be too)