|
|
--- |
|
|
base_model: Qwen/Qwen2.5-3B-Instruct |
|
|
library_name: peft |
|
|
license: mit |
|
|
datasets: |
|
|
- RussianNLP/Mixed-Summarization-Dataset |
|
|
language: |
|
|
- ru |
|
|
pipeline_tag: summarization |
|
|
--- |
|
|
|
|
|
# InternVL2_5-4B-QLoRA-LLM-RussianSummarization |
|
|
|
|
|
[\[📂 GitHub\]](https://github.com/H1merka/InternVL2_5-4B-QLoRA-LLM-RussianSummarization) [\[🤗 HF\]](https://huggingface.co/H1merka/InternVL2_5-4B-QLoRA-LLM-RussianSummarization) |
|
|
|
|
|
## Introduction |
|
|
|
|
|
This is the QLoRA adapter for LLM part of [InternVL2_5-4B](https://huggingface.co/OpenGVLab/InternVL2_5-4B) multimodal model |
|
|
|
|
|
## Model architecture |
|
|
|
|
|
For more information you can visit these pages: |
|
|
|
|
|
Full model: [InternVL2_5-4B](https://huggingface.co/OpenGVLab/InternVL2_5-4B) |
|
|
|
|
|
LLM part: [Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) |
|
|
|
|
|
ViT: [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) |
|
|
|
|
|
## Fine-tuning strategy |
|
|
|
|
|
Fine-tuning was made using QLoRA method on Kaggle GPU P100 with 10000 elements from [Mixed-Summarization-Dataset](https://huggingface.co/datasets/RussianNLP/Mixed-Summarization-Dataset) dataset |
|
|
|
|
|
## Results |
|
|
|
|
|
Training loss, validation loss, SummaC were chosen as evaluation metrics. |
|
|
|
|
|
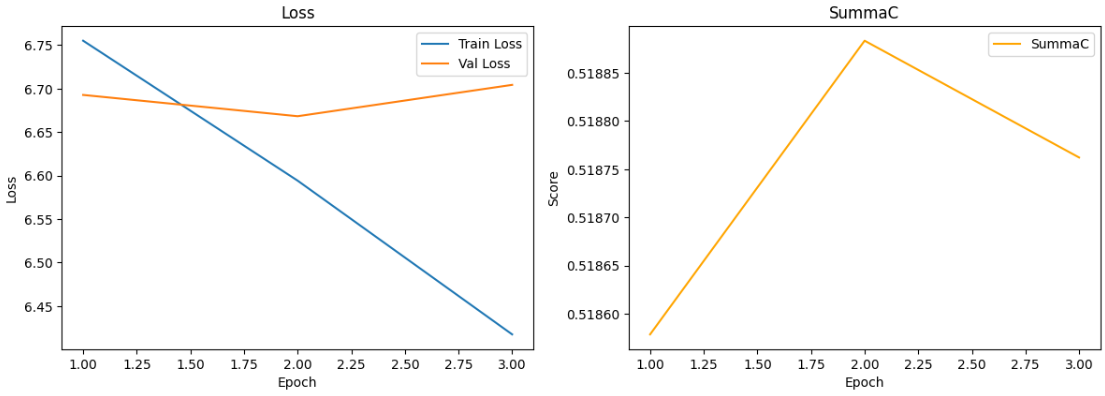 |
|
|
|
|
|
## License |
|
|
|
|
|
This project is released under the MIT License. This project uses the pre-trained Qwen2.5-3B-Instruct, which is licensed under the Apache License 2.0. |
|
|
|
|
|
## Citation |
|
|
|
|
|
If you find this project useful in your research, please consider citing: |
|
|
|
|
|
```BibTeX |
|
|
@article{chen2024expanding, |
|
|
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling}, |
|
|
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others}, |
|
|
journal={arXiv preprint arXiv:2412.05271}, |
|
|
year={2024} |
|
|
} |
|
|
@article{gao2024mini, |
|
|
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance}, |
|
|
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others}, |
|
|
journal={arXiv preprint arXiv:2410.16261}, |
|
|
year={2024} |
|
|
} |
|
|
@article{chen2024far, |
|
|
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites}, |
|
|
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others}, |
|
|
journal={arXiv preprint arXiv:2404.16821}, |
|
|
year={2024} |
|
|
} |
|
|
@inproceedings{chen2024internvl, |
|
|
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks}, |
|
|
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others}, |
|
|
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, |
|
|
pages={24185--24198}, |
|
|
year={2024} |
|
|
} |
|
|
``` |
