
🧠 SmolLM3
Collection
Smol, multilingual, long-context reasoner
•
14 items
•
Updated
•
96
We are releasing intermediate checkpoints of SmolLM3 to enable further research.
For more details, check the SmolLM GitHub repo with the end-to-end training and evaluation code:
We release checkpoints every 40,000 steps, which equals 94.4B tokens. The GBS (Global Batch Size) in tokens for SmolLM3-3B is 2,359,296. To calculate the number of tokens from a given step:
nb_tokens = nb_step * GBS
Stage 1: Steps 0 to 3,450,000 (86 checkpoints) config
Stage 2: Steps 3,450,000 to 4,200,000 (19 checkpoints) config
Stage 3: Steps 4,200,000 to 4,720,000 (13 checkpoints) config

For the additional 2 stages that extend the context length to 64k, we sample checkpoints every 4,000 steps (9.4B tokens) for a total of 10 checkpoints:
Long Context 4k to 32k config
Long Context 32k to 64k config

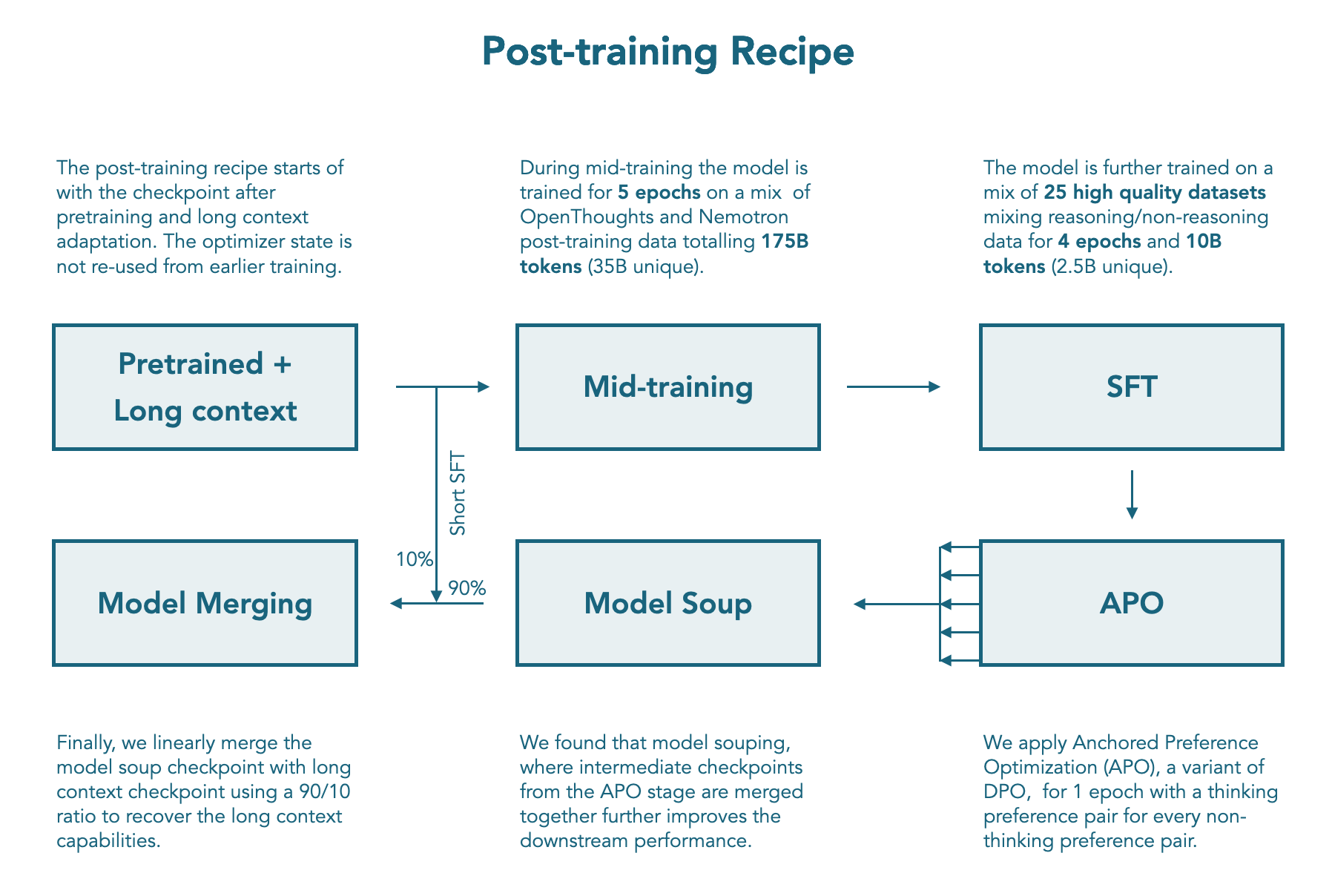
We release checkpoints at every step of our post-training recipe: Mid training, SFT, APO soup, and LC expert.
# pip install transformers
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM3-3B-checkpoints"
revision = "stage1-step-40000" # replace by the revision you want
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if hasattr(torch, 'mps') and torch.mps.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(checkpoint, revision=revision)
model = AutoModelForCausalLM.from_pretrained(checkpoint, revision=revision).to(device)
inputs = tokenizer.encode("Gravity is", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
@misc{bakouch2025smollm3,
title={{SmolLM3: smol, multilingual, long-context reasoner}},
author={Bakouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward and Roucher, Aymeric and Reedi, Aksel Joonas and Gallouédec, Quentin and Rasul, Kashif and Habib, Nathan and Fourrier, Clémentine and Kydlicek, Hynek and Penedo, Guilherme and Larcher, Hugo and Morlon, Mathieu and Srivastav, Vaibhav and Lochner, Joshua and Nguyen, Xuan-Son and Raffel, Colin and von Werra, Leandro and Wolf, Thomas},
year={2025},
howpublished={\url{https://huggingface.co/blog/smollm3}}
}
Base model
HuggingFaceTB/SmolLM3-3B-Base