
Обучение своей модели

Здравствуйте! Можно ли обучить 25 часов записей речи своей модели на основе вашей модели? Какая длительность записей при нарезке датасета в pydub будет оптимальна? Какая видеокарта потребуется для наибольшей стабильности модели? Можете ли вы обучить русскому dio tts?
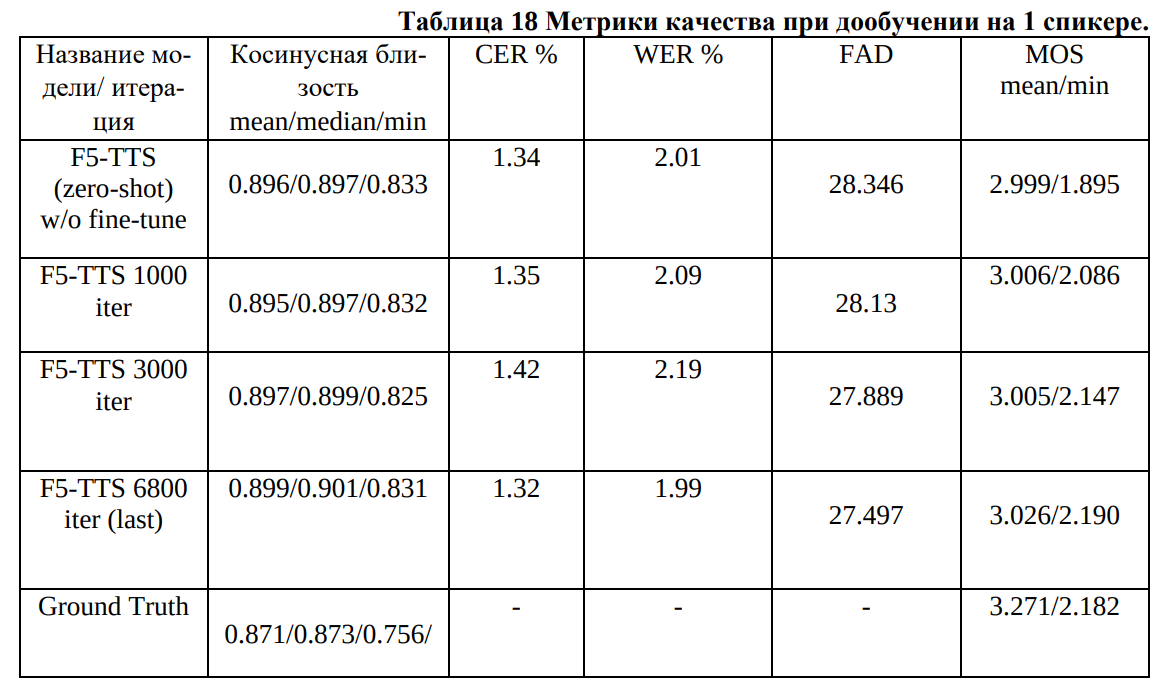
Привет Mikhail2024ru, я пробовал дополнительно дообучить на основе данного чекпоинта на одного спикера. Результаты стали лучше при клонировании голоса, можешь посмотреть метрики в таблице. Дообучал на датасете RUSLAN, используя 29.54 часов аудио. Так что 25 часов должно хватить.
Из советов по нарезке могу подсказать, чтобы распределение продолжительности аудио была близка к равномерному (от 6-30 секунд), чтобы не было такого, чтобы большинство аудио менее 2-3 секунд, иначе могут возникнуть проблемы с генерацией длинных предложений.
При интерфейсе модели лучше использовать промт от 5-6 до 12 секунд. Аудио промт обрезается до первых 12 секунд, если подать на вход длинный промт.
Я тестировал только на 4090, поэтому точнее не подскажу. А так для интерфейса должны подходить RTX от 3 серии.
Можешь поделиться ссылкой на dio tts, посмотрю.
Misha24-10, привет) Можно ли хоть какой-то видео гайд сделать по дообучению с чекпоинта: какие параметры задавать, сколько эпох, и т.д.? Нужно ли следить за перетренированностью модели? Подойдут ли .mp3 файлы после нарезки в pydub, или только .wav? Есть ли смысл обучать один голос на двух арендованных rtx 3090, или для f5 достаточно и одной видеокарты?
- Для дообучения на определенном голосе можешь воспользоваться этим гайдом - github.com/SWivid/F5-TTS.
Есть удобный градио интерфейс для обучения - finetune_gradio.py, только в коде придется изменить путь до pretrain модели на данный чекпоинт, чтобы не обучать с нуля.
Параметры которые я использовал для дообучения на ruslan (используя V100 32GB). Тут я не подбирал параметры, тут можешь поэкспериментировать.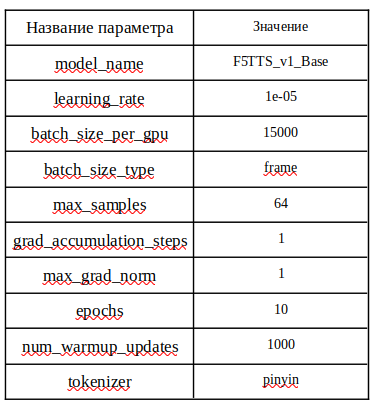 .
.
По функции потерь сложно сказать как сильно переобучается модель, поэтому лучше сравнивать чекпоинты (можно на слух).
Можно использовать .mp3 файлы, finetune_gradio поддерживает файлы следующих форматов: (".wav", ".ogg", ".opus", ".mp3", "*.flac").
Также для дообучения желательно использовать аудио с частотой дискретизации (sample rate) 24000 ГЦ. В противном случае произойдёт неявное преобразование в этот формат.Можно начать дообучать на 1 карте. При необходимости можешь увеличить grad_accumulation_steps.
По dio tts - в ближайшее время не смогу.
"Для дообучения на определенном голосе можешь воспользоваться этим гайдом - github.com/SWivid/F5-TTS."
Честно говоря, по нему не совсем ясно, как тренировать свою модель с контрольной точки вашего файнтюна. Можете записать небольшой видео гайд, как правильно нарезать датасет на чанки и если обучать на colab\kaggle, что именно нужно поменять в коде? Или если обучать на локальной версии, тоже, сам процесс обучения - этапы? Вы один из первых, кто разобрался с файнтюном, для менее "одарённых" людей можете показать этот процесс подробнее?
Привет, Михаил, сделаю гайд - мини статью как дообучить свою кастомную модель