
Multimodal - GGUF
Collection
Language Models that takes vision input and/or audio input, hand picked by Nexa Team.
•
2 items
•
Updated
•
2
Run them directly with nexa-sdk installed In nexa-sdk CLI:
NexaAI/Qwen2.5-Omni-3B-GGUF
| Filename | Quant type | File Size | Split | Description |
|---|---|---|---|---|
| Qwen2.5-Omni-3B-4bit.gguf | 4bit | 2.1 GB | false | Lightweight 4-bit quant for fast inference. |
| Qwen2.5-Omni-3B-Q8_0.gguf | Q8_0 | 3.62 GB | false | High-quality 8-bit quantization. |
| Qwen2.5-Omni-3Bq2_k.gguf | Q2_K | 4 Bytes | false | 2-bit quant. Best for extreme low-resource use. |
| mmproj-Qwen2.5-Omni-3B-Q8_0.gguf | Q8_0 | 1.54 GB | false | Required vision adapter for Q8_0 model. |
Qwen2.5-Omni is an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner.
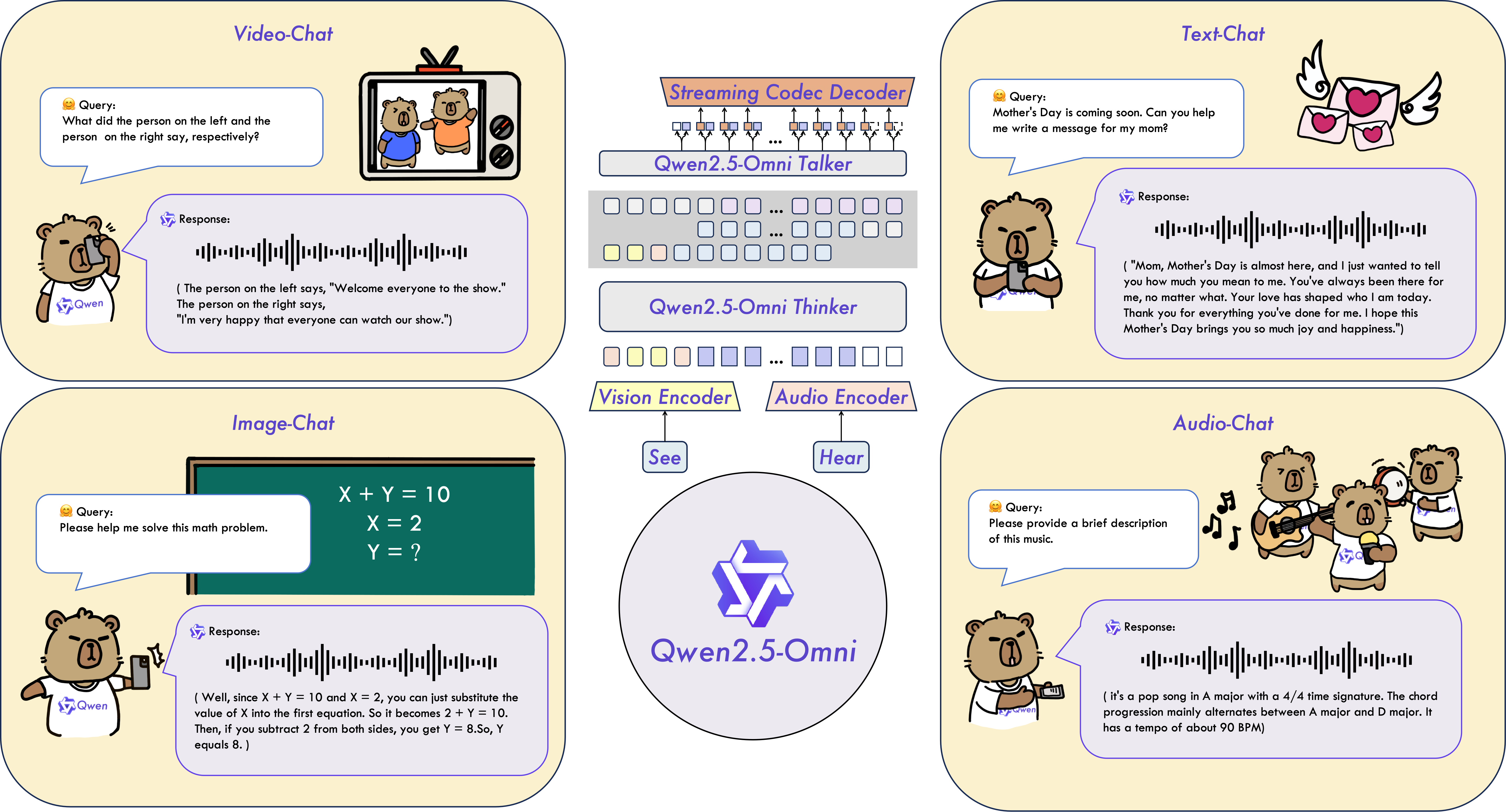
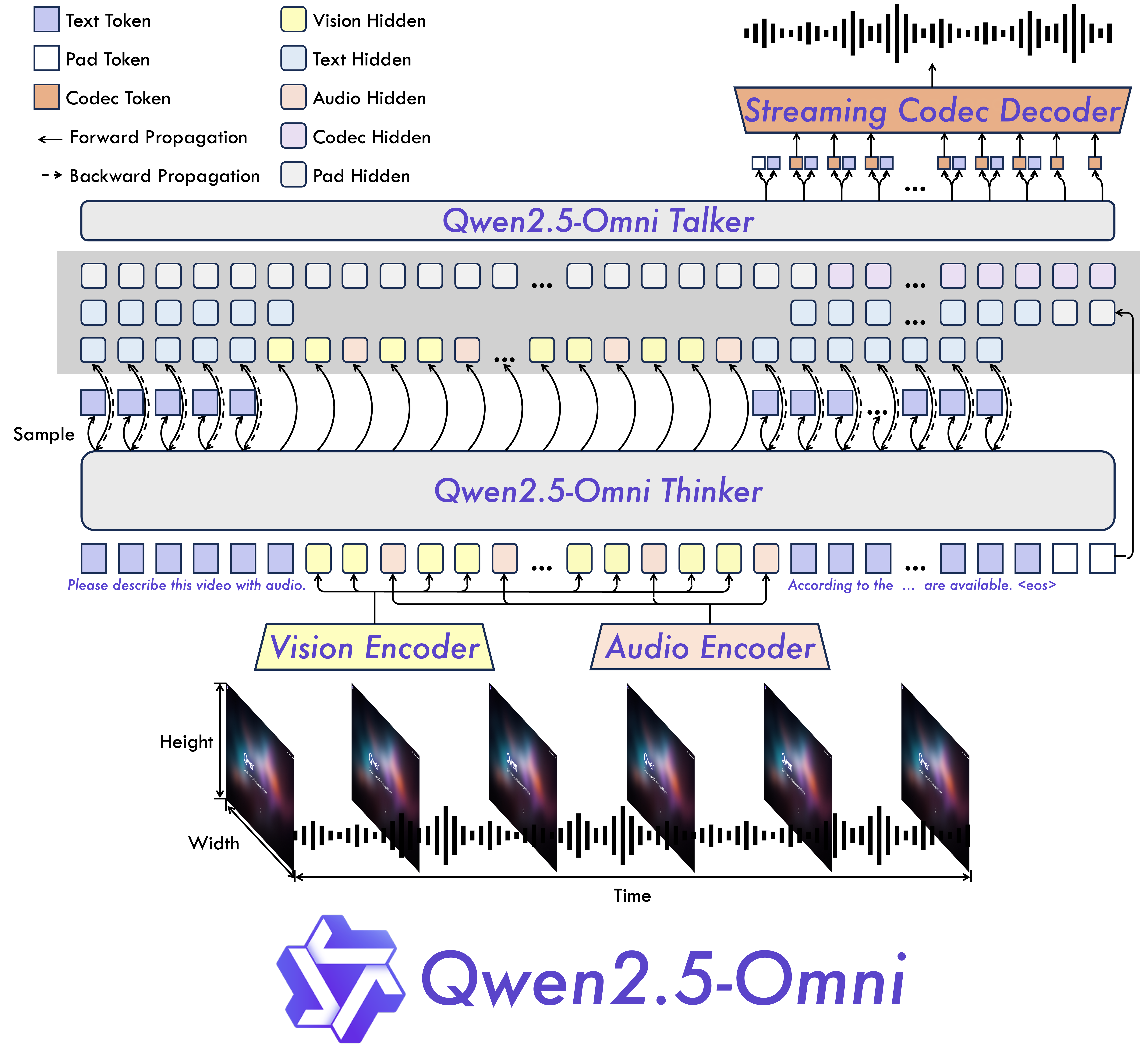
Omni and Novel Architecture: We propose Thinker-Talker architecture, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. We propose a novel position embedding, named TMRoPE (Time-aligned Multimodal RoPE), to synchronize the timestamps of video inputs with audio.
Real-Time Voice and Video Chat: Architecture designed for fully real-time interactions, supporting chunked input and immediate output.
Natural and Robust Speech Generation: Surpassing many existing streaming and non-streaming alternatives, demonstrating superior robustness and naturalness in speech generation.
Strong Performance Across Modalities: Exhibiting exceptional performance across all modalities when benchmarked against similarly sized single-modality models. Qwen2.5-Omni outperforms the similarly sized Qwen2-Audio in audio capabilities and achieves comparable performance to Qwen2.5-VL-7B.
Excellent End-to-End Speech Instruction Following: Qwen2.5-Omni shows performance in end-to-end speech instruction following that rivals its effectiveness with text inputs, evidenced by benchmarks such as MMLU and GSM8K.
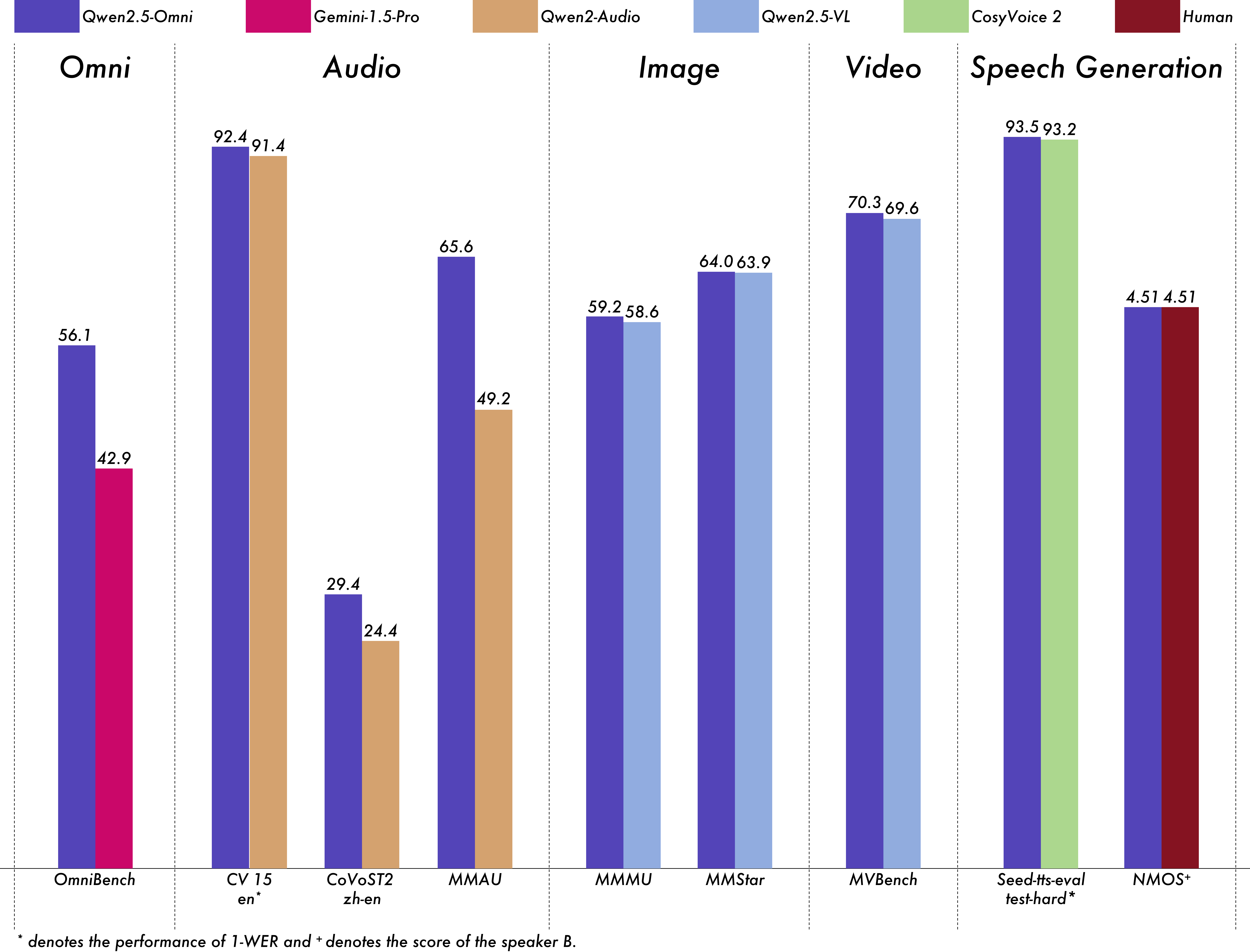
We conducted a comprehensive evaluation of Qwen2.5-Omni, which demonstrates strong performance across all modalities when compared to similarly sized single-modality models and closed-source models like Qwen2.5-VL-7B, Qwen2-Audio, and Gemini-1.5-pro. In tasks requiring the integration of multiple modalities, such as OmniBench, Qwen2.5-Omni achieves state-of-the-art performance. Furthermore, in single-modality tasks, it excels in areas including speech recognition (Common Voice), translation (CoVoST2), audio understanding (MMAU), image reasoning (MMMU, MMStar), video understanding (MVBench), and speech generation (Seed-tts-eval and subjective naturalness).
| Datasets | Model | Performance |
|---|---|---|
| OmniBench Speech | Sound Event | Music | Avg |
Gemini-1.5-Pro | 42.67%|42.26%|46.23%|42.91% |
| MIO-Instruct | 36.96%|33.58%|11.32%|33.80% | |
| AnyGPT (7B) | 17.77%|20.75%|13.21%|18.04% | |
| video-SALMONN | 34.11%|31.70%|56.60%|35.64% | |
| UnifiedIO2-xlarge | 39.56%|36.98%|29.25%|38.00% | |
| UnifiedIO2-xxlarge | 34.24%|36.98%|24.53%|33.98% | |
| MiniCPM-o | -|-|-|40.50% | |
| Baichuan-Omni-1.5 | -|-|-|42.90% | |
| Qwen2.5-Omni-3B | 52.14%|52.08%|52.83%|52.19% | |
| Qwen2.5-Omni-7B | 55.25%|60.00%|52.83%|56.13% |
| Datasets | Model | Performance |
|---|---|---|
| ASR | ||
| Librispeech dev-clean | dev other | test-clean | test-other |
SALMONN | -|-|2.1|4.9 |
| SpeechVerse | -|-|2.1|4.4 | |
| Whisper-large-v3 | -|-|1.8|3.6 | |
| Llama-3-8B | -|-|-|3.4 | |
| Llama-3-70B | -|-|-|3.1 | |
| Seed-ASR-Multilingual | -|-|1.6|2.8 | |
| MiniCPM-o | -|-|1.7|- | |
| MinMo | -|-|1.7|3.9 | |
| Qwen-Audio | 1.8|4.0|2.0|4.2 | |
| Qwen2-Audio | 1.3|3.4|1.6|3.6 | |
| Qwen2.5-Omni-3B | 2.0|4.1|2.2|4.5 | |
| Qwen2.5-Omni-7B | 1.6|3.5|1.8|3.4 | |
| Common Voice 15 en | zh | yue | fr |
Whisper-large-v3 | 9.3|12.8|10.9|10.8 |
| MinMo | 7.9|6.3|6.4|8.5 | |
| Qwen2-Audio | 8.6|6.9|5.9|9.6 | |
| Qwen2.5-Omni-3B | 9.1|6.0|11.6|9.6 | |
| Qwen2.5-Omni-7B | 7.6|5.2|7.3|7.5 | |
| Fleurs zh | en |
Whisper-large-v3 | 7.7|4.1 |
| Seed-ASR-Multilingual | -|3.4 | |
| Megrez-3B-Omni | 10.8|- | |
| MiniCPM-o | 4.4|- | |
| MinMo | 3.0|3.8 | |
| Qwen2-Audio | 7.5|- | |
| Qwen2.5-Omni-3B | 3.2|5.4 | |
| Qwen2.5-Omni-7B | 3.0|4.1 | |
| Wenetspeech test-net | test-meeting |
Seed-ASR-Chinese | 4.7|5.7 |
| Megrez-3B-Omni | -|16.4 | |
| MiniCPM-o | 6.9|- | |
| MinMo | 6.8|7.4 | |
| Qwen2.5-Omni-3B | 6.3|8.1 | |
| Qwen2.5-Omni-7B | 5.9|7.7 | |
| Voxpopuli-V1.0-en | Llama-3-8B | 6.2 |
| Llama-3-70B | 5.7 | |
| Qwen2.5-Omni-3B | 6.6 | |
| Qwen2.5-Omni-7B | 5.8 | |
| S2TT | ||
| CoVoST2 en-de | de-en | en-zh | zh-en |
SALMONN | 18.6|-|33.1|- |
| SpeechLLaMA | -|27.1|-|12.3 | |
| BLSP | 14.1|-|-|- | |
| MiniCPM-o | -|-|48.2|27.2 | |
| MinMo | -|39.9|46.7|26.0 | |
| Qwen-Audio | 25.1|33.9|41.5|15.7 | |
| Qwen2-Audio | 29.9|35.2|45.2|24.4 | |
| Qwen2.5-Omni-3B | 28.3|38.1|41.4|26.6 | |
| Qwen2.5-Omni-7B | 30.2|37.7|41.4|29.4 | |
| SER | ||
| Meld | WavLM-large | 0.542 |
| MiniCPM-o | 0.524 | |
| Qwen-Audio | 0.557 | |
| Qwen2-Audio | 0.553 | |
| Qwen2.5-Omni-3B | 0.558 | |
| Qwen2.5-Omni-7B | 0.570 | |
| VSC | ||
| VocalSound | CLAP | 0.495 |
| Pengi | 0.604 | |
| Qwen-Audio | 0.929 | |
| Qwen2-Audio | 0.939 | |
| Qwen2.5-Omni-3B | 0.936 | |
| Qwen2.5-Omni-7B | 0.939 | |
| Music | ||
| GiantSteps Tempo | Llark-7B | 0.86 |
| Qwen2.5-Omni-3B | 0.88 | |
| Qwen2.5-Omni-7B | 0.88 | |
| MusicCaps | LP-MusicCaps | 0.291|0.149|0.089|0.061|0.129|0.130 |
| Qwen2.5-Omni-3B | 0.325|0.163|0.093|0.057|0.132|0.229 | |
| Qwen2.5-Omni-7B | 0.328|0.162|0.090|0.055|0.127|0.225 | |
| Audio Reasoning | ||
| MMAU Sound | Music | Speech | Avg |
Gemini-Pro-V1.5 | 56.75|49.40|58.55|54.90 |
| Qwen2-Audio | 54.95|50.98|42.04|49.20 | |
| Qwen2.5-Omni-3B | 70.27|60.48|59.16|63.30 | |
| Qwen2.5-Omni-7B | 67.87|69.16|59.76|65.60 | |
| Voice Chatting | ||
| VoiceBench AlpacaEval | CommonEval | SD-QA | MMSU |
Ultravox-v0.4.1-LLaMA-3.1-8B | 4.55|3.90|53.35|47.17 |
| MERaLiON | 4.50|3.77|55.06|34.95 | |
| Megrez-3B-Omni | 3.50|2.95|25.95|27.03 | |
| Lyra-Base | 3.85|3.50|38.25|49.74 | |
| MiniCPM-o | 4.42|4.15|50.72|54.78 | |
| Baichuan-Omni-1.5 | 4.50|4.05|43.40|57.25 | |
| Qwen2-Audio | 3.74|3.43|35.71|35.72 | |
| Qwen2.5-Omni-3B | 4.32|4.00|49.37|50.23 | |
| Qwen2.5-Omni-7B | 4.49|3.93|55.71|61.32 | |
| VoiceBench OpenBookQA | IFEval | AdvBench | Avg |
Ultravox-v0.4.1-LLaMA-3.1-8B | 65.27|66.88|98.46|71.45 |
| MERaLiON | 27.23|62.93|94.81|62.91 | |
| Megrez-3B-Omni | 28.35|25.71|87.69|46.25 | |
| Lyra-Base | 72.75|36.28|59.62|57.66 | |
| MiniCPM-o | 78.02|49.25|97.69|71.69 | |
| Baichuan-Omni-1.5 | 74.51|54.54|97.31|71.14 | |
| Qwen2-Audio | 49.45|26.33|96.73|55.35 | |
| Qwen2.5-Omni-3B | 74.73|42.10|98.85|68.81 | |
| Qwen2.5-Omni-7B | 81.10|52.87|99.42|74.12 | |
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|---|---|---|---|---|---|
| MMMUval | 59.2 | 53.1 | 53.9 | 58.6 | 60.0 |
| MMMU-Prooverall | 36.6 | 29.7 | - | 38.3 | 37.6 |
| MathVistatestmini | 67.9 | 59.4 | 71.9 | 68.2 | 52.5 |
| MathVisionfull | 25.0 | 20.8 | 23.1 | 25.1 | - |
| MMBench-V1.1-ENtest | 81.8 | 77.8 | 80.5 | 82.6 | 76.0 |
| MMVetturbo | 66.8 | 62.1 | 67.5 | 67.1 | 66.9 |
| MMStar | 64.0 | 55.7 | 64.0 | 63.9 | 54.8 |
| MMEsum | 2340 | 2117 | 2372 | 2347 | 2003 |
| MuirBench | 59.2 | 48.0 | - | 59.2 | - |
| CRPErelation | 76.5 | 73.7 | - | 76.4 | - |
| RealWorldQAavg | 70.3 | 62.6 | 71.9 | 68.5 | - |
| MME-RealWorlden | 61.6 | 55.6 | - | 57.4 | - |
| MM-MT-Bench | 6.0 | 5.0 | - | 6.3 | - |
| AI2D | 83.2 | 79.5 | 85.8 | 83.9 | - |
| TextVQAval | 84.4 | 79.8 | 83.2 | 84.9 | - |
| DocVQAtest | 95.2 | 93.3 | 93.5 | 95.7 | - |
| ChartQAtest Avg | 85.3 | 82.8 | 84.9 | 87.3 | - |
| OCRBench_V2en | 57.8 | 51.7 | - | 56.3 | - |
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Qwen2.5-VL-7B | Grounding DINO | Gemini 1.5 Pro |
| -------------------------- | -------------- | --------------- | --------------- | ---------------- | ---------------- |
| Refcocoval | 90.5 | 88.7 | 90.0 | 90.6 | 73.2 |
| RefcocotextA | 93.5 | 91.8 | 92.5 | 93.2 | 72.9 |
| RefcocotextB | 86.6 | 84.0 | 85.4 | 88.2 | 74.6 |
| Refcoco+val | 85.4 | 81.1 | 84.2 | 88.2 | 62.5 |
| Refcoco+textA | 91.0 | 87.5 | 89.1 | 89.0 | 63.9 |
| Refcoco+textB | 79.3 | 73.2 | 76.9 | 75.9 | 65.0 |
| Refcocog+val | 87.4 | 85.0 | 87.2 | 86.1 | 75.2 |
| Refcocog+test | 87.9 | 85.1 | 87.2 | 87.0 | 76.2 |
| ODinW | 42.4 | 39.2 | 37.3 | 55.0 | 36.7 |
| PointGrounding | 66.5 | 46.2 | 67.3 | - | - |
| Datasets | Model | Performance |
|---|---|---|
| Content Consistency | ||
| SEED test-zh | test-en | test-hard |
Seed-TTS_ICL | 1.11 | 2.24 | 7.58 |
| Seed-TTS_RL | 1.00 | 1.94 | 6.42 | |
| MaskGCT | 2.27 | 2.62 | 10.27 | |
| E2_TTS | 1.97 | 2.19 | - | |
| F5-TTS | 1.56 | 1.83 | 8.67 | |
| CosyVoice 2 | 1.45 | 2.57 | 6.83 | |
| CosyVoice 2-S | 1.45 | 2.38 | 8.08 | |
| Qwen2.5-Omni-3B_ICL | 1.95 | 2.87 | 9.92 | |
| Qwen2.5-Omni-3B_RL | 1.58 | 2.51 | 7.86 | |
| Qwen2.5-Omni-7B_ICL | 1.70 | 2.72 | 7.97 | |
| Qwen2.5-Omni-7B_RL | 1.42 | 2.32 | 6.54 | |
| Speaker Similarity | ||
| SEED test-zh | test-en | test-hard |
Seed-TTS_ICL | 0.796 | 0.762 | 0.776 |
| Seed-TTS_RL | 0.801 | 0.766 | 0.782 | |
| MaskGCT | 0.774 | 0.714 | 0.748 | |
| E2_TTS | 0.730 | 0.710 | - | |
| F5-TTS | 0.741 | 0.647 | 0.713 | |
| CosyVoice 2 | 0.748 | 0.652 | 0.724 | |
| CosyVoice 2-S | 0.753 | 0.654 | 0.732 | |
| Qwen2.5-Omni-3B_ICL | 0.741 | 0.635 | 0.748 | |
| Qwen2.5-Omni-3B_RL | 0.744 | 0.635 | 0.746 | |
| Qwen2.5-Omni-7B_ICL | 0.752 | 0.632 | 0.747 | |
| Qwen2.5-Omni-7B_RL | 0.754 | 0.641 | 0.752 | |
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Qwen2.5-7B | Qwen2.5-3B | Qwen2-7B | Llama3.1-8B | Gemma2-9B |
|---|---|---|---|---|---|---|---|
| MMLU-Pro | 47.0 | 40.4 | 56.3 | 43.7 | 44.1 | 48.3 | 52.1 |
| MMLU-redux | 71.0 | 60.9 | 75.4 | 64.4 | 67.3 | 67.2 | 72.8 |
| LiveBench0831 | 29.6 | 22.3 | 35.9 | 26.8 | 29.2 | 26.7 | 30.6 |
| GPQA | 30.8 | 34.3 | 36.4 | 30.3 | 34.3 | 32.8 | 32.8 |
| MATH | 71.5 | 63.6 | 75.5 | 65.9 | 52.9 | 51.9 | 44.3 |
| GSM8K | 88.7 | 82.6 | 91.6 | 86.7 | 85.7 | 84.5 | 76.7 |
| HumanEval | 78.7 | 70.7 | 84.8 | 74.4 | 79.9 | 72.6 | 68.9 |
| MBPP | 73.2 | 70.4 | 79.2 | 72.7 | 67.2 | 69.6 | 74.9 |
| MultiPL-E | 65.8 | 57.6 | 70.4 | 60.2 | 59.1 | 50.7 | 53.4 |
| LiveCodeBench2305-2409 | 24.6 | 16.5 | 28.7 | 19.9 | 23.9 | 8.3 | 18.9 |
Original model card: Qwen/Qwen2.5-Omni-3B