
🚀 Introducing : HQQ-270M
Overview :-
HQQ-270M model is developed by Nukeverse AI by finetuning Gemma-3 It specializes in transforming complex, multi-layered user queries into optimized, high-quality Google search queries .
⚠️ Usage Requirement :
All input queries must begin with the prefix HQQ: ( short for High Quality Query ) .
This ensures the model knows the input is intended for query optimization .
🔍 What does it do?
- Converts Deep research prompts into precise search queries.
- Handles Broad or ambiguous questions by breaking them into focused, search-ready chunks.
- Enhances information retrieval by optimizing queries for search engines.
This model is ideal for :
- Researchers
- Students
- Analysts
- Anyone needing faster + higher-quality search results .
✨ Key Features :
- Fine-tuned from Gemma-3 → retains strong language reasoning .
- Fast & Efficient → Gemma's architecture is designed to make the model fast & efficient .
- Optimized for real-world queries → search queries are short, relevant, and actionable.
- Prefix-activated (
HQQ:) → ensures model is used for its intended purpose.
📦 How to Use
🔧 Installation
pip install transformers accelerate huggingface_hub
🖥️ Inference
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NukeverseAi/HQQ-270M")
model = AutoModelForCausalLM.from_pretrained("NukeverseAi/HQQ-270M")
system_prompt = """
Convert text after "HQQ: " into an optimized Google search query. Extract key terms, remove filler words, focus on searchable keywords.
"""
query = "HQQ: What are the economic, political, and environmental implications of large-scale adoption of nuclear fusion by 2050?"
messages = [
{"role": "system", "content": system_prompt },
{"role": "user", "content": query }
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
🚀 Example Output :-
Input:
HQQ: What are the economic, political, and environmental implications of large-scale adoption of nuclear fusion by 2050?
Output :
"economic political environmental implications" "large-scale adoption nuclear fusion" 2050
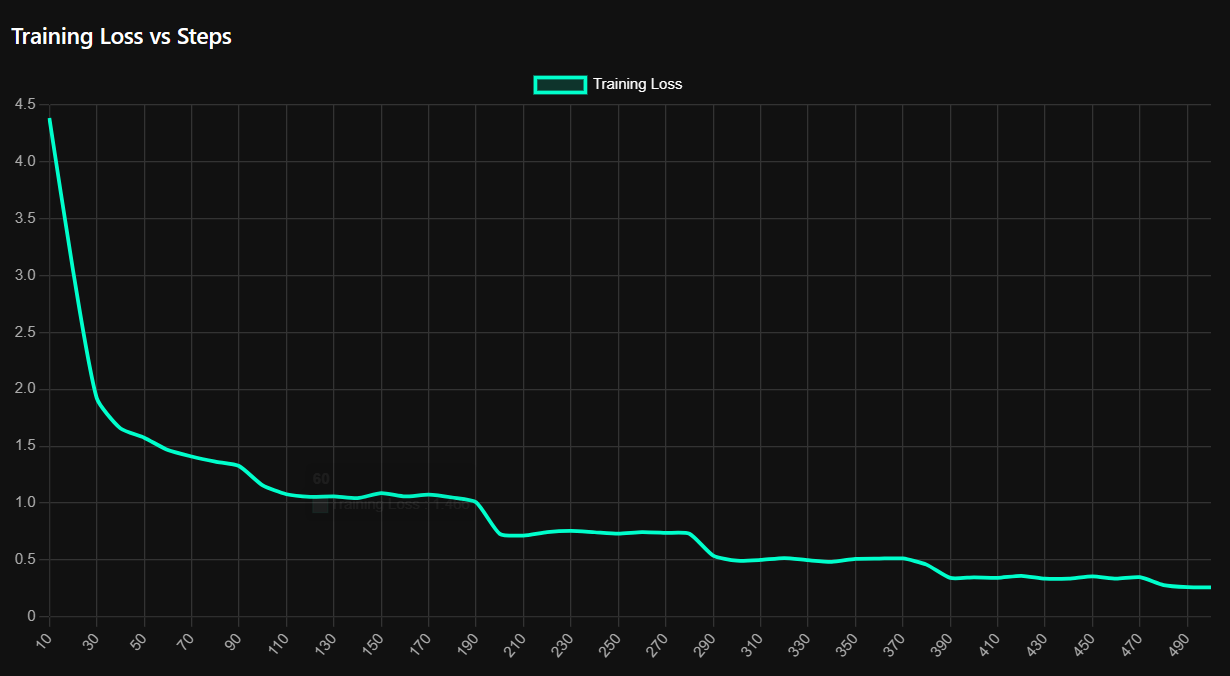
Training Loss vs Steps :-
Note : 500 Steps / ~6 Epochs
📊 Intended Use :-
This model is intended for :
- Query optimization for Google search and other search engines
- Information retrieval pipelines .
- Assisting deep research tasks .
⚠️ Important : Input must always begin with HQQ: . Without this prefix , results may be unpredictable .
📜 License
This model is released under the Nukeverse AI License v1.0.
You may freely use, modify, and distribute this model, including for commercial purposes .
However, any use must clearly state :
"Made by Nukeverse AI"
📄 Full license: LICENSE
🏢 About Nukeverse AI
We are Nukeverse AI, from BHARAT 🕉️ . building next-generation productivity tools, AI agents, and research accelerators .
📌 Citation
If you use this model, please cite :
@misc{2025-NukeverseAi-HQQ-270M,
title = {HQQ-270M},
author = {NukeverseAi},
year = {2025},
url = {https://huggingface.co/NukeverseAi/HQQ-270M}
}
- Downloads last month
- 43