
metadata
tags:
- indobert
- sentiment-analysis
- text-classification
- social-media
- indonesian
- django
- fine-tuned
- academic-evaluation
model-index:
- name: IndoBERT Sentiment Classifier For University Review - University XYZ
results:
- task:
type: text-classification
name: Sentiment Analysis
dataset:
name: Online Lecture Sentiment Dataset
type: custom-dataset
metrics:
- type: accuracy
value: 0.89
name: Accuracy
- type: f1
value: 0.88
name: F1 Score
- type: precision
value: 0.87
name: Precision
- type: recall
value: 0.89
name: Recall
IndoBERT Sentiment Classifier for Social Media Posts – Universitas XYZ
This model is a fine-tuned IndoBERT transformer for performing sentiment analysis on Indonesian social media text (Twitter) related to university services. It classifies input text into positive, neutral, or negative sentiment categories.
🧠 Model Description
The model is built upon indobert-base-p2, a BERT-based transformer pre-trained on over 220 million Indonesian words. The fine-tuning process was done on 7500 samples containing balanced sentiment labels related to online academic services.
- Label classes: Positive, Neutral, Negative
- Preprocessing: Case folding, punctuation removal, stopword removal, stemming, tokenization (using IndoBERT tokenizer)
✅ Intended Use
- Analyzing Indonesian tweets about universities
- Sentiment-driven dashboards for academic service quality
- NLP applications in education sector
⚠️ Limitations
- Domain-specific to university-related sentiment
- May not generalize well to informal or slang-heavy text
- Sarcasm or mixed-sentiment detection is not supported
- Doesn’t handle toxicity or hate speech detection
📊 Dataset
- Source: Custom crawled tweets via keywords and hashtags (e.g.
#telkomuniversity,Universitas XYZ) - Size: 7500 samples
- Split: 70% train, 10% validation, 20% test
- Labels: 2500 positive, 2500 neutral, 2500 negative
- Language: Indonesian
⚙️ Training Procedure
Hyperparameters
- Learning rate: 5e-5
- Batch size: 8
- Epochs: 3
- Optimizer: Adam (β1=0.9, β2=0.999, ε=1e-8)
- Scheduler: Linear
- Seed: 42
Framework Versions
- Transformers: 4.24.0
- PyTorch: 1.13.0
- Tokenizers: 0.13.2
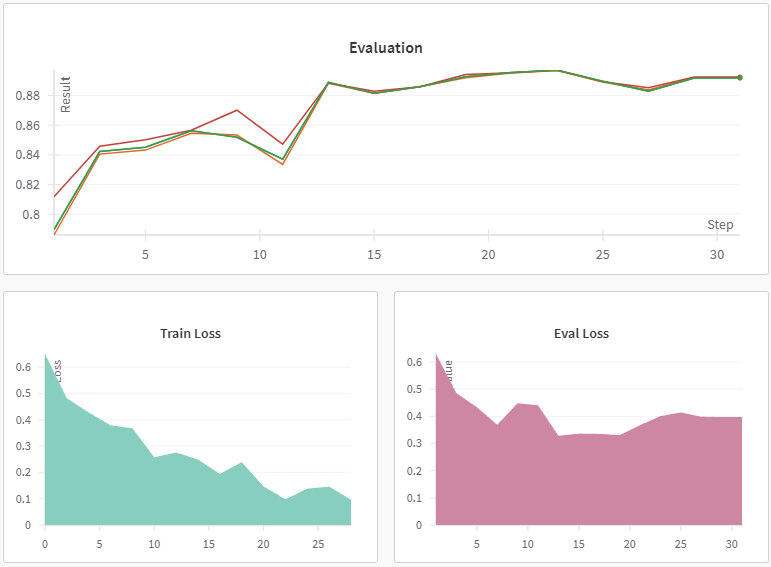
📈 Evaluation Metrics
| Metric | Score |
|---|---|
| Accuracy | 89% |
| F1 Score | 88% |
| Precision | 87% |
| Recall | 89% |
💻 Deployment Context
This model was integrated into a Django-based sentiment dashboard application with:
- A custom Twitter crawler
- Real-time sentiment classification
- Wordclouds and sentiment breakdowns by time period
- Admin tools for filtering, deleting, and exporting data
📄 Citation
If you use this model or its components, please cite:
@article{wijaya2023indobert,
author = {Kurniadi Ahmad Wijaya and Ade Romadhony and Donni Richasdy},
title = {Implementasi Model IndoBERT pada Dashboard Sentimen Media Sosial (Studi Kasus Universitas XYZ)},
journal = {eProceedings of Engineering},
volume = {10},
number = {4},
year = {2023},
month = {September},
url = {https://openlibrary.telkomuniversity.ac.id},
}