
EditReward
Collection
EditReward: A Human-Aligned Reward Model for Instruction-Guided Image Editing
•
10 items
•
Updated
•
3
![]()
This repository contains the official implementation of the paper EditReward: A Human-Aligned Reward Model for Instruction-Guided Image Editing.
We introduce EditReward, a human-aligned reward model powered by a high-quality dataset for instruction-guided image editing. EditReward is trained with EditReward-Data, a large-scale, high-fidelity preference dataset comprising over 200K manually annotated preference pairs. This dataset covers diverse edits produced by seven state-of-the-art models across twelve distinct sources, ensuring high alignment with human judgment.
EditReward demonstrates superior alignment with human preferences in instruction-guided image editing tasks, achieving state-of-the-art human correlation on established benchmarks like GenAI-Bench, AURORA-Bench, ImagenHub, and our new EditReward-Bench.
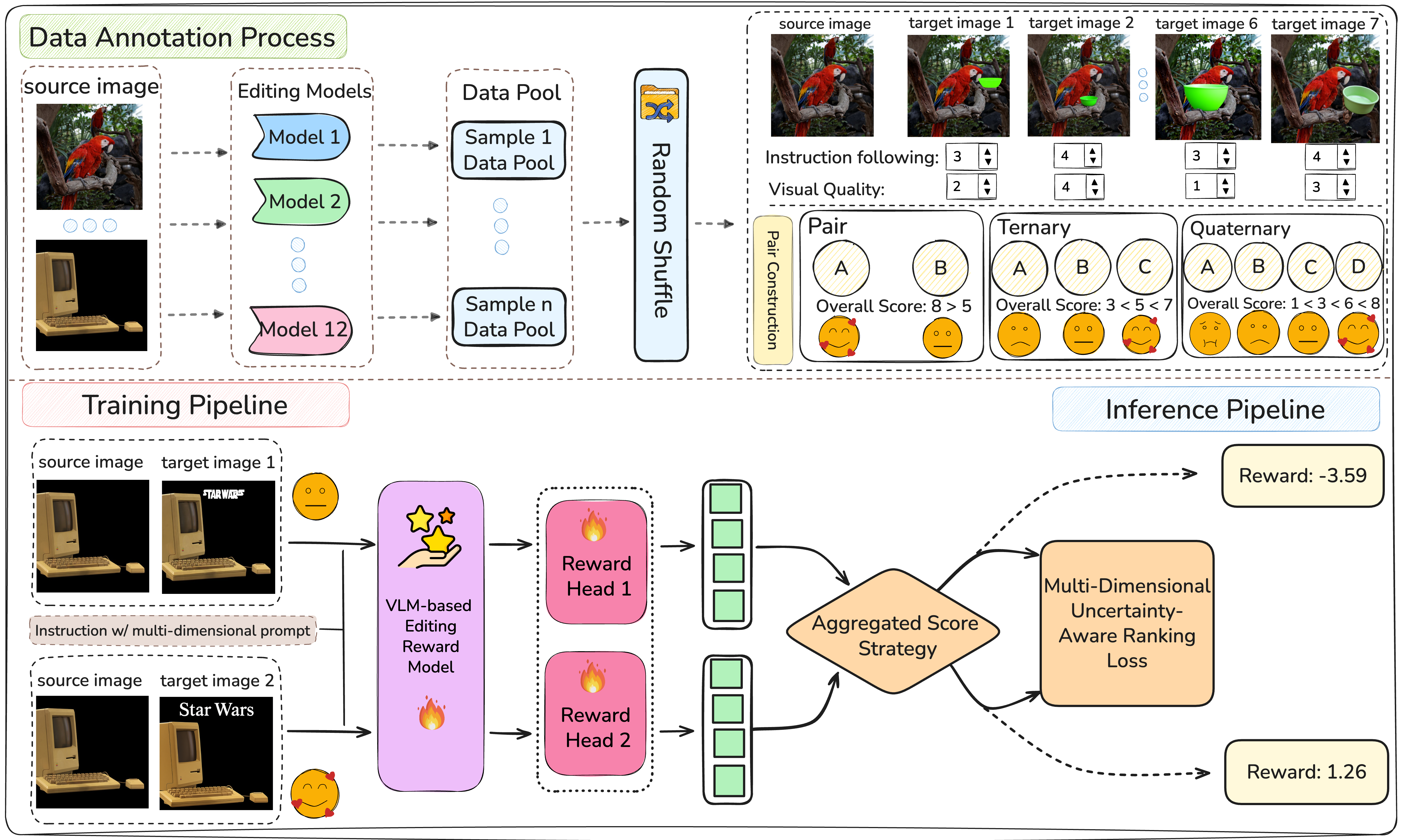
To use the EditReward model for inference, follow these steps. For more details including installation and training, please refer to the GitHub Repository.
git clone https://github.com/TIGER-AI-Lab/EditReward.git
cd EditReward
conda create -n edit_reward python=3.10 -y
conda activate edit_reward
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install datasets pillow openai -U megfile sentencepiece deepspeed fire omegaconf matplotlib peft trl==0.8.6 tensorboard scipy transformers==4.56.1 accelerate
# Recommend: Install flash-attn
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.2.post1/flash_attn-2.7.2.post1+cu12torch2.5cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
import os
import sys
# Add project root to Python path (optional, for local development)
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import torch
from EditReward import EditRewardInferencer
# ------------------------------------------------------------------------------
# Example script for evaluating edited images with EditReward
# ------------------------------------------------------------------------------
# Path to model checkpoint (update to your own local or HF path)
CHECKPOINT_PATH = "your/local/path/to/checkpoint"
CONFIG_PATH = "config/EditReward-MiMo-VL-7B-SFT-2508.yaml"
# Initialize reward model
inferencer = EditRewardInferencer(
config_path=CONFIG_PATH,
checkpoint_path=CHECKPOINT_PATH,
device="cuda", # or "cpu"
reward_dim="overall_detail", # choose reward dimension if applicable
rm_head_type="ranknet_multi_head"
)
# Example input data -----------------------------------------------------------
# image_src = [
# "../assets/examples/source_img_1.png",
# "../assets/examples/source_img_1.png",
# ]
# image_paths = [
# "../assets/examples/target_img_1.png",
# "../assets/examples/target_img_2.png",
# ]
image_src = [
"your/local/path/to/source_image_1.jpg",
"your/local/path/to/source_image_2.jpg",
]
image_paths = [
"your/local/path/to/edited_image_1.jpg",
"your/local/path/to/edited_image_2.jpg",
]
# example instruction: "Add a green bowl on the branch"
# prompts = [
# "Add a green bowl on the branch",
# "Add a green bowl on the branch"
# ]
prompts = [
"your first editing instruction",
"your second editing instruction"
]
# ------------------------------------------------------------------------------
# Main evaluation modes
# ------------------------------------------------------------------------------
if __name__ == "__main__":
mode = "pairwise_inference" # or "single_inference"
if mode == "pairwise_inference":
# ----------------------------------------------------------
# Pairwise comparison: compares two edited images side-by-side
# ----------------------------------------------------------
with torch.no_grad():
rewards = inferencer.reward(
prompts=prompts,
image_src=image_src,
image_paths=image_paths
)
scores = [reward[0].item() for reward in rewards]
print(f"[Pairwise Inference] Image scores: {scores}")
elif mode == "single_inference":
# ----------------------------------------------------------
# Single image scoring: evaluates one edited image at a time
# ----------------------------------------------------------
with torch.no_grad():
rewards = inferencer.reward(
prompts=[prompts[0]],
image_src=[image_src[0]],
image_paths=[image_paths[0]]
)
print(f"[Single Inference] Image 1 score: {[reward[0].item() for reward in rewards]}")
with torch.no_grad():
rewards = inferencer.reward(
prompts=[prompts[0]],
image_src=[image_src[0]],
image_paths=[image_paths[1]]
)
print(f"[Single Inference] Image 2 score: {[reward[0].item() for reward in rewards]}")
EditReward achieves superior alignment with human preferences in instruction-guided image editing tasks. The following tables show its performance against other models on various benchmarks.
| Method | GenAI-Bench | AURORA-Bench | ImagenHub | EditReward-Bench (Overall) |
|---|---|---|---|---|
| Random | 25.90 | 33.43 | -- | 13.84 |
| Human-to-Human | -- | -- | 41.84 | -- |
| Proprietary Models | ||||
| GPT-4o | 53.54 | 50.81 | 38.21 | 28.31 |
| GPT-5 | 59.61 | 47.27 | 40.85 | 37.81 |
| Gemini-2.0-Flash | 53.32 | 44.31 | 23.69 | 33.47 |
| Gemini-2.5-Flash | 57.01 | 47.63 | 41.62 | 38.02 |
| Open-Source VLMs | ||||
| Qwen2.5-VL-3B-Inst | 42.76 | 30.69 | -2.54 | 26.86 |
| Qwen2.5-VL-7B-Inst | 40.48 | 38.62 | 18.59 | 29.75 |
| Qwen2.5-VL-32B-Inst | 39.28 | 37.06 | 26.87 | 28.72 |
| MiMo-VL-7B-SFT-2508 | 57.89 | 30.43 | 22.14 | 31.19 |
| ADIEE | 59.96 | 55.56 | 34.50 | -- |
| Reward Models (Ours) | ||||
| EditReward (on Qwen2.5-VL-7B) | 63.97 | 59.50 | 36.18 | 36.78 |
| EditReward (on MiMo-VL-7B) | 65.72 | 63.62 | 35.20 | 38.42 |
| Method | EditReward-Bench (K=2) | EditReward-Bench (K=3) | EditReward-Bench (K=4) | EditReward-Bench (Overall) |
|---|---|---|---|---|
| Random | 25.81 | 11.33 | 1.35 | 13.84 |
| Human-to-Human | -- | -- | -- | -- |
| Proprietary Models | ||||
| GPT-4o | 45.69 | 27.33 | 7.31 | 28.31 |
| GPT-5 | 57.53 | 38.51 | 12.84 | 37.81 |
| Gemini-2.0-Flash | 52.43 | 33.33 | 13.51 | 33.47 |
| Gemini-2.5-Flash | 58.61 | 39.86 | 12.16 | 38.02 |
| Open-Source VLMs | ||||
| Qwen2.5-VL-3B-Inst | 51.07 | 20.27 | 2.71 | 26.86 |
| Qwen2.5-VL-7B-Inst | 52.69 | 24.67 | 3.38 | 29.75 |
| Qwen2.5-VL-32B-Inst | 50.54 | 25.27 | 4.05 | 28.72 |
| MiMo-VL-7B-SFT-2508 | 49.46 | 30.41 | 9.46 | 31.19 |
| ADIEE | -- | -- | -- | -- |
| Reward Models (Ours) | ||||
| EditReward (on Qwen2.5-VL-7B) | 56.99 | 36.00 | 10.81 | 36.78 |
| EditReward (on MiMo-VL-7B) | 56.45 | 42.67 | 11.49 | 38.42 |
Please kindly cite our paper if you use our code, data, models or results:
@misc{wu2025editrewardhumanalignedrewardmodel,
title={EditReward: A Human-Aligned Reward Model for Instruction-Guided Image Editing},
author={Keming Wu and Sicong Jiang and Max Ku and Ping Nie and Minghao Liu and Wenhu Chen},
year={2025},
eprint={2509.26346},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.26346},
}
We would like to thank the HPSv3, VideoAlign and GenAI-Bench codebase for providing valuable references.
For questions and support:
Base model
Qwen/Qwen2.5-VL-7B-Instruct