
Tetris-Neural-Network-Q-Learning
Overview
PyTorch implementation of a simplified Tetris-playing AI using Q-Learning.
The Tetris board is just 4×4, with the agent deciding in which of the 4 columns to drop the next piece. The agent’s neural network receives a 16-dimensional board representation (flattened 4×4) and outputs 4 Q-values, one for each possible move. Through repeated training (via self-play and the Q-Learning algorithm), the agent learns to fill the board without making illegal moves—eventually achieving a perfect score.
Project Structure
├── model.py # Contains the TetrisAI class and TetrisNet model (PyTorch)
├── train.py # Main training script
├── evaluate.py # Script to load the model checkpoint and interactively run the game
├── tetris.py # Defines the GameState and game logic
├── representation.py # Defines how the game state is turned into a 1D list of ints
└── checkpoints # Directory where model checkpoints (.pth) are saved/loaded
Model Architecture
- Input Layer (16 units): Flattened 4x4 board state, where each cell is
0(empty) or1(occupied). - Hidden Layers: Dense layers (64 → 64 → 32) with ReLU activations.
- Output Layer (4 units): Linear activation, representing the estimated Q-value for each move (column 1–4).
Training
- Game Environment: A 4x4 Tetris-like grid where each move places a block in one of the four columns.
- Reward Function:
- Immediate Reward: Increase in the number of occupied squares, minus
- Penalty: A scaled standard deviation of the “column depth” to encourage balanced play.
- Q-Learning Loop:
- For each move, the model is passed the current game state and returns predicted Q-values.
- An action (move) is chosen based on either:
- Exploitation: Highest Q-value prediction (greedy choice).
- Exploration: Random move to discover new states.
- The agent observes the new state and reward, and stores this experience (state, action, reward, next_state) to update the model.
Reward Function
The reward function for each action is based on two parts:
Board Occupancy
- The reward starts with the number of occupied squares on the board (i.e., how many cells are filled).
Penalty for Unbalanced Columns
- Next, the standard deviation of each column's unoccupied cell count is calculated.
- A higher standard deviation means one column may be much taller or shorter than others, which is undesirable in Tetris.
- By subtracting this standard deviation from the occupancy-based reward, the agent is penalized for building unevenly and is encouraged to keep the board as level as possible.
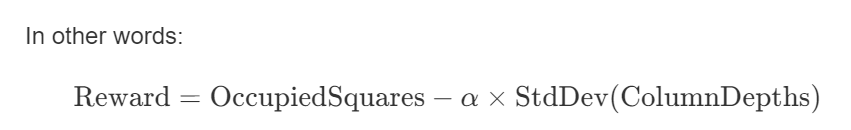
Where alpha is a weighting factor (in this case effectively 1, or any scalar you choose) that determines the penalty's intensity. This keeps the board balanced and helps the agent learn a more efficient Tetris strategy.
Installation & Usage
Clone this repo or download the source code.
Install Python (3.8+ recommended).
Install dependencies:
pip install torch numpy- You may also need other libraries like pandas or statistics depending on your environment.
Training:
- Adjust the hyperparameters (learning rate, exploration rate, etc.) in
train.pyif desired. - Run:
- Adjust the hyperparameters (learning rate, exploration rate, etc.) in
python train.py
- This script will generate a
checkpointX.pthfile in checkpoints/ upon completion (or periodically during training).
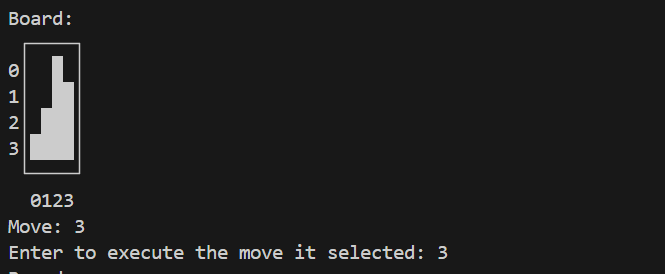
Evaluation:
- Ensure you have a valid checkpoint saved, for example
checkpoint14.pth. - Run:
python evaluate.py- The script will load the checkpoint, instantiate the
TetrisAI, and then interactively show how the AI plays Tetris. You can step through the game move by move in the console.
- Ensure you have a valid checkpoint saved, for example