
Public Models
Collection
Some of them are finetuned and some of them are created by me!
•
6 items
•
Updated
Boring’s Experimental Transformer for Autoregression (Flax) A 130M parameter autoregressive language model built using a custom Flax pipeline, loads of tuning, and a sprinkle of existential dread.
Trained on determination, fueled by suffering, powered by free TPUs.
{
num_heads=12,
attention_dim=768,
vocab_size=50260,
num_blocks=12,
ff_dim=2304,
dropout_rate=0.1,
max_len = 8192,
use_fash_attention = False,
attn_chunks = 1,
emb_init_range = 0.02,
use_rope = True,
emb_scaling_factor = 1,
res_scale = 1
}
{
"peaklr":5e-4,
"warmup_percent":0.03,
"min_value":1e-8,
"training_decay":"cosine",
"weight_decay": 0.1,
"min_warmup_value":2e-4,
"b1": 0.9,
"b2": 0.95,
"eps": 1e-7
}
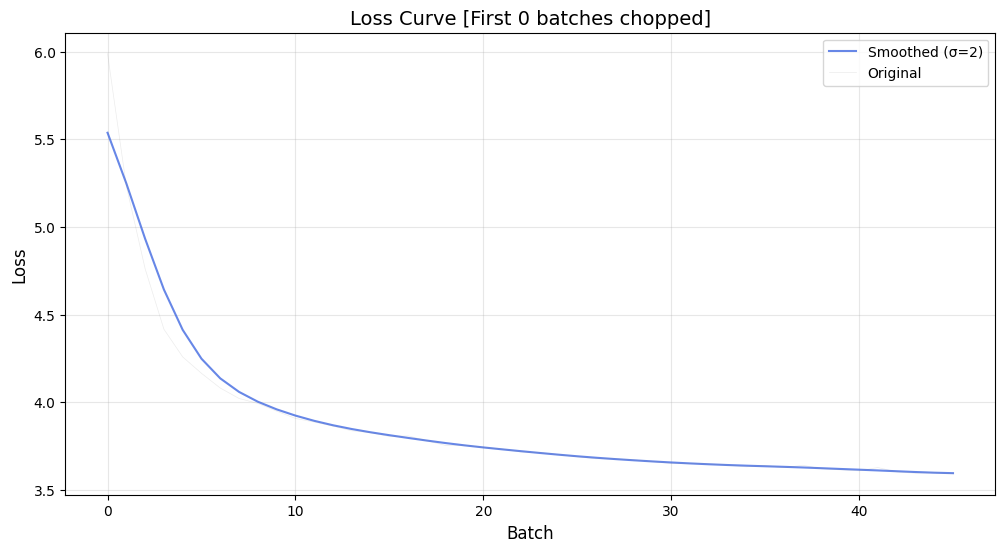
Final Validation Loss: 3.59
Validation loss Graphs:
Training loss Graphs:
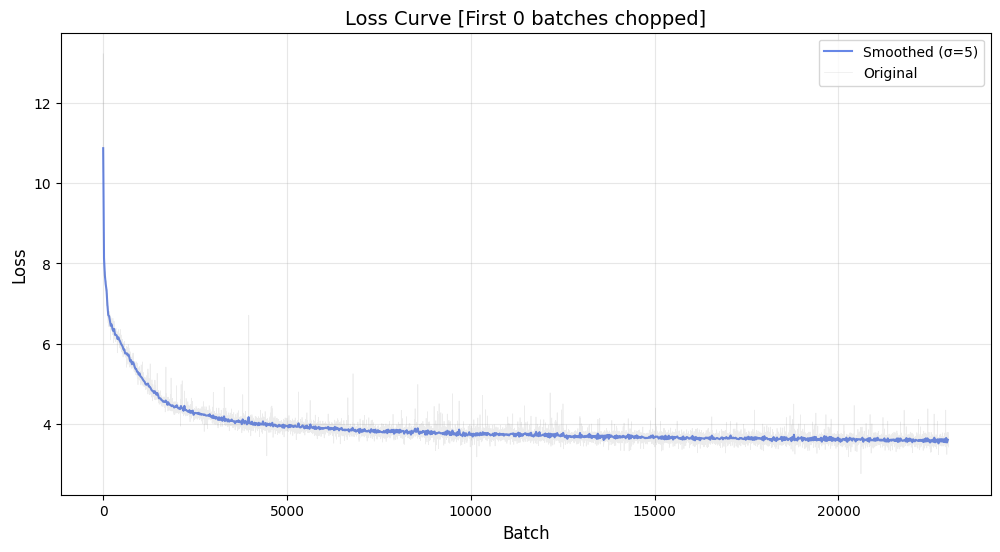
For detailed stats, refer to stats.json in the model files.
pip install BwETAF==0.5.1
import BwETAF
# 🔍 Quick API test
prompt = "The meaning of life is"
output = BwETAF.SetUpAPI(prompt, "WICKED4950/BwETAFv2-130M")
print(output)
# ⬇️ Load from Hugging Face Hub
model = BwETAF.load_hf("WICKED4950/BwETAFv2-130M")
# 📁 Load from local path
BwETAF.load_model("path/to/model")
# 💾 Save to local directory
model.save_model("path/to/save")
# 🔧 Inspect model
params = model.trainable_variables
structure = model.model_struct
☁️ Colab support and examples coming soon!
The BwETAFv2 architecture introduces several refinements over its predecessors, improving convergence, training stability, and scalability. Below is an architecture-level overview shared across all models in this series.
Attention: Standard multi-head self-attention (no GQA, no MQA, no FlashAttention)
FFN: Uses Swish-GLU with FF dimension = 3 × model_dim
Norm Layer: RMSNorm, pre-layer
Positional Encoding: RoPE on embeddings and K/Q vectors
Precision:
bfloat16 (bf16)float32Tokenization: GPT-2 BPE (vocab_size = 50257)
Bias Terms: No biases in K/Q/V dense projections
Optimizer: AdamW
Batch Size: 32 per step
Learning Schedule: Cosine decay with linear warmup
Chinchilla Scaling Law: Followed (20× tokens per parameter)
Context Window during Training:
| Model Name | Params | Tokens Seen | TPUv2-8 Hours | Val Loss | Context Length |
|---|---|---|---|---|---|
| BwETAFv2-53M | 53M | 1.34B | 3.21 | 3.77 | 2048 |
| BwETAFv2-130M | 130M | 3.01B | 19.32 | 3.59 | 4096 |
fused_computation.1 (if you spot me lurking in any AI-related servers)