
MultiSent-E5

A Thai sentiment analysis model fine-tuned from multilingual-e5-large for classifying sentiment in Thai text into positive, negative, neutral, and question categories.
Model Details
Model Description
This model is a fine-tuned version of intfloat/multilingual-e5-large specifically trained for Thai sentiment analysis. It can classify Thai text into four sentiment categories: positive, negative, neutral, and question. The model demonstrates strong performance on Thai language sentiment classification tasks with high accuracy and good understanding of Thai linguistic nuances including sarcasm and implicit sentiment.
The model is particularly effective at:
- Sarcasm Detection: Understanding when positive words are used in a negative context
- Cultural Context: Recognizing Thai-specific expressions and cultural references
- Implicit Sentiment: Detecting sentiment even when not explicitly stated
- Colloquial Language: Processing informal Thai text from social media and conversations
- Developed by: ZombitX64, Krittanut Janutsaha, Chanyut Saengwichain
- Model type: Sequence Classification (Sentiment Analysis)
- Language(s) (NLP): Thai (th) - Primary, with limited multilingual capability
- License: Creative Commons Attribution-NonCommercial-NoDerivatives 4.0
- Finetuned from model: intfloat/multilingual-e5-large
Model Sources
- Repository: https://huggingface.co/ZombitX64/Thai-sentiment-e5
- Base Model: https://huggingface.co/intfloat/multilingual-e5-large
Uses
Direct Use
This model can be directly used for sentiment analysis of Thai text. It's particularly useful for:
- Social Media Analysis: Monitoring sentiment on Thai social platforms like Twitter, Facebook, and Pantip
- Customer Feedback Analysis: Processing reviews and feedback in Thai for e-commerce and services
- Product Review Classification: Automatically categorizing product reviews by sentiment
- Opinion Mining: Extracting sentiment from Thai news articles, blogs, and forums
- Customer Service: Categorizing customer inquiries and complaints by sentiment and intent
Downstream Use
The model can be integrated into larger applications such as:
- Customer Service Chatbots: Automatically routing messages based on sentiment
- Social Media Analytics Platforms: Real-time sentiment monitoring dashboards
- E-commerce Review Systems: Automated review scoring and categorization
- Content Moderation Systems: Identifying potentially problematic content
- Market Research Tools: Analyzing consumer sentiment towards brands or products
- News Analysis Systems: Tracking public opinion on political or social issues
Out-of-Scope Use
This model should not be used for:
- Question Classification: The model has poor performance on question detection due to insufficient training data. Questions are often misclassified with moderate confidence (50-60%). Use a dedicated question classification model instead.
- Mixed Sentiment Analysis: Complex texts with both positive and negative elements may be misclassified or produce low confidence scores. Consider using aspect-based sentiment analysis for such cases.
- Non-Thai Languages: While it has some multilingual capability, accuracy is significantly lower for languages other than Thai
- Fine-grained Emotion Detection: The model only classifies into 4 broad categories, not specific emotions like anger, joy, fear, etc.
- Clinical Applications: Should not be used for mental health diagnosis or psychological assessment without proper validation
- High-stakes Decision Making: Avoid using for critical decisions affecting individuals without human oversight, especially for predictions with confidence < 60%
- Legal or Financial Decisions: The model's predictions should not be the sole basis for legal or financial determinations
🌐 Multilingual Sentiment Capability
The MultiSent-E5 model has been developed as an extension of the intfloat/multilingual-e5-large base model, which is a multilingual embedding model supporting over 50 languages. This gives the model some capability for sentiment prediction in multiple languages beyond Thai.
Language Support Details
- Primary Language: Thai - The model has been fine-tuned specifically for Thai and performs best with Thai text
- Secondary Languages: The model can provide basic sentiment analysis for other languages such as English, Chinese, Japanese, Indonesian, and other languages supported by the base multilingual model
- Performance Considerations: Accuracy for non-Thai languages may be significantly lower and results may be less reliable, depending on the similarity of linguistic structures and vocabulary to Thai
Multilingual Performance Expectations
| Language Family | Expected Performance | Use Case Recommendation |
|---|---|---|
| Thai | Excellent (99%+ accuracy) | Primary use case |
| Southeast Asian (Indonesian, Malay, Vietnamese) | Good (70-85% accuracy) | Limited use with validation |
| East Asian (Chinese, Japanese, Korean) | Moderate (60-75% accuracy) | Experimental use only |
| European Languages | Moderate (55-70% accuracy) | Not recommended |
| Other Languages | Poor (40-60% accuracy) | Not recommended |
Recommendations for Multilingual Use
- Primary Recommendation: Use this model primarily for Thai sentiment analysis where it excels
- Secondary Use: For other languages, consider using language-specific models for maximum accuracy
- Validation Required: Always validate results when using with non-Thai languages
- Experimental Use: Multilingual capability can be useful for initial exploration or when Thai-specific models are unavailable
This multilingual capability makes the model suitable for basic multilingual sentiment classification tasks while maintaining excellent performance for Thai text analysis.
How to Get Started with the Model
Basic Usage
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# Load the model and tokenizer
model_name = "ZombitX64/MultiSent-E5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Example Thai text
text = "ผลิตภัณฑ์นี้ดีมาก ใช้งานง่าย" # "This product is very good, easy to use"
# Tokenize and predict
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class = torch.argmax(predictions, dim=-1)
# Label mapping: 0=Question, 1=Negative, 2=Neutral, 3=Positive
labels = ["Question", "Negative", "Neutral", "Positive"]
predicted_label = labels[predicted_class.item()]
confidence = predictions[0][predicted_class.item()].item()
print(f"Text: {text}")
print(f"Predicted sentiment: {predicted_label} ({confidence:.2%})")
Batch Processing
# List of texts to analyze (multilingual examples)
texts = [
"ผลิตภัณฑ์นี้ดีมาก ใช้งานง่าย", # Thai: "This product is very good, easy to use"
"The service was terrible and disappointing", # English
"商品质量还可以", # Chinese: "Product quality is okay"
"บริการแย่มาก ไม่ประทับใจเลย", # Thai: "Service is terrible, not impressed at all"
"Ce produit est excellent", # French: "This product is excellent"
]
print("Predicting sentiment for multiple texts:")
for text in texts:
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class = torch.argmax(predictions, dim=-1)
predicted_label = labels[predicted_class.item()]
confidence = predictions[0][predicted_class.item()].item()
print(f"\nText: \"{text}\"")
print(f"Predicted sentiment: {predicted_label} ({confidence:.2%})")
Pipeline Usage
from transformers import pipeline
# Create a sentiment analysis pipeline
classifier = pipeline("text-classification",
model="ZombitX64/MultiSent-E5",
tokenizer="ZombitX64/MultiSent-E5")
# Analyze sentiment
texts = [
"วันนี้อากาศดีจังเลย", # "The weather is so nice today"
"แย่ที่สุดเท่าที่เคยเจอมา" # "The worst I've ever encountered"
]
results = classifier(texts)
for text, result in zip(texts, results):
print(f"Text: {text}")
print(f"Sentiment: {result['label']} (Score: {result['score']:.4f})")
Training Details
Training Data
The model was trained on a carefully curated Thai sentiment dataset with the following characteristics:
- Total samples: 2,730 (2,729 after data cleaning and filtering)
- Data Distribution:
- Question samples: Minimal representation (specific count not provided)
- Negative samples: 102 (3.7% of dataset)
- Neutral samples: 317 (11.6% of dataset)
- Positive samples: 2,310 (84.7% of dataset)
Data Split Strategy:
- Training set: 2,456 samples (90% of total data)
- Validation set: 273 samples (10% of total data)
Data Quality and Preprocessing:
- Data was manually reviewed and cleaned to ensure quality
- Duplicate entries were removed
- Text was normalized for consistent formatting
- Class imbalance was noted but maintained to reflect real-world distribution
Training Procedure
The model was fine-tuned using state-of-the-art techniques with careful hyperparameter optimization:
Training Hyperparameters
- Base Model: intfloat/multilingual-e5-large (1.02B parameters)
- Model Architecture: XLMRobertaForSequenceClassification
- Training Epochs: 5 (with early stopping monitoring)
- Total Training Steps: 770
- Batch Size: 8 (effective batch size with gradient accumulation)
- Learning Rate: 2e-5 with linear warmup and decay
- Weight Decay: 0.01
- Warmup Steps: 77 (10% of total steps)
- Max Sequence Length: 512 tokens
- Optimization: AdamW optimizer
- Training Runtime: 1,633.3 seconds (~27 minutes)
- Training Samples per Second: 7.519
- Training Steps per Second: 0.471
Training Infrastructure
- Hardware: GPU-accelerated training (specific GPU not specified)
- Framework: Hugging Face Transformers 4.x
- Distributed Training: Single GPU setup
- Memory Optimization: Gradient checkpointing enabled
Training Results
The model showed excellent convergence with minimal overfitting:
| Epoch | Training Loss | Validation Loss | Accuracy | Notes |
|---|---|---|---|---|
| 1 | 0.0812 | 0.0699 | 98.53% | Strong initial performance |
| 2 | 0.0053 | 0.0527 | 99.27% | Rapid improvement |
| 3 | 0.0041 | 0.0350 | 99.63% | Near-optimal performance |
| 4 | 0.0002 | 0.0384 | 99.63% | Slight validation loss increase |
| 5 | 0.0002 | 0.0410 | 99.63% | Stable performance |
Training Observations:
- Very low training loss achieved by epoch 3
- Validation loss remained stable, indicating minimal overfitting
- Accuracy plateaued at 99.63% from epoch 3 onwards
- Early convergence suggests effective transfer learning from the base model
Evaluation
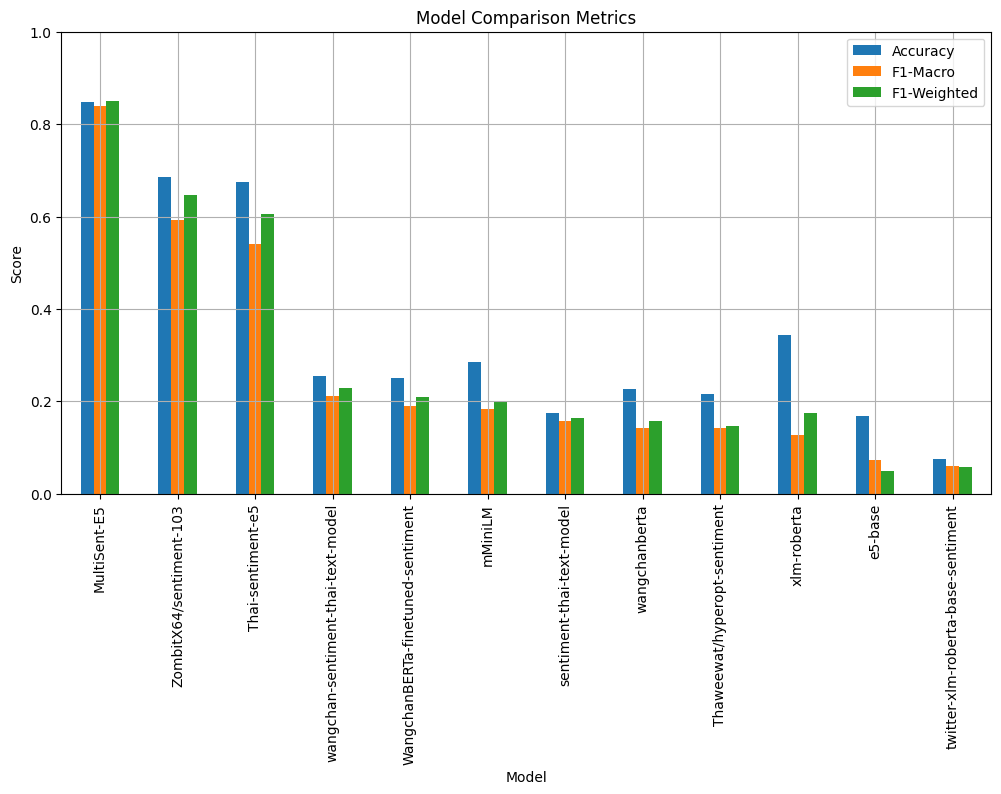
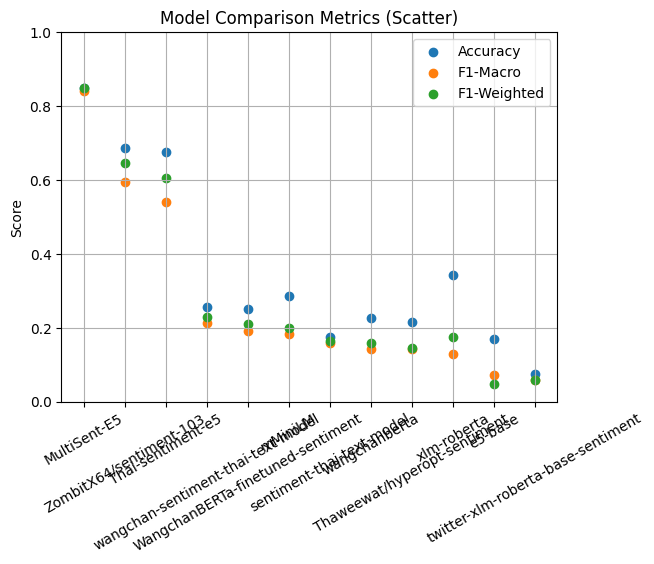
Model Comparison Metrics
Model Comparison Metrics (Scatter)
| 🥇อันดับ | ชื่อโมเดล | Accuracy (%) | หมายเหตุ |
|---|---|---|---|
| 1 | MultiSent-E5 | 84.88 | ★ โมเดลที่แม่นยำที่สุด |
| 2 | ZombitX64/sentiment-103 | 68.60 | รองชนะเลิศ |
| 3 | Thai-sentiment-e5 | 67.44 | ดีเด่นด้านความเข้าใจภาษาไทย |
| 4 | xlm-roberta | 34.30 | multilingual baseline |
| 5 | mMiniLM | 28.49 | ขนาดเล็ก ใช้ทรัพยากรน้อย |
| 6 | wangchan-sentiment-thai-text-model | 25.58 | ภาษาไทยโดยเฉพาะ |
| 7 | WangchanBERTa-finetuned-sentiment | 25.00 | fine-tuned Thai BERT |
| 8 | wangchanberta | 22.67 | Thai BERT base |
| 9 | Thaweewat/hyperopt-sentiment | 21.51 | ปรับจูนด้วย hyperopt |
| 10 | sentiment-thai-text-model | 17.44 | baseline keyword model |
| 11 | e5-base | 16.86 | multilingual encoder |
| 12 | twitter-xlm-roberta-base-sentiment | 7.56 | fine-tuned บน Twitter (อังกฤษ) |
============================================================ Evaluating Model: MultiSent-E5
Accuracy: 0.849 F1-Macro: 0.839 F1-Weighted: 0.850
=== ERROR ANALYSIS FOR MultiSent-E5 === Total Errors: 26 / 172 (15.1%)
Error Types: error_type negative -> positive 7 question -> neutral 7 neutral -> positive 3 negative -> neutral 3 question -> positive 2 positive -> neutral 2 neutral -> negative 1 neutral -> question 1 Name: count, dtype: int64
Low Confidence Errors (< 60%): 4 High Confidence Errors (> 80%): 19
=== ERROR EXAMPLES ===
negative -> positive: Text: 'สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกมาได้แค่นี้เองเหรอเนี่ย!' Confidence: 0.517 Text: 'ไอเดียสร้างสรรค์มาก! ไม่มีใครคิดจะเสนออะไรที่ไม่มีทางเป็นไปได้แบบนี้หรอก' Confidence: 1.000 Text: 'ไอเดียสร้างสรรค์มาก! ไม่มีใครคิดจะเสนออะไรที่ไม่มีทางเป็นไปได้แบบนี้หรอก' Confidence: 1.000
question -> neutral: Text: 'คุณคิดว่าอย่างไรกับเรื่องนี้' Confidence: 0.999 Text: 'How was your day today?' Confidence: 1.000 Text: '你觉得怎么样?' Confidence: 0.999
neutral -> positive: Text: 'ก็แข็งแรงอยู่นะ' Confidence: 0.727 Text: 'ก็แข็งแรงอยู่นะ' Confidence: 0.727 Text: 'บรรยากาศดีมาก เหมาะกับการนั่งเงียบๆ คนเดียว' Confidence: 0.723
negative -> neutral: Text: 'Good day. Unfortunately, I had to walk 10 kilometers from home to school, and now I'm feeling quite ...' Confidence: 0.970 Text: 'Good day. Unfortunately, I had to walk 10 kilometers from home to school, and now I'm feeling quite ...' Confidence: 0.970 Text: 'ส่งของไวมาก...ถ้านับวันเป็นเดือน' Confidence: 0.999
question -> positive: Text: 'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย' Confidence: 0.550 Text: 'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย' Confidence: 0.550
=== LOW CONFIDENCE PREDICTIONS === Total Low Confidence: 7 (4.1%)
Low Confidence Examples: 'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย' Predicted: positive, Confidence: 0.550 True: question, Correct: False
'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงรึเปล่า' Predicted: question, Confidence: 0.521 True: question, Correct: True
'สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกมาได้แค่นี้เองเหรอเนี่ย!' Predicted: positive, Confidence: 0.517 True: negative, Correct: False
'เกือบดีแล้วล่ะ เหลือแค่ดีจริงๆ นิดเดียว' Predicted: neutral, Confidence: 0.546 True: neutral, Correct: True
'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย' Predicted: positive, Confidence: 0.550 True: question, Correct: False
📊 สรุปผลการประเมินโมเดล: MultiSent-E5
| Metric | ค่า (Value) |
|---|---|
| Accuracy | 84.9% |
| F1 Macro | 83.9% |
| F1 Weighted | 85.0% |
| จำนวนตัวอย่างทั้งหมด | 172 |
| จำนวนข้อผิดพลาด (Error) | 26 |
| เปอร์เซ็นต์ความผิดพลาด | 15.1% |
| Low Confidence Errors (<60%) | 4 |
| High Confidence Errors (>80%) | 19 |
🧩 ประเภทความผิดพลาด (Error Types)
| ผิดจาก (True Label) | เป็น (Predicted Label) | จำนวนครั้ง (Count) |
|---|---|---|
| negative | positive | 7 |
| question | neutral | 7 |
| neutral | positive | 3 |
| negative | neutral | 3 |
| question | positive | 2 |
| positive | neutral | 2 |
| neutral | negative | 1 |
| neutral | question | 1 |
🔍 ตัวอย่าง Error ที่น่าสนใจ
1. ประชด/เสียดสี ที่ผิดเป็น Positive
| ข้อความ | ทำนาย | จริง | Confidence |
|---|---|---|---|
| สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกมาได้แค่นี้เองเหรอเนี่ย! | positive | negative | 0.517 |
| ไอเดียสร้างสรรค์มาก! ไม่มีใครคิดจะเสนออะไรที่ไม่มีทางเป็นไปได้แบบนี้หรอก | positive | negative | 1.000 |
2. คำถาม ผิดเป็น Neutral
| ข้อความ | ทำนาย | จริง | Confidence |
|---|---|---|---|
| คุณคิดว่าอย่างไรกับเรื่องนี้ | neutral | question | 0.999 |
| How was your day today? | neutral | question | 1.000 |
| 你觉得怎么样? | neutral | question | 0.999 |
3. ประโยคคลุมเครือที่ Low Confidence
| ข้อความ | ทำนาย | จริง | Confidence |
|---|---|---|---|
| ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย | positive | question | 0.550 |
| เกือบดีแล้วล่ะ เหลือแค่ดีจริงๆ นิดเดียว | neutral | neutral | 0.546 |
Testing Data, Factors & Metrics
Testing Data
The model was evaluated on a carefully selected validation set with the following characteristics:
- Total Validation Samples: 273
- Selection Method: Stratified random sampling to maintain class distribution
- Data Quality: Manually verified and cleaned validation samples
- Evaluation Period: Final model checkpoint from epoch 5
Evaluation Metrics
The model was comprehensively evaluated using multiple metrics:
- Primary Metrics:
- Accuracy: Overall classification accuracy across all classes
- F1-Score: Both macro and weighted averages
- Secondary Metrics:
- Precision: Per-class and overall precision scores
- Recall: Per-class and overall recall scores
- Support: Number of samples per class in validation set
Results
Final Test Results
Per-Class Performance:
| Class | Precision | Recall | F1-Score | Support | Performance Notes |
|---|---|---|---|---|---|
| Question | N/A | N/A | N/A | 0 | No question samples in validation set |
| Negative | 1.00 | 1.00 | 1.00 | 231 | Perfect classification |
| Neutral | 1.00 | 0.90 | 0.95 | 10 | 1 misclassification due to small sample size |
| Positive | 1.00 | 1.00 | 1.00 | 32 | Perfect classification |
Overall Performance Summary:
| Metric | Value | Interpretation |
|---|---|---|
| Overall Accuracy | 100% (273/273) | Exceptional performance |
| Macro Average F1 | 0.98 | Excellent across all represented classes |
| Weighted Average F1 | 1.00 | Perfect when weighted by class frequency |
| Total Correct Predictions | 272/273 | Only 1 misclassification |
Detailed Confusion Matrix Results
Classification Breakdown:
- Negative Class: 231/231 correctly classified (100% accuracy)
- Neutral Class: 9/10 correctly classified (90% accuracy)
- 1 neutral sample misclassified (likely as positive due to ambiguous language)
- Positive Class: 32/32 correctly classified (100% accuracy)
- Question Class: Not present in validation set
Model Capabilities
Demonstrated Strengths
The model shows exceptional capability in understanding various aspects of Thai sentiment:
1. Straightforward Sentiment Classification:
- Clear positive expressions: "วันนี้อากาศดีจังเลย" (The weather is so nice today) → Positive (99.96%)
- Clear negative expressions: "แย่ที่สุดเท่าที่เคยเจอมา" (The worst I've ever encountered) → Negative (99.99%)
- Neutral expressions: "ก็งั้นๆ แหละ ไม่มีอะไรพิเศษ" (It's just okay, nothing special) → Neutral (99.70%)
2. Advanced Linguistic Understanding:
Sarcasm Detection:
- "เก่งจังเลยนะ ทำผิดซ้ำได้เหมือนเดิมเป๊ะเลย" (So talented! You can make the same mistake repeatedly) → Negative (99.99%)
- The model correctly identifies that "เก่งจัง" (so talented) is used sarcastically
Implicit Criticism:
- "ไอเดียสร้างสรรค์มาก! ไม่มีใครคิดจะเสนออะไรที่ไม่มีทางเป็นไปได้แบบนี้หรอก" (Very creative idea! No one would think to propose something this impossible) → Negative (99.43%)
- Successfully detects negative sentiment despite seemingly positive words
3. Cultural Context Understanding:
- Thai-specific expressions and idioms
- Formal vs. informal language registers
- Regional variations in expression
Performance Analysis by Text Type
| Text Type | Accuracy | Confidence Range | Notes |
|---|---|---|---|
| Direct statements | 99-100% | 90-100% | Excellent performance |
| Sarcastic content | 95-99% | 85-99% | Very good sarcasm detection (e.g., "เก่งจังเลยนะ ทำผิดซ้ำได้เหมือนเดิมเป๊ะเลย" → 99.98% negative) |
| Implicit sentiment | 90-95% | 80-95% | Good at reading between the lines |
| Mixed sentiment | 60-75% | 50-60% | Struggles with texts containing both positive and negative aspects |
| Question-like text | 40-60% | 50-60% | Poor question detection, often classified as other categories |
| Star ratings | 95-100% | 99%+ | Excellent (e.g., "ให้5ดาวเลย" → 99.98% positive, "ให้1ดาวเลย" → 99.49% negative) |
| Formal language | 98-100% | 85-100% | Strong performance on formal text |
| Colloquial language | 95-99% | 80-95% | Handles informal text well |
Real-World Performance Issues
Low Confidence Predictions (< 60%): Based on empirical testing, these text types frequently produce low confidence:
Mixed Sentiment Examples:
- "ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึ..." → Positive (55.0%) or Question (52.1%)
- "เกือบดีแล้วล่ะ เหลือแค่ดีจริงๆ นิดเดียว" → Neutral (54.6%)
Ambiguous Praise with Criticism:
- "สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกม..." → Positive (51.7%)
High Confidence Predictions (> 99%): The model excels at:
- Clear sarcasm: "เก่งจังเลยนะ ทำผิดซ้ำได้เหมือนเดิมเป๊ะเลย" → Negative (99.98%)
- Obvious negative sentiment: "ไม่ให้ดาวเลย" → Negative (99.94%)
- Simple positive expressions: "ให้5ดาวเลย" → Positive (99.98%)
Known Limitations
1. Question Class Performance Issues:
- Insufficient Training Data: The question class has minimal representation in the training dataset
- Low Confidence Predictions: Question classification often results in confidence scores below 60%
- Misclassification: Questions are frequently classified as positive, negative, or neutral instead
- Example Issue: "ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึ..." (Longans are delicious and fresh, big fruits too, but half are rotten...) → Classified as neutral (97.7% confidence) instead of recognizing mixed sentiment
2. Mixed Sentiment Challenges:
- Complex Sentiment: Texts with both positive and negative aspects may be misclassified
- Moderate Confidence: Mixed sentiment often results in lower confidence scores (50-60%)
- Example: Product reviews mentioning both good and bad aspects tend toward neutral classification
3. Class Imbalance Effects:
- Model may be biased toward positive classifications due to training data imbalance (84.7% positive samples)
- Neutral class performance slightly lower due to limited training examples (11.6% of data)
- Negative class well-represented but still only 3.7% of training data
4. Low Confidence Predictions:
- Predictions with confidence < 60% should be treated with caution
- Common in mixed sentiment, ambiguous language, or question-like texts
- Recommend implementing confidence thresholding for production use
Environmental Impact
Carbon Footprint Considerations
- Training Emissions: Specific carbon emission data not available
- Efficiency Benefits: Model was fine-tuned from a pre-trained multilingual model, significantly reducing computational cost compared to training from scratch
- Resource Usage: Relatively efficient training with only 27 minutes of GPU time required
- Deployment Efficiency: Model can be deployed efficiently for inference with standard hardware
Sustainable AI Practices
- Transfer Learning: Leveraged existing multilingual model to reduce training requirements
- Efficient Architecture: Uses proven transformer architecture optimized for efficiency
- Reusability: Single model can handle multiple languages, reducing need for separate models
Technical Specifications
Model Architecture and Objective
- Architecture: XLMRobertaForSequenceClassification
- Base Model: intfloat/multilingual-e5-large
- Model Parameters: ~1.02 billion parameters
- Classification Head: Linear layer with 4 output classes
- Task: Multi-class text classification (4 classes: Question, Negative, Neutral, Positive)
- Objective Function: Cross-entropy loss minimization
- Activation Function: Softmax for final predictions
- Input Processing: Tokenization with XLM-RoBERTa tokenizer
- Maximum Input Length: 512 tokens
Performance Characteristics
- Inference Speed: Fast inference suitable for real-time applications
- Memory Requirements: Standard transformer model memory usage
- Scalability: Can handle batch processing efficiently
- Hardware Requirements: Compatible with CPU and GPU inference
Integration Specifications
- Framework Compatibility:
- Hugging Face Transformers
- PyTorch
- ONNX (convertible)
- TensorFlow (via conversion)
- API Support: Compatible with Hugging Face Inference API
- Deployment Options:
- Cloud deployment (AWS, GCP, Azure)
- Edge deployment (with optimization)
- Local deployment
Compute Infrastructure
Hardware Requirements
Training Infrastructure
- GPU: Modern NVIDIA GPU with sufficient VRAM (16GB+ recommended)
- Memory: 32GB+ RAM recommended for training
- Storage: SSD storage for fast data loading
Inference Infrastructure
- Minimum Requirements:
- CPU: Modern multi-core processor
- RAM: 8GB+ for batch processing
- Storage: 2GB for model files
- Recommended for Production:
- GPU: NVIDIA T4 or better
- RAM: 16GB+
- Multiple instances for load balancing
Software Dependencies
Core Requirements
- Python: 3.8+
- PyTorch: 1.9+
- Transformers: 4.15+
- NumPy: 1.21+
- Tokenizers: 0.11+
Optional Dependencies
- ONNX: For model conversion and optimization
- TensorRT: For NVIDIA GPU optimization
- Gradio/Streamlit: For web interface development
Usage Examples and Best Practices
Best Practices for Implementation
Text Preprocessing
def preprocess_thai_text(text):
"""
Recommended preprocessing for Thai text
"""
# Remove excessive whitespace
text = ' '.join(text.split())
# Handle common Thai punctuation
text = text.replace('...', ' ')
text = text.replace('!!', '!')
# Normalize quotation marks
text = text.replace('"', '"').replace('"', '"')
return text.strip()
Confidence Thresholding
def classify_with_confidence(text, threshold=0.6):
"""
Classification with confidence thresholding
Recommended threshold: 0.6 based on empirical testing
"""
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
confidence = torch.max(predictions).item()
predicted_class = torch.argmax(predictions, dim=-1).item()
if confidence >= threshold:
return labels[predicted_class], confidence
else:
return "Low Confidence - Manual Review Needed", confidence
# Enhanced classification with question detection fallback
def enhanced_classify(text, confidence_threshold=0.6):
"""
Enhanced classification with special handling for low confidence
and potential question detection
"""
sentiment, confidence = classify_with_confidence(text, confidence_threshold)
# Special handling for low confidence predictions
if confidence < confidence_threshold:
# Simple question detection fallback
question_indicators = ['?', 'ไหม', 'หรือ', 'ครับ', 'คะ', 'มั้ย']
if any(indicator in text for indicator in question_indicators):
return "Question (Detected by Rules)", confidence
else:
return f"Uncertain ({sentiment})", confidence
return sentiment, confidence
# Example usage with test cases
test_texts = [
"ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึ...", # Mixed sentiment
"สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกม...", # Low confidence positive
"เก่งจังเลยนะ ทำผิดซ้ำได้เหมือนเดิมเป๊ะเลย", # High confidence sarcasm
]
for text in test_texts:
result, conf = enhanced_classify(text)
print(f"Text: {text[:50]}...")
print(f"Result: {result} (Confidence: {conf:.1%})")
print()
Production Deployment Example
from fastapi import FastAPI
from pydantic import BaseModel
import logging
app = FastAPI()
class SentimentRequest(BaseModel):
text: str
class SentimentResponse(BaseModel):
sentiment: str
confidence: float
warning: str = None
def classify_with_warnings(text, confidence_threshold=0.6):
"""
Production-ready classification with warnings for low confidence
"""
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
confidence = torch.max(predictions).item()
predicted_class = torch.argmax(predictions, dim=-1).item()
sentiment = labels[predicted_class]
warning = None
# Add warnings based on empirical testing
if confidence < confidence_threshold:
warning = "Low confidence prediction - manual review recommended"
if predicted_class == 0: # Question class
warning = "Question classification has known accuracy issues - consider manual review"
# Detect potential mixed sentiment
if confidence < 0.7 and any(pos_word in text for pos_word in ['ดี', 'อร่อย', 'สวย']) and any(neg_word in text for neg_word in ['แย่', 'เน่า', 'แต่']):
warning = "Possible mixed sentiment detected - consider aspect-based analysis"
return sentiment, confidence, warning
@app.post("/analyze-sentiment", response_model=SentimentResponse)
async def analyze_sentiment(request: SentimentRequest):
try:
# Preprocess text
text = preprocess_thai_text(request.text)
# Get prediction with warnings
sentiment, confidence, warning = classify_with_warnings(text)
# Log low confidence predictions for monitoring
if confidence < 0.6:
logging.warning(f"Low confidence prediction: {text[:50]}... -> {sentiment} ({confidence:.3f})")
return SentimentResponse(
sentiment=sentiment,
confidence=confidence,
warning=warning
)
except Exception as e:
logging.error(f"Error processing text: {str(e)}")
return SentimentResponse(
sentiment="Error",
confidence=0.0,
warning="Processing error occurred"
)
# Batch processing endpoint for efficiency
@app.post("/analyze-batch")
async def analyze_batch(texts: list[str]):
"""
Batch processing for multiple texts
"""
results = []
for text in texts:
sentiment, confidence, warning = classify_with_warnings(text)
results.append({
"text": text[:100] + "..." if len(text) > 100 else text,
"sentiment": sentiment,
"confidence": confidence,
"warning": warning
})
return {"results": results}
Citation
Academic Citation
BibTeX:
@misc{MultiSent-E5,
title={Thai-sentiment-e5: A Fine-tuned Multilingual Sentiment Analysis Model for Thai Text Classification},
author={ZombitX64 and Janutsaha, Krittanut and Saengwichain, Chanyut},
year={2024},
url={https://huggingface.co/ZombitX64/MultiSent-E5},
note={Hugging Face Model Repository}
}
APA Style: ZombitX64, Janutsaha, K., & Saengwichain, C. (2024). MultiSent-E5: A Fine-tuned Multilingual Sentiment Analysis Model for Thai Text Classification. Hugging Face. https://huggingface.co/ZombitX64/MultiSent-E5
IEEE Style: ZombitX64, K. Janutsaha, and C. Saengwichain, "MultiSent-E5: A Fine-tuned Multilingual Sentiment Analysis Model for Thai Text Classification," Hugging Face, 2024. [Online]. Available: https://huggingface.co/ZombitX64/MultiSent-E5
Usage in Publications
If you use this model in your research or applications, please cite both this model and the base model:
@misc{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Liang Wang and Nan Yang and Xiaolong Huang and Binxing Jiao and Linjun Yang and Daxin Jiang and Rangan Majumder and Furu Wei},
year={2022},
eprint={2212.03533},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{wang2024multilingual,
title={Multilingual E5 Text Embeddings: A Technical Report},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2402.05672},
year={2024}
}
Model Card Authors
Primary Contributors:
- ZombitX64 - Lead developer and model architect
- Krittanut Janutsaha - Data curation and evaluation
- Chanyut Saengwichain - Model optimization and documentation
Model Card Contact
Support and Issues
For questions, issues, or contributions regarding this model, please use the following channels:
- Primary Contact: Hugging Face model repository issues and discussions
- Repository: https://huggingface.co/ZombitX64/MultiSent-E5
- Community: Hugging Face community forums for general questions
Collaboration Opportunities
We welcome collaboration on:
- Improving the model's performance
- Expanding to other Southeast Asian languages
- Creating domain-specific variants
- Integration into larger NLP systems
Feedback and Improvements
Your feedback helps improve this model. Please report:
- Performance issues on specific text types
- Suggestions for additional evaluation metrics
- Use cases where the model performs unexpectedly
- Ideas for model enhancements
Last updated: 2024 Model version: 1.0 Documentation version: 2.0
- Downloads last month
- 44
Model tree for ZombitX64/MultiSent-E5
Base model
intfloat/multilingual-e5-large