
Great quality model! Very low perplexity!

Heya
@anikifoss
just wanted to congratulate you for having the lowest perplexity quant that I've measured thus far! Your DQ4_K is very close to full quality Q8_0 perplexity while saving a lot of space and fitting comfortably in a single 768GB RAM NUMA node. Great job and thanks for all your help testing and getting this merged into ik_llama.cpp for max speed as well!
Q8_0Final estimate: PPL = 2.9507 +/- 0.01468DQ4_KFinal estimate: PPL = 2.9691 +/- 0.01480UD-Q4_K_XLFinal estimate: PPL = 3.0612 +/- 0.01550
Your quant might be good for @ChuckMcSneed as discussed here and @Nark103 as discussed here
After doing a lot of quants and testing even more, my impression is that Kimi-K2-Instruct is more sensitive to quantization of the attn/shexp/blk.0.ffn* tensors than DeepSeek. This would likely make sense given Kimi-K2 architecture uses half the attn heads and 33% of the first ffn dense layers while adding more routed exps as shown in this image.
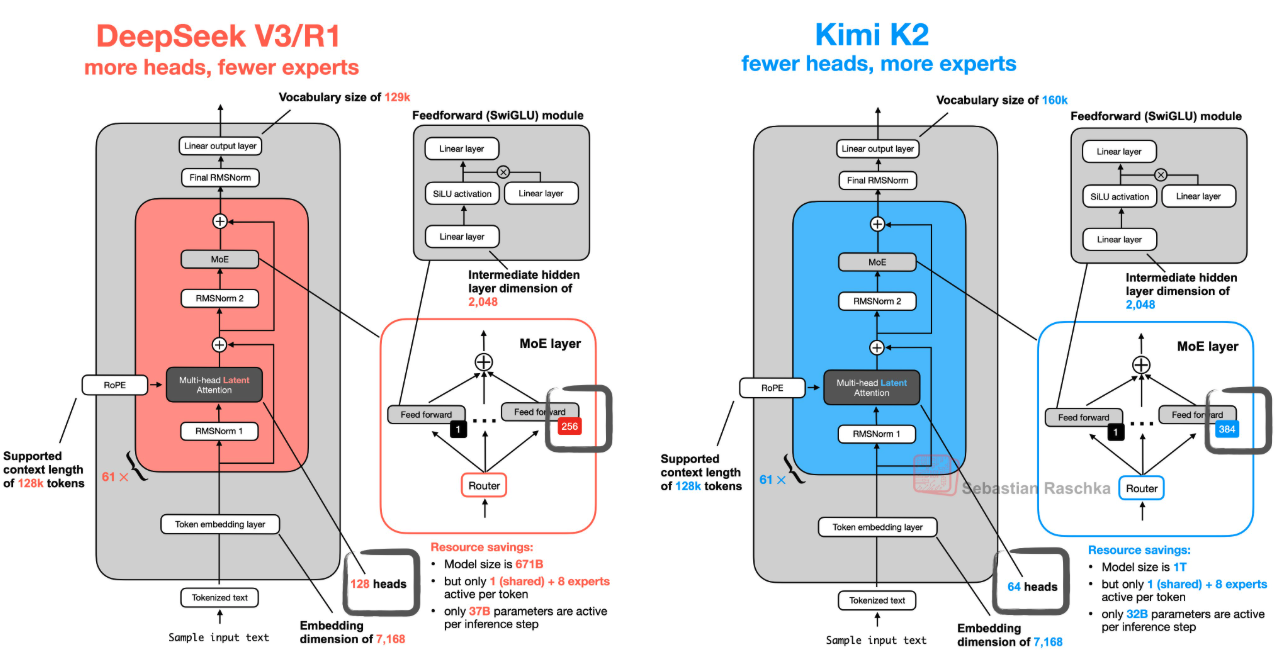{kind=link}
Cheers!
P.S. Have fun playing with your "new" AMD GPUs haha!
Thanks for checking the perplexity! I'm suprised there are enough people who want to use chunky quants. "There are dozens of us, DOZENS!"
Reading the other posts gave me more ideas: I should try quantizing token_embd.weight and output.weight as f16
Right, @ChuckMcSneed was showing the original fp8 safetensors actually has bf16 for some tensors including token embedding.
While f16 has better "precision" as it were over a lower range of numbers, bf16 allows for a wider range with bigger min and max values.
I can't find a good image to show the difference. But if you cast bf16 to f16 be careful of potential clipping if the bf16 values including numbers outside the range you can represent with f16.
I'm not really sure how to check for this. There might be something in the available tooling already though, or it might print a warning before clipping values?
I can't find a good image to show the difference. But if you cast bf16 to f16 be careful of potential clipping if the bf16 values including numbers outside the range you can represent with f16.
Good point, I should keep those bf16 if they already are. I think bf16 is also supported in GGUF.
aye, i've only ever used bf16 gguf for the "original" from which i make the quants. though i've seen others use f16 for some models in the past. i try to keep the GGUF the dtype as whatever the safetensors are using.
also cool seeing updates on your 4x new GPUs! (i gotta ask over there if your success with ROCm/HIP was with mainline llama.cpp or ik? i got vulkan working with both mainline and ik, but rocm only with mainline last i tried.
also cool seeing updates on your 4x new GPUs! (i gotta ask over there if your success with ROCm/HIP was with mainline llama.cpp or ik? i got vulkan working with both mainline and ik, but rocm only with mainline last i tried.
Yeah, ik_llama is missing ROCm support entirely. I tried Vulka, but it only detects 16GB for each MI50 GPU. Aparently it's a bug that can be fixed by flashing MI50's BIOS, but I decided not to flash just yet.