Test-Driving the LLMD Inference Engine by ZML 🚀







ZML just released a technical preview of their new Inference Engine: LLMD, and it’s worth checking out. Here’s why I'm super excited about it:
- ⚡️ Lightweight — At just 2.4GB, the container is small, which means fast startup times and efficient autoscaling.
- 🧠 Optimized — has Flash Attention 3 (on NVIDIA) and AITER kernels (on AMD) out of the box.
- 🛠 Simple Setup — Just mount your model and run the container.
- 🎮 Cross-Platform GPU Support — Works on both NVIDIA and AMD GPUs.
- 🏎 High Performance
- 🧡 Written in Zig — For all Zig fans out there.
How to Test It (Easily)
I don’t have a beefy remote machine with an NVIDIA GPU ready to SSH into, and maybe you don’t either. So here’s a dead-simple way to try it out on Hugging Face Inference Endpoints 🔥
1. Prerequisites
- You’ll need a Hugging Face account with a valid payment method set up.
- Once you're ready, go to endpoints.huggingface.co
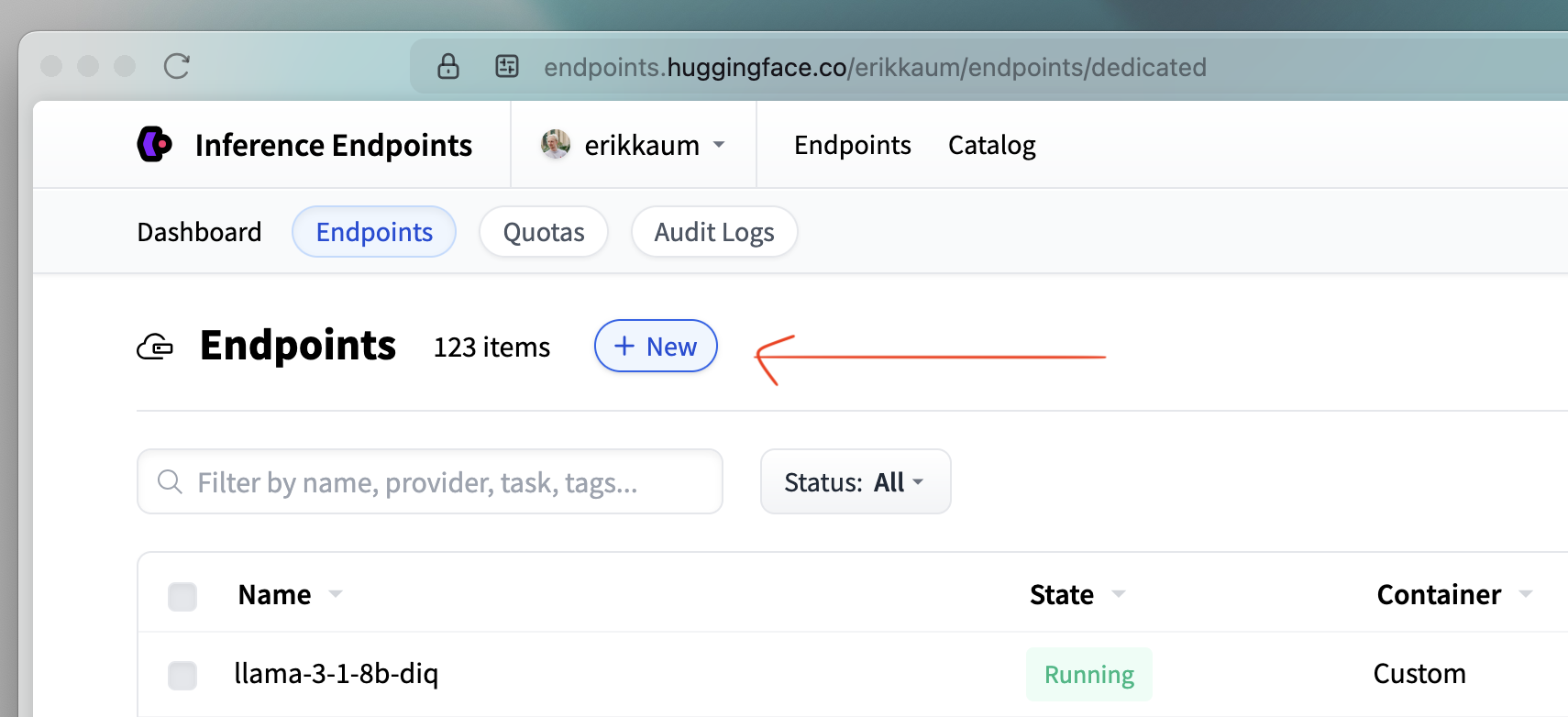
2. Choose the Model
Click "New" to start a new Inference Endpoint.
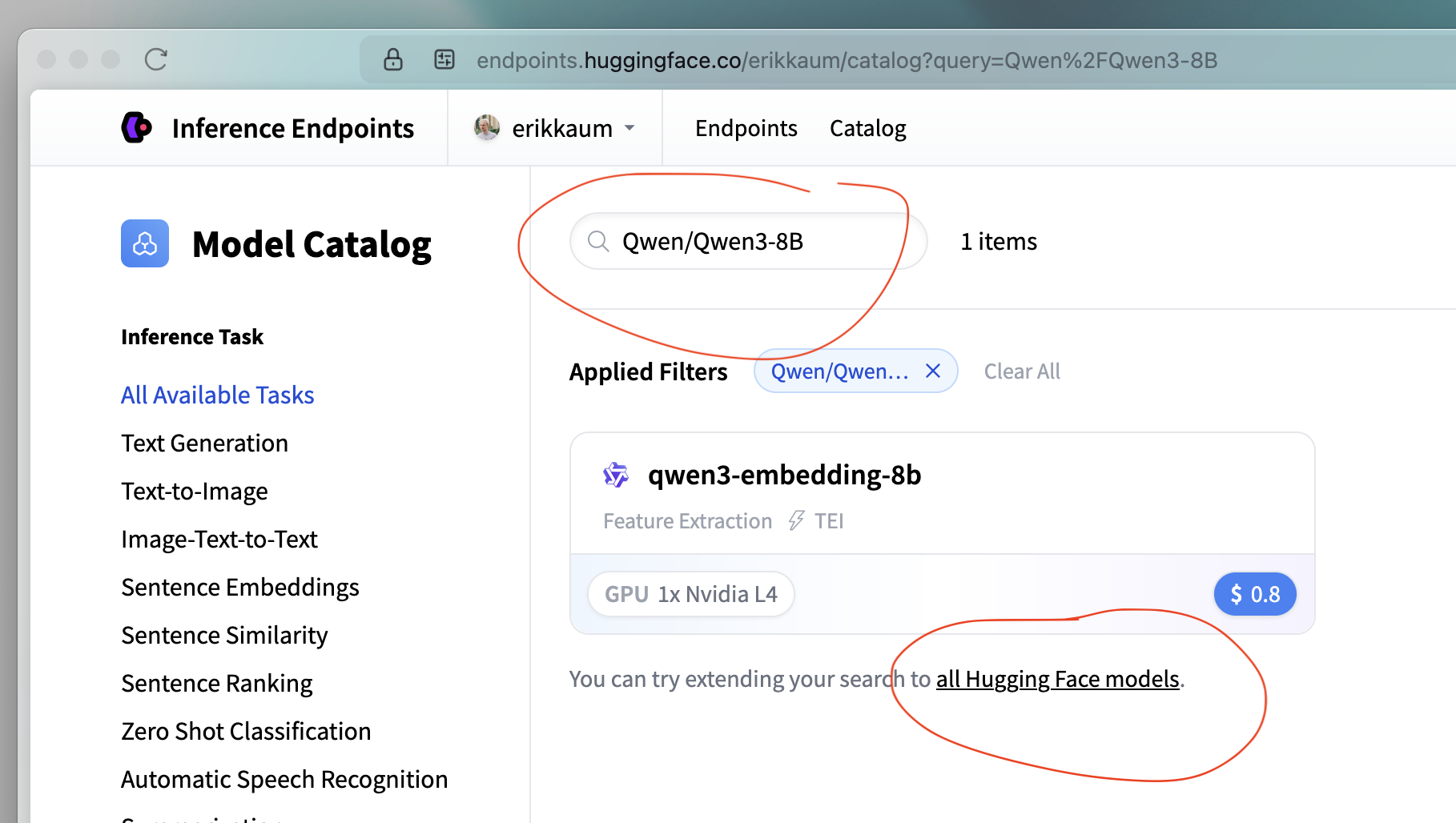
In the filter bar, search for
Qwen/Qwen3-8B.It won’t show up immediately so click “try extending your search to all Hugging Face models.”
In the modal that appears, you should see
Qwen3-8Bas the top result.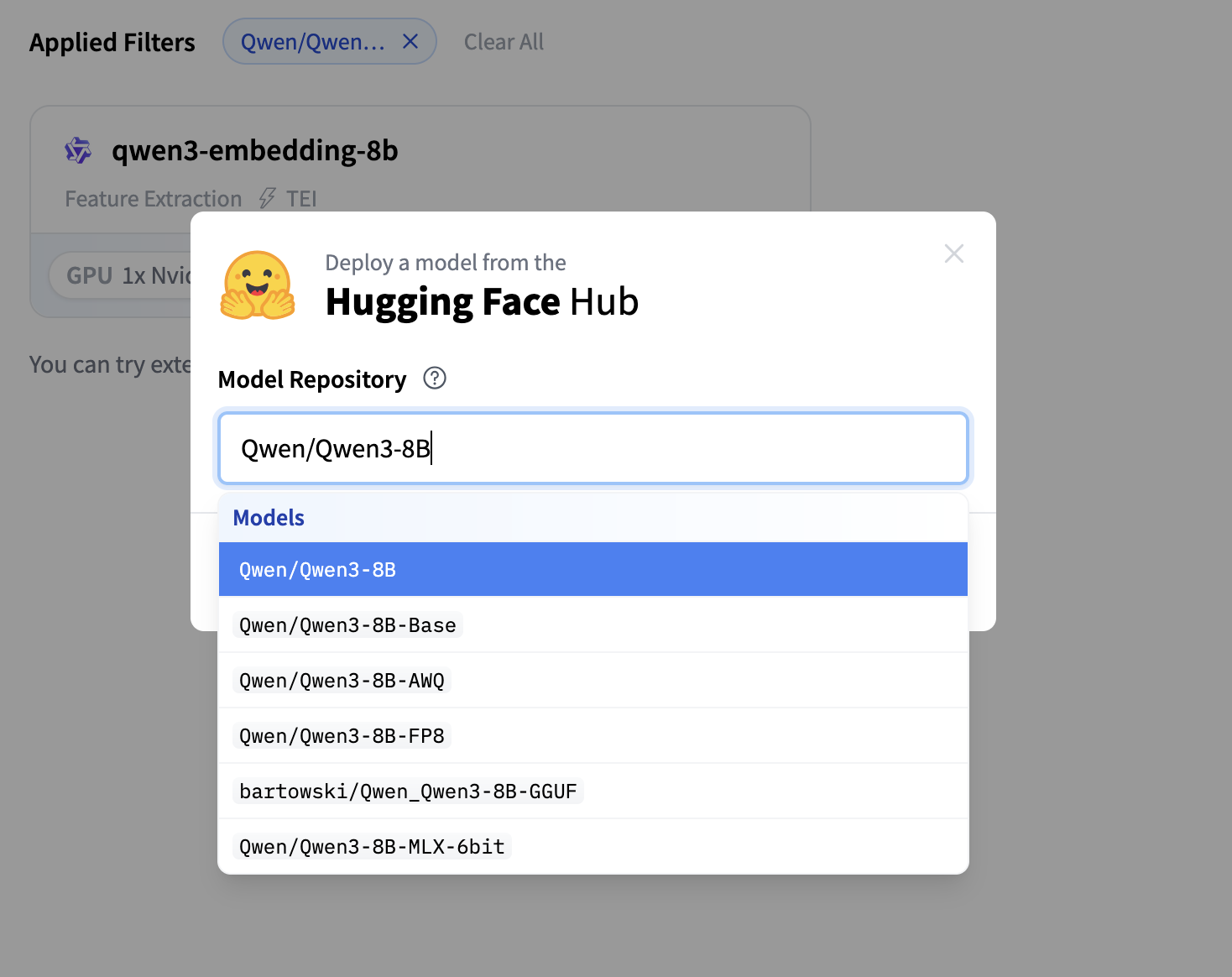
Click "Deploy Model" 🚀
3. Configure the Endpoint
GPU: Choose an NVIDIA L4. Good enough for testing Qwen3-8B without breaking the bank.
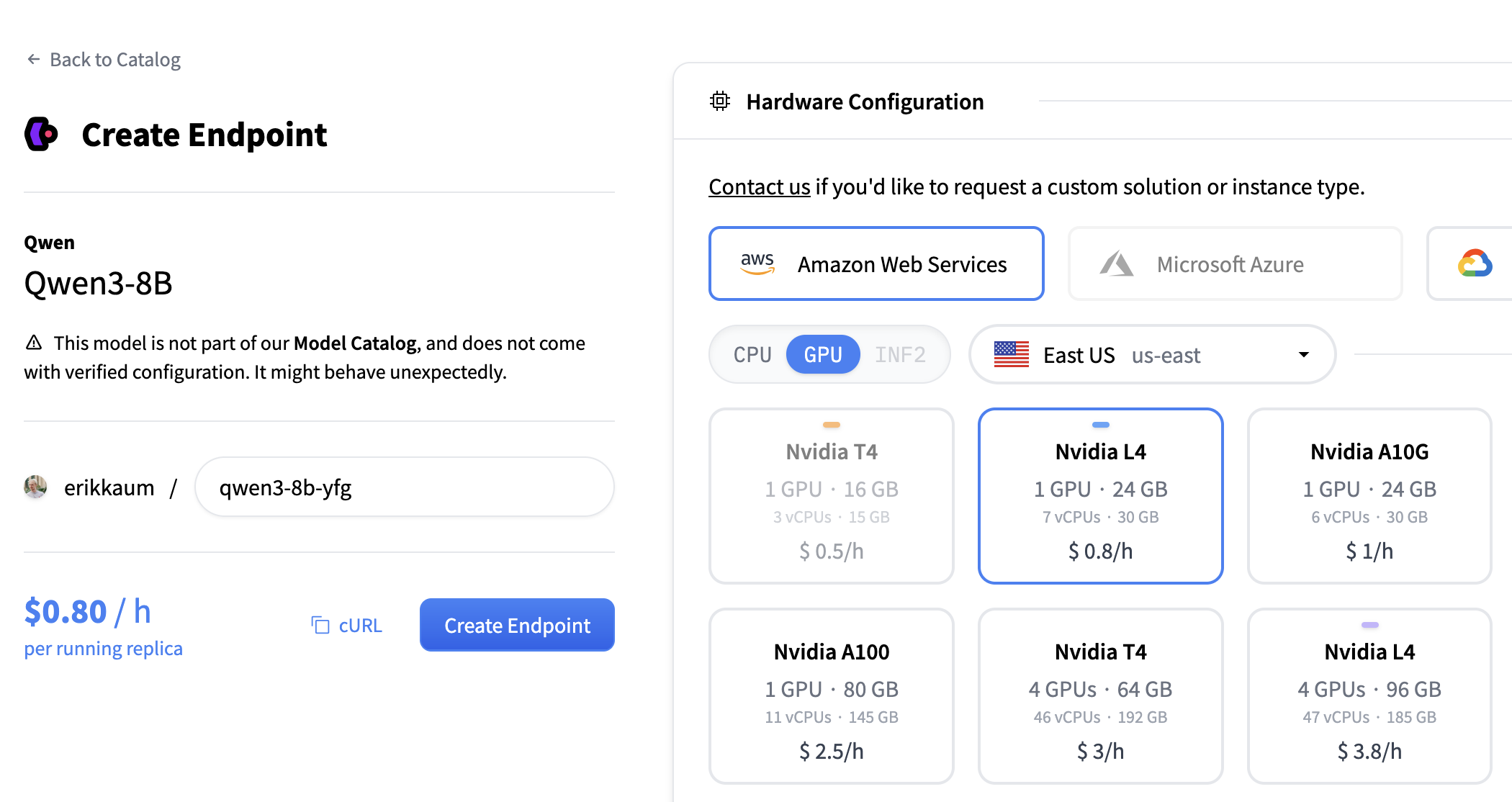
Container configuration:
- Select “custom”
- Container URL:
zmlai/llmd:latest - Container port:
8000 - Health route:
/v1/models(to my knowledge LLMD doesn’t expose a dedicated health route, but this works fine for the Kubernetes readiness probe.)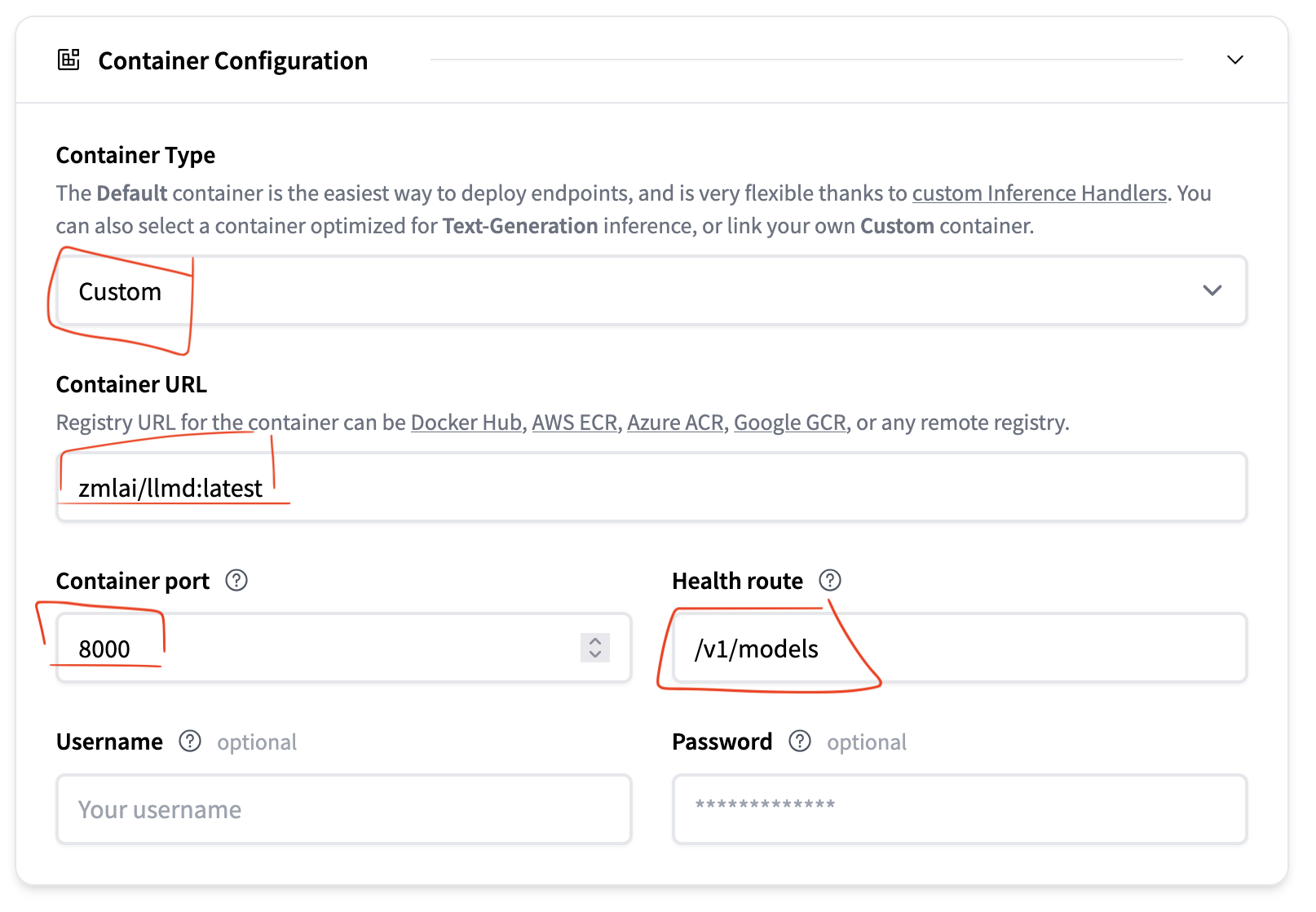
Advanced configuration:
- Set container arguments to:
This tells LLMD where to find the model weights (they’ll be automatically mounted at--model-dir=/repository/repository).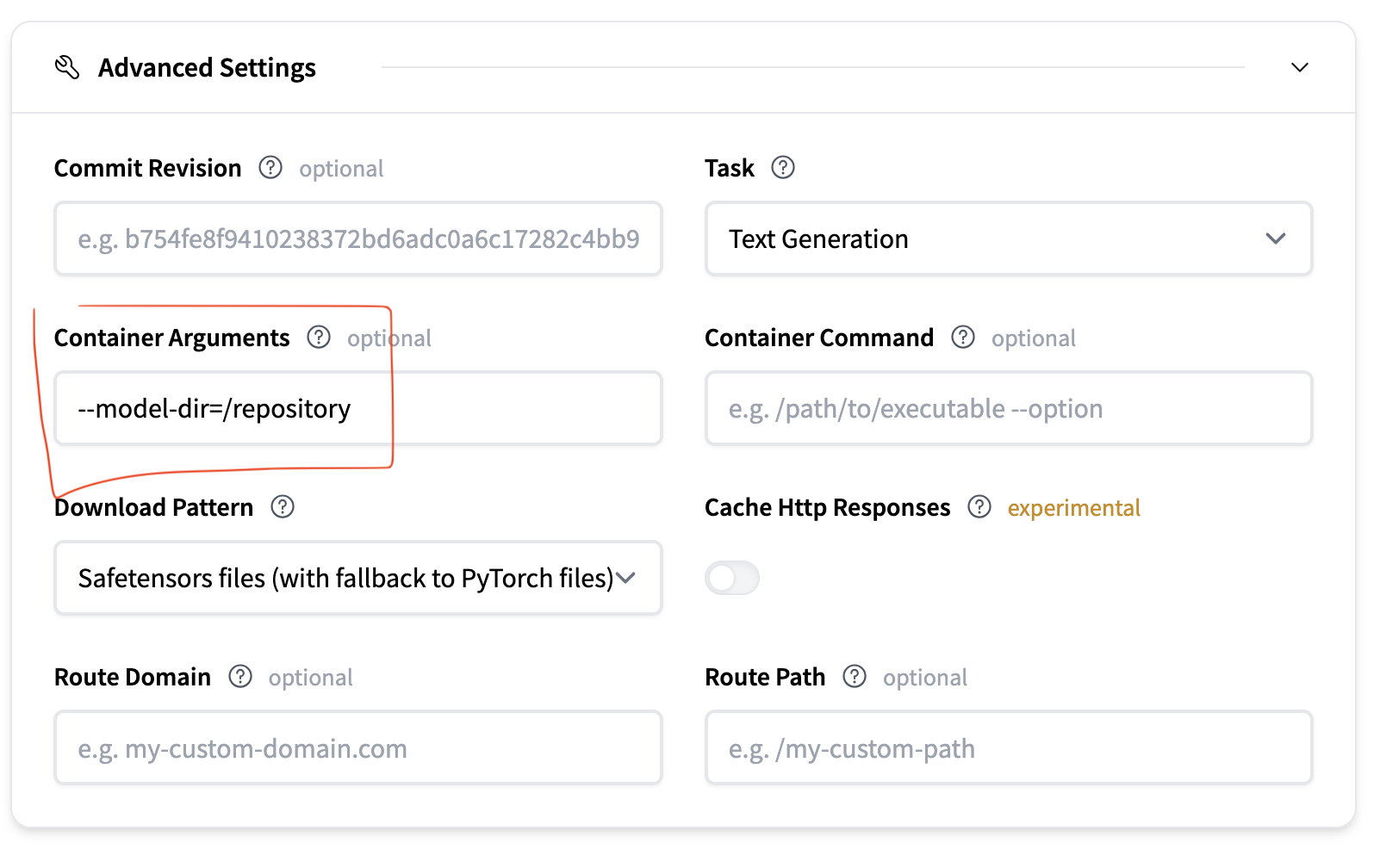
- Set container arguments to:
Click "Create Endpoint" and you’re off!
4. Call the model
After a few minutes your Inference Endpoint status changes from Initializing to Running. You can check the logs to make sure things are working 👍
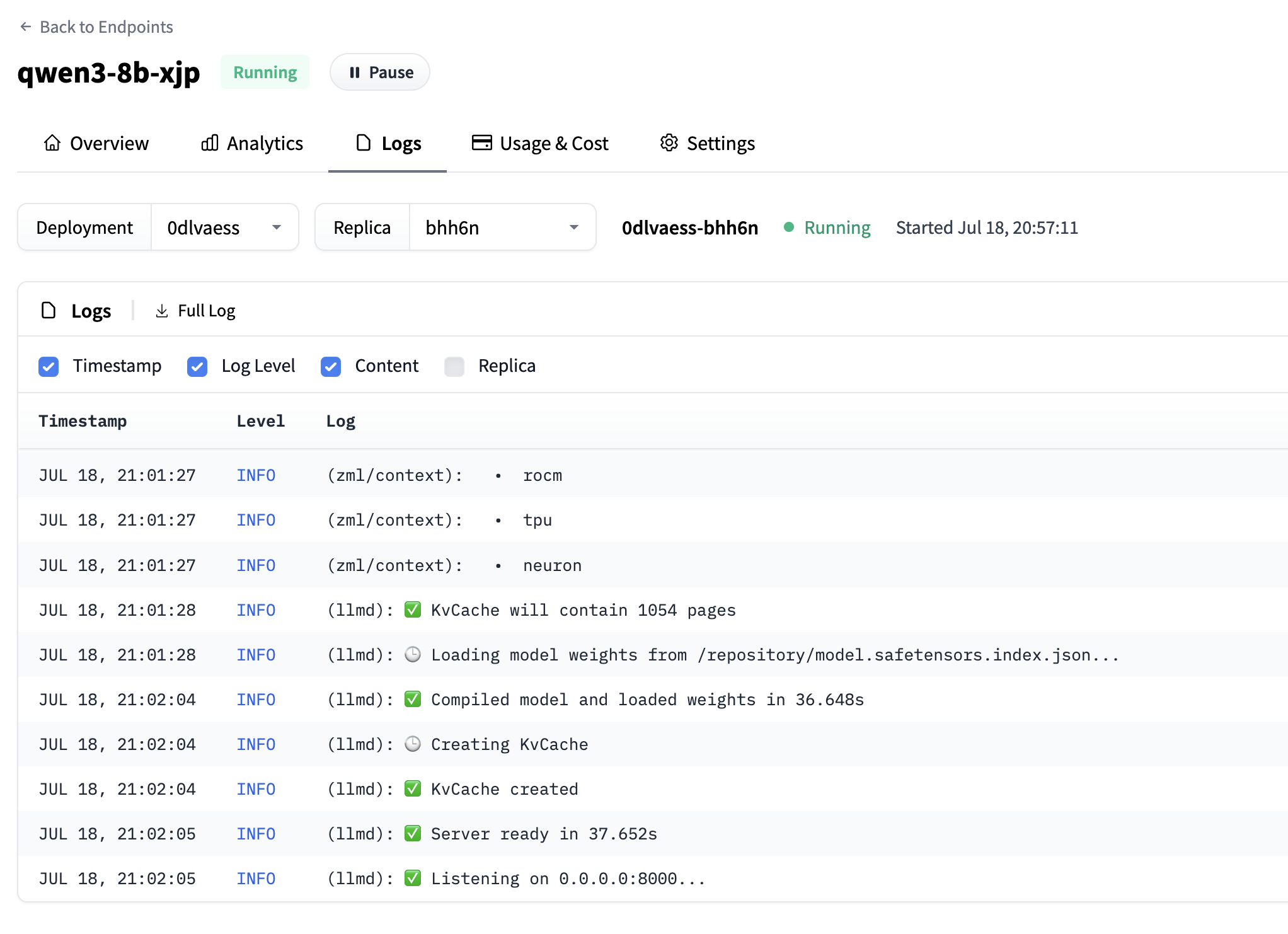
Now grab the inference URL. Then fire up your terminal and make a request:
curl https://<your-url>.endpoints.huggingface.cloud/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer hf_xxx" \
-d '{
"model": "qwen3",
"messages": [
{ "role": "user", "content": "Can you please let us know more details about your " }
],
"max_tokens": 150
}'
The result should be something like:
```json
{
"id": "id",
"choices": [
{
"finish_reason": "length",
"index": 0,
"message": {
"content": "<think>\nOkay, the user is asking for more details about me, but their message is cut off. They wrote, \"Can you please let us know more details about your\" and then it ends. I need to figure out how to respond appropriately.\n\nFirst, I should acknowledge that their message is incomplete. Maybe they intended to ask about my capabilities, features, or something else. Since they mentioned \"more details about your,\" it's possible they were going to ask about my functions, how I work, or my purpose.\n\nI should respond politely, letting them know that their message is incomplete and ask them to clarify their question. That way, I can provide a helpful answer. I need to make sure my response is friendly and encourages them",
"refusal": null,
"role": "assistant"
},
"logprobs": null
}
],
"created": 1752865521425,
"model": "qwen3",
"system_fingerprint": "",
"object": "chat.completion",
"usage": {
"completion_tokens": 150,
"prompt_tokens": 40,
"total_tokens": 40,
"completion_tokens_details": null,
"prompt_tokens_details": null
}
}
Nice 🔥
Next
Keep in mind that this is still a technical preview, not yet production-ready. Expect some rough edges or things that may break.
Current limitations:
- It supports the currently only llama and qwen3 model types.
- Can only run on a single GPU, so larger models that need to be sharded on multiple GPUs won't work
- Maximum batch size of 16.
- Doesn't support prefix caching
If you try it out, the ZML team would probably appreciate any feedback you have. And same goes for us, if you’ve got thoughts or feedback on Inference Endpoints, leave a comment below 🙌
Happy hacking!






