
cosmos-predict2-2b-t2i-ex-q2_k.gguf

Seems that https://huggingface.co/calcuis/cosmos-predict2-gguf/blob/main/cosmos-predict2-2b-t2i-ex-q2_k.gguf is unusable, gives only noise as output
after a try of ex3-one i will say how it is
i can also try different samplers, it was euler with normal scheduler
ex3 is a garbage too
also with dpm++2m and karras
cosmos-predict2-2b-t2i-ex-q3_k_m.gguf is usable, but not good.
maybe it will be great to have something smaller than q3_K_M but still usable. I am checking now how is q4
cosmos-predict2-2b-t2i-ex3-q4_0.gguf is good
ex3 doesn't change the quality; just taken out extra state and pos embedder tensors to avoid warning message since those tensors never been used in this case
btw, 14b-v2w-q2_k should be usable

@GeorgyGUF
In the hobbyist local LLM community, it is conventional wisdom that smaller models are much more sensitive to quantization damage than larger models. So it is expected that a 2 bit quant (which Q2_K denotes) of the 2B version would be unusable. But why do you need such a small quant when the uncompressed model is already so small? At this point, it is the text encoder, not the diffusion model that is taking up most of the VRAM.
Also, QX_0 and QX_1 quants are legacy quants, which use a naive quantization scheme and are considered to be very inefficient in terms of quantization "accuracy" per memory footprint. I am not sure why people in the local image/video generation community appear to keep using them. For your specific problem about finding the best possible quant that is smaller than Q3_K_M, the answer should be IQ3_M, but unfortunately
@calcuis
and
@city96
do not seem to upload IQ quants. IQ quants are the most footprint-efficient quants that are currently available in the GGUF format, but I am not sure if there is a reason why they do not work well with diffusion models specifically.
Below is a benchmark comparing the various quantization schemes. Do note that this graph contains both imatrix and non-imatrix quants, and they should not be compared with each other. (imatrix uses calibration data to determine which weights are more important, and biases the final quantized values towards the more important weights)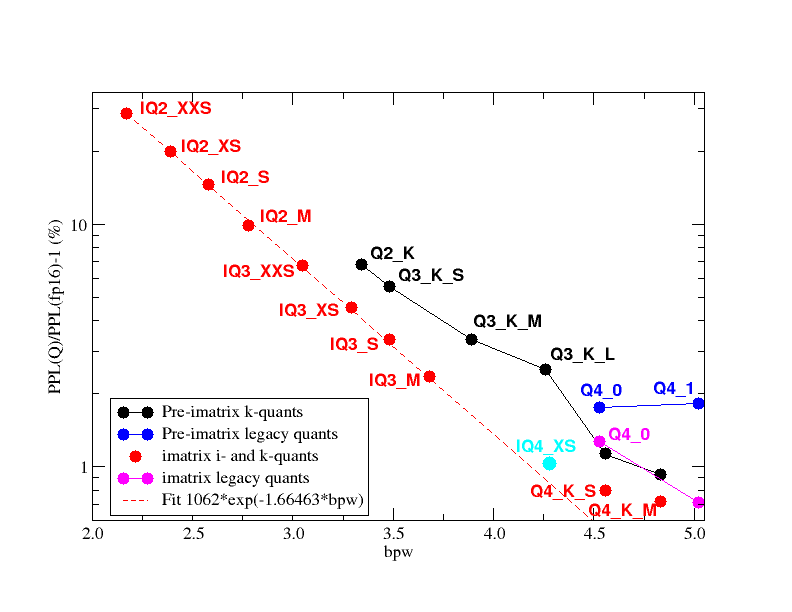
not every tensor can be quantized; most of the time, q2 is for quick test; runnable or not, since the speed should be the fastest, and you can form a spectrum for further evaluation; and not all of them are not usable, i.e., llama-q2, ace-q2, qmnigen2-q2, and etc., do works pretty good
@calcuis
Could you look into providing IQ quants, such as IQ2_M, IQ3_XS and IQ4_XS as well? Those should provide a significant saving in VRAM footprint at literally the same quality as their QX_K counterparts, from experience with local LLMs. Below is a diagram showing directly comparing IQ quants and K quants: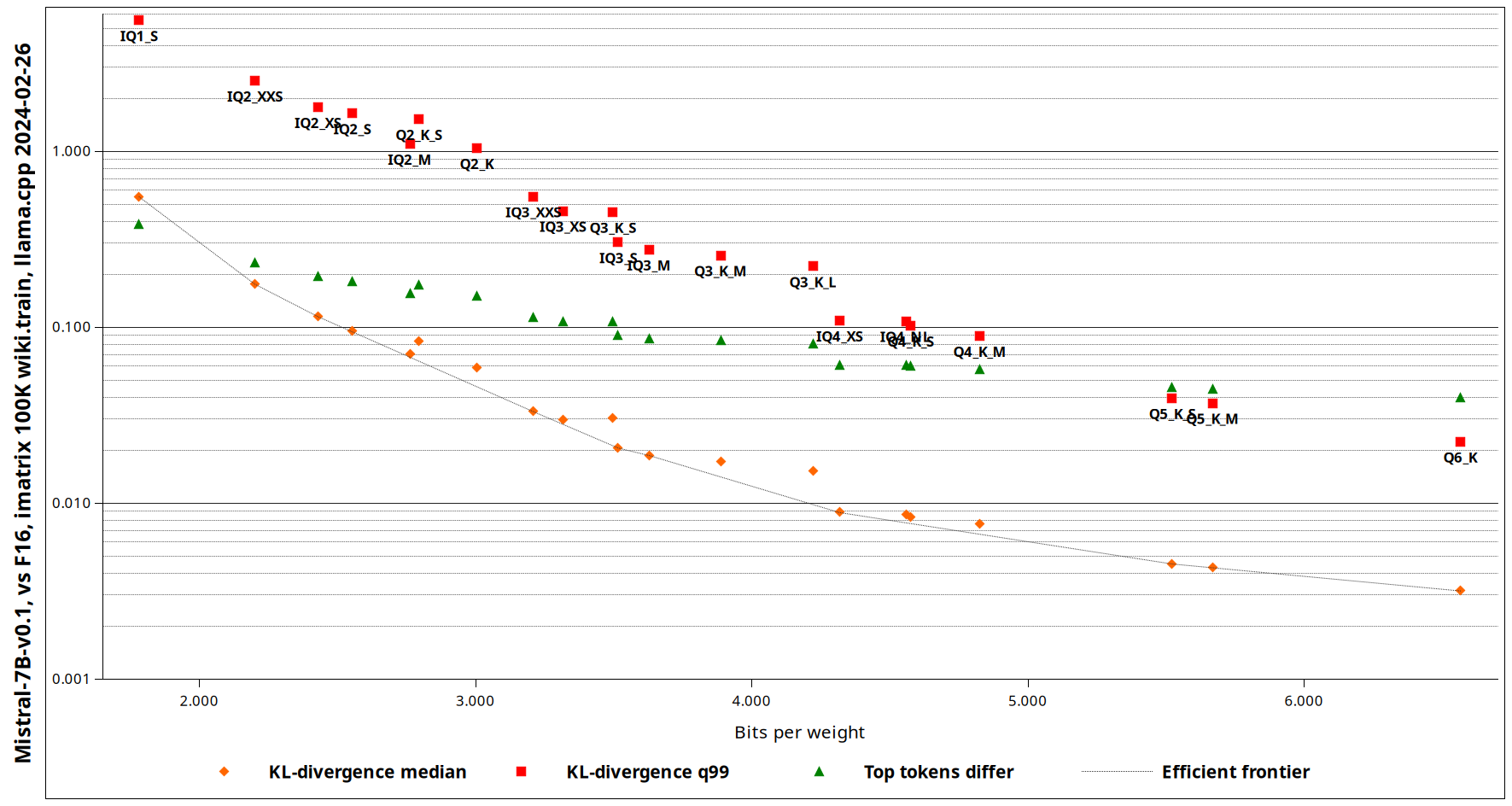
Also, the other method to improve GGUF quantization quality for LLMs is imatrix, which involves using calibration data to determine the more important weights. This is the only repo I can find where someone tried using it to generate GGUFs for image generation models: https://huggingface.co/Eviation/flux-imatrix
Do you think it is possible to replicate that as well?
imatrix is a different calculation; need to rewrite the dequantizor or make a new one (engine); otherwise those i-quants won't work; and it seems just substitute the lower tail; most of time, we might drop it due to the quality issues, making those files unusable..
Hang on, imatrix and IQ quants are 2 different, separate things. Imatrix uses calibration data and can be used to improve any type of GGUF quant in theory. IQ quants, K quants and even legacy quants can all be generated with or without imatrix. It makes absolutely no difference to the inference software whether or not imatrix is used, because the format of the quantized weights is identical, only that the scale and offset values are different.
IQ quants are a newer type of quant that uses a more sophisticated algorithm to achieve better efficiency than K quants, at the cost of somewhat reduced inference speed on CPUs and maybe non Nvidia GPUs.
So are you referring to generating/inferencing IQ quants, or generating imatrix quants, or both?
it's different quant and dequant logic guess; thanks, we might get back to that while clearing up those stuffs on-hand
Hang on, imatrix and IQ quants are 2 different, separate things. Imatrix uses calibration data and can be used to improve any type of GGUF quant in theory. IQ quants, K quants and even legacy quants can all be generated with or without imatrix. It makes absolutely no difference to the inference software whether or not imatrix is used, because the format of the quantized weights is identical, only that the scale and offset values are different.
IQ quants are a newer type of quant that uses a more sophisticated algorithm to achieve better efficiency than K quants, at the cost of somewhat reduced inference speed on CPUs and maybe non Nvidia GPUs.
So are you referring to generating/inferencing IQ quants, or generating imatrix quants, or both?
supported; working
Very cool, although IQ4_NL is not really ideal (as you can see from the figure I posted), it is the other IQ quants like IQ4_XS, IQ3_M and smaller IQ quants that provide a meaningful improvement over K quants. I think IQ3_M in particular might be noteworthy to @GeorgyGUF if he is still interested in this, because he was specifically looking for something smaller than Q3_K_M that is still usable.
but this graph cannot be applied; it doesn't show/reveal the whole picture; the calculation is more sophisticated in i-quants; generally speaking, standard quants, q8_0, 5_0, 5_1, 4_0, 4_1, should be fastest, it's a very basic calculation; k quants involve more steps but just fixed variable; i quant has linear and matrix arrays, need to sort out something like slope, curve and pattern, might need to wait longer; by comparing only the 4-bit quants (across bits comparison is not fair), could run each of them, mark the final loading time, you will probably know something
since the quality for the same bit quants are identical, iq3, s, xxs, (no iq3_m actually) might not worth to do it, wait longer than 4_0, and get a worser quality; let's see how far can be reached in that case
But the point is to get maximum quality for the VRAM footprint, even if inference speed needs to be sacrificed. With Nvidia GPUs, the speed loss is very insignificant when using IQ quants for LLMs. What is the difference in speed between IQ quants and K quants for diffusion models?
Edit: IQ4_NL is supposedly able to give higher inference speed when running LLMs on ARM CPUs, but I also do not notice this when running LLMs on my phone (Samsung S24) either, so I just use IQ4_XS anyway because it is somehow not noticeably slower than Q4_K_S, but significantly smaller.
it's ok to get the smaller i quants for a huge text model; since we are trying to bypass numpy for a faster loading outcome; that's a different story; but let's explore more and sort out any possibility for handling this
But the point is to get maximum quality for the VRAM footprint, even if inference speed needs to be sacrificed. With Nvidia GPUs, the speed loss is very insignificant when using IQ quants for LLMs. What is the difference in speed between IQ quants and K quants for diffusion models?
depends on what type of machines you used; we are providing all s, k, i & t quants in kontext now; welcome to test it yourself, btw, for iq4_xs, iq3_s and iq3_xxs, might need to push to numpy for dequant for the time being; check model card for details; thanks