
gguf quantized version of wan2.2-s2v (all gguf: incl. encoders + vae)
- drag wan to >
./ComfyUI/models/diffusion_models - drag umt5xxl [3.47GB] to >
./ComfyUI/models/text_encoders - drag wav2vec2 [632MB] to >
./ComfyUI/models/audio_encoders - drag pig [254MB] to >
./ComfyUI/models/vae
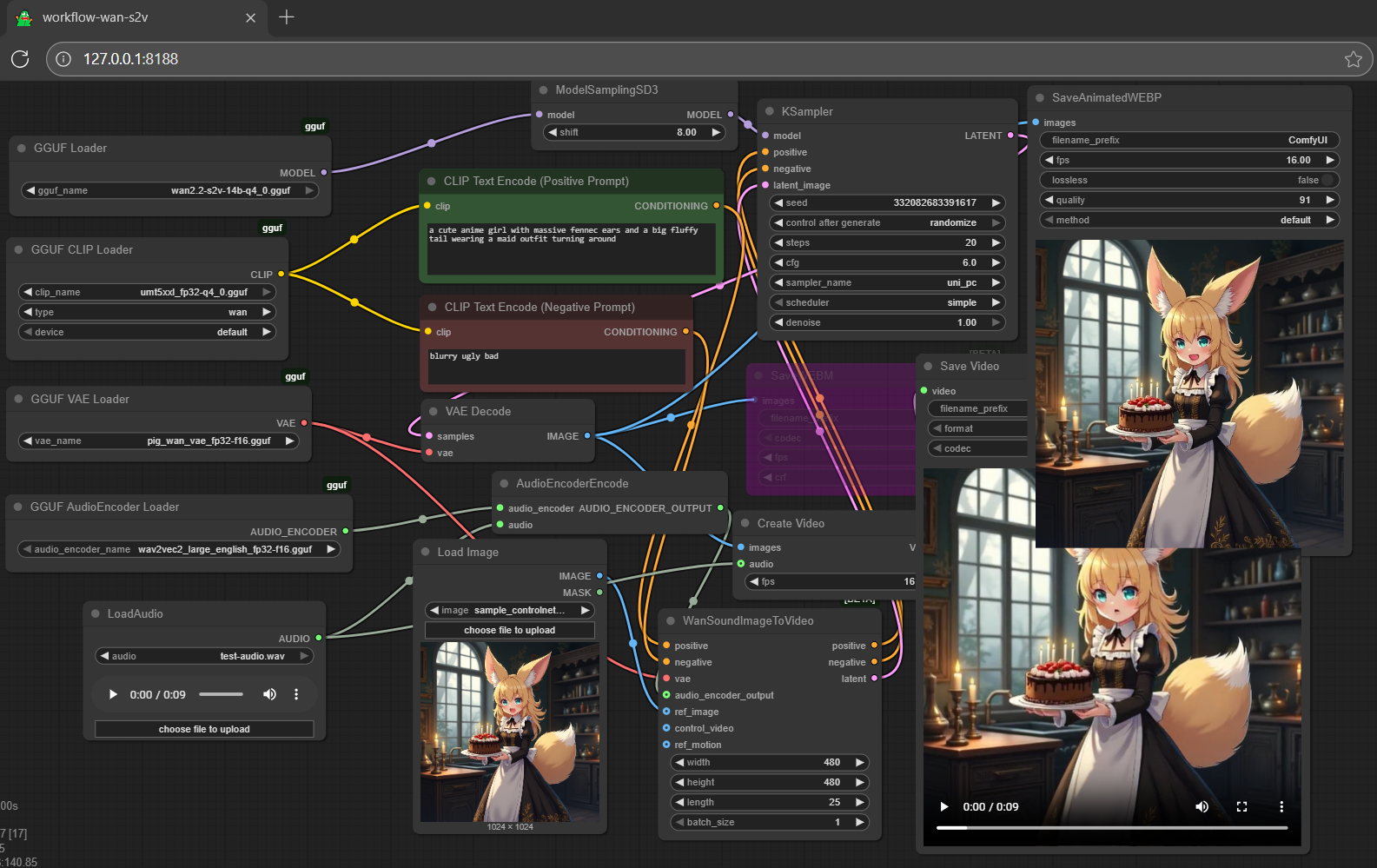

- Prompt
- a cute anime girl with massive fennec ears and a big fluffy tail wearing a maid outfit
- Negative Prompt
- blurry ugly bad

- Prompt
- a cute anime girl with massive fennec ears and a big fluffy tail wearing a maid outfit turning around
- Negative Prompt
- blurry ugly bad
- Prompt
- a conversation between cgg and connector
- Negative Prompt
- blurry ugly bad
note: the new GGUF AudioEncoder Loader on test; running gguf audio encoder wav2vec2 w/o ending error msg compare to fp16 safetensors (depends how long of your prompt/video)
reference
- for the lite workflow (save >70% loading time), get the
lite lorafor 4/8-step operation here - or opt to use scaled fp8 e4m3 safetensors
audio encoderhere and/or fp8 e4m3vaehere (don't even need to switch to native loaders asGGUF AudioEncoder LoaderandGGUF VAE Loadersupport both gguf and fp8 scaled safetensors files) - gguf-node (pypi|repo|pack)
- Downloads last month
- 1,304
Hardware compatibility
Log In
to view the estimation
2-bit
3-bit
4-bit
5-bit
6-bit
8-bit
16-bit
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
Model tree for calcuis/wan-s2v-gguf
Base model
Wan-AI/Wan2.2-S2V-14B