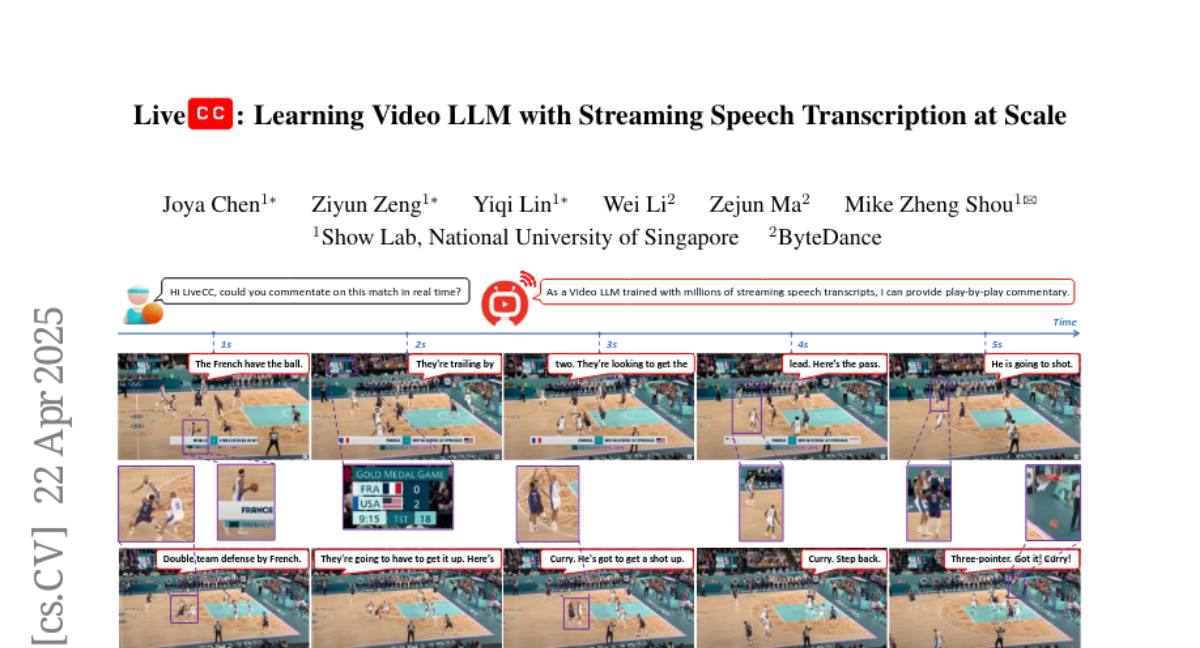
Learning Video LLM with Streaming Speech Transcription at Scale (CVPR 2025)
Joya Chen PRO
chenjoya
AI & ML interests
Video LLM
Recent Activity
upvoted
a
paper
about 5 hours ago
FocusUI: Efficient UI Grounding via Position-Preserving Visual Token Selection
upvoted
a
paper
2 days ago
ShowUI-π: Flow-based Generative Models as GUI Dexterous Hands
Organizations