
url
stringlengths 53
56
| repository_url
stringclasses 1
value | labels_url
stringlengths 67
70
| comments_url
stringlengths 62
65
| events_url
stringlengths 60
63
| html_url
stringlengths 41
46
| id
int64 450k
1.69B
| node_id
stringlengths 18
32
| number
int64 1
2.72k
| title
stringlengths 1
209
| user
dict | labels
list | state
stringclasses 1
value | locked
bool 2
classes | assignee
null | assignees
sequence | milestone
null | comments
sequence | created_at
timestamp[s] | updated_at
timestamp[s] | closed_at
timestamp[s] | author_association
stringclasses 3
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
104k
⌀ | reactions
dict | timeline_url
stringlengths 62
65
| performed_via_github_app
null | state_reason
stringclasses 2
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/coleifer/peewee/issues/2519 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2519/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2519/comments | https://api.github.com/repos/coleifer/peewee/issues/2519/events | https://github.com/coleifer/peewee/issues/2519 | 1,113,659,655 | I_kwDOAA7yGM5CYRkH | 2,519 | drop_tables does not delete "schema" tables in MySQL | {
"login": "ascaron37",
"id": 8329544,
"node_id": "MDQ6VXNlcjgzMjk1NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8329544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ascaron37",
"html_url": "https://github.com/ascaron37",
"followers_url": "https://api.github.com/users/ascaron37/followers",
"following_url": "https://api.github.com/users/ascaron37/following{/other_user}",
"gists_url": "https://api.github.com/users/ascaron37/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ascaron37/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ascaron37/subscriptions",
"organizations_url": "https://api.github.com/users/ascaron37/orgs",
"repos_url": "https://api.github.com/users/ascaron37/repos",
"events_url": "https://api.github.com/users/ascaron37/events{/privacy}",
"received_events_url": "https://api.github.com/users/ascaron37/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"So the reason the drop doesn't work is because Peewee, when \"safe=True\" (the default), attempts to check if the table exists in the current db. To get this working, you can just specify `safe=False`:\r\n\r\n```python\r\n# This will skip the check that the table exists, and then issue the\r\n# appropriate drop table.\r\ndb1.drop_tables([Model2], safe=False)\r\n```",
"Perfect, thank you!"
] | 2022-01-25T09:48:21 | 2022-01-25T18:14:51 | 2022-01-25T15:40:33 | NONE | null | I have a problem testing my application with MySQL. I have two separate databases on one MySQL server, say DB1 and DB2. I create a DB Object with `db1 = MySQLDatabase('DB1', ...)`. All my models from DB2 have a schema attribute in the inner Meta class:
```
class DBModel(Model):
class Meta:
database = db1
class Model2(DBModel):
id = AutoField()
class Meta:
schema = 'DB2'
```
In the application this works well, but for testing purposes I want to create and drop all tables. All models from the first DB get created and deleted properly. My problem now is that creating the tables in the second DB works as expected, but drop_tables does not drop the tables from the second DB.
```
db1.create_tables((Model2,)) # creates the table in the second DB
db1.drop_tables((Model2,)) # does not drop tables from second DB
```
Is my usage of the schema attribute a lucky incident from the standpoint that it works in my application? Can I force drop_tables to delete also the tables from the other schemas? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2519/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2519/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2518 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2518/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2518/comments | https://api.github.com/repos/coleifer/peewee/issues/2518/events | https://github.com/coleifer/peewee/issues/2518 | 1,111,184,135 | I_kwDOAA7yGM5CO1MH | 2,518 | PooledMySQLDatabase MaxConnectionsExceeded | {
"login": "Ahern542968",
"id": 32890883,
"node_id": "MDQ6VXNlcjMyODkwODgz",
"avatar_url": "https://avatars.githubusercontent.com/u/32890883?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Ahern542968",
"html_url": "https://github.com/Ahern542968",
"followers_url": "https://api.github.com/users/Ahern542968/followers",
"following_url": "https://api.github.com/users/Ahern542968/following{/other_user}",
"gists_url": "https://api.github.com/users/Ahern542968/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Ahern542968/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Ahern542968/subscriptions",
"organizations_url": "https://api.github.com/users/Ahern542968/orgs",
"repos_url": "https://api.github.com/users/Ahern542968/repos",
"events_url": "https://api.github.com/users/Ahern542968/events{/privacy}",
"received_events_url": "https://api.github.com/users/Ahern542968/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"http://docs.peewee-orm.com/en/latest/peewee/playhouse.html#pool\r\n\r\nYou are not managing your connections.\r\n\r\nCall connect at the beginning of a request/thread, and close() at the end. This ensures that your conns are returned to the pool."
] | 2022-01-22T02:08:23 | 2022-01-22T13:10:42 | 2022-01-22T13:10:42 | NONE | null | I use PooledMySQLDatabase for a pool , when I with atomic for create , but case MaxConnectionsExceeded
```
def logic_create_event_item(operate_dict):
user_id = operate_dict["user_id"]
content_type = "event"
event_id = operate_dict["event_id"]
operate_type = "create"
user_operate_log = UserOperateLog.get_or_none(
UserOperateLog.user_id == user_id, UserOperateLog.content_type == content_type,
UserOperateLog.event_id == event_id, UserOperateLog.operate_type == operate_type)
if user_operate_log:
return
with settings.DB.atomic() as txn:
try:
user_operate_log = UserOperateLog()
user_operate_log.user_id = user_id
user_operate_log.content_type = content_type
user_operate_log.content_id = event_id
user_operate_log.operate_type = operate_type
user_operate_log.content = "创建埋点"
user_operate_log.save(force_insert=True)
except Exception as e:
txn.rollback()
raise e
```

| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2518/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2518/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2517 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2517/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2517/comments | https://api.github.com/repos/coleifer/peewee/issues/2517/events | https://github.com/coleifer/peewee/issues/2517 | 1,110,727,085 | I_kwDOAA7yGM5CNFmt | 2,517 | Select with complex where statement don't transform correctly | {
"login": "spacialhufman",
"id": 33603355,
"node_id": "MDQ6VXNlcjMzNjAzMzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/33603355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/spacialhufman",
"html_url": "https://github.com/spacialhufman",
"followers_url": "https://api.github.com/users/spacialhufman/followers",
"following_url": "https://api.github.com/users/spacialhufman/following{/other_user}",
"gists_url": "https://api.github.com/users/spacialhufman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/spacialhufman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/spacialhufman/subscriptions",
"organizations_url": "https://api.github.com/users/spacialhufman/orgs",
"repos_url": "https://api.github.com/users/spacialhufman/repos",
"events_url": "https://api.github.com/users/spacialhufman/events{/privacy}",
"received_events_url": "https://api.github.com/users/spacialhufman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Peewee will generate that `0 = 1` when you write an expression that evalutes to `WHERE x IN ()` (which is always false):\r\n\r\n```python\r\n.where(Model.field.in_([]))\r\n```\r\n\r\nSo in your example, at least one of your lists is empty, or alternatively your `tickets` iterator is a generator or something and returns a list, but when iterated the 2nd time it is consumed and returns an empty list."
] | 2022-01-21T17:36:05 | 2022-01-21T17:44:28 | 2022-01-21T17:44:28 | NONE | null | I was building a complex query in my app which is describe below:
`query = (self.repository.getSelect((
fieldId,
fieldReceivedAt,
fieldMac,
fieldCode,
fieldDomain,
fieldStatus
))
.where(
fieldId.between(initialId, endId + 10000) &
SystemEventModel.Message.contains('done query') &
self.__getCodeFuncField().in_([t.code for t in tickets]) &
SystemEventModel.FromHost.in_([t.mac for t in tickets])
)
.order_by(fieldCode))`
The sintax seems correct by when I run the application, the ORM makes my query look like below:
`SELECT t1.ID AS id, t1.ReceivedAt AS received_at, t1.FromHost AS mac, TRIM(SUBSTR(SUBSTR(t1.Message, INSTR(t1.Message, '#'), 11), 1, INSTR(SUBSTR(t1.Message, INSTR(t1.Message, '#'), 11), ' '))) AS code, TRIM(IF((INSTR(t1.Message, 'dns name exists') > 0), 'dns name exists, but no appropriate record', SUBSTR(TRIM(SUBSTR(SUBSTR(t1.Message, INSTR(t1.Message, '#'), 100), INSTR(SUBSTR(t1.Message, INSTR(t1.Message, '#'), 100), ' '), 100)), 1, INSTR(TRIM(SUBSTR(SUBSTR(t1.Message, INSTR(t1.Message, '#'), 100), INSTR(SUBSTR(t1.Message, INSTR(t1.Message, '#'), 100), ' '), 100)), ' ')))) AS domain, TRIM(IF((INSTR(t1.Message, 'dns name exists') > 0), 1, IF((INSTR(t1.Message, 'dns does not exist') > 0), 0, 2))) AS status FROM SystemEvents AS t1 WHERE ((((id BETWEEN 23706618 AND 23726554) AND (t1.Message LIKE '%done query%')) AND (TRIM(SUBSTR(SUBSTR(t1.Message, INSTR(t1.Message, '#'), 11), 1, INSTR(SUBSTR(t1.Message, INSTR(t1.Message, '#'), 11), ' '))) IN ('#118729', '#118730', '#12485651', '#12485652', '#12485653', '#129837753', '#129837754', '#1301639'))) AND (0 = 1)) ORDER BY code`
Why the last where was transformed into `(0 = 1)` if it is a **where in** statement?
Any help would be appreciated.
Thanks | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2517/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2517/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2516 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2516/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2516/comments | https://api.github.com/repos/coleifer/peewee/issues/2516/events | https://github.com/coleifer/peewee/issues/2516 | 1,107,573,649 | I_kwDOAA7yGM5CBDuR | 2,516 | generate_models from DatabaseProxy ValueError | {
"login": "LLjiahai",
"id": 30220658,
"node_id": "MDQ6VXNlcjMwMjIwNjU4",
"avatar_url": "https://avatars.githubusercontent.com/u/30220658?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LLjiahai",
"html_url": "https://github.com/LLjiahai",
"followers_url": "https://api.github.com/users/LLjiahai/followers",
"following_url": "https://api.github.com/users/LLjiahai/following{/other_user}",
"gists_url": "https://api.github.com/users/LLjiahai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LLjiahai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LLjiahai/subscriptions",
"organizations_url": "https://api.github.com/users/LLjiahai/orgs",
"repos_url": "https://api.github.com/users/LLjiahai/repos",
"events_url": "https://api.github.com/users/LLjiahai/events{/privacy}",
"received_events_url": "https://api.github.com/users/LLjiahai/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"In this case, just instantiate the introspector directly - or pass it the underlying db instance:\r\n\r\n```python\r\n# Option 1:\r\nintrospector = Introspector(MySQLMetadata(database))\r\nintrospector.generate_models()\r\n\r\n# Option 2:\r\nmodels = generate_models(db.obj)\r\n```",
"I gave this another look and made a better fix. Going forward introspection will work with a proxy just fine."
] | 2022-01-19T02:42:34 | 2022-01-19T23:55:00 | 2022-01-19T16:22:41 | NONE | null | db = DatabaseProxy()
db.initialize(RetryMySQLDatabase.get_db_instance(**kw_config))
models = generate_models(db)
ValueError: Introspection not supported for <peewee.DatabaseProxy object at 0x000002859D87FE40> | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2516/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2516/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2515 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2515/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2515/comments | https://api.github.com/repos/coleifer/peewee/issues/2515/events | https://github.com/coleifer/peewee/issues/2515 | 1,106,872,487 | I_kwDOAA7yGM5B-Yin | 2,515 | How to get all data from my Model? | {
"login": "peepo5",
"id": 72892531,
"node_id": "MDQ6VXNlcjcyODkyNTMx",
"avatar_url": "https://avatars.githubusercontent.com/u/72892531?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/peepo5",
"html_url": "https://github.com/peepo5",
"followers_url": "https://api.github.com/users/peepo5/followers",
"following_url": "https://api.github.com/users/peepo5/following{/other_user}",
"gists_url": "https://api.github.com/users/peepo5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/peepo5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/peepo5/subscriptions",
"organizations_url": "https://api.github.com/users/peepo5/orgs",
"repos_url": "https://api.github.com/users/peepo5/repos",
"events_url": "https://api.github.com/users/peepo5/events{/privacy}",
"received_events_url": "https://api.github.com/users/peepo5/received_events",
"type": "User",
"site_admin": false
} | [] | closed | true | null | [] | null | [
"You need to read the documentation.\r\n\r\nTake 10 or 15 minutes and go through the quick start.\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/quickstart.html#retrieving-data",
"So I have to iterate over the select to get any results? Your answer to my question did not help.",
"http://docs.peewee-orm.com/en/latest/peewee/querying.html#selecting-a-single-record\r\n\r\nhttp://docs.peewee-orm.com/en/latest/peewee/querying.html#selecting-multiple-records",
"To answer my own question, yes you must iterate. @coleifer are there any ways of not iterating to save time? like recieving an array of classes instead of just something to iterate upon. Thanks. And please give some explanation rather than just sending a link, thank you.",
"https://docs.python.org/3/library/functions.html#func-list"
] | 2022-01-18T12:50:29 | 2022-01-18T20:08:55 | 2022-01-18T12:57:12 | NONE | off-topic | My class looks like this:
```py
class WaitPayment(BaseModel):
txn_id = TextField(unique=True, primary_key=True)
discord_id = TextField()
ms_expires = DecimalField()
```
and I want to recieve all of its records as a dict. However, when I use `WaitPayment.select()` or `WaitPayment.select().dicts()`, it returns:
```sql
SELECT "t1"."txn_id", "t1"."discord_id", "t1"."ms_expires" FROM "waitpayment" AS "t1"
```
in the terminal, which is not what I want. I do not want the sql query, I want the result. Any help? Thanks. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2515/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2515/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2514 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2514/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2514/comments | https://api.github.com/repos/coleifer/peewee/issues/2514/events | https://github.com/coleifer/peewee/issues/2514 | 1,105,342,191 | I_kwDOAA7yGM5B4i7v | 2,514 | Field argument 'help_text' seem have not realized in MySQL... | {
"login": "xfl12345",
"id": 17960863,
"node_id": "MDQ6VXNlcjE3OTYwODYz",
"avatar_url": "https://avatars.githubusercontent.com/u/17960863?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xfl12345",
"html_url": "https://github.com/xfl12345",
"followers_url": "https://api.github.com/users/xfl12345/followers",
"following_url": "https://api.github.com/users/xfl12345/following{/other_user}",
"gists_url": "https://api.github.com/users/xfl12345/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xfl12345/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xfl12345/subscriptions",
"organizations_url": "https://api.github.com/users/xfl12345/orgs",
"repos_url": "https://api.github.com/users/xfl12345/repos",
"events_url": "https://api.github.com/users/xfl12345/events{/privacy}",
"received_events_url": "https://api.github.com/users/xfl12345/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The `help_text` and `verbose_name` are used for integrations with flask-peewee (or other user-facing applications) and do not have any impact on the schema."
] | 2022-01-17T04:03:44 | 2022-01-17T14:23:27 | 2022-01-17T14:23:27 | NONE | null | I think the 'help_text' parameter may become the 'comment' value in MySQL.
It did not work as i expect.
Neigther of 'verbose_name' parameter.
I would appreciate if the little feature has been realized.
Thanks a lot.
(BTW: peewee is so much easier to use than SQLAlchemy!!!Can't help coding with peewee.) | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2514/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2514/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2513 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2513/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2513/comments | https://api.github.com/repos/coleifer/peewee/issues/2513/events | https://github.com/coleifer/peewee/issues/2513 | 1,101,868,467 | I_kwDOAA7yGM5BrS2z | 2,513 | Unreliable hybrid_fields order in model_to_dict(model, extra_attrs=hybrid_fields) bug? | {
"login": "neutralvibes",
"id": 26578830,
"node_id": "MDQ6VXNlcjI2NTc4ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26578830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/neutralvibes",
"html_url": "https://github.com/neutralvibes",
"followers_url": "https://api.github.com/users/neutralvibes/followers",
"following_url": "https://api.github.com/users/neutralvibes/following{/other_user}",
"gists_url": "https://api.github.com/users/neutralvibes/gists{/gist_id}",
"starred_url": "https://api.github.com/users/neutralvibes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neutralvibes/subscriptions",
"organizations_url": "https://api.github.com/users/neutralvibes/orgs",
"repos_url": "https://api.github.com/users/neutralvibes/repos",
"events_url": "https://api.github.com/users/neutralvibes/events{/privacy}",
"received_events_url": "https://api.github.com/users/neutralvibes/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"~~Despite spending a few hours on it, a slap from myself helped me realise that perhaps OrderedDict isn't being used, despite database fields seemingly reproduced in reliable in order.~~ Nope, dict keys became reliably ordered from python 3.7.",
"Dict keys are not sorted -- exactly. This is not an issue in my opinion, this is just the nature of dictionaries. A dictionary is an inherently unordered data-structure, and while later Python preserves the insert order, it's not something to rely upon.\r\n\r\nYou already have your list of attrs - so you probably want to do something like: `table.append([getattr(model, attr) for attr in list_of_attrs])`. Or just pull the keys out of the resulting dict in the order you need them.",
"First, many thanks for reviewing.\r\n\r\nDicts have guaranteed order as of python 3.7 so can be relied upon. \r\n I have looked at the underlyng code and the reason is you convert the input to a `Set`. The reason for the lack of stability is because of a shortcut you use to convert the input.\r\n\r\n~~~python\r\n_clone_set = lambda s: set(s) if s else set()\r\n~~~\r\n\r\nSets still do not have this assurance, and I wonder if using a List would be better saving on converting many rows of data for the sake of it. I bow to your superior knowledge so shall leave it there.\r\n\r\nThanks again.",
"We don't bow to anyone in Peewee!\r\n\r\nI think my recommendation to you is the same:\r\n\r\n* either do not use `model_to_dict()` and just grab the attrs you want explicitly\r\n* or, once you have the dict back, pull the fields out of it explicitly using a list comprehension or the like"
] | 2022-01-13T14:38:27 | 2022-01-13T16:26:25 | 2022-01-13T16:11:07 | NONE | null | # Hybrid fields output order from model_to_dict - bug?
## Problem
- Python Version: 3.7.6
I have a case where a gui table requires row data in tuple format. This must be ordered correctly in relation to the provided headers. The data is supplied by a model with a couple of hybrid fields.
I am finding that irrespective of the order provided to the `extra_attrs` parameter of `model_to_dict`, while the order of the data directly from the database is predictable, the order of the resultant hybrid fields attached is not in my case.
## Example
Here is an example missing definitions but, I hope gives enough to demonstate with a fictious Person table where `status` and `age` are hybrids getting their data from other Person fields.
~~~python
# Fields to list, * denotes hybrid field
display_list = [ 'id', 'name', '*status', '*age' ]
# Get hybrids list
hybrid_fields = [ f for f in display_list if f.startswith('*') ]
# Printing shows supplied order consistently
print(f'hybrids: {hybrid_fields}')
# Output: hybrids: ['status', 'age']
# Grab list of non hybrid fields to extract
only_prep = [ f for f in display_list if not f.startswith('*') ]
# Get attributes for `only_list` from table class
only_list = ( attrgetter(*only_prep)(Person) ) if len(only_prep) else ()
print(only_list)
# Output: (<AutoField: Person.id>, <CharField: Person.name>)
table_data = [] # to hold return from encapsulating function
for rec in Person.select():
row = model_to_dict( rec, only=only_list, extra_attrs=hybrid_fields )
print( row.keys() )
# Expected: dict_keys(['id', 'name', 'status','age']) ....and so on
# Sometimes on python restart: dict_keys(['id', 'name', 'age', 'status']) .... notice the change in the last two.
table_data.append( tuple(row.values()) )
~~~
## Tales of the unexpected
What is bizzare is that while python is running the order returned seems fixed. Run the program from scratch a few times after a period then it can alternate.
## Advice appreciated
Not sure if I'm doing something wrong. Tried making `hybrid_fields ` a tuple with no joy. Any suggestions would be appreciated as I am not sure if this is a bug or an interface with the keyboard problem.
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2513/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2513/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2512 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2512/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2512/comments | https://api.github.com/repos/coleifer/peewee/issues/2512/events | https://github.com/coleifer/peewee/issues/2512 | 1,097,482,999 | I_kwDOAA7yGM5BakL3 | 2,512 | potential raw_unicode_escape error when debugging customized BINARY field | {
"login": "est",
"id": 23570,
"node_id": "MDQ6VXNlcjIzNTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/23570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/est",
"html_url": "https://github.com/est",
"followers_url": "https://api.github.com/users/est/followers",
"following_url": "https://api.github.com/users/est/following{/other_user}",
"gists_url": "https://api.github.com/users/est/gists{/gist_id}",
"starred_url": "https://api.github.com/users/est/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/est/subscriptions",
"organizations_url": "https://api.github.com/users/est/orgs",
"repos_url": "https://api.github.com/users/est/repos",
"events_url": "https://api.github.com/users/est/events{/privacy}",
"received_events_url": "https://api.github.com/users/est/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Did you not read the [code comment](https://github.com/coleifer/peewee/blob/master/peewee.py#L658-L661)? This is not part of the public API.",
"> Did you not read the code comment? This is not part of the public API.\r\n\r\nHi coleifer, I am using `logger.debug(\"sql is %s\", query)` with one of the parameter as a customized mysql BINARY field. I think it fits the code comment of \"This function is intended for debugging or logging purposes ONLY\".\r\n\r\nUnless there's another way to debug the SQL I am unaware of?\r\n",
"The correct way to do this is:\r\n\r\n```python\r\n\r\nquery = MyModel.select().where(MyModel.foo == 'bar')\r\nsql, params = query.sql()\r\n```\r\n\r\nYou can inspect the sql string, which contains proper placeholders for the parameters, and the parameters themselves."
] | 2022-01-10T05:49:22 | 2022-01-10T16:27:42 | 2022-01-10T14:01:50 | NONE | null | Hi,
I created a BINARY field following the doc
https://docs.peewee-orm.com/en/latest/peewee/models.html#creating-a-custom-field
When debugging the SQL, peewee will try `utf8` or `raw_unicode_escape` the `bytes()` parameter, at one time my bytes happens to be `b"\x0ee\xd4\xee\xff\xc0\x02r\xc2\\U0'\x00"`, which will error in [_query_val_transform](https://github.com/coleifer/peewee/blob/master/peewee.py#L683)
```
UnicodeDecodeError
'rawunicodeescape' codec can't decode bytes in position 9-11: truncated \UXXXXXXXX escape
```
I think it's because we assume the in SQL parameter, `bytes()` are displayable strings but unfortunately it will fail when there's an illegal "\U" literal inside the string. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2512/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2512/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2511 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2511/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2511/comments | https://api.github.com/repos/coleifer/peewee/issues/2511/events | https://github.com/coleifer/peewee/issues/2511 | 1,095,551,899 | I_kwDOAA7yGM5BTMub | 2,511 | Joined and grouped foreign key values are not cached | {
"login": "conqp",
"id": 3766192,
"node_id": "MDQ6VXNlcjM3NjYxOTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/3766192?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/conqp",
"html_url": "https://github.com/conqp",
"followers_url": "https://api.github.com/users/conqp/followers",
"following_url": "https://api.github.com/users/conqp/following{/other_user}",
"gists_url": "https://api.github.com/users/conqp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/conqp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/conqp/subscriptions",
"organizations_url": "https://api.github.com/users/conqp/orgs",
"repos_url": "https://api.github.com/users/conqp/repos",
"events_url": "https://api.github.com/users/conqp/events{/privacy}",
"received_events_url": "https://api.github.com/users/conqp/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Please consult the docs here: http://docs.peewee-orm.com/en/latest/peewee/relationships.html#avoiding-the-n-1-problem\r\n\r\nFurthermore, you cannot go from \"many\" -> \"many\" in a single go without using prefetch. You can join \"upwards\" no problem, e.g., select all Systems and also grab their Deployment:\r\n\r\n```python\r\n# This executes in a single query.\r\nquery = System.select(System, Deployment).join(Deployment)\r\nfor system in query:\r\n print(system.id, system.deployment.annotation)\r\n```\r\n\r\nWe cannot do the reverse automatically, e.g., get deployments and all their systems, because of SQL's tabular nature.\r\n\r\nSo you can either:\r\n\r\n1. Use `prefetch()` (although I strongly advise profiling this beforehand to see if it actually provides any measurable improvements)\r\n2. Use N+1, e.g., for each deployment also query its systems.\r\n\r\nAlso note that in your first query you are not actually aggregating anything, and the query probably doesn't do what you think it does.\r\n\r\nThe docs provide many examples: http://docs.peewee-orm.com/en/latest/peewee/relationships.html#avoiding-the-n-1-problem\r\n\r\nLastly, queries generated by accessing a backref are not cached -- accessing the backref creates a new query. If you want to iterate over a backref multiple times you can just assign it to a local variable:\r\n\r\n```python\r\n\r\nuser = User.get(User.username == 'charlie')\r\ntweets = user.tweets\r\n# Query is only evaluated once:\r\nfor t in tweets: pass\r\nfor t in tweets: pass\r\n```"
] | 2022-01-06T17:54:30 | 2022-01-06T19:10:06 | 2022-01-06T19:06:58 | CONTRIBUTOR | null | I have a case where I want to select a one-to-many relation.
According to the [docs](http://docs.peewee-orm.com/en/latest/peewee/querying.html#aggregating-records), this can be done with appropriate selects, joins and group-bys.
However, peewee does not cache query, but executes it again, if I access the backref:
```python
from logging import DEBUG, basicConfig
basicConfig(level=DEBUG)
from hwdb import System, Deployment
select = Deployment.select(System, Deployment).join(System, on=System.deployment == Deployment.id).where(Deployment.id == 354).group_by(Deployment)
dep = select.get()
print(dep.systems)
print(list(dep.systems))
```
Result:
```python
DEBUG:peewee:('SELECT `t1`.`id`, `t1`.`Group`, `t1`.`deployment`, `t1`.`dataset`, `t1`.`openvpn`, `t1`.`ipv6address`, `t1`.`pubkey`, `t1`.`created`, `t1`.`configured`, `t1`.`fitted`, `t1`.`operating_system`, `t1`.`monitor`, `t1`.`serial_number`, `t1`.`model`, `t1`.`last_sync`, `t2`.`id`, `t2`.`customer`, `t2`.`type`, `t2`.`connection`, `t2`.`address`, `t2`.`lpt_address`, `t2`.`scheduled`, `t2`.`annotation`, `t2`.`testing`, `t2`.`timestamp` FROM `hwdb`.`deployment` AS `t2` INNER JOIN `hwdb`.`system` AS `t1` ON (`t1`.`deployment` = `t2`.`id`) WHERE (`t2`.`id` = %s) GROUP BY `t2`.`id`, `t2`.`customer`, `t2`.`type`, `t2`.`connection`, `t2`.`address`, `t2`.`lpt_address`, `t2`.`scheduled`, `t2`.`annotation`, `t2`.`testing`, `t2`.`timestamp` LIMIT %s OFFSET %s', [354, 1, 0])
SELECT `t1`.`id`, `t1`.`Group`, `t1`.`deployment`, `t1`.`dataset`, `t1`.`openvpn`, `t1`.`ipv6address`, `t1`.`pubkey`, `t1`.`created`, `t1`.`configured`, `t1`.`fitted`, `t1`.`operating_system`, `t1`.`monitor`, `t1`.`serial_number`, `t1`.`model`, `t1`.`last_sync` FROM `hwdb`.`system` AS `t1` WHERE (`t1`.`deployment` = 354)
DEBUG:peewee:('SELECT `t1`.`id`, `t1`.`Group`, `t1`.`deployment`, `t1`.`dataset`, `t1`.`openvpn`, `t1`.`ipv6address`, `t1`.`pubkey`, `t1`.`created`, `t1`.`configured`, `t1`.`fitted`, `t1`.`operating_system`, `t1`.`monitor`, `t1`.`serial_number`, `t1`.`model`, `t1`.`last_sync` FROM `hwdb`.`system` AS `t1` WHERE (`t1`.`deployment` = %s)', [354])
[<System: 36>, <System: 359>]
```
As you can see from the last debug output, peewee executes another query to retrieve the related records.
Shouldn't it have cached them from the initial join?
Vanilla peewee test script:
```python
from configparser import ConfigParser
from datetime import datetime
from logging import DEBUG, basicConfig
from peewee import Model, MySQLDatabase
from peewee import BooleanField, CharField, DateField, DateTimeField, ForeignKeyField, FixedCharField
basicConfig(level=DEBUG)
CONFIG = ConfigParser()
CONFIG.read('/usr/local/etc/hwdb.conf')
DATABASE = MySQLDatabase(
'hwdb',
host='localhost',
user='hwdb',
passwd=CONFIG.get('db', 'passwd')
)
class Deployment(Model):
"""A customer-specific deployment of a terminal."""
class Meta:
database = DATABASE
schema = database.database
scheduled = DateField(null=True)
annotation = CharField(255, null=True)
testing = BooleanField(default=False)
timestamp = DateTimeField(null=True)
class System(Model):
"""A physical computer system out in the field."""
class Meta:
database = DATABASE
schema = database.database
deployment = ForeignKeyField(
Deployment, null=True, column_name='deployment', backref='systems',
on_delete='SET NULL', on_update='CASCADE', lazy_load=False)
pubkey = FixedCharField(44, null=True, unique=True)
created = DateTimeField(default=datetime.now)
configured = DateTimeField(null=True)
fitted = BooleanField(default=False)
monitor = BooleanField(null=True)
serial_number = CharField(255, null=True)
model = CharField(255, null=True) # Hardware model.
last_sync = DateTimeField(null=True)
select = Deployment.select(System, Deployment).join(System, on=System.deployment == Deployment.id).where(Deployment.id == 354).group_by(Deployment)
dep = select.get()
print(dep.systems)
print(list(dep.systems))
```
Result:
```python
DEBUG:peewee:('SELECT `t1`.`id`, `t1`.`deployment`, `t1`.`pubkey`, `t1`.`created`, `t1`.`configured`, `t1`.`fitted`, `t1`.`monitor`, `t1`.`serial_number`, `t1`.`model`, `t1`.`last_sync`, `t2`.`id`, `t2`.`scheduled`, `t2`.`annotation`, `t2`.`testing`, `t2`.`timestamp` FROM `hwdb`.`deployment` AS `t2` INNER JOIN `hwdb`.`system` AS `t1` ON (`t1`.`deployment` = `t2`.`id`) WHERE (`t2`.`id` = %s) GROUP BY `t2`.`id`, `t2`.`scheduled`, `t2`.`annotation`, `t2`.`testing`, `t2`.`timestamp` LIMIT %s OFFSET %s', [354, 1, 0])
SELECT `t1`.`id`, `t1`.`deployment`, `t1`.`pubkey`, `t1`.`created`, `t1`.`configured`, `t1`.`fitted`, `t1`.`monitor`, `t1`.`serial_number`, `t1`.`model`, `t1`.`last_sync` FROM `hwdb`.`system` AS `t1` WHERE (`t1`.`deployment` = 354)
DEBUG:peewee:('SELECT `t1`.`id`, `t1`.`deployment`, `t1`.`pubkey`, `t1`.`created`, `t1`.`configured`, `t1`.`fitted`, `t1`.`monitor`, `t1`.`serial_number`, `t1`.`model`, `t1`.`last_sync` FROM `hwdb`.`system` AS `t1` WHERE (`t1`.`deployment` = %s)', [354])
[<System: 36>, <System: 359>]
```
If I remove the select and join, it still works:
```python
select = Deployment.select().where(Deployment.id == 354).group_by(Deployment)
```
It seems like `lazy_load=False` is being entirely ignored. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2511/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2511/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2510 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2510/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2510/comments | https://api.github.com/repos/coleifer/peewee/issues/2510/events | https://github.com/coleifer/peewee/issues/2510 | 1,094,163,850 | I_kwDOAA7yGM5BN52K | 2,510 | table_exists(MyModel) should raise error | {
"login": "jonashaag",
"id": 175722,
"node_id": "MDQ6VXNlcjE3NTcyMg==",
"avatar_url": "https://avatars.githubusercontent.com/u/175722?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonashaag",
"html_url": "https://github.com/jonashaag",
"followers_url": "https://api.github.com/users/jonashaag/followers",
"following_url": "https://api.github.com/users/jonashaag/following{/other_user}",
"gists_url": "https://api.github.com/users/jonashaag/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonashaag/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonashaag/subscriptions",
"organizations_url": "https://api.github.com/users/jonashaag/orgs",
"repos_url": "https://api.github.com/users/jonashaag/repos",
"events_url": "https://api.github.com/users/jonashaag/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonashaag/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks, this method now accepts a model class."
] | 2022-01-05T09:45:29 | 2022-01-05T13:41:17 | 2022-01-05T13:41:06 | CONTRIBUTOR | null | Misuse of `table_exists` API always returns `False`:
```py
db.table_exists(MyModel)
```
IMO this should either raise an error, or be identical to
```py
db.table_exists(MyModel.table_name)
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2510/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2510/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2509 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2509/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2509/comments | https://api.github.com/repos/coleifer/peewee/issues/2509/events | https://github.com/coleifer/peewee/issues/2509 | 1,092,086,129 | I_kwDOAA7yGM5BF-lx | 2,509 | Add ModelSelect to __all__ for linting | {
"login": "1kastner",
"id": 5236165,
"node_id": "MDQ6VXNlcjUyMzYxNjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/5236165?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/1kastner",
"html_url": "https://github.com/1kastner",
"followers_url": "https://api.github.com/users/1kastner/followers",
"following_url": "https://api.github.com/users/1kastner/following{/other_user}",
"gists_url": "https://api.github.com/users/1kastner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/1kastner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/1kastner/subscriptions",
"organizations_url": "https://api.github.com/users/1kastner/orgs",
"repos_url": "https://api.github.com/users/1kastner/repos",
"events_url": "https://api.github.com/users/1kastner/events{/privacy}",
"received_events_url": "https://api.github.com/users/1kastner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm going to pass - I don't really see a need to export this."
] | 2022-01-02T19:35:36 | 2022-01-04T14:28:11 | 2022-01-04T14:28:11 | NONE | null | First of all thank you very much for creating this project and sharing it under the MIT license!
Recently I have started to rely more on type-hinting in my projects to have better tool support and in some cases making my intentions more obvious for the readers of the code. While doing that, I got the warning that ModelSelect is not part of the official interface as it is not listed in `__all__`. However, I would like to pass a query which is not yet executed to another method or function and only there execute it. Thus my request to add `ModelSelect` to `__all__` and treat it as an official part of the API.
Of course there could be design choices or other ideas that contradict this. In that case I would love to learn more about the future intentions of how this project will continue. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2509/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2509/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2508 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2508/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2508/comments | https://api.github.com/repos/coleifer/peewee/issues/2508/events | https://github.com/coleifer/peewee/issues/2508 | 1,091,487,002 | I_kwDOAA7yGM5BDsUa | 2,508 | how to search by pair of columns | {
"login": "sherrrrr",
"id": 31510228,
"node_id": "MDQ6VXNlcjMxNTEwMjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/31510228?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sherrrrr",
"html_url": "https://github.com/sherrrrr",
"followers_url": "https://api.github.com/users/sherrrrr/followers",
"following_url": "https://api.github.com/users/sherrrrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sherrrrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sherrrrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sherrrrr/subscriptions",
"organizations_url": "https://api.github.com/users/sherrrrr/orgs",
"repos_url": "https://api.github.com/users/sherrrrr/repos",
"events_url": "https://api.github.com/users/sherrrrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sherrrrr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Here is an example (tested with mariadb 10.6):\r\n\r\n```python\r\nclass Reg(Model):\r\n key = CharField()\r\n value = TextField()\r\n\r\nReg.insert_many([('k%02d' % i, 'v%02d' % i) for i in range(100)]).execute()\r\ncols = Tuple(Reg.key, Reg.value)\r\nvalues = [('k02', 'v02'), ('k04', 'v04'), ('k06', 'v06')]\r\nquery = (Reg.select()\r\n .where(cols.in_(values))\r\n .order_by(Reg.key))\r\nfor reg in query:\r\n print(reg.key, reg.value)\r\n\r\n# Prints:\r\n# k02 v02\r\n# k04 v04\r\n# k06 v06\r\n```"
] | 2021-12-31T09:08:14 | 2021-12-31T14:29:40 | 2021-12-31T14:28:25 | NONE | null | How can I write something like this using peewee in mysql?
```
SELECT whatever
FROM t
WHERE (col1, col2)
IN ((val1a, val2a), (val1b, val2b), ...) ;
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2508/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2508/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2507 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2507/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2507/comments | https://api.github.com/repos/coleifer/peewee/issues/2507/events | https://github.com/coleifer/peewee/issues/2507 | 1,090,305,263 | I_kwDOAA7yGM5A_Lzv | 2,507 | Does not accept pandas dataframe int/float columns with NA | {
"login": "ashishkumarazuga",
"id": 78608338,
"node_id": "MDQ6VXNlcjc4NjA4MzM4",
"avatar_url": "https://avatars.githubusercontent.com/u/78608338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ashishkumarazuga",
"html_url": "https://github.com/ashishkumarazuga",
"followers_url": "https://api.github.com/users/ashishkumarazuga/followers",
"following_url": "https://api.github.com/users/ashishkumarazuga/following{/other_user}",
"gists_url": "https://api.github.com/users/ashishkumarazuga/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ashishkumarazuga/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ashishkumarazuga/subscriptions",
"organizations_url": "https://api.github.com/users/ashishkumarazuga/orgs",
"repos_url": "https://api.github.com/users/ashishkumarazuga/repos",
"events_url": "https://api.github.com/users/ashishkumarazuga/events{/privacy}",
"received_events_url": "https://api.github.com/users/ashishkumarazuga/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This error is being thrown by your database, via your database driver, and is not raised by Peewee."
] | 2021-12-29T06:42:55 | 2021-12-29T13:49:30 | 2021-12-29T13:49:30 | NONE | null | The pandas dataframe containing columns which are int64 or float64 in nature, containing NA or NaN are not accepted by peewee. And throws a `DataError('integer out of range\n')`, during an insert.
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2507/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2507/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2506 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2506/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2506/comments | https://api.github.com/repos/coleifer/peewee/issues/2506/events | https://github.com/coleifer/peewee/issues/2506 | 1,090,269,083 | I_kwDOAA7yGM5A_C-b | 2,506 | distutils has been deprecated in Python 3.10 | {
"login": "tirkarthi",
"id": 3972343,
"node_id": "MDQ6VXNlcjM5NzIzNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3972343?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tirkarthi",
"html_url": "https://github.com/tirkarthi",
"followers_url": "https://api.github.com/users/tirkarthi/followers",
"following_url": "https://api.github.com/users/tirkarthi/following{/other_user}",
"gists_url": "https://api.github.com/users/tirkarthi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tirkarthi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tirkarthi/subscriptions",
"organizations_url": "https://api.github.com/users/tirkarthi/orgs",
"repos_url": "https://api.github.com/users/tirkarthi/repos",
"events_url": "https://api.github.com/users/tirkarthi/events{/privacy}",
"received_events_url": "https://api.github.com/users/tirkarthi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Steve Dower @zooba, a Microsoft employee, is railroading through this idiotic pep. From what I can see there are quite a few people who disagree with his decision:\r\n\r\nhttps://discuss.python.org/t/pep-632-deprecate-distutils-module/5134/29\r\n\r\nHe comes off as a smug, smarmy nitwit who cannot appreciate that real world users will be affected by this decision. Once again, Microsoft employees shitting up the party? Or just another petty tyrant who found a source of narcissistic supply in open source? You decide.",
"As much as I sympathize with the reaction, the code should be updated in the future. It seems that the pep isn't going away.",
"Fallback to the vendored distutils inside setuptools for now: 7ab5e401d85c1eec7aafbbe2fdf3c0344f82422b",
"Anyone who stumbles upon this and can find examples of prior art for projects that build C extensions and are going through a similar migration, I'd appreciate links. I glanced around at a few projects I'm familiar with, and all of them are still on `distutils`."
] | 2021-12-29T04:56:21 | 2021-12-30T01:02:47 | 2021-12-29T20:47:49 | NONE | null | https://www.python.org/dev/peps/pep-0632/#migration-advice
https://github.com/coleifer/peewee/blob/5a55933ed28b261fbe100568125fffe0ba854b99/setup.py#L5-L8 | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2506/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2506/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2505 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2505/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2505/comments | https://api.github.com/repos/coleifer/peewee/issues/2505/events | https://github.com/coleifer/peewee/issues/2505 | 1,083,846,770 | I_kwDOAA7yGM5AmjBy | 2,505 | formatargspec was removed in Python 3.11 | {
"login": "tirkarthi",
"id": 3972343,
"node_id": "MDQ6VXNlcjM5NzIzNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3972343?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tirkarthi",
"html_url": "https://github.com/tirkarthi",
"followers_url": "https://api.github.com/users/tirkarthi/followers",
"following_url": "https://api.github.com/users/tirkarthi/following{/other_user}",
"gists_url": "https://api.github.com/users/tirkarthi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tirkarthi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tirkarthi/subscriptions",
"organizations_url": "https://api.github.com/users/tirkarthi/orgs",
"repos_url": "https://api.github.com/users/tirkarthi/repos",
"events_url": "https://api.github.com/users/tirkarthi/events{/privacy}",
"received_events_url": "https://api.github.com/users/tirkarthi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"That doesn't matter. The stdlib-provided mock is used for any python 3 or newer, and that old version is vendored for Python 2.x users.",
"Got it, sorry for the noise."
] | 2021-12-18T14:43:19 | 2021-12-19T01:41:07 | 2021-12-19T01:01:30 | NONE | null | https://github.com/coleifer/peewee/blob/5a55933ed28b261fbe100568125fffe0ba854b99/tests/libs/mock.py#L190
https://docs.python.org/3.11/whatsnew/3.11.html#removed
> the formatargspec function, deprecated since Python 3.5; use the inspect.signature() function and Signature object directly. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2505/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2505/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2504 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2504/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2504/comments | https://api.github.com/repos/coleifer/peewee/issues/2504/events | https://github.com/coleifer/peewee/issues/2504 | 1,083,132,854 | I_kwDOAA7yGM5Aj0u2 | 2,504 | PostgresqlExtDatabase. Model with JSONField raise exception on any action with search (get, get_or_create, etc.) | {
"login": "olvinroght",
"id": 49984942,
"node_id": "MDQ6VXNlcjQ5OTg0OTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/49984942?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/olvinroght",
"html_url": "https://github.com/olvinroght",
"followers_url": "https://api.github.com/users/olvinroght/followers",
"following_url": "https://api.github.com/users/olvinroght/following{/other_user}",
"gists_url": "https://api.github.com/users/olvinroght/gists{/gist_id}",
"starred_url": "https://api.github.com/users/olvinroght/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/olvinroght/subscriptions",
"organizations_url": "https://api.github.com/users/olvinroght/orgs",
"repos_url": "https://api.github.com/users/olvinroght/repos",
"events_url": "https://api.github.com/users/olvinroght/events{/privacy}",
"received_events_url": "https://api.github.com/users/olvinroght/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Refer to the docs: https://www.postgresql.org/docs/current/datatype-json.html\r\n\r\nBut, simply, you cannot compare `json` values. I am not aware of any reason why you would want to use `json` over `jsonb`, so I would suggest that you just use `BinaryJSONField` (which additionally supports indexing).\r\n\r\nIf you really want to use `JSONField` then you should not use `get_or_create()` but instead use `insert(...).on_conflict()` and rely on a unique constraint."
] | 2021-12-17T10:50:01 | 2021-12-17T14:04:18 | 2021-12-17T14:02:59 | NONE | null | ```python
from playhouse.postgres_ext import PostgresqlExtDatabase, JSONField
from peewee import Model, CharField
database = PostgresqlExtDatabase("Test", user="user", password="password",
host="localhost", port=5432, autorollback=True)
class TestJSONModel(Model):
name = CharField(unique=True)
json_value = JSONField()
class Meta:
database = database
TestJSONModel.create_table()
model, created = TestJSONModel.get_or_create(
name="test_json_model_1",
json_value={"key1": "value1"}
)
```
It raises an exception:
```none
Traceback (most recent call last):
File "\venv\lib\site-packages\peewee.py", line 3160, in execute_sql
cursor.execute(sql, params or ())
psycopg2.errors.UndefinedFunction: ERROR: operator does not exist: json = json
LINE 1: ..."name" = 'test_json_model_1'), ("t1"."json_value" = CAST('{"...
^
HINT: No operator matches the given name and argument type(s). You might need to add explicit type casts.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "\test.py", line 24, in <module>
model, created = TestJSONModel.select(
File "\venv\lib\site-packages\peewee.py", line 1911, in inner
return method(self, database, *args, **kwargs)
File "\venv\lib\site-packages\peewee.py", line 1982, in execute
return self._execute(database)
File "\venv\lib\site-packages\peewee.py", line 2155, in _execute
cursor = database.execute(self)
File "\venv\lib\site-packages\playhouse\postgres_ext.py", line 490, in execute
cursor = self.execute_sql(sql, params, commit=commit)
File "\venv\lib\site-packages\peewee.py", line 3167, in execute_sql
self.commit()
File "\venv\lib\site-packages\peewee.py", line 2933, in __exit__
reraise(new_type, new_type(exc_value, *exc_args), traceback)
File "\venv\lib\site-packages\peewee.py", line 191, in reraise
raise value.with_traceback(tb)
File "\venv\lib\site-packages\peewee.py", line 3160, in execute_sql
cursor.execute(sql, params or ())
peewee.ProgrammingError: ERROR: operator does not exist: json = json
LINE 1: ..."name" = 'test_json_model_1'), ("t1"."json_value" = CAST('{"...
^
HINT: No operator matches the given name and argument type(s). You might need to add explicit type casts.
```
Same happens on any other query where `json_value` comparison used. Code above produces next query:
```sql
SELECT ("t1"."name" = %s), ("t1"."json_value" = CAST(%s AS json)) FROM "testjsonmodel" AS "t1"
```
As far as I understood, it's not possible to compare JSON fields, only their string values, so it will be good if peewee handles it internally instead of raising an exception.
This happens only with `JSONField`, `BinaryJSONField` works well. There's [a question](https://stackoverflow.com/q/32843213/10824407) on Stack Overflow with same issue.
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2504/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2504/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2503 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2503/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2503/comments | https://api.github.com/repos/coleifer/peewee/issues/2503/events | https://github.com/coleifer/peewee/issues/2503 | 1,079,774,294 | I_kwDOAA7yGM5AXAxW | 2,503 | how to convert peewee column field_type to db column_type | {
"login": "LLjiahai",
"id": 30220658,
"node_id": "MDQ6VXNlcjMwMjIwNjU4",
"avatar_url": "https://avatars.githubusercontent.com/u/30220658?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LLjiahai",
"html_url": "https://github.com/LLjiahai",
"followers_url": "https://api.github.com/users/LLjiahai/followers",
"following_url": "https://api.github.com/users/LLjiahai/following{/other_user}",
"gists_url": "https://api.github.com/users/LLjiahai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LLjiahai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LLjiahai/subscriptions",
"organizations_url": "https://api.github.com/users/LLjiahai/orgs",
"repos_url": "https://api.github.com/users/LLjiahai/repos",
"events_url": "https://api.github.com/users/LLjiahai/events{/privacy}",
"received_events_url": "https://api.github.com/users/LLjiahai/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-12-14T13:41:15 | 2021-12-14T14:34:46 | 2021-12-14T14:34:46 | NONE | null | ps: field_a = peewee .CharField(max_length=255) to mysql column_type varchar(255) | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2503/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2503/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2502 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2502/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2502/comments | https://api.github.com/repos/coleifer/peewee/issues/2502/events | https://github.com/coleifer/peewee/issues/2502 | 1,077,359,121 | I_kwDOAA7yGM5ANzIR | 2,502 | AttributeError: 'Expression' object has no attribute 'execute' | {
"login": "thisnugroho",
"id": 49790011,
"node_id": "MDQ6VXNlcjQ5NzkwMDEx",
"avatar_url": "https://avatars.githubusercontent.com/u/49790011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thisnugroho",
"html_url": "https://github.com/thisnugroho",
"followers_url": "https://api.github.com/users/thisnugroho/followers",
"following_url": "https://api.github.com/users/thisnugroho/following{/other_user}",
"gists_url": "https://api.github.com/users/thisnugroho/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thisnugroho/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thisnugroho/subscriptions",
"organizations_url": "https://api.github.com/users/thisnugroho/orgs",
"repos_url": "https://api.github.com/users/thisnugroho/repos",
"events_url": "https://api.github.com/users/thisnugroho/events{/privacy}",
"received_events_url": "https://api.github.com/users/thisnugroho/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The `get_or_none()`, when used on a select query, does not accept any parameters -- though the error message is unhelpful here.\r\n\r\nIn your code you are:\r\n\r\n1. `SomeModel.select()` which creates a `ModelSelect` query\r\n2. Call the `get_or_none()` method on the `ModelSelect` query\r\n\r\nI think what you intended to do is this:\r\n\r\n```python\r\n\r\nSomeModel.select().where(SomeModel.field == value).get_or_none()\r\n```\r\n\r\nAlternatively, you can use the *shortcut* method on model, which *does* accept an expression:\r\n\r\n```python\r\n\r\nSomeModel.get_or_none(SomeModel.field == value)\r\n```\r\n\r\n* http://docs.peewee-orm.com/en/latest/peewee/api.html#Model.get_or_none"
] | 2021-12-11T02:11:25 | 2021-12-11T12:25:38 | 2021-12-11T12:25:38 | NONE | null | It's appear after upgrading from version 3.14.4 to peewee latest version 3.14.8,
i decide to upgrade because i want to using `Model.get_or_none()` function, it's not available in previous version.
and the error appear i'm trying to running this:
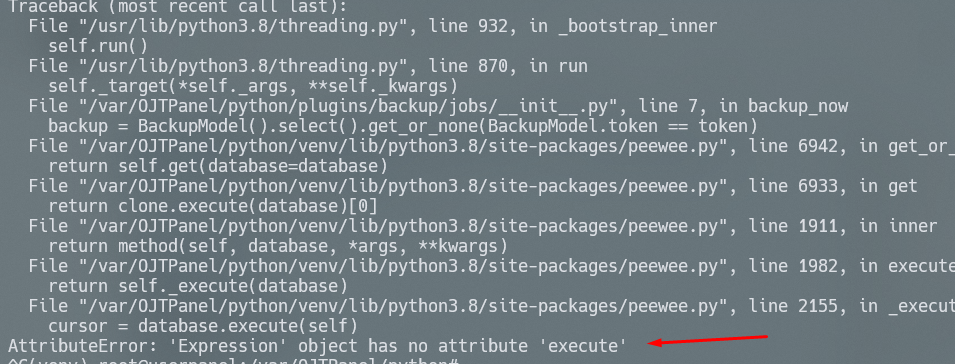
```python
SomeModel().select().get_or_none(SomeModel.field== value)
```
my configuration looklike this:
```python
db = MySQLDatabase(
env("DB_DATABASE"),
user=env("DB_USERNAME"),
password=env("DB_PASSWORD"),
host=env("DB_HOST"),
port=int(env("DB_PORT")),
)
```
is there something that i need to adjust ? or i'm just missing something.
screenshoot:
details
OS:Ubuntu 20.04
MYSQL Version = 8.0.27 | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2502/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2502/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2501 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2501/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2501/comments | https://api.github.com/repos/coleifer/peewee/issues/2501/events | https://github.com/coleifer/peewee/pull/2501 | 1,076,661,651 | PR_kwDOAA7yGM4vq1ly | 2,501 | Allow to use peewee.SQL from `from_` | {
"login": "d0d0",
"id": 553292,
"node_id": "MDQ6VXNlcjU1MzI5Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/553292?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/d0d0",
"html_url": "https://github.com/d0d0",
"followers_url": "https://api.github.com/users/d0d0/followers",
"following_url": "https://api.github.com/users/d0d0/following{/other_user}",
"gists_url": "https://api.github.com/users/d0d0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/d0d0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d0d0/subscriptions",
"organizations_url": "https://api.github.com/users/d0d0/orgs",
"repos_url": "https://api.github.com/users/d0d0/repos",
"events_url": "https://api.github.com/users/d0d0/events{/privacy}",
"received_events_url": "https://api.github.com/users/d0d0/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I don't really like this solution. The join will not correctly set-up the model graph, so the best solution in my opinion is to write:\r\n\r\n```python\r\nq = User.select(User, Tweet).from_(SQL(f'`users` as `t1` USE INDEX(`user_id`) ')).join(Tweet)\r\nfor x in q.objects():\r\n # assume username is on User table, and content is on Tweet table.\r\n print(x.username, x.content)\r\n```"
] | 2021-12-10T09:58:34 | 2021-12-10T17:46:55 | 2021-12-10T17:46:54 | NONE | null | **Problem:**
Tried to apply custom SQL to `from_` function from this example https://github.com/coleifer/peewee/issues/1289#issuecomment-307128658 However in my query, I use some joins.
Here is example
```python
q = User.select(User, Tweet).from_(SQL(f'`users` as `t1` USE INDEX(`user_id`) ')).join(Tweet)
for x in q:
print(x)
```
But without fix, exception is thrown
```
Traceback (most recent call last):
File "JetBrains\PyCharm2021.2\scratches\scratch_71.py", line 27, in <module>
for file in q:
File "venv\lib\site-packages\peewee.py", line 4408, in next
self.cursor_wrapper.iterate()
File "venv\lib\site-packages\peewee.py", line 4325, in iterate
self.initialize() # Lazy initialization.
File "venv\lib\site-packages\peewee.py", line 7587, in initialize
if curr not in self.joins:
TypeError: unhashable type: 'SQL'
```
**Solution**
When initializing ModelCursorWrapper skip SQL instances | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2501/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2501/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2501",
"html_url": "https://github.com/coleifer/peewee/pull/2501",
"diff_url": "https://github.com/coleifer/peewee/pull/2501.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2501.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2500 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2500/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2500/comments | https://api.github.com/repos/coleifer/peewee/issues/2500/events | https://github.com/coleifer/peewee/issues/2500 | 1,074,152,643 | I_kwDOAA7yGM5ABkTD | 2,500 | Query "where not in empty list" does not work as expected | {
"login": "skontar",
"id": 10827040,
"node_id": "MDQ6VXNlcjEwODI3MDQw",
"avatar_url": "https://avatars.githubusercontent.com/u/10827040?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skontar",
"html_url": "https://github.com/skontar",
"followers_url": "https://api.github.com/users/skontar/followers",
"following_url": "https://api.github.com/users/skontar/following{/other_user}",
"gists_url": "https://api.github.com/users/skontar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skontar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skontar/subscriptions",
"organizations_url": "https://api.github.com/users/skontar/orgs",
"repos_url": "https://api.github.com/users/skontar/repos",
"events_url": "https://api.github.com/users/skontar/events{/privacy}",
"received_events_url": "https://api.github.com/users/skontar/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The problem is python operator precedence. The following work as expected:\r\n\r\n```python\r\n\r\nPerson.select().where(Person.name.not_in([]))\r\n\r\nPerson.select().where(~(Person.name << []))\r\n\r\nPerson.select().where(~(Person.name.in_([])))\r\n```",
"Thanks for reply. I see now, I got confused by SQL operator precedence. \r\nWould it not be better to translate to `WHERE (NOT \"t1\".\"name\" IN ())` for empty list, similarly as it does for non-empty list?\r\n\r\nI understand the reasoning and the problem, but I think this can potentially mask the issue until the list becomes empty one day and return unexpected results."
] | 2021-12-08T08:43:36 | 2021-12-08T15:59:19 | 2021-12-08T15:33:57 | NONE | null | I was using equivalent of `.where(~Person.name << some_list)` and it behaves unexpectedly when the list is empty. See below example.
```python
import peewee
from peewee import *
db = SqliteDatabase(':memory:')
class Person(Model):
name = CharField()
class Meta:
database = db
db.create_tables([Person])
Person(name="Alice").save()
Person(name="Bob").save()
Person(name="Cliff").save()
q = Person.select().where(Person.name << ['Bob'])
print(q)
# SELECT "t1"."id", "t1"."name" FROM "person" AS "t1" WHERE ("t1"."name" IN ('Bob'))
print(list(q.tuples()))
# [(2, 'Bob')]
q = Person.select().where(~Person.name << ['Bob'])
print(q)
# SELECT "t1"."id", "t1"."name" FROM "person" AS "t1" WHERE (NOT "t1"."name" IN ('Bob'))
print(list(q.tuples()))
# [(1, 'Alice'), (3, 'Cliff')]
q = Person.select().where(Person.name << [])
print(q)
# SELECT "t1"."id", "t1"."name" FROM "person" AS "t1" WHERE (0 = 1)
print(list(q.tuples()))
# []
q = Person.select().where(~Person.name << [])
print(q)
# SELECT "t1"."id", "t1"."name" FROM "person" AS "t1" WHERE (0 = 1)
# Expected: SELECT "t1"."id", "t1"."name" FROM "person" AS "t1" WHERE (1 = 1) ??? Maybe?
print(list(q.tuples()))
# []
# Expected: [(1, 'Alice'), (2, 'Bob'), (3, 'Cliff')]
print(peewee.__version__)
# 3.14.8
print(peewee.sqlite3.sqlite_version)
# 3.34.1
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2500/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2500/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2499 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2499/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2499/comments | https://api.github.com/repos/coleifer/peewee/issues/2499/events | https://github.com/coleifer/peewee/pull/2499 | 1,073,938,441 | PR_kwDOAA7yGM4vh8NM | 2,499 | Add BlackSheep integration | {
"login": "q0w",
"id": 43147888,
"node_id": "MDQ6VXNlcjQzMTQ3ODg4",
"avatar_url": "https://avatars.githubusercontent.com/u/43147888?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/q0w",
"html_url": "https://github.com/q0w",
"followers_url": "https://api.github.com/users/q0w/followers",
"following_url": "https://api.github.com/users/q0w/following{/other_user}",
"gists_url": "https://api.github.com/users/q0w/gists{/gist_id}",
"starred_url": "https://api.github.com/users/q0w/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/q0w/subscriptions",
"organizations_url": "https://api.github.com/users/q0w/orgs",
"repos_url": "https://api.github.com/users/q0w/repos",
"events_url": "https://api.github.com/users/q0w/events{/privacy}",
"received_events_url": "https://api.github.com/users/q0w/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I really can't keep up with these new async-framework-of-the-day things. Additionally, connection handling doesn't work the way you might expect with async, so this is probably incorrect anyways."
] | 2021-12-08T02:20:08 | 2021-12-09T08:27:38 | 2021-12-08T23:43:29 | NONE | null | null | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2499/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2499/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2499",
"html_url": "https://github.com/coleifer/peewee/pull/2499",
"diff_url": "https://github.com/coleifer/peewee/pull/2499.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2499.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2498 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2498/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2498/comments | https://api.github.com/repos/coleifer/peewee/issues/2498/events | https://github.com/coleifer/peewee/issues/2498 | 1,071,183,911 | I_kwDOAA7yGM4_2Pgn | 2,498 | Peewee 2 does not work with python 3.10 | {
"login": "ribx",
"id": 4598953,
"node_id": "MDQ6VXNlcjQ1OTg5NTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/4598953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ribx",
"html_url": "https://github.com/ribx",
"followers_url": "https://api.github.com/users/ribx/followers",
"following_url": "https://api.github.com/users/ribx/following{/other_user}",
"gists_url": "https://api.github.com/users/ribx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ribx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ribx/subscriptions",
"organizations_url": "https://api.github.com/users/ribx/orgs",
"repos_url": "https://api.github.com/users/ribx/repos",
"events_url": "https://api.github.com/users/ribx/events{/privacy}",
"received_events_url": "https://api.github.com/users/ribx/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"That version is not receiving patches, unfortunately. Your best bet is to fork it and patch it. You won't lose sync with upstream if you stay on 2.x."
] | 2021-12-04T11:06:22 | 2021-12-04T13:11:43 | 2021-12-04T13:11:42 | NONE | null | The problem is, that the exports of the `collections` modules were moved to `collections.abc`:
```
docker run --rm -ti python:3.10 sh -c 'pip install cython &>/dev/null && pip install peewee==2.10.2'
....
Collecting peewee==2.10.2
Downloading peewee-2.10.2.tar.gz (516 kB)
|████████████████████████████████| 516 kB 3.7 MB/s
ERROR: Command errored out with exit status 1:
command: /usr/local/bin/python -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-i073ept4/peewee_0592019e5eb643a48b6ef02e66fcd5d8/setup.py'"'"'; __file__='"'"'/tmp/pip-install-i073ept4/peewee_0592019e5eb643a48b6ef02e66fcd5d8/setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-pip-egg-info-efaxgva5
cwd: /tmp/pip-install-i073ept4/peewee_0592019e5eb643a48b6ef02e66fcd5d8/
Complete output (7 lines):
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-install-i073ept4/peewee_0592019e5eb643a48b6ef02e66fcd5d8/setup.py", line 64, in <module>
version=__import__('peewee').__version__,
File "/tmp/pip-install-i073ept4/peewee_0592019e5eb643a48b6ef02e66fcd5d8/peewee.py", line 124, in <module>
from collections import Callable
ImportError: cannot import name 'Callable' from 'collections' (/usr/local/lib/python3.10/collections/__init__.py)
----------------------------------------
```
```
$ docker run --rm -ti python:3.9
>>> from collections import Callable
<stdin>:1: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.10 it will stop working
```
The fix should be quite simple, by just replacing `collections` with `collections.abc`.
I am stuck to peewee 2 because I am using this extension:
https://github.com/cour4g3/peewee-mssql
I can also create a PR. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2498/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2498/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2497 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2497/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2497/comments | https://api.github.com/repos/coleifer/peewee/issues/2497/events | https://github.com/coleifer/peewee/issues/2497 | 1,070,778,439 | I_kwDOAA7yGM4_0shH | 2,497 | Support for "<@" in PostgreSQL arrays | {
"login": "joaodlf",
"id": 3275379,
"node_id": "MDQ6VXNlcjMyNzUzNzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3275379?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/joaodlf",
"html_url": "https://github.com/joaodlf",
"followers_url": "https://api.github.com/users/joaodlf/followers",
"following_url": "https://api.github.com/users/joaodlf/following{/other_user}",
"gists_url": "https://api.github.com/users/joaodlf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/joaodlf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joaodlf/subscriptions",
"organizations_url": "https://api.github.com/users/joaodlf/orgs",
"repos_url": "https://api.github.com/users/joaodlf/repos",
"events_url": "https://api.github.com/users/joaodlf/events{/privacy}",
"received_events_url": "https://api.github.com/users/joaodlf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for the suggestion - this is implemented as `contained_by`.",
"Thanks for the **incredible** feedback in such a short notice, do you plan on releasing a minor version with this feature any time in the near future?",
"Besides this one change, there aren't really any other notable changes yet to justify a new release, in my opinion -- everything else is just docs or example updates. I'll probably wait until after the holidays.\r\n\r\nIf you want to use this now, but don't want to pin to `master` branch, I'd suggest just implementing your own subclass of ArrayField that implements `contained_by()` and using that in the meantime."
] | 2021-12-03T16:51:46 | 2021-12-06T13:57:46 | 2021-12-03T17:10:59 | NONE | null | Peewee currently supports `@>` (`.contains()`) and `&&` (`contains_any()`) - [docs](https://docs.peewee-orm.com/en/latest/peewee/playhouse.html?highlight=array#ArrayField.contains)
It would be nice for Peewee to also support `<@`, as expressed in the [PostgreSQL docs](https://www.postgresql.org/docs/current/functions-array.html):
> anyarray <@ anyarray → boolean
>
> Is the first array contained by the second?
>
> ARRAY[2,2,7] <@ ARRAY[1,7,4,2,6] → t
Note that this is a completely different behavior to `@>`:
> anyarray @> anyarray → boolean
>
> Does the first array contain the second, that is, does each element appearing in the second array equal some element of the first array? (Duplicates are not treated specially, thus ARRAY[1] and ARRAY[1,1] are each considered to contain the other.)
>
> ARRAY[1,4,3] @> ARRAY[3,1,3] → t
I would imagine this implemented as something like `.contained_by()`? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2497/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2497/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2496 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2496/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2496/comments | https://api.github.com/repos/coleifer/peewee/issues/2496/events | https://github.com/coleifer/peewee/pull/2496 | 1,070,550,586 | PR_kwDOAA7yGM4vW_gK | 2,496 | Fix link to SQLAlchemy Hybrid Attributes docs | {
"login": "jonathanmach",
"id": 12788052,
"node_id": "MDQ6VXNlcjEyNzg4MDUy",
"avatar_url": "https://avatars.githubusercontent.com/u/12788052?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonathanmach",
"html_url": "https://github.com/jonathanmach",
"followers_url": "https://api.github.com/users/jonathanmach/followers",
"following_url": "https://api.github.com/users/jonathanmach/following{/other_user}",
"gists_url": "https://api.github.com/users/jonathanmach/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonathanmach/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonathanmach/subscriptions",
"organizations_url": "https://api.github.com/users/jonathanmach/orgs",
"repos_url": "https://api.github.com/users/jonathanmach/repos",
"events_url": "https://api.github.com/users/jonathanmach/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonathanmach/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-12-03T12:39:40 | 2021-12-03T17:35:56 | 2021-12-03T14:56:05 | CONTRIBUTOR | null | Broken link: http://docs.sqlalchemy.org/en/improve_toc/orm/extensions/hybrid.html
New link: https://docs.sqlalchemy.org/en/14/orm/extensions/hybrid.html | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2496/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2496/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2496",
"html_url": "https://github.com/coleifer/peewee/pull/2496",
"diff_url": "https://github.com/coleifer/peewee/pull/2496.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2496.patch",
"merged_at": "2021-12-03T14:56:05"
} |
https://api.github.com/repos/coleifer/peewee/issues/2495 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2495/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2495/comments | https://api.github.com/repos/coleifer/peewee/issues/2495/events | https://github.com/coleifer/peewee/issues/2495 | 1,069,862,567 | I_kwDOAA7yGM4_xM6n | 2,495 | TypeError: int() argument must be a string, a bytes-like object or a number when importing models | {
"login": "koadjunky",
"id": 8714421,
"node_id": "MDQ6VXNlcjg3MTQ0MjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8714421?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/koadjunky",
"html_url": "https://github.com/koadjunky",
"followers_url": "https://api.github.com/users/koadjunky/followers",
"following_url": "https://api.github.com/users/koadjunky/following{/other_user}",
"gists_url": "https://api.github.com/users/koadjunky/gists{/gist_id}",
"starred_url": "https://api.github.com/users/koadjunky/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koadjunky/subscriptions",
"organizations_url": "https://api.github.com/users/koadjunky/orgs",
"repos_url": "https://api.github.com/users/koadjunky/repos",
"events_url": "https://api.github.com/users/koadjunky/events{/privacy}",
"received_events_url": "https://api.github.com/users/koadjunky/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm not going to download or run that code, but you are welcome to paste a short snippet demonstrating the issue - or even just the actual traceback...",
"```\r\n(PeeWee-error) maciej@pippin:~/PeeWee-error$ python dsp_be/logic/planet.py \r\nTraceback (most recent call last):\r\n File \"dsp_be/logic/planet.py\", line 14, in <module>\r\n factory = Factory.create(planet=earth)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 6393, in create\r\n inst.save(force_insert=True)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 6603, in save\r\n pk = self.insert(**field_dict).execute()\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 1911, in inner\r\n return method(self, database, *args, **kwargs)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 1982, in execute\r\n return self._execute(database)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 2761, in _execute\r\n return super(Insert, self)._execute(database)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 2479, in _execute\r\n cursor = database.execute(self)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 3172, in execute\r\n sql, params = ctx.sql(query).query()\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 614, in sql\r\n return obj.__sql__(self)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 2738, in __sql__\r\n self._simple_insert(ctx)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 2588, in _simple_insert\r\n return self._generate_insert((self._insert,), ctx)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 2710, in _generate_insert\r\n return ctx.sql(CommaNodeList(all_values))\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 614, in sql\r\n return obj.__sql__(self)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 1777, in __sql__\r\n ctx.sql(self.nodes[n_nodes - 1])\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 614, in sql\r\n return obj.__sql__(self)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 1777, in __sql__\r\n ctx.sql(self.nodes[n_nodes - 1])\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 614, in sql\r\n return obj.__sql__(self)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 1383, in __sql__\r\n return ctx.value(self.value, self.converter)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 626, in value\r\n value = converter(value)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 5242, in db_value\r\n return self.rel_field.db_value(value)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 4569, in db_value\r\n return value if value is None else self.adapt(value)\r\n File \"/home/maciej/.pyenv/versions/PeeWee-error/lib/python3.8/site-packages/peewee.py\", line 4629, in adapt\r\n return int(value)\r\nTypeError: int() argument must be a string, a bytes-like object or a number, not 'Planet'\r\n```",
"Looks like you have code here on line 14:\r\n\r\n```python\r\nfactory = Factory.create(planet=earth)\r\n```\r\n\r\nThe definition of `Factory.planet` (I'm guessing) is not a `ForeignKeyField` perhaps, when it should be. Possibly you put it as an IntegerField or something?",
"It only happens if models are in different files. Merge it into one - and it works.\r\n\r\n```\r\n(PeeWee-error) maciej@pippin:~/PeeWee-error$ cat dsp_be/logic/__init__.py \r\nfrom typing import List, Type\r\n\r\nfrom peewee import DatabaseProxy, SqliteDatabase, Model\r\n\r\ndb_proxy = DatabaseProxy()\r\n\r\n\r\nclass BaseModel(Model):\r\n class Meta:\r\n database = db_proxy\r\n\r\n\r\ndef test_database(tables: List[Type[Model]]):\r\n db = SqliteDatabase(':memory:')\r\n db_proxy.initialize(db)\r\n db_proxy.connect()\r\n db_proxy.create_tables(tables)\r\n```\r\n\r\n```\r\n(PeeWee-error) maciej@pippin:~/PeeWee-error$ cat dsp_be/logic/planet.py \r\nfrom peewee import Field, CharField\r\n\r\nfrom dsp_be.logic import test_database, BaseModel\r\n\r\n\r\nclass Planet(BaseModel):\r\n name: Field = CharField()\r\n\r\n\r\nif __name__ == '__main__':\r\n from dsp_be.logic.factory import Factory\r\n test_database([Planet, Factory])\r\n earth = Planet.create(name='Earth')\r\n factory = Factory.create(planet=earth)\r\n```\r\n\r\n```\r\n(PeeWee-error) maciej@pippin:~/PeeWee-error$ cat dsp_be/logic/factory.py \r\nfrom peewee import Field, ForeignKeyField\r\n\r\nfrom dsp_be.logic import test_database, BaseModel\r\nfrom dsp_be.logic.planet import Planet\r\n\r\n\r\nclass Factory(BaseModel):\r\n planet: Field = ForeignKeyField(Planet, backref=\"planets\")\r\n\r\n\r\nif __name__ == '__main__':\r\n test_database([Planet, Factory])\r\n earth = Planet.create(name='Earth')\r\n factory = Factory.create(planet=earth)\r\n```",
"You've got some bug in your code. This works fine for me:\r\n\r\n```python\r\n# testx/__init__.py\r\nfrom peewee import *\r\n\r\ndb = DatabaseProxy()\r\n\r\nclass BaseModel(Model):\r\n class Meta:\r\n database = db\r\n\r\n# testx/factory.py\r\nfrom peewee import ForeignKeyField\r\nfrom testx import BaseModel\r\nfrom testx.planet import Planet\r\n\r\nclass Factory(BaseModel):\r\n planet = ForeignKeyField(Planet)\r\n\r\n# testx/planet.py\r\nfrom peewee import TextField\r\nfrom testx import BaseModel\r\n\r\nclass Planet(BaseModel):\r\n name = TextField()\r\n\r\n# testx/main.py\r\nfrom peewee import *\r\nfrom testx import db\r\nfrom testx.planet import Planet\r\nfrom testx.factory import Factory\r\n\r\n\r\n_db = SqliteDatabase(':memory:')\r\ndb.initialize(_db)\r\ndb.create_tables([Factory, Planet])\r\n\r\np = Planet.create(name='earth')\r\nFactory.create(planet=p)\r\nprint(Factory.get().planet.name) # \"earth\"\r\n```",
"I copied part of planet.py into main.py similar to your snippet and now it works. Weird.\r\n```\r\n# dsp_be/logic/main.py\r\nfrom peewee import SqliteDatabase\r\n\r\nfrom dsp_be.logic import test_database\r\n\r\n\r\nif __name__ == '__main__':\r\n from dsp_be.logic.factory import Factory, Planet\r\n test_database([Factory, Planet])\r\n earth = Planet.create(name='Earth')\r\n factory = Factory.create(planet=earth)\r\n```\r\nCan be used as an workaround through. Thanks for hint!"
] | 2021-12-02T18:33:08 | 2021-12-02T20:47:19 | 2021-12-02T20:01:14 | NONE | null | Python: 3.8.11
peewee: 3.14.8
I have two files with two models connected with foreign key: factory.py and planet.py. Each file has identical test code (except imports). Calling 'python dsp_be/logic/factory.py' works. Calling 'python dsp_be/logic/planet.py' throws an exception:
TypeError: int() argument must be a string, a bytes-like object or a number, not 'Planet'
Minimal code demonstrating the issue attached. Add "." to PYTHONPATH before executing.
[PeeWee-error.zip](https://github.com/coleifer/peewee/files/7644256/PeeWee-error.zip)
The Internet is silent about the issue, I only found this https://stackoverflow.com/questions/26181642/peewee-foreignkeyfield-doesnt-accept-appropriate-foreign-key-field but the solution is not working for me (outdated?). I'll be grateful for any hint. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2495/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2495/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2494 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2494/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2494/comments | https://api.github.com/repos/coleifer/peewee/issues/2494/events | https://github.com/coleifer/peewee/issues/2494 | 1,067,754,583 | I_kwDOAA7yGM4_pKRX | 2,494 | pwiz uses wildcard imports of peewee | {
"login": "tdennisliu",
"id": 34557499,
"node_id": "MDQ6VXNlcjM0NTU3NDk5",
"avatar_url": "https://avatars.githubusercontent.com/u/34557499?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tdennisliu",
"html_url": "https://github.com/tdennisliu",
"followers_url": "https://api.github.com/users/tdennisliu/followers",
"following_url": "https://api.github.com/users/tdennisliu/following{/other_user}",
"gists_url": "https://api.github.com/users/tdennisliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tdennisliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tdennisliu/subscriptions",
"organizations_url": "https://api.github.com/users/tdennisliu/orgs",
"repos_url": "https://api.github.com/users/tdennisliu/repos",
"events_url": "https://api.github.com/users/tdennisliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/tdennisliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This is a convention that is used throughout peewee examples, as well as my own code. Peewee module defines `__all__`, which controls what objects are exported, and I am happy with that. In your own code you are welcome to use whatever style you like, though."
] | 2021-11-30T22:57:07 | 2021-12-01T00:38:23 | 2021-12-01T00:38:23 | NONE | null | Hiya,
I've found pwiz very helpful in setting up my scripts, but since it wildcard imports `peewee` into the script. See below from the README:
```
from peewee import *
import datetime
db = SqliteDatabase('my_database.db')
class BaseModel(Model):
class Meta:
database = db
class User(BaseModel):
username = CharField(unique=True)
class Tweet(BaseModel):
user = ForeignKeyField(User, backref='tweets')
message = TextField()
created_date = DateTimeField(default=datetime.datetime.now)
is_published = BooleanField(default=True)
```
I find this very difficult to troubleshoot if something goes wrong, and it takes a long time to simply find and replace the classes.
What I would like to see:
```
import peewee as pw
import datetime
db = pw.SqliteDatabase('my_database.db')
class BaseModel(pw.Model):
class Meta:
database = db
class User(BaseModel):
username = pw.CharField(unique=True)
class Tweet(BaseModel):
user = pw.ForeignKeyField(User, backref='tweets')
message = pw.TextField()
created_date = pw.DateTimeField(default=datetime.datetime.now)
is_published = pw.BooleanField(default=True)
```
The [python docs](https://docs.python.org/3/tutorial/modules.html#importing-from-a-package) do state that this practise should be avoided.
As far as I can tell it's not too difficult to change this behaviour for pwiz, and I can set up a PR.
Thoughts? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2494/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2494/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2493 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2493/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2493/comments | https://api.github.com/repos/coleifer/peewee/issues/2493/events | https://github.com/coleifer/peewee/issues/2493 | 1,065,846,586 | I_kwDOAA7yGM4_h4c6 | 2,493 | fn.Avg() gets coerced into integer | {
"login": "gjask",
"id": 3306648,
"node_id": "MDQ6VXNlcjMzMDY2NDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3306648?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gjask",
"html_url": "https://github.com/gjask",
"followers_url": "https://api.github.com/users/gjask/followers",
"following_url": "https://api.github.com/users/gjask/following{/other_user}",
"gists_url": "https://api.github.com/users/gjask/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gjask/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gjask/subscriptions",
"organizations_url": "https://api.github.com/users/gjask/orgs",
"repos_url": "https://api.github.com/users/gjask/repos",
"events_url": "https://api.github.com/users/gjask/events{/privacy}",
"received_events_url": "https://api.github.com/users/gjask/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"You want to specify `.coerce(False)`:\r\n\r\n```python\r\n\r\nTestTable.select(\r\n fn.Avg(TestTable.value).coerce(False).alias(\"avg_value\"),\r\n).scalar()\r\n```",
"http://docs.peewee-orm.com/en/latest/peewee/api.html#Function.coerce"
] | 2021-11-29T10:09:09 | 2021-11-29T13:51:52 | 2021-11-29T13:50:55 | NONE | null | When using `fn.Avg()` on integer field, result will also gets coerced into integer. To illustrate problem I have created this example.
```python
class TestTable(Model):
id = AutoField()
value = IntegerField()
```
```sql
insert into testtable (value) values (3), (4);
select * from testtable;
+----+-------+
| id | value |
+----+-------+
| 1 | 3 |
| 2 | 4 |
+----+-------+
```
```python
val = TestTable.select(
fn.Avg(TestTable.value).alias("avg_value"),
).scalar()
print(val, type(val)
# 3 <class 'int'>
```
The expected result would be `3.5` or `Decimal(3.5)`
peewee = 3.14.8
database is MySQL
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2493/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2493/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2492 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2492/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2492/comments | https://api.github.com/repos/coleifer/peewee/issues/2492/events | https://github.com/coleifer/peewee/issues/2492 | 1,064,369,878 | I_kwDOAA7yGM4_cP7W | 2,492 | Bug related to create_table function in your Model | {
"login": "kezzhang",
"id": 42364982,
"node_id": "MDQ6VXNlcjQyMzY0OTgy",
"avatar_url": "https://avatars.githubusercontent.com/u/42364982?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kezzhang",
"html_url": "https://github.com/kezzhang",
"followers_url": "https://api.github.com/users/kezzhang/followers",
"following_url": "https://api.github.com/users/kezzhang/following{/other_user}",
"gists_url": "https://api.github.com/users/kezzhang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kezzhang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kezzhang/subscriptions",
"organizations_url": "https://api.github.com/users/kezzhang/orgs",
"repos_url": "https://api.github.com/users/kezzhang/repos",
"events_url": "https://api.github.com/users/kezzhang/events{/privacy}",
"received_events_url": "https://api.github.com/users/kezzhang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I could swear I ran all the examples and they worked so possibly something has changed. 2.x is unmaintained since Feb 2018 so hard to say."
] | 2021-11-26T11:22:24 | 2021-11-26T12:44:29 | 2021-11-26T12:44:29 | NONE | null | It is actually about one of your examples in version 2.9.1 and before, redis_vtable, in line 208, RedisView.create_table(), this will report error. But when I change that line to something like cursor.execute("create virtual table redisview using RedisModule()"), the whole program worked.
So I highly doubt that there is something wrong with your create_table function especially under the apsw_ext situation. Besides, when you truly want to do extensions for something, doing it halfway is worse than nothing. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2492/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2492/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2491 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2491/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2491/comments | https://api.github.com/repos/coleifer/peewee/issues/2491/events | https://github.com/coleifer/peewee/issues/2491 | 1,062,176,736 | I_kwDOAA7yGM4_T4fg | 2,491 | FlaskDb wrapper from extension | {
"login": "nabinbhusal80",
"id": 24907850,
"node_id": "MDQ6VXNlcjI0OTA3ODUw",
"avatar_url": "https://avatars.githubusercontent.com/u/24907850?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nabinbhusal80",
"html_url": "https://github.com/nabinbhusal80",
"followers_url": "https://api.github.com/users/nabinbhusal80/followers",
"following_url": "https://api.github.com/users/nabinbhusal80/following{/other_user}",
"gists_url": "https://api.github.com/users/nabinbhusal80/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nabinbhusal80/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nabinbhusal80/subscriptions",
"organizations_url": "https://api.github.com/users/nabinbhusal80/orgs",
"repos_url": "https://api.github.com/users/nabinbhusal80/repos",
"events_url": "https://api.github.com/users/nabinbhusal80/events{/privacy}",
"received_events_url": "https://api.github.com/users/nabinbhusal80/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I've implemented this, thanks for the suggestion. The endpoints can be specified using:\r\n\r\n```python\r\nFLASKDB_EXCLUDED_ROUTES = ('view1', 'view2'...)\r\n\r\n# Or,\r\nflask_db = FlaskDB(app, excluded_routes=set('view1', 'view2',...))\r\n```",
"Hey @coleifer thank you so much for the solution. Somehow i missed it in docs. I was banging my head on this for a while. So amazing to see the quick response on this. \r\nI really appreciate it."
] | 2021-11-24T09:13:45 | 2021-11-24T18:49:11 | 2021-11-24T14:30:09 | NONE | null | Hi I am using FlaskDb on my flask application which always opens connection to db on each request and closes connection once request ends. This is a great feature but I have some endpoints which don't require anything from db and they kind of live for long time because complex computations.
How do I exempt db connections for specific endpoints? Or is there any other way i can use this? Your help will be appreciated. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2491/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2491/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2490 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2490/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2490/comments | https://api.github.com/repos/coleifer/peewee/issues/2490/events | https://github.com/coleifer/peewee/issues/2490 | 1,060,162,877 | I_kwDOAA7yGM4_MM09 | 2,490 | Remote Postgres Use Case | {
"login": "aiqc",
"id": 74990642,
"node_id": "MDQ6VXNlcjc0OTkwNjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/74990642?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aiqc",
"html_url": "https://github.com/aiqc",
"followers_url": "https://api.github.com/users/aiqc/followers",
"following_url": "https://api.github.com/users/aiqc/following{/other_user}",
"gists_url": "https://api.github.com/users/aiqc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aiqc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aiqc/subscriptions",
"organizations_url": "https://api.github.com/users/aiqc/orgs",
"repos_url": "https://api.github.com/users/aiqc/repos",
"events_url": "https://api.github.com/users/aiqc/events{/privacy}",
"received_events_url": "https://api.github.com/users/aiqc/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Yes, peewee supports all the same parameters as psycopg2, so:\r\n\r\n```python\r\n\r\n# for example:\r\ndb = PostgresqlDatabase('db_name', host='192.168.1.30', port=5432, user='postgres', password='xyz')\r\n```\r\n\r\nPsycopg2 connection doc: https://www.psycopg.org/docs/module.html#psycopg2.connect"
] | 2021-11-22T13:32:39 | 2021-11-22T13:42:07 | 2021-11-22T13:42:07 | NONE | null | Hiya.
It sounded like you were fishing for use cases with respect to Postgres in the docs.
> https://docs.peewee-orm.com/en/latest/peewee/playhouse.html?highlight=postgresql#PostgresqlExtDatabase
>
> In the future I would like to add support for more of postgresql’s features. If there is a particular feature you would like to see added, please open a Github issue.
I'm using and love PeeWee w SQLite for local development and vertical scale (single desktop/ server). It's a great way to provide a 1-line install for contributors and open source users.
I was hoping to drop a SQLite file into AWS EFS and mount many jobs/users to it simultaneously, but concurrent writes over NFS are a no-go zone for SQLite. Right now I have to manually manage my own lock file.
So my solution would be to serve PSQL via AWS RDS. I searched for "postgresql" in the peewee docs because I don't want to switch ORMs. However, I didn't see anything like database IP address or port - so I was wondering if this implementation would support a remote psql db? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2490/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2490/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2489 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2489/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2489/comments | https://api.github.com/repos/coleifer/peewee/issues/2489/events | https://github.com/coleifer/peewee/issues/2489 | 1,058,826,022 | I_kwDOAA7yGM4_HGcm | 2,489 | CharField with unique constraint is case insensitive | {
"login": "rmskinsa2",
"id": 86251795,
"node_id": "MDQ6VXNlcjg2MjUxNzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/86251795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rmskinsa2",
"html_url": "https://github.com/rmskinsa2",
"followers_url": "https://api.github.com/users/rmskinsa2/followers",
"following_url": "https://api.github.com/users/rmskinsa2/following{/other_user}",
"gists_url": "https://api.github.com/users/rmskinsa2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rmskinsa2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rmskinsa2/subscriptions",
"organizations_url": "https://api.github.com/users/rmskinsa2/orgs",
"repos_url": "https://api.github.com/users/rmskinsa2/repos",
"events_url": "https://api.github.com/users/rmskinsa2/events{/privacy}",
"received_events_url": "https://api.github.com/users/rmskinsa2/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"https://stackoverflow.com/questions/463764/are-unique-indices-case-sensitive-in-mysql",
"@coleifer Is there a way to make the column case sensitive via PeeWee, or is this something we need to do directly in the db?",
"You should be able to specify the collation directly via Peewee:\r\n\r\n```python\r\nkey = CharField(collation='utf8_bin', unique=True)\r\n\r\n# Specify character set as well:\r\nkey = CharField(collation='utf8_bin', constraints=[SQL('character set utf8')], unique=True)\r\n```\r\n\r\nI haven't tested this myself, but this is based somewhat on the above-linked StackOverflow answer.",
"Thank you! I'll try that and report back here in case someone else needs the info in future.",
"For future folks: changing the `collation` and `constraints` kwargs on the `CharField`, followed by dropping/adding the column with Playhouse didn't change anything. But running some raw sql did:\r\n```\r\n # Make the name column case sensitive\r\n collate_sql = \"\"\"\r\n ALTER TABLE db.tbl\r\n MODIFY COLUMN col VARCHAR(255) COLLATE utf8_bin;\r\n \"\"\"\r\n db.execute_sql(collate_sql)\r\n```\r\nVerified by running `SHOW FULL COLUMNS FROM tbl;`\r\n\r\nNOTE the `MODIFY COLUMN` vs `ALTER COLUMN`. When I used `ALTER COLUMN` I kept getting a syntax error. But for some reason `MODIFY COLUMN` worked. I'm too unfamiliar with db administration and too strapped on time to know why, but figured I'd include that factoid."
] | 2021-11-19T19:01:51 | 2021-11-23T17:26:46 | 2021-11-19T19:46:46 | NONE | null | I have a `CharField` defined like so:
```
class ToucanDomain(db.Model):
name = CharField(unique=True, null=False)
```
I would like to create two entries, one with `name='SaTScan'` and another with `name='satscan'`. However, I get the following error, because on `create` the field appears to be case insensitive.
```
>>> ToucanDomain.create(name='SaTScan')
<ToucanDomain: 1>
>>> ToucanDomain.create(name='satscan')
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/peewee.py", line 3099, in execute_sql
cursor.execute(sql, params or ())
File "/usr/local/lib/python3.7/site-packages/pymysql/cursors.py", line 170, in execute
result = self._query(query)
File "/usr/local/lib/python3.7/site-packages/pymysql/cursors.py", line 328, in _query
conn.query(q)
File "/usr/local/lib/python3.7/site-packages/pymysql/connections.py", line 517, in query
self._affected_rows = self._read_query_result(unbuffered=unbuffered)
File "/usr/local/lib/python3.7/site-packages/pymysql/connections.py", line 732, in _read_query_result
result.read()
File "/usr/local/lib/python3.7/site-packages/pymysql/connections.py", line 1075, in read
first_packet = self.connection._read_packet()
File "/usr/local/lib/python3.7/site-packages/pymysql/connections.py", line 684, in _read_packet
packet.check_error()
File "/usr/local/lib/python3.7/site-packages/pymysql/protocol.py", line 220, in check_error
err.raise_mysql_exception(self._data)
File "/usr/local/lib/python3.7/site-packages/pymysql/err.py", line 109, in raise_mysql_exception
raise errorclass(errno, errval)
pymysql.err.IntegrityError: (1062, "Duplicate entry 'satscan' for key 'toucandomain_name'")
```
Is this expected behavior? If so, is there a way around it? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2489/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2489/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2488 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2488/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2488/comments | https://api.github.com/repos/coleifer/peewee/issues/2488/events | https://github.com/coleifer/peewee/issues/2488 | 1,058,357,797 | I_kwDOAA7yGM4_FUIl | 2,488 | how to make order_by smarter | {
"login": "viponedream",
"id": 16624529,
"node_id": "MDQ6VXNlcjE2NjI0NTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/16624529?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/viponedream",
"html_url": "https://github.com/viponedream",
"followers_url": "https://api.github.com/users/viponedream/followers",
"following_url": "https://api.github.com/users/viponedream/following{/other_user}",
"gists_url": "https://api.github.com/users/viponedream/gists{/gist_id}",
"starred_url": "https://api.github.com/users/viponedream/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/viponedream/subscriptions",
"organizations_url": "https://api.github.com/users/viponedream/orgs",
"repos_url": "https://api.github.com/users/viponedream/repos",
"events_url": "https://api.github.com/users/viponedream/events{/privacy}",
"received_events_url": "https://api.github.com/users/viponedream/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-11-19T10:08:36 | 2021-11-19T14:10:53 | 2021-11-19T14:10:53 | NONE | null | i want to accept a parameter,
def get_all_order_by(self, _order_by) -> list:
table = self.get_table()
res = table.select().order_by(table._order_by.desc()) --> this doesnot work
item_list = [d.to_item() for d in res]
return item_list | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2488/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2488/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2487 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2487/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2487/comments | https://api.github.com/repos/coleifer/peewee/issues/2487/events | https://github.com/coleifer/peewee/issues/2487 | 1,053,927,057 | I_kwDOAA7yGM4-0aaR | 2,487 | JSONField - Peewee cannot serialize Pendulum DateTime | {
"login": "johnziebro",
"id": 90479072,
"node_id": "MDQ6VXNlcjkwNDc5MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/90479072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/johnziebro",
"html_url": "https://github.com/johnziebro",
"followers_url": "https://api.github.com/users/johnziebro/followers",
"following_url": "https://api.github.com/users/johnziebro/following{/other_user}",
"gists_url": "https://api.github.com/users/johnziebro/gists{/gist_id}",
"starred_url": "https://api.github.com/users/johnziebro/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/johnziebro/subscriptions",
"organizations_url": "https://api.github.com/users/johnziebro/orgs",
"repos_url": "https://api.github.com/users/johnziebro/repos",
"events_url": "https://api.github.com/users/johnziebro/events{/privacy}",
"received_events_url": "https://api.github.com/users/johnziebro/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
">I'd like to better understand the roundtrip process for serializing and deserializing.\r\n\r\nThe sqlite3 json data-type requires the data to be serialized into json. Simple as that. When reading row data off a cursor the JSONField will deserialize it back to an object.\r\n\r\nThe problem is actually rather from python's own `json` module not supporting `datetime`-like out of the box. Which is a pretty glaring oversight in my opinion, but something to take up with the core team.",
"@coleifer could you let me know if this would be a good strategy to follow?\r\n\r\nGenerally speaking, the [direction for encoding per this stackoverflow](https://stackoverflow.com/a/27058505/1663382) is to subclass json.JSONEncoder/JSONDecoder with a custom class, then provide it to json.dumps/loads as the 'cls' parameter using functools.partial. I believe what I was hung up on from the Peewee doc's was how to use the custom encoder and that json_loads was missing from the example.\r\n\r\n```\r\nclass DateTimeEncoder(JSONEncoder)\r\n # custom encode implementation here\r\n ...\r\n\r\nclass DateTimeDecoder(JSONDecoder)\r\n # custom decode implementation here\r\n ...\r\n\r\n# assign dumps and loads functions\r\nmy_json_dumps = functools.partial(json.dumps, cls=DateTimeEncoder)\r\nmy_json_loads = functools.partial(json.loads, cls=DateTimeDecoder)\r\n\r\nclass SomeModel(Model):\r\n # Specify our custom serialization function.\r\n json_data = JSONField(json_dumps=my_json_dumps, json_loads=my_json_loads)\r\n```",
"There are a number of options: https://stackoverflow.com/questions/11875770/how-to-overcome-datetime-datetime-not-json-serializable",
"For posterity or if anyone else needs an example as I did not see this in any other closed issues, @coleifer thanks again! \r\n\r\n### Solution\r\n```\r\nimport json\r\nimport pendulum as pdlm\r\nfrom functools import partial\r\n\r\n\r\nclass PendulumDateTimeEncoder(json.JSONEncoder):\r\n \"\"\"\r\n Provides json encoding as string for pendulum.DateTime objects\r\n including timezone or UTC.\r\n \"\"\"\r\n\r\n def default(self, object):\r\n\r\n # handle pendulum.DateTime objects\r\n if isinstance(object, pdlm.DateTime):\r\n\r\n # generate ISO 8601 string\r\n return object.to_iso8601_string()\r\n\r\n return super().default(object)\r\n\r\n\r\nclass PendulumDateTimeDecoder(json.JSONDecoder):\r\n \"\"\"\r\n Provides json datetime stored as string decoding for\r\n pendulum.DateTime objects.\r\n \"\"\"\r\n\r\n def decode(self, object):\r\n\r\n # handle pendulum.DateTime objects\r\n if isinstance(object, str):\r\n\r\n # load as json string\r\n object = json.loads(object)\r\n\r\n # return ISO 8601 string as pendulum DateTime\r\n return pdlm.parse(object)\r\n\r\n return super().decode(object)\r\n\r\n\r\n# assign dumps and loads functions\r\ncustom_dumps = partial(json.dumps, cls=PendulumDateTimeEncoder)\r\ncustom_loads = partial(json.loads, cls=PendulumDateTimeDecoder)\r\n```\r\n\r\n### Test\r\n```\r\nnow = pdlm.now('UTC')\r\ndumped = custom_dumps(now)\r\nloaded = custom_loads(dumped)\r\nassert loaded == now, \"Round-trip serialization failed.\"\r\nassert loaded.tz.name == \"UTC\", \"Timezone round-trip failure.\"\r\n```\r\n\r\n### ORM Class\r\n```\r\nclass TimelineModel(BaseModel):\r\n \"\"\" ORM model for Timeline. \"\"\"\r\n intervals = JSONField(json_dumps=custom_dumps, json_loads=custom_loads)\r\n```"
] | 2021-11-15T17:38:08 | 2021-11-15T20:21:22 | 2021-11-15T17:55:31 | NONE | null | ### Issue
The Pendulum module's purpose is to be a drop-in replacement for the standard datetime class. In most cases Pendulum's DateTime class can be treated the same as datetime.datetime. However, when attempting to save with Peewee into a JSONField, DateTime throws a TypeError as not serializable.
Per [Pendulum's FAQ](https://pendulum.eustace.io/faq/) this issue is to be expected:
> Unlike other datetime libraries for Python, Pendulum is a drop-in replacement for the standard datetime class (it inherits from it), so, basically, you can replace all your datetime instances by DateTime instances in you code (**_exceptions exist for libraries that check the type of the objects by using the type function like sqlite3 or PyMySQL for instance_**).
### Peewee Doc's Solution
Per Peewee docs for [JSONField](http://docs.peewee-orm.com/en/latest/peewee/sqlite_ext.html?highlight=JSONField#JSONField), the solution is to customize the serialization:
> To customize the JSON serialization or de-serialization, you can specify a custom json_dumps and json_loads callables. These functions should accept a single paramter: the object to serialize, and the JSON string, respectively. To modify the parameters of the stdlib JSON functions, you can use functools.partial
```
# Do not escape unicode code-points.
my_json_dumps = functools.partial(json.dumps, ensure_ascii=False)
class SomeModel(Model):
# Specify our custom serialization function.
json_data = JSONField(json_dumps=my_json_dumps)
```
### Questions
I'd like to better understand the roundtrip process for serializing and deserializing. In the future, it would be helpful for a more extensive example in the docs. The use case is to be able to save and load Pendulum DateTimes into and from Peewee. I don't exactly see how to accomplish this using partial with json.dumps. My understanding is that I would need to subclass json.JSONEncoder and json.JSONDecoder.
**Could you provide some additional direction in how to accomplish this or a more efficient route? Maybe I am missing something about using json.dumps. Thank you in advance.**
### Error
> Traceback (most recent call last):
> ...
> File "/home/----/Projects/rf/.venv/lib/python3.8/site-packages/playhouse/sqlite_ext.py", line 142, in db_value
> value = fn.json(self._json_dumps(value))
> File "/usr/lib/python3.8/json/__init__.py", line 231, in dumps
> return _default_encoder.encode(obj)
> File "/usr/lib/python3.8/json/encoder.py", line 199, in encode
> chunks = self.iterencode(o, _one_shot=True)
> File "/usr/lib/python3.8/json/encoder.py", line 257, in iterencode
> return _iterencode(o, 0)
> File "/usr/lib/python3.8/json/encoder.py", line 179, in default
> raise TypeError(f'Object of type {o.__class__.__name__} '
> TypeError: Object of type DateTime is not JSON serializable
> python-BaseException | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2487/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2487/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2486 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2486/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2486/comments | https://api.github.com/repos/coleifer/peewee/issues/2486/events | https://github.com/coleifer/peewee/issues/2486 | 1,051,493,025 | I_kwDOAA7yGM4-rIKh | 2,486 | `get_or_create` isn't automatically including the primary key | {
"login": "rbracco",
"id": 47190785,
"node_id": "MDQ6VXNlcjQ3MTkwNzg1",
"avatar_url": "https://avatars.githubusercontent.com/u/47190785?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rbracco",
"html_url": "https://github.com/rbracco",
"followers_url": "https://api.github.com/users/rbracco/followers",
"following_url": "https://api.github.com/users/rbracco/following{/other_user}",
"gists_url": "https://api.github.com/users/rbracco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rbracco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rbracco/subscriptions",
"organizations_url": "https://api.github.com/users/rbracco/orgs",
"repos_url": "https://api.github.com/users/rbracco/repos",
"events_url": "https://api.github.com/users/rbracco/events{/privacy}",
"received_events_url": "https://api.github.com/users/rbracco/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm getting some really weird results. I tried to hack around it by calling `ModelResult.get(audio_id=af.id, model_id=tm.id)` and manually updating if it existed, and if it didnt, catching the `DoesNotExist` and manually creating the `ModelResult` with\r\n\r\n```\r\nmax_id = ModelResult.select(fn.MAX(ModelResult.id)).scalar() + 1\r\nmr = ModelResult(\r\n id=max_id,\r\n prediction=pred,\r\n loss=loss,\r\n audio_id=af.id,\r\n model_id=tm.id,\r\n )\r\nmr.save()\r\n```\r\nIt worked for like 20 rows and then the rows stopped getting added and the ID stopped incrementing. I set a breakpoint and everything looks good in the ModelResult instance but mr.save() is returning 0. I searched and found #1198 which makes me think something is really wrong. \r\n\r\n**Edit:** I started using `mr.save(force_insert=True)` which worked and then checked the docs and saw that it happens when you create your own non-integer primary key which I don't think I did. My schema doesn't use `PrimaryKey` anywhere but I checked the schema in SQLite browser and I now see that the `id` field for `ModelResult` is `NUMERIC` not `INTEGER`. I'm not sure how this happened but I believe that's the issue. I'm going to explore a bit more and I'll post here and close out if I confirm. ",
"There's nothing wrong with peewee, surely this is something in your code or schema.\r\n\r\n```python\r\nclass Audio(Base):\r\n name = TextField()\r\n\r\nclass Note(Base):\r\n name = TextField()\r\n\r\nclass Result(Base):\r\n audio = ForeignKeyField(Audio)\r\n note = ForeignKeyField(Note, null=True)\r\n\r\ndb.create_tables([Audio, Note, Result])\r\n\r\na1 = Audio.create(name='a1')\r\na2 = Audio.create(name='a2')\r\nn1 = Note.create(name='n1')\r\nn2 = Note.create(name='n2')\r\n\r\nr1a, created = Result.get_or_create(audio=a1)\r\nassert created\r\nr1b, created = Result.get_or_create(audio=a1)\r\nassert not created\r\nassert r1a.id == r1b.id\r\n\r\nr2a, created = Result.get_or_create(audio=a2, note=n2)\r\nassert created\r\nr2b, created = Result.get_or_create(audio=a2, note=n2)\r\nassert not created\r\nassert r2a.id == r2b.id\r\n```"
] | 2021-11-12T01:21:19 | 2021-11-12T13:47:52 | 2021-11-12T13:47:52 | NONE | null | I have a field `ModelResult` with a foreignkey for an `Audio` class. I recently updated `ModelResult` to take a 2nd foreign key for a `Model` class. When I call `get_or_create` I get the error `IntegrityError: NOT NULL constraint failed: modelresult.id`. For some reason the id isn't being automatically included/incremented, but if I include it manually in the defaults (e.g. {"id": 10000000}, it works). My intention is that if a row exists with that combination of audio and model, update it, otherwise create it. Any idea where I might be going wrong?
Thank you by the way, peewee is a pleasure to work with.
```
audio = AudioFile.get(AudioFile.filename == fname)
tm, created = TrainModel.get_or_create(name=model_name)
defaults = {
"prediction": pred,
"loss": loss,
}
mr, created = ModelResult.get_or_create(audio_id=audio, model_id=tm, defaults=defaults)
# if mr already exists, update it with new values
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2486/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2486/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2485 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2485/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2485/comments | https://api.github.com/repos/coleifer/peewee/issues/2485/events | https://github.com/coleifer/peewee/pull/2485 | 1,051,246,165 | PR_kwDOAA7yGM4ua5_k | 2,485 | Document example usage of object_id_name | {
"login": "pylipp",
"id": 10617122,
"node_id": "MDQ6VXNlcjEwNjE3MTIy",
"avatar_url": "https://avatars.githubusercontent.com/u/10617122?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pylipp",
"html_url": "https://github.com/pylipp",
"followers_url": "https://api.github.com/users/pylipp/followers",
"following_url": "https://api.github.com/users/pylipp/following{/other_user}",
"gists_url": "https://api.github.com/users/pylipp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pylipp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pylipp/subscriptions",
"organizations_url": "https://api.github.com/users/pylipp/orgs",
"repos_url": "https://api.github.com/users/pylipp/repos",
"events_url": "https://api.github.com/users/pylipp/events{/privacy}",
"received_events_url": "https://api.github.com/users/pylipp/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I found the text and admonition confusing, even in context. I'll pass for now but will think about whether some improvement to the docs is needed for this situation."
] | 2021-11-11T18:22:13 | 2021-11-11T22:46:25 | 2021-11-11T22:46:24 | NONE | null | In combination with `column_name` defined, an AttributeError is raised otherwise.
This behavior was confusing me at first, until I found #1302. The docs (apart from the ForeignKeyField API) don't mention object_id_name | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2485/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2485/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2485",
"html_url": "https://github.com/coleifer/peewee/pull/2485",
"diff_url": "https://github.com/coleifer/peewee/pull/2485.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2485.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2484 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2484/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2484/comments | https://api.github.com/repos/coleifer/peewee/issues/2484/events | https://github.com/coleifer/peewee/issues/2484 | 1,046,845,023 | I_kwDOAA7yGM4-ZZZf | 2,484 | Insert doesn't return lastrowid for Postgresql | {
"login": "sebo-b",
"id": 51707418,
"node_id": "MDQ6VXNlcjUxNzA3NDE4",
"avatar_url": "https://avatars.githubusercontent.com/u/51707418?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sebo-b",
"html_url": "https://github.com/sebo-b",
"followers_url": "https://api.github.com/users/sebo-b/followers",
"following_url": "https://api.github.com/users/sebo-b/following{/other_user}",
"gists_url": "https://api.github.com/users/sebo-b/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sebo-b/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sebo-b/subscriptions",
"organizations_url": "https://api.github.com/users/sebo-b/orgs",
"repos_url": "https://api.github.com/users/sebo-b/repos",
"events_url": "https://api.github.com/users/sebo-b/events{/privacy}",
"received_events_url": "https://api.github.com/users/sebo-b/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Postgres/psycopg2 does not provide a lastrowid db-api method -- you need to use RETURNING with postgres. This is handled automatically for you when you use the models APIs, but **not** when you are using the low-level query builder (e.g. `Table`)."
] | 2021-11-07T20:44:01 | 2021-11-08T14:22:51 | 2021-11-08T14:22:51 | NONE | null | Minimal test case:
```
test = Table('test',('id','value'),primary_key='id')
test.bind(db)
lastRowId = test.insert({test.value: 10}).execute()
```
Actual:
lastRowId is None
Expected:
lastRowId contains generated primary key
In Postgresql implementation, for receiving inserted id RETURNING clause is used. The following code works correctly:
`lastRowId = test.insert({test.value: 10}).returning(test.id).execute()`
however in the current implementation equivalent to this is used:
`lastRowId = test.insert({test.value: 10}).returning('id').execute()`
Postrgres returns something like this: `Column(name='?column?', type_code=25)`
which then is wrapped and looks like this `{'?column?': 'id'}`
then `last_insert_id` is trying to access `cursor[0][0]` which raises an error so None is returned
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2484/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2484/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2483 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2483/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2483/comments | https://api.github.com/repos/coleifer/peewee/issues/2483/events | https://github.com/coleifer/peewee/pull/2483 | 1,044,521,423 | PR_kwDOAA7yGM4uFWu9 | 2,483 | Insert link to gevent docs for monkey-patching | {
"login": "pylipp",
"id": 10617122,
"node_id": "MDQ6VXNlcjEwNjE3MTIy",
"avatar_url": "https://avatars.githubusercontent.com/u/10617122?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pylipp",
"html_url": "https://github.com/pylipp",
"followers_url": "https://api.github.com/users/pylipp/followers",
"following_url": "https://api.github.com/users/pylipp/following{/other_user}",
"gists_url": "https://api.github.com/users/pylipp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pylipp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pylipp/subscriptions",
"organizations_url": "https://api.github.com/users/pylipp/orgs",
"repos_url": "https://api.github.com/users/pylipp/repos",
"events_url": "https://api.github.com/users/pylipp/events{/privacy}",
"received_events_url": "https://api.github.com/users/pylipp/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Not a fan of links becoming stale?\r\n"
] | 2021-11-04T09:34:33 | 2021-11-04T15:08:27 | 2021-11-04T12:55:15 | NONE | null | null | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2483/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2483/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2483",
"html_url": "https://github.com/coleifer/peewee/pull/2483",
"diff_url": "https://github.com/coleifer/peewee/pull/2483.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2483.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2482 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2482/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2482/comments | https://api.github.com/repos/coleifer/peewee/issues/2482/events | https://github.com/coleifer/peewee/issues/2482 | 1,043,929,853 | I_kwDOAA7yGM4-ORr9 | 2,482 | Postgres: db.create_tables() throws table already exists error | {
"login": "dhrumilp31",
"id": 87986360,
"node_id": "MDQ6VXNlcjg3OTg2MzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/87986360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dhrumilp31",
"html_url": "https://github.com/dhrumilp31",
"followers_url": "https://api.github.com/users/dhrumilp31/followers",
"following_url": "https://api.github.com/users/dhrumilp31/following{/other_user}",
"gists_url": "https://api.github.com/users/dhrumilp31/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dhrumilp31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dhrumilp31/subscriptions",
"organizations_url": "https://api.github.com/users/dhrumilp31/orgs",
"repos_url": "https://api.github.com/users/dhrumilp31/repos",
"events_url": "https://api.github.com/users/dhrumilp31/events{/privacy}",
"received_events_url": "https://api.github.com/users/dhrumilp31/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"You need to re-bind the models to the postgres database in order for them to be created on the Pg database:\r\n\r\n```python\r\ndb = PostgresqlDatabase('prodigy_db', user='usr', password='pwd', host='host', port=5432)\r\ndb.bind(models.values())\r\ndb.create_tables(list(models.values()), safe=False)\r\n```",
"Thanks @coleifer, it worked. Appreciate the quick response. "
] | 2021-11-03T18:22:09 | 2021-11-03T19:21:28 | 2021-11-03T19:13:39 | NONE | null | I am trying to load schema from existing SQLite database and using those definitions, would like to create three new tables in Postgres db. Following is the code that I am using:
````
from peewee import SqliteDatabase, PostgresqlDatabase, Model
from playhouse.reflection import generate_models, print_model, print_table_sql
# Load existing prodigy database
sqlite_db = SqliteDatabase("prodigy.db")
models = generate_models(sqlite_db)
print('Models: {}'.format(models))
# Connect to a Postgres database and create tables
db = PostgresqlDatabase('prodigy_db', user='usr', password='pwd', host='host', port=5432)
db.create_tables(list(models.values()), safe=False)
print('DB: {}'.format(db.get_tables()))
db.close()
````
Schema:
````
dataset
id AUTO PK
name VARCHAR
created INT
meta BLOB
session INT
index(es)
name UNIQUE
example
id AUTO PK
input_hash INT
task_hash INT
content BLOB
link
id AUTO PK
example INT FK: example.id
dataset INT FK: dataset.id
index(es)
example_id
dataset_id
````
Which creates the models successfully, but fails to create new tables in Postgres based on those models.
```
Models: {'dataset': <Model: dataset>, 'example': <Model: example>, 'link': <Model: link>}
Traceback (most recent call last):
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 3160, in execute_sql
cursor.execute(sql, params or ())
sqlite3.OperationalError: table "dataset" already exists
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "setup_db.py", line 15, in <module>
db.create_tables(list(models.values()), safe=False)
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 3348, in create_tables
model.create_table(**options)
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 6721, in create_table
cls._schema.create_all(safe, **options)
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 5828, in create_all
self.create_table(safe, **table_options)
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 5683, in create_table
self.database.execute(self._create_table(safe=safe, **options))
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 3173, in execute
return self.execute_sql(sql, params, commit=commit)
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 3167, in execute_sql
self.commit()
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 2933, in __exit__
reraise(new_type, new_type(exc_value, *exc_args), traceback)
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 191, in reraise
raise value.with_traceback(tb)
File "/home/ubuntu/prodigy/venv/lib/python3.6/site-packages/peewee.py", line 3160, in execute_sql
cursor.execute(sql, params or ())
peewee.OperationalError: table "dataset" already exists
```
The error says table 'dataset' already exists, but here is the describe table command on prodigy_db:
<img width="709" alt="Screen Shot 2021-11-03 at 2 14 28 PM" src="https://user-images.githubusercontent.com/87986360/140168892-5ff90270-72f9-4599-be92-7ffec2f1f211.png">
Am I missing something here? Thanks in advance.
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2482/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2482/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2481 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2481/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2481/comments | https://api.github.com/repos/coleifer/peewee/issues/2481/events | https://github.com/coleifer/peewee/pull/2481 | 1,039,103,926 | PR_kwDOAA7yGM4t07z6 | 2,481 | Fix type in querying.rst | {
"login": "stenci",
"id": 5955495,
"node_id": "MDQ6VXNlcjU5NTU0OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/5955495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stenci",
"html_url": "https://github.com/stenci",
"followers_url": "https://api.github.com/users/stenci/followers",
"following_url": "https://api.github.com/users/stenci/following{/other_user}",
"gists_url": "https://api.github.com/users/stenci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stenci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stenci/subscriptions",
"organizations_url": "https://api.github.com/users/stenci/orgs",
"repos_url": "https://api.github.com/users/stenci/repos",
"events_url": "https://api.github.com/users/stenci/events{/privacy}",
"received_events_url": "https://api.github.com/users/stenci/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-10-29T02:28:32 | 2021-10-29T11:09:10 | 2021-10-29T11:09:10 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2481/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2481/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2481",
"html_url": "https://github.com/coleifer/peewee/pull/2481",
"diff_url": "https://github.com/coleifer/peewee/pull/2481.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2481.patch",
"merged_at": "2021-10-29T11:09:10"
} |
https://api.github.com/repos/coleifer/peewee/issues/2480 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2480/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2480/comments | https://api.github.com/repos/coleifer/peewee/issues/2480/events | https://github.com/coleifer/peewee/issues/2480 | 1,038,288,678 | I_kwDOAA7yGM494wcm | 2,480 | ReconnectMixin with atomic cause exception | {
"login": "mattangus",
"id": 5302804,
"node_id": "MDQ6VXNlcjUzMDI4MDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5302804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mattangus",
"html_url": "https://github.com/mattangus",
"followers_url": "https://api.github.com/users/mattangus/followers",
"following_url": "https://api.github.com/users/mattangus/following{/other_user}",
"gists_url": "https://api.github.com/users/mattangus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mattangus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mattangus/subscriptions",
"organizations_url": "https://api.github.com/users/mattangus/orgs",
"repos_url": "https://api.github.com/users/mattangus/repos",
"events_url": "https://api.github.com/users/mattangus/events{/privacy}",
"received_events_url": "https://api.github.com/users/mattangus/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The transaction details are wrapped by the driver, so I can't really comment on why this is the case with pymysql. I'd suggest possibly trying to ping the db before beginning transactions if its possible your connection has been idle for quite some time. You can do this quite easily.\r\n\r\nhttps://pymysql.readthedocs.io/en/latest/modules/connections.html#pymysql.connections.Connection.ping\r\n\r\n```python\r\n\r\ndb = ReconnectMySQLDatabase(...)\r\n\r\ntry:\r\n db.connection().ping(reconnect=False)\r\nexcept:\r\n db.close()\r\n db.connect()\r\n```\r\n\r\nCouple things to consider, though. Why are you leaving open connections sitting idle for a long time? This may indicate a problematic design. If this is a web app, you should probably be using the PooledMySQLDatabase and opening/closing connections each request. If this is something else, however, I'd suggest either a) connect/close when you need to do work, or b) use something like the code above to ensure connection liveness."
] | 2021-10-28T09:23:19 | 2021-10-28T13:01:01 | 2021-10-28T13:01:01 | NONE | null | Using the `ReconnectMixin` and executing a query after a long wait inside an `atomic` block causes an exception.
Here is some sample code:
```python
class ReconnectMySQLDatabase(ReconnectMixin, pw.MySQLDatabase):
"""Class to make MySQL automatically reconnect after long periods without querying the database
"""
pass
DB = ReconnectMySQLDatabase(...)
# wait a long time
tweets = Tweet.select()
with DB.atomic():
for t in tweets:
t.user = "me"
Tweet.bulk_update(tweets, fields=["user"], batch_size=100)
```
This will cause an exception saying that the connection was reset inside a transaction.
Shouldn't the transaction initialization cause the reconnect. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2480/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2480/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2479 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2479/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2479/comments | https://api.github.com/repos/coleifer/peewee/issues/2479/events | https://github.com/coleifer/peewee/issues/2479 | 1,037,145,443 | I_kwDOAA7yGM490ZVj | 2,479 | tests.apsw_ext.TestAPSWExtension tests failing (LockedError) after 10be40b2ea3d76a9 (RETURNING support) | {
"login": "mgorny",
"id": 110765,
"node_id": "MDQ6VXNlcjExMDc2NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/110765?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mgorny",
"html_url": "https://github.com/mgorny",
"followers_url": "https://api.github.com/users/mgorny/followers",
"following_url": "https://api.github.com/users/mgorny/following{/other_user}",
"gists_url": "https://api.github.com/users/mgorny/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mgorny/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mgorny/subscriptions",
"organizations_url": "https://api.github.com/users/mgorny/orgs",
"repos_url": "https://api.github.com/users/mgorny/repos",
"events_url": "https://api.github.com/users/mgorny/events{/privacy}",
"received_events_url": "https://api.github.com/users/mgorny/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for reporting and bisecting, I've got a fix and will push a new release later today.",
"Thank you, I can confirm that tests pass on master now."
] | 2021-10-27T08:47:59 | 2021-10-27T14:01:59 | 2021-10-27T12:45:32 | NONE | null | I'm getting 12 test errors with the git master (and 3.14.6) release that are regressions compared to 3.14.4. An example test error looks like the following:
```
======================================================================
ERROR: test_update_delete (tests.apsw_ext.TestAPSWExtension)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/tmp/peewee/tests/base.py", line 246, in tearDown
self.database.drop_tables(self.requires, safe=True)
File "/tmp/peewee/peewee.py", line 3352, in drop_tables
model.drop_table(**kwargs)
File "/tmp/peewee/peewee.py", line 6730, in drop_table
cls._schema.drop_all(safe, drop_sequences, **options)
File "/tmp/peewee/peewee.py", line 5838, in drop_all
self.drop_table(safe, **options)
File "/tmp/peewee/peewee.py", line 5711, in drop_table
self.database.execute(self._drop_table(safe=safe, **options))
File "/tmp/peewee/peewee.py", line 3173, in execute
return self.execute_sql(sql, params, commit=commit)
File "/tmp/peewee/playhouse/apsw_ext.py", line 122, in execute_sql
cursor.execute(sql, params or ())
apsw.LockedError: LockedError: database table is locked
```
Full build and test log: [test.log](https://github.com/coleifer/peewee/files/7424610/test.log)
I have reproduced the problem with Python 3.8.12 and 3.10.0.
A quick bisect points to the following commit as the first bad one:
```
commit 10be40b2ea3d76a9e410e1e5d0a7b5c1c58c8467 (refs/bisect/bad)
Author: Charles Leifer <[email protected]>
Date: 2021-10-21 15:52:55 +0200
Add provisional support for RETURNING for sqlite_ext/mariadb.
Sqlite has kind-of unusual behavior with regards to lastrowid and the
rowid in general, so I'm retaining the original behavior for the
standard SqliteDatabase, but using SqliteExtDatabase will now support
RETURNING for Sqlite 3.35 or newer.
Similarly, MariaDBConnectorDatabase will also support RETURNING for
MariaDB 10.5 or newer.
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2479/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2479/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2478 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2478/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2478/comments | https://api.github.com/repos/coleifer/peewee/issues/2478/events | https://github.com/coleifer/peewee/issues/2478 | 1,034,798,619 | I_kwDOAA7yGM49rcYb | 2,478 | Implementation of Modulo operator in documentation | {
"login": "gaspardbb",
"id": 40466739,
"node_id": "MDQ6VXNlcjQwNDY2NzM5",
"avatar_url": "https://avatars.githubusercontent.com/u/40466739?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gaspardbb",
"html_url": "https://github.com/gaspardbb",
"followers_url": "https://api.github.com/users/gaspardbb/followers",
"following_url": "https://api.github.com/users/gaspardbb/following{/other_user}",
"gists_url": "https://api.github.com/users/gaspardbb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gaspardbb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gaspardbb/subscriptions",
"organizations_url": "https://api.github.com/users/gaspardbb/orgs",
"repos_url": "https://api.github.com/users/gaspardbb/repos",
"events_url": "https://api.github.com/users/gaspardbb/events{/privacy}",
"received_events_url": "https://api.github.com/users/gaspardbb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"What database driver are you using this with, out of curiosity? The example works fine with Sqlite but I'm wondering if this is a result of psycopg2 doing its mogrifying client-side.",
"This was with Postgre. Indeed, the issue was raised on l. 3144, `cursor.execute(sql, params or ())`."
] | 2021-10-25T07:55:13 | 2021-10-25T17:54:53 | 2021-10-25T14:32:07 | NONE | null | ## Problem
In the [documentation](https://docs.peewee-orm.com/en/latest/peewee/query_operators.html?#adding-user-defined-operators), it is said that the modulo operator can be implemented with
```python
from peewee import *
from peewee import Expression # the building block for expressions
def mod(lhs, rhs):
return Expression(lhs, '%', rhs)
```
This gives a `IndexError: list index out of range`, due to the `%` causing string formatting issues.
## Fix
Replacing `%` with `%%`.
```python
def mod(lhs, rhs):
return Expression(lhs, '%%', rhs)
```
That's not a big issue, but when we know nothing about Python 2 string formatting and SQL, it's a bit unsettling :) | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2478/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2478/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2477 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2477/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2477/comments | https://api.github.com/repos/coleifer/peewee/issues/2477/events | https://github.com/coleifer/peewee/pull/2477 | 1,034,480,322 | PR_kwDOAA7yGM4tl8nk | 2,477 | removed a consider-using-in pitfall case | {
"login": "NaelsonDouglas",
"id": 8750259,
"node_id": "MDQ6VXNlcjg3NTAyNTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8750259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NaelsonDouglas",
"html_url": "https://github.com/NaelsonDouglas",
"followers_url": "https://api.github.com/users/NaelsonDouglas/followers",
"following_url": "https://api.github.com/users/NaelsonDouglas/following{/other_user}",
"gists_url": "https://api.github.com/users/NaelsonDouglas/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NaelsonDouglas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NaelsonDouglas/subscriptions",
"organizations_url": "https://api.github.com/users/NaelsonDouglas/orgs",
"repos_url": "https://api.github.com/users/NaelsonDouglas/repos",
"events_url": "https://api.github.com/users/NaelsonDouglas/events{/privacy}",
"received_events_url": "https://api.github.com/users/NaelsonDouglas/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'll pass."
] | 2021-10-24T18:15:28 | 2021-10-24T20:03:29 | 2021-10-24T20:03:29 | NONE | null | **Problem**:
The code was incurring into the consider-using-in pitfall case, as described by Pylint documentation here https://github.com/vald-phoenix/pylint-errors/blob/master/plerr/errors/refactoring/R1714.md
**Solution**:
Applied adequate refactoring. Only a single line of code was changed | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2477/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2477/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2477",
"html_url": "https://github.com/coleifer/peewee/pull/2477",
"diff_url": "https://github.com/coleifer/peewee/pull/2477.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2477.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2476 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2476/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2476/comments | https://api.github.com/repos/coleifer/peewee/issues/2476/events | https://github.com/coleifer/peewee/issues/2476 | 1,033,428,716 | I_kwDOAA7yGM49mN7s | 2,476 | Just warrning when insert_many NULL value into a Not Allow Null field | {
"login": "ThaoPN",
"id": 19179219,
"node_id": "MDQ6VXNlcjE5MTc5MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/19179219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ThaoPN",
"html_url": "https://github.com/ThaoPN",
"followers_url": "https://api.github.com/users/ThaoPN/followers",
"following_url": "https://api.github.com/users/ThaoPN/following{/other_user}",
"gists_url": "https://api.github.com/users/ThaoPN/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ThaoPN/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ThaoPN/subscriptions",
"organizations_url": "https://api.github.com/users/ThaoPN/orgs",
"repos_url": "https://api.github.com/users/ThaoPN/repos",
"events_url": "https://api.github.com/users/ThaoPN/events{/privacy}",
"received_events_url": "https://api.github.com/users/ThaoPN/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Your first query \"add_one_null_row()\" is not specifying any value at all for `not_null_field`, while your second query \"add_multiple_null_row()\" is explicitly specifying NULL for `not_null_field`. I am guessing that older MySQL (with its many quirks) handles these situations differently, raising an IntegrityError for the first case, but possibly silently converting the second case to an empty string or something like that?\r\n\r\nIn short: I think this is a MySQL thing. Both the error *and* the warning are generated by MySQL. I suspect there is a MySQL setting you can enable which will cause the IntegrityError to be raised in both cases -- possibly you are on an old MySQL or running with relaxed settings?\r\n\r\nIn any case, I suggest consulting the MySQL docs or checking out StackOverflow.\r\n\r\nWhen I run this on MariaDB 10.4, I get an IntegrityError for *both* queries -- as expected. The first query gives the integrityerror for Column \"text\" cannot be null, and the second query gives the integrityerror for Column \"not_null_field\" cannot be null."
] | 2021-10-22T10:29:27 | 2021-10-22T15:30:58 | 2021-10-22T15:30:19 | NONE | null | I have a table like below
```
CREATE TABLE `tests` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`text` varchar(45) NOT NULL,
`not_null_field` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=latin1;
```
and the code I used to insert data:
```
class Test(BaseModel):
id = AutoField()
text = CharField(null=False)
not_null_field = CharField(null=False)
class Meta:
table_name = "tests"
def add_one_null_row():
Test.insert_many([{Test.text: None}]).execute()
def add_multiple_null_row():
Test.insert_many(
[
{Test.text: "abc", Test.not_null_field: None}
]
).execute()
```
When I `insert_many` with one record like above, I got the error `peewee.IntegrityError: (1048, "Column 'not_null_field' cannot be null")`
But when I `insert_many` with more than one record, I just got a warning
`.../python3.7/site-packages/pymysql/cursors.py:170: Warning: (1048, "Column 'not_null_field' cannot be null")`
and the data be inserted successfully with `not_null_field` is `empty`.
The query I got:
```
INSERT INTO `tests` (`text`, `not_null_field`) VALUES ('abc', NULL), ('abc', NULL)
```
I don't know why I just got a warning but an error here, somebody help to correct me. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2476/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2476/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2475 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2475/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2475/comments | https://api.github.com/repos/coleifer/peewee/issues/2475/events | https://github.com/coleifer/peewee/issues/2475 | 1,033,356,408 | I_kwDOAA7yGM49l8R4 | 2,475 | Join with subquery column alias not included in result row | {
"login": "larsch",
"id": 15712,
"node_id": "MDQ6VXNlcjE1NzEy",
"avatar_url": "https://avatars.githubusercontent.com/u/15712?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/larsch",
"html_url": "https://github.com/larsch",
"followers_url": "https://api.github.com/users/larsch/followers",
"following_url": "https://api.github.com/users/larsch/following{/other_user}",
"gists_url": "https://api.github.com/users/larsch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/larsch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/larsch/subscriptions",
"organizations_url": "https://api.github.com/users/larsch/orgs",
"repos_url": "https://api.github.com/users/larsch/repos",
"events_url": "https://api.github.com/users/larsch/events{/privacy}",
"received_events_url": "https://api.github.com/users/larsch/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The reason for this is that Peewee is attempting to reconstruct the model-graph, so the \"sum\" attribute (which logically belongs to Bar) is placed in `row.bar.sum`.\r\n\r\nHere:\r\n\r\n```python\r\n\r\nsq = (Bar.select(Bar.foo_id, fn.SUM(Bar.value).alias('sum'))\r\n .group_by(Bar.foo_id))\r\nquery = (Foo.select(Foo.name, sq.c.sum.alias('sum'))\r\n .join(sq, on=(Foo.id == sq.c.foo_id))\r\n .order_by(Foo.name))\r\n\r\nfor foo in query:\r\n print(foo.name, foo.bar.sum)\r\n\r\n# BarBaz 13\r\n# BazFoo 13\r\n# FooBar 13\r\n```\r\n\r\nIf you want all attributes simply put on the model being selected, specify `.objects()` in your outer query:\r\n\r\n```python\r\nfor foo in query.objects():\r\n print(foo.name, foo.sum)\r\n```\r\n\r\nDetails here: http://docs.peewee-orm.com/en/latest/peewee/relationships.html#selecting-from-multiple-sources"
] | 2021-10-22T09:10:28 | 2021-10-22T15:16:21 | 2021-10-22T15:16:21 | NONE | null | peewee version: 3.14.4
I can't figure out how to get the aliased column of the subquery out of the result. It is not present in `row.__dict__` and accessing gives `AttributeError: object has no attribute`. Below is a distilled reproduction of the issue.
Running the `query.sql()` manually with sqlite3 actually produces the expected values and columns, so the query generator works, but the column is not accessible in the result.
```python
from peewee import *
database = SqliteDatabase('join_alias.db')
class BaseModel(Model):
class Meta:
database = database
class Foo(BaseModel):
id = AutoField(unique=True)
name = TextField()
class Bar(BaseModel):
id = AutoField(unique=True)
foo_id = IntegerField()
value = IntegerField(default=0)
with database:
database.create_tables([Foo, Bar])
f1 = Foo.create(name='FooBar')
f2 = Foo.create(name='BarBaz')
f3 = Foo.create(name='BazFoo')
b1a = Bar.create(foo_id=f1.id, value=7)
b1b = Bar.create(foo_id=f1.id, value=6)
b2a = Bar.create(foo_id=f2.id, value=5)
b2c = Bar.create(foo_id=f2.id, value=8)
b3a = Bar.create(foo_id=f3.id, value=9)
b3b = Bar.create(foo_id=f3.id, value=4)
subquery = (
Bar
.select(Bar.foo_id, fn.SUM(Bar.value).alias('sum'))
.group_by(Bar.foo_id))
query = (
Foo
.select(Foo.name, subquery.c.sum.alias('sum'))
.join(subquery, on=(Foo.id == subquery.c.foo_id)))
for row in query.execute():
print(row.name)
#print(row.sum) # Foo object has no attribute 'sum'
#row.__dict__ doesn't contain sum
```
Attempting to access `row.sum`:
```
Traceback (most recent call last):
File "...\join_alias.py", line 47, in <module>
print(row.sum)
AttributeError: 'Foo' object has no attribute 'sum'
```
The `Foo.__dict__` objects returned, missing the `sum` field are:
```
{'__data__': {'name': 'FooBar'}, '_dirty': set(), '__rel__': {}, 'bar': <Bar: None>}
{'__data__': {'name': 'BarBaz'}, '_dirty': set(), '__rel__': {}, 'bar': <Bar: None>}
{'__data__': {'name': 'BazFoo'}, '_dirty': set(), '__rel__': {}, 'bar': <Bar: None>}
```
The generated query is:
```sql
SELECT
t1.name,
t2.sum AS sum
FROM
foo AS t1
INNER JOIN (
SELECT
t3.foo_id,
SUM(t3.value) AS sum
FROM
bar AS t3
GROUP BY
t3.foo_id
) AS t2 ON (t1.id = t2.foo_id)
```
and when run directly with sqlite3, gives exactly the expected result:
|name|sum|
|-|-|
|FooBar|13|
|BarBaz|13|
|BazFoo|13|
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2475/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2475/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2474 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2474/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2474/comments | https://api.github.com/repos/coleifer/peewee/issues/2474/events | https://github.com/coleifer/peewee/issues/2474 | 1,027,995,383 | I_kwDOAA7yGM49Rfb3 | 2,474 | Union queries containing order_by | {
"login": "SilvanVerhoeven",
"id": 44174681,
"node_id": "MDQ6VXNlcjQ0MTc0Njgx",
"avatar_url": "https://avatars.githubusercontent.com/u/44174681?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SilvanVerhoeven",
"html_url": "https://github.com/SilvanVerhoeven",
"followers_url": "https://api.github.com/users/SilvanVerhoeven/followers",
"following_url": "https://api.github.com/users/SilvanVerhoeven/following{/other_user}",
"gists_url": "https://api.github.com/users/SilvanVerhoeven/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SilvanVerhoeven/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SilvanVerhoeven/subscriptions",
"organizations_url": "https://api.github.com/users/SilvanVerhoeven/orgs",
"repos_url": "https://api.github.com/users/SilvanVerhoeven/repos",
"events_url": "https://api.github.com/users/SilvanVerhoeven/events{/privacy}",
"received_events_url": "https://api.github.com/users/SilvanVerhoeven/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"There's a little helper you can use to wrap a select query:\r\n\r\n```python\r\nclass A(Base):\r\n a = TextField()\r\n\r\nclass B(Base):\r\n b = TextField()\r\n\r\ndb.create_tables([A, B])\r\n\r\nA.insert_many([('a%d' % i,) for i in range(10)]).execute()\r\nB.insert_many([('b%d' % i,) for i in range(10)]).execute()\r\n\r\nq1 = A.select(A.a).order_by(A.a).limit(5)\r\nq2 = B.select(B.b).order_by(B.b).limit(5)\r\n\r\n# Wrap the queries in the form SELECT * FROM (SELECT ... LIMIT 5)\r\nwq1 = q1.select_from(SQL('*'))\r\nwq2 = q2.select_from(SQL('*'))\r\n\r\n# Create the union - note that it may be necessary to re-bind the\r\n# query to the database. I've fixed this, but it is not contained in the\r\n# current release on PyPI.\r\nu = (wq1 | wq2).bind(db)\r\n\r\nfor row in u:\r\n print(row)\r\n```\r\n\r\nThis prints:\r\n\r\n```\r\n{'a': 'a0'}\r\n{'a': 'a1'}\r\n{'a': 'a2'}\r\n{'a': 'a3'}\r\n{'a': 'a4'}\r\n{'a': 'b0'}\r\n{'a': 'b1'}\r\n{'a': 'b2'}\r\n{'a': 'b3'}\r\n{'a': 'b4'}\r\n```"
] | 2021-10-16T08:47:41 | 2021-10-18T14:06:06 | 2021-10-18T13:37:39 | NONE | null | I receive two queries from separate modules and want to combine the queries using `UNION` (or `UNION ALL`). The following works like a charm in MySQL:
```python
def fetch_orders_query(limit, **kwargs):
return ModuleA.fetch_orders_query(limit // 2, **kwargs) | ModuleB.fetch_orders_query(limit // 2, **kwargs)
# Resulting SQL query
('(SELECT *fields* FROM *table* AS `t1` WHERE (*predicate1*) ORDER BY *field_1* LIMIT *x*) UNION (SELECT *fields* FROM *table* AS `t2` WHERE (*predicate2*) ORDER BY *field_2* LIMIT *y*)')
```
Yet in SQLite, it throws the error `sqlite3.OperationalError: ORDER BY clause should come after UNION not before`. I couldn't find a working solution for peewee, yet I was trying to write a query like proposed in this StackOverflow post: https://stackoverflow.com/questions/10812910/combine-two-statements-with-limits-using-union, without success.
Is there a clean way to solve this issue in peewee? Executing both queries separately and combining the results is not a preferred solution, as the database is on an external server and network operations are extremely expensive performance-wise. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2474/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2474/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2473 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2473/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2473/comments | https://api.github.com/repos/coleifer/peewee/issues/2473/events | https://github.com/coleifer/peewee/issues/2473 | 1,025,972,748 | I_kwDOAA7yGM49JxoM | 2,473 | Support for psycopg3 | {
"login": "elderlabs",
"id": 30255476,
"node_id": "MDQ6VXNlcjMwMjU1NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/30255476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/elderlabs",
"html_url": "https://github.com/elderlabs",
"followers_url": "https://api.github.com/users/elderlabs/followers",
"following_url": "https://api.github.com/users/elderlabs/following{/other_user}",
"gists_url": "https://api.github.com/users/elderlabs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/elderlabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/elderlabs/subscriptions",
"organizations_url": "https://api.github.com/users/elderlabs/orgs",
"repos_url": "https://api.github.com/users/elderlabs/repos",
"events_url": "https://api.github.com/users/elderlabs/events{/privacy}",
"received_events_url": "https://api.github.com/users/elderlabs/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"There are a number of psycopg3 changes that look to be backwards-incompatible (which is understandable) but will likely be a pain to identify and work around. Parameter binding, especially, looks like it has changed quite a bit.\r\n\r\nIt's definitely on my radar and will be added to Peewee, but I will probably wait a bit to add support. If anyone is interested in the meantime, feel free to implement this in a standalone/extension module.",
"Hello\r\n\r\nI looked at your extension but I wondering, can I use this in conjuction with PostgresqlExtDatabase?\r\n\r\nAny plans on built-in support for psycopg3? Considering is also adding it in their next release and it is a stable release..",
"Are there any specific features of `PostgresqlExtDatabase` you were intending to use - e.g. jsonb, arrays? I'll have to spend some time seeing what works and what doesn't, since we use some helpers from `psycopg2.extras` (e.g. `Json`).",
"I'm going through all my raw SQL code currently, but if I'm not mistaken I will have some jsonb-specifics.\r\n\r\nI will use psycopg2 for now though, but it would be great to see support for 3.",
"No, I agree with you, things are going to be moving towards psycopg3 in the coming years so I'll want to be ready for that. Thanks for the ping on this, I'll be aiming to getting parity for psycopg3 with the current PostgresqlExtDatabase. No definitive timeline but it's a priority for me."
] | 2021-10-14T05:38:37 | 2023-03-30T15:35:45 | 2021-10-14T13:08:32 | NONE | null | Preemptive ticket here. The maintainer of psycopg2 has busied themself with its next iteration, [psycopg3](https://github.com/psycopg/psycopg). Are there plans to add support for the project; is there already native support by design? This ticket's more to see if the project's on your radar as it has officially released, and support for psycopg2 might be in decline fairly soon.
Thanks. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2473/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2473/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2472 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2472/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2472/comments | https://api.github.com/repos/coleifer/peewee/issues/2472/events | https://github.com/coleifer/peewee/issues/2472 | 1,025,820,130 | I_kwDOAA7yGM49JMXi | 2,472 | Model.bulk_create() ignores id of instances | {
"login": "balloonz",
"id": 6794239,
"node_id": "MDQ6VXNlcjY3OTQyMzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6794239?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/balloonz",
"html_url": "https://github.com/balloonz",
"followers_url": "https://api.github.com/users/balloonz/followers",
"following_url": "https://api.github.com/users/balloonz/following{/other_user}",
"gists_url": "https://api.github.com/users/balloonz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/balloonz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/balloonz/subscriptions",
"organizations_url": "https://api.github.com/users/balloonz/orgs",
"repos_url": "https://api.github.com/users/balloonz/repos",
"events_url": "https://api.github.com/users/balloonz/events{/privacy}",
"received_events_url": "https://api.github.com/users/balloonz/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Why are you manually specifying the ID for an auto-incrementing (opaque) primary key? The `bulk_create()` API is a shorthand for generating an `insert_many()`. Just use `insert_many()` if you really want to explicitly set these, I suppose.",
"I was importing some data into the database which involve relational data.\r\nI thought `bulk_create()` as an alternative to `insert_many()` may also work.\r\nIf it is intended behavior, I will stick to `insert_many()`. \r\nThanks for the quick response. \r\n\r\n",
"If you want, you can disable the primary keys `auto_increment` attribute during bulk loading, but (especially if you're just creating the models to insert the data only) insert many is probably a fine choice."
] | 2021-10-14T00:50:11 | 2021-10-14T02:31:06 | 2021-10-14T00:53:01 | NONE | null | It seems that Model.create() method respects id while Model.bulk_create ignores id of instances.
my model class:
```
class Book(Model):
title = CharField(default="")
author = CharField(default="")
created_date = DateTimeField(default=datetime.now)
class Meta:
database = SqliteDatabase(":memory:")
```
The following code prints [(1, 'A'), (2, 'B'), (4, 'D'), (5, 'C')].
```
with db.atomic():
Book.create(id=1, title="A")
Book.create(id=2, title="B")
Book.create(id=5, title="C")
Book.create(id=4, title="D")
print([(book.id, book.title) for book in Book.select()])
```
The following code prints:
[(1, 'A'), (2, 'B'), (5, 'C'), (4, 'D')]
[(1, 'A'), (2, 'B'), (3, 'C'), (4, 'D')]
```
book_items = [
Book(id=1, title="A"),
Book(id=2, title="B"),
Book(id=5, title="C"),
Book(id=4, title="D"),
]
with db.atomic():
Book.bulk_create(book_items, batch_size=50)
print([(book.id, book.title) for book in book_items])
print([(book.id, book.title) for book in Book.select()])
```
Also, the unsaved instances are kept unchanged and therefore inconsistent with the instances returned by Model.select(). | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2472/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2472/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2471 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2471/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2471/comments | https://api.github.com/repos/coleifer/peewee/issues/2471/events | https://github.com/coleifer/peewee/issues/2471 | 1,024,681,147 | I_kwDOAA7yGM49E2S7 | 2,471 | Mariadb | {
"login": "chrisemke",
"id": 63082743,
"node_id": "MDQ6VXNlcjYzMDgyNzQz",
"avatar_url": "https://avatars.githubusercontent.com/u/63082743?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chrisemke",
"html_url": "https://github.com/chrisemke",
"followers_url": "https://api.github.com/users/chrisemke/followers",
"following_url": "https://api.github.com/users/chrisemke/following{/other_user}",
"gists_url": "https://api.github.com/users/chrisemke/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chrisemke/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chrisemke/subscriptions",
"organizations_url": "https://api.github.com/users/chrisemke/orgs",
"repos_url": "https://api.github.com/users/chrisemke/repos",
"events_url": "https://api.github.com/users/chrisemke/events{/privacy}",
"received_events_url": "https://api.github.com/users/chrisemke/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Added basic support in: `playhouse.mysql_ext.MariaDBConnectorDatabase`"
] | 2021-10-13T02:00:36 | 2021-10-13T13:12:14 | 2021-10-13T13:09:23 | NONE | null | Analyze the possibility of adding support to the mariadb database using the [official connector](https://pypi.org/project/mariadb/) | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2471/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2471/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2470 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2470/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2470/comments | https://api.github.com/repos/coleifer/peewee/issues/2470/events | https://github.com/coleifer/peewee/issues/2470 | 1,023,317,868 | I_kwDOAA7yGM48_pds | 2,470 | Potential "list index out of range" in FunctionTable SQLite Extension | {
"login": "ecpost",
"id": 16603401,
"node_id": "MDQ6VXNlcjE2NjAzNDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/16603401?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ecpost",
"html_url": "https://github.com/ecpost",
"followers_url": "https://api.github.com/users/ecpost/followers",
"following_url": "https://api.github.com/users/ecpost/following{/other_user}",
"gists_url": "https://api.github.com/users/ecpost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ecpost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ecpost/subscriptions",
"organizations_url": "https://api.github.com/users/ecpost/orgs",
"repos_url": "https://api.github.com/users/ecpost/repos",
"events_url": "https://api.github.com/users/ecpost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ecpost/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The columns you can filter on are added as HIDDEN columns *after* the exported columns. So you would have:\r\n\r\n```\r\ntable func: series(<start=0>, <stop=None>, <step=1>)\r\n\r\nclass Series(TableFunction):\r\n params = ['start', 'stop', 'step']\r\n columns = ['value']\r\n\r\n...\r\n\r\nCREATE VIRTUAL TABLE series(start, stop, step, value HIDDEN)\r\n```\r\n\r\nWhen looking up the constrained column, we subtract from it the number of \"non-hidden\" columns to get the index of the hidden/parameterized column.\r\n\r\nI've added a check that this value does not drop below zero: 56fe72362a65199eb75bf25684eb290c57e3a37f",
"Ah, ok. So that line is only meant to apply to those hidden columns, which would only be the non-negative cases. Thanks for the quick response and fix!"
] | 2021-10-12T03:27:06 | 2021-10-12T18:05:32 | 2021-10-12T13:05:08 | NONE | null | Hi,
I ran into an issue with this line in FunctionTable's pwBestIndex() function in _sqlite_ext.pyx:
```
columns.append(table_func_cls.params[pConstraint.iColumn -
table_func_cls._ncols])
```
The value of iColumn is some number less than _ncols, so the index into the list is always negative. If it's _too_ negative, it goes past the start of params, causing an "IndexError: list index out of range" exception.
If you need some sample code demonstrating the problem, I'll put something together.
I'm happy to work on a fix and submit a pull request, but I'm having trouble figuring out the intended logic. (I'm wondering why column positions are involved in indexing into the params list. Although I do see that params are relevant here and in the filter step.) Maybe it was partly to deal with the constraints of SQLite's virtual table API. But anyway, if I can help at all, let me know. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2470/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2470/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2469 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2469/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2469/comments | https://api.github.com/repos/coleifer/peewee/issues/2469/events | https://github.com/coleifer/peewee/issues/2469 | 1,015,445,089 | I_kwDOAA7yGM48hnZh | 2,469 | UPDATE queries don't work because Value objects sqlify as ? | {
"login": "Gaming32",
"id": 42721887,
"node_id": "MDQ6VXNlcjQyNzIxODg3",
"avatar_url": "https://avatars.githubusercontent.com/u/42721887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Gaming32",
"html_url": "https://github.com/Gaming32",
"followers_url": "https://api.github.com/users/Gaming32/followers",
"following_url": "https://api.github.com/users/Gaming32/following{/other_user}",
"gists_url": "https://api.github.com/users/Gaming32/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Gaming32/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Gaming32/subscriptions",
"organizations_url": "https://api.github.com/users/Gaming32/orgs",
"repos_url": "https://api.github.com/users/Gaming32/repos",
"events_url": "https://api.github.com/users/Gaming32/events{/privacy}",
"received_events_url": "https://api.github.com/users/Gaming32/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Detailed walkthrough of `Context.value`:\r\n```python\r\n def value(self, value, converter=None, add_param=True):\r\n # add_param = True\r\n # converter = <bound method Field.db_value of <CharField: User.token>>\r\n # value = 'ba8a310b920ece30e4e28e6f67d40a53'\r\n if converter:\r\n value = converter(value)\r\n elif converter is None and self.state.converter:\r\n # Explicitly check for None so that \"False\" can be used to signify\r\n # that no conversion should be applied.\r\n value = self.state.converter(value)\r\n\r\n # value is still 'ba8a310b920ece30e4e28e6f67d40a53'\r\n if isinstance(value, Node):\r\n with self(converter=None):\r\n return self.sql(value)\r\n elif is_model(value):\r\n # Under certain circumstances, we could end-up treating a model-\r\n # class itself as a value. This check ensures that we drop the\r\n # table alias into the query instead of trying to parameterize a\r\n # model (for instance, passing a model as a function argument).\r\n with self.scope_column():\r\n return self.sql(value)\r\n\r\n self._values.append(value) # Values obtains the value 'ba8a310b920ece30e4e28e6f67d40a53'\r\n return self.literal(self.state.param or '?') if add_param else self # self.literal('?') is called, as add_param is True\r\n```",
"The ? is the param placeholder. Parameters are bound the placeholders. This is to avoid sql injections.",
"It prevents the database from being updated though",
"How do I put a string into my database then?",
"Do you mean to imply that the fundamental operation of updating data is completely broken?",
"```python\r\ndb = SqliteDatabase(':memory:')\r\n\r\nclass User(Model):\r\n token = TextField()\r\n class Meta:\r\n database = db\r\n\r\nUser.create_table()\r\n\r\nuser = User.create(token='')\r\nuser.save()\r\n\r\nuser.token = 'new-token'\r\nuser.save()\r\n\r\nuser_db = User.get(User.id == user.id)\r\nprint(user_db.id, user_db.token)\r\n\r\nUser.update(token='new2').where(User.id == user.id).execute()\r\n\r\nuser_db = User.get(User.id == user.id)\r\nprint(user_db.id, user_db.token)\r\n```\r\n\r\nPrints\r\n\r\n```\r\n1 new-token\r\n1 new2\r\n```",
"Why was my comment deleted? I need legitimate help here. "
] | 2021-10-04T17:35:00 | 2021-10-04T21:07:59 | 2021-10-04T17:56:02 | NONE | null | Whenever I update a user's token using one of the two following pieces of code:
```python
# 1
user.token = token
user.save(only=['token'])
# 2
User.update({User.token: token}).where(User.unique_id == user_id).execute()
```
The following query is executed:
```sql
UPDATE "user" SET "token" = ? WHERE ("user"."unique_id" = ?)
```
All my arguments are dropped! As a result, the database is not updated. I've found that this appears to be because the `add_param` argument in `Context.value` is `True` by default. However, simply changing this to `False` does not work either (I didn't think it would, but I still tried it so I could say I did). | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2469/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2469/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2468 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2468/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2468/comments | https://api.github.com/repos/coleifer/peewee/issues/2468/events | https://github.com/coleifer/peewee/issues/2468 | 1,014,019,009 | I_kwDOAA7yGM48cLPB | 2,468 | Bulk update of all null DateTimeFields fails | {
"login": "milesgranger",
"id": 13764397,
"node_id": "MDQ6VXNlcjEzNzY0Mzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/13764397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/milesgranger",
"html_url": "https://github.com/milesgranger",
"followers_url": "https://api.github.com/users/milesgranger/followers",
"following_url": "https://api.github.com/users/milesgranger/following{/other_user}",
"gists_url": "https://api.github.com/users/milesgranger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/milesgranger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/milesgranger/subscriptions",
"organizations_url": "https://api.github.com/users/milesgranger/orgs",
"repos_url": "https://api.github.com/users/milesgranger/repos",
"events_url": "https://api.github.com/users/milesgranger/events{/privacy}",
"received_events_url": "https://api.github.com/users/milesgranger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This is a Postgres limitation - for some reason Postgres does not behave well with certain data-types in these expressions. Related issues:\r\n\r\n* #2457\r\n* #2308\r\n* #2292\r\n* https://dba.stackexchange.com/questions/228046/why-do-i-need-to-cast-null-to-column-type/228058#228058\r\n\r\nI cannot really offer a solution at this time, other than to suggest using individual updates / calls to `save()`. Doing updates in a loop inside a transaction may be just as fast (if not faster) than the `bulk_update` anyways.",
"Thank you, appreciate the information! :pray: "
] | 2021-10-02T11:19:46 | 2021-10-02T14:39:29 | 2021-10-02T13:48:56 | NONE | null | Hello there! :wave:
I believe I've encountered a bug in an otherwise terrific library.
Summary
---
When performing a bulk update of models, where the model has a nullable `DateTimeField` and every model in the list to `bulk_update` has this field set to `None` will result in a an error complaining about it being of type timestamp but expression is of type text.
Example
---
```python
def test_bulk_update_of_all_null_datetime_fields(postgresdb):
class Foobar(peewee.Model):
class Meta:
database = db
col1 = peewee.IntegerField(primary_key=True)
col2 = peewee.DateTimeField(null=True,)
Foobar.create_table()
models = [Foobar(col1=i, col2=datetime.now()) for i in range(2)]
Foobar.bulk_create(models)
models = [Foobar(col1=i, col2=None) for i in range(2)]
try:
Foobar.bulk_update(models, fields=["col2"])
except:
db.rollback()
# Updating a single model in the list to non-null will work fine.
models[0].col2 = datetime.now()
Foobar.bulk_update(models, fields=["col2"])
```
This is the SQL all nulls generate
```sql
UPDATE "foobar"
SET "col2" = CASE "foobar"."col1" WHEN 0 THEN NULL WHEN 1 THEN NULL END
WHERE ("foobar"."col1" IN (0, 1))
```
Which will result in
```bash
2021-10-02 11:07:19.084 UTC [60] ERROR: column "col2" is of type timestamp without time zone but expression is of type text at character 30
2021-10-02 11:07:19.084 UTC [60] HINT: You will need to rewrite or cast the expression.
2021-10-02 11:07:19.084 UTC [60] STATEMENT: UPDATE "foobar" SET "col2" = CASE "foobar"."col1" WHEN 0 THEN NULL WHEN 1 THEN NULL END WHERE ("foobar"."col1" IN (0, 1))
```
manually modifying the query to cast the nulls to timestamps will work
```sql
UPDATE "foobar"
SET "col2" = CASE "foobar"."col1" WHEN 0 THEN NULL::timestamp WHEN 1 THEN NULL::timestamp END
WHERE ("foobar"."col1" IN (0, 1))
```
---
System ubuntu 18.04
peewee version 3.14.4
Python3.7
Postgresql 12 | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2468/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2468/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2467 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2467/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2467/comments | https://api.github.com/repos/coleifer/peewee/issues/2467/events | https://github.com/coleifer/peewee/issues/2467 | 1,009,708,412 | I_kwDOAA7yGM48Lu18 | 2,467 | Question: Why Rollback do not work for Postgres? | {
"login": "iamthen0ise",
"id": 1730030,
"node_id": "MDQ6VXNlcjE3MzAwMzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1730030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iamthen0ise",
"html_url": "https://github.com/iamthen0ise",
"followers_url": "https://api.github.com/users/iamthen0ise/followers",
"following_url": "https://api.github.com/users/iamthen0ise/following{/other_user}",
"gists_url": "https://api.github.com/users/iamthen0ise/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iamthen0ise/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iamthen0ise/subscriptions",
"organizations_url": "https://api.github.com/users/iamthen0ise/orgs",
"repos_url": "https://api.github.com/users/iamthen0ise/repos",
"events_url": "https://api.github.com/users/iamthen0ise/events{/privacy}",
"received_events_url": "https://api.github.com/users/iamthen0ise/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"You are using the transaction bit incorrectly I would say. Here's how I would do it:\r\n\r\n```python\r\n\r\nfor item in insert_items:\r\n with db.atomic() as txn:\r\n try:\r\n model.create(**item)\r\n except IntegrityError:\r\n txn.rollback()\r\n else:\r\n txn.commit()\r\n```",
"Still getting `current transaction is aborted, commands ignored until end of transaction block` using described method.",
"I'm sure you have some bug in your code. This works just fine:\r\n\r\n```python\r\ndb = PostgresqlDatabase('peewee_test')\r\n\r\nclass Reg(Model):\r\n key = CharField(unique=True)\r\n class Meta:\r\n database = db\r\n\r\ndb.create_tables([Reg])\r\nfor k in 'abcadaec':\r\n with db.atomic() as txn:\r\n try:\r\n Reg.create(key=k)\r\n except IntegrityError:\r\n txn.rollback()\r\n else:\r\n txn.commit()\r\n\r\nassert [r.key for r in Reg.select().order_by(Reg.key)] == list('abcde')\r\ndb.drop_tables([Reg])\r\n\r\n```",
"Hmm, it works for soft inserts like `model.get_or_create()`, but causes block for strict `create` operation.\r\n\r\nDon't know if it good by design, but it helps me and all working like magic now. Will check the sources for reference.\r\n\r\nThank you for your help! :) "
] | 2021-09-28T12:47:50 | 2021-09-28T14:07:05 | 2021-09-28T13:14:53 | NONE | null | Hi!
Explicit rollback do not work. Moreover, it block all the transactions until the program end.
Peewee Versions is: 3.14.4
Code:
```python
from playhouse.pool import PooledPostgresqlExtDatabase
from playhouse.postgres_ext import (
Model,
CharField,
)
def get_db():
return PooledPostgresqlExtDatabase(
DB_NAME,
user=DB_USER,
password=DB_PASS,
host=DB_HOST,
port=DB_PORT,
max_connections=32,
autocommit=False,
autorollback=False,
stale_timeout=300,
)
class ItemsModel(Model):
name = CharField()
model = ItemsModel()
insert_items = []
for item in insert_items:
db = get_db()
with db.transaction():
try:
model.create(**item)
db.commit()
except Exception as e:
db.rollback()
```
Any help is highly appreciated!
Thank you! | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2467/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2467/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2466 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2466/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2466/comments | https://api.github.com/repos/coleifer/peewee/issues/2466/events | https://github.com/coleifer/peewee/issues/2466 | 1,006,237,428 | I_kwDOAA7yGM47-fb0 | 2,466 | Peewee cleanups all Model.dirty_fields with only params | {
"login": "penja",
"id": 2717390,
"node_id": "MDQ6VXNlcjI3MTczOTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2717390?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/penja",
"html_url": "https://github.com/penja",
"followers_url": "https://api.github.com/users/penja/followers",
"following_url": "https://api.github.com/users/penja/following{/other_user}",
"gists_url": "https://api.github.com/users/penja/gists{/gist_id}",
"starred_url": "https://api.github.com/users/penja/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/penja/subscriptions",
"organizations_url": "https://api.github.com/users/penja/orgs",
"repos_url": "https://api.github.com/users/penja/repos",
"events_url": "https://api.github.com/users/penja/events{/privacy}",
"received_events_url": "https://api.github.com/users/penja/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks, this should be fixed now.",
"@coleifer Thank you for so hot fix."
] | 2021-09-24T08:54:36 | 2021-09-24T13:03:01 | 2021-09-24T12:44:38 | NONE | null | For me was unexpected behavior with cleanup model dirty fields if we save model with `only` params.
https://github.com/coleifer/peewee/blob/master/peewee.py#L6600-L6601
In my opinion, The saved field should be just removed from dirty fields.
Please see invalid behavior in the following code snippet.
```
import peewee
from peewee import *
import logging
import sys
log = logging.getLogger()
log.setLevel(logging.DEBUG)
handler = logging.StreamHandler(sys.stdout)
log.addHandler(handler)
print(peewee.__version__)
db = SqliteDatabase(":memory:")
class Example(Model):
class Meta:
database = db
name = CharField()
description = CharField(null=True)
db.create_tables([Example])
model = Example.create(name="foo", description="bar")
model.name = "bazz"
model.description = "example bar"
model.save(only=[Example.name])
#some other business logic
if model.dirty_fields:
model.save()
model = Example.get_by_id(model)
print(model.name, model.description)
assert model.name == "bazz"
assert model.description == "example bar"
```
Output
```
3.14.4
('CREATE TABLE IF NOT EXISTS "example" ("id" INTEGER NOT NULL PRIMARY KEY, "name" VARCHAR(255) NOT NULL, "description" VARCHAR(255))', [])
('INSERT INTO "example" ("name", "description") VALUES (?, ?)', ['foo', 'bar'])
('UPDATE "example" SET "name" = ? WHERE ("example"."id" = ?)', ['bazz', 1])
('SELECT "t1"."id", "t1"."name", "t1"."description" FROM "example" AS "t1" WHERE ("t1"."id" = ?) LIMIT ? OFFSET ?', [1, 1, 0])
bazz bar
Traceback (most recent call last):
File "dummy_sqlite.py", line 36, in <module>
assert model.description == "example bar"
AssertionError
```
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2466/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2466/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2465 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2465/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2465/comments | https://api.github.com/repos/coleifer/peewee/issues/2465/events | https://github.com/coleifer/peewee/issues/2465 | 1,000,010,798 | I_kwDOAA7yGM47mvQu | 2,465 | UNSIGNED BIGINT AUTO_INCREMENT support in create_tables? | {
"login": "sherrrrr",
"id": 31510228,
"node_id": "MDQ6VXNlcjMxNTEwMjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/31510228?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sherrrrr",
"html_url": "https://github.com/sherrrrr",
"followers_url": "https://api.github.com/users/sherrrrr/followers",
"following_url": "https://api.github.com/users/sherrrrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sherrrrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sherrrrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sherrrrr/subscriptions",
"organizations_url": "https://api.github.com/users/sherrrrr/orgs",
"repos_url": "https://api.github.com/users/sherrrrr/repos",
"events_url": "https://api.github.com/users/sherrrrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sherrrrr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"You overrode the pk, now just subclass `ForeignKeyField` and override the field_type property:\r\n\r\n```python\r\nclass UnsignedBigAutoField(BigAutoField):\r\n field_type = 'BIGINT UNSIGNED AUTO_INCREMENT'\r\n\r\nclass UnsignedForeignKeyField(ForeignKeyField):\r\n field_type = 'BIGINT UNSIGNED'\r\n\r\nclass User(Base):\r\n id = UnsignedBigAutoField()\r\n\r\nclass Tweet(Base):\r\n id = UnsignedBigAutoField()\r\n user = UnsignedForeignKeyField(User)\r\n```"
] | 2021-09-18T11:28:21 | 2021-09-18T18:31:02 | 2021-09-18T18:31:02 | NONE | null | I am using mysql and use UNSIGNED BIGINT as primary key. According to as [issue542](https://github.com/coleifer/peewee/issues/542), I try to use BIGINT UNSIGNED like this
```python
class UnsignedBigAutoField(BigAutoField):
field_type = 'BIGINT UNSIGNED'
```
and I try to use `ForeignKeyField` in models.
```
class User(Model):
id = UnsignedBigAutoField(primary_key=True)
class Tweet(Model):
id = UnsignedBigAutoField(primary_key=True)
user = ForeignKeyField(User, backref='tweets')
```
I want to use peewee to create tables, later I realize that inherite `AutoField` with `auto_increment = True` does't affect sql, there is no AUTO_INCREMENT in create table sql. What's more, when try to create `Tweet`, user_id's type is BIGINT without UNSIGNED beacuse of ForeignKeyField's [field_type](https://github.com/coleifer/peewee/blob/master/peewee.py#L5213).
so I write this
```python
class UnsignedBigAutoField(IntegerField):
auto_increment = True
field_type = 'BIGINT UNSIGNED AUTO_INCREMENT'
def __init__(self, *args, **kwargs):
if kwargs.get('primary_key') is False:
raise ValueError('%s must always be a primary key.' % type(self))
kwargs['primary_key'] = True
super(UnsignedBigAutoField, self).__init__(*args, **kwargs)
```
and this would cause `user_id` in Tweet have `AUTO_INCREMENT`.
So is there a solution to use UNSIGNED BIGINT as primary key and foreign key when I want to create table using peewee? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2465/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2465/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2464 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2464/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2464/comments | https://api.github.com/repos/coleifer/peewee/issues/2464/events | https://github.com/coleifer/peewee/issues/2464 | 997,743,671 | I_kwDOAA7yGM47eFw3 | 2,464 | Why store _database in ThreadSafeDatabaseMetadata? | {
"login": "sherrrrr",
"id": 31510228,
"node_id": "MDQ6VXNlcjMxNTEwMjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/31510228?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sherrrrr",
"html_url": "https://github.com/sherrrrr",
"followers_url": "https://api.github.com/users/sherrrrr/followers",
"following_url": "https://api.github.com/users/sherrrrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sherrrrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sherrrrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sherrrrr/subscriptions",
"organizations_url": "https://api.github.com/users/sherrrrr/orgs",
"repos_url": "https://api.github.com/users/sherrrrr/repos",
"events_url": "https://api.github.com/users/sherrrrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sherrrrr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
">At first I thought every request is default to master, then I found that if one request switch to slave, _database in User became slave, then if gevent switch to another greenlet with a new request, then User's database is default to slave.\r\n\r\nYeah, I think you're right actually, and the implementation needs a change. Originally the idea I had was to just make sure that binding was a thread-safe operation, and that within a running thread, a different thread cannot alter the db. But, as you indicate, it also makes sense to me to preserve the \"default\" db.\r\n\r\nYou can use your patch or you can try out this commit: 00498bfc073569a63cb30fa43d706fdcc3e14dc0"
] | 2021-09-16T04:00:42 | 2021-09-16T13:29:17 | 2021-09-16T13:29:02 | NONE | null | ```python
class ThreadSafeDatabaseMetadata(Metadata):
"""
Metadata class to allow swapping database at run-time in a multi-threaded
application. To use:
class Base(Model):
class Meta:
model_metadata_class = ThreadSafeDatabaseMetadata
"""
def __init__(self, *args, **kwargs):
# The database attribute is stored in a thread-local.
self._database = None
self._local = threading.local()
super(ThreadSafeDatabaseMetadata, self).__init__(*args, **kwargs)
def _get_db(self):
return getattr(self._local, 'database', self._database)
def _set_db(self, db):
self._local.database = self._database = db
database = property(_get_db, _set_db)
```
I'm using peewee with gevent, and try to use `ThreadSafeDatabaseMetadata` to make sure every request can set its db to master/slave.
Here is how I define my model.
```python
class User(Model):
id = BigAutoField(primary_key=True)
class Meta:
database = master
model_metadata_class = ThreadSafeDatabaseMetadata
```
At first I thought every request is default to master, then I found that if one request switch to slave, `_database` in `User` became slave, then if gevent switch to another greenlet with a new request, then User's database is default to slave.
Of course this can be solved by every request first call something like `master.bind([ALLMODELS])`, but if that so, why is `_database` necessary? Can I remove `_database` in `ThreadSafeDatabaseMetadata` and use like this?
```python
class ThreadSafeDatabaseMetadata(Metadata):
def __init__(self, *args, **kwargs):
# database attribute is stored in a thread-local.
self._local = threading.local()
super(ThreadSafeDatabaseMetadata, self).__init__(*args, **kwargs)
def _get_db(self):
return getattr(self._local, 'database', master) # default use master
def _set_db(self, db):
self._local.database = db
database = property(_get_db, _set_db)
```
And I think `ThreadSafeDatabaseMetadata`'s behavior is a bit confusing, and didn't find it in the document. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2464/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2464/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2463 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2463/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2463/comments | https://api.github.com/repos/coleifer/peewee/issues/2463/events | https://github.com/coleifer/peewee/issues/2463 | 994,155,602 | MDU6SXNzdWU5OTQxNTU2MDI= | 2,463 | Help on select() and get() methods | {
"login": "Sonotoki-da",
"id": 34913890,
"node_id": "MDQ6VXNlcjM0OTEzODkw",
"avatar_url": "https://avatars.githubusercontent.com/u/34913890?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sonotoki-da",
"html_url": "https://github.com/Sonotoki-da",
"followers_url": "https://api.github.com/users/Sonotoki-da/followers",
"following_url": "https://api.github.com/users/Sonotoki-da/following{/other_user}",
"gists_url": "https://api.github.com/users/Sonotoki-da/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sonotoki-da/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sonotoki-da/subscriptions",
"organizations_url": "https://api.github.com/users/Sonotoki-da/orgs",
"repos_url": "https://api.github.com/users/Sonotoki-da/repos",
"events_url": "https://api.github.com/users/Sonotoki-da/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sonotoki-da/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The problem is here. Calling `query.get()` returns a model instance (if one exists) or raises a `DoesNotExist` if not. You are comparing the return value to `is True` -- and while the result (a model instance) is \"truthy\", it is *not* `True` - it is a model instance.\r\n\r\n```python\r\nif q.get_user_status(user_id=123456) is True:\r\n print(\"Subscribed\")\r\nelse:\r\n print(\"Not subscribed yet\")\r\n```\r\n\r\nYou should instead write:\r\n\r\n```python\r\ntry:\r\n user = q.get_user_status(user_id=123456)\r\nexcept q.TgUser.DoesNotExist:\r\n # user with id=123456 does not exist\r\n print('user does not exist')\r\nelse:\r\n if user.subscribed:\r\n print('subscribed')\r\n else:\r\n print('not subscribed')\r\n```",
"omg... Thank you very much! > < It's working now!\r\nAnd sorry for taking your time to this kind of question :') I'll study further!"
] | 2021-09-12T13:11:21 | 2021-09-12T15:23:16 | 2021-09-12T13:53:01 | NONE | null | I've already searched for solutions in the Issues, but couldn't find an answer, nor understand properly :')
OS: Windows
Python: 3.6.8, 3.9.6
IDE: VSCode
Tested purposely in 3.6.8 (saw the peewee is developed with that version). Thought maybe I can get the code work.
The ```TgUser.select(TgUser.subscribed).where(TgUser.user_id == id)``` line is just doesn't work properly. It should be returning True (as in the db, the subscribed record is set to True for that user)
Here's my rough code:
`queries.py`
```python
from datetime import date
import peewee as p
db = p.SqliteDatabase('database.db')
class TgUser(p.Model):
user_id = p.IntegerField(unique=True)
username = p.CharField(null=True)
first_name = p.CharField()
last_name = p.CharField(null=True)
msg_count = p.IntegerField(default=0)
subscribed = p.BooleanField()
joined = p.DateField()
bot_status = p.CharField(default='member')
class Meta:
database = db
def create_db():
db.create_tables([TgUser])
return db
def register_user(values: dict, joined: date, subscribed: bool) -> bool:
user = {}
for x in ['user_id', 'username', 'first_name', 'last_name']:
user.update({x: values.get(x, None)})
data, exist = TgUser.get_or_create(**user, joined=joined, subscribed=subscribed)
return exist
def get_user_status(user_id: int) -> bool:
q = TgUser.select(TgUser.subscribed).where(TgUser.user_id == user_id)
return q.get()
```
`test.py`
```python
import queries as q
from datetime import datetime
db = q.create_db()
values = {
'user_id': 123456,
'username': '@some_user',
'first_name': 'SomeUser',
}
q.register_user(values, joined=datetime.now(), subscribed=True)
if q.get_user_status(user_id=123456) is True:
print("Subscribed")
else:
print("Not subscribed yet")
```
Out:
`Not subscribed yet`
Please help, any suggestion is appreciated! I just wanted to stop writing raw SQL queries | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2463/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2463/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2462 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2462/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2462/comments | https://api.github.com/repos/coleifer/peewee/issues/2462/events | https://github.com/coleifer/peewee/issues/2462 | 991,707,639 | MDU6SXNzdWU5OTE3MDc2Mzk= | 2,462 | ThreadSafeDatabaseMetadata in doc is not compatible with inheritance | {
"login": "sherrrrr",
"id": 31510228,
"node_id": "MDQ6VXNlcjMxNTEwMjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/31510228?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sherrrrr",
"html_url": "https://github.com/sherrrrr",
"followers_url": "https://api.github.com/users/sherrrrr/followers",
"following_url": "https://api.github.com/users/sherrrrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sherrrrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sherrrrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sherrrrr/subscriptions",
"organizations_url": "https://api.github.com/users/sherrrrr/orgs",
"repos_url": "https://api.github.com/users/sherrrrr/repos",
"events_url": "https://api.github.com/users/sherrrrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sherrrrr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This is expected, if somewhat non-obvious. The whole purpose of using the `ThreadSafeDatabaseMetadata` is for when you plan to switch the database at run-time in a multi-threaded application, so the assumption is that at multiple points during runtime you will be explicitly binding the models to a database, e.g.:\r\n\r\n```python\r\n\r\n# BaseModel declares that it uses ThreadSafeDatabaseMetadata\r\n\r\nclass A(BaseModel):\r\n pass\r\n\r\nclass B(BaseModel):\r\n pass\r\n\r\nmaster = PostgresqlDatabase(...)\r\nreplica = PostgresqlDatabase(...)\r\n\r\n# Explicitly bind the models.\r\nmaster.bind([A, B])\r\n```\r\n\r\nWith that said, it *should* still inherit the \"default\" or original Meta.database, so I will put together a patch for this.",
"b782657823a64fcdef6674cadccb2f2679933e6f"
] | 2021-09-09T03:05:37 | 2021-09-09T13:31:37 | 2021-09-09T13:31:36 | NONE | null | [ThreadSafeDatabaseMetadata in doc](http://docs.peewee-orm.com/en/latest/peewee/database.html#thread-safety-and-multiple-databases)
```python
import threading
from peewee import Metadata
class ThreadSafeDatabaseMetadata(Metadata):
def __init__(self, *args, **kwargs):
# database attribute is stored in a thread-local.
self._local = threading.local()
super(ThreadSafeDatabaseMetadata, self).__init__(*args, **kwargs)
def _get_db(self):
return getattr(self._local, 'database', self._database)
def _set_db(self, db):
self._local.database = self._database = db
database = property(_get_db, _set_db)
class BaseModel(Model):
class Meta:
# Instruct peewee to use our thread-safe metadata implementation.
model_metadata_class = ThreadSafeDatabaseMetadata
```
when you try to use a baseModel
```python
class BaseModel(Model):
class Meta:
database = db
model_metadata_class = ThreadSafeDatabaseMetadata
class User(BaseModel):
id = BigAutoField(primary_key=True)
```
`User._meta.database` will not correctly inherit `BaseMoel._meta.database` because User's meta_options init in this way.
```
for k in base_meta.__dict__:
if k in all_inheritable and k not in meta_options:
meta_options[k] = base_meta.__dict__[k]
```
where `database` is not in `base_meta.__dict__` but `_database`.
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2462/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2462/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2461 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2461/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2461/comments | https://api.github.com/repos/coleifer/peewee/issues/2461/events | https://github.com/coleifer/peewee/issues/2461 | 987,336,488 | MDU6SXNzdWU5ODczMzY0ODg= | 2,461 | Trying to do bulk_update AttributeError: 'dict' object has no attribute '_pk' | {
"login": "bgriffen",
"id": 2667869,
"node_id": "MDQ6VXNlcjI2Njc4Njk=",
"avatar_url": "https://avatars.githubusercontent.com/u/2667869?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bgriffen",
"html_url": "https://github.com/bgriffen",
"followers_url": "https://api.github.com/users/bgriffen/followers",
"following_url": "https://api.github.com/users/bgriffen/following{/other_user}",
"gists_url": "https://api.github.com/users/bgriffen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bgriffen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bgriffen/subscriptions",
"organizations_url": "https://api.github.com/users/bgriffen/orgs",
"repos_url": "https://api.github.com/users/bgriffen/repos",
"events_url": "https://api.github.com/users/bgriffen/events{/privacy}",
"received_events_url": "https://api.github.com/users/bgriffen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"It turns out you can't feed it a list of dictionaries like you can with `insert_many`. I worked around it by creating a list of instances. Not sure if this is the best solution to my situation but it works.\r\n\r\n```python\r\nupdates = []\r\nfor u in self.update_l:\r\n e = db.PaperDB(**u)\r\n updates.append(e)\r\n\r\nwith self.dbase.atomic():\r\n db.PaperDB.bulk_update(updates,fields=self.cols, batch_size=1000)\r\n```\r\n",
"The docs should make this clear: http://docs.peewee-orm.com/en/latest/peewee/api.html#Model.bulk_update\r\n\r\nAlso note that the way `bulk_update()` is implemented, it uses a couple tricks to try to do it efficiently. **However** it may actually be more performant and simple to just issue an UPDATE for each model instance/row and do this within a transaction. I suggest going with the simplest possible thing until you find that it has become a significant bottleneck."
] | 2021-09-03T02:31:33 | 2021-09-03T12:11:44 | 2021-09-03T12:11:44 | NONE | null | I am trying to do a bulk_update using the example provided.
```python
class BaseModel(pw.Model):
class Meta:
database = get_testdb('papers.db')
pass
class PaperDB(BaseModel):
pmid = pw.IntegerField(unique=True)
title = pw.CharField()
abstract = pw.TextField()
journal = pw.CharField()
authors = pw.CharField()
pubdate = pw.DateField()
mesh_terms = pw.CharField()
publication_types = pw.CharField()
chemical_list = pw.CharField()
keywords = pw.CharField()
doi = pw.CharField()
delete = pw.BooleanField()
affiliations = pw.CharField()
pmc = pw.IntegerField()
other_id = pw.CharField()
medline_ta = pw.CharField()
nlm_unique_id = pw.IntegerField()
issn_linking = pw.CharField()
country = pw.CharField()
pubyear = pw.IntegerField()
pubmonth = pw.IntegerField()
pubday = pw.IntegerField()
....
# in code
with self.dbase.atomic():
for idx in range(0, num_papers_update, n_batch):
# self.update_l is a list of dictionaries containing info from dataframe
# self.update_l = dfi.loc[self.update_pmid].reset_index().to_dict('records')
db.PaperDB.bulk_update(self.update_l[idx:idx+n_batch],fields=[db.PaperDB.pmid,
db.PaperDB.title,
db.PaperDB.abstract,
db.PaperDB.journal,
db.PaperDB.authors,
db.PaperDB.pubdate,
db.PaperDB.mesh_terms,
db.PaperDB.publication_types,
db.PaperDB.chemical_list,
db.PaperDB.keywords,
db.PaperDB.doi,
db.PaperDB.delete,
db.PaperDB.affiliations,
db.PaperDB.pmc,
db.PaperDB.other_id,
db.PaperDB.medline_ta,
db.PaperDB.nlm_unique_id,
db.PaperDB.issn_linking,
db.PaperDB.country,
db.PaperDB.pubyear,
db.PaperDB.pubmonth,
db.PaperDB.pubday])
```
but I am getting this error:
```bash
264 if ~os.path.exists(self.fname_excludes):
in update_db(self, current_pmids)
138 db.PaperDB.publication_types,
139 db.PaperDB.chemical_list,
--> 140 db.PaperDB.keywords,
141 db.PaperDB.doi,
142 db.PaperDB.delete,
~/anaconda3/lib/python3.8/site-packages/peewee.py in bulk_update(cls, model_list, fields, batch_size)
6350
6351 for batch in batches:
-> 6352 id_list = [model._pk for model in batch]
6353 update = {}
6354 for field, attr in zip(fields, attrs):
~/anaconda3/lib/python3.8/site-packages/peewee.py in <listcomp>(.0)
6350
6351 for batch in batches:
-> 6352 id_list = [model._pk for model in batch]
6353 update = {}
6354 for field, attr in zip(fields, attrs):
AttributeError: 'dict' object has no attribute '_pk'
```
Also do I really have to supply all the fields from the model? Is there a way to just do it on all fields or say the ones being ingested in that item? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2461/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2461/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2460 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2460/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2460/comments | https://api.github.com/repos/coleifer/peewee/issues/2460/events | https://github.com/coleifer/peewee/issues/2460 | 979,798,538 | MDU6SXNzdWU5Nzk3OTg1Mzg= | 2,460 | Multiple condition splicing | {
"login": "Baloneo",
"id": 16448666,
"node_id": "MDQ6VXNlcjE2NDQ4NjY2",
"avatar_url": "https://avatars.githubusercontent.com/u/16448666?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Baloneo",
"html_url": "https://github.com/Baloneo",
"followers_url": "https://api.github.com/users/Baloneo/followers",
"following_url": "https://api.github.com/users/Baloneo/following{/other_user}",
"gists_url": "https://api.github.com/users/Baloneo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Baloneo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Baloneo/subscriptions",
"organizations_url": "https://api.github.com/users/Baloneo/orgs",
"repos_url": "https://api.github.com/users/Baloneo/repos",
"events_url": "https://api.github.com/users/Baloneo/events{/privacy}",
"received_events_url": "https://api.github.com/users/Baloneo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"There are a couple ways, but probably the one I recommend for dynamically building up a query is to use reduce:\r\n\r\n```python\r\n\r\nexprs = []\r\nif name:\r\n exprs.append(ProductType.name == name)\r\nif other:\r\n exprs.append(ProductType.other == other)\r\n\r\nif exprs:\r\n query = query.where(reduce(operator.and_, exprs))\r\n```\r\n\r\nSince you're using the same operator (AND) you can also just chain the calls:\r\n\r\n```python\r\n\r\nquery = ProductType.select()\r\nif name:\r\n query = query.where(ProductType.name == name)\r\nif other:\r\n query = query.where(ProductType.other == other)\r\n...\r\n```",
"thanks!"
] | 2021-08-26T03:36:40 | 2021-08-26T13:25:49 | 2021-08-26T13:05:23 | NONE | null | Sometimes the front end will pass an empty string, if where condition like this:
```
ProductType.demand_side == ""
```
will not find results, so I used the following code
```python
name = current_schema_data.get('name')
demand_side = current_schema_data.get('demand_side')
expression = 1
if name:
expression &= (ProductType.product_name == name)
if demand_side:
expression &= (ProductType.demand_side == demand_side)
sql = ProductType.select().where(expression)
print(sql)
```
```
SELECT `t1`.`id`, `t1`.`create_time`, `t1`.`update_time`, `t1`.`product_name`, `t1`.`fk_organization_id`, `t1`.`unit`, `t1`.`type`, `t1`.`calc_type`, `t1`.`demand_side` FROM `product_type` AS `t1` WHERE (1 AND (`t1`.`demand_side` = '34')) LIMIT 100 OFFSET 0
```
It always has `Where(1 and FOO)` or `Where 1`, How to remove it?
I have try using `expression = None`, But the results it found are all empty
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2460/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2460/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2459 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2459/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2459/comments | https://api.github.com/repos/coleifer/peewee/issues/2459/events | https://github.com/coleifer/peewee/issues/2459 | 979,239,136 | MDU6SXNzdWU5NzkyMzkxMzY= | 2,459 | BETWEEN does not work with datetime objects in SQlite | {
"login": "LVerneyPEReN",
"id": 58298410,
"node_id": "MDQ6VXNlcjU4Mjk4NDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/58298410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LVerneyPEReN",
"html_url": "https://github.com/LVerneyPEReN",
"followers_url": "https://api.github.com/users/LVerneyPEReN/followers",
"following_url": "https://api.github.com/users/LVerneyPEReN/following{/other_user}",
"gists_url": "https://api.github.com/users/LVerneyPEReN/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LVerneyPEReN/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LVerneyPEReN/subscriptions",
"organizations_url": "https://api.github.com/users/LVerneyPEReN/orgs",
"repos_url": "https://api.github.com/users/LVerneyPEReN/repos",
"events_url": "https://api.github.com/users/LVerneyPEReN/events{/privacy}",
"received_events_url": "https://api.github.com/users/LVerneyPEReN/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Sqlite does not have a dedicated date/datetime type. It is up to you, the developer, to ensure that your datetimes are stored in a way that supports correct lexicographic ordering. Additionally, Peewee does not apply any conversion at all to datetime objects - it hands them as-is to the db driver. It is actually the sqlite driver that is handling the conversion for sqlite: (`import sqlite3; sqlite3.adapters`). This is consistent and supports lexicographic ordering, but if you've stored your datetimes in ISO format in Sqlite, then you may have some work to do to get them working properly with python's sqlite3 module.\r\n\r\nYou can:\r\n\r\n* register a different adapter for `datetime.datetime` that converts them to string in iso format - this may be the easiest\r\n* write a custom `DateTimeField` subclass that implements a `db_value()` method that returns the datetime in isoformat\r\n* update your data to use the python format (probably undesirable, but mentioning it as a possibility)\r\n\r\nAll that said, at the end of the day this is not really a peewee issue -- this is a consequence of the behavior of the python sqlite driver and sqlite's own lack of a dedicated datetime type.",
"Thanks for the very quick response, this is indeed an issue due to having iso formatted values in db!\r\n\r\nI tried to debug how they happened to get there, and it seems `DateTimeField` does not convert iso formatted datetime strings to a date object, but rather append them silently to the database.\r\n\r\nThis seems to be an easy mistake which could happen often, and quite silent.\r\n\r\nWhat about extending https://github.com/coleifer/peewee/blob/master/peewee.py#L4971-L4975 to also support isoformat formats?\r\n\r\nI think something like\r\n\r\n```python\r\nformats = [\r\n '%Y-%m-%dT%H:%M:%S.%f%z',\r\n '%Y-%m-%dT%H:%M:%S.%f',\r\n '%Y-%m-%d %H:%M:%S.%f',\r\n '%Y-%m-%dT%H:%M:%S%z',\r\n '%Y-%m-%dT%H:%M:%S',\r\n '%Y-%m-%d %H:%M:%S',\r\n '%Y-%m-%d',\r\n]\r\n```\r\n\r\nshould handle all these cases properly.\r\n\r\n**EDIT**: The same formats addition is probably required as well in `DateField` and `TimeField`. I may have missed something, but I don't see any reason why isoformatted strings would not get promoted to relevant date objects for proper addition by peewee.\r\n\r\nThanks!",
"That will allow you to read them back but the problem is still that the data in your db was written in iso format.\r\n\r\nSubclassing and implementing your formats and the corresponding db_value() method should cover all the bases.",
"To expand on my comment, there are 2 sides to the adaptation process. The side where you take a python value (a datetime in this example) and convert it to something the db understands, and the other side where you get a value from the db and convert it to something python understands.\r\n\r\nJust extending the `formats` won't really help because it only affects the 2nd side (going from db -> python). That's why I suggested implementing `db_value()` which will correctly convert the datetime to an isoformat string before sending it to the db.\r\n\r\n```python\r\n\r\n# minimal example\r\nclass ISODateTimeField(DateTimeField):\r\n def db_value(self, val):\r\n if val is not None:\r\n return val.isoformat()\r\n def python_value(self, val):\r\n if val is not None:\r\n return datetime.datetime.strptime(val, '%Y-%m-%dT%H:%M:%S.%f')\r\n```",
"Sorry, I think my latest comment may not have been clear about the details of my error (and history) and my proposal.\r\n\r\nFirst, I should emphasize that BETWEEN operation is behaving as expected for datetime objects. The issue boils down to database insertion. Then, I should also emphasize that I do not have a pre-existent database but am creating a database from scratch using Peewee from the beginning and pushing data into it.\r\n\r\nMy mistake and the source of this issue boils down to how Peewee deals with incompatible values with compatible types for datetime fields.\r\n\r\nHere is a minimal illustration about upon the quickstart page of the docs :\r\n\r\n\r\n```python\r\nfrom datetime import datetime\r\nfrom peewee import *\r\n\r\ndb = SqliteDatabase('people.db')\r\n\r\nclass Person(Model):\r\n name = CharField()\r\n birthday = DateTimeField()\r\n\r\n class Meta:\r\n database = db # This model uses the \"people.db\" database.\r\n\r\ndb.connect()\r\ndb.create_tables([Person])\r\n\r\n\r\n# Create a person with a datetime object as birthday, this is the most typical use case\r\nuncle_bob = Person(name='Bob', birthday=datetime(1960, 1, 15, 1, 0, 0))\r\nuncle_bob.save()\r\n\r\n# Create a person with a string representing a date. String format matches one of https://github.com/coleifer/peewee/blob/master/peewee.py#L4971-L4975 so we hit https://github.com/coleifer/peewee/blob/master/peewee.py#L4948 and it is promoted to datetime object.\r\n# This is therefore **the same behavior** as before, as expected\r\nuncle_sam = Person(\r\n name='Sam',\r\n birthday=\"1960-01-15 01:00:00\"\r\n)\r\nuncle_sam.save()\r\n\r\n# Create a person with an isoformatted string. This format does not match any of the known formats for DateTimeField, so we hit https://github.com/coleifer/peewee/blob/master/peewee.py#L4949-L4951 which is completely silent and the value is inserted as is in the database.\r\n# This is how I ended up with isoformatted dates in my db, by (incorrectly) manipulating an isoformatted string at some point (while I thought I had a datetime object) and Peewee / sqlite3 not throwing any error at me.\r\nuncle_tom = Person(\r\n name='tom',\r\n birthday=\"1960-01-15T01:00:00Z\"\r\n)\r\nuncle_tom.save()\r\n\r\n# Note that when the object type is incompatible, sqlite3 will shout. But for any string which does not match a known date format, it gets inserted as is in the db.\r\nuncle_guy = Person(name='Guy', birthday=\"This is definitely not a date\")\r\nuncle_guy.save() #\r\n```\r\n\r\n\r\n\r\nI feel like the fact that Peewee supports some date string formats is giving the wrong message that passing string instead of datetime object is safe, and one is likely to assume isoformatted datetime is fine. This is not the case.\r\n\r\nSo, I would like Peewee to minimize the possibility to reproduce this error (while trying to reduce the extra work on Peewee to a minimum) by:\r\n* Adding new formats in https://github.com/coleifer/peewee/blob/master/peewee.py#L4971-L4975 to support isoformatted dates the same way as the other date format. See https://github.com/coleifer/peewee/issues/2459#issuecomment-905605324.\r\n* Probably add a `logging.warning` item in https://github.com/coleifer/peewee/blob/master/peewee.py#L4950 so that this promotion error is no longer silent and the user has some form of easy discovery that they are not using Peewee the right way.\r\n\r\nI can offer to handle a PR for this if this can be useful and you agree with my reading of this issue.",
"I'd suggest doing stronger validation before insertion into the DB and keeping in mind Sqlite's loose typing -- for fiddly things like datetimes this can be a gotcha for Sqlite users as it is up to you to be consistent about how you insert them to preserve ordering. I don't plan to make changes on the Peewee side at this time."
] | 2021-08-25T14:47:27 | 2021-08-26T13:01:18 | 2021-08-25T14:58:55 | NONE | null | Hi,
I have an issue where `BETWEEN` operation which does not work with a `DateTimeField` in SQLite when checking against Python `datetime.datetime` objects.
It seems this is due to the default adapter being used for such formats in SQLite is `str` conversion, which is not the same as an `isoformat`. Therefore, lexicographic comparison is broken afterwards.
See
```python
>>> import datetime
>>> str(datetime.datetime.now())
'2021-08-25 16:44:43.952660'
>>> datetime.datetime.now().isoformat()
'2021-08-25T16:44:56.216273'
```
And the extra "T" between date and time part.
Thanks! | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2459/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2459/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2458 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2458/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2458/comments | https://api.github.com/repos/coleifer/peewee/issues/2458/events | https://github.com/coleifer/peewee/issues/2458 | 978,766,431 | MDU6SXNzdWU5Nzg3NjY0MzE= | 2,458 | select (15 minutes) vs execute_sql (35 seconds) | {
"login": "netsamir",
"id": 1165885,
"node_id": "MDQ6VXNlcjExNjU4ODU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1165885?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/netsamir",
"html_url": "https://github.com/netsamir",
"followers_url": "https://api.github.com/users/netsamir/followers",
"following_url": "https://api.github.com/users/netsamir/following{/other_user}",
"gists_url": "https://api.github.com/users/netsamir/gists{/gist_id}",
"starred_url": "https://api.github.com/users/netsamir/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/netsamir/subscriptions",
"organizations_url": "https://api.github.com/users/netsamir/orgs",
"repos_url": "https://api.github.com/users/netsamir/repos",
"events_url": "https://api.github.com/users/netsamir/events{/privacy}",
"received_events_url": "https://api.github.com/users/netsamir/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi,\r\n\r\nI think I have found the solution to my problem by logging with DEBUG.\r\n\r\nI have rewritten the query like that :\r\n\r\n for row in User.select(User.Service, fn.count(1).alias('count')).group_by(User.Service):\r\n print(row.Service, row.count)\r\n\r\n DEBUG:peewee:('SELECT \"t1\".\"Service\", count(?) AS \"count\" FROM \"sag\" AS \"t1\" GROUP BY \"t1\".\"Service\"', [1])\r\n\r\ninstead of \r\n\r\n DEBUG:peewee:('SELECT \"t1\".\"id\", \"t1\".\"LogSysTime\", \"t1\".\"LogCorrelationId\", \"t1\".\"ApplicationId\", \"t1\".\"UnitName\", \"t1\".\"Primitive\", \"t1\".\"Priority\", \"t1\".\"RequControl\", \"t1\".\"RequtRef\", \"t1\".\"RequType\", \"t1\".\"Requestor\", \"t1\".\"Resp\", \"t1\".\"ReserRef\", \"t1\".\"ResponseControl\", \"t1\".\"Service\", \"t1\".\"Status\", \"t1\".\"SwtRef\", \"t1\".\"SwRequestRef\", \"t1\".\"SwResponseRef\", \"t1\".\"SwTime\", \"t1\".\"TransferRef\", \"t1\".\"PayloadSize\", count(?) AS \"count\" FROM \"sag\" AS \"t1\" GROUP BY \"t1\".\"Service\"', [1])",
"If you were using postgres your first query would not have even run because you were selecting all columns but only grouping by one of them.\r\n\r\nThe second query is correct:\r\n\r\n q = User.select(User.Service, fn.count(User.id).alias('count')).group_by(User.Service)"
] | 2021-08-25T06:25:21 | 2021-08-25T12:34:13 | 2021-08-25T12:34:13 | NONE | null | Hi,
Please find below two very simple script that execute the exact same query, but:
- The first one, `select`, takes 15 min to complete
- The second one, `execute_sql`, takes 35 seconds to complete
Do you know how to improve performance of the first script please ?
### Here are the details of the database:
The database I am using is : sqlite3. It is 5.1GB.
$ sqlite3 --version
3.7.17 2013-05-20 00:56:22 118a3b35693b134d56ebd780123b7fd6f1497668
[ins] In [7]: print_table_sql(Sag)
CREATE TABLE IF NOT EXISTS "sag" (
"id" INTEGER NOT NULL PRIMARY KEY,
"LogSysTime" DATETIME NOT NULL,
"LogId" VARCHAR(255) NOT NULL,
"Apd" VARCHAR(255) NOT NULL,
"UnitName" VARCHAR(255) NOT NULL,
"Primitive" VARCHAR(255),
"Priority" VARCHAR(255),
"RequestControl" VARCHAR(255),
"RequestRef" VARCHAR(255),
"RequestType" VARCHAR(255),
"Sender" VARCHAR(255),
"Receiver" VARCHAR(255),
"ReceiverRef" VARCHAR(255),
"ResponseControl" VARCHAR(255),
"Service" VARCHAR(255),
"Status" VARCHAR(255),
"SwtRef" VARCHAR(255),
"SwtRequestRef" VARCHAR(255),
"SwtResponseRef" VARCHAR(255),
"SwtTime" VARCHAR(255),
"TransferRef" VARCHAR(255),
"PayloadSize" INTEGER
)
### Here are the details of the scripts:
1. Script : `select`
$ cat script1.py
from parser_User_stats_all_traffic import User, db
from peewee import *
db = SqliteDatabase('user_db.sqlite')
\# database schema and creation
for row in User.select(User, fn.count(1).alias('count')).group_by(User.Service):
print(row.Service, row.count)
$ time python script1.py
<output>
real 15m7.341s
user 1m10.136s
sys 1m6.303s
**Additional info:** This script create 2 temporary files with 4.4 GB and then it hanged for quiet some time without consuming CPU nor Memory.
2. Script : `execute_sql`
$ cat script2.py
from parser_User_stats_all_traffic import User, db
from peewee import *
db = SqliteDatabase('user_db.sqlite')
\# database schema and creation
for row in db.execute_sql('select Service, count(1) from User group by Service'):
print(row)
$ time python script2.py
<output>
real 0m35.093s
user 0m19.478s
sys 0m9.827s
**Additional info:** It creates 2 temporary files of 147 MB and return. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2458/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2458/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2457 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2457/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2457/comments | https://api.github.com/repos/coleifer/peewee/issues/2457/events | https://github.com/coleifer/peewee/issues/2457 | 975,841,918 | MDU6SXNzdWU5NzU4NDE5MTg= | 2,457 | UUIDField with bulk_update fails | {
"login": "milesgranger",
"id": 13764397,
"node_id": "MDQ6VXNlcjEzNzY0Mzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/13764397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/milesgranger",
"html_url": "https://github.com/milesgranger",
"followers_url": "https://api.github.com/users/milesgranger/followers",
"following_url": "https://api.github.com/users/milesgranger/following{/other_user}",
"gists_url": "https://api.github.com/users/milesgranger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/milesgranger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/milesgranger/subscriptions",
"organizations_url": "https://api.github.com/users/milesgranger/orgs",
"repos_url": "https://api.github.com/users/milesgranger/repos",
"events_url": "https://api.github.com/users/milesgranger/events{/privacy}",
"received_events_url": "https://api.github.com/users/milesgranger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"See #2308"
] | 2021-08-20T18:47:28 | 2021-08-20T20:22:26 | 2021-08-20T20:22:26 | NONE | null | Summary
---
It appears using `Model.bulk_update` with a model using a `UUIDField` fails.
Minimal Example
---
```python
def test_uuid_bulk_update(db):
n_rows = 1_000
class Foo(peewee.Model):
class Meta:
database = db
pk = peewee.IntegerField(primary_key=True)
bar = peewee.UUIDField()
if Foo.table_exists():
Foo.drop_table()
Foo.create_table()
data = [
{"pk": i, "bar": uuid.uuid3(uuid.NAMESPACE_URL, f"{i}")} for i in range(n_rows)
]
with db.atomic():
Foo.bulk_create((Foo(**kwargs) for kwargs in data))
updates = [
{"pk": item["pk"], "bar": uuid.uuid3(uuid.NAMESPACE_URL, f"{i*1.5}")}
for i, item in enumerate(data[:100])
]
# Saving them individually works fine.
# for update in updates:
# Foo(**update).save()
# This fails.
Foo.bulk_update([Foo(**kwargs) for kwargs in updates], fields=["bar"])
```
Using a `TextField` instead will work fine in the code above.
Error
---
```
> with __exception_wrapper__:
cursor = self.cursor(commit)
try:
cursor.execute(sql, params or ())
E psycopg2.errors.DatatypeMismatch: column "bar" is of type uuid but expression is of type text
E LINE 1: UPDATE "foo" SET "bar" = CASE "foo"."pk" WHEN 0 THEN 'e0a687...
E ^
E HINT: You will need to rewrite or cast the expression.
```
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2457/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2457/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2456 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2456/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2456/comments | https://api.github.com/repos/coleifer/peewee/issues/2456/events | https://github.com/coleifer/peewee/issues/2456 | 970,796,314 | MDU6SXNzdWU5NzA3OTYzMTQ= | 2,456 | Is there a module that implements Mock? | {
"login": "ekiim",
"id": 6476691,
"node_id": "MDQ6VXNlcjY0NzY2OTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6476691?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ekiim",
"html_url": "https://github.com/ekiim",
"followers_url": "https://api.github.com/users/ekiim/followers",
"following_url": "https://api.github.com/users/ekiim/following{/other_user}",
"gists_url": "https://api.github.com/users/ekiim/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ekiim/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ekiim/subscriptions",
"organizations_url": "https://api.github.com/users/ekiim/orgs",
"repos_url": "https://api.github.com/users/ekiim/repos",
"events_url": "https://api.github.com/users/ekiim/events{/privacy}",
"received_events_url": "https://api.github.com/users/ekiim/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"No, mocking a sql database is an extremely complex affair. Most people use shallow mocks or just an in memory sqlite database for testing."
] | 2021-08-14T02:04:42 | 2021-08-14T15:11:04 | 2021-08-14T15:11:04 | NONE | null | Hello, I'm trying to find out if there is a module for mocking for models.
I know it's a small project, I'm interested in finding one. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2456/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2456/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2455 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2455/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2455/comments | https://api.github.com/repos/coleifer/peewee/issues/2455/events | https://github.com/coleifer/peewee/pull/2455 | 963,324,836 | MDExOlB1bGxSZXF1ZXN0NzA1OTYxMzQx | 2,455 | Update api.rst | {
"login": "aparcar",
"id": 16000931,
"node_id": "MDQ6VXNlcjE2MDAwOTMx",
"avatar_url": "https://avatars.githubusercontent.com/u/16000931?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aparcar",
"html_url": "https://github.com/aparcar",
"followers_url": "https://api.github.com/users/aparcar/followers",
"following_url": "https://api.github.com/users/aparcar/following{/other_user}",
"gists_url": "https://api.github.com/users/aparcar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aparcar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aparcar/subscriptions",
"organizations_url": "https://api.github.com/users/aparcar/orgs",
"repos_url": "https://api.github.com/users/aparcar/repos",
"events_url": "https://api.github.com/users/aparcar/events{/privacy}",
"received_events_url": "https://api.github.com/users/aparcar/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Actually the solution is as simple as `(idlist.split(\",\") if idlist else [])`",
"a643a6952372e22ce658c8ca9a23322bb4b2ab57"
] | 2021-08-08T00:12:24 | 2021-08-08T13:17:59 | 2021-08-08T13:17:59 | NONE | null | The example is wrong since it doesn't split the `idlist`.
This is the same function as used in the test. However the example has a case with an empty list (`[]`) which won't work, since `None.split(",")` won't work. Any simple solutions here? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2455/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2455/timeline | null | null | true | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2455",
"html_url": "https://github.com/coleifer/peewee/pull/2455",
"diff_url": "https://github.com/coleifer/peewee/pull/2455.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2455.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2454 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2454/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2454/comments | https://api.github.com/repos/coleifer/peewee/issues/2454/events | https://github.com/coleifer/peewee/issues/2454 | 962,626,425 | MDU6SXNzdWU5NjI2MjY0MjU= | 2,454 | Insert Many\Upsert (PostgreSQL) doesn't work with M2M relations | {
"login": "madMathematician971",
"id": 63659861,
"node_id": "MDQ6VXNlcjYzNjU5ODYx",
"avatar_url": "https://avatars.githubusercontent.com/u/63659861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/madMathematician971",
"html_url": "https://github.com/madMathematician971",
"followers_url": "https://api.github.com/users/madMathematician971/followers",
"following_url": "https://api.github.com/users/madMathematician971/following{/other_user}",
"gists_url": "https://api.github.com/users/madMathematician971/gists{/gist_id}",
"starred_url": "https://api.github.com/users/madMathematician971/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/madMathematician971/subscriptions",
"organizations_url": "https://api.github.com/users/madMathematician971/orgs",
"repos_url": "https://api.github.com/users/madMathematician971/repos",
"events_url": "https://api.github.com/users/madMathematician971/events{/privacy}",
"received_events_url": "https://api.github.com/users/madMathematician971/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"How is an upsert supposed to work across multiple tables? I think you do not understand how many-to-many actually works -- there is a junction table. There is no such thing as website.regions - that information is stored in the through table."
] | 2021-08-06T10:51:31 | 2021-08-06T19:51:44 | 2021-08-06T19:51:44 | NONE | null | Hello everyone,
Trying to utilize an upsert along with an insert_many query for a model with m2m relation.
The error I get is `'ManyToManyField' object has no attribute '_sort_key'`
The code example is provided below. Trying to figure out if this is expected behavior due to the fact that ManyToManyField is not a usual peewee field in the default sense or if it's a bug.
```
class Region(_BaseModel):
name = pw.CharField(unique=True)
class Website(_BaseModel):
name = pw.CharField()
url = pw.CharField(unique=True)
regions = pw.ManyToManyField(Region, backref='websites')
WebsiteRegion = Website.regions.get_through_model()
```
(_Base model has a UUID4 id assigned to it)
However, when I'm trying to use an upsert which was implemented before M2M relation was added to Website Model and worked just fine, I get the error listed above ('ManyToManyField' object has no attribute '_sort_key')
The upsert setup:
```
query = Website.insert_many(self.data).returning(*self.__RETURNING).on_conflict(
conflict_target=[Website.url],
preserve=[Website.url],
update={
Website.name: EXCLUDED.name,
Website.regions: EXCLUDED.regions,
}
)
```
where self.data is a valid list of pydantic models converted to dicts and self.__RETURNING is a valid list of `Website` model attributes desired to be returned.
Perhaps I am missing something required for m2m to work in the upsert?
I already have a workaround utilizing a loop with `website = Website.create(<data>)` and a default `website.regions.add(regions: List[UUID])` for populating m2m, but still having a working upsert for m2m would be great if possible, as create and update in a loop is less efficient than an upsert.
Anyone faced a similar issue with upsert and m2m before and what were your solutions \ workarounds?
Appreciate your time!
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2454/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2454/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2453 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2453/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2453/comments | https://api.github.com/repos/coleifer/peewee/issues/2453/events | https://github.com/coleifer/peewee/issues/2453 | 962,161,857 | MDU6SXNzdWU5NjIxNjE4NTc= | 2,453 | Problem with ended parentheses alias | {
"login": "wes9319",
"id": 11861951,
"node_id": "MDQ6VXNlcjExODYxOTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/11861951?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wes9319",
"html_url": "https://github.com/wes9319",
"followers_url": "https://api.github.com/users/wes9319/followers",
"following_url": "https://api.github.com/users/wes9319/following{/other_user}",
"gists_url": "https://api.github.com/users/wes9319/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wes9319/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wes9319/subscriptions",
"organizations_url": "https://api.github.com/users/wes9319/orgs",
"repos_url": "https://api.github.com/users/wes9319/repos",
"events_url": "https://api.github.com/users/wes9319/events{/privacy}",
"received_events_url": "https://api.github.com/users/wes9319/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I don't know if I can change this logic without introducing a possible regression for users who select arbitrary sql functions and do not alias them. The current logic looks if there's a \".\" within the column name, takes the stuff to the right of it and strips `\"` and `)`, e.g.:\r\n\r\nUPPER(\"t1\".\"name\") -> \"name\") -> name\r\n\r\nThe downside is that this logic is also being applied to explicitly-given aliases. Let me think about it.",
"The fix involved basically ensuring that user-provided aliases would be preserved, but at the same time I've tried to improve the logic when guessing at the intended destination column when it is not provided."
] | 2021-08-05T20:13:40 | 2021-08-08T13:29:16 | 2021-08-08T13:28:36 | NONE | null | I had a problem trying to query data and assign an alias ended by a parentheses to each row, the data indeed is correct but the last parentheses of the alias gets cut off in the result data. Here's an example:
```
SUM(IF((((`t2`.`class` IN (%s, %s, %s)) AND (`t2`.`concept` != %s)) AND (`t3`.`cost_id` = %s)), IFNULL((`t2`.`value` * (`t3`.`value` / %s)), %s), %s)) AS `cost center (CCA)`,
```
The result is:
```
'cost center (CCA': Decimal('139.704440000000')
```
The value is correct but the the alias is wrong due to the missing parentheses, is it possible to fix this in any way? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2453/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2453/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2452 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2452/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2452/comments | https://api.github.com/repos/coleifer/peewee/issues/2452/events | https://github.com/coleifer/peewee/issues/2452 | 959,535,883 | MDU6SXNzdWU5NTk1MzU4ODM= | 2,452 | Accessing views via models not possible | {
"login": "SilvanVerhoeven",
"id": 44174681,
"node_id": "MDQ6VXNlcjQ0MTc0Njgx",
"avatar_url": "https://avatars.githubusercontent.com/u/44174681?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SilvanVerhoeven",
"html_url": "https://github.com/SilvanVerhoeven",
"followers_url": "https://api.github.com/users/SilvanVerhoeven/followers",
"following_url": "https://api.github.com/users/SilvanVerhoeven/following{/other_user}",
"gists_url": "https://api.github.com/users/SilvanVerhoeven/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SilvanVerhoeven/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SilvanVerhoeven/subscriptions",
"organizations_url": "https://api.github.com/users/SilvanVerhoeven/orgs",
"repos_url": "https://api.github.com/users/SilvanVerhoeven/repos",
"events_url": "https://api.github.com/users/SilvanVerhoeven/events{/privacy}",
"received_events_url": "https://api.github.com/users/SilvanVerhoeven/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"What version of sqlite are you using?",
"The requirements.txt requires peewee 3.9.6",
"No, what version of sqlite.",
"I'm sorry. SQLite 3.31.1 (retrieved via `select sqlite_version()`)",
"This example code is working fine for me, I suppose you have some issue in your code or you can try updating your peewee if the code below does not work for you:\r\n\r\n```python\r\nfrom peewee import *\r\n\r\ndb = SqliteDatabase(':memory:')\r\n\r\nclass Foo(Model):\r\n name = TextField()\r\n class Meta: database = db\r\n\r\ndb.create_tables([Foo])\r\nfor name in ('huey', 'mickey', 'zaizee'):\r\n Foo.create(name=name)\r\n\r\ndb.execute_sql('create view foo_view as select upper(name) as name from foo')\r\nclass FooView(Foo):\r\n class Meta:\r\n primary_key = False\r\n table_name = 'foo_view'\r\n\r\nprint([row.name for row in FooView.select()])\r\n```\r\n\r\nPrints: `['HUEY', 'MICKEY', 'ZAIZEE']`"
] | 2021-08-03T21:38:10 | 2021-08-04T17:24:16 | 2021-08-04T17:23:18 | NONE | null | I try to access a view in my SQLite database following the instructions from https://stackoverflow.com/questions/38707331/does-peewee-support-interaction-with-mysql-views. I figured that the article's `db_table` needs to be replaced with `table_name` in the current version of peewee. I used the following SQL statement to create the view: `db.execute_sql('CREATE VIEW IF NOT EXISTS foo_view AS SELECT UPPER(name) AS name FROM foo')`.
Unfortunately, even after this update my `FooView` model only returns `None` for the name. Printing the vars via `print([vars(fv) for fv in FooView.select(FooView.name)])` shows why:
`[{'__data__': {}, '_dirty': set(), '__rel__': {}, 't1': 'HUEY'}, {'__data__': {}, '_dirty': set(), '__rel__': {}, 't1': 'MICKEY'}, {'__data__': {}, '_dirty': set(), '__rel__': {}, 't1': 'ZAIZEE'}]`
Compare this to the output of `print([vars(fv) for fv in Foo.select(Foo.name)])`:
`[{'__data__': {'name': 'huey'}, '_dirty': set(), '__rel__': {}}, {'__data__': {'name': 'mickey'}, '_dirty': set(), '__rel__': {}}, {'__data__': {'name': 'zaizee'}, '_dirty': set(), '__rel__': {}}}]`
Interestingly enough, setting `Foo.Meta.table_name` to `foo_view` yields the same result as simply using `FooView`.
I wonder if this is a bug in peewee or whether I am doing something wrong. Help much appreciated! | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2452/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2452/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2451 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2451/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2451/comments | https://api.github.com/repos/coleifer/peewee/issues/2451/events | https://github.com/coleifer/peewee/issues/2451 | 957,674,183 | MDU6SXNzdWU5NTc2NzQxODM= | 2,451 | Peewee does not automatically reconnect to MySQL Error: peewee.InterfaceError: (0, '') | {
"login": "Baloneo",
"id": 16448666,
"node_id": "MDQ6VXNlcjE2NDQ4NjY2",
"avatar_url": "https://avatars.githubusercontent.com/u/16448666?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Baloneo",
"html_url": "https://github.com/Baloneo",
"followers_url": "https://api.github.com/users/Baloneo/followers",
"following_url": "https://api.github.com/users/Baloneo/following{/other_user}",
"gists_url": "https://api.github.com/users/Baloneo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Baloneo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Baloneo/subscriptions",
"organizations_url": "https://api.github.com/users/Baloneo/orgs",
"repos_url": "https://api.github.com/users/Baloneo/repos",
"events_url": "https://api.github.com/users/Baloneo/events{/privacy}",
"received_events_url": "https://api.github.com/users/Baloneo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"db.close()\r\n```\r\n'Attempting to close database while '\r\npeewee.OperationalError: Attempting to close database while transaction is open\r\n```",
"```\r\n\r\nclass ReconnectMixin(object):\r\n \"\"\"\r\n Mixin class that attempts to automatically reconnect to the database under\r\n certain error conditions.\r\n\r\n For example, MySQL servers will typically close connections that are idle\r\n for 28800 seconds (\"wait_timeout\" setting). If your application makes use\r\n of long-lived connections, you may find your connections are closed after\r\n a period of no activity. This mixin will attempt to reconnect automatically\r\n when these errors occur.\r\n\r\n This mixin class probably should not be used with Postgres (unless you\r\n REALLY know what you are doing) and definitely has no business being used\r\n with Sqlite. If you wish to use with Postgres, you will need to adapt the\r\n `reconnect_errors` attribute to something appropriate for Postgres.\r\n \"\"\"\r\n reconnect_errors = (\r\n # Error class, error message fragment (or empty string for all).\r\n (OperationalError, '2006'), # MySQL server has gone away.\r\n (OperationalError, '2013'), # Lost connection to MySQL server.\r\n (OperationalError, '2014'), # Commands out of sync.\r\n (InterfaceError, \"(0, '')\"), # add error \r\n\r\n # mysql-connector raises a slightly different error when an idle\r\n # connection is terminated by the server. This is equivalent to 2013.\r\n (OperationalError, 'MySQL Connection not available.'),\r\n )\r\n\r\n def __init__(self, *args, **kwargs):\r\n super(ReconnectMixin, self).__init__(*args, **kwargs)\r\n\r\n # Normalize the reconnect errors to a more efficient data-structure.\r\n self._reconnect_errors = {}\r\n for exc_class, err_fragment in self.reconnect_errors:\r\n self._reconnect_errors.setdefault(exc_class, [])\r\n self._reconnect_errors[exc_class].append(err_fragment.lower())\r\n\r\n def execute_sql(self, sql, params=None, commit=SENTINEL):\r\n try:\r\n return super(ReconnectMixin, self).execute_sql(sql, params, commit)\r\n except Exception as exc:\r\n exc_class = type(exc)\r\n if exc_class not in self._reconnect_errors:\r\n raise exc\r\n\r\n exc_repr = str(exc).lower()\r\n print('exc_repr', exc_repr, 'ccc', self._reconnect_errors[exc_class])\r\n for err_fragment in self._reconnect_errors[exc_class]:\r\n if err_fragment in exc_repr:\r\n break\r\n else:\r\n raise exc\r\n\r\n if not self.is_closed():\r\n print('in_transaction --->', db.in_transaction())\r\n self.close()\r\n self.connect()\r\n\r\n return super(ReconnectMixin, self).execute_sql(sql, params, commit)\r\n```\r\n`self.is_closed()` is `False`, but `db.in_transaction()` is `True`, in close function:\r\n```\r\n def close(self):\r\n with self._lock:\r\n if self.deferred:\r\n raise InterfaceError('Error, database must be initialized '\r\n 'before opening a connection.')\r\n if self.in_transaction():\r\n raise OperationalError('Attempting to close database while '\r\n 'transaction is open.')\r\n is_open = not self._state.closed\r\n try:\r\n if is_open:\r\n with __exception_wrapper__:\r\n self._close(self._state.conn)\r\n finally:\r\n self._state.reset()\r\n return is_open\r\n```\r\n\r\nalways raise OperationalError, caused to never reconnect successfully, Is there any good solution?\r\n\r\n\r\n",
"The reconnecting mixin does not play well with transactions, but this should make sense to you if you think about it. What is peewee supposed to do upon reconnect? Re-execute any previous queries that were executed in the transaction?\r\n\r\nIn cases like these you probably need to handle it at the application level. Attempting to steamroll over the problems by reconnecting is not a good solution in any event."
] | 2021-08-02T02:10:27 | 2021-08-02T13:02:56 | 2021-08-02T13:02:56 | NONE | null | ```
class ReconnectMySQLDatabase(ReconnectMixin, MySQLDatabase):
pass
db = ReconnectMySQLDatabase(current_config.MYSQL_DB_NAME, host=current_config.MYSQL_DB_IP,
port=current_config.MYSQL_DB_PORT, user=current_config.MYSQL_DB_USER,
password=current_config.MYSQL_DB_PASSWORD)
try:
with db.atomic():
_insert_into_table(data, ENERGY_TABLE_NAME_DEFAULT())
_insert_into_table(data, ENERGY_TABLE_NAME_MONTH())
_insert_into_table(data, ENERGY_TABLE_NAME_DAY())
except Exception as e:
logger.exception('Error')
```
1 stop mysql server
```
docker-compose down -f mysql-docker-compose.yml
```
2 log outout
```
Traceback (most recent call last):
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 3297, in commit
return self._state.conn.commit()
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/pymysql/connections.py", line 469, in commit
self._execute_command(COMMAND.COM_QUERY, "COMMIT")
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/pymysql/connections.py", line 793, in _execute_command
raise err.InterfaceError(0, "")
pymysql.err.InterfaceError: (0, '')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 4209, in __exit__
self.commit(False)
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 4188, in commit
self.db.commit()
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 3297, in commit
return self._state.conn.commit()
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 2917, in __exit__
reraise(new_type, new_type(exc_value, *exc_args), traceback)
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 190, in reraise
raise value.with_traceback(tb)
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 3297, in commit
return self._state.conn.commit()
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/pymysql/connections.py", line 469, in commit
self._execute_command(COMMAND.COM_QUERY, "COMMIT")
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/pymysql/connections.py", line 793, in _execute_command
raise err.InterfaceError(0, "")
peewee.InterfaceError: (0, '')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 3301, in rollback
return self._state.conn.rollback()
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/pymysql/connections.py", line 479, in rollback
self._execute_command(COMMAND.COM_QUERY, "ROLLBACK")
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/pymysql/connections.py", line 793, in _execute_command
raise err.InterfaceError(0, "")
pymysql.err.InterfaceError: (0, '')
```
3 start MySql service
```
docker-compose -f mysql-docker-compose.yml up -d
```
still insert error.
But sometimes stop mysql service, the error output is:
```
Traceback (most recent call last):
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 3080, in connect
self._state.set_connection(self._connect())
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/peewee.py", line 3982, in _connect
conn = mysql.connect(db=self.database, **self.connect_params)
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/pymysql/connections.py", line 353, in __init__
self.connect()
File "/home/baloneo/kexin-code/data-collection-service/.venv/lib/python3.8/site-packages/pymysql/connections.py", line 664, in connect
raise exc
pymysql.err.OperationalError: (2003, "Can't connect to MySQL server on '192.168.1.80' ([Errno 111] Connection refused)")
```
It can automatically reconnect.
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2451/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2451/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2450 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2450/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2450/comments | https://api.github.com/repos/coleifer/peewee/issues/2450/events | https://github.com/coleifer/peewee/issues/2450 | 955,993,414 | MDU6SXNzdWU5NTU5OTM0MTQ= | 2,450 | SQL from migrator | {
"login": "konradkur",
"id": 22791650,
"node_id": "MDQ6VXNlcjIyNzkxNjUw",
"avatar_url": "https://avatars.githubusercontent.com/u/22791650?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/konradkur",
"html_url": "https://github.com/konradkur",
"followers_url": "https://api.github.com/users/konradkur/followers",
"following_url": "https://api.github.com/users/konradkur/following{/other_user}",
"gists_url": "https://api.github.com/users/konradkur/gists{/gist_id}",
"starred_url": "https://api.github.com/users/konradkur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/konradkur/subscriptions",
"organizations_url": "https://api.github.com/users/konradkur/orgs",
"repos_url": "https://api.github.com/users/konradkur/repos",
"events_url": "https://api.github.com/users/konradkur/events{/privacy}",
"received_events_url": "https://api.github.com/users/konradkur/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This is not really exposed. Operations may be composed of multiple steps, so the migrations module uses an abstraction (`Operation`) to run potentially multiple queries. Additionally, steps may include validation that requires a previous step having been run (before the sql is generated). How do you get the sql for an operation in general, though (which may be composed of sub-operations)?\r\n\r\n```python\r\n# i think this should, generally, work\r\nop = migrator.add_column('my_sqlite_table', 'new_col', TextField(default=''))\r\nq = [op]\r\nwhile q:\r\n item = q.pop()\r\n if isinstance(item, Operation):\r\n kw = item.kwargs.copy()\r\n kw['with_context'] = True\r\n q.append(getattr(migrator, item.method)(*item.args, **kw))\r\n elif isinstance(item, list):\r\n q.extend(item[::-1])\r\n elif isinstance(item, Node):\r\n print(migrator.make_context().sql(item).query())\r\n else:\r\n print(item.query())\r\n```\r\n\r\nAlternatively, you can attach a sql log handler:\r\n\r\n```python\r\nimport logging\r\nlogger = logging.getLogger('peewee')\r\nlogger.addHandler(logging.StreamHandler())\r\nlogger.setLevel(logging.DEBUG)\r\n```"
] | 2021-07-29T16:06:18 | 2021-07-29T21:27:43 | 2021-07-29T21:27:43 | NONE | null | Hello my friends,
`migrate(
migrator.add_column('some_table', 'title', title_field),
migrator.add_column('some_table', 'status', status_field),
migrator.drop_column('some_table', 'old_column'),
)`
how to get SQL code?
thanks, Konrad | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2450/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2450/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2449 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2449/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2449/comments | https://api.github.com/repos/coleifer/peewee/issues/2449/events | https://github.com/coleifer/peewee/issues/2449 | 950,542,342 | MDU6SXNzdWU5NTA1NDIzNDI= | 2,449 | Can't import models before creating a Database object | {
"login": "AidenEllis",
"id": 64432103,
"node_id": "MDQ6VXNlcjY0NDMyMTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/64432103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AidenEllis",
"html_url": "https://github.com/AidenEllis",
"followers_url": "https://api.github.com/users/AidenEllis/followers",
"following_url": "https://api.github.com/users/AidenEllis/following{/other_user}",
"gists_url": "https://api.github.com/users/AidenEllis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AidenEllis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AidenEllis/subscriptions",
"organizations_url": "https://api.github.com/users/AidenEllis/orgs",
"repos_url": "https://api.github.com/users/AidenEllis/repos",
"events_url": "https://api.github.com/users/AidenEllis/events{/privacy}",
"received_events_url": "https://api.github.com/users/AidenEllis/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-07-22T11:05:04 | 2021-07-22T12:28:55 | 2021-07-22T12:28:55 | NONE | null | . | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2449/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2449/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2448 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2448/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2448/comments | https://api.github.com/repos/coleifer/peewee/issues/2448/events | https://github.com/coleifer/peewee/issues/2448 | 946,093,107 | MDU6SXNzdWU5NDYwOTMxMDc= | 2,448 | Dynamic table names refer to global variables | {
"login": "Baloneo",
"id": 16448666,
"node_id": "MDQ6VXNlcjE2NDQ4NjY2",
"avatar_url": "https://avatars.githubusercontent.com/u/16448666?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Baloneo",
"html_url": "https://github.com/Baloneo",
"followers_url": "https://api.github.com/users/Baloneo/followers",
"following_url": "https://api.github.com/users/Baloneo/following{/other_user}",
"gists_url": "https://api.github.com/users/Baloneo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Baloneo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Baloneo/subscriptions",
"organizations_url": "https://api.github.com/users/Baloneo/orgs",
"repos_url": "https://api.github.com/users/Baloneo/repos",
"events_url": "https://api.github.com/users/Baloneo/events{/privacy}",
"received_events_url": "https://api.github.com/users/Baloneo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"table name is not a pointer, it is set and stored in the model class' `table_name` attribute. If you want to change it at run-time, then you need to call `ModelClass._meta.set_table_name()`."
] | 2021-07-16T09:06:40 | 2021-07-16T13:05:42 | 2021-07-16T13:05:41 | NONE | null | ```
GLOBAL_VAR_TABLE_NAME = "foo_table"
def make_table_name(model_class):
model_name = model_class.__name__
return GLOBAL_VAR_TABLE_NAME
class BaseModel(Model):
class Meta:
table_function = make_table_name
class User(BaseModel):
# table_name will be "user_tbl".
```
update global variable
```
GLOBAL_VAR_TABLE_NAME = "bar_table"
```
but
```
User().save()
```
still is foo_table, why?
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2448/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2448/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2447 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2447/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2447/comments | https://api.github.com/repos/coleifer/peewee/issues/2447/events | https://github.com/coleifer/peewee/pull/2447 | 945,804,361 | MDExOlB1bGxSZXF1ZXN0NjkxMDc5ODQy | 2,447 | Delete TODO.rst | {
"login": "alexpirine",
"id": 1610035,
"node_id": "MDQ6VXNlcjE2MTAwMzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1610035?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexpirine",
"html_url": "https://github.com/alexpirine",
"followers_url": "https://api.github.com/users/alexpirine/followers",
"following_url": "https://api.github.com/users/alexpirine/following{/other_user}",
"gists_url": "https://api.github.com/users/alexpirine/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alexpirine/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexpirine/subscriptions",
"organizations_url": "https://api.github.com/users/alexpirine/orgs",
"repos_url": "https://api.github.com/users/alexpirine/repos",
"events_url": "https://api.github.com/users/alexpirine/events{/privacy}",
"received_events_url": "https://api.github.com/users/alexpirine/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I like to keep it as a placeholder in case I want to fill it in."
] | 2021-07-15T22:46:55 | 2021-07-16T00:35:08 | 2021-07-16T00:35:07 | NONE | null | Seems like it hasn't been used for two years. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2447/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2447/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2447",
"html_url": "https://github.com/coleifer/peewee/pull/2447",
"diff_url": "https://github.com/coleifer/peewee/pull/2447.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2447.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2446 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2446/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2446/comments | https://api.github.com/repos/coleifer/peewee/issues/2446/events | https://github.com/coleifer/peewee/issues/2446 | 945,654,400 | MDU6SXNzdWU5NDU2NTQ0MDA= | 2,446 | This ORM doesn't seem to work anymore. | {
"login": "Evert-Arends",
"id": 16082595,
"node_id": "MDQ6VXNlcjE2MDgyNTk1",
"avatar_url": "https://avatars.githubusercontent.com/u/16082595?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Evert-Arends",
"html_url": "https://github.com/Evert-Arends",
"followers_url": "https://api.github.com/users/Evert-Arends/followers",
"following_url": "https://api.github.com/users/Evert-Arends/following{/other_user}",
"gists_url": "https://api.github.com/users/Evert-Arends/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Evert-Arends/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Evert-Arends/subscriptions",
"organizations_url": "https://api.github.com/users/Evert-Arends/orgs",
"repos_url": "https://api.github.com/users/Evert-Arends/repos",
"events_url": "https://api.github.com/users/Evert-Arends/events{/privacy}",
"received_events_url": "https://api.github.com/users/Evert-Arends/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I want to apologize. This worked like a charm. My database tool however is completely fucked. Sorry for the inconvenience."
] | 2021-07-15T18:38:26 | 2021-07-15T19:04:51 | 2021-07-15T19:04:51 | NONE | null | I'm using Python 3.9.6, and the example provided in the readme is broken:
```
import datetime
import peewee
db = peewee.SqliteDatabase('my_database.db')
class BaseModel(peewee.Model):
class Meta:
database = db
class User(BaseModel):
username = peewee.CharField(unique=True)
class Tweet(BaseModel):
user = peewee.ForeignKeyField(User, backref='tweets')
message = peewee.TextField()
created_date = peewee.DateTimeField(default=datetime.datetime.now)
is_published = peewee.BooleanField(default=True)
db.connect()
db.create_tables([User, Tweet])
charlie = User.create(username='charlie')
huey = User(username='huey')
huey.save()
# No need to set `is_published` or `created_date` since they
# will just use the default values we specified.
Tweet.create(user=charlie, message='My first tweet')
```
Accourding to the readme this code should be working? I would expect a database with 2 tables and some data in it. The db is created but empty. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2446/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2446/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2445 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2445/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2445/comments | https://api.github.com/repos/coleifer/peewee/issues/2445/events | https://github.com/coleifer/peewee/pull/2445 | 937,125,654 | MDExOlB1bGxSZXF1ZXN0NjgzNzMxNDc3 | 2,445 | Fixes bug in JSON IN query for iterables | {
"login": "dustinrb",
"id": 3378450,
"node_id": "MDQ6VXNlcjMzNzg0NTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3378450?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dustinrb",
"html_url": "https://github.com/dustinrb",
"followers_url": "https://api.github.com/users/dustinrb/followers",
"following_url": "https://api.github.com/users/dustinrb/following{/other_user}",
"gists_url": "https://api.github.com/users/dustinrb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dustinrb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dustinrb/subscriptions",
"organizations_url": "https://api.github.com/users/dustinrb/orgs",
"repos_url": "https://api.github.com/users/dustinrb/repos",
"events_url": "https://api.github.com/users/dustinrb/events{/privacy}",
"received_events_url": "https://api.github.com/users/dustinrb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I don't like this patch for a couple of reasons, nor am I sure I understand the goal behind supporting such a query. Namely because it mutates the expression state when sql() is called, which is not done elsewhere in the codebase. Additionally, searching for an exact array within a json field seems problematic because there's no possibility of doing so efficiently from the database perspective.\r\n\r\nI'm going to pass on this patch, but will look at the original issue and give it some thought."
] | 2021-07-05T14:04:18 | 2021-07-05T14:57:19 | 2021-07-05T14:57:19 | NONE | null | Resolves issue #2444 | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2445/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2445/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2445",
"html_url": "https://github.com/coleifer/peewee/pull/2445",
"diff_url": "https://github.com/coleifer/peewee/pull/2445.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2445.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2444 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2444/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2444/comments | https://api.github.com/repos/coleifer/peewee/issues/2444/events | https://github.com/coleifer/peewee/issues/2444 | 937,124,555 | MDU6SXNzdWU5MzcxMjQ1NTU= | 2,444 | IN queries on fields with iterable Python representations | {
"login": "dustinrb",
"id": 3378450,
"node_id": "MDQ6VXNlcjMzNzg0NTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3378450?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dustinrb",
"html_url": "https://github.com/dustinrb",
"followers_url": "https://api.github.com/users/dustinrb/followers",
"following_url": "https://api.github.com/users/dustinrb/following{/other_user}",
"gists_url": "https://api.github.com/users/dustinrb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dustinrb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dustinrb/subscriptions",
"organizations_url": "https://api.github.com/users/dustinrb/orgs",
"repos_url": "https://api.github.com/users/dustinrb/repos",
"events_url": "https://api.github.com/users/dustinrb/events{/privacy}",
"received_events_url": "https://api.github.com/users/dustinrb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I see why you closed #2445; it didn't make sense to single out the IN clause in that part of the code.\r\n\r\nI think the broader issue is that you cannot use any field for an IN query where it's Python representation is a sequence. You might be able to get around this by calling\r\n\r\n```python\r\n...where(KeyData.data.in_(KeyData.data.db_value(i) in [[1], [2], [1,2]]))...\r\n```\r\nbut that seems unintuitive from the user perspective. \r\n\r\nPerhaps the better solution would be to handle this in the `Field._in` with the understanding that if the user provides an iterable that each item has `Field.db_value` called on it before it's formed into an Expression.\r\n\r\nI'm happy to work on a patch. I'm just too unfamiliar with codebase to architect this.",
"I've implemented a [fix](https://github.com/dustinrb/peewee/tree/json_in_query) that converts `multi_types` to Values in the Expression generated by the `.in_` function instead of mutating one SQL generation.\r\n\r\nThis process occurs outside of a Context block. Will that pose any issues the node tree when generating SQL? ",
"I looked at the patch and it has the same problem.\r\n\r\nFor now, you can always try:\r\n\r\n```python\r\nvls = [Value(l, unpack=False) for l in list_of_lists]\r\n.where(KeyData.data.in_(vls))\r\n```",
"Thanks for looking into this.\r\n\r\nMaybe I'm not sure what the exact issue is. Your interim fix is essentially what my second patch does in the Field class which happens before SQL generation. Are you saying that query input should be untouched before it's handed over to the SQL generating code? In that case it feels like a better solution would be to add a flag to allow shallow unpacking for a single Expression and/or NodeList.\r\n\r\nThanks for letting me satisfy my curiosity. Let me know if you'd like me to keep working on a fix.",
"This is a bit of a strange one, so I'm going to close for now, but will revisit should it occur in another context."
] | 2021-07-05T14:03:13 | 2021-07-30T14:48:41 | 2021-07-30T14:48:41 | NONE | null | When using arrays in a JSON field, the IN operator unpacks all the values into a single list. For example:
```python
itr_select_query = (KeyData
.select()
.where(KeyData.data.in_(
[[1], [2], [1,2]]
)))
```
will generate the SQL query:
```python
('SELECT "t1"."id", "t1"."key", "t1"."data" FROM "key_data" AS "t1" WHERE ("t1"."data" IN ((json(?)), (json(?)), (json(?), json(?))))', ['1', '2', '1', '2'])
```
instead of:
```python
('SELECT "t1"."id", "t1"."key", "t1"."data" FROM "key_data" AS "t1" WHERE ("t1"."data" IN ((json(?)), (json(?)), (json(?), json(?))))', ['[1]', '[2]', '[1, 2]'])
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2444/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2444/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2443 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2443/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2443/comments | https://api.github.com/repos/coleifer/peewee/issues/2443/events | https://github.com/coleifer/peewee/pull/2443 | 936,477,112 | MDExOlB1bGxSZXF1ZXN0NjgzMTg5MDU0 | 2,443 | Fix decimal.InvalidOperation error for empty string | {
"login": "soyoung97",
"id": 29880214,
"node_id": "MDQ6VXNlcjI5ODgwMjE0",
"avatar_url": "https://avatars.githubusercontent.com/u/29880214?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/soyoung97",
"html_url": "https://github.com/soyoung97",
"followers_url": "https://api.github.com/users/soyoung97/followers",
"following_url": "https://api.github.com/users/soyoung97/following{/other_user}",
"gists_url": "https://api.github.com/users/soyoung97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/soyoung97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/soyoung97/subscriptions",
"organizations_url": "https://api.github.com/users/soyoung97/orgs",
"repos_url": "https://api.github.com/users/soyoung97/repos",
"events_url": "https://api.github.com/users/soyoung97/events{/privacy}",
"received_events_url": "https://api.github.com/users/soyoung97/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"FYI, this was the full stack trace for my application.\r\n```Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/site-packages/flask/app.py\", line 2309, in __call__\r\n return self.wsgi_app(environ, start_response)\r\n File \"/usr/local/lib/python3.6/site-packages/flask/app.py\", line 2295, in wsgi_app\r\n response = self.handle_exception(e)\r\n File \"/usr/local/lib/python3.6/site-packages/flask/app.py\", line 1741, in handle_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/usr/local/lib/python3.6/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/usr/local/lib/python3.6/site-packages/flask/app.py\", line 2292, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/usr/local/lib/python3.6/site-packages/flask/app.py\", line 1815, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/usr/local/lib/python3.6/site-packages/flask/app.py\", line 1718, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/usr/local/lib/python3.6/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/usr/local/lib/python3.6/site-packages/flask/app.py\", line 1813, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/usr/local/lib/python3.6/site-packages/flask/app.py\", line 1799, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/Users/soyoung/Desktop/coding/research/sql/sql-instruction-web/views.py\", line 121, in inner\r\n return fn(cur_db, table, *args, **kwargs)\r\n File \"/Users/soyoung/Desktop/coding/research/sql/sql-instruction-web/views.py\", line 179, in table_content\r\n total_pages=total_pages)\r\n File \"/usr/local/lib/python3.6/site-packages/flask/templating.py\", line 135, in render_template\r\n context, ctx.app)\r\n File \"/usr/local/lib/python3.6/site-packages/flask/templating.py\", line 117, in _render\r\n rv = template.render(context)\r\n File \"/usr/local/lib/python3.6/site-packages/jinja2/environment.py\", line 1090, in render\r\n self.environment.handle_exception()\r\n File \"/usr/local/lib/python3.6/site-packages/jinja2/environment.py\", line 832, in handle_exception\r\n reraise(*rewrite_traceback_stack(source=source))\r\n File \"/usr/local/lib/python3.6/site-packages/jinja2/_compat.py\", line 28, in reraise\r\n raise value.with_traceback(tb)\r\n File \"/Users/soyoung/Desktop/coding/research/sql/sql-instruction-web/templates/table_content.html\", line 1, in top-level template code\r\n {% extends \"base_table.html\" %}\r\n File \"/Users/soyoung/Desktop/coding/research/sql/sql-instruction-web/templates/base_table.html\", line 1, in top-level template code\r\n {% extends \"base_tables.html\" %}\r\n File \"/Users/soyoung/Desktop/coding/research/sql/sql-instruction-web/templates/base_tables.html\", line 1, in top-level template code\r\n {% extends \"base.html\" %}\r\n File \"/Users/soyoung/Desktop/coding/research/sql/sql-instruction-web/templates/base.html\", line 42, in top-level template code\r\n {% block content %}{% endblock %}\r\n File \"/Users/soyoung/Desktop/coding/research/sql/sql-instruction-web/templates/base_table.html\", line 29, in block \"content\"\r\n {% block inner_content %}\r\n File \"/Users/soyoung/Desktop/coding/research/sql/sql-instruction-web/templates/table_content.html\", line 36, in block \"inner_content\"\r\n {% for row in query %}\r\n File \"/usr/local/lib/python3.6/site-packages/peewee.py\", line 4378, in next\r\n self.cursor_wrapper.iterate()\r\n File \"/usr/local/lib/python3.6/site-packages/peewee.py\", line 4297, in iterate\r\n result = self.process_row(row)\r\n File \"/usr/local/lib/python3.6/site-packages/peewee.py\", line 7450, in process_row\r\n result[attr] = converters[i](row[i])\r\n File \"/usr/local/lib/python3.6/site-packages/peewee.py\", line 4681, in python_value\r\n return decimal.Decimal(text_type(value))\r\ndecimal.InvalidOperation: [<class 'decimal.ConversionSyntax'>]```",
"So sqlite does not have an actual dedicated Decimal field. It interprets the value as numeric, I believe, but it looks like in your table you have empty string (`''`) instead of NULL or 0. Python cannot convert empty string into a decimal, so you get the error.\r\n\r\nTo fix this either:\r\n\r\n1. update all decimal values stored as '' to be 0\r\n2. update all decimal values stored as '' to be NULL\r\n3. use a different field type or different column storage.",
"For what it's worth, it looks like @nitinprakash96 copy/pasted a bit of code directly from my project `sqlite-web`. I don't know what the deal is, but it looks like he's created a shittier version of my project. You might have better luck using it:\r\n\r\nhttps://github.com/coleifer/sqlite-web",
"Oh I didn't know that there was original code! thanks for the pointer! I'll change my codebase to https://github.com/coleifer/sqlite-web.\r\nBy the way, (I have to test whether this problem also happens or not after changing the codebase but if so,) I just thought that it'll be great if we can treat this exception at the peewee library level, since currently I cannot update the original database (It is given to me as official training data). However thanks for the solution and fast response!",
"I would like to be able to fix at the library level, but it seems like a fairly particular edge-case arising from a couple different problems:\r\n\r\n1. the use of DECIMAL type in sqlite (sqlite is weakly-typed and inconsistent data values can be a problem. See: https://www.sqlite.org/datatype3.html#type_affinity )\r\n2. storing empty string in a numeric column instead of NULL or 0\r\n3. peewee conversion logic for non-null decimal values\r\n\r\nLike I said, I think there's a couple issues in play, but my suggestion would be to fix-up the data if you can.",
"Thanks so much for additional pointer. I'm not an expert at sqlite, so I didn't know about this issue. Now I fully understand that this is an edge case, and it should be better treated at the database level. Thanks again for your consideration! I really appreciate it :)"
] | 2021-07-04T15:04:28 | 2021-07-06T03:20:34 | 2021-07-04T22:36:20 | NONE | null | Hello, thank you for making such a good opensource code!
I was working with [sqlite db viewer](https://github.com/nitinprakash96/sqlite-db-viewer) that uses peewee.
However, when I was trying to iterate through None values at integer field (by {% for row in query %} in html code), there was a peewee error saying decimal.InvalidOperation.
I think this issue could also be related with [this pull request](https://github.com/coleifer/peewee/commit/cd07f4e01a1262166d8944736e11d0681fb76214), since the error appeared at returning value of the function python_value `decimal.Decimal(text_type(value))`.
After inspection, I found out that sometimes an empty string('') comes into this function(which it shouldn't since empty string is not a number) and by adding a filter (adding `and row[i] != ''` at ModelDictCursorWrapper), I managed to solve this problem.
*Please note that I am new to this code and I may be not understanding this perfectly, so please correct me if I'm wrong in solving this problem.
Attatched below is my original code, error traceback, and pdb operations.
Thank you!
### Error Traceback


### Setting try-catch pdb and results at python_value at peewee.py


### Filtering String values

### Correctly displayed application (mine)


Here, I think what caused the problem is the ibb, hbp, sh, sf, g_idp column, which has Nonetype values as well as numbers(0). Adding this code to handle exceptions for this case would be great! | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2443/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2443/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2443",
"html_url": "https://github.com/coleifer/peewee/pull/2443",
"diff_url": "https://github.com/coleifer/peewee/pull/2443.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2443.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2442 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2442/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2442/comments | https://api.github.com/repos/coleifer/peewee/issues/2442/events | https://github.com/coleifer/peewee/issues/2442 | 935,515,520 | MDU6SXNzdWU5MzU1MTU1MjA= | 2,442 | how should i use ModelSelect.select()? | {
"login": "CooperWanng",
"id": 45349258,
"node_id": "MDQ6VXNlcjQ1MzQ5MjU4",
"avatar_url": "https://avatars.githubusercontent.com/u/45349258?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CooperWanng",
"html_url": "https://github.com/CooperWanng",
"followers_url": "https://api.github.com/users/CooperWanng/followers",
"following_url": "https://api.github.com/users/CooperWanng/following{/other_user}",
"gists_url": "https://api.github.com/users/CooperWanng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CooperWanng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CooperWanng/subscriptions",
"organizations_url": "https://api.github.com/users/CooperWanng/orgs",
"repos_url": "https://api.github.com/users/CooperWanng/repos",
"events_url": "https://api.github.com/users/CooperWanng/events{/privacy}",
"received_events_url": "https://api.github.com/users/CooperWanng/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"If you are explicitly re-selecting columns, you need to specify which columns you want.",
"> If you are explicitly re-selecting columns, you need to specify which columns you want.\r\n\r\nthanks,the usage of peewee differs between the two versions(3.6->3.14)"
] | 2021-07-02T07:52:58 | 2021-07-11T13:58:45 | 2021-07-02T12:59:02 | NONE | null | I ran into a problem when I used select function of ModelSelect
>query = Auth.select(Auth.id) # Model.select()
select t1.id FROM auth AS t1;
query = Auth.select(Auth.id).select() # ModelSelect.select()
> select FROM auth AS t1;
how should i do?
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2442/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2442/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2441 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2441/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2441/comments | https://api.github.com/repos/coleifer/peewee/issues/2441/events | https://github.com/coleifer/peewee/pull/2441 | 935,050,691 | MDExOlB1bGxSZXF1ZXN0NjgyMDMxOTUw | 2,441 | Add reuse_if_open flag to playhouse.dataset.DataSet | {
"login": "Xezed",
"id": 22517386,
"node_id": "MDQ6VXNlcjIyNTE3Mzg2",
"avatar_url": "https://avatars.githubusercontent.com/u/22517386?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Xezed",
"html_url": "https://github.com/Xezed",
"followers_url": "https://api.github.com/users/Xezed/followers",
"following_url": "https://api.github.com/users/Xezed/following{/other_user}",
"gists_url": "https://api.github.com/users/Xezed/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Xezed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Xezed/subscriptions",
"organizations_url": "https://api.github.com/users/Xezed/orgs",
"repos_url": "https://api.github.com/users/Xezed/repos",
"events_url": "https://api.github.com/users/Xezed/events{/privacy}",
"received_events_url": "https://api.github.com/users/Xezed/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-07-01T17:09:50 | 2021-07-01T20:35:45 | 2021-07-01T20:35:45 | NONE | null | Hey :)
I need to use the existing connection with `DataSet`.
This pull request will allow me to do so.
Thank you for your work on the project. :rays_of_love: | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2441/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2441/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2441",
"html_url": "https://github.com/coleifer/peewee/pull/2441",
"diff_url": "https://github.com/coleifer/peewee/pull/2441.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2441.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2440 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2440/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2440/comments | https://api.github.com/repos/coleifer/peewee/issues/2440/events | https://github.com/coleifer/peewee/issues/2440 | 934,606,810 | MDU6SXNzdWU5MzQ2MDY4MTA= | 2,440 | [QueryBuilder] Missing alias when filtering on a nested subquery | {
"login": "kozlek",
"id": 3019422,
"node_id": "MDQ6VXNlcjMwMTk0MjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/3019422?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kozlek",
"html_url": "https://github.com/kozlek",
"followers_url": "https://api.github.com/users/kozlek/followers",
"following_url": "https://api.github.com/users/kozlek/following{/other_user}",
"gists_url": "https://api.github.com/users/kozlek/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kozlek/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kozlek/subscriptions",
"organizations_url": "https://api.github.com/users/kozlek/orgs",
"repos_url": "https://api.github.com/users/kozlek/repos",
"events_url": "https://api.github.com/users/kozlek/events{/privacy}",
"received_events_url": "https://api.github.com/users/kozlek/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Have you tried attaching an alias to your subquery? Here's my code and the output, which looks OK to me:\r\n\r\n```python\r\n# Get product IDs of best-selling products.\r\nbp = (Sales\r\n .select(Sales.c.product_id, fn.SUM(Sales.c.price).alias('price__sum'))\r\n .group_by(Sales.c.product_id)\r\n .alias('bp')) # NB\r\n\r\n# Select 10 best-selling products.\r\ntop10 = (Select([bp], [bp.c.product_id, bp.c.price__sum])\r\n .order_by(bp.c.price__sum.desc())\r\n .limit(10))\r\n\r\nprod = (Product\r\n .select(Product.c.product_id, Product.c.title)\r\n .where(Product.c.product_id.in_(top10)))\r\n\r\nprint(prod.sql())\r\n```\r\n\r\nOutput:\r\n\r\n```sql\r\nSELECT \"t1\".\"product_id\", \"t1\".\"title\" \r\nFROM \"product\" AS \"t1\"\r\nWHERE (\"t1\".\"product_id\" IN (\r\n SELECT \"bp\".\"product_id\", \"bp\".\"price__sum\" \r\n FROM (\r\n SELECT \"t2\".\"product_id\", SUM(\"t2\".\"price\") AS \"price__sum\" \r\n FROM \"sales\" AS \"t2\" \r\n GROUP BY \"t2\".\"product_id\"\r\n ) AS \"bp\" \r\n ORDER BY \"bp\".\"price__sum\" DESC \r\n LIMIT ?)\r\n)\r\n```",
"Another thing you might try, which seems a bit more idiomatic, would be to use a common table expression for the top 10 products:\r\n\r\n```python\r\ntop10 = (Sales\r\n .select(Sales.c.product_id, fn.SUM(Sales.c.price))\r\n .group_by(Sales.c.product_id)\r\n .order_by(fn.SUM(Sales.c.price).desc())\r\n .limit(10)\r\n .cte('top10', columns=('product_id', 'price__sum')))\r\n\r\nquery = (Product\r\n .select(Product.c.id, Product.c.title)\r\n .join(top10, on=(Product.c.id == top10.c.product_id))\r\n .with_cte(top10))\r\n```\r\n\r\nSQL:\r\n\r\n```sql\r\n\r\nWITH \"top10\" (\"product_id\", \"price__sum\") AS (\r\n SELECT \"t1\".\"product_id\", SUM(\"t1\".\"price\") \r\n FROM \"sales\" AS \"t1\" \r\n GROUP BY \"t1\".\"product_id\" \r\n ORDER BY SUM(\"t1\".\"price\") DESC \r\n LIMIT ?) \r\nSELECT \"t2\".\"id\", \"t2\".\"title\" FROM \"products\" AS \"t2\" \r\nINNER JOIN \"top10\" ON (\"t2\".\"id\" = \"top10\".\"product_id\")\r\n```",
"Thanks for your answers 🙂\r\n\r\nAttaching aliases seems to work on my simple examples, I'll try to implement that on the complex ones now and I will stick \r\nwith that if it works well 👌\r\nIf I manage to find patch, I will still try to fix auto alias attachement as it is very practical in some cases 🙂\r\n\r\nI would love to use CTE like I'm used to with Postgres, but here I'm working with a Clickhouse OLAP data warehouse which has a limited support for CTE...\r\nAt the time I'm writing these lines, there is no suitable query builder on the python market that supports Clickhouse specificity out of the box. Starting with Peewee's query builder and code some extensions to support Clickhouse flavoured operations (like JOIN USING) was the easiest solution ; way better than restarting a whole query builder from scratch.\r\n\r\nThanks again for your work on Peewee 👏"
] | 2021-07-01T09:08:27 | 2021-07-02T13:37:33 | 2021-07-01T13:23:25 | NONE | null | Hi !
I'm using peewee's QueryBuilder API these days and I'm enjoying its powerful capabilities 😃
However, I have a complex use case where I need to produce a `WHERE IN <subquery>` condition ; where `subquery` is itself a subquery (nested subquery).
## Issue
I've tried to recreate a minimal example.
Let's say we have two tables:
- product(product_id, title)
- sales(product_id, price)
Now let's request the title of the 10 best-seller products.
We expect to have the following SQL:
```sql
SELECT "t1"."product_id" AS "product_id", "t1"."title" AS "title"
FROM "product" AS "t1"
WHERE ("t1"."product_id" IN (
SELECT "t2"."product_id" AS "product_id", "t2"."price__sum" AS "price__sum"
FROM (
SELECT "t3"."product_id" AS "product_id", sum("t3"."price") AS "price__sum"
FROM "sales" AS "t3"
GROUP BY "t3"."product_id"
) AS "t2"
ORDER BY "t2"."price__sum" DESC
LIMIT 10
)
)
```
I'm aware we can write the following query in a totally different way, but I'm working with a complex system that needs to have the query written this way (that's why I'm using the QueryBuilder rather than the ORM).
Using peewee's QueryBuilder API, we'll do something like this:
```python
import peewee
# let's define 2 tables
t_product = peewee.Table("product")
t_sales = peewee.Table("sales")
# create a first subquery that computes the sum of the sales
subquery_best_products = t_sales.select(
t_sales.c.product_id.alias("product_id"), peewee.fn.sum(t_sales.c.price).alias("price__sum")
).group_by(t_sales.c.product_id)
# subquery from this previous subquery to order_by and limit 10
nested_subquery_best_products = (
subquery_best_products.select_from(
subquery_best_products.c.product_id.alias("product_id"),
subquery_best_products.c.price__sum.alias("price__sum"),
)
.order_by(subquery_best_products.c.price__sum.desc())
.limit(10)
)
# select the title of the 10 best products
query = t_product.select(
t_product.c.product_id.alias("product_id"), t_product.c.title.alias("title")
).where(t_product.c.product_id.in_(nested_subquery_best_products))
```
This issue is that `query` will compile into the following:
```sql
SELECT "t1"."product_id" AS "product_id", "t1"."title" AS "title"
FROM "product" AS "t1"
WHERE ("t1"."product_id" IN (
SELECT "t2"."product_id" AS "product_id", "t2"."price__sum" AS "price__sum"
FROM (
SELECT "t3"."product_id" AS "product_id", sum("t3"."price") AS "price__sum"
FROM "sales" AS "t3"
GROUP BY "t3"."product_id"
)
ORDER BY "t2"."price__sum" DESC
LIMIT 10
)
)
```
We miss the `t2` alias definition, while it is used in the returning section of the generated SQL !
To ensure that our `nested_subquery_best_products` is correct, we can compile it standalone:
```sql
SELECT "t1"."product_id" AS "product_id", "t1"."price__sum" AS "price__sum"
FROM (
SELECT "t2"."product_id" AS "product_id", sum("t2"."price") AS "price__sum"
FROM "sales" AS "t2" GROUP BY "t2"."product_id"
) AS "t1"
ORDER BY "t1"."price__sum" DESC
LIMIT 10
```
The aliases are a bit different (that's normal), but they are correctly defined.
So the issue might be scoped to the usage of a nested subquery into a where expression.
## Solution (WIP)
I'm digging in peewee's internals and I figured out aliases are applied conditionally depending of the scope of the current context. I guess that when the nested subquery is run in standalone mode, the scope is correctly set to SCOPE_SOURCE, while it is set to SCOPE_NORMAL when compiling where expression.
I'll be happy to provide a MR if I manage to find a working patch 👌
Thanks in advance for your help 🙏 | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2440/reactions",
"total_count": 6,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/coleifer/peewee/issues/2440/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2439 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2439/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2439/comments | https://api.github.com/repos/coleifer/peewee/issues/2439/events | https://github.com/coleifer/peewee/issues/2439 | 933,280,236 | MDU6SXNzdWU5MzMyODAyMzY= | 2,439 | migrate leave foreignkey out of consideration | {
"login": "woshimanong1990",
"id": 13585117,
"node_id": "MDQ6VXNlcjEzNTg1MTE3",
"avatar_url": "https://avatars.githubusercontent.com/u/13585117?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/woshimanong1990",
"html_url": "https://github.com/woshimanong1990",
"followers_url": "https://api.github.com/users/woshimanong1990/followers",
"following_url": "https://api.github.com/users/woshimanong1990/following{/other_user}",
"gists_url": "https://api.github.com/users/woshimanong1990/gists{/gist_id}",
"starred_url": "https://api.github.com/users/woshimanong1990/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/woshimanong1990/subscriptions",
"organizations_url": "https://api.github.com/users/woshimanong1990/orgs",
"repos_url": "https://api.github.com/users/woshimanong1990/repos",
"events_url": "https://api.github.com/users/woshimanong1990/events{/privacy}",
"received_events_url": "https://api.github.com/users/woshimanong1990/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The foreign keys are returned by `pragma foreign_key_list(\"...\")`. I'm not sure I understand the issue you're describing."
] | 2021-06-30T03:55:50 | 2021-06-30T13:17:55 | 2021-06-30T13:17:55 | NONE | null | I drop a field to a tabel ,but not I success. Finally, I found, it's a bug.
you create a tmp table and then, drop old tabel. BUT, leave foreignkey out of consideration
`
# Find any foreign keys we may need to remove.
self.database.get_foreign_keys(table)
`
do nothing
I used sqlite.
maybe I should use `PRAGMA foreign_keys=OFF` first | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2439/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2439/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2438 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2438/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2438/comments | https://api.github.com/repos/coleifer/peewee/issues/2438/events | https://github.com/coleifer/peewee/issues/2438 | 933,265,316 | MDU6SXNzdWU5MzMyNjUzMTY= | 2,438 | migrator.add_column throws error on column with default value for sqlite | {
"login": "binh-vu",
"id": 4346739,
"node_id": "MDQ6VXNlcjQzNDY3Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4346739?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/binh-vu",
"html_url": "https://github.com/binh-vu",
"followers_url": "https://api.github.com/users/binh-vu/followers",
"following_url": "https://api.github.com/users/binh-vu/following{/other_user}",
"gists_url": "https://api.github.com/users/binh-vu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/binh-vu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/binh-vu/subscriptions",
"organizations_url": "https://api.github.com/users/binh-vu/orgs",
"repos_url": "https://api.github.com/users/binh-vu/repos",
"events_url": "https://api.github.com/users/binh-vu/events{/privacy}",
"received_events_url": "https://api.github.com/users/binh-vu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Closing the issue. I found the root of this problem.\r\n\r\nI added the new field to my model definition with index. When I run my migration script, peewee saw a new field, it doesn't create the column. However, it creates the index. So the database has an index of an unknown column. A query to create column is fine, but an update query to that column throws error in python. Dropping the index and it works as expected."
] | 2021-06-30T03:13:57 | 2021-06-30T04:03:10 | 2021-06-30T04:03:10 | NONE | null | Peewee version: `3.14.4`
SQLite version: `3.33.0`
When I run,
```
migrator = SqliteMigrator(db)
with db.atomic():
migrate(
migrator.add_column("table", 'is_deleted', BooleanField(default=True)),
)
```
It throws the following error:
```
peewee.DatabaseError: database disk image is malformed
```
This behavior contradicts to the [documentation](https://docs.peewee-orm.com/en/latest/peewee/playhouse.html#supported-operations)
I investigated more and found that:
* When the table is empty, it executes this query: `ALTER TABLE "table" ADD COLUMN "is_deleted" INTEGER`
* However, then the table is not empty, it executes this query: `UPDATE "table" SET "is_deleted" = ?`. Manually executing the query on my sqlite database, it throws the error: `Result: no such column: is_deleted`.
* I dump the content of the database to an sql file and re-import them on new database but still get the same error.
* Interestingly, `add_column` (nullable), then `apply_default` also doesn't work and I got the same error. Turns out the query `UPDATE ...` causing the issue. So I need to do it in one query `ALTER TABLE "table" ADD COLUMN "is_deleted" INTEGER NOT NULL DEFAULT 0`. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2438/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2438/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2437 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2437/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2437/comments | https://api.github.com/repos/coleifer/peewee/issues/2437/events | https://github.com/coleifer/peewee/issues/2437 | 932,902,106 | MDU6SXNzdWU5MzI5MDIxMDY= | 2,437 | How do I union queries where the model contains a JSON field? | {
"login": "dsmurrell",
"id": 4035854,
"node_id": "MDQ6VXNlcjQwMzU4NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4035854?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dsmurrell",
"html_url": "https://github.com/dsmurrell",
"followers_url": "https://api.github.com/users/dsmurrell/followers",
"following_url": "https://api.github.com/users/dsmurrell/following{/other_user}",
"gists_url": "https://api.github.com/users/dsmurrell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dsmurrell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dsmurrell/subscriptions",
"organizations_url": "https://api.github.com/users/dsmurrell/orgs",
"repos_url": "https://api.github.com/users/dsmurrell/repos",
"events_url": "https://api.github.com/users/dsmurrell/events{/privacy}",
"received_events_url": "https://api.github.com/users/dsmurrell/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Doing a bit of searching, it looks like the UNION operation is trying to take out duplicates and needs to compare the JSON content... is there any way in the union from peewee that I can specify that I'd like only apply distinct on say `id`?",
"Yes, you need to use UNION ALL if you don't want duplicates removed (which is why you're getting that error). You can use `.union_all()` or the addition operator overload.",
"Thanks, I came across that option in my searches.\r\n\r\nSo you're saying that if I am concerned about duplicates, I can `.union_all()`, and then use `.distinct(model.id)`?\r\n\r\nI was typing this out below before you responded but then I got consumed by something else:\r\n\r\n\"Trying out `BinaryJSONField` instead of `JSONField` now and this seems to work (using union and BinaryJSONFields), but I'm not sure what the implications are of changing our whole schema to use `BinaryJSONField` instead of `JSONField` everywhere. Are these supposed to be interchangeable or will changing the schema change the data in some way?\"\r\n\r\nI'd imagine the we don't want to be doing JSON equality operations anyway to filter distinct records so I'll try out using distinct after union_all. Thanks again for the help!",
"This is a part of the SQL specification, that UNION must perform some type of equality to remove duplicates, whereas UNION ALL is not constrained in that way."
] | 2021-06-29T16:35:24 | 2021-06-29T18:53:32 | 2021-06-29T17:57:26 | NONE | null | If I have two or more queries to join (say q1, q2 and q3) and I'm using set operations on them like:
`query = q1 & q2` or `query = q2 | q3` or `query = q1 - q3`
I know that there is a limitation that the selected columns for these should be the same, but I'm finding that I get the errors:
`peewee.ProgrammingError: could not identify an equality operator for type json`
`psycopg2.errors.UndefinedFunction: could not identify an equality operator for type json`
whenever all fields are selected and the model includes a `JSONField` from `playhouse.postgres_ext`
Is this any way to resolve this? My use case is that I'm passing a list of queries through to another function where I want to union them and so I don't have the luxury of adding `.where(xyz)` statements onto an exiting query to limit the selection using multiple where filters. Also, the set operations seem more powerful in general as passing a list of where params is quite limiting. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2437/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2437/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2436 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2436/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2436/comments | https://api.github.com/repos/coleifer/peewee/issues/2436/events | https://github.com/coleifer/peewee/issues/2436 | 931,789,027 | MDU6SXNzdWU5MzE3ODkwMjc= | 2,436 | What you think about rename to "peewo"? | {
"login": "Timtaran",
"id": 60805088,
"node_id": "MDQ6VXNlcjYwODA1MDg4",
"avatar_url": "https://avatars.githubusercontent.com/u/60805088?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Timtaran",
"html_url": "https://github.com/Timtaran",
"followers_url": "https://api.github.com/users/Timtaran/followers",
"following_url": "https://api.github.com/users/Timtaran/following{/other_user}",
"gists_url": "https://api.github.com/users/Timtaran/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Timtaran/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Timtaran/subscriptions",
"organizations_url": "https://api.github.com/users/Timtaran/orgs",
"repos_url": "https://api.github.com/users/Timtaran/repos",
"events_url": "https://api.github.com/users/Timtaran/events{/privacy}",
"received_events_url": "https://api.github.com/users/Timtaran/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-06-28T17:16:07 | 2021-06-28T17:22:28 | 2021-06-28T17:22:28 | NONE | null | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2436/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2436/timeline | null | completed | null | null |
|
https://api.github.com/repos/coleifer/peewee/issues/2435 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2435/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2435/comments | https://api.github.com/repos/coleifer/peewee/issues/2435/events | https://github.com/coleifer/peewee/issues/2435 | 931,134,143 | MDU6SXNzdWU5MzExMzQxNDM= | 2,435 | Some obstacles when trying to add a driver for ClickHouse | {
"login": "pm5",
"id": 119645,
"node_id": "MDQ6VXNlcjExOTY0NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/119645?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pm5",
"html_url": "https://github.com/pm5",
"followers_url": "https://api.github.com/users/pm5/followers",
"following_url": "https://api.github.com/users/pm5/following{/other_user}",
"gists_url": "https://api.github.com/users/pm5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pm5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pm5/subscriptions",
"organizations_url": "https://api.github.com/users/pm5/orgs",
"repos_url": "https://api.github.com/users/pm5/repos",
"events_url": "https://api.github.com/users/pm5/events{/privacy}",
"received_events_url": "https://api.github.com/users/pm5/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I've fixed the first item, thank you for bringing that to my attention.\r\n\r\nThe second item will not be so easy, since it implies that you are passing the parameters as a `dict`. Every other driver I know of just uses a tuple to represent the query parameters, so there is probably some work involved in getting this working. It looks like this driver is implemented very idiosyncratically compared to the others, e.g.\r\n\r\n```\r\n>>> cursor.executemany('INSERT INTO test (x) VALUES', [[200]])\r\n```\r\n\r\nWhat the heck is going on here? Is the driver inserting placeholders?\r\n\r\nI'd suggest taking it up with the clickhouse implementer(s) to see about getting this resolved upstream, as it will likely be rather tricky with Peewee."
] | 2021-06-28T03:38:57 | 2021-06-28T12:50:43 | 2021-06-28T12:50:43 | NONE | null | I saw #912 and tried to add a driver for [ClickHouse](https://clickhouse.tech/) using [clickhouse-driver](https://clickhouse-driver.readthedocs.io/en/latest/features.html#python-db-api-2-0) but there seems to be some obstacles:
- The [documentation](http://docs.peewee-orm.com/en/latest/peewee/database.html#adding-a-new-database-driver) seems outdated. `Database._connect` is no longer taking arguments and one has to use `foodb.connect(self.database, **self.connect_params)` instead.
- The DB API 2.0 implemented by clickhouse-driver specifically uses Python extended format codes for SQL parameters, i.e. `%(name)s`, which is [allowed](https://www.python.org/dev/peps/pep-0249/#paramstyle). I've found `Database.param` in peewee, but it seems a bit hard to get it work with this format.
Any suggestions? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2435/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2435/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2434 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2434/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2434/comments | https://api.github.com/repos/coleifer/peewee/issues/2434/events | https://github.com/coleifer/peewee/issues/2434 | 930,942,716 | MDU6SXNzdWU5MzA5NDI3MTY= | 2,434 | time generation on linux vs windows | {
"login": "naamlev",
"id": 66517559,
"node_id": "MDQ6VXNlcjY2NTE3NTU5",
"avatar_url": "https://avatars.githubusercontent.com/u/66517559?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/naamlev",
"html_url": "https://github.com/naamlev",
"followers_url": "https://api.github.com/users/naamlev/followers",
"following_url": "https://api.github.com/users/naamlev/following{/other_user}",
"gists_url": "https://api.github.com/users/naamlev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/naamlev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/naamlev/subscriptions",
"organizations_url": "https://api.github.com/users/naamlev/orgs",
"repos_url": "https://api.github.com/users/naamlev/repos",
"events_url": "https://api.github.com/users/naamlev/events{/privacy}",
"received_events_url": "https://api.github.com/users/naamlev/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I think you are misusing `prefetch()`. In your first example, you shouldn't need prefetch at all if each X has only one (or zero) Y / Z. Just write:\r\n\r\n```python\r\n(X\r\n .select(X, Y, Z)\r\n .join_from(X, Y, JOIN.LEFT_OUTER)\r\n .join_from(X, Z, JOIN.LEFT_OUTER))\r\n```\r\n\r\nFor your new version, since a Z can have many T's (if I'm reading this correctly), then yes you would probably be best off to use `prefetch()`. Again, though, you may be able to reuse the above snippet for the X, Y, and Z portions and just use prefetch for the T's.\r\n\r\nI cannot really advise on how to optimize this, it depends so much on how many rows of X, Y, Z and T you are getting, what database you are using, etc, etc. It might be possible to use an aggregation to roll-up the related T's and skip using prefetch altogether.\r\n\r\nAre you able to express the entire query in a single SQL SELECT (using plain old sql)? If yes, then we can probably optimize this. If no, then it will be hard to say.\r\n\r\nI'll reopen this if there is a bug, but feel free to respond and I will do my best to help you."
] | 2021-06-27T14:19:49 | 2021-06-27T14:56:44 | 2021-06-27T14:56:43 | NONE | null | Hey ,
I am using peewee 3.13.2
Part of the project include using join over multiple tables and retrieving foreign keys using prefetch.
I've recently added to the join new table that has many to many relationship and prefetch to retrieve it key.
**example:**
_old version:_
X.select(X)
.join_from(X, Y, peewee.JOIN.LEFT_OUTER)
.join_from(X, Z, peewee.JOIN.LEFT_OUTER)
.where(query)
.prefetch(Y, Z)
_new version:_
X.select(X)
.join_from(X, Y, peewee.JOIN.LEFT_OUTER)
.join_from(X, Z, peewee.JOIN.LEFT_OUTER)
.join_from(Z, T, peewee.JOIN.LEFT_OUTER)
.switch(X)
.where(query)
.prefetch(Y, Z,T)
**questions**
1. is there a better why (lower time complexity) to model this behavior without limiting the query that the user can give?
2. why do i get better time complexity in windows?
* The same branch (and same test) get on windows: 340 sec and in linux:870 sec
* Just for comparison before the change i've got windows:200 sec linux: 250 sec | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2434/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2434/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2433 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2433/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2433/comments | https://api.github.com/repos/coleifer/peewee/issues/2433/events | https://github.com/coleifer/peewee/issues/2433 | 930,723,091 | MDU6SXNzdWU5MzA3MjMwOTE= | 2,433 | Prefetching from multiple models | {
"login": "jonathanmach",
"id": 12788052,
"node_id": "MDQ6VXNlcjEyNzg4MDUy",
"avatar_url": "https://avatars.githubusercontent.com/u/12788052?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonathanmach",
"html_url": "https://github.com/jonathanmach",
"followers_url": "https://api.github.com/users/jonathanmach/followers",
"following_url": "https://api.github.com/users/jonathanmach/following{/other_user}",
"gists_url": "https://api.github.com/users/jonathanmach/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonathanmach/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonathanmach/subscriptions",
"organizations_url": "https://api.github.com/users/jonathanmach/orgs",
"repos_url": "https://api.github.com/users/jonathanmach/repos",
"events_url": "https://api.github.com/users/jonathanmach/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonathanmach/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"You don't need prefetch. Prefetch is for when the direction of traversal is reversed, e.g. you have a list of users and you want to get all their kits as well.\r\n\r\nJust do joins (you'll need aliases because you reference User multiple times):\r\n\r\n```python\r\n\r\nOrderUser = User.alias()\r\nOrderApprover = User.alias()\r\nKitClaimer = User.alias()\r\nKitCanceller = User.alias()\r\nq = (Kit.select(Kit, Order, OrderUser, OrderApprover, KitClaimer, KitCanceller)\r\n .join_from(Kit, Order)\r\n .join_from(Order, OrderUser, JOIN.INNER, on=Order.user)\r\n .join_from(Order, OrderApprover, JOIN.INNER, on=Order.approved_by_user)\r\n .join_from(Kit, KitClaimer, JOIN.LEFT_OUTER, on=Kit.claimed_by_user)\r\n .join_from(Kit, KitCanceller, JOIN.LEFT_OUTER, on=Kit.cancelled_by_user))\r\n```"
] | 2021-06-26T15:54:47 | 2021-06-28T15:46:49 | 2021-06-26T21:51:42 | CONTRIBUTOR | null | Hi all! Hoping everyone is safe!
I've read the documentation about N+1 queries and prefetch, but I'm facing a strange behavior.
Let's say I have the following models:
```
Users
Orders
user (FK)
approved_by_user (FK)
Kits
order (FK)
claimed_by_user (FK)
cancelled_by_user (FK)
```
```python
# I can query for Kits and prefetch Users:
for kit in prefetch(Kits.select(), Users):
print(kit.claimed_by_user)
print(kit.cancelled_by_user)
# 👍 Works fine, no N+1 queries 🎉
---
# or query for Kits and prefetch Orders:
for kit in prefetch(Kits.select(), Orders):
print(kit.order)
# 👍 Works fine, no N+1 queries 🎉
---
# But I can't prefetch both Users and Orders:
for kit in prefetch(Kits.select(), Orders, Users):
print(kit.claimed_by_user)
print(kit.cancelled_by_user)
print(kit.order) # It generates N+1 queries here❗️ 😨😨
```
I imagine I'm missing some small detail here.
My main goal is to respond to a REST request with a JSON in the following format:
```
[
Kits
claimed_by_user : {...}
cancelled_by_user : {...}
order : {user: {...}, approved_by_user: {...}}
]
```
Thanks in advance! | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2433/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2433/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2432 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2432/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2432/comments | https://api.github.com/repos/coleifer/peewee/issues/2432/events | https://github.com/coleifer/peewee/issues/2432 | 928,623,933 | MDU6SXNzdWU5Mjg2MjM5MzM= | 2,432 | Question: Is there a way to use one field to set another field when the create method is used? | {
"login": "dsmurrell",
"id": 4035854,
"node_id": "MDQ6VXNlcjQwMzU4NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4035854?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dsmurrell",
"html_url": "https://github.com/dsmurrell",
"followers_url": "https://api.github.com/users/dsmurrell/followers",
"following_url": "https://api.github.com/users/dsmurrell/following{/other_user}",
"gists_url": "https://api.github.com/users/dsmurrell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dsmurrell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dsmurrell/subscriptions",
"organizations_url": "https://api.github.com/users/dsmurrell/orgs",
"repos_url": "https://api.github.com/users/dsmurrell/repos",
"events_url": "https://api.github.com/users/dsmurrell/events{/privacy}",
"received_events_url": "https://api.github.com/users/dsmurrell/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I think I got there:\r\n\r\n```\r\n @classmethod\r\n def create(cls, **query):\r\n query['email_lower'] = query[\"email\"].lower()\r\n return super(Users, cls).create(**query)\r\n```\r\n\r\n@coleifer, is there any reason to use signals over this way of doing it?",
"The proper way to do this would probably be to just create an index on the lower-case version of the email, since I assume you only are using it for uniqueness or querying.\r\n\r\n```sql\r\ncreate unique index \"user_email_lower\" on users(lower(email))\r\n```\r\n\r\nIf you really want to have it in its own field, then I'd override the `save()` method.\r\n\r\n```python\r\ndef save(self, *args, **kwargs):\r\n self.email_lower = self.email.lower()\r\n return super(...).save(*args, **kwargs)\r\n```"
] | 2021-06-23T20:40:16 | 2021-06-24T13:05:28 | 2021-06-24T13:05:28 | NONE | null | There are multiple uses of the `Users.create(email=X)` method in our codebase. Is there any way to modify the Users class or override the create method to make a field `email_lower` get set to another field that is always passed in (`email`)?
I've tried:
```
def create(self, **kwargs):
super().create(email_lower=kwargs["email"].lower(), **kwargs)
```
but I think that this doesn't work because the object isn't instantiated before the `create` method on the subclass is called.
I also tried this:
```
def __init__(self, **kwargs):
super(Users, self).__init__(email_lower=kwargs["email"].lower(), **kwargs)
```
but it didn't work either. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2432/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2432/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2431 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2431/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2431/comments | https://api.github.com/repos/coleifer/peewee/issues/2431/events | https://github.com/coleifer/peewee/pull/2431 | 921,538,451 | MDExOlB1bGxSZXF1ZXN0NjcwNTI2Mzgw | 2,431 | feat(style): let the output follows PEP8 | {
"login": "HydrogenDeuterium",
"id": 36532302,
"node_id": "MDQ6VXNlcjM2NTMyMzAy",
"avatar_url": "https://avatars.githubusercontent.com/u/36532302?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HydrogenDeuterium",
"html_url": "https://github.com/HydrogenDeuterium",
"followers_url": "https://api.github.com/users/HydrogenDeuterium/followers",
"following_url": "https://api.github.com/users/HydrogenDeuterium/following{/other_user}",
"gists_url": "https://api.github.com/users/HydrogenDeuterium/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HydrogenDeuterium/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HydrogenDeuterium/subscriptions",
"organizations_url": "https://api.github.com/users/HydrogenDeuterium/orgs",
"repos_url": "https://api.github.com/users/HydrogenDeuterium/repos",
"events_url": "https://api.github.com/users/HydrogenDeuterium/events{/privacy}",
"received_events_url": "https://api.github.com/users/HydrogenDeuterium/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Eh, I'll pass."
] | 2021-06-15T15:43:38 | 2021-06-15T15:58:08 | 2021-06-15T15:58:07 | NONE | null | when using pwiz generates file to import,IDE always warning 'PEP 8: E302
expected 2 blank lines, found 1'.
I try to fix it. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2431/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2431/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2431",
"html_url": "https://github.com/coleifer/peewee/pull/2431",
"diff_url": "https://github.com/coleifer/peewee/pull/2431.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2431.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2430 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2430/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2430/comments | https://api.github.com/repos/coleifer/peewee/issues/2430/events | https://github.com/coleifer/peewee/issues/2430 | 919,888,943 | MDU6SXNzdWU5MTk4ODg5NDM= | 2,430 | [Feature request] Add more items to the log output | {
"login": "iHalt10",
"id": 24728342,
"node_id": "MDQ6VXNlcjI0NzI4MzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24728342?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iHalt10",
"html_url": "https://github.com/iHalt10",
"followers_url": "https://api.github.com/users/iHalt10/followers",
"following_url": "https://api.github.com/users/iHalt10/following{/other_user}",
"gists_url": "https://api.github.com/users/iHalt10/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iHalt10/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iHalt10/subscriptions",
"organizations_url": "https://api.github.com/users/iHalt10/orgs",
"repos_url": "https://api.github.com/users/iHalt10/repos",
"events_url": "https://api.github.com/users/iHalt10/events{/privacy}",
"received_events_url": "https://api.github.com/users/iHalt10/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm going to pass on this for now."
] | 2021-06-13T21:55:20 | 2021-06-14T12:57:04 | 2021-06-14T12:57:04 | NONE | null | Hello, this is a small feature request, but I'd like to add more items to the log output.
```py
from peewee import *
import logging
logger = logging.getLogger('peewee')
logger.addHandler(logging.StreamHandler())
logger.setLevel(logging.DEBUG)
a_db = SqliteDatabase('a.db')
b_db = SqliteDatabase('b.db')
class A(Model):
name = TextField()
class Meta:
database = a_db
class B(Model):
name = TextField()
class Meta:
database = b_db
a_db.create_tables([A])
b_db.create_tables([B])
# Output:
# ('CREATE TABLE IF NOT EXISTS "a" ("id" INTEGER NOT NULL PRIMARY KEY, "name" TEXT NOT NULL)', [])
# ('CREATE TABLE IF NOT EXISTS "b" ("id" INTEGER NOT NULL PRIMARY KEY, "name" TEXT NOT NULL)', [])
```
In the above, it is difficult to understand "which database was executed", can change it to the following code?
```py
...
def execute_sql(self, sql, params=None, commit=SENTINEL):
logger.debug((sql, params, self.database))
# Output:
# ('...', [], 'a.db')
...
```
> https://github.com/coleifer/peewee/blob/master/peewee.py#L3146
Or, I would like to have a function that can extend the log output more items, in addition to the "(sql, params)" items.
```py
...
class Database(_callable_context_manager):
...
def get_log_items(self, sql, params, db):
return (sql, params)
def execute_sql(self, sql, params=None, commit=SENTINEL):
logger.debug(self.get_log_items(sql, params, self))
...
```
myself code
```py
...
def my_get_log_items(sql, params, db):
return (sql, params, db.database)
db = SqliteDatabase('a.db')
db.get_log_items = my_get_log_items
db.execute_sql(...)
# Output:
# ('...', [], 'a.db')
```
Umm...
If you have time, I'd appreciate your opinion.
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2430/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2430/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2429 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2429/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2429/comments | https://api.github.com/repos/coleifer/peewee/issues/2429/events | https://github.com/coleifer/peewee/issues/2429 | 919,671,266 | MDU6SXNzdWU5MTk2NzEyNjY= | 2,429 | create_table / drop_table implementation for MySQLMigrator and other engines | {
"login": "krokwen",
"id": 4995998,
"node_id": "MDQ6VXNlcjQ5OTU5OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/4995998?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/krokwen",
"html_url": "https://github.com/krokwen",
"followers_url": "https://api.github.com/users/krokwen/followers",
"following_url": "https://api.github.com/users/krokwen/following{/other_user}",
"gists_url": "https://api.github.com/users/krokwen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/krokwen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/krokwen/subscriptions",
"organizations_url": "https://api.github.com/users/krokwen/orgs",
"repos_url": "https://api.github.com/users/krokwen/repos",
"events_url": "https://api.github.com/users/krokwen/events{/privacy}",
"received_events_url": "https://api.github.com/users/krokwen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Peewee has a schema migrations module: http://docs.peewee-orm.com/en/latest/peewee/playhouse.html#schema-migrations\r\n\r\nI don't quite understand the issue, so I don't know what to tell you, but this doesn't seem to me a peewee-specific issue.",
"I'm talking about same module.\nIt's not able to create/drop table by itself.\nFor now you can create or drop table only with existing model class. But how to do it when model is no longer exists?\n\nOr i have to define model class in migration script every time? It's a huge crutch...\n",
"I don't really understand the problem. If you have the model class, just import it into the migration and call `create_table()` - without the model definition Peewee has no idea what columns to add or anything. For dropping a table, I also don't see why this shouldn't be possible by using a model class imported from your app -- run the migration(s), then remove the model code.\r\n\r\nYou can also stub out a model class if all you need to do is drop it, or just run `database.execute_sql('DROP TABLE...')`."
] | 2021-06-12T22:09:25 | 2021-06-13T16:06:04 | 2021-06-13T00:45:08 | NONE | null | It's a required functionality for cases when you have global schema changes,
Use case:
day 1: Model A. Dataset A
day 2: Model B. Dataset B
day 3: Model B updated. Dataset A patrially moved to model B
day 4: Model A is no longer needed and removed from code.
And i have to apply these changes on late environment that on 'day 1'
So, in this case it's impossible to use model's create and drop methods, because at the moment of migration run the old model will be already removed from code, but i have to apply all the changes in migrations. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2429/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2429/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2428 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2428/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2428/comments | https://api.github.com/repos/coleifer/peewee/issues/2428/events | https://github.com/coleifer/peewee/issues/2428 | 918,622,711 | MDU6SXNzdWU5MTg2MjI3MTE= | 2,428 | Cannot reset ForeignKeyField to None | {
"login": "orsinium",
"id": 9638362,
"node_id": "MDQ6VXNlcjk2MzgzNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9638362?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/orsinium",
"html_url": "https://github.com/orsinium",
"followers_url": "https://api.github.com/users/orsinium/followers",
"following_url": "https://api.github.com/users/orsinium/following{/other_user}",
"gists_url": "https://api.github.com/users/orsinium/gists{/gist_id}",
"starred_url": "https://api.github.com/users/orsinium/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/orsinium/subscriptions",
"organizations_url": "https://api.github.com/users/orsinium/orgs",
"repos_url": "https://api.github.com/users/orsinium/repos",
"events_url": "https://api.github.com/users/orsinium/events{/privacy}",
"received_events_url": "https://api.github.com/users/orsinium/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This was happening because peewee only cleared the related object reference (the A instance on B) if the actual value of the FK changed. Since it was `NULL` to start with (e.g. A.id is None), peewee did not register that there was anything to do. In practice I don't believe this would lead to any inconsistency in the database, but I can see how it might be confusing.\r\n\r\nFixed.",
"Thank you for the answer! I think I understand now: setting b.a to None was interpreted as setting b.a.id to None, which is already true. In my application, I distinguish between \"the A record is not created yet\" and \"there is no A record related to this B record\". So you're right, it was confusing. I found a workaround, though, by implementing `A.__bool__`."
] | 2021-06-11T11:24:44 | 2021-06-13T14:59:08 | 2021-06-11T12:58:56 | NONE | null | ```python
import peewee
class A(peewee.Model):
pass
class B(peewee.Model):
a = peewee.ForeignKeyField(A, null=True)
b = B(a=A())
# works as expected:
b.a
# <A: None>
# unexpected:
b.a = None
b.a
# <A: None>
```
Expected behavior: when `None` is assigned to the ForeignKeyField, the field value is None.
Actual behavior: assigning `None` to the ForeignKeyField has no effect.
How to reset a foreign key to None? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2428/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2428/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2427 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2427/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2427/comments | https://api.github.com/repos/coleifer/peewee/issues/2427/events | https://github.com/coleifer/peewee/issues/2427 | 913,595,164 | MDU6SXNzdWU5MTM1OTUxNjQ= | 2,427 | peewee create and use id field for deferred foreign key with primary_key=true | {
"login": "penja",
"id": 2717390,
"node_id": "MDQ6VXNlcjI3MTczOTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2717390?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/penja",
"html_url": "https://github.com/penja",
"followers_url": "https://api.github.com/users/penja/followers",
"following_url": "https://api.github.com/users/penja/following{/other_user}",
"gists_url": "https://api.github.com/users/penja/gists{/gist_id}",
"starred_url": "https://api.github.com/users/penja/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/penja/subscriptions",
"organizations_url": "https://api.github.com/users/penja/orgs",
"repos_url": "https://api.github.com/users/penja/repos",
"events_url": "https://api.github.com/users/penja/events{/privacy}",
"received_events_url": "https://api.github.com/users/penja/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-06-07T14:12:07 | 2021-06-08T00:05:47 | 2021-06-08T00:05:47 | NONE | null | Hello. We have the deferred foreign key that used like primary key in new table. In this case peewee ignore `primary_key=True` param in column declaration and try to use `id` like identifier in all sql queries.
Please see invalid behavior in following code snippet.
```
import peewee
from peewee import *
import logging
import sys
log = logging.getLogger()
log.setLevel(logging.DEBUG)
handler = logging.StreamHandler(sys.stdout)
log.addHandler(handler)
print(peewee.__version__)
db = SqliteDatabase(":memory:")
class Base(Model):
class Meta:
database = db
class B(Base):
a = DeferredForeignKey("A", primary_key=True)
x = CharField(null=True)
class A(Base):
id = AutoField()
db.create_tables([B, A])
```
Output
```
root@87a4315fc6f4:/vagrant# python dummy_sqlite.py
3.14.4
('CREATE TABLE IF NOT EXISTS "a" ("id" INTEGER NOT NULL PRIMARY KEY)', [])
('CREATE TABLE IF NOT EXISTS "b" ("id" INTEGER NOT NULL PRIMARY KEY, "a_id" INTEGER NOT NULL PRIMARY KEY, "x" VARCHAR(255))', [])
Traceback (most recent call last):
File "/usr/local/lib/python3.8/site-packages/peewee.py", line 3144, in execute_sql
cursor.execute(sql, params or ())
sqlite3.OperationalError: table "b" has more than one primary key
During handling of the above exception, another exception occurred:
```
Thanks in advance for your response and probably for the fix.
P.S There is workaround by in my opinion this is not obvious!
```
class B(Base):
class Meta:
primary_key = False
a = DeferredForeignKey("A", primary_key=True)
x = CharField(null=True)
#or
class B(Base):
class Meta:
primary_key = peewee.CompositeKey("a")
a = DeferredForeignKey("A")
x = CharField(null=True)
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2427/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2427/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2426 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2426/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2426/comments | https://api.github.com/repos/coleifer/peewee/issues/2426/events | https://github.com/coleifer/peewee/issues/2426 | 912,118,561 | MDU6SXNzdWU5MTIxMTg1NjE= | 2,426 | Syntax error when selecting in VALUES | {
"login": "Hippopotas",
"id": 9470058,
"node_id": "MDQ6VXNlcjk0NzAwNTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/9470058?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Hippopotas",
"html_url": "https://github.com/Hippopotas",
"followers_url": "https://api.github.com/users/Hippopotas/followers",
"following_url": "https://api.github.com/users/Hippopotas/following{/other_user}",
"gists_url": "https://api.github.com/users/Hippopotas/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Hippopotas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Hippopotas/subscriptions",
"organizations_url": "https://api.github.com/users/Hippopotas/orgs",
"repos_url": "https://api.github.com/users/Hippopotas/repos",
"events_url": "https://api.github.com/users/Hippopotas/events{/privacy}",
"received_events_url": "https://api.github.com/users/Hippopotas/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This works fine for me:\r\n\r\n```python\r\ndb = SqliteDatabase(':memory:')\r\n\r\nclass KV(Model):\r\n key = TextField()\r\n value = IntegerField()\r\n class Meta:\r\n database = db\r\n\r\ndb.create_tables([KV])\r\n\r\nKV.insert_many([('k1', 1), ('k2', 2), ('k3', 3), ('k4', 4), ('k5', 5)]).execute()\r\n\r\nvl = ValuesList([('k1', 1), ('k3', 3), ('k5', 5)])\r\nvl_e = EnclosedNodeList([vl])\r\n\r\nquery = (KV.select()\r\n .where(Tuple(KV.key, KV.value).in_(vl_e)))\r\nfor row in query:\r\n print(row.key, row.value)\r\n```\r\n\r\nPrints:\r\n\r\n```\r\nk1 1\r\nk3 3\r\nk5 5\r\n```",
"Hm. I ran your example code, but got the same error. Could I ask what the sql being generated is?\r\n\r\nEdit: never mind, ignore me. I reinstalled everything, and now it miraculously works. Sorry for the bother."
] | 2021-06-05T06:27:19 | 2021-06-06T05:12:51 | 2021-06-05T13:35:46 | NONE | null | Peewee version: 3.4.14
SQLite version: 3.35
When running code of the form (as recommended in issues [2344](https://github.com/coleifer/peewee/issues/2344), [2411](https://github.com/coleifer/peewee/issues/2411), [2414](https://github.com/coleifer/peewee/issues/2414)):
```python
foo = [(1, 2), (3, 4)]
bar = ValuesList(foo, columns=('col1', 'col2'))
baz = EnclosedNodeList([bar])
t1.select().where(Tuple(t1.col1, t1.col2).in_(baz))
```
I am getting a different kind of error: `OperationalError: near ",": syntax error`
The query it is attempting to execute is apparently (in (query, param) form)
```
('SELECT "t1"."col1", "t1"."col2" FROM "t1" WHERE (("t1"."col1", "t1"."col2") IN (VALUES (?, ?), (?, ?)))',
[1, 2, 3, 4])
```
The same occurs on
```python
t1.raw("""SELECT col1 FROM t1 WHERE ((col1, col2) IN (VALUES (1, 2))""").execute()
```
After some tinkering, it appears that the problematic syntax is the comma between `col1, col2`
I am unsure why this is happening. I played around with the parentheses a bit, but could not figure out a fix.
This does not occur on non-row-values queries, e.g.
```
t1.select().where(t1.col1 << [1, 2, 3])
('SELECT "t1"."col1", "t1"."col2" FROM "t1" WHERE ("t1"."col1" IN (?, ?, ?))',
[1, 2, 3])
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2426/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2426/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2425 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2425/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2425/comments | https://api.github.com/repos/coleifer/peewee/issues/2425/events | https://github.com/coleifer/peewee/issues/2425 | 911,302,399 | MDU6SXNzdWU5MTEzMDIzOTk= | 2,425 | Multi-encoding support in playhouse DataSet | {
"login": "JarneVerhaeghe",
"id": 61466015,
"node_id": "MDQ6VXNlcjYxNDY2MDE1",
"avatar_url": "https://avatars.githubusercontent.com/u/61466015?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JarneVerhaeghe",
"html_url": "https://github.com/JarneVerhaeghe",
"followers_url": "https://api.github.com/users/JarneVerhaeghe/followers",
"following_url": "https://api.github.com/users/JarneVerhaeghe/following{/other_user}",
"gists_url": "https://api.github.com/users/JarneVerhaeghe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JarneVerhaeghe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JarneVerhaeghe/subscriptions",
"organizations_url": "https://api.github.com/users/JarneVerhaeghe/orgs",
"repos_url": "https://api.github.com/users/JarneVerhaeghe/repos",
"events_url": "https://api.github.com/users/JarneVerhaeghe/events{/privacy}",
"received_events_url": "https://api.github.com/users/JarneVerhaeghe/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-06-04T09:16:26 | 2021-06-04T12:50:29 | 2021-06-04T12:50:29 | NONE | null | It appears the DataSet module from playhouse does not support other encodings such as 'latin-1'.
I locally solved it by adjusting the open_file, thaw, and freeze function to have an extra argument:
Line 21-22
```
def open_file(f, mode,encoding_='utf8'):
return open(f, mode, encoding=encoding_)
```
Line 152-156
```
def freeze(self, query, format='csv', filename=None, file_obj=None, encoding='utf8',
**kwargs):
self._check_arguments(filename, file_obj, format, self._export_formats)
if filename:
file_obj = open_file(filename, 'w',encoding)
```
Line 164-168
```
def thaw(self, table, format='csv', filename=None, file_obj=None,
strict=False, encoding='utf8', **kwargs):
self._check_arguments(filename, file_obj, format, self._export_formats)
if filename:
file_obj = open_file(filename, 'r',encoding)
```
This issue is more of a suggestion for multi-encoding support. I did not want to open a pull request for this.
| {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2425/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2425/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2423 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2423/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2423/comments | https://api.github.com/repos/coleifer/peewee/issues/2423/events | https://github.com/coleifer/peewee/issues/2423 | 907,659,141 | MDU6SXNzdWU5MDc2NTkxNDE= | 2,423 | Create tables from ModelSelect outside the public schema | {
"login": "albireox",
"id": 568775,
"node_id": "MDQ6VXNlcjU2ODc3NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/568775?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albireox",
"html_url": "https://github.com/albireox",
"followers_url": "https://api.github.com/users/albireox/followers",
"following_url": "https://api.github.com/users/albireox/following{/other_user}",
"gists_url": "https://api.github.com/users/albireox/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albireox/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albireox/subscriptions",
"organizations_url": "https://api.github.com/users/albireox/orgs",
"repos_url": "https://api.github.com/users/albireox/repos",
"events_url": "https://api.github.com/users/albireox/events{/privacy}",
"received_events_url": "https://api.github.com/users/albireox/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I've chosen to support this by allowing a tuple for the `table_name` parameter. So:\r\n\r\n```python\r\n\r\nquery = SomeModel.select()...\r\nquery.create_table('my_new_table')\r\n\r\n# OR\r\nquery.create_table(('schema', 'my_new_table'))\r\n```"
] | 2021-05-31T18:43:49 | 2021-06-16T13:08:58 | 2021-06-16T13:07:57 | NONE | null | I think there is a bug or limitation in the `ModelSelect.create_table()` method. The way it works right now, you can only create tables in the public schema. This is because `Entity` expects multiple arguments, one for each part of the path, but `create_table` can send only one. If you pass the whole path as a string (e.g., `sandbox.test_table`) it gets quoted as `"sandbox.test_table"` which still points to the public schema.
I think the solution is either to allow to pass a tuple to `create_table()` (which will break compatibility) or to change the function signature so that it's more greedy getting the arguments so that you can pass `create_table('sandbox', 'test_table')` and all those arguments make it to the `Entity` instance. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2423/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2423/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2422 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2422/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2422/comments | https://api.github.com/repos/coleifer/peewee/issues/2422/events | https://github.com/coleifer/peewee/pull/2422 | 906,971,690 | MDExOlB1bGxSZXF1ZXN0NjU3ODgxODkz | 2,422 | Update quickstart.rst | {
"login": "universuen",
"id": 52519513,
"node_id": "MDQ6VXNlcjUyNTE5NTEz",
"avatar_url": "https://avatars.githubusercontent.com/u/52519513?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/universuen",
"html_url": "https://github.com/universuen",
"followers_url": "https://api.github.com/users/universuen/followers",
"following_url": "https://api.github.com/users/universuen/following{/other_user}",
"gists_url": "https://api.github.com/users/universuen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/universuen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/universuen/subscriptions",
"organizations_url": "https://api.github.com/users/universuen/orgs",
"repos_url": "https://api.github.com/users/universuen/repos",
"events_url": "https://api.github.com/users/universuen/events{/privacy}",
"received_events_url": "https://api.github.com/users/universuen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Opener requested I delete this PR. Unfortunately, I don't believe I can delete this - I don't see an option in the github UI."
] | 2021-05-31T02:07:36 | 2021-06-03T15:16:24 | 2021-05-31T22:36:20 | NONE | null | Found a missing word | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2422/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2422/timeline | null | null | false | {
"url": "https://api.github.com/repos/coleifer/peewee/pulls/2422",
"html_url": "https://github.com/coleifer/peewee/pull/2422",
"diff_url": "https://github.com/coleifer/peewee/pull/2422.diff",
"patch_url": "https://github.com/coleifer/peewee/pull/2422.patch",
"merged_at": null
} |
https://api.github.com/repos/coleifer/peewee/issues/2421 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2421/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2421/comments | https://api.github.com/repos/coleifer/peewee/issues/2421/events | https://github.com/coleifer/peewee/issues/2421 | 905,310,745 | MDU6SXNzdWU5MDUzMTA3NDU= | 2,421 | Preferred way to do `database.execute_sql` ? | {
"login": "andersentobias",
"id": 4043059,
"node_id": "MDQ6VXNlcjQwNDMwNTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4043059?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andersentobias",
"html_url": "https://github.com/andersentobias",
"followers_url": "https://api.github.com/users/andersentobias/followers",
"following_url": "https://api.github.com/users/andersentobias/following{/other_user}",
"gists_url": "https://api.github.com/users/andersentobias/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andersentobias/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andersentobias/subscriptions",
"organizations_url": "https://api.github.com/users/andersentobias/orgs",
"repos_url": "https://api.github.com/users/andersentobias/repos",
"events_url": "https://api.github.com/users/andersentobias/events{/privacy}",
"received_events_url": "https://api.github.com/users/andersentobias/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Peewee has been on 3.0 for about 3 years now, so you might want to upgrade as there are many improvements.\r\n\r\nThat said, as long as you're opening the pool connection before the request starts, and closing it (returning it back to the pool) after the request, then your code should work just fine."
] | 2021-05-28T12:26:05 | 2021-05-28T12:36:58 | 2021-05-28T12:36:58 | NONE | null | We're using a DB connection pool with peewee 2.8.0.
We needed to optimize a query by writing handwritten SQL to our PostgreSQL db.
What is the preferred way of doing such a query?
We're using peewee together with a Flask app, if that helps.
Right now, the code is:
```python
database = PooledPostgresqlExtDatabase(...)
# Lots of code...
def func():
cursor = database.execute_sql('SELECT ...') # More code obviously.
result = cursor.fetchall()
# ...
```
Note that we're not closing the db cursor manually. | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2421/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2421/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2420 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2420/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2420/comments | https://api.github.com/repos/coleifer/peewee/issues/2420/events | https://github.com/coleifer/peewee/issues/2420 | 903,470,809 | MDU6SXNzdWU5MDM0NzA4MDk= | 2,420 | How to get BaseModel Fields? | {
"login": "beucismis",
"id": 40023234,
"node_id": "MDQ6VXNlcjQwMDIzMjM0",
"avatar_url": "https://avatars.githubusercontent.com/u/40023234?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/beucismis",
"html_url": "https://github.com/beucismis",
"followers_url": "https://api.github.com/users/beucismis/followers",
"following_url": "https://api.github.com/users/beucismis/following{/other_user}",
"gists_url": "https://api.github.com/users/beucismis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/beucismis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/beucismis/subscriptions",
"organizations_url": "https://api.github.com/users/beucismis/orgs",
"repos_url": "https://api.github.com/users/beucismis/repos",
"events_url": "https://api.github.com/users/beucismis/events{/privacy}",
"received_events_url": "https://api.github.com/users/beucismis/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Post questions on stackoverflow or IRC. This is for tracking issues.\r\n\r\n```python\r\n\r\nUser._meta.fields # dict of field name -> field instance\r\nUser._meta.sorted_fields # list of field instances in order\r\nUser._meta.sorted_field_names # Just the names\r\n```",
"Thanks."
] | 2021-05-27T09:35:26 | 2021-05-27T12:49:13 | 2021-05-27T12:43:22 | NONE | null | I want to get the defined `Fields` as a list.
```
class User(BaseModel):
id = BigIntegerField(primary_key=True)
nick = CharField(unique=True)
age = SmallIntegerField(unique=True)
class Meta:
database = db
``` | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2420/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2420/timeline | null | completed | null | null |
https://api.github.com/repos/coleifer/peewee/issues/2419 | https://api.github.com/repos/coleifer/peewee | https://api.github.com/repos/coleifer/peewee/issues/2419/labels{/name} | https://api.github.com/repos/coleifer/peewee/issues/2419/comments | https://api.github.com/repos/coleifer/peewee/issues/2419/events | https://github.com/coleifer/peewee/issues/2419 | 901,992,407 | MDU6SXNzdWU5MDE5OTI0MDc= | 2,419 | The client was disconnected by the server because of inactivity. | {
"login": "GreatBahram",
"id": 14103831,
"node_id": "MDQ6VXNlcjE0MTAzODMx",
"avatar_url": "https://avatars.githubusercontent.com/u/14103831?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GreatBahram",
"html_url": "https://github.com/GreatBahram",
"followers_url": "https://api.github.com/users/GreatBahram/followers",
"following_url": "https://api.github.com/users/GreatBahram/following{/other_user}",
"gists_url": "https://api.github.com/users/GreatBahram/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GreatBahram/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GreatBahram/subscriptions",
"organizations_url": "https://api.github.com/users/GreatBahram/orgs",
"repos_url": "https://api.github.com/users/GreatBahram/repos",
"events_url": "https://api.github.com/users/GreatBahram/events{/privacy}",
"received_events_url": "https://api.github.com/users/GreatBahram/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks"
] | 2021-05-26T08:28:09 | 2021-05-26T15:36:53 | 2021-05-26T12:38:35 | NONE | null | Hi there,
I got this exception when I have a long connection that exceeds both `wait_timeout` and `interactive_timeout` timeouts:
```python
File "/usr/lib/python3/dist-packages/peewee.py", line 5513, in get
return sq.get()
File "/usr/lib/python3/dist-packages/peewee.py", line 5911, in get
return clone.execute(database)[0]
File "/usr/lib/python3/dist-packages/peewee.py", line 1587, in inner
return method(self, database, *args, **kwargs)
File "/usr/lib/python3/dist-packages/peewee.py", line 1658, in execute
return self._execute(database)
File "/usr/lib/python3/dist-packages/peewee.py", line 1809, in _execute
cursor = database.execute(self)
File "/usr/lib/python3/dist-packages/peewee.py", line 2666, in execute
return self.execute_sql(sql, params, commit=commit)
File "/usr/lib/python3/dist-packages/peewee.py", line 2660, in execute_sql
self.commit()
File "/usr/lib/python3/dist-packages/peewee.py", line 2451, in __exit__
reraise(new_type, new_type(*exc_args), traceback)
File "/usr/lib/python3/dist-packages/peewee.py", line 178, in reraise
raise value.with_traceback(tb)
File "/usr/lib/python3/dist-packages/peewee.py", line 2653, in execute_sql
cursor.execute(sql, params or ())
File "/usr/lib/python3/dist-packages/MySQLdb/cursors.py", line 209, in execute
res = self._query(query)
File "/usr/lib/python3/dist-packages/MySQLdb/cursors.py", line 315, in _query
db.query(q)
File "/usr/lib/python3/dist-packages/MySQLdb/connections.py", line 226, in query
_mysql.connection.query(self, query)
peewee.OperationalError: (4031, 'The client was disconnected by the server because of inactivity. See wait_timeout and interactive_timeout for configuring this behavior.')
```
I spotted the [shortcuts](https://github.com/coleifer/peewee/blob/master/playhouse/shortcuts.py) module inside the peewee code handles these errors: 2006,2013, 2014. I think this can be added to the `ReconnectMixin` class as well.
Do you want me to add this into the `ReconnectMixin` class? | {
"url": "https://api.github.com/repos/coleifer/peewee/issues/2419/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/coleifer/peewee/issues/2419/timeline | null | completed | null | null |